一种主题脉落的生成方法和系统与流程
1.本发明涉及计算机应用领域,具体而言,涉及一种主题脉落的生成方法和系统。
背景技术:
2.如今互联网信息爆炸式增长,信息来源繁多,面临着凌乱无序,过多冗余的问题。因此需要一种技术方法,用计算机来自动处理这些信息,把相同主题的信息归纳起来,就可以为信息工作者对信息的使用、生产、以及后期处理提供有效的帮助。例如新闻类信息的事件脉络生成,主要是为了解决在新闻舆情系统中,哪些新闻文章是指向同一个事件,这些同一个事件的新闻文章,时序是怎样的,从而得知这个事件的脉络是怎样发展的。
3.目前常用的方式有神经网络文本分类和文本向量的方法来做主题归纳,但是用神经网络文本分类的方法来做主题归纳,由于考虑全盘文本,语气词感叹词形容词会导致非常大的干扰,分类边界会不清晰;完全依赖神经网络,可微调性也比较差。用文本向量的方法来做主题归纳,容易关联错误,比如“姐夫”“妹夫”会认为是相近,结果就是匹配更多不相关的主题。
4.因此需要一种事件脉络生成的方法,可以清晰、准确、灵活地对话题信息归纳,生成主题脉落。
技术实现要素:
5.为实现以上目的,本发明提供了一种主题脉落的生成方法,包括以下步骤:
6.获取话题集合;
7.构建主题的信息结构:一个主题的信息结构包括多个话题,其中一个话题包括多个话题文本;
8.抽取话题文本的基础信息,生成所述话题文本的多角度描述信息;
9.根据基础信息和多角度描述信息构建图谱网络;图谱网络进行主题梳理,获取有效话题有序集合;
10.根据有效话题有序集合生成主题脉落。
11.其中,生成话题文本的多角度描述信息包括:从话题文本中抽取三元组后,选择有效的三元组;其中三元组的元素包括主语、谓语和宾语。
12.进一步的,图谱网络结构包括:标题节点、元素节点、节点路径,节点路径为标题与元素节点的间的关系;
13.进一步的,根据基础信息和多角度描述信息构建图谱网络,即将基础信息和多角度描述信息的元素填入图谱网络的结构。
14.进一步的,主题梳理包括:
15.通过图谱路径搜索获取关联的话题集合;
16.对关联话题进行关联度计算,获取有效话题集合;
17.对有效话题集合进行时间过滤;
18.根据时间对有效话题进行排序,生成有效话题有序集合;
19.对有效话题有序集合进行主题归类,生成主题脉落。
20.进一步的,话题文本的基础信息包括并不限于:地点、对象名称,其中对象名称包括人名、机构名。
21.进一步的,抽取三元组的步骤包括:
22.对话题文本进行分词处理,获取文本关键词,关键词包括动词和名词;
23.从关键词中提取动词,作为三元组的谓语;
24.以谓语为标准,上下文查找名词确定主语;
25.以谓语为标准,上下文查找名词确定宾语。
26.进一步的,上下文查找名词确定主语还包括对所述主语进行完整词义处理;上下文查找名词确定宾语还包括对宾语进行完整词义处理。
27.选择有效的三元组的过程包括:
28.量化三元组,获取三元组分值;
29.根据三元组积分进行排序,过滤可淘汰三元组。
30.另一方面,本发明提供了一种主题脉落的生成系统,其特征在于,包括:
31.话题获取模块:用于获取话题集合,输出所述话题集合元素的内容;
32.信息结构处理模块:用于处理话题集合元素的文本内容,对文本内容进行信息结构化的处理,将文本内容解析为话题文本,根据话题文本输出基础信息和多角度描述信息;
33.图谱网络应用模块:根据信息结构处理模块的输出内容,构建图谱网络,输出有效话题有序集合;图谱网络结构包括:标题节点、元素节点、节点路径;其中,节点路径为标题与元素节点的间的关系;
34.主题脉落输出模块:根据有效话题有序集合生成主题脉落。
35.进一步的,信息处理模块包括:
36.信息提取子模块:用于抽取话题文本的基础信息,基础信息包括地点、对象名称;
37.三元组处理子模块:用于从话题文本中抽取、完善三元组,三元组的元素包括主语、谓语和宾语,完善三元组包括补齐三元组的内容、筛除无效三元组;
38.图谱网络应用模块包括:
39.图谱网络生成模块:根据信息处理模块输出的基础信息和多角度描述信息和图谱网络的结构,生成图谱网络;
40.图谱网络计算模块:计算指定话题的关联度,输出有效话题集合;
41.集合梳理模块:用于对图谱网络计算模块输出的有效话题集合进行时间过滤和排序,输出有效话题有序集合。
42.根据本发明,将同一个话题下的文本内容按相同事件准确归类,并分析出事件话题的先后时间顺序以形成主题脉落,实现过程清晰、灵活、高效、具有可扩展性。
附图说明
43.图1是根据本发明实施例提供的相同事件的微博话题原始信息图;
44.图2是根据本发明实施例提供的主题脉落的生成方法流程图;
45.图3是根据本发明实施例提供的主题信息结构图;
46.图4是根据本发明实施例提供的图谱网络结构图;
47.图5是根据本发明实施例提供的微博主题脉落图;
48.图6是根据本发明实施例提供的主题脉落的生成系统结构图。
具体实施方式
49.下面结合说明书附图对本发明的具体实现方式做一详细描述。
50.本发明要解决的问题,例如新闻类信息的事件脉络生成,主要是为了解决在新闻舆情系统中,哪些新闻文章是指向同一个事件,这些同一个事件的新闻文章,时序是怎样的,从而得知这个事件的脉络是怎样发展的。即通过技术手段,将同一个话题下的文本内容按相同事件归类,并分析出事件话题的先后时间顺序。
51.本文中以微博场景下的一个案例举例进行说明:微博的内容具备话题性质,信息的创作者,会以#号嵌入话题的标题,所以每一个话题天然的聚合了该话题下的发布信息,本例内容如图1所示。但话题与话题之间虽然是同一个事件,以一定的时间先后顺序构成了整个事件,但微博本身并没有联系。
52.将事件的话题关联起来的步骤,首先看主题的结构,如图3所示:一个主题包括多个话题,话题包含标题,每个话题下有创作者发布的内容(即话题文本),发布的时间,显然话题所描述的事件存在于话题文本里,那么只要分析话题文本就能找到关联的方法。另一方面,相同事件的话题下的话题文本存在的共同点需要梳理出来,我们在描述一件事情的时候,通常会说时间(when),地点(where),人物(who),以及对事件各角度的描述 (what)。其中事件各角度的描述又可以分为主谓宾三元组。比如“央视记者探访云南野象群昨晚停留村庄”“云南野象群吃掉村庄的玉米”都是可以抽取出三元组的。只要我们把时间,地点,人物,事件各角度的描述三元组提取出来,并用一定的技术方法计算话题之间的得分,就能知道两个话题到底是不是属于同一个事件。
53.本发明提供的主题脉落的生成方法,将话题文本的基础元素进行归纳,对事件各角度的描述三元组进行提取,判断多个话题之间的联系,并且效率高、灵活。
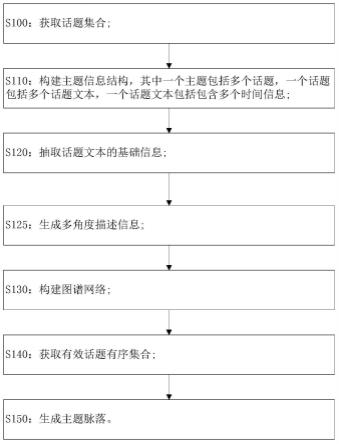
54.图2是本发明实施例中一种主题脉落的生成方法流程图,如图所示,包括以下步骤:
55.s100:获取话题集合;
56.首先,获取需要进行脉落梳理的话题集合,并对集合内的元素进行符号定义,一个话题下的单个话题文本用x表示,话题元素用s表示,n表示该话题下的话题文本数量,全部话题的集合用e表示。
57.s110:构建主题的信息结构:其结构如图3所示,其中,一个主题的所述信息结构包括多个话题(即话题集合e中的话题),其中一个话题包括多个话题文本,一个话题文本包含多个时间,在本例中,时间是构成主题脉落的重要元素。
58.s120:抽取所述话题文本的基础信息;话题文本的基础信息包括时间、地点、对象名称,其中对象名称包括人名、机构名,具体实现方法如下:
59.1、时间处理:话题文本中对时间的表达存在多种情况,如直接表达时间、内容中没有时间通过发表时间推算时间、多个时间等。通过时间处理,对时间数据的格式进行统一。
60.其中的话题发表时间产生集合pts。对话题产生时间集合pts进行计算,获取最小
值,min_pts作为话题的产生时间,计算规则如下:
61.pts=[pt
x0
,pt
x1
,...pt
xn-1
]
[0062]
min_pts=min(pts)
[0063]
对于话题的事件,通过时间处理得到一组事件相关的时间`t
x
,与发表的时间pt
x
合并在一起就是该篇内容的时间集合t
x
,话题下全部内容的时间集合都合并在一起就是话题时间集合times。并对话题时间集合times,求最大最小值,就能标记出话题时间边界:
[0064]
min_times=min(times)
[0065]
max_times=max(times)
[0066]
2、地点处理:处理话题下的内容对地点的描述,并对描述进行完整的补充,即在地区信息中包括国家、省份,城市,县(区),表示为地区l
x
。话题下全部内容的地区集合都合并在一起就是话题地区集合locs,表示如下:
[0067]
locs=[l
x0
,l
x1
,...l
xn-1
]。
[0068]
3、人物机构名称处理:话题文本的人物机构名称,一般是 "北京医院","央视","外交部","河南省人大"这样的文本片段,本发明中采用自然语言处理(nlp)模型提取人名,机构名。并对话题集合下全部话题文本的人物机构名称集合进行合并,即话题人物机构名称集合ners,表示如下:
[0069]
ners=[p
x0
,p
x1
,...p
xn-1
]。
[0070]
s125:生成话题文本的多角度描述信息;
[0071]
多角度描述信息指对事件各个方面的完整、结构化的说明。在一段文本内容中,会有主语,谓语,宾语,定语,状语及其他名词修饰词、语气感叹词,在本步骤中,去掉与文本核心关系不大的词,只保留核心的词,同时保持上下文意思不变。在本发明中,通过句法分析以及词性来抽取主谓宾三元组,并采用算法选择有效的三元组。主谓宾三元组即各角度描述信息的体现形式之一。本例中执行方法如下:
[0072]
①
抽取主谓宾三元组
[0073][0074]
三元组包括三个基本元素主语、谓语、宾语,根据中文的句法,有时候会缺少主语或者宾语,但大部分不会缺谓语,所以可以先从谓语入手,找上下文的名词,就可以找出三个元素。
[0075]
因此,本方法中,对话题文本进行分词处理,获取文本关键词,一般情况下,关键词
可以是动词也可以是名词;
[0076]
获取关键词后,提取动词作为三元组的谓语,再以谓语为标准,上下文查找名词确定主语和宾语。在缺少主语或者宾语的语义环境下,获取谓语后,通过此步骤获得主语或者宾语。主语和宾语还可以根据不同的情况进行再次加工,分别主语和宾语的完整词义处理。
[0077]
完整词义处理就是为了更加能准确表达主语和宾语,增加了一个处理,即以名词为中心,再找上下文的修饰词,以此构成更加准确的主语和宾语。
[0078]
具体操作时,文本内容x的分词(sentences)与分词的词性(pos)都可以从分词工具得到。例如:
[0079]
["央视","记者","探访","云南","野象群","昨晚","停留","村庄"]
[0080]
["nn","nn","vv","nr","nn","nt","vv","nn"]
[0081]
有两个vv,'探访'和'停留',当以'停留'为中心找上下文名词时,会得到('野象群','停留','村庄')。当以'探访'为中心找上下文名词时,会得到('记者','探访','野象群')。对主语“记者”进行完整词义处理,即以' 记者'为中心,通过名词找修饰词,对“记者”处理后生成“央视记者”,最终得到('央视记者','探访','野象群')。
[0082]
通过这种方式提取出两个三元组,即对事件的两个角度的描述。
[0083]
句法分析伪代码如下:
[0084][0085]
通过上述处理,获得多组与内容x所描述事件相关的三元组,构成话题三元组集合`spos,`spos=[e
x0
,e
x1
,...e
xn-1
]。
[0086]
②
三元组排序与过滤
[0087]
话题三元组集合中数量太多,需要对三元组进行一个排序,只取最主要的,能够代表事件的。在本发明中,采用量化三元组的方式实现排序,即获取三元组的分值。
[0088]
本发明中采用话题下所有文本的tf-idf权重值(可以从分词工具得到) 来给三元组量化打分,做法如下:
[0089]
先把话题下所有文本s输入分词工具的tf-i df函数得到分词的权重值,格式如下{'央视':0.62,'记者':0.76,'探访':0.85,'云南':0.79,'野象群':0.93,'昨晚':0.53,'停留':0.77,'村庄':0.58};
[0090]
然后遍历话题三元组集合`spos,假如三元组包含tfidfs中的词,就将该词的权重
值累加给这个三元组,如此每个三元组都会得到一个综合权重值,全部三元组的综合权重值集合用ws表示。将三元组集合`spos按三元组的分值即权重值ws排序,并抽取最大的前10个三元组,就是话题对事件各角度的描述,用spos表示。
[0091]
三元组排序与过滤伪代码如下:
[0092][0093]
在本发明中,对三元组进行了过滤,只保留了主要三元组,对于下一步的构建图谱网络的事物,进一步缩小了关联范围,提高的各元素的有效性和关联度。
[0094]
s130:根据基础信息和多角度描述信息构建图谱网络;
[0095]
通过s120和s125,获取了大量的符合规范的数据信息,在本步骤中,定义话题集合的属性,并将以上步骤获取的信息赋值给对应的属性,如下表所示:
[0096][0097]
构建图谱网络的结构:标题节点(用方框表示)、元素节点(用椭圆框表示)、节点路径,其中,节点路径为标题与元素节点的间的关系。
[0098]
根据基础信息和多角度描述信息构成的话题集合各元素的属生来构建图谱网络,指将基础信息和多角度描述信息的元素填入图谱网络的标题结点、元素节点和节点路径中。具体实现方式如下:
[0099]
a.将e中的每个话题s的标题作为标题节点(用方框表示);
[0100]
b.话题地区集合,话题人物机构名称集合,以及话题对事件各角度的描述三元组,里面的各个文本元素作为元素节点(用椭圆框表示);
[0101]
c.话题s与文本元素之间的关系作为节点之间的路径;
[0102]
其中,地区中的国家,路径为“国家”,地区中的省份,路径为“省份”,地区中的城市,路径为“城市”。
[0103]
其中,人物机构名称,则统一路径为“人物”。
[0104]
其中,对事件各角度的描述三元组,三元组的主语宾语则统一路径为“主宾语”。这是因为主语和宾语在不同的描述角度时,会互相交换。
[0105]
三元组的谓语则路径为“谓语”。
[0106]
例如:有三个话题。
[0107]
话题1:央视记者探访云南野象群昨晚停留村庄
[0108][0109]
话题2:云南野象群吃掉村庄的玉米
[0110]
[0111]
话题3:90后女孩用16道菜还原云南地图
[0112][0113][0114]
对以上属性搭建图谱结构生成的图谱网络如图4。
[0115]
s140:对所述图谱网络进行主题梳理,获取有效话题有序集合;
[0116]
首先从图谱网络的中抽取任意其中一个标题节点(用root表示),以该标题节点的属性作为搜索条件,在全部话题的图谱网络中找出与该标题节点属于同一个事件的其他标题节点(即话题),并将这些话题按时间先后顺序排序。
[0117]
1)通过图谱路径搜索获取关联的话题集合:
[0118]
2)对所述关联话题进行关联度计算,获取有效话题集合e
score
;
[0119]
3)有效话题集合e
score
进行时间过滤,进一步完善有效话题集合`e
final
;
[0120]
4)对有效话题集合排序,获取有效话题有序集合。
[0121]
s150:根据有效话题有序集合,生成主题脉落。
[0122]
在本例中,将`e
final
话题按集合的时间排序,成为有效话题有序集合:
[0123]
`e
final
话题集合按每个话题的min_pts时间进行排序(sort),结果标记为 e
final
,这个话题集合就是和root属于同一个事件,并且按照时间先后顺序的事件脉络集合e
final
=sort(`e
final
,min_pts)。
[0124]
对有效话题有序集合排序后,按时间进行展示,并进行主题归类,如图5 所示,生成主题脉落。
[0125]
图6是本发明提供的主题脉落的生成系统结构图,如图所示,生成系统包括:
[0126]
p610话题获取模块:用于获取话题集合,输出话题集合元素的内容;
[0127]
此模块获取话题的方式,支持多个元素构成新的集合,也支持在已有集合中添加新的元素。例如从微博中一次批量提取多条微博将其内容文本构成新的集合,也可以在已有的话题集合中添加新的微博文本内容。新增的内容元素或者新建的内容集合输出给p620信息结构处理模块。
[0128]
p620信息结构处理模块:用于处理话题集合元素的文本内容,对文本内容进行信息结构化的处理,将文本内容解析为话题文本,根据话题文本输出基础信息和多角度描述信息,总结下来,即将获取p610话题获取模块输出的话题集合中各元素的内容,将其内容按规范的结构进行抽取和拆分。在生成系统的子模块上,根据从文本信息到图谱网络到脉落
信息的过程中,其数据的存在形态不同而有不同的处理环境进行封装,以便于子模块的互相独立,提高灵活性和可维护性。具体的执行结构包括以下部分:
[0129]
p621信息提取子模块:用于抽取话题集合元素中话题文本的基础信息,如地点、对象名称、时间,对具有不同特征的信息进行不同的加工方式:
[0130]
1、时间处理功能块:收集发表时间、文本内容中的一个或多个时间,并对时间数据的格式进行统一,支持多种时间格式的处理,支持多种情况下的时间数据输出,例如:特定时间值,包括时间范围内的最大值最小值、时间集合。
[0131]
2、地点处理功能块:处理话题下的内容对地点的描述,并对描述进行完整的补充。
[0132]
3、名称处理功能块:对话题集合下全部话题文本的人物机构名称进行提取和合并,提取过程支持模型训练。
[0133]
p622三元组处理子模块:用于从话题文本中抽取、完善三元组,三元组的元素包括主语、谓语和宾语,并对三元组的元素进行补全和完善,包括对缺少主宾语的情况下补齐主宾语,对去掉与文本核心关系不大的三元组。三元组处理子模块,从实现上进行功能封装,包括:
[0134]
1、三元组抽取功能块:将输入的话题文本进行分词处理,获取文本关键词,根据语义分析抽出谓语,在谓语的基础上分析和完善主语、宾语。
[0135]
2、三元组加工功能块:对三元组进行量化、筛选和排序。
[0136]
p620信息结构处理模块还提供输出接口,将基础信息、三元组信息按接口规范输出,用于流程中的下一个模块生成图谱网络,本接口支持的数据方式不限于文本,可扩展为图片、音视频等。
[0137]
p630图谱网络应用模块:根据p620信息结构处理模块的输出内容,构建图谱网络,并输出有效话题有序集合。本模块中的图谱网络结构包括:标题节点、元素节点,标题节点与元素节点之间的关系用节点路径表示。
[0138]
本模块实现图谱网络的生成及其应用,包括从生成图谱网络到根据图谱元素计算相关的联系,根据功能对模块进行封装,包括以下三个子模块:
[0139]
p631图谱网络生成子模块:根据信息处理模块输出的基础信息和多角度描述信息结合图谱网络的结构,生成图谱网络。在结构上,可以根据需求进行调整,在元素的类型上,可以扩展。例如本发明中的图谱网络中为了保护关联的准确度,只考虑了人物机构名称、地点、时间、三元组这几个文本元素,随着需求变化,可以增加图片等其他元素。
[0140]
p632图谱网络计算子模块:计算指定话题的关联度,输出有效话题集合。
[0141]
在本发明中,指定图谱网络的一个标题节点作为root话题的标题节点,以该节点的元素节点作为搜索条件,在全部话题的集合e对应的图谱网络中找出属于同一个事件的其他话题。在计算子模块中,还支持其他算法的实现,例如,以某个元素节点对应的其他元素进行搜索,定义计算方式、定义输出方式等。
[0142]
p633集合梳理子模块:用于对图谱网络计算模块输出的有效话题集合进行时间过滤和排序,输出有效话题有序集合。
[0143]
对于有效话题集合的梳理,不限于对时间过滤和排序,还可以根据需求进行扩展。
[0144]
p640:主题脉落输出模块:根据有效话题有序集合生成主题脉落。
[0145]
通过本发明,收集各来源的事件信息,将同一个类型事件下的内容按一定的归类
规则进行分类,应用在新闻类信息的事件脉络生成场景上,可以控制分类的准确度,保证分类过程的计算效率,提高可扩展性,清晰、准确、灵活地对话题信息归纳,生成主题脉落。
[0146]
以上公开的仅为本发明的几个具体实施例,但是,本发明并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1