一种基于自适应的密度峰值聚类方法
1.本发明涉及计算机技术应用领域,具体是一种基于自适应的密度峰值聚类方法。
背景技术:
2.聚类是研究分类问题的一种统计分析方法,其所要求划分的类是未知的。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其它的簇中的对象相异。聚类被广泛应用于多个领域,如机器学习、模式识别、图像处理、信息检索等。针对不同的应用和数据特性已出现了千余种不同的聚类算法,但不同的聚类算法都有其特定的适用范围和不足。
3.传统的聚类算法大致可以分为划分聚类方法、层次聚类方法、密度聚类方法、网格聚类方法、模型聚类方法等。基于划分的聚类算法中最著名的两个算法分别是k-means算法和fcm(fuzzy c-means)算法,基于层次的聚类算法中三个有名的算法分别是cure(clustering using representative)算法和chameleon算法,基于密度的聚类算法中最为著名的是dbscan算法,基于网格的聚类算法的典型代表是sting算法和clique算法,较为有名的几个模型聚类方法是classi和em。
4.2014年,rodriguez和laio在《science》上发表了dpc(density peak)聚类算法[17],为聚类算法的设计提供了一种新的思路,引领了一新的聚类算法研究方向。该算法可以识别出任意形状的数据,能直观的找到簇的数量,也能非常容易地发现异常点,而且,其参数唯一、使用简单、具有非常好的鲁棒性。
[0005]
但dpeak算法也有诸多不足之处,如1)复杂度高,不适用于复杂数据,2)不能自适应选择密度峰值、截断距离和簇的数目,3)计算局部密度时,若没有考虑到数据的局部结构会导致簇的丢失,假峰和无峰,4)高维数据适用性差等。
技术实现要素:
[0006]
鉴于此,本发明主要解决密度峰值聚类算法不能自适应选取簇的数目,人工选取聚类中心的问题。本发明主要使用了迪杰斯特拉算法自动化确定簇的数目以及模糊c-均值聚类算法自适应选取聚类中心。
[0007]
为了达到上述目的,本发明的算法具体步骤如下:。
[0008]
步骤一:确定样本数据集x,源点s以及距离矩阵matrix。
[0009]
步骤二:根据欧氏距离矩阵matrix和源点s,使用迪杰斯特拉算法得到已找到最短路径的节点数组,从源点到已找到最短路径的节点的最短距离数组以及最短路径数组。
[0010]
步骤三:从最短路径数组中选取数组长度最长的一组最短路径,构成一个簇,簇的数目加一。
[0011]
步骤四:使用样本数据点集删除最短路径节点数组中的数据点,从而获取剩余点。
[0012]
步骤五:使用样本数据点集删除步骤三中已获取簇中的数据点,从而获取参与下次算法的数据点,返回到步骤二,获取下一个簇。经过多次迭代,获取最终簇的数目。
[0013]
步骤六:使用dpc算法计算数据点i的局部密度ρi,其公式为:
[0014]
步骤七:计算点i与其他密度更高的点之间的最小距离,其公式为:对于密度最高的点,则可以取:
[0015]
步骤八:dpc用上述两个变量,局部密度和最小距离构建ρ-δ决策图,将ρ和δ都较大的点选取为初始聚类中心,然后把剩下的点分配到比其密度大且离其最近的已分配的点的所在簇。
[0016]
步骤九:将dpc得到的初始化聚类中心和通过迪杰斯特拉算法得到的簇的数目作为模糊c-均值算法的输入条件,同时设置指数权重因子为2。
[0017]
步骤十:初始化迭代次数t,令t=0。
[0018]
步骤十一:根据初始化聚类中心集vi,算出μ
ij
,其公式为:
[0019]
步骤十二:根据vi和μ
ij
,计算出目标函数j,其公式为:
[0020]
步骤十三:根据μ
ij
,计算出新的vi,其公式为:
[0021]
步骤十四:根据新的vi,代入公式:计算出新的μ
ij
。
[0022]
步骤十五:根据新的vi和新的μ
ij
,代入公式:计算出新的目标函数j。
[0023]
步骤十六:判断j
(t)-j
(t+1)
》0是否成立,若成立,则令t=t+1,并转到步骤十三,否则,终止运算。
[0024]
步骤十七:经过多次迭代后,得到最终的聚类中心集v和隶属度矩阵u,由此划分数据集,得到聚类结果。
附图说明
[0025]
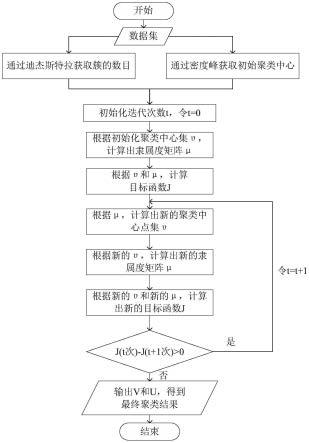
图1为本发明基于自适应的密度峰值聚类方法的流程图。
具体实施方式
[0026]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清除、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0027]
如图1所示,本发明提供了一种基于自适应的密度峰值聚类方法,其基本实现过程如下:
[0028]
1.输入数据集
[0029]
2.使用迪杰斯特拉算法自适应选取簇的数目。
[0030]
根据已确定的欧氏距离矩阵matrix和源点s,使用迪杰斯特拉算法得到已找到最短路径的节点数组,从源点到已找到最短路径的节点的最短距离数组以及最短路径数组。
[0031]
从最短路径数组中选取数组长度最长的一组最短路径,构成一个簇,簇的数目加一。
[0032]
使用样本数据点集删除最短路径节点数组中的数据点,从而获取剩余点。
[0033]
使用样本数据点集删除已获取簇中的数据点,从而获取参与下次算法的数据点,返回到算法起始的地方,获取下一个簇。经过多次迭代,获取最终簇的数目。
[0034]
3.使用dpc算法获取初始聚类中心。
[0035]
计算数据点i的局部密度ρi,其公式为:
[0036]
计算点i与其他密度更高的点之间的最小距离,其公式为:对于密度最高的点,则可以取:
[0037]
dpc用上述两个变量,局部密度和最小距离构建ρ-δ决策图,将ρ和δ都较大的点选取为初始聚类中心,然后把剩下的点分配到比其密度大且离其最近的已分配的点的所在簇。
[0038]
4.使用模糊c-均值聚类算法自适应获取聚类中心。
[0039]
将dpc得到的初始化聚类中心和通过迪杰斯特拉算法得到的簇的数目作为模糊c-均值算法的输入条件,同时设置指数权重因子为2。
[0040]
初始化迭代次数t,令t=0。
[0041]
根据初始化聚类中心集vi,算出μ
ij
,其公式为:
[0042]
根据vi和μ
ij
,计算出目标函数j,其公式为:
[0043]
根据μ
ij
,计算出新的vi,其公式为:
[0044]
根据新的vi,代入公式:计算出新的μ
ij
。
[0045]
根据新的vi和新的μ
ij
,代入公式:计算出新的目标函数j。
[0046]
判断j
(t)-j
(t+1)
》0是否成立,若成立,则令t=t+1,并转到步骤十三,否则,终止运算。
[0047]
经过多次迭代后,得到最终的聚类中心集v和隶属度矩阵u,由此划分数据集,得到聚类结果。
[0048]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1