一种应用于闪存的基于等差校验矩阵的LDPC码译码器的制作方法
本发明属于非易失性存储器中的纠错编码技术领域,特别涉及一种应用于闪存纠错领域的低硬件面积、高通过率的等差准循环ldpc码译码器。
背景技术:
目前,nand闪存的重点应用领域已经从桌面端向移动端大幅度倾斜,例如手机、平板、u盘和固态硬盘等。nand闪存的一个重要的发展趋势是tlc(trinary-levelcell)技术的发展。最早的nand闪存使用的是slc(single-levelcell)技术,即在每个存储单元中存储1-bit信息。随着移动设备的发展所带来的对存储容量需求的不断提高,mlc(multi-levelcell)技术应运而生,实现了在每个存储单元中存储2-bit信息的功能。目前,市场上最受广泛应用的是tlc技术,即在每个存储单元中存储3-bit信息。相比于slc和mlc,tlc有着存储容量更大的优点。然而,由于tlc中相邻电压的间隔变得更小,随之而来的是源误码率更高的缺点。因此,设计可靠的纠错编码技术,尤其是ldpc码的纠错编码技术,是一个刻不容缓的任务,并将成为新一代闪存应用的关键技术。
nand闪存的另一个重要的发展趋势是其芯片读写速度的急剧提升。传统的nand闪存采用的是标准nand闪存接口的独立存储芯片,与之相比较,emmc(embeddedmultimediacard)和ufs(universalflashstorage)标准的存储芯片是将nand闪存和相对应的控制器集成封装成一体。这样的封装方式不仅节省了空间,还减轻了主机处理器对nand闪存在坏块管理、错误纠正、磨损均衡和垃圾回收等管理方面的负担。ufs2.0单通道理论传输速度可达到600mb/s,如果是双通道可提高至1200mb/s,是emmc5.0(400mb/s)的3倍。三星、东芝、闪迪、海力士等公司均在近年来扩大了ufs2.0标准的存储芯片的生产,与此同时还投入了对ufs2.1标准的存储芯片的量产,进一步提升了芯片的读写速度。因此,设计高吞吐率的ldpc解码器,也是掌握新一代闪存纠错技术的重中之重。
准循环ldpc码由于其校验矩阵的规则结构,为工业界的标准所普遍采纳。目前,应用于闪存纠错的准循环ldpc码均为高码率(0.86~0.94)的ldpc码。由于高码率的限制,许多译码器通常采用按列分组的最小和译码算法,每次对校验矩阵中的一列进行操作。然而,对于一般的准循环ldpc码,在采取按列分组的最小和译码算法时,均需要采用较大的桶形移位器,以确保前后两列的变量节点可以对齐。大维度桶形移位器的使用,占据了整个译码器相当大比重的一部分硬件面积(占20%~25%)。此外,在采取按列分组的最小和译码算法时,准循环ldpc码子矩阵的维度即为其译码并行度。当采用的准循环ldpc码的子矩阵维度扩大时,桶形移位器的规模成倍扩大,使得准循环ldpc码译码器的吞吐率遭受到了严重的制约。
技术实现要素:
发明目的:本发明针对目前ldpc码译码器的缺陷,公开了一种低硬件面积、高吞吐率的ldpc码译码器。特别地,本译码器适用但不局限于闪存纠错领域。
技术方案:一种应用于闪存的基于等差校验矩阵的ldpc码译码器,包括输入数据存储器、变量节点单元、校验节点单元、定偏移移位器、选择器、寄存器、存储器、输出数据存储器和符号存储器;
输入译码器的信道信息首先存放于输入数据存储器中;开始译码后,变量节点单元接收输入数据存储器中的信道信息和寄存器中存储的c2v(校验节点传给变量节点)信息,并计算出更新后的v2c(变量节点传给校验节点)信息。变量节点单元共1个,计算的是校验矩阵中的一列。
变量节点单元同时还计算了当前变量节点所连接的校验节点是否满足校验(所连接的校验节点之和是否为零),且其结果将用于提前终止译码。
变量节点单元将更新后的v2c信息的符号位存入符号存储器,用于计算下一次迭代中的c2v信息。
变量节点单元更新结束后,校验节点单元接收更新后的v2c信息和符号存储器中存储的上次迭代中的c2v符号位信息,并计算出更新后的c2v信息。校验节点单元共5个,对应的是校验矩阵中连接于当前变量节点的5个校验节点。
在本译码器采取按列分组的最小和译码算法时,c2v信息即每行中的first_min(第一最小值)、second_min(第二最小值)、first_min_index(第一最小值的地址)、second_min_index(第二最小值的地址),以及global_sign(全局符号)。
第一最小值和第二最小值的地址表示的是其在本行中的位置。
校验节点单元更新结束后,5条更新后的c2v信息分别送入5个定偏移移位器中。5个定偏移移位器的偏移量依次为0~4,对应校验矩阵中连续5行的公差。
移位结束后,5条移位后的c2v信息通过选择器分配到5个寄存器以及存储器中。校验矩阵中,当前变量节点从上至下共连接了5个校验节点,后4个校验节点的c2v信息会在下一列的迭代中立即被使用,所以通过选择器存入5个寄存器之中的4个;第一个校验节点的c2v信息不会在下一列迭代中立即被使用,所以通过选择器存入存储器;存储器将会取出一条预先存放的立即被用于下一列迭代的c2v信息,通过选择器存入5个寄存器中的最后剩余的1个。至此,5个寄存器存储了5条c2v信息,且它们将被送入变量节点单元,用于下一列v2c信息的计算。
当所有列的消息都被更新过一次(进行一次v2c信息与c2v信息的迭代),我们称按列分组的最小和译码算法完成了一次迭代,并令迭代次数自加1。
如果译码器在规定的迭代次数内完成了译码,译码器将提前终止迭代,把结果输出到输出数据存储器,并宣告译码成功;反之,如果译码器在达到最大的迭代次数后仍未完成译码,译码器将终止迭代,并宣告译码失败。
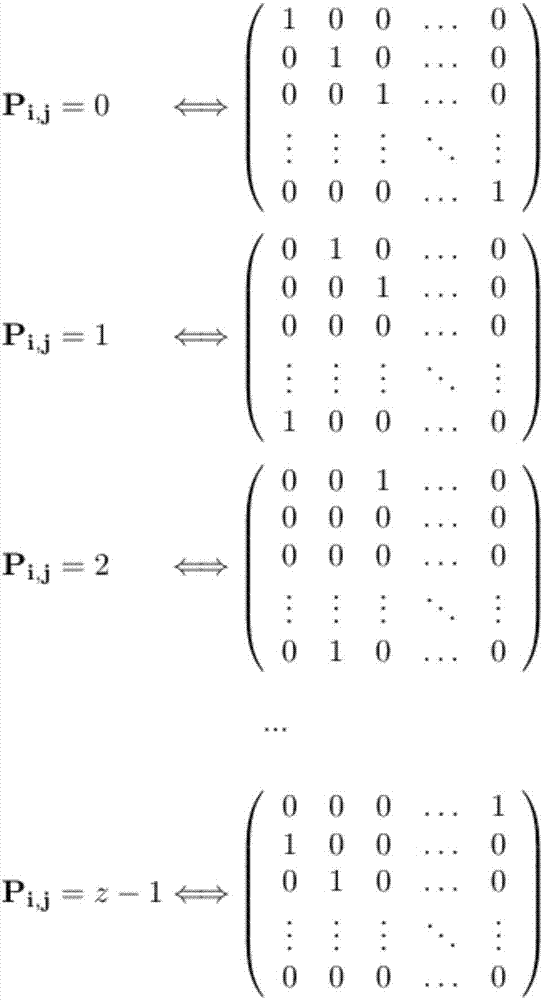
准循环ldpc码的校验矩阵可以用偏移参数pi,j来表示。每个偏移参数对应了一个z×z的单位矩阵的循环右移矩阵,且其偏移量为pi,j,其中,z即为子矩阵的维度。特别地,pi,j=0对应的即是维度为z的单位矩阵。
基础的等差准循环ldpc码经过矩阵扩展操作后得到扩展后的等差准循环ldpc码。等差准循环ldpc码的校验矩阵中每行(或每列)的偏移参数均为等差数列,且每行(或每列)的公差依次递增1。设等差准循环ldpc码的校验矩阵的列重(每列所包含的非空元素的个数)r=5。对基础的等差准循环ldpc码的子校验矩阵从上至下依次往后错位一列,即可得到错位后的子校验矩阵。把所得的错位后的子校验矩阵复制两份(共3份),即可得到扩展后的等差准循环ldpc码的子校验矩阵。以此类推,对多个毗邻的基础的等差准循环ldpc码的子校验矩阵采取相同的操作,可以得到扩展后等差准循环ldpc码的校验矩阵。特别地,设对毗邻的10个子校验矩阵采取相同的扩展方式,可以得到一个行列比为1:10的扩展后的校验矩阵,且此矩阵的列重r=5,行重s=50,码率r=0.9。在扩展后的等差准循环校验矩阵中,非空部分表示维度为z的单位矩阵的循环右移矩阵,空白部分表示维度为z的全零矩阵。
扩展后的校验矩阵没有短环,即4元环。
等差准循环ldpc码扩展后的校验矩阵中的每一列都有5个校验节点,对应了5条移位后的c2v信息。其中第1条移位后的c2v信息会被分配到存储器(因为它不会在下一时刻被使用),后4条移位后的c2v信息会被分配到寄存器(因为它们会在下一时刻被使用)。5条移位后的c2v信息通过选择器分配到对应的寄存器和存储器中,存储器中的c2v信息通过选择器分配到对应的寄存器中。
译码器兼容1-bit硬信息软解码和2-bit软信息软解码。
在译码开始后,译码器首先从闪存读取本帧(即码字)第一bit的对数似然比信息,并把读取的信息存放到输入数据存储器中。当本帧所有信息存储完毕后,译码器开始对1-bit的硬信息进行软解码。具体如下:在每个时钟,输入数据存储器都会按顺序取出z*1bit信息,输入变量节点单元,经由校验节点单元、定偏移移位器,最终通过选择器把数据存入对应的寄存器或者存储器中,完成本列的信息更新。在所有列都按上述方法更新后,我们称之完成了一次迭代,迭代次数自加1。通过变量节点单元判断本次迭代后中间结果是否满足校验,如果满足校验,则宣布1-bit硬信息软译码成功,并把结果输出至输出数据存储器;如果不满足校验,则判断迭代次数是否达到最大次数。如果迭代未达到最大次数,则返回继续进行下一次迭代;如果迭代已经达到最大次数,则宣告1-bit硬信息软译码失败。
在1-bit硬信息软译码宣告失败后,从闪存中读取本帧(即码字)第二bit的对数似然比信息,并把读取的信息存放到输入数据存储器中。当本帧所有信息存储完毕后,结合之前已经读取的第一bit信息,译码器开始对2-bit的软信息进行软解码。具体如下:在每个时钟,输入数据存储器都会按顺序取出z*2bit信息,输入变量节点单元,经由校验节点单元、定偏移移位器,最终通过选择器把数据存入对应的寄存器或者存储器中,完成本列的信息更新。在所有列都按上述方法更新后,我们称之完成了一次迭代,迭代次数自加1。通过变量节点单元判断本次迭代后中间结果是否满足校验,如果满足校验,则宣布2-bit软信息软译码成功,并把结果输出至输出数据存储器;如果不满足校验,则判断迭代次数是否达到最大次数。如果迭代未达到最大次数,则返回继续进行下一次迭代;如果迭代已经达到最大次数,则宣告2-bit软信息软译码失败。
1-bit硬信息软译码是指:从闪存读取的对数似然比用1-bit量化,并采取按列分组的最小和译码算法进行迭代译码;2-bit软信息软译码是指:从闪存读取的对数似然比用2-bit量化,并采取按列分组的最小和译码算法进行迭代译码。
本译码器不局限于按行成等差数列的校验矩阵,对于按斜对角线成等差数列的校验矩阵,存储器与寄存器的存储逻辑需要调整。对于按行成等差数列的校验矩阵:通过两个5选1的选择器来选择存储器的输入、输出接口与对应的寄存器r0~r4相连;对于按斜对角线成等差数列的校验矩阵:存储器的输入接口固定与寄存器r0对应的校验节点单元c0相连,存储器的输出接口固定与寄存器r4相连,并且每个时钟寄存器r1~r4的数据都会存入前一个寄存器。
本译码器的有益效果为:本译码器使用的码型基于等差准循环ldpc码,并对其校验矩阵作了矩阵扩展操作;在采取按列分组的最小和译码算法时,利用了等差准循环ldpc码校验矩阵的特性,避免了桶形移位器的使用;由于避免了桶形移位器的使用,准循环ldpc码子矩阵维度的扩大将不会严重影响译码器的硬件面积,因此可以通过扩大子矩阵的维度来增加译码的并行度,从而提升译码器的吞吐率;通过本译码器对1-bit硬信息软译码和2-bit软信息软译码的兼容使用,降低了闪存的平均读写次数,从而提高了闪存的使用寿命。
附图说明
图1a为准循环ldpc码校验矩阵的示意图;
图1b为准循环ldpc码校验矩阵中每个元素所对应的子矩阵的示意图;
图2a为等差准循环ldpc码校验矩阵的示意图;
图2b为等差准循环ldpc码的一部分作矩阵扩展操作的示意图;
图2c为等差准循环ldpc码扩展后的校验矩阵的示意图;
图3为本译码器参数具体化后的实例的架构图;
图4为本译码器参数具体化后的中间变量存储细节的示意图;
图5为本译码器的译码流程图;
图6为当码型按斜对角线等差时,存储结构调整方式的示意图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
为使本译码器的技术方法和优点更为清晰,现将译码器参数具体化并参照附图,对本译码器进行更为详细的阐述。
如图1a所示,准循环ldpc码的校验矩阵可以用偏移参数pi,j来表示。如图1b所示,每个偏移参数对应了一个z×z的单位矩阵的循环右移矩阵,且其偏移量为pi,j,其中,z即为子矩阵的维度。特别地,pi,j=0对应的即是维度为z的单位矩阵。
等差准循环ldpc码是一种特殊的准循环ldpc码。如图1a所示,本实例中的等差准循环ldpc码的偏移参数pi,j=(i×j)modz。本译码器适用但不局限于本实例中的等差准循环ldpc码。
如图2a、2c所示,流程200即是对基础的等差准循环ldpc码210作的矩阵扩展操作,矩阵230即是其扩展后的等差准循环ldpc码。
如图2a所示,等差准循环ldpc码210即是本实例中所用的码型,其校验矩阵中每行(或每列)的偏移参数均为等差数列,且每行(或每列)的公差依次递增1。特别地,本实例中的等差准循环ldpc码的校验矩阵的列重(每列所包含的非空元素的个数)r=5。对图2a所示的子校验矩阵211从上至下依次往后错位一列,即可得到如图2b所示的矩阵221。把所得矩阵复制两份(共3份),即可得到如图2b所示的矩阵222和223。在本实例中,复制倍数t=3,可以得到如图2b所示的矩阵220,即如图2c所示的矩阵231。同样地,对如图2a所示的子校验矩阵212采取相同的操作,可以得到如图2c所示的矩阵232。以此类推,对如图2a中多个毗邻的子校验矩阵210采取相同的操作,可以得到如图2c所示的扩展后的等差准循环ldpc码的校验矩阵230。特别地,本实例中对如图2a中毗邻的10个矩阵采取相同的扩展方式,可以得到一个行列比为1:10的扩展后的校验矩阵,且此矩阵的列重r=5,行重s=50,码率r=0.9。在如图2c所示的扩展后的等差准循环校验矩阵230中,非空部分表示维度为z的单位矩阵的循环右移矩阵,空白部分表示维度为z的全零矩阵。
需要理解,扩展后的校验矩阵没有短环,即4元环。
如图3所示的是本实例中的译码器的硬件架构300。输入译码器的信道信息首先存放于输入数据存储器310中。开始译码后,变量节点单元320接收输入数据存储器310中的信道信息和寄存器370~374中存储的c2v(校验节点传给变量节点)信息,并计算出更新后的v2c(变量节点传给校验节点)信息。变量节点单元共1个,计算的是如图2c所示的校验矩阵中的一列。
需要理解,变量节点单元320同时还计算了当前变量节点所连接的校验节点是否满足校验(所连接的校验节点之和是否为零),且其结果将用于提前终止译码。
需要理解,变量节点单元320将更新后的v2c信息的符号位存入符号存储器330,用于计算下一次迭代中的c2v信息。
变量节点单元320更新结束后,校验节点单元340~344接收更新后的v2c信息和符号存储器330中存储的上次迭代中的c2v符号位信息,并计算出更新后的c2v信息。校验节点单元共5个,对应的是如图2c所示的校验矩阵中连接于当前变量节点的5个校验节点。
需要理解,在本译码器采取按列分组的最小和译码算法时,c2v信息即每行中的first_min(第一最小值)、second_min(第二最小值)、first_min_index(第一最小值的地址)、second_min_index(第二最小值的地址),以及global_sign(全局符号)。
需要理解,第一最小值和第二最小值的地址表示的是其在本行中的位置。在本实例中,其取值范围为0~49。
校验节点单元340~344更新结束后,5条更新后的c2v信息分别送入5个定偏移移位器350~354中。定偏移移位器350~354的偏移量依次为0~4,对应的是如图2c所示的校验矩阵中连续5行的公差分别为0~4。
移位结束后,5条移位后的c2v信息通过选择器360分配到5个寄存器370~374以及存储器380中。如图2c所示的校验矩阵中,当前变量节点从上至下共连接了5个校验节点,后4个校验节点的c2v信息会在下一列的迭代中立即被使用,所以通过选择器360存入5个寄存器之中的4个;第一个校验节点的c2v信息不会在下一列迭代中立即被使用,所以通过选择器360存入存储器380;存储器380将会取出一条预先存放的立即被用于下一列迭代的c2v信息,通过选择器390存入5个寄存器中的最后剩余的1个。至此,寄存器370~374存储了5条c2v信息,且它们将被送入变量节点单元320,用于下一列v2c信息的计算。
需要理解,当所有列的消息都被更新过一次(进行一次v2c信息与c2v信息的迭代),我们称按列分组的最小和译码算法完成了一次迭代,并令迭代次数自加1。
需要理解,如果译码器在在规定的迭代次数内完成了译码,译码器将提前终止迭代,把结果输出到输出数据存储器315,并宣告译码成功;反之,如果译码器在达到最大的迭代次数后仍未完成译码,译码器将终止迭代,把结果输出到输出数据存储器315,并宣告译码失败。
如图2c所示的矩阵中的每一列都有5个校验节点,对应了5条移位后的c2v信息。其中第1条移位后的c2v信息会被分配到存储器(因为它不会在下一时刻被使用),后4条移位后的c2v信息会被分配到寄存器(因为它们会在下一时刻被使用)。为了更好地理解如图3所示的选择器360如何把5条移位后的c2v信息分配到对应的寄存器370~374和存储器380中,以及选择器390如何把存储器380中的c2v信息分配到对应的寄存器370~374中,其具体的分配流程被展示在图4的400中。
400展示了多个时钟具体的存储细节。410处是译码器的译码时钟,每个时钟处理的是等差准循环ldpc码中对应的一列。
420处对应的是等差准循环ldpc码的每列的5个校验节点单元c0~c4,即如图3所示的校验节点单元340~344。在本例中,每个时钟下c0~c4所对应的pi,j的具体数值如表420所示。
430处对应的是定偏移移位器s0~s4,即如图3所示的定偏移移位器350~354。在本例中,每个时钟下s0~s4所对应的移位值具体数值如表430所示。
需要理解,定偏移移位器s0其移位值是0,等价于直通;定偏移移位器s1其移位值除了1之外,还有12这一个特殊值,用于使校验矩阵最后一列与首列对齐;定偏移移位器s2其移位值除了2之外,还有24这一个特殊值,用于使校验矩阵最后一列与首列对齐;定偏移移位器s3其移位值除了3之外,还有36这一个特殊值,用于使校验矩阵最后一列与首列对齐;定偏移移位器s4其移位值除了4之外,还有48这一个特殊值,用于使校验矩阵最后一列与首列对齐。
需要理解,如图2c中的231处所示,移位器的移位值是根据前后两列偏移值之差决定的。
440处对应的是寄存器r0~r4,即如图3所示的寄存器370~374。在本例中,每个时钟下存储的具体c2v信息如表440所示。
需要理解,表440中mi代表的是第i行的c2v信息。
需要理解,表440中的inf代表的是初始化时,寄存器或存储器中读出的值全赋最大值。
450处对应的是存储器m0,即如图3所示的存储器380。在本例中,每个时钟下存储器的读、写地址和读、写数据如表450所示。以第11个时钟为例,表示经过移位器s1移位后的c2v信息m11被写入存储器的地址1中。同时地,在存储器中被读出的c2v信息m0被存入寄存器r0中。
需要理解,此处存储器的读数延时为两个时钟。因此,当第8个时钟给出读地址0后,在第10个时钟m0才被读出。
需要理解,本译码器兼容1-bit硬信息软解码和2-bit软信息软解码。在使用1-bit硬信息进行软译码时,本译码器对输入的对数似然比采取1-bit量化,中间计算结果采取4-bit量化;在使用2-bit软信息进行软译码时,本译码器对输入的对数似然比采取2-bit量化,中间计算结果采取4-bit量化。本译码器的具体实施流程500如图5所示:
在510处译码开始后,在520处译码器首先从闪存读取本帧(即码字)第一bit的对数似然比信息,并把读取的信息存放到如图3所示的输入数据存储器310中。当本帧所有信息存储完毕后,在521处译码器开始对1-bit的硬信息进行软解码。具体如下:在每个时钟,输入数据存储器310都会按顺序取出z*1bit信息,输入变量节点单元320,经由校验节点单元340~344、定偏移移位器350~354,最终通过选择器360把数据存入对应的寄存器370~374或者存储器380中,完成本列的信息更新。在所有列都按上述方法更新后,我们称之完成了一次迭代,迭代次数自加1。在522处,通过变量节点单元320判断本次迭代后中间结果是否满足校验,如果满足校验,则在523处宣布1-bit硬信息软译码成功,并把结果输出至输出数据存储器315;如果不满足校验,则在525处判断迭代次数是否达到最大次数。如果迭代未达到最大次数,则返回524处继续进行下一次迭代;如果迭代已经达到最大次数,则在526处宣告1-bit硬信息软译码失败。
在1-bit硬信息软译码宣告失败后,在530处从闪存中读取本帧(即码字)第二bit的对数似然比信息,并把读取的信息存放到如图3所示的输入数据存储器310中。当本帧所有信息存储完毕后,结合之前已经读取的第一bit信息,在531处译码器开始对2-bit的软信息进行软解码。具体如下:在每个时钟,输入数据存储器310都会按顺序取出z*2bit信息,输入变量节点单元320,经由校验节点单元340~344、定偏移移位器350~354,最终通过选择器360把数据存入对应的寄存器370~374或者存储器380中,完成本列的信息更新。在所有列都按上述方法更新后,我们称之完成了一次迭代,迭代次数自加1。在532处,通过变量节点单元320判断本次迭代后中间结果是否满足校验,如果满足校验,则在533处宣布2-bit软信息软译码成功,并把结果输出至输出数据存储器315;如果不满足校验,则在535处判断迭代次数是否达到最大次数。如果迭代未达到最大次数,则返回534处继续进行下一次迭代;如果迭代已经达到最大次数,则在536处宣告2-bit软信息软译码失败。
需要理解,1-bit硬信息软译码是指:从闪存读取的对数似然比用1-bit量化,并采取按列分组的最小和译码算法进行迭代译码;2-bit软信息软译码是指:从闪存读取的对数似然比用2-bit量化,并采取按列分组的最小和译码算法进行迭代译码。
由于闪存的寿命(即读写次数)有限,本译码器最多对闪存进行2-bit的读取。如果1-bit硬信息软译码和2-bit软信息软译码均宣告失败,则本译码器在540处宣布译码失败,并结束译码。此外,本译码器对闪存最多进行2-bit读取是为了考虑本译码器在闪存纠错领域的实用性,并非为了限制本译码器的适用范围。
本实例为了方便阐明本译码器的架构,采取了子矩阵维度z=61,列重r=5,行重s=50,复制倍数t=3。可以求得码长n=s×z×t=9150,码率r=1-r/s=0.9。
本实例所采用的上述参数仅为阐明本译码器的架构,非为限制本译码器的应用场景。本译码器适用于任意的等差准循环ldpc码校验矩阵,非限制于公比依次为0~4的等差准循环ldpc码校验矩阵。此外,本译码器非限制于按行成等差数列的矩阵,也适用于按斜对角线成等差数列的矩阵。对于按斜对角线成等差数列的矩阵,存储器与寄存器的存储顺序需要按照如图6的600处所示,作出从结构610到结构620的调整。结构610是通过两个5选1的选择器来选择存储器的输入、输出接口与对应的寄存器r0~r4相连;结构620中,存储器的输入接口固定与寄存器r0对应的c0相连,存储器的输出接口固定与寄存器r4相连,并且每个时钟寄存器r1~r4的数据都会存入前一个寄存器。
本译码器适用于任意需求高码率、高吞吐率ldpc译码的应用场景,非限制于闪存纠错领域。此外,本译码器非限制于特定的实现,本译码器可在诸如asic(专用集成电路)、fpga(现场可编程门阵列)等任意适当的硬件处理器上实现。
- 还没有人留言评论。精彩留言会获得点赞!