一种基于变权重随机森林的硬盘故障预测方法及系统
本发明属于信息处理技术领域,特别是涉及一种基于变权重随机森林的硬盘故障预测方法及系统。
背景技术:
如今,越来越多的工业级机构依靠数据中心来存储和处理数据。数据中心的崩溃可能会导致巨大的损失甚至会导致灾难性的后果。据统计,硬盘是数据中心最大的故障源之一,仅硬盘故障就占取数据中心所有硬件故障的71.1%。因此,采取一些措施来处理硬盘故障问题是十分迫切的。
自我检测、分析和报告技术(smart)普遍应用于硬盘中,以监视和分析硬盘的内部属性。研究表明,通过使用smart属性来预测即将发生的故障这种主动容灾机制是可行的。为了提高硬盘故障的预测准确度,已经基于smart属性做出了许多努力,其中就包括分析硬盘驱动器的故障行为,设计用于预测硬盘故障的机器学习算法。这些工作大部分都集中在硬盘故障的主动检测上,可以预先检测硬盘故障,并给出二进制的结果,将硬盘确定为健康盘和故障盘。
近年来,研究者尝试使用其他统计学和机器学习方法结合来解决硬盘故障预测问题。
李静等人使用决策树(dt)和梯度提升回归树(cbrt)两种模型对硬盘进行了故障预测,在168196块硬盘的实际数据集上进行实验,最终dt在误判率低于0.01%的情况下,取得了超过93%的预测准确率,cbrt在不出现误判率的情况下,取得了90%的预测准确率。
王梓杰等人提出一种基于主成分分析(pca)与随机森林算法的轴承故障趋势预测方法,把预测结果与bp神经网络模型预测的结果进行对比,结果表明随机森林在故障趋势预测上在精度相较于bp神经网络有显著提高,是一种有效的故障趋势预测方法。史干东等人使用随机森林算法对异步电动机转子断条进行故障诊断,经实验得出该方法性能良好。rajhansgondane等人使用概率随机森林对不同数据集进行分类实验,在许多基准数据集上报告的实验结果表明,与随机森林相比,提出的概率随机森林能够实现更好的性能。杨冬英为解决在故障诊断中数据不均衡的问题提出了一种精确度加权随机森林算法,经实验得出该算法简化随机森林计算的复杂度,加快程序运行,降低故障诊断的错误率。
技术实现要素:
技术方案,为了解决上述背景技术中的技术问题:
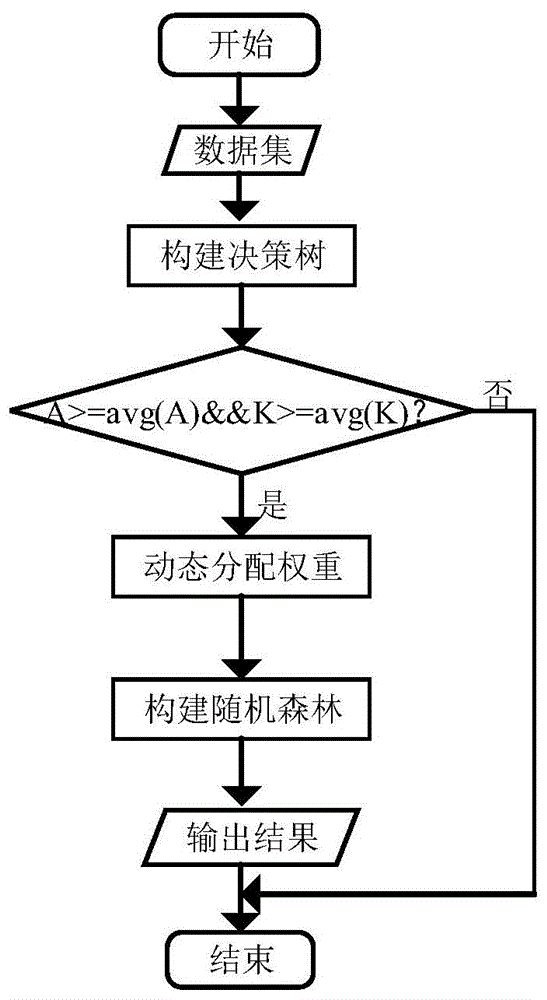
本发明的第一目的是提供一种基于变权重随机森林的硬盘故障预测方法,包括:
步骤一:数据预处理:考虑到决策树的节点分裂信息值可能为0的情况,提出分裂信息值与分裂信息平均值之和来代替单一的分裂信息值。
步骤二:根据精度a和多样性值k选取优秀的决策树。在随机森林预测模型的构建过程中,随着决策树的数量增加,并不会影响整体模型产生过拟合现象,且预测效果并不会随着决策树数量的增加而变得更好。但是当决策树数量增加到一定数量时,会影响随机森林整体模型的运行效率,从而影响最终的分类结果。故而选取性能较优的决策树,去除性能不理想的决策树是十分必要的。
步骤三:根据决策树ti的分类准确率计算其权重w(ti)。
步骤四:构建变权重随机森林模型对硬盘进行预测。
优选地:步骤一的计算方法如下:
其中,splitinfo(d)表示节点d的分裂信息,计算公式为:
gain(d,vi)表示节点d的信息增益,计算公式为:
gain(d,vi)=info(d)-info(d,vi)(3)
info(d)=-plog2(p)-qlog2(q)(4)
其中,info(d)表示节点d上的信息熵,info(d,vi)表示此次分裂得到的子节点上的信息熵之和;p、q满足条件p+q=1,分别表示包含在节点d内的两类数据样本的分布比例。
本专利的第二发明目的是提供一种基于变权重随机森林的硬盘故障预测系统,包括:
数据预处理模块:考虑到决策树的节点分裂信息值可能为0的情况,提出分裂信息值与分裂信息平均值之和来代替单一的分裂信息值。
选取模块:根据精度a和多样性值k选取优秀的决策树。
权重计算模块:根据决策树ti的分类准确率计算其权重w(ti)。
预测模块:构建变权重随机森林模型对硬盘进行预测。
本专利的第三发明目的是提供一种实现上述基于变权重随机森林的硬盘故障预测方法的计算机程序。
本专利的第四发明目的是提供一种实现上述基于变权重随机森林的硬盘故障预测方法的信息数据处理终端。
本专利的第五发明目的是提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行上述的基于变权重随机森林的硬盘故障预测方法。
本发明的优点及积极效果为:
通过采用上述技术方案,本发明具有如下的技术效果:
本发明针对数据中心大规模硬盘发生故障所造成的灾难性后果问题,提出了一种基于变权重随机森林的硬盘故障预测方法。首先,关于数据集的处理方面,根据gainratio值选取有效的smart属性,简化了维度较高、冗余数据较多的复杂原始数据集。然后,根据精度和多样性值选取决策树并对其分配权重,来组成变权重随机森林模型对硬盘进行故障预测。最后,进行可行性分析。实验结果达到93.12%的故障检测率和0.008%的误报率,相较于其他机器学习模型,以使用同一数据集为前提,提高了故障检测率的同时,大大降低了误报率,与其他现有方案相比具有一定的优越性,为硬盘故障的预测问题提供了新的解决思路。同时,大大延长了故障硬盘的提前预测时间,为之后的有效数据迁移提供了充足的时间,从而达到了保护数据的目的。
附图说明
图1为本发明优选实例的流程图;
图2为本发明优选实例中硬盘故障预测决策树分类示例图;
图3为准确率和误报率随决策树个数变化示意图;
图4为准确率和误报率随特征属性数量变化示意图。
具体实施方式
为能进一步了解本发明的发明内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下。
请参阅图1和图2,具体方案为:
一种基于变权重随机森林的硬盘故障预测方法,包含下列步骤:
步骤一:数据预处理:考虑到决策树的节点分裂信息值可能为0的情况,提出分裂信息值与分裂信息平均值之和来代替单一的分裂信息值。计算方法如下:
其中,splitinfo(d)表示节点d的分裂信息,计算公式为:
gain(d,vi)表示节点d的信息增益,计算公式为:
gain(d,vi)=info(d)-info(d,vi)(3)
info(d)=-plog2(p)-qlog2(q)(4)
其中,info(d)表示节点d上的信息熵,info(d,vi)表示此次分裂得到的子节点上的信息熵之和;p、q满足条件p+q=1,分别表示包含在节点d内的两类数据样本的分布比例。
根据gainratio值,表1列出了所挑选的基本属性。
表1数据集保留的基本smart属性
步骤二:根据精度a和多样性值k选取优秀的决策树。
在随机森林预测模型的构建过程中,随着决策树的数量增加,并不会影响整体模型产生过拟合现象,且预测效果并不会随着决策树数量的增加而变得更好。但是当决策树数量增加到一定数量时,会影响随机森林整体模型的运行效率,从而影响最终的分类结果。故而选取性能较优的决策树,去除性能不理想的决策树是十分必要的。
构建随机森林的过程中,以个体的精度和多样性为准选取性能优的决策树。
计算公式如下:
然而,此处多样性值k估计的是两棵树ti和tj之间的多样性,当计算树ti与其他树之间的多样性时,将组合分类器的预测视为tj,将问题转化为计算两棵树之间的多样性。具体计算公式如下:
步骤三:根据决策树ti的分类准确率计算其权重w(ti)。计算公式如下:
其中,accu(ti)表示决策树ti的分类准确率,dtr为准确预测到的故障硬盘数目,dt为实际上的故障硬盘数目。如公式(11)所示,accu(ti)越大,表示决策树ti的分类效果越好。
步骤四:构建变权重随机森林模型对硬盘进行预测。本发明提出的算法得到的最终预测结果是选取的每棵决策树的预测结果及为其分配的权重进行综合计算的结果。首先将训练数据集输入本文算法来得出每棵决策树的预测结果,然后分别统计经过该算法所得到不同预测结果(健康/故障)的决策树被分配的权重总和,如果预测结果为健康的决策树被分配的权重总和大于结果为故障的决策树被分配的权重总和,那么变权重随机森林算法的预测结果则为健康,反之,本发明算法的预测结果为故障。
一种基于预训练卷积神经网络关系抽取系统,包括:
数据预处理模块:考虑到决策树的节点分裂信息值可能为0的情况,提出分裂信息值与分裂信息平均值之和来代替单一的分裂信息值。
选取模块:根据精度a和多样性值k选取优秀的决策树。
权重计算模块:根据决策树ti的分类准确率计算其权重w(ti)。
预测模块:构建变权重随机森林模型对硬盘进行预测。
下面通过具体的实验详细阐述上述技术方案:
本发明的实验环境是:intel(r)core(tm)i5-4590cpu,8gb内存,操作系统为windows7旗舰版,在matlab环境下进行实验。实验需要sklearn机器学习库,pandas,numpy,matplotlib科学计算库和绘图库。
本发明实验数据皆来自backblaze数据集。
数据集与特征选择
本发明数据集来自于backblaze公开数据集,共选取35491块硬盘,提前为其标识好健康盘和故障盘。关于每块健康盘记录其168h时间内的smart属性信息,关于每块故障盘记录了其发生故障前600h内的smart属性信息,健康盘和故障盘的采样间隔都是1h,即每隔1h记录一条smart属性信息。表2描述了选取的该数据子集的具体信息。
表2实验数据集信息
同前期研究工作的硬盘属性信息选取一样,对于每个硬盘我们从smart记录中读取23个相对来说有价值的属性信息,但是由于部分属性值在记录周期中并不会随着健康盘或故障盘的变化而发生变化,表明这些属性对预测结果不具有影响性,所以我们忽略这些属性的取值。根据gainratio值,表1列出了所挑选的基本属性。
表1数据集保留的基本smart属性
第一列是属性编号,第二列是属性名称,第三列是信息增益比率gainratio值。信息增益比率越大说明该特征对于减少样本的不确定性程度的能力越大,也就代表这个特征越好根据gainratio值的大小,依次选取特征属性。
在机器学习中,数据标准化对其稳定性有重要意义,所以将数据进行标准化处理是十分必要的。本发明采用min-max数据标准化方法将数据进行了归一化处理,即将所有特征属性值归一到[-1,1]区域中。采用的数据标准化的公式如下:
其中,x为原始属性值,xmin为属性最小值,xmax为属性最大值,由该公式计算得出的标准化结果xnor在[-1,1]这个闭区间中,从而达到将特征属性值标准化的目的。
首先,将样本集随机划分为30个子样本集。其次,分别划分训练集和测试集来训练30个决策树模型,这样可以提高模型的泛化能力。
为了使实验结果更加具有说服力,本发明使用模型在数据中心的实际应用方式,即按照硬盘运行时间的先后顺序来对训练集和测试集进行划分,而不是简单的随机划分。
按时间序列将数据划分为训练集和测试集。由于健康盘的数量较多,所以在每个健康盘中随机选取3个样本,这样最大程度上消除了数量不平衡这一问题的同时保留了足够多的信息来描述每个硬盘的健康程度,其中将一周内前70%的样本作为训练集,后30%作为测试集;由于故障盘的数量较少,所以选择故障盘内所有样本进行划分,而我们并不清楚故障盘发生故障的先后顺序,所以只能按照7:3的比率来将故障盘随机划分训练集和测试集,即选取70%为训练集,30%为测试集。
评价指标
主要采用故障检测率(failuredetectionrate,fdr)和误报率(falsealarmrate,far)两个评价指标。除此之外,为了使故障硬盘中存储的重要数据可以及时迁移,还采用了每个故障硬盘的提前预测时间(tia)这一评价指标,表示潜在硬盘故障提前被模型预测出来的时间。
表3分类结果混淆矩阵
fdr表示预测到的故障盘数量与实际上故障盘数量的比值;far表示误判为故障盘的健康盘数量与实际上健康盘数量的比值。计算公式如下:
根据表3所示,tp为准确预测健康盘的数量,tn为准确预测故障盘的数量;fp为将故障盘错误预测为健康盘的数量,fn为将健康盘错误预测为故障盘的数量。
实验结果分析
根据实验设计本发明对权重的分配进行控制,图3所示为变权重随机森林的实验结果:准确率fdr和误判率far随着随机森林中决策树数量的增加发生的变化。其中决策树的权值随着自身准确率和平均准确率的变化而变化。由于权重值是变化的,故而也会对实验结果产生一定的影响。图3显示的数据是实验中预测效果最好的一组结果.可以看出决策树数量为1时,即决策树模型的预测结果为准确率为91.90%、误报率为0.03%,实验结果较好。但是随着决策、树的数量增加,可以看出实验结果正在逐渐趋于稳定,准确率稳步增加,最终在决策树数量为26时,准确率为93.98%,之后在94%左右浮动,最高为94.33%。误判率呈下降趋势,在决策树量为25时,达到了接近于0的结果,之后随着决策树数量的增加,误判率反而上升。
最终,可以看出当决策树的数量为25时,实验效果最好,即准确率为92.99%,误判率为0.011%,平均预警提前时间为351.54h。
图4显示的数据是在23个属性中选择的属性个数不同时,准确率fdr和误判率far的变化。可以看出当选取的特征属性过少时,最终实验结果不是很理想,即在特征属性为10时,准确率为88.95%、误判率为0.12%,准确率不是很高的同时有着很高的误判率,效果明显不理想。随着特征属性数量的增加,准确率再上升,误判率在下降。当特征属性数量为12时,准确率达到了93%左右,误判率接近于0,效果较好,之后随着特征属性数量的增加,准确率和误判率的变化幅度较小,且准确率呈现小幅度上升趋势,在93%上下浮动,但是当特征属性数量增加到18时,准确率有了一个明显的下降,此时准确率为92%左右,之后随着特征属性数量的增加,准确度一直在92%上下徘徊。随着特征属性数量的增加,误判率反而呈现小幅度的上升趋势。最终可以确定本发明选取的12个属性是必要的。
最后,选择递归神经网络、决策树、传统随机森林和变权重随机森林这四个模型对同一数据集进行实验,并将得到的最终结果进行对比。表4列出了这四个模型的最终结果,可以看出在同一数据集上,相较于递归神经网络,决策树的准确率略低,但是其误判率大大低于递归神经网络,平均预警提前时间也较好。本发明介绍的变权重随机森林模型相较于其他三种模型提高了预测准确率的同时,很大程度降低了误判率,近似于0%。此外,得到了较好的平均预警提前时间。
表4各模型结果对比
一种实现上述基于变权重随机森林的硬盘故障预测方法的信息数据处理终端。
一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行上述的基于变权重随机森林的硬盘故障预测方法。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solidstatedisk(ssd))等。
以上所述仅是对本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!