一种黑产场景下恶意云机器人的识别方法及系统与流程
本发明涉及一种黑产场景下恶意云机器人的识别方法及系统,属于计算机软件技术领域。
背景技术:
网络机器人检测是随着互联网的迅猛发展而产生的研究领域。通常,传统的网络机器人指通过internet向web服务器发送请求,以请求资源的自治系统。网络机器人根据其用途分为良性和恶意两大类。典型的良性网络机器人包括搜索引擎索引器和用于从internet获取、分析和归档信息的爬虫等。良性网络机器人使得海量信息的有效提取和利用变得十分便利。而恶意网络机器人往往通过抓取网站内容,帮助一些不法行为的实施。例如建立钓鱼网站、制造虚假下载量、生成垃圾邮件等。此外,在线游戏中的作弊机器人也很猖獗。为了识别这些恶意机器人,减少它们对于正常网络活动的影响,目前已有方法以web服务器访问日志文件为研究对象,有针对性地研究了特定场景下网络机器人的准确检测。
已有的网络机器人检测方法根据其原理可以分为四类:语法日志分析、流量模式分析、基于学习的技术和图灵测试系统。语法日志分析依赖于知识库中的先验知识如http头部的user-agent域、ip地址等,通过和web服务器访问日志中的内容进行匹配,推断该条日志是否为机器人产生。该方法严重依赖知识库,而知识库往往只能涵盖部分情况,还需要对其进行不断的更新和维护。另外,http头部字段内容是可以伪造的。这导致语法日志分析方法虽然原理简单、易操作,但是准确率和召回率低。流量模式分析方法是对日志进行深度分析,寻找机器人流量不同于正常人类用户流量的流量模式。和语法日志分析的简单匹配不同,流量模式分析涉及对请求资源类型、请求量大小、引用位置、时间等不同维度的字段的统计和分析,勾勒出机器人流量所独有的流量特征和浏览模式。然后根据发现的模式,对后续访问日志进行分类。相比于语法日志分析方法,流量模式分析能更深入、更准确地发现网络机器人。但其模式的确定需要特征和其表征的现实意义对应起来,这使得一些隐式特征不能被充分挖掘。基于学习的技术很大程度上缓解了这个问题。基于学习的技术在流量模式分析的基础上,使用机器学习算法,学习机器人流量和正常用户流量的模式。这种模式是隐式的、更接近本质的。一个成功的模型理论上可以正确识别对应场景下所有的网络机器人。因此更难被机器人绕开。图灵测试系统和前三种方法不同,它需要用户参与图灵测试,以检测被测试的用户是否为机器人。这种方法是实时的,但其需要用户的交互,这在被动测量中是不能实现的,而且不利于用户体验的提升。
固然针对网络机器人的检测已形成较为成熟的方法,但已有研究都是针对特定场景的网络机器人的。随着移动互联网、电子商务服务和web2.0应用的快速发展,越来越多的交易和服务依赖网络进行。在这种情况下出现了一种危害极大的恶意网络机器人。它们使用的极其复杂的策略,利用应用程序的业务逻辑漏洞进行虚假点击、促销滥用、虚假账户批量注册以及其他类型的欺诈。由于这些恶意机器人与应用程序交互的方式与正常用户相同,并且它们会对流量进行篡改,例如使用伪装的user-agent字段,因此难以检测。这些恶意机器人已成为黑产中的重要一环,被用于薅羊毛、黄牛刷票等,使企业遭受巨大经济损失,同时正常用户的服务体验也受到严重影响。captcha测试虽然已经被用于识别恶意网络机器人,但不断升级的恶意机器人可以绕过多种captcha测试,而更复杂的captcha测试会使用户体验变差。如何有效、准确地检测这些恶意机器人的ip已经成为企业对抗黑产的关键。而目前还没有针对黑产场景下恶意机器人识别的有效方法。这类机器人策略复杂,对正常用户的模仿性极高,传统的网络机器人检测方法显然很难识别。需要研究一种新的方法,来识别该场景下的恶意网络机器人。
已有数据表明,2017年互联网数据中心(idc)产生的恶意机器人流量占82.7%,比2016年增长37%。云服务的高性能、低成本和易于自动化是恶意机器人使用idc主机作为载体的主要原因。这样的恶意机器人被称为云机器人。有效检测云机器人可以大大缓解用于黑产的恶意机器人的识别问题。
技术实现要素:
针对现有技术中存在的缺陷与不足,本发明提供了一种识别用于薅羊毛、刷票等黑产活动的恶意云机器人的方法与系统。本发明不依赖于web服务器访问日志,而是对服务器端接收到的原始流量进行分析判别,识别客户端ip中的恶意云机器人ip。本发明提出一种恶意云机器人的样本提取和标注方法,为机器学习模型提供可靠的数据基础。本发明针对薅羊毛、刷票类的黑产场景,实现了一种恶意云机器人识别原型系统,其多层流量统计特征提取模块既保护了用户隐私,又能提取恶意云机器人区别于正常用户的隐式特征,高准确率识别恶意云机器人。该系统还包含了模型反馈迭代模块,可以对机器学习模型进行调整,以应对随着时间和网络环境变化产生的概念漂移。
本发明是通过以下技术方案实现的:
一种黑产场景下恶意云机器人的识别方法,包括以下步骤:
(1)在服务器端实时收集客户端发来的待测流量;
(2)对待测流量进行样本提取,并进一步提取样本中与恶意云机器人识别模型相对应的特征向量;
(3)将步骤(2)中得到的待测流量的特征向量作为输入,通过该恶意云机器人识别模型进行识别;
其中,所述恶意云机器人识别模型通过下述方法构建:
在服务器端实时收集客户端发来的流量,存储并提取样本,使用恶意云机器人数据库对样本数据进行标注,若初始样本的客户端ip包含在该数据库中,则将该初始样本标记为恶意云机器人样本;反之,则标记为人类用户样本;
对样本流量数据进行多层流量统计特征的提取,得到特征向量;
基于机器学习方法,利用特征向量训练多种分类器,选取具有最优效果的分类器,得到恶意云机器人识别模型。
进一步地,上述识别方法中流量样本的提取方法为:
将流量按照客户端ip-时间段进行汇聚,每个客户端在一定时间段内的流集合作为一个初始样本;
更进一步地,所述流指具有相同五元组的包序列:{源ip,目的ip,源端口,目的端口,tcp};所述一定时间段优选为1h。
进一步地,上述识别方法中流量样本的标注方法为:
由于恶意云机器人流量来自于idc,而其他正常用户流量理论上都应该来自于真实人类用户,因此使用ipip.net提供的权威idcip数据库作为基准,对初始样本进行标注;若初始样本的客户端ip包含在该数据库中,则将该初始样本标记为恶意云机器人样本;反之,则标记为人类用户样本;该数据库包含2亿idcip,并且每周对数据库进行实时更新。
进一步地,上述识别方法中提取的特征向量包括:
基本特征、操作系统指纹特征、ttl相关特征、端口相关特征和应用层统计特征。
进一步地,所述恶意云机器人识别模型构建过程具体为:
(1)选择分类算法并设置分类算法的参数;
(2)将提取的特征向量数据集分为训练集与验证集,利用训练集训练恶意云机器人分类模型,利用验证集评估模型分类效果;
(3)根据样本固有标签,计算恶意云机器人的准确率和召回率,若准确率和召回率不低于预设阈值,则当下的分类器为最优分类器;否则,返回步骤(1),更换算法和参数,重新训练模型,直至满足预设阈值,得到初步满足要求的分类器。
(4)后续可根据步骤(3)中得到的分类器在真实环境中的表现,对该分类器的参数进行迭代调整,得到最优分类器。
更进一步地,步骤(1)中所述分类算法包括:朴素贝叶斯、逻辑回归、支持向量机、决策树和随机森林。
更进一步地,步骤(3)中所述预设阈值由用户根据具体业务场景需求分别预设准确率和召回率的阈值。。
一种黑产场景下恶意云机器人的识别系统,包括:
样本提取与标注模块:在服务器端实时收集客户端发来的原始流量,存储并提取样本,使用数据库对流量样本数据进行标注,若初始样本的客户端ip包含在该数据库中,则将该初始样本标记为恶意云机器人样本;反之,则标记为人类用户样本;
特征向量提取模块:对流量样本数据进行多层流量统计特征的提取,得到特征向量;
分类器训练模块:基于机器学习方法,利用特征向量训练多种分类器,选取具有最优效果的分类器,得到恶意云机器人识别模型;
恶意云机器人识别模块:收集待测流量,进行样本提取和特征向量提取,利用上述最优分类器进行恶意云机器人的识别。
本发明的有益效果为:(1)针对薅羊毛、刷票等黑产场景,所述系统可以直接部署在企业的业务服务器端,识别恶意云机器人ip,减少经济损失;亦可帮助相关机关打击黑产犯罪。
(2)以原始流量为对象进行分析,相比于web服务器访问日志,使用原始流量可以最大程度上减少原始信息的损失,保留潜在的有用信息。样本提取采用“客户端ip-时间段”为主键,对原始流量进行汇聚。这一样本提取方法对一个客户端ip在一定时间段内发出的流量进行汇聚,即是对该客户端在该时间段内的行为进行整合,以便发现恶意云机器人的独特行为模式。考虑到信息量和实时性的权衡,最终选取1小时作为一个观察区间。因此原始流量是以小时-ip为主键进行汇聚,得到样本。标注方法采用权威数据库。由于恶意云机器人流量来自idc主机,因此从ipip.net获得定时更新的包含2亿个idcip的数据库,并以此为依据对样本进行标注。
(3)针对原始流量,提出了多层流量统计特征。多层流量特征包含基本特征、操作系统指纹特征、ttl相关特征、端口相关特征和应用层统计特征五部分,涵盖了网络层、传输层、应用层的多个字段及其统计量,最大程度上揭示了恶意云机器人流量和正常用户流量之间的本质区别,同时,多层流量统计特征不涉及任何具体的应用层字段信息,也无需对流量进行解密操作,保护了用户的隐私。。
(4)通过对机器学习分类算法和参数进行选择和调整,达到较好的分类效果。然后用后续真实世界数据集进行评估验证,确保模型的准确率和泛化能力。
(5)可以对服务器的流量进行准实时分类,满足在线部署系统的需求;也可以根据需求对整个系统进行调整,适应性地改变时间间隔。
附图说明
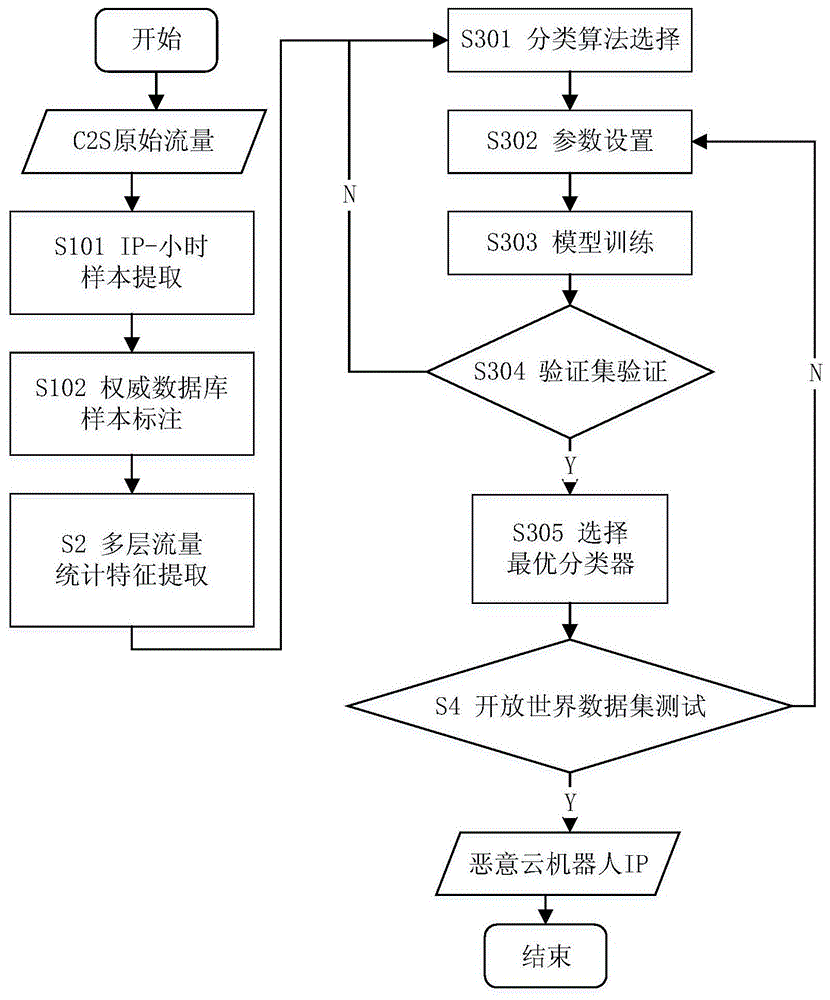
图1为本发明的方法流程图。
图2为多层流量统计特征。
具体实施方式
为了使本技术领域的人员更好地理解本发明实施例中的技术方案,并使本发明的目的、特征和优点能够更加明显易懂,下面结合附图对本发明中技术核心作进一步详细的说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本发明的方案包括以下步骤(参照图1):
首先在服务器(s)端实时捕获客户端(c)发来的原始流量并存储。
步骤s101,将原始流量按照客户端ip-小时进行汇聚,每个客户端每个小时的流集合作为一个初始样本。这里的流指具有相同五元组的包序列:{源ip,目的ip,源端口,目的端口,tcp}。
步骤s102,使用权威数据库对初始样本进行标注。由于恶意云机器人流量来自于idc,因此使用ipip.net提供的权威idcip数据库作为基准,对初始样本进行标注。该数据库包含2亿idcip,并且每周对数据库进行实时更新。若初始样本的客户端ip包含在该数据库中,则将该初始样本标记为恶意云机器人样本。否则的话,标记为人类用户样本。
步骤s2,对初始样本进行多层流量统计特征的提取,得到特征向量,作为后续机器学习方法的输入样本。多层流量统计特征包括五部分,分别是基本特征、操作系统指纹特征、ttl相关特征、端口相关特征和应用层统计特征。图2介绍了多层流量统计特征。以下对其进行说明:
基本特征是对初始样本包含的流和包的全貌进行刻画,包括对端节点的数量、数据包总数、总字节数、流的数量、每个流的包数的统计值(包括最大值、最小值、中位数、平均值、方差和标准差)、每个流的总字节数的统计值,以及每个流的持续时间的统计值等。
操作系统指纹特征包含网络层和传输层中能反映操作系统的字段信息。根据统计数据,大部分人类用户倾向于使用windows、macos、android等有有好图形化界面的操作系统,而部署在id主机上的恶意云机器人则更可能使用linux操作系统。因此,操作成系统指纹可以在恶意云机器人和人类用户之间提供较好的区分度。该部分特征包含tcp最大分段大小(mss),tcp窗口大小,tcp窗口比例(ws)和no-option选项的频数统计。这些字段根据区分度较大的值编码成特征向量。
ttl相关特征是具有不均匀分箱长度的直方图分布,包含初始样本中出现的ttl值统计和跳数统计,其中跳数为初始ttl值减去初始样本中观察得到的ttl值。每个初始样本中的ttl值按照7个分箱编码成7维频率向量,7个分箱为[0,32],[33,52],[53,64],[65,119],[120,128],[129,192],[193,255]。跳数与之类似,按照24个特定值和区间编码成24维频率向量,分别是0,1,2,...,20,[21,25],[26,30],[31,]。
端口相关特征也是具有不均匀分箱长度的直方图分布,包含[0,1023],[1024,10000],[15000,15500],[29000,33000],[40000,50000],[50000,65535]6个客户端端口集合。由于恶意云机器人的目标性极强,其对于服务和端口的使用都更为单一。因此有区分度的端口区间统计可以帮助区分恶意云机器人和正常用户。
应用层统计特征也是利用了恶意云机器人访问服务集中且较为单一的特点,包括几个应用层协议字段的统计特征,如针对每个初始样本,http请求中的方法类型统计,http头部不同host和url字段值的数量以及它们在http请求中相应的数据包和字节数,ssl/tls头部不同sni字段值的数量及其对应的数据包和字节数。
初始样本经过步骤s2的多层流量统计特征提取后,得到多维特征向量,作为后续构建机器学习模型的输入。
步骤s301,选择分类算法。常用的机器学习算法有朴素贝叶斯、逻辑回归,支持向量机、决策树和随机森林。
步骤s302,设置分类算法的参数。初始可使用默认参数。后期可根据预测结果,对相应算法的不同参数使用网格搜索确定最优值。
步骤s303,训练模型。将步骤s2得到的特征向量和其对应的标签随机分出4/5作为训练集,输入到步骤s301和s302选择好的机器学习算法中进行训练。得到用于分类恶意云机器人和正常人类用户的模型。
步骤s304,验证集验证分类效果。使用步骤s303中划分剩下的1/5作为验证集,将其特征向量输入到训练好的模型中,得到预测结果。该结果是对ip-小时为单位的样本的预测,对于一个客户端ip对应多个样本的情况,进行投票,选择多数结果作为该ip的最终预测结果。然后根据其固有标签,计算恶意云机器人的准确率和召回率。若准确率和召回率满足预设阈值,则当下的分类器为最优分类器。否则,返回步骤301,更换算法和参数,重新训练模型,直至满足预设阈值,得到最优分类器。
步骤s305,根据s304的结果迭代分类器,并保存最优的分类器。
步骤s4,在服务器上捕获原始流量作为开放世界数据集。对其进行步骤s101,s102,s2后,将得到的特征向量输入步骤s305得到的最优分类器中。然后参照步骤s304,计算其恶意云机器人的准确率和召回率。若不满足期待阈值,则返回步骤s302进行参数调整。然后重新训练模型,直到步骤s4得到的恶意云机器人的准确率和召回率满足期待阈值。此时可得到准确的恶意云机器人ip。程序结束。
经过上述步骤,最终产生一个可以部署到实时和离线的流量环境中的恶意云机器人识别系统。该系统输入待识别流量,经过样本提取、样本标注、多层流量特征统计提取转换为特征向量,然后输入到上述最优分类器中,分类器输出对应客户端ip的类别标签,即可判定是否为恶意云机器人。
以上所述实施例仅表达了本发明的实施方式,其描述较为具体,但并不能因此理解为对本发明专利范围的限制。应当指出,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应当以所附权利要求为准。
实施例
通过恶意云机器人识别原型系统识别线上交易欺诈机器人。2018年7月,在某互联网公司用于托管线上交易业务的服务器上连续采集了14天的原始流量,对其进行样本提取和标注后,共得到98570个恶意云机器人样本和164786个正常人类用户样本,其对应的去重ip个数分别为30368和151840。取前七天的样本作为实验数据集,采用五折交叉验证训练机器学习模型,其中训练集和验证集的比例为4:1。后七天的样本作为开放世界数据集,用于对模型的泛化能力进行测试。经过机器学习算法的选择和参数的调整,得到的最优分类器为随机森林分类器,其在开放世界数据集上对恶意云机器人的准确率和召回率均达到90%以上。
- 还没有人留言评论。精彩留言会获得点赞!