一种基于强化学习的隐私保护数据发布方法与流程
1.本发明涉及数据安全发布领域,具体涉及一种基于强化学习的隐私保护数据发布方法。
背景技术:
2.既有数据发布的隐私保护方法通常仅关注数据的隐私性以及数据的可用性,鲜有对隐私保护后发布的数据如何实现有效地知识挖掘和价值发现进行考量。这种将数据隐私保护与数据挖掘目标割裂的处理方式加重了数据的信息损失,导致数据发布后,用户对数据挖掘的效能低下。因此,如何在隐私保护效果和数据挖掘效能之间达到协同平衡,既能使数据达到隐私保护要求,又能使数据挖掘更有效成为目前亟待解决的难点问题。
3.随着数据挖掘算法在隐私保护领域的广泛应用,隐私保护技术不断完善。ahmed等人提出一种用于隐私保护数据挖掘的深度强学习方法,该方法通过使用删除动态计算的数据来隐藏敏感信息,并在隐私保护和知识挖掘之间寻求平衡,在大型数据集上具有普适性。cheng等人将非敏感规则、数据损失作为优化目标,从而使数据效用最大化。此外,一些学者还从“隐私定价”的角度对数据挖掘的隐私保护机制进行了一系列研究。aperjis设计了一种数据发布机制,通过中介获取个体对隐私的重视程度,并获取用户对数据的需求,通过一种定价的方式为用户提供数据;chen等人提出一种基于强化学习的隐私数据定价方法,该方法构建了基于用户角色的定价模型,并提出一种基于经验矩阵的数据定价策略算法,利用强化学习方法,通过不断地进行数据交互以获得出价经验,实现了数据隐私性与数据交易收益的最大化,但此方法在迭代求解过程中要不断试错,时间开销较大。
4.针对数据发布场景下难以平衡隐私保护与数据挖掘之间协同关系的问题,借助集成聚类以及强化学习等算法,将“先隐私保护后数据挖掘”的串行操作模型转化为“隐私保护操作与数据挖掘操作”交互进行的模型,并设计基于强化学习的隐私保护数据发布方法,进而达成隐私保护与数据挖掘的平衡。
技术实现要素:
5.本发明提出了一种基于强化学习的隐私保护数据发布方法(areinforcement learning-based approach to privacy-preserving data publishing),旨在针对隐私保护导致的数据挖掘效能降低问题,引入深度强化学习的模型,建立隐私保护和数据挖掘两个智能体之间的博弈,进而设计基于强化学习的隐私保护数据发布方法,达到隐私保护与数据挖掘的协同平衡。
6.为了解决上述问题,本发明首先依据不同角色构建了交互模型,借助贝叶斯网络修正算法和相互独立的聚类算法的集成来分别模拟隐私保护智能体和数据挖掘智能体,将“先隐私保护后数据挖掘”的串行操作过程改进为隐私保护与知识挖掘集成模型的“交替式迭代”训练算法。具体而言,一方面,基于数据重匿名架构,数据拥有者拥有对数据的支配权和对数据进行隐私保护的义务,另一方面,针对数据使用者的角色通过集成算法模拟数据
挖掘需求,并以此构建隐私保护智能和数据挖掘智能体,通过两个智能体间的博弈交互,在交互过程中引入深度强化学习算法,通过不断更新原有的行动策略,以此获得更高的奖励回报,最终使得两者的收益最大化,此时数据隐私性与数据挖掘的效用达到平衡。
7.为了达到上述目的,本发明采用了下列技术方案:
8.1)隐私保护智能体的构建
9.隐私保护智能体旨在保护隐私的同时最小化信息损失。将数据转化为贝叶斯网络,并将传统隐私保护方法迁移至贝叶斯网络上,数据的微隐私和泛隐私均得以保护。而依据数据挖掘智能体的需求,隐私保护智能体发布满足需求的数据是通过迭代地修正贝叶斯网络来实现的,修正贝叶斯网络的方式包含两种,分别从结构上和属性概率上修正:第一,通过添加、删除、翻转边可以改变贝叶斯网络结构,从而得到新的数据;第二,通过修改属性节点的概率分布值也可以使贝叶斯网络生成的数据发生改变,从而达到隐私保护要求。本发明利用代价函数cost对贝叶斯网络修正与更新过程造成的信息损失进行度量,其定义如下:
10.定义1(代价函数)。给定一个贝叶斯网络,记iai为某个节点的第i个信息属性,mint(iai)和maxt(iai)分别为修改该属性的最小值和最大值,而贝叶斯网络生成数据后,minea(iai)和maxea(iai)分别为等价类ea中该属性的最小值和最大值,对等价类ea中的属性iai修改为值域[minea(iai),maxea(iai)],其信息损失可定义为:
[0011][0012]
其中,|ea|为该等价类中记录的个数,在等价类ea上,所有信息属性修改后的信息损失为:
[0013][0014]
显然,对于数据集d,所有信息属性修改后的信息损失为:
[0015][0016]
将损失函数做归一化处理后,可以得到贝叶斯网络在经过修正处理后的代价函数为:
[0017][0018]
2)数据挖掘智能体
[0019]
多个相互独立的聚类算法的集成学习可以很好的模拟数据挖掘的各类需求任务,数据挖掘智能体利用n(n>1)种相互独立的聚类算法分别对数据进行聚类操作,通过分析簇内、簇间的距离,比较聚类结果与隐私保护智能体修正数据之间的差异,来实现与隐私保护智能体的交互。通过引入相似性度量来计算记录之间、记录与簇之间、簇与簇之间的距离;其次,引入共现矩阵来刻画样本聚类的稳定性大小,若多次聚类的结果不低于某个阈值,则认为该簇是符合数据挖掘要求的等价簇。相关定义如下:
[0020]
(1)相似性度量
[0021]
定义2(等价簇)。给定数据集d(x,ia,sa),若对于任意聚类算法,总存在t条记录{x1,x2,...,x
t
},(t≥1),使得数据集d分别聚类为n类,则将聚为的类簇称为等价簇,记为{e1,e2,...,en},对于任意等价簇其组内的记录不可再分,敌
手也无法通过掌握信息属性ia来获取敏感属性sa。
[0022]
定义3(记录间距离)。数据集d中任意两条记录xa,xb在属性取值上差异程度的均值定义为记录间距离,记为dist(xa,xb),它可以表示一个等价簇内相关记录的相似性。
[0023]
两个不同记录的相同信息属性值xa(iai)和xb(iai)间的差异定义为:
[0024][0025]
则两记录间距离表示为:
[0026][0027]
定义4(记录到等价簇距离)。对于无法有效聚类的记录xc与等价簇ei的距离,用dist(xc,ei)来表示,其公式为:
[0028][0029]
(2)共现矩阵
[0030]
除了度量样本间的相似性,样本的稳定性也是聚类分析考虑的重要指标,本发明利用集成聚类的方法来度量样本稳定性大小。具体而言,对原始数据使用n种独立的聚类算法,得到的不同聚类结果使用共现矩阵来表示。
[0031]
共现矩阵中,元素p
ij
表示在多次聚类结果中,样本xi与xj被聚为一类的频率,p
ij
越大则说明两个样本间的确定性关系越强,其公式为:
[0032][0033]
其中,c
l
(xi)表示在l次聚类中,样本xi所属的类簇,i[
·
]表示指示函数,
[0034][0035]
由于基于集成聚类的结果不一定满足数据挖掘的需求,则需要通过隐私保护智能体迭代地修正数据转化为的贝叶斯网络,以此生成新的数据,此时,两个智能体之间形成博弈。在博弈的过程,隐私保护智能体利用贝叶斯网络修正方法,数据挖掘智能体实施聚类操作,以此进行迭代,进而同时达到隐私保护与数据挖掘的需求。本发明定义修改后贝叶斯网络生成数据与原始贝叶斯网络生成数据之间的差距为||d
′‑d*
||2,当两者之间的差距小于阈值δ时,也即||d
′‑d*
||2<δ时,数据满足数据挖掘智能体的需求。基于此,本发明将深度强化学习的方法引入两者的博弈过程,使得两者在博弈过程中达到一种协同平衡。
[0036]
3)基于深度强化学习的隐私保护算法
[0037]
考虑到隐私保护智能体对于隐私保护的要求是数据挖掘者智能体无法直接得到的信息,也即两者需通过交互过程不断优化动作值函数,以此获取奖励,最终达到协同平衡。隐私保护智能体对隐私的保护程度决定了其对数据效用的评估,数据挖掘智能体迭代地与隐私保护智能体进行交互,两者在交互中获得收益越高,数据效用越大。通过引入深度强化学习,能有效解决数据隐私性与数据效用最大化的协同平衡问题。
[0038]
首先,本发明将隐私保护智能体对数据隐私保护的要求用参数σ∈[0,1]来量化,σ值越高,说明数据拥有者对隐私要求的程度越高。对于数据挖掘智能体而言,聚类结果的稳定性要达到指定阈值,且修改后贝叶斯网络生成的数据与原始贝叶斯网络生成数据之间的
差距应小于δ,也可将数据挖掘智能体的数据挖掘需求看作δ,所以本发明假设隐私保护智能体依据数据挖掘智能体需求δ修改数据所获收益期望为δ。当且仅当在满足数据挖掘的前提下隐私保护智能体所获收益期望不低于对数据的隐私保护程度σ,也即δ≥σ时,隐私保护智能体才会提供数据给数据挖掘智能体。
[0039]
若用收益r(δ,σ)来表示两者交互过程中获取的总奖励函数,则:
[0040][0041]
收益r(δ,σ)可看作以σ为参数的奖励函数。给定σ的分布,可知两者交互中总收益期望为:
[0042]
e[r(δ,σ)]=∑f
σ
(δ)(δ-cost)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0043]
其中,f
σ
(δ)表示两者接受收益期望的概率。
[0044]
在模型中,假设隐私保护智能体与数据挖掘智能体进行m次交互,在第m∈{1,2,3,...m}次交互时的状态为σm。交互开始前,数据挖掘者将数据挖掘需求上传至数据平台,数据挖掘智能体将数据进行聚类,并将得到的聚类结果与隐私保护智能体生成的原始数据比较。隐私保护智能体根据需求对贝叶斯网络做出修正后,对比本方的隐私保护需求σ,决定是否接受数据挖掘智能体的数据请求。若在第m次交互中,隐私保护智能体修改数据所获收益期望为δi,则两者对应可获奖励为:
[0045]ri
(δi,σm)=f
σ
(δ
i-cost)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0046]
在f
σ
(
·
)未知的前提下,需应用学习策略来确定收益期望最高的奖励状态学习策略为一次交互中数据挖掘智能体与隐私保护智能体所获最大奖励函数的策略。动作值函数公式为:
[0047]
q(s
t
,a
t
)
←rt
+γmaxq(s
t+1
,a
t+1
)
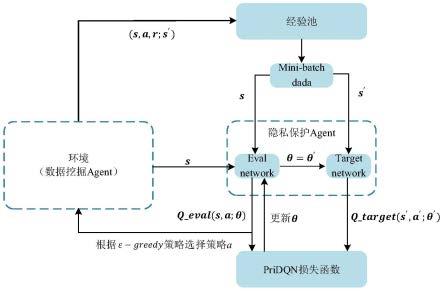
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0048]
其中:
[0049]
·st
表示当前的奖励状态;
[0050]
·at
表示在s
t
状态下隐私保护智能体是否接收数据挖掘智能体数据请求;
[0051]
·st+1
表示隐私保护智能体在s
t
状态下执行a
t
后的奖励状态;
[0052]
·
q(s
t
,a
t
)表示在s
t
状态下执行a
t
后两者获得的总期望收益;
[0053]
·rt
表示在s
t
状态下执行了a
t
后两者得到的即时奖励值函数;
[0054]
·
maxq(s
t+1
,a
t+1
)表示两者在s
t+1
状态下价值最高的总期望收益;
[0055]
·
γ表示折损率。
[0056]
隐私保护智能体通过与数据挖掘智能体的数据挖掘需求进行交互,不断地更新动作值函数,最终收敛于平衡点,两者在交互过程中可以获取最大奖励,同时使得数据效用最高。
[0057]
与现有技术相比本发明具有以下优点:
[0058]
1)面向数据挖掘的场景,提出了基于强化学习的隐私保护数据发布方法,将对数据的隐私保护操作和数据挖掘操作由串行改进为交互进行。
[0059]
2)通过构造隐私保护智能体和数据挖掘智能体之间的博弈,最终达到在保护隐私的同时保证了数据挖掘的有效性。
附图说明
[0060]
图1为集成聚类与共现矩阵;
[0061]
图2为pridqn算法过程;
[0062]
图3为cancer数据集下各方法的弱后悔值结果比较;
[0063]
图4为sachs数据集下各方法的弱后悔值结果比较;
[0064]
图5为insurance数据集下各方法的弱后悔值结果比较。
具体实施方式
[0065]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0066]
具体实施方式一:
[0067]
一种基于强化学习的隐私保护数据发布方法,包括以下步骤:
[0068]
步骤1,数据拥有者利用贝叶斯生成技术将其所拥有的原数据转化为贝叶斯网络,然后将生成的贝叶斯网络上传至数据中心(数据中心可以是云计算平台等可信且具有强大算力的第三方平台),由于数据中心是作为数据的存储和计算被引入系统平台,数据中心本身并不是数据的使用者,因此,仅将与原数据同分布的贝叶斯网络上传至数据中心,割裂了数据与其所含个体隐私信息之间的映射关系,进而实现对原数据的第一重匿名化保护(这里称之为对数据的内层匿名),具体步骤如下:
[0069]
步骤1.1,对原数据d进行有放回采样,采样比例为θ(0<θ<<1),生成采样数据d
θ
;
[0070]
步骤1.2,数据拥有者分别对采样数据d
θ
和原数据d运用基于k2算法的贝叶斯网络结构学习方法生成相应的贝叶斯网络,并使用bic(bayesian information criterion)指标对两个贝叶斯网络进行打分(评估),分别记为和scored;
[0071]
步骤1.3,若则增大采样比例θ,令θ=min(θ+μ,1),并跳转到步骤1.1,其中,η(η>0)为预设的阈值,μ(0<μ<<1)为采样比例增量;
[0072]
步骤1.4,将由采样数据生成的贝叶斯网络上传至数据中心。
[0073]
步骤2,由数据中心构建隐私保护智能体,通过迭代地修正贝叶斯网络来实现对原数据的第二重匿名(这里称之为对数据的外层匿名),具体步骤如下:
[0074]
步骤2.1,对贝叶斯网络通过添加、删除、翻转边的方式进行单位化修正操作,其中,单位化只是每一轮次只能进行{添加,删除,翻转}操作集中的一项操作;
[0075]
步骤2.2,使用代价函数评估对贝叶斯网络进行修正操作前后的信息损失;
[0076]
将隐私保护智能体修正贝叶斯网络的过程以算法1表示,命名为bnm算法,算法的核心过程描述如下:
[0077]
[0078][0079]
步骤3,由数据中心构建数据挖掘智能体,利用3种独立的聚类算法(k-means、均值漂移、dbscan)分别对数据进行聚类操作,通过分析簇内、簇间的距离,比较聚类结果与隐私保护智能体修正数据之间的差异,来实现与隐私保护智能体的交互。具体步骤如下:
[0080]
步骤3.1,通过引入相似性度量dist来计算记录之间、记录与簇之间、簇与簇之间的距离;
[0081]
步骤3.2,引入共现矩阵来刻画样本聚类的稳定性大小,若多次聚类的结果不低于某个阈值,则认为该簇是符合数据挖掘要求的等价簇。本实施例利用集成聚类的方法来度量样本稳定性大小,对原始数据使用3种独立的聚类算法,得到的不同聚类结果使用共现矩阵来表示,如图1所示。
[0082]
共现矩阵中,元素p
ij
表示在多次聚类结果中,样本xi与xj被聚为一类的频率,p
ij
越大则说明两个样本间的确定性关系越强,其公式为:
[0083][0084]
其中,c
l
(xi)表示在l次聚类中,样本xi所属的类簇,i[
·
]表示指示函数,
[0085][0086]
基于集成聚类的共现矩阵表示,若p
ij
≥2/3,则认为聚类结果是稳定的,且满足数据效用需求。本发明为数据挖掘智能体设计了基于集成聚类的数据挖掘算法,命名为cpp算法,该算法依据属性和记录的相似性度量,借助相互独立聚类算法的集成,通过考察数据的共线性来模拟数据挖掘智能体。cpp算法伪代码如下:
[0087]
[0088][0089]
步骤4,通过隐私保护和数据挖掘两个智能体之间的交互来获取奖励,不断优化动作值函数,进而同时满足隐私保护和数据挖掘的需求。具体步骤如下:
[0090]
步骤4.1,将隐私保护智能体对数据隐私保护的要求用参数σ∈[0,1]来量化,σ值越高,说明数据拥有者对隐私要求的程度越高。对于数据挖掘智能体而言,聚类结果的稳定性要达到指定阈值,且修改后贝叶斯网络生成的数据与原始贝叶斯网络生成数据之间的差距应小于δ,也可将数据挖掘智能体的数据挖掘需求看作δ,所以本发明假设隐私保护智能体依据数据挖掘智能体需求δ修改数据所获收益期望为δ,当且仅当在满足数据挖掘的前提下隐私保护智能体所获收益期望不低于对数据的隐私保护程度σ,也即δ≥σ时,隐私保护智能体才会提供数据给数据挖掘智能体;
[0091]
步骤4.2,使用收益r(δ,σ)来表示两者交互过程中获取的总奖励函数,其中,
[0092][0093]
收益r(δ,σ)可看作以σ为参数的奖励函数。给定σ的分布,可知两者交互中总收益期望为:
[0094]
e[r(δ,σ)]=∑f
σ
(δ)(δ-cost)
[0095]
其中,f
σ
(δ)表示两者接受收益期望的概率。
[0096]
交互开始前,数据挖掘者将数据挖掘需求上传至数据平台,数据挖掘智能体将数据进行聚类,并将得到的聚类结果与隐私保护智能体生成的原始数据比较。隐私保护智能体根据需求对贝叶斯网络做出修正后,对比本方的隐私保护需求σ,决定是否接受数据挖掘智能体的数据请求。若在第m次交互中,隐私保护智能体修改数据所获收益期望为δi,则两
者对应可获奖励为:
[0097]ri
(δi,σm)=f
σ
(δ
i-cost)
[0098]
在f
σ
(
·
)未知的前提下,需应用学习策略来确定收益期望最高的奖励状态学习策略为一次交互中数据挖掘智能体与隐私保护智能体所获最大奖励函数的策略。动作值函数公式为:
[0099]
q(s
t
,a
t
)
←rt
+γmaxq(s
t+1
,a
t+1
)
[0100]
其中:
[0101]
·st
表示当前的奖励状态;
[0102]
·at
表示在s
t
状态下隐私保护智能体是否接收数据挖掘智能体数据请求;
[0103]
·st+1
表示隐私保护智能体在s
t
状态下执行a
t
后的奖励状态;
[0104]
·
q(s
t
,a
t
)表示在s
t
状态下执行a
t
后两者获得的总期望收益;
[0105]
·rt
表示在s
t
状态下执行了a
t
后两者得到的即时奖励值函数;
[0106]
·
maxq(s
t+1
,a
t+1
)表示两者在s
t+1
状态下价值最高的总期望收益;
[0107]
·
γ表示折损率。
[0108]
隐私保护智能体通过与数据挖掘智能体的数据挖掘需求进行交互,不断地更新动作值函数,最终收敛于平衡点,两者在交互过程中可以获取最大奖励,同时,同时使得数据效用最高。本发明提出基于强化学习的隐私保护数据发布方法,命名为pridqn算法,通过隐私保护和数据挖掘两个智能体之间的交互来获取奖励,不断优化动作值函数,进而同时满足隐私保护和数据挖掘的需求。
[0109]
pridqn算法过程如图2所示。其中,隐私保护智能体通过设立经验池,将训练过程中的状态、动作与奖励等存储在经验池中,引入深度神经网络模型,计算现有的q值q_eval,并利用更新较慢的target网络更新q值q_target,提高训练的稳定性和收敛性。数据挖掘者智能体作为环境,将数据挖掘结果和当前的状态反馈给隐私保护智能体,与隐私保护智能体进行交互。此外,算法使用了ε-greedy策略选取在状态s
t
下最大的q(s
t
,a)来更新q,将行为策略和目标策略分开,可以在更新状态值函数的同时,得到全局最优解。pridqn算法的核心步骤描述如下:
[0110][0111]
具体实施方式二:
[0112]
与具体实施方式一不同的是,本实施方式通过迭代地修正贝叶斯网络来实现对原数据的第二重匿名方法,通过修改属性节点的概率分布值也可以使贝叶斯网络生成的数据发生改变,从而达到隐私保护要求,具体步骤如下:
[0113]
步骤2.1,对贝叶斯网络实施敏感属性值泛化、t-近邻性和-多样性三种隐私保护方式进行单位化修正操作,其中,单位化只是每一轮次只能进行{敏感属性值泛化,t-近邻性,-多样性}操作集中的一项操作;
[0114]
敏感属性值泛化操作:根据数据拥有者对数据属性设置的属性值泛化层次树,将属性值域中待匿名保护的属性叶节点与其同父节点的所有兄弟叶节点聚合为一个属性节点并由其直接父节点进行替换,形成新的叶节点,该叶节点所对应的属性值概率分布继承自参与聚合的所有原叶节点,其值为所有参与聚合节点的概率分布之和;
[0115]
t-近邻保护操作:a)将待匿名保护的属性值域空间中导致信息熵最大化的值分布情况定义为理论基准(其分布值记为x
min
),属性值概率分布最大者定义为待平滑基准(其分布值记为x
max
);b)使用方差进行度量,将定义为平滑操作单位(其中,m为正整数),对理论基准和待平滑基准进行迭代式单位修正,即每一轮次修正使得
若使得属性各值出现概率与理论基准的方差不高于t则停止迭代,否则跳转执行a)。
[0116]-多样性保护操作:将待隐私保护属性在贝叶斯网络中的值域空间进行扩充,使得其值域空间中不同值的数量大于等于基于修正后属性中各值的概率分布根据信息熵最大化的修正原则,在每一轮修正的过程中,a)仅选择一个概率分布最大的值作为待修正的目标对象(其分布值记为x
max
)且当前属性值域空间中不同值的数量记为将其高于均值的概率分布值平均分配给新增的属性值即b)跳转执行a),直至(为预设的概率分布最小阈值,且)。
[0117]
在实施例中设计了对比实验来模拟所提出的方法,并分析其性能。dqn算法是一种离线学习(off-policy)算法,在与其相反的在线学习(on-policy)算法中,智能体是通过初始的策略自主产生训练样本,然后将训练的样本返向更新策略,其行为策略和目标策略是同一个策略;而在off-policy算法中,智能体则是将目标策略和行为策略分开,通过行为策略来不断优化目标策略,从而达到全局最优。为验证本章提出pridqn算法的有效性,设计的对比实验将在线学习sarsa[67]算法以及离线学习q-learning算法与本发明所提出的pridqn算法进行了比较,通过对比在相同条件下算法获取收益的大小以及收敛时间来对算法进行评估。
[0118]
本实验所采用数据集如表1所示。实验基于k-anonymity隐私保护方法进行,采用python语言实现来实现,实验的环境为:一台pc机,64位windows 10系统,intel@xeon(r)cpu e5-2630 0@2.30ghz
×
12,geforce gtx980ti/pcle/sse2。
[0119]
表1标准网络数据集表
[0120][0121]
sarsa算法在更新时借助实际的经验值进行迭代,该算法能够以100%的概率收敛于最优策略和动作值函数,前提是要有足够长的学习时间和交互次数;q-learning算法是对sarsa算法的优化,由于在更新策略时采用了贪心策略,所以相较于sarsa算法能更快的收敛。将两种基准算法应用于隐私保护中,与本文的pridqn算法在三种不同类型的数据集下进行对比实验,并统计结果。
[0122]
实验相关参数设定如下:
[0123]
·
神经网络的宽度和层数分别设置为128和3;
[0124]
·
σ:σ用来模拟隐私保护智能体对于隐私保护的要求,实验中,生成以均值为0.5,标准差为0.1的正态分布随机数由于的值可能会落在[0,1]之外,所以做出以下规定:
[0125][0126]
·
k:三个数据集中k的取值分别为k=5、k=8、k=10;
[0127]
·
m:实验中,交互次数设定为m=20000;
[0128]
·
α:步长α=0.002
[0129]
·
γ:实验前对不同的衰减因子γ进行了模拟,选取了最优结果γ=0.9用于后续实验;
[0130]
·
ε:探索概率ε=0.1;
[0131]
·
δ:原始数据与新生成数据之间差距的阈值δ=0.2;
[0132]
表2 cancer数据集下各算法收益效果的比较
[0133][0134]
表3 sachs数据集下各算法收益效果的比较
[0135][0136]
表4 insurance数据集下各算法收益效果的比较
[0137][0138]
根据公式11,通过记录两者交互过程中获得收益来观察算法的收敛情况,表2、表3和表4为q-learning算法、sarsa算法、pridqn三种算法分别在cancer、sachs、insurance三个不同数据集上获得收益的情况。
[0139]
由表2~表4的实验结果可以得出以下结论:在给定参数的条件下,本章提出的pridqn算法在三个数据集上都表现出了比其他两种方法更优的性能,在一定的交互次数内都达到了收敛且获得了更高的收益。在小型数据集cancer上,三种方法所获收益均随着交互次数的增加而收敛,pridqn算法的收益最高,比其余两种方法的收益提高了16.44%~39.12%;在中型数据集sachs上,q-learning算法的收益呈现振荡的趋势,sarsa算法和pridqn算法均达到了收敛,且pridqn算法的收益高于其余两种算法24.29%~61.48%;在
大型数据集insurance上,其余两种方法在交互次数内均没有收敛,而pridqn算法达到了收敛,且收益同样提高了22.08%~90.16%。这表明,本章提出的pridqn算法在所给出的数据集上都表现出了良好的性能,尤其是在大型数据集上的表现更加优于其余两种算法,说明该算法能够使数据隐私性与数据挖掘的有效性达到协同平衡。
[0140]
此外,在实验过程中,需应用学习策略来确定收益期望最高的奖励状态,学习策略的性能可用“弱后悔值(weak regret)”[70]
来评估,其公式为:
[0141][0142]
它表示的是在第t次交互时,待评估策略对应的总收益与一个始终选择“最优”动作状态的策略之间的差距,这里的“最优”是一种事后意义上的最优,即在已知数据满足两者需求的条件下,可以分别计算每个动作状态的累计收益,进而找出收益最大的动作状态。换言之,弱后悔值表示在交互中造成的损失价值,弱后悔值越小,则表明选择的学习策略越好。
[0143]
实验记录了在三种数据集下,三种算法的弱后悔值的结果如图3~图5所示。结果表明,在三种数据集下,pridqn算法的弱后悔值曲线收敛速度最快,弱后悔值随交互次数的增长最为缓慢,且弱后悔值相对于其他两种方法最小,由此证实了本文提出pridqn算法的学习策略较其他两种基准算法的优越性。
[0144]
实验还将pridqn算法的收敛时间进行了记录,表5展示了pridqn算法分别在三个数据集上进行5次实验的结果,计算得到其均值和标准差。从结果可以看出:pridqn算法收敛时间随着数据集的复杂程度增大而增大,收敛时间分别控制在424.95s、786.25s、1160.19s左右,由于参数的设定会导致5次实验收敛的时间在一定的范围内波动,但总体上pridqn在时间开销上表现出良好的效果。
[0145]
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1