大规模MIMO系统下行链路中基于密度的用户分组方法与流程
本发明属于大规模MIMO中改进信道容量方法研究的相关领域,尤其涉及一种FDD系统中,大规模MIMO下行链路中基于密度用户分组方法。
背景技术:
过去几十年中,无线网络中对数据传输速率的需求急剧增加,然而有限的频谱资源极大的限制了传输速率的增长,于是大规模MIMO凭借其高频谱利用率和高能量利用率,被认为是下一代无线通信系统的核心技术。大规模MIMO系统通过在基站端和用户端都装备几十上百根天线,来满足日益增长的传输速率需求,同时不增加额外的通信带宽。而且大规模MIMO可以降低系统延时,简化系统MAC层,并且鲁棒性更强。然而与TDD系统中的大规模MIMO不同,对于FDD系统中的大规模MIMO,存在一个知致命缺陷。TDD系统的上下行信道存在相互作用,可以利用上行传输进行下行信道估计;而FDD系统的上下行信道不存在这样的相互作用,并且大规模的天线系统会要求极大的信道估计开销,严重影响大规模MIMO的实际应用。为了解决这个问题,Ansuman Adhikary等学者提出了一个联合空间分集和多路复用(JSDM)方案,该方案将小区内用户进行分组后,再采用二级预编码方案,从而极大降低了系统的信道估计的开销。在JSDM方案中,用户分组主要是为了对系统进行降维处理,而二级预编码则极大简化了预编码的计算复杂度,二级预编码中,第一级的预波束成形编码用于消除用户的组间干扰,而第二级的预编码是为了消除组内用户间的干扰;但是在JSDM中,用户分组的结果将会对系统速率有较大的影响。
技术实现要素:
本发明基于JSDM方案中用户分组和二级预编码技术提出了联合基于密度的用户分组的方法,通过找到合适的用户间距离度量方式,采用基于密度的聚类,利用用户的密度分布信息将一个小区中的所有用户分成几个小组,能够大大提高系统速率。
为实现上述目的,本发明采用如下的技术方案:
一种大规模MIMO下行链路中基于密度用户分组方法包括以下步骤:
步骤1、计算出所有用户相互之间的距离,得到距离矩阵;
步骤2、根据距离矩阵得到k-dist图,根据图中包含的用户密度分布信息得到DBSCAN算法的两个重要参数:半径和最小用户数阈值;
步骤3、根据所述两个参数以后就从任意一个用户开始进行聚类,得到最终的用户分组结果。
作为优选,步骤1具体为:计算任意两个用户之间的距离,得到K×K维的距离矩阵dis,矩阵中第(k,j)个元素表示用户k和用户j之间的距离,表示为[dis]k,j=S(Uk,Uj),其中,S(Uk,Uj)为根据基于子空间投影的相似度量方法计算得到的用户间距离。
作为优选,步骤2具体为:设用户j的k-dist表示是用户j与离他最近的第k个用户之间的距离,在得到每个用户的k-dist值后,将这些值升序排列,然后画成k-dist图,得到的k-dist图包含了用户的密度分布信息,所述k-dist图中第一个波谷中的第一个点是阈值点;其中,k-dist图中的k值等于Minpts,所述阈值点对应的y轴的值就是得到的eps值。
作为优选,步骤3具体为:首先随机选择一个用户k作为初始用户,并且遍历所有未标记为“已处理”的用户,找出可以从用户k直接密度可达的用户集合,得到用户k的eps-邻域Neps(k),如果|Neps(k)|=1,那么用户k就是噪声用户,将该用户标记为“已处理”,然后再从未标记为“已处理”的用户中随机选择下一个用户;如果1<|Neps(k)|<Minpts,那么用户k就是边缘用户,不对用户k进行任何操作,而是从未标记为“已处理”的用户中随机选择下一个用户;如果|Neps(k)|≥Minpts,那么用户k就是核心用户,就可以开始一个组的聚类了;从核心用户k开始聚类一个组,Neps(k)就是该组的一部分,然后再从Neps(k)中的所有用户中找核心用户,如果存在核心用户q,则将该核心用户的eps-邻域Neps(q)中的所有用户也归到该组中,将这些用户都标记为“已处理”,并且从新加入到用户中搜索核心用户,重复上述步骤,不断聚类,直到没有新的核心用户为止,所有加入该组的用户就组成了一个用户组;一个组聚类结束后,再从未标记为“已处理”的用户中随机选择一个用户,继续上述所有的步骤,直到所有用户都被标记为“已处理”,这时候所有用户或者是噪声用户,或者已经被分好组,到此为止,用户分组阶段就结束了;
用户分组结束后,每个组通过求组内所有用户的协方差均值得到每个组的中心协方差,即然后利用近似BD算法求出预波束成形矩阵B,消除组间干扰后,利用MAX用户选择算法,对每个组分别进行用户选择,最后用迫零预编码算法求出预编码矩阵P;
在用户选择结束后,假设第g组中有Sg个用户被选中可以传输数据,则表示整个小区中被选中的所有用户的数量,用表示第g组中第s个用户的即时信干噪比(SINR),定义为:
其中P表示基站提供的信号功率,表示用户gs的预编码向量,是预编码矩阵Pg的第s列,和分别表示用户的组间干扰和组内干扰,分别定义为
于是用户gs的速率和系统的和速率C分别可以通过下式计算得出
本方法利用用户自身的密度分布信息对用户进行分组,得到的分组结果充分体现了用户在小区中的分布情况,给后续的处理提供了良好的基础。实验结果表明,本方法在一定程度上改善了系统吞吐量。
附图说明
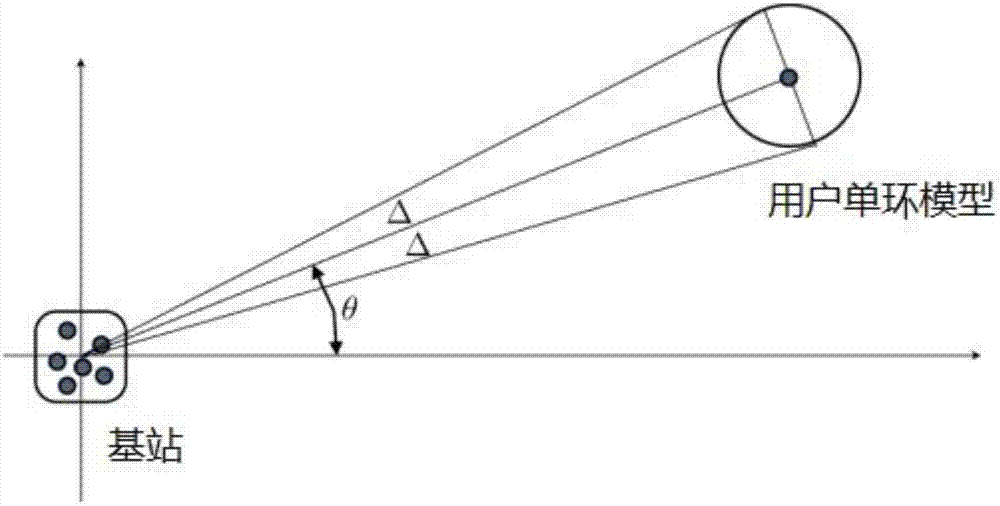
图1、单环模型图;
图2、6-dist图;
图3、最终系统合率比较图;
图4、大规模MIMO下行链路中基于密度用户分组方法的流程图。
具体实施方式
本发明实施例提供一种大规模MIMO下行链路中基于密度用户分组方法,利用k-dist图预估用户的密度分布情况,然后采用DBSCAN算法对用户进行分组,极大降低了大规模MIMO系统的计算复杂度。
本发明方法是在JSDM方案的基础上提出了基于密度的用户分组的方法,JSDM方案是Ansuman Adhikary等人在信道相关性基础上提出的降低大规模MIMO复杂度的方案,主要特点有2个:第一个是将所有用户根据信道相关性的相似度进行分组,第二个将预编码矩阵分为两级,分别消除组间干扰和组内干扰。本方法的物理模型是在单小区FDD系统中,考虑大规模MIMO系统中的下行链路,发射端是基站,接收端是K个用户,基站端装备有M根天线的均匀线阵,用户为单天线用户,信道模型可以表示为
其中z:是一个K×1维的矢量,表示加性高斯白噪声,x是M×1维的矢量,表示基站的传输信号,y是K×1维的矢量,表示用户端接收到的信号,而hk表示的是用户k的信道信息,是一个M×1维的矢量。在基站端采用维度为M×S的线性预编码矩阵V,因此传输信号可以表示为x=Vd,其中d表示S×1维的数据矢量,S是下行数据流的数量。采用二级预编码后,预编码矩阵可以表示为:V=BP,其中B是第一级的预波束成形编码,维度为M×b,P是第二级的传统多用户预编码矩阵,维度为b×S。于是信道模型可以重新表示为:
y=[h1,h2...,hK]HBPd+z
考虑传输天线的相关性,JSDM方案采用了单环模型,用户相对于基站的方位角为θk,角度扩展为Δk,用λ表示载波波长,两根天线间的距离可以表示为λD。于是在均匀线阵中,用户k的信道协方差矩阵的第m行,第n列的元素可以按照下式计算得到
考虑非视距传播模型,用户k的信道信息hk:其中Rk是用户k的信道协方差矩阵,维度为M×M。为了计算协方差矩阵Rk,考虑图1的单环模型,用户k所在地的方位角为θk,角度扩展为Δk,而均匀线阵中,两根天线间的距离为λD,其中λ为波长。根据这些信息,用户k的第m根和第n根天线间的相关性可以通过下式计算得到
将Rk进行特征值分解可以得到其中Λk是r×r维的对角矩阵,其对角元素为Rk的非零特征值,Uk是M×r维的高酉矩阵,其每一列都是Λk对应的特征向量,而r是Rk的秩。不考虑非视距传播的情况,用户k的信道矢量可以表示为hk:CN(0,Rk),应用Karhunen-Loeve变换,用户k的信道矢量可以表示为
其中
在JSDM方案中,小区内所有的用户被分成了G个组,同一组内的用户共用一个信道协方差矩阵,其中第g组中的所有用户的信道协方差都记作秩记作rg。假设第g组中有Kg个用户,且那么系统的预波束成形矩阵可以表示为B=[B1,...,BG],其中Bg是M×bg维的第g组的预波束成形矩阵,Bg是根据二阶信道统计信息计算得到的,用来抑制组间干扰(INGI)。同时系统的预编码矩阵可以表示为P=[P1,...,PG],其中Pg是bg×Sg维的第g组的预编码矩阵,用来一直组内用户间的干扰(INAI)。在这里,bg是第g组中波束的数量,Sg是第g组中独立数据流的数量,需要满足和且由于在一个组内,数据流是在波束上传输的,传输的独立数据流数量比波束数还多是不可能做到的,因此还必须满足b≥S和bg≥Sg。将第g组的信道矩阵记作系统的信道矩阵记作H=[H1,...,HG],于是第g组接收到的信号可以表示为:
在本方法中,预波束成形矩阵Bg用近似块对角(DB)算法计算得到,预编码矩阵Pg用迫零预编码算法计算。
在JSDM方案中,所有的用户根据各自的信道协方差被分到不同的组中。分完组后,每个用户组的中心协方差通过计算该组内所有用户的协方差的平均值得到。用户分组在JSDM方案中的作用十分重要,用户分组会影响预波束成形矩阵Bg的计算,也会影响用户选择的结果。现在已经有人提出了几种低复杂度的用户分组方法,比如说K-均值(K-Means)用户分组算法和K-中心点(K-Medoids)用户分组算法,本方法采用的是基于密度(DBSCAN)的用户分组算法。DBSAN算法根据用户的密度分布将所有用户分成几个不同的组,与前两种算法比较,后者不需要指定分组的数量,而是可以根据用户的密度分布自动发现分组数。而且与K-Means算法和K-Medoids只能发现圆形或球形的簇不同,DBSCAN算法可以发现任意形状的簇。同时,DBSCAN算法还可以检测出噪声点,这个特性至少有2个优势:首先,噪声点会影响组中心协方差的计算准确度,检测出噪声点并舍弃可以使组中心协方差更具代表性,从而减少干扰;其次,检测出的噪声点在用户选择阶段必定是被舍弃的,提前将噪声点检测出并舍弃,可以提前减少不必要的计算量,在一定程度上降低计算复杂度。
正式开始用户分组之前,需要确定用户间距离度量方法。本方法采用的是基于子空间投影的相似度度量方法。用Uk表示用户k的协方差特征矩阵,Vg表示第g组的中心协方差特征矩阵,那么用户k与第g组之间的距离定义如下:
类似的,用户k与用户j之间的距离定义如下:
从定义中可以看出,两个用户之间的相似度越高,距离就越近,也就是S(Uk,Uj)越小。根据基于子空间投影的相似度度量方法就可以得到用户的距离矩阵dis。
利用DBSCAN算法进行分组,需要指定2个参数:表示用户半径的eps,以及表示给定用户在半径内成为核心对象的最小邻域用户数Minpts。另外,在DBSCAN算法中有几个定义需要说明。
定义1:用u表示所有用户的集合,那么用Neps(k)表示用户k的eps-邻域,即在用户k的eps半径内的所有用户的集合,定义为:Neps(k)={j∈u|dis(k,j)≤eps}
定义2:当满足条件|Neps(k)|≥Minpts时,用户是核心用户;当满足条件1<|Neps(k)|<Minpts时,用户是边缘用户;当满足条件|Neps(k)|=1时,用户是噪声用户。需要注意的是,随着分组的进行,边缘用户可能会成为某个组的一员,或是成为噪声用户。
定义3:当满足条件j∈Neps(k)和|Neps(k)|≥Minpts时,用户j可以从用户k直接密度可达。
定义4:若有一条用户链o1,...,on,其中o1=k,on=j,且对于任意1<i≤n,用户oi都可以从用户oi-1直接密度可达,那么,用户j可以从用户k密度可达。
定义5:若存在用户o,用户j和用户k都可以从用户o密度可达,那么,用户j和用户k就是密度相连的。
明确了以上几个定义后,就可以开始对用户进行基于密度的分组了,如图4所示。
基于密度分组的第一步,就是要计算任意两个用户之间的距离,得到K×K维的距离矩阵dis,矩阵中第(k,j)个元素表示用户k和用户j之间的距离,表示为[dis]k,j=S(Uk,Uj),其中S(Uk,Uj)就是根据基于子空间投影的相似度量方法计算得到的用户间距离。
用户分组的第二步就要确定参数eps和Minpts。得到距离矩阵后,参数Minpts根据经验值得到,而得到参数Minpts需要利用k-dist图。用户j的k-dist表示的是用户j与离他最近的第k个用户之间的距离,得到每个用户的k-dist值后,将这些值升序排列,然后画成图,如附图中的图2所示。得到的k-dist图包含了用户的密度分布信息。k-dist图中距离的忽然增加表明了密度的急剧变化,因此图中的第一个波谷,波谷中的第一个点是阈值点,如图2中的箭头所指向的点,参数eps可以根据阈值点得到。在本方法中,k-dist图中的k值等于Minpts,得到阈值点后,阈值点对应的y轴的值就是得到的eps值。
确定参数eps和Minpts后,用户分组就可以正式开始了。首先随机选择一个用户k作为初始用户,并且遍历所有未标记为“已处理”的用户,找出可以从用户k直接密度可达的用户集合,得到用户k的eps-邻域Neps(k)。如果|Neps(k)|=1,那么用户k就是噪声用户,将该用户标记为“已处理”,然后再从未标记为“已处理”的用户中随机选择下一个用户;如果1<|Neps(k)|<Minpts,那么用户k就是边缘用户,不对用户k进行任何操作,而是从未标记为“已处理”的用户中随机选择下一个用户;如果|Neps(k)|≥Minpts,那么用户k就是核心用户,就可以开始一个组的聚类了。从核心用户k开始聚类一个组,Neps(k)就是该组的一部分,然后再从Neps(k)中的所有用户中找核心用户,如果存在核心用户q,则将该核心用户的eps-邻域Neps(q)中的所有用户也归到该组中,将这些用户都标记为“已处理”,并且从新加入到用户中搜索核心用户,重复上述步骤,不断聚类,直到没有新的核心用户为止,所有加入该组的用户就组成了一个用户组。一个组聚类结束后,再从未标记为“已处理”的用户中随机选择一个用户,继续上述所有的步骤,直到所有用户都被标记为“已处理”,这时候所有用户或者是噪声用户,或者已经被分好组,到此为止,用户分组阶段就结束了。
用户分组结束后,每个组通过求组内所有用户的协方差均值得到每个组的中心协方差,即然后利用近似BD算法求出预波束成形矩阵B,消除组间干扰后,利用MAX用户选择算法,对每个组分别进行用户选择,最后用迫零预编码算法求出预编码矩阵P。
在用户选择结束后,假设第g组中有Sg个用户被选中可以传输数据,则表示整个小区中被选中的所有用户的数量。用表示第g组中第s个用户的即时信干噪比(SINR),定义为:
其中P表示基站提供的信号功率,在本方法中,信号功率均匀分配给所有用户。表示用户gs的预编码向量,是预编码矩阵Pg的第s列,和分别表示用户的组间干扰和组内干扰,分别定义为
于是用户gs的速率和系统的和速率C分别可以通过下式计算得出
如图3所示,实验结果显示,与K-均值和K-中心算法相比,本方法不需要事先指定分组数,可以找出任意形状和尺寸的聚类,还可以剔除噪声点,得到更理想的分组结果,从而得到较好的系统合率的增加。
由于在发射端和接收端都有几十到上百根天线,大规模MIMO系统可以得到很高的频谱效率和能量效率,也因此,大规模MIMO系统作为5G技术,越来越受到人们的关注。然而对于频分多工(FDD)系统,CSIT反馈量会随着大规模MIMO系统中天线数的增加而急剧增大,这已经成为了大规模MIMO系统在实际应用中的瓶颈。为了应对大规模MIMO系统中由于下行估计和上行反馈占用资源过多而引发的问题,Ansuman Adhikary等人提出了一个联合空间分集合多路复用(JSDM)方案。该方案的主要思想有2个:用户分组和二级预编码。首先,系提取各用户信道协方差的特征矩阵,并将拥有相似特征矩阵的所有用户分在同一组,然后系统采用二级预编码,分组处理用户。该JSDM方案极大降低了系统维度,因此减少了下行训练和上行反馈的消耗。在这个方案的基础上,本发明提出了基于密度的用户分组方案,本发明首先提出了度量各用户信道协方差的特征矩阵之间相似度的度量方式,然后采用DBSCAN算法,利用用户之间的密度分布将所有用户分组。DBSCAN算法的优势在于可以将用户分成任何形状和大小的组,而不仅仅是圆形,同时本发明采用了k-dist图来预估用户的密度分布,并据此确定DBSCAN算法的2个重要参数:半径和最小用户数阈值。本方案改善了系统用户分组的方法,得到了更好的系统吞吐量。
- 还没有人留言评论。精彩留言会获得点赞!
- 用于经由聚合的帧进行的多用户上行链路控制和调度的方法和装置与制造工艺
- 传送下行链路参考信号的方法和设备和多小区协作通信系统中传送控制信息的方法和设备与制造工艺
- 用于在无线通信系统中发送下行链路信号的方法和装置与制造工艺
- 卫星和与其相关联的终端之间的交换通信的方法与制造工艺
- 用户装置以及上行链路数据发送方法与制造工艺
- 多SIM/多待机设备中的上行链路定时调节的制造方法与工艺
- 利用上行链路和下行链路加权度量在LTE中进行频率内和频率间切换的制造方法与工艺
- 在基于OFDM的系统中通过SINR测量进行的定时偏移估计的制造方法与工艺
- 测量E‑UTRAN中的上行链路中的分组延迟的方法和装置与制造工艺
- 用于在干扰场景中提高上行链路覆盖的系统和方法与制造工艺