一种地理信息系统的地址自动分析匹配方法与流程
1.本发明涉及信息、控制技术领域,且更具体地涉及一种地理信息系统的地址自动分析匹配方法。
背景技术:
2.在目前gis行业应用中存在很多海量地址数据的情况,传统的数据处理方式已经不能满足数据处理的相关要求。现有的方法是逐条对地址进行拆分解析,并从基础地理数据库中提取与该地址相匹配的空间信息,但会存在以下问题:一、地址数据落地过程大部分工作需要由人工处理;二、 地址数据不规范,存在很多垃圾数据,人工处理难度较高;三、对于海量地址数据的处理需要耗费大量的时间和精力,处理效率低下;四、数据处理过 程中存在较多的人为失误。
3.申请号 cn201110272550.5工开了一种地理信息系统的地址自动分析匹配系统,该技术应用构建了配置管理模块,其用来读取系统配置参数;数据库控制模块,其与配置管理模块连接,并用来进行数据库的连接、读取、写入的操作;数据预处理模块,其与数据库控制模块连接,并对分析数据进行预处理,剔除相关垃圾数据;地址解析模块,其与数据预处理模块连接,并根据地址解析规则对原始地址进行解析;地址解析规则模块,其与地址解析模块连接,并用于地址解析规则配置定义,协同地址解析模块一起工作;地址匹配模块,其与地址解析模块连接,并负责协调和调用相关模块进行地址匹配分析;这种方法虽然使用地址自动分析匹配工具可提高数据处理的效率和精度,节约数据处理的成本。但是该方法系统繁冗,运行效率不高。
4.cn201910068995.8一种地理信息系统的地址自动分析匹配系统包括短信编辑终端、文本信息、智能无线通讯终端、视频录制设备、视频压缩编码以及传输模块、gps接收器、单片机、地理编码数据库和cdma基站,所述单片机输出端与智能无线通讯终端输入端通过局域网连接,所述智能无线通讯终端输出端与cdma基站和地理编码数据库输入端均通过局域网连接。与现有技术相比本发明的安装有短信编辑终端、视频录制设备和gps接收器,通过其可以录制地址处视频,编辑地址文本和地理实时位置,通过其可以进行多种类地理位置的发送,且短信编辑终端、视频录制设备和gps接收器均与智能无线通讯终端通过局域网连接,通过其方便信息的快速输送。这种方法无法实现地理信息系统的地址自动分析和匹配,自动化分析能力低下,匹配度不高,地理信息系统的地址处理和应用能力较低。
技术实现要素:
5.针对上述技术的不足,本发明公开一种地理信息系统的地址自动分析匹配方法,能够实现地理信息系统的地址自动分析和匹配,自动化分析能力强,匹配度高,大大提高了地理信息系统的地址处理和应用能力。
6.本发明采用以下技术方案:一种地理信息系统的地址自动分析匹配方法,其中包括以下步骤:
步骤一、在不断数据更新过程中读取地理信息系统的地址信息,并对读取的数据信息初始化处理;在本步骤中,初始化处理包括数据滤除、剔除和粗大数据信息处理;步骤二、对读取到的地理信息系统地址信息演绎、编码和搜索;在本步骤中,通过mmas算法模型实现数据不断更新过程中的信息检索和演绎,以提高地理信息系统的地址自动化追溯效率;(s21)、将不同的地理信息系统的地址数据信息记作为蚂蚁信息元素,对mmas算法模型进行初始化设置;(s22)、设置不同的地理信息系统的地址数据信息更新过程中的运动轨迹,运动轨迹更新方法通过以下公式进行:(1)在公式(1)中,表示地理信息系统的地址数据信息的信息素,表示地理信息系统的初始地址信息,表示地理信息系统下一个访问地址信息,表示地理信息系统的地址数据信息追溯过程中的蚂蚁元素,表示地理信息系统的地址数据信息追溯过程中的蚂蚁元素更新释放信息素的时间,表示释放信息素时最合适的蚂蚁元素;其中有:
ꢀꢀꢀꢀ
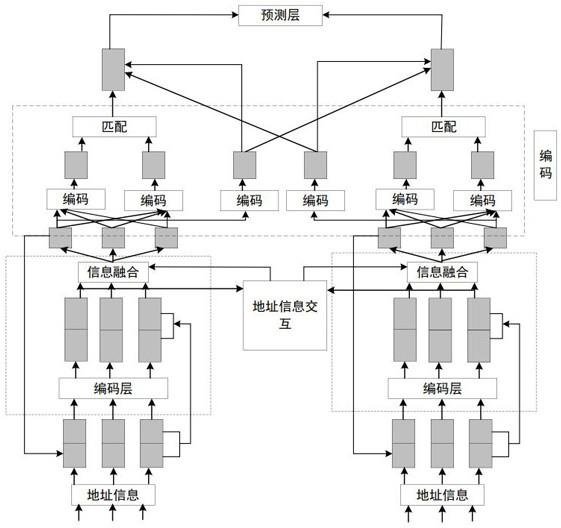
(2)公式(2)中,表示为在不断迭代计算过程中,输出的最优解或者在不断搜索过程中输出的全局最优解值;(s23)、设置最大值和最小值限制,假设介于和之间,每次蚂蚁元素进行信息更新后,在的情况下,则将二者取值为相同的形式,即;(s24)、对蚂蚁元素信息素轨迹进行平滑化处理,则处理公式为:(3)在公式(3)中,的值介于0和1之间,为蚂蚁元素进行平滑化之前的信息素轨迹量,为蚂蚁元素进行平滑化之后的信息素轨迹量;步骤三、地理信息系统的地址自动分析,分析方法是将mmas算法模型输出的数据信息重新编码,并将编码完毕的数据信息进行数据分类;通过时间复杂度的衡量算法实现数据信息分析;步骤四、地理信息系统的地址自动匹配,采用的方法是地址信息批量匹配算法模型; 其中批量匹配算法模型包括输入层、词嵌入层、拼接层、编码器和相关度模块,其中所述输入层的输出端与词嵌入层的输入端连接,所述词嵌入层的输出端与拼接层的输入端连接,所述拼接层的输出端与编码器的输入端连接,所述编码器的输出端与相关度模块的输出端连接;步骤五、输出自动化匹配后的地理信息系统的地址信息。
7.作为本发明进一步的技术方案,时间复杂度的衡量算法的方法为:
时间复杂度衡量算法将编号后的地理信息系统的地址数据信息用来表示,,为数据集中第个样本在的分量,且需满足公式(4)至公式(5)条件:(4)公式(4)中,当公式(4)成立时,则表示地理信息系统的地址在用户允许的范围内;在不断的数据信息更新过程中,所有地理信息系统的地址数据信息表示为:
ꢀꢀꢀ
(5)公式(5)中,其中表示地理信息系统的地址数据信息类型,在衡量地理信息系统的地址生成时间时,通过以下公式表示:
ꢀꢀ
(6)公式(6)中,为常数,将地理信息系统的地址高维数据时间复杂度表示为,;表示地址编码数据信息;定义时间复杂度的衡量算法目标函数为:(7)公式(7)中,表示地理信息系统的地址数据维度,表示所有地理信息系统的地址数据信息经历地址编码和降维后的数据信息,地理信息系统的地址信息在分配编码时,需要满足的函数。
8.作为本发明进一步的技术方案,所述输入层用于输入地理信息系统的地址信息;所述词嵌入层用于将地理信息系统的地址信息嵌入设置在批量匹配算法模型中,以实现分层计算;所述拼接层用于将地理信息系统的地址信息通过不同形式的编码拼接在一起,以实现不同地理信息系统的地址信息的混合应用;所述编码器用于将地理信息系统的地址信息通过文字、数字、字母或者字符进行编码;所述相关度模块用于将编码后的地理信息系统的地址信息通过相关度函数分析相关性。
9.作为本发明进一步的技术方案,批量匹配算法模型的工作方法为:首先地理信息系统的地址数据信息的第层输入信息记作为,输出信息记作为,表示经过词嵌入层后输出的结果,当模型为多层结构时,第层的输入为第一层输入和之前层的输出拼接后得到的,表示为:
(8)公式(8)中,表示第一层输入,表示进行拼接,、表示输出序列,表示序列中的数量,模型的输出由嵌入层得到的原始故障特征、残差特征和网络层故障信息的编码特征组成,完成模型的故障信息批量匹配任务;编码器中神经网络采用填充的方式进行卷积,保证数据的输入维度不发生变化,输出的地理信息系统地址编码信息表示为:(9)公式(9)中,表示数据长度,表示词向量的维度,表示卷积后的输出,表示填充操作,表示卷积核数量;将两个经过编码器的地理信息系统的地址信息序列作为交互层的输入,利用编码器计算当前地理信息系统的地址信息中向量与另一个序列的相关度,长度为的地理信息系统的地址信息表示为,另一个长度为的地理信息系统的地址信息表示为,相关度表示为:(10)公式(10)中,表示地理信息系统的地址信息的相关度,表示前馈网络,、表示地理信息系统的地址信息中的向量。
10.本发明的技术方案区别于现有技术的优点在于:本发明能够实现地理信息系统的地址自动分析和匹配,自动化分析能力强,匹配度高,大大提高了地理信息系统的地址处理和应用能力。
附图说明
11.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图,其中:图1为本发明流程示意图;图2为本发明mmas算法模型流程示意图;图3为本发明批量匹配算法模型结构示意图;图4为本发明批量匹配算法模型一种实施例示意图。
具体实施方式
12.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的实施例仅用于说明和解释本发明,并不用于限定本发明。
13.如图1-图4所示,一种地理信息系统的地址自动分析匹配方法,包括以下步骤:步骤一、在不断数据更新过程中读取地理信息系统的地址信息,并对读取的数据
信息初始化处理;在本步骤中,初始化处理包括数据滤除、剔除和粗大数据信息处理;步骤二、对读取到的地理信息系统地址信息演绎、编码和搜索;在本步骤中,通过mmas算法模型实现数据不断更新过程中的信息检索和演绎,以提高地理信息系统的地址自动化追溯效率;(s21)、将不同的地理信息系统的地址数据信息记作为蚂蚁信息元素,对mmas算法模型进行初始化设置;(s22)、设置不同的地理信息系统的地址数据信息更新过程中的运动轨迹,运动轨迹更新方法通过以下公式进行:(1)在公式(1)中,表示地理信息系统的地址数据信息的信息素,表示地理信息系统的初始地址信息,表示地理信息系统下一个访问地址信息,表示地理信息系统的地址数据信息追溯过程中的蚂蚁元素,表示地理信息系统的地址数据信息追溯过程中的蚂蚁元素更新释放信息素的时间,表示释放信息素时最合适的蚂蚁元素;其中有:
ꢀꢀꢀꢀ
(2)公式(2)中,表示为在不断迭代计算过程中,输出的最优解或者在不断搜索过程中输出的全局最优解值;(s23)、设置最大值和最小值限制,假设介于和之间,每次蚂蚁元素进行信息更新后,在的情况下,则将二者取值为相同的形式,即;(s24)、对蚂蚁元素信息素轨迹进行平滑化处理,则处理公式为:(3)在公式(3)中,的值介于0和1之间,为蚂蚁元素进行平滑化之前的信息素轨迹量,为蚂蚁元素进行平滑化之后的信息素轨迹量;步骤三、地理信息系统的地址自动分析,分析方法是将mmas算法模型输出的数据信息重新编码,并将编码完毕的数据信息进行数据分类;通过时间复杂度的衡量算法实现数据信息分析;步骤四、地理信息系统的地址自动匹配,采用的方法是地址信息批量匹配算法模型; 其中批量匹配算法模型包括输入层、词嵌入层、拼接层、编码器和相关度模块,其中所述输入层的输出端与词嵌入层的输入端连接,所述词嵌入层的输出端与拼接层的输入端连接,所述拼接层的输出端与编码器的输入端连接,所述编码器的输出端与相关度模块的输出端连接;步骤五、输出自动化匹配后的地理信息系统的地址信息。
14.在上述实施例中,时间复杂度的衡量算法的方法为:时间复杂度衡量算法将编号后的地理信息系统的地址数据信息用来表示,
,为数据集中第个样本在的分量,且需满足公式(4)至公式(5)条件:(4)公式(4)中,当公式(4)成立时,则表示地理信息系统的地址在用户允许的范围内;在具体实施例中,将地理信息系统的地址通过数据信息编码映射在数据集区间内,以将地理信息系统的地址信息在一定的区间范围内量化表示。
15.在不断的数据信息更新过程中,所有地理信息系统的地址数据信息表示为:
ꢀꢀꢀ
(5)公式(5)中,其中表示地理信息系统的地址数据信息类型,在具体实施例中,在数据信息不断更新过程中,将所有的地址信息叠加,以表示已经生成地理信息系统的地址数据信息,并对生成的地理信息系统的地址数据信息进行标记。
16.在衡量地理信息系统的地址生成时间时,通过以下公式表示:
ꢀꢀ
(6)公式(6)中,为常数,将地理信息系统的地址高维数据时间复杂度表示为,;表示地址编码数据信息;在具体实施例中,在生成地址数据信息时,将高纬度数据信息转换转为低纬度数据信息,不仅有利于后期数据信息计算,还同时有利于后期信息处理。经过处理后的所有地理信息系统的地址数据信息编码量大于高纬度数据信息量。则定义时间复杂度的衡量算法目标函数为:(7)公式(7)中,表示地理信息系统的地址数据维度,表示所有地理信息系统的地址数据信息经历地址编码和降维后的数据信息,地理信息系统的地址信息在分配编码时,需要满足的函数。
17.在具体实施例中,时间复杂度的衡量算法目标函数的作用是对地理信息系统的地址数据的演绎,将原始的地理信息系统的地址数据转换为除去高维度数据信息的地址数据信息。
18.地理信息系统(geographic information system或 geo-information system,gis)有时又称为“地学信息系统”。该系统是一种特定的十分重要的空间信息系统。它是在计算机硬、软件系统支持下,对整个或部分地球表层(包括大气层)空间中的有关地理分布数据进行采集、储存、管理、运算、分析、显示和描述的技术系统。
19.地址编码技术在地址定位和空间信息整合方面的作用,以及地址编码在应用和技术发展方面的特性。基于对国内外地理编码技术的应用方法和领域的研究,总结了它的发展现状和在应用中存在的问题,
在上述实施例中,所述输入层用于输入地理信息系统的地址信息;所述词嵌入层用于将地理信息系统的地址信息嵌入设置在批量匹配算法模型中,以实现分层计算;所述拼接层用于将地理信息系统的地址信息通过不同形式的编码拼接在一起,以实现不同地理信息系统的地址信息的混合应用;所述编码器用于将地理信息系统的地址信息通过文字、数字、字母或者字符进行编码;所述相关度模块用于将编码后的地理信息系统的地址信息通过相关度函数分析相关性。
20.在上述实施例中,批量匹配算法模型的工作方法为:首先地理信息系统的地址数据信息的第层输入信息记作为,输出信息记作为,表示经过词嵌入层后输出的结果,当模型为多层结构时,第层的输入为第一层输入和之前层的输出拼接后得到的,表示为:(8)公式(8)中,表示第一层输入,表示进行拼接,、表示输出序列,表示序列中的数量,模型的输出由嵌入层得到的原始故障特征、残差特征和网络层故障信息的编码特征组成,完成模型的故障信息批量匹配任务;在具体实施例中,批量匹配算法模型是一种批量处理地理信息系统的地址信息的信息新型算法,该算法套设神经网络算法模型,通过将算法划分不同的数据信息等级,以将不同的数据信息套设进去,进而提高数据计算精度和能力。在输入层批量匹配前的数据信息输入,在进行匹配计算后,则输出另一种数据信息。在中间层通过表示套设过程。将不同的地理信息系统的地址数据信息进行拼接后,能够融合不同形式地理信息系统的地址数据信息。通过这种方法能够提高地理信息系统的地址数据信息的计算容量。
21.编码器中神经网络采用填充的方式进行卷积,保证数据的输入维度不发生变化,输出的地理信息系统地址编码信息表示为:(9)公式(9)中,表示数据长度,表示词向量的维度,表示卷积后的输出,表示填充操作,表示卷积核数量;在具体实施例中,通过将多种不同的地理信息系统的地址数据信息进行编码,能够区分不同的地理信息系统的地址数据信息。
22.将两个经过编码器的地理信息系统的地址信息序列作为交互层的输入,利用编码器计算当前地理信息系统的地址信息中向量与另一个序列的相关度,长度为的地理信息系统的地址信息表示为,另一个长度为的地理信息系统的地址信息表示为,相关度表示为:
(10)公式(10)中,表示地理信息系统的地址信息的相关度,表示前馈网络,、表示地理信息系统的地址信息中的向量。
23.通过对一组序列进行相关度加权求和得到上下文向量和,并包含当前向量对另一组序列中的关注信息,通过词级交互层的信息提取,得到另一个故障文本的上下文信息,信息融合层从多个角度进行模型的序列融合。在具体实施例中,地理信息系统的地址数据信息通过匹配后,能够使用户快速找到经过处理后的地理信息系统的地址数据信息, 大大提高了地理信息系统的地址数据信息处理和计算能力。
24.虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些具体实施方式仅是举例说明,本领域的技术人员在不脱离本发明的原理和实质的情况下,可以对上述方法和系统的细节进行各种省略、替换和改变。例如,合并上述方法步骤,从而按照实质相同的方法执行实质相同的功能以实现实质相同的结果则属于本发明的范围。因此,本发明的范围仅由所附权利要求书限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1