一种基于层数分割的异构计算方法及装置与流程
1.本发明实施例涉及数据处理技术领域,特别是涉及一种基于层数分割的异构计算方法及装置。
背景技术:
2.随着人工智能在端侧计算系统中的广泛应用,卷积神经网络(convolutional neural network,以下简称cnn)被广泛部署于各类异构计算平台。cnn由于计算量大,实时性要求高等特点,逐渐成为人工智能领域的瓶颈。
3.现有技术中,常见的解决方案包括:1、使用低复杂度的cnn模型,这使得现有的各种算法模型无法得益。
4.2、使用大算力的嵌入式神经网络处理器(neural-network process units,以下简称npu),或者多个npu互联,这使得成本大幅度上升。
5.3、将cnn模型及数据发送到云平台上进行计算,再将结果返回,由于cnn数据量大导致的网络传输延迟、不同云平台之间的同步,导致该方法并不能满足实时性要求。
6.常见的嵌入式系统通常都包含npu、gpu(graphic processing unit,图形处理器)和cpu(central processing unit,中央处理器)等不同类型的硬件单元,通常只有npu执行cnn的推理工作,而gpu、cpu等硬件相对比较空闲,因为目前各类深度学习算子都可以在不同的硬件上实现,因此利用系统中gpu、cpu的性能余量以辅助npu的cnn推理工作成为了可能。
技术实现要素:
7.本发明提供一种基于层数分割的异构计算方法及装置,通过将卷积神经网络按层数分割成子模型后分配到多个处理器的硬件单元,从而在有剩余算力的系统提高了卷积神经网络的加速计算效率。
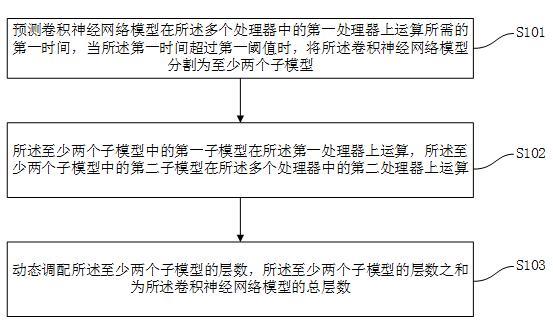
8.本发明实施例提供一种基于层数分割的异构计算方法,基于多个处理器进行运算,包括:预测卷积神经网络模型在所述多个处理器中的第一处理器上运算所需的第一时间,当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型;所述至少两个子模型中的第一子模型在所述第一处理器上运算,所述至少两个子模型中的第二子模型在所述多个处理器中的第二处理器上运算;动态调配所述至少两个子模型的层数,所述至少两个子模型的层数之和为所述卷积神经网络模型的总层数。
9.优选地,预测所述卷积神经网络模型在所述多个处理器中的所述第一处理器和所述第二处理器上运算所需的第二时间,当所述第二时间超过第二阈值时,将所述卷积神经网络模型分割为三个子模型;所述三个子模型中的所述第一子模型在所述第一处理器上运算,所述三个子模型
中的所述第二子模型在所述第二处理器上运算,所述三个子模型中的第三子模型在所述多个处理器中的第三处理器上运算。
10.优选地,所述当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型,包括所述至少两个子模型中的所述第一子模型在所述第一处理器上运算,所述至少两个子模型中的所述第二子模型在所述第二处理器上运算,所述至少两个子模型中的第三子模型在所述多个处理器中的第三处理器上运算。
11.优选地,所述动态调配所述至少两个子模型的层数包括根据所述多个处理器的历史性能余量进行动态调配。
12.优选地,所述根据所述多个处理器的历史性能余量进行动态调配包括获取所述多个处理器在预设时间内的单位时间内空闲忙碌时间比值,所述多个处理器的单位时间内空闲忙碌时间比值通过以下公式计算:其中,为所述多个处理器的单位时间内空闲忙碌时间比值,为所述多个处理器单位时间内的空闲时间,为所述多个处理器单位时间内的忙碌时间。
13.优选地,所述动态调配所述至少两个子模型的层数包括根据所述多个处理器的实时忙碌状态进行动态调配,当监测到所述第一处理器当前负载过重且所述第二处理器有较大性能余量时,下一帧将所述第一子模型在所述第一处理器上进行运算,将所述第二子模型在所述第二处理器上进行运算;当监测到所述第二处理器当前负载过重且所述多个处理器中的第三处理器有较大性能余量时,下一帧将所述第二子模型在所述第二处理器上进行运算,将所述至少两个子模型中的第三子模型在所述第三处理器上进行计算。
14.优选地,根据所述至少两个子模型的数量,为子模型间共享的输入输出层分配多块共享物理内存;当所述至少两个子模型包括所述第一子模型和所述第二子模型时,所述多块共享物理内存包括第一共享物理内存和第二共享物理内存;当所述至少两个子模型包括所述第一子模型、所述第二子模型和第三子模型时,所述多块共享物理内存包括所述第一共享物理内存、所述第二共享物理内存和第三共享物理内存。
15.优选地,所述多块共享物理内存用于支持所述第一子模型、所述第二子模型的输出以及所述第二子模型、所述第三子模型的读取;当所述多块共享物理内存包括所述第一共享物理内存和所述第二共享物理内存时,所述第一共享物理内存用于存放第i帧第一子模型或第二子模型的输出,所述第一共享物理内存还用于第i帧第二子模型或第三子模型的读取;所述第二共享物理内存用于存放第i+1帧第一子模型或第二子模型的输出,所述第二共享物理内存还用于第i+1帧第二子模型或第三子模型的读取;当所述多块共享物理内存包括所述第一共享物理内存、所述第二共享物理内存、
所述第三共享物理内存时,所述第三共享物理内存用于存放第i+2帧第一子模型或第二子模型的输出,所述第三共享物理内存还用于第i+2帧第二子模型或第三子模型的读取;其中,i为自然数,i≥1。
16.优选地,所述多个处理器包括嵌入式神经网络处理器、图形处理器和中央处理器中的至少两个。
17.本发明实施例还提供一种基于层数分割的异构计算装置,基于多个处理器进行运算,包括:预测模块,其用于预测卷积神经网络模型在所述多个处理器中的第一处理器上运算所需的第一时间,当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型;运算模块,其用于将所述至少两个子模型中的第一子模型在所述第一处理器上运算,所述至少两个子模型中的第二子模型在所述多个处理器中的第二处理器上运算;动态调配模块,其用于动态调配所述至少两个子模型的层数,所述至少两个子模型的层数之和为所述卷积神经网络模型的总层数。
18.与现有技术相比,本发明实施例的技术方案具有以下有益效果:本发明实施例的基于层数分割的异构计算方法及装置,预测卷积神经网络模型在所述多个处理器中的第一处理器上运算所需的第一时间,当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型;所述至少两个子模型中的第一子模型在所述第一处理器上运算,所述至少两个子模型中的第二子模型在所述多个处理器中的第二处理器上运算;动态调配所述至少两个子模型的层数,所述至少两个子模型的层数之和为所述卷积神经网络模型的总层数,通过卷积神经网络按层数分割成子模型后分配到多个处理器的硬件单元,从而在有剩余算力的系统提高了卷积神经网络的加速计算效率;进一步地,根据所述至少两个子模型的数量,为子模型间共享的输入输出层分配多块共享物理内存;当所述至少两个子模型包括所述第一子模型和所述第二子模型时,所述多块共享物理内存包括第一共享物理内存和第二共享物理内存;当所述至少两个子模型包括所述第一子模型、所述第二子模型和第三子模型时,所述多块共享物理内存包括所述第一共享物理内存、所述第二共享物理内存和第三共享物理内存,通过分配多块共享物理内存,从而保证第n层神经网络子模型能够读到正确的数据。
附图说明
19.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,而不是全部实施例。对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
20.图1为本发明的一个实施例提供的基于层数分割异构计算方法的流程示意图;图2为本发明的另一个实施例提供的基于层数分割异构计算方法的流程示意图;图3为本发明的一个实施例提供的基于层数分割异构计算装置的模块示意图;图4为本发明的一个实施例提供的基于层数分割异构计算方法的多个处理器实时状态示意图;
图5为本发明的一个实施例提供的基于层数分割异构计算方法的多个共享物理内存示意图。
具体实施方式
21.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
22.下面以具体的实施例对本发明的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
23.基于现有技术存在的问题,本发明实施例提供一种基于层数分割的异构计算方法及装置,通过将卷积神经网络按层数分割成子模型后分配到嵌入式神经网络处理器、图形处理器和中央处理器的硬件单元,从而在有剩余算力的系统提高了卷积神经网络的加速计算效率。
24.图1为本发明的一个实施例提供的基于层数分割异构计算方法的流程示意图。现在参看图1,本发明实施例提供一种基于层数分割的异构计算方法,基于多个处理器进行运算,包括:步骤s101:预测卷积神经网络模型在所述多个处理器中的第一处理器上运算所需的第一时间,当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型;步骤s102:所述至少两个子模型中的第一子模型在所述第一处理器上运算,所述至少两个子模型中的第二子模型在所述多个处理器中的第二处理器上运算;步骤s013:动态调配所述至少两个子模型的层数,所述至少两个子模型的层数之和为所述卷积神经网络模型的总层数。
25.在一些实施例中,多个处理包括嵌入式神经网络处理器、图形处理器和中央处理器中的至少两个。
26.在步骤s101中,预测卷积神经网络模型在所述多个处理器中的第一处理器上运算所需的第一时间,具体包括根据所述多个处理器的历史性能余量进行动态调配,以及根据所述多个处理器的实时忙碌状态进行动态调配。
27.当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型,也就是说,如果预测到第一处理器无法及时处理卷积神经网络模型,为了加速计算效率,将卷积神经网络分割为至少两个子模型。第一阈值可以根据系统历史数据进行设置,在此不再赘述。
28.将所述卷积神经网络模型分割为至少两个子模型,具体包括:遍历n层卷积神经网络模型的所有网络层,计算每一层网络层的计算量c[i],例如卷积层计算量为2*权重数量*输出尺寸,并通过累加得到总的计算量sum=c[1]+c[2]
…
+c[n]。
[0029]
在步骤s102中,所述至少两个子模型中的第一子模型在所述第一处理器上运算,所述至少两个子模型中的第二子模型在所述多个处理器中的第二处理器上运算。第一处理器可以是嵌入式神经网络处理器和图形处理器中的任一个,第二处理器可以是图形处理器和中央处理器中的任一个。
[0030]
例如第一子模型在第一处理器,即嵌入式神经网络处理器上进行运算,第二子模
型在第二处理器,即图形处理器上进行运算,也可以是第一子模型在第一处理器,即图形处理器上进行运算,第二子模型在第二处理器,即中央处理器上进行运算。
[0031]
在步骤s103中,动态调配所述至少两个子模型的层数,所述至少两个子模型的层数之和为所述卷积神经网络模型的总层数。例如至少两个子模型中的第一子模型层数为a,至少两个子模型中的第二子模型层数为b,第一子模型层数a和第二子模型层数b的层数之和为卷积神经网络模型的总层数n。
[0032]
在一些实施例中,预测所述卷积神经网络模型在所述多个处理器中的所述第一处理器和所述第二处理器上运算所需的第二时间,当所述第二时间超过第二阈值时,将所述卷积神经网络模型分割为三个子模型;也就是说,如果预测到第一处理器和第二处理器都无法及时处理卷积神经网络模型,为了加速计算效率,将卷积神经网络分割为三个子模型。第二阈值可以根据系统历史数据进行设置,在此不再赘述。
[0033]
例如三个子模型中的第一子模型层数为a,三个子模型中的第二子模型层数为b,三个子模型中的第三子模型层数为c,第一子模型层数a、第二子模型层数b和第三子模型层数c的层数之和为卷积神经网络模型的总层数n。
[0034]
所述三个子模型中的所述第一子模型在所述第一处理器上运算,所述三个子模型中的所述第二子模型在所述第二处理器上运算,所述三个子模型中的第三子模型在所述多个处理器中的第三处理器上运算。第一处理器可以是嵌入式神经网络处理器,第二处理器可以是图形处理器,第三处理器可以是中央处理器。
[0035]
例如第一子模型在第一处理器,即嵌入式神经网络处理器上进行运算,第二子模型在第二处理器,即图形处理器上运算,第三子模型在第三处理器,即中央处理器上运算。
[0036]
在一些实施例中,所述当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型,包括所述至少两个子模型中的所述第一子模型在所述第一处理器上运算,所述至少两个子模型中的所述第二子模型在所述第二处理器上运算,所述至少两个子模型中的第三子模型在所述多个处理器中的第三处理器上运算。
[0037]
例如当所述第一时间超过第一阈值时,将所述卷积神经网络模型分为三个子模型,第一子模型在第一处理器,即嵌入式神经网络处理器上进行运算,第二子模型在第二处理器,即图形处理器上运算,第三子模型在第三处理器,即中央处理器上运算。
[0038]
在一些实施例中,所述动态调配所述至少两个子模型的层数包括根据所述多个处理器的历史性能余量进行动态调配。
[0039]
在一些实施例中,所述根据所述多个处理器的历史性能余量进行动态调配包括获取所述多个处理器在预设时间内的单位时间内空闲忙碌时间比值,所述多个处理器的单位时间内空闲忙碌时间比值通过以下公式计算:其中,为所述多个处理器的单位时间内空闲忙碌时间比值,为所述多个处理器单位时间内的空闲时间,为所述多个处理器单位时间内的忙碌时间。
[0040]
具体地,嵌入式神经网络处理器的单位时间内空闲忙碌时间比值通过以下公式计
算:其中,为嵌入式神经网络处理器的单位时间内空闲忙碌时间比值,为嵌入式神经网络处理器单位时间内的空闲时间,为嵌入式神经网络处理器单位时间内的忙碌时间。
[0041]
图形处理器的单位时间内空闲忙碌时间比值通过以下公式计算:其中,为图形处理器的单位时间内空闲忙碌时间比值,为图形处理器单位时间内的空闲时间,为图形处理器单位时间内的忙碌时间。
[0042]
中央处理器的单位时间内空闲忙碌时间比值通过以下公式计算:其中,为嵌入式神经网络处理器的单位时间内空闲忙碌时间比值,为嵌入式神经网络处理器单位时间内的空闲时间,为嵌入式神经网络处理器单位时间内的忙碌时间。
[0043]
图4为本发明的一个实施例提供的基于层数分割异构计算方法的多个处理器实时状态示意图。现在参看图4,在一些实施例中,所述动态调配所述至少两个子模型的层数包括根据所述多个处理器的实时忙碌状态进行动态调配,当监测到所述第一处理器当前负载过重且所述第二处理器有较大性能余量时,下一帧将所述第一子模型在所述第一处理器上进行运算,将所述第二子模型在所述第二处理器上进行运算;当监测到所述第二处理器当前负载过重且所述多个处理器中的第三处理器有较大性能余量时,下一帧将所述第二子模型在所述第二处理器上进行运算,将所述至少两个子模型中的第三子模型在所述第三处理器上进行计算。
[0044]
系统在一些实时状态情况下,系统的负载会增加,例如在自动驾驶里需要转弯时、车速提高提升了传感器的频率时、倒车增加了倒车影像的检测时,处理器就会出现当前负载过重的现象。
[0045]
如果输入数据的频率增加,根据处理器的实时忙碌状态,就能预测该处理器是否还能按时完成计算,例如当监测到第一处理器,即嵌入式神经网络处理器当前负载过重,那么就判断为算力不够,下一帧将第一子模型在嵌入式神经网络处理器上进行运算,将第二子模型在第二处理器,即图形处理器上进行运算。例如当监测到第二处理处理器,即图形处理器当前负载过重,下一帧将第二子模型在图形处理器上进行运算,将第三子模型在所述第三处理器,即中央处理器上进行计算。
[0046]
在一些实施例中,将整个神经网络模型分别在空闲的嵌入式神经网络处理器、图形处理器和中央处理器上运行几遍,得到在上述三种处理器上的初步的运算时间、和。
[0047]
进一步可以得到三种处理器的可用算力,嵌入式神经网络处理器的可用算力为,图形处理器的可用算力为,中央处理器的可用算力为。
[0048]
在一些实施例中,第一子模型从第一层到第a层,这a层总的计算量为,剩余部分为第二子模型,其层数为n-a。
[0049]
如果系统预测图形处理器无法按时完成卷积神经网络模型运算时,则将第二子模型继续进行分割,分割后的第二子模型的层数从n-a层降为b层,即从a+1层到第a+1+b层。b层第二子模型的运算量为,为实时更新的数据。
[0050]
在一些实施例中,根据所述至少两个子模型的数量,为子模型间共享的输入输出层分配多块共享物理内存;当所述至少两个子模型包括所述第一子模型和所述第二子模型时,所述多块共享物理内存包括第一共享物理内存和第二共享物理内存;当所述至少两个子模型包括所述第一子模型、所述第二子模型和第三子模型时,所述多块共享物理内存包括所述第一共享物理内存、所述第二共享物理内存和第三共享物理内存。
[0051]
第一共享物理内存、第二共享物理内存、第三共享物理内存用于第一子模型、第二子模型、第三子模型之间共享内存多缓存。图5为本发明的一个实施例提供的基于层数分割异构计算方法的多个共享物理内存示意图。现在参看图5,在一些实施例中,所述多块共享物理内存用于支持所述第一子模型、所述第二子模型的输出以及所述第二子模型、所述第三子模型的读取;当所述多块共享物理内存包括所述第一共享物理内存和所述第二共享物理内存时,所述第一共享物理内存用于存放第i帧第一子模型或第二子模型的输出,所述第一共享物理内存还用于第i帧第二子模型或第三子模型的读取;所述第二共享物理内存用于存放第i+1帧第一子模型或第二子模型的输出,所述第二共享物理内存还用于第i+1帧第二子模型或第三子模型的读取;当所述多块共享物理内存包括所述第一共享物理内存、所述第二共享物理内存、所述第三共享物理内存时,所述第三共享物理内存用于存放第i+2帧第一子模型或第二子模型的输出,所述第三共享物理内存还用于第i+2帧第二子模型或第三子模型的读取;其中,i为自然数,i≥1。
[0052]
如图5所示,i+1帧第一子模型和i帧第二子模型,在时间上是并行执行的,如果没有第一共享物理内存,则i帧第二子模型不一定能够读取到i帧第一子模型写入内存的数据,因为有可能i+1帧第一子模型的写操作先于i帧第二子模型的读取操作。正是通过分配
多块共享物理内存,从而保证第n层神经网络子模型能够读到正确的数据。
[0053]
在一些实施例中,所述多个处理器包括嵌入式神经网络处理器、图形处理器和中央处理器中的至少两个。
[0054]
图2为本发明的另一个实施例提供的基于层数分割异构计算方法的流程示意图。现在参看图2,本发明的一实施例提供一种基于层数分割的异构计算方法,基于多个处理器进行运算,包括:步骤s201:预测卷积神经网络模型在所述多个处理器中的第一处理器上运算所需的第一时间,当所述第一时间超过第一阈值时,将所述神经网络模型分割为至少两个子模型;步骤s202:所述至少两个子模型中的第一子模型在所述第一处理器上运算,所述至少两个子模型中的第二子模型在所述多个处理器中的第二处理器上运算;步骤s203:预测所述卷积神经网络模型在所述多个处理器中的所述第一处理器和所述第二处理器上运算所需的第二时间,当所述第二时间超过第二阈值时,将所述卷积神经网络模型分割为三个子模型;步骤s204:所述三个子模型中的所述第一子模型在所述第一处理器上运算,所述三个子模型中的所述第二子模型在所述第二处理器上运算,所述三个子模型中的第三子模型在所述多个处理器中的第三处理器上运算;步骤s205:动态调配所述至少两个子模型的层数,所述至少两个子模型的层数之和为所述卷积神经网络模型的总层数。
[0055]
图3为本发明的一个实施例提供的基于层数分割异构计算装置的模块示意图。现在参看图3,本发明实施例还提供一种基于层数分割的异构计算装置,基于多个处理器进行运算,包括:预测模块31,其用于预测卷积神经网络模型在所述多个处理器中的第一处理器上运算所需的第一时间,当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型;运算模块32,其用于将所述至少两个子模型中的第一子模型在所述第一处理器上运算,所述至少两个子模型中的第二子模型在所述多个处理器中的第二处理器上运算;动态调配模块33,其用于动态调配所述至少两个子模型的层数,所述至少两个子模型的层数之和为所述卷积神经网络模型的总层数。
[0056]
综上所述,本发明实施例的基于层数分割的异构计算方法及装置,预测卷积神经网络模型在所述多个处理器中的第一处理器上运算所需的第一时间,当所述第一时间超过第一阈值时,将所述卷积神经网络模型分割为至少两个子模型;所述至少两个子模型中的第一子模型在所述第一处理器上运算,所述至少两个子模型中的第二子模型在所述多个处理器中的第二处理器上运算;动态调配所述至少两个子模型的层数,所述至少两个子模型的层数之和为所述卷积神经网络模型的总层数,通过卷积神经网络按层数分割成子模型后分配到多个处理器的硬件单元,从而在有剩余算力的系统提高了卷积神经网络的加速计算效率;进一步地,根据所述至少两个子模型的数量,为子模型间共享的输入输出层分配多块共享物理内存;当所述至少两个子模型包括所述第一子模型和所述第二子模型时,所述多块共享物理内存包括第一共享物理内存和第二共享物理内存;当所述至少两个子模型包括所述第一子模型、所述第二子模型和第三子模型时,所述多块共享物理内存包括所述第一共享物理内存、所述第二共享物理内存和第三共享物理内存,通过分配多块共享物理内存,从而保证第n层神经网络子模型能够读到正确的数据。
[0057]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依
然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1