基于证据推理规则的缺血性脑卒中程度辨识建模方法
1.本发明涉及一种基于脑皮层血管数据和证据推理规则的缺血性脑卒中程度辨识建模方法。
背景技术:
2.脑卒中主要分为缺血性脑卒中(即脑梗塞)和出血性脑卒中(即脑出血)两类,缺血性脑卒中的发病率高于出血性脑卒中,占脑卒中患者总数的60%-70%。据世界卫生组织研究报道,世界范围内脑卒中已成为仅次于癌症和冠心病的致死原因。
3.近年来,我国脑血管疾病数量呈急剧上升的趋势,且以22.45%的死亡率位列疾病致死原因的首位。脑卒中具有较高的复发率和致残率,由此导致75%脑卒中患者表现为不同程度的肢体功能障碍,如偏瘫、偏身感觉障碍、姿势与肌张力异常等进而导致日常行为能力的丧失,对个体、家庭以及劳动力造成了严重的影响,给生活、工作以及社会均带来了沉重的负担。中国老龄化社会即将到来,我国脑卒中临床康复面临巨大挑战。
4.目前临床上仍主要采用以行为表现评估为主的评定量表对患者进行神经功能损伤鉴定和康复水平评定,这种传统的脑卒中康复评定方式具有明显缺陷。康复理疗师自身水平和主观性负面影响以及患者自身个体差异所导致的量表内容不匹配、不准确等问题限制康复水平的准确评定及康复方案的有效制定。而如果能直观观察损伤血管的血流变化和再生情况以及神经组织损伤和恢复情况,就可以使患者的康复水平得到准确评定。因此,一套客观、准确、直观、科学的脑卒中程度辨识模型就成为当前一个必要的需求。
技术实现要素:
5.本发明针对现有技术的不足,提出一种基于脑皮层血管数据和证据推理规则的缺血性脑卒中程度辨识建模方法。
6.本发明包括以下步骤:
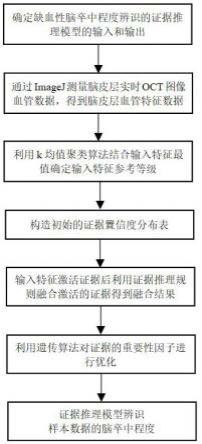
7.确定脑卒中程度辨识模型的输入特征和输出框架,所述输入特征即为脑皮层血管二维图像特征数据,输出框架即为脑卒中程度。
8.获取样本数据集,所述样本数据集包括训练数据集和验证数据集。
9.根据所述样本数据集确定输入特征参考等级并构建证据的相似性分布表,通过似然归一化得到证据的置信度分布表,通过专家经验确定证据的可靠性因子和证据的重要性因子。
10.计算输入特征数据与其参考等级之间的匹配度分布,融合输入特征数据激活的参考等级证据得到特征证据。
11.通过递归证据推理规则融合所述输入特征证据,得到输入特征对输出的支持程度。
12.根据所述证据的重要性因子和脑卒中程度辨识模型输出结果的均方误差构建优化目标函数,将优化后的模型作为最终辨识模型。
13.本发明方法的创新性在于针对脑皮层血管的损伤、恢复与神经组织损伤、恢复有正相关性,将生物医学研究基础与人工智能的方法相结合,建立一套基于脑皮层血管oct图像数据和证据推理规则的缺血性脑卒中程度辨识建模方法。
14.本发明的有益效果:
15.第一,应用本发明提供的建模方法,可构建辨识缺血性脑卒中程度的模型,辨识结果不受主观因素影响,更为客观、科学、准确。
16.第二,将脑皮层损伤血管数据作为辨识脑卒中程度的依据,以大鼠脑皮层损伤血管数据(输入)和脑卒中程度(输出)的非线性映射关系建模,利用证据推理规则从脑皮层血管样本数据中总结规律,推理样本数据的脑卒中程度。
附图说明
17.图1是本发明的流程示意图。
18.图2是150个大鼠脑皮层实时oct图像血管样本数据的脑卒中诊断程度与真实程度变化趋势对比图。
具体实施方式
19.以下结合图1对本发明方法原理进行详细说明。
20.基于证据推理规则的缺血性脑卒中程度辨识建模方法,包括步骤:
21.确定脑卒中程度辨识模型的输入特征和输出框架,所述输入特征即为脑皮层血管二维图像特征数据,输出框架即为脑卒中程度;
22.具体地,构造缺血性脑卒中程度的证据推理模型,模型输入为x={x1,x2,x3,x4,x5},其中x1为缺血区域占比,x2为血管面积占比,x3为大血管占比,x4为中血管占比,x5为小血管占比;划分缺血性脑卒中程度为轻微、轻度、中度、重度、严重5个程度构成该模型的输出集合θ={d1,d2,d3,d4,d5},每一个命题dj(j=1,2,...,5)对应一种脑卒中程度,记p(θ)。将x1,x2,x3,x4,x5和dj(j=1,2,...,5)表示成样本集合si={[x1,x2,x3,x4,x5,dj]|j=1,2,...,5},其中[x1,x2,x3,x4,x5,dj]为一个样本向量。将脑卒中程度dj状态下获取的样本数据x
1,j
,x
2,j
,x
3,j
,x
4,j
,x
5,j
构成样本集合qj={x
1,j
,x
2,j
,x
3,j
,x
4,j
,x
5,j
}。分别获取各个脑卒中程度下的样本数据,构成样本集
[0023]
获取样本数据集,所述样本数据集包括训练数据集和验证数据集;
[0024]
根据所述样本数据集确定输入特征参考等级并构建证据的相似性分布表,通过似然归一化得到证据的置信度分布表,通过专家经验确定证据的可靠性因子和证据的重要性因子;
[0025]
计算输入特征数据与其参考等级之间的匹配度分布,融合输入特征数据激活的参考等级证据得到特征证据;
[0026]
通过递归证据推理规则融合所述输入特征证据,得到输入特征对输出的支持程度;
[0027]
根据所述证据的重要性因子和脑卒中程度辨识模型输出结果的均方误差构建优化目标函数,将优化后的模型作为最终辨识模型。
[0028]
在一些实施例中,所述样本数据集的获取步骤包括:
[0029]
通过连续观测大鼠脑皮层血管缺血前后变化的动物光窗模型,利用光相干层析成像术实时记录血管堵塞前后血管的损伤和再生情况,得到不同缺血性脑卒中程度的皮层血管oct图像;
[0030]
根据所述脑皮层血管oct图像分析脑皮层血管特征信息,从图像中获得脑皮层血管二维特征数据;
[0031]
通过imagej基于全局自动阈值的图像二值化处理,对所述脑皮层血管oct图像二值化,统计脑皮层血管二维特征数据。
[0032]
具体地,通过imagej软件测量大鼠脑皮层oct图像的血管数据,从图像中提取大鼠脑皮层血管的二维特征数据。首先将脑皮层oct图像转化为8-bit类型的图像,使用imagej测量大鼠脑皮层血管区域。手动选取脑皮层血管区域内的缺血区域,缺血区域与脑皮层血管区域之比即为缺血区域占比;利用imagej软件得到脑皮层血管总面积,脑皮层血管总面积与脑皮层血管区域之比即为脑皮层血管面积占比;将大鼠脑皮层血管按大血管、中血管、毛细血管分为3类血管,利用imagej测量得到3种脑皮层血管类型比例。
[0033]
在一些实施例中,基于所述脑皮层血管二维特征数据集确定输入特征数据的参考等级,构建所述证据的相似性分布表的步骤包括:
[0034]
计算每一个脑皮层血管二维特征数据轮廓值的平均值,通过k均值聚类得到脑皮层血管二维特征数据的聚类中心,聚类中心数为输入特征即所述脑皮层血管二维特征数据轮廓值的平均值;
[0035]
通过所述脑皮层血管二维特征数据集的最小值、最大值以及所述脑皮层血管二维特征数据的聚类中心确定脑皮层血管每一种二维特征数据的参考等级;
[0036]
计算所述样本数据集输入特征数据与其参考等级的匹配度分布用以构建证据的相似性分布表,所述输入特征数据被包含于输出框架所有脑卒中程度。
[0037]
具体地,确定输入特征x1,x2,x3,x4,x5的参考值,对样本集u中的每一个输入特征进行k均值聚类,聚类中心为其中ti为第i个特征的聚类中心数,由样本集中每一特征的轮廓值的平均值确定。
[0038]
将第i个输入特征xi的最小值li和最大值按递增顺序组成该特征的参考等级例如五个输入特征分别划分2、3、3、4、3个聚类时,每个特征对应的轮廓值的平均值最大。将每一个脑皮层血管输入特征数据的最小值、最大值和聚类中心作为参考等级,则缺血区域占比、血管总面积占比、血管类型比例各包含4、5、5、6、5个参考等级,分别为:
[0039]
av={0.01426,0.06588,0.15153,0.23961}
[0040]ap
={0.39521,0.45214,0.50012,0.55014,0.60012}
[0041]amax
={0.30148,0.32107,0.35147,0.39875,0.44831}
[0042]amiddle
={0.29750,0.29987,0.30145,0.30897,0.31012,0.31471}
[0043]amin
={0.23698,0.25961,0.29876,0.37412,0.40102}。
[0044]
根据以上公式构建五个脑皮层血管特征的证据置信度分布表如表1至表5所示。
[0045]
表1缺血区域占比的证据置信度分布表
[0046][0047]
表2血管总面积占比的证据置信度分布表
[0048][0049]
表3大血管占比的证据置信度分布表
[0050][0051]
表4中血管占比的证据置信度分布表
[0052][0053]
表5毛细血管占比的证据置信度分布表
[0054][0055]
进一步说,所述根据所述证据的相似性分布表通过似然归一化得到证据的置信度分布表。
[0056]
进一步说,计算所述样本数据集输入特征数据与其参考等级之间的匹配度分布,融合输入特征数据激活的参考等级证据得到特征证据包括步骤:
[0057]
根据专家经验确定参考等级证据的可靠性因子和重要性因子,所述参考等级证据即为所述证据的置信度分布表每个输入特征数据参考等级对输出框架中不同输出的支持程度;
[0058]
计算所述样本数据集输入特征数据与其参考等级的匹配度分布,并确定对应参考等级证据;
[0059]
根据所述输入特征数据的匹配度分布和对应参考等级证据融合得到特征证据。
[0060]
具体地,将输入特征向量x={x1,x2,x3,x4,x5}导入证据推理模型输出dj,从150个样本集中随机选取样本a[0.03459,0.51743,0.35218,0.315,0.26509,轻微]为例来说明,具体步骤如下:
[0061]
计算输入特征x中输入向量xi与输入特征参考等级的匹配度具体求取过程如下:
[0062]
设定xi对参考等级的匹配度为当或时,=1,输
入特征xi对其他参考等级的匹配度均为0;当时,输入特征xi对参考等级和的匹配度由下两式计算得到。同样的,输入特征xi对其他参考等级的匹配度均为0;
[0063][0064][0065]
样本a的缺血区域占比v=0.03459,v的值与参考等级和的匹配度分别为和激活证据和血管总面积占比p=0.51743,p的值与参考等级和的匹配度分别为和激活证据和大血管占比max=0.35218,max的值与参考等级和的匹配度分别为的匹配度分别为和激活证据和中血管占比middle=0.315,middle的值大于参考等级的最大值,所以该特征激活证据并且毛细血管占比min=0.26509,min的值与参考等级和的匹配度分别为和激活证据和
[0066]
在一些实施例中,所述参考等级证据融合得到特征证据的融合方式为:
[0067][0068]
其中,和为所述第i个脑皮层血管二维输入特征数据与其第z和z+1个参考等级的匹配度分布,β
z,j
和β
z+1,j
为第z和z+1个参考等级证据对第j个输出的支持程度,为脑皮层血管第i个二维输入特征数据对第j个输出的支持程度。
[0069]
具体地,对于输入特征xi,当时,xi激活参考等级和对应的两条证据和由证据和通过下式可得输入特征xi的证据ei。
[0070][0071][0072]
其中,表示当输入特征xi激活参考等级和对应的两条证据和时,输出dj的可能性。由此可得输入特征xi对应的全部证据ei(i=1,2,...,5)。根据表1至表5和样本a最终激活的证据为:
[0073]
e1={(d1:0.165),(d2:0.045),(d3:0.250),(d4:0.268),(d5:0.272)};
[0074]
e2={(d1:0.421),(d2:0.095),(d3:0.291),(d4:0.193),(d5:0)};
[0075]
e3={(d1:0.347),(d2:0.028),(d3:0.349),(d4:0.273),(d5:0.003)};
[0076]
e4={(d1:0.978),(d2:0),(d3:0.022),(d4:0),(d5:0)};
[0077]
e5={(d1:0.393),(d2:0.200),(d3:0.149),(d4:0.194),(d5:0.064)}。
[0078]
在一些实施例中,通过递归证据推理规则融合所述特征证据,得到输入特征对输出的支持程度,所述融合计算公式为:
[0079][0080]
其中,m
j,i
和m
j,(i-1)
为第i和i-1个脑皮层血管二维特征证据对第j个输出的支持程度,ri为第i个特征证据的可靠性因子,m
p(θ),e(i-1)
为第i-1个脑皮层血管二维特征证据的幂集,为第i和i-1个脑皮层血管二维特征证据对第j个输出的支持程度的交集,m
j,e(i,i-1)
为第i和i-1个脑皮层血管二维特征证据融合后的证据对第j个输出的支持程度。
[0081]
具体地,当输入特征向量x={x1,x2,x3,x4,x5}中每个特征的证据相互独立时,可以通过递归证据推理规则融合5个证据ei,得到特征向量x的对5个不同程度的输出的支持程度,如下:
[0082][0083][0084]mp(θ),e(i)
=(1-ri)m
p(θ),e(i-1)
[0085]
其中,p
j,e(5)
为证据e1、e2、e3、e4、e5对第j个输出的联合置信度,表示当脑皮层血管特征向量为x={x1,x2,x3,x4,x5}时,脑卒中程度被认为是dj的可信度;m
j,(i-1)
=w
(i-1)
p
j,(i-1)
表示基本信度赋值;ri和wi表示证据的可靠性因子和重要性因子,满足0≤ri≤1和0≤wi≤1。由于样本集中样本的脑卒中程度是由领域专家经验确定的,为不失一般性,假设样本集的初始证据可信度为0.96,同时考虑到所用数据在通过imagej处理时会有人为处理误差,因此初始证据可靠性设为0.94。根据支持程度对五条证据进行融合,得到最终的输出结果为:
[0086]
o(a)={(d1:0.687),(d2:0.02),(d3:0.149),(d4:0.125),(d5:0.02)}
[0087]
通过上可以对脑皮层特征向量为x={x1,x2,x3,x4,x5}的脑卒中程度进行辨识,o(a)中最大值对应的dj即为证据推理模型诊断样本a[0.03459,0.51743,0.35218,0.315,0.26509,轻微]对应的脑卒中程度,即d1轻微程度的脑卒中。
[0088]
在一些实施例中,根据所述证据的重要性因子和模型输出结果的均方误差构建优化目标函数,优化模型的步骤包括:
[0089]
根据模型诊断准确率和证据的初始重要性因子构造基于最小均方差的优化目标函数;
[0090]
基于遗传算法的优化过程中,初始种群在[0,1]之间通过随即方式产生,初始种群数量为60,将优化目标函数作为适应度函数;
[0091]
更新脑卒中程度辨识模型中优化后的证据重要性因子。
[0092]
具体地,为了使脑卒中程度辨识模型能够更加准确的反映输入特征与输出之间的关系,利用样本集对模型参数进行优化,优化步骤包括:
[0093]
将样本集特征输入带入待优化的证据推理模型,经过计算可以得到辨识准确率ua,构造基于最小均方差的优化目标函数:
[0094][0095]
其中待优化参数为:
[0096][0097]
基于遗传算法的优化过程中,初始种群在[0,1]之间通过随即方式产生,初始种群数量为60,将优化模型目标函数作为适应度函数,也即f(x)=1-ua,将优化后的模型作为最终辨识模型。
[0098]
所述样本数据集根据连续观测大鼠在体脑皮层血管oct图像数据确定,所述训练数据集为缺血性脑卒中的训练数据集,所述验证数据集为缺血性脑卒中的验证数据集。
[0099]
本发明实验选取150个大鼠脑皮层血管数据样本集,辨识准确率为0.9133。图2是150个大鼠脑皮层实时oct图像血管参数样本数据的脑卒中辨识程度与真实程度变化趋势对比图。
[0100]
由实验结果可以得出:第一,应用本发明提供方法,成功的开拓了脑卒中患者卒中程度辨识的新方法,将脑卒中患者的脑卒中程度辨识从传统以行为表现评估为主的评定量表拓展到以脑皮层血管数据为依据的证据推理规则模型辨识。第二,不同于传统的评定量表诊断卒中程度,本发明提供的建模方法以脑皮层血管数据为依据,直击病灶,更加客观、科学、准确。第三,在本次150个脑皮层血管数据样本集诊断大鼠卒中程度的实验中,基于脑皮层血管数据与证据推理规则的脑卒中程度辨识模型的辨识准确率为0.9133,充分证明了本方法的有效性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1