一种远距离手势识别方法及装置
1.本发明涉及计算机视觉和手势识别领域,具体涉及一种远距离手势识别方法及装置。
背景技术:
2.手势识别在人与人之间的交流和人与机器之间的交互中发挥着重要的作用,在手语识别和自然人机交互领域中有着广阔的应用前景。由于手势变化复杂多样,持续时间也具有很大的不确定性,再加上拍摄角度和距离以及光照条件的影响,手势的检测和识别是一项挑战性很大的任务。
3.手势的识别需要考虑手部形状、位置的变化,人工设计的特征描述子很难覆盖到手势的细节特征,而深度神经网络具有很好的特征表征能力,在图像和视频视觉任务上显示出其强大的优势。因此,目前主流的手势识别方法是基于深度神经网络学习表达手势复杂的空间形态特征和时序运动特征。卷积神经网络(convolutional neural networks,cnns)被广泛用于提取图像的空间特征。对于时序运动特征的表示,主要有三种方法:第一种是基于光流(opticalflow)、运动向量,这种方式计算量非常大,而且易受光照和遮挡情况影响,鲁棒性差;第二种是使用循环神经网络(recurrent neural networks,rnns)提取时序特征,这种方式将卷积神经网络提取到的图像特征输入到循环神经网络中提取运动特征,模型庞大复杂,优化困难,而且往往需要对原始视频进行大幅度的下采样,这样容易丢失关键信息;第三种是基于3d卷积,使用三维卷积核在两个空间维度和一个时间维度上进行卷积,同时提取空间特征和时序特征,这种方式在能够很好的建模和融合时空特征,但是需要设计合适的卷积核和网络结构,在保证识别精度的同时提高预测速度。
4.现有的手势识别方法关注的是面对面交流、手势控制驾驶等近距离交互场景,如中国发明专利cn108932500a和cn113255602a。在这些场景中,手势发出者距离摄像头很近,因此手部在采集的画面中是显著且容易被识别的,然而在很多场景中,需要远距离的控制与交互。如会议场景中与会者希望通过手势控制会议大屏一体机进行幻灯片的放映,家居观影时通过手势调节播放进度、声音等。在远距离情况下,手势发生的区域在摄像机视野中的占比很小,手势细节不足,同时背景也会带来更多的干扰,手势识别具有更大的难度。
技术实现要素:
5.本发明的目的是针对上述现有技术中手势识别精度低、速度慢以及无法识别远距离手势的问题,提供一种远距离手势识别方法及装置,能够提取更鲁棒的视频特征,并且能够捕捉远距离手势,进行精准识别。
6.本发明为实现上述目的,采用如下技术方案:
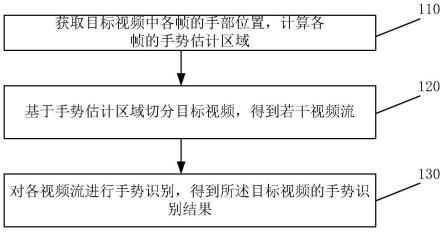
7.一种远距离手势识别方法,其步骤包括:
8.获取目标视频中帧p1的手部位置h1,并基于所述手部位置h1,计算帧p1的手势估计区域 q1;
9.获取目标视频中帧pi的手部位置hi,并当所述手部位置hi落在帧p
i-1
的手势估计区域qj之内时,将所述手势估计区域qj作为所述帧pi的手势估计区域,否则基于所述手部位置hi,计算帧pi的手势估计区域q
j+1
;
10.基于手势估计区域qj切分所述目标视频,得到若干视频流s
t
;
11.对各所述视频流s
t
进行手势识别,得到所述目标视频的手势识别结果。
12.进一步地,所述获取目标视频中帧p1的手部位置h1,包括:
13.在手部位置训练集上对yolo v4 tiny检测模型进行监督训练,得到手部检测器;
14.将所述帧p1的图像输入所述手部检测器,得到所述手部位置h1。
15.进一步地,所述基于所述手部位置h1,计算帧p1的手势估计区域q1,包括:以所述手部位置h1为中心,分别向外扩展rw倍手部宽度及rh倍手部高度的矩形区域。
16.进一步地,所述基于手势估计区域qj切分所述目标视频,得到视频流s
t
,包括:
17.在各帧pi中获取若干关键帧;
18.使用同一手势估计区域qj中的关键帧,构建视频流s
t
。
19.进一步地,所述在各帧pi中获取关键帧,包括:
20.针对具有同一手势估计区域qj的帧pi与帧p
i-1
,分别将所述手势估计区域qj转化为灰度图像f
cur
和灰度图像f
pre
;
21.计算所述灰度图像f
cur
与灰度图像f
pre
的帧差图;
22.基于设定的像素值阈值,将所述帧差图转变为二值图;
23.基于所述二值图,在所述手势估计区域qj中统计大于像素值阈值的像素数;
24.计算所述像素数占所述手势估计区域qj的像素总数的比例,并依据所述比例,判断所述帧pi是否为关键帧。
25.进一步地,所述对各所述视频流s
t
进行手势识别,得到所述目标视频的手势识别结果,包括:
26.利用滑动窗口,获取所述视频流s
t
的若干窗口;
27.将窗口视频流输入基于3d resnext-101卷积神经网络的多模态手势识别模型,用于预测该窗口的手势类别,其中所述手势识别模型的每个resnext残差模块后都对来自不同模态视频流的特征图进行加权融合;
28.当连续n个窗口的手势类别都被预测为手势类别lc时,将该手势类别lc作为所述视频流s
t
中的一个预测结果;
29.统计所述视频流s
t
中的预测结果,得到所述目标视频的手势识别结果。
30.进一步地,所述不同模态视频流包括:rgb视频流和深度视频流。
31.进一步地,当连续m个窗口的手势类别被预测为非手势类别lc时,判断所述手势类别lc已结束。
32.一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一所述方法。
33.一种电子设备,其特征在于,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一所述方法。
34.本发明与现有技术相比的有益效果在于:
35.(1)多模态数据驱动:通过设计的多模态手势识别模型,融合rgb和深度两种模态
的数据特征进行预测。两种数据特征相互补充,具有更强的抗干扰性和更高的识别精度;
36.(2)远距离识别:提出手势区域估计方法,能够在远距离情况下快速定位手势;
37.(3)识别速度快精度高:提出关键帧采样方法,能够使用较少的帧进行精准的手势预测,同时能够应对不同类别手势持续时间和个体手势速度差异的影响;
38.(4)检测手势出现的具体位置:在识别手势类别的同时还能够检测手势在视频中出现的具体位置,能够对视频中出现的多个手势进行检测和识别。
附图说明
39.图1为本发明远距离手势识别智能系统流程示意图。
40.图2为多模态手势识别网络模型结构图。
具体实施方式
41.下面将结合附图和一个具体的实施例进一步详细阐述本发明,但本发明并不限定于这一实施例。
42.本发明基于rgb-d数据和3d卷积神经网络进行远距离手势识别,首先需要构建远距离手势数据集,为模型提供训练数据。本实施例中采用kinect v4设备采集rgb-d视频数据, rgb流和深度流的分辨率分别为1280
×
720和640
×
570,以30fps的帧率同步采集。30个受试者被随机分配到5个场景中进行手势的采集。采集距离在1m到4m之间。采集完成后为每个手势标注类别及其在视频中的开始帧和结束帧,并标注每个视频帧中手部的位置 (x,y,w,h),(x,y)为手部矩形包围框的中心点坐标,w和h分别为矩形框的宽和高。
43.为了估计手势发生区域,需要训练一个手部检测器。本实施例采用yolo v4 tiny检测模型,在构建的数据集上利用手部位置标注进行监督训练,保存性能最好的模型权重。
44.远距离条件下手势在摄像视野内不够显著,因此本发明提出的方法中基于手部位置估计手势发生区域,以快速缩小手势范围,进行更精确的识别,具体步骤如下:
45.1)使用训练好的手部检测器检测当前帧中手部的位置,记为r
hand
=(x,y,w,h),其中 (x,y)为手部矩形包围区域r
hand
的中心点坐标,w和h分别为区域的宽和高;
46.2)估计手势可能发生的区域为以手部为中心,向外扩展rw倍(例如5倍)手部宽度,rh倍(例如4倍)手部高度的矩形区域,记为r
ges
=(x,y,rw×
w,rh×
h);
47.3)为每个新来的帧重复步骤1),若当前帧中的手部位置落在上一帧估计的手势区域内,则保持原来估计的手势区域不变,否则,进行步骤2),估计新的手势区域。
48.不同手势的持续时间不同,并且每个个体做手势的速度也会有差异,持续时间长的手势需要长距离的时序特征才能够识别,单纯增加特征窗口的大小会使得模型计算量很大,识别速度慢,本发明中提出关键帧采样法,去除相似的冗余帧,使模型能够以较少的计算量得到长距离的时序特征,保证识别的精度和速度。关键帧采样步骤如下:
49.1)从当前帧和上一帧裁剪相应的手势估计区域,并转化为灰度图像,记为f
cur
和f
pre
,计算两个手势估计区域的帧差图:
50.f
diff
=|f
cur-f
pre
|
51.2)取像素值阈值25,将帧差图f
diff
转变为二值图f
bin
,即像素值大于25的位置赋值为 1,代表两帧之间在该位置的改变量足够大,否则赋值为0;
52.3)统计二值图中值为1的像素数占总像素数的比例:
[0053][0054]
其中w和h分别为二值图f
bin
的宽和高,当r>0.3时认为当前帧为关键帧,保留以用于手势识别,否则认为是冗余帧,直接舍弃。
[0055]
手势识别模型基于resnext-101卷积神经网络设计,如图2所示,用两个3d resnext
‑ꢀ
101网络分别提取rgb视频流和深度视频流的特征,并在每个resnext残差模块后都对特征图进行加权校正,通过两个模态数据特征的融合和权重再分配使模型关注那些更加有效和鲁棒的特征。模型训练步骤如下:
[0056]
1)预处理:对数据集中的手势进行区域估计和关键帧采样,然后将数据按照7:3的比例分为训练集和验证集两部分;
[0057]
2)训练:在预处理后的rgb-d视频数据上训练多模态手势识别模型,利用手势类别及手势起始位置标注数据作为监督信号;
[0058]
3)测试:在验证集上测试模型性能,保存性能最好的模型权重。
[0059]
对于给定的视频或摄像头实时采集的视频流,本发明的远距离手势识别方法具体步骤如下:
[0060]
1)获取目标视频中帧p1的手部位置h1,并基于所述手部位置h1,计算帧p1的手势估计区域q1;
[0061]
2)获取目标视频中帧pi的手部位置hi,并当所述手部位置hi落在帧p
i-1
的手势估计区域 qj之内时,将所述手势估计区域qj作为所述帧pi的手势估计区域,否则基于所述手部位置hi,计算帧pi的手势估计区域q
j+1
;
[0062]
3)基于手势估计区域qj切分所述目标视频,得到若干视频流s
t
;
[0063]
4)利用滑动窗口,获取所述视频流s
t
的若干窗口;
[0064]
5)将窗口视频流输入基于3d resnext-101卷积神经网络的多模态手势识别模型,用于预测该窗口的手势类别,其中所述手势识别模型的每个resnext残差模块后都对来自不同模态视频流的特征图进行加权融合;
[0065]
6)当连续n个窗口的手势类别都被预测为手势类别lc时,将该手势类别lc作为所述视频流s
t
中的一个预测结果;
[0066]
7)统计所述视频流s
t
中的预测结果,得到所述目标视频的手势识别结果。
[0067]
本发明提出的方法基于手部位置估计手势发生区域,将手势识别的范围大大缩小,减少了远距离情况下大量的背景干扰,同时聚焦于手势特征,提高了远距离手势识别的精度。使用关键帧采样减少了手势持续时间和速度的影响,同时减少了模型的计算量,保证了模型识别的精度和速度。设计的基于3d卷积神经网络的手势识别模型综合利用多模态数据信息进行识别,抗干扰性更强,精度更高。
[0068]
以上仅为本发明的一个优选的具体实施例,应当指出,凡在本发明基本原理方法之内做出修改、等同替换等得到的方案,均包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1