多列交错DIMM布局和路由拓扑的制作方法
多列交错dimm布局和路由拓扑
1.相关申请
2.本技术要求由hoi san leung于2019年4月30日提交的题为multi
‑
column interleaved dimm placement and routing topology的美国专利申请号16/398,861的优先权,其内容通过引用整体并入本文。
技术领域
3.本公开总体涉及计算机体系结构,并且更具体地,涉及多列交错双列直插式存储器模块(dimm)布局和路由拓扑。
背景技术:
4.数据中心使用服务器来提供工作负载运行所需的计算资源(例如,处理、存储器空间、网络和磁盘i/o等)。随着工作负载的激增和计算需求的增加,需要扩大或“扩展”服务器资源以满足不断增长的需求。有两种方式扩展数据中心中的服务器资源。第一种是添加更多服务器或“横向扩展”。例如,假设企业有运行五个应用并使用物理服务器80%的计算能力的虚拟服务器。如果企业需要部署更多的工作负载,而物理服务器缺乏足够的计算能力来支持额外的工作负载,则企业可能需要部署额外的服务器来支持新的工作负载。横向扩展体系结构也称为集群或受扰式计算方法,其中多个小型服务器分担单个应用的计算负载。例如,任务关键型工作负载可能部署在两台或多台服务器上,处理在这些服务器之间被分担,这样如果一台服务器出现故障,另一台可以接管并维持应用的可用性。如果需要更多冗余,可以使用额外的服务器节点来横向扩展集群。
5.技术以及服务器计算能力的进步增加了单个服务器可能提供的资源量。今天的服务器在类似大小的机箱内比以前的型号具有多得多的处理、存储器和i/o能力。这种方法被称为“纵向扩展”,因为物理服务器可以处理更多和/或更大的工作负载。再次参考上述示例,使用纵向扩展方法,可以在下一个技术更新周期中部署具有多得多的计算资源的新服务器,将所有工作负载从旧服务器迁移到新服务器,让旧服务器停止服务或将其分配给其他任务,并留下显著更多的可用资源来处理额外的生产工作负载,而不会显著增加数据中心空间或能量需求。
6.作为一个特定示例,服务器存储器需求一直在增加,cpu供应商正在添加越来越多的存储器通道来满足这一需求。但是,除非印刷电路板(pcb)上有空间(或“不动产”)可用于容纳额外的存储器插槽,例如用于双列直插式存储器模块(dimm),否则可能无法使用额外的存储器通道。这在使用较小pcb例如用于半宽形状因子处理器刀片的情况下尤其更加困难。
附图说明
7.结合附图参考以下描述可以更好地理解本文中的实施例,其中相同的附图标记表示相同或功能相似的元件,其中:
8.图l是示出例如可以在本文描述的实施例中部署的示例对称多处理(“smp”)系统的简化框图;
9.图2是示出包括设置在宽母板上的两个处理器的2路smp系统的常规布置的简化框图;
10.图3是示出根据本文描述的实施例的特征的4路smp系统的布置的简化框图,用于实现纵向扩展服务器的互连方法;
11.图4是示出例如可以在本文描述的实施例中部署的处理器复合体和到平台控制器集线器(pch)的连接的简化框图;
12.图5是示出将存储器插座(socket)添加到传统处理器复合体拓扑的困难的简化框图;
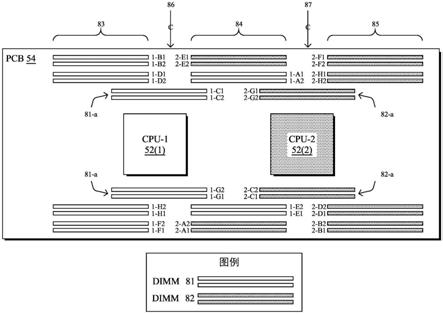
13.图6是示出根据本文描述的一个或多个实施例的多列交错双列直插式存储器模块(dimm)布局和路由拓扑的简化框图;
14.图7是示出根据本文描述的一个或多个实施例的印刷电路板(pcb)的堆叠的一部分的示例的简化框图,该示例将传统的pcb堆叠与用于多列交错dimm拓扑的pcb堆叠进行比较;
15.图8a
‑
8c是示出根据本文描述的一个或多个实施例的用于多列交错dimm拓扑的pcb堆叠的各部分的示例布局图的简化框图;和
16.图9是示出能够在系统中的处理器中执行指令以用于实现本文描述的实施例的各种特征的示例机器的组件的简化框图。
具体实施方式
17.概述
18.本发明的方面在独立权利要求中陈述并且优选特征在从属权利要求中陈述。一个方面的特征可以单独或与其他方面组合应用于每个方面。
19.根据本公开的一个或多个实施例,印刷电路板(pcb)具有第一中央处理器(cpu)插座和与第一cpu插座基本对齐的第二cpu插座。pcb还具有与第一cpu插座互连的第一多个双列直插式存储器模块(dimm)插座和与第二cpu插座互连的第二多个dimm插座,第一多个dimm插座位于第一cpu插座的相反的第一侧和第二侧,第二多个dimm插座位于第二cpu插座的相反的第一侧和第二侧并且在平行于第一多个dimm插座的方向上。第一多个dimm插座跨第一cpu插座的相反的第一侧和第二侧两者而布置在pcb上的至少第一列dimm插座和第二列dimm插座中。第二多个dimm插座跨第二cpu插座的相反的第一侧和第二侧两者而布置在pcb上的至少第二列dimm插座和第三列dimm插座中,使得第二列dimm插座包含来自第一多个dimm插座和第二多个dimm插座中的每一个的交错的dimm插座。
20.根据本公开的一个或多个附加实施例,第一列和第二列由第一cpu插座的中心线分隔,第二列和第三列由第二cpu插座的中心线分隔。在一个实施例中,第一多个dimm插座中最靠近第一cpu插座的部分被进一步设置在pcb上的第一cpu插座的中心线上,并且第二多个dimm插座中最靠近第二cpu的部分被进一步设置在pcb上的第二cpu插座的中心线上。
21.下面描述其他实施例,并且此概述并不旨在限制本公开的范围。
22.描述
23.如前所述,数据中心中使用的服务器实现有两种主要类型;即,纵向扩展和横向扩展。两种类型的服务器都使用多个处理器。在纵向扩展服务器中,处理器通过缓存一致性链路相互连接,并且全部在单个操作系统软件下协同工作。这种将多个处理器连接在一起的方式也可以称为对称多处理(“smp”),并且缓存一致性链路可以称为smp链路。纵向扩展服务器通常(但不总是)用于高性能数据库、分析和计算服务器中的应用。另一方面,横向扩展服务器不使用处理器之间的缓存一致性链路,每个处理器子系统作为具有自己操作系统软件的独立服务器工作。
24.纵向扩展服务器的实现尤其具有挑战性。任意两个处理器之间的缓存一致性链路需要非常高的带宽(数据速率)互连。这些互连由多个并行的高速串行器/解串器(“serdes”)通道实现为束,被称为“端口”。serdes是一对功能块,通常用于高速通信以补偿有限的i/o。serdes块在每个方向的串行和并行接口之间转换数据。serdes的主要目的是通过单条/差分线路提供数据传输,以最小化i/o引脚和互连的数量。serdes功能包括两个功能块,包括并行输入串行输出(“piso”)块(也称为并串转换器)和串行输入并行输出(“sipo”)块(也称为串并转换器)。piso块可以包括并行时钟输入、数据输入线集合和输入数据锁存器。内部或外部锁相环(“pll”)可用于将输入的并行时钟乘以串行频率。piso的最简单形式具有单个移位寄存器,该移位寄存器对于每个并行时钟接收并行数据一次,并以更高的串行时钟速率将其移出。sipo块可以包括接收时钟输出、数据输出线集合和输出数据锁存器。可以使用串行时钟恢复技术从数据中恢复接收时钟。不传输时钟的serdes使用参考时钟将pll锁定到正确的tx频率,避免数据流中可能出现的低谐波频率。sip块将输入时钟分频为并行速率。典型的实现有两个连接为双缓冲器的寄存器。在这样的实现中,一个寄存器用于在串行流中计时,另一个用于保存较慢的并行端的数据。
25.典型的实现可能会在每个端口采用20个或更多serdes通道。对于双向通信,可能有发送端口(“tx端口”)和接收端口(“rx端口”)。由于纵向扩展系统包括多个处理器,因此每个处理器会有多个tx/rx端口对,每个端口依次具有多个高速serdes通道。这在系统中造成了巨大的互连挑战。本文描述的实施例解决了设计模块化纵向扩展服务器系统中的这种互连挑战。特别地,本文描述的实施例采用2路对称多处理器(“smp”)系统实现作为构建块来实现4路和8路(以及更多)smp系统。smp系统是多处理器系统,具有集中式共享存储器,称为“主存储器”,在具有两个或更多同质处理器的单个操作系统下运行。
26.图1示出示例常规smp系统10的简化框图。如图1所示,smp系统(例如smp系统10)是紧密耦合的多处理器系统,具有独立运行的同质处理器12的池,每个处理器对不同的数据执行不同的程序,具有共享资源(例如主存储器14和i/o 16)的能力,并通过系统总线或交叉开关18连接。每个处理器12通常与专用高速缓存存储器20相关联以加速主存储器数据访问并减少系统总线流量。提供总线仲裁器22用于仲裁处理器12对系统总线18的访问。
27.根据本文描述的实施例的特征,2路smp系统实现仅使用用于实现4路和8路系统的传统2路系统的宽度的一半。在某些实施例中,通过沿着印刷电路板的长度将处理器一个接一个地放置(称为阴影核心放置)来实现这种半宽2路smp系统。如图2所示,常规的或传统的2路smp系统30包括两个处理器或cpu 32,它们布置在宽母板34上。每个cpu 32包括多个缓存一致性smp链路36,所有这些链路都连接到服务器系统30的在图2中统一由附图标记40指定的中板或背板上布置的相应连接器38。如下文将更详细地描述的,图2中所示的方法需要
具有两倍于本文描述的半宽smp实现的宽度的母板。系统30不可配置用于4路和8路smp实现;因此,2、4和8路smp实现需要单独的母板设计。
28.在本文描述的某些实施例中,缓存一致性链路被拆分,使得它们的一半进入中板(或背板),而另一半进入设置在系统机箱前侧的前板。这种方法只需要在前侧和后侧使用较小尺寸的连接器,从而实现良好的空气流动并调节处理器及其子系统的工作温度。这种布置还显著降低了布线密度要求,使得smp链路可以在更少的印刷电路板层中布线,这与将所有缓存一致性链路带到前侧或后侧的实现相反。这种布置在图3中示出,其示出了根据本文描述的实施例的特征的4路smp系统50,用于实现纵向扩展服务器的互连方法。
29.如图3所示,smp系统50包括四个cpu 52(1)
‑
52(4),其中两个(即cpu 52(1)和52(2))设置在第一母板54(1)上,其中两个(即,52(3)和52(4))设置在第二相同的母板54(2)上。cpu 52(1)
‑
52(4)中的每一个具有多个缓存一致性链路,这些链路将每个cpu互连到另一个cpu。根据本文描述的实施例的特征,系统中一半的缓存一致性链路(即,连接cpu 52(1)和52(4)的链路以及连接cpu 52(2)和52(3)的链路)连接到系统50机箱的前板62上的协议无关电转接驱动器60、61,另一半缓存一致性链路(例如,连接cpu 52(2)和cpu 52(4)的缓存一致性链路和连接cpu 52(1)和52(3)的缓存一致性链路)连接到系统50机箱的背板(或中板)66上的转接驱动器64、65。在一些实现中,可能不需要协议无关电转接驱动器,在这种情况下,缓存一致性链路将直接连接到连接器。结果,并且根据本文描述的实施例的特征,母板54(1)和54(2)中的每一个的宽度是母板34(图2)的宽度的一半。将认识到,母板54(1)、54(2)中的每一个可以对应于刀片服务器或“刀片”。
30.连接到前板和连接到背板的缓存一致性链路经过精心选择,以便可以轻松地为4路和8路smp实现重新配置系统,处理器之间的最大距离为一跳。连接到前侧和后侧的缓存一致性链路往往更长,因此会导致高信号损失,从而导致信号完整性问题。为避免信号完整性问题,可以部署协议无关宽带电信号放大器或转接驱动器(例如转接驱动器60、61、64、65)以补偿由互连介质的长的长度造成的损失。替代地,某些实施例可利用双轴电缆(“twinax”)或同轴电缆将缓存一致性链路连接到背板和前/中板,而无需使用转接驱动器(仅phy层)。这种twinax或同轴电缆也可以选择性地用于产生最高损耗的tx/rx端口,而其他tx/rx端口则布线在印刷电路板或母板上。电缆可以通过高密度连接器附接到印刷电路板,或者直接压合到印刷电路板通孔。连接器和/或通孔可以平行于气流方向定向以避免其阻塞。(注意,“通孔”是铜管,用于连接来自不同布线层的信号或将静态电源和接地连接到pcb上的各个平面。)
31.通常,连接到背板/中板和/或前板的高速链路承载缓存一致性smp数据。但是,在一些不需要多路smp系统的场景中,可以使用相同的高速链路来承载处理器i/o流量(例如pcie数据)或网络数据,以扩展诸如存储的系统能力。4路和8路(及以上)smp系统在实现更高服务器密度的更小外形规格中实施尤其具有挑战性。本文描述的实施例在模块化2路处理器子系统中实现互连smp链路的方法,其又用于构建以紧凑外形规格实现的4路和8路系统。
32.本文描述的实施例能够实现比传统实现更高的服务器密度;特别是,在6u外形规格中,最多四个4路系统和最多两个8路系统,而传统系统需要10u或更高的外形规格才能实现相当数量的可比系统。此外,该系统可以轻松地重新配置用于2路、4路和8路smp实现。需
要更少的印刷电路板层,从而降低服务器母板的成本,并且与高达8s的基于节点集中器或多路复用器的实现相比,主题实施例能够实现更低的延迟和更高的性能。
33.图4示出了印刷电路板(pcb)(例如,母板)54的简化示例,其中示出了用于cpu
‑
1 52(1)和cpu
‑
2 52(2)的两个处理器插座的处理器复合体与互连链路67互连,其中一个处理器(例如,cpu
‑
1)通过链路68直接连接到平台控制器集线器(pch)69,并且第二处理器(例如,cpu
‑
2)通过在两个cpu之间的接口链路67访问pch。如图所示,每个处理器具有一组dimm 70,对于每个处理器成对列出为用于cpu
‑
1的1
‑
a1/a2、1
‑
b1/b2、1
‑
c1/c2和1
‑
d1/d2,以及用于cpu
‑
2的2
‑
a1/a2、2
‑
b1/b2、2
‑
c1/c2和2
‑
d1/d2。因此,图4中的半宽pcb 54总共可以安装24个dimm,即每个cpu 12(十二)个dimm(即,每个插座使用6(六)个“存储器通道”—其中存储器通道是将cpu与dimm连接的独立接口集,每个存储器通道保持两个(或三个)dimm)。注意,dimm可能是rdimm、lrdimm、3ds lrdimm等,具有ddr4或ddr5或更高的速度(如开发)。
34.—多列交错dimm布局和路由拓扑—
35.当前的pcb技术使用几种不同类型的拓扑布局来放置dimm连接器(例如,菊花链、三通、星形等),以最大化每个存储器通道的dimm连接器数量,以实现高存储器容量,同时以存储器通道可以支持的最高可能的频率运行。然而,随着越来越多的dimm连接器被添加到pcb以获得更高的存储器容量,保持尽可能短的走线长度变得越来越困难,因为连接额外dimm连接器的信号走线在传统拓扑中被加长。此外,距离多核插座最远的dimm连接器通常会设置存储器总线可以运行的速度,因此添加更多存储器插槽传统上意味着更慢的存储器速度。
36.尤其是双倍数据速率(ddr)同步动态随机存取存储器(sdram)多年来一直在不断进步,以达到跨代(ddr、ddr2、ddr3、ddr4、ddr5和更多的世代可能仍在开发)的越来越高的速度。以2933mt/s或更高速度运行的ddr4/5设计具有非常严格的设计要求,例如:最大走线长度、字节组内的走线长度匹配、走线到走线间距、走线到via间距、dimm到dimm间距、pcb厚度和用于data(数据)和address(地址)/cmd(命令)/ctrl(控制)线的gnd/pwr参考。由于额外的存储器通道和dimm要求,这些设计问题变得更加复杂。例如,数据位dq[7:0]有8个网,需要与选通网(dqs,高端cpu中的每个字节组通常有两个差分对)进行长度匹配。如果dimm放置不正确,它将显著增加走线长度以及网之间的走线长度差异,需要更多pcb不动产来进行长度匹配(或更多布线层),最终增加板厚(机械设计约束)。此外,较长的通道长度会增加插入损耗和串扰(近端和远端),从而降低时序和电压裕度。最后,如果dimm放置不当,在data和clk(时钟)/cmd/add(地址)/ctrl组上提供接地(gnd)和电源(pwr)参考将极具挑战性,从而增加设计风险。
[0037]
此外,如上所述,服务器存储器需求一直在增加,cpu供应商正在添加越来越多的存储器通道来满足这一需求。然而,印刷电路板(pcb)的空间限制(特别是对于较小的pcb(例如,半宽))使得难以容纳额外的双列直插式存储器模块dimm。传统的一列dimm放置方法(如上图4所示)由cpu引脚驱动,对设计提出了进一步的限制,使得无法利用额外的存储器通道容量。例如,图5示出了图4的单列拓扑设计如何不能在cpu的任一侧容纳额外的dimm(即在不增加pcb的尺寸的情况下(这在许多设计应用中是固定的),额外的dimm会超出pcb 54的板边界)。
[0038]
因此,本公开通过组合以下更详细描述的两个独特设计方面,即多列dimm布局和
dimm交错(来自不同cpu组),提供了新颖的多列交错dimm布局和路由拓扑。特别是,这里的多列交错dimm拓扑克服了传统单列dimm拓扑由于pcb不动产限制而受到的限制,并且在仍然满足必要的设计约束的情况下充分利用增加的存储器带宽和cpu能力。例如,下面描述的实施例的说明性结果是半宽pcb,它可以为每个cpu安装16(十六)个dimm(每个插座八个存储器通道),总共32个dimm,而不会增加半宽刀片的尺寸。(其他尺寸和总dimm计数也可以使用这里的技术来实现,这里提到的那些只是为了说明的示例。)
[0039]
在操作上,图6示出了根据本文实施例的特征的用于多列交错dimm的示例配置,其中白色dimm 81属于cpu
‑
1 52(1),而阴影dimm 82属于cpu
‑
2 52(2)。这种独特的设计特征有助于安装所有32个dimm,尽管实施例的板空间非常有限(例如,半宽板)。
[0040]
特别是,如图6所示,印刷电路板(pcb)54具有在pcb上的第一中央处理单元(cpu)插座52(1)和与第一cpu插座基本对齐的第二cpu插座52(2)。此外,pcb具有与第一cpu插座52(1)(例如,通过存储器通道)互连的第一多个双列直插式存储器模块(dimm)81,其中第一多个dimm插座位于第一cpu插座的相反的第一侧和第二侧,如图所示。pcb上的第二多个dimm插座82可以与第二cpu插座52(2)互连,其中第二多个dimm插座也位于第二cpu插座的相反的第一侧和第二侧并且在平行于第一多个dimm插座的方向上。注意,第一多个dimm插座和第二多个dimm插座被配置用于双倍数据速率(ddr)第4代(ddr4)多个dimm插座或ddr第5代(ddr5)dimm中的一者或任何其他合适的dimm配置。
[0041]
根据本文的实施例,第一多个dimm插座81(跨第一cpu插座的相反的第一侧和第二侧)布置在pcb上的至少第一列83和第二列84的dimm插座中,而第二多个dimm插座82(跨第二cpu插座的相反的第一侧和第二侧)布置在pcb上的至少第二列84和第三列85的dimm插座中,使得第二列的dimm插座包含来自第一多个dimm插座81和第二多个dimm插座82中的每一个的交错的dimm插座。
[0042]
在一个示例实施例中,第一列83和第二列84由第一cpu插座52(1)的中心线86分隔,并且第二列84和第三列85由第二cpu插座52(2)的中心线87分隔。在一个具体实施例中,第一多个dimm插座中最靠近第一cpu插座的部分(81
‑
a)被进一步设置在pcb上的第一cpu插座的中心线上,第二多个dimm插座中最靠近第二cpu插座的部分(82
‑
a)被进一步设置在pcb上的第二cpu插座的中心线上。
[0043]
使用以上说明性的成对命名约定,第一多个dimm插座中最靠近第一cpu插座的部分81
‑
a包括位于第一cpu插座的第一侧的两个dimm插座,即1
‑
c1/c2,以及位于第一cpu插座的第二侧的两个dimm插座,即1
‑
g1/g2。相反,第二多个dimm插座中最靠近第二cpu插座的部分82
‑
a包括位于第二cpu插座的第一侧的两个dimm插座,即2
‑
g1/g2,以及位于第二cpu插座的第二侧的两个dimm插座,即2
‑
c1/c2。(注意,第一cpu插座和第二cpu插座的引脚可能示例性地彼此旋转180度,因此cpu插座的“第一侧”和cpu插座的“第二侧”对应pcb的相同侧,但在电气上,第一cpu插座的第一侧的引脚将对应于第二cpu插座的第二侧的引脚。)
[0044]
第一列83中的第一多个dimm插座81可以示例性地包括位于第一cpu插座52(1)的第一侧的四个dimm插座,例如1
‑
b1/b2和1
‑
d1/d2,如图所示,以及位于第一cpu插座的第二侧的四个dimm插座,例如1
‑
f1/f2和1
‑
h1/h2。类似地,第三列85中的第二多个dimm插座82包括位于第二cpu插座52(2)的第一侧的四个dimm插座,例如2
‑
f1/f2和2
‑
h1/h2,以及位于第二cpu插座的第二侧的四个dimm插座,例如,2
‑
b1/b2和2
‑
d1/d2。在该示例中,第二列84中的
第一多个dimm插座81包括位于第一cpu插座52(1)的第一侧的两个dimm插座,例如1
‑
a1/a2,以及位于第一cpu插座的第二侧的两个dimm插座,例如1
‑
e1/e2。另外,第二列84中的第二多个dimm插座82包括位于第二cpu插座52(2)的第一侧的两个dimm插座,例如2
‑
e1/e2,以及位于第二cpu插座的第二侧的两个dimm插座,例如2
‑
a1/a2。
[0045]
基于cpu插座的引脚设计(cpu上的引脚被分配或分组以进行连接的方式),特定通道的存储器接口引脚通常会聚集在一起用于连接目的。因此,如图6所示的dimm的说明性布局提供了最大的性能,同时对功能约束的影响最小。例如,将第一cpu插座和第二cpu插座互连到第一多个dimm插座和第二多个dimm插座的存储器通道可以规定第一cpu插座和第二cpu插座的引脚旋转到提供存储器通道中最长存储器通道的最短的长度的方向(在四种可能的旋转方向中,即90度增量)。此外,将第一cpu插座和第二cpu插座互连到第一多个dimm插座和第二多个dimm插座的存储器通道是基于说明性设计配置的,使得最长存储器通道(例如,到pcb边缘的dimm)小于或等于所需的6.8英寸。
[0046]
值得注意的是,pcb层堆叠设计在系统设计中也发挥着重要作用,尤其是对于存储器速度通常最高的高性能cpu。在设计堆叠时必须满足某些设计约束,如下表1所示。这些约束是由机械布局和拓扑、热气流和电气参数(如传播延迟、阻抗和串扰)驱动的。
[0047]
约束参数pcb板厚140密耳(最大)铜箔厚度1oz用于信号;2oz用于电源pcb介电常数(dk)~3.4
‑
4.0损耗角正切(df)~0.0013电源平面空隙由时钟组共享通道长度2.5
‑
7.0”(最大)布线层22(最大)dimm间距340密耳
[0048]
表1
[0049]
图7示出了pcb的堆叠的一部分(例如,示出了说明性的22层中的8层)的示例,将传统pcb堆叠(左,105)与用于本文的多列交错dimm拓扑的示例(非限制性)pcb堆叠(右,110)进行了比较。可以看出,堆叠110与传统堆叠105不同。值得注意的是,g02和g06的近参考用于最小化clk组信号(地址、cmd、ctrl)所需的平面空隙,从而最小化层数,从而最小化板厚度(传统堆叠105需要为时钟组布线创建多个平面空隙,如g02、g04和g06所示)。此外,这种设计有助于保持pcb厚度小于所需的140密耳。
[0050]
特别是关于g02和g06的近参考被用于最小化clk组信号所需的平面空隙,从而最小化层数并因此最小化板厚度,如图8a
‑
8c所示,例如,根据本文的技术示出了说明性pcb的各个层的简化布局,其中在图8a中,上面的整个pcb 54的层g02(122)被示出具有用于vddq(到存储器芯片的输出缓冲器的电源电压,即到dimm 81/82的引脚120)到最里面的dimm 81
‑
a和82
‑
a的平面空隙132。(注意,层上的大部分剩余空间(不专用于其他电路)可能是接地(gnd)。)如图8b所示,由于这里的说明性堆叠设计,层g04(124)被示出为没有用于vddq的平面空隙。最后,在图8c中,层g06(126)被示出为具有到相应dimm引脚120的平面空隙136vddq。另一方面,传统的层堆叠将使gnd平面空隙填充有用于层g02、g04和g06的vddq(电
源)。(注意,为简洁起见,未显示其他层,但可以基于此处描述的说明性布局建立进一步的布局效率。)
[0051]
因此,上述设计实现了在pcb上放置更多dimm以利用所有存储器通道的目标,同时满足设计中的电气、机械和热约束。也就是说,多列交错dimm设计优化了pcb空间的使用,以达到完整的32
‑
dimm配置(以获得最大性能),同时保持对说明性半宽板上的所有i/o设备的支持。该设计特别考虑避免任何机械约束违规(例如,组件放置/拓扑、板厚度、dimm间距、cpu和dimm方向等),同时还满足热条件要求并最小化(例如避免)任何功率分布影响。此外,多列交错dimm设计还满足电气限制,例如通道布线长度、dimm之间的桩线长度(或dimm间距)(其中“桩线”是额外的电延迟,会降低迹线桩线或via桩线上的信号质量)、过孔长度(与板厚度有关)、strobe(选通)和clk(时钟)组上的正确平面参考、串扰最小化、满足电压和时序裕量的信号质量等。
[0052]
因此,本文描述的技术提供多列交错dimm布局和路由拓扑。特别地,本文的实施例帮助在具有更多存储器通道(增加带宽)的pcb上扩展dimm拓扑,其中多列设计连同交错式dimm解决了上文详述的众多设计挑战,显著降低了设计风险。
[0053]
值得注意的是,将认识到,附图中所示的各种刀片可以使用一个或多个计算机设备来实现,该计算机设备包括体现在一个或多个有形介质中的软件,用于促进这里描述的活动。用于实现刀片的计算机设备还可以包括存储设备(或存储元件),用于存储在实现这里概述的功能时要使用的信息。此外,用于实现刀片的计算机设备可以包括一个或多个能够执行软件或算法以执行本说明书中讨论的功能的处理器。这些设备还可以在适当的情况下并基于特定需求将信息保存在任何合适的存储元件(随机存取存储器(“ram”)、rom、eprom、eeprom、asic等)、软件、硬件或任何其他合适的组件、设备、元件或对象中。此处讨论的任何存储器项应被解释为包含在广义术语“存储元件”内。类似地,本说明书中描述的任何潜在的处理元件、模块和机器都应被解释为包含在广义术语“处理器”内。每个网络元件还可以包括用于在网络环境中接收、发送和/或以其他方式传送数据或信息的合适的接口。
[0054]
注意,在某些示例实现中,本文概述的各种功能可以通过在一个或多个有形介质中编码的逻辑(例如,在专用集成电路(“asic”)、数字信号处理器(“dsp”)指令中提供的嵌入式逻辑、由处理器或其他类似机器等执行的软件(可能包括目标代码和源代码))来实现。在这些实例中的一些情况下,存储元件可以存储用于这里描述的操作的数据。这包括能够存储被执行以执行本说明书中描述的活动的软件、逻辑、代码或处理器指令的存储元件。处理器可以执行与数据相关联的任何类型的指令,以实现本说明书中详述的操作。在一个示例中,处理器可以将元素或物品(例如,数据)从一种状态或事物转换为另一种状态或事物。在另一个示例中,这里概述的活动可以用固定逻辑或可编程逻辑(例如,由处理器执行的软件/计算机指令)来实现,并且这里标识的元件可以是某种类型的可编程处理器、可编程数字逻辑(例如,现场可编程门阵列(“fpga”)、可擦除可编程只读存储器(“eprom”)、电可擦除可编程rom(“eeprom”))或包含数字逻辑、软件、代码、电子指令或任何其适当组合的asic。
[0055]
应当注意,这里讨论的大部分基础设施可以作为任何类型的网络元件的一部分来提供。如本文所用,术语“网络元件”或“网络设备”可包括计算机、服务器、网络设备、主机、路由器、交换机、网关、网桥、虚拟设备、负载平衡器、防火墙、处理器、模块或任何其他可操作以在网络环境中交换信息的合适设备、组件、元件或对象。此外,网络元件可以包括促进
其操作的任何合适的硬件、软件、组件、模块、接口或对象。这可能包括允许有效交换数据或信息的适当算法和通信协议。
[0056]
在一种实现中,网络元件/设备可以包括用于实现(或促进)这里讨论的管理活动的软件。这可以包括图中所示的任何组件、引擎、逻辑等的实例的实现。此外,这些设备中的每一个都可以具有内部结构(例如,处理器、存储元件等)以促进本文描述的一些操作。在其他实施例中,这些管理活动可以在这些设备的外部执行,或者包括在一些其他网络元件中以实现预期功能。替代地,这些网络设备可以包括可以与其他网络元件协调以实现这里描述的管理活动的软件(或交互软件)。在其他实施例中,一个或多个设备可以包括任何合适的算法、硬件、软件、组件、模块、接口或有助于其操作的对象。
[0057]
转到图9,其中示出了示例机器(或装置)210的简化框图,其在某些实施例中可以包括这里所示出的刀片服务器之一,其可以在参考这里提供的附图所示出和描述的实施例中实现。示例机器210对应于可以部署在此处描述的环境中的网络元件和计算设备。特别地,图9示出了机器的示例形式的框图表示,其中软件和硬件使机器210执行本文讨论的任何一个或多个活动或操作。如图9所示,机器210可以包括处理器212、主存储器213、辅助存储器214、无线网络接口215、有线网络接口216a、虚拟网络接口216b、用户接口217和可移除介质驱动器218(包括计算机可读介质219)。总线211(例如系统总线和存储器总线)可以提供处理器212和机器210的存储器、驱动器、接口和其他组件之间的电子通信。机器210可以是物理的或虚拟设备,例如在管理程序上运行或在容器内运行的虚拟路由器。
[0058]
处理器212也可以被称为中央处理单元(“cpu”),可以包括能够执行机器可读指令并且按照机器可读指令的指示对数据执行操作的任何通用或专用处理器。主存储器213可由处理器212直接访问以访问机器指令并且可以是随机存取存储器(“ram”)或任何类型的动态存储器(例如,动态随机存取存储器(“dram”))的形式。辅助存储器214可以是任何非易失性存储器,例如硬盘,其能够存储包括可执行软件文件在内的电子数据。外部存储的电子数据可以通过一个或多个可移除介质驱动器218提供给计算机210,其可以被配置为接收任何类型的外部介质,例如光盘(“cd”)、数字视频光盘(“dvd”)、闪存驱动器、外部硬盘驱动器等。
[0059]
可以提供无线、有线和虚拟网络接口215、216a和216b以实现机器210和其他机器或节点之间经由网络的电子通信。在一个示例中,无线网络接口215可以包括无线网络控制器(“wnic”),其具有合适的发送和接收组件,例如收发器,用于在网络内进行无线通信。有线网络接口216a可以使机器210能够通过诸如以太网电缆之类的有线线路物理连接到网络。无线和有线网络接口215和216a都可以被配置为促进使用合适的通信协议(例如因特网协议套件(“tcp/ip”))的通信。仅出于说明的目的,机器210被示为具有无线和有线网络接口215和216a。虽然一个或多个无线和硬线接口可以在机器210中提供或者在外部连接到机器210,但是只需要一个连接选项来使机器210能够连接到网络。
[0060]
可以在一些机器中提供用户接口217以允许用户与机器210交互。用户接口217可以包括显示设备,例如图形显示设备(例如,等离子显示面板(“pdp”)、液晶显示器显示器(“lcd”)、阴极射线管(“crt”)等)。此外,还可以包括任何适当的输入机制,例如键盘、触摸屏、鼠标、轨迹球、语音识别、触摸板和应用程序编程接口(api)等。
[0061]
可移除介质驱动器218表示被配置为接收任何类型的外部计算机可读介质(例如,
计算机可读介质219)的驱动器。体现在此描述的活动或功能的指令可以存储在一个或多个外部计算机可读介质上。此外,此类指令还可以或替代地在执行期间至少部分地驻留在机器210的存储元件内(例如,在主存储器213或处理器212的高速缓存存储器中),或在机器210的非易失性存储元件(例如,辅助存储器214内)。因此,机器210的其他存储元件也构成计算机可读介质。因此,“计算机可读介质”旨在包括能够存储由机器210执行的指令的任何介质,该指令使机器执行本文公开的任何一个或多个活动。
[0062]
图9未显示附加硬件,其可以适当地耦合到处理器212和以存储器管理单元(“mmu”)、附加对称多处理元件、物理存储器、外围组件互连(“pci”)总线和相应的桥、小计算机系统接口(“scsi”)/集成驱动电子(“ide”)元件等形式的其他组件。机器210可以包括任何额外的合适的硬件、软件、组件、模块、接口或促进其操作的对象。这可能包括允许对数据进行有效保护和通信的适当算法和通信协议。此外,还可以在机器210中配置任何合适的操作系统以适当地管理其中的硬件组件的操作。
[0063]
参考机器210示出和/或描述的元件旨在用于说明目的并且不意味着暗示机器的架构限制,例如根据本公开使用的那些。此外,在适当的情况下并基于特定需要,每台机器可以包括更多或更少的组件,并且可以作为虚拟机或虚拟设备运行。如本说明书中在此使用的,术语“机器”旨在涵盖任何计算设备或网络元件,例如服务器、虚拟服务器、逻辑容器、路由器、个人计算机、客户端计算机、网络设备、交换机、网桥、网关、处理器、负载平衡器、无线lan控制器、防火墙或可操作以影响或处理网络环境中的电子信息的任何其他合适的设备、组件、元素或对象。
[0064]
在一个示例实现中,某些网络元件或计算设备可以实现为物理和/或虚拟设备,并且可以包括促进其操作的任何合适的硬件、软件、组件、模块或对象,以及在网络环境中用于接收、发送和/或以其他方式传送数据或信息的合适接口。这可能包括允许有效交换数据或信息的适当算法和通信协议。
[0065]
此外,在此处描述和示出的实施例中,与各种网络元件相关联的一些处理器和存储元件可以被移除或以其他方式合并,使得单个处理器和单个存储器位置负责某些活动。替代地,某些处理功能可以分开并且分开的处理器和/或物理机器可以实现各种功能。一般而言,图中描绘的布置在其表示中可能更合乎逻辑,而物理架构可包括这些元素的各种排列、组合和/或混合。必须注意的是,无数可能的设计配置可用于实现此处概述的操作目标。因此,相关的基础设施有无数的替代安排、设计选择、设备可能性、硬件配置、软件实现、设备选项等。
[0066]
在一些示例实施例中,一个或多个存储器可以存储用于这里描述的各种操作的数据。这包括至少一些能够存储指令(例如,软件、逻辑、代码等)的存储器元件,这些指令被执行以执行本说明书中描述的活动。处理器可以执行与数据相关联的任何类型的指令,以实现本说明书中详述的操作。在一个示例中,一个或多个处理器可以将元素或物品(例如,数据)从一种状态或事物转换为另一种状态或事物。在另一个示例中,这里概述的活动可以用固定逻辑或可编程逻辑(例如,由处理器执行的软件/计算机指令)来实现,并且这里标识的元件可以是某种类型的可编程处理器、可编程数字逻辑(例如,现场可编程门阵列(“fpga”)、可擦除可编程只读存储器(“eprom”)、电可擦除可编程只读存储器(“eeprom”))、包含数字逻辑、软件、代码、电子指令的asic、闪存、光盘、cd
‑
rom、dvd rom、磁卡或光卡、适
合存储电子指令的其他类型的机器可读介质,或其任何合适的组合。
[0067]
本文所示环境的组件可以在适当的情况下并基于特定需要将信息保存在任何合适类型的存储器(例如,随机存取存储器(“ram”)、只读存储器(“rom”)、可擦除可编程rom(“eprom”)、电可擦除可编程rom(“eeprom”)等)、软件、硬件或任何其他合适的组件、设备、元件或对象中。此处讨论的任何存储器项应被解释为包含在广义术语“存储元件”内。这里描述的网络环境正在读取、使用、跟踪、发送、传输、通信或接收的信息可以在任何数据库、寄存器、队列、表、高速缓存、控制列表或其他存储结构中提供,所有这些都可以在任何合适的时间范围内引用。任何这样的存储选项都可以包括在此处使用的广义术语“存储元件”内。类似地,本说明书中描述的任何潜在处理元件和模块都应被解释为包含在广义术语“处理器”内。
[0068]
综上所述,在一个实施例中,印刷电路板(pcb)具有第一中央处理器(cpu)插座和与第一cpu插座基本对齐的第二cpu插座,并且还具有与第一cpu插座互连的第一多个双列直插式存储器模块(dimm)插座和(在平行于第一多个dimm插座的方向上)与第二cpu插座互连的第二多个dimm插座。第一多个dimm插座布置在pcb上的至少第一列和第二列dimm插座中,并且第二多个dimm插座布置在pcb上的至少第二列和第三列dimm插座中,使得第二列dimm插座包含来自第一多个dimm插座和第二多个dimm插座中的每一个的交错的dimm插座。
[0069]
注意,通过这里提供的众多示例,可以根据两个、三个、四个或更多个网络元件来描述交互。然而,这样做只是为了清楚和举例。应当理解,该系统可以以任何合适的方式合并。沿着类似的设计备选方案,图中所示的计算机、模块、组件和元件中的任一个可以以各种可能的配置组合,所有这些显然都在本说明书的广泛范围内。在某些情况下,通过仅参考有限数量的网络元件来描述给定的一组流的一个或多个功能可能更容易。应当理解,如图中所示的本文描述的实施例及其教导易于扩展并且可以容纳大量组件以及更复杂/精密的布置和配置。因此,所提供的示例不应限制范围或抑制系统的广泛教导,因为它可能应用于无数其他架构。
[0070]
同样重要的是要注意,参考前面的图所描述的操作和步骤仅说明了可以由系统执行或在系统内执行的一些可能场景。在不脱离所讨论概念的范围的情况下,可以适当地删除或移除这些操作中的一些操作,或者可以显着修改或改变这些步骤。此外,这些操作的时序可以显著改变并且仍然实现本公开中教导的结果。前面的操作流程是为了示例和讨论的目的而提供的。该系统提供了相当大的灵活性,因为在不脱离所讨论概念的教导的情况下可以提供任何合适的布置、时间顺序、配置和定时机制。
[0071]
在前述描述中,为了解释的目的,阐述了许多具体细节以提供对所公开实施例的透彻理解。然而,对于本领域技术人员来说显而易见的是,可以在没有这些具体细节的情况下实践所公开的实施例。在其他情况下,结构和设备以框图形式示出以避免混淆所公开的实施例。此外,说明书中对“一个实施例”、“示例实施例”、“实施例”、“另一实施例”、“一些实施例”、“各种实施例”、“其他实施例”、“替代实施例”等的引用旨在表示与此类实施例相关联的任何特征(例如,元件、结构、模块、组件、步骤、操作、特性等)包括在本公开的一个或多个实施例中。
[0072]
虽然已经示出和描述了提供多列交错dimm布局和路由拓扑的说明性实施例,但是应当理解,可以在本文的实施例的意图和范围内进行各种其他适配和修改。例如,虽然本文
中关于使用某些类型的存储器或存储器协议描述了某些实施例,但本文中的实施例不限于此,并且在其他实施例中可以与其他类型的存储器一起使用。此外,虽然可能已经示出、描述或暗示了某些处理或处理器协议或术语,但是可以相应地使用其他合适的协议或术语。
[0073]
前面的描述是针对特定实施例的。然而,显而易见的是,可以对所描述的实施例进行其他变化和修改,以实现它们的一些或全部优点。因此,该描述仅作为示例而不是限制本文实施例的范围。因此,所附权利要求的目的是覆盖落入本文实施例的真实意图和范围内的所有此类变化和修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1