一种基于注意力机制的多尺度目标检测方法
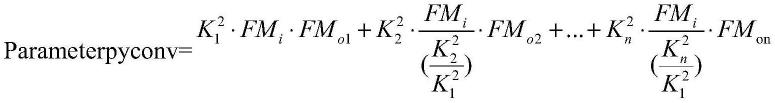
1.本发明属于目标检测技术领域,特别是涉及一种基于注意力机制的多尺度目标检测方法。
背景技术:
2.目标检测负责识别和定位数字图像中的单个或多个目标,是计算机视觉领域的重要研究任务之一,也是许多其他任务(例如目标跟踪、实例分割、图像描述生成等)的重要环节。在过去的二十年内,目标检测的发展历程分为两个时期:传统的目标检测时期以及基于深度学习的目标检测时期。传统的目标检测方法采用滑动窗口技术筛选目标区域,通过人工设计的算法提取图像特征,最后利用分类器判定目标类别。随着深度学习技术的不断发展,基于卷积神经网络的目标检测技术逐渐替代了传统的目标检测算法,在精确度和速度方面都取得了明显提升。
3.yolov3目标检测模型对于较小的目标、目标分布密集、复杂的背景结构的遥感影像的检测不能满足现有的需求。原始yolov4目标检测已经不能有效的以及快速的识别具体物体,不能满足高精确度以及快速的响应时间。现在需要更快速以及精确度更高的目标检测模型来满足物体检测需求。
技术实现要素:
4.本发明针对现有技术的不足,提供一种基于注意力机制的多尺度目标检测方法,对原始yolov4网络进行修改,使用coordattention注意力机制,有利于主干网络获取图像特征的空间位置信息,对更感兴趣的对象进行特征提取,提高模型对空间特征提取能力。pyconv多尺度卷积能够提高图像特征融合能力,扩大卷积核的感受野,使模型能够处理多尺度的目标,因为卷积核和卷积深度的灵活性,能够灵活处理不同大小的目标物体,对于输入的特征图在不同尺度核上处理时,不会提升计算成本以及模型的参数量。使用reslayer结构,解决深层网络容易产生梯度消失以及学习退化的问题,增强模型对特征图特征信息的提取能力。
5.为了达到上述目的,本发明提供的技术方案是,一种基于注意力机制的多尺度目标检测方法,包括如下步骤:
6.步骤1,获取图像数据集;
7.步骤2,对图像数据集进行预处理,并划分训练集、测试集、验证集;
8.步骤3,建立基于注意力机制的多尺度目标检测的目标检测模型,所述目标检测模型包括cspdarknet53主干网络、spp池化模块、rp-panet特征融合模块、检测头部几个部分,其中,在cspdarknet53主干网络中添加coordinate attention注意力机制,有效的提高对于特征图的提取;
9.步骤4,训练目标检测模型;
10.步骤5,基于训练好的目标检测模型进行目标检测,将待识别数据集图像输入到训
练好的目标检测模型中,模型对图像进行分类、输出物体的名称以及识别的置信度,完成识别。
11.进一步的,在主干网络cspdarknet53的第一层结构中引入coordinate attention注意力机制模块;coordattention注意力机制分为两个阶段:第一阶段为coordattention信息的嵌入,对输入的特征图,先经过一个残差结构,然后使用尺寸为(h,1)和(1,w)的池化核,分别在水平坐标和竖直坐标方向对每个通道进行编码,得到特征和和表示高度为h的第c个通道的输出特征,xc(h,i)表示在第c个通道上,高度为h,宽为i位置的特征层;表示宽度为w的第c个通道的输出特征,xc(j,w)表示在第c个通道上,宽为w,高为j位置的特征层,w和h分别表示输入特征图的宽和高;上述获取的特征,分别沿着水平和竖直两个空间方向进行特征的聚合,得到一对具有方向感知的注意力图,使得注意力模块能够捕捉到图像特征的空间位置信息和精确的位置信息,使网络更准确的定位感兴趣的对象;
12.第二个阶段为coordinate attention生成,通过第一个阶段获取的信息,将xc(h,i)和xc(j,w)进行concatenate操作得到特征图xc(i,j),使用一个共享的1
×
1卷积进行f1变换操作:f=δ(f1([zh,zw])),式中,[.,.]为沿着空间维数的concatenate操作,δ为非线性激活函数,f是空间信息在水平和垂直方向上进行编码的中间特征映射,zh表示在高这个维度上的输出特征,zw表示在宽这个维度上的输出特征;然后沿着空间维数将f分解为2个单独的张量fh∈r
c/r
×h和fw∈r
c/r
×w,其中fh表示垂直方向空间信息的中间特征图,fw表示水平方向空间信息的中间特征图,r表示缩减因子;gw=σ(fw(fw)),gh=σ(fh(fh)),式中,gw表示水平方向的权重矩阵,gh表示垂直方向的权重矩阵,fw表示在水平方向使用卷积变换函数f,fh表示在垂直方向使用进行卷积变函数f,σ是sigmoid激活函数,对于分解的两个空间方向的张量,通过fh和fw这2个1
×
1的卷积操作将fh和fw的通道数变为一致,通过r的大小,适当调节f的通道数,达到降低模型复杂性和计算开销的目的,最后分别给gw和gh,作为注意力的权重;最终ca模块的输出特征为:yc(i,j)表示最终输出的特征图,表示在垂直方向第c个通道的注意力权重,表示在水平方向第c个通道的注意力权重。
[0013]
进一步的,在rp-panet特征融合模块中引入pyconv卷积模块,pyconv卷积模块的处理过程如下;
[0014]
设置fmi为输入的特征图,pyconv的层次为{level1,level2,
…
,leveln},提供的多尺度卷积核为kn是指卷积核的大小;每个卷积核对应的深度为不同层次的卷积核输出的特征图为{fm
o1
,fm
o2
,
…
,fm
on
},输出的特征图的宽度和高度是不变的,pyconv的参数量为:
[0015][0016]
pyconv的计算量为:
[0017][0018]
最后各个层次特征图组成最后的输出特征图表示为:fmo=fm
o1
+fm
o1
+...+fm
on
,其中w表示输入特征图的的宽,h表示输入特征图的的高。
[0019]
进一步的,在rp-panet特征融合模块中引入reslayer结构,对于输入的特征图,经过reslayer结构后会分成左右两个分支进行卷积运算,右边的分支,只进行卷积操作,左边的分支,首先进行卷积操作,然后进入n个残差网络块,对特征图的特征进行深度提取,不会造成梯度的发散,n层残差网络块处理后,与右边的分支的特征层进行concat操作,扩大特征图通道,提高特征图的特征信息,最后进行卷积操作进一步对图像特征进行提取;其中每个卷积操作之后还连接了bn层和silu层;
[0020]
xi表示第i层残差网络块的输出,残差函数记为f(),leakyrelu函数记为l(),wi表示i层的随机参数,每层残差网络块的输入输出都为正,可以得出:
[0021]
x
i+1
层残差网络块输出特征为:
[0022]
x
i+1
=l(xi+f(xi,wi))=xi+f(xi,wi)
[0023]
x
i+2
层残差网络块输出特征为:
[0024]
x
i+2
=l(x
i+1
+f(x
i+1
,w
i+1
))=x
i+1
+f(x
i+1
,w
i+1
)=xi+f(xi,wi)+f(x
i+1
,w
i+1
)
[0025]
xn层残差网络块输出特征为:
[0026][0027]
残差网络块的梯度更新值可以表示为:
[0028][0029]
由于每层残差网络块的输出结果都为正,所以di》0,在这种情况下,随着网络的加深,不会造成梯度消失。
[0030]
进一步的,步骤3中目标检测模型的具体处理过程如下;
[0031]
数据集中的每幅图像经过改进后的cspdarknet53主干网络进行特征提取后,输出第一输出特征层,第二输出特征层,第三输出特征层;
[0032]
所述第一输出特征层定义为:x1;
[0033]
所述第二输出特征层定义为:x2;
[0034]
所述第三输出特征层定义为:x3;
[0035]
所述第三输出特征层先经过3次卷积,然后经过spp模块进行池化操作,再经过3次卷积,得到池化后第三输出特征层;
[0036]
所述池化后第三输出特征层定义为:x3’;
[0037]
所述py-panet特征融合模块包括:
[0038]
第一reslayer模块、第二reslayer模块、第三reslayer模块、第四reslayer模块、第一上采样层、第二上采样层、第一下采样层、第二下采样层、第一卷积连接层、第二卷积连接层、第三卷积连接层、第四卷积连接层;
[0039]
所述第一上采样层定义为:up1;
[0040]
所述第二上采样层定义为:up2;
[0041]
所述第一下采样层定义为:down1;
[0042]
所述第二下采样层定义为:down2;
[0043]
所述第一卷积连接层定义为:concat1;
[0044]
所述第二卷积连接层定义为:concat2;
[0045]
所述第三卷积连接层定义为:concat3;
[0046]
所述第四卷积连接层定义为:concat4;
[0047]
所述第一reslayer模块定义为:reslayer1;
[0048]
所述第二reslayer模块定义为:reslayer2;
[0049]
所述第三reslayer模块定义为:reslayer3;
[0050]
所述第四reslayer模块定义为:reslayer4;
[0051]
x1、x2和x3’输入rp-panet特征融合模块,x3’经过up1,进行上采样操作得到改变通道数后的特征层,再进行多尺度卷积操作对特征层进行特征融合,再与x2一起进入concat1,concat1操作对x3’和x2特征层进行通道数整合得到特征层x23’,经过reslayer1,对整合的特征层x23’进行更深层次的特征融合,特征融合后的x23’再经过up2,进行上采样操作得到改变通道数后的特征层,再进行多尺度卷积操作对特征层进行特征融合,再与x1一起进入concat2,concat2操作对特征融合后的x23’和x1特征层进行通道数整合,经过reslayer2进行深度特征融合后,得到第一最终输出特征层,定义为head1,x1经过down1,进行下采样操作得到改变通道数后的特征层,再与特征融合后的x23’一起进入concat3,经过reslayer3对特征层进行特征融合,得到第二最终输出特征层,定义为head2,x2经过down2,进行下采样操作得到改变通道数后的特征层,与x3’一起进入concat4,经过reslayer3对特征层进行特征融合,得到第三最终输出特征层,定义为head3;
[0052]
最后将head1,head2,head3传入检测头部。
[0053]
进一步的,步骤4中训练目标检测模型的实现过程如下;
[0054]
步骤4.1,根据cspdarnet53模块的初始训练权重,对图像数据集进行训练,得到预训练权重;
[0055]
步骤4.2,基于步骤4.1的预训练权重,再根据添加的coordinate attention注意力机制,进行训练,进一步得到添加coordinate attention注意力机制后的训练权重;
[0056]
步骤4.3,基于步骤4.2的训练权重,在rp-panet中添加多尺度卷积操作pyconv进行训练,第二训练权重;
[0057]
步骤4.4,基于步骤4.3的第二训练权重,在rp-panet中添加reslayer进行训练,得到完整的训练模型。
[0058]
与现有技术相比,本发明的优点和有益效果:本发明利用的coordattention注意力机制,对目标的空间位置和通道间的关系进行捕捉,更加准确找到感兴趣的对象,增强网络对于图像特征的提取能力;pyconv模块,扩大卷积核的感受野,通过不同大小的卷积核,使模型能够处理多尺度的目标,提高模型的特征提取能力;reslayer模块,有效防止模型在深层网络中梯度发散,造成模型难以收敛的问题,进一步提高模型在深层网络中的特征提取能力。
附图说明
[0059]
图1为本发明整体流程图。
[0060]
图2为本发明中coordinate attention注意力机制模型图。
[0061]
图3为本发明中pyconv卷积结构图。
[0062]
图4为本发明中组卷积结构图。
[0063]
图5为本发明reslayer结构图
[0064]
图6为本发明中整体模型结构图。
具体实施方式
[0065]
下面结合附图和实施例对本发明的技术方案作进一步说明。
[0066]
如图1所示,本发明实施例提供的一种基于注意力机制的多尺度目标检测方法,其具体步骤如下:
[0067]
步骤1:图像的获取:基于使用的数据集,提取对应的图片,将提取的图片按照pascal voc数据集格式将图片命名,同时创建名为annotations、imagesets、jpegimages的三个文件夹;
[0068]
步骤2:图像预处理:
[0069]
步骤2.1图像标记:在步骤1获取的图片,运用图像标注工具labelimg对图像中的物体进行标注,标注出物体的位置以及名称。
[0070]
步骤2.2划分数据集:将标记好数据集按照合适的百分比划分为训练集、测试集、验证集。
[0071]
步骤3:建立基于注意力机制的多尺度目标检测目标检测模型
[0072]
步骤3.1:在主干网络cspdarknet53的第一层结构中引入coordinate attention注意力机制模块,如图2所示,coordattention注意力机制分为两个阶段:第一阶段为coordattention信息的嵌入,对输入的特征图,先经过一个残差结构,然后使用尺寸为(h,1)和(1,w)的池化核,分别在水平坐标和竖直坐标方向对每个通道进行编码,即在宽和高两个维度(水平方向x和垂直方向y)上进行平均池化,得到特征和和表示高度为h的第c个通道的输出特征,xc(h,i)表示在第c个通道上,高度为h,宽为i位置的特征层;表示宽度为w的第c个通道的输出特征,xc(j,w)表示在第c个通道上,宽为w,高为j位置的特征层,w和h分别表示输入特征图的宽和高。上述获取的特征,分别沿着水平和竖直两个空间方向进行特征的聚合,得到一对具有方向感知的注意力图,使得注意力模块能够捕捉到图像特征的空间位置信息和精确的位置信息,使网络更准确的定位感兴趣的对象。第二个阶段为coordinate attention生成,通过第一个阶段获取的信息,将xc(h,i)和xc(j,w)进行concatenate操作得到特征图xc(i,j),使用一个共享的1
×
1卷积进行f1变换操作:f=δ(f1([zh,zw])),式中,[.,.]为沿着空间维数的concatenate操作,δ为非线性激活函数,f是空间信息在水平和垂直方向上进行编码的中间特征映射,zh表示在高这个维度上的输出特征,zw表示在宽这个维度上的输出特征。然后沿着空间维数将f分解为2个单独的张量fh∈r
c/r
×h和fw∈r
c/r
×w,其中fh表示垂直方向空间信息的中间特征图,fw表示
水平方向空间信息的中间特征图,r表示缩减因子;gw=σ(fw(fw)),gh=σ(fh(fh)),式中,gw表示水平方向的权重矩阵,gh表示垂直方向的权重矩阵,fw表示在水平方向使用卷积变换函数f,fh表示在垂直方向使用进行卷积变函数f,σ是sigmoid激活函数,对于分解的两个空间方向的张量,通过fh和fw这2个1
×
1的卷积操作将fh和fw的通道数变为一致,通过r的大小,适当调节f的通道数,达到降低模型复杂性和计算开销的目的,最后分别给gw和gh,作为注意力的权重。最终ca模块的输出特征为:yc(i,j)表示最终输出的特征图,表示在垂直方向第c个通道的注意力权重。表示在水平方向第c个通道的注意力权重。coordattention注意力机制,更有利于主干网络获取图像特征的空间位置信息,对更感兴趣的对象进行特征提取。图2中,residual表示残差结构,re-weight表示对模型设置新的权重。
[0073]
步骤3.2:在rp-panet特征融合模块中引入pyconv卷积模块(即多尺度卷积操作),如图3所示,pyconv有n个不同类型的卷积核构成,从level1到leveln卷积核的大小逐渐降低,但是卷积核的深度逐渐变大,核深度的变化与核尺度的变化是互斥的。因为卷积核和卷积深度的灵活性,使pyconv能够灵活处理不同大小的目标物体,对于输入的特征图在不同尺度核上处理时,不会提升计算成本以及模型的参数量。
[0074]
如图3所示,fmi为输入的特征图,pyconv的层次为{level1,level2,
…
,leveln},提供的多尺度卷积核为kn是指卷积核的大小;每个卷积核对应的深度为不同层次的卷积核输出的特征图为{fm
o1
,fm
o2
,
…
,fm
on
},输出的特征图的宽度和高度是不变的。pyconv的参数量为:
[0075][0076]
pyconv的计算量为:
[0077][0078]
最后各个层次特征图组成最后的输出特征图表示为:fmo=fm
o1
+fm
o1
+...+fm
on
,其中w表示输入特征图的的宽,h表示输入特征图的的高。
[0079]
其中,fmi的分母指的是在图4中组卷积所示被分割的组数。无论每个层次设计的卷积核大小和卷积核深度是多少,pyconv的参数量和计算量与常规卷积一样,不会增加额外的计算量和参数量。
[0080]
如图4所示,对于输入的特征图,当组数为1时,卷积核的深度等于特征图的数量,每个输入特征图都连接到每个输出特征图,当组数为2时,输入特征图被分为2组,进行独立的分组卷积,卷积核的深度减少两倍,当组数为3时,输入特征图被分为3组,卷积核的深度减少3倍,随着组数的增加,特征图的连接性和卷积深度都会降低。组数不同时,参数量和计算量减少的程度不同。
[0081]
步骤3.3:将reslayer结构引入rp-panet特征融合模块中,如图5所示,对于输入的特征图,会分成左右两个分支进行卷积运算,右边的分支,只进行卷积操作,左边的分支,首
先进行卷积操作,然后进入n个残差网络块,对特征图的特征进行深度提取,不会造成梯度的发散,n层残差网络块处理后,与右边的分支的特征层进行concat操作,扩大特征图通道,提高特征图的特征信息,最后进行卷积操作进一步对图像特征进行提取。
[0082]
reslayer解决深层网络容易产生梯度消失以及学习退化的问题,证明如下:
[0083]
xi表示第i层残差网络块的输出,残差函数记为f(),leakyrelu函数记为l(),wi表示i层的随机参数,每层残差网络块的输入输出都为正,可以得出:
[0084]
x
i+1
层残差网络块输出特征为:
[0085]
x
i+1
=l(xi+f(xi,wi))=xi+f(xi,wi)
[0086]
x
i+2
层残差网络块输出特征为:
[0087]
x
i+2
=l(x
i+1
+f(x
i+1
,w
i+1
))=x
i+1
+f(x
i+1
,w
i+1
)=xi+f(xi,wi)+f(x
i+1
,w
i+1
)
[0088]
xn层残差网络块输出特征为:
[0089][0090]
残差网络块的梯度更新值可以表示为:
[0091][0092]
由于每层残差网络块的输出结果都为正,所以di》0,在这种情况下,随着网络的加深,不会造成梯度消失。
[0093]
结合pyconv和reslayer模块,设计rp-panet结构,提高模型特征融合模块对于多尺度目标的特征融合能力,防止模型在深层网络中梯度发散,造成模型难以收敛的问题。
[0094]
步骤3.4:模型的整体结构如图6所示,首先图片会经过cspdarknet53主干网络进行特征图的特征提取,后面经过3次卷积,到达spp结构,通过不同尺度的池化进一步的进行特征的提取,再经过3次卷积,进入rp-panet结构,此时有两条路径,一条路径是上采样与cspdarknet53的输出26
×
26
×
512的特征图进行concat操作后进行五次卷积操作,另一条是前进与上面下采样的特征图进行concat操作与五次卷积后输出到头部。cspdarknet53的输出26
×
26
×
512的特征图与spp输出进过上采样后的特征图进行特征融合后也有两条路径,一条是继续上采样与cspdarknet53的输出52
×
52
×
256的特征图进行concat操作以及五次卷积操作,另一条路径是继续前向传播,与第一条路径的特征图经过下采样后的特征图进行特征融合前向传播将特征图输出到头部以及继续下采样与spp结构输出的特征图进行concat操作以及五次卷积后将特征图输出到头部。cspdarknet53的输出52
×
52
×
256的特征图与上采样后的cspdarknet53的输出26
×
26
×
512的特征图进行concat操作以及五次卷积操作后也有两条路径,一条路径是下采样与26
×
26
×
512的特征图前向传播的特征图进行特征融合,另一条路径是直接将特征图输出到头部。
[0095]
步骤3.4所述一种基于注意力机制的多尺度目标检测方法包括:
[0096]
cspdarknet53主干网络、spp池化模块、rp-panet特征融合模块、检测头部;
[0097]
数据集中每幅图像经过改进后的cspdarknet53主干网络进行特征提取后,输出第一输出特征层,第二输出特征层,第三输出特征层;
[0098]
所述第一输出特征层定义为:x1;
[0099]
所述第二输出特征层定义为:x2;
[0100]
所述第三输出特征层定义为:x3;
[0101]
所述第三输出特征层先经过3次卷积,然后经过spp模块进行池化操作,再经过3次卷积,得到池化后第三输出特征层;
[0102]
所述池化后第三输出特征层定义为:x3’;
[0103]
所述py-panet特征融合模块包括:
[0104]
第一reslayer模块、第二reslayer模块、第三reslayer模块、第四reslayer模块、第一上采样层、第二上采样层、第一下采样层、第二下采样层、第一卷积连接层、第二卷积连接层、第三卷积连接层、第四卷积连接层;
[0105]
所述第一上采样层定义为:up1;
[0106]
所述第二上采样层定义为:up2;
[0107]
所述第一下采样层定义为:down1;
[0108]
所述第二下采样层定义为:down2;
[0109]
所述第一卷积连接层定义为:concat1;
[0110]
所述第二卷积连接层定义为:concat2;
[0111]
所述第三卷积连接层定义为:concat3;
[0112]
所述第四卷积连接层定义为:concat4;
[0113]
所述第一reslayer模块定义为:reslayer1;
[0114]
所述第二reslayer模块定义为:reslayer2;
[0115]
所述第三reslayer模块定义为:reslayer3;
[0116]
所述第四reslayer模块定义为:reslayer4;
[0117]
x1、x2和x3’输入rp-panet特征融合模块,x3’经过up1,进行上采样操作得到改变通道数后的特征层,再进行多尺度卷积操作对特征层进行特征融合,再与x2一起进入concat1,concat1操作对x3’和x2特征层进行通道数整合得到特征层x23’,经过reslayer1,对整合的特征层x23’进行更深层次的特征融合,特征融合后的x23’经过up2,进行上采样操作得到改变通道数后的特征层,再进行多尺度卷积操作对特征层进行特征融合,再与x1一起进入concat2,concat2操作对特征融合后的x23’和x1特征层进行通道数整合,经过reslayer2进行深度特征融合后,得到第一最终输出特征层,定义为head1,x1经过down1,进行下采样操作得到改变通道数后的特征层,再与特征融合后的x23’一起进入concat3,经过reslayer3对特征层进行特征融合,得到第二最终输出特征层,定义为head2,x2经过down2,进行下采样操作得到改变通道数后的特征层,与x3’一起进入concat4,经过reslayer3对特征层进行特征融合,得到第三最终输出特征层,定义为head3;
[0118]
最后将head1,head2,head3传入检测头部。
[0119]
步骤4:训练目标检测模型。
[0120]
步骤4.1:根据cspdarnet53模块的初始训练权重,对图像数据集进行训练,得到预训练权重。
[0121]
步骤4.2:基于步骤4.1的预训练权重,再根据添加的coordinate attention注意力机制,进行训练,进一步得到添加coordinate attention注意力机制后的训练权重。
[0122]
步骤4.3:基于步骤4.2的训练权重,在rp-panet中添加pyconv进行训练,第二训练
权重。
[0123]
步骤4.4:基于步骤4.3的第二训练权重,在rp-panet中添加reslayer进行训练,得到完整的训练模型。
[0124]
步骤5:基于建立的目标检测模型进行目标检测:将待识别数据集图像输入到训练好的目标检测模型中,模型对图像进行分类、输出物体的名称以及识别的置信度,完成识别。
[0125]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1