通过从驻留在内容关联滤筛中的基本数据单元导出数据的数据的无损简化的制作方法
本公开内容涉及数据存储、取回和通信。更具体来说,本公开内容涉及使用内容关联滤筛(content-associativesieve)的数据的无损简化。
背景技术:
当今的信息时代以巨量数据的产生、捕获和分析为标志。新的数据从多样的来源产生,这方面的实例包括购买交易记录、企业及政府记录和通信、电子邮件、社交媒体发帖、数字图片和视频、机器日志、来自嵌入式设备的信号、数字传感器、蜂窝电话全球定位卫星、航天卫星、科学计算以及大挑战科学。数据以多样的格式生成,其中得许多数据是无结构的,并且不适合输入到传统的数据库中。企业、政府和个人以前所未有的速度生成数据,并且在存储、分析和传送该数据方面遇到困难。为了保存累积的数据,每年在购买存储系统方面要花费数百亿美元。在用以处理数据的计算机系统上也要花费类似地巨大金额。
在最现代的计算机和存储系统中,在被组织成存储分级结构的多层存储上容纳和部署数据。需要被经常并且快速地存取的数据被放置在最快速但是也最昂贵的层级,大多数数据(包括用于备份的拷贝)则优选地被存储在最密集并且最便宜的存储介质中。最快速并且最昂贵的数据存储层级是计算机系统的非易失性随机存取存储器或ram,其驻留在紧邻微处理器核心的位置并且为随机数据存取给出最低等待时间和最高带宽。逐渐地更密集并且更便宜但是也更慢的各层(其对于随机存取具有逐渐地更高的等待时间和更低的带宽)包括非易失性固态存储器或闪存存储装置、硬盘驱动器(hdd)并且最后是磁带驱动器。
为了更加有效地存储和处理不断增加的数据,计算机行业持续对数据存储介质的密度和速度以及对计算机的处理能力作出改进。但是数据量的增加速度远远超出计算和数据存储系统的容量和密度的改进。来自2014年的数据存储行业的统计数据表明,在过去的几年里所产生并捕获的新数据构成全世界至今所捕获的数据的一大部分。全世界至今为止所产生的数据的数量估计超出多个泽字节(一个泽字节是1021个字节)。数据的大量增加对于必须可靠地存储、处理和传送该数据的数据存储、计算和通信系统提出了高要求。这就促使更多地使用无损数据简化或压缩技术来紧缩(compact)数据,从而能够以更低的成本来存储并且同样高效地处理和传送数据。
已经出现了多种无损数据简化(reduction)或压缩技术,并且近年来发生了演进。这些技术对数据进行检查以寻找数据中的某种形式的冗余,并且利用该冗余在没有任何信息损失的情况下实现数据足迹(datafootprint)的简化。对于期望利用数据中的特定形式的冗余的给定技术,所实现的数据简化的程度取决于在数据中找到该特定形式的冗余的频度。所希望的是数据简化技术能够灵活地发现并且利用数据中的任何可用的冗余。由于数据源自多种来源和环境并且具有多种格式,因此对于用以应对这一多样数据的通用无损数据简化技术的开发和采用的兴趣很大。除了字母表之外通用数据简化技术不需要关于输入数据的先验知识;因此通用数据简化技术一般可以被应用于任何和所有数据,而不需要事先知道数据的结构和统计分布特性。
可以被用来比较数据压缩技术的不同实现方式的优度(goodness)量度包括在目标数据集上实现的数据简化的程度,实现压缩或简化的效率,以及解压缩并取回数据以供未来使用的效率。效率量度评估解决方案的性能和成本有效性。性能量度包括新数据可以被消耗并简化的吞吐量或摄取速率,对输入数据进行简化所需要的等待时间或时间,数据可以被解压缩并取回的吞吐量或速率,以及解压缩并取回数据所需要的等待时间或时间。成本量度包括任何所需的专用硬件组件的成本,比如微处理器核心或微处理器利用(中央处理单元利用),专用暂时存储器的数量和存储器带宽,以及对于保存数据的各个存储层级所需要的存取次数和带宽。应当提到的是,在简化数据足迹的同时提供高效且快速的压缩以及解压缩和取回不仅具有降低存储和传送数据的总体成本的好处,而且还具有高效地允许对于数据的后续处理的好处。
当前在业内所使用的许多通用数据压缩技术是从在1977年由abrahamlempel和jacobziv开发的lempel-ziv压缩方法导出的,例如参见jacobziv和abrahamlempel的“auniversalalgorithmforsequentialdatacompression(用于顺序数据压缩的通用算法)”,ieeetransactionsoninformationtheory,vol.it-23,no.3,1977年5月。这种方法成为允许通过因特网的高效数据传输的基础。lempel-ziv方法(也就是lz77、lz78及其变体)通过用引用替换串的重复出现而简化数据足迹,其中所述引用是针对在顺序呈现的输入数据流的滑动窗口内所见到的所述串的先前的出现。在消耗来自输入数据流的给定数据块的新鲜串时,这些技术搜索过先前在直到窗口长度的当前和先前块内所见到的所有串。如果所述新鲜串是重复,则用对原始串的后向引用将其替换。如果通过重复串所消除的字节数目大于后向引用所需的字节数目,则实现了数据的简化。为了搜索过在窗口中所见到的所有串,并且为了提供最大串匹配,这些技术的实现方式采用多种方案,其中包括迭代扫描以及建立包含在窗口中见到的所有串的字典的临时簿记结构。在消耗新的输入字节以组装新鲜串时,这些技术或者扫描过现有窗口中的所有字节,或者对串的字典进行引用(随后是一些计算)以便判定是否找到重复并且用后向引用将其替换(或者判定是否需要对字典进行添加)。
lempel-ziv压缩方法常常伴随有应用于数据的第二优化,其中基于其在正被压缩的数据块中的出现频率或概率对源符号进行动态重编码,所述动态重编码常常采用可变宽度编码方案从而对于频率更高的符号使用长度更短的代码,从而导致数据的简化。例如参见davida.huffman的“amethodfortheconstructionofminimum-redundancycodes(用于构造最小冗余代码的方法)”,proceedingsoftheire–instituteofradioengineers,1952年9月,pp.1098-1101。这种技术被称作huffman重编码,并且通常需要第一遍经过数据以计算频率以及第二遍经过数据以实际编码数据。围绕这一主题的几种变型也在使用之中。
使用这些技术的一个实例是一种被称作“deflate”的方案,该方案将lempel-zivlz77压缩方法与huffman重编码相组合。deflate提供了压缩流数据格式规范,所述规范规定一种用于把字节序列表示成(通常更短的)比特序列的方法,以及一种用于把所述比特序列打包成字节的方法。deflate方案最初由pkware,inc.的phillipw.katz设计用于pkzip归档实用程序。例如参见phillipw.katz的标题为“stringsearcher,andcompressorusingsame(串搜索器以及使用串搜索器的压缩器)”的美国专利5,051,745,1991年9月24日。美国专利5,051,745描述了一种用于针对预定目标串(输入串)搜索符号矢量(窗口)的方法。所述解决方案采用具有针对窗口中的每一个符号的指针的指针阵列,并且使用一种散列方法对窗口中的可能位置进行过滤,其中需要在所述可能位置处搜索输入串的完全相同的拷贝。随后是在这些位置处进行扫描和串匹配。
deflate方案被实施在用于数据压缩的zlib库中。zlib是作为例如linux、macosx、ios之类的几种软件平台以及多种游戏机的关键组件的软件库。zlib库提供deflate压缩和解压缩代码以供zip(文件归档)、gzip(单文件压缩)、png(用于无损压缩图像的便携式网络图形格式)以及许多其他应用来使用。zlib现在被广泛用于数据传输和存储。服务器和浏览器的大多数http事务使用zlib来压缩和解压缩数据。类似的实现方式正越来越多地被数据存储系统使用。
由intelcorp.在2014年4月公布的一篇标题为“highperformancezlibcompressionon
现有的数据压缩方案通常使用当代微处理器上的单一处理器核心操作在从10mb/秒到200mb/秒的摄取速率下。为了进一步提升摄取速率,采用多个核心,或者减小窗口大小。使用定制硬件加速器会实现摄取速率的进一步改进,但是成本会增加。
前面所描述的现有数据压缩方法在通常具有单一消息或文件或者几个文件的大小的本地窗口中能够有效地利用较短的串和符号等级的细粒度冗余。但是当在操作于较大或极大的数据集上并且需要高数据摄取和数据取回速率的应用中使用这些方法时则存在严重的限制和缺陷。
一个重要的限制是这些方法的实用实现方式只能在本地窗口内高效地利用冗余。虽然这些实现方式可以接受任意长的输入数据流,但是效率决定在将于其中发现细粒度冗余的窗口的大小方面存在限制。这些方法是高度计算密集型的,并且需要对于窗口中的所有数据的频繁和快速的存取。在消耗产生新鲜输入串的输入数据的每一个新鲜字节(或几个字节)时触发各种簿记结构的串匹配和查找。为了达到所期望的摄取速率,用于串匹配的窗口和相关联的机器必须主要驻留在处理器高速缓存子系统中,从而在实践中对窗口大小构成约束。
例如为了在单一处理器核心上达到200mb/秒的摄取速率,每个所摄取字节的平均可用时间预算(包括所有数据存取和计算)是5ns,这在使用具有3.4ghz操作频率的当代处理器的情况下意味着17个时钟。这一预算容许对于芯片上高速缓存的存取(花费少量循环)以及随后的一些串匹配。当前的处理器具有几兆字节容量的芯片上高速缓存。对于主存储器的存取花费超出200个循环(~70ns),因此主要驻留在存储器中的更大窗口将使得摄取速率进一步变慢。此外,随着窗口大小增大以及去到重复串的距离增大,规定后向引用的长度的成本也增加,从而只能致使在更大的范围内搜索更长的串的重复。
在大多数当代数据存储系统上,存储在存储分级结构的各个层级上的数据的足迹比系统中的存储器容量大几个数量级。举例来说,虽然系统可以提供数百吉字节的存储器,但是驻留在闪存存储装置中的活跃数据的数据足迹可以是数十太字节,并且存储系统中的总数据可以处于数百太字节到多个拍字节的范围。此外,对于每一个相继层级,对于后续存储层级的可实现的数据存取吞吐量下降一个数量级或更多。当滑动窗口变大到无法容纳在存储器中时,这些技术受到对于接下来的数据存储等级的随机io(输入或输出操作)存取的显著更低的带宽和更高等待时间的节制。
例如考虑具有4千字节的传入数据的一个文件或页面,所述文件或页面可以通过对已经存在于数据中并且分散在256太字节足迹上的例如100个平均长度为40字节的串进行引用而从现有数据组装。每一项引用将花费6个字节来规定其地址以及用于串长度的1个字节,同时有望节省40个字节。虽然在本例中描述的页面可以被压缩多于五倍,但是对应于该页面的摄取速率将受到获取并验证100个重复串所需的对于存储系统的100次或更多次io存取的限制(即使可以完美地以低成本预测这些串驻留在何处)。在用尽存储系统的所有带宽的情况下,给出250000次随机io存取/秒(这意味着对于4kb页面的1gb/秒的随机存取带宽)的存储系统只能以10mb/秒的摄取速率每秒压缩2500个这样的4kb大小的页面,从而使其不可用作存储系统。
具有太字节或拍字节量级的大窗口大小的传统压缩方法的实现方式将受到对存储系统的减小的数据存取带宽的困扰,并且将是不可接受地缓慢。因此,这些技术的实用实现方式只有在能够容纳于处理器高速缓存或系统存储器中的窗口大小上本地存在冗余的情况下才能高效地发现和利用所述冗余。如果冗余数据在空间上或时间上与传入数据分开多个太字节、拍字节或艾字节,这些实现方式由于受到存储存取带宽的限制将无法以可接受的速度发现冗余。
传统方法的另一个限制在于其不合适于随机数据存取。跨越被压缩的整个窗口的各个数据块需要在能够对任何块内的任何组块进行存取之前被解压缩。这就对窗口的大小构成了实用限制。此外,传统上在未压缩数据上实施的操作(例如搜索操作)无法高效地在已压缩数据上实施。
传统方法(特别是基于lempel-ziv的方法)的另一个限制在于其仅仅沿着一个维度搜索冗余——也就是用后向引用替换完全相同的串。huffman重编码方案的限制在于其需要经过数据两遍以便计算频率并且随后进行重编码。这样在更大的块上就变得较慢。
在全局数据存储库上检测长重复串的数据压缩方法使用数字指纹处理与散列方案的组合。这种压缩处理被称作数据去重复(deduplication)。最基本的数据去重复技术把文件分解成固定大小块,并且在数据储存库中寻找重复块。如果创建了文件的拷贝,则第一文件中的每一个块将在第二文件中具有重复,并且可以用针对原始块的引用替换所述重复。为了加快潜在地重复块的匹配,采用一种散列方法。散列函数是把一个串转换成被称作其散列值的数字值的函数。如果两个串相等,其散列值也相等。散列函数把多个串映射到给定的散列值,从而可以把长串简化成长度短得多的散列值。散列值的匹配将比两个长串的匹配快得多;因此首先进行散列值的匹配以便过滤掉可能是重复的可能串。如果输入串或块的散列值匹配存在于储存库中的串或块的散列值,随后则可以把输入串与储存库中的具有相同散列值的每一个串进行比较以便证实重复的存在。
把文件分解成固定大小块是简单且方便的,并且固定大小块在高性能存储系统中是高度期望的。但是这种技术在其所能够发现的冗余的数量方面存在限制,这意味着这些技术的压缩等级较低。举例来说,如果对第一文件进行拷贝以创建第二文件,并且即使如果只把单一字节的数据插入到第二文件中,则所有下游块的对准都将改变,每一个新块的散列值将被重新计算,并且所述数据去重复方法将不再能找到所有重复。
为了解决数据去重复方法中的这一限制,行业内采用了使用指纹处理在匹配内容的位置处同步和对准数据流。后面的这种方案导致基于指纹的可变大小块。michaelrabin展示出如何能够使用随机选择的不可约多项式对比特串进行指纹处理,例如参见michaelo.rabin的“fingerprintingbyrandompolynomials(通过随机多项式进行指纹处理)”,centerforresearchincomputingtechnology,harvarduniversity,tr-15-81,1981年。在这种方案中,随机选择的素数p被用来对长字符串进行指纹处理,这是通过计算被视为大整数对p取模的该串的余数。这种方案需要在k比特整数上实施整数运算,其中k=log2(p)。或者可以使用k次随机不可约多项式,指纹则是数据的多项式表示对素多项式取模。
这种指纹处理方法被使用在数据去重复系统中以便识别将在该处建立组块边界的适当位置,从而使得系统可以在全局储存库中寻找这些组块的重复。可以在找到特定值的指纹时设定组块边界。作为这种用法的一个实例,通过采用32次或更低次多项式,可以对于输入数据中的每一个48字节串计算指纹(在输入的第一字节处开始,并且在随后的每一个相继字节处进行)。随后可以检查32比特指纹的13个低位比特,并且每当这13个比特的值是预先规定的值(例如值1)时则设定断点。对于随机数据,所述13个比特具有该特定值的概率将是213分之1,因此对于每8kb可能会遇到近似一个这样的断点,从而导致平均大小为8kb的可变大小组块。所述断点或组块边界将会有效地对准到取决于数据内容的指纹。当很久没有找到指纹时,可以在某一预先规定的阈值处强制断点,从而使得系统确保为储存库创建短于预先规定的大小的组块。例如参见athichamuthitacharoen、benjiechen和davidmazières的“alow-bandwidthnetworkfilesystem(低带宽网络文件系统)”,sosp‘01,proceedingsoftheeighteenthacmsymposiumonoperatingsystemsprinciples,10/21/2001,pp.174-187。
由michaelrabin和richardkarp开发的rabin-karp串匹配技术提供了对于指纹处理和串匹配的效率的进一步改进(例如参见michaelo.rabin和r.karp的“efficientrandomizedpattern-matchingalgorithms(高效的随机化模式匹配算法)”,ibmjour.ofres.anddev.,vol.31,1987年,pp.249-260)。应当提到的是,检查m字节子串的指纹的指纹处理方法可以在o(m)的时间内评估指纹处理多项式函数。由于这种方法将需要被应用在开始于例如n字节输入流的每一个字节的子串上,因此在整个数据流上实施指纹处理所需的总工作量将是o(n×m)。rabin-karp识别出被称作滚动散列(rollinghash)的散列函数,在所述滚动散列上,通过独立于子串的长度仅仅进行恒定次数的运算,有可能从前一个子串计算下一个子串的散列值。因此,在向右移位一个字节之后,可以在新的m字节串上递增进行指纹计算。这样就把用以计算指纹的工作量减少到o(1),并且把用于对整个数据流进行指纹处理的总工作量减少到o(n),从而与数据的大小成线性。这样就大大加快了指纹的计算和识别。
对于前面描述的数据去重复方法的典型的数据存取和计算要求可以被如下描述。对于给定的输入,一旦完成指纹处理从而创建组块,并且在计算出用于该组块的散列值之后,这些方法首先需要针对存储器和后续存储层级的一个存取集合,以便搜索并且查找保持储存库中的所有组块的散列值的全局散列表。这通常将需要针对存储的第一io存取。在散列表中找到匹配之后是第二存储io集合(取决于在储存库中存在多少具有相同散列值的组块,这通常是一次但是也可以多于一次),以便获取具有相同散列值的实际数据组块。最后实施逐字节匹配以便把输入组块与所获取的潜在匹配组块进行比较,从而确认并且识别重复。随后是用对原始块的引用替换新的重复块的第三存储io存取(针对元数据空间)。如果在全局散列表中没有匹配(或者如果没有找到复制),系统需要一次io以把新的块输入到储存库中,并且需要另一次io来更新全局散列表以便输入新的散列值。因此,对于较大的数据集(其中元数据和全局散列表无法容纳在存储器中,因此需要存储io对其进行存取),这样的系统对于每个输入组块可能需要平均三次io。通过采用多种过滤器可能实现进一步的改进,从而常常可以在无需用以对全局散列表进行存取的第一存储io的情况下检测到全局散列表中的缺失,从而把对其中一些组块进行处理所需的io次数减少到两次。
给出250000次随机io存取/秒(这意味着对于4kb页面的1gb/秒的随机存取带宽)的存储系统每秒可以摄取大约83333(250000除以每个输入组块3次io)个平均大小为4kb的输入组块并且对其进行去重复,从而在用尽存储系统的所有带宽的情况下允许333mb/秒的摄取速率。如果仅使用存储系统的一半带宽(从而使得另一半可用于对所存储的数据进行存取),这样的去重复系统仍然可以给出166mb/秒的摄取速率。如果在系统中有足够的处理能力可用,则(受到i/o带宽限制的)这些摄取速率是可以实现的。因此,在给定足够处理能力的情况下,数据去重复系统能够以经济的io在全局数据范围内找到较大的数据重复,并且在当代存储系统上以每秒数百兆字节的摄取速率给出数据简化。
基于前面的描述应当清楚的是,虽然这些去重复方法在全局范围内找到长串的重复方面是有效的,但是其主要在找到大的重复方面是有效的。如果数据在更细的粒度上存在变化或修改,则使用这种方法将不会找到可用的冗余。这大大减小了这些方法对其有效的数据集的广度。这些方法已被使用在特定的数据存储系统和应用中,例如对于数据的定期备份,其中正被备份的新数据只有几个文件被修改,其余部分都是已被保存在先前的备份中的文件的重复。同样地,基于数据去重复的系统常常被部署在其中产生数据或代码的多份精确拷贝的环境中,比如数据中心中的虚拟化环境。但是随着数据演进并且更加一般地或者在更细的粒度上被修改,基于数据去重复的技术则失去其有效性。
一些方法(其通常被采用在数据备份应用中)不实施输入数据与其散列值匹配输入的串之间的实际的逐字节比较。这样的解决方案依赖于使用例如sha-1之类的强散列函数的低冲突概率。但是由于冲突(其中多个不同的串可以映射到相同的散列值)的有限非零概率,这样的方法不能被视为提供无损数据简化,因此将不满足主存储和通信的高数据完整性要求。
一些方法组合多种现有的数据压缩技术。在这样的设置中,通常首先对数据应用全局数据去重复方法。随后在经过去重复的数据集上并且采用小窗口,应用与huffman重编码相组合的lempel-ziv串压缩方法以实现进一步的数据简化。
但是尽管采用了所有至此已知的技术,在不断增长和累积的数据的需求与世界经济使用最佳可用现代存储系统所能可负担地适应的情况之间仍然存在几个数量级的差距。在给定不断增长的数据所需要的非常高的存储容量需求的情况下,仍然需要进一步简化数据足迹的改进的方式。仍然需要开发解决现有技术的限制或者沿着尚未被现有技术解决的维度利用数据中的可用冗余的方法。与此同时,能够以可接受的速度并且以可接受的处理成本高效地存取和取回数据仍然非常重要。
总而言之,长期以来一直需要能够利用较大和极大的数据集中的冗余并且提供高数据摄取和数据取回速率的无损数据减损解决方案。
技术实现要素:
这里所描述的实施例涉及可以在较大和极大的数据集上实施无损数据简化并且同时提供高数据摄取和数据取回速率的技术和系统,并且不受困于现有数据压缩系统的缺点和限制。
具体来说,一些实施例可以基于数据组块识别一个或多个基本数据单元,其中所述识别包括使用数据组块的内容导航经过基于基本数据单元的内容组织基本数据单元的数据结构。接下来,所述实施例可以基于数据组块以及所识别出的一个或多个基本数据单元确定重建程序,从而可以通过对所述一个或多个基本数据单元应用所述重建程序而重建数据组块。所述实施例随后可以生成数据组块的无损简化表示,其中所述无损简化表示包括对所识别出的一个或多个基本数据单元当中的每一个基本数据单元的引用以及对重建程序的描述。
附图说明
图1a示出了根据这里所描述的一些实施例的用于数据简化的方法和装置,其把输入数据因式分解成各个单元并且从驻留在基本数据存储库中的基本数据单元导出这些单元。
图1b-1g示出了根据这里所描述的一些实施例的图1a中所示的方法和装置的各种变型。
图1h给出了根据这里所描述的一些实施例的描述蒸馏数据(distilleddata)的结构的格式和规范的一个实例。
图1i到1p示出了对应于图1a到图1g中示出的用于数据简化的方法和装置的各种变型的输入数据到无损简化形式的概念性变换。
图2示出了根据这里所描述的一些实施例的通过把输入数据因式分解成各个单元并且从驻留在基本数据存储库中的基本数据单元导出这些单元而进行数据简化的处理。
图3a、3b、3c、3d和3e示出了根据这里所描述的一些实施例的可以被用来基于其名称对基本数据单元进行组织的不同的数据组织系统。
图3f给出了根据这里所描述的一些实施例的自描述树节点数据结构。
图3g给出了根据这里所描述的一些实施例的自描述叶节点数据结构。
图3h给出了根据这里所描述的一些实施例的包括导航前瞻字段的自描述叶节点数据结构。
图4示出了根据这里所描述的一些实施例的如何可以把256tb的基本数据组织成树形式的一个实例,并且呈现出如何可以把树布置在存储器和存储装置中。
图5a-5c示出了关于如何可以使用这里所描述的实施例组织数据的一个实际的实例。
图6a-6c分别示出了根据这里所描述的一些实施例的如何可以把树数据结构用于参照图1a-1c描述的内容关联映射器。
图7a提供了根据这里所描述的一些实施例的可以在重建程序中规定的变换的一个实例。
图7b示出了根据这里所描述的一些实施例的从基本数据单元导出候选单元的结果的实例。
图8a-8e示出了根据这里所描述的一些实施例的如何通过把输入数据因式分解成固定大小单元并且把所述单元组织在参照图3d和3e描述的树数据结构中而实施数据简化。
图9a-9c示出了根据这里所描述的一些实施例的基于图1c中示出的系统的datadistillationtm(数据蒸馏)方案的一个实例。
图10a提供了根据这里所描述的一些实施例的关于如何对基本数据单元应用在重建程序中规定的变换以产生导出单元(derivativeelement)的一个实例。
图10b-10c示出了根据这里所描述的一些实施例的数据取回处理。
图11a-11g示出了根据这里所描述的一些实施例的包括datadistillationtm机制(可以利用软件、硬件或者其组合来实施)的系统。
图11h示出了根据这里所描述的一些实施例的datadistillationtm装置如何可以与范例通用计算平台进行接口。
图12a-12b示出了根据这里所描述的一些实施例的使用datadistillationtm装置在受到带宽约束的通信介质上传送数据。
图12c-12k示出了根据这里所描述的一些实施例的由datadistillationtm装置对于各种使用模型所产生的简化数据的各个分量(或组成部分)。
具体实施方式
给出后面的描述是为了使得本领域技术人员能够制作和使用本发明,并且是在特定应用及其需求的情境中所提供的。本领域技术人员将很容易认识到针对所公开的实施例的各种修改,并且这里所定义的一般原理可以被应用于其他实施例和应用而不会背离本发明的精神和范围。因此,本发明不限于所示出的实施例,而是应当符合与这里所公开的原理和特征相一致的最宽泛的范围。在本公开内容中,当某一短语对于一个实体集合使用术语“和/或”时,除非另行表明,否则所述短语涵盖所述实体集合的所有可能组合。举例来说,短语“x、y和/或z”涵盖以下其中组合:“只有x”,“只有y”,“只有z”,“x和y,但是没有z”,“x和z,但是没有y”,“y和z,但是没有x”,以及“x、y和z”。
使用内容关联滤筛的数据的高效无损简化
在这里所描述的一些实施例中,数据被组织和存储,以便在整个数据集的全局范围内高效地发现和利用冗余。输入数据流被分解成被称作单元的构成片段或组块,并且以比单元本身更细的粒度检测和利用各个单元当中的冗余,从而减缩所存储的数据的总体足迹。识别出被称作基本数据单元的一个单元集合并且将其用作数据集的共同的共享构建块,并且将其存储在被称作基本数据存储库或滤筛的结构中。基本数据单元简单地是具有特定大小的比特、字节或数位的序列。取决于实现方式,基本数据单元可以是固定大小或可变大小。输入数据的其他构成单元从基本数据单元导出,并且被称作导出单元。因此,输入数据被因式分解成基本数据单元和导出单元。
基本数据存储库对基本数据单元进行排序和组织,从而使得可以按照内容关联方式对基本数据存储库进行搜索和存取。在给定一些输入内容和一些限制的情况下可以对基本数据存储库进行查询以取回包含该内容的基本数据单元。在给定输入单元的情况下,可以使用所述单元的值或者所述单元中的特定字段的值对基本数据存储库进行搜索,以便快速地提供一个基本数据单元或者较小的基本数据单元集合,从中可以导出输入单元并且只利用规定所述导出所需的最小存储。在一些实施例中,基本数据存储库中的单元被组织成树形式。通过在基本数据单元上实施变换从基本数据单元导出导出单元,这样的变换被规定在重建程序中,所述重建程序描述如何从一个或多个基本数据单元生成导出单元。距离阈值规定关于导出单元的所存储足迹的大小的限制。该阈值有效地规定导出单元与基本数据单元的最大可允许距离,并且还对可以被用来生成导出单元的重建程序的大小作出限制。
导出数据的取回是通过在由所述导出规定的一个或多个基本数据单元上执行重建程序而实现的。
在本公开内容中,前面描述的通用无损数据简化技术可以被称作datadistillationtm处理。所述处理实施类似于化学中的蒸馏的功能——把混合物分离成其构成单元。基本数据存储库也被称作滤筛或datadistillationtm滤筛。
在这种方案中,输入数据流被因式分解成一个单元序列,其中每一个单元是基本数据单元或者从一个或多个基本数据单元导出的导出单元。每一个单元被变换成无损简化表示,所述无损简化表示在基本数据单元的情况下包括对基本数据单元的引用,并且在导出单元的情况下包括对所述导出中所涉及的一个或多个基本数据单元的引用,以及关于重建程序的描述。因此,输入数据流被因式分解成处于无损简化表示中的单元序列。(出现在无损简化表示中的)该单元序列被称作蒸馏数据流或蒸馏数据。蒸馏数据中的单元序列与输入数据中的单元序列具有一一对应关系,也就是说蒸馏数据中的单元序列中的第n个单元对应于输入数据中的单元序列中的第n个单元。
在本公开内容中描述的通用无损数据简化技术接收输入数据流并且将其转换成蒸馏数据流与基本数据存储库的组合,从而使得蒸馏数据流和基本数据存储库的足迹的总和通常小于输入数据流的足迹。在本公开内容中,蒸馏数据流和基本数据存储库被统称作无损简化数据,并且将被可互换地称作“简化数据流”或“简化数据”或“reduceddata(简化数据)”。同样地,对于通过本公开内容中描述的无损数据简化技术所产生的出现在无损简化格式中的单元序列,可互换地使用以下术语:“简化输出数据流”、“简化输出数据”、“蒸馏数据流”、“蒸馏数据”以及“distilleddata(蒸馏数据)”。
图1a示出了根据这里所描述的一些实施例的用于数据简化的方法和装置,其把输入数据因式分解成各个单元并且从驻留在基本数据存储库中的基本数据单元导出这些单元。该图示出了数据简化或datadistillationtm方法和装置的总体方块图,并且提供了功能组件、结构和操作的总览。图1a中示出的组件和/或操作可以使用软件、硬件或其组合来实现。
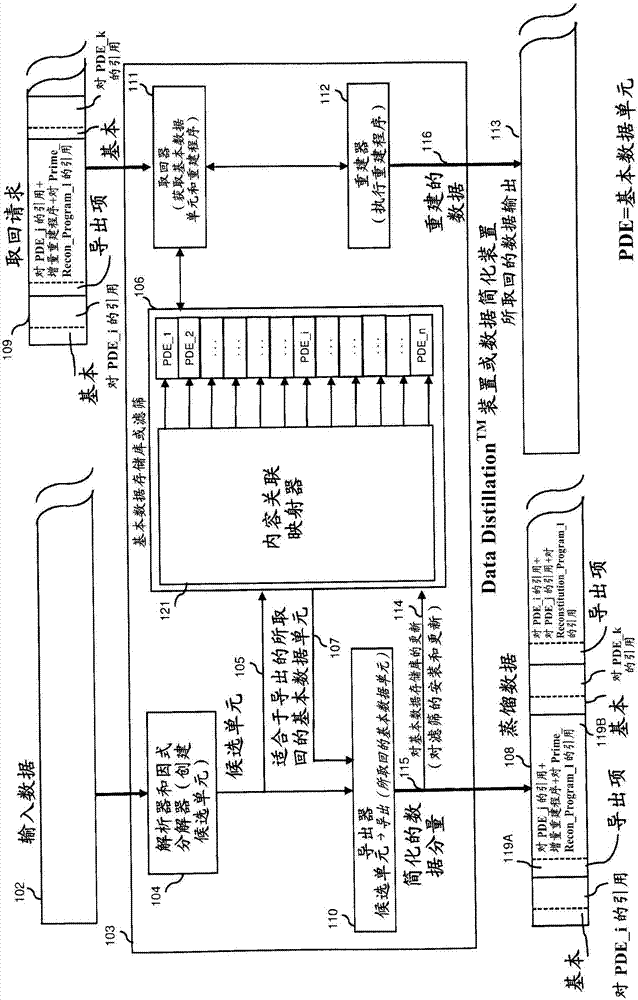
从输入数据流接收字节序列并且将其作为输入数据102给出到数据简化装置103,其也被称作datadistillationtm装置。解析器和因式分解器104对传入数据进行解析并且将其分解成组块或候选单元。因式分解器决定将在输入流中的何处插入中断以便把该流切分成候选单元。一旦识别出数据中的两处接连的中断,则由解析器和因式分解器创建候选单元105并且将其给出到基本数据存储库106,所述基本数据存储库也被称作datadistillationtm滤筛。
datadistillationtm滤筛或基本数据存储库106包含所有基本数据单元(在图1a中被标记成pde),并且基于其值或内容对其进行排序和组织。所述滤筛提供对于两种存取的支持。首先,可以通过对基本数据单元驻留在滤筛中的位置的位置的引用对每一个基本数据单元进行直接存取。其次,可以通过使用内容关联映射器121按照内容关联方式对各个单元进行存取,所述内容关联映射器121可以通过软件、硬件或其组合来实施。针对滤筛的这种第二存取形式是一项重要的特征,并且由所公开的实施例使用来识别与候选单元105精确地匹配的基本数据单元,或者用来识别可以从中导出候选单元的基本数据单元。具体来说,在给定候选单元(例如候选单元105)的情况下,可以对基本数据存储库106进行搜索(基于候选单元105的值或者基于候选单元105中的特定字段的值),以便快速地提供一个基本数据单元107或者基本数据单元107的较小集合,从中可以导出候选单元并且只利用规定所述导出所需的最小存储。
可以利用其值分散在数据空间内的一个基本数据单元集合对所述滤筛或基本数据存储库106进行初始化。或者根据这里参照图1a-c和图2所描述的datadistillationtm处理,所述滤筛最初可以是空的,并且可以随着摄取数据将基本数据单元动态地添加到所述滤筛。
导出器110接收候选单元105以及所取回的适合于导出的基本数据单元107(从基本数据存储库106相关联地取回的内容),确定是否可以从这些基本数据单元当中的一个或多个导出候选单元105,生成简化数据分量115(由对相关的基本数据单元的引用和重建程序构成),并且向基本数据存储库提供更新114。如果候选单元是所取回的基本数据单元的重复,则导出器在蒸馏数据108中放入对位于基本数据存储库中的基本数据单元的引用(或指针),并且还有表明这是基本数据单元的指示。如果没有找到重复,则导出器把候选单元表达成在一个或多个所取回的基本数据单元上实施的一项或多项变换的结果,其中所述变换序列被统称作重建程序,例如重建程序119a。每一项导出可能需要由导出器构造该项导出自身所独有的程序。重建程序规定可以对基本数据单元应用的例如插入、删除、替换、串联、算术以及逻辑运算之类的变换。如果导出单元的足迹(被计算成重建程序的大小加上针对所需的基本数据单元的引用的大小)处在关于候选单元的特定的指定距离阈值之内(以便允许数据简化),则把候选单元改订成导出单元并且由重建程序与对(多个)相关基本数据单元的引用的组合替换——这些形成本例中的简化数据分量115。如果超出所述阈值,或者如果没有从基本数据存储库取回适当的基本数据单元,则可以指示基本数据存储库把所述候选安装成新鲜基本数据单元。在这种情况下,导出器在蒸馏数据中放入对新添加的基本数据单元的引用,并且还有表明这是基本数据单元的指示。
对数据取回的请求(例如取回请求109)可以采取对基本数据存储库中的包含基本数据单元的位置的引用的形式,或者在导出项的情况下可以采取对基本数据单元的此类引用与相关联的重建程序的组合的形式(或者在基于多个基本数据单元的导出项的情况下是对多个基本数据单元的引用与相关联的重建程序的组合)。通过使用对基本数据存储库中的基本数据单元的一项或多项引用,取回器111可以对基本数据存储库进行存取以便取回一个或多个基本数据单元,并且把所述一个或多个基本数据单元以及重建程序提供到重建器112,所述重建器112在所述一个或多个基本数据单元上执行(在重建程序中规定的)变换以便生成重建数据116(也就是所请求的数据),并且响应于数据取回请求将其递送到取回数据输出113。
在该实施例的一种变型中,基本数据单元可以通过压缩形式(使用本领域内已知的技术,包括huffman编码和lempelziv方法)被存储在滤筛中,并且在需要时被解压缩。这样做的优点是简化了基本数据存储库的总体足迹。唯一的约束在于内容关联映射器121必须像以前一样继续提供对于基本数据单元的内容关联存取。
图1b和1c示出了根据这里所描述的一些实施例的图1a中所示的方法和装置的变型。在图1b中,重建程序可以被存储在基本数据存储库中,并且像基本数据单元那样被对待。对重建程序的引用或指针119b被提供在蒸馏数据108中,而不是提供重建程序119a本身。如果重建程序由其他导出项共享,并且如果对重建程序的引用或指针(加上在重建程序与对重建程序的引用之间作出区分所需的任何元数据)所需的存储空间小于重建程序本身,则实现进一步的数据简化。
在图1b中,重建程序可以像基本数据单元那样被对待和存取,并且作为基本数据单元被存储在基本数据存储库中,从而允许从基本数据存储库对重建程序进行内容关联搜索和取回。在用以创建导出单元的导出处理期间,一旦导出器110确定对于导出所需要的重建程序,其随后可以确定该候选重建程序是否已经存在于基本数据存储库中,或者确定是否可以从已经存在于基本数据存储库中的另一个条目导出该候选重建程序。如果候选重建程序已经存在于基本数据存储库中,则导出器110可以确定对所述预先存在的条目的引用,并且把所述引用包括在蒸馏数据108中。如果可以从已经驻留在基本数据存储库中的现有条目导出候选重建程序,则导出器可以把候选重建程序的导出项或改订递送到蒸馏数据,也就是说导出器在蒸馏数据中放入对预先存在于基本数据存储库中的条目的引用连同从所述预先存在的条目导出候选重建程序的增量重建程序。如果候选重建程序既不存在于基本数据存储库中也无法从基本数据存储库中的条目导出,则导出器110可以把重建程序添加到基本数据存储库中(把重建程序添加到存储库的操作可以返回对新添加的条目的引用),并且把对重建程序的引用包括在蒸馏数据108中。
图1c给出了根据这里所描述的一些实施例的图1b中所示的方法和装置的一种变型。具体来说,图1c中的被用来存储和查询重建程序的机制类似于被用来存储和查询基本数据单元的机制,但是重建程序被保持在与包含基本数据单元的结构分开的结构中。这样的结构中的条目被称作基本重建程序(在图1c中被标记为prp)。回想到基本数据存储库106包括支持快速内容关联查找操作的内容关联映射器121。图1c中示出的实施例包括类似于内容关联映射器121的内容关联映射器122。在图1c中,内容关联映射器122和内容关联映射器121被显示成基本数据存储库或滤筛106的一部分。在其他实施例中,内容关联映射器122和重建程序可以与基本数据存储库或滤筛106分开存储。
在该实施例的一种变型中,基本数据单元可以通过压缩形式(使用本领域内已知的技术,包括huffman编码和lempelziv方法)被存储在滤筛中,并且在需要时被解压缩。同样地,基本重建程序可以通过压缩形式(使用本领域内已知的技术,包括huffman编码和lempelziv方法)被存储在基本重建程序滤筛中,并且在需要时被解压缩。这样做的优点是减缩了基本数据滤筛和基本重建程序滤筛的总体足迹。唯一的约束在于内容关联映射器121和122必须像以前一样继续提供对于基本数据单元和基本重建程序的内容关联存取。
图1d给出了根据这里所描述的一些实施例的图1a中所示的方法和装置的一种变型。具体来说,在图1d所描述的实施例中,基本数据单元被内联存储在蒸馏数据中。基本数据滤筛或基本数据存储库106继续提供对于基本数据单元的内容关联存取,并且继续在逻辑上包含基本数据单元。其保持对内联位于蒸馏数据中的基本数据单元的引用或链接。例如在图1d中,基本数据单元130内联位于蒸馏数据108中。基本数据滤筛或基本数据存储库106保持对基本数据单元130的引用131。同样地,在这种设置中,导出单元的无损简化表示将包含对所需的基本数据单元的引用。在数据取回期间,取回器111将从所需的基本数据单元所处的位置获取所述基本数据单元。
图1e给出了根据这里所描述的一些实施例的图1d中所示的方法和装置的一种变型。具体来说,在图1e所描述的实施例中,与图1b中所示出的设置一样,重建程序可以从其他基本重建程序导出,并且被规定为增量重建程序加上对基本重建程序的引用。这样的基本重建程序像基本数据单元一样被对待,并且在逻辑上被安装在基本数据滤筛中。此外,在这种设置中,基本数据单元和基本重建程序都被内联存储在蒸馏数据中。基本数据滤筛或基本数据存储库106继续提供对于基本数据单元和基本重建程序的内容关联存取,并且继续在逻辑上包含这些基本数据单元和基本重建程序,同时保持对这些基本数据单元和基本重建程序内联位于蒸馏数据中的位置的引用或链接。例如在图1e中,基本数据单元130内联位于蒸馏数据108中。同样地在图1e中,基本重建程序132内联位于蒸馏数据中。基本数据滤筛或基本数据存储库106保持对基本数据单元130(即pde_i)的引用131(即reference_to_pde_i),以及对基本重建程序132(即prime_recon_program_l)的引用133(即reference_to_pde_j)。同样地,在这种设置中,导出单元的无损简化表示将包含对所需的基本数据单元和所需的基本重建程序的引用。在数据取回期间,取回器111将从所需的分量在相应的蒸馏数据中所处的位置获取所述分量。
图1f给出了根据这里所描述的一些实施例的图1e中所示的方法和装置的一种变型。具体来说,在图1f所描述的实施例中,与图1c中所示出的设置一样,基本数据滤筛108包含分开的映射器——用于基本数据单元的内容关联映射器121和用于基本重建程序的内容关联映射器122。
图1g给出了图1a到1f中所示的方法和装置的一种更加一般化的变型。具体来说,在图1g所描述的实施例中,基本数据单元可以位于基本数据滤筛中或者内联位于蒸馏数据中。一些基本数据单元可以位于基本数据滤筛中,其他的基本数据单元则内联位于蒸馏数据中。同样地,基本重建程序可以位于基本数据滤筛中或者内联位于蒸馏数据中。一些基本重建程序可以位于基本数据滤筛中,其他的基本重建程序则内联位于蒸馏数据中。基本数据滤筛在逻辑上包含所有基本数据单元和基本重建程序,并且在基本数据单元或基本重建程序内联位于蒸馏数据中的情况下,基本数据滤筛提供对其位置的引用。
前面对于把输入数据因式分解成各个单元并且从驻留在基本数据存储库中的基本数据单元导出这些单元的用于数据简化的方法和装置的描述仅仅是出于说明和描述的目的而给出的。所述描述不意图进行穷举或者把本发明限制到所公开的形式。因此,本领域技术人员将会想到许多修改和变型。
图1h给出了根据这里所描述的一些实施例的描述用于datadistillationtm处理的方法和装置的图1a中的蒸馏数据119a的结构的格式和规范的一个实例。由于datadistillationtm处理把输入数据因式分解成基本数据单元和导出单元,因此用于数据的无损简化表示的格式在蒸馏数据中标识这些单元并且描述这些单元的各个分量。自描述格式标识蒸馏数据中的每一条记录,表明其是基本数据单元还是导出单元,并且描述各个分量,也就是对安装在滤筛中的一个或多个基本数据单元的引用,对安装在基本数据存储库中的重建程序的引用(如图1b的119b),或者对存储在重建程序(rp)存储库中的重建程序的引用(如图1c的119c),以及内联重建程序(rp)。重建程序(rp)存储库也被可互换地称作基本重建程序(prp)存储库。图1h中的格式通过在多个基本数据单元上执行重建程序而规定导出,其中导出单元和每一个基本数据单元的大小是独立地可规定的。图1h中的格式还规定内联位于蒸馏数据中而不是位于基本数据存储库内的基本数据单元。这是通过操作码编码7规定的,其规定单元的类型是内联位于蒸馏数据中的基本数据单元。蒸馏数据使用该格式被存储在数据存储系统中。该格式中的数据被数据取回器111消耗,从而可以获取并且随后重建数据的各个分量。
图1i到1p示出了对应于图1a到图1g中示出的用于数据简化的方法和装置的各种变型的输入数据到无损简化形式的概念性变换。图1i示出了输入数据流如何被因式分解成候选单元,并且随后候选单元被视为基本数据单元或导出单元。最后,数据被变换成无损简化形式。图1i到1n示出了对应于各个实施例的无损简化形式的各种变型。
图1i和图1j示出了通过图1a中所示的方法和装置所产生的数据的无损简化形式的实例。图1i中的无损简化形式包括内容关联映射器,并且是允许连续的进一步数据摄取以及针对现有的基本数据单元简化该数据的形式,与此同时,图1j中的无损简化形式不再保留内容关联映射器,从而导致更小的数据足迹。图1k和图1l示出了通过图1c中所示的方法和装置所产生的数据的无损简化形式的实例。图1k中的无损简化形式包括内容关联映射器,并且是允许连续的进一步数据摄取以及针对现有的基本数据单元和基本重建程序简化该数据的形式,与此同时,图1l中的无损简化形式不再保留内容关联映射器,从而导致更小的数据足迹。
图1m和图1n示出了通过图1f中所示的方法和装置所产生的数据的无损简化形式的实例,其中基本数据单元和基本重建程序内联位于蒸馏数据中。图1m中的无损简化形式包括内容关联映射器,并且是允许连续的进一步数据摄取以及针对现有的基本数据单元和基本重建程序简化该数据的形式,与此同时,图1n中的无损简化形式不再保留内容关联映射器,从而导致更小的数据足迹。图1o和图1p示出了通过图1g中所示的方法和装置所产生的数据的无损简化形式的实例,其中基本数据单元和基本重建程序可以内联位于蒸馏数据中或者位于基本数据滤筛中。图1o中的无损简化形式包括内容关联映射器,并且是允许连续的进一步数据摄取以及针对现有的基本数据单元和基本重建程序简化该数据的形式,与此同时,图1p中的无损简化形式不再保留内容关联映射器,从而导致更小的数据足迹。
在图1a到p所示出的实施例的变型中,简化数据的各个分量可以使用本领域内已知的技术(比如huffman编码和lempelziv方法)被进一步简化或压缩,并且通过该压缩形式被存储。这些分量可以随后在需要被使用在数据蒸馏装置中时被解压缩。这样做的好处是进一步简化了数据的总体足迹。
图2示出了根据这里所描述的一些实施例的通过把输入数据因式分解成各个单元并且从驻留在基本数据存储库中的基本数据单元导出这些单元而进行数据简化的处理。随着输入数据到达,其可以被解析和因式分解或者分解成一系列候选单元(操作202)。从输入消耗下一个候选单元(操作204),并且基于候选单元的内容对基本数据存储库实施内容关联查找,以便查看是否存在可以从中导出候选单元的任何适当的单元(操作206)。如果基本数据存储库没有找到任何这样的单元(操作208的“否”分支),则候选单元将作为新的基本数据单元被分配并且输入到滤筛中,并且在蒸馏数据中为候选单元创建的条目将是对新创建的基本数据单元的引用(操作216)。如果对基本数据存储库的内容关联查找确实产生可以潜在地从中导出候选单元的一个或多个适当的单元(操作208的“是”分支),则在所取回的基本数据单元上实施分析和计算以便从中导出候选单元。应当提到的是,在一些实施例中,首先仅获取用于适当的基本数据单元的元数据并且在所述元数据上实施分析,并且只有在认为有用的情况下才随后获取适当的基本数据单元(在这些实施例中,用于基本数据单元的元数据提供关于基本数据单元的内容的一些信息,从而允许系统基于元数据快速地排除匹配或者评估可导出性)。在其他实施例中,基本数据存储库直接取回基本数据单元(也就是说在取回基本数据单元之前并不首先取回元数据以便对元数据进行分析),从而在所取回的基本数据单元上实施分析和计算。
实施第一检查以便查看候选是否任何这些单元的重复(操作210)。可以使用任何适当的散列技术加速这一检查。如果候选与从基本数据存储库取回的基本数据单元完全相同(操作210的“是”分支),则蒸馏数据中的为候选单元创建的条目由对该基本数据单元的引用以及表明该条目是基本数据单元的指示所替换(操作220)。如果没有找到重复(操作210的“否”分支),则基于候选单元从基本数据存储库取回的条目被视为潜在地可以从中导出候选单元的条目。以下是基本数据存储库的重要、新颖而且并非是显而易见的特征:当没有在基本数据存储库中找到重复时,基本数据存储库可以返回基本数据单元,所述基本数据单元虽然并非与候选单元完全相同,却是可以潜在地通过对(多个)基本数据单元应用一项或多项变换而导出候选单元的单元。所述处理随后可以实施分析和计算,以便从最适当的基本数据单元或者适当的基本数据单元的集合导出候选单元(操作212)。在一些实施例中,所述导出把候选单元表达成在一个或多个基本数据单元上实施的变换的结果,这样的变换被统称作重建程序。每一项导出可能需要构造其自身独有的程序。除了构造重建程序之外,所述处理还可以计算通常表明存储候选单元的改订以及从所述改订重建候选单元所需要的存储资源和/或计算资源的水平的距离量度。在一些实施例中,导出单元的足迹被用作从(多个)基本数据单元到候选的距离度量——具体来说,距离量度可以被定义成重建程序的大小加上对在导出中所涉及的一个或多个基本数据单元的引用的大小的总和。可以选择具有最短距离的导出。把对应于该导出的距离与距离阈值进行比较(操作214),如果该距离没有超出距离阈值,则接受该导出(操作214的“是”分支)。为了产生数据简化,所述距离阈值必须总是小于候选单元的大小。举例来说,距离阈值可以被设定到候选单元大小的50%,从而使得只有在导出项的足迹小于或等于候选单元足迹的一半时才接收导出项,从而对于为之存在适当导出的每一个候选单元确保2x或更大的简化。距离阈值可以是预定的百分比或分数,其或者是基于用户规定的输入或者是由系统选择。距离阈值可以由系统基于系统的静态或动态参数确定。一旦导出被接收,候选单元被改订并且被重建程序与对一个或多个基本数据单元的引用的组合所替换。蒸馏数据中的为候选单元创建的条目被所述导出所替换,也就是说被表明这是导出单元的指示连同重建程序加上对在导出中所涉及的一个或多个基本数据单元的引用所替换(操作218)。另一方面,如果对应于最佳导出的距离超出距离阈值(操作214中的“否”分支),则将不会接收任何可能的导出项。在这种情况下,候选单元可以作为新的基本数据单元被分配并且输入到滤筛中,并且在蒸馏数据中为候选单元创建的条目将是对新创建的基本数据单元的引用连同表明这是基本数据单元的指示(操作216)。
最后,所述处理可以检查是否存在任何附加的候选单元(操作222),并且如果还有更多候选单元则返回操作204(操作222的“是”分支),或者如果没有更多候选单元则终止处理(操作222的“否”分支)。
可以采用多种方法来实施图2中的操作202,也就是对传入数据进行解析并且将其分解成候选单元。因式分解算法需要决定将在字节流中的何处插入中断以便把该流切分成候选单元。可能的技术包括(而不限于)把流分解成固定大小块(比如4096字节的页面),或者应用指纹处理方法(比如对输入流的子串应用随机素多项式的技术)以便在数据流中定位变成单元边界的指纹(这种技术可以导致可变大小单元),或者对输入进行解析以便检测报头或者某种预先声明的结构并且基于该结构来界定单元。可以对输入进行解析以便检测通过图式(schema)声明的特定结构。可以对输入进行解析以便在数据中检测预先声明的模式、语法或规则表达法的存在。一旦识别出数据中的两处接连的中断,则创建候选单元(所述候选单元是位于所述两处接连的中断之间的数据)并且将其呈现到基本数据存储库以供内容关联查找。如果创建了可变大小单元,则需要规定候选单元的长度并且作为元数据与候选单元一起携带。
基本数据存储库的一项重要功能是基于为之给出的候选单元而提供内容关联查找并且快速地提供一个基本数据单元或者较小的基本数据单元集合,从中可以导出候选单元并且只利用规定所述导出所需的最小存储。在给定较大数据集的情况下,这是一个困难的问题。在给定以太字节计的数据的情况下,即使对于千字节大小的单元,仍然要搜索数以十亿计的单元并且从中作出选择。这一问题在更大的数据集上甚至会更加严重。因此变得很重要的是使用适当的技术对单元进行组织和排序,并且随后在单元的该组织内检测相似性和可导出性,以便能够快速地提供适当的基本数据单元的较小集合。
可以基于每一个单元(也就是基本数据单元)的值对滤筛中的条目进行排序,从而可以按照升序或降序通过值来安排所有的条目。或者可以沿着基于单元中的特定字段的值的主轴对条目进行排序,随后是使用单元的其余内容的次要轴。在本上下文中,字段是来自单元的内容的邻接字节的集合。可以通过对单元的内容应用指纹处理方法来定位字段,从而使得指纹的位置标识字段的位置。或者可以选择单元内容内部的特定的固定偏移量以便定位字段。还可以采用其他方法以定位字段,其中包括而不限于对单元进行解析以便检测所声明的特定结构并且定位该结构内的字段。
在另一种形式的组织中,单元内的特定字段或字段组合可以被视为维度,从而可以使用这些维度的串联以及随后的每一个单元的剩余内容对数据单元进行排序和组织。一般来说,字段与维度之间的对应性或映射可以是任意地复杂。例如在一些实施例中,确切地一个字段可以映射到确切地一个维度。在其他实施例中,多个字段的组合(例如f1、f2和f3)可以映射到一个维度。可以通过串联两个字段或者通过对其应用任何其他适当的功能而实现字段的组合。重要的要求是被用来对单元进行组织的字段、维度以及单元的剩余内容的安排必须允许通过其内容唯一地识别所有基本数据单元并且在滤筛中对其进行排序。
在一些实施例中,单元的内容可以被表示成下面的表达法:单元=头部.*sig1.*sig2.*…sigi.*…sign.*尾部,其中“头部”是包括单元的开头字节的字节序列,“尾部”是包括单元的结尾字节的字节序列,“sig1”、“sig2”、“sigi”和“sign”是表征单元的单元内容主体内的特定长度的各个签名或模式或规则表达法或字节序列。各个签名之间的表达法“.*”是通配符表达法,也就是允许除了表达法“.*”之后的签名之外的其他任何值的任意数目的中间字节的规则表达法标记。在一些实施例中,n元组(sig1,sig2,…sigi,…sign)被称作单元的骨架数据结构或骨架,并且可以被视为单元的简化实质子集或实质。在其他实施例中,(n+2)元组(头部,sig1,sig2,…sigi,…sign,尾部)被称作单元的骨架数据结构或骨架。或者可以采用头部或尾部连同其余签名的n+1元组。
可以对单元的内容应用指纹处理方法,以便确定单元内容内的骨架数据结构的各个分量(或签名)的位置。或者可以选择单元内容内部的特定的固定偏移量以便定位分量。还可以采用其他方法来定位骨架数据结构的分量,其中包括而不限于对单元进行解析以便检测所声明的特定结构并且定位该结构内的分量。可以基于其骨架数据结构在滤筛中对基本数据单元进行排序。换句话说,单元的骨架数据结构的各个分量可以被视为维度,从而可以使用这些维度的串联以及随后的每一个单元的剩余内容对滤筛中的基本数据单元进行排序和组织。
一些实施例把输入数据因式分解成候选单元,其中每一个候选单元的大小显著大于对全局数据集中的所有此类单元进行存取所需要的引用的大小。关于被分解成此类数据组块(并且按照内容关联方式被存取)的数据的一项观察是,实际的数据关于数据组块所能规定的全部可能值是非常稀疏的。例如考虑1泽字节数据集。需要大约70个比特对数据集中的每一个字节进行寻址。在128字节(1024比特)的组块大小下,在1泽字节数据集中近似有263个组块,因此需要63个比特(少于8个字节)对所有组块进行寻址。应当提到的是,1024比特的单元或组块可以具有21024个可能值当中的一个,而数据集中的给定组块的实际值的数目最多是263个(如果所有组块都不同的话)。这表明实际的数据关于通过一个单元的内容所能达到或命名的值的数目是极为稀疏的。这就允许使用非常适合于组织非常稀疏的数据的树结构,从而允许高效的基于内容的查找,允许把新的单元高效地添加到树结构,并且在对于树结构本身所需要的增量存储方面是成本有效的。虽然在1泽字节数据集中仅有263个不同的组块,从而只需要63个区分信息比特将其区别开,但是相关的区分比特可能分散在单元的整个1024个比特上,并且对于每一个单元出现在不同的位置处。因此,为了完全区分所有单元,仅仅检查来自内容的固定的63比特是不够的,相反,整个单元内容都需要参与单元的分拣,特别在提供对于数据集中的任一个和每一个单元的真实内容关联存取的解决方案中尤其是如此。在datadistillationtm框架中,希望能够在被用来对数据进行排序和组织的框架内检测可导出性。考虑到所有前述内容,基于内容的树结构(其随着检查更多内容逐渐地区分数据)是对经过因式分解的数据集中的所有单元进行排序和区分的适当组织。这样的结构提供了可以被作为可导出单元的分组或者具有类似的可导出性属性的单元分组来对待的许多中间子树等级。这样的结构可以利用表征每一个子树的元数据或者利用表征每一个数据单元的元数据通过分级方式被加强。这样的结构可以有效地传达其所包含的整个数据的构成,包括数据中的实际值的密度、邻近性和分布。
一些实施例把基本数据单元按照树形式组织在滤筛中。每一个基本数据单元具有从该基本数据单元的整个内容构造的独特“名称”。该名称被设计成足以唯一地标识基本数据单元,并且将其与树中的所有其他单元作出区分。可以通过几种方式从基本数据单元的内容构造名称。名称可以简单地由基本数据单元的所有字节构成,这些字节按照其存在于基本数据单元中的相同顺序出现在名称中。在另一个实施例中,被称作维度的特定字段或字段组合(其中字段和维度在前面作了描述)被用来形成名称的开头字节,基本数据单元的其余内容则形成名称的其余部分,从而使得基本数据单元的整个内容都参与创建单元的完整并且唯一的名称。在另一个实施例中,单元的骨架数据结构的字段被选择成维度(其中字段和维度在前面作了描述),并且被用来形成名称的开头字节,基本数据单元的其余内容形成名称的其余部分,从而使得基本数据单元的整个内容都参与创建单元的完整并且唯一的名称。
每一个基本数据单元的名称被用来在树中对基本数据单元进行排序和组织。对于大多数实际的数据集,即使是大小非常大的那些数据集(比如由258个4kb大小单元构成的1泽字节数据集),也预期到名称的较小字节子集将常常可以用来对树中的大部分基本数据单元进行分拣和排序。
图3a、3b、3c、3d和3e示出了根据这里所描述的一些实施例的可以被用来基于其名称对基本数据单元进行组织的不同的数据组织系统。
图3a示出了前缀树(trie)数据结构,其中基于来自每一个基本数据单元的相继字节的值把基本数据单元组织在逐渐更小的群组中。在图3a所示的实例中,每一个基本数据单元具有从该基本数据单元的整个内容构造的独特名称,该名称简单地由基本数据单元的所有字节构成,这些字节按照其存在于基本数据单元中的相同顺序出现在名称中。前缀树的根节点表示所有基本数据单元。前缀树的其他节点表示基本数据单元的子集或群组。从前缀树的根节点或第1级(在图3a中被标记成根302)开始,基于其名称的最高有效字节(在图3a中被标记成n1)的值把基本数据单元分组到子树中。在其名称的最高有效字节中具有相同值的所有基本数据单元将被一起分组到共同的子树中,并且通过该值标示的链接将从根节点存在到表示该子树的节点。例如在图3a中,节点303表示分别在其对应名称的最高有效字节n1中具有相同的值2的基本数据单元的子树或群组。在图3a中,该群组包括基本数据单元305、306和307。
在前缀树的第二级,每一个基本数据单元的名称的第二最高有效字节被用来把每一个基本数据单元群组进一步划分成更小的子组。例如在图3a中,使用第二最高有效字节n2把由节点303表示的基本数据单元群组进一步细分成各个子组。节点304表示在其对应名称的最高有效字节n1中具有值2并且在第二最高有效字节n2中具有值1的基本数据单元的子组。该子组包括基本数据单元305和306。
所述细分处理在前缀树的每一级继续,从而创建从亲代节点到每一个子代节点的链接,其中子代节点表示通过亲代节点表示的基本数据单元的一个子集。这一处理继续到在前缀树的叶子处只有单独的基本数据单元为止。叶节点表示叶子的群组。在图3a中,节点304是叶节点。由节点304表示的基本数据单元的群组包括基本数据单元305和306。在图3a中,通过使用其名称的第三最高有效字节,该群组被进一步细分成单独的基本数据单元305和306。值n3=3导致基本数据单元305,值n3=5则导致基本数据单元306。在该例中,其完整名称当中的仅仅3个有效字节就足以完全标识基本数据单元305和306。同样地,来自名称的仅仅两个有效字节就足以标识基本数据单元307。
该例示出了在基本数据单元的给定混合中如何只有名称的一个字节子集用来在树中标识基本数据单元,并且不需要整个名称以到达独有的基本数据单元。此外,基本数据单元或者基本数据单元的群组可能分别需要不同数目的有效字节以便能够对其进行唯一标识。因此,从根节点到基本数据单元的前缀树深度对于不同的基本数据单元可以是不同的。此外,在前缀树中,每一个节点可能具有下降到下方的子树的不同数目的链接。
在这样的前缀树中,每一个节点具有由规定如何到达该节点的字节序列构成的名称。举例来说,对应于节点304的名称是“21”。此外,在树中的当前单元分布中唯一地标识单元的来自单元名称的字节子集是从根节点去到该基本数据单元的“路径”。例如在图3a中,具有值213的路径301标识基本数据单元305。
这里所描述的前缀树结构可能会产生很深的树(也就是具有许多等级的树),这是因为树中的单元名称的每一个区分字节都为前缀树增加了一级深度。
应当提到的是,图3a-3e中的树数据结构是从左向右绘制的。因此当我们从图的左侧向图的右侧移动时,我们从树的更高等级移动到树的较低等级。在给定节点的下方(也就是说朝向图3a-3e中的给定节点的右侧),对于通过来自名称的区分字节的特定值所选择的任何子代,驻留在该子代下方的各个子树中的所有单元在单元名称中的该相应字节中都将具有相同的值。
现在我们将描述一种在给定输入候选单元的情况下对前缀树进行内容关联查找的方法。此方法涉及使用候选单元的名称对前缀树结构进行导航,随后进行后续的分析和筛选以便决定作为总体内容关联查找的结构将返回什么。换句话说,前缀树导航处理返回第一结果,随后在该结果上实施分析和筛选以便确定总体内容关联查找的结果。
为了开始前缀树导航处理,来自候选单元的名称的最高有效字节的值将被用来选择从根节点到一个后续节点的链接(由该值表示),所述后续节点表示在其名称的最高有效字节中具有该相同值的基本数据单元的子树。从该节点继续,检查来自候选单元的名称的第二字节并且选择由该值标示的链接,从而前进到前缀树中的更深(或更低)一级,并且选择现在与候选单元共享来自其名称的至少两个有效字节的基本数据单元的更小子组。这一处理继续到到达单一基本数据单元为止,或者继续到没有链接与来自候选单元的名称的相应字节的值相匹配为止。在这些条件当中的任一条件下,树导航处理终止。如果到达单一基本数据单元,则可以将其返回以作为前缀树导航处理的结果。如果没有,一种替换方案是报告“错失(miss)”。另一种替换方案是返回以导航终止的节点为根部的子树中的多个基本数据单元。
一旦前缀树导航处理终止,可以使用其他标准或要求对前缀树导航处理的结果进行分析和筛选,以便确定作为内容关联查找的结果应当返回什么。举例来说,当由前缀树导航处理返回单一基本数据单元或多个基本数据单元时,在有资格作为内容关联查找的结果被返回之前,可以附加地要求其与候选单元的名称共享特定最小数目的字节(否则内容关联查找返回错失)。筛选要求的另一个实例可以是如果前缀树导航处理在没有到达单一基本数据单元的情况下终止从而返回多个基本数据单元(以前缀树导航终止的节点为根部)以作为前缀树导航处理的结果,则只有在所述多个基本数据单元的数目少于所规定的特定限制的情况下,这些单元才将有资格作为总体内容关联查找的结果被返回(否则内容关联查找返回错失)。可以采用多项要求的组合来确定内容关联查找的结果。通过这种方式,查找处理将报告“错失”或返回单一基本数据单元,或者如果不是单一基本数据单元,则是可能作为用于导出候选单元的良好起点的基本数据单元的集合。
下面描述的图3b-3e涉及图3a中示出的树数据结构的变型和修改。虽然这些变型提供了优于图3a中示出的前缀树数据结构的改进和优点,但是用于对所述数据结构进行导航的处理类似于前面参照图3a所描述的处理。也就是说,在对于图3b-3e中示出的树数据结构的树导航终止之后,实施后续分析和筛选以便确定总体内容关联查找的结果,所述总体处理返回错失、单一基本数据单元或者可能作为用于导出候选单元的良好起点的基本数据单元的集合。
图3b示出了可以被用来基于其名称对基本数据单元进行组织的另一种数据组织系统。在图3b所示出的实例中,每一个基本数据单元具有从该基本数据单元的整个内容构造的独特名称,该名称简单地由基本数据单元的所有字节构成,这些字节按照其存在于基本数据单元中的相同顺序出现在名称中。图3b示出了一种更加紧凑的结构,其中单一链接采用来自下方子树中的基本数据单元的名称的多个字节(而不是使用在图3a的前缀树中的单一字节),以便产生细分或下一级的分组。从亲代节点到子代节点的链接现在由多个字节标示。此外,来自任何给定亲代节点的每一个链接可以采用不同数目的字节以便区分和标识与该链接相关联的子树。例如在图3b中,从根节点到节点308的链接通过使用来自名称的4个字节(n1n2n3n4=9845)来区分,从根节点到节点309的链接则通过使用来自名称的3个字节(n1n2n3=347)来区分。
应当提到的是,在(使用来自给定候选单元的)树导航期间,当到达树中的任何亲代节点时,树导航处理需要确保检查来自候选单元的名称的足够多的字节以便明确地决定将要选择哪一个链接。为了选择给定的链接,来自候选项的名称的字节必须与标示去到该特定链接的过渡的所有字节相匹配。同样地,在这样的树中,树的每一个节点具有由规定如何到达该节点的字节序列构成的名称。举例来说,节点309的名称可以是“347”,这是因为其表示一个基本数据单元的群组(例如单元311和312),其中所述基本数据单元的名称的3个开头字节是“347”。在使用其名称的开头3个字节是347的候选单元对树进行查找时,该数据模式导致树导航处理到达如图3b中示出的节点309。同样地,在树中的当前单元混合当中唯一地标识单元的来自该单元的字节子集是从根节点去到该基本数据单元的“路径”。例如在图3b中,字节序列3475导致基本数据单元312,并且在该例中示出的基本数据单元混合当中唯一地标识基本数据单元312。
对于多样并且稀疏的数据,可以证明图3b中的树结构比图3a的前缀树结构更加灵活和紧凑。
图3c示出了可以被用来基于其名称对基本数据单元进行组织的另一种数据组织系统。在图3c所示出的实例中,每一个基本数据单元具有从该基本数据单元的整个内容构造的独特名称,该名称简单地由基本数据单元的所有字节构成,这些字节按照其存在于基本数据单元中的相同顺序出现在名称中。图3c示出了(针对图3b中所描述的组织的)另一种变型,其使得树更加紧凑,并且(在必要和/或有用时)通过使用规则表达法来规定导致各种链接的来自基本数据单元名称的值而对子树中的单元进行分组。通过使用规则表达法允许对相同子树下的在相应字节上共享相同表达法的单元进行高效的分组;随后可以是对于子树内的不同基本数据单元的更加局部的歧义消除。此外,通过使用规则表达法允许以更加紧凑的方式来描述把单元映射到任何下方的子树所需要的字节的值。这样进一步减少了规定树所需要的字节数目。举例来说,规则表达法318规定28个接连的“f”的模式;如果在树导航期间遵循该链接,我们可以到达包括模式320的单元314,所述模式320具有依照规则表达法318的28个接连的“f”。同样地,到达单元316的路径具有使用规定具有16个接连的“0”的模式的规则表达法的链接或分支。对于这样的树,树导航处理需要检测并执行这样的规则表达法以便确定将要选择哪一个链接。
图3d示出了可以被用来基于其名称对基本数据单元进行组织的另一种数据组织系统。在图3d所示出的实例中,每一个基本数据单元具有从该基本数据单元的整个内容构造的独特名称。对每一个单元应用指纹处理方法,以便识别包含评估到所选指纹的内容的字段的位置。在单元中找到的第一指纹的位置处的字段被作为维度对待,来自该字段的特定数目的字节(例如x个字节,其中x显著小于单元中的字节数目)被提取出来并且被用作单元名称的开头字节,名称的其余字节由基本数据单元的其余字节构成,并且按照其存在于基本数据单元中的相同循环顺序出现。该名称被用来对树中的基本数据单元进行组织。在该例中,当在单元中没有检测到指纹时,通过简单地按照其存在于单元中的顺序使用单元的所有字节而制订名称。一个单独的子树(通过表明没有找到指纹的指示标示)基于其名称保持并组织所有这样的单元。
如图3d中所示,可以对单元338(其包含t个字节的数据,也就是b1b2b3…bt)应用指纹处理技术,以便在标识将被选择成“维度1”的字节bi+1处获得指纹位置“指纹1”。接下来,可以提取来自由“指纹1”标识的位置的x个字节以形成“维度1”,并且这x个字节可以被用作图3d中的每一个单元的名称的开头字节n1n2…nx。随后串联来自单元338的t-x个字节(从bi+x+1开始并且随后绕回到b1b2b3…bi)并且将其用作名称的其余字节nx+1nx+2…nt。当在单元中没有找到指纹时,名称n1n2…nt简单地是来自单元338的b1b2b3…bt。使用其名称在树中对基本数据单元进行分拣和组织。举例来说,在使用路径13654…06经历树的两个等级之后识别出并且到达基本数据单元(pde)330,其中字节13654…0是作为来自维度1的字节的n1n2…nx。从根部沿着链接334(通过表明没有找到指纹的指示标示)到达的节点335处的单独子树保持并组织其内容未评估到所选指纹的所有基本数据单元。因此,在这种组织中,一些链接(例如链接336)可以使用由按照与单元中相同的顺序出现的单元的字节构成的名称对单元进行组织,其他链接(例如链接340)则可以使用利用指纹制订的名称对单元进行组织。
在接收到候选单元时,所述处理应用前面描述的相同技术来确定候选单元的名称,并且使用该名称对树进行导航以进行内容关联查找。因此,对基本数据单元(在其被安装到树中时)和候选单元(在从解析器和因式分解器接收到候选单元时)应用相同并且一直的处理,以便创建其名称。树导航处理使用候选单元的名称对树进行导航。在该实施例中,如果在候选单元中没有找到指纹,则树导航处理沿着组织并包含其内容未评估到指纹的基本数据单元的子树向下导航。
图3e示出了可以被用来基于其名称对基本数据单元进行组织的另一种数据组织系统。在图3e所示出的实例中,每一个基本数据单元具有从该基本数据单元的整个内容构造的独特名称。对每一个单元应用指纹处理方法,以便识别包含评估到两个指纹当中的任一个的内容的字段的位置。单元中的第一指纹(图3e中的指纹1)的第一次出现位置处的字段被作为第一维度(维度1)对待,第二指纹(图3e中的指纹2)的第一次出现位置处的字段被作为第二维度(维度2)对待。使用指纹处理寻找单元上的两个不同指纹导致四种可能的情形:(1)在单元中找到全部两个指纹,(2)找到指纹1但是没有找到指纹2,(3)找到指纹2但是没有找到指纹1,以及(4)没有找到指纹。基本数据单元可以被分组到对应于每一种情形的4个子树中。在图3e中,“fp1”标示指纹1的存在,“fp2”标示指纹2的存在,“~fp1”标示指纹1的缺失,并且“~fp2”标示指纹2的缺失。
对于所述4种情形当中的每一种,如下创建单元的名称:(1)当找到全部两个指纹时,可以提取来自由“指纹1”标识的位置的x个字节以形成“维度1”,并且可以提取来自由“指纹2”标识的位置的y个字节以形成“维度2”,这x+y个字节可以被用作图3e中的每一个这样的单元的名称的开头字节n1n2…nx+y。随后通过循环方式提取来自单元348的其余的t-(x+y)个字节(在来自第一维度的字节之后开始),并且将其串联并且用作名称的其余字节nx+y+1nx+y+2…nt。(2)当找到指纹1但是没有找到指纹2时,可以提取来自由“指纹1”标识的位置的x个字节以形成在前维度,并且这x个字节可以被用作每一个这样的单元的名称的开头字节n1n2…nx。随后串联来自单元348的其余的t-x个字节(从bi+x+1开始并且随后绕回到b1b2b3…bi),并且将其用作名称的其余字节nx+1nx+2…nt。(3)当找到指纹2但是没有找到指纹1时,可以提取来自由“指纹2”标识的位置的y个字节以形成在前维度,并且这y个字节可以被用作每一个这样的单元的名称的开头字节n1n2…ny。随后串联来自单元348的其余的t-y个字节(从bj+y+1开始并且随后绕回到b1b2b3…bj),并且将其用作名称的其余字节ny+1ny+2…nt。(4)当在单元中没有找到指纹时,名称n1n2…nt简单地是来自单元348的b1b2b3…bt。因此对于这4种情形当中的每一种存在单独的子树。对于所述四种情形可以如下概括用以提取针对单元348的名称(n1n2n3…nt)的处理:
(1)指纹1和指纹2都被找到:
n1-nx←bi+1–bi+x=来自维度1的x个字节
nx+1–nx+y←bj+1–bj+y=来自维度2的y个字节
nx+y+1…nt=其余的字节(来自大小为t个字节的候选单元)=bi+x+1bi+x+2bi+x+3...bjbj+y+1bj+y+2bj+y+3...btb1b2b3...bi
(2)找到指纹1但是没有找到指纹2:
n1-nx←bi+1–bi+x=来自维度1的x个字节
nx+1…nt=其余的字节(来自大小为t个字节的候选单元)=bi+x+1bi+x+2bi+x+3...btb1b2b3...bi
(3)找到指纹2但是没有找到指纹1:
n1–ny←bj+1–bj+y=来自维度2的y个字节
ny+1…nt=其余的字节(来自大小为t个字节的候选单元)=bj+y+1bj+y+2bj+y+3...btb1b2b3...bj
(4)没有找到指纹:
n1-nx←b1–bt
在接收到候选单元时,所述处理应用前面描述的相同技术以确定候选单元的名称。在该实施例中,对候选单元应用前面描述的4种名称构造方法(取决于是否找到指纹1和指纹2),正如在被输入到滤筛中时对其所应用的那样。因此,对基本数据单元(在其被安装到树中时)和候选单元(在从解析器和因式分解器接收到候选单元时)应用相同并且一致的处理,以便创建其名称。树导航处理使用候选单元的名称对树进行导航以便进行内容关联查找。
如果内容关联查找是成功的,则将产生在特定维度的位置处于候选单元具有相同模式的基本数据单元。举例来说,如果在候选单元中找到全部两个指纹,则树导航处理将从根节点开始沿着树的链接354向下。如果候选单元具有作为“维度1”的模式“99…3”和作为“维度2”的模式“7…5”,则树导航处理将到达节点334。这样就到达包含可能是导出目标的两个基本数据单元(pde352和pde353)的子树。实施附加的分析和筛选(通过首先检查元数据,并且需要的话通过随后获取和检查实际的基本数据单元)以便确定哪一个基本数据单元最适合于导出。因此,这里所描述的实施例识别出可以被使用在滤筛中的多种树结构。可以采用这样的结构或者其变型的组合以便对基本数据单元进行组织。一些实施例通过树形式来组织基本数据单元,其中单元的整个内容被用作该单元的名称。但是各个字节出现在单元名称中的序列不一定是所述字节出现在单元中的序列。单元的特定字段被作为维度提取出来,并且被用来形成名称的开头字节,单元的其余字节构成名称的其余部分。使用这些名称在滤筛中通过树形式对单元进行排序。名称的开头数位被用来区分树的更高分支(或链接),其余数位被用来逐渐地区分树的所有分支(或链接)。树的每一个节点可以具有从该节点发出的不同数目的链接。此外,来自一个节点的每一个链接可以通过不同数目的字节被区分和标示,并且通过使用规则表达法以及用以表达其规范的其他有力方式可以实现对于这些字节的描述。所有这些特征导致紧凑的树结构。对各个单元基本数据单元的引用驻留在树的叶节点处。
在一个实施例中,可以对构成基本数据单元的字节应用指纹处理方法。驻留在通过指纹识别出的位置处的一定数目的字节可以被用来构成单元名称的一个分量。可以组合一个或多个分量以便提供一个维度。多个指纹可以被用来识别多个维度。这些维度被串联并且被用作单元名称的开头字节,单元的其余字节构成单元名称的其余部分。由于维度位于通过指纹识别出的位置处,因此提高了从来自每一个单元的一致的内容形成名称的可能性。在通过指纹定位的字段处具有相同内容值的单元将沿着树的相同枝干被分组在一起。通过这种方式,类似的单元将在树数据结构中被分组在一起。通过使用其名称的替换制订,可以把没有在其中找到指纹的单元一起分组在单独的子树中。
在一个实施例中,可以对单元的内容应用指纹处理方法,以便确定单元内容内的(前面所描述的)骨架数据结构的各个分量(或签名)的位置。或者可以选择单元内容内部的特定的固定偏移量以定位分量。还可以采用其他方法来定位单元的骨架数据结构的分量,其中包括而不限于对单元进行解析以便检测所声明的特定结构并且定位该结构内的分量。骨架数据结构的各个分量可以被视为维度,从而使用这些维度的串联以及随后的每一个单元的其余内容来创建每一个单元的名称。名称被用来对树中的基本数据单元进行排序和组织。
在另一个实施例中,对单元进行解析以便检测单元中的特定结构。该结构中的特定字段被识别成维度。多个这样的维度被串联并且被用作名称的开头字节,单元的其余字节构成单元名称的其余部分。由于维度位于通过对单元进行解析并且检测其结构而识别出的位置处,因此提高了从来自每一个单元的一致的内容形成名称的可能性。在通过所述解析定位的字段处具有相同内容值的单元将沿着树的相同枝干被分组在一起。通过这种方式,同样地,类似的单元将在树数据结构中被分组在一起。
在一些实施例中,树数据结构中的每一个节点包括自描述规范。树节点具有一个或多个子代。每一个子代条目包含关于去到该子代的链接上的区分字节的信息以及对该子代节点的引用。子代节点可以是树节点或叶节点。图3f给出了根据这里所描述的一些实施例的自描述树节点数据结构。图3f中示出的树节点数据结构规定(a)关于从根节点到该树节点的路径的信息,包括所有以下分量或者其中的一个子集:用以到达该树节点的来自名称的实际字节序列,从根节点到达该节点所消耗的名称的字节数目,关于所消耗的该字节数目是否大于某一预先规定的阈值的指示,以及描述去到该节点的路径并且对于树的内容关联搜索以及对于涉及树的构造的决定是有用的其他元数据,(b)该节点所具有的子代的数目,以及(c)对于每一个子代(其中每一个子代对应于树的一个分支)规定(1)子代id,(2)为了沿着树的该链接向下过渡所需要的来自名称的后继字节的区分字节的数目,(3)对于沿着该链接向下的来自名称的字节的实际值的规定,以及(4)对该子代节点的引用。
图3g给出了根据这里所描述的一些实施例的自描述叶节点数据结构。叶节点具有一个或多个子代。每一个子代是去到一个基本数据单元的链接。每一个子代条目包含关于去到该基本数据单元的链接上的区分字节的信息,对该基本数据单元的引用,重复和导出项的计数,以及关于该基本数据单元的其他元数据。图3g中示出的叶节点数据结构规定(a)关于从根节点到该叶节点的路径的信息,包括所有以下组成部分或者其中的一个子集:用以到达该叶节点的来自名称的实际字节序列,从根节点到达该节点所消耗的名称的字节数目,关于所消耗的该字节数目是否大于某一预先规定的阈值的指示,以及描述去到该节点的路径并且对于树的内容关联搜索以及对于涉及树的构造的决定是有用的其他元数据,(b)该节点所具有的子代的数目,以及(c)对于每一个子代(其中每一个子代对应于该叶节点下方的一个基本数据单元)规定(1)子代id,(2)为了沿着树的该链接向下过渡到一个基本数据单元所需要的来自名称的后继字节的区分字节的数目,(3)对于沿着该枝干向下的来自名称的字节的实际值的规定,(4)对在树的该路径上终止树的基本数据单元的引用,(5)关于多少重复和导出项指向该基本数据单元的计数(这被用来确定在删除存储系统中的数据时是否可以从滤筛中删除条目),以及(6)包括基本数据单元的大小等等的对应于基本数据单元的其他元数据。
为了提高新鲜的基本数据单元被安装到树中的效率,一些实施例把一个附加的字段合并到被保持在树的叶节点处的对应于每一个基本数据单元的叶节点数据结构中。应当提到的是,当必须把新鲜的单元插入到树中时,可能需要所讨论的子树中的每一个基本数据单元的名称或内容的附加字节以便决定将把所述新鲜单元插入到子树中的何处,或者是否触发子树的进一步分割。对于这些附加字节的需求可能需要获取其中几个所讨论的基本数据单元,以便对于这些单元当中的每一个提取出关于所述新鲜单元的相关区分字节。为了减少并且优化(并且在某些情况下完全消除)对于这一任务所需的io的次数,叶节点中的数据结构包括来自该叶节点下方的每一个基本数据单元的名称的特定数目的附加字节。这些附加字节被称作导航前瞻字节,并且帮助关于新鲜的传入单元对基本数据单元进行分拣。对应于给定的基本数据单元的导航前瞻字节在该基本数据单元被安装到滤筛中时被安装到叶节点结构中。可以使用多种标准静态地或者动态地选择将为此目的保留的字节数目,其中包括所涉及的子树的深度以及该子树中的基本数据单元的密度。例如对于正被安装在树的较浅等级的基本数据单元,解决方案可以添加比驻留在非常深的树中的基本数据单元更长的导航前瞻字节。此外,当新鲜的单元正被安装到滤筛中时,并且如果在现有的目标子树中已经有许多导航前瞻字节(从而提高了即将发生再分割的可能性),则在所述新鲜的基本数据单元被安装到子树中时可以为之保留附加的导航前瞻字节。
图3h给出了包括导航前瞻字段的对应于叶节点的叶节点数据结构。该数据结构规定(a)关于从根节点到该叶节点的路径的信息,包括所有以下组成部分或者其中的一个子集:用以到达该叶节点的来自名称的实际字节序列,从根节点到达该节点所消耗的名称的字节数目,关于所消耗的该字节数目是否大于某一预先规定的阈值的指示,以及描述去到该节点的路径并且对于树的内容关联搜索以及对于涉及树的构造的决定是有用的其他元数据,(b)该节点所具有的子代的数目,以及(c)对于每一个子代(其中每一个子代对应于该叶节点下方的一个基本数据单元)规定(1)子代id,(2)为了沿着树的该链接向下过渡到一个基本数据单元所需要的来自名称的后继字节的区分字节的数目,(3)对于沿着该枝干向下的字节的实际值的规定,(4)对在树的该路径上终止树的基本数据单元的引用,(5)规定为所述基本数据单元保留多少导航前瞻字节的导航前瞻字段以及这些字节的实际值,(6)关于多少重复和导出项指向该基本数据单元的计数(这被用来确定在删除存储系统中的数据时是否可以从滤筛中删除条目),以及(7)包括基本数据单元的大小等等的对应于基本数据单元的其他元数据。
在一些实施例中,树的各个分支被用来把各个数据单元映射到各个群组或范围中,其中所述群组或范围是通过对沿着导向作为范围定界符的子代子树的链接的区分字节进行解释而形成的。该子代子树中的所有单元将使得单元中的相应字节的值小于或等于对于去到所述特定子代子树的链接所规定的区分字节的值。因此,每一个子树现在将表示其值落在特定范围内的一组单元。在给定的子树内,该树的每一个后续等级将逐渐地把单元集合划分成更小的范围。该实施例为图3f中示出的自描述树节点结构的组成部分提供了不同的解释。图3f中的n个子代通过其在树节点数据结构中的区分字节的值被排序,并且表示非重叠范围的有序序列。对于n个节点存在n+1个范围,最低的或第1个范围由小于或等于最小条目的值构成,并且第n+1个范围由大于第n个条目的值构成。第n+1个范围将被作为超出范围而对待,因此n个链接导向下方的n个子树或范围。
例如在图3f中,子代1定义最低范围并且使用6个字节(值为abef12d6743a)来区分其范围——对应于子代1的范围是从00000000到abef12d6743a。如果候选单元的相应的6个字节落在该范围内(包括端值),则将选择对应于该子代的链接。如果候选单元的相应的6个开头字节大于范围定界符abef12d6743a,则子代1将不会被选择。为了检查候选单元是否落在对应于子代2的范围内必须满足两个条件——首先候选必须处于紧接着的前一个子代的范围之外(在该例中是子代1),其次其名称中的相应字节必须小于或等于对应于子代2的范围定界符。在该例中,对应于子代2的范围定界符由值为dcfa的2个字节描述。因此,对应于候选单元的2个相应字节必须小于或等于dcfa。使用这种方法,可以对候选单元和树节点中的所有子代进行检查,以便检查候选单元落在所述n+1个范围当中的哪一个范围内。对于图3f中示出的实例,如果候选单元的名称的4个相应字节大于对应于子代n的链接的区分字节的值f3231929,则将检测到错失状况。
可以对树导航处理进行修改以便容纳这一新的范围节点。在到达范围节点时,为了选择从该节点发出的给定链接,来自候选的名称的字节必须落在对于该特定链接所定义的范围内。如果来自候选的名称的字节的值大于所有链接中的相应字节的值,则候选单元落在下方子树所跨越的所有范围之外——在这种情况下(其被称作“超出范围状况”)检测到错失状况,并且树导航处理终止。如果候选单元的名称的开头字节落在由沿着导向子代子树的链接的相应的区分字节所确定的范围之内,树导航继续到下方的该子树。除非由于“超出范围状况”而终止,否则树导航可以逐渐地沿着树继续下到更深处,直到其到达叶节点数据结构为止。
这种范围节点可以结合在图3a-3e中描述的前缀树节点被采用在树结构中。在一些实施例中,树结构的特定数目的等级的上方节点可以是前缀树节点,其中树遍历是基于候选单元的名称的开头字节与沿着树的链接的相应字节之间的精确匹配。后续节点可以是具有通过候选的名称的相应字节落在其中的范围所决定的树遍历的范围节点。当树导航处理终止时,正如在本文献中早前所描述的那样,多种标准可以被用来决定作为总体内容关联查找侧结果将返回什么。
前面对用于表示和使用树节点和叶节点的方法和装置的描述仅仅是出于说明和描述的目的而给出的。其并不意图作出穷举或者把本发明限制到所公开的形式。因此,本领域技术人员将认识到许多修改和变型。
在给出候选单元以作为输入时,可以对前面描述的树节点和叶节点结构进行遍历,并且可以基于候选单元的内容对树实施内容关联查找。将从候选单元的字节构造候选单元的名称,正如基本数据单元的名称是当基本数据单元被安装在滤筛中时从其内容构造的。在给定输入候选单元的情况下,对树进行内容关联查找的方法涉及使用候选单元的名称对树结构进行导航,随后进行分析和筛选以便决定作为总体内容关联查找的结果将返回什么。换句话说,树导航处理返回第一输出结果,随后在该结果上实施分析和筛选,以便确定总体内容关联查找的结果。
如果存在具有与候选相同的名称开头字节(或者落在相同范围内的字节)的任何基本数据单元,树将通过由链接标示的单元子树的形式来标识基本数据单元的该子集。一般来说,每一个树节点或叶节点可以存储允许树导航处理决定将选择哪一个外出链接(如果存在的话)以便导航到树中的下一个更低等级的信息,这是基于输入单元的名称的相应字节以及在沿着所选链接对树进行导航时所到达的节点的身份。如果每一个节点都包含该信息,则树导航处理可以通过递归方式向下导航树中的每一个等级,直到没有找到匹配(此时树导航处理可以返回存在于以当前节点为根部的子树中的一个基本数据单元集合)或者到达一个基本数据单元(此时树导航处理可以返回该基本数据单元以及任何相关联的元数据)为止。
一旦树导航处理终止,可以使用其他标准和要求对树导航处理的结果进行分析和筛选,以便确定作为总体内容关联查找的结果应当返回什么。首先,可以挑选在其名称中具有最多数目的与候选相同的开头字节的基本数据单元。其次,当由树导航处理返回单一基本数据单元或多个基本数据单元时,在有资格作为内容关联查找的结果被返回之前,可以附加地要求其与候选单元的名称共享特定的最少数目的字节(否则内容关联查找返回错失)。筛选要求的另一个实例可以是,如果树导航处理在没有到达单一基本数据单元的情况下终止并且从而作为树导航处理的结果返回多个基本数据单元(以树导航终止的节点为根部),则只有在这些单元的数目小于所规定的特定限制(比如4-16个单元)的情况下,所述多个基本数据单元才将有资格作为总体内容关联查找的结果被返回(否则内容关联查找返回错失)。可以采用多项要求的组合来确定内容关联查找的结果。如果仍有多个候选,则可以检查导航前瞻字节并且还有相关联的元数据,以便决定哪些基本数据单元是最适当的。如果仍然无法把选择收窄到单一基本数据单元,则可以把多个基本数据单元提供到导出功能。通过这种方式,查找处理将报告“错失”或返回单一基本数据单元,或者如果不是单一基本数据单元,则是可能作为用于导出候选单元的良好起点的基本数据单元的集合。
树需要被设计成用于高效的内容关联存取。具有良好平衡的树对于大部分数据将提供可比的存取深度。预期树的几个上方等级将常常驻留在处理器高速缓存中,接下来的几个等级驻留在快速存储器中,并且后续等级驻留在闪存存储装置中。对于非常大的数据集,可能有一个或多个等级需要驻留在闪存存储装置或者甚至是盘中。
图4示出了根据这里所描述的一些实施例的如何可以把256tb的基本数据组织成树形式的一个实例,并且呈现出如何可以把树布置在存储器和存储装置中。假设每个节点平均展开64(26)个子代,则可以通过到达(平均)驻留在树的第6级(也就是说在5次链接遍历或跳跃之后)的叶节点数据结构(例如在图3h中描述)而存取对某一基本数据单元的引用。因此,在5次跳跃之后,树的第6级处的此类结构将与另外的230个此类节点并列驻留,每一个节点平均具有64个子代(这些子代是对基本数据单元的引用),从而容纳近似640亿个基本数据单元。在4kb的单元大小下,这样就容纳256tb个基本数据单元。
树可以被布置成使得可以如下遍历树的6个等级:3个等级驻留在芯片上高速缓存中(其中包含规定对应于去到近似256k个节点的链接的过渡的近似四千个“上方等级”树节点数据结构),存储器中的2个等级(其中包含规定对应于去到近似10亿个叶节点的链接的过渡的1600万个“中间等级”树节点数据结构),以及闪存存储装置中的第6级(容纳10亿个叶节点数据结构)。驻留在闪存存储装置中的树的该第6级的10亿个叶节点数据结构提供对640亿个基本数据单元的引用(每个叶节点平均64个单元)。
在图4所示的实例中,在第4和第5级,每一个节点对于每个单元专用平均16个字节(对应于子代id的1个字节,例如对pde的6字节引用,加上用于字节计数的一个字节,加上用以规定实际过渡字节以及一些元数据的平均8个字节)。在第6级,每一个叶节点对于每个单元专用平均48个字节(对应于子代id的1个字节,用于字节计数的1个字节,用以规定实际过渡字节的8个字节,对基本数据单元的6字节引用,用于来自该基本数据单元的导出项计数的1个字节,16个字节的导航前瞻,对应于基本数据单元的大小的2个字节,以及13个字节的其他元数据),因此对于树所需的闪存存储装置中的总容量(包括对基本数据单元的引用并且包括任何元数据)是大约3个太字节。对于树的上方节点所需的总容量是这一大小的一小部分(这是因为节点更少,规定对子代节点的更严格的引用所需的字节更少,并且每个节点所需的元数据更少)。在该例中,上方树节点对于每个单元专用平均8个字节(对应于子代id的1个字节,用于字节计数的1个字节,加上用以规定实际过渡字节的平均3-4个字节,以及对子代节点的2-3字节引用)。在该例中,总体上使用3tb(或者256tb的1.17%)的附加装置把具有256tb的基本数据的合成数据集分拣到10亿个群组中。
在图4所示出的实例中,256tb的基本数据包含640亿个4kb基本数据单元,为了完全区分所述640亿个基本数据单元需要少于5字节(或36比特)的地址。从内容关联角度来看,如果数据的混合使得在前3个等级当中的每一个等级处消耗平均4字节的渐进式名称,并且在接下来的3个等级当中的每一个等级处消耗8个字节,从而总共(平均)36字节(288比特)的名称将区分所有640亿个基本数据单元。这36个字节将少于构成每一个单元的4kb的1%。如果可以通过其字节的1%(或者甚至5-10%)来标识4kb的基本数据单元,则(构成大部分字节的)其余字节可以容许微扰,并且具有此类微扰的候选仍然可以到达该基本数据单元并且可以考虑从该基本数据单元导出。
应当提到的是,(为了区分下方的各个子树)在任何给定的链接上所需的字节数目将由构成数据集的单元混合中的实际数据决定。同样地,从给定节点发出的链接数目也将随着数据而改变。自描述树节点和叶节点数据结构将生命对于每一个链接所需的字节的实际数目和值,以及从任何节点发出的链接的数目。
可以施加进一步的控制以便限制在树的各个等级处专用的高速缓存、存储器和存储装置的数量,以便在增量存储的已分配预算内把输入分拣到尽可能多的已区分群组中。为了应对其中存在需要非常深的子树来完全区分单元的数据密度和口袋(pocket)的情况,可以通过以下步骤高效地应对这样的密度:把相关单元的更大集合分组到树的特定深度(例如第6级)处的平坦群组中,并且在其上实施流线式搜索和导出(这是通过首先检查导航前瞻和元数据以确定最佳基本数据单元,或者(作为回退)对于其余的数据仅仅寻找重复而不是由所述方法提供的完全导出)。这样将避免产生非常深的树。另一种替换方案是允许(具有许多等级的)很深的树,只要这些等级能够容纳在可用的存储器中。当更深的等级溢出到闪存或盘时,可以采取一些步骤以使得树从该等级往后变平坦,从而最小化原本将由于针对存储在闪存或盘中的更深等级的树节点的多次相继存取而招致的等待时间。
预期来自单元名称的全部字节当中的相对较小的一部分将常常足以标识每一个基本数据单元。使用这里所描述的实施例在多种真实世界数据集上实施的研究证实,基本数据单元的一个较小的字节子集可以用来对大部分单元进行排序从而允许所述解决方案。因此,这样的解决方案在对于其操作所需的存储的数量方面是高效的。
在对于来自图4的实例所需的存取方面,对于每一个传入的4kb输入组块(或候选单元),所述方法将需要实施一次以下存取以便对树结构进行查询并且到达叶节点:三个高速缓存引用、两个存储器引用(或者可能有多个存储器引用)加上来自闪存存储装置的单一io,以便对叶节点数据结构进行存取。来自存储装置的该单一io将获取一个4kb页面,其将保有对应于一组近似64个单元的叶节点数据结构的信息,从而将包括专用于所讨论的基本数据单元的48个字节。这48个字节将包括关于所讨论的基本数据单元的元数据。这将结束树查找处理。随后所需要的io的次数将取决于候选单元结果是重复、导出项还是将被安装在滤筛中的新鲜基本数据单元。
作为某一基本数据单元的重复的候选单元将需要1次io来获取该基本数据单元,以便验证重复。一旦验证了重复,将再需要一次io以更新树中的元数据。因此,重复单元的摄取在树查找之后将需要两次io,从而一共是3次io。
没有通过树查找并且既不是重复也不是导出项的候选单元需要另外的1次io以把该单元作为新的基本数据单元存储在滤筛中,并且需要另一次io以更新树中的元数据。因此,没有通过树查找的候选单元的摄取在树查找之后将需要2次io,从而导致一共3次io。但是对于其中树查找处理在不需要存储io的情况下终止的候选单元,对于摄取这样的候选单元一共只需要2次io。
作为导出项(而非重复)的候选单元将首先需要1次io以获取计算导出所需的基本数据单元。由于预期最经常的导出将是源自单一基本数据单元(而不是多个基本数据单元),因此对于获取该基本数据单元将只需要单一io。在成功完成导出之后,将再需要1次io以把重建程序和导出细节存储在为该单元在存储装置中创建的条目中,并且需要另一次io以更新树中的元数据(比如计数等等)以便反映出新的导出项。因此,变成导出项的候选单元的摄取在第一树查找之后需要3次附加的io,从而一共是4次io。
总而言之,为了摄取候选单元并且对其应用datadistillationtm方法(同时在非常大的数据集上全局利用冗余)需要大致3到4次io。与传统的数据去重复技术所需要的情况相比,对于每个候选单元通常只有另外的一次io,其回报是能够以比所述单元本身更细的粒度在数据集上全局地利用冗余。
给出250000次随机io存取/秒(这意味着对于4kb页面的1gb/秒的随机存取带宽)的存储系统每秒可以摄取大约62500(250000除以平均大小分别为4kb的每个输入组块4次io)个输入组块并且对其实施datadistillationtm方法。这在用尽存储系统的所有带宽的情况下允许250mb/秒的摄取速率。如果仅使用存储系统的一半带宽(从而使得另一半可用于对所存储的数据进行存取),这样的datadistillationtm系统仍然可以给出125mb/秒的摄取速率。因此,在给定足够处理能力的情况下,datadistillationtm系统能够以经济的io(在比所述单元本身更细的粒度上)在数据集上全局地利用冗余,并且在当代存储系统上以每秒数百兆字节的摄取速率给出数据简化。
因此,正如测试结果所证实的那样,这里所描述的实施例实现了以经济的io存取并且利用对于装置所需的最小增量存储从大容量数据存储库搜索单元(从中可以导出输入单元并且只利用规定所述导出所需的最小存储)的复杂任务。如此构造的这一框架使得使用全部单元字节的更小百分比找到适合于导出的单元成为可行,从而留下大部分字节可用于微扰和导出。解释这一方案为何对于大部分数据能够有效工作的一项重要洞察在于,树提供了易于使用的细粒度结构,从而允许定位在滤筛中标识单元的区分和区别字节,并且尽管这些字节分别处于数据中的不同深度和位置,在树结构中可以高效地对其进行隔离和存储。
图5a-5c示出了关于如何可以使用这里所描述的实施例组织数据的一个实际的实例。图5a示出了512字节的输入数据以及因式分解的结果(例如实施图2中的操作202的结果)。在该例中应用指纹处理以确定数据中的中断,从而使得接连的中断标识候选单元。使用粗体和常规字体示出了交替的候选单元。举例来说,第一候选单元是“b8ac83d9dc7caf18f2f2e3f783a0ec69774bb50bbe1d3ef1ef8a82436ec43283bc1c0f6a82e19c224b22f9b2”,下一个候选单元是“ac83d9619ae5571ad2bbcc15d3e493eef62054b05b2dbccce933483a6d3daab3cb19567dedbe33e952a966c49f3297191cf22aa31b98b9dcd0fb54a7f761415e”,后面以此类推。如图所示,图5a中的输入被因式分解成12个可变大小候选单元。每一个组块的开头字节被用来在滤筛中对单元进行排序和组织。图5b示出了如何可以使用其名称并且使用图3b中所描述的树结构按照树形式把图5a中示出的12个候选单元组织成滤筛中的基本数据单元。每一个单元具有从该单元的整个内容构造的独特名称。在该例中,由于应用了指纹处理以确定12个候选单元之间的中断,因此每一个候选单元的开头字节将已经被对准到锚指纹:因此,每一个名称的开头字节将已经是从锚定在该指纹处的内容的第一维度构造的。名称的开头字节组织各个单元。举例来说,如果单元名称中的第一字节等于“0x22”,则取得顶部链接以选择基本数据单元#1。应当提到的是,使用不同数目的字节对图5b中的各个链接进行区分,正如参照图3b中示出的树数据结构所解释的那样。
图5c示出了如何可以使用参照图3d描述的树数据结构对图5a中示出的12个候选单元进行组织。进一步对每一个单元的内容应用指纹处理,以便识别单元内容内的第二指纹。把从第一指纹(其已经存在于每一个单元的边界处)的位置处提取出的内容字节与第二指纹串联,从而形成被用来对单元进行组织的名称的开头字节。换句话说,单元名称被如下构造:来自(分别通过锚指纹和第二指纹定位的)两个维度或字段的数据字节被串联形成名称的开头字节,随后是其余的字节。作为针对名称构造的这一选择的结果,(相比于图5b)不同的字节序列导向图5c中的各个基本数据单元。例如为了到达基本数据单元#4,树导航处理首先取得对应于作为第一维度(即第一指纹)处的字段的开头字节的“46093f9d”的链接,并且随后取得对应于作为位于第二维度(即第二指纹)处的字段的开头字节的“c4”的链接。
图6a-6c分别示出了根据这里所描述的一些实施例如何可以把树数据结构用于参照图1a-1c描述的内容关联映射器121和122。
一旦解决了找到(从中尝试导出候选单元的)适当的基本数据单元的困难问题,所述问题就被收窄到检查一个基本数据单元或者基本数据单元的较小子集并且从中最优地导出候选单元,其中只利用规定所述导出所需的最小存储。其他目标包括把对于存储系统的存取次数保持到最低程度,并且把导出时间和重建时间保持到可以接受。
导出器必须把候选单元表达成在一个或多个基本数据单元上实施的变换的结果,并且必须把这些变换规定成将被用来在取回数据时重新生成导出项的重建程序。每一项导出可能需要构造其自身所独有的程序。导出器的功能是识别这些变换,并且创建具有最小足迹的重建程序。可以采用多种变换,其中包括在一个或多个基本数据单元上或者在每一个单元的特定字段上实施的算术、代数或逻辑运算。此外还可以使用字节操纵变换,比如串联、插入、替换和删除一个或多个基本数据单元中的字节。
图7a提供了根据这里所描述的一些实施例的可以在重建程序中规定的变换的一个实例。在该例中规程的变换的词汇表包括在单元中的规定长度的字段上实施的算术运算,以及在基本数据单元中的规定偏移量处插入、删除、附加和替换所声明的长度的字节。导出器可以采用多种技术和操作来检测候选单元与一个或多个基本数据单元之间的相似性和差异并且用来构造重建程序。导出器可以利用在底层硬件中可用的词汇表来实施其功能。所述工作的最终结果是在对于重建程序所规定的词汇表中规定变换,并且在这样做时使用最小数量的增量存储并且采取还允许快速数据取回的方式。
导出器可以利用底层机器的处理能力并且在为之分配的处理预算内工作,以便在系统的成本-性能约束内提供尽可能最佳的性能。鉴于微处理器核心更容易获得,并且鉴于针对存储装置的io存取较为昂贵,因此datadistillationtm解决方案被设计成利用当代微处理器的处理能力,以便高效地实施本地分析以及从少数几个基本数据单元导出候选单元的内容。预期datadistillationtm解决方案(在非常大的数据上)的性能将不受计算处理的速率限制(rate-limited),而是受到典型存储系统的io带宽的速率限制。举例来说,预期几个微处理器核心就将足以实施所需的计算和分析,从而在支持250000次io/秒的典型的基于闪存的存储系统上支持每秒几百兆字节的摄取速率。应当提到的是,来自当代微处理器,比如intelxeon处理器e5-2687w(10核,3.1ghz,25mb高速缓存)的两个这样的微处理器核心是可以从处理器获得的全部计算能力的一部分(十分之二)。
图7b示出了根据这里所描述的一些实施例的从基本数据单元导出候选单元的结果的实例。具体来说,数据模式“elem”是存储在基本数据存储库中的基本数据单元,并且数据模式“cand”是将从基本数据单元导出的候选单元。已经突出显示出“cand”与“elem”之间的18个共同的字节。重建程序702规定如何可以从数据模式“elem”导出数据模式“cand”。如图7b中所示,重建程序702示出了如何从“elem”导出“cand”,这是通过使用1字节替换、6字节插入、3字节删除、7字节批量替换。用以规定导出项的成本是20字节+3字节引用=23字节,从而是原始大小的65.71%。应当提到的是,所示出的重建程序702是所述程序的人类可读表示,并且可能不是所述程序被这里所描述的实施例实际存储的方式。同样地,在图7b中还示出了基于算术运算(比如乘法和加法)的其他重建程序。举例来说,如果“elem”是bc1c0f6a790c82e19c224b22f900ac83d9619ae5571ad2bbec152054ffffff83并且“cand”是bc1c0f6a790c82e19c224b22f91c4da1aa0369a0461ad2bbec152054ffffff83,则如图所示可以使用乘法(00ac83d9619ae557)*2a=[00]1c4da1aa0369a046导出8字节差异。用以规定导出项的成本是4字节+3字节引用=7字节,从而是原始大小的20.00%。或者如果“elem”是bc1c0f6a790c82e19c224b22f9b2ac83ffffffffffffffffffffffffffffb283并且“cand”是bc1c0f6a790c82e19c224b22f9b2ac8300000000000000000000000000002426,则如图所示可以使用加法导出16字节差异,例如通过把0x71a3加到开始于偏移量16的16字节区段并且丢弃进位。用以规定导出项的成本是5字节+3字节引用=8字节,从而是原始大小的22.85%。应当提到的是,图7a中的范例编码仅仅是出于说明的目的而选择的。图7b中的实例具有32字节的数据大小,因此对于单元内的长度和偏移量字段有5比特就足够了。对于较大的单元(例如4kb单元),这些字段的大小将需要被增加到12比特。同样地,所述范例编码容许3字节或24比特的引用大小。这应当允许引用1600万个基本数据单元。如果引用需要能够对例如256tb的数据中的任何位置进行寻址,则引用的大小将需要是6个字节。当这样的数据集被因式分解成4kb单元时,规定引用所需要的6个字节将是4kb单元的大小的一小部分。
规定(从一个或多个基本数据单元导出的)导出单元所需的信息的大小是重建程序的大小与规定所需的(一个或多个)基本数据单元所需的引用大小之和。把候选单元规定为导出单元所需的信息的大小被称作候选与基本数据单元的距离。当可以从多个基本数据单元集合当中的任一个集合可行地导出候选时,则把具有最短距离的基本数据单元集合选择成目标。
当需要从多于一个基本数据单元导出候选单元时(通过组装从这些基本数据单元当中的每一个基本数据单元导出的提取项),导出器需要考虑到针对存储系统的附加存取的成本,并且将该成本与更小的重建程序和更小的距离的益处进行权衡。一旦对于候选创建了最优的重建程序,将其距离与距离阈值进行比较;如果没有超出阈值,则接受导出。一旦接受导出,就把候选单元改订为导出单元,并且由基本数据单元于重建程序的组合替换。为候选单元创建的蒸馏数据中的条目被重建程序加上对相关基本数据单元的一项或多项引用替换。如果对应于最佳导出的距离超出距离阈值,则导出项将不被接受。
为了产生数据简化,所述距离阈值必须总是小于候选单元的大小。举例来说,距离阈值可以被设定到候选单元大小的50%,从而使得只有在导出项的足迹小于或等于候选单元足迹的一半时才接收导出项,从而对于为之存在适当导出的每一个候选单元确保2x或更大的简化。距离阈值可以是预定的百分比或分数,其或者是基于用户规定的输入或者是由系统选择。距离阈值可以由系统基于系统的静态或动态参数确定。
图8a-8e示出了根据这里所描述的一些实施例如何通过把输入数据因式分解成固定大小单元并且把所述单元组织在参照图3d和3e描述的树数据结构中而实施数据简化。图8a示出了如何可以把输入数据简单地因式分解成32字节组块。具体来说,图8a示出了前10个组块,并且随后示出了例如出现在4200万个组块之后的另外几个组块。图8b示出了使用名称把基本数据单元组织在滤筛中,所述名称被构造成使得名称的开头字节由来自单元内容中的3个维度(对应于锚指纹、第二指纹和第三指纹的位置)的内容构成。具体来说,在图8b中,每一个32字节组块成为具有32个字节的候选单元(固定大小块)。对单元的内容应用指纹处理方法。每一个单元具有如下构造的名称:来自单元的三个维度或字段(分别通过锚指纹、第二指纹和第三指纹定位)的数据的字节被串联形成名称的开头字节,随后是单元的其余字节。名称被用来在滤筛中组织单元。如图8b中所示,前10个组块不包含重复或导出项,并且作为单元相继被安装在滤筛中。图8b示出了在第10个组块被消耗之后的滤筛。图8c示出了在消耗了数据输入的附加的几百万个单元之后(例如在给出了接下来的4200万个组块之后)的某一后续时间点处的滤筛内容。针对重复或导出项检查滤筛。无法从单元导出的组块被安装在滤筛中。图8c示出了在消耗了4200万个组块之后的滤筛,其中例如包含16000010个单元(可以利用3个字节的引用地址进行逻辑寻址),其余的26000000个组块则成为导出项。图8d示出了随后被呈现到滤筛并且被识别为滤筛中的某一条目(被示出为单元编号24789)的重复的新鲜输入的一个实例。在该例中,滤筛把单元24789(组块9)识别成对应于组块42000011的最适当的单元。导出功能确定新的组块是确切的重复,并且将其替换成对单元24789的引用。用以表示导出项的成本是3字节引用相比于35b的原始大小,从而是原始大小的8.57%。图8d示出了被转换成滤筛中的某一条目(被示出为单元编号187126)的导出项的输入(组块42000012)的第二实例。在该例中,滤筛确定不存在确切的匹配。其把单元187125和187126(组块8和1)识别成最适当的单元。从所述最适当的单元导出新的单元。在图8d中示出了导出相比于单元187125和导出相比于单元187126。用以表示导出项相比于单元187125的成本是39字节+3字节引用=42字节,从而是原始大小的120.00%。用以表示导出项相比于单元187126的成本是12字节+3字节引用=15字节,从而是原始大小的42.85%。选择最佳导出(相比于单元187126)。将重建大小与阈值进行比较。举例来说,如果阈值是50%,则该导出项(42.85%)被接受。图8e提供了从基本数据单元导出的数据组块的两个附加的实例,其中包括通过从两个基本数据单元导出而实际创建导出项的一个实例。在第一实例中给出组块42000013。滤筛把单元9299998(组块10)识别成最适当的单元。在图8e中示出了导出相比于单元9299998。用以表示导出项的成本是4字节+3字节引用=7字节,从而是原始大小的20.00%。将重建大小与阈值进行比较。举例来说,如果阈值是50%,则该导出项(20.00%)被接受。在第二实例中给出组块42000014。在该例中,组块42000014使得该组块的一般可以从单元9299997最佳地导出,该组块的另一半则可以从单元9299998最佳地导出。因此,创建多单元导出项以产生进一步的数据简化。在图8e中示出了多单元导出。用以表示该多单元导出项的成本是3字节引用+3字节+3字节引用=9字节,从而是原始大小的25.71%。将重建大小与阈值进行比较,例如如果阈值是50%,则该导出项(25.71%)被接受。应当提到的是,来自单一单元导出项的最佳结果将是45.71%。
图8a-e示出了datadistillationtm系统的一个重要优点:可以在消耗和产生固定大小块的同时有效地实施数据简化。应当提到的是,固定大小块在高性能存储系统中是高度期望的。通过使用datadistillationtm装置,由许多固定大小的块构成的较大的传入输入文件可以被因式分解成许多固定大小的单元,从而使得所有基本数据单元都具有固定的大小。对应于每一个导出单元的潜在的可变大小重建程序被包装在一起并且被内联保持在蒸馏数据文件中,其随后可以被组块成固定大小块。因此,出于所有实际的目的,可以在存储系统中消耗和产生固定大小块的同时实施强力的数据简化。
图9a-c示出了首先在图1c中示出的系统的datadistillationtm方案的一个实例:这种方案采用可以通过内容关联方式被存取的单独的基本重建程序存储库。这样的结构允许检测到构成已经存在于基本重建程序存储库中的重建程序。这样的导出项可以被改订成引用现有的重建程序。这允许检测重建程序当中的冗余。在图9a中摄取输入数据。对所述数据应用指纹处理方法,并且在指纹位置处设定组块边界。如图所示,输入被因式分解成8个候选单元(在图9a中通过粗体和常规字体示出了交替的组块)。在图9b中,所述8个候选单元被示出为组织在滤筛中。每一个单元具有从该单元的整个内容构造的独特名称。在该例中,单元名称被如下构造:来自两个维度或字段(分别通过锚指纹和第二指纹定位)的数据的字节被串联形成名称的开头字节,随后是其余字节。名称被用来在滤筛中对单元进行排序,并且还通过树结构提供对滤筛的内容关联存取。图9b还示出了包含基本重建程序的第二内容关联结构。图9c示出了重复重建。假设所到来的55字节候选单元(图9c中示出)并非任何基本数据单元的重复。单元3被选择成最适当的单元——前2个维度对于pde2和3是相同的,但是开始于88a7的其余字节与单元3匹配。利用一个12字节重建程序(rp)从单元3导出所述新的输入。编码如图7a中所示。对于该例应当注意到的是,最大单元大小是64比特,并且所有偏移量和长度都被编码成6比特值,而不是图7a中所示的5比特长度和偏移量。对rp存储库进行搜索并且没有找到这一新rp。该rp被插入到基本rp存储库中并且基于其值被排序。所述新单元被改订成对基本数据单元3的引用以及对rp存储库中的引用4处的新创建的基本重建程序的引用。对应于该导出单元的总存储大小是:3字节pde引用、3字节rp引用、12字节rp=18字节,从而是相比于将其存储为pde的大小的31.0%。后面假设所述55字节候选单元的一份拷贝到达。与前面一样,基于单元3创建一个12比特rp。对rp存储库进行搜索,并且找到具有基本rpid=3、rp引用=4的rp。该候选单元在系统中被表示成针对基本数据单元3的引用和针对重建程序4的引用。对于该导出单元所增加的总存储大小现在是:3字节pde引用、3字节rp引用=6字节,从而是相比于将其存储为pde的大小的10.3%。
图10a提供了根据这里所描述的一些实施例的关于如何对基本数据单元应用在重建程序中规定的变换以产生导出单元的一个实例。该例示出了被规定从编号为187126的基本数据单元(该基本数据单元也被示出在图8c的滤筛中)导出的导出单元,这是通过对该基本数据单元应用由所示出的重建程序规程的四种变换(插入、替换、删除和附加)。如图10a中所示,从滤筛加载单元187126,并且执行重建程序以便从单元187126导出组块42000012。图10b-10c示出了根据这里所描述的一些实施例的数据取回处理。每一项数据取回请求实质上采取蒸馏数据中的一个单元的形式,并且在无损简化格式中被呈现到取回引擎。对应于每一个单元的无损简化格式包含对相关联的(多个)基本数据单元的引用以及重建程序。datadistillationtm装置的取回器获取基本数据单元和重建程序,并且将其提供到重建器以供重建。在获取了对应于蒸馏数据的某一单元的相关基本数据单元和重建程序之后,重建器执行重建程序以便生成处于其原始未简化形式的所述单元。数据取回处理执行重建所需的工作量关于重建程序的大小和基本数据单元的大小成线性。因此,通过所述系统可以实现高数据取回速率。
显而易见的是,为了把一个单元从蒸馏数据中的无损简化形式重建到其原始未简化形式,只需要获取对于该单元所规定的(多个)基本数据单元和重建程序。因此,为了重建给定的单元,不需要对其他单元进行存取或重建。这就使得datadistillationtm装置即使在为针对重建和取回的随机请求序列服务时仍然是高效的。应当提到的是,例如lempelziv方法之类的传统压缩方法需要获取并且解压缩包含所期望的块的整个数据窗口。举例来说,如果存储系统采用lempel-ziv方法使用32kb的窗口压缩4kb数据库,则为了获取和解压缩给定的4kb块,需要获取和解压缩整个32kb窗口。由于为了给出所期望的数据需要消耗更多带宽并且需要解压缩更多数据,这样就构成了性能惩罚。datadistillationtm装置则不会招致这样的惩罚。
datadistillationtm装置可以通过多种方式被集成到计算机系统中,以便通过高效地在系统中的整个数据上全局发现并利用冗余的方式对数据进行组织和存储。图11a-11g示出了根据这里所描述的一些实施例的包括datadistillationtm机制(可以利用软件、硬件或者其组合来实施)的系统。图11a给出了通用计算平台,其中软件应用运行在系统软件上,系统软件执行在硬件平台上,硬件平台由处理器、存储器和数据存储组件构成。图11b示出了被集成到平台的应用层中的datadistillationtm装置,每一个特定应用使用所述装置利用对应于该应用的数据集内的冗余。图11c示出了被采用来为在其上方应用的所有应用提供数据虚拟化层或服务的datadistillationtm装置。图11de和11e示出了datadistillationtm装置与范例计算平台的操作系统、文件系统和数据管理服务的两种不同形式的集成。其他集成方法包括(而不限于)与硬件平台中的嵌入式计算堆栈集成,比如采用在如图11f中所示的基于闪存的数据存储子系统中的嵌入式计算堆栈。
图11g给出了datadistillationtm装置与图11d中示出的范例计算平台的集成的附加细节。图11g示出了datadistillationtm装置的组件,其中解析器和因式分解器、导出器、取回器和重建器作为软件在通用处理器上执行,并且内容关联映射结构驻留在存储分级结构的几个等级上。基本数据存储库可以驻留在存储介质(比如基于闪存的存储驱动器)中。
图11h示出了datadistillationtm装置如何可以与范例通用计算平台进行接口。
文件系统(或档案系统(filesystem))把文件(例如文本文档、电子数据表、可执行文件、多媒体文件等等)与标识符(例如文件名、文件句柄等等)相关联,并且允许通过使用与文件相关联的标识符在文件上实施操作(例如读取、写入、插入、附加、删除等等)。由文件系统实施的命名空间可以是平坦的或分级的。此外,命名空间可以被分层,例如顶层标识符可以被解析成相继的更低层处的一个或多个标识符,直到顶层标识符被完全解析为止。通过这种方式,文件系统提供对于物理地存储文件内容的(多个)物理数据存储设备和/或存储介质(例如计算机存储器、闪存驱动器、盘驱动器、网络存储设备、cd-rom、dvd等等)的抽象。
被用于在文件系统中存储信息的物理存储设备和/或存储介质可以使用一种或多种存储技术,并且可以位于相同的网络位置处或者可以分布在不同的网络位置处。在给定与文件相关联的标识符以及被请求在文件上实施的一项或多项操作的情况下,文件系统可以(1)识别一个或多个物理存储设备和/或存储介质,并且(2)使得由文件系统识别出的物理存储设备和/或存储介质实施被请求在与所述标识符相关联的文件上实施的操作。
每当在系统中实施读取或写入操作时,可能涉及不同的软件和/或硬件组件。术语“读取器”可以指代在系统中实施给定的读取操作时在所述系统中涉及的软件和/或硬件组件的选集,并且术语“写入器”可以指代在系统中实施给定的写入操作时在所述系统中涉及的软件和/或硬件组件的选集。这里所描述的数据简化方法和装置的一些实施例可以由在实施给定的读取或写入操作时所涉及的系统的一个或多个软件和/或硬件组件利用,或者可以被合并到其中。不同的读取器和写入器可以利用或合并不同的数据简化实现方式。但是,利用或合并特定数据简化实现方式的每一个写入器将对应于同样利用或合并相同的数据简化实现方式的读取器。应当提到的是,在系统中实施的一些读取和写入操作可能不会利用或合并数据简化装置。举例来说,当datadistillationtm装置或数据简化装置103取回基本数据单元或者把新的基本数据单元添加到基本数据存储库时,其可以在没有数据简化的情况下直接实施读取和写入操作。
具体来说,在图11h中,写入器150w可以总体上涉及在实施给定的写入操作时所涉及的系统的软件和/或硬件组件,并且读取器150r可以总体上涉及在实施给定的读取操作时所涉及的系统的软件和/或硬件组件。如图11h中所示,写入器150w向datadistillationtm装置或数据简化装置103提供输入数据,并且从datadistillationtm装置或数据简化装置103接收蒸馏数据108。读取器150r向datadistillationtm装置或数据简化装置103提供取回请求109,并且从datadistillationtm装置或数据简化装置103接收所取回的数据输出113。
对应于图11h的实现方式实例包括而不限于在应用、操作系统内核、文件系统、数据管理模块、设备驱动程序或者闪存或盘驱动器的固件中合并或利用datadistillationtm装置或数据简化装置103。这跨越了在图11b-f描述的多种配置和使用。
图12a示出了根据这里所描述的一些实施例使用datadistillationtm装置在受到带宽约束的通信介质上传送数据。在所示出的设置中,通信节点a创建将被发送到通信节点b的文件集合。节点a采用datadistillationtm装置把输入文件转换成蒸馏数据或蒸馏文件,其中包含对安装在基本数据存储库中的基本数据单元的引用以及用于导出单元的重建程序。节点a随后把蒸馏文件连同基本数据存储库发送到节点b(可以在发送蒸馏文件之前、同时或之后发送基本数据存储库;此外,可以通过相同的通信信道或者通过与被用于发送蒸馏文件的通信信道不同的通信信道发送基本数据存储库)。节点b把基本数据存储库安装在相应结构的末端,并且随后通过驻留在datadistillationtm装置中的取回器和重建器馈送蒸馏文件,以便产生由节点a创建的原始文件集合。因此,通过在受到带宽约束的通信介质的全部两端采用datadistillationtm装置仅发送简化数据,使得对于所述介质的使用更加高效。应当提到的是,使用datadistillationtm允许利用更大范围内的冗余(超出使用例如lempel-ziv之类的传统技术的可行范围),从而可以高效地传送非常大的文件或文件群组。
我们现在将讨论在广域网设置中使用datadistillationtm装置,其中各个工作组协作共享分散在多个节点上的数据。当数据被初次创建时,可以如图12a中所示对其进行简化和传送。广域网在每一个站点处保持数据的拷贝,以便允许对于数据的快速本地存取。使用datadistillationtm装置可以简化每一个站点处的足迹。此外,在任何站点处进行新鲜数据的后续摄取时,可以利用新鲜数据与已有的基本数据存储库的内容之间的任何冗余以便对新鲜数据进行简化。
在这样的设置中,需要把针对任何给定站点处的数据的任何修改传送到所有其他站点,从而把每一个站点处的基本数据存储库保持一致。因此,如图12b中所示,根据这里所描述的一些实施例,可以把例如基本数据存储库的安装和删除之类的更新以及元数据更新传送到每一个站点处的基本数据存储库。举例来说,在把新鲜的基本数据单元安装到给定站点处的滤筛中时,所述基本数据单元需要被传送到所有其他站点。每一个站点可以使用该基本数据单元的值按照内容关联方式对滤筛进行存取,并且确定需要把新的条目添加在滤筛中的何处。同样地,在从给定站点处的滤筛中删除某一基本数据单元时,需要更新所有其他站点以反映出所述删除。可以实现这一点的一种方式是通过把所述基本数据单元传送到所有站点,从而使得每一个站点可以使用所述基本数据单元对滤筛进行内容关联存取,以便确定需要删除叶节点中的哪一个条目,连同针对树中的相关链接的必要更新以及从存储库中删除该基本数据单元。另一种方法是向所有站点传送对所述基本数据单元所驻留的叶节点中的用于所述基本数据单元的条目的引用。
因此,datadistillationtm装置可以被用来简化存储在广域网的各个站点处的数据的足迹,以及对网络的通信链接进行高效的使用。
图12c-12k示出了根据这里所描述的一些实施例的由datadistillationtm装置对于各种使用模型所产生的简化数据的各个分量。
图12c示出了datadistillationtm装置1203如何摄取输入文件1201,并且在完成蒸馏处理之后生成蒸馏文件集合1205和基本数据滤筛或基本数据存储库1206。图12c的基本数据滤筛或基本数据存储库1206本身由两个组成部分构成,即如图12d中所示的映射器1207和基本数据单元(或pde)1208。
映射器1207本身之内具有两个组成部分,即定义总体的树的树节点数据结构集合以及叶节点数据结构集合。树节点数据结构集合可以被放置到一个或多个文件中。同样地,叶节点数据结构集合可以被放置到一个或多个文件中。在一些实施例中,被称作树节点文件的单一文件保持对应于为给定数据集(输入文件1201)的基本数据单元创建的树的整个树节点数据结构集合,并且被称作叶节点文件的另一个单一文件保持对应于为该数据集的基本数据单元创建的树的整个叶节点数据结构集合。
在图12d中,基本数据单元1208包含为给定的数据集(输入文件1201)创建的基本数据单元集合。所述基本数据单元集合可以被放置到一个或多个文件中。在一些实施例中,被称作pde文件的单一文件保持为所述给定数据集创建的整个基本数据单元集合。
树节点文件中的树节点将包含对树节点文件内的其他树节点的引用。树节点文件中的最深等级(或最低等级)的树节点将包含对叶节点文件中的叶节点数据结构中的条目的引用。叶节点文件中的叶节点数据结构中的条目将包含对pde文件中的基本数据单元的引用。
在图12e中示出了树节点文件、叶节点文件和pde文件,该图示出了由所述装置创建的所有分量的细节。图12e示出了包括名称为file1、file2、file3…filen的n个文件的输入文件集合1201,所述文件被datadistillationtm装置简化从而产生蒸馏文件集合1205和基本数据滤筛的各个分量,也就是树节点文件1209、叶节点文件1210和pde文件1211。蒸馏文件1205包括名称为file1.dist、file2.dist、file3.dist…filen.dist的n个文件。datadistillationtm装置把输入数据因式分解成其构成单元,并且创建两个类别的数据单元——基本数据单元和导出单元。蒸馏文件包含处于无损简化格式中的数据单元的描述,并且包含对pde文件中的基本数据单元的引用。输入文件1201中的每一个文件在蒸馏文件1205中具有相应的蒸馏文件。举例来说,输入文件1201中的file11212对应于蒸馏文件1205中的名称为file1.dist1213的蒸馏文件。
应当提到的是,图12e示出了由数据蒸馏装置基于根据图1a的蒸馏数据和基本数据存储库的组织而创建的各个组成部分,其中重建程序被放置在蒸馏文件中的单元的无损简化表示中。应当提到的是,(根据图1b的)一些实施例可以把重建程序放置在基本数据存储库中,并且将其像基本数据单元一样对待。蒸馏文件中的单元的无损简化表示将包含对基本数据存储库中的重建程序的引用(而不是包含重建程序本身)。在这些实施例中,重建程序将像基本数据单元一样被对待,并且在pde文件1211中产生。在另一个实施例中,根据图1c,重建程序与基本数据单元分开存储并且被存储在称作重建程序存储库的结构中。在这样的实施例中,蒸馏文件中的单元的无损简化表示将包含对重建程序存储库中的重建程序的引用。在这样的实施例中,如图12f中所示,除了产生对应于基本数据单元的树组织的树节点文件1209、叶节点文件1210和pde文件1211之外,所述装置还将产生被称作重建树节点文件1219和重建叶节点文件1220的树和叶节点文件的第二集合,连同被称作rp文件1221的包含所有重建程序的文件。
图12e中所示的datadistillationtm装置还把管理其操作的配置和控制信息存储在树节点文件1209、叶节点文件1210、pde文件1211和蒸馏文件1205当中的一项或多项中。或者可以生成包含该信息的第五分量。类似地对于图12f中示出的装置,所述配置和控制信息可以被存储在图12f所示的各个分量当中的一个或多个分量中,或者可以被存储在为此目的生成的另一个分量中。
图12g示出了datadistillationtm装置的使用的总览,其中给定的数据集(输入文件1221)被馈送到datadistillationtm装置1203,并且被处理以产生无损简化数据集(无损简化数据集1224)。输入数据集1221可以由文件、对象、块、组块或来自数据流的提取项的选集构成。应当提到的是,图12e示出了其中所述数据集由文件构成的实例。图12g的输入数据集1221对应于图12e的输入文件1201,图12g的无损简化数据集1224则包括图12e中示出的四个组成部分,即图12e的蒸馏文件1205、树节点文件1209、叶节点文件1210和pde文件1211。在图12g中,datadistillationtm装置利用为之给出的输入数据集的整个范围内的数据单元当中的冗余。
datadistillationtm装置可以被配置成利用输入数据集的一个子集中的冗余,并且提供对应于为之给出的每一个数据子集的无损简化。举例来说,如图12h中所示,输入数据集1221可以被分割成许多更小的数据选集,每一个选集在本公开内容中被称作“批次”或“数据的批次”或“数据批次”。图12h示出了被配置成摄取输入数据批次1224并且产生无损简化数据批次1225的datadistillationtm装置。图12h示出输入数据集1221由若干数据选集构成,也就是数据批次1…数据批次i…数据批次n。数据被每次一个数据批次呈现到datadistillationtm装置,并且利用每一个数据批次的范围内的冗余以生成无损简化数据批次。举例来说,来自输入数据集1221的数据批次i1226被馈送到所述装置,并且无损简化数据批次i1228被递送到无损简化数据集1227。来自输入数据集1221的每一个数据批次被馈送到所述装置,并且相应的无损简化数据批次被递送到无损简化数据集1227。在消耗并且简化了所有数据批次1…数据批次i…数据批次n之后,输入数据集1221被简化到无损简化数据集1227。
虽然datadistillationtm装置的设计在利用全局数据范围内的冗余方面已经是高效的,但是前面的技术可以被用来进一步加快数据简化处理并且进一步改进其效率。通过把数据批次的大小限制到能够容纳到系统的可用存储器中,可以提高数据简化处理的吞吐量。举例来说,其大小是许多太字节或甚至拍字节的输入数据集可以被分解成分别具有例如256gb大小的许多数据批次,并且每一个数据批次可以被快速地简化。通过使用具有256gb的存储器的单一处理器核心(intelxeone5-1650v3,haswell3.5ghz处理器),在我们的实验室中已经实施了利用256gb的范围内的冗余的此类解决方案,从而给出每秒几百兆字节的数据摄取速率,同时在各种数据集上给出2-3x的简化水平。应当提到的是,256gb的范围比32kb大几百万倍,而32kb是lempelziv方法在现今的处理器上给出10mb/秒到200mb/秒之间的摄取性能的窗口大小。因此,通过适当地限制冗余的范围,通过潜在地牺牲一些简化可以实现数据蒸馏处理的速度方面的改进。
图12i示出了图12h中的设置的一种变型,并且示出了运行在多个处理器上以便显著提升输入数据集的数据简化(并且还有数据重建/取回)吞吐量的多个数据蒸馏处理。图12i示出了被分割成x个数据批次的输入数据集1201,所述x个独立数据批次被馈送到运行在独立处理器核心上的j个独立处理中(每一个处理被分配足够的存储器以容纳将被馈送到该处的任何数据批次)以得到并行执行,并且对于数据简化以及重建/取回都产生近似j倍的加速。图12j示出了由datadistillationtm装置对于一个使用模型产生的简化数据的各个分量,其中在输入数据集的简化之后不再需要保留映射器。这样的使用模型的实例是特定种类的数据备份和数据归档应用。在这样的使用模型中,对于简化数据的仅有的后续使用是从简化数据集重建和取回输入数据集。在这样的情形中,通过在数据简化完成之后不再存储映射器可以把简化数据的足迹进一步简化。图12j示出了被馈送到所述装置的输入文件1201,从而产生蒸馏文件1205和pde文件1211——这些组成部分(或分量)构成这种情形中的简化数据。应当提到的是,仅使用蒸馏文件1205和pde文件1211可以完全重新生成并恢复输入文件1201。回想到对应于蒸馏文件中的每一个单元的无损简化表示包含重建程序(在需要时)以及对pde文件中的基本数据单元的引用。与pde文件相耦合,这就是执行重建所需的全部信息。
应当提到的是,图12j示出了由数据蒸馏装置基于根据图1a的蒸馏数据和基本数据存储库的组织而创建的各个分量,其中重建程序被放置在蒸馏文件中的单元的无损简化表示中。应当提到的是,(根据图1b的)一些实施例可以把重建程序放置在基本数据存储库中,并且将其像基本数据单元一样对待。蒸馏文件中的单元的无损简化表示将包含对基本数据存储库中的重建程序的引用(而不是包含重建程序本身)。在这些实施例中,重建程序将像基本数据单元一样被对待,并且在pde文件1211中产生。在另一个实施例中,根据图1c,重建程序与基本数据单元分开存储并且被存储在称作重建程序存储库的结构中。在这样的实施例中,蒸馏文件中的单元的无损简化表示将包含对重建程序存储库中的重建程序的引用。在这样的实施例中,除了产生对应于基本数据单元的pde文件之外,所述装置还将产生被称作rp文件的包含所有重建程序的文件。这在图12k中示出,该图对于其中不再需要保留映射器的使用模型示出了简化数据的分量。图12k示出了包括蒸馏文件1205、pde文件1211和rp文件1221的简化数据分量。
使用这里所描述的实施例在多种真实世界数据集上实施数据简化以便确定这些实施例的有效性。所研究的真实世界数据集包括企业电子邮件的enron语料库,各种美国政府记录和文献,被输入到mongodbnosql数据库中的美国交通部记录,以及可由公众获得的企业powerpoint演示。通过使用这里所描述的实施例并且把输入数据因式分解成平均4kb的可变大小单元(通过指纹处理确定边界),在这些数据集上实现了3.23x的平均数据简化。3.23x的简化意味着简化数据的大小等于原始数据的大小除以3.23x,从而得到具有31%压缩比的简化足迹。通过使用等效的参数发现传统的数据去重复技术在这些数据集上给出了1.487x的数据简化。通过使用这里所描述的实施例并且把输入数据因式分解成4kb的固定大小单元,在这些数据集上实现了1.86x的平均数据简化。通过使用等效的参数发现传统的数据去重复技术在这些数据集上给出了1.08x的数据简化。因此发现datadistillationtm解决方案与传统的数据去重复解决方案相比给出了显著更好的数据简化。
测试运行还证实基本数据单元的较小字节子集可以用来对滤筛中的大部分单元进行排序,从而允许对于其操作需要最小增量存储的解决方案。
结果证实datadistillationtm装置高效地允许以比单元本身更细的粒度在整个数据集上全局地利用数据单元当中的冗余。以经济的数据存取和io实现了通过本方法给出的无损数据简化,其中采用本身只需要最小增量存储的数据结构,并且只使用在现今的多核微处理器上可用的全部计算处理能力的一部分。在前面的章节中描述的实施例涉及在较大和极大的数据集上实施无损数据简化并且同时提供高数据摄取和数据取回速率的系统和技术,并且不受困于传统技术的缺点和限制。
给出前面的描述是为了使得本领域技术人员能够制作和使用所述实施例。在不背离本公开内容的精神和范围的情况下,本领域技术人员将很容易认识到针对所公开的实施例的各种修改,并且这里所定义的一般原理适用于其他实施例和应用。因此,本发明不限于所示出的实施例,而是应被给予与这里所公开的原理和特征一致的最广范围。
在本公开内容中描述的数据结构和代码可以部分地或完全地被存储在计算机可读存储介质和/或硬件模块和/或硬件装置上。计算机可读存储介质包括而不限于易失性存储器、非易失性存储器、磁性和光学存储设备(比如盘驱动器、磁带、cd(紧致盘)、dvd(数字通用盘或数字视频盘))或者能够存储代码和/或数据的现在已知或后来开发的其他介质。在本公开内容中描述的硬件模块或装置包括而不限于专用集成电路(asic)、现场可编程门阵列(fpga)、专用或共享处理器以及/或者现在已知或后来开发的其他硬件模块或装置。
在本公开内容中描述的方法和处理可以部分地或完全地被具体实现为存储在计算机可读存储介质或设备中的代码和/或数据,从而当计算机系统读取并执行所述代码和/或数据时,所述计算机系统实施相关联的方法和处理。所述方法和处理还可以部分地或完全地被具体实现在硬件模块或装置中,从而当所述硬件模块或装置被激活时,其实施相关联的方法和处理。应当提到的是,所述方法或处理可以使用代码、数据以及硬件模块或装置的组合来具体实现。
前面关于本发明的实施例的描述仅仅是出于说明和描述的目的而给出的。所述描述不意图进行穷举或者把本发明限制到所公开的形式。因此,本领域技术人员将会想到许多修改和变型。此外,前面的公开内容不意图限制本发明。
- 还没有人留言评论。精彩留言会获得点赞!