1.本发明涉及多目标跟踪技术领域,特别是涉及多目标行人跟踪方法及系统。
背景技术:
2.本部分的陈述仅仅是提到了与本发明相关的背景技术,并不必然构成现有技术。
3.目标跟踪一直是机器视觉领域比较富有挑战性的研究方向,近年来多目标跟踪变成了许多研究者的重点研究对象,多目标跟踪是为视频中不同物体赋予相应id,并在后面所有帧中跟踪物体,不同物体具有不同id,相同物体id理论上一直不会变。与目标检测不同的是,目标跟踪可以在后续帧中精准查找同一物体,还可以实现物体的轨迹预测,这些特性使得多目标跟踪在自动驾驶、智能监控等方面有着大量应用空间。
4.近年来随着gpu设备不断更新换代,深度学习变成了研究热门,基于深度学习的目标跟踪有着与传统方法相比更高的准确率和实时性。其中经典的deepsort多目标跟踪算法已经应用于许多方面,它对多目标跟踪中id switch,实时性差等问题提出了一系列解决方案。
5.传统deepsort中检测器和特征提取器采用大规模神经网络,有着精度高,实时性强,漏检率、id switch少等优点。但同时使用成本较高,对于一些硬件条件差的小设备、移动端等没有足够的存储空间、gpu、散热来支撑算法运行。
技术实现要素:
6.为了解决现有技术的不足,本发明提供了多目标行人跟踪方法及系统;目标检测部分使用最新的yolov5,目标跟踪使用deepsort,在跟踪器中修改传统deepsort的特征提取网络,使用更加轻量化的shufflenetv2代替,在保持精度的同时缩小模型权重大小。
7.第一方面,本发明提供了多目标行人跟踪方法;
8.多目标行人跟踪方法,包括:
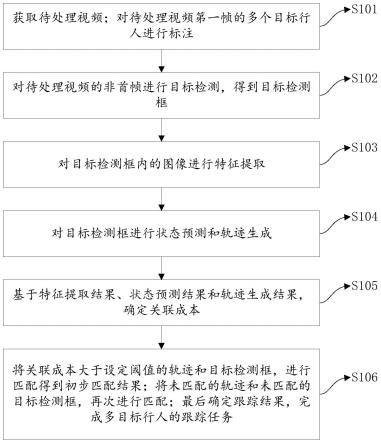
9.获取待处理视频;对待处理视频第一帧的多个目标行人进行标注;
10.对待处理视频的非首帧进行目标检测,得到目标检测框;
11.对目标检测框内的图像进行特征提取;
12.对目标检测框进行状态预测和轨迹生成;
13.基于特征提取结果、状态预测结果和轨迹生成结果,确定关联成本;
14.将关联成本大于设定阈值的轨迹和目标检测框,进行匹配得到初步匹配结果;将未匹配的轨迹和未匹配的目标检测框,再次进行匹配;最后确定跟踪结果,完成多目标行人的跟踪任务。
15.第二方面,本发明提供了多目标行人跟踪系统;
16.多目标行人跟踪系统,包括:
17.获取模块,其被配置为:获取待处理视频;对待处理视频第一帧的多个目标行人进行标注;
18.目标检测模块,其被配置为:对待处理视频的非首帧进行目标检测,得到目标检测框;
19.特征提取模块,其被配置为:对目标检测框内的图像进行特征提取;
20.状态预测和轨迹生成模块,其被配置为:对目标检测框进行状态预测和轨迹生成;
21.关联成本确定模块,其被配置为:基于特征提取结果、状态预测结果和轨迹生成结果,确定关联成本;
22.跟踪模块,其被配置为:将关联成本大于设定阈值的轨迹和目标检测框,进行匹配得到初步匹配结果;将未匹配的轨迹和未匹配的目标检测框,再次进行匹配;最后确定跟踪结果,完成多目标行人的跟踪任务。
23.第三方面,本发明还提供了一种电子设备,包括:
24.存储器,用于非暂时性存储计算机可读指令;以及
25.处理器,用于运行所述计算机可读指令,
26.其中,所述计算机可读指令被所述处理器运行时,执行上述第一方面所述的方法。
27.第四方面,本发明还提供了一种存储介质,非暂时性地存储计算机可读指令,其中,当所述非暂时性计算机可读指令由计算机执行时,执行第一方面所述方法的指令。
28.第五方面,本发明还提供了一种计算机程序产品,包括计算机程序,所述计算机程序当在一个或多个处理器上运行的时候用于实现上述第一方面所述的方法。
29.与现有技术相比,本发明的有益效果是:
30.本发明使用基于上述原则提出的shufflenetv2网络于传统deepsort结合,替换deepsort跟踪器中的特征提取网络,大大降低了模型复杂程度、权重参数大小,shufflenetv2在shufflenetv1的基础上做了大量修改,修改了逐点卷积和瓶颈结构这种会增加内存访问成本的操作等。修改后的deepsort可以实现在硬件设备差的低性能嵌入式终端设备上运行,增大了算法的应用性。
附图说明
31.构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
32.图1为本发明的方法流程图;
33.图2(a)和图2(b)为shufflenetv2网络结构中block和下采样层结构示意图;
34.图3(a)和图3(b)为两种网络模型的大小对比;
35.图4为最终检测效果示意图。
具体实施方式
36.应该指出,以下详细说明都是示例性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
37.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,术语“包括”和“具有”以及他们的任何变形,
意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
38.在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
39.本实施例所有数据的获取都在符合法律法规和用户同意的基础上,对数据的合法应用。
40.实施例一
41.本实施例提供了多目标行人跟踪方法;
42.如图1所示,多目标行人跟踪方法,包括:
43.s101:获取待处理视频;对待处理视频第一帧的多个目标行人进行标注;
44.s102:对待处理视频的非首帧进行目标检测,得到目标检测框;
45.s103:对目标检测框内的图像进行特征提取;
46.s104:对目标检测框进行状态预测和轨迹生成;
47.s105:基于特征提取结果、状态预测结果和轨迹生成结果,确定关联成本;
48.s106:将关联成本大于设定阈值的轨迹和目标检测框,进行匹配得到初步匹配结果;将未匹配的轨迹和未匹配的目标检测框,再次进行匹配;最后确定跟踪结果,完成多目标行人的跟踪任务。
49.进一步地,所述s102:对待处理视频的非首帧进行目标检测,得到目标检测框;是采用训练后的yolov5s目标检测网络来进行目标检测。
50.进一步地,yolov5s目标检测网络,包括:依次连接的用于特征提取的cspnet网络和用于特征融合的panet网络。
51.进一步地,所述训练后的yolov5s目标检测网络,训练过程包括:
52.构建第一训练集;其中,第一训练集为已知目标检测框的视频;
53.将第一训练集输入到yolov5s目标检测网络中,对网络进行训练,得到训练后的yolov5s目标检测网络。
54.示例性的,采用yolov5s目标检测算法作为跟踪系统的检测器,用于获得目标的boudingbox,使用该算法能够保证跟踪系统的精度、速度和可靠性;
55.所采用的yolov5s是通过减小conv模块和cspnet模块在整个神经网络中的数量,从而缩小了yolov5默认网络结构的宽度(width_multiple)和深度(depth_multiple),使检测器更加轻量、运行速度更快。相较于传统的跟踪算法所采用的基于人工特征提取的检测器或基于深度学习的two-stage、yolov3和改良的yolov3等检测器,本发明使用的yolov5s具备更好的性能和更快的速度,可以满足行人跟踪系统在各种轻量化和嵌入式场景的需求。
56.yolov5s的网络结构分为主干网络(backbone)和特征融合网络(head),其中主干网络的使用cspnet(cross stage partial networks)跨阶段局部网络模块,该模块的模型复杂度低,通过较小的计算量可以实现的梯度组合丰富。yolov5s的特征融合网络使用了路径聚合网络(panet),将backbone层中的信息进行进一步的加工和处理,增强了对异常尺度目标的检测能力。在本发明中,通过配置pytorch的.yaml文件来拼接神经网络的各个模块,通过深度学习训练得到最终可用的检测器。
57.进一步地,所述s103:对目标检测框内的图像进行特征提取;具体包括:
58.采用训练后的特征提取网络shufflenet v2,对目标检测框内的图像进行特征提取。
59.进一步地,所述训练后的特征提取网络shufflenet v2;训练过程包括:
60.构建第二训练集;其中,第二训练集为已知特征标签的图像;
61.将第二训练集,输入到特征提取网络shufflenet v2,对网络进行训练,得到训练后的特征提取网络shufflenet v2。
62.示例性地,使用shufflenetv2作为骨干网络代替deepsort原reid网络中的特征提取网络对检测器中获得目标boundingbox中图像进行特征提取。
63.进一步地,所述shufflenetv2网络是由stage1-stage7依次连接组成;
64.stage1由卷积核大小为3*3步距为2的卷积层和步距为2的最大池化层组成;
65.stage2由一层下采样和三层block层组成;
66.stage3由一层下采样和七层block层组成;
67.stage4由一层下采样和三层block层组成;
68.stage5由卷积核大小为1*1的卷积层组成;
69.stage6由全局池化层组成;
70.stage7由全连接层组成。
71.如图2(a)所示,在shufflenetv2网络结构中。
72.block层引入channel split运算,在block层接收到来自上一层的输出后,c个通道的输入被划分成两个分支,分别有c
′
和c-c
′
个通道。其中一个分支为恒等函数,另一个分支由三个卷积组成:两个1*1卷积和一个逐通道卷积。两分支最后经concat拼接,从而保证通道数量保持不变,最后进行channel shuffle操作保证两分支间能进行信息交流。
73.如图2(b)所示,下采样层是对block层进行了修改,删除了channel split运算,由一条经逐通道卷积层、1*1卷积层的分支与另一条经1*1卷积层、逐通道卷积层、1*1卷积层的分支concat拼接后进行channel shuffle组成的。
74.进一步地,所述s104:对目标检测框进行状态预测和轨迹生成;具体包括:
75.采用卡尔曼滤波算法,对目标检测框进行状态预测;
76.结合卡尔曼滤波算法的结果,对目标检测框进行轨迹生成。
77.进一步地,采用卡尔曼滤波算法,对目标检测框进行状态预测;具体包括:
78.定义八维的状态空间其中(u,v)为boundingbox的中心坐标,γ为纵横比,h为boundingbox的高,为图像坐标中相应的速度。把boundingbox坐标作为物体状态的直接测量,使用卡尔曼滤波器完成目标的状态估计。卡尔曼滤波器的输入值:每个轨迹的均值和方差。卡尔曼滤波器的输出值:返回给定状态估计的投影平均值和协方差矩阵。
79.进一步地,结合卡尔曼滤波算法的结果,对目标检测框进行轨迹生成;具体包括:
80.统计每个轨迹距离上次匹配成功的帧数ak,当卡尔曼滤波器预测轨迹(track)在下一帧的位置时,ak=ak+1,若某一轨迹在下一帧与检测的位置信息和外观特征关联上,则ak置0。
81.设置一个预定义的最大寿命值a
max
,当ak>a
max
时,删除轨迹;当ak≤a
max
时,保留轨迹。
82.当检测的位置信息和外观特征不能与轨迹相匹配时,暂时定义它为一个新轨迹,试用期为3帧,若3帧内没有与之匹配的检测,删除轨迹。
83.进一步地,所述s105:基于特征提取结果、状态预测结果和轨迹生成结果,确定关联成本;具体包括:
84.计算预测状态与目标检测框之间的第一距离;
85.计算轨迹中已存储的特征向量与目标检测框内图像特征向量之间的第二距离;
86.对第一、第二距离进行加权求和,将求和结果作为关联成本。
87.进一步地,所述第一距离为马氏距离;第二距离为余弦距离。
88.示例性地,基于特征提取结果、状态预测结果和轨迹生成结果,确定关联成本;具体包括:
89.(1)合并运动信息时,计算卡尔曼预测状态和新检测目标框之间的马氏距离。
[0090][0091]
i表示第i个轨迹,j表示第j个检测。马氏距离通过测算检测与平均轨迹位置的距离超过多少标准差来考虑状态估计的不确定性。通过逆卡方分布计算阈值,排除可能性小的关联。
[0092]
(2)合并外观信息时,在外观空间中计算轨迹和检测之间的最小余弦距离。
[0093][0094]
计算每一个检测经过shufflenetv2提取得到的特征向量与轨迹中已储存的特征向量计算余弦距离,其中轨迹中存储的特征向量数量通过budget参数设置,默认为100,每个检测与轨迹之间有budget个余弦距离,在此取数值最小的余弦距离作为检测与轨迹之间的余弦距离。
[0095]
(3)关联问题的成本函数为以上两指标的加权和:
[0096]ci,j
=λd
(1)
(i,j)+(1-λ)d
(2)
(i,j)
[0097]
当运动不确定性低时,马氏距离才能发挥效果,但在图像空间问题中,运用线性运动系统估计的卡尔曼预测的状态分布只能提供粗略估计,所以当计算关联成本时,可以将参数λ看作无限小,仅使用外观信息进行关联。但基于外观信息的余弦距离和基于运动信息的马氏距离都必须小于其规定的阈值。
[0098]
进一步地,所述s106:将关联成本大于设定阈值的轨迹和目标检测框,进行匹配得到初步匹配结果;将未匹配的轨迹和未匹配的目标检测框,再次进行匹配;最后确定跟踪结果,完成多目标行人的跟踪任务;具体包括:
[0099]
采用匈牙利算法进行匹配得到初次匹配结果;
[0100]
采用交并比iou(intersection over union)匹配算法,对未匹配的轨迹和未匹配的目标检测框,再次进行匹配;最后确定跟踪结果,完成多目标行人的跟踪任务。
[0101]
示例性地,级联匹配使用外观特征的余弦距离和马氏距离作为度量方法,级联匹配中一个轨迹的不确定性会随着它未匹配次数的增加而增加,因此要将最近匹配上的轨迹比其他轨迹有更高的匹配优先级。
[0102]
检测和轨迹经过马氏距离和余弦距离处理过后生成的代价矩阵作为匈牙利算法的输入,得到线性匹配结果;
[0103]
将未匹配的轨迹、未匹配的检测、未确认的卡尔曼预测结果再次进行iou匹配。最后确定跟踪结果,完成多目标跟踪过程。
[0104]
其中,一个轨迹在以往帧匹配上检测超过三次,转为确认状态;轨迹匹配检测低于三次视为未确认状态。
[0105]
示例性地,所述方法还包括:制作数据集,用来训练算法中的检测器和特征提取器,对数据集进行预处理;
[0106]
算法训练reid特征提取网络时使用的数据集为行人重识别的market-1501数据集。该数据集由清华大学采集,包括1501个行人,其中训练集包括751人,包含12936张图像,测试机包括750人,包含19732张图像;
[0107]
对数据集进行数据预处理,原数据集中目录下即为具体图片文件,并没有体现id,利用数据预处理脚本文件将同一id的图像(同一个人)放在同一文件夹内,并将该文件夹命名为此人id。例如将maket-1501中bounding_box_train下所有0001开头的图片放在预处理后的0001文件夹下,bounding_box_test下所有图片文件同理;
[0108]
经过数据处理后,数据集大体分为训练集、验证集、query、gallery。通过训练集训练后得到的模型可以对query和gallery内图片提取特征并计算相似度,对于每个query在gallery中找出与其相似的图片。
[0109]
示例性地,所述方法还包括:配置用于神经网络模型训练和测试的python和pytorch编程环境:
[0110]
通过anaconda创建虚拟环境,pycharm作为集成开发环境。anaconda是一个开源的python发行版本,包含大量安装好的软件包可供深度学习开发使用。其中conda是一个开源的包、环境管理器,可实现在一台机器上便捷的安装不同的软件包、使用多个环境并在多环境间进行自由切换的功能。
[0111]
使用pytorch深度学习框架。使用conda创建一个使用python3.7版本,名为torch1.7的环境,进入环境后安装pytorch1.7、cuda、cudnn以及运行程序所需的相关依赖包;
[0112]
相关算法设计、训练通过nvidia rtx3060 gpu进行。为解决大量并行计算加快运行速度,需要安装nvidia推出的用于自家gpu的并行计算框架cuda,同时安装用于深度神经网络的gpu加速库cudnn。本发明所用cuda和cudnn版本均为11.0。
[0113]
示例性地,所述方法包括:对轻量化后的模型进行测试,确保效果真实有效;
[0114]
采用经过预处理后的数据集;
[0115]
修改deepsort.yaml文件中reid_ckpt的路径为使用新模型重新训练后得到的权重地址;
[0116]
修改特征提取器中模型为shufflenetv2,更改model_path和权重路径等参数,运行可执行文件观察实验结果。
[0117]
使用yolov5s模型作为deepsort的检测器,使用改进后的shufflenetv2替换deepsort跟踪器中的特征提取网络,保证精度的前提下,把权重文件大小降低,使得内存小、无gpu、散热等硬件条件差的小设备也可以达到实时跟踪效果。
[0118]
示例性地,数据集的收集与预处理;所述的数据集的收集与预处理,使用market-1501数据集重新训练追踪器中的特征提取网络,首先使用dataset.py脚本将数据集中图片划分为训练集和测试集,并分别将数据集和测试集中同一id的图片放入同一文件夹下。
[0119]
示例性地,配置虚拟环境,安装依赖包;所述的配置虚拟环境,安装依赖包,通过anaconda创建虚拟环境,在虚拟环境中安装pytorch、cuda、cudnn以及运行程序所需相关依赖。使用pycharm作为ide,并调用conda创建的虚拟环境torch1.7。
[0120]
示例性地,检测器和跟踪器的训练,使用改进后的shufflenetv2作为deepsort跟踪器中的特征提取网络,导入新模型,并将原模型删除,使用训练脚本文件train.py对新的特征提取网络进行训练,通过设置合适的epoch和batch size进行回归训练,直至损失收敛,保存当前的权值文件。
[0121]
示例性地,测试模型效果中所述的测试模型效果,在特征提取器脚本文件导入修改后的shufflenetv2模型,修改特征提取器中所需的特征提取网络权重路径,使用此时修改后的deepsort用于多目标行人追踪,测试模型效果,观察id switch情况。
[0122]
示例性地,本实验训练、测试的平台为红米redmig,具体硬件配置为nvidia geforce rtx 3060(6g)、amd ryzen 7 5800h with radeon graphics。
[0123]
示例性地,本实验采用python作为编译语言,采用pytorch深度学习框架,项目代码整体结构主要包括deep、sort、configs、yolov5、demo.py、tracker.py、requirements.txt等文件。其中sort文件夹用来存储追踪器所需要的一些工具,如kalman_filter.py存放卡尔曼滤波器相关代码、nn_matching.py通过计算马氏距离余弦距离等来计算最近邻距离、track.py存储轨迹信息等。configs文件目录下的deep_sort.yaml用来存放deepsort算法中一些重要参数。deep文件夹下用来存放特征提取网络模型结构、特征提取器、特征提取网络训练脚本文件等。requirements.txt用来下载运行程序的依赖包。
[0124]
首先对数据集进行数据预处理,原数据集中目录下即为具体图片文件,利用数据预处理脚本文件dataset.py将同一id的图像(同一个人)放在同一文件夹内,并将该文件夹命名为此人id。例如将maket-1501中bounding_box_train下所有0001开头的图片放在预处理后的0001文件夹下,经过数据处理后,数据集大体分为训练集、验证集、query、gallery。通过训练集训练后得到的模型可以对query和gallery内图片提取特征并计算相似度,对于每个query在gallery中找出与其相似的图片。运行数据预处理脚本后,在数据集文件夹内生成一个名为pytorch的文件夹,其中包含训练测试新网络模型用的train、val、query、gallery等文件夹,将其移动至deepsort的deep文件夹下。
[0125]
打开deep文件夹内train.py文件,导入shufflenetv2模型结构,将数据集路径改为数据预处理后的名为pytorch的文件夹路径,设置训练轮数为100,batch-size设为24,num_workers设为0,在终端运行python-train.py开始训练。
[0126]
在deep/checkpoint文件夹下找到名为ckpt.t8的权重文件,将根目录下configs内deep_sort.yaml文件中reid_ckpt权重文件路径修改为ckpt.t8的路径,继续更改deep文件夹下feature_extractor.py文件,导入shufflenetv2模型,更改model_path和权重路径等参数。运行测试可执行文件,得到实验结果,将实验结果和改进前网络训练的结果进行对比。
[0127]
图3(a)和图3(b)为两种网络模型的大小对比;图4为最终检测效果示意图。
[0128]
表1 shufflenetv2的网络结构示意图
[0129][0130]
实施例二
[0131]
本实施例提供了多目标行人跟踪系统;
[0132]
多目标行人跟踪系统,包括:
[0133]
获取模块,其被配置为:获取待处理视频;对待处理视频第一帧的多个目标行人进行标注;
[0134]
目标检测模块,其被配置为:对待处理视频的非首帧进行目标检测,得到目标检测框;
[0135]
特征提取模块,其被配置为:对目标检测框内的图像进行特征提取;
[0136]
状态预测和轨迹生成模块,其被配置为:对目标检测框进行状态预测和轨迹生成;
[0137]
关联成本确定模块,其被配置为:基于特征提取结果、状态预测结果和轨迹生成结果,确定关联成本;
[0138]
跟踪模块,其被配置为:将关联成本大于设定阈值的轨迹和目标检测框,进行匹配得到初步匹配结果;将未匹配的轨迹和未匹配的目标检测框,再次进行匹配;最后确定跟踪结果,完成多目标行人的跟踪任务。
[0139]
此处需要说明的是,上述获取模块、目标检测模块、特征提取模块、状态预测和轨迹生成模块、关联成本确定模块和跟踪模块对应于实施例一中的步骤s101至s106,上述模块与对应的步骤所实现的示例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为系统的一部分可以在诸如一组计算机可执行指令的计算机系统中执行。
[0140]
上述实施例中对各个实施例的描述各有侧重,某个实施例中没有详述的部分可以参见其他实施例的相关描述。
[0141]
所提出的系统,可以通过其他的方式实现。例如以上所描述的系统实施例仅仅是示意性的,例如上述模块的划分,仅仅为一种逻辑功能划分,实际实现时,可以有另外的划分方式,例如多个模块可以结合或者可以集成到另外一个系统,或一些特征可以忽略,或不执行。
[0142]
实施例三
[0143]
本实施例还提供了一种电子设备,包括:一个或多个处理器、一个或多个存储器、以及一个或多个计算机程序;其中,处理器与存储器连接,上述一个或多个计算机程序被存储在存储器中,当电子设备运行时,该处理器执行该存储器存储的一个或多个计算机程序,以使电子设备执行上述实施例一所述的方法。
[0144]
应理解,本实施例中,处理器可以是中央处理单元cpu,处理器还可以是其他通用处理器、数字信号处理器dsp、专用集成电路asic,现成可编程门阵列fpga或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0145]
存储器可以包括只读存储器和随机存取存储器,并向处理器提供指令和数据、存储器的一部分还可以包括非易失性随机存储器。例如,存储器还可以存储设备类型的信息。
[0146]
在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。
[0147]
实施例一中的方法可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器、闪存、只读存储器、可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。为避免重复,这里不再详细描述。
[0148]
本领域普通技术人员可以意识到,结合本实施例描述的各示例的单元及算法步骤,能够以电子硬件或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
[0149]
实施例四
[0150]
本实施例还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成实施例一所述的方法。
[0151]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:刘海英 郑太恒 邓立霞 孙凤乾 王超平
- 技术所有人:齐鲁工业大学
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、李老师:1.计算力学 2.无损检测
- 2、毕老师:机构动力学与控制
- 3、袁老师:1.计算机视觉 2.无线网络及物联网
- 4、王老师:1.计算机网络安全 2.计算机仿真技术
- 5、王老师:1.网络安全;物联网安全 、大数据安全 2.安全态势感知、舆情分析和控制 3.区块链及应用
- 如您是高校老师,可以点此联系我们加入专家库。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
精彩留言,会给你点赞!
专利分类正在加载中....