一种基于联合检测和关联的在线多目标跟踪方法
1.本发明属于图像处理领域,具体涉及一种基于联合检测和关联的在线多目标跟踪方法。
背景技术:
2.随着人工智能的发展,视觉目标跟踪可以运用到很多领域,例如运动校正、无人驾驶和安防监控等;目标检测方法和数据关联方法是在线多目标跟踪(online multi-object tracking,mot)中最重要的两个方法,近年来,关于这两种方法在在线目标跟踪应用中主要有两种技术路径。一是两阶段法,即将这两个分离的模块分别进行处理和优化。但这导致了复杂的模型设计,并需要冗余的模型参数需要学习。二是一阶段法,即将两个子任务整合成一个端到端的模型来优化模型。一阶段方法在单个网络中执行对象检测和对象跟踪,因此,两个子任务可以在目标表示提取中共享模型参数,可显着降低跟踪成本。然而,一阶段法的主要存在以下几种缺点:首先,对象检测和数据关联之间存在模态差异。前者只涉及空间信息的处理,后者涉及时间序列上的数据关联。这些差异使得一阶段法模型的设计更加困难。其次,mot数据集中现有的检测结果或标签没有相应的检测模型实现。因此,检测网络的输出和关联网络的输入之间的边界框不一致阻止了整个端到端mot模型中的训练过程。最后,随着检测子模块的持续训练,关联子模块推断的边界框也没有相应的ground truth。这些因素使得难以获得一个端到端模型来实现mot。
技术实现要素:
3.本发明的目的在于提供一种基于联合检测和关联的在线多目标跟踪方法,将目标检测和关联结合到一个单一的神经网络中,实现端到端联合处理对象检测与mot任务。
4.本发明提供的这种基于联合检测和关联的在线多目标跟踪方法,包括如下步骤:
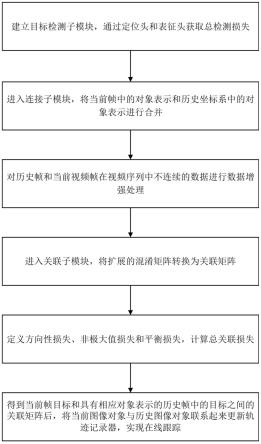
5.s1.建立目标检测子模块,通过定位头和表征头获取总检测损失;
6.s2.进入连接子模块,将当前帧中的对象表示和历史坐标系中的对象表示进行合并;
7.s3.对历史帧和当前视频帧在视频序列中不连续的数据进行数据增强处理;
8.s4.进入关联子模块,将扩展的混淆矩阵转换为关联矩阵;
9.s5.定义方向性损失、非极大值损失和平衡损失,计算总关联损失;
10.s6.得到当前帧目标和具有相应对象表示的历史帧中的目标之间的关联矩阵后,将当前图像对象与历史图像对象联系起来更新轨迹记录器,实现在线跟踪。
11.所述的步骤s1,包括将单个视频帧f作为输入,所述的步骤s1,包括将单个视频帧f作为输入,表示三维矩阵;w为宽度;h为宽度;3表示通道数;获得每个视频帧的对象边界框和相应的数学表示;设置主干网络,并在主干网络中添加预测头和表征头;定位头用于定位目标边界框,表征头用于计算对象表示。
12.主干网络采用resnet-34;利用dla(deep layer aggregation,深度聚集)的一种
变体方法作为目标检测子模块的主干;
13.定位头包括,定位头的输入为主干网络的输出表示;每个定位头具有3
×
3内核大小和256输出通道,然后1
×
1卷积以产生定位输出,具体为生成热力图头和尺寸头:
14.使用热力图头预测对象中心,热力图头具体为,对于第i帧视频帧中的真实边界框使用热力图头预测对象中心,热力图头具体为,对于第i帧视频帧中的真实边界框表示第i帧左上角横坐标值;表示第i帧左上角纵坐标值;表示第i帧右下角横坐标值;表示第i帧右下角纵坐标值;获得第i帧中心位置pi的目标,求第i帧图上的位置qi,其中g表示第一下采样因子;当前点位置处的热力图头响应rq定义为其中,表示三维矩阵;qk表示第k个点的位置;σ为高斯核;根据焦点损失形成热力图头损失函数lh作为训练目标:
[0015][0016]
其中,n表示当前视频帧中的目标数量;表示当前点位置q处的预测热图响应,当前点位置q处的预测热图响应的类号ch=1;α表示焦点损失第一超参数;β表示焦点损失第二超参数;log(
·
)表示取对数,用于简便计算;
[0017]
尺寸头具体为,尺寸头用于预测对象围绕其中心位置的宽度和高度;尺寸头的输出定义为其中尺寸头的输出的类号cz=2;表示三维矩阵;g表示第一下采样因子;w为宽度;h为宽度;虽然定位精度与对象表示没有直接关系,但会影响检测子任务的性能;对于视频帧中的一个真实框bi,根据得到第i帧框的大小zi,并且第i帧预测的边界框大小定义为,并且第i帧预测的边界框大小定义为表示第i帧左上角横坐标值;表示第i帧左上角纵坐标值;表示第i帧右下角横坐标值;表示第i帧右下角纵坐标值;将偏移头的输出表示为其中偏移头输出的类号cd=2;第i帧图上的真实位移di表示为pi表示第i帧中心位置;将第i帧中心位置位移表示为因此尺寸头和偏移头的类似损失ls为:
[0018][0019]
其中,n表示当前视频帧中的目标数量;zi表示第i帧框的大小;表示第i帧预测
的边界框大小;di表示图上的真实位移;表示中心位置位移;||
·
||1表示l1范数;
[0020]
因此,定位头损失l
p
为前两个损失的组合:
[0021]
l
p
=lh+ls[0022]
其中,lh表示热力图头损失函数;ls表示尺寸头和偏移头的类似损失;
[0023]
表征头包括,生成的表示图为其中表示三维矩阵;s表示第二下采样因子;w为宽度;h为宽度;生成的表示图的输出通道ce=128;通过表征头学习的中心位置p的目标表征置p的目标表征表示元素个数为c的一维向量;对于第i帧视频帧中的真实边界框bi,获得第i帧热图上的目标中心位置在第i帧某个位置学习一个身份表示并输出到一维分类概率向量v(k),并将第i帧地面实况分类标签表示为ui(j);因此,身份分类损失lc被构造为:
[0024][0025]
其中,n表示帧的总数;j表示数据集中所有身份的总数;v(j)表示身份的预测值;j表示数据集中身份的计数变量;log(
·
)表示取对数,用于简便计算;
[0026]
总检测损失为ld=l
p
+lc,lc为身份分类损失;l
p
为定位头损失。
[0027]
所述的步骤s2,包括进入连接子模块sj,将当前视频帧f
t
的表示矩阵r
t
沿垂直方向复制到当前帧中的表示张量并将前n帧中的表示矩阵r
t-n
沿水平方向复制到前n帧中的表示张量将当前帧中的表示张量m
t
和前n帧中的表示张量m
t-n
沿着对象表示的通道方向合并到,当前帧和前n帧之间的混淆张量nm表示每帧的最大目标数;表示三维矩阵;t表示当前时刻。
[0028]
所述的步骤s3,包括将历史帧f
t-n
和当前视频帧f
t
由n帧分隔,其中n∈[0,n
a-1],na表示最大历史帧数目;以0.25的概率对每个轨迹上的历史帧f
t-n
和当前视频帧f
t
进行采样;将视频帧整形为大小w
×h×
3;w为宽度;h为宽度;对采样视频帧使用概率为0.5的水平翻转,沿着对象表示的方向逐步实现了从256到1的维度压缩,卷积核大小为1
×
1。
[0029]
所述的步骤s4,包括进入关联子模块,将扩展的混淆矩阵m
t,tn
转换为关联矩阵,通过利用所提出的关联子模块获得帧间关联,并利用每帧的最大目标数nm预测历史帧f
t-n
和当前视频帧f
t
之间的对象关联矩阵ma;沿水平和垂直方向,向历史帧f
t-n
和当前视频帧f
t
之间的对象关联矩阵ma中插入零向量用于进行泛化。
[0030]
所述的步骤s5,包括利用历史帧f
t-n
和当前视频帧f
t
之间的相似性关联编码;在历史帧f
t-n
和当前视频帧f
t
之间的对象关联矩阵ma后附加一列,构建第一扩展矩阵m1,nm表示每帧的最大目标数;表示三维矩阵;nm表示每帧的最大目标数;表示二维矩阵;最后附加的垂直向量表示从历史帧f
t-n
中消失的当前跟踪对象;最后一行中附加的水平向量表示在当前帧f
t
中进入视野的新兴目标;第一扩展矩阵m1的第m行将历史
帧f
t-n
中的第m个对象与当前帧f
t
的第nm+1个对象关联起来;nm+1表示最大目标数+1;通过执行softmax函数对第一扩展矩阵m1的水平方向上的扩展概率向量进行归一化;输出关联矩阵a1的水平向量表示当前视频帧f
t
中所有目标与所有目标之间的关联概率在当前视频帧f
t
中,a1表示第一关联矩阵预测值;将总关联损失ls定义为方向性损失ld、非极大值损失lm和平衡损失lb的总和,ls=ld+lm+lb,
[0031]
方向性损失ld为:
[0032][0033]
其中,b1表示b
t-n,t
删除最后一个水平向量;b2表示b
t-n,t
删除最后一个垂直向量;b
t-n,t
表示历史帧与当前帧的关联矩阵真实值;
⊙
表示hadamard乘积;log(
·
)表示取对数,用于简便计算;nm表示每帧的最大目标数;a2表示第二关联矩阵预测值;
[0034]
非极大值损失lm为:
[0035][0036]
其中,nm表示每帧的最大目标数;b3表示b
t-n,t
删除最后一个垂直向量和最后一个水平向量;log(
·
)表示取对数,用于简便计算;am表示第三关联矩阵预测值;am=max(ac,ar),max(
·
)表示取最大值;ac表示a1删除最后一个垂直向量和最后一个水平向量被裁剪到nm×
nm的纬度获得的矩阵;ar表示a2删除最后一个垂直向量和最后一个水平向量被裁剪到nm×
nm的纬度获得的矩阵;
[0037]
平衡损失lb为,
[0038][0039]
其中,ac表示去除最后列的关联矩阵预测值;ar表示去除最后行的关联矩阵预测值。
[0040]
所述的步骤s6,包括得到当前视频帧f
t
目标和具有相应对象表示的历史帧f
t-n
中的目标之间的关联矩阵后,将当前图像对象与历史图像对象联系更新轨迹记录器t
t
;在初始时刻,轨迹记录器具有相同数量的轨道,一个帧仅通过检测子模块传输一次,对象表示被重复使用若干次来评估与剩余图像的相似性;基于关联矩阵;通过复制累加器的最后一个垂直向量,将许多轨道分配给累积矩阵中的特定末检测对象列,实现在线跟踪。
[0041]
本发明提供的这种基于联合检测和关联的在线多目标跟踪方法,设计了一个端到端架构来联合处理对象检测和在线mot任务;将目标检测和关联结合到一个单一的神经网络中,为了解决目标检测子模块的输出与关联子模块的输入之间的边界框不一致问题,提出了联合子模块和合适的训练数据生成方法,直接利用目标表示将不同帧中的对象关联起来,同时设计了一个两阶段的训练方法来训练检测子模块和关联子模块,并完全以端到端模式执行在线mot过程。本发明结构简单高效。
附图说明
[0042]
图1为本发明方法的流程示意图。
[0043]
图2为本发明实施例的流程示意图。
[0044]
图3为本发明实施例的关联子模块流程示意图。
具体实施方式
[0045]
如图1为本发明方法的流程示意图:本发明提供的这种基于联合检测和关联的在线多目标跟踪方法,包括如下步骤:
[0046]
s1.建立目标检测子模块,通过定位头和表征头获取总检测损失;
[0047]
s2.进入连接子模块,将当前帧中的对象表示和历史坐标系中的对象表示进行合并;
[0048]
s3.对历史帧和当前视频帧在视频序列中不连续的数据进行数据增强处理;
[0049]
s4.进入关联子模块,将扩展的混淆矩阵转换为关联矩阵;
[0050]
s5.定义方向性损失、非极大值损失和平衡损失,计算总关联损失;
[0051]
s6.得到当前帧目标和具有相应对象表示的历史帧中的目标之间的关联矩阵后,将当前图像对象与历史图像对象联系起来更新轨迹记录器,实现在线跟踪。
[0052]
所述的步骤s1,包括将单个视频帧f作为输入,所述的步骤s1,包括将单个视频帧f作为输入,表示三维矩阵;w为宽度;h为宽度;3表示通道数;获得每个视频帧的对象边界框和相应的数学表示;设置主干网络,并在主干网络中添加预测头和表征头;定位头用于定位目标边界框,表征头用于计算对象表示。
[0053]
如图2为本发明实施例的流程示意图。主干网络对于mot任务至关重要,为了同时考虑模型复杂性和精度,采用resnet-34;利用dla(deep layer aggregation,深度聚集)的一种变体方法作为目标检测子模块的主干,可适应各种尺度的目标。与原始dla相比,dla的变体在低层和高层表示之间有额外的旁路。另外,上采样过程中的所有修改同样有利于缓解对齐问题。
[0054]
定位头包括,定位头的输入为主干网络的输出表示;每个定位头具有3
×
3内核大小和256输出通道,然后1
×
1卷积以产生定位输出,具体为生成一个低分辨率的热力图头和尺寸头:
[0055]
使用热力图头预测对象中心,当定位头与真正的中心目标位置重叠时,热力图头在某个位置的输出为1,输出值随着到目标中心位置的距离增加而减小。热力图头具体为,对于第i帧视频帧中的真实边界框对于第i帧视频帧中的真实边界框表示第i帧左上角横坐标值;表示第i帧左上角纵坐标值;表示第i帧右下角横坐标值;表示第i帧右下角纵坐标值;获得第i帧中心位置pi的目标,因此,通过将中心位置除以第一下采样因子来计算表示第i帧图上的位置qi,其中g表示第一下采样因子,g=4。形式
上,当前点位置处的热力图头响应rq定义为其中,表示三维矩阵;qk表示第k个点的位置;σ为高斯核,为目标大小的函数。根据焦点损失形成热力图头损失函数lh作为训练目标:
[0056][0057]
其中,n表示当前视频帧中的目标数量;表示当前点位置q处的预测热图响应,当前点位置q处的预测热图响应的类号ch=1;α表示焦点损失第一超参数;β表示焦点损失第二超参数;log(
·
)表示取对数,用于简便计算;
[0058]
尺寸头具体为,尺寸头用于预测对象围绕其中心位置的宽度和高度;尺寸头的输出定义为其中尺寸头的输出的类号cz=2;表示三维矩阵;g表示第一下采样因子;w为宽度;h为宽度;虽然定位精度与对象表示没有直接关系,但会影响检测子任务的性能。对于视频帧中的一个真实框bi,根据得到第i帧框的大小zi,并且第i帧预测的边界框大小定义为,并且第i帧预测的边界框大小定义为表示第i帧左上角横坐标值;表示第i帧左上角纵坐标值;表示第i帧右下角横坐标值;表示第i帧右下角纵坐标值。此外,fairmot表明具有中心位置的细化边界框对于提高mot精度很重要,主干网络中的第一下采样因子将发挥强大的量化效果。偏移头用于更准确地检测目标,虽然检测精度提升的优势微乎其微,偏移头是mot数据关联的导人,因为对象表示是基于极其精确的边界框学习的。将偏移头的输出表示为其中偏移头输出的类号cd=2;第i帧图上的真实位移di表示为pi表示第i帧中心位置;将第i帧中心位置位移表示为因此尺寸头和偏移头的类似损失ls为:
[0059][0060]
其中,n表示当前视频帧中的目标数量;zi表示第i帧框的大小;表示第i帧预测的边界框大小;di表示图上的真实位移;表示中心位置位移;||
·
||1表示l1范数;
[0061]
因此,定位头损失l
p
为前两个损失的组合:
[0062]
l
p
=lh+ls[0063]
其中,lh表示热力图头损失函数;ls表示尺寸头和偏移头的类似损失。
[0064]
表征头包括,表征头的目的为提取可以区分各种跟踪目标的表示。在理想情况下,不同行人之间的差异大于同一行人之间的差异。为了实现这一目标,基于主干网络输出为
检测到的目标学习对象表示。生成的表示图为其中表示三维矩阵;s表示第二下采样因子;w为宽度;h为宽度;生成的表示图的输出通道ce=128;通过表征头学习的中心位置p的目标表征中心位置p的目标表征表示元素个数为c的一维向量;将跟踪目标识别视为分类问题,训练数据集中所有相同身份的目标都被视为一个标签;对于第i帧视频帧中的真实边界框bi,获得第i帧热图上的目标中心位置在第i帧某个位置学习一个身份表示并输出到一维分类概率向量v(k),并将第i帧地面实况分类标签表示为ui(j);因此,身份分类损失lc被构造为:
[0065][0066]
其中,n表示帧的总数;j表示数据集中所有身份的总数;v(j)表示身份的预测值;j表示数据集中身份的计数变量;log(
·
)表示取对数,用于简便计算;
[0067]
总检测损失为ld=l
p
+lc,lc为身份分类损失;l
p
为定位头损失。
[0068]
所述的步骤s2,包括进入连接子模块sj,将当前视频帧f
t
的表示矩阵r
t
沿垂直方向复制到当前帧中的表示张量并将前n帧中的表示矩阵r
t-n
沿水平方向复制到前n帧中的表示张量将当前帧中的表示张量m
t
和前n帧中的表示张量m
t-n
沿着对象表示的通道方向合并到,当前帧和前n帧之间的混淆张量nm表示每帧的最大目标数;表示三维矩阵;t表示当前时刻。
[0069]
所述的步骤s3,包括历史帧f
t-n
和当前视频帧f
t
在视频序列中不一定是连续的,将历史帧f
t-n
和当前视频帧f
t
由n帧分隔,其中n∈[0,n
a-1],na表示最大历史帧数目;使用跳过的视频帧进行训练,有利于在当前帧与一系列历史视频帧之间的数据关联中使用现有的mot方法。此外,mot中使用的训练数据始终缺乏捕捉背景变化、相机失真和许多现实效果以保持mot鲁棒性的能力。在所提出的跟踪方法中,训练数据涉及足够多的不相关跟踪属性,以增强mot模型的鲁棒性。因此,对mot训练数据集进行后续的数据增强。以0.25的概率对每个轨迹上的历史帧f
t-n
和当前视频帧f
t
进行采样。然后,这些视频帧被重新整形为指定的大小w
×h×
3;对采样视频帧使用概率为0.5的水平翻转,沿着对象表示的方向逐步实现了从256到1的维度压缩,卷积核大小为1
×
1,同时不会相互影响表示图中的相邻通道。
[0070]
如图3为本发明实施例的关联子模块流程示意图;所述的步骤s4,包括进入关联子模块,将扩展的混淆矩阵m
t,tn
转换为关联矩阵,通过利用所提出的关联子模块获得帧间关联,如图2的后半部分所示,并利用每帧的最大目标数nm预测历史帧f
t-n
和当前视频帧f
t
之间的对象关联矩阵ma;沿水平和垂直方向,向历史帧f
t-n
和当前视频帧f
t
之间的对象关联矩阵ma中插入零向量(作为对象占位符)以进行泛化。
[0071]
所述的步骤s5,包括利用历史帧f
t-n
和当前视频帧f
t
之间的相似性关联编码来考虑多个目标的消失和出现;考虑到目标消失,在历史帧f
t-n
和当前视频帧f
t
之间的对象关联矩阵ma后附加一列,构建第一扩展矩阵m1,nm表示每帧的最大目标数;
表示三维矩阵;nm表示每帧的最大目标数;表示二维矩阵;最后附加的垂直向量表示从历史帧f
t-n
中消失的当前跟踪对象。最后一行中附加的水平向量表示在当前帧f
t
中进入视野的新兴目标;如图3顶部所示。第一扩展矩阵m1的第m行将历史帧f
t-n
中的第m个对象与当前帧f
t
的第nm+1个对象关联起来;nm+1表示最大目标数+1;通过执行softmax函数对第一扩展矩阵m1的水平方向上的扩展概率向量进行归一化;因此,输出关联矩阵a1的水平向量表示当前视频帧f
t
中所有目标与所有目标之间的关联概率在当前视频帧f
t
中,包括当前视频帧中末识别的目标。a1表示第一关联矩阵预测值;将总关联损失ls定义为方向性损失ld、非极大值损失lm和平衡损失lb的总和,ls=ld+lm+lb,
[0072]
具体来说,使用方向性损失ld来抑制消失和出现的错误目标关联。
[0073][0074]
其中,b1表示b
t-n,t
删除最后一个水平向量;b2表示b
t-n,t
删除最后一个垂直向量;b
t-n,t
表示历史帧与当前帧的关联矩阵真实值;
⊙
表示hadamard乘积;log(
·
)表示取对数,用于简便计算;nm表示每帧的最大目标数;a2表示第二关联矩阵预测值;
[0075]
利用非极大值损失和平衡损失来训练关联子模块;非极大值损失lm在关联计算的消失和出现中惩罚非最大关联。
[0076][0077]
其中,nm表示每帧的最大目标数;b3表示b
t-n,t
删除最后一个垂直向量和最后一个水平向量;log(
·
)表示取对数,用于简便计算;am表示第三关联矩阵预测值;am=max(ac,ar),max(
·
)表示取最大值;ac表示a1删除最后一个垂直向量和最后一个水平向量被裁剪到nm×
nm的纬度获得的矩阵;ar表示a2删除最后一个垂直向量和最后一个水平向量被裁剪到nm×
nm的纬度获得的矩阵,如图3所示。
[0078]
平衡损失lb惩罚消失和出现之间的任何不平衡。这意味着出现的对象数和消失的对象数相等,
[0079][0080]
其中,ac表示去除最后列的关联矩阵预测值;ar表示去除最后行的关联矩阵预测值。
[0081]
所述的步骤s6,包括得到当前视频帧f
t
目标和具有相应对象表示的历史帧f
t-n
中的目标之间的关联矩阵后,将当前图像对象与历史图像对象联系起来更新轨迹记录器t
t
;在初始时刻,即t=0时,轨迹记录器具有相同数量的轨道,一个帧仅通过检测子模块传输一次,但对象表示被重复使用若干次来评估与剩余图像的相似性;基于关联矩阵;通过复制累加器的最后一个垂直向量,可以将许多轨道分配给累积矩阵中的特定末检测对象列,实现在线跟踪。
[0082]
具体实施例为:
[0083]
在本实施例中,使用mot15和mot17两个不同的mot基准数据集上广泛测试了所提出方法的总体性能,如表1所示为本发明实施例的测试结果,具体为。
[0084]
表1
[0085][0086]
其中,jde为现有一阶段mot方法。mdp_subcnn、cda_ddal、eamtt、ap_hwdpl、rar15、dman、mtdf、famnet、tracktor++和sst为现有二阶段mot方法。本方法(即joint detection association network,jdan)与之前多种广泛使用的mot方法相比,本方法在两个mot基准数据上获得了最好的idf1(正确识别的检测结果与真实值和预测检测结果的平均数之比)分数、mt(命中的目标轨迹占ground truth总轨迹的比例)、ml(丢失的目标轨迹占ground truth总轨迹的比例)、hz(频率),优于所有二阶段方法的mota(标准mot准确度,最重要的评价指标)分数,id_sw(id切换次数)也获得不错的成绩,获得了接近帧率的跟踪速度,这代表了出色的mot性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1