基于人脸识别的智能门禁防疫系统的制作方法
[0001]
本发明涉及门禁系统技术领域,具体为基于人脸识别的智能门禁防疫系统。
背景技术:
[0002]
当前,受到新型冠状肺炎病毒全球大流行的影响,如何“高效、快速、安全”地做好人员身份认证和鉴别已成为一个研究热点。当今数字信息化社会的快速发展,楼宇、小区的安防信息化程度也逐步地提高。
[0003]
生物特征识别技术被定义为利用人体生物特征进行身份认证的技术。准确来说,生物特征识别技术是通过计算机与声学、光学、生物传感器和生物统计学原理等技术手段的结合,来提取人体生物的固有生理特征和行为特征进行识别的手段。生物特征识别主要包括指纹识别、静脉识别、虹膜识别和人脸识别等技术,其中指纹识别、经脉识别、虹膜识别需要通过特定的采集工具来采集特征,采集成本较高,采集过程繁琐复杂,并且容易被复制和盗取;而人脸识别是利用人脸图像来提取脸部独有的特征,比如眼睛、鼻子、嘴巴等特征进行识别的过程。它与传统的虹膜、指纹和掌纹识别相比,具有远程性、隐蔽性、便捷、高效等优点,从而逐渐被应用于司法、军队、金融、公安、边检、政府、医疗等领域。
[0004]
目前,人脸识别研究主要分为检测、识别、特征提取三个方面,其中人脸检测包括人脸定位检测、人脸活体检测等;人脸识别主要有人脸识别、表情识别、年龄识别等。
[0005]
虽然人脸识别研究已经取得了一些充满科技感的成果,但是这些研究成果,往往都是需要用户的配合,是在比较理想的条件下才能实现预想地效果。因此大多实际应用中的人脸识别准确度与传统的指纹识别、虹膜识别、掌纹识别等技术相比还存在一定的差距。所以,如何提高非约束性下的人脸识别准确率是极具研究价值的。其中,影响人脸识别准确率的因素主要包括:
[0006]
(1)光照环境因素
[0007]
在采集人脸图像的过程中,由于拍摄角度、光照强度、采集设备等因素会造成采集图像的阴暗不均匀的现象。所以,如何减小光照因素对识别准确度的影响至关重要。
[0008]
(2)人脸表情因素
[0009]
人类脸部结构属于非刚性物体,具有十分丰富的表情,而不同表情会造成脸部轮廓的改变,脸部轮廓的变化会改变脸部特征点的位置,计算机很难能够准确地表达。因此,表情因素一直是人脸识别领域深入研究的重要课题。
[0010]
(3)人脸角度因素
[0011]
监控摄像头往往安装在距离地面很高的距离,很难采集到人的正脸图像,导致脸部特征的缺失,造成人脸信息的不足,降低人脸识别的准确率。
[0012]
(4)外物遮挡因素
[0013]
在实际生活中,人们经常会佩戴墨镜、口罩、围巾等一些装饰品,但这些装饰品对面部形成的遮挡会造成人类面部固有结构的缺失直接影响脸部特征提取。因此,如何减少或者消除遮挡物对人脸识别的影响是研究的重点。
[0014]
利用人脸识别技术,分别对戴口罩和正常人脸进行识别,然后在决策级进行判别输出,整个系统可以实现多层安全控制的智能门禁系统,这样不仅提高了传统门禁的安全性,还具有较大的应用价值。
技术实现要素:
[0015]
本部分的目的在于概述本发明的实施方式的一些方面以及简要介绍一些较佳实施方式。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
[0016]
鉴于上述和/或现有门禁防疫系统中存在的问题,提出了本发明。
[0017]
因此,本发明的目的是提供基于人脸识别的智能门禁防疫系统,利用人脸识别技术,分别对戴口罩和正常人脸进行识别,然后在决策级进行判别输出,整个系统可以实现多层安全控制的智能门禁系统,这样不仅提高了传统门禁的安全性,还具有较大的应用价值。
[0018]
为解决上述技术问题,根据本发明的一个方面,本发明提供了如下技术方案:
[0019]
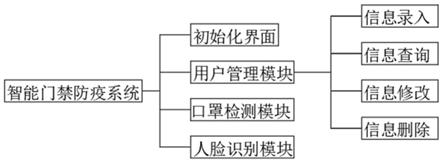
基于人脸识别的智能门禁防疫系统,其包括:初始化界面、用户管理模块、口罩检测模块和人脸识别模块;
[0020]
初始化界面,进入初始化界面后,各个功能模块在界面中显示,点击进入各个模块后即可实现功能;
[0021]
用户管理模块,拥有后台管理员权限管理住户信息,在后台可以对用户进行信息录入、信息查询、信息修改以及信息删除功能;
[0022]
(1)信息录入:可以通过初始化界面点击实现对用户录入信息以及录入信息纠错功能;
[0023]
(2)信息查询:用户录入的信息可以通过初始化界面点击进行查询;
[0024]
(3)信息修改:用户录入的信息可以通过初始化界面点击进行修改;
[0025]
(4)信息删除:用户录入的信息可以通过初始化界面点击进行删除;
[0026]
口罩检测模块,通过实时检测和图片检测,图片检测是对用户数据进行建库训练,实时检测是正常情况下对用户检测,识别佩戴口罩的人员人脸信息;
[0027]
人脸识别模块,通过实时检测和图片检测,图片检测是对用户数据进行建库训练,实时检测是正常情况下对用户检测,识别人脸信息。
[0028]
作为本发明所述的基于人脸识别的智能门禁防疫系统的优选方案,其中:所述口罩检测模块和人脸识别模块基于yolov3进行人脸检测和口罩检测,且基于resnet网络训练进行身份识别。
[0029]
作为本发明所述的基于人脸识别的智能门禁防疫系统的优选方案,其中:所述用户管理模块中用户仅需录入一张照片即可实现人脸口罩识别,同时在第一次录入信息成功后,同一人再用其他用户名字录入时会检测出已存储用户信息,保证用户信息不回重复录入。
[0030]
作为本发明所述的基于人脸识别的智能门禁防疫系统的优选方案,其中:所述口罩检测模块和人脸识别模块的特征采集部分建立paddlehub模型采集数据,lbph识别器提取图像特征,face_recognition人脸识别模型对标签上的人脸数据集进行测试。
[0031]
作为本发明所述的基于人脸识别的智能门禁防疫系统的优选方案,其中:程序均基于python语言实现,在windows、ubuntu-amd架构、ubuntu-arm架构和mac系统上均能够运行。
[0032]
与现有技术相比:该门禁系统的实现的主要操作步骤是,首先人员走进门禁前,门禁系统会对其进行人脸口罩识别,从数据库中提取住户信息比对。若判定为没有戴口罩或者不是住户则不开启门禁,若判定为戴口罩且为住户则开启门禁,该基于人脸识别的智能门禁防疫系统,利用人脸识别技术,分别对戴口罩和正常人脸进行识别,然后在决策级进行判别输出,整个系统可以实现多层安全控制的智能门禁系统,这样不仅提高了传统门禁的安全性,还具有较大的应用价值。
附图说明
[0033]
为了更清楚地说明本发明实施方式的技术方案,下面将结合附图和详细实施方式对本发明进行详细说明,显而易见地,下面描述中的附图仅仅是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
[0034]
图1为本发明的系统功能模块图;
[0035]
图2为本发明的人脸识别流程图;
[0036]
图3为本发明的口罩识别流程图;
[0037]
图4为本发明的准确率曲线图;
[0038]
图5为本发明的残差块结构图。
具体实施方式
[0039]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。
[0040]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施方式的限制。
[0041]
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的实施方式作进一步地详细描述。
[0042]
本发明提供基于人脸识别的智能门禁防疫系统,利用人脸识别技术,分别对戴口罩和正常人脸进行识别,然后在决策级进行判别输出,整个系统可以实现多层安全控制的智能门禁系统,这样不仅提高了传统门禁的安全性,还具有较大的应用价值,包括:初始化界面、用户管理模块、口罩检测模块和人脸识别模块;
[0043]
请再次参阅图1、图2和图3,初始化界面,进入初始化界面后,各个功能模块在界面中显示,点击进入各个模块后即可实现功能;
[0044]
用户管理模块,拥有后台管理员权限管理住户信息,在后台可以对用户进行信息录入、信息查询、信息修改以及信息删除功能;
[0045]
(5)信息录入:可以通过初始化界面点击实现对用户录入信息以及录入信息纠错功能;
[0046]
(6)信息查询:用户录入的信息可以通过初始化界面点击进行查询;
[0047]
(7)信息修改:用户录入的信息可以通过初始化界面点击进行修改;
[0048]
(8)信息删除:用户录入的信息可以通过初始化界面点击进行删除;
[0049]
口罩检测模块,通过实时检测和图片检测,图片检测是对用户数据进行建库训练,实时检测是正常情况下对用户检测,识别佩戴口罩的人员人脸信息;
[0050]
人脸识别模块,通过实时检测和图片检测,图片检测是对用户数据进行建库训练,实时检测是正常情况下对用户检测,识别人脸信息;
[0051]
请再次参阅图1和图2,所述口罩检测模块和人脸识别模块基于yolov3进行人脸检测和口罩检测,且基于resnet网络训练进行身份识别。
[0052]
请再次参阅图1和图2,所述用户管理模块中用户仅需录入一张照片即可实现人脸口罩识别,同时在第一次录入信息成功后,同一人再用其他用户名字录入时会检测出已存储用户信息,保证用户信息不回重复录入。
[0053]
请再次参阅图2和图3,所述口罩检测模块和人脸识别模块的特征采集部分建立paddlehub模型采集数据,lbph识别器提取图像特征,face_recognition人脸识别模型对标签上的人脸数据集进行测试。
[0054]
请再次参阅图1,程序均基于python语言实现,在windows、ubuntu-amd架构、ubuntu-arm架构和mac系统上均能够运行;
[0055]
(1)paddlehub是飞桨预训练模型管理和迁移学习工具,通过paddlehub可以使用高质量的预训练模型结合fine-tune api快速完成迁移学习到应用部署的全流程工作。其提供了飞桨生态下的高质量预训练模型,涵盖了图像分类、目标检测、词法分析、语义模型、情感分析、视频分类、图像生成、图像分割、文本审核、关键点检测等主流模型。
[0056]
通过飞桨预训练模型管理与迁移学习工具padddlehub已经提供的预训练模型,实现一键检测人们是否佩戴口罩的应用。该模型可以有效检测在密集人流区域中携带和未携戴口罩的所有人脸,同时判断该者是否佩戴口罩,目前已在众多场景中落地应用。
[0057]
pyramidbox-lite是基于2018年百度发表于计算机视觉顶级会议eccv 2018的论文pyramidbox而研发的轻量级网络模型,该模型基于主干网络faceboxes建立,对于光照、口罩遮挡、表情变化和尺度变化常见问题具有很强的鲁棒pyramidbox_lite_mobile_mask/pyramidbox_lite_server_mask两个模型均基于wider face数据集和百度自采人脸数据集进行训练,支持预测,可用于检测人脸是否佩戴口罩。pyramidbox_lite_server_mask模型是针对服务器端部署的模型,适合部署于主机服务器等算力较好的设备上。pyramidbox_lite_mobile_mask模型是针对于移动端优化过的模型,适合部署于移动端或者边缘检测等算力受限的设备上,
[0058]
(2)lbph识别器
[0059]
基于近年局部特点提取方法出现。为了不输入的图象的高维数据,仅仅使用的局部特点描写图象的方法被提出,提取的特点(很有希望的)对局部遮挡、光照变化、小样本等情况更强健。有关局部特点提取的方法有盖伯小波(gabor waelets),离散傅立叶变换(discrete cosinus transform,dct),局部二值模式(local binary patterns,lbp)。
[0060]
lbp的基本思想是对图像的像素和它局部周围像素进行对比后的结果进行求和。把这个像素作为中心,对相邻像素进行阈值比较。如果中心像素的亮度大于等于他的相邻
像素,把他标记为1,否则标记为0。你会用二进制数字来表示每个像素,比如11001111。因此,由于周围相邻8个像素,你最终可能获取2^8个可能组合,被称为局部二值模式,有时被称为lbp码。再将lbp图像分为gardx*grady个区域,获取每个区域的lbp编码直方图,继而得到整幅图像的lbp编码直方图,通过比较不同人脸图像lbp编码直方图达到人脸识别的目的,其优点是不会受到光照、缩放、旋转和平移的影响。
[0061]
(3)face_recognition人脸识别模型
[0062]
face_recognition是一个功能强大,简单易用的人脸识别开源项目,具有完整的开发文档和应用程序案例,并且与raspberry pi兼容。项目基于c++开源库dlib中的深度学习模型,用标签上的人脸数据集进行测试,有高达99.38%的准确率。
[0063]
该程序基于yolov3进行人脸检测和口罩检测,基于resnet网络训练进行身份识别:yolov3用于目标检测效果很好,而口罩作为目标物体符合要求,所以选用了该网络进行检测。利用resnet实现构建识别器实时人脸识别,实时性较好,并且能保证不错的精度,并且python库dlib中提供的人脸检测方法(使用hog特征或卷积神经网方法),并使用提供的深度残差网络(resnet)实现实时人脸识别,通过调用dlib中已经训练好的模型进行实时人脸识别,但是因为用预训练模型是基于不戴口罩的人脸识别,用于人脸口罩识别的效果可能不佳,所以本程序利用戴口罩数据进行训练得到分类器。
[0064]
yolov3算法是在v1和v2的基础上形成的,其调整了网络结构,利用多尺度特征进行对象检测,对象分类用logistic取代了softmax。在基本的图像特征提取方面,yolov3采用了称之为darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络residual network的做法,在一些层之间设置了快捷链路(shortcut connections)。这里残差块就是进行一次3x3、步长为2的卷积,然后保存该卷积layer,再进行一次1x1的卷积和一次3x3的卷积,并把这个结果加上layer作为最后的结果。此外,主干网络darknet53每一个卷积使用了特有的darknetconv2d结构,这里的darknetconv2d是指每一次卷积的时候进行l2正则化,完成卷积后进行batchnormalization标准化与leakyrelu。
[0065]
yolov2曾采用passthrough结构来检测细粒度特征,yolov3更进一步采用了3个不同尺度的特征图来进行对象检测。结合上图看,卷积网络在79层后,经过下方几个黄色的卷积层得到一种尺度的检测结果。相比输入图像,这里用于检测的特征图有32倍的下采样。比如输入是416*416的话,这里的特征图就是13*13了。由于下采样倍数高,这里特征图的感受野比较大,因此适合检测图像中尺寸比较大的对象。为了实现细粒度的检测,第79层的特征图又开始作上采样(从79层往右开始上采样卷积),然后与第61层特征图融合(concatenation),这样得到第91层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的对象。最后,第91层特征图再次上采样,并与第36层特征图融合(concatenation),最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的图像。
[0066]
预测对象类别时不使用softmax,改成使用logistic的输出进行预测。这样能够支持多标签对象(比如一个人有woman和person两个标签)。
[0067]
yolov3借鉴了残差网络结构,形成更深的网络层次,以及多尺度检测,提升了map及小物体检测效果。如果采用coco map50做评估指标(不是太介意预测框的准确性的话),yolov3的表现相当惊人,在精确度相当的情况下,yolov3的速度是其它模型的3、4倍。因此,
在这种情况下,yolov3是最适合做口罩检测的模型。
[0068]
resnet网络
[0069]
深度卷积网络自然的整合了低中高不同层次的特征,特征的层次可以靠加深网络的层次来丰富。从而,在构建卷积网络时,网络的深度越高,可抽取的特征层次就越丰富。所以一般我们会倾向于使用更深层次的网络结构,以便取得更高层次的特征。但是在使用深层次的网络结构时我们会遇到两个问题,梯度消失,梯度爆炸问题和网络退化的问题。但是当使用更深层的网络时,会发生梯度消失、爆炸问题,这个问题很大程度通过标准的初始化和正则化层来基本解决,这样可以确保几十层的网络能够收敛,但是随着网络层数的增加,梯度消失或者爆炸的问题仍然存在。由此引出了resnet网络。
[0070]
请参阅图5,resnet使用了一个新的思想,resnet的思想是假设我们涉及一个网络层,存在最优化的网络层次,那么往往我们设计的深层次网络是有很多网络层为冗余层的。那么我们希望这些冗余层能够完成恒等映射,保证经过该恒等层的输入和输出完全相同。具体哪些层是恒等层,这个会有网络训练的时候自己判断出来。将原网络的几层改成一个残差块,可以看到x是这一层残差块的输入,也称作f(x)为残差,x为输入值,f(x)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,f(x)加入了这一层输入值x,然后再进行激活后输出。在第二层输出值激活前加入x,这条路径称作shortcut连接。
[0071]
resnet的过人之处,是他很大程度上解决了当今深度网络头疼的网络退化问题和梯度消失问题。使用残差网络结构h(x)=f(x)+x代替原来的没有shortcut连接的h(x)=x,这样更新冗余层的参数时需要学习f(x)=0比学习h(x)=x要容易得多。而shortcut连接的结构也保证了反向传播更新参数时,很难有梯度为0的现象发生,不会导致梯度消失。
[0072]
数据集包含有戴口罩的人、不戴口罩的人、用手或其他物品遮挡脸的人等多种情况,确保样本的多样性和全面性。样本图像分为两个子集,即用于面部检测的训练集(用于训练模型参数)和验证集(用于验证预测准确性):训练集包括1300张“带遮罩”图像和1300张“无遮罩”图像,验证集包括300张“带遮罩”图像,300张“无遮罩”图像。关于人脸识别模型,我们使用ms-celeb-1m构建了训练集,并使用lfw建立了验证集,lfw是业界广泛用于研究人脸识别模型准确性的公共基准。
[0073]
分别用yolov3网络和resnet网络训练数据集。并在数据库中预先存入户主的照片信息,用训练好的yolov3模型进行口罩识别,用resnet模型在获取特征向量之后可以使用欧式距离和本地的人脸特征向量进行人脸匹配。该算法无需切割人脸图像,直接用人脸口罩图像进行训练即可得到较好的实时识别效果。
[0074]
在具体的使用时,该门禁系统的实现的主要操作步骤是,首先人员走进门禁前,门禁系统会对其进行人脸口罩识别,从数据库中提取住户信息比对。若判定为没有戴口罩或者不是住户则不开启门禁,若判定为戴口罩且为住户则开启门禁。
[0075]
实施例
[0076]
请参阅图4,我们采用武汉大学的口罩遮挡人脸数据集(rmfd),包括(1)真实口罩人脸识别数据集:从网络爬取样本,经过整理、清洗和标注后,含525人的5千张口罩人脸、9万正常人脸。(2)模拟口罩人脸识别数据集:给公开数据集中的人脸戴上口罩,得到1万人、50万张人脸的模拟口罩人脸数据集。
[0077]
人脸识别模块性能测试的评价指标主要包括:查准率、查全率和时间延迟。所以下面将结合测试集分别测试人脸识别模块的查准率、查全率和时间延迟来综合分析人脸识别模块的性能。
[0078]
人脸识别模块主要包括视频关键帧提取、口罩检测与人脸特征提取、人脸识别三个模块,时间延迟主要是由这三个模块产生。从数据集中随机挑选1000张图片作为测试集,分别计算在测试集下三个模块所用的具体时间。
[0079]
表1各模块时间延迟
[0080][0081]
结合上表可知,两种方法在关键帧提取模块提取的关键帧数量和使用时间相差不多,说明数据集的环境对关键帧的提取影响不大。但是两种方法在口罩检测与人脸特征提取和人脸识别模块用时有明显差别,表明yolov3+resnet模型用时较短。
[0082]
虽然在上文中已经参考实施方式对本发明进行了描述,然而在不脱离本发明的范围的情况下,可以对其进行各种改进并且可以用等效物替换其中的部件。尤其是,只要不存在结构冲突,本发明所披露的实施方式中的各项特征均可通过任意方式相互结合起来使用,在本说明书中未对这些组合的情况进行穷举性的描述仅仅是出于省略篇幅和节约资源的考虑。因此,本发明并不局限于文中公开的特定实施方式,而是包括落入权利要求的范围内的所有技术方案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1