基于正交试验筛选Lasso回归预测烧成曲线的方法与流程
基于正交试验筛选lasso回归预测烧成曲线的方法
技术领域
1.本发明涉及数据预测技术领域,尤其涉及基于正交试验筛选lasso回归预测烧成曲线的方法。
背景技术:
2.建筑陶瓷砖的烧成环节是建筑陶瓷砖生产的关键环节,该环节是由辊道窑炉系统完成。俗话说“生于原料,死于烧成”则是说明烧成工序的重要性。由于该工序主要负责将瓷砖从施釉后的釉坯状态,经过一段时间的烧成和传动运输后,输送出窑炉成为半成品。而在烧成过程中,瓷砖的变化情况是不可见的,且辊道窑的长度较长,从100多米到400多米长度长短不一,最后瓷砖的质量状况调整,只能通过后工序分级检测才能判断烧成制度的好与坏。当原料、配方、窑炉烧成制度等发生波动的时候,势必会造成瓷砖产品的质量异常和波动。
3.窑炉工程师为了适应这一系列的变化,则会通过对窑炉的烧成制度进行调整来实现产品质量达标。这个调整过程快则1-2小时,慢则1-2天。遇到找不到原因的时候,半年都可能出现生产不正常的情况。这一系列的调整方法全部依靠窑炉工程技术人员的经验进行调整,如果经验稍差或者熟悉当前窑炉的技术工程师流失,则会造成生产的极大不稳定,引起产线陶瓷砖的产量和质量的降低。
技术实现要素:
4.本发明的目的在于提出基于正交试验筛选lasso回归预测烧成曲线的方法,以解决上述问题。
5.为达此目的,本发明采用以下技术方案:
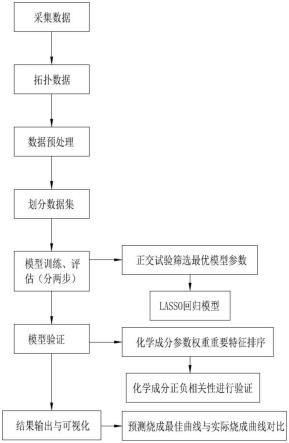
6.基于正交试验筛选lasso回归预测烧成曲线的方法,包括如下步骤:
7.s1:采集数据源,所述数据源包括窑炉烧成温度曲线数据、生产工艺数据、原料物理化学检测数据、窑尾半成品瓷砖变形度数据和产品分级质量数据;
8.s2:按照产品编号、产线号、前后工序时间戳及工序间时间差进行逻辑关联,根据逻辑关联对数据源进行数据拓扑,得到数据集;
9.s3:对所述数据集进行数据清洗,得到清洗好的基础数据集;
10.s4:建立正交筛选模型,利用所述正交筛选模型进行正交实验,筛选出适用于预测模型的数据变量;
11.s5:将筛选出的数据变量作为变量参数搭建基础函数,利用所述基础函数对基础数据集进行预处理,该预处理包括设置优等品率阈值、窑尾半成品瓷砖变形度筛选、物理性能参数变量筛选、原料特征统计以及窑炉烧成温度数据统计;
12.s6:对经过基础函数预处理的基础数据集中的各类数据进行归一化处理;
13.s7:将归一化处理后的基础数据集划分为训练集、验证集和测试集;
14.s8:利用训练集训练并生成lasso回归预测模型,利用测试集对lasso回归预测模
型的预测结果进行测试,利用验证集对lasso回归预测模型的预测结果进行验证;所述lasso回归预测模型用于输出预测的窑炉温度曲线。
15.作为一种可选的实施例,所述lasso回归预测模型为:
[0016][0017]
其中,代表残差平方和;代表为惩罚项目;λ为惩罚因子,λ>0;βj为回归系数;yi为拟合值;x
ij
为自变量数据;n为参数个数;m为样本个数。
[0018]
作为一种可选的实施例,所述利用训练集训练lasso回归预测模型时,包括以下步骤:
[0019]
设置惩罚因子为λ=[λ1、λ2、
…
、λn],其中,λ1、λ2、
…
、λn的值互不相等且在区间(0,1]内;
[0020]
将惩罚因子为λ=[λ1、λ2、
…
、λn]中的不同惩罚因子建立lasso回归预测模型,得到具有不同惩罚因子的lasso回归预测模型,对应标记为:model-1、model-2、
…
、model-n;
[0021]
设置第一模型评估指标,包括r2指标和mape指标,模型的r2分数越趋近于1,效果越好;模型的mape值越趋近于0,效果越好;
[0022]
输出经训练、测试以及验证后model-1、model-2、
…
、model-n的r2、mape得分,根据r2指标和mape指标选出最好的lasso回归预测模型。
[0023]
作为一种可选的实施例,所述建立正交筛选模型包括如下步骤:
[0024]
构建多项式模型函数,包括输入曲线、输出曲线和设定第二模型评估指标,所述第二模型评估指标包括:
[0025]
r2指标:模型的r2分数越趋近于1,效果越好;
[0026]
mape指标:模型的mape值越趋近于0,效果越好;
[0027]
特征排序分数指标:特征排序分数越大,排序靠前权重越大的参数的越多,越符合工艺先验知识;
[0028]
物料趋势分数指标;物料趋势分数越大,符合先验趋势的参数的越多,越符合工艺先验;
[0029]
设置用于存储参数的空列表函数;
[0030]
构建计算多项式函数;
[0031]
构建结构化输出数据集;
[0032]
构建正交筛选函数,优选正交试验因子:
[0033]
设置分级数据中的优等品率大于90%作为阈值,筛选窑炉最佳烧成曲线数据,得到正交试验因子:优等品率阈值[0,0.9];
[0034]
将窑尾变形记录按照工厂检验标准设置为合格=1,不合格=0,得到正交试验因子:窑尾变形记录变量[0,1];
[0035]
设置化学成分含量<0.1%是否去除,得到正交试验因子:化学成分检测数据阈值[0,0.1];
[0036]
设置烧后白度、热膨胀系数是否去除或去除一个变量,得到正交试验因子:物理性能检测数据[none,['烧后白度','热膨胀系数'],['烧后白度'],['热膨胀系数']];
[0037]
设置模型的最大学习深度,得到正交试验因子:模型最大学习深度参数[3,6,9];
[0038]
设置模型的学习率,得到正交试验因子:模型学习率参数[0.1,0.2,0.4];
[0039]
设置模型的集成评估器,得到正交试验因子:[10,50,100];
[0040]
构建正交试验函数进行正交试验,正交试验因子包括优等品率阈值[0,0.9],窑尾变形记录变量[0,1],化学成分检测数据阈值[0,0.1],物理性能检测数据[none,['烧后白度','热膨胀系数'],['烧后白度'],['热膨胀系数']],模型最大学习深度参数[3,6,9],模型学习率参数[0.1,0.2,0.4]和模型集成评估参数[10,50,100],得到864个正交试验模型;
[0041]
利用第二模型评估指标对各个正交试验模型进行评估,得到模型的r2分数、mape分数、特征排序分数以及物料趋势分数,并按r2分数、mape分数、特征排序分数以及物料趋势分数进行排名,将各个正交试验模型的mape分数排名、特征排序分数排名以及物料趋势分数排名相加求平均值,得出各个正交试验模型的平均排名,确定排名最前的正交试验模型所选择的数据变量。
[0042]
作为一种可选的实施例,所述步骤s3包括如下步骤:
[0043]
步骤s31:对数据集进行总体分析,判断不同数据源的数据颗粒度及数据缺失情况,匹配原料物理化学检测数据颗粒度,按照窑炉设备数据采集频次进行数据填充处理;
[0044]
步骤s32:对匹配好颗粒度的数据集进行清洗,包括格式内容清洗、逻辑错误清洗、异常值清洗以及缺失值清洗。
[0045]
作为一种可选的实施例,窑炉温度曲线数据包括窑炉中t1-tn的n个温度点温度绘制而成的温度曲线;
[0046]
生产工艺数据包括压机成型数据、干燥窑温度数据以及釉线施釉数据;
[0047]
原料物理化学检测检测数据包括原料的化学成分和物理性能参数;
[0048]
窑尾半成品瓷砖变形数据包括半成品瓷砖凸变形度与凹变形度;
[0049]
产品分级质量数据包括瓷砖优等品率、一级品率、合格品率、次品率、总产量以及各类缺陷数据。
[0050]
作为一种可选的实施例,所述设置优等品率阈值,是指设定优等品率大于某个代表生产工艺及生产过程为优秀的阈值,小于该值则说明生产状态不佳;
[0051]
所述窑尾半成品瓷砖变形度筛选是对窑尾半成品瓷砖变形度记录的数据进行筛选,按照工厂变形度控制标准判定合格与不合格标准,筛选合格或不合格产品对应的窑炉运行参数数据;
[0052]
所述物理性能参数变量筛选是对粉料和釉料检测的物理性能参数进行筛选,以判定各个物理性能参数是否对模型预测结果造成影响;
[0053]
所述原料特征统计是指利用变异系数对原料物理性能参数和化学成分参数进行特征统计分析;
[0054]
所述窑炉烧成温度数据统计指对采集的窑炉历史温度数据进行统计分析,筛选剔除异常值。
[0055]
作为一种可选的实施例,还包括以下步骤:
[0056]
s9:构建多输出回归模型特征重要性的函数,以平均特征重要性进行排序,输出对
窑炉烧成温度影响最大的前k项变量参数;
[0057]
s10:利用工艺理论知识与工艺经验,对对窑炉烧成温度影响最大的前k项变量参数的排序和化学成分正负相关性进行验证,判断lasso回归预测模型的预测准确性;
[0058]
s11:将lasso回归预测模型预测的窑炉温度曲线与实际的窑炉温度曲线进行可视化对比。
[0059]
本发明还公开了一种预测烧成曲线的设备,包括存储器,处理器及存储在所述存储器上并可在所述处理器上运行的基于正交试验筛选lasso回归预测烧成曲线的方法程序,所述处理器执行所述基于正交试验筛选lasso回归预测烧成曲线的方法程序时实现上述的基于正交试验筛选lasso回归预测烧成曲线的方法的步骤。
[0060]
本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质上存储有基于正交试验筛选lasso回归预测烧成曲线的方法程序,所述基于正交试验筛选lasso回归预测烧成曲线的方法程序被处理器执行时实现上述的基于正交试验筛选lasso回归预测烧成曲线的方法的步骤。
[0061]
与现有技术相比,本发明实施例具有以下有益效果:
[0062]
本发明通过建立lasso回归预测模型进行最佳烧成曲线预测,解决了窑炉烧成制度调整依靠人工经验调整的弊端,减少工人试错成本和试错时间,提高窑炉产质量,提高企业效益。其中,在本发明的实施例采用两步走的模式,先采集影响窑炉对瓷砖烧成质量的数据变量,通过多项式拟合,构建正交试验,筛选出最优的模型参数,以确定哪些变量适合用于最佳烧成曲线的预测,为后续lasso回归预测模型的建立筛选出数据变量;再建立lasso回归预测模型进行最佳烧成曲线预测,大大提高lasso回归预测模型对最佳烧成曲线预测的准确性。
附图说明
[0063]
图1是本发明流程示意图。
具体实施方式
[0064]
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
[0065]
在本发明的描述中,需要理解的是,术语“纵向”、“横向”“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征,用于区别描述特征,无顺序之分,无轻重之分。
[0066]
下面结合图1描述本发明实施例的基于正交试验筛选lasso回归预测烧成曲线的方法,包括如下步骤:
[0067]
s1:采集数据源,所述数据源包括窑炉烧成温度曲线数据、生产工艺数据、原料物理化学检测数据、窑尾半成品瓷砖变形度数据和产品分级质量数据;
[0068]
s2:按照产品编号、产线号、前后工序时间戳及工序间时间差进行逻辑关联,根据逻辑关联对数据源进行数据拓扑,得到数据集;通过构建原料检测、生产工艺数据、窑炉烧成制度数据、分级产品数据之间逻辑关系,串联原料物理化学检测数、生产工艺参数、设备运行参数、窑炉烧成制度、产品检测数据、产品分级数据之间的逻辑关系,为后续建模搭建基础数据集。其中,所述窑炉烧成制度数据包括温度、压力、气氛、传动等数据;温度数据包括从t1-tn的n个温度点温度;压力数据包括窑内负压、零压位、t1-tn的各仓位压力;气氛数据是指窑炉内部各仓位气氛属于氧化气氛或还原气氛;传动数据是指窑炉电机传动过程中的传动速度、频率数据。通过按照产品编号、产线号、前后工序时间戳及工序间时间差进行逻辑关联,实现窑炉烧成温度曲线数据、窑尾半成品瓷砖变形度数据、生产工艺数据、原料物理化学检测数据、产品分级质量数据一一对应。具体的,计算从压机成型至储砖主站环节的精确时间,储砖主站到抛光上砖机的模糊时间。从抛光上砖机至分级处的精确时间。(1)压机成型处粉料检测数据及成型数据与釉线、窑炉等数据匹配需要加上砖坯在釉线运行时间、砖坯从进干燥窑到出干燥窑的运行时间、以及砖坯从进入窑炉到出窑炉的烧成时间、砖坯出窑炉到窑尾储砖站的传输时间。(2)储砖站到抛光线上砖处于离散状态,通常采用模糊时间匹配,以当班总上砖量除以当班时间为每小时瓷砖半成品加工数据。(3)抛光上砖机时间加上半成品在抛光线传输时间则匹配到分级处的时间。
[0069]
s3:对所述数据集进行数据清洗,得到清洗好的基础数据集;
[0070]
s4:建立正交筛选模型,利用所述正交筛选模型进行正交实验,筛选出适用于预测模型的数据变量;
[0071]
s5:将筛选出的数据变量作为变量参数搭建基础函数,利用所述基础函数对基础数据集进行预处理,该预处理包括设置优等品率阈值、窑尾半成品瓷砖变形度筛选、物理性能参数变量筛选、原料特征统计以及窑炉烧成温度数据统计;
[0072]
s6:对经过基础函数预处理的基础数据集中的各类数据进行归一化处理;数据的归一化处理是数据标准化中的一种,即将数据统一映射到[0,1]区间上。归一化是统一在0-1之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。通过进行归一化处理能提升模型的收敛速度以及提升模型的精度。具体地,归一化处理的公式为:其中,x:表示处理后的新数据;xi’:表示原始样本数据;μ:表示样本数据的均值;σ:表示样本数据的标准差。
[0073]
s7:将归一化处理后的基础数据集划分为训练集、验证集和测试集;
[0074]
s8:利用训练集训练并生成lasso回归预测模型,利用测试集对lasso回归预测模型的预测结果进行测试,利用验证集对lasso回归预测模型的预测结果进行验证;所述lasso回归预测模型用于输出预测的窑炉温度曲线。
[0075]
本发明通过建立lasso回归预测模型进行最佳烧成曲线预测,解决了窑炉烧成制度调整依靠人工经验调整的弊端,减少工人试错成本和试错时间,提高窑炉产质量,提高企业效益。其中,在本发明的实施例采用两步走的模式,先采集影响窑炉对瓷砖烧成质量的数
据变量,通过多项式拟合,构建正交试验,筛选出最优的模型参数,以确定哪些变量适合用于最佳烧成曲线的预测,为后续lasso回归预测模型的建立筛选出数据变量;再建立lasso回归预测模型进行最佳烧成曲线预测,大大提高lasso回归预测模型对最佳烧成曲线预测的准确性。
[0076]
作为一种可选的实施例,所述lasso回归预测模型为:
[0077][0078]
其中,代表残差平方和;代表为惩罚项目;λ为惩罚因子,λ>0;βj为回归系数;yi为拟合值;x
ij
为自变量数据;n为参数个数;m为样本个数。
[0079]
作为一种可选的实施例,所述利用训练集训练lasso回归预测模型时,包括以下步骤:
[0080]
设置惩罚因子为λ=[λ1、λ2、
…
、λn],其中,λ1、λ2、
…
、λn的值互不相等且在区间(0,1]内;
[0081]
将惩罚因子为λ=[λ1、λ2、
…
、λn]中的不同惩罚因子建立lasso回归预测模型,得到具有不同惩罚因子的lasso回归预测模型,对应标记为:model-1、model-2、
…
、model-n;
[0082]
设置第一模型评估指标,包括r2指标和mape指标,模型的r2分数越趋近于1,效果越好;模型的mape值越趋近于0,效果越好;其中,r2分数采用公式(1)计算,mape值采用公式(2)计算;
[0083][0084][0085]
其中,为模型的预测值;yi为观察值,为平均观察值;
[0086]
输出经训练、测试以及验证后model-1、model-2、
…
、model-n的r2、mape得分,根据r2指标和mape指标选出最好的lasso回归预测模型。
[0087]
作为一种可选的实施例,所述建立正交筛选模型包括如下步骤:
[0088]
构建多项式模型函数,包括输入曲线、输出曲线和设定第二模型评估指标,其中,输入的曲线是指输入的各个点位烧成温度组成的曲线,输出曲线是指输出的各个点位烧成温度组成的曲线;所述第二模型评估指标包括:
[0089]
r2指标:模型的r2分数越趋近于1,效果越好;
[0090]
mape指标:模型的mape值越趋近于0,效果越好;
[0091]
特征排序分数指标:特征排序分数越大,排序靠前权重越大的参数的越多,越符合工艺先验知识;具体地,在本发明里,对于物料有权重分类,如:粉料、面釉、抛釉三种物料各占比30%,40%,30%,这就是大类权重,然后粉料中的铝、硅、钾、钠、钙、镁各种元素的权重也不一样,这是子类权重,特征排序分数,就是按照权重总表把各个物料权重的分数算出
来,然后再排序,做评估。
[0092]
物料趋势分数指标;物料趋势分数越大,符合先验趋势的参数的越多,越符合工艺先验;物料趋势分数:穷举参数,1倍方差取样,最高温度点及取样参数的斜率;正相关斜率为正,负相关斜率为负;符合工艺先验趋势+1*加总权重分数;不符合-1*加总权重分数;加总所有穷举的参数;在本发明中,粉料和釉料中的化学元素与烧成温度有的是正相关的,如三氧化二铝,含量越大,温度越高;但有些是负相关的,如氧化钾,含量越大,温度越低。物料趋势分数就是看看各种原料成分在最高温度点的趋势是否符合工艺先验趋势,符合就是正的加总权重分数,不符合,就是负的加总权重分数。
[0093]
设置用于存储参数的空列表函数;
[0094]
构建计算多项式函数;
[0095]
构建结构化输出数据集;
[0096]
构建正交筛选函数,优选正交试验因子:
[0097]
设置分级数据中的优等品率大于90%作为阈值,筛选窑炉最佳烧成曲线数据,得到正交试验因子:优等品率阈值[0,0.9];
[0098]
将窑尾变形记录按照工厂检验标准设置为合格=1,不合格=0,得到正交试验因子:窑尾变形记录变量[0,1];例如,工厂检验窑尾平整度标准:半成品对角线变形度+0.7~-0.4,四边变形度+0.5~-0.3,波浪、塌边变形度+0.2~-0.2,弯角+0.3~-0.3,其中+代表凸变形,-代表凹变形。如变形度检测数据未超出上述范围则判定该批次半成品瓷砖平整度合格=1,超出上述标准则判定为不合格=0。
[0099]
设置化学成分含量<0.1%是否去除,得到正交试验因子:化学成分检测数据阈值[0,0.1];
[0100]
部分化学成分在粉料和釉料中含量较低,如<0.1%,结合工艺实际经验,需要考虑在选择模型变量的时候考虑这些含量小的变量是否会对模型的预测造成影响。因此设置去除化学成分<0.1%的数据变量=0.1,保留所有检测数据变量=0,即,正交试验因子[0,0.1]。
[0101]
设置烧后白度、热膨胀系数是否去除或去除一个变量,得到正交试验因子:物理性能检测数据[none,['烧后白度','热膨胀系数'],['烧后白度'],['热膨胀系数']];部分物理性能检测数据变量如烧后白度、热膨胀系数等变量,结合工艺实际经验,需要考虑在选择模型变量的时候考虑这些变量是否会对模型的预测造成影响。因此设置对应的正交试验因子不去除=none,去除两个=['烧后白度','热膨胀系数'],去除一个='烧后白度'、'热膨胀系数',即[none,['烧后白度','热膨胀系数'],['烧后白度'],['热膨胀系数']]。
[0102]
设置模型的最大学习深度,得到正交试验因子:模型最大学习深度参数[3,6,9];
[0103]
设置模型的学习率,得到正交试验因子:模型学习率参数[0.1,0.2,0.4];
[0104]
设置模型的集成评估器,得到正交试验因子:[10,50,100];
[0105]
构建正交试验函数进行正交试验,正交试验因子包括优等品率阈值[0,0.9],窑尾变形记录变量[0,1],化学成分检测数据阈值[0,0.1],物理性能检测数据[none,['烧后白度','热膨胀系数'],['烧后白度'],['热膨胀系数']],模型最大学习深度参数[3,6,9],模型学习率参数[0.1,0.2,0.4]和模型集成评估参数[10,50,100],得到864个正交试验模型;
[0106]
利用第二模型评估指标对各个正交试验模型进行评估,得到模型的r2分数、mape
分数、特征排序分数以及物料趋势分数,并按r2分数、mape分数、特征排序分数以及物料趋势分数进行排名,将各个正交试验模型的mape分数排名、特征排序分数排名以及物料趋势分数排名相加求平均值,得出各个正交试验模型的平均排名,确定排名最前的正交试验模型所选择的数据变量。
[0107]
作为一种可选的实施例,所述步骤s3包括如下步骤:
[0108]
步骤s31:对数据集进行总体分析,判断不同数据源的数据颗粒度及数据缺失情况,匹配原料物理化学检测数据颗粒度,按照窑炉设备数据采集频次进行数据填充处理;
[0109]
步骤s32:对匹配好颗粒度的数据集进行清洗,包括格式内容清洗、逻辑错误清洗、异常值清洗以及缺失值清洗。
[0110]
具体地,格式内容清洗是日期格式、时间戳单位、数值格式、全半角格式以及不应存在的字符清洗等;逻辑错误清洗是数据重复清洗、不合理值清洗、矛盾内容修正等;异常值是指一组测定值中与平均值的偏差超过两倍标准差的测定值。与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。异常值清洗是指对超出3倍标准差的值高度异常值进行数据清洗,包括删除、视为缺失值、平均值修正、盖帽法、分箱法、回归插补、多重插补等;缺失值清洗是指对所采集数据表中的缺失值进行特殊值填充、平均值填充、热卡填充、最近邻法、删除缺失值等方法进行缺失值处理,使数据集完整。
[0111]
作为一种可选的实施例,窑炉温度曲线数据包括窑炉中t1-tn的n个温度点温度绘制而成的温度曲线;
[0112]
生产工艺数据包括压机成型数据、干燥窑温度数据以及釉线施釉数据;所述压机成型数据包括成型压力、冲压行程、冲压次数、排气时间以及格栅运行参数;所述干燥温度数据是指将生坯进行干燥的温度数据,包括从瓷砖进入干燥窑炉到出干燥窑经过的干燥窑众的1-n个温度点;所述釉线施釉数据包括淋釉重量、釉浆比重、釉浆流速、砖坯温度以及砖坯表面横截面淋釉偏差数据;
[0113]
原料物理化学检测检测数据包括原料的化学成分和物理性能参数;所述原料的化学成分包括粉料化学成分和釉料化学成分;所述原料的物理性能参数包括粉料水分、粉料颗粒度、粉料容重、烧后白度、热膨胀系数、烧成收缩率、釉浆比重、釉浆流速、釉浆筛余、砖坯施釉量;
[0114]
窑尾半成品瓷砖变形数据包括半成品瓷砖凸变形度与凹变形度;凸变形包括四条边变形度、对角线变形度,用正数表示凸变形;凹变形包括四条边变形度、对角线变形度,用负数表示凹变形;0表示砖面平整,未发生变形。
[0115]
产品分级质量数据包括瓷砖优等品率、一级品率、合格品率、次品率、总产量以及各类缺陷数据;所述产品分级质量数据是指产品经过分级后统计的产质量数据,包括产量、优等品率、一级品率、合格品率、次品率;各种缺陷数量,如变形、熔洞、针孔等。
[0116]
作为一种可选的实施例,所述设置优等品率阈值,是指设定优等品率大于某个代表生产工艺及生产过程为优秀的阈值,小于该值则说明生产状态不佳;如设置优等品率>90%的生产状态为优秀,则优等品率阈值设定为90%,即0.9。
[0117]
所述窑尾半成品瓷砖变形度筛选是对窑尾半成品瓷砖变形度记录的数据进行筛选,按照工厂变形度控制标准判定合格与不合格标准,筛选合格或不合格产品对应的窑炉运行参数数据;
sdram,ddrsdram)、增强型同步动态随机存取存储器(enhanced sdram,esdram)、同步连接动态随机存取存储器(synch link dram,sldram)和直接内存总线随机存取存储器(direct rambus ram,drram)。本发明实施例描述的系统和方法的存储器旨在包括但不限于这些和任意其它适合类型的存储器。
[0129]
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有基于正交试验筛选lasso回归预测烧成曲线的方法程序,所述基于正交试验筛选lasso回归预测烧成曲线的方法程序被处理器执行时实现上述的基于正交试验筛选lasso回归预测烧成曲线的方法的步骤。
[0130]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0131]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0132]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0133]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0134]
根据本发明实施例的基于正交试验筛选lasso回归预测烧成曲线的方法的其他构成等以及操作对于本领域普通技术人员而言都是已知的,这里不再详细描述。
[0135]
在本说明书的描述中,参考术语“实施例”、“示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0136]
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1