一种基于点云弱监督的实例分割方法与流程
1.本发明涉及人工智能领域,尤其涉及一种基于点云弱监督的实例分割方法。
背景技术:
2.近年来,自动驾驶系统越来越受到学术界和工业界的重视。现有的图像实例分割技术通常利用有监督学习的方法训练深度学习模型,从而在推断时能够对图片生成代表其实例分割结果的实例掩码(instance mask)。而高质量的实例分割技术能够对自动驾驶系统提供显著的帮助,例如一些算法利用实例分割结果来将激光雷达和图像数据进行融合,从而提高跨模态三维目标检测的性能。
3.然而,为了实现有监督学习,对训练数据集进行实例分割标注的成本极高,尤其是在自动驾驶场景下,图像内通常包含了大量的人、车、非机动车以及其他障碍物等实例。想要对数以百万的训练样本完成高质量的标注通常需要投入大量的人力物力。现有的有监督实例分割方法如mask r-cnn和condinst等,都严重依赖于人工标注的质和量,使得这些方法难以利用较大规模的数据。
4.为了降低成本,人们开发出了弱监督实例分割方法,如boxinst方法和pointsup方法等。而弱监督实例分割方法都利用了部分人工标注,尽管其成本较低,但仍然需要安排额外的人力和时间进行人工标注,并且弱监督实例分割方法的性能较低。因此,需要进一步研究成本低且有效的实例分割技术。
技术实现要素:
5.本发明的任务是提供一种基于点云弱监督的实例分割方法,能够直接利用激光雷达采集的点云指导实例分割模型的弱监督训练,而不需要对图像进行完整的掩码标注,实现在不引入额外人工标注成本的情况下,进一步提高弱监督实例分割模型的性能。
6.在本发明的第一方面,针对现有技术中存在的问题,本发明提供一种基于点云弱监督的实例分割方法来解决,包括:
7.将激光雷达点云投影到图像平面形成投影点云;
8.对投影点云进行提纯,去除因激光雷达和相机之间的视差导致的重叠点得到提纯点云;
9.将提纯点云中的点分配前景标签/背景标签;以及
10.以具有前景标签/背景标签的提纯点云为监督信号训练分割器,并利用分割器进行实例分割预测掩码。
11.在本发明的一个实施例中,在所述将激光雷达点云映射到图像平面形成投影点云的步骤之前,还包括:输入图像,通过图像特征提取器提取图像特征,其中图像特征作为训练分割器的输入特征;以及
12.标注图像中物体的三维包围盒。
13.在本发明的一个实施例中,在训练分割器时,采用点误差损失函数和图一致性损
失函数来约束分割器的输出。
14.在本发明的一个实施例中,其中将激光雷达点云投影到图像平面形成投影点云包括:
15.激光雷达点云在齐次坐标系下表示为通过变换矩阵将所述激光雷达点云从激光雷达坐标系投影到相机坐标系下,再通过相机矩阵进一步投影到图像平面形成投影点云,其中投影点云为:
[0016][0017]
其中是所述激光雷达点云投影到图像平面后在齐次坐标表示下的点的集合。
[0018]
在本发明的一个实施例中,其中对投影点云进行提纯,去除因激光雷达和相机之间的视差导致的重叠点得到提纯点云包括:
[0019]
将投影到图像平面得到的每个像素p
2d
和其对应的激光雷达点的深度真值组成稀疏深度图以及
[0020]
使用一个二维滑动窗口来遍历整张稀疏深度图,在每一个窗口内,投影点云根据相对深度被分割成临近点和远距点其中相对深度超过深度阈值的点为远距点相对深度未超过深度阈值的点为临近点
[0021][0022]
其中p(x,y)表示在二维滑动窗口中一个坐标为(x,y)的像素对应的激光雷达点云中的点,τ
depth
表示深度阈值,采用所述深度阈值能够过滤掉距离较远的点,d(x,y)表示坐标为(x,y)的像素对应的深度值,d
min
和d
max
分别表示在二维滑动窗口内的最小深度值和最大深度值;
[0023]
通过计算临近点中的最小包络范围,将邻近点的最小包络范围内距离较远的点作为重叠点去除,得到提纯提纯点云其中重叠点为:
[0024][0025]
其中x
min
,x
max
是临近点中在x轴上的最小值和最大值,y
min
,y
max
是临近点中在y轴上的最小值和最大值。
[0026]
在本发明的一个实施例中,其中将提纯点云中的点分配前景标签/背景标签包括:
[0027]
根据所述提纯点云和所述三维包围盒之间的位置关系,将所述提纯点云分为在三维包围盒内的点和在三维包围盒外的点在三维包围盒内的点作为正样本,并分配前景标签,将中围绕在所述三维包围盒附近的一部分点作为负样本,分配背景标签,其中正样本和负样本的数量共s个;
[0028]
根据图像特征相似度将所述正样本和负样本的伪标签传播到周围8个像素上。
[0029]
在本发明的一个实施例中,其中将中围绕在所述三维包围盒附近的一部分点作为负样本,分配背景标签包括:
[0030]
首先将所述三维包围盒的8个定点投影到图像平面,然后计算得到最小的包络矩形选择中能够投影落在包络矩形b内的部分点作为负样本
[0031]
在本发明的一个实施例中,其中根据图像特征相似度将所述正样本和负样本的伪标签传播到周围8个像素上包括:
[0032]
当图像特征相似度超过相似度阈值时,将选自正样本和负样本的候选点pc的标签传播到图像周围8个像素上,使得这8个像素具有与候选点pc同样的类别标签,其中标签传播的判断公式为:
[0033][0034]
其中l(p)是点p被分配的伪标签,是候选点pc在图像上周围的8个像素,是点p从经过预训练得到的图像特征提取器中抽取的图像特征,τ
dense
是相似度阈值。
[0035]
在本发明的一个实施例中,其中在训练分割器时,采用点误差损失函数和图一致性损失函数来约束分割器的输出包括:
[0036]
采用双线性插值方法构建点误差损失函数,其中通过点误差损失函数能够衡量预测掩码与伪标签之间损失,点误差损失函数为:
[0037][0038]
其中k为图像中实例的总数,s为所有带有伪标签的点,p
ks
是第k个实例中的第s个点,l
ks
则为点p
ks
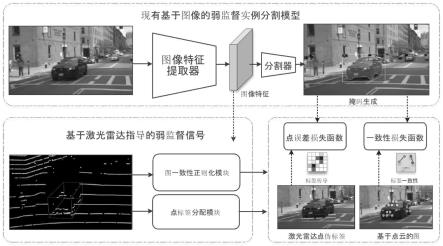
的伪标签,l
point
表示点误差损失。
[0039]
在本发明的一个实施例中,其中在训练分割器时,采用点误差损失函数和图一致性损失函数来约束分割器的输出包括:
[0040]
利用所述提纯点云构建一个无向图g=《v,e》,其中所述提纯点云中的点作为节点组成v,e为边,根据两个节点之间的图像特征相似度和三维几何特征相似度来确定两个节点之间是否形成一条边和是否具有相同的伪标签,其中图像特征相似度和三维几何特征相似度的加权和为:
[0041]wij
=w1s
image
(i,j)+w2s
geometry
(i,j),
[0042]
其中w1和w2是图像特征相似度和三维几何特征相似度的平衡权重,s
image
(i,j)和s
geometry
(i,j)分别表示节点pi和pj之间的图像特征相似度和三维几何特征相似度,w
ij
表示图总相似度;当图总相似度w
ij
大于相似度阈值τ时,两个节点之间形成一条边,且具有相同的伪标签,否则两个节点之间不存在一条连边,且两个节点的伪标签不相同;
[0043]
根据节点之间存在一条连边时,分割器预测的掩码相近,能够利用图一致性损失函数来约束分割器的输出:
[0044][0045]
其中n=|v|为无向图中所有的节点,和分别为节点pi和节点pj的预测掩码,l
consistency
表示图一致性损失。
[0046]
本发明至少具有下列有益效果:本发明公开的一种基于点云弱监督的实例分割方法,能够直接利用激光雷达采集的点云指导实例分割器的弱监督训练,而并不需要对图像进行完整的掩码标注,实现在不引入额外人工标注成本的情况下,进一步提高弱监督实例分割模型的性能,并且具有利用海量无标注激光雷达数据完成实例分割器训练的潜力。
附图说明
[0047]
为了进一步阐明本发明的各实施例的以上和其它优点和特征,将参考附图来呈现本发明的各实施例的更具体的描述。可以理解,这些附图只描绘本发明的典型实施例,因此将不被认为是对其范围的限制。
[0048]
图1示出了根据现有技术的boxinst方法进行实例分割的过程示意图;
[0049]
图2示出了根据现有技术的pointsup方法进行实例分割过程中的取点示意图;
[0050]
图3示出了根据本发明的一个实施例的基于点云弱监督的实例分割方法的流程;以及
[0051]
图4示出了根据本发明的一个实施例的点标签分配模块的示意图。
具体实施方式
[0052]
应当指出,各附图中的各组件可能为了图解说明而被夸大地示出,而不一定是比例正确的。
[0053]
在本发明中,各实施例仅仅旨在说明本发明的方案,而不应被理解为限制性的。
[0054]
在本发明中,除非特别指出,量词“一个”、“一”并未排除多个元素的场景。
[0055]
在此还应当指出,在本发明的实施例中,为清楚、简单起见,可能示出了仅仅一部分部件或组件,但是本领域的普通技术人员能够理解,在本发明的教导下,可根据具体场景需要添加所需的部件或组件。
[0056]
在此还应当指出,在本发明的范围内,“相同”、“相等”、“等于”等措辞并不意味着二者数值绝对相等,而是允许一定的合理误差,也就是说,所述措辞也涵盖了“基本上相同”、“基本上相等”、“基本上等于”。
[0057]
在此还应当指出,在本发明的描述中,术语“中心”、“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是明示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为明示或暗示相对重要性。
[0058]
另外,本发明的实施例以特定顺序对工艺步骤进行描述,然而这只是为了方便区分各步骤,而并不是限定各步骤的先后顺序,在本发明的不同实施例中,可根据工艺的调节来调整各步骤的先后顺序。
[0059]
现有的图像实例分割技术通常利用有监督学习的方法训练深度学习模型,从而在推断时能够对图片生成代表其实例分割结果的掩码(instance mask)。在自动驾驶场景下,图像内通常包含了大量的人、车、非机动车以及其他障碍物等实例,对训练数据集进行实例分割标注实现有监督学习的成本极高。
[0060]
由于有监督学习对训练数据标注的依赖极大,所以现有技术从弱监督学习出发,通过只对原始数据进行低成本的弱标注,并利用基于弱标注的弱监督学习技术来完成弱监督实例分割任务。这种基于弱标注的弱监督学习技术主要有boxinst方法和pointsup方法等。
[0061]
图1示出了根据现有技术的boxinst方法进行实例分割的过程示意图。
[0062]
如图1所示,boxinst方法仅仅利用各个实例的三维包围盒作为监督信号实现弱监督实例分割。并且该方法在公开数据集上能够达到90%左右有监督实例分割的性能。尽管boxinst方法的性能无法与有监督实例分割匹敌,但由于标注成本极低,从而具备利用海量数据的能力。
[0063]
具体来说,boxinst的核心建立在一个假设之上:当包围盒紧密围绕着物体时,三维包围盒上至少有一个像素和物体重叠(视为正样本),而检测框外一定和物体无关(视为负样本)。于是该方法通过引入重投影误差来实现对预测结果和三维包围盒结果的对齐。
[0064]
引入重投影误差的目的是对预测掩码和真值包围盒掩码分别在x轴和y轴方向的投影之间的差距进行惩罚。从而实现让预测掩码在投影后尽量接近于真值包围盒掩码的投影。重投影误差的损失函数具体可表示为:
[0065][0066]
其中表示预测掩码,b表示真值包围盒掩码,和分别表示预测掩码在x和y轴上的投影,而projx(b)和projy(b)分别表示真值包围盒掩码在x和y轴上的投影。l(x,y)表示两项(预测掩码与真值包围盒掩码)之间的dice损失(dice loss):
[0067][0068]
此外,为了约束在训练过程中预测掩码不会完全变成三维包围盒,boxinst方法还利用了成对损失来约束预测掩码。成对损失函数基于如下假设:如果两个像素颜色相似,则它们的类别标签很可能相同。于是成对损失可表达成:
[0069][0070][0071]
其中表示在坐标x,y位置的点的预测类别,p(ye=1)表示坐标x,y位置的点和k,l两个点是否属于同一个类别(同为前景或同为背景)。
[0072]
图2示出了根据现有技术的pointsup方法进行实例分割过程中的取点示意图。
[0073]
仅仅利用包围盒作为监督信号只能在一些公开数据集上达到有监督学习方法性能的85%。如图2所示,pointsup方法则在盒监督(boxinst方法)的基础上,额外添加了从包
围盒内随机采样并人工标注类别(标注为前景/背景)的几个点,并将这些点作为弱监督信号来训练弱监督实例分割模型。
[0074]
pointsup方法通过较低成本的额外标注,实现对模型性能的大幅度提升,实验证实pointsup方法不但远超过boxinst方法的性能,同时还能达到有监督学习方法的大约97%的性能。
[0075]
自动驾驶系统通常会装载激光雷达(lidar)来捕捉点云数据,而点云作为一种能够高精度反映深度真值的数据,能够提供很强的实例分割监督信号。具体来说,点云能够捕捉感兴趣的物体的轮廓,所以当将激光雷达点云投影到二维图像后,自然地能够提供点级别的监督信号。此外,三维几何形状特征能够为实例分割提供额外的信息。
[0076]
受到pointsup只利用少数人工标注的像素点即可带来成功的启发,本发明提出对激光雷达点云中的点进行自动标注,并投影到二维空间上作为提供监督信号的样本点,从而在自动驾驶场景下实现低成本的弱监督实例分割。
[0077]
基于点云弱监督的实例分割主要包括点标签分配(point label assignment)模块和图一致性正则(graph-based consistency regularization)模块。点标签分配模块用来通过一系列规则手段为激光雷达点云分配前景/背景标签。图一致性正则模块通过同时编码几何一致性和形态一致性来进一步约束分割器预测生成高质量的掩码。
[0078]
图3示出了根据本发明的一个实施例的基于点云弱监督的实例分割方法的流程。
[0079]
如图3所示,基于点云弱监督的实例分割方法包含图像实例分割分支(上部)和点云处理分支(下部)。图像实例分割分支包括现有基于图像的弱监督实例分割模型,过程如下:输入图像,利用图像特征提取器提取图像特征,将图像特征作为输入特征来训练分割器,最后利用分割器对图像进行预测,生成掩码。在现有基于图像的弱监督实例分割模型在训练的过程中需要人工标注图像中物体的三维包围盒(bounding box)和三维包围盒中人工标注类别的几个点作为监督信号。点云处理分支的目的是利用激光雷达获取的点云作为监督信号代替现有基于图像的弱监督实例分割模型中需要人工标注点的部分。在此,设计了点标签分配模块和图一致性正则模块。激光雷达能够通过点标签分配模块和图一致性正则化模块来提供额外的弱监督信号,最终这些信号以点误差损失函数和图一致性损失函数的方式来完成对现有弱监督实例分割模型的点云监督训练。在整个过程中并不需要人工针对点云进行额外标注,所以没有引入额外的人工成本。
[0080]
点标签分配模块输入激光雷达点云和三维包围盒并且输入这些点云中的点的伪标签(pseudo labels)。具体来说,首先将激光雷达点云投影到图像平面,然后过滤掉因激光雷达和相机之间的视差导致的噪声点(重叠点)(由于激光雷达位置高于相机,所以部分激光雷达点云并不会在图像中有对应的像素)。然后使用一组规则来为激光雷达点云中的每个点分配一个前景或背景的二分类标签。最终将这些点标签按照特征相似度为权重向邻近的像素传递。
[0081]
图4示出了根据本发明的一个实施例的点标签分配模块的示意图。
[0082]
为了利用激光雷达所能提供的监督信息,发明人设计了一个点标签分配模块来将激光雷达点云中的三维点分配一个二分类标签从而作为标注来训练分割器。如图4所示,将原始点云(激光雷达点云)向图像平面投影形成投影点云,通过对投影点云进行提纯,删除部分重叠点后获得提纯点云,最终通过规则将提纯点云中的点分配前景/背景的标签。
[0083]
点云投影
[0084]
原始点云向图像平面投影形成投影点云的过程称为点云投影。三维空间中包含n个点的点云可以在齐次坐标系(homogeneous coordinate system)下表示为变换矩阵用来将激光雷达点云从激光雷达坐标系投影到相机坐标系下,再通过相机矩阵进一步投影到图像平面。因此,原始点云投影到图像平面的二维点集(投影点云)可表示为:
[0085][0086]
其中是原始点云投影到图像平面后在齐次坐标表示下的点的集合。
[0087]
深度指导的点提纯
[0088]
对投影点云进行提纯,删除部分重叠点的过程称为深度指导的点提纯。在很多自动驾驶系统中,激光雷达位于车顶部,而相机则安装在车前方或挡风玻璃内,这会导致两种传感器之间产生视差。视差使得一些被投影到图像平面的前景像素,在三维点云空间中并不一定是前景点。在此,基于同一个物体表面点的深度变化不应该突变的假设,采用深度指导的点提纯方法将这些重叠点剔除。
[0089]
具体来说,首先将投影到图像平面得到的每个像素p2d和其对应的三维点(激光雷达点)的深度(z轴)真值组成一张稀疏深度图该图为一张稀疏图像,如果在某一坐标位置有对应的三维点(激光雷达点),则该位置的值为投影到图像平面的像素p2d对应的三维点的深度值,若该位置无对应的三维点,则该位置的值为0。然后使用一个二维滑动窗口来遍历整张稀疏深度图。在每一个窗口内,投影点云根据相对深度被分割成临近点和远距点两个集合。
[0090][0091]
其中p(x,y)表示在二维滑动窗口w中一个坐标为(x,y)的像素对应的点云中的点;τ
depth
表示深度阈值,采用深度阈值能够过滤掉所有距离比较远的点;d(x,y)表示坐标为(x,y)的像素对应的深度值,p(x,y)则表示当d(x,y)≠0时,该像素位置对应的三维点;d
min
和d
max
分别表示在二维滑动窗口内的最小和最大深度值。
[0092]
与之类似,所有相对深度超过深度阈值的点为远距点然而,并不是所有远距离的点都是重叠点,所以通过计算临近点中的最小包络范围,将邻近点的最小包络范围内距离较远的点当做重叠点过滤掉:
[0093][0094]
其中x
min
,x
max
,y
min
,y
max
是所有临近点中在x和y轴上的最小值和最大值。这是因为在一个较小的二维滑动窗口范围内,前景点的深度不应该有剧烈的变化。当一个具有较大深度值的点周围有一些较小深度值的点,这个点有很高的概率是重叠点。去除重叠点后的提纯点云可表示为:
[0095][0096]
其中,表示重叠点,表示临近点,表示远距点,表示提纯点云。
[0097]
标签分配
[0098]
在完成对投影点云的提纯后,将剩余的提纯点云中的点分配为正负样本(前景/背景),即标签分配。
[0099]
首先根据提纯点云和所有实例的三维包围盒之间的位置关系,可以将提纯点云分为两个子集:表示在三维包围盒内的点,表示在三维包围盒外的点。将所有出现在三维包围盒内的的点作为正样本,分配前景标签。通常来说,只有少部分点属于能够作为正样本,而大部分点属于不在三维包围盒内的为了减少运算量,通常只使用中围绕在三维包围盒附近的一部分点作为负样本参与训练。具体的采样方式如下:首先将三维包围盒的8个定点(三维包围盒的8个顶点)投影到图像平面,然后计算得到最小的包络矩形该包络矩形表示为一个松弛的二维包围盒(因为三维包围盒投影到二位平面上通常无法和图像中的实例完全重叠,且尺寸会略大一些)。最终选择中能够投影落在包络矩形b内的部分点作为采样后的负样本,记为具体对于中每个候选点的标签分配策略如下:
[0100][0101]
其中1表示点被分配为正样本,0表示点被分配为负样本,-1表示点被忽略。为了在训练过程中并行加速,确定正样本和负样本的数量之和为s个,以一定的正负采样率从和中共采样s个点。如果中共采样s个点。如果将从提纯点云中按照高斯分布随机采样来补充缺失,否则从中采样s个点。最终获得s个点和它们的伪标签。
[0102]
标签传播
[0103]
经过标签分配保留的点投影到图像后非常稀疏,因此进一步将s个点的伪标签依据图像特征相似度传播到周边的像素上(标签传播),从而提供密集的监督信号。从s个正样本和负样本中选择一个候选点pc,然后根据图像特征相似度判断是否将候选点pc的伪标签传播到图像周围8个像素上,遍历s个正样本和负样本。标签传播的判断公式为:
[0104][0105]
其中l(p)是点p被分配的伪标签,是候选点pc在图像上周围的8个像素,是点p从经过预训练得到的图像特征提取器中抽取的图像特征,τ
dense
是相似度阈值。当图像特征相似度超过相似度阈值时,将该候选点px的标签传播到
图像周围8个像素上,使得这8个像素具有与候选点pc同样的类别标签。否则不传递标签,因为当两个点的图像特征相似度较低时,无法判断它们的是否属于同一个类别。最终经过标签传播后得到一个带有伪标签的密集点集。
[0106]
激光雷达点损失
[0107]
对于利用掩码进行实例分割的方法来说,(分割器)输出的掩码可以表示为其中h和w是分割器输出掩码的分辨率。利用双线性插值方法来对点p的位置进行预测采用双线性插值方法构建基于点的二元交叉熵损失函数(称为点误差损失函数):
[0108][0109]
其中k为图像中实例的总数,s为所有带有伪标签的点,p
ks
是第k个实例中的第s个点,l
ks
则为点p
ks
的伪标签,(l
point
表示点误差损失)。由于预测掩码)是通过将点p周围紧邻像素插值得到的,所以该损失函数不但能够在当前点处进行优化,也能够将误差反向传播到该点的邻近像素上。通过基于点的二元交叉熵损失函数能够获得边缘锐度较高的实例分割掩码。
[0110]
尽管前述的点标签分配模块能够提供提纯后的伪标签,但是仍然可能因为以下两点而存在不准确的标签:(1)由于标定不准确导致的系统误差。例如在一些物体的边缘,激光雷达获取的点可能会投影到二维图像平面中的背景处。(2)由于车辆挡风玻璃等材质的低反射率和高透射率,激光雷达的光束有可能穿过玻璃而检测到背景。这会导致点标签分配模块对这些错误的点分配错误的伪标签。为了解决这个问题,设计一个图一致性正则模块。图一致性正则模块通过探索各个相邻的空间点之间的相似度关系来约束分割器生成合理的预测掩码。该模块首先将点云中的每个点作为节点,以三维几何特征相似度与图像特征相似度的加权和作为边构建一个无向图。这个基于图的相似度能够正则化实例分割的预测掩码。图一致性正则模块通过一个图一致性损失函数来监督分割器的训练过程,从而提升分割器的性能。图一致性正则模块包括两个部分:基于相似度的建图方法和一致性正则。
[0111]
基于相似度的建图方法
[0112]
给定根据上述点标签分配模块得到的点集合构建了一个无向图g=《v,e》。其中v由中的所有点组成,边e则需要依据两个节点之间的图像特征相似度和三维几何特征相似度来度量:
[0113]wij
=w1s
image
(i,j)+w2s
geometry
(i,j),
[0114]
其中w1和w2是图像特征相似度和三维几何特征相似度的平衡权重,s
image
(i,j)和s
geometry
(i,j)分别表示节点pi和pj之间的图像特征相似度和三维几何特征相似度,w
ij
表示图总相似度。
[0115]
为了构建图像特征相似度,首先利用卷积神经网络模型(图像特征提取器)提取的图像的特征图然后利用双线性插值来获取点图像特征最终两个节点pi和pj之间的图像特征相似度可以表示为:
[0116]simage
(i,j)=f(pi)
t
f(pj),
[0117]
而对于三维几何特征相似度,考虑图像上每个在点集中的像素在原始激光雷达系统下的三维点p
3d
,并计算这些三维点之间的三维几何特征相似度:
[0118][0119]
其中m为归一化常数,‖
·
‖2是2范数,是三维点p
3d
中的第i个点,是三维点p
3d
中的第j个点。然后将s
image
(i,j)和s
geometry
(i,j)通过权重结合在一起共同形成了两点之间连边的权重。
[0120]
一致性正则
[0121]
在弱监督学习中,一致性先验假设认为在同一个结构(通常指同一簇或者流形)中的点更有可能具有相似的标签。当图总相似度w
ij
较大时,两个点将会更加相似,于是它们更应该具备相同的标签。在此定义一个相似度阈值τ来决定两点之间是否形成一条边。
[0122][0123]
其中e
ij
∈e,当两个节点pi和pi之间的图总相似度w
ij
大于相似度阈值τ,则认为这两个点之间存在一条连边,节点pi和pj的伪标签相同,反之则节点pi和pj之间不存在一条连边,两者的伪标签也不相同。与点标签分配模块类似,此处利用无向图g来约束分割器预测出相似的标签一致性。
[0124]
一致性正则具体表示为:当边e
ij
=1时,分割器预测的掩码和应该尽可能相近。可以用二元交叉熵损失函数来定义该损失(图一致性损失):
[0125][0126]
其中n=|v|为无向图中所有的节点,和分别为节点pi和节点pj的预测掩码,l
consistency
表示图一致性损失。该公式表明,当两个节点pi和pj之间不存在连边时(即e
ij
=0),该损失函数为0,而当两点之间存在连边时,则会让两个点的预测结果尽可能相似。
[0127]
最终将两个损失函数合并到一起作为总损失函数监督分割器的训练:
[0128]
l=l
point
+l
consistency
,
[0129]
通过该方法即可在无任何对于点云的进行额外标注的情况下,以激光雷达点云作为监督信号约束分割器的预测,能够提升分割器的预测性能,完成弱监督的实例分割任务。
[0130]
该基于点云弱监督的实例分割方法附加在pointsup方法和boxinst方法这两个弱监督方法上进行了实验验证,实验结果参见表1。采用实例分割的标准评估指标来评价实例分割的结果,包括平均精确度(average precision,ap)、当交并比阈值为50%时的平均精确度(ap
50
)、当交并比阈值为75%时的平均精确度(ap
75
)、小尺寸物体的平均精确度(aps)、中等尺寸物体的平均精确度(apm)、大尺寸物体的平均精确度(ap
l
)。ap、ap
50
、ap
75
、aps、apm和ap
l
的数值越大,代表分割器(模型)的性能越好。在某一自有的标注数据集上进行性能验证。将激光雷达点云作为监督信号附加现有的弱监督方法的分割器的训练中,并利用训练
完成的分割器进行实例分割的掩码预测,结果表明将激光雷达点云作为监督信号附加现有的弱监督方法的分割器的训练过程中,能够提升分割器的性能,接近采用有监督方法实例分割的性能。
[0131]
表1基于点云弱监督的实例分割方法的实验结果、现有半监督方法的实例分割结果以及有监督方法的实例分割结果对比。
[0132][0133]
与现有的弱监督方法相比,基于点云弱监督的实例分割方法完全不引入额外的人工标注成本,并且可以作为其他弱监督方法的补充。在现有的方法上叠加本方法,能够进一步地提升弱监督实例分割器的整体性能,能够用极低的成本达到接近有监督学习方法的性能,并且具有利用海量数据大规模训练分割器的潜力。
[0134]
虽然本发明的一些实施方式已经在本技术文件中予以了描述,但是本领域技术人员能够理解,这些实施方式仅仅是作为示例示出的。本领域技术人员在本发明的教导下可以想到众多的变型方案、替代方案和改进方案而不超出本发明的范围。所附权利要求书旨在限定本发明的范围,并藉此涵盖这些权利要求本身及其等同变换的范围内的方法和结构。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1