用于处理音频信号的方法和装置与流程
本发明涉及用于处理娱乐系统中的音频信号的方法和装置。
背景技术:
娱乐系统当前使用各种不同的音频源。这里每个音频源典型地具有特定音量,该音量由所使用的各硬件、软件和相关音频轨道预定。在改变音频源之后,用户通常被迫调整或重新调整主音量以获得与先前主观感知相同的音量。被称作术语“响度”的感知的音量取决于音频信号的频率、振幅和时间位置。
根据线上维基百科全书,响度是人类音量感知的比例映射量(比照http://www.wikipedia.de标题“Lautheit”[响度],2015年8月3日版)。
响度是心理声学术语,其描述若干测试人员主要评估感知音量的方式。响度取决于声压水平、频谱和声音随时间推移的特性。响度的感知由内耳中声音的处理类型和方式引起。根据神经细胞的激励强度,声音被评估为更大声或更小声。当声音被感知为两倍大时,响度总体是两倍大。
已知用于定量确定响度的标准化测量方法。然而,在本发明的上下文中使用的术语“响度”总体意在被理解为心理声学加权音量,其可以对应于根据标准化测量方法限定的响度(以宋(sone)测量),但也可以利用可选的方法(在适当情况下简化)限定。
在实时处理期间调整音频信号的音量的算法是已知的。然而,这些算法使用均衡器、压缩器或限制器改变相关声音轨道或由于该调整使它们降低动态范围。此外,这种类型的算法通常需要高的处理和存储能力。
关于现有技术,仅以示例的形式参照WO 2013/154823A2、WO 2004/111994A2、EP 1 805 891B1、EP 1 629 463A2、EP 1 835 487A2和EP 1 763 923A1。
技术实现要素:
本发明的目标是提供一种用于处理音频信号的方法和装置,其中可以获得在每种情况下对来自不同音频源的音频信号中主观感知的音量或响度的最佳对应效果。
该目标通过根据独立权利要求1的特征的方法和根据权利要求8的特征的装置来实现。
在根据本发明的用于处理娱乐系统中的音频信号的方法中,来自至少一个音频源的音频信号在由娱乐系统回放期间被改变以调整到心理声学响度设置值,其中在每种情况下基于平均心理声学响度最大值执行该改变,平均心理声学响度最大值是在预定时间间隔中针对相关音频源所确定的。
根据一个实施例,来自至少两个不同音频源的音频信号在娱乐系统回放期间被改变以调整到心理声学响度设置值。
本发明尤其基于执行将不同音频源实时调整到心理声学响度设置值的构思。根据本发明的方法尤其基于音频流的实时数据,而不需要知道未来值。而且,来自一个或多个音频源的音频信号在每种情况下被处理,该处理对每种情况下来自其它音频源的音频信号没有依赖性。
根据本发明的方法不需要用于例如由相同音频源回放的不同音乐或歌曲的音量调整。作为替代,来自娱乐系统不同音频源的音频信号的动态调整根据各自最大主观感知的响度而实施。
如上文中已经提到的,术语“响度”表示与用户心理声学感知的音量近似成比例的量。该响度可以根据相关标准计算,但也可以由简化的粗略计算限定。尤其地,可以根据机动车辆中的特定标准而调整用于响度限定所需的频率加权(例如通过将典型的背景噪声谱纳入考虑)。
根据一个实施例,音频信号在每种情况下在改变事件中乘以振幅,该振幅取决于各相关音频源。
根据一个实施例,该振幅在每种情况下计算为响度设置值和平均心理声学响度最大值的商。
根据一个实施例,平均心理声学响度最大值的估算基于针对各音频源存储的响度数据而实施。
本发明还设计用于处理音频信号的装置,其中来自至少一个音频源的音频信号在娱乐系统回放期间可被改变以调整到心理声学响度设置值,其中该装置配置用于实施具有上述特性的方法。关于该装置的优势和有利设计,参照上述与本发明的方法相关作出的陈述。
根据本发明的处理尤其基于长期的信号信息。这通过极端数据简化来实现。由于在通常情况下振幅的变化只是在无内存重写的情况下非常缓慢地进行,因此娱乐系统的听众或用户不能感知到动态音量或响度变化。而且,因此调整过程非常稳定并仅需要相对较低的处理能量。
本发明进一步的设计存在于说明书和从属权利要求中。
在下文中使用优选实施例并参照附图更详细地说明本发明。
附图说明
在图中:
图1示出了说明根据本发明用于音量调整的方法的示意图;
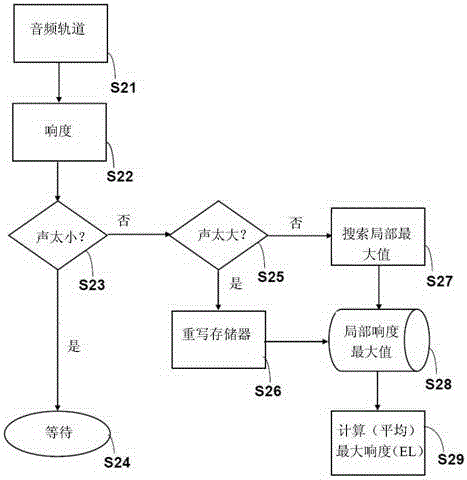
图2示出了用于说明使用根据本发明的方法执行的最大响度估算的流程图;
图3示出了用于说明根据图2中的步骤S22的响度限定的可行实施方式;以及
图4示出了根据图2的步骤S29计算平均最大响度的示意性表示。
具体实施方式
根据图1,在根据本发明的用于音量调整的方法中,输入音频信号11通过乘以由源决定和时间决定的振幅15来改变,从而获得输出音频信号16。振幅15由常数计算得出,通过音量设置值(SET)13除以来自音量存储器14的估算平均最大心理声学音量12(在下文中参照图2更详细地说明)得到该常数。为了避免由于振幅15突变所引起的信号失真,振幅值优选地随随时间逐渐减弱。
为了计算振幅,根据本发明的方法尤其需要心理声学音量平均最大值的估算,其中针对该估算实施的过程在下文中参照图2的流程图描述。
此处,估算的平均最大响度在下文被称作EL值(EL=“估算的平均最大响度”)。使用过去可用的各音频源音频信号的音量数据计算EL值。
为了计算EL值,首先根据特定音频轨道的信号频率测量当前响度(图2中步骤S21和S22)。以这种方式测量的响度值被用于确定固定时间间隔内的局部最大值。各当前响度最大值被存储在存储器中,其中在每种情况下根据询问S25(“太大声”?),如果各自存在的EL值超出了限定的公差,那么存储在该存储器中的值在步骤S26中被重写。如果音频轨道的当前响度小于预定值,那么调整在步骤S23(“太小声”?)中暂停。
在每种情况下根据步骤S28获得存储音频轨道响度特性的数据,其依据固定时间间隔内的局部最大值的搜索(步骤S27)。因此存在于存储器中的值包含相关音频源的音频信号的各响度最大值。根据存储的响度最大值计算EL值(步骤S29)。
如果没有可用的以前的音量值(例如由于涉及新的未知音频源)或者如果当前音量大体大于EL值,执行新EL值的快速近似确定。该近似值基于传入音频轨道的新响度最大值。只要发现新的平均最大值,利用该值重写存储器内容并且再次执行根据本发明的计算。
图3示出了用于图2的步骤22中的响度限定的示意性算法的示例。音频轨道(S22a)被细分为单独的频率成分(例如通过傅里叶分析)。在步骤S22b中,心理声学估算滤波器被应用到该离散谱中,例如带通滤波器,该滤波器可以具有向下开放的抛物线形,其在人耳感知最大值处具有最大值。以这种方式获得的加权谱成分的平方被加和并且与步骤S22c中的标准化常数相乘以产生表示当前响度的值(S22d)。除了图3中所示的响度限定之外,也可以想到针对响度限定的各种其它算法。
图4示出了用于确定图2的步骤S29所使用的平均最大响度的可行方法,其仅以示例方式给出。存在于存储器中的音频信号优选——但并非必须——在步骤30细分为单独的框(在该情形中是三个)。在步骤31,函数被应用到单独的区段,函数提供与最大值(对应于步骤S28)接近的值,例如和/或和/或其中意指适用的全部值(mean=平均值,max=最大值并且std=标准偏差)。在32处,“遗忘因子”λ可以可选地被应用到与最大值接近的单独的值,其中0<λ<1。因此,与最近的信号相比,以前的信号被给予较少的权重。最终,在33处,以这种方式获得的值被相加以形成和(如必要,在之前的平方之后)并且因此在34处获得值EL。此外,用于确定EL值的各种其它算法是明显可行的。
- 还没有人留言评论。精彩留言会获得点赞!