恶意网站识别方法和系统与流程
本发明涉及恶意网站识别领域,特别是涉及恶意网站识别方法和系统。
背景技术:
随着互联网技术的发展以及机器学习技术逐步普及,自动化技术在互联网安全领域的攻防双方都得到了充分地利用。恶意网站和携带恶意的页面亦使用自动化技术进行自我伪装、自我复制、自我散播。恶意网站网页识别技术提升的同时,恶意网站的生成技术也在逐步升级。操作系统、浏览器、防火墙等软件修正了部分安全漏洞,防范了部分安全威胁,其新增功能极大地方便了用户的日常生活、工作生活、金融方式等,但新增功能也同时暴露了新漏洞,引来了使用新型技术的新威胁,导致网站使用新增功能的同时,引入了恶意代码,使升级后的网页成为恶意网页。如何提升恶意网站识别的自动化处理效率,成为网站安全技术领域亟待解决的问题。
技术实现要素:
发明实施例提供一种恶意网站识别方法和系统,可以提高恶意网站识别的处理效率。所述方法包括:
确定待识别网站;
根据特征库,获取所述待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,所述特征库为根据网站提取的地址特征、页面内容特征和全域特征的集合;
将所述待识别地址特征、所述待识别内容特征、所述待识别全域特征和恶意模型进行计算,获取恶意网站匹配度,所述恶意模型包括根据恶意地址特征、恶意内容特征、恶意全域信息,以及所述恶意地址特征权重值、所述恶意内容特征权重值和所述恶意全域信息权重值获取的模型;
当所述恶意网站匹配度大于恶意网站识别阈值时,确定所述待识别网站为恶意网站。
在其中一个实施例中,所述待识别地址特征,包括:
地址长度向量、地址数量向量和地址结构向量其中的一种或任意组合,其中:
所述地址长度向量包括地址长度、域名长度、子域名长度、路径总长度和参数总长度中的其中一种或任意组合;
所述地址数量向量包括地址字符数量、地址字符数量、子域名数量和特殊符号数量、指定字符集数量和参数内指定字符数量中的其中一种或任意组合;
所述地址结构向量包括用户名存在标识、密码存在标识、协议使用标识、域名结构标识中的其中一种或任意组合。
在其中一个实施例中,所述待识别内容特征,包括:
标签向量和/或属性向量,其中:
所述标签向量包括标签内容长度、标签内保护目标特征关键词数量、标签图像资源、标签数量、标签内特征关键字频率中的其中一种或任意组合;
所述属性向量包括属性数量、属性外链数量、属性外链域名、属性长度、隐藏属性数量中的其中一种或任意组合。
在其中一个实施例中,所述待识别全域特征,包括:
ip向量、域名记录向量和证书记录向量其中的一种或任意组合,其中:
所述ip向量包括ip恶意标识、ip恶意关联标识、ip恶意段数量中的其中一种或任意组合;
所述域名记录向量包括域名恶意记录标识、域名所有人恶意标识、域名注册时间中的其中一种或任意组合;
所述证书记录向量包括证书所有人记录、证书注册时间、证书可信度中的其中一种或任意组合。
在其中一个实施例中,所述将所述待识别地址特征、所述待识别内容特征、所述待识别全域特征和恶意模型进行计算,获取恶意网站匹配度,还包括:
分别将所述待识别地址特征和恶意地址子模型进行计算,将所述待识别内容特征和恶意内容特征子模型进行计算,将所述待识别全域特征和恶意全域特征子模型进行计算,分别获取恶意地址匹配度、恶意内容匹配度和恶意全域匹配度;
将所述恶意地址匹配度、所述恶意内容匹配度和所述恶意全域匹配度和所述恶意模型进行计算,获取恶意网站匹配度,其中,所述恶意模型还包括:
根据恶意地址匹配度、恶意内容匹配度和恶意全域匹配度以及所述恶意地址匹配度权重值、恶意内容匹配度权重值和恶意全域匹配度权重值获取的模型。
在其中一个实施例中,所述恶意模型,包括:
根据恶意地址特征、恶意内容特征、恶意全域信息和预设的期望识别模型,利用机器学习算法,分别获取所述恶意地址特征的恶意地址特征权重值、所述恶意内容特征的恶意内容特征权重值、所述恶意全域信息的恶意全域信息权重值,所述预设的期望识别模型为期望识别出的恶意网站的组合;
根据所述恶意地址特征、所述恶意内容特征、所述恶意全域信息,以及所述恶意地址特征权重值、所述恶意内容特征权重值和所述恶意全域信息权重值获取恶意模型。
在其中一个实施例中,根据预设的特征库,提取待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,将上述待识别特征与恶意模型进行计算后,获取恶意网站匹配度,并将所述恶意网站匹配度和预设的恶意网站识别阈值进行比较后,确定所述待识别网站是否为恶意网站。通过对页面地址特征、页面内容特征和页面全域特征进行的提取,与预先设定的根据不同的识别需求构建的恶意特征识别进行计算的方法,本发明可自动快速的从恶意网站可能存在的所有方面进行自动设别,并能按照不同的恶意网站识别模型进行有针对性的识别,提高了恶意网站的识别效率和针对性。
在其中一个实施例中,所述待识别地址特征,包括了地址长度向量、地址数量向量和地址结构向量其中的一种或任意组合,将所述待识别网站的地址特征进行了全方位的衡量,使得根据所述待识别地址特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,所述待识别内容特征,包括了标签向量和/或属性向量,将所述待识别网站的内容特征进行了全方位的衡量,使得根据所述待识别内容特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,所述待识别全域特征,包括了ip向量、域名记录向量和证书记录向量其中的一种或任意组合,将所述待识别网站的全域特征进行了全方位的衡量,使得根据所述待识别全域特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,在恶意模型内部,还设置有恶意地址子模型、恶意内容特征子模型和恶意全域特征子模型,用于分别对待识别地址特征、待识别内容特征和待识别全域特征进行计算,分别获取恶意地址匹配度、恶意内容匹配度和恶意全域匹配度后在获取整个恶意模型的恶意匹配度。由于分别设置了恶意地址特征子模型、恶意内容特征子模型和恶意全域特征子模型,可以分别针对恶意地址、恶意内容和恶意全域信息进行更有针对性的恶意匹配度的计算,从而使得恶意网站的识别效率更高。
在其中一个实施例中,所述恶意地址子模型、恶意内容特征子模型和恶意全域特征子模型,分别根据预设的期望识别模型,利用机器学习算法,分别获取各自的权重值后构建而成。因此所述三个子模型的构建过程,根据不同的恶意网站识别需求,进行机器学习算法,提高了恶意网站识别的针对性、提高了恶意网站的识别效率以及准确率。
本发明还提供一种恶意网站识别系统,包括:
待识别网站确定模块,用于确定待识别网站;
特征获取模块,用于根据特征库,获取所述待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,所述特征库为根据网站提取的地址特征、页面内容特征和全域特征的集合;
恶意网站匹配度获取模块,用于将所述待识别地址特征、所述待识别内容特征、所述待识别全域特征和恶意模型进行计算,获取恶意网站匹配度,所述恶意模型包括根据恶意地址特征、恶意内容特征、恶意全域信息,以及所述恶意地址特征权重值、所述恶意内容特征权重值和所述恶意全域信息权重值获取的模型;
恶意网站确定模块,用于当所述恶意网站匹配度大于恶意网站识别阈值时,确定所述待识别网站为恶意网站。
在其中一个实施例中,所述待识别地址特征,包括:
地址长度向量、地址数量向量和地址结构向量其中的一种或任意组合,其中:
所述地址长度向量包括地址长度、域名长度、子域名长度、路径总长度和参数总长度中的其中一种或任意组合;
所述地址数量向量包括地址字符数量、地址字符数量、子域名数量和特殊符号数量、指定字符集数量和参数内指定字符数量中的其中一种或任意组合;
所述地址结构向量包括用户名存在标识、密码存在标识、协议使用标识、域名结构标识中的其中一种或任意组合。
在其中一个实施例中,所述待识别内容特征,包括:
标签向量和/或属性向量,其中:
所述标签向量包括标签内容长度、标签内保护目标特征关键词数量、标签图像资源、标签数量、标签内特征关键字频率中的其中一种或任意组合;
所述属性向量包括属性数量、属性外链数量、属性外链域名、属性长度、隐藏属性数量中的其中一种或任意组合。
在其中一个实施例中,所述待识别全域特征,包括:
ip向量、域名记录向量和证书记录向量其中的一种或任意组合,其中:
所述ip向量包括ip恶意标识、ip恶意关联标识、ip恶意段数量中的其中一种或任意组合;
所述域名记录向量包括域名恶意记录标识、域名所有人恶意标识、域名注册时间中的其中一种或任意组合;
所述证书记录向量包括证书所有人记录、证书注册时间、证书可信度中的其中一种或任意组合。
在其中一个实施例中,所述恶意网站匹配度获取模块,还用于:
分别将所述待识别地址特征和恶意地址子模型进行计算,将所述待识别内容特征和恶意内容特征子模型进行计算,将所述待识别全域特征和恶意全域特征子模型进行计算,分别获取恶意地址匹配度、恶意内容匹配度和恶意全域匹配度;其中,所述恶意模型还包括根据恶意地址匹配度、恶意内容匹配度和恶意全域匹配度以及所述恶意地址匹配度权重值、恶意内容匹配度权重值和恶意全域匹配度权重值获取的模型。
在其中一个实施例中,所述恶意模型,包括:
根据恶意地址特征、恶意内容特征、恶意全域信息和预设的期望识别模型,利用机器学习算法,分别获取所述恶意地址特征的恶意地址特征权重值、所述恶意内容特征的恶意内容特征权重值、所述恶意全域信息的恶意全域信息权重值,所述预设的期望识别模型为期望识别出的恶意网站的组合;
根据所述恶意地址特征、所述恶意内容特征、所述恶意全域信息,以及所述恶意地址特征权重值、所述恶意内容特征权重值和所述恶意全域信息权重值获取恶意模型。
在其中一个实施例中,根据预设的特征库,提取待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,将上述待识别特征与恶意模型进行计算后,获取恶意网站匹配度,并将所述恶意网站匹配度和预设的恶意网站识别阈值进行比较后,确定所述待识别网站是否为恶意网站。通过对页面地址特征、页面内容特征和页面全域特征进行的提取,与预先设定的根据不同的识别需求构建的恶意特征识别进行计算的方法,本发明可自动快速的从恶意网站可能存在的所有方面进行自动设别,并能按照不同的恶意网站识别模型进行有针对性的识别,提高了恶意网站的识别效率和针对性。
在其中一个实施例中,所述待识别地址特征,包括了地址长度向量、地址数量向量和地址结构向量其中的一种或任意组合,将所述待识别网站的地址特征进行了全方位的衡量,使得根据所述待识别地址特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,所述待识别内容特征,包括了标签向量和/或属性向量,将所述待识别网站的内容特征进行了全方位的衡量,使得根据所述待识别内容特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,所述待识别全域特征,包括了ip向量、域名记录向量和证书记录向量其中的一种或任意组合,将所述待识别网站的全域特征进行了全方位的衡量,使得根据所述待识别全域特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,在恶意模型内部,还设置有恶意地址子模型、恶意内容特征子模型和恶意全域特征子模型,用于分别对待识别地址特征、待识别内容特征和待识别全域特征进行计算,分别获取恶意地址匹配度、恶意内容匹配度和恶意全域匹配度后在获取整个恶意模型的恶意匹配度。由于分别设置了恶意地址特征子模型、恶意内容特征子模型和恶意全域特征子模型,可以分别针对恶意地址、恶意内容和恶意全域信息进行更有针对性的恶意匹配度的计算,从而使得恶意网站的识别效率更高。
在其中一个实施例中,所述恶意地址子模型、恶意内容特征子模型和恶意全域特征子模型,分别根据预设的期望识别模型,利用机器学习算法,分别获取各自的权重值后构建而成。因此所述三个子模型的构建过程,根据不同的恶意网站识别需求,进行机器学习算法,提高了恶意网站识别的针对性、提高了恶意网站的识别效率以及准确率。
附图说明
图1为一个实施例的恶意网站识别方法的流程示意图;
图2为另一个实施例的恶意网站识别方法的流程示意图;
图3为一个实施例的恶意网站识别系统的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
图1为一个实施例的恶意网站识别方法的流程示意图,如图1所示的恶意网站识别方法,包括:
步骤s100,确定待识别网站。
具体的,确定一个待识别的网站,所述待识别网站可能是恶意网站,也可能是正常的网站。
步骤s200,根据特征库,获取所述待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,所述特征库为根据网站提取的地址特征、页面内容特征和全域特征的集合。
具体的,所述特征库,为本实施例中,根据后续的恶意模型的计算需求,需要在所述待识别网站中提取的特征,具体包括地址特征、内容特征和全域信息特征三部分。
其中所述提取待识别地址特征,包括将待识别网站的地址按照统一的格式化标准进行处理,并从格式化后的待识别网站地址中提取待识别地址特征。还包括根据预设的保护目标或白名单目标,获取不需要进行恶意网站识别的待识别网站信息。所述保护目标如政府、企业、组织等高公信力、高敏感、高关注的网站,以其网站的基础域名为目标。所述白名单目标包括已知可信页面,包括客户企业、忽略反馈、误报反馈等网站的基础域名或页面。
所述提取待识别内容特征,包括预先构建行业字典特征库和保护目标特征库,并根据所述行业字典特征库和保护目标特征库,对所述待识别内容特征,进行有针对性的提取。所述行业字典特征库包括根据词语频率和行业相关性的概率及各个词语特征的权重值等组成的特征库;所述保护目标特征库,包括保护目标网站内页面内容生成的词语频率概率的权重值组成的特征库。
所述提取待识别全域特征,包括不局限于页面自身的,扩展到增加特征值所覆盖的整个网络行为,包括待识别网站的所有人的注册时间等,与所述待识别网站有关联的全部关联信息。
步骤s300,将所述待识别地址特征、所述待识别内容特征、所述待识别全域特征和恶意模型进行计算,获取恶意网站匹配度,所述恶意模型包括根据恶意地址特征、恶意内容特征、恶意全域信息,以及所述恶意地址特征权重值、所述恶意内容特征权重值和所述恶意全域信息权重值获取的模型。
具体的,根据恶意网站的识别需求,为不同的恶意特征设定不同的权重值后,构建恶意特征和与其对应的权重值组成的模型,用于计算从待识别网站中提取的待识别地址特征、待识别内容和待识别全域特征,获取恶意网站匹配度。
步骤s400,当所述恶意网站匹配度大于恶意网站识别阈值时,确定所述待识别网站为恶意网站。
具体的,通过预设的恶意网站识别阈值,可以根据恶意网站的识别需求,给出不同的设定,从而得到不同的恶意网站识别结果,
在本实施例中,根据预设的特征库,提取待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,将上述待识别特征与恶意模型进行计算后,获取恶意网站匹配度,并将所述恶意网站匹配度和预设的恶意网站识别阈值进行比较后,确定所述待识别网站是否为恶意网站。通过对页面地址特征、页面内容特征和页面全域特征进行的提取,与预先设定的根据不同的识别需求构建的恶意特征识别进行计算的方法,本发明可自动快速的从恶意网站可能存在的所有方面进行自动设别,并能按照不同的恶意网站识别模型进行有针对性的识别,提高了恶意网站的识别效率和针对性。
在其中一个实施例中,所述待识别地址特征,包括:地址长度向量、地址数量向量和地址结构向量其中的一种或任意组合,其中:
所述地址长度向量包括地址长度、域名长度、子域名长度、路径总长度和参数总长度中的其中一种或任意组合;
所述地址数量向量包括地址字符数量、地址字符数量、子域名数量和特殊符号数量、指定字符集数量和参数内指定字符数量中的其中一种或任意组合;
所述地址结构向量包括用户名存在标识、密码存在标识、协议使用标识、域名结构标识中的其中一种或任意组合。
具体的,所述待识别地址特征,包括:
解析格式:protocal://username:password@domain:port/path/filename.ext?query;
指定字符集:@%_-&#?;
dot:点符号。rising.com.cn中存在2个;
特征为:
urllength:url包含的字符数量,url的长度;
tokeninurl:url中包含指定字符集的数量;
protocal:使用https协议为0,其他为1;
username:存在为1,不存在为0;
password:存在为1,不存在为0;
domainlength:域名总长度。url中解析出domain位置内包含的字符数量;
domainisip:域名是否为ip。domain位置内为ip格式内容是为1,其他为0;
subdomaincount:子域名数量。domain位置内非ip格式时dot数量+1,ip格式时为0;
subdomainmaxlength:子域名最大长度。domain位置内非ip格式时,dot分割的子字符串数量的最大值。www.rising.com.cn中值为6,ip格式时为0;
tokenindomain:域名内特殊符号数量。domain位置内包含指定字符集的数量;
port:端口号标准。与协议相关,是标准协议端口号时为0,其他为1;
tokeninpath:路径内包含指定字符集的数量;
pathlength:路径总长度;
pathdepths:路径深度。路径path位置内包含/符号数量;
querylength:参数总长度;
tokeninquery:参数query位置内包含指定字符集的数量。
在本实施例中,所述待识别地址特征,包括了地址长度向量、地址数量向量和地址结构向量其中的一种或任意组合,将所述待识别网站的地址特征进行了全方位的衡量,使得根据所述待识别地址特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,所述待识别内容特征,包括:
标签向量和/或属性向量,其中:
所述标签向量包括标签内容长度、标签内保护目标特征关键词数量、标签图像资源、标签数量、标签内特征关键字频率中的其中一种或任意组合;
所述属性向量包括属性数量、属性外链数量、属性外链域名、属性长度、隐藏属性数量中的其中一种或任意组合。
具体的,所述待识别内容特征,包括:
title标签内容长度;
title标签内保护目标特征关键词存在数量;
img标签图像资源;
input标签个数;
src属性个数;
src属性外链个数;
src属性外链域名;
href属性个数;
href属性外链个数;
href属性外链域名;
target属性个数;
target属性长度;
target属性中以#开头个数;
隐藏属性(visiblity:hidden)个数;
不显示属性(display:none)个数;
script标签内特征关键字频率。
在本实施例中,所述待识别内容特征,包括了标签向量和/或属性向量,将所述待识别网站的内容特征进行了全方位的衡量,使得根据所述待识别内容特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,所述待识别全域特征,包括:
ip向量、域名记录向量和证书记录向量其中的一种或任意组合,其中:
所述ip向量包括ip恶意标识、ip恶意关联标识、ip恶意段数量中的其中一种或任意组合;
所述域名记录向量包括域名恶意记录标识、域名所有人恶意标识、域名注册时间中的其中一种或任意组合;
所述证书记录向量包括证书所有人记录、证书注册时间、证书可信度中的其中一种或任意组合。
具体的,所述待识别全域特征包括:
ip恶意记录:存在为1,其他为0;
ip恶意关联记录:存在为1,其他为0;
ip在恶意段:恶意ip数/ip段内可用ip数;
域名恶意记录:存在为1,其他为0;
域名所有人恶意记录:所有人姓名、电话、公司等信息可疑度值;
域名注册时间:1(当前时间-注册时间)/1年;值为负数时归零;
ca证书所有人恶意记录:所有人姓名、电话、公司等信息可疑度值;
ca证书注册时间:1(当前时间-注册时间)/1年;值为负数时归零;
ca证书颁发中心可疑度值。
在本实施例中,所述待识别全域特征,包括了ip向量、域名记录向量和证书记录向量其中的一种或任意组合,将所述待识别网站的全域特征进行了全方位的衡量,使得根据所述待识别全域特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。
在其中一个实施例中,所述将所述待识别地址特征、所述待识别内容特征、所述待识别全域特征和恶意模型进行计算,获取恶意网站匹配度,采用线性回归计算方法,所述线性回归类计算方法是一个简单的计算机可实现计算的且运算时间在可接受范围内的函数。函数的输入是从业务值转化来的数值向量,输出是可转化为业务值的数值或数值向量。获得这个函数方法有多种方式,包括:rank类对比或计算方法:特征+权重=权重值,例如人工打分,策略加权平均等;线性回归类:分类方法+优化方法=模型函数;分类方法:决策树、最小距离等;优化方法:线性拟合、梯度下降、聚类等。
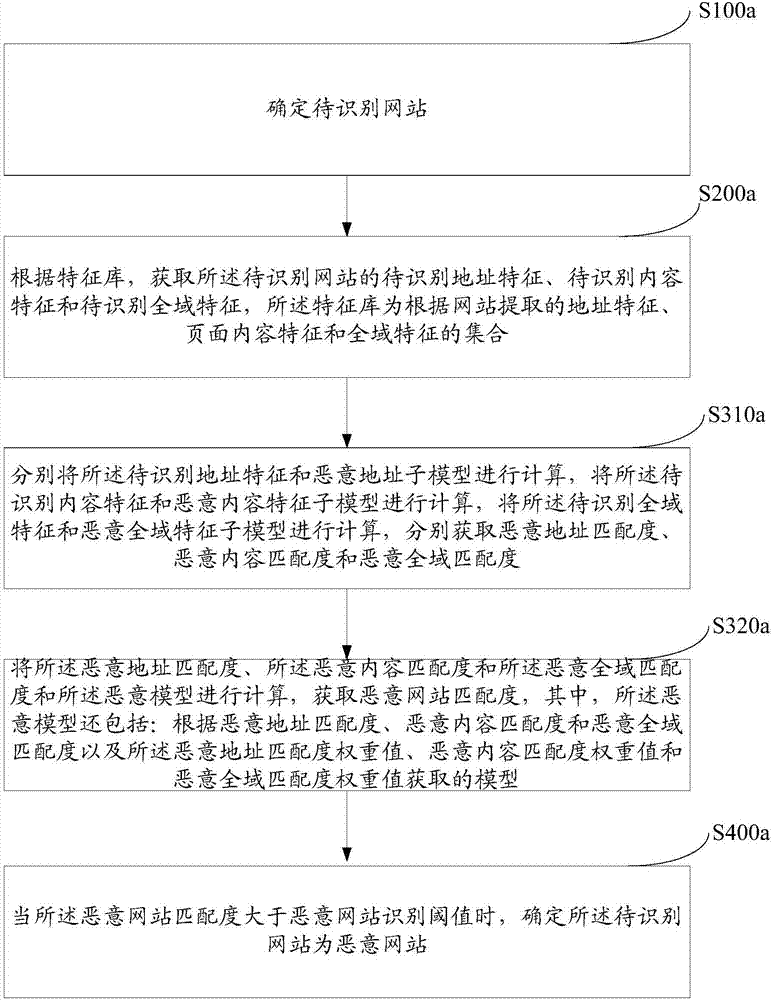
图2为另一个实施例的恶意网站识别方法的流程示意图,如图2所示的恶意网站识别方法,包括:
步骤s100a,确定待识别网站。
具体的,同步骤s100。
步骤s200a,根据特征库,获取所述待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,所述特征库为根据网站提取的地址特征、页面内容特征和全域特征的集合。
具体的,同步骤s200。
步骤s310a,分别将所述待识别地址特征和恶意地址子模型进行计算,将所述待识别内容特征和恶意内容特征子模型进行计算,将所述待识别全域特征和恶意全域特征子模型进行计算,分别获取恶意地址匹配度、恶意内容匹配度和恶意全域匹配度。
具体的,所述恶意地址子模型的构建,包括获取格式化的待识别网站地址,所述的统一的格式化标准包括通用浏览器标准。然后从格式化后的待识别网站地址中提取目标域名信息,进一步从所述域名信息中提取根域名、二级域名(若存在)、主域名信息生成第一特征集合。获取保护目标域名信息,提取所述保护目标域名信息中的主域名信息,生成第二特征集合。根据所述第一特征集合和第二特征集合,生成所述恶意地址特征权重值。根据所述恶意地址特征和所述恶意地址特征权重值,构建恶意地址子模型。
所述将所述待识别地址特征和恶意地址子模型进行计算,包括根据提取的待识别地址特征,将所有待识别地址特征进行均一化处理:r(x)=(value(x)-min(total))/(max(total)-min(total));对均一化之后的待识别地址特征使用支持向量机机器学习算法(svm)进行计算。所述机器学习算法将待识别地址特征分割为白空间和灰空间两个部分,所述白空间为正常页面所在的空间,所述灰空间为未知或恶意页面所在的空间。
所述恶意内容特征子模型的构建,还包括构建一个恶意特征库,所述恶意特征库包括页面中的恶意标签、木马病毒链接、恶意隐藏标签、反馈特征等。将所属恶意特征库和所述行业字典特征库以及所述保护目标特征库结合。提取待识别网站的页面特征和高权重高频词生成待识别内容特征,针对所述待识别内容特征使用以期望交叉熵为距离的支持向量机(svm)生成,所述期望交叉熵即为kl距离(kullback-leiblerdivergence)。
所述保护目标特征库生成方法包括:获取并解析保护目标页面内容;统一格式化页面至标准文档对象模型(htmldom);解析页面特征生成特征向量;解析页面非标签词;统一格式化可见词:可见标签内可见词首尾连接;使用字典分词,并计算词频集,权重为一;统一格式化权重标签内可见词;使用字典分词,计算词频并增加权重与词频集合并;重新根据权重和频率排序获得词序列表;以词序、权重、频率,使用叶贝斯算法计算生成。
步骤s320a,将所述恶意地址匹配度、所述恶意内容匹配度和所述恶意全域匹配度和所述恶意模型进行计算,获取恶意网站匹配度,其中,所述恶意模型还包括根据恶意地址匹配度、恶意内容匹配度和恶意全域匹配度以及所述恶意地址匹配度权重值、恶意内容匹配度权重值和恶意全域匹配度权重值获取的模型。
具体的,根据不同的恶意网站识别需求,为不同的子模型的匹配结果设定不同的权重值后,获取全部待识别特征的总的匹配模型。
所述针对各子模型的匹配结果的计算,
步骤s400a,当所述恶意网站匹配度大于恶意网站识别阈值时,确定所述待识别网站为恶意网站。
具体的,同步骤s400。
在本实施例中,在恶意模型内部,还设置有恶意地址子模型、恶意内容特征子模型和恶意全域特征子模型,用于分别对待识别地址特征、待识别内容特征和待识别全域特征进行计算,分别获取恶意地址匹配度、恶意内容匹配度和恶意全域匹配度后在获取整个恶意模型的恶意匹配度。由于分别设置了恶意地址特征子模型、恶意内容特征子模型和恶意全域特征子模型,可以分别针对恶意地址、恶意内容和恶意全域信息进行更有针对性的恶意匹配度的计算,从而使得恶意网站的识别效率更高。
在其中一个实施例中,所述恶意模型,包括:
根据恶意地址特征、恶意内容特征、恶意全域信息和预设的期望识别模型,利用机器学习算法,分别获取所述恶意地址特征的恶意地址特征权重值、所述恶意内容特征的恶意内容特征权重值、所述恶意全域信息的恶意全域信息权重值,所述预设的期望识别模型为期望识别出的恶意网站的组合;
根据所述恶意地址特征、所述恶意内容特征、所述恶意全域信息,以及所述恶意地址特征权重值、所述恶意内容特征权重值和所述恶意全域信息权重值获取恶意模型。
具体的,利用机器学习算法,分别计算所述意地址特征的恶意地址特征权重值、所述恶意内容特征的恶意内容特征权重值、所述恶意全域信息的恶意全域信息权重值,可以快速高效的给出符合期望识别模型的恶意网站匹配结果。其中所述预设的期望识别模型,也是根据恶意网站的识别需求进行灵活设定的,进一步提高恶意网站识别的灵活性。
在其中一个实施例中,所述恶意地址子模型、恶意内容特征子模型和恶意全域特征子模型,分别根据预设的期望识别模型,利用机器学习算法,分别获取各自的权重值后构建而成。因此所述三个子模型的构建过程,根据不同的恶意网站识别需求,进行机器学习算法,提高了恶意网站识别的针对性、提高了恶意网站的识别效率以及准确率。
图3为一个实施例的恶意网站识别系统的结构示意图,如图3所示的恶意网站识别系统,包括:
待识别网站确定模块100,用于确定待识别网站;
特征获取模块200,用于根据特征库,获取所述待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,所述特征库为根据网站提取的地址特征、页面内容特征和全域特征的集合;所述待识别地址特征,包括地址长度向量、地址数量向量和地址结构向量其中的一种或任意组合,其中:所述地址长度向量包括地址长度、域名长度、子域名长度、路径总长度和参数总长度中的其中一种或任意组合;所述地址数量向量包括地址字符数量、地址字符数量、子域名数量和特殊符号数量、指定字符集数量和参数内指定字符数量中的其中一种或任意组合;所述地址结构向量包括用户名存在标识、密码存在标识、协议使用标识、域名结构标识中的其中一种或任意组合。
所述待识别内容特征,包括标签向量和/或属性向量,其中所述标签向量包括标签内容长度、标签内保护目标特征关键词数量、标签图像资源、标签数量、标签内特征关键字频率中的其中一种或任意组合;所述属性向量包括属性数量、属性外链数量、属性外链域名、属性长度、隐藏属性数量中的其中一种或任意组合。
所述待识别全域特征,包括ip向量、域名记录向量和证书记录向量其中的一种或任意组合,其中所述ip向量包括ip恶意标识、ip恶意关联标识、ip恶意段数量中的其中一种或任意组合;所述域名记录向量包括域名恶意记录标识、域名所有人恶意标识、域名注册时间中的其中一种或任意组合;所述证书记录向量包括证书所有人记录、证书注册时间、证书可信度中的其中一种或任意组合。
恶意网站匹配度获取模块300,用于将所述待识别地址特征、所述待识别内容特征、所述待识别全域特征和恶意模型进行计算,获取恶意网站匹配度,所述恶意模型包括根据恶意地址特征、恶意内容特征、恶意全域信息,以及所述恶意地址特征权重值、所述恶意内容特征权重值和所述恶意全域信息权重值获取的模型;还用于分别将所述待识别地址特征和恶意地址子模型进行计算,将所述待识别内容特征和恶意内容特征子模型进行计算,将所述待识别全域特征和恶意全域特征子模型进行计算,分别获取恶意地址匹配度、恶意内容匹配度和恶意全域匹配度;其中,所述恶意模型还包括根据恶意地址匹配度、恶意内容匹配度和恶意全域匹配度以及所述恶意地址匹配度权重值、恶意内容匹配度权重值和恶意全域匹配度权重值获取的模型。所述恶意模型,包括根据恶意地址特征、恶意内容特征、恶意全域信息和预设的期望识别模型,利用机器学习算法,分别获取所述恶意地址特征的恶意地址特征权重值、所述恶意内容特征的恶意内容特征权重值、所述恶意全域信息的恶意全域信息权重值,所述预设的期望识别模型为期望识别出的恶意网站的组合;根据所述恶意地址特征、所述恶意内容特征、所述恶意全域信息,以及所述恶意地址特征权重值、所述恶意内容特征权重值和所述恶意全域信息权重值获取恶意模型。
恶意网站确定模块400,用于当所述恶意网站匹配度大于恶意网站识别阈值时,确定所述待识别网站为恶意网站。
在本实施例中,根据预设的特征库,提取待识别网站的待识别地址特征、待识别内容特征和待识别全域特征,将上述待识别特征与恶意模型进行计算后,获取恶意网站匹配度,并将所述恶意网站匹配度和预设的恶意网站识别阈值进行比较后,确定所述待识别网站是否为恶意网站。通过对页面地址特征、页面内容特征和页面全域特征进行的提取,与预先设定的根据不同的识别需求构建的恶意特征识别进行计算的方法,本发明可自动快速的从恶意网站可能存在的所有方面进行自动设别,并能按照不同的恶意网站识别模型进行有针对性的识别,提高了恶意网站的识别效率和针对性。所述待识别地址特征,包括了地址长度向量、地址数量向量和地址结构向量其中的一种或任意组合,将所述待识别网站的地址特征进行了全方位的衡量,使得根据所述待识别地址特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。所述待识别内容特征,包括了标签向量和/或属性向量,将所述待识别网站的内容特征进行了全方位的衡量,使得根据所述待识别内容特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。所述待识别全域特征,包括了ip向量、域名记录向量和证书记录向量其中的一种或任意组合,将所述待识别网站的全域特征进行了全方位的衡量,使得根据所述待识别全域特征识别出的恶意网站更加全面,提高了恶意网站的识别成功率。在恶意模型内部,还设置有恶意地址子模型、恶意内容特征子模型和恶意全域特征子模型,用于分别对待识别地址特征、待识别内容特征和待识别全域特征进行计算,分别获取恶意地址匹配度、恶意内容匹配度和恶意全域匹配度后在获取整个恶意模型的恶意匹配度。由于分别设置了恶意地址特征子模型、恶意内容特征子模型和恶意全域特征子模型,可以分别针对恶意地址、恶意内容和恶意全域信息进行更有针对性的恶意匹配度的计算,从而使得恶意网站的识别效率更高。所述恶意地址子模型、恶意内容特征子模型和恶意全域特征子模型,分别根据预设的期望识别模型,利用机器学习算法,分别获取各自的权重值后构建而成。因此所述三个子模型的构建过程,根据不同的恶意网站识别需求,进行机器学习算法,提高了恶意网站识别的针对性、提高了恶意网站的识别效率以及准确率。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!