一种求解回归问题的神经网络量化方法
1.本发明涉及神经网络技术领域,尤其涉及一种求解回归问题的神经网络量化方法。
背景技术:
2.随着人工智能技术飞速发展,神经网络不仅被广泛应用在图像识别、目标检测、自然语言处理等分类任务中,也被越来越多的研究者用来解决物理、化学、材料、医学等领域的回归预测问题,如凝聚态物理中的分子动力学计算,研究表明基于神经网络的分子动力学计算比采用传统方法快4~6个数量级。然而,神经网络模型中的乘法运算和非线性激活函数都需要大量的硬件开销和较大的时间延迟。与此同时,相较于分类神经网络,回归神经网络对数值精度要求更高。因此,在回归神经网络模型的硬件实现时,需要更大的硬件开销来保证计算精度,这将导致硬件设备的面积和功耗较大、计算速度较慢,一方面增大了硬件设计的制造成本,另一方面也阻碍了回归神经网络在边缘设备上的部署。
3.为了解决上述问题,目前亟需一种求解回归问题的神经网络量化方法,在保证回归神经网络计算精度的同时,减少硬件实现时的资源开销,提高硬件计算的速度。
技术实现要素:
4.本发明提供了一种求解回归问题的神经网络量化方法,能够解决现有技术的问题。通过在训练阶段对回归神经网络中的乘法运算和激活函数进行量化和简化,达到便于硬件实现,降低硬件资源开销,提高硬件计算速度的目的。实现本发明目的的技术解决方案为:
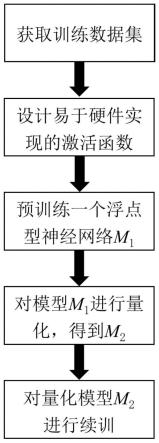
5.一种求解回归问题的神经网络量化方法,步骤如下:
6.s1,获取训练数据集,所述训练数据集包括样本数据x和对应的标签y。
7.s2,设计一个易于硬件实现的非线性激活函数a()。
8.s3,基于激活函数a()和s1中的训练集,预训练一个32位浮点型的全连接层神经网络模型m1。
9.s4,调用s3中的m1模型,将模型的浮点型权重值量化成2的整数次幂的形式,并将模型的浮点型偏置值、各层浮点型输入输出以及激活函数的输入输出进行定点量化,得到量化后的神经网络m2。
10.s5,将训练集输入至s4中的量化网络模型m2,利用损失函数的反向传播和梯度下降,对模型m2进行训练。
11.进一步地,s1中,训练集中的样本数据x包括但不限于由原始数据变化得到的适于网络训练的特征数据集。
12.进一步地,s2中,设计的易于硬件实现的非线性激活函数a()的表达式为(但不限于):
[0013][0014]
a()与双曲正切激活函数具有相似的函数图像。在网络模型的硬件实现时,用向右移位的操作代替a()中的除法运算。
[0015]
进一步地,s3中,全连接层神经网络模型m1由输入层、隐藏层、输出层组成,隐藏层的计算公式如式(2)所示,包括一个矩阵乘运算和一个非线性激活函数a(),输出层的计算式如式(3)所示:
[0016]
xi=a(x
i-1
wi+bi)(2)
[0017]
x
l
=x
l-1wl
+b
l
(3)
[0018]
其中,l表示神经网络的层数;xi表示第i层的输出;x
i-1
表示第i层的输入(也是第i-1层的输出);wi是第i层的权重;bi是第i层的偏置。
[0019]
进一步地,s3中,模型训练使用的损失函数为均方误差损失函数,其表达式为式(4):
[0020][0021]
其中,n为样本的个数;yi为训练集中的标签值;为网络模型的预测值。
[0022]
进一步地,s4中,浮点型权重值的量化公式如式(5)所示:
[0023][0024]
其中,w表示量化前的权重值;wq表示量化后的权重值;qk()表示量化函数;k表示量化后的wq包含k个2的整数次幂的和;nk为指数,其取值范围为整数;s表示权重w的正负性,其取值范围为{-1,0,1}。当k为1时,量化函数q(w)的表达式如式(6)所示:
[0025][0026]
在网络模型的硬件实现时,层输入值与权重之间的乘法运算直接用以2为基数的移位求和操作代替,如式(7)所示:
[0027][0028]
其中,xq表示量化后的层输入;p(x,n)表示移位函数,其表达式如式(8)所示:
[0029][0030]
进一步地,s4中,模型的浮点型偏置值、各层浮点型输入输出以及激活函数的输入输出采用的定点量化公式如式(9)所示:
[0031][0032]
其中,a表示待量化的32位浮点数;aq表示量化后的值;round()表示四舍五入取整操作;m表示量化后的小数位比特数。
[0033]
进一步地,s5中,在模型m2的训练阶段,在所有量化操作点均使用straight-through estimator(ste),直接把量化数据的梯度作为对应浮点型数据的梯度。因此,损失函数对权重矩阵的梯度为:
[0034][0035]
其中,l为损失函数;w为权重矩阵;wq为量化后的权重矩阵。续训阶段使用的是损失函数也为均方误差损失函数,其表达式如式(4)。
[0036]
进一步地,模型m2中的量化参数已经处于最优解附近,因此训练m2时采用一个较小的学习率,避免续训时因学习率过大而导致损失函数直接越过全局最优解。同时,模型m2的训练步数也少于模型m1的训练步数。
[0037]
本发明与现有技术相比,其显著优点在于,本发明针对解决回归问题的神经网络,通过在训练阶段对回归神经网络模型进行量化处理,在保证拟合精度的情况下,能够大幅减少推理时的运算量,便于将网络模型部署到半定制或全定制的硬件平台中,极大地减少了硬件资源开销,加快了回归神经网络的计算速度。
附图说明
[0038]
图1是本发明的操作流程图;
[0039]
图2是本发明实施例中设计的激活函数a()与双曲正切函数tanh()的图像;
[0040]
图3是本发明实施例中全连接层神经网络的结构示意图;
[0041]
图4是本发明实施例中不同k值的量化模型拟合精度同预训练模型拟合精度的对比。
具体实施方式
[0042]
以下将结合说明书附图和具体实施例对本发明作进一步详细说明。
[0043]
本发明涉及一种求解回归问题的神经网络量化方法,如图1所示,该方法首先获取训练数据集,所述训练数据集包括样本数据和对应的标签;然后设计一个易于硬件实现的非线性激活函数,并基于该激活函数预训练一个32位浮点型的全连接层神经网络模型;调用预训练的模型,将浮点型权重值量化成2的整数次幂的形式,并将模型的浮点型偏置值、各层浮点型输入输出以及激活函数的输入输出进行定点量化,得到量化后的神经网络;最后利用反向传播和梯度下降算法对量化网络模型进行训练,保存最终的模型。接下来以分子动力学计算领域的硅(si)系统的原子受力拟合为实施例进行具体说明:
[0044]
1.获取si系统的训练数据集,该数据集包括由si原子的坐标转换得到的特征数据,以及对应的三维受力。
[0045]
2.设计一个易于硬件实现的非线性激活函数a(),其表达式为(但不限于):
[0046][0047]
a()与双曲正切激活函数tanh()具有相似的函数图像,如图2所示。在硬件实现时,用向右移两位的操作代替a()中的除法运算,因此a()中最复杂的电路实现部分仅为一个乘法器。相较于双曲正切激活函数tanh()的电路实现,a()可节省大量的硬件开销。
[0048]
3.基于激活函数a()和si系统的训练集,预训练一个32位浮点型的全连接层神经网络模型m1。
[0049]
如图3所示,网络模型m1由输入层、隐藏层、输出层组成,隐藏层的计算公式如式(2)所示,包括一个矩阵乘运算和一个非线性激活函数a(),输出层的计算式如式(3)所示:
[0050]
xi=a(x
i-1
wi+bi)(2)
[0051]
x
l
=x
l-1wl
+b
l
(3)
[0052]
其中,l表示神经网络的层数;xi表示第i层的输出;x
i-1
表示第i层的输入(也指第i-1层的输出);wi是第i层的权重;bi是第i层的偏置。
[0053]
预训练阶段使用的损失函数为均方误差损失函数,其表达式为式(4):
[0054][0055]
其中,n为样本的个数;yi为训练集中的标签值;为网络模型的预测值。
[0056]
预训练阶段使用的学习率大小为0.01。
[0057]
4.调用m1模型,将模型的浮点型权重值量化成2的整数次幂的形式,并将模型的浮点型偏置值、各层浮点型输入输出以及激活函数的输入输出进行定点量化,得到量化后的神经网络m2。
[0058]
浮点型权重值的量化公式如式(5)所示:
[0059][0060]
其中,w表示量化前的权重值;wq表示量化后的权重值;qk()表示量化函数;k表示量化后的wq包含k个2的整数次幂的和;nk为指数,其取值范围为整数;s表示权重w的正负性,其取值范围为{-1,0,1}。当k为1时,量化函数q(w)的表达式如式(6)所示:
[0061][0062]
在网络模型的硬件实现时,层输入值与权重之间的乘法运算直接用以2为基数的移位求和操作代替,如式(7)所示:
[0063][0064]
其中,xq表示量化后的层输入,p(x,n)表示移位函数,其表达式如式(8)所示:
[0065][0066]
对于本实施例,k的值分别取1、2、3、4、5得到的si原子受力拟合精度与预训练模型的拟合精度对比如图4所示。当k=3时,续训的量化模型已经达到与预训练的32位浮点型模型相当的拟合精度,再增大k的值,精度改善不大,但会增加硬件实现时的资源开销。综合考虑模型的拟合精度和硬件开销,取k=3时为最优。
[0067]
同时,对模型中的浮点型偏置值、各层浮点型输入输出以及激活函数的输入输出进行定点量化,量化公式如式(9)所示:
[0068][0069]
其中,a表示待量化的32位浮点数;aq表示量化后的值;round()表示四舍五入取整操作;m表示量化后的小数位比特数。本实施例中,对m取值为10。
[0070]
5.将si系统的训练集输入至量化网络模型m2,利用损失函数的反向传播和梯度下降,对模型m2进行训练。
[0071]
在模型m2的训练阶段,在所有量化操作点均使用straight-through estimator(ste),直接把量化数据的梯度作为对应浮点型数据的梯度。因此,损失函数对权重矩阵的梯度为:
[0072][0073]
其中,l为损失函数;w为权重矩阵;wq为量化后的权重矩阵。
[0074]
续训阶段使用的损失函数也为均方误差损失函数,其表达式如式(4)。续训阶段使用的学习率大小为0.0001。
[0075]
综上所述,本发明实施例针对解决回归问题的神经网络,通过在训练阶段对回归神经网络模型进行量化处理,用移位操作代替复杂的乘法操作,并设计了一种电路实现简单的非线性激活函数,在保证网络模型拟合精度的情况下,能够大幅减少推理时的运算量,便于将网络模型部署到半定制或全定制的硬件平台中,达到减少硬件资源开销,加快回归神经网络计算速度的目的。
[0076]
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制。参照该实施例的说明,本领域的普通技术人员应该可以理解并对本发明的技术方案进行相关的修改或替换,而不脱离本发明的实质和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1