语义分析知识库构建方法和配电自动化终端运维知识库
1.本发明属于电力技术领域,具体涉及语义分析知识库构建方法和配电自动化终端运维知识库。
背景技术:
2.配电自动化终端主要用于配电网正常运行时的电压电流数据采集与监测、配电开关状态采集与开合遥控等。配电自动化终端是配电自动化系统的重要组成部分。随着配电自动化系统在国家电网和南方电网的大规模推广应用,配电自动化终端、配套的通信系统以及配电主站的数量呈现爆发式增长态势。目前多个城市的配电自动化终端达到数万级别,配电自动化主站与配电自动化终端通过通信系统实现双向交互,为配电网调度、运行与维护提供信息化支撑。
3.相比输电网中的自动化设备,配电自动化终端运行环境复杂得多。如作为配电自动化终端的一种主要类型,安装于架空线路的馈线终端单元往往在高空放置,运维检修非常不便。另外一方面,海量的配电自动化终端也必然导致配电网运维人员压力过大,其突出的一方面为大量的现场巡视人员技术培训不足,无法判断配电自动化终端所处的运行状态,也无法给出相应的维护建议。
4.为减轻目前的配电自动化终端运维人员的压力,现有的措施往往是延长配电自动化终端的巡视周期,这会导致配电自动化终端失效概率大大增加。另外一种措施则是采用在线监测方法来实现配电自动化终端的状态检修,但如何实现配电自动化终端的信息采集以及准确的状态评价,仍处于前期研究阶段,近期无法达到实用化水平。
技术实现要素:
5.本发明要解决的技术问题是:提供语义分析知识库构建方法和配电自动化终端运维知识库,用于实现自动采集配电自动化终端的信息以及准确评价运维状态的功能。
6.本发明为解决上述技术问题所采取的技术方案为:语义分析知识库构建方法,包括以下步骤:
7.s1:获取关于配电自动化终端的运行巡视信息和维护信息的自然语言描述资料;
8.s2:对步骤s1得到的自然语言描述资料进行去停用词处理,用于过滤对配电自动化终端运维知识库无帮助的字词;
9.s3:设c1、c2、
…
、cm分别表示第1个、第2个、
…
、第m个词,每个词至少包括1个中文字符,组建配电自动化终端运维知识库词典{c1,c2,
…
,cm};
10.s4:利用双向匹配最大算法对步骤s2得到的自然语言描述资料进行分词处理,得到分词结果;
11.s5:根据步骤s4得到的分词结果和基于注意力机制的长短期记忆神经网络,形成配电自动化终端运维知识库。
12.按上述方案,所述的步骤s1中,自然语言描述资料的形式包括语音和文字。
13.按上述方案,所述的步骤s2中,具体步骤为:过滤自然语言中包括“的、地、得、是、如下、了、吃饭、休息”的字。
14.按上述方案,所述的步骤s3中,具体步骤为:
15.s31:根据现有的配电网运维检修规程提取描述设备运行和维护的词条,形成配电自动化终端运行巡视和维护自然语言描述的词典{c1,c2,
…
,cn};
16.s32:设xi为自然语言描述中得到的2个中文字、3个中文字和4个中文字的第i个字符串,n(xi)为第i个字符串出现的频次,n
set
为设定的裕度;统计分析2个中文字、3个中文字、4个中文字在现场巡视人员形成的所有历史自然语言描述资料中出现的频率,若n(xi)≥n
set
,则在专家校验通过后加入词典,形成配电自动化终端运维知识库词典{c1,c2,
…
,cn,
…
,cm},m≥n。
17.进一步的,所述的步骤s4中,具体步骤为:
18.s41:选择步骤s2得到的自然语言描述资料中的任意一条语句;
19.s42:在语句中从左往右取字符串,设字符串的最大长度为步骤s3得到的词典中所有词的最大长度max{leng(ci),1≤i≤m},leng(ci)为第i个词ci的字符数;
20.s43:扫描词典,若字符串在词典中匹配到至少一个词条,则在语句中去掉该字符串,跳转至步骤s42对该语句的其他字符串进行处理;若字符串无法匹配词典中的任意一个词条,则进入步骤s44;
21.s44:删除字符串最右边的1个字符,形成新的字符串a,跳转至步骤s43;直至对语句完成所有分割,并得到该分割结果中词的最大长度la;
22.s46:在语句中从左往右取字符串,字符串的最大长度设置方法与步骤s42相同;
23.s47:扫描词典,若字符串在词典中匹配到至少一个词条,则在语句中去掉该字符串,跳转至步骤s46对该语句的其他字符串进行处理;若字符串无法匹配词典中的任意一个词条,则进入步骤s48;
24.s48:删除字符串最左边的1个字符,形成新的字符串a,跳转至步骤s47;直至对语句完成所有分割,并得到该分割结果中词的最大长度lb;
25.s49:若步骤s44和步骤s48得到的语句分割结果相同,则分割结果即为分词结果;
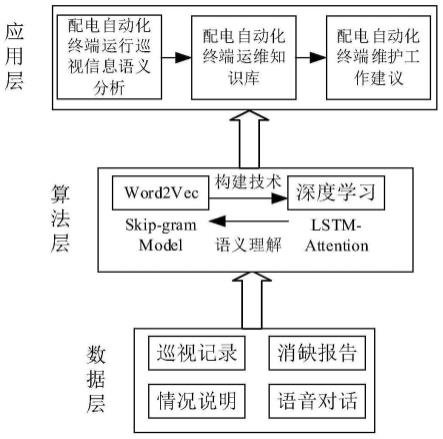
26.若步骤s44和步骤s48得到的语句分割结果不同,且la》lb,则选取步骤s44得到的语句分割结果;
27.若步骤s44和步骤s48得到的语句分割结果不同,且la《lb,则选取步骤s46得到的语句分割结果。
28.按上述方案,所述的步骤s5中,具体步骤为:
29.s51:对每一次配电自动化终端的运维信息的自然语言进行分词处理,形成该次配电自动化终端的运行巡视信息的自然语言的分词结果和维护信息的自然语言的分词结果;
30.s52:利用词向量word2vec的skip-gram模型对运行巡视信息的自然语言的分词结果进行编码,得到ins向量;
31.s53:利用词向量word2vec的skip-gram模型对维护信息的自然语言的分词结果进行编码,得到mnt向量;
32.s54:构建基于注意力机制的lstm-attention长短期记忆神经网络,将ins向量作为输入变量,将mnt向量做为输出结果;
33.s55:根据配电自动化终端的历史运维信息得到的典型ins向量与典型mnt向量,对步骤s54构建的lstm-attention长短期记忆神经网络进行训练,实现连接配电自动化终端的运行巡视信息的自然语言描述与维护信息的自然语言描述的lstm-attention配电自动化终端运维知识库。
34.按上述方案,还包括以下步骤:
35.s6:在现场开展配电自动化终端运行巡视时,巡视人员用自然语言描述掌握到的待评估的配电自动化终端的状态;通过词向量word2vec的skip-gram模型得到该次描述的分词结果的编码向量ins
p
;将ins
p
送入步骤s5得到的lstm-attention配电自动化终端运维知识库,得到对应的配电自动化终端的维护结果的编码向量mnt
p
;通过词向量word2vec的skip-gram模型把编码向量mnt
p
转换成自然语言,实现配电自动化终端维护工作的自动推荐功能。
36.一种基于语义分析知识库构建方法的配电自动化终端运维知识库,包括从底层依次向上的数据层、算法层和应用层;数据层包括巡视记录、消缺报告、情况说明和语音对话;算法层包括基于词向量word2vec的skip-gram模型和基于深度学习的lstm-attention长短期记忆神经网络;基于词向量word2vec的skip-gram模型构建基于深度学习的lstm-attention长短期记忆神经网络;基于深度学习的lstm-attention长短期记忆神经网络用于对基于词向量word2vec的skip-gram模型进行语义理解;应用层包括依次连接的配电自动化终端运行巡视信息语义分析模块、配电自动化终端运维知识库和配电自动化终端维护工作建议模块。
37.一种计算机存储介质,其内存储有可被计算机处理器执行的计算机程序,该计算机程序执行语义分析知识库构建方法。
38.本发明的有益效果为:
39.1.本发明在配电自动化终端运维工作中引入自然语言语义分析技术,通过对现场巡视人员对配电自动化终端运行状态的自然语言描述自动抽取关键信息,形成配电自动化终端描述文本;采用包括分词技术与深度学习算法语义分析的知识库构建方法构建配电自动化终端运维知识库;代替了人工通过手持设备或计算机录入配电自动化终端运行状态的繁杂工作,实现了自动采集配电自动化终端的信息以及准确评价运维状态的功能。
40.2.本发明通过对配电自动化终维信息的自然语言描述的语义分析,对分词结果进行编码与深度学习训练形成的配电自动化终端运维知识库,根据巡视人员给出的配电自动化终端状态描述自然语言自动推荐相应的配电自动化终端维护工作,实现了在户外恶劣环境下对配电自动化终端巡视信息的快速分析处理,有利于现场人员提高自身开展配电自动化终端维护工作的水平。
附图说明
41.图1是本发明实施例的架构图。
42.图2是本发明实施例的流程图。
具体实施方式
43.下面结合附图和具体实施方式对本发明作进一步详细的说明。
44.参见图1,本发明的实施例包括数据层、算法层和应用层。
45.参见图2,本发明实施例的语义分析知识库构建方法,包括以下步骤:
46.s1:根据配电自动化终端现场巡视人员的观察与分析,获取关于配电自动化终端运行相关信息,以及采取的相应维护相关信息的自然语言描述资料,形式包括语音、文字等。
47.s2:对配电自动化终端运维相关自然语言描述资料进行去停用词处理。此步骤主要为了过滤对配电自动化终端运维知识库无帮助的字词,主要方法是直接过滤掉自然语言描述资料中“的、地、得、是、如下、了、吃饭、休息”等字。
48.s3:形成配电自动化终端运维知识库词典{c1,c2,
…
,cm},c1、c2、
…
、cm分别表示第1个、第2个、
…
、第m个词,每个词至少包括1个中文字符。
49.s31:首先根据现有的配电网运维检修规程提取描述设备运行、维护相关的词条,形成配电自动化终端运维检修自然语言描述的词典{c1,c2,
…
,cn};
50.s32:然后统计分析2个中文字、3个中文字、4个中文字在现场巡视人员形成的所有历史自然语言描述资料中出现的频率,若n(xi)≥n
set
,则提交给专家校验,通过后一并加入到词典中。xi为自然语言描述中得到的2个中文字、3个中文字和4个中文字的第i个字符串,n(xi)表示所给出的第i个字符串出现的频次,n
set
为设定的裕度。最终形成配电自动化终端运维知识库词典{c1,c2,
…
,cn,
…
,cm}。
51.s4:利用双向匹配最大算法对配电自动化终端运维相关自然语言描述资料进行分词处理。
52.s41:对于配电自动化终端运维相关自然语言描述资料中任意一句话;
53.s42:从左往右取字符串,取的字符串最大长度为第3步中得到的词典中所有词的最大长度max{leng(ci),1≤i≤m},leng(ci)为第i个词ci的字符数;
54.s43:扫描步骤s3得到的词典,如果所取的字符串在步骤s3得到的词典中,则在该句话中去掉所取的字符串,跳转至步骤s42对该句话剩下的字符串开始处理;否则进入步骤s44;
55.s44:如果所取的字符串无法匹配词典中的任意一个词条,则将所取字符串的最右边的1个字符删掉,形成新的字符串a,跳转至步骤s43处理;
56.s45:重复进行步骤s42到步骤s44,直至对语句完成所有的分割,并得到该分割结果中词的最大长度la;
57.s46:重新开展步骤s42和步骤s43,并通过步骤s43处理后,如果所取的字符串无法匹配词典中的任意一个词条,则将所取字符串的最左边的1个字符删掉,形成新的字符串b,再次跳转至步骤s43处理。循环执行本步骤中的流程,直至对语句完成所有的分割,并得到该分割结果中词的最大长度lb。
58.s47:若步骤s45和步骤s46得到的语句分割结果相同,则分割结果即为分词结果;如果步骤s45和步骤s46得到的语句分割结果不同,则若la》lb,则选取步骤s45得到的语句分割结果,否则选取步骤s46得到的语句分割结果。
59.s5:基于注意力机制的长短期记忆神经网络(lstm-attention),基于步骤s4得到的分词方法,形成配电自动化终端运维知识库。
60.s51:对于每一次某具体配电自动化终端运行、维护的自然语言进行分词处理,形
成该次配电自动化终端运行巡视、维护自然语言的分词结果;
61.s52:对该次配电自动化终端运行巡视自然语言的分词结果进行编码,具体利用word2vec(word to vector,词向量)中的skip-gram模型实现分析结果的编码,得到ins向量;
62.s53:对该次配电自动化终端维护自然语言的分词结果进行编码,具体利用word2vec(word to vector,词向量)中的skip-gram模型实现分析结果的编码,得到mnt向量;
63.s54:构建基于注意力机制的长短期记忆神经网络(lstm-attention),输入变量为步骤s52得到的ins向量,输出结果为步骤s53得到的mnt向量。
64.s55:利用现场积累的运维资料,得到典型的ins向量与mnt向量,对步骤s54构建的lstm-attention网络进行训练,最终实现连接配电自动化终端运行巡视自然描述语言与维护自然描述语言的知识库。
65.s6:在现场开展配电自动化终端运维时,巡视人员根据掌握到的待评估的配电自动化终端状态,直接用自然语言进行描述;通过词向量中的skip-gram模型实现得到该次描述分词结果的编码向量ins
p
,将ins
p
送入步骤s5得到的lstm-attention配电自动化终端运维知识库,得到对应的配电自动化终端维护结果的编码向量mnt
p
向量,通过词向量中的skip-gram模型转换成自然语言,实现配电自动化终端维护工作的自动推荐。
66.通过上述过程,形成本发明实施例的典型配电自动化终端的运维知识库如下:
67.68.69.[0070][0071]
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1