一种两阶段的长文本相似度计算方法
1.本发明涉及文本相似度计算方法,具体涉及一种基于深度学习模型与图算法的两阶段的长文本相似度计算方法。
背景技术:
2.文本相似度计算是自然语言处理的一类重要任务,相关技术致力于使用技术手段度量文本之间的相似程度。对于不同长度的文本,需要适配不同的文本相似度计算方法。在计算长文本相似度时需要将大量文本信息进行提取压缩与匹配计算,这在新闻推荐、文章推荐、引文推荐、文档聚类等方面有重要应用。
3.现有技术大多采用基于关键词提取的方法,通过提取少数关键词作为长文本的代表,然后参与进一步的相似度计算。由于计算结果依赖于少数几个关键词,这种方法损失了大量语义信息,鲁棒性差。
4.基于深度学习模型的方法使用深度学习模型对全文进行编码后计算其相似度。但现有的深度学习模型只能在长度为数百个词以内的文本序列上取得较好的编码效果。而类似书本这样的长文本经常有数万字甚至数十万字,现有的模型不能较好地编码。并且,由于相似度计算都在隐空间进行,可解释性很差。
5.此外,上述两类技术都只考虑了被比较的长文本之间的信息,计算过程相对孤立,缺乏对群体信息的利用。
技术实现要素:
6.本发明提供一种基于深度学习模型与图算法的两阶段的长文本相似度计算方法,利用文本自身的语义信息,以及与群体信息的协作,两阶段地计算得到书本级别长文本的相似度。
7.本发明的原理是:对一组长文本,在第一阶段,使用多种检测方法检测得到每条长文本之间的相似句子对;在第二阶段,将相似句子对按其所在长文本合并汇总,将每条长文本抽象表示成图上的节点,进行图上的推理交互运算,让信息在节点间传递,获得融合了群体信息的高层次节点表示;最终,根据节点特征,获得长文本之间的文本相似度。
8.本发明提供的技术方案如下:一种两阶段的长文本相似度计算方法,包括如下步骤:在第一阶段相似句子检测阶段,包括:基于深度学习模型构建句向量提取模型,句向量提取模型包括语义相似检测模型和转述相似检测模型;通过句向量提取模型将文本转换为句向量;使用多种检测方法检测得到每条长文本之间多种相似类型的相似句子对;在第二阶段图结构计算阶段,包括:计算得到基础相似度;
基于图算法,将长文本相似句子对和基础相似度表示成相似句子关系图;相似句子关系图上的每个节点表示一条长文本;通过相似句子关系图的推理交互运算,获得融合群体信息的高层次节点表示;更新节点特征信息,节点特征向量上每个维度的值即对应长文本之间的文本相似度;根据节点特征,获得长文本之间的文本相似度。
9.进一步地,上述两阶段的长文本相似度计算方法在相似句子检测阶段之前,首先将每条长文本分割为句子;通过对比学习微调预训练的语言表征模型bert模型或roberta模型,得到句向量提取模型;通过句向量提取模型包括的语义相似检测模型和转述相似检测模型分别提取长文本句子和子句的句向量,从而将长文本转换为句向量。
10.进一步地,通过如下步骤得到句向量提取模型:11)通过进行句子语义相似性对比学习训练,微调bert模型,得到语义相似检测模型;包括:对提取得到的句向量,采用丢弃法处理,构造得到对比学习的正例;将一个训练批次中其他句向量作为对比学习的负例;用于训练的损失函数采用基于句向量和构造的正例及负例计算的损失函数;将训练好的模型命名为语义相似检测模型;12)通过进行句子转述相似性对比学习训练,微调bert模型,得到转述相似检测模型;包括:从句子文本中提取出句向量;对每个句子内部按逗号分割为子句,在句子文本中随机选择和打乱子句,得到新句子文本;对从新句子文本中提取的句向量采用丢弃法处理构造对比学习的正例;将一个训练批次中其他句子文本所提取的向量作为对比学习的负例;bert模型微调的损失函数包含与;与步骤11)采用的损失函数相同;计算是基于句向量和构造的正例及负例计算得到损失函数;最终损失函数为:;其中,是需要被设置的超参数,用于调节模型对句子结构重组和语意差异之间的侧重程度;得到的模型即命名为转述相似检测模型。
11.进一步地,第一阶段多种检测方法包括三种相似型句子对的检测方法;三种相似型句子对分别是:语义相似型句子对、转述相似型句子对和局部相似型句子对。
12.a. 检测语义相似型句子对时,执行如下操作:a1. 将每条长文本按表示句子分割的标点符号分割为句子;a2. 使用语义相似检测模型提取所有句子的特征向量,记为;a3. 对句子的特征向量去重复,得到;对每个特征向量,找到其topk个相似的向量;并将获得的所有向量对记为;a4. 计算中向量距离的第t百分位数,作为相似性阈值;a5. 过滤出中特征向量距离小于的句子对,即为语义相似型句子对;b. 检测转述相似型的句子对时,执行如下操作:b1. 将每条长文本按表示句子分割的标点符号分割为句子;
b2. 使用转述相似检测模型提取所有句子的特征向量,记为;b3. 对句子的特征向量去重复,得到;对每个特征向量,找到其topk个相似的向量;将获得的所有向量对计为;b4. 计算中向量距离的第t百分位数,作为相似性阈值;b5. 过滤出中特征向量距离小于的句子对,即为转述相似型句子对;c. 检测局部相似型的句子对时,执行如下操作:c1. 将每条长文本按表示句子分割的标点符号分割为句子后,在句子内部按逗号分割为子句;c2. 使用语义相似检测模型提取所有子句的特征向量,记为;c3. 对句子的特征向量去重复,得到;对每个特征向量,找到其topk个相似的向量;将获得的所有向量对计为;c4. 计算中向量距离的第t百分位数,作为相似性阈值;c5. 过滤出中特征向量距离小于的子句对;c6. 对成功匹配的子句对,追溯到对应的句子对,即为局部相似型句子对。
13.进一步地,将三种类型的相似句子对检测结果进行合并汇总后,根据文本总长度对数值进行标准化处理,得到长文本的基础相似度。
14.进一步地,计算基础相似度是:设有两条长文本,,检测到和中的个句子相似,则两条长文本的基础相似度按如下计算得到:其中,和分别为两条长文本中的句子总数量。
15.进一步地,将长文本和其基础相似度表示成相似句子关系图;相似句子关系图中的每个节点代表一条长文本,;节点特征是一个独热向量,向量的维度是长文本总数n;如果两条长文本,之间存在相似句子,则长文本对应的节点之间有一条边;对于长文本,有特征向量:;两条长文本,对应节点之间的边的权重;是基础相似度。
16.进一步地,在关系图上进行两次信息的传递和聚合运算,得到新的节点特征信息并更新;计算方式如下:其中,、是图上节点、的初始特征向量值;是分别第一次和第二次运算自定义的权重,用于调节两次图上信息聚合的比例;、为图上节点、经过第一次更新后的特征向量值;最终得到节点特征向量,其中,代表了长文本和长文本的文本相似度。
17.与现有技术相比,本发明的有益效果:利用本发明提供的技术方案,在计算长文本相似度时,将长文本拆分为细粒度的句子进行编码和比较,充分利用了被比较文本本身的语义信息;还将长文本抽象成图上的
节点,通过图上的信息传播和聚合,让节点表示融合了群体信息;同时因为相似句子可以直观地查看到,本发明提供的长文本的相似度计算方法可使得长文本相似度具有较强的可解释性,提升文本处理的有效性和精度。
附图说明
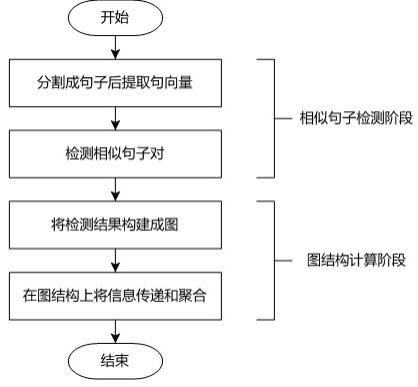
18.图1为本发明提供的两阶段计算长文本相似度的流程框图。
19.图2为本发明方法的相似句子检测阶段的流程框图。
20.图3为本发明方法的图结构计算阶段的流程框图。
具体实施方式
21.下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
22.本发明提供一种基于深度学习模型与图算法的两阶段的长文本相似度计算方法, 利用文本自身的语义信息,以及与群体信息的协作,两阶段地计算得到书本级别长文本的相似度。对一组长文本,在第一阶段,使用多条检测路径检测每条长文本之间的相似句子对;在第二阶段,对匹配的句子对按其来源聚合成图,将每条长文本抽象表示成图上的节点,进行图上的推理交互运算,让信息在节点间传递,获得融合了群体信息的高层次节点表示;最终,根据节点特征,获得长文本之间的文本相似度。
23.图1所示为本发明提供的基于深度学习模型与图算法的两阶段计算长文本相似度的流程。包括如下步骤:第一阶段是相似句子检测阶段:1) 基于深度学习模型(可使用bert模型或roberta模型)构建句向量提取模型,对长文本中的句子和子句提取句向量。
24.2) 根据句向量的相似性,检测得到多种类型的相似句子对。
25.第二阶段是图结构计算阶段:3) 将相似句子对按其来源(所在长文本)构建成图结构。
26.4) 在图上进行信息的传递和聚合运算,更新节点特征信息。
27.节点特征向量上每个维度的值即对应长文本之间的文本相似度。
28.本发明方法具体实施包括:1)将长文本按表示句子分割的标点符号分割为句子,在句子内部按逗号分割为子句。使用对比学习微调好的句向量提取模型(包括语义相似检测模型和转述相似检测模型)分别提取句子和子句的句向量。
29.2)针对语义相似型、转述相似型、局部相似型三种类型的句子文本相似模式,根据句向量的距离,检测出相似句向量,得到对应的相似句子对。
30.3)将三种类型的相似句子对检测结果合并统计后,使用长文本的句子数量对统计结果进行标准化处理。将相似句子对按其来源聚合成图。每条长文本代表图上一个节点,边的权重是两条长文本间相似句子对的数量。
31.4)在图上进行两次信息的传递和聚合运算,融合群体信息后更新节点特征。
32.节点特征向量上每个维度的值即对应长文本之间的文本相似度。
33.下面通过实例对本发明做进一步说明。
34.实施例1对n本文本格式的电子书,将其视作n条长文本,使用本发明提出的方法计算各条长文本两两之间的文本相似度。本方法包括两个阶段,相似句子检测阶段和图结构计算阶段(如图1所示)。
35.1)在进行相似句子检测之前,先要构建得到句向量提取模型,用于将文本转换为句向量。首先将所有长文本分割为句子;再通过对比学习微调预训练的语言表征模型bert bidirectional encoder representation from transformers)模型(或roberta模型),得到句向量提取模型;通过句向量提取模型将文本句子转换为句向量;11)通过进行句子语义相似性对比学习训练来微调bert模型,得到语义相似检测模型。
36.对每个分割后的句子,首先,从句子中提取出句向量。对从句子中提取的句向量通过进行丢弃法(dropout)处理来构造该句子的对比学习的正例,将一个训练批次中其他句子文本所提取的向量作为该句子的对比学习的负例。训练的损失函数采用基于句向量和构造的正例及负例计算的损失函数,其设计与simcse(simple contrastive learning of sentence embeddings,句嵌入简单对比学习)的设计相同。将训练好的模型命名为语义相似检测模型,记为。
37.12)通过进行句子转述相似性对比学习训练来微调bert模型,得到转述相似检测模型。
38.对每个句子,首先,从句子中提取出句向量。bert模型微调的损失函数包含与两部分。与的损失函数相同。在计算时,对每个句子,在句子内部按逗号分割为子句,在句子文本中随机选择和打乱子句,得到新句子文本。从新句子文本中提取的句向量进行dropout处理构造该句子的对比学习的正例,将一个训练批次中其他句子文本所提取的向量作为该句子的对比学习的负例。是基于句向量和构造的正例及负例计算的损失函数,其设计与句嵌入简单对比学习simcse的设计相同。最终的训练的损失函数是:其中,是需要被设置的超参数,它调节了模型对句子结构重组和语意差异之间的侧重程度。得到的模型即命名为转述相似检测模型,记为。
39.2)在长文本t间检测得到相似型句子对(如图2所示,具体实施时通过设计三种相似型的句子对的检测方法检测得到三种相似型句子对)。
40.a. 检测语义相似型句子对时,执行如下操作:a1. 将每条长文本按表示句子分割的标点符号分割为句子;a2. 使用语义相似检测模型提取所有句子的特征向量,记为;a3. 对句子的特征向量去重复,得到;对每个特征向量,找到其topk个相似的向量;并将获得的所有向量对记为;a4. 计算中向量距离的第t百分位数,作为相似性阈值;a5. 过滤出中特征向量距离小于的句子对,即为语义相似型句子对;b. 检测转述相似型的句子对时,执行如下操作:
b1. 将每条长文本按表示句子分割的标点符号分割为句子;b2. 使用转述相似检测模型提取所有句子的特征向量,记为;b3. 对句子的特征向量去重复,得到;对每个特征向量,找到其topk个相似的向量;将获得的所有向量对计为;b4. 计算中向量距离的第t百分位数,作为相似性阈值;b5. 过滤出中特征向量距离小于的句子对,即为转述相似型句子对;c. 检测局部相似型的句子对时,执行如下操作:c1. 将每条长文本按表示句子分割的标点符号分割为句子后,在句子内部按逗号分割为子句;c2. 使用语义相似检测模型提取所有子句的特征向量,记为;c3. 对句子的特征向量去重复,得到;对每个特征向量,找到其topk个相似的向量;将获得的所有向量对计为;c4. 计算中向量距离的第t百分位数,作为相似性阈值;c5. 过滤出中特征向量距离小于的子句对;c6. 对成功匹配的子句对,追溯到对应的句子对,即为局部相似型句子对。
41.得到了检测出的相似句子对结果后,进入图结构计算阶段(如图3所示)。
42.3)将三种类型的相似句子对检测结果进行合并汇总后,根据文本总长度对数值进行标准化处理,得到长文本的基础相似度。具体而言,假设有两条长文本,,检测到和中的个句子相似(包括三类相似),两条长文本中的句子总数量是和,那这两条长文本的基础相似度按如下计算:4)将长文本和其基础相似度抽象表示成相似句子关系图。相似句子关系图中的每个节点代表一条长文本,;节点特征是一个独热向量,向量的维度是长文本总数n;对于长文本,有特征向量:如果两条长文本,之间存在相似句子,则长文本对应的节点之间有一条边,边的权重有:重有:是上一步计算的基础相似度;5)在关系图上进行两次信息的传递和聚合运算,得到新的节点特征信息并更新。计算方式如下:其中,是分别第一次和第二次运算自定义的权重,用于调节两次图上信息聚合的比例。最终得到节点特征向量,其中,代表了长文本和长文本的文本相似度。
43.采用本发明方法计算长文本相似度,将长文本拆分为细粒度的句子进行编码和比
较,充分利用了被比较文本本身的语义信息;还将长文本抽象成图上的节点,通过图上的信息传播和聚合,其中的节点表示融合了群体信息;相似句子可直观地查看,可使得长文本具有较强的可解释性,提升文本处理的有效性和精度。
44.需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1