一种基于分布式集群的视频图像信息采集方法与流程
本发明涉及网络安防领域,具体而言,涉及一种基于分布式集群的视频图像信息采集方法。
背景技术:
随着深度学习、视频智能分析和大数据技术的发展,对海量视频图像数据进行深度挖掘、分析已经具备条件,这些数据需要一个集中存储视频图像的数据库来支撑。视频图像数据库存储来自智能化采集设备的视频片段文件、图像文件及其所含的人员、车辆、物品、场景和视频图像标签等对象,同时对各业务系统提供数据服务接口,支撑各种应用需求。视频图像数据库每天接收的数据量可达几千万到上亿,这些数据对各应用系统的业务开展至关重要。
例如,中国发明专利:201910134543.5,公开了一种基于大数据的信息采集方法,所述基于大数据的信息采集系统包括:数据源模块、数据传输模块、中央控制模块、检索模块、信息集成模块、信息管理模块、大数据分析模块、平衡模块、云存储模块、显示模块。本发明通过大数据分析模块得到分析结果存储在分布式数据库的分析结果表中,不需要到分布式数据库中海量的大数据中获取大数据,所以耗时短且易于实现;同时,通过平衡模块根据数据平衡策略和大数据集群负载和性能数据动态调整数据平衡的网络带宽,重新启动数据平衡程序,能够在保障集群正常数据生产的同时,提高集群数据平衡的效率和弹性。
又例如,中国发明专利:201710373026.4,公开了一种基于分布式集群的数据采集系统,所述系统包括主采集节点、数据解析模块和多个子采集节点;所述主采集节点连接多个所述子采集节点,所述子采集节点用于采集数据,所述主采集节点用于接收各个所述子采集节点采集的数据;所述数据解析模块用于分别计算各个所述子采集节点采集的数据的变化速率,根据所述变化速率调节各个所述子采集节点的数据采集频率;本发明所公开的系统,能通过变化速率调节各个所述子采集节点的数据采集频率,从而使得各个子采集节点的采集频率与其所采集到的数据的变化速率相适应。
基于上述现有技术的不足,无法解决数据库每天持续稳定的接收存储,高达几千万到上亿条视频图像信息和结构化描述信息的数据量。
技术实现要素:
针对现有技术不能解决数据库每天持续稳定的接收存储,高达几千万到上亿条视频图像信息和结构化描述信息的数据量。
本发明的目的在于提供一种基于分布式集群的视频图像信息采集方法,步骤如下:
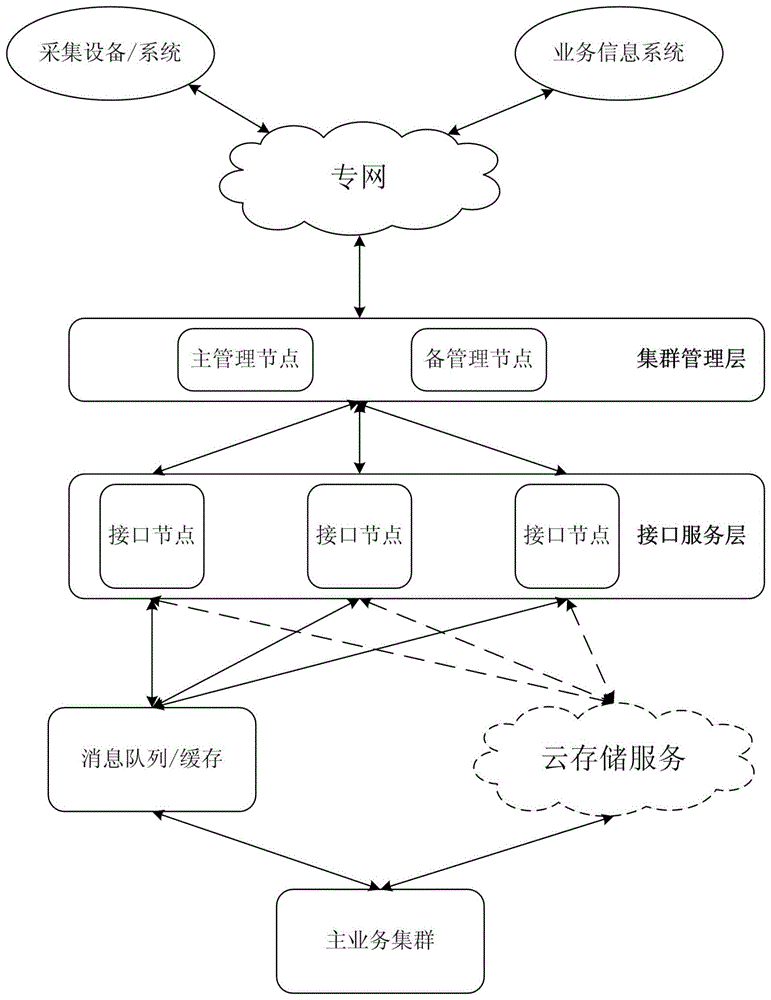
步骤1,采集设备/系统中的数据互连专网,数据通过专网互连存储到集群区,集群区存储的数据再次通过专网互连提供给业务信息系统;
步骤2,集群区由集群管理层和接口服务层组成,集群区的集群管理层向专网提供一个固定的ip端口;
步骤3,集群区中的集群管理层有主管理节点和备管理节点;集群管理层中的主管理节点和备管理节点共连接相同且独立ip端口提供数据传输服务;
步骤4,接口服务层由nginx作为管理多个独立无状态的接口节点,接口节点采用http长连接方式连接集群管理层中的主管理节点和备管理节点;
步骤5,接口服务层中的接口节点分别互连信息队列/缓存和云存储服务;
步骤6,信息队列/缓存互连主业务集群,主业务集群互连云存储服务。
进一步的,步骤3所述的主管理节点若出现故障,备管理节点启动切换继续提供服务,启动切换主管理节点和备管理节点根据配置的优先级,主管理节点和备管理节点相互启动切换时间为0.1-2s。
进一步的,步骤3所述集群管理层作为所有外部专网请求的入口,集群管理层需对外提供一个固定的ip,当主管理节点发生故障时,备管理节点继续使用同一个ip对外提供服务。
进一步的,步骤3所述集群管理层通过主管理节点和备管理节点的方式实现管理节点的高可用,采用keepalived实现主管理节点和备管理节点的故障转移和自动恢复,采用故障转移和自动恢复步骤如下:
步骤3.1,keepalived使用的虚拟路由冗余协议(vrrp)在一个路由器组之间共享一个虚拟ip,路由器组里设置一个主节点和多个备节点,主节点将对外的ip绑定到自身机器上,定期发组播包,备节点收不到组播包时将主节点标记为异常,根据配置的优先级来选举一个备节点当作主节点,以保持通信的连续性、可靠性,消除单节点故障;
步骤3.2,keepalived定期执行用户指定的脚本,在集群管理层中主管理节点和备管理节点所在机器上编辑健康检查脚本,实现主管理节点和备管理节点故障的迁移,健康检查脚本执行步骤如下:
步骤3.2.1,运行linux命令检查管理节点;
步骤3.2.2,linux命令检查集群管理层中的管理节点,若管理节点异常,管理节点自动重启,等待15-30毫秒,再次检查重启后的管理节点是否正常,检查结果显示正常,linux命令结束;
步骤3.2.3,若自动重启后的管理节点的检查结果为异常,linux命令判断管理节点为故障,linux命令继续分析故障管理节点状态,故障管理节点状态为主管理节点时,给指定的管理员发告警邮件,将故障管理节点自动优先级降低5,然后中止keepalived进程;
步骤3.2.4,linux命令同步检查同一个虚拟路由组的其他keepalived,若有keepalived接收不到主管理节点的组播包,keepalived尝试访问集群管理层向专网提供的服务地址;
步骤3.2.5,尝试访问集群管理层向专网提供的ip地址异常,再次尝试连接默认网关ping;
步骤3.2.6,若默认网关ping无法连通,linux命令判定自身所在检查的服务器有网络故障,给管理员发告警邮件;
步骤3.2.7,若默认网关ping连通,linux命令判定集群管理层中主管理节点有故障,自动将虚拟ip绑定到自身所在服务器上,接管主管理节点的任务。
进一步的,步骤3所述的接口服务层,在接收集群管理层发送的图像和视频片段时,进行解析校验,然后解码图像和视频片段。
进一步的,步骤4所述nginx根据接口节点的响应时间,将集群管理层发送的图像和视频片段分配到处理速度最快的接口节点,以保证接口服务层的每个接口节点处理等量的视频图像。
进一步的,步骤4所述nginx自动检查所管理的接口节点健康状态,自动将故障接口节点从列表中删除;在检查到故障的接口节点恢复正常后,将接口节点加入列表继续提供服务。
进一步的,步骤4所述nginx同时提供动态增加接口节点,在有新的接口节点需要加入接口服务层时,通过修改nginx程序管理的接口节点列表并给nginx发usr1的进程信号,实现不停止服务进行扩容。
进一步的,步骤4所述接口节点互连信息队列/缓存,接口节点内部的实时信息存储到信息队列/缓存中,以实现接口节点无任务,当执行任务的接口节点出现故障时,其他接口节点从信息队列/缓存中提取任务当下状态,继续执行任务。
进一步的,步骤4中所述接口节点在收到集群管理层发送的信息后,先将信息进行拆分,图片与视频文件存储至信息队列/缓存中,结构化信息通过nfs网络文件系统存储至云存储服务中,以缩短信息处理时间。
进一步的,步骤4所述接口节点互连云存储服务中的云存节点,每个接口节点独立互连多个云存节点。
进一步的,步骤5所述云存储服务中的云存节点,当接口节点对多个云存节点写文件时,通过如下执令寻找指定的云存节点,执令步骤如下:
步骤5.1,将云存节点从0开始按顺序编号;
步骤5.2,对每条视频片段或图片文件生成唯一的id号,id号由设备编号+时间戳+类别+流水号组成;
步骤5.3,将生成唯一的id号分别除于云存节点的总数,取余数得到规律的结果,根据规律的结果选择ip为最终的云存节点。
进一步的,步骤6所述主业务集群自动判断其他系统对存储在信息队列/缓存和云存储服务中数据的需求和数据中有关注的目标信息,则向其他系统转发符合条件的数据。
相对于现有技术,本发明提供的一种基于分布式集群的视频图像信息采集方法有以下显著的优越效果:
1、采用基于分布式集群的视频图像信息采集方法,每天接收几千万到上亿条视频图像信息及其结构化描述信息,能持续稳定的接收及存储。
2、采用单万兆网口同时进行数据采集与转发的情况下,能持续稳定地收发600m/s的视频短片+图像文件,相关结构化描述信息7700条/s。
3、采用基于分布式集群的视频图像信息采集方法,提高视频、图片信息处理能力及成本时间的节约。
4、采用基于分布式集群的视频图像信息采集方法,实现不停服务同时对集群进行扩容。
附图说明
图1是一种基于分布式集群的视频图像信息采集方法流程图;
图2是一种基于分布式集群的视频图像信息采集方法中云存储控制台图;
具体实施方式
如图1、图2所示,所述一种基于分布式集群的视频图像信息采集方法,包括如下步骤:
步骤1,采集设备/系统中的数据互连专网,数据通过专网互连存储到集群区,集群区存储的数据再次通过专网互连提供给业务信息系统;
步骤2,集群区由集群管理层和接口服务层组成,集群区的集群管理层向专网提供一个固定的ip端口;
步骤3,集群区中的集群管理层有主管理节点和备管理节点;集群管理层中的主管理节点和备管理节点共连接相同且独立ip端口提供数据传输服务;
步骤4,接口服务层由nginx作为管理多个独立无状态的接口节点,接口节点采用http长连接方式连接集群管理层中的主管理节点和备管理节点;
步骤5,接口服务层中的接口节点分别互连信息队列/缓存和云存储服务;
步骤6,信息队列/缓存互连主业务集群,主业务集群互连云存储服务。
进一步的,步骤3所述的主管理节点若出现故障,备管理节点启动切换继续提供服务,启动切换主管理节点和备管理节点根据配置的优先级,主管理节点和备管理节点相互启动切换时间为0.1-2s。
进一步的,步骤3所述集群管理层作为所有外部专网请求的入口,集群管理层需对外提供一个固定的ip,当主管理节点发生故障时,备管理节点继续使用同一个ip对外提供服务。
进一步的,步骤3所述集群管理层通过主管理节点和备管理节点的方式实现管理节点的高可用,采用keepalived实现主管理节点和备管理节点的故障转移和自动恢复,采用故障转移和自动恢复步骤如下:
步骤3.1,keepalived使用的虚拟路由冗余协议(vrrp)在一个路由器组之间共享一个虚拟ip,路由器组里设置一个主节点和多个备节点,主节点将对外的ip绑定到自身机器上,定期发组播包,备节点收不到组播包时将主节点标记为异常,根据配置的优先级来选举一个备节点当作主节点,以保持通信的连续性、可靠性,消除单节点故障;
步骤3.2,keepalived定期执行用户指定的脚本,在集群管理层中主管理节点和备管理节点所在机器上编辑健康检查脚本,实现主管理节点和备管理节点故障的迁移,健康检查脚本执行步骤如下:
步骤3.2.1,运行linux命令检查管理节点;
步骤3.2.2,linux命令检查集群管理层中的管理节点,若管理节点异常,管理节点自动重启,等待15-30毫秒,再次检查重启后的管理节点是否正常,检查结果显示正常,linux命令结束;
步骤3.2.3,若自动重启后的管理节点的检查结果为异常,linux命令判断管理节点为故障,linux命令继续分析故障管理节点状态,故障管理节点状态为主管理节点时,给指定的管理员发告警邮件,将故障管理节点自动优先级降低5,然后中止keepalived进程;
步骤3.2.4,linux命令同步检查同一个虚拟路由组的其他keepalived,若有keepalived接收不到主管理节点的组播包,keepalived尝试访问集群管理层向专网提供的服务地址;
步骤3.2.5,尝试访问集群管理层向专网提供的ip地址异常,再次尝试连接默认网关ping;
步骤3.2.6,若默认网关ping无法连通,linux命令判定自身所在检查的服务器有网络故障,给管理员发告警邮件;
步骤3.2.7,若默认网关ping连通,linux命令判定集群管理层中主管理节点有故障,自动将虚拟ip绑定到自身所在服务器上,接管主管理节点的任务。
进一步的,步骤3所述的接口服务层,在接收集群管理层发送的图像和视频片段时,进行解析校验,然后解码图像和视频片段。
进一步的,步骤4所述nginx根据接口节点的响应时间,将集群管理层发送的图像和视频片段分配到处理速度最快的接口节点,以保证接口服务层的每个接口节点处理等量的视频图像。
进一步的,步骤4所述nginx自动检查所管理的接口节点健康状态,自动将故障接口节点从列表中删除;在检查到故障的接口节点恢复正常后,将接口节点加入列表继续提供服务。
进一步的,步骤4所述nginx同时提供动态增加接口节点,在有新的接口节点需要加入接口服务层时,通过修改nginx程序管理的接口节点列表并给nginx发usr1的进程信号,实现不停止服务进行扩容。
进一步的,步骤4所述接口节点互连信息队列/缓存,接口节点内部的实时信息存储到信息队列/缓存中,以实现接口节点无任务,当执行任务的接口节点出现故障时,其他接口节点从信息队列/缓存中提取任务当下状态,继续执行任务。
进一步的,步骤4中所述接口节点在收到集群管理层发送的信息后,先将信息进行拆分,图片与视频文件存储至信息队列/缓存中,结构化信息通过nfs网络文件系统存储至云存储服务中,以缩短信息处理时间。
进一步的,步骤4所述接口节点互连云存储服务中的云存节点,每个接口节点独立互连多个云存节点。
进一步的,步骤5所述云存储服务中的云存节点,当接口节点对多个云存节点写文件时,通过如下执令寻找指定的云存节点,执令步骤如下:
步骤5.1,将云存节点从0开始按顺序编号;
步骤5.2,对每条视频片段或图片文件生成唯一的id号,id号由设备编号+时间戳+类别+流水号组成;
步骤5.3,将生成唯一的id号分别除于云存节点的总数,取余数得到规律的结果,根据规律的结果选择ip为最终的云存节点。
进一步的,步骤6所述主业务集群自动判断其他系统对存储在信息队列/缓存和云存储服务中数据的需求和数据中有关注的目标信息,则向其他系统转发符合条件的数据。
以上所述仅为本发明优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!