基于最大熵强化学习的自动驾驶汽车决策规划方法
1.本发明属于自动驾驶汽车领域,涉及一种基于最大熵强化学习的自动驾驶汽车决策规划方法。
背景技术:
2.驾驶员操作不当已经成为交通系统中影响安全的主要因素。作为智能交通运输系统的一环,在改善交通安全方面有着巨大潜力的自动驾驶技术,引起了国内外研究人员的重视。
3.由于同时涉及横向与纵向运动,车辆换道行为风险较高、逻辑复杂。当前的决策规划方法主要分为基于规则的、基于优化的与基于学习的。基于规则的方法受限于人工设计的、僵化的规则,换道策略过于保守,并且只适用于特定场景。基于优化的方法将换道决策规划问题看作一个有约束的非线性、非凸优化问题。由于该优化问题求解难度高,该类方法难以满足实时性要求。基于学习的方法可利用驾驶数据,自动生成具有泛化性的驾驶经验,有适应各种场景的潜力。但当前基于学习的决策规划方法的数据利用率与稳定性不足。同时,驾驶数据采集成本高、采集风险大,并且数据难以体现环境车辆与目标车辆间的交互。
4.因此,需要一种新的自动驾驶汽车高速公路决策规划方法来解决以上问题。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种基于最大熵强化学习的自动驾驶汽车高速公路决策规划方法,通过仿真训练环境提供的交互性训练数据,提高基于学习的方法的数据利用率、最优性和稳定。
6.为达到上述目的,本发明提供如下技术方案:
7.一种基于最大熵强化学习的自动驾驶汽车高速公路决策规划方法,具体包括以下步骤:
8.s1:构建基于最大熵强化学习的决策规划模型,该模型包括:状态空间、动作空间、奖励函数、策略函数与评价模型;
9.s2:构建具有交互性的高速公路仿真训练场景:使用二自由度汽车运动学模型描述训练场景中车辆的运动,并利用基于规则的智能决策规划模型控制环境车辆,使环境具有交互特性;
10.s3:训练基于最大熵强化学习的决策规划模型。
11.进一步,步骤s1中,构建基于最大熵强化学习的决策规划模型,具体包括:
12.s11:搭建状态空间s:以关键的环境信息构建状态空间,包括目标车辆的位置、速度和航向角,一定范围内的环境车辆相对目标车辆的相对位置、相对速度及其航向角;状态空间表示环境中可能出现的全部状态。状态是目标车辆对环境的观测,最大熵强化学习模型将获得的状态作为决策规划的基础。
13.s12:确定动作空间a:动作空间由车辆加速度与前轮转向角组成,以此控制目标车
辆的移动;动作空间表示最大熵强化学习模型可采取的动作。
14.s13:构建奖励函数r:奖励函数是安全指标r
safe
、高效指标r
speed
、舒适指标r
comfort
和合规指标r
rule
四个指标的加权求和,即:
15.r=k1r
safe
+k2r
speed
+k3r
comfort
+k4r
rule
16.其中,k1、k2、k3、k4为各项的权重,安全指标r
safe
要求目标车辆未发生碰撞或者驶向道路外,高效指标r
speed
要求目标车辆的行驶速度接近期望速度,舒适指标r
comfort
要求车辆的侧向加速度较小,合规指标r
rule
鼓励车辆在最右侧车道行驶并鼓励车辆沿着所在车道中心线行驶;
17.s14:给定策略函数π的结构:使用多层感知机拟合策略函数π,其中;策略函数表示状态与动作间的映射关系;
18.s15:给定评价模型的结构:评价模型包括两对评价函数与目标评价函数;两个评价函数q1、q2与两个目标评价函数q
tar-1
、q
tar-2
均由相同结构的多层感知机拟合;目标评价函数的作用是提高模型的数据利用率,使用两对评价函数与目标评价函数是为了提高模型的稳定性。评价模型以最大化奖励与策略熵的加权和为评价标准,评估最大熵强化学习模型采取的动作。
19.进一步,步骤s2中,构建具有交互性的高速公路仿真训练场景,具体包括以下步骤:
20.s21:规定仿真环境中,车辆的运动皆由二自由度的运动学模型描述:
[0021][0022][0023]
其中,x、y、v分别是车辆的纵向位置、横向位置、横摆角以及速度,x’、y’、v’分别是纵向位置、横向位置、横摆角以及速度的一阶导数,a是加速度,lr、lf是车辆的重心到前轴、后轴的距离,β是车辆的重心处的侧偏角,δ是转向角;
[0024]
s22:搭建基于规则的环境车辆决策规划模型:为了使环境车辆能对环境的变化主动做出反应,从而使仿真环境具有交互性,赋予环境车辆一种基于规则的智能决策规划模型;
[0025]
s23:随机初始化环境车辆在仿真环境中的初始位置、初始速度与期望速度。
[0026]
进一步,步骤s3中,训练基于最大熵强化学习的决策规划模型,具体包括:模型初始化,生成交互式训练数据,更新评价模型、策略函数和温度系数,测试模型性能。
[0027]
进一步,步骤s3中,训练最大熵强化学习模型,具体包括以下步骤:
[0028]
s31:初始化最大熵强化学习的决策规划模型,包括模型的超参数、策略函数与评价函数;
[0029]
s32:在仿真训练环境中加入目标车辆,生成交互性的训练数据(s
t
,a
t
,r
t
,s
t+1
),;将训练数据添加至数据库;
[0030]
s33:从数据库中提取训练数据,以梯度下降法分别更新评价模型的两个评价函数,下降梯度为:
[0031][0032][0033]
其中,m是采样的样本数,|m|表示样本集合的大小,s
t
、a
t
、r
t
分别是车辆在t时刻所处的状态、采取的动作、获得的奖励,qi是第i个评价函数,θi是评价函数qi的参数,y(
·
)是对评价函数值的预测,q
tar-j
是第j个目标函数,π(
·
|s
t
)表示策略函数,是在下一时刻的状态s
t+1
下,根据策略函数采样的下一时刻的行为;α是温度系数;γ是折扣因子;
[0034]
s34:以梯度下降法更新策略函数,下降梯度为:
[0035][0036]
其中,ψ是策略函数的参数,是在下一时刻的状态s
t+1
下,根据策略函数采样的下一时刻的行为;
[0037]
s35:以梯度下降法更新温度系数,下降梯度为:
[0038][0039]
其中,α是温度系数,h0为目标熵值;
[0040]
s36:分别更新评价模型的两个目标评价函数:
[0041]
θ
tar,i
=ρθ
tar,i
+(1-ρ)θi,for i=1,2
[0042]
其中,ρ为软更新系数,θ
tar,i
是目标函数q
tar-i
的参数,θi是评价函数qi的参数;
[0043]
s37:迭代更新最大熵强化学习模型:最大熵强化学习模型收敛后,测试最大熵强化学习模型,若不满足期望,则优化最大熵强化学习模型的超参数和奖励函数,并返回至步骤s31。
[0044]
本发明的有益效果在于:
[0045]
1)本发明设计了一种具有交互特性的仿真训练环境,使训练数据更符合真实交通场景特征,有利于提高最大熵强化学习模型在真实交通场景中的决策规划性能。
[0046]
2)本发明设计了一种基于最大熵强化学习的决策规划模型,有利于提高模型的数据利用率、最优性与稳定性。
[0047]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0048]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0049]
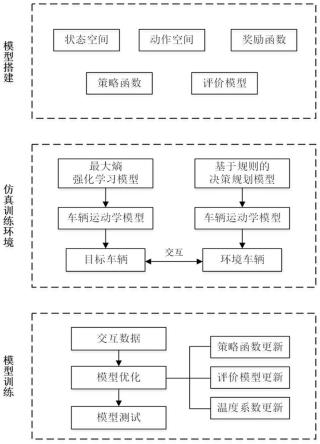
图1为本发明基于最大熵强化学习的自动驾驶汽车决策规划方法的逻辑结构图;
[0050]
图2为最大熵强化学习决策规划模型结构示意图;
[0051]
图3为仿真训练环境示意图;
[0052]
图4为最大熵强化学习决策规划模型训练过程示意图。
具体实施方式
[0053]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0054]
请参阅图1~图4,本发明提供了一种基于最大熵强化学习的自动驾驶汽车高速公路决策规划方法。考虑到现实交通环境中车辆间的交互行为,因此提供一种交互性的仿真训练环境,用于提供交互性训练数据。同时,考虑到自动驾驶车辆决策规划问题对稳定性与行驶效率的要求,提出一种稳定性更好、行驶效率更高、样本利用率更高的基于最大熵强化学习的决策规划方法。该方法具体包括以下步骤:
[0055]
步骤s1:构建最大熵强化学习模型,如图2所示,具体包括以下步骤:
[0056]
s11:搭建状态空间s:状态空间包括目标车辆的位置、速度,一定范围内的环境车辆相对目标车辆的相对位置、相对速度,即
[0057]
s=(se,si)
[0058][0059][0060]-l<δx
ie
<l,i≤4,i∈n
[0061]
其中,se指目标车辆,si指环境车辆,[-l,l]指目标车辆的观测范围,x,y是车辆的纵向、横向位置,v
x
,vy是车辆的纵向、横向速度,指航向角。
[0062]
s12:确定动作空间a:动作空间由车辆加速度与前轮转向角组成,以此控制目标车辆的移动,即a=(a,δ),s.t.a∈[-4,4]m/s2,δ∈[-0.1,0.1]rad。
[0063]
s13:构建奖励函数r:奖励函数从安全、高效、舒适三个方面对最大熵强化学习模型采取的动作进行评估。安全指标要求目标车辆未发生碰撞或者驶出道路:
[0064][0065]
其中,k1为一个惩罚值,c=1指发生碰撞或者驶出道路。
[0066]
高效指标要求目标车辆的行驶速度接近期望速度,但不能超出期望速度区间:
[0067][0068]
其中,[v
min
,v
max
]指期望的速度区间,ve指本车的速度。
[0069]
舒适指标要求目标车辆以较小的侧向加速度行驶:
[0070][0071]
此外,目标车辆应尽可能的跟随车道中心线,并在高速公路的最左侧车道行驶:
[0072]rrule
=k
4.1
l
ind
+k
4.2dl
[0073]
其中,l
ind
指目标车辆所在车道的编号,d
l
指目标车辆与所在车道的中心线的距离。
[0074]
最终,奖励函数为r=k1r
safe
+k2r
speed
+k3r
comfort
+k4r
rule
,其中k1,k2,k3,k4为各项的权重。
[0075]
s14:给定策略函数π的结构:规定策略函数遵循高斯分布,并使用多层感知机π
φ
拟合该高斯分布。多层感知机为含两个隐含层的全连接神经网络,每个隐含层的神经元个数为128。
[0076]
s15:给定评价函数q的结构:评价模型包括两个评价函数q1、q2与两个目标评价函数q
tar-1
、q
tar-2
。两对评价函数与目标评价函数均由含两个隐含层的全连接神经网络构成,每个隐含层的神经元个数为128。
[0077]
步骤s2:构建交互性训练环境,如图3所示,具体包括以下步骤:
[0078]
s21:规定仿真环境中,车辆的运动皆由二自由度的运动学模型描述:
[0079][0080][0081]
其中,x、y、v分别是车辆的纵向位置、横向位置、横摆角以及速度,lr、lf是车辆的重心到前轴、后轴的距离,β是车辆的重心处的侧偏角。
[0082]
s22:搭建基于规则的环境车辆决策规划模型:为了使环境车辆能对环境的变化主动做出反应,从而使仿真环境具有交互性,赋予环境车辆基于规则的决策规划模型。其中,构建环境车辆决策规划模型,具体包括以下步骤:
[0083]
s221:环境车辆的决策规划模型根据前车信息,输出加速度指令a:
[0084][0085]ddes
=d0+v
·
(t0+0.1
·
δv)
[0086]
其中,a
max
为最大加速度,v为车辆纵向速度,v
des
为车辆纵向期望速度,m为加速度参数,d
des
为车辆纵向期望距离,d0为车辆纵向最小距离,t0为车辆最小碰撞时间,δv为与前车的相对速度。
[0087]
s222:环境车辆的决策规划模型通过评估各个车道,输出满足安全与收益指标的车道作为目标车道:
[0088][0089]
其中,v0指该决策规划模型控制的车辆,v1指当前车道上的后车,v2指期望车道上的后车,δa指加速度变化量。
[0090]
s223:环境车辆的决策规划模型根据目标车道,输出转向角指令δ:
[0091][0092][0093]
其中,l指v0的长度,wr指期望的横摆角速度,指横摆角,δd
lat
指与目标车道的横向距离。
[0094]
s23:随机初始化环境车辆在仿真环境中的初始位置、初始速度与期望速度。
[0095]
步骤s3:训练最大熵强化学习模型,如图4所示,具体包括以下步骤:
[0096]
s31:初始化最大熵强化学习模型,包括模型的超参数,策略函数与评价函数。
[0097]
s32:在仿真训练环境中加入目标车辆,生成交互性的训练数据(s
t
,a
t
,r
t
,s
t+1
);将训练数据添加至数据库。
[0098]
s33:从数据库中提取训练数据,以梯度下降法分别更新评价模型的两个评价函数,下降梯度为:
[0099][0100][0101]
其中,m是采样的样本数,|m|表示样本集合的大小,是在下一时刻的状态s
t+1
下,根据策略采样的下一时刻的行为;s
t
为车辆在t时刻在状态空间s中的取值。θi是评价函数qi的参数。α是温度系数,用来权衡最大熵强化学习模型对奖励与熵的偏好。
[0102]
s34:以梯度下降法更新策略函数,下降梯度为:
[0103][0104]
其中,ψ是策略函数的参数。
[0105]
s35:以梯度下降法更新温度系数,下降梯度为:
[0106][0107]
其中,α是温度系数,h0为目标熵值。
[0108]
s36:分别更新评价模型的两个目标评价函数:
[0109]
θ
tar,i
=ρθ
tar,i
+(1-ρ)θi,for i=1,2
[0110]
其中,ρ为软更新系数,θ
tar,i
是目标函数q
tar-i
的参数,θi是评价函数qi的参数。
[0111]
s37:迭代更新最大熵强化学习模型:最大熵强化学习模型收敛后,测试最大熵强
化学习模型,若不满足期望,则优化最大熵强化学习模型的超参数和奖励函数中的权重,并返回至步骤s31。最终模型的超参数如表1所示。
[0112]
表1模型的超参数取值
[0113]
超参数名称值学习率0.0005折扣因子γ0.9软更新系数ρ0.02回忆库容量1000000最小训练样本256目标熵值h
0-2
[0114]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1