一种面向动态交通场景的路面三维重建方法和系统
1.本发明涉及路面健康监测领域,具体涉及一种面向动态交通场景的路面三维重建方法和系统。
背景技术:
2.路面状况对交通运输的安全性、舒适性和经济性都有巨大影响,而路面健康监测是保证道路正常运营的基础。当前路面病害自动化检测大多是基于二维图像,而基于路面三维模型可以实现更准确的病害识别,同时可以得到各类病害的三维尺寸信息。随着三维测量技术的发展,路表三维数据的采集已经成为当前研究的热点。
3.目前,路面三维测量技术主要可以分为激光成像法和立体视觉法两种。目前大部分多功能路面检测车搭配的三维测量装置都是基于激光成像技术,其成像方式主要采用tof(time of flight)原理或者结构光原理。虽然激光三维成像可以快速生成路面模型,但其易受强光、震动影响,且设备成本高昂。
4.因此,基于彩色图像的立体视觉三维成像成为低成本、高精度路面三维重建的替代方法。根据相机数量,立体视觉三维重建主要可以分为双目立体成像和单目立体成像。双目立体成像是通过位置固定的两个相机间产生的视差,来还原场景深度。双目立体成像的优点是成像速度快,但其也存在建模分辨率差的缺点,且相机安装位置的偏移会导致三维重建的不准确。
5.单目立体成像可以通过单台相机在移动过程中拍摄的图像来生成三维模型。在交通基础设施三维重建领域,单目立体成像主要采用无人机摄影来实现场景三维重建。基于多视角路面图像,通过图像特征匹配和对极几何来生成路面三维点云模型。虽然无人机单目立体成像已经可以实现大尺度道路场景的三维重建,但其在应用过中仍存在以下两个难点:(1)无人机立体摄影仅能在封闭道路上实施,开放道路上运行的车辆会遮挡路面并在建模过程中产生大量噪声;(2)为了观察到被车辆遮挡的路面区域,只能大幅增加图像采集密度,导致建模处理时间暴增。
6.为了实现航拍图像上车辆的自动化识别,当前研究已经尝试采用图像处理方法或深度学习进行地物识别,如道路、桥梁等建筑物。但目前目标识别方法的计算量都较大,且不同高度无人机图像上的物体尺寸变化会对识别精度产生巨大影响。
技术实现要素:
7.本发明的目的在于克服上述现有技术的缺点,提供一种面向动态交通场景的路面三维重建方法和系统,以解决现有技术在道路运营环境下受移动车辆遮挡影响而导致重构模型缺失和大量表面噪声问题,以及大视域路面三维重构效率低下问题。
8.为达到上述目的,本发明采用以下技术方案予以实现:
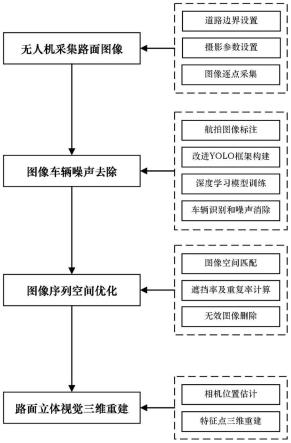
9.一种面向动态交通场景的路面三维重建方法,包括以下步骤:
10.步骤1,采集无人机拍摄的图像;
11.步骤2,将拍摄的图像作为预测集图像输入至改进yolo车辆检测器中,获得拍摄预测集图像中车辆的坐标文件;以车辆的坐标文件为基准,将预测集图像中车辆边界框内的区域单值化;
12.步骤3,通过特征提取法获得预测集图像中相邻图像间的空间关系,通过相邻图像之间的空间关系和每张图像上的车辆边界框,计算相邻图像间的实际遮挡率和地面重叠率,结合图像序列空间优化识别无效图像,去除无效图像,获得预处理图像;
13.结合预处理图像和图像的坐标文件,通过立体视觉重建路面三维形貌。
14.本发明的进一步改进在于:
15.优选的,步骤1前,从电子地图中提取计划拍摄路面区域的边界坐标,生成飞行区域文件,将飞行区域文件导入无人机中,无人机对计划拍摄路面区域拍摄。
16.优选的,步骤2中通过改进yolo车辆检测器获得拍摄预测集图像中车辆的坐标文件过程为:
17.(1)将拍摄的图像以初始(512,512,3)的尺寸输入至改进yolo车辆检测器中,初步预测出车辆边界框,并统计车辆平均像素宽度;
18.(2)根据训练集图像上车辆平均像素宽度和预测集图像上车辆平均像素宽度的比值,计算缩放因子k。
19.(3)通过缩放因子调节预测集图像输入尺寸为(512*k,512*k,3),再次输入至深度学习框架,预测出最终准确的车辆边界框。
20.优选的,所述改进yolo车辆检测器的获得过程为:
21.对骨干特征提取网中的第6层、第12层和第14层从输入的图像提取出的图像分别进行采样、拼接及特征提取,然后通过标准卷积,在9个预定义的锚点框基础上,预测边界框的类型、位置以及置信度,获得预测图像的车辆边界框角点坐标文件数据集;
22.对比标注的图像车辆边界框角点坐标文件数据集和预测的图像车辆边界框角点坐标文件数据集,获得误差,训练yolo车辆检测器,直至所述误差小于设定值,获得改进yolo车辆检测器;
23.所述骨干特征提取网包括1个cbl模块和13个dbr模块;所述cbl模块包括一个标准卷积层、1个批量归一化层和一个leaky relu激活层;所述dbr模块包括一个深度可分离卷积层、一个批量归一化层和一个relu激活层组成。
24.优选的,步骤3中,所述相邻图像间的空间关系通过以下公式计算:
[0025][0026]
其中,为图像上的特征点,r为旋转矩阵,t为平移矩阵;通过多个特征点对,计算出旋转矩阵r和平移矩阵t的实际值,获得相邻图像间的空间关系。
[0027]
优选的,步骤3中,识别无效图像的过程为:
[0028]
(1)设原始图像序列的重叠率为ior
max
,则优化后最低的图像重叠率为ior
min
=1-2*(1-ior
max
);
[0029]
(2)从第1张图像开始以2步间隔进行搜索,计算第i张图像和第i+2张图像组合得到的遮挡率ocr1,即两张图像车辆重叠区域占图像重叠区域的比例。同时,可以得到车辆遮挡位置以外区域的实际地面重叠率gor1;
[0030]
(3)计算第i张图像、第i+1张图像和第i+2张图像组合得到的遮挡率ocr2,即三张图像车辆重叠区域占图像重叠区域的比例,同时,可以得到车辆遮挡位置以外区域的实际地面重叠率gor2。
[0031]
(4)若ocr2》ocr1且gor2》gor1,则保留第i+1张图像,否则删除第i+1张图像。
[0032]
优选的,遮挡率ocr的计算公式为:
[0033]
遮挡率ocr=两张图像叠加后仍有车辆遮挡的部分的面积/原始图像面积;
[0034]
地面重叠率gor的计算公式为:
[0035]
地面重叠率gor=两张图像叠加后去除车辆遮挡部分的面积/原始图像面积。
[0036]
优选的,步骤4中,首先将预处理图像和步骤1中图像的坐标相匹配,初步估计相机在拍摄不同照片之间的相对空间位置;提取每张图像上的特征点,并匹配相邻图像的特征点;根据特征点对和空间对极几何,反算出相机的空间坐标;根据相机空间坐标解算图像上所有特征点的空间三维坐标,得到点云模型,进而通过立体视觉重建路面三维形貌。
[0037]
一种面向动态交通场景的路面三维重建,包括:
[0038]
图像采集模块,用于采集无人机拍摄的图像;
[0039]
坐标获取模块,将拍摄的图像作为预测集图像输入至改进yolo车辆检测器中,获得拍摄预测集图像中车辆的坐标文件;以车辆的坐标文件为基准,将预测集图像中车辆边界框内的区域单值化;
[0040]
图像序列优化模块,通过特征提取法获得预测集图像中相邻图像间的空间关系,通过相邻图像之间的空间关系和每张图像上的车辆边界框,计算相邻图像间的实际遮挡率和地面重叠率,结合图像序列空间优化识别无效图像,去除无效图像,获得预处理图像;
[0041]
重建模块,用于结合预处理图像和图像的坐标文件,通过立体视觉重建路面三维形貌。
[0042]
与现有技术相比,本发明具有以下有益效果:
[0043]
本发明公开了一种面向动态交通场景的路面三维重建方法和系统,本发明基于无人机立体摄影和深度学习实现动态交通影响下的路面三维重建,采用轻量化深度学习框架去除航拍图像上的车辆噪声,并通过图像序列空间优化自动调整不同车流密度区域内的图像重叠率,以提高路面三维建模质量和速度。本发明的优势为:
[0044]
(1)该图像三维重建框架可以针对开放道路环境下的路面三维重建,不受运行车辆影响;(2)航拍图像上的车辆噪声可以被快速识别和消除,不同高度无人机图像上的车辆尺寸变化不会影响识别精度;(3)可以识别不同车流密度下所需图像数量,优化航拍图像序列的空间分布,减少无效图像;(4)能够保证重建路面点云模型的完整性和空间精度,同时提升大尺度场景的三维建模速度。
附图说明
[0045]
图1为本发明的整体框架图;
[0046]
图2为无人机图像车辆识别深度学习框架图;
[0047]
图3为无人机图像车辆识别与噪声消除效果图;
[0048]
图4为无人机图像空间关系估计;
[0049]
图5为车辆遮挡率和地面重叠率的计算示意图;
[0050]
图6为无人机图像序列空间优化框架图;
[0051]
图7为无人机图像序列优化前后的空间分布图;
[0052]
其中,(a)为路段1原始图像序列;(b)为路段1空间优化后的图像序列;(c)为路段2原始图像序列;(d)为路段2空间优化后的图像序列;
[0053]
图8为本发明在交通影响下的路面三维重建效果图;
[0054]
其中,(a)为路段1重建的三维模型;(b)为路段2重建的三维模型;
[0055]
图9为本发明建模速度的对比图。
具体实施方式
[0056]
下面结合附图对本发明做进一步详细描述:
[0057]
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制;术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性;此外,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
[0058]
参考图1,本发明提供了一种基于无人机立体摄影和深度学习的路面快速三维重建方法,具体包含以下步骤:
[0059]
步骤1,通过多旋翼无人机自动采集开放道路上路面图像,并记录图像拍摄时的空间坐标。
[0060]
步骤1.1,在电子地图中,提取计划拍摄路面区域的边界坐标,生成kml格式飞行区域文件,具体的,预选出的航测路面区域的边界坐标应为闭环形式,即{(x1,y1),(x2,y2),
…
,(xn,yn),(x1,y1)}。
[0061]
步骤1.2,将生成的飞行区域文件导入无人机,并设置摄影参数,即相机倾角、相机分辨率、摄影高度、纵向重叠率和横向重叠率。具体的,应根据不同的交通环境及建模精度需求设置摄影参数。在开放交通的道路上,无人机飞行高度应不低于10米,相机倾角介于60~90度之间,相邻拍摄的图像纵向重叠率不小于90%,图像横向重叠率不小于60%。
[0062]
步骤1.3,执行航拍任务,获取不同路面位置的航拍图像,并记录图像拍摄时的位置信息,生成与图像名称匹配的xml坐标文件。
[0063]
通过步骤1,获得了计划拍摄路面区域的kml格式飞行区域文件,以及拍摄的图像的xml坐标文件。
[0064]
步骤2,构建改进yolo(you only look once)深度学习框架检测车辆位置,并去除含有车辆的区域。
[0065]
该部分分为前期的训练阶段和实际应用过程中的使用阶段。
[0066]
(一)训练阶段
[0067]
步骤2.1,选取部分航拍图像作为训练集图像进行标注,通过边界框标记出图像上的车辆位置,生成边界框角点坐标文件,图像标注过程中不需要区分具体车型,仅需将车辆
边界框归为一类,为标注图像。
[0068]
步骤2.2,参考图2,构建融合深度可分离卷积(depthwise separable convolution)和图像分辨率主动调整单元的改进yolo深度学习框架,即为yolo车辆检测器,用于采用边界框来定位航拍图像上的各类车辆位置。其中,改进yolo车辆检测器所嵌入的深度可分离卷积包括逐通道卷积和逐点卷积两个部分。改进yolo车辆检测器所嵌入的图像分辨率主动调整单元的目的是为了增强模型的泛化性能。原始yolo深度学习框架中标准卷积替换为深度可分离卷积,以减少计算量,提高特征提取性能。
[0069]
同时采用图像分辨率主动调整单元来根据不同航拍高度图像上车辆尺寸大小,调整网络输入图像的分辨率。整体框架如下:改进yolo网络的输入是三通道彩色图像,在训练阶段图像的输入尺寸为(512,512,3),因原始图像需要转换为(512*k,512*k,3)尺寸的输入图像,其中k为缩放系数,512*k需要是32的倍数。通过图像分辨率主动调整单元来初步预测图像上车辆的像素大小,并根据大小选择合适的缩放系数k,生成最佳分辨率的输入图像。
[0070]
步骤2.3,使用标注好的尺寸为(512,512,3)的图像数据集,输入至步骤2.2建立好的模型中,训练构建好的yolo车辆检测器中。
[0071]
yolo车辆检测器预测图像边界框角点坐标文件的过程为,针对调整过分辨率的输入图像,首先通过骨干网进行特征提取,骨干网包括基本组件cbl模块和dbr模块。cbl模块包括1个标准卷积层(c),1个批量归一化层(b)和1个leaky relu激活层(l)。dbr模块由1个深度可分离卷积层(d)、1个批量归一化层(b)和1个relu激活层(r)组成。骨干特征提取网络由1个cbl模块和13个dbr模块组成,末端通过空间金字塔池进行特征融合。将骨干特征提取网络中的第6层、第12层、第14层(末端)提取的图像特征分别进行上采样、拼接以及特征提取。最终通过标准卷积,在9个预定义的锚点框基础上,预测边界框的类型、位置以及置信度,获得每一个图像的边界框角点坐标文件,形成每一个图像的车辆边界框角点坐标文件数据集。
[0072]
估计预测图像与标注图像之间的误差,以ciou定义模型损失,直到训练损失稳定,预测值误差小于预设值。网络训练过程可采取迁移学习、训练冻结、动态学习率、早停等训练技术。
[0073]
(二)使用阶段
[0074]
步骤2.4,将训练好的改进yolo车辆检测器用于识别、定位不同航拍图像上的各类车辆,进而高精度的预测出其他边界框的位置,应用图像分辨率主动调整单元,使用检测器预测其他数据集,主要包括以下步骤:
[0075]
(1)预测集图像以初始(512,512,3)尺寸输入改进yolo车辆检测器,初步预测出车辆边界框,并统计车辆平均像素宽度;
[0076]
(2)根据训练集图像上车辆平均像素宽度和预测集图像上车辆平均像素宽度的比值,计算缩放因子k。
[0077]
(3)调节预测集图像输入尺寸为(512*k,512*k,3),再次输入改进yolo车辆检测器,预测出最终准确的车辆边界框,即预测集图像的坐标文件。
[0078]
将预测得到的边界框内部像素的rgb值重置为(255,255,255),以此消除图像上的车辆噪声。
[0079]
图3展示了改进yolo深度学习框架在各个不同航拍图像数据集上的车辆识别结
果。在高精度预测边界框的位置后,将边界框内部图像像素重置为(255,255,255),即将含有车辆的区域单值化。
[0080]
步骤3,重新匹配图像位置,计算不同图像间的地面重叠率以及遮挡率,动态优化图像的空间分布,减少航拍照片数量。
[0081]
步骤3.1,通过特征提取算法提取所有图像上的特征点,根据特征点的相似度,匹配相邻图像上的特征点,得到相邻图像实际的重叠区域和相对位置关系。图像特征提取算法可采用sift(scale invariant feature transform)算法、surf(speeded up robust feature)算法、fast(features from accelerated segment test)算法等。相邻图像的位置关系式,可通过多个已知的点对求解,得到旋转矩阵和平移矩阵。
[0082]
参考图4,为了估计航拍图像之间实际的空间关系,通过特征提取算法提取所有图像上的特征点并根据相似度匹配相邻图像上的特征点,生成特征点对
[0083]
相邻图像实际的重叠区域和相对位置关系可以通过旋转矩阵r和平移矩阵t描述:
[0084][0085]
通过多个特征点对,解算出旋转矩阵r和平移矩阵t的实际值,即可获得图像间的空间关系。
[0086]
步骤3.2,参见图5,根据相邻图像的空间位置以及图像上的车辆遮挡位置,计算图像间实际的遮挡率ocr和地面重叠率gor。车辆遮挡率即多张图像上车辆重叠区域占图像重叠区域的比例,地面重叠率即车辆遮挡位置以外区域的重叠比例。原始图像序列的重叠率应不低于90%,优化后的图像重叠率应介于80%~90%之间。地面重叠率应大于70%,以保证路面三维重建时的对齐精度。
[0087]
具体的,
[0088]
遮挡率ocr=两张图像叠加后仍有车辆遮挡的部分的面积/原始图像面积。
[0089]
地面重叠率gor=两张图像叠加后去除车辆遮挡部分的面积/原始图像面积。
[0090]
步骤3.3,根据图像间实际的遮挡率和地面重叠率,通过图像序列空间优化来识别无效照片,减少三维重建所使用的图像数量。
[0091]
参考图6,根据图像间的实际遮挡率ocr和地面重叠率gor,通过以下步骤优化图像序列的空间分布,
[0092]
(1)设原始图像序列的重叠率为ior
max
,则优化后最低的图像重叠率为ior
min
=1-2*(1-ior
max
);
[0093]
(2)从第1张图像开始以2步间隔进行搜索,计算第i张图像和第i+2张图像组合得到的遮挡率ocr1,即两张图像车辆重叠区域占图像重叠区域的比例。同时,可以得到车辆遮挡位置以外区域的实际地面重叠率gor1。
[0094]
(3)计算第i张图像、第i+1张图像和第i+2张图像组合得到的遮挡率ocr2,即三张图像车辆重叠区域占图像重叠区域的比例,同时,可以得到车辆遮挡位置以外区域的实际地面重叠率gor2。
[0095]
(4)若ocr2》ocr1且gor2》gor1,则保留第i+1张图像,否则删除第i+1张图像。
[0096]
参考图7,展示了两个路段在航拍图像序列空间优化前后的图像分布,优化后可以
大幅减少参与建模的图像数量,有效减小在车流量小区域的图像密度,删除冗余的图像。
[0097]
步骤4,基于预处理的航拍图像,通过立体视觉重建路表面三维形貌。
[0098]
步骤4.1,将步骤3生成的预处理图像与步骤1提取的图像坐标重新匹配,初步估计相机的相对空间位置;提取每张照片上的特征点,并匹配相邻图像的特征点;根据特征点对和空间对极几何,反算出相机的空间坐标。
[0099]
步骤4.2,根据得到的相机空间坐标,解算图像上所有特征点的空间三维坐标,得到点云模型。
[0100]
作为优选的方案之一,步骤2、3中的航拍图像预处理操作可以和步骤4中的图像三维重建操作同步进行,分批进行处理。
[0101]
基于预处理图像序列,通过立体视觉反算相机的精确位置,并估计图像上特征点的空间坐标,生成的点云模型如图8所示。同时,对本发明生成的路面点云模型进行了空间精度验证。
[0102]
本发明还公开了一种面向动态交通场景的路面三维重建,包括:
[0103]
图像采集模块,用于采集无人机拍摄的图像;
[0104]
坐标获取模块,将拍摄的图像作为预测集图像输入至改进yolo车辆检测器中,获得拍摄预测集图像中车辆的坐标文件;以车辆的坐标文件为基准,将预测集图像中车辆边界框内的区域单值化;
[0105]
图像序列优化模块,通过特征提取法获得预测集图像中相邻图像间的空间关系,通过相邻图像之间的空间关系和每张图像上的车辆边界框,计算相邻图像间的实际遮挡率和地面重叠率,结合图像序列空间优化识别无效图像,去除无效图像,获得预处理图像;
[0106]
重建模块,用于结合预处理图像和图像的坐标文件,通过立体视觉重建路面三维形貌。
[0107]
下表1展示了数字模型测量与手工测量结果的比较。本实施例三维重建的7米、12米和20米模型的平均相对误差分别为0.23%、0.23%和0.29%,发现不同摄影高度和交通量下生成的路面点云模型都具有较高水平的空间精度。
[0108]
表1数字模型测量精度
[0109]
[0110][0111]
参考图9,对比了本发明建模方法和传统建模方法在路面三维重建上的处理时间。相较于传统建模方法,本发明建模方法的建模时间平均可以减少38.28%。根据不同路段的交通流情况,本发明的优化效率介于30~50%之间。
[0112]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1