一种基于图匹配网络的语义类代码克隆检测方法
1.本发明涉及大型软件维护中的克隆检测技术,具体涉及一种基于图匹配网络的代码克隆检测方法。
背景技术:
2.随着计算机的发展,计算机软件已经在社会各个领域得到了广泛的应用,在现代社会中扮演着举足轻重的角色,发挥了重要的作用。随着各行各业对软件系统的需求日益扩增,现代软件系统的代码规模逐渐扩大,导致现代软件系统的开发往往需要耗费大量的人力以及时间。为了提高现代软件系统开发人员在软件开发中的效率,开发人员在开发软件过程中往往会复用一些已有的代码。复用代码的方法主要包括从代码仓库中搜索满足需求的代码,对代码简要修改和复制到目标软件系统中、使用成熟的开发框架例如spring、tensorflow等、针对具体任务使用前人总结的设计模式。上述方法虽然提高了开发人员的软件开发效率,但也催生了代码克隆现象。代码克隆是指代码仓库中两段相同或相似的代码。根据已有的研究工作显示,代码克隆已经广泛的存在于现代软件系统之中。在linux操作系统内核中包含27%-35%的代码存在代码克隆,在当前最大的代码仓库github中,超过70%的代码都存在代码克隆。虽然重复使用已有的代码可以显著提升软件开发人员的开发效率,但是重复使用已有代码也有可能引入潜藏的漏洞,如在复用代码时,为根据上下文对代码进行更改,使得引入预期外的控制流或数据流。因此代码克隆检测尤为重要。利用代码克隆检测,软件维护人员可以根据已知的恶意程序代码或含有漏洞的代码检测在软件中其他可能潜藏的恶意软件代码和含有漏洞的代码。
3.根据两段代码的相似程度的不同,一般将代码克隆分为四类。第一类代码克隆指除了注释和空格不同,其他都相同的两段代码。第二类代码克隆指仅仅函数名或变量名不同的两段代码。第三类代码克隆指在保持语法结构不变的基础上,在代码语句上略有增删的两段代码。第四类代码克隆也叫做语义类代码克隆,指语法结构不同,但是代码语义相同的两段代码。针对代码克隆的种类不同,现有主要有基于匹配和基于深度学习的方法检测代码克隆。基于匹配的代码克隆检测方法,主要通过将代码进行一些转换,再根据代码转换之后的表示形式,利用对应的相似比较算法,判断两段代码是否相似。例如zu yue等人在ase2020会议上发表的文章“ccgraph:a pdg-based code clone detector with approximate graph matching(一种利用相似图匹配算法的基于程序依赖图的克隆检测方法,简称ccgraph)”,将代码转化为包含其数据流信息和控制流信息的程序依赖图。为了比较两段代码的程序依赖图的相似性,他们使用weisfeiler-lehman图核算法来比较两个图的相似性,最后根据两个图的相似性是否超过既定阈值来判断两段代码是否是克隆代码。基于匹配的克隆检测方法速度较快,不需要前期准备工作,并且在前三种类型的代码克隆检测中可以取得较好的准确率和召回率。但是在解决语义类代码克隆问题时,基于匹配的克隆检测方法的准确率和召回率都有显著下降,导致开发人员在查找语义类克隆检测时,仍然需要花费大量的人力物力检查匹配的克隆检测方法的输出结果。基于深度学习的代码
克隆检测方法是使用深度学习模型将代码转化为可以表示其含义的高维向量,通过训练深度学习模型,可以使克隆代码的向量在高维空间之中更近似。在判断一对代码是否是克隆代码时,使用训练好的深度学习模型将他们转化为高维向量,根据代码向量距离判断两段代码是否是克隆代码。例如hao yu等人在icpc2019会议上发表的文章“neural detection of semantic code clones via tree-based convolution(基于树型卷积的语义代码克隆检测方法,简称tbccd)”,将代码转化为抽象语法树,然后利用树型卷积模型将代码的抽象语法树转化为向量,最后比较代码向量的相似度判断代码是否为克隆代码。基于深度学习的代码克隆方法可以更有效的理解代码的语义,因此可以有效检测出语义类代码克隆。但是目前的基于深度学习的代码克隆检测方法主要使用以lstm网络为代表的基于文本的深度学习模型,只学习了代码的文本和语法信息,在准确率和召回率仍有待提高。
4.综上,如何提供一种检测语义类代码克隆的方法,更好地挖掘代码中的信息,更好地使用深度学习模型学习代码语义,使得代码克隆检测更准确,是本领域技术人员正在探讨的热点问题。
技术实现要素:
5.本发明要解决的技术问题是针对语义类克隆检测结果不准确,代码语义信息获取不全面问题,提供一种基于图匹配网络的代码克隆检测方法。此方法基于深度学习检测代码克隆的方法框架,抽取代码的数据流控制流信息构建代码语义图,更完整的提取代码语义信息。使用图匹配网络,可以更有效地学习代码语义图的语义信息,进而更准更全地查找语义类代码克隆。
6.为解决上述问题,本发明的技术方案是:首先构建由代码补全模块、代码中间表示提取模块、语义图构建模块、代码向量生成模块和向量相似度计算器构成的代码克隆检测系统。然后使用语义类代码克隆数据集对代码向量生成模块中的深度学习模型进行训练,调整深度学习网络模型参数。最后使用代码克隆检测系统对用户输入的待检测代码进行代码补全、提取代码中间表示、构建代码语义图,训练后的代码向量生成模块将代码语义图转化为对应的高维向量v1和v2,再使用向量相似度计算器判断向量的相似度是否超过既定阈值。
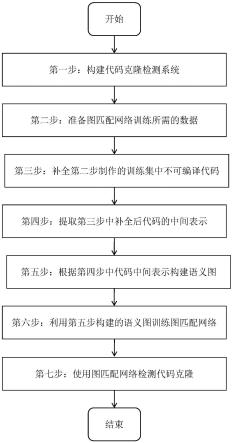
7.本发明包含以下步骤:
8.第一步,构建代码克隆检测系统。代码克隆检测系统由代码补全模块、代码中间表示提取模块、语义图构建模块、代码向量生成模块和向量相似度计算器构成。
9.代码补全模块与代码中间表示提取模块相连,使用jcoffee-1.0工具(见p gupta等人在icsme会议上发表的文献“jcoffee:using compiler feedback to make partial code snippets compilable”使用编译器反馈来使代码片段可编译,下载地址:https://github.com/piyush69/jcoffee)对输入的代码对c1,c2分别进行补全,得到补全后的代码对c
‘1,c
‘2,使c
‘1,c
‘2可以进行编译,将c
‘1,c
‘2发送给代码中间表示提取模块。
10.代码中间表示提取模块与代码补全模块、语义图构建模块相连,将从代码补全模块接收的c
‘1,c
‘2分别进行编译,提取c
‘1,c
‘2编译过程中的代码中间表示,构成代码中间表示对r1,r2。将r1,r2发送给语义图构建模块。
11.语义图构建模块与代码中间表示提取模块、代码向量生成模块相连,从代码中间
表示提取模块接收r1,r2,从r1,r2中提取代码的常量、变量、操作符、api、数据流和控制流信息,分别构建可以表示代码语义的语义图,得到语义图对g1,g2,将g1,g2发送给代码向量生成模块。
12.代码向量生成模块与语义图构建模块、向量相似度计算器相连,从代码向量生成模块接收g1,g2,使用图匹配网络(见y li等人在pmlr2019的文献“graph matching networks for learning the similarity of graph structured objects”:使用图匹配网络来学习图结构目标的相似性)将g1,g2分别映射为高层向量空间中的两个代码向量v1,v2,将v1,v2发送给向量相似度计算器。
13.向量相似度计算器与代码向量生成模块相连,计算v1,v2的向量相似度sim,根据sim是否超过设定的阈值来判断v1,v2所表示的代码对c1,c2是否属于语义类代码克隆。
14.第二步,代码补全模块采用代码补全方法补全数据集中的代码。方法为:
15.2.1使用bigclonebench数据集作为训练代码,bigclonebench数据集来自j svajlenko等人发表在icsme2015会议上的文献“evaluating clone detection tools with bigclonebench”:使用bigclonebench检验代码克隆检测工具。其中bigclonebench数据集包含44种功能的代码,共8961段代码。在构建克隆代码对时,从bigclonebench数据集中任意抽取两段代码可以构成一个代码对,若抽取的两段代码功能相同,则为克隆代码对,否则为非克隆代码对。从bigclonebench数据集中总共可以构建11,241,933对克隆代码以及69,057,588对非克隆代码。由于从bigclonebench数据集中构建的代码对数量庞大,使用全部的代码对讲消耗过多的时间和资源,因此在使用时仅仅从所有代码对中选择n(80299521=11,241,933+69,057,588≥n≥10,000)对代码以及对应的标注作为训练集用于模型训练。由于bigclonebench数据集中存在代码不可编译,无法提取其代码中间表示,因此需要对代码进行补全。
16.2.2令可编译代码集合data={};
17.2.3令变量n=1;
18.2.4从训练集中抽取第n个代码段ccn,判断ccn是否可编译,若ccn可编译,转2.5,否则转2.6;
19.2.5将ccn加入data中,令n=n+1,转2.9;
20.2.6使用jcoffee-1.0工具补全ccn,得到补全后的代码cc
′n,转2.7;
21.2.7判断cc
′n是否可编译,若可编译,转2.8,否则转2.9;
22.2.8将cc
′n加入data中,令n=n+1,转2.9;
23.2.9若n≥n,说明bigclonebench数据集中的所有代码均已经过补全,令补全后的data中数据总数m=n,将补全后的data发送给代码中间表示提取模块,转第三步;否则转2.4;
24.第三步,代码中间表示提取模块从代码补全模块接收可编译代码集合data,采用代码中间表示提取方法从data中提取代码中间表示,构建代码中间表示集合ir。具体方法为:
25.3.1令代码中间表示集合ir={};
26.3.2令变量m=1;
27.3.3从data中抽取第m个代码ccm,若ccm为java语言代码,转3.4;若为c语言代码,则
转3.5;
28.3.4提取java代码的代码中间表示,方法为:
29.3.4.1使用javac编译代码ccm,得到二进制文件classm;
30.3.4.2根据二进制文件classm,使用soot-4.1.0工具(见r vall
é
e-rai等人在casc1999会议上的文献“soot:a java bytecode optimization framework”:soot:一个java字节码优化框架,下载地址:http://soot-oss.github.io/soot/)提取代码的中间表示rm,将rm加入ir,令m=m+1,转3.6;
31.3.5利用llvm-9.0工具(见c lattner等人在cgo2004会议上发表的文献“llvm:a compilation framework for lifelong program analysis&transformation”llvm:一个程序分析和转化的编译器框架,下载地址:https://releases.llvm.org/download.html)编译代码ccm,得到代码ccm的中间表示rm,将rm加入ir,令m=m+1,转3.6;
32.3.6若m》m,说明已为所有可编译代码提取代码中间表示,将代码中间表示集合ir发送至语义图构建模块,转第四步;若m≤m,转3.3。
33.第四步,语义图构建模块从代码表示提取模块接收代码中间表示集合ir,采用语义图集合构建方法根据ir构建语义图集合sg,方法为:
34.4.1令语义图集合sg={};
35.4.2令变量p=0;
36.4.3从ir中抽取第p个代码中间表示r
p
,由于代码的中间表示中常常包含了语义无关的噪音,例如所使用的编译器类型,或编译过程中的通用信息等,而语义相关的关键信息通常是指代码中实际实现代码语义的指令,因此为了构建语义图首先需要从r
p
中提取关键语义表示信息,过滤无用噪音信息。方法是:
37.4.3.1初始化关键语义表示信息队列s
p
为空;
38.4.3.2初始化变量a=1,初始化标识flag=0;
39.4.3.3判断r
p
的第a行代码是否包含函数名,若包含函数名,说明此时已检索到代码中间表示关键指令信息起始位置,转到4.3.5,否则转到4.3.4;
40.4.3.4令a=a+1,若a≤r
p
的长度,转4.3.3;若a》r
p
的长度,转4.3.12;
41.4.3.5将加入到s
p
中,令a=a+1;
42.4.3.6由于根据代码生成的指令在“{}”符号的范围内,因此根据判断是否包含符号“{”或“}”可判断当前中间表示行是否为中间表示的起始位置、结束位置或中间位置。若包含符号“{”,说明为中间表示语句块的开始位置,转4.3.7;若包含符号“}”,说明为中间表示语句块的结束位置,转4.3.9;若既不包含“{”,也不包含“}”,说明为中间表示语句块的中间位置,转4.3.8;
43.4.3.7令flag=1,表示开始存储中间表示关键指令信息,转4.3.10;
44.4.3.8若flag=1,将加入到s
p
中,转4.3.10;
45.4.3.9令flag=0,表示停止存储中间表示关键指令信息,转4.3.11;
46.4.3.10令a=a+1,转4.3.6;
47.4.3.11令a=a+1,若a小于r
p
的长度,转4.3.3,否则转4.3.12;
48.4.3.12得到关键语义表示信息队列s
p
,s
p
中的元素为过滤掉了无用噪音信息的r
p
中的代码,转4.4;
49.4.4语义图构建模块采用语义图构建方法根据s
p
构建语义图g
p
。方法是:
50.4.4.1初始化语义图g
p
为空,即初始化语义图g
p
的节点集合v
p
、数据流边集合e_data
p
和控制流边集合e_control
p
为空;
51.4.4.2语义图构建模块为g
p
的节点集合v
p
添加变量节点,方法是:
52.4.4.2.1初始化变量k=1;
53.4.4.2.2判断s
p
第k个元素是否为变量声明语句,若是变量声明语句,转4.4.2.3向v
p
中添加变量节点;否则转4.4.2.4;
54.4.4.2.3利用正则表达式从中提取变量var以及var的类型type,根据变量var以及var的类型type,以三元组的形式构建变量节点(var,type,v
var
),v
var
是变量节点的标识,表示此节点的类型为变量节点,v
var
中存储的值为var,var数据类型为type,将变量节点(var,type,v
var
)加入v
p
中;
55.4.4.2.4令k=k+1,若k大于s
p
的长度,说明已经将所有变量节点加入到v
p
中,转到4.4.3;否则转4.4.2.2;
56.4.4.3语义图构建模块为g
p
的节点集合v
p
添加语句块节点,方法是:
57.4.4.3.1初始化变量k=1;
58.4.4.3.2判断s
p
第k个元素是否为语句块声明语句,即判断中是否包含关键词“label%”,若包含“label%”,转4.4.3.3向v
p
中添加语句块节点;否则转4.4.3.4;
59.4.4.3.3利用正则表达式从中提取语句块标识符marker,根据标识符marker,以二元组的形式构建语句块标识符节点(marker,v
control
),v
control
是语句块标识符节点的标识,表示此节点类型为语句块标识符节点,v
control
中存储的值为marker,将语句块标识符节点(marker,v
control
)加入v
p
中;
60.4.4.3.4令k=k+1,若k大于s
p
的长度,说明已经将所有变量节点加入到v
p
中,转到4.4.4;否则转4.4.3.2;
61.4.4.4语义图构建模块为语义图g
p
添加操作符节点、数据流边和控制流边,操作符节点包括函数调用节点、运算符节点、取值操作符节点,方法是:
62.4.4.4.1初始化变量k=1;
63.4.4.4.2初始化变量u=1;
64.4.4.4.3判断s
p
中第k个元素是否为语句块声明语句,即是否包含关键词“label%”,若是语句块声明语句,转4.4.4.4提取当前语句块的语句块标识符节点;否则转4.4.4.5;
65.4.4.4.4利用正则表达式从中提取语句块标识符marker,对变量u赋值,使u=marker,说明当前的中间表示语句属于语句块标识符节点(u,v
control
)所代表的语句块,v
control
表示此节点类型为语句块标识符节点,v
control
中存储的值为u;
66.4.4.4.5判断是否为函数调用语句,即判断是否包含“invoke”关键词,若包含“invoke”,转4.4.4.6向g
p
的节点集合v
p
中添加函数调用节点,并添加对应的数据流和控制
流边;否则转4.4.4.15;
67.4.4.4.6使用正则表达式从中提取调用函数的函数名method、函数调用的输入变量var
in
、函数的返回值变量var
return
。根据函数名method,以二元组的形式构建函数调用节点(method,v
invoke
),v
invoke
是构建函数调用节点的标识,表示此节点类型为函数调用节点,v
invoke
中存储的值为method,将函数调用节点(method,v
invoke
)加入v
p
中。在g
p
的控制流边集合e_control
p
中以三元组的形式添加控制流边((u,v
control
),(method,v
invoke
),e
control-flow
),表示函数调用节点(method,v
invoke
)属于语句块标识符节点(u,v
control
)所代表的语句块,e
control-flow
表示添加的边的属性为控制流边。在g
p
的数据流边集合e_data
p
中以三元组形式添加两条数据流边,分别为((var
in
,type,v
var
),(method,v
invoke
),e
data-flow
)和((method,v
invoke
),(var
return
,type,v
var
),e
data-flow
),说明数据从变量节点(var
in
,type,v
var
)输入函数调用节点(method,v
invoke
)进行函数调用计算,经过函数调用计算得到的数据从函数调用节点(method,v
invoke
)输出到变量节点(var
return
,type,v
var
),e
data-flow
表示添加的边的属性为数据流边;
68.4.4.4.7判断s
p
中第w个元素是否为数据运算语句,即是否包含关键词“/”、“%”、“+”、
“‑”
、“*”、“cmp”中的任意一个,若是数据运算语句,转4.4.4.8向v
p
中添加运算符节点,并添加对应的数据流和控制流边;否则转4.4.4.15;
69.4.4.4.8使用正则表达式从中提取数据运算的运算符op、参与运算的变量var
in
、运算的结果变量var
return
。根据运算符op,以二元组的形式构建运算符节点(op,v
operator
),v
operator
是运算符节点的标识,表示此节点为运算符节点,v
operator
中存储的值为op,将运算符节点(op,v
operator
)加入v
p
中。在g
p
的控制流边集合e_control
p
中添加控制流边((u,v
control
),(op,v
operator
),e
control-flow
),表示运算符节点(op,v
operator
)属于语句块标识符节点(u,v
control
)所代表的语句块。在g
p
的数据流边集合e_data
p
中以三元组的形式添加两条数据流边,即((var
in
,type,v
var
),(op,v
operator
),e
data-flow
)和((op,v
operator
),(var
return
,type,v
var
),e
data-flow
),表示数据从变量节点(var
in
,type,v
var
)输入运算符节点(op,v
operator
),运算后的数据从运算符节点(op,v
operator
)输出到变量节点(var
return
,type,v
var
);
70.4.4.4.9判断s
p
中第w个元素是否为数组取值语句,即是否包含取值操作符“getelem”,若包含关键词“getelem”,转4.4.4.10向g
p
中添加操作符节点,并添加对应的数据流和控制流边;否则转4.4.4.15;
71.4.4.4.10使用正则表达式从中提取数组变量var
in
,并提取结果变量var
return
。以二元组的形式构建取值操作符节点(getelem,v
operator
),表示运算符节点v
operator
中存储的值为取值操作符getelem,将取值操作符节点加入v
p
中。在g
p
的控制流边集合e_control
p
中添加控制流边((u,v
control
),(getelem,v
operator
),e
control-flow
),表示取值操作符节点(getelem,v
operator
)属于语句块标识符节点(u,v
control
)所代表的语句块。在g
p
的数据流边集合e_data
p
中以三元组的形式添加两条数据流边,即((var
in
,type,v
var
),(getelem,v
operator
),e
data-flow
),和((getelem,v
operator
),(var
return
,type,v
var
),e
data-flow
),表示数组中的数据从数组变量节点(var
in
,type,v
var
)输入取值操作符节点(getelem,v
operator
),经过取值操作从数组变量中得到的数据从取值操作符节点(getelem,v
operator
)输出到结果变量节
点(var
return
,type,v
var
);
72.4.4.4.11判断s
p
中第w个元素是否为判断语句或跳转语句,即是否包含关键词“goto”或“if”,若包含关键词“goto”或“if”,转4.4.4.12向g
p
中添加控制流边;否则转4.4.4.15;
73.4.4.4.12使用正则表达式从中提取判断语句或跳转语句的目标语句块节点标识符newmarker。在g
p
的控制流边集合e_control
p
中以三元组的形式添加控制流边((u,v
control
),(newmarker,v
control
),e
control-flowr
),表示程序执行时将从当前语句块标识符节点(u,v
control
)所代表的语句块跳转到语句块标识符节点(newmarker,v
control
)所代表的语句块。
74.4.4.4.13判断s
p
中第w个元素是否为赋值语句或类型转换语句,即是否包含关键词“=”,若包含关键词“=”,转4.4.4.14向g
p
中添加数据流边;否则转4.4.4.15;
75.4.4.4.14使用正则表达式从中提取输入变量var
in
以及输出变量var
return
。在g
p
的数据流边集合e_data
p
中以三元组的形式添加数据流边((var
in
,type,v
var
),(var
return
,type,v
var
),e
data-flow
),说明数据从变量var
in
输出到变量var
return
中。
76.4.4.4.15令k=k+1,若k大于s
p
的长度,说明得到g
p
,将g
p
加入语义图集合sg中,转4.5;否则,转到4.4.4.3;
77.4.5若p大于代码中间表示数据集ir的大小,则得到语义图集合sg,转第五步;否则令p=p+1,转4.3;
78.第五步,根据语义图集合sg制作代码向量生成模块所需的训练数据集。方法为:
79.5.1令变量i=1;
80.5.2初始化训练数据集trainingset={};
81.5.3随机从语义图集合sg中任意抽取两个语义图,令第i次抽取的语义图为和若和所对应的代码功能相同,则标注labeli为true,表示和所对应的代码为克隆代码;否则标注labeli为false,表示和所对应的代码不为克隆代码;令第i个三元组将di放入训练数据集trainingset,转5.4;
82.5.4令i=i+1,若i》10,000,则训练集制作完成,将训练数据集trainingset发送到代码向量生成模块,转第六步;否则转5.3;
83.第六步:采用trainingset训练代码向量生成模块,得到可以表示语义图信息的图匹配网络。具体方法是:
84.6.1设置训练图匹配网络所需参数。方法是:
85.6.1.1设置图匹配网络包含网络层数t=4;
86.6.1.2设置图匹配网络学习率ir=0.001;
87.6.1.3设置训练轮数num_epochs=50;
88.6.1.4初始化训练轮数epochs=0;
89.6.2令变量i=1;
90.6.3从训练数据集trainingset中抽取第i个数据di,
91.6.4采用第一初始化方法初始化中节点的向量值与边的权重值,得到初始化后的第一语义图方法如下:
92.6.4.1使用word2vec模型(见t mikolov等人2013年发表在arxiv网站的文献“efficient estimation of word representations in vector space”,有效的表示文字在向量空间)初始化中节点的向量值。从的节点集合v
i1
中顺序选择节点x,x∈v
i1
,将节点x中存储的内容输入word2vec模型,将word2vec模型输出值作为节点x的初始化向量
93.6.4.2令的数据流边集合中每条边的权重值为1;
94.6.4.3令的控制流边集合中每条边的权重值为-1;
95.6.5采用第二初始化方法初始化中节点的向量值与边的权重值,得到初始化后的第二语义图方法如下:
96.6.5.1使用word2vec模型初始化中节点的向量值。从的节点集合v
i2
中顺序选择节点z,z∈v
i2
,将节点z中存储的内容输入word2vec模型,将word2vec模型输出值作为节点z的初始化向量
97.6.5.2令的数据流边集合中每条边的权重值为1;
98.6.5.3令的控制流边集合中每条边的权重值为-1;
99.6.6采用迭代更新方法更新第一语义图中各节点的向量表示,得到第一最终语义图迭代更新方法如下:
100.6.6.1初始化变量t=1;
101.6.6.2从的节点集合v
i1
中顺序选择第一节点x,x∈v
i1
,若的节点集合v
i1
中所有节点都已被选择,则转6.6.7;否则转6.6.3;
102.6.6.3计算在第t次迭代时,中的节点与的相似性,方法是:
103.6.6.3.1从的节点集合v
i2
中顺序选择第二节点,令第二节点为z,z∈v
i2
,若的节点集合v
i2
中所有节点都已被选择,则转6.6.3.3;否则转6.6.3.2;
104.6.6.3.2计算x与z的相似度αz→
x
,其中指x在t-1次迭代后的向量表示,指z在t-1次迭代后的向量表示,指中任意一个不是z的节点在t-1次迭代后的向量表示,转到6.6.3.1;
105.6.6.3.3计算在第t次迭代时x与的节点集合v
i2
中所有节点的相似度和中所有节点的相似度和
106.6.6.4计算在第t次迭代时,第一语义图中与x有边相连的其他节点即第三节点y传递给x的消息向量和,方法是:
107.6.6.4.1在中除x外的节点集合v
i1-x中顺序选择第三节点,令第三节点为y,记
连接x和y的边为e
xy
,若v
i1-x中的所有节点都已被选择,则转6.6.4.4;否则转6.6.4.2;
108.6.6.4.2判断边e
xy
是否存在于的数据流边集合或的控制流边集合中,若存在,转6.6.4.3;否则转6.6.4.1;
109.6.6.4.3计算中y对x的消息向量my→
x
,其中sum为求和函数,指x在t-1次迭代后的向量表示,指y在t-1次迭代后的向量表示,e
xy
指连接x和y的边的权重值,转到6.6.4.1;
110.6.6.4.4计算在第t次迭代时,第一语义图中的x与其有边相连的所有第三节点y对x传递的消息向量和传递的消息向量和
111.6.6.5更新中x在第t次迭代后的向量表示中x在第t次迭代后的向量表示其中gru表示门控循环神经网络,表示利用门控循环神经网络,根据第t-1次迭代后x节点的向量与中与节点x相连的其他节点传递的消息向量和x与的节点集合v
i2
中所有节点的相似度和6.6.3.3中计算得到的生成第t次迭代后的向量表示
112.6.6.6令t=t+1。若t小于t,转6.6.2;否则说明迭代更新完毕,得到第一最终语义图转6.7;
113.6.7采用6.6所述迭代更新方法更新中各节点的向量表示,得到第二最终语义图
114.6.8计算的向量表示v
i1
,其中mlp为多层感知器模型,表示利用多层感知器模型将中所有节点的向量汇总为向量v
i1
,其中为经过t轮迭代后得到的最终语义图中各个节点的向量值;
115.6.9计算的向量表示v
i2
,
116.6.10利用余弦相似度函数比较v
i1
,v
i2
的相似度。判断sim是否大于相似度阈值α,一般0.7≤α<1,若是,则认为和所对应的代码是克隆代码,即模型预测结果label
predict
=true,否则和所对应的代码不为克隆代码,模型预测结果label
predict
=false;
117.6.11若label
predict
不等于labeli,则转6.12;否则转6.15;
118.6.12若labeli=false,跳转到6.13;若labeli=true则跳转到6.14;
119.6.13计算模型调整值loss=-(1-sim)
×
ir,将loss输入word2vec模型,word2vec模型自动更新模型中的参数,转6.15;
120.6.14设置向量调整值loss=(1-sim)
×
ir,将loss输入word2vec模型,word2vec模型自动更新模型中的参数,转6.15;
121.6.15令i=i+1,若i大于语义图数据集sg的大小,说明已训练完一轮,转6.16;否则
转6.3;
122.6.16令epochs=epochs+1,若epochs等于num_epochs,说明训练完毕,得到了可以表示语义图信息的图匹配网络,也即得到了训练后的代码向量生成模块,转第七步;否则转6.2,开始新一轮训练;
123.第七步:使用代码克隆系统检测用户输入的一对待检测代码c1,c2,判断c1,c2是否是克隆代码对,方法是:
124.7.1令待检测代码集合test={c1,c2};
125.7.2代码补全模块采用第二步所述代码补全方法对待检测代码集合test进行代码补全,得到补全后可编译的待检测代码集合test_data={c
‘1,c
‘2};
126.7.3代码中间表示提取模块采用第三步所述代码中间表示提取方法从对test_data提取代码中间表示,构建待检测代码集合的代码中间表示集合test_ir,test_ir={r1,r2};
127.7.4语义图生成模块采用第四步所述语义图集合构建方法根据test_ir构建待检测代码集合的语义图集合test_sg={g1,g2};
128.7.5训练好的代码向量生成模块根据test_sg中的第一语义图g1和第二语义图g2,生成其对应的向量值v1和v2,方法如下;
129.7.5.1采用6.4所述第一初始化方法初始化g1,得到初始化后的语义图ig1,采用6.5所述第二初始化方法初始化g2得到初始化后的语义图ig2;;
130.7.5.2采用6.6所述迭代更新方法迭代更新初始化语义图ig1和ig2中节点的向量,分别得到最终语义图fg1和fg2;
131.7.5.3计算fg1的向量值v1,
132.7.5.4计算fg2的向量值v2,
133.7.6训练好的向量生成模块利用余弦相似度函数比较v1和v2的相似度。的相似度。判断sim是否大于相似度阈值α,若sim》α,则认为g1和g2所对应的代码是克隆代码,即模型预测结果label
predict
=true;若sim≤α,g1和g2所对应的代码不为克隆代码,模型预测结果label
predict
=false。
134.采用本发明可以达到以下技术效果:
135.1、采用本发明可以有效的检测语义类代码克隆。采用本发明在bigclonebench数据集上对本文方法在检测克隆代码的效果进行测试。经过12小时的模型训练,可以有效检测到bigclonebench中超过44%的代码克隆,并且保证58%的准确率。而已有方法“neural detection of semantic code clones via tree-based convolution”(基于树型卷积的代码克隆语义检测)在检测到37%代码克隆时,仅能取得31%的准确度。
136.2、本发明第三步中利用编译器在编译代码过程中,对代码的中间表示信息,更准确完整地挖掘到代码中的语义信息(即有效信息),在第四步中根据挖掘出的代码关键语义信息,构建语义图,可以更好的表达代码中间表示中的语义信息。在第六步中使用图匹配网络更好的挖掘代码语义特征。相比于基于字符或者基于语法的克隆检测方法,本发明基于图匹配网络的方法可以更准确的提取代码的实际语义,因此本发明也取得了超过其他方法
的代码克隆检测效果。
137.3、本发明在第二步对输入代码克隆检测系统的代检测代码进行了补全,使其在不可编译时,仍能使用本发明进行代码克隆检测,具有良好的泛用性。
附图说明:
138.图1为本发明整体流程图。
139.图2为本发明第一步构建的代码克隆检测系统逻辑结构图。
具体实施方式
140.下面结合附图对本发明进行说明。图1是本发明整体流程图。如图1所示,本发明包括以下步骤:
141.第一步,构建代码克隆检测系统。代码克隆检测系统如图2所示,由代码补全模块、代码中间表示提取模块、语义图构建模块、代码向量生成模块和向量相似度计算器构成。
142.代码补全模块与代码中间表示提取模块相连,使用jcoffee-1.0工具对输入的代码对c1,c2分别进行补全,得到补全后的代码对c
‘1,c
‘2,将c
‘1,c
‘2发送给代码中间表示提取模块。
143.代码中间表示提取模块与代码补全模块、语义图构建模块相连,将从代码补全模块接收的c
‘1,c
‘2分别进行编译,提取c
‘1,c
‘2编译过程中的代码中间表示,构成代码中间表示对r1,r2。将r1,r2发送给语义图构建模块。
144.语义图构建模块与代码中间表示提取模块、代码向量生成模块相连,从代码中间表示提取模块接收r1,r2,从r1,r2中提取代码的常量、变量、操作符、api、数据流和控制流信息,分别构建可以表示代码语义的语义图,得到语义图对g1,g2,将g1,g2发送给代码向量生成模块。
145.代码向量生成模块与语义图构建模块、向量相似度计算器相连,从代码向量生成模块接收g1,g2,使用图匹配网络将g1,g2分别映射为高层向量空间中的两个代码向量v1,v2,将v1,v2发送给向量相似度计算器。
146.向量相似度计算器与代码向量生成模块相连,计算v1,v2的向量相似度sim,根据sim是否超过设定的阈值来判断v1,v2所表示的代码对c1,c2是否属于语义类代码克隆。
147.第二步,代码补全模块采用代码补全方法补全数据集中的代码。方法为:
148.2.1使用bigclonebench数据集作为训练代码,bigclonebench数据集包含44种功能的代码,共8961段代码。在构建克隆代码对时,从bigclonebench数据集中任意抽取两段代码可以构成一个代码对,若抽取的两段代码功能相同,则为克隆代码对,否则为非克隆代码对。从bigclonebench数据集中总共可以构建11,241,933对克隆代码以及69,057,588对非克隆代码。从所有代码对中选择n(80299521=11,241,933+69,057,588≥n≥10,000)对代码以及对应的标注作为训练集用于模型训练。由于bigclonebench数据集中存在代码不可编译,无法提取其代码中间表示,因此需要对代码进行补全。
149.2.2令可编译代码集合data={};
150.2.3令变量n=1;
151.2.4从训练集中抽取第n个代码段ccn,判断ccn是否可编译,若ccn可编译,转2.5,否
则转2.6;
152.2.5将ccn加入data中,令n=n+1,转2.9;
153.2.6使用jcoffee-1.0工具补全ccn,得到补全后的代码cc
′n,转2.7;
154.2.7判断cc
′n是否可编译,若可编译,转2.8,否则转2.9;
155.2.8将cc
′n加入data中,令n=n+1,转2.9;
156.2.9若n≥n,说明bigclonebench数据集中的所有代码均已经过补全,令补全后的data中数据总数m=n,将补全后的data发送给代码中间表示提取模块,转第三步;否则转2.4;
157.第三步,代码中间表示提取模块从代码补全模块接收可编译代码集合data,采用代码中间表示提取方法从data中提取代码中间表示,构建代码中间表示集合ir。具体方法为:
158.3.1令代码中间表示集合ir={};
159.3.2令变量m=1;
160.3.3从data中抽取第m个代码ccm,若ccm为java语言代码,转3.4;若为c语言代码,则转3.5;
161.3.4提取java代码的代码中间表示,方法为:
162.3.4.1使用javac编译代码ccm,得到二进制文件classm;
163.3.4.2根据二进制文件classm,使用soot-4.1.0工具提取代码的中间表示rm,将rm加入ir,令m=m+1,转3.6;
164.3.5利用llvm-9.0工具编译代码ccm,得到代码ccm的中间表示rm,将rm加入ir,令m=m+1,转3.6;
165.3.6若m》m,说明已为所有可编译代码提取代码中间表示,将代码中间表示集合ir发送至语义图构建模块,转第四步;若m≤m,转3.3。
166.第四步,语义图构建模块从代码表示提取模块接收代码中间表示集合ir,采用语义图集合构建方法根据ir构建语义图集合sg,方法为:
167.4.1令语义图集合sg={};
168.4.2令变量p=0;
169.4.3从ir中抽取第p个代码中间表示r
p
,方法是:
170.4.3.1初始化关键语义表示信息队列s
p
为空;
171.4.3.2初始化变量a=1,初始化标识flag=0;
172.4.3.3判断r
p
的第a行代码是否包含函数名,若包含函数名,说明此时已检索到代码中间表示关键指令信息起始位置,转到4.3.5,否则转到4.3.4;
173.4.3.4令a=a+1,若a≤r
p
的长度,转4.3.3;若a》r
p
的长度,转4.3.12;
174.4.3.5将加入到s
p
中,令a=a+1;
175.4.3.6若包含符号“{”,说明为中间表示语句块的开始位置,转4.3.7;若包含符号“}”,说明为中间表示语句块的结束位置,转4.3.9;若既不包含“{”,也不包含“}”,说明为中间表示语句块的中间位置,转4.3.8;
176.4.3.7令flag=1,表示开始存储中间表示关键指令信息,转4.3.10;
177.4.3.8若flag=1,将加入到s
p
中,转4.3.10;
178.4.3.9令flag=0,表示停止存储中间表示关键指令信息,转4.3.11;
179.4.3.10令a=a+1,转4.3.6;
180.4.3.11令a=a+1,若a小于r
p
的长度,转4.3.3,否则转4.3.12;
181.4.3.12得到关键语义表示信息队列s
p
,s
p
中的元素为过滤掉了无用噪音信息的r
p
中的代码,转4.4;
182.4.4语义图构建模块采用语义图构建方法根据s
p
构建语义图g
p
。方法是:
183.4.4.1初始化语义图g
p
为空,即初始化语义图g
p
的节点集合v
p
、数据流边集合e_data
p
和控制流边集合e_control
p
为空;
184.4.4.2语义图构建模块为g
p
的节点集合v
p
添加变量节点,方法是:
185.4.4.2.1初始化变量k=1;
186.4.4.2.2判断s
p
第k个元素是否为变量声明语句,若是变量声明语句,转4.4.2.3向v
p
中添加变量节点;否则转4.4.2.4;
187.4.4.2.3利用正则表达式从中提取变量var以及var的类型type,根据变量var以及var的类型type,以三元组的形式构建变量节点(var,type,v
var
),v
var
是变量节点的标识,表示此节点的类型为变量节点,v
var
中存储的值为var,其数据类型为type,将变量节点(var,type,v
var
)加入v
p
中;
188.4.4.2.4令k=k+1,若k大于s
p
的长度,说明已经将所有变量节点加入到v
p
中,转到4.4.3;否则转4.4.2.2;
189.4.4.3语义图构建模块为g
p
的节点集合v
p
添加语句块节点,方法是:
190.4.4.3.1初始化变量k=1;
191.4.4.3.2判断s
p
第k个元素是否为语句块声明语句,即判断中是否包含关键词“label%”,若包含“label%”,转4.4.3.3向v
p
中添加语句块节点;否则转4.4.3.4;
192.4.4.3.3利用正则表达式从中提取语句块标识符marker,根据标识符marker,以二元组的形式构建语句块标识符节点(marker,v
control
),v
control
是语句块标识符节点的标识,表示此节点类型为语句块标识符节点,其中存储的值为marker,将语句块标识符节点(marker,v
control
)加入v
p
中;
193.4.4.3.4令k=k+1,若k大于s
p
的长度,说明已经将所有变量节点加入到v
p
中,转到4.4.4;否则转4.4.3.2;
194.4.4.4语义图构建模块为语义图g
p
添加操作符节点、数据流边和控制流边,操作符节点包括函数调用节点、运算符节点、取值操作符节点,方法是:
195.4.4.4.1初始化变量k=1;
196.4.4.4.2初始化变量u=1;
197.4.4.4.3判断s
p
中第k个元素是否为语句块声明语句,即是否包含关键词“label%”,若是语句块声明语句,转4.4.4.4提取当前语句块的语句块标识符节点;否则转4.4.4.5;
198.4.4.4.4利用正则表达式从中提取语句块标识符marker,对变量u赋值,使u=
marker,说明当前的中间表示语句属于语句块标识符节点(u,v
control
)所代表的语句块,v
control
表示此节点类型为语句块标识符节点,v
control
中存储的值为u;
199.4.4.4.5判断是否为函数调用语句,即判断是否包含“invoke”关键词,若包含“invoke”,转4.4.4.6向g
p
的节点集合v
p
中添加函数调用节点,并添加对应的数据流和控制流边;否则转4.4.4.15;
200.4.4.4.6使用正则表达式从中提取调用函数的函数名method、函数调用的输入变量var
in
、函数的返回值变量var
return
。根据函数名method,以二元组的形式构建函数调用节点(method,v
invoke
),v
invoke
是构建函数调用节点的标识,表示此节点类型为函数调用节点,v
invoke
中存储的值为method,将函数调用节点(method,v
invoke
)加入v
p
中。在g
p
的控制流边集合e_control
p
中以三元组的形式添加控制流边((u,v
control
),(method,v
invoke
),e
control-flow
),表示函数调用节点(method,v
invoke
)属于语句块标识符节点(u,v
control
)所代表的语句块,e
control-flow
表示添加的边的属性为控制流边。在g
p
的数据流边集合e_data
p
中以三元组形式添加两条数据流边,分别为((var
in
,type,v
var
),(method,v
invoke
),e
data-flow
)和((method,v
invoke
),(var
return
,type,v
var
),e
data-flow
),说明数据从变量节点(var
in
,type,v
var
)输入函数调用节点(method,v
invoke
)进行函数调用计算,经过函数调用计算得到的数据从函数调用节点(method,v
invoke
)输出到变量节点(var
return
,type,v
var
),e
data-flow
表示添加的边的属性为数据流边;
201.4.4.4.7判断s
p
中第w个元素是否为数据运算语句,即是否包含关键词“/”、“%”、“+”、
“‑”
、“*”、“cmp”中的任意一个,若是数据运算语句,转4.4.4.8向v
p
中添加运算符节点,并添加对应的数据流和控制流边;否则转4.4.4.15;
202.4.4.4.8使用正则表达式从中提取数据运算的运算符op、参与运算的变量var
in
、运算的结果变量var
return
。根据运算符op,以二元组的形式构建运算符节点(op,v
operator
),v
operator
是运算符节点的标识,表示此节点为运算符节点,v
operator
中存储的值为op,将运算符节点(op,v
operator
)加入v
p
中。在g
p
的控制流边集合e_contrpl
p
中添加控制流边((u,v
control
),(op,v
operator
),e
control-flow
),表示运算符节点(op,v
operator
)属于语句块标识符节点(u,v
control
)所代表的语句块。在g
p
的数据流边集合e_data
p
中以三元组的形式添加两条数据流边,即((var
in
,type,v
var
),(op,v
operator
),e
data-flow
)和((op,v
operator
),(var
return
,type,v
var
),e
data-flow
),表示数据从变量节点(var
in
,type,v
var
)输入运算符节点(op,v
operator
),运算后的数据从运算符节点(op,v
operator
)输出到变量节点(var
return
,type,v
var
);
203.4.4.4.9判断s
p
中第w个元素是否为数组取值语句,即是否包含取值操作符“getelem”,若包含关键词“getelem”,转4.4.4.10向g
p
中添加操作符节点,并添加对应的数据流和控制流边;否则转4.4.4.15;
204.4.4.4.10使用正则表达式从中提取数组变量var
in
,并提取结果变量var
return
。以二元组的形式构建取值操作符节点(getelem,v
operator
),表示运算符节点v
operator
中存储的值为取值操作符getelem,将取值操作符节点加入v
p
中。在g
p
的控制流边集合e_control
p
中添加控制流边((u,v
control
),(getelem,v
operator
),e
control-flow
),表示取值操作符节点(getelem,v
operator
)属于语句块标识符节点(u,v
control
)所代表的语句块。在g
p
的数据流边集
合e_data
p
中以三元组的形式添加两条数据流边,即((var
in
,type,v
var
),(getelem,v
operator
),e
data-flow
),和((getelem,v
operator
),(var
return
,type,v
var
),e
data-flow
),表示数组中的数据从数组变量节点(var
in
,type,v
var
)输入取值操作符节点(getelem,v
operator
),经过取值操作从数组变量中得到的数据从取值操作符节点(getelem,v
operator
)输出到结果变量节点(var
return
,type,v
var
);
205.4.4.4.11判断s
p
中第w个元素是否为判断语句或跳转语句,即是否包含关键词“goto”或“if”,若包含关键词“goto”或“if”,转4.4.4.12向g
p
中添加控制流边;否则转4.4.4.15;
206.4.4.4.12使用正则表达式从中提取判断语句或跳转语句的目标语句块节点标识符newmarker。在g
p
的控制流边集合e_control
p
中以三元组的形式添加控制流边((u,v
control
),(newmarker,v
control
),e
control-flowr
),表示程序执行时将从当前语句块标识符节点(u,v
control
)所代表的语句块跳转到语句块标识符节点(newmarker,v
control
)所代表的语句块。
207.4.4.4.13判断s
p
中第w个元素是否为赋值语句或类型转换语句,即是否包含关键词“=”,若包含关键词“=”,转4.4.4.14向g
p
中添加数据流边;否则转4.4.4.15;
208.4.4.4.14使用正则表达式从中提取输入变量var
in
以及输出变量var
return
。在g
p
的数据流边集合e_data
p
中以三元组的形式添加数据流边((var
in
,type,v
var
),(var
return
,type,v
var
),e
data-flow
),说明数据从变量var
in
输出到变量var
return
中。
209.4.4.4.15令k=k+1,若k大于s
p
的长度,说明得到g
p
,将g
p
加入语义图集合sg中,转4.5;否则,转到4.4.4.3;
210.4.5若p大于代码中间表示数据集ir的大小,则得到语义图集合sg,转第五步;否则令p=p+1,转4.3;
211.第五步,根据语义图集合sg制作代码向量生成模块所需的训练数据集。方法为:
212.5.1令变量i=1;
213.5.2初始化训练数据集trainingset={};
214.5.3随机从语义图集合sg中任意抽取两个语义图,令第i次抽取的语义图为和若和所对应的代码功能相同,则标注labeli为true,表示和所对应的代码为克隆代码;否则标注labeli为false,表示和所对应的代码不为克隆代码;令第i个三元组将di放入训练数据集trainingset,转5.4;
215.5.4令i=i+1,若i》10,000,则训练集制作完成,将训练数据集trainingset发送到代码向量生成模块,转第六步;否则转5.3;
216.第六步:采用trainingset训练代码向量生成模块,得到可以表示语义图信息的图匹配网络。具体方法是:
217.6.1设置训练图匹配网络所需参数。方法是:
218.6.1.1设置图匹配网络包含网络层数t=4;
219.6.1.2设置图匹配网络学习率ir=0.001;
220.6.1.3设置训练轮数num_epochs=50;
221.6.1.4初始化训练轮数epochs=0;
222.6.2令变量i=1;
223.6.3从训练数据集trainingset中抽取第i个数据di,
224.6.4采用第一初始化方法初始化中节点的向量值与边的权重值,得到初始化后的第一语义图方法如下:
225.6.4.1使用word2vec模型初始化中节点的向量值:从的节点集合v
i1
中顺序选择节点x,x∈v
i1
,将节点x中存储的内容输入word2vec模型,将word2vec模型输出值作为节点x的初始化向量
226.6.4.2令的数据流边集合中每条边的权重值为1;
227.6.4.3令的控制流边集合中每条边的权重值为-1;
228.6.5采用第二初始化方法初始化中节点的向量值与边的权重值,得到初始化后的第二语义图
229.6.5.1使用word2vec模型初始化中节点的向量值,从的节点集合v
i2
中顺序选择节点z,z∈v
i2
,将节点z中存储的内容输入word2vec模型,将word2vec模型输出值作为节点z的初始化向量
230.6.5.2令的数据流边集合中每条边的权重值为1;
231.6.5.3令的控制流边集合中每条边的权重值为-1;
232.6.6采用迭代更新方法更新第一语义图中各节点的向量表示,得到第一最终语义图迭代更新方法如下:
233.6.6.1初始化变量t=1;
234.6.6.2从的节点集合v
i1
中顺序选择第一节点x,x∈v
i1
,若的节点集合v
i1
中所有节点都已被选择,则转6.6.7;否则转6.6.3;
235.6.6.3计算在第t次迭代时,中的节点与的相似性,方法是:
236.6.6.3.1从的节点集合v
i2
中顺序选择第二节点,令第二节点为z,z∈v
i2
,若的节点集合v
i2
中所有节点都已被选择,则转6.6.3.3;否则转6.6.3.2;
237.6.6.3.2计算x与z的相似度αz→
x
,其中指x在t-1次迭代后的向量表示,指z在t-1次迭代后的向量表示,指中任意一个不是z的节点在t-1次迭代后的向量表示,转到6.6.3.1;
238.6.6.3.3计算在第t次迭代时x与的节点集合v
i2
中所有节点的相似度和中所有节点的相似度和
239.6.6.4计算在第t次迭代时,第一语义图中与x有边相连的其他节点即第三节点y传递给x的消息向量和,方法是:
240.6.6.4.1在中除x外的节点集合v
i1-x中顺序选择第三节点,令第三节点为y,记连接x和y的边为e
xy
,若v
i1-x中的所有节点都已被选择,则转6.6.4.4;否则转6.6.4.2;
241.6.6.4.2判断边e
xy
是否存在于的数据流边集合或的控制流边集合中,若存在,转6.6.4.3;否则转6.6.4.1;
242.6.6.4.3计算中y对x的消息向量my→
x
,其中sum为求和函数,指x在t-1次迭代后的向量表示,指y在t-1次迭代后的向量表示,e
xy
指连接x和y的边的权重值,转到6.6.4.1;
243.6.6.4.4计算在第t次迭代时,第一语义图中的x与其有边相连的所有第三节点y对x传递的消息向量和y对x传递的消息向量和
244.6.6.5更新中x在第t次迭代后的向量表示中x在第t次迭代后的向量表示其中gru表示门控循环神经网络,表示利用门控循环神经网络,根据第t-1次迭代后x节点的向量与中与节点x相连的其他节点传递的消息向量和x与的节点集合v
i2
中所有节点的相似度和6.6.3.3中计算得到的生成第t次迭代后的向量表示
245.6.6.6令t=t+1。若t小于t,转6.6.2;否则说明迭代更新完毕,得到第一最终语义图转6.7;
246.6.7采用6.6所述迭代更新方法更新中各节点的向量表示,得到第二最终语义图
247.6.8计算的向量表示v
i1
,其中mlp为多层感知器模型,表示利用多层感知器模型将中所有节点的向量汇总为向量v
i1
,其中为经过t轮迭代后得到的最终语义图中各个节点的向量值;
248.6.9计算的向量表示v
i2
,
249.6.10利用余弦相似度函数比较v
i1
,v
i2
的相似度。判断sim是否大于相似度阈值α,一般0.7≤α<1,若是,则认为和所对应的代码是克隆代码,即模型预测结果label
predict
=true,否则和所对应的代码不为克隆代码,模型预测结果label
predict
=false;
250.6.11若label
predict
不等于labeli,则转6.12;否则转6.15;
251.6.12若labeli=false,跳转到6.13;若labeli=true则跳转到6.14;
252.6.13计算模型调整值loss=-(1-sim)
×
ir,将loss输入word2vec模型,word2vec
模型自动更新模型中的参数,转6.15;
253.6.14设置向量调整值loss=(1-sim)
×
ir,将loss输入word2vec模型,word2vec模型自动更新模型中的参数,转6.15;
254.6.15令i=i+1,若i大于语义图数据集sg的大小,说明已训练完一轮,转6.16;否则转6.3;
255.6.16令epochs=epochs+1,若epochs等于num_epochs,说明训练完毕,得到了可以表示语义图信息的图匹配网络,也即得到了训练后的代码向量生成模块,转第七步;否则转6.2,开始新一轮训练;
256.第七步:使用代码克隆系统检测用户输入的一对待检测代码c1,c2,判断c1,c2是否是克隆代码对,方法是:
257.7.1令待检测代码集合test={c1,c2};
258.7.2代码补全模块采用第二步所述代码补全方法对待检测代码集合test进行代码补全,得到补全后可编译的待检测代码集合test_data={c
‘1,c
‘2};
259.7.3代码中间表示提取模块采用第三步所述代码中间表示提取方法从对test_data提取代码中间表示,构建待检测代码集合的代码中间表示集合test_ir,test_ir={r1,r2};
260.7.4语义图生成模块采用第四步所述语义图集合构建方法根据test_ir构建待检测代码集合的语义图集合test_sg={g1,g2};
261.7.5训练好的代码向量生成模块根据test_sg中的第一语义图g1和第二语义图g2,生成其对应的向量值v1和v2,方法如下;
262.7.5.1采用6.4所述第一初始化方法初始化g1,得到初始化后的语义图ig1,采用6.5所述第二初始化方法初始化g2得到初始化后的语义图ig2;
263.7.5.2采用6.6所述迭代更新方法迭代更新初始化语义图ig1和ig2中节点的向量,分别得到最终语义图fg1和fg2;
264.7.5.3计算fg1的向量值v1,
265.7.5.4计算fg2的向量值v2,
266.7.6训练好的向量生成模块利用余弦相似度函数比较v1和v2的相似度。的相似度。判断sim是否大于相似度阈值α,若sim》α,则认为g1和g2所对应的代码是克隆代码,即模型预测结果label
predict
=true;若sim≤α,g1和g2所对应的代码不为克隆代码,模型预测结果label
predict
=false。
267.表1是本发明与其他代码克隆检测方法在bigclonebench数据集上训练与测试结果的对比表。
268.克隆检测方法准确率召回率f1值ccgraph0.280.390.32tbccd0.310.370.35本发明0.580.440.50
269.表1
270.所有实验基于一台ubuntu16.04操作系统,搭载2080tigpu,主要编码语言为python。在第四步主要利用python中networkx库实现构建语义图,第五步中从bigclonebench数据集中抽取10,000对代码作为训练集,在训练集中,克隆代码对与非克隆代码对比例为1:1,第六步中利用pytorch库实现图匹配网络。
271.为了更高的评估本发明与背景技术之间的效果,选用准确率、召回率和f1值作为评估指标。准确率为克隆检测工具报告的克隆代码对中,判断正确的比例,召回率为克隆检测工具正确判断的克隆代码对,在所有克隆对中的占比。由于相似度阈值α的调节会导致召回率和准确率无法兼顾,例如调高相似度阈值α,会导致准确率提高,召回率下降。f1指标的计算为(准确率+召回率)/2
×
准确率
×
召回率,可以综合评估准确率和召回率。
272.根据实验结果显示,经过12小时的模型训练,可以有效的检测到bigclonebench中超过44%的代码克隆(即可以找出44%占比的克隆代码对),并且保证58%的准确率(即找到的克隆代码对中有58%是真正的克隆代码对),f1值为0.50。而已有最优方法tbccd在同等实验时,只能检测到37%代码克隆,且仅能取得31%的准确度,f1值仅为0.35。另一个常用克隆检测方法ccgraph只能检测到39%代码克隆,且仅能取得28%的准确度,f1值仅为0.32。因此本发明相比现有方法对代码克隆的检测准确率有较大提高。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1