一种基于DEA的共同配送网点选址评价方法
一种基于dea的共同配送网点选址评价方法
技术领域
1.本发明涉及共同配送选址评价领域,具体涉及一种基于dea模型的共同配送网点选址评价方法。
背景技术:
2.共同配送旨在采用联合运输的方式减少各快递企业单独运输带来资源浪费问题,随着我国快递行业飞速发展,对共同配送的需求愈加迫切。各个快递企业分散作业会带来需求分散的问题进而导致快递作业重复资源浪费的缺点,共同配送将成为解决这一问题的关键方法。同时近年来快递市场整体增速放缓,整体行业发展将从增量攫取向存量争夺转变,各个快递企业也面临着市场化整合升级的考验,共同配送网络的合理规划可以有效降低快递单票成本提升快递流转效率。通过基于dea的共同配送网点选址方法在共配网点选址时不仅需要考虑外部空间优化同时增加企业内部管理对选址的影响,计算不同网点实现共同配送前的效率可以解决真实场景下的快递路线重合、成本居高不下等问题。
技术实现要素:
3.为解决上述技术问题,本发明采用的技术方案是:
4.本发明根据全链条快递网络结构规划,在经过的全部快递节点之间完成流程的规划,目标是在不超过车辆容载量和时间窗约束的条件下实现总成本最低、总时间最短、总效率最高三重目标。采用三阶段的算法求解方法,层层倒推,最终得到优越性最高的快递网络结构。第一阶段解决快递驿站选址问题,利用无监督学习算法的优越性得到最优驿站聚类数。第二阶段解决共配网点选址和配送路径最优问题,利用免疫算法在已知的快递驿站位置的确定共配网点的位置实现总路线成本最低,第三阶段利用dea评价方法计算和排序快递网点效率,对共配网点位置进行筛选,确定最优位置。本发明具体采用如下技术方案:
5.一种基于dea的共同配送网点选址评价方法,该方法包括如下步骤:
6.(1)模型构建
7.已知在不受交通管辖时间范围内车辆可以在网点i,j之间的任意道路通行,此时的运输距离设为在交通管辖的时间范围内时,车辆需要绕行并且通过最短距离到达目标共配网点,此时的运输距离设为即:
[0008][0009]
其中,p
ij
为在共同配送网点ij之间进行运输的不同的q条路径之间的距离,t
ki
为车辆对于共配网点i的开始配送时间,[μ1,μ2]为交通管制的时间范围;
[0010]
目标函数表示为:
[0011][0012]
其中,f2为车辆的固定动用成本,k为车辆的集合,n为共同配送网点的集合,为
车辆的平均行驶速度,λ表示相邻交通信号灯之间的平均距离,φ表示每个交通信号灯的期望通行时间,c2为车辆的单位距离的运输成本,x
ijk2
为车辆是否从网点i到达网点j的决策变量,r
2n
为车辆的实际装载量,w2为车辆的最大载重量,y
k2
表示车辆是否会产生调用成本的决策变量;
[0013]
约束条件表示为:
[0014]
保证运输车辆配送的快递总重量不超过配送车辆的最大装载量
[0015][0016]
保证车辆的运输在共同配送中心的工作时间段内进行
[0017][0018]
其中,为共同配送分拨中心的工作时间;
[0019]
车辆在不受交通管制情况下的正常行驶距离
[0020]
p
ij
=minp
ij
[0021]
车辆在交通管制的时间约束下的最小行驶距离
[0022]
p
ij
=min(p
ij-minp
ij
)
[0023]
共配网点的实际需求量与车辆的实际运输量相同
[0024][0025]
其中,rn为网点的需求量,
[0026]
每辆车辆只能对应一个共同配送网点进行运输
[0027][0028]
车辆k2是否从共配网点i运输到共配网点j
[0029][0030]
车辆k2是否会产生调用成本
[0031][0032]
(2)确定最优驿站和共配网点的位置
[0033]
基于步骤(1)模型,利用无监督学习的粒子群优化算法对聚类数据向量的适用性来进行聚类,其中使用k-means聚类来产生初始种群,得到城市内安置的合理快递驿站位置;根据聚类结果得到最优的快递驿站位置,通过免疫算法得到合理的共配网点位置;
[0034]
(3)利用dea对于共配网点效率进行评价:
[0035]
根据熵权法计算共配网点效率,通过数据标准化、求各指标信息熵并通过信息熵计算确定各评价指标的权重,权重确定后,通过数据包络分析方法对多个绩效衡量指标的同类决策单元相对效率的有效性计算共配网点的运营效率:
[0036]
设产出指标的权重为un,投入指标的权重为vm,共yj个产出指标,xi个投入指标。对每一部分,效率评价指数为:
[0037][0038]
根据计算得到的各个共配网点的运营效率,进行筛选,得到最优的共配网点位置。
[0039]
优选地,所述产出指标包括进出库工作效率、快递处理效率、服务质量;所述投入指标包括网点总面积、网点人员数量、网点设备数量、网点总成本;
[0040]
所述进出库工作效率=(入库时间-收货时间/平均进港时长)+(出货时间-出库时间/平均出港时长);
[0041]
快递处理效率=派件量/快递员人数;
[0042]
服务质量为虚假签收投诉率、遗失破损率、升级投诉受理申诉率、二次投诉率的加权平均值。
[0043]
与现有技术相比,本发明具有如下有益效果:
[0044]
(1)现有的快递驿站繁多且覆盖范围重复,造成资源浪费现象,本发明利用无监督学习的粒子群算法求解聚类算法得到城市内安置的合理快递驿站位置。
[0045]
(2)通过聚类结果得到最优的快递驿站位置,再通过免疫算法得到合理的共配网点位置,除了考虑外部空间优化对共配网点选址的影响同时加入内部管理对选址的影响,利用熵权法和dea算法相结合的方法计算得到各个共配网点的效率,增加共配网点的选址条件,使得共配网点选址问题在经济成本最低的条件下实现运行效率最高的目标。
[0046]
(3)基于现有实行的交通管制,对日常生活中常见且对城市运输较有影响的路段交通管制在快递运输层次进行了分析和研究,并在这种交通管制情形下构建了城市干线运输车辆路径规划模型,有助于构建智能化、协同化、低成本化、高效化的总体城市快递网络。
附图说明
[0047]
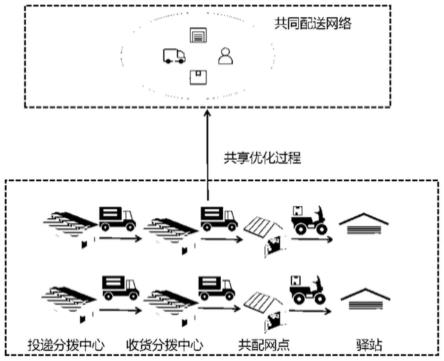
图1是共同配送共享优化过程图。
[0048]
图2是共同配送快递运输方式图。
[0049]
图3是存在交通管制情况下的运输路线变动图。
[0050]
图4是某市共配网点图。
[0051]
图5某市驿站聚类图。
[0052]
图6共配网点选址及最优路线图。
[0053]
图7共配网点间运输路线图。
具体实施方式
[0054]
在实现共享前各个快递企业采用单独配送的方式,在a、b两个城市分别设有各自的送货分拨中心和收货分拨中心、网点和驿站,有不同载重量的干线运输车辆和支线运输车辆。如图2所示,实现共享后分别设置送货城市a的分拨中心,收货城市b的分拨中心、共配网点和快递驿站。车辆从送货城市a的分拨中心出发,经过干线运输到达收货城市b的分拨中心,经过分拨后到达共配网点进行配送到达各个区域的快递驿站完成整个快递运输过程。
[0055]
(一)模型构建
[0056]
图3模拟了存在交通管制情况下的运输路线变动,在交通约束的时间段[μ1,μ2]外,
货车可以通过路径a在分拨中心a和共配网点n={1,2,...,n}之间进行配送,在交通约束的时间段[μ1,μ2]内,车辆必须绕行通过路径b进行运输。
[0057]
a:分拨中心
[0058]
n={0,1,2,...,n}:共同配送网点的集合,其中0表示从开始出发的收货城市的分拨中心
[0059]
h={0,1,2...,h}:处于路段管辖区域内的共配网点
[0060]
k2={1,2,...,k
2m
}:车辆的集合
[0061]
在共同配送网点ij之间进行运输的不同的q条路径之间的距离[μ1,μ2]:交通管制的时间范围
[0062]
共同配送分拨中心的工作时间
[0063]
w2:车辆的最大载重量
[0064]
车辆的实际装载量
[0065]rn
:网点的需求量
[0066]
f2:车辆的固定动用成本
[0067]
c2:车辆的单位距离的运输成本;
[0068]
φ:表示每个交通信号灯的期望通行时间
[0069]
γ:表示相邻交通信号灯之间的平均距离
[0070]
车辆的平均行驶速度
[0071]
t
ki
:车辆对于共配网点i的开始配送时间
[0072]
决策变量表示车辆是否从网点i到达网点j
[0073]
决策变量表示车辆是否会产生调用成本
[0074]
已知在不受交通管辖时间范围内车辆可以在网点i,j之间的任意道路通行那么此时的运输距离设为与之相反当在交通管辖的时间范围内时车辆需要绕行并且通过最短距离到达目标共配网点,此时的运输距离设为即:
[0075][0076]
目标函数可以表示为:
[0077][0078]
目标函数由三部分组成,分别为车辆固定动用成本,车辆的运输成本以及车辆的调用成本。调用成本是通过计算车辆的满载率确定的。
[0079]
约束条件可以表示为:
[0080]
保证运输车辆配送的快递总重量不超过配送车辆的最大装载量
[0081][0082]
保证车辆的运输在共同配送中心的工作时间段内进行
[0083][0084]
车辆在不受交通管制情况下的正常行驶距离
[0085]
p
ij
=minpj[0086]
车辆在交通管制的时间约束下的最小行驶距离
[0087]
p
ij
=min(p
ij-minp
ij
)
[0088]
共配网点的实际需求量与车辆的实际运输量相同
[0089][0090]
每辆车辆只能对应一个共同配送网点进行运输
[0091][0092]
车辆k2是否从共配网点i运输到共配网点j
[0093]
x
ijk2
=0
[0094]
x
ijk2
=1
[0095]
车辆k2是否会产生调用成本
[0096]yk2
=1
[0097]yk2
=0
[0098]
(二)算法实现
[0099]
(1)利用无监督聚类算法选择最优驿站的位置
[0100]
目前国内大多数住宅和办公楼采用快递员配送上门的服务,这种服务可以提升快递的安全性,提高客户的服务体验,但由于时效性的约束可能会出现二次配送的缺点还会出现同一客户但不同快递公司的快递员重复上门配送造成的资源浪费的缺点。根据实际情况发现快递驿站可供所有快递收派件,并且广泛、均匀覆盖在每个城市的各个区域可以最高效率得满足客户的需求,因此对采用配送员上门配送服务的区域进行聚类分析,将临近的终端客户点聚集在一起可以有效降低车辆的配送成本。
[0101]
本发明利用粒子群优化算法对聚类数据向量的适用性来进行聚类,开发了一种pso和k-means相结合的聚类算法,其中使用k-means聚类来产生初始种群。k-means算法比pso算法收敛更快,但通常聚类精度较低。通过k-means产生初始种群,可以进一步提高pso聚类算法的性能,与单独使用两种传统算法比较,很大程度得减少了初始解的依赖性且具有更好的收敛性以减少误差。
[0102][0103][0104]
(2)利用效率评价方法和免疫算法确定快递共配网点位置
[0105]
针对于目前不同快递企业的网点在同一区域内重复建立,利用在已知上一层级的驿站聚类结果和服务时间的前提下,加入时间窗约束利用tsptw问题的思想得到共同配送网点的建设数量和位置以及相关的服务范围。
[0106]
已知共同分拨中心和网点的坐标条件下,在有交通路径管辖约束的条件下以最小化时间和经济成本为目标根据一级车辆的额定载重量约束、时间窗约束利用vrptw问题的思想解决车辆路径规划问题,得到从城市b出发到达各个共配网点的最佳路径。
[0107]
在合理划分服务范围确定驿站位置后,通过免疫算法确定共配网点的位置。免疫算法是遗传算法的一种优化形式,免疫算法可以弥补传统遗传算法在初始群体分布不均匀时容易产生的不成熟收敛问题。
[0108][0109][0110]
除了快递网点的地理位置这一基本指标,在网点聚类分析时还需要考虑效率这一指标对于共配网点选址的影响,末端网点拥有车辆、人员、设备等快递资源,同时承担收派件的功能,因此各快递资源的因素对于网点效率评价的影响不容忽视。下表列出了影响快递网点效率的指标:
[0111]
表1网点效率评价指标表
[0112][0113][0114]
(3)利用dea对于网点效率进行评价:
[0115]
对于某项指标,可以用熵值来判断某个指标的离散程度,其信息熵值越小,指标的离散程度越大,该指标对综合评价的影响(即权重)就越大。因此,可利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。利用熵权法计算快递网点效率,通过数据标准化、求各指标信息熵并通过信息熵的计算公式确定各评价指标的权重。
[0116][0117][0118][0119][0120]
假设有k个指标x1,x2,
……
,xk,其中xi={x1,x2,...,xn},式(1)利用数据标准化将数据化为y1,y2,...,y
k,
,式(2)(3)根据信息论中关于信息熵的定义,得到各指标的信息熵e1,e2,...,ek,最后式(4)通过各信息熵计算得到评价指标的权重。
[0121]
在利用熵权法确定了评价指标所占的权重后,通过数据包络分析(dea)方法对多个绩效衡量指标的同类决策单元相对效率的有效性计算快递网点的运营效率。下表列出投入产出的关键指标:
[0122]
表2投入产出关键指标表
[0123]
[0124][0125]
设产出指标的权重为un,投入指标的权重为vm,共yj个产出指标,xi个投入指标。对每一部分,效率评价指数为:
[0126][0127]
建立ccr模型,设有n个部门,称为n个决策单元,每个决策单元都有p种投入和q种产出,分别用不同的经济指标表示。这样,由n个决策单元构成的多指标投入和多指标产出的评价系统,对于每一个决策单元dmuj都有相应的效率评价指数:
[0128][0129]
通过适当的取权系数v和u,使得
[0130]
hj≤1,j=1,
…
,n
[0131]
如以第j0个决策单元的效率指数为目标,以所有决策单元的效率指数为约束,就构造了如下的ccr(c2r)模型:
[0132][0133][0134]
u≥0,v≥0
[0135]
x
ij
:第j个决策单元对第i种类型输入的投入总量.x
ij
》0;
[0136]yrj
:第j个决策单元对第r种类型输出的产出总量.y
rj
》0;
[0137]
vi:对第i种类型输入的一种度量,权系数;
[0138]
ur:对第r种类型输出的一种度量,权系数;
[0139]
i:1,2,
…
,m;
[0140]
r:1,2,
…
,s;
[0141]
j:1,2,
…
,n;
[0142]hj
:效率评价指数;
[0143]
上述规划模型是一个分式规划,使用charnes-cooper变化,令:
[0144][0145]
由
[0146]
可变成如下的线性规划模型p:
[0147][0148]
s.t.w
t
x
j-μ
t
yj≥0,j=1,2,...n
[0149]wt
x0=1
[0150]
w≥0,μ≥0
[0151]
利用线性规划的最优解来定义决策单元j0的有效性,从模型可以看出,该决策单元j0的有效性是相对其他所有决策单元而言的。对于ccr模型可以用线性规划表达,而线性规划一个重要的有效理论是对偶理论,通过建立对偶模型更容易从理论和经济意义上作深入分析。对偶规划(d):
[0152]
minθ
[0153][0154][0155]
λj≥0,j=1,2,...n
[0156]
θ无约束
[0157]
其中,λj为dmu的线性系数,θ
*
为效率值,0《θ
*
《1。
[0158]
为了讨论和计算应用方便,进一步引入松弛变量s+和剩余变量s-,将上面的不等式约束变为等式约束,可变成:
[0159]
minθ
[0160][0161][0162]
λj≥0,j=1,2,...n
[0163]
θ无约束,s
+
≥0,s-≤0
[0164]
其中,s
+
:松弛变量,s-:剩余变量。
[0165]
将上述规划(d)直接定义为规划(p)的对偶规划。
[0166]
dea方法不对数据进行其他处理,只需要投入和产出数据即可,不需要考虑各个数据之间的表达式关系,省去了假定函数形式可以避免有效统计分析中函数形式所带来的误差。利用熵权法和dea算法相结合的方法可以得到各个网点的效率值。通过免疫算法得到可以作为共配网点的坐标位置,再通过熵权法和dea算法结合得到的网点效率对上述结果进行筛选,得到最优的共配网点位置。
[0167]
(4)利用ga算法求解带时间窗的车辆路径规划问题
[0168]
利用基于pso的聚类算法确定了快递驿站的位置和免疫算法、效率评价方法确定了快递网点位置后,对车辆在共配网点和共同分拨站中心之间运输的路径进行规划。在进行路径规划时需要考虑各个共配网点的时间窗约束以及城市内的交通管制约束,以路径成本最低为目标函数利用遗传算法求解带时间窗的车辆路径规划问题:
[0169]
[0170][0171]
(三)实例分析
[0172]
某市总面积16410.54平方千米,下设16个区,约2200万常住人口。根据2020年某市邮政行业发展统计公报显示,某市邮政企业和快递服务企业业务收入累计完成约400亿元,业务总量累计完成约480亿元,某市的快递行业发展持续稳固前进。本发明整理某市的快递分拨中心和网点运行数据进行分析并提出合理的发展建议。通过简单整理得到某市的150家驿站,如图4所示。
[0173]
利用粒子群优化算法和k-means聚类算法相结合的方法解决快递驿站聚类的问题,可以提高粒子群算法的性能且减少误差。采用150个快递驿站的真实数据输入pso聚类模型中,可以得到如图5所示的聚类图。
[0174]
实现了各快递驿站的聚类后,得到了30个最佳的快递驿站,将此数据输入第二阶段的选址和路径规划模型中,用免疫算法对模型进行求解,以配送成本最低为目标得到15个最佳的共配网点位置,将网点位置复原到某市地图中,可以得到图6。
[0175]
利用熵权法计算得到30个聚类网点的效率评价指标,本发明从快件处理速度、劳动生产率、服务质量三个不同的维度评价快递网点效率,对基础数据进行收集和处理可以得到下表:
[0176][0177]
从表中可以发现这30个网点的综合得分为72.418分,最大值122.003分,最低值24.075分,最值与网点综合得分相差较大说明各个网点的运行效率参差不齐且差距悬殊。快递处理速度的权重最高其次为进出库工作效率和服务质量,但三者之间的差距均不大表明三个评价维度对快递网点效率评价的影响逐维度递减但相对一致。
[0178]
得到各个产出指标的权重后,将其带入dea模型进行求解,可以得到下表的30个网点的效率值:
[0179]
表3网点评价指标及效率值
[0180][0181]
通过分析以上评价指标可以发现,综合效率最大值为1、最小值为0.613、平均值为0.88,效率值相差较大,在已经聚类得到的15个网点中进行再次筛选去掉综合效率低于0.7的三个网点可以得到效率较高且位置最佳的12个共配网点,这12个共配网点均匀的分布在中国某市的各个区域,再将最优的共配网点坐标输入带时间窗的车辆路径规划模型中,可以得到如图7的运行结果。
[0182]
得到共配中心的位置和对应的运输路线:
[0183]
route1:0-》3-》7-》10-》11-》6-》4-》2-》0;route2:0-》5-》9-》1-》0;route3:0-》8-》0;
[0184]
对成本进行基础的计算,网点的成本包括派件成本、场地成本、工作人员成本和设施成本四部分。派件成本计算包括运输过程的每一部分所产生的成本,以上海到北京的一票件来计算,面单费用2元/票(包含派送费用1.5元),中转费用航空2元/kg、汽运0.5元/kg,扶持派费0.5元/票,操作费0.5元/票,因此一票件的派件成本为5.5元。场地成本主要是网点的租用费用,在某市区建设快递网点每平米每天的租金约为4元。快递公司的场地除了用于作业分拣外,还要用于办公、住宿等。工作人员成本主要是快递员每月的工资,在北京,现在一个快递员的底薪在3500元左右,加上提成每个月大概是5800元,除此之外,快递公司大多是包食宿的,平均200元/人/月,综合下来每人每月工资为6000元。设施成本来自于快递驿站所使用的的扫描设备,每把pda的价格大约为2000元。从共配中心出发到各个共配网点完成运输任务的车辆固定成本为1000/辆,可变成本为10元/公里。从共配网点到各个快递驿站的一级车辆固定成本为800元/辆,可变成本为8元/公里。
[0185]
在已知各个共配网点位置的条件下,利用一级配送车辆将快递从共配网点配送至各个快递共享驿站产生另一部分成本,舍去运行效率较低的三个共配网点剩余11个共配网点与余下的18个共配驿站进行匹配和路径优化,可以得到调用了10辆一级车辆,最短的配送总路径为68.25公里,总成本为993.6241万元。下面对实现共配前后的情况进行对比分析:
[0186] 单独配送共同配送增减量增减比例一级车辆数(辆)15010-14093.3%车辆数(辆)303-1240%共配中心数/分拨中心数(个)131-1292.3%快递网点数/自提点数(个)15011-13992.7%运输里程(公里)2654537-211780.0%配送里程(公里)86268.25-793.7592.1%总成本(元)233334369936241-1339719557.41%
[0187]
实现共享后的运输成本有超过50%的下降,同时通过对快递网点效率进行筛选使得共配网点的运行效率都保持在70%以上,可以有效改善快递网点工作效率低下、无效的重复性操作等问题。
[0188]
共同配送是近年来共享快递的发展趋势之一,本论文采用三阶段求解的方法对共同配送网络规划问题进行了研究。研究发现将单独配送转变为共同配送不仅可以减少快递设施的无效建设量还可以在一定程度上降低快递成本提升快递运输效率,共同配送的发展前景广阔。论文仅研究了包含三个层级的快递网络,在未来将继续对于多种复杂的快递网络结构进行深入优化和研究,并不断提升解决问题算法的精确度,为解决更复杂的共同配送问题提供有效的应用方案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1