一种结合yolo3与flownet2网络的监控视频压缩及解压方法与流程
本发明涉及深度学习领域,具体地说是一种结合yolo3与flownet2网络的监控视频压缩及解压方法。
背景技术:
视频压缩一直是学术界和工业界的研究热点之一。随着信息技术的飞速发展,多媒体信息逐渐成为人类获取外界信息最主要的载体。视频压缩是通过视频编码改变视频内容格式的过程,目标是减少视频所占用的储存空间。当今的视频存储中,有很大一部分来自监控视频。特别随着数字化生活的进一步推进,日常生活中会产生大量高清监控视频。
与普通视频相比,监控视频往往有如下几种特点:一、视频内容稳定:对于监控视频的性质而言,监控视频内容场景通常比较稳定,少有剧烈变化,视频帧数通常较低。特别在夜间,监控视频内容往往不发生改变;二、视频背景固定:由于监控摄像头往往是固定的,监控视频背景在较长一段时间中基本不会发生改变;三、视频目标明确:监控视视频目通常具有较高的针对性,大多聚焦于对行人以及车辆的监控,视频目标明确。因此,监控视频比普通视频具有更高的压缩潜力。
传统的视频压缩方法(h.263,h264等)基于帧内预测、帧间预测、量化和编码等技术对视频进行压缩,对普通视频压缩已经取得了优秀的成果,并且广泛应用到实际中。但是传统的视频压缩方法需要储存每一帧的数据,这种方法并不能很好的压缩监控视频,监控视频中仍存在大量时间与内容冗余信息。
近年来,随着深度学习技术的发展,尤其是卷积神经网络在图像处理和计算机领域的成功,让利用深度学习技术对视频进行高效压缩成为可能。鉴于此,研发一种基于深度学习技术对视频进行压缩的方法具有十分重要的现实意义。
技术实现要素:
本发明的技术任务是针对现有技术的不足,提供一种结合yolo3与flownet2网络的监控视频压缩及解压方法,本方法通过yolo3网络对输入的监控视频帧数据进行目标检测,对检测到目标帧数据通过flownet2提取光流数据并进行压缩并储存,删除了监控视频中大量时间与空间上的冗余信息。本方法在监控视频上比传统的视频压缩方法如h.263,h.264等具有更高的压缩比,节省了存储空间,提升了储存效益。
本发明解决其技术问题所采用的技术方案是:
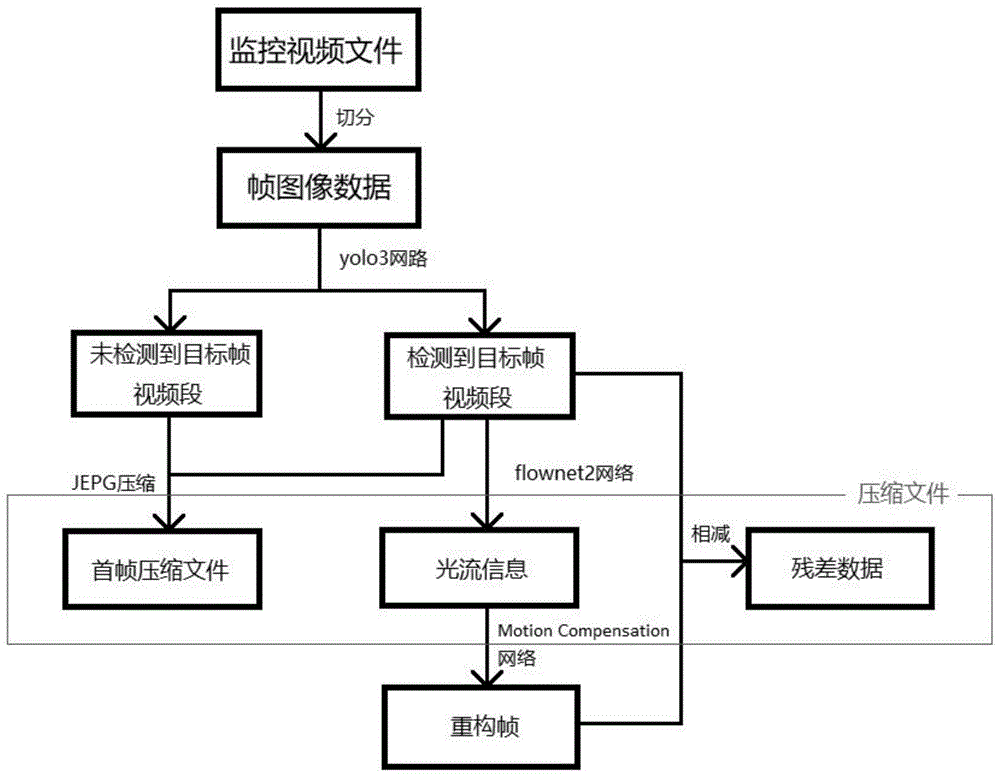
1、本发明提供一种结合yolo3与flownet2网络的监控视频压缩及解压方法,该方法的实现步骤如下:
s1、准备监控视频文件;
s2、切分视频文件,将视频文件切分成一帧一帧的图像文件,提取视频文件中的所有帧图像数据;
s3、利用yolo3网络对帧图像数据进行目标检测,检测目标根据实际需求设置;
s4、对检测到目标与未检测到目标的视频段首帧图像数据进行压缩;
s5、利用flownet2网络提取检测到目标的视频段相邻帧之间光流信息;
s6、利用网络重构一帧并与原帧相减获得残差数据;
s7、对光流信息以及残差数据进行取整量化以及算术编码熵编码。
方案优选地,步骤s2中,通过ffmpeg工具提取视频文件中的所有帧图像数据。
方案优选地,步骤s4中,利用jpeg或jpeg2000对检测到目标与未检测到目标的视频段首帧图像数据进行压缩。
方案优选地,步骤s4中,对连续的未检测到目标的帧图像数据,对首帧使用传统图像压缩方式进行压缩并保持,其余帧图像不保存;
对连续的检测到目标的帧图像数据,对首帧使用传统图像压缩方式进行压缩并保持;
方案优选地,步骤s5中,对连续的检测到目标的帧图像数据,对其余帧图像利用flownet2网络提取检测到目标的视频段相邻帧之间光流信息。
方案优选地,步骤s6中,将光流信息与其前一帧图像数据利用motioncompensation网络重构该帧。
2、本发明另提供一种监控视频解压缩的方法,该方法的实现步骤如下:
a、对首帧图像数据进行解压;
b、对未检测到目标的视频段复制首帧数据;
c、对检测到目标的视频段利用光流信息以及残差数据通过motioncompensation网络重构该段帧数据;
d、将所有重构帧图像合成完整视频。
方案优选地,步骤a中,利用jpeg或jpeg2000对首帧图像数据进行解压。
方案优选地,步骤c中,对检测到目标的视频段利用光流信息以及残差数据通过motioncompensation网络重构该段帧数据。
方案优选地,步骤d中,将所有重构帧图像通过ffmpeg工具合成完整视频。
本发明的一种结合yolo3与flownet2网络的监控视频压缩及解压方法与现有技术相比所产生的有益效果是:
本发明通过yolo3网络对输入的监控视频帧数据进行目标检测,对检测到目标帧数据通过flownet2提取光流数据并进行压缩并储存,删除了监控视频中大量时间与空间上的冗余信息。本方法在监控视频上比传统的视频压缩方法如h.263,h.264等具有更高的压缩比。
附图说明
为了更清楚地描述本发明自动喷雾结合捕尘网的工作原理,下面将附上简图作进一步说明。
附图1是本发明一种结合yolo3与flownet2网络的监控视频压缩方法的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
请参阅图1,本发明的一种结合yolo3与flownet2网络的监控视频压缩方法,该方法通过yolo3网络对输入的监控视频帧数据进行目标检测,对检测到目标帧数据通过flownet2提取光流数据并进行压缩并储存,
该方法的实现步骤如下:
s1、准备监控视频文件;
s2、切分视频文件,将视频文件切分成一帧一帧的图像文件,提取视频文件中的所有帧图像数据;
s3、利用yolo3网络对帧图像数据进行目标检测,检测目标根据实际需求设置;
s4、对检测到目标与未检测到目标的视频段首帧图像数据进行压缩;
s5、利用flownet2网络提取检测到目标的视频段相邻帧之间光流信息;
s6、利用网络重构一帧并与原帧相减获得残差数据;
s7、对光流信息以及残差数据进行取整量化以及算术编码熵编码。
上述步骤s2中,通过ffmpeg工具提取视频文件中的所有帧图像数据。
上述步骤s4中,利用传统图像压缩方式(jpeg或jpeg2000)对检测到目标与未检测到目标的视频段首帧图像数据进行压缩。
上述步骤s4中,对连续的未检测到目标的帧图像数据,对首帧使用传统图像压缩方式(jpeg或jpeg2000)进行压缩并保持,其余帧图像不保存;
对连续的检测到目标的帧图像数据,对首帧使用传统图像压缩方式进行压缩并保持;
上述步骤s5中,对连续的检测到目标的帧图像数据,对其余帧图像利用flownet2网络提取检测到目标的视频段相邻帧之间光流信息。
上述步骤s6中,将光流信息与其前一帧图像数据利用motioncompensation网络重构该帧。
具体实施步骤如下:
一:提取输入监控视频中每一帧图像数据,表示为
i1,i2,i3...。
二:使用yolo3网络对帧图像数据进行目标检测,检测目标根据实际需求设置,如设置为行人与车辆。
三:对连续的未检测到目标的帧图像数据,如i1~i10,对首帧(i1)使用传统图像压缩方式(如jpeg或jpeg2000)进行压缩并保存。其余帧图像不保存。
四:对连续的检测到目标(行人和车辆)帧图像数据,如i11~i18,对首帧(i11)使用传统图像压缩方式(如jpeg或jpeg2000)进行压缩并保存。
五:对其余帧(i12~i18),通过flownet2网络(用符号
六:将光流信息f12~f18与其前一帧图像数据i11~i17通过motioncompensation网络(用符号
即
七:将重构帧i′12与原帧i12相减获得残差数据r
即r12=i12-i′12
八:对光流信息f以及残差数据r进行量化与熵编码并保存。
实施例二
本发明提供一种监控视频解压缩的方法,该方法的实现步骤如下:
a、对首帧图像数据进行解压;
b、对未检测到目标的视频段复制首帧数据;
c、对检测到目标的视频段利用光流信息以及残差数据通过motioncompensation网络重构该段帧数据;
d、将所有重构帧图像合成完整视频。
上述步骤a中,利用传统图像解压方式(jpeg或jpeg2000)对首帧图像数据进行解压。
上述步骤c中,对检测到目标的视频段利用光流信息以及残差数据通过motioncompensation网络重构该段帧数据。
上述步骤d中,将所有重构帧图像通过ffmpeg工具合成完整视频。
具体实施步骤如下:
一:将保存的首帧数据通过传统图像压缩方式(如jpeg或jpeg2000)进行解压重构图片。
二:对未检测到目标的连续帧段复制首帧数据。
三:对检测到目标的帧段通过光流信息f以及残差数据r重构该段帧数据。
即
尽管已描述了本申请的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。
显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
除说明书所述的技术特征外,均为本专业技术人员的已知技术。
- 还没有人留言评论。精彩留言会获得点赞!