一种基于社交媒体短文本的用户异常精神状态分级评估方法与流程
1.本发明涉及网络安全与公共心理卫生领域,尤其涉及一种基于社交媒体短文本的用户异常精神状态分级评估方法,是一种用于进行快速分级评估网络社交媒体用户异常精神状态的方法。
背景技术:
2.现代社会中,承受着越来越大的工作压力与生活压力的人们面临着着愈发加剧的各种精神状态异常——包括且不限于抑郁、自残、自杀倾向——等的困扰。这些精神状态异常会同时在身心上给人带来痛苦的体验的同时,进一步给整个社会造成工作效率的减弱,社会关系的破坏,乃至生产力的损失。相关研究表明,大部分的精神状态异常并没有恶化至使患者求医的程度:事实上,例如抑郁着一样精神状态异常,就有接近70%的潜在患者从未主动寻求抑或接受过相关心理治疗。这个问题在如今的疫情大环境带来的愈发明显的孤岛效应下变得更加严重。人们对于自身精神状态异常的缺乏自觉甚至讳疾忌医,已经成为现代生产关系的一个“定时炸弹”。
3.同时,在现代社会中人们愈发倾向于在新兴的社交媒体上分享自己的生活琐事、抒发自己的内心情感、以及表露自己的真实心绪。在程度或深或浅的虚拟身份下,人们往往能直抒己见,展现出自我的精神状态。这就使得社交媒体上用户发布的内容在有关用户精神状态的评估中拥有越来越高的可参考性。通过对社交媒体用户发布内容的分析,在用户求医之前就对其可能拥有的异常精神状态的早期症状判别变得具有可行性。事实上,包括抑郁在内的基于社交媒体用户发布内容的多种异常精神状态的评估研究已经取得了颇具参考性的成果。
4.然而,大多数相关研究针对的均为可疑用户——乃至单个帖子——的二分评估,即可疑与否的非此即彼的判断。这种二元判断研究在该领域中对后续的研究开展无疑是有益的,然而在实际应用中作用却非常有限,皆因其既无法在一批标记为可疑的用户中进一步地进行最可疑的那一小批的判别。因为作为可疑群体的用户个体数量较大而其中真正具有精神状态异常的数量又相对较小,所以相关社交媒体运营方与医疗设施直接对原始可疑用户群体采取无差别的治疗等措施效率极为低下。要使得相关研究的实用化变得可能,那么对原始的二元判断的分级便迫在眉睫。
5.实际上,已投入实际应用中的网络社交媒体用户异常精神状态的评估技术要比上述提及的学术研究进度更为滞后,主要表现在:
6.(1)并非运用机器学习相关技术,而是更多的依赖于实时短文本的正则式匹配与相关敏感词的关键词匹配,与在此之上的人工筛选。这导致了劳动的重复与浪费,并且这种评估方法因其依赖于筛选员工的主观性而不具有足够的客观性和稳定性。
7.(2)各个社交媒体app的运营公司相互之间拒绝在此公共心理卫生安全的问题解决方案上相互合作,不共享用户数据库、评测标准、与具体部署细节,导致该问题的实际解决进度极为缓慢。
8.(3)并无分级评估,而是将所有可疑对象用户不论可疑(严重)程度进行统一处理,导致了相关公共卫生资源的极大浪费。
技术实现要素:
9.本发明所要解决的技术问题是提供一种基于社交媒体短文本的用户异常精神状态分级评估方法,旨在解决现有的社交媒体用户精神状态快速准确检测的需求,它克服了现有技术存在的效率低下、进步缓慢、识别精度低等问题,并且同时具有学术研究与实际应用上的可拓展性。
10.本发明所要解决的技术问题是通过以下技术方案来实现的:
11.一种基于社交媒体短文本的用户异常精神状态分级评估方法,包括以下步骤:
12.基于机器学习领域针对社交媒体历史短文本语料数据集的分级分类任务模型的训练与部署使用,依次包括以下三个核心方法:数据集构建,模型构建与训练,以及模型部署与更新。下面将详细进行叙述:
13.数据集构建:
14.包括原始数据收集与综合数据标注。这一核心方法主要获取模型最初的训练与测试所用的数据,应当包括用户群体的基本信息,其对应的历史发言短文本数据与其对应的异常精神状态标注的可疑(严重)程度。
15.原始数据收集的采集方法主要为合法网络爬虫爬取公开数据与开源数据集的使用。
16.其中,开源数据集可以是仅有用户信息与原始文本数据的数据集;也可以是有预先二元人工标注的数据集,例如针对潜在抑郁症用户的d-readdit数据集;
17.或者是有相关问卷调查结果支撑的数据集,例如同样是针对潜在抑郁症用户的对相关用户进行了基于贝克抑郁量表(bdi)的问卷调查并提供结果的erisk-2021数据集。
18.无论对之后的综合数据标注有怎样的支撑,这些原始数据无一例外都有用户与其历史发言短文本的数据对应关系。
19.综合数据标注:
20.主要对已拥有的数据集中的用户基于其历史发言短文本进行人工标注其是否罹患某种异常精神状态的可疑(严重)程度。
21.该方法主要从三个方向进行考量:专家标注、规则判断与权威标准。
22.专家标注指的是在用户发言可信度较高的前提下,请相关异常精神状态的心理学研究工作者或者是网络社交媒体(论坛)管理员进行基于文本的分级判断与标定。
23.规则判断主要包括正则式判断、自定义规则组判断与用户置信度判断。
24.正则式判断包括对于特定异常精神状态基于相关敏感词与特定发言模式的正则式构建与匹配,来对单个短文本进行可疑(严重)程度的标定,自定义规则组判断包括对于特定异常精神状态基于历史发言短文本进行用户人格侧写分析与最新短文本的场景模拟,来对特定用户在特定短文本下进行可疑(严重)程度的标定。
25.用户置信度判断包括对于特定异常精神状态基于用户信息与历史发言模式的一致性检测,来对单个用户进行发言短文本的置信度标定,权威标准指依照特定异常精神状态的权威著作与量表进行基于严重程度的症状表现划分依据,再以此作为对照来对特定用
户进行可疑(严重)程度的标定。
26.例如对于抑郁症可以采用《精神障碍的诊断与统计手册》(dsm-iv)进行参考、对于自杀倾向可以采用《哥伦比亚自杀严重程度量表》(c-ssrs)进行参考等。
27.模型构建与训练包括词向量提取,隐层构建,分类层构建与训练。
28.词向量提取采用机器学习领域中针对自然语言处理任务最普遍的word2vec思路完成从输入的自然语言形式的原始数据到单词级别特征向量的提取,来作为下一阶段隐层的的输入数据。此阶段可以采用bert/electra/roberta/longformer/albert/ct-bert等预训练词向量模型进行集成编码。
29.隐层构建采用复合结构,具体为两个seq2seq模型平行接受词嵌入输入(其中模型a为基于人工神经网络结构的模型,而模型b为异于人工神经网络结构的模型,比如说基于图结构的模型),然后平行输出至自注意力隐层。分类层构建采用例如softlabel等的多级顺次分类机制来进行分级分类。至此模型建立完整,输入为用户的历史短文本数据,输出为该用户基于特定异常精神状态的的分级分类标签。
30.注意到单个模型仅能一对一分级分类单个特定异常精神状态,因此对普遍意义的分级分类检测,模型的数量会随待检测的异常精神状态数量线性增长。
31.模型部署与更新包括封装,边缘化计算与联合迁移学习。
32.封装采用checkpoint技术等选取表现最优模型,封装并定义接口,然后部署至边缘设备。该模型可在边缘设备上进行分类与数据收集,并将数据闲时上传至数据中心;
33.数据中心可定时对成规模的新数据基于训练好的模型进行迁移学习,并将迁移学习后的增量模型更新至边缘设备,来提高分类精度。
34.上述即为本技术所述的“一种基于社交媒体短文本的用户异常精神状态分级评估方法”的完整流程。
35.本发明通过上述技术方案,具有以下有益效果:
36.本发明通过上述的技术方案,能够对使用社交媒体的用户在发布新消息时进行实时的异常精神状态分级检测,相较于现有的方案而言精度更高,反应更快,迭代更新能力更强,更客观而具有参考价值,从而为社交媒体运营方与相关公共心理卫生服务提供方提供一个更为高效便捷的处理意见参考。
附图说明
37.图1为本技术方法一实施例的基础流程图
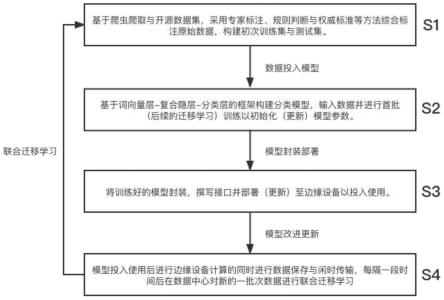
38.图2为本技术方法一实施例针对步骤s1(数据收集)的流程示意图
39.图3为本技术方法一实施例针对步骤s2(模型构建)的流程示意图
具体实施方式
40.如图1、图2、图3所示的一种基于社交媒体短文本的用户异常精神状态分级评估方法,包括以下步骤:
41.参考图1为本技术所描述的一种基于社交媒体短文本的用户异常精神状态分级评估方法的整体流程图。该方法包括以下步骤:
42.步骤s1:基于爬虫爬取与开源数据集采集原始数据,采用专家标注、规则判断与权
威标准等方法综合标注原始数据构建数据集。
43.步骤s2:基于词向量层-复合隐层-分类层的框架构建分类模型,输入数据并进行训练以确定模型参数。
44.步骤s3:将训练好的模型封装,撰写接口并部署至边缘设备以投入使用。本实施例中,假定合作社交媒体产品为微博,则作为微博客户端应用的某一个api进行封装与接口撰写,并在用户的智能机上进行边缘计算。
45.步骤s4:封装后投入使用的模型在进行边缘设备计算的同时进行数据保存与闲时传输,每隔一段时间后在数据中心对新的一批次数据进行联合迁移学习。
46.本实施例中,假定合作社交媒体产品为微博,则会在微博用户发布新消息时进行实时而迅速的高精度抑郁症分级检测(并将检测结果返回到数据中心以待后续处理),并随着微博客户端的版本更新一同更新本实施例的模型。
47.参考图2为本技术方法一实施例针对步骤s1,即数据收集步骤的流程示意图。该步骤包括以下子步骤:
48.步骤s11a:爬虫爬取社交媒体公开短文本数据与对应用户信息。本实施例中,假定合作社交媒体产品为微博,则可直接联系微博方获取公开短文本数据与对应用户信息。
49.步骤s11b:获取开源社交媒体短文本数据集。本实施例中,可获取“fine-grained depression analysis based on chinese micro-blog reviews”一文作者团队所使用的通过中文微博评论构建了一个用于抑郁症分析的人工注释数据集。
50.步骤s11c:模型已投入使用的前提下,定期获取的新原始数据。本实施例中,获得的新原始数据结构应类似步骤s11a中获取的数据。
51.步骤s12:统一定义原始数据向量维度,进行数据清洗与格式一致化。本实施例中无需赘述。
52.步骤s13a-e:即数据综合标注中使用的各个方法。本实施例中,步骤s13a专家标注可采用临时聘请抑郁症相关工作人士进行人工标注;步骤s13b正则式判断可撰写基于中文语境下抑郁症相关度高的敏感词进行正则式匹配;步骤s13c自定义规则组判断可基于历史短文本中表露出的时间、地点、人物、事件等要素进行场景模拟,同时基于用户的自我描述进行人格侧写,并以这些来进行对用户的抑郁症严重程度的人工标注;步骤s13d置信度判断可基于用户的元信息进行人工标定可信程度;步骤s13e权威标准可基于《精神障碍的诊断与统计手册》(dsm-iv)进行症状严重度标准制定并依次人工标注。
53.步骤s14:对标注后的数据进行标签平衡与域自适应,接着再构建训练集与测试集。本实施例中无需赘述。
54.参考图3为本技术方法一实施例针对步骤s2,即模型构建与训练步骤的流程示意图。该步骤包括以下子步骤:
55.步骤s21:建立词向量提取层。本实施例中可采用longformer预训练模型进行单词级别特征向量的提取集成编码。
56.步骤s22a-b:建立复合隐层中的平行层。本实施例中平行模型的模型a采用bi-lstm架构,模型b采用textgcn架构分别进行构造。
57.步骤s23:建立复合隐层中的自注意力隐层。本实施例中可参照transformer架构进行构造。
58.步骤s24:建立分类输出层。本实施例中可采用softlabel有序分级分类标准进行构造。
59.本实施例中,对本技术所提供的一种基于社交媒体短文本的用户异常精神状态分级评估方法进行了详细介绍,并基于一种特定情况进行阐述。以上实施例仅用于帮助理解本技术的方法与核心思路,在实际应用中的具体实施方式与范围上均可能有所变动。因此,本实施例不应理解为对本技术的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1