一种基于数据分析的智能路况管理系统的制作方法
本发明涉及智慧交通与数据挖掘以及自然语言处理领域,特别涉及一种基于数据分析的智能路况管理系统。
背景技术:
随着日益激烈的媒体竞争,广播电台正朝着节目多元化,频道专业化的方向发展,广播以时效性强,参与度高为特点,为听众(特别是出租车司机、私家车车主)提供及时、有效的各类信息。对于交通广播电台而言,提供及时、有效的实时路况信息是其最主要的任务。
随着社会的发展,汽车的数量迅速增加,交通拥堵已经成为各大城市面临的重大课题。各路段的实时路况和拥堵情况,已经成为司机行车是否选择该路段的重要指标。
智能时代的来临让传统行业面临着转型升级,如何高效的使用紧缺的人力和高效快速的计算机资源是各行各业所面临的问题。计算机可以代替人类进行一些复杂繁琐的工作,使得人从繁琐的工作中解放出来,利用人类能动性的大脑,创造更多的价值。
传统的路况管理系统,很大程度上依赖于人工操作,耗时、耗力。传统的路况分析是在相应的关键路段安装摄像头等视频监控设备,通过这些监控设备,相关部门及人员可以得知放置有监控设备路段的交通状况。这样的方法存在许多缺点,例如:需要人工监视各个十字路口的交通状况,再进行人工分析,通过播音主持广播消息发给出行的驾驶者。这一过程使得消息具有很大的滞后性。再者,人工监控效率低、容易出错,同时人工监控成本非常高。
然而,基于大数据、全球定位系统(GPS)、无线网络通信技术建立了地理信息与车载系统为核心的智能交通路况管理平台,可以通过综合的分析车辆行驶的信息进行实时的路况信息播送。
社交媒体作为新闻资讯的重要传播者,在互联网的平台上已经展示出范围大,传播速度快等优点,如何利用社交网络收集整理信息也是非常重要以及必要的渠道。微信由于其独特的开放性和交互性,使其成为很好的信息收集平台。
本系统使用微信收集路况信息,通过智能语义分析对微信平台上大量冗杂的数据进行分析,抽取出有用的数据信息使用。
技术实现要素:
本发明的目的在于提出一种基于数据分析的智能路况管理系统,以解决目前路况管理系统信息发布的滞后性、耗力、耗时等不足,实现了大量复杂的交通路况数据的高效管理和运用。
为实现上述目的,本发明提出了一种基于数据分析的智能路况管理系统,包括实时路况数据处理子系统、绕行方案信息管理子系统;
实时路况数据处理子系统用于提取设定区域内的拥堵路段信息,并结合对应路段的历史数据分析拥堵路段的拥堵情况变化趋势;具体包括构建存储信息数据库和拥堵状况的展示;
构建存储信息数据库:
以固定频率获取设定区域内各主要路段的拥堵情况数据,并将所获得的拥堵情况数据经过数据处理后存入存储信息数据库;所述拥堵情况数据包括二次网格号、路链级别、路链号、路链长度、车速、旅行时间、拥堵程度、拥堵路段数、终端距离及路段长度信息;
拥堵状况的展示:
以固定频率获取设定区域内各主要路段当前的拥堵情况数据,并将所获得的拥堵情况数据经过数据处理后存入存储信息数据库,同时根据拥堵程度在地图上以不同颜色进行展示;
绕行方案信息管理子系统包括编辑人员终端和主持人使用展示终端;
编辑人员终端用于录入拥堵路段多种包含地名的绕行路线方案,并自动识别所包含的地名,并对录入各方案中的地名进行绕行路线生成和绕行方案的旅行时间计算,选择绕行方案的旅行时间最短且该绕行方案中平均每公里旅行时间满足设定阈值的方案推送至主持人使用展示终端;
主持人使用展示终端用于接收和显示编辑人员终端发送的拥堵路段的旅行时间最短的绕行方案。
所述的存储信息数据库由24张表构成,对应每天24小时,每个表记录对应的一小时内的拥堵情况数据。
拥堵情况数据的数据处理方法为:对相邻的道路入口和出口之间的多个路段进行合并形成新的路段,使一组相邻的道路入口和出口之间的道路信息只有一条;对新的路段的路链号进行上行和下行的区分处理;
分别构建数据索引信息表和路名索引信息表,其中数据索引信息表包括路链号、路链级别;路名索引信息表包括二次网格号、路链号、路名、起点、终点、方向。
本发明的一种基于数据分析的智能路况管理系统还包括路况修改编辑子系统,该子系统用于对存储信息数据库中的数据进行读取和修改。
本发明的一种基于数据分析的智能路况管理系统还包括微信路况信息智能处理子系统,该子系统对获取微信用户发来的文字信息并对其进行智能语义分析处理,分析出属于交通事故、施工信息、交通管制的信息,并自动推送给路况编辑终端设备,以供路况编辑人员对该条信息进行审核;
该子系统包含利用人工标注的交通路况信息分类数据训练好的朴素贝叶斯模型,对输入的文字信息进行筛选的方法包括以下步骤:
步骤S21,使用斯坦福汉语分词系统对获取的文字信息进行分词以及词性标注;
步骤S22,将步骤S21中得到的分词以及词性标注后的文字信息输入朴素贝叶斯模型,对输入的文字信息分别计算其属于交通事故、施工信息、交通管制各类别的概率,并依据概率对输入的文字信息的分类。
本发明中利用人工标注的交通路况信息分类数据训练朴素贝叶斯模型的方法为:
通过人工标注的交通路况信息分类数据构建训练数据集,该分类数据包括文字信息、分词、词性标注;将训练数据集中的分类数据训练朴素贝叶斯模型,得出不同特征词表征不同分类可能性的条件概率,其公式为:
其中,w为一个词语;label为分类标签,分为交通事故、施工信息、交通管制和其他四类;s为一条文字信息。
本发明中对输入的文字信息分别计算其属于交通事故、施工信息、交通管制各类别的概率的方法为:通过模糊匹配,选择匹配概率大于60%的特征词为匹配词,并且使用其参数作为分类概率,然后根据匹配度进行线性加权计算分类概率,公式如下所示:
其中n是匹配的字符数,N为总字符数,αi为加权系数;
根据TF-IDF统计方法计算得到输入的文字信息的分类。
所述绕行方案信息管理子系统中绕行路线生成的方法为:基于预先构建的由各路名及对应道路上地名构成的混合数据库,通过模糊匹配,根据编辑人员终端录入的各条绕行路线方案中包含的地名,匹配出最吻合的地名,并判断匹配出的地名是否是连成一条绕行路线,如不能则向编辑人员终端发送重新录入的信息提示;根据实时路况数据处理子系统生成的路名索引信息表匹配绕行路线的二次网格号、路链号,生成各绕行方案的路线信息;
所述绕行方案信息管理子系统中绕行方案的旅行时间计算的方法为:根据各绕行方案的路线信息和绕行路线中各路段的路长及最新的车速,计算对应绕行方案的旅行时间,计算公式为
其中T为总旅行时间,n表示该绕行路线有n个路段,Pi为第i个路段的路径长,Vi为第i个路段的平均车速。
本发明解决了目前路况管理系统信息发布的滞后性、耗力、耗时等不足,实现了大量复杂的交通路况数据的高效管理和运用。
附图说明
图1是本实施例系统框架示意图;
图2是本实施例拥堵路段情况数据处理流程示意图;
图3是本实施例微信路况信息智能处理流程示意图;
图4是本实施例拥堵路段绕行方案处理流程图。
具体实施方式
下面将结合附图对本发明加以详细说明,应指出的是,所描述的实施例仅旨在便于对本发明的理解,而对其不起任何限定作用。
为了实现本发明方法,实施例考虑到处理步骤以及涉及的用户数量和资源数量,如果在单机实现应该最好保证处理器不低于2GHz,内存不小于6GB,可以采用任何语言编写,本例使用java语言实现。
本发明的基于数据分析的智能路况管理系统包括实时路况数据处理子系统、绕行方案信息管理子系统,进一步优化后还包括路况修改编辑子系统、微信路况信息智能处理子系统,为了更完善的进行技术方案的描述,本实施例将对包含四个子系统的基于数据分析的智能路况管理系统,并以北京市交通信息为例子进行详细描述。
本实施例的基于数据分析的智能路况管理系统包括实时路况数据处理子系统、绕行方案信息管理子系统、路况修改编辑子系统、微信路况信息智能处理子系统,如图1所示。
1、实时路况数据处理子系统
实时路况数据处理子系统用于提取设定区域内的拥堵路段信息,并结合对应路段的历史数据分析拥堵路段的拥堵情况变化趋势;具体包括构建存储信息数据库和拥堵状况的展示;
构建存储信息数据库:
以固定频率从北京市交通委获取北京市各主要路段拥堵情况数据,并将所获得的拥堵情况数据经过数据处理后存入存储信息数据库;所述拥堵情况数据包括二次网格号、路链级别、路链号、路链长度、车速、旅行时间、拥堵程度、拥堵路段数、终端距离及路段长度信息。
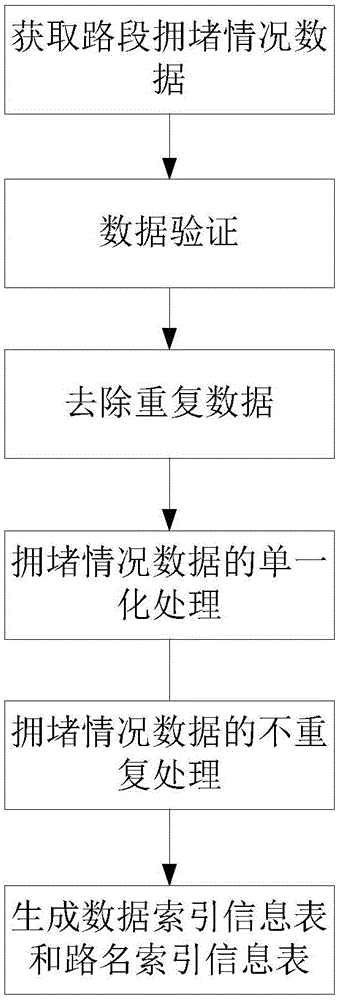
本实施例的拥堵情况数据的数据处理如图2所示。
在获得拥堵情况数据时进行数据验证:将获得拥堵情况数据按定义错误纠正协议,即重复发送一个属性的数据,通过两次接收到的数据进行对比,如果两次数据一致则认为数据接收成功,录入存储信息数据库;否则标注该条数据无效,抛弃错误数据。存储信息数据库在系统运行之前执行SQL脚本构建,存储信息数据库字段内容和交通路况数据完全一致。
对获得的拥堵情况数据进行分析处理的方法是:去除重复数据;并对相邻的道路入口和出口之间的多个路段进行合并形成新的路段,使一组相邻的道路入口和出口之间的道路信息只有一条,实现拥堵情况数据的单一化处理;对新的路段的路链号进行上行和下行的区分,实现拥堵情况数据的不重复处理;生成单一且不重复的路链号、路链级别形成索引信息表,包括数据索引信息表和路名索引信息表,其中数据索引信息表包括路链号、路链级别,路名索引信息表包括二次网格号、路链号、路名、起点、终点、方向。由于数据量较大,通过索引方式可以加速后续检索速度。
单一化处理的目的在于:有的路很长,如高速,他们具有相同的起点和终点,但对应着不同的路段,每个路段划分很细,这样虽然利于数据展示,却不利于用户问路况的查询;因此将此类路段合并,将具有相同的起点和终点的路段合并后形成单一化的路段。不重复处理的目的在于:由于一条路的双向有完全一致的二次网格号和路链号,因此将此类数据去重,即对路链号进行处理,本实施例中将下行数据加上10000、上行数据为原始值进行区分。
本实施例在数据处理过程包含了索引表的抽取、缓存表向地图及历史信息数据库的数据传送。由于接受数据的频率较高及数据量较大,以北京地区为例,平均2分钟从北京市交通委的交通路况信息系统接收14万条数据,如果使用时根据路链号以及网格号查询数据会降低系统性能,因此系统初始化时会对介入的数据进行分析,抽取其索引与数据库存储ID的关系,形成索引表,以达到加速后期检索速度的目的。索引表包括二次网格号、路链号、数据存储ID等信息。缓存表的设计主要为了数据的完备性,因为与数据源连接的速度没有达到理想水平,导致14万条数据的接收需要持续一段时间,此时如果进行数据的检索有的地区会出现空数据,因此系统需要去调用旧数据造成效率低下,在设计延时允许的条件下,缓存表接受所有数据后再向数据库中转存。
拥堵状况的展示:
以固定频率获取设定区域内各主要路段当前的拥堵情况数据,并将所获得的拥堵情况数据经过数据处理后存入存储信息数据库,同时根据拥堵程度在地图上以红绿黄等不同颜色进行展示;本实施例中依据历史数据通过差分分类分析与折线图组合的方式分析路段拥堵情况变化趋势;
所述的存储信息数据库由24张表构成,对应每天24小时,每个表记录对应的一小时内的拥堵情况数据。采用该设计主要是由于数据量大,对历史数据进行挖掘时数据库效率较低,为了降低数据库长度,便于数据分时间端分析,以及利于并行处理,因此按照每天24小时,将数据库设计为24张表,每个表记录每天本小时的数据,系统使用最新数据只需要通过当前时间找到其对应的数据表,然后读取最新的数据。
2、微信路况信息智能处理子系统
该系统针对微信信息数据杂乱的特点,对微信数据进行智能语义分析处理,选出有用的数据,并且进行数据的预分类,将处理后的信息提交给编辑使用如附图4所示。
对获取微信用户发来的文字信息并对其进行智能语义分析处理,分析出属于交通事故、施工信息、交通管制的信息和其他信息四类,若为交通事故、施工信息、交通管制信息则自动推送给路况编辑终端设备,以供路况编辑人员对该条信息进行审核;若为其他信息则删除该信息。
该子系统包含利用人工标注的交通路况信息分类数据训练好的朴素贝叶斯模型,对输入的文字信息进行筛选的方法包括以下步骤:
步骤S21,使用斯坦福汉语分词系统对获取的文字信息进行分词以及词性标注。如“建国门附近发生交通事故”,被系统标注为“建国门/地名附近/位置发生/动词交通/形容词事故/名词”。
步骤S22,将步骤S21中得到的分词以及词性标注后的文字信息输入朴素贝叶斯模型,对输入的文字信息分别计算其属于交通事故、施工信息、交通管制各类别的概率,并依据概率对输入的文字信息的分类。
利用人工标注的交通路况信息分类数据训练朴素贝叶斯模型的方法为:通过人工标注的交通路况信息分类数据构建训练数据集,该分类数据包括文字信息、分词、词性标注;将训练数据集中的分类数据训练朴素贝叶斯模型,得出不同特征词表征不同分类可能性的条件概率,其公式如公式(1)所示:
其中,w为一个词语;label为分类标签,分为交通事故、施工信息、交通管制和其他四类;s为一条文字信息。
对输入的文字信息分别计算其属于交通事故、施工信息、交通管制各类别的概率的方法为:通过模糊匹配,选择匹配概率大于60%的特征词为匹配词,并且使用其参数作为分类概率,然后根据匹配度进行线性加权计算分类概率,如公式(2)所示:
其中n是匹配的字符数,N为总字符数,αi为加权系数;
根据TF-IDF统计方法计算得到输入的文字信息的分类。
3、绕行方案信息管理子系统
该系统包括编辑人员终端和主持人使用展示终端;
如图4所示是本实施例拥堵路段绕行方案处理流程示意图。
编辑人员终端用于录入北京市拥堵路段多种包含地名的绕行路线方案,如保福寺桥到学院桥,并自动识别所包含的地名,并对录入各方案中的地名进行绕行路线生成和绕行方案的旅行时间计算,选择绕行方案的旅行时间最短且该绕行方案中平均每公里旅行时间满足设定阈值的方案推送至主持人使用展示终端;在本实施例中,此处所设定阈值为根据不同路况下的平均车辆时速计算的每公里的旅行时间,例如北京统计的各时段的平均时速为30km/h,即平均每公里旅行时间为2分钟为所设定的阈值。
主持人使用展示终端用于接收和显示编辑人员终端发送的拥堵路段的旅行时间最短的绕行方案。
所述绕行方案信息管理子系统中绕行路线生成的方法为:基于预先构建的由各路名及对应道路上地名构成的混合数据库,通过模糊匹配,根据编辑人员终端录入的各条绕行路线方案中包含的地名,匹配出最吻合的地名,并判断匹配出的地名是否是连成一条绕行路线,如不能则向编辑人员终端发送重新录入的信息提示;根据实时路况数据处理子系统生成的路名索引信息表匹配绕行路线的二次网格号、路链号,生成各绕行方案的路线信息;
本实施例中所构建的包含北京地名和路名的混合数据库,所存储的主要内容是道路上的节点地名以及其向路名的映射,数据库中地名和对应的路名分别对应地名字段和路名字段,表示地名对应到路名,同时路名也作为地名的一种加入地名字段,便于系统检索使用。
所述绕行方案信息管理子系统中绕行方案的旅行时间计算的方法为:根据各绕行方案的路线信息和绕行路线中各路段的路长及最新的车速,计算对应绕行方案的旅行时间,计算公式如公式(3)所示
其中T为总旅行时间,n表示该绕行路线有n个路段,Pi为第i个路段的路径长,Vi为第i个路段的平均车速。
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!