一种大规模数据流中电信欺诈风险识别方法与流程
本发明涉及一种大规模数据流中电信欺诈风险识别方法,属于数据挖掘与机器学习和商务智能等领域。
背景技术:
电信欺诈检测是目前国内外电信行业中一个重要的问题,它威胁到人们的财产安全,同时给电信正常运营带来巨大的困扰。因此运营商、政府部门都试图采取各种手段和技术进行电信欺诈的检测和识别。
如何利用当前先进的数据挖掘技术辅助监管部门,进行诈骗交易识别和潜在风险识别成为当下一项重要的挑战,这涉及到数据挖掘领域的分类聚类、异常检测等背景知识。在实际的问题中,每天呼叫的数据量非常大,涉及的被叫用户达到了百万级以上;对这些被叫用户按照号码过滤和历史长度过滤等规则筛选出风险值相对较高的被叫用户,并对其进行静态特征和历史特征进行提取,费时费力,还不能得到精确的诈骗概率。
当前的电信诈骗活动往往存在着某种特定的序列特征和通联特征的行为模式,例如录音型诈骗电话的连续呼叫、诈骗主叫往往倾向于呼叫更多的被叫用户,以提高其诈骗的成功率。因此,传统的面向单时点的呼叫信令特征提取方法已经难以满足电信诈骗检测需求。正常和异常呼叫行为在多维显式或隐含的风险空间中存在显著差异。诈骗主叫与正常主叫的历史特征往往是不一样的,如何将主叫号码的历史信息融入到检测模型中,是衡量主叫号码攻击风险效果的关键因素。
现有电信诈骗检测手段中,基于话音分析等技术只能识别较为显著欺诈特征的欺诈行为,但大量隐蔽性更强、特征不显著、手法较新的电话诈骗的出现,给电信欺诈检测工作带来了巨大挑战。
技术实现要素:
本发明鉴于风险被叫与正常被叫的序列通联结构之间存在着某种差异,风险主叫与正常主叫的攻击特征等方面也存在着不同的特点,提出了一种大规模数据流中电信欺诈风险识别方法。
具体步骤如下:
步骤一、从呼叫记录数据库中按照号码特征和历史序列长度,过滤筛选若干高风险被叫用户和主叫用户记录,作为分析对象;
步骤二、根据分析对象构建欺诈被叫索引数据库;
索引数据库包括高风险被叫的原始呼叫记录索引、序列特征索引、通联关系索引,以及疑似诈骗主叫的攻击风险索引和历史特征索引等。
步骤三、对不同的索引分别进行预处理,提取各个索引对应的显著特征作为后续风险模型的输入。
所述的预处理包括对离散型的属性特征做one-hot编码,对连续型的属性特征做标准化处理。
对每个被叫号码提取的特征包括:风险被叫的呼叫级别特征、呼叫序列特征、通联关系特征等;其中,高风险被叫的原始呼叫记录索引对应的特征为风险被叫的呼叫级别特征;序列特征索引对应的特征是呼叫序列特征;通联关系索引对应的特征是通联关系索引;
对每个主叫号码提取的特征包括:其呼叫级别的特征和历史序列特征等。其中,主叫的攻击风险索引对应的是主叫的呼叫级别特征;历史特征索对应的特征是历史序列特征。
步骤四、采用二级级联分类模型,分别考虑每个主叫的呼叫级别的特征和历史序列特征,计算各主叫号码的攻击风险值,进而得到对应的每个被叫号码的攻击风险值。
二级级联分类模型包括两个分类模型,第一个模型以主叫端呼叫记录的静态属性作为特征,进行cdr风险分析,得到初始的风险值r1;第二个模型以第一个模型推出的高风险主叫为基础,融入了主叫号码的历史序列特征,进行主叫号码的风险分析,得到二级模型输出的风险值r2;
将两次风险分析的结果取最大值作为该cdr的攻击风险值rcdr,即:rcdr=max{r1,r2}。最后将与该主叫对应的被叫号码最近联系过的l个主叫中,选择cdr的攻击风险值中最大值作为该被叫号码的攻击风险值,即:rcaller=max{rcdri},i=1,…,l。
步骤五、针对每个高风险被叫用户的呼叫序列特征,采用基于滑动窗口的异常检测方法计算每个滑动窗口的风险值,最后保留每个被叫号码最近的滑动窗口异常得分的最大值,作为各自的序列风险值。
以每个滑动窗口为单位,通过提取n个滑动窗口的显著特征作为序列特征进行异常检测,通过训练异常检测的模型,得出每个滑动窗口的异常得分rwindowi(i=1,2…,n),最终该被叫号码的序列风险值为其n个滑动窗口风险值的最大值,即:rsequence=max{rwindowi},(i=1,2…,n)。
步骤六、针对每个被叫号码的通联关系特征,构造被叫号码与主叫号码的通联关系二部图,计算每个被叫号码的通联风险值,实现风险在通联关系网络中的传递。
利用基于line的网络表示学习方法获取主叫用户和被叫用户的网络分布式表示向量,随后利用网络分布式表示向量计算主叫和被叫用户之间的相似度,并筛选出与给定被叫最相似的k个主叫号码,接着借助主叫号码的风险分析获取这k个主叫号码历史风险值,再结合主被叫之间的相似度对k个主叫风险值进行加权,作为待分析被叫的通联风险值。
步骤七、借助逻辑回归模型,对每个被叫号码的攻击风险、序列风险和通联风险进行融合,得出每个被叫号码各自的综合风险值。
将某个被叫号码的攻击风险、序列风险和通联风险分别输入逻辑回归模型,输出该被叫号码的综合风险值,通过与设定的特定阈值threshold相比,如果输出的综合风险值高于设定的threshold,则将当前被叫号码标记为高风险被叫,否则标记为正常被叫。
本发明的优势在于:
1)、一种大规模数据流中电信欺诈风险识别方法,通过将主叫号码的历史信息融入到构建的二级级联分类模型中,提高了主叫号码和被叫号码攻击风险预测的精度。
2)、一种大规模数据流中电信欺诈风险识别方法,将多维的风险指标进行融合,使得最终的综合风险值具有较高的稳定性和可解释性。
3)、一种大规模数据流中电信欺诈风险识别方法,容易实现并行化计算,可以实现较高的分类和检测效率。
附图说明
图1是本发明大规模数据流中电信欺诈风险识别方法的原理图;
图2是本发明大规模数据流中电信欺诈风险识别方法的流程图。
具体实施方式
下面将结合附图和实例对本发明作进一步的详细说明。
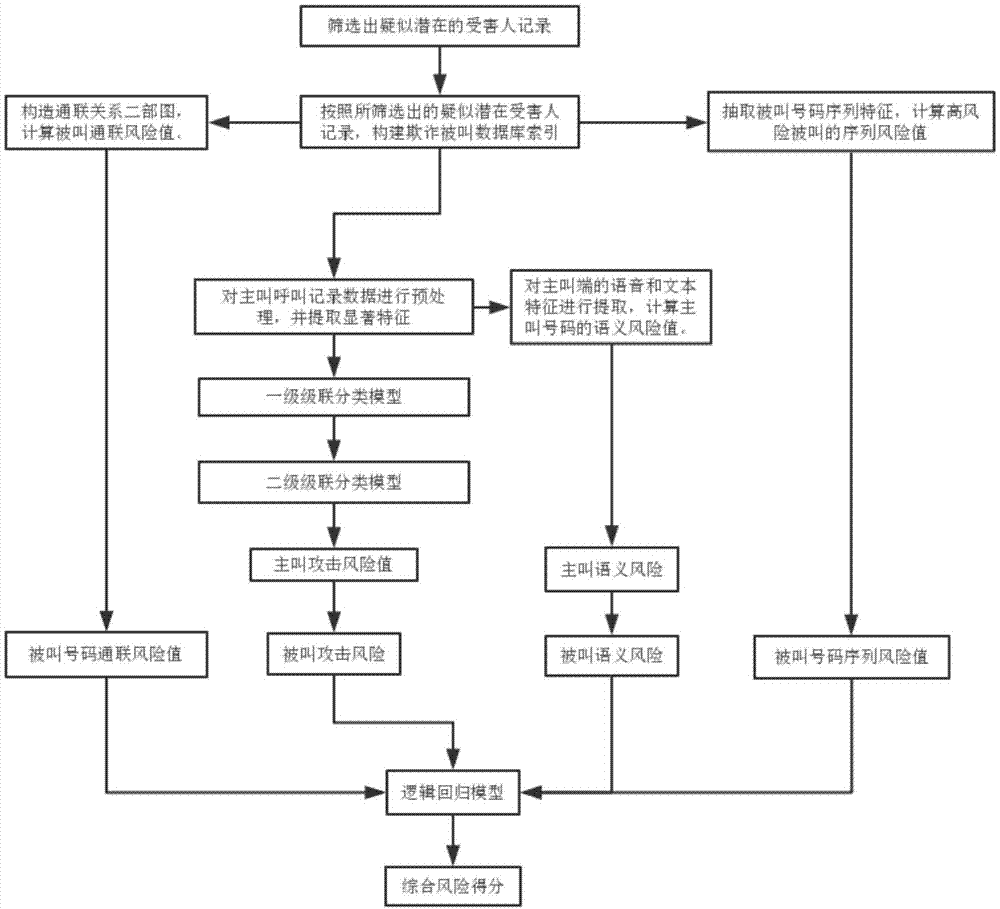
本发明一种大规模数据流中电信欺诈风险识别方法,基于异质的主被叫用户行为信息,实现电信高风险被叫用户风险建模。具体而言,所述方法包括:首先,对原始的被叫集合进行初步的筛选:按照规则从原始的呼叫记录数据库中筛选出一定数量的高风险主被叫用户记录;并构建欺诈被叫索引数据库;然后,对高风险被叫的呼叫记录数据做预处理,并提取显著特征作为后续风险模型的输入;采用二级级联分类的模型,根据主叫端的呼叫记录数据和历史特征数据,将与被叫号码最近联系过的l个主叫中的攻击风险最大值作为该被叫号码的攻击风险值;计算主叫号码的攻击风险值;采用基于滑动窗口的异常检测方法,从被叫的序列呼叫记录中抽取出高风险被叫的序列特征,计算每个被叫号码的的序列风险值;构造被叫号码与主叫号码的通联关系二部图,实现攻击风险在通联关系网络中的传递,计算每个被叫号码的通联风险值;通过训练逻辑回归模型,对被叫号码的攻击风险、序列风险和通联风险多维风险值风险进行融合,得出风险被叫最终的综合风险值。
如图1和图2所示,具体步骤如下:
步骤一、从呼叫记录数据库中按照特定的筛选过滤规则,筛选出若干数量的疑似潜在的受害人记录,作为后续分析的数据对象。
受害人包括高风险被叫用户和主叫用户;
筛选规则为号码特征筛选和历史序列长度过滤等;
步骤二、根据分析对象构建欺诈被叫索引数据库;
索引数据库包括高风险被叫的原始呼叫记录索引、序列特征索引、通联关系索引,以及疑似诈骗主叫的攻击风险索引和历史特征索引等。
步骤三、对不同的索引分别进行预处理,提取各个索引对应的显著特征作为后续风险模型的输入。
所述的预处理包括对离散型的属性特征(如:呼叫地等)做one-hot编码,对连续型的属性特征做标准化处理。
对每个被叫号码提取的特征包括:风险被叫的呼叫级别特征、呼叫序列特征、通联关系特征等;其中,高风险被叫的原始呼叫记录索引对应的特征为风险被叫的呼叫级别特征;序列特征索引对应的特征是呼叫序列特征;通联关系索引对应的特征是通联关系索引;
对每个主叫号码进行语音和文本的特征提取,计算主叫号码的语义风险值,包括主叫语义风险和被叫语义风险。
提取的特征包括:其呼叫级别的特征和历史序列特征等。其中,主叫的攻击风险索引对应的是主叫的呼叫级别特征;历史特征索对应的特征是历史序列特征。
步骤四、采用二级级联分类模型,分别考虑每个主叫的呼叫级别的特征和历史序列特征,计算各主叫号码的攻击风险值,进而得到对应的每个被叫号码的攻击风险值。
二级级联分类模型包括两个分类模型,第一个模型以主叫端呼叫记录的静态属性作为特征,进行cdr风险分析,推出高风险主叫,得到初始的风险值r1;第二个模型以第一个模型推出的高风险主叫为基础,融入了主叫号码的历史序列特征,进行主叫号码的风险分析,得到二级模型输出的风险值r2;
将两次风险分析的结果取最大值作为该cdr的攻击风险值rcdr,即:rcdr=max{r1,r2}。最后将与该主叫对应的被叫号码最近联系过的l个主叫中,选择cdr的攻击风险值中最大值作为该被叫号码的攻击风险值,即:rcaller=max{rcdri},i=1,…,l。
步骤五、针对每个高风险被叫用户的呼叫序列特征,采用基于滑动窗口的异常检测方法,计算每个滑动窗口的风险值,最后保留该被叫最近的滑动窗口异常得分的最大值,作为每个被叫号码的序列风险值。
以每个滑动窗口为单位,通过提取n个滑动窗口的显著特征作为序列特征,如呼叫时间间隔,呼叫时长、呼叫成功率等,进行异常检测,通过训练isolationforest等异常检测的模型,得出每个滑动窗口的异常得分rwindowi(i=1,2…,n),最终该被叫号码的序列风险值为其n个滑动窗口风险值的最大值,即:rsequence=max{rwindowi},(i=1,2…,n)。
最后保留该被叫最近的滑动窗口异常得分的最大值,作为高风险被叫的序列风险值。
步骤六、针对每个被叫号码的通联关系特征,构造被叫号码与主叫号码的通联关系二部图,计算每个被叫号码的通联风险值,实现风险在通联关系网络中的传递。
首先构造主叫和被叫二部结构图,利用基于line的网络表示学习方法获取主叫用户和被叫用户的网络分布式表示向量,随后利用上述向量计算主叫和被叫用户之间的相似度,并筛选出与给定被叫最相似的k个主叫号码,接着借助主叫号码风险分析获取这k个主叫号码历史风险值,再结合主被叫之间的相似度对k个主叫风险值进行加权,作为待分析被叫的通联风险值。
步骤七、借助逻辑回归模型,对每个被叫号码的攻击风险、序列风险和通联风险进行融合,得出每个被叫号码各自的综合风险值。
逻辑回归模型的每个维度分别对应风险被叫的攻击风险、序列风险和通联风险,最终通过设定特定阈值threshold,用训练好的模型预测风险被叫的综合风险值,如果模型输出的综合风险值高于设定的threshold,则将其标记为高风险被叫,否则标记为正常被叫。
到大规模流数据环境下高风险被叫用户的识别和风险评估的方法,本方法通过建立二级的级联风险模型,在一级静态属性特征的预测结果基础上,再进行二级的诈骗检测分析,并将主叫号码的历史信息融入到了二级检测模型中。对潜在受害用户的进行多维风险建模,将被叫用户的综合风险分解为攻击风险、序列风险和通联风险等维度,能够更准确地进行被叫风险识别。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!