分布式消息系统的制作方法
本申请涉及分布式消息系统的集群运维管理技术领域,具体来说,涉及一种分布式消息系统的集群运维管理方法和装置。
背景技术:
分布式消息作为中间件成员中不可缺失的部分,在目前绝大部分的系统架构中都使用分布式消息来解决系统或应用间异步通讯的问题。分布式消息经历了多次重大的架构升级后,核心技术架构已日趋成熟。现阶段主流的开源分布式消息系统都是基于topic(主题)和group(组)的概念实现整个分布式消息系统。其中,apachekafka、apacherocketmq(rocketmetaqueue,开源的消息中间件)、apachepulsar是开源分布式消息系统大军中的领军代表。越来越多的系统或应用使用分布式消息系统来实现系统或应用间的异步解耦、削峰限流等功能来提升自身系统或应用的高并发性能,以及保障系统或应用的安全性和稳定性。然而,即使是再成熟的系统,也离不开日常的监控巡查,也离不开出现异常问题的处理,更离不开人工的参与。在分布式消息系统中,一个或多个物理集群构成整个分布式消息的整体逻辑服务形态,在一个简单的集群中至少包含3-5台物理或虚拟服务节点。如此庞大的服务节点规模给运维带来了巨大的压力和挑战。因此,分布式消息系统非常需要一套完善的可视化的运维工具,帮助开发人员和运维人员高效地完成日常巡检,问题处理等工作。
经调研,apachekafka、apacherocketmq和apachepulsar作为目前几款主流的分布式消息系统,在可视化运维工具方面都存在诸多问题。例如,apachekafka作为大数据、流处理首选的分布式消息系统,原生只提供了命令行工具来获取kafka集群运行时的监控数据。命令行代码效率极低,交互性较差,而且提供的监控数据极为有限,对开发人员和运维人员日常监控和问题排查带来了极大的困难。而apacherocketmq作为后起之秀,在金融等高安全、高要求的领域占有一席之地。rocketmq原生除了提供类似kafka一样的命令行工具外,也提供了原生的可视化控台。与kafka相比,以及较大的降低了开发人员和运维人员使用的难度,提升了运维工作的效率。但是,rocketmq原生可视化控台无论从功能性,还是可视化角度都略显简陋。
现有技术存在的问题:
apacherocketmq提供了一套简单可视化控台rocketmqconsole。rocketmqconsole可以简单的监控集群的配置、实时的健康状态,消息流入流出的统计等功能。
rocketmqconsole在权限方面没有做任何控制,作为一款在生产环境运行的管理系统,权限本身就是保障安全的第一道关卡。rocketmqconsole本身除了提供简单的运维监控功能外,还提供了直接对集群产生直接影响的多种操作。例如:创建topic、删除topic、创建group、删除group等等。诸如此类的操作都有可能威胁到集群的稳定性和安全性。没有权限的保障,任何有权访问rocketmqconsole的人员都有可能对生产造成有意或无意的影响。
rocketmqconsole只对集群中的broker(rocketmq最核心模块,主要负责topic消息存储、管理和分发)有实时健康状态的监控,没有对nameserver的健康状态进行监控。nameserver是apacherocketmq整体架构中重要的角色之一,nameserver主要管理整个集群的元数据内容,所有生产和消费实例都必须通过nameserver中的元数据来找到对应的broker,才能正常的收发消息。所以,nameserver的健康状态同样重要。
rocketmqconsole虽然可以维护集群上的消息资源,如topic、group等。但是无法对物理资源进行管理,如:broker、nameserver等。由于rocketmqconsole本身没有监控nameserver的状态,因此也没有提供任何对nameserver服务节点的管理方法。rocketmqconsole能够实时监控broker的健康状况,但是当出现broker发生异常状态时,如磁盘损害、网卡损害、服务器故障等等,rocketmqconsole可以检测到集群中的异常broker处于不可用状态,但没有任何告警提示,也没有提供动态摘除替换功能。
技术实现要素:
针对相关技术中的上述问题,本申请提出一种分布式消息系统,至少能够提供可视化的运维监控和安全性的运维平台从而更有效解决生产中集群可能发生的故障。
本申请的技术方案是这样实现的:
根据本申请的一个方面,提供了一种分布式消息系统,包括:
集群;
指标采集器,用于从集群采集监控指标;
运维管理系统,通过指标采集器进行指标数据的查询和读取,并下发客户端资源元数据以使应用使用资源。
根据本发明的实施例,集群包括nameserver集群和broker集群,其中,nameserver集群管理broker集群中所有broker的元数据。
根据本发明的实施例,运维管理系统支持集群正向迁移和集群反向回滚迁移。
根据本发明的实施例,运维管理系统基于基本角色管理资源使用权限和资源查询权限,第一基本角色具有第一资源使用权限和第一资源查询权限,第二基本角色具有第二资源使用权限和第二资源查询权限。
根据本发明的实施例,监控指标包括发送端通用指标、消费端通用指标,其中:发送端通用指标包括:发送每秒事务处理率(tps)、发送总量、发送者实例数和发送者连接中的至少一种;消费端通用指标包括:消息堆积量、消费速率、消费者实例数和消费者连接中的至少一种。
根据本发明的实施例,监控指标包括服务端通用指标,服务端通用指标至少包括:集群发送每秒事务处理率、集群发送总量、集群发送者实例数和集群发送者连接、集群消息堆积量、集群消费速率、集群消费者实例数和集群消费者连接中的至少一种。
根据本发明的实施例,运维管理系统调用经扩展的分布式消息系统服务端摘除接口将故障节点加入黑名单且不再接收黑名单中故障节点的上报信息;运维管理系统将不在黑名单中故障节点分配新创建资源。
本申请的有益技术效果在于:
充分利用原生命令行工具,为开发人员和运维人员提供更丰富的数据和统计汇总信息,且通过可视化的方式给开发人员和运维人员提炼关键指标数据展现,帮助他们处理日常的巡检和问题排查工作;
解决了运维平台安全性的问题,可以有效避免系统在“裸跑”状态下隐藏的安全风险;
对集群故障相关的处理提出了更好的解决方案,可以在开发人员和运维人员发现集群当中存在故障节点后,快速的摘除故障节点,并且快速的替换新的节点来恢复集群状态,从而降低故障发生后影响的时间,节约开发人员和运维人员的故障处理时间。
附图说明
为了更清楚地说明本申请实施例,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本申请实施例的分布式消息系统的架构图;
图2是根据本申请实施例的分布式消息系统的资源申请流程图;
图3是根据本申请实施例的分布式消息系统的集群迁移流程图;
图4是根据本申请实施例的分布式消息系统的客户端迁移切换流程图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本申请保护的范围。
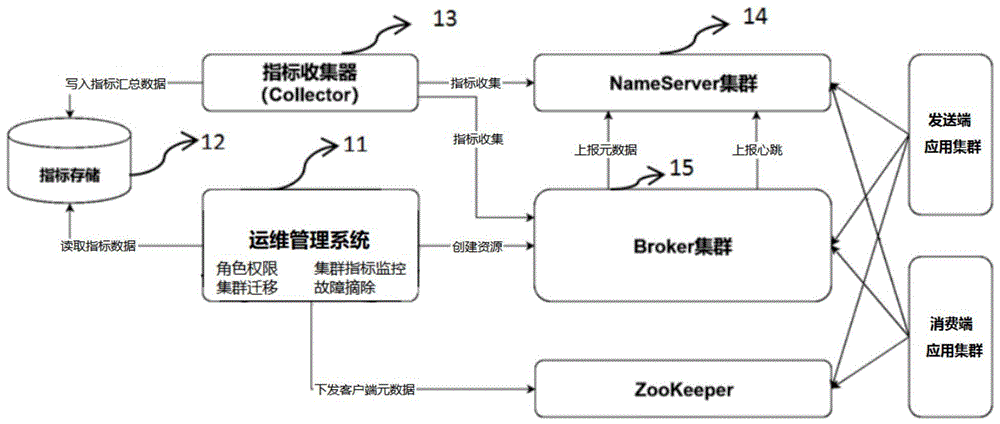
根据本申请的实施例,提供了一种基于分布式消息系统的集群运维管理方法和装置。图1示出了根据本申请实施例的基于分布式消息系统的集群运维管理方法和装置架构图。参考图1所示,本发明的基于分布式消息系统的集群运维管理方法包括:运维管理系统按照角色权限管理分布式消息系统的资源权限;运维管理系统监控分布式消息系统指标,指标由指标收集器收集、存储且运维管理系统提供指标查询可视化显示;以及运维管理系统实现故障摘除。
本发明的上述技术方案,通过支持基于分布式消息系统的集群运维管理方法和装置,能够提供可视化的运维监控和安全性的运维平台从而更有效解决生产中集群可能发生的故障。
本发明主要基于apacherocketmq实现分布式消息系统,所有的api调用以apacherocketmq的实际api说明,但是本发明设计及实现的运维管理系统接口层都按照不同的分布式消息系统类型做了接口层的兼容和扩展。
集群运维管理系统是整个分布式消息系统重要的部分之一,给开发人员和运维人员提供一个可视化、自助化的运维管理平台。如图1中11处所示,主要功能包括:角色权限、资源(topic、group等)自助化申请/下发、流程化审批、集群指标监控、集群迁移、故障摘除、流量摘除、消息查询、消息回溯、消息轨迹。
运维管理系统控制着整个分布式消息系统的资源创建、系统监控、信息查询等各种丰富的功能。
图2示出了角色权限和运维管理系统处理资源使用的流程,流程需严格按照角色的权限进行流转:
运维平台划分三个基本角色:系统管理员21、应用管理员22和应用成员23。
应用成员23负责自助创建应用使用的资源24,并发起提交审核25。待审核完成后下发客户端资源元数据27,使应用能够真正使用资源。
应用管理员22负责管理应用成员的权限分配,以及审核应用成员提交的资源申请26。
系统管理员21负责应用管理员的权限分配,以及应用管理员审核后资源申请的集群分配27。
运维管理系统对不同角色的查询权限也有严格的限制:
应用成员23和应用管理员22只能查看授权应用下的基础数据和监控数据;
系统管理员21可以查看所有数据。
由于不同的分布式消息系统有着较大的细节参数的区别,因此,运维管理系统按照不同的服务角色,归纳总结了几种通用的分布式消息系统的监控指标。如表一所示:
表一监控指标统计表
所有指标都由图1中的指标收集器(collector)13统一收集、汇总、统计、并存放到对应指标存储12中,再由运维管理系统按需查询展示。
集群迁移是通过制定预先设置的备份策略来完成批量的客户端统一迁移功能,迁移必须保证消息的不丢失。
迁移具体流程设计详见图3。迁移过程由运维系统通过配置下发触发客户端的重连机制,重连时客户端会按照迁移流程中下发的配置进行动态的连接切换。迁移的核心主要有三点,第一,需要保证消费端做双监听31。第二,当完成消费端双监听之后,才能切换发送端32。第三,当发送端全部切换成功后,消费端才能断开原集群的连接33。通过以上三点能够保证在迁移过程中消息不会丢失。
客户端切换流程可参见图4,首先目标集群同步元数据41,接下来消费者订阅目标集群42,切换集群后生产端消息发送到目标集群源集群的连接断开43,之后集群其他服务器执行同样切换44。
如图3所示,完整的迁移流程中除了正向的迁移外,还支持反向回滚,如图3中34、35和36处所示。反向回滚的流程和正向迁移一致,同样保证回滚过程消息不丢失。
如图1中所示的broker故障摘除,集群运维系统通过元数据整理的方式来实现集群中故障broker的摘除。nameserver14负责管理所有broker15的元数据,包括所有的broker状态,topic、group等信息。当开发人员或运维人员在运维管理系统中操作摘除指定broker15时,系统将调用nameserver14的摘除api(原生版本无此功能,二次开发功能),api会将指定broker加入到黑名单中,nameserver14将不再接收黑名单中broker15的心跳包,运维管理控台同样不在将新创建资源分配到黑名单的broker中,这样保证了故障broker不会继续污染整个集群,彻底地被动态摘除。
本发明设计方法和装置可以应用到各类分布式消息中间件,不局限于主流的开源分布式消息系统。目前设计中集群摘除和替换均采用手工操作方式,通过额外的监控策略和异常检测算法可以实现自动化的摘除和替换,即可减少人工参与的运维工作,又可降低了故障的影响时间。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!