一种结合四叉树自适应编码的可逆信息隐藏方法与流程
本发明属于图像编码及信息隐藏技术领域,具体涉及一种结合四叉树自适应编码的可逆信息隐藏方法。
背景技术:
可逆信息隐藏是指能在宿主信息中嵌入额外信息后,合法接受方能正确提取额外信息,并无失真恢复出原始宿主信息的一种技术,在多媒体认证、数字产品知识产权保护等诸多的多媒体安全领域应用广泛。当前的图像可逆数据隐藏技术主要包括无损压缩、直方图平移、整数变换三类。技术指标主要是嵌入容量(单位bpp,即单位像素嵌入的比特数)和嵌入后的峰值信噪比(简称psnr,单位db,衡量图像经过嵌入后的失真程度)。提高嵌入容量是当前可逆信息隐藏研究主要目标之一。
现有的大部分算法存在图像分块的预处理阶段,但是均采用2*2、3*3等固定分块模式,虽然避免了较大的计算复杂度,但未充分考虑图像内容(医学图像等特殊图像中存在大量的平滑区域,而纹理图像等存在大量的纹理复杂区域),因此现有算法在针对平滑区域、纹理复杂区域明显的一些图像等特殊图像中的嵌入容量有待改善。
例如,一方面,医疗图像对图像清晰度要求高,美国政府已颁布法律规定医疗处理中不允许使用有损压缩,因为由于图像不清晰导致的医生误诊带来的社会问题严重,且医疗成像设备价格昂贵、图像获取代价高昂,因此适合可逆信息隐藏。另一方面,医学序列图像的帧内冗余和帧间冗余很大,存在大量平滑区域可以用来嵌入。尚没有对这类特殊图像进行内容自适应分块并将图像压缩、自适应编码、可逆数据隐藏等技术进行融合的自适应算法
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种结合四叉树自适应编码的可逆信息隐藏方法,将图像压缩、自适应编码、可逆数据隐藏技术融合到自适应算法中,对医疗图像等平滑区域与纹理复杂区域分布较为明显的特殊图像进行内容自适应分块处理。
本发明采用以下技术方案:
一种结合四叉树自适应编码的可逆信息隐藏方法,主要包括编码端信息嵌入与解码端的信息提取,所述编码端信息嵌入步骤为:
s1、以原图像作为初始图像块,根据图像块的像素情况对当前图像块进行判断,确定图像块类别;
s2、若当前图像块属于可嵌入块,则进行信息嵌入,若当前图像块属于不可嵌入块,则判断当前图像块大小,若图像块大小为2*2,不再划分并不做嵌入,否则按照四叉数分块规则将当前图像块划分为不重叠的四个大小相同的图像块,并逐个执行步骤s1;
s3、将步骤s2产生的四叉数编码信息单独传给解码端,解码端根据该信息,进行图像解码和后续的信息提取过程;
s4、解码端根据解码信息进行四叉数解码,并根据每一个图像块所属的类别进行信息提取和图像恢复操作。
进一步的,步骤s1中,所述图像块包括可嵌入块和不可嵌入块,所述可嵌入块包括极度平滑块、一般平滑块和一般可嵌入块。
进一步的,所述极度平滑块为图像块像素值完全相同的图像块;所述一般平滑块为使用cbp预测法进行图像预测得到的预测误差值中0、1、-1占比大于40%的图像块;所述一般可嵌入块为使用cbp预测法进行图像预测得到的预测误差值中0、1、-1占比大于20%且小于40%的图像块;剩余为不可嵌入块。
进一步的,所述极度平滑块的嵌入方式为保留块中最右下方的像素值,其余位置逐行扫描逐像素的所有比特被额外信息依次替代。
进一步的,所述一般平滑块的嵌入方式为采取dpcm无损压缩方法对该图像块进行无损压缩,压缩后的比特逐行逐像素的保存在原图像块中,按顺序保存额外信息比特。
进一步的,所述一般可嵌入块的嵌入方式为采取基于cbp预测的预测误差直方图平移法进行嵌入,嵌入过程的相关参数保存为额外信息的一部分进行保存用于信息提取。
进一步的,步骤s3中,所述四叉数编码信息具体为:将所述图像块划分为a、b、c、d四个互不重叠且大小相同的图像块,每一次划分代表四叉数的一层节点,其中,a=1表示不需要再划分,a=0表示需要划分。
进一步的,每个所述图像块的编码信息后对应存储两个比特作为额外信息。
进一步的,所述极度平滑块的额外信息用00表示,所述一般平滑块的额外信息用01表示,所述一般可嵌入块的额外信息用10表示,所述不可嵌入块的额外信息用11表示。
与现有技术相比,本发明至少具有以下有益效果:
采取了图像内容自适应的策略,因此可逆信息隐藏的嵌入容量与非自适应方法相比有所改善,特别对于拥有大量平滑区域以及纹理复杂区域并且两种区域分布明显的特殊图像(如医学影像图像)性能提升更为明显。
进一步的,分类方法可以结合图像块像素平滑情况以及不同嵌入方式的特点,自适应选择嵌入方式:ⅰ类图像块所有像素的像素值相同,可以仅保留一个像素的像素值,在其他像素位置全部进行数据替代以嵌入;ⅱ类图像块平滑程度一般,可以达到较好的无损图像压缩效果(压缩比较高),适合无损压缩后进行数据嵌入;ⅲ类图像块平滑程度不如ⅱ类,但仍可以利用其它嵌入方式进行数据嵌入;ⅳ类平滑程度最差,不适合数据嵌入,因此划分为不可嵌入块,不进行任何操作。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明四叉数编码解码示意图;
图2为本发明图像块划分示意图。
具体实施方式
本发明公开了一种结合四叉树自适应编码的可逆信息隐藏方法,包括编码端信息嵌入与解码端的信息提取两个过程,所述编码端信息嵌入具体过程如下:
s1、将原图像作为初始图像块,根据图像块的像素情况对当前图像块进行判断,确定图像块类别;
确定图像块类型:
所述图像块类型包括:极度平滑块(ⅰ类)、一般平滑块(ⅱ类)、一般可嵌入块(ⅲ类)和不可嵌入块(ⅳ)四种类型,其中ⅰ类、ⅱ类、ⅲ类统称为可嵌入块。
当图像块像素值完全相同时,确定图像块类别为ⅰ类(极度平滑块);
当图像块不属于ⅰ类,且采取checkerboardbasedprediction(cbp)预测误差法得到的预测误差值中0、1、-1占比大于40%时,确定图像块类别为ⅱ类(一般平滑块);
当图像块不属于ⅰ、ⅱ类且采取cbp预测误差法的预测误差值中0、1、-1占比大于20%且小于40%时,确定图像块类别为ⅲ类(一般可嵌入块);
当以上条件均不符合时,确定图像块类别为ⅳ类(不可嵌入块)。
实验表明,利用cbp预测误差算法对自然图像进行预测时,得出的预测误差值服从均值为0的拉普拉斯分布。因此,图像块内0、1、-1的比值大小可以代表该图像块的复杂度(平坦程度),比值越大,代表图像块越平坦,比值越小,代表图像块越复杂,选择20%、40%这两个数值,来源于实验所得,属于经验值,选择0、1、-1这三个数据,因为后面的直方图平移嵌入算法的嵌入性能与图像块中0、1、-1的个数有关。
请参阅图2,所述信息嵌入步骤如下:
若当前图像块属于ⅰ类,则保留块中最右下方的像素值,其余位置逐行扫描逐像素的所有比特被额外信息依次替代以嵌入;
若当前图像块属于ⅱ类,则采取dpcm(无损预测编码)无损压缩方法对该图像块进行无损压缩(压缩过程的相关参数保存作为额外信息的一部分进行保存用于将来的无损恢复),压缩后的比特逐行逐像素的保存在原图像块中,由于压缩腾出的位置按顺序保存额外信息比特以实现嵌入,也可以使用huffman编码、算术编码等无损压缩算法。
若当前图像块属于ⅲ类,则采取基于cbp预测的prediction-errorexpansionhistogramshifting法(预测误差直方图平移法)进行嵌入,嵌入过程的相关参数保存为额外信息的一部分进行保存用于将来的信息提取。可逆数据隐藏算法还可以使用例如基于med预测的其他预测误差直方图平移算法。
s2、若当前图像块属于不可嵌入块时(ⅳ类),则判断当前图像块大小,若图像块大小为2*2,不再划分并不做任何嵌入,否则进行四叉数划分为四个图像块,并逐个执行步骤s1。
s3、将以上步骤产生的四叉数编码信息作为额外信息的一部分依次嵌入到图像中,解码端首先提取该信息,以进行图像解码和后续的信息提取过程。
s4、信息提取与图像恢复
解码端首先根据解码信息进行四叉数解码,并根据每一个图像块所属的类别进行信息提取和图像恢复操作,具体过程见dpcm(无损预测编码)解压缩和cbp预测误差直方图平移法的信息提取与图像恢复过程。
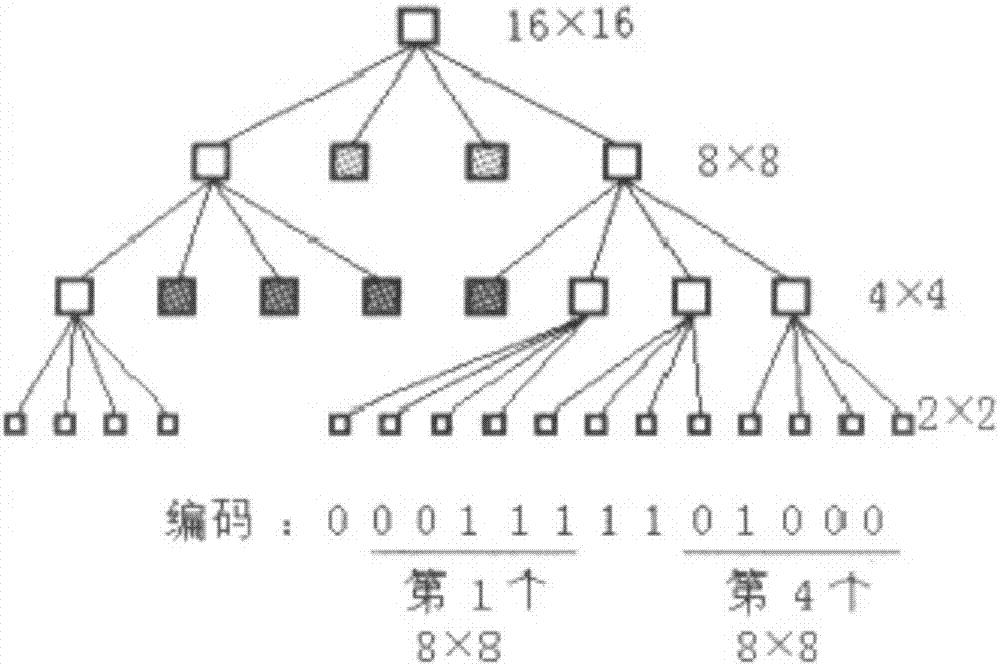
请参阅图1,四叉数编码与解码具体如下:
若某图像块不需要进一步拆分,则用四叉数上的一个叶子节点表示并用1表示;否则划分为四个互不重叠的大小相同的图像块,并用a1b1c1d1表示。
其中,a1、b1、c1、d1分别表示第一图像块、第二图像块、第三图像块、第四图像块,若第一图像块不需要继续划分,则a1=1,否则a1=0,依次类推a2b2c2d2,每一次划分代表四叉数的一层节点。由于图像块大小最小为2*2,故当图像块大小为4*4时,仅需要使用1个比特:1代表不需要再划分,0代表需要划分为4个2*2块。解码过程为相反的过程。
此外,将该图像块类别用两个信息比特保存在对应编码后面,即每个图像块编码信息后再额外存储两个比特:“00”代表该图像块属于aⅰ类;“01”代表该图像块属于ⅱ类;“10”代表该图像块属于ⅲ类;“11”代表该图像块属于ⅳ类。
该编码解码方式简单易行,计算复杂度低且占用带宽少,发送方可以达到标识图像自适应分块情况以及每个图像块所属类别的目的,接收方也可以根据解码结果确定图像分块情况并识别出每个图像块所属的种类。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!