声音处理装置、声音处理方法和声音处理程序与流程
1.本公开涉及声音处理装置、声音处理方法和声音处理程序。
背景技术:
2.存在声场声音收集生成装置,其利用通过使用波前合成方法从由多个麦克风收集的声场信号生成的驱动信号来驱动扬声器,以便虚拟地再现声音收集位置处的声场(例如,参见专利文献1)。
3.引文列表
4.专利文献
5.专利文献1:日本专利申请公开号2015
‑
171111
技术实现要素:
6.本发明要解决的问题
7.然而,在某些情况下,只有声场的再现不能给正在收听声音的收听者足够的真实感。因此,本公开提出了一种能够增强给正在收听声音的收听者的真实感的声音处理装置、声音处理方法和声音处理程序。
8.问题的解决方案
9.根据本公开的声音处理装置包括获取单元、存储单元和处理单元。获取单元被配置为获取关于收听声音内容的用户观看的位置的位置信息。存储单元被配置为存储关于该位置处的声音的声音信息。处理单元被配置为基于声音信息将声音内容的声音特性转换成根据位置的声音特性,并且被配置为再生声场。
附图说明
10.[图1]是示出根据本公开的声音处理装置的声音过程的概述的说明图;
[0011]
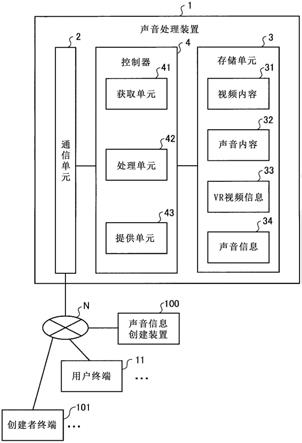
[图2]是示出根据本公开的声音处理装置的配置示例的框图;
[0012]
[图3]是根据本公开的用于创建vr整体球形视频的方法的说明图;
[0013]
[图4]是示出根据本公开的声音信息的示例的说明图;
[0014]
[图5]是根据本公开的hrtf测量方法的说明图;
[0015]
[图6]是根据本公开的hrtf测量方法的说明图;
[0016]
[图7]是根据本公开的声音处理装置的操作示例的说明图;
[0017]
[图8]是根据本公开的声音处理装置的操作示例的说明图;
[0018]
[图9]是根据本公开的声音处理装置的操作示例的说明图;
[0019]
[图10]是根据本公开的声音处理装置的操作示例的说明图;
[0020]
[图11]是示出由根据本公开的声音处理装置的控制器执行的处理的示例的流程图;
[0021]
[图12]是示出由根据本公开的声音处理装置的控制器执行的处理的示例的流程
图;
[0022]
[图13]是示出由根据本公开的声音处理装置的控制器执行的处理的示例的流程图。
具体实施方式
[0023]
在下文中,将参考附图详细描述本公开的实施例。应注意,在以下每个实施例中,相同的部分由相同的附图标记表示,因此将省略重复的描述。
[0024]
(1.声音过程的概述)
[0025]
图1是示出根据本公开的声音处理装置1的声音处理的概述的说明图。声音处理装置1是将诸如电影、现场音乐表演、音乐作品的宣传视频、电视节目、音乐作品等声音内容的声音特性转换成声音记录位置的声音特性的装置,以便在再现声音记录位置的声场的同时再生声场。
[0026]
在此处,在某些情况下,声音处理装置1不能仅通过再现声音记录位置的声场来给声音内容的收听者足够的真实感。具体地,在测量声音内容的声音特性的测量位置和声音内容的再生位置相同的情况下,声音处理装置1能够给予收听者好像收听者正停留在该位置的感觉。然而,在其他情况下,真实感减半。
[0027]
例如,即使在声音处理装置1向在家观看和收听电影的用户提供电影的声音内容的情况下,其中,电影院的混响特性、回声特性等被再现并转换成声音特性,也难以给用户留下呆在电影院的感觉,因为用户的停留位置是用户的家。
[0028]
因此,声音处理装置1利用例如诸如虚拟现实(以下称为vr:虚拟现实)的技术来再现测量了声音内容的声音信息的测量位置,然后再生已经再现测量位置的声音特性的声音内容的声场。
[0029]
例如,如图1所示,声音处理装置1预先存储电影的视频内容d1、电影的声音内容d2和电影院的声音信息d3,此外,还存储电影院内的vr整体球形视频d4(步骤s01)。电影院的声音信息d3包括与电影院中的声音特性相关的各种参数。
[0030]
然后,例如,当声音处理装置1从用户u携带的诸如智能手机的用户终端11获取电影内容的提供请求时,声音处理装置1向用户u的用户终端11发送并提供电影的视频内容d1和电影的声音内容d2。
[0031]
在这种情况下,声音处理装置1基于电影院的声音信息d3将电影的声音内容d2的声音特性转换成电影院的声音特性,并且向用户终端11提供电影院内的声音特性以及vr整体球形视频d4(步骤s02)。
[0032]
电影院内的vr整体球形视频d4包括安装在电影院中的屏幕的图像和周围环境的图像,包括电影院的观众座位、墙壁、天花板等。声音处理装置1将指示电影院内的vr整体球形视频d4中的屏幕位置被设置为电影的视频内容d1的显示位置的信息添加到电影的视频内容d1,并且向用户终端11提供电影的视频内容d1。
[0033]
因此,声音处理装置1能够在例如用户u佩戴的头戴式显示器12上显示电影院内的vr整体球形视频d4,并且在vr整体球形视频d4的屏幕上显示电影的视频内容d1(步骤s03)。
[0034]
同时,声音处理装置1能够再生视频内容d1的声音内容d2的声场,其中,声音特性已经通过例如用户u佩戴的耳机13被转换成电影院中的声音特性(步骤s04)。
[0035]
以这种方式,声音处理装置1能够允许用户u收听声音内容d2,同时允许用户u不仅视觉识别投影在屏幕上的电影的视频内容d1,而且视觉识别屏幕的周围环境,例如,电影院的观众座位、墙壁、天花板等。
[0036]
因此,声音处理装置1能够给在家观看和收听电影视频内容的用户u以逼真的感觉,例如,就好像用户u正在电影院观看电影一样。在此处,在头戴式显示器12上显示电影院内的vr整体球形视频d4。然而,声音处理装置1可以显示再现电影院内部的三维计算机图形(3dcg)视频,而不是电影院内部的vr整体球形视频d4。应注意,已经参考图1描述的声音处理装置1的操作是一个示例。稍后将参照图7至图10描述声音处理装置1的其他操作示例。
[0037]
(2.声音处理装置的配置)
[0038]
接下来,将参照图2描述声音处理装置1的配置的示例。图2是示出根据本公开的声音处理装置1的配置示例的框图。如图2所示,声音处理装置1包括通信单元2、存储单元3和控制器4。
[0039]
通信单元2由例如网络接口卡(nic)等实现。连接通信单元2,以使得能够通过诸如互联网的通信网络n以有线或无线方式与用户终端11、声音信息创建装置100和创建者终端101进行信息通信。
[0040]
声音信息创建装置100是创建声音信息34的装置,这将在后面描述。此外,创建者终端101是由创建者使用的终端设备,该创建者创建将由声音处理装置1提供给用户u的声音内容32。
[0041]
存储单元3例如由诸如随机存取存储器(ram)或闪存(flash memory)等半导体存储元件或诸如硬盘、光盘等存储装置来实现。这样的存储单元3存储视频内容31、声音内容32、vr视频信息33、声音信息34等。
[0042]
视频内容31表示多个视频数据,例如,电影、现场音乐表演、音乐作品的宣传视频、电视节目等,并且表示由声音处理装置1提供给用户终端11的内容数据。
[0043]
声音内容32表示多条音频数据,例如,电影、现场音乐表演、音乐作品的宣传视频、电视节目、音乐作品等,并且表示将由声音处理装置1提供给用户终端11的内容数据。
[0044]
vr视频信息33包括在不同位置捕捉的多个vr整体球形视频。在此处,将参照图3描述用于创建vr整体球形视频的方法的示例。图3是根据本公开的用于创建vr整体球形视频的方法的说明图。
[0045]
如图3所示,在创建vr整体球形视频的情况下,360度摄像头102安装在再生声音内容32的每个位置,并且360度摄像头102捕捉包括该位置的前、后、上、下、左和右的全向图像,以便捕捉vr整体球形视频vr。
[0046]
因此,例如,360度摄像头102安装在电影院中,以捕捉图像,从而能够创建vr整体球形视频vr,包括图1所示的电影院的屏幕和诸如电影院的观众座位、墙壁、天花板等屏幕的周围环境的图像。
[0047]
应注意,在图1所示的示例中,已经给出了安装了单个屏幕的电影院,作为示例。然而,在本公开中,可以创建电影院的vr整体球形视频vr,包括安装在前表面、左表面和右表面以及底面上的四个屏幕。
[0048]
在这种情况下,声音处理装置1在四个屏幕的正面的单个屏幕上显示视频内容31,并且在其他三个屏幕上显示电影院的周围环境。同样在这种配置中,声音处理装置1能够增
强给予用户的真实感。
[0049]
返回图2,将描述声音信息34。声音信息34包括关于每个位置处的声音的多条信息,其中,再生声音内容32的声场。在此处,将参照图4描述声音信息34的示例。图4是示出根据本公开的声音信息34的示例的说明图。
[0050]
如图4所示,声音信息34被提供给由声音处理装置1为其提供视频内容31或声音内容32的每个用户。声音信息34表示用户id、用户头部相关传递函数(以下称为hrtf:头部相关传递函数)、位置、vr视频和声音参数相互关联的信息。
[0051]
用户id是用于识别每个用户的识别信息。hrtf是每个用户独有的功能信息,它以数学方式表示声音是如何从声源传到用户耳朵的。在此处,将参照图5和图6描述hrtf测量方法。
[0052]
图5和图6是根据本公开的hrtf测量方法的说明图。例如,在已经参照图1描述的测量电影院的声音信息d3中包括的hrtf的情况下,要求用户u在电影院mt的观众座位上佩戴耳麦14,并且从电影院的扬声器sp输出测试信号ts的声音,如图5所示。
[0053]
然后,声音信息创建装置100获取已经由附接到用户u的左耳的耳用麦克风14收集的音频信号sl和已经由附接到用户u的右耳的耳用麦克风14收集的音频信号sr。
[0054]
然后,声音信息创建装置100基于已经获取的两个音频信号sl和sr之间的时间偏差、信号水平(强度)偏差、共振差异等来导出用户u的hrtf。以这种方式,声音信息创建装置100实际上测量用户u听到的测试信号ts,以便能够导出用户u的精确hrtf。
[0055]
应注意,hrtf根据用户u收听测试信号ts的位置(环境)而不同。为此,例如,在存在多个用户希望在收听声音内容32的同时观看视频的位置的情况下,用户有必要来到每个位置,以测量和导出hrtf。这种行为将成为用户的负担。
[0056]
因此,声音信息创建装置100还能够在多个位置处导出用户u的hrtf,同时减轻用户u的负担。例如,如图6所示,在由附接到用户u的耳朵的耳用麦克风14收集的音频信号中,声波特性在开始的预定周期部分中具有取决于用户u的周期,并且在该周期之后,声波特性具有取决于位置的周期。
[0057]
因此,例如,要求用户u来到一个位置,并且由耳用麦克风14收集测试信号ts的声音,使得声音信息创建装置100获取取决于用户u的一部分周期的音频信号波形。随后,都配备有耳用麦克风14的仿真玩偶dm安装在用户u期望的多个位置,使得声音信息创建装置100获取一部分周期的音频信号波形,同时声波特性取决于位置。
[0058]
然后,声音信息创建装置100合成取决于用户u的那部分周期的音频信号波形和取决于已经通过使用分别安装在多个位置处的仿真玩偶获得的位置的那部分周期的音频信号波形,并且基于合成信号导出用户u在每个位置处的hrtf。
[0059]
因此,声音信息创建装置100能够在用户u期望的多个位置导出用户u的hrtf,同时减轻用户u的负担,尽管精度略低于实际测量的情况。
[0060]
此外,声音信息创建装置100例如要求用户u拍摄用户耳朵的照片并发送图像数据,以便能够基于耳朵的图像数据来估计和导出用户u的hrtf。在这种情况下,当输入包括耳朵图像的图像数据时,声音信息创建装置100利用机器学习的学习模型来输出对应于耳朵的hrtf,以导出用户u的hrtf。
[0061]
因此,声音信息创建装置100能够估计和导出用户的hrtf,而不要求用户来测量
hrtf的位置。因此,能够进一步减轻用户u的hrtf测量负担。
[0062]
返回图3,将连续描述声音信息34。声音信息34中包括的位置是识别信息,用于识别已经预先登记的用户u在收听声音内容32的同时期望观看的位置。vr视频是用于识别对应于包括在声音信息34中的位置的vr整体球形视频的识别信息。
[0063]
声音参数分别与指示每个位置处的多个音频输出位置中的每一个的混响周期等的混响特性和音频波的反射系数等的回声特性的数值相关联。声音信息创建装置100测量每个位置处的实际声音,并基于已经收集的声音导出声音参数。因此,声音信息创建装置100能够导出对应于实际位置的精确声音参数。应注意,在图4中,每个项目的数据在概念上被表示为“a01”或“b01”。然而,在现实中,对应于每个项目的特定数据存储在每个项目的数据中。
[0064]
声音信息创建装置100将已经创建的声音信息34发送到声音处理装置1。声音处理装置1将从声音信息创建装置100接收的声音信息34存储在存储单元3中。应注意,此处已经给出了关于声音信息创建装置100创建声音信息34的情况的描述。然而,声音处理装置1可以包括与声音信息创建装置100类似的功能和配置,使得声音处理装置1可以创建要存储在存储单元3中的声音信息34。
[0065]
返回图2,将描述控制器4。控制器4包括例如微型计算机,该微型计算机包括中央处理单元(cpu)、只读存储器(rom)、随机存取存储器(ram)、输入和输出端口以及各种电路。
[0066]
控制器4包括获取单元41、处理单元42和提供单元43,其通过使用随机存取存储器作为工作区域,由cpu执行存储在rom中的各种程序(对应于根据实施例的声音处理程序的示例)来起作用。
[0067]
应注意,控制器4中包括的获取单元41、处理单元42和提供单元43可以部分或全部包括硬件,例如,专用集成电路(asic)或现场可编程门阵列(fpga)。
[0068]
获取单元41、处理单元42和提供单元43均实现或执行将在下面描述的信息处理的动作。应注意,控制器4的内部配置不限于图2所示的配置,并且可以具有另一种配置,只要该配置执行稍后将描述的信息处理。
[0069]
获取单元41例如从用户u获取视频内容31和声音内容32的提供请求。此外,在从用户u获取视频内容31和声音内容32的提供请求的情况下,获取单元41从用户终端11获取关于收听声音内容32的用户要观看的位置的信息。
[0070]
例如,在从用户终端11获取电影的视频内容d1和电影的声音内容d2的提供请求并且从用户终端11获取指示电影院的信息作为位置信息的情况下,获取单元41将已经从用户终端11获取的信息输出到处理单元42。
[0071]
在从获取单元41输入已经从用户终端11获取的信息的情况下,处理单元42基于声音信息34,将声音内容32的声音特性转换成根据与已经从用户终端11获取的位置信息相对应的位置的声音特性,并将已经经过转换的声音特性输出到提供单元43。
[0072]
在这种情况下,处理单元42对每个用户u应用用户u的hrtf,以转换声音内容32的声音特性。因此,处理单元42能够转换声音内容32的声音特性,以便为用户u做出最佳声音特性。处理单元42将已经从用户终端11获取的信息与已经经过声音特性转换的声音内容32一起输出到提供单元43。
[0073]
提供单元43向用户终端11发送从处理单元42输入的声音内容32、对应于位置信息
的位置的vr整体球形视频、以及用户已经对其做出提供请求的视频内容31。
[0074]
因此,例如,如图1所示,声音处理装置1能够允许用户u不仅视觉识别投影在屏幕上的电影的视频内容d1,而且视觉识别屏幕的周围环境,例如,电影院的观众座位、墙壁、天花板等。
[0075]
然后,与此同时,声音处理装置1能够允许用户收听电影的声音内容d2,其中,声音特性已经被转换成电影院的声音特性。因此,声音处理装置1能够给在家观看和收听电影视频内容的用户u以逼真的感觉,例如,就好像用户u正在电影院观看电影一样。
[0076]
应注意,迄今为止,已经描述了获取单元41从用户终端11获取视频内容31和声音内容32的提供请求的情况。然而,在一些情况下,获取单元41从用户终端11获取用户u的停留位置的图像以及对声音内容32的提供请求。
[0077]
在这种情况下,处理单元42根据用户u的停留位置转换声音内容32的声音特性,提供单元43将已经经过转换的声音内容32发送到用户终端11,并且用户终端11再生声音内容32的声场。稍后将参照图7和图8描述声音处理装置1的这种操作示例。
[0078]
此外,在一些情况下,获取单元41从已经创建了声音内容32的创建者获取对声音内容32的声音信息34和再生声音内容32的声场的位置的vr整体球形视频的提供请求。稍后将参照图10描述这种情况下的声音处理装置1的操作示例。
[0079]
(3.声音处理装置的操作示例)
[0080]
接下来,将参照图7至图10描述声音处理装置1的操作示例。图7至图10是根据本公开的声音处理装置1的操作示例的说明图。
[0081]
如图7所示,在一些情况下,声音处理装置1的获取单元41获取例如图像pic1和对声音内容32的提供请求,在图像pic1中,当用户u停留在车辆c内时,用户终端11已经捕捉用户u的停留位置(在此处,车辆c的内部)。
[0082]
在这种情况下,声音处理装置1从停留位置的图像pic1预测停留位置的声音特性,将声音内容32的声音特性转换成已经预测的声音特性,并且使得用户终端11再生声场。例如,声音处理装置1的处理单元42进行图像pic1的图像识别,并且确定用户u的停留位置是车辆c内部的空间。
[0083]
然后,处理单元42从图像pic1估计车辆中前后方向的长度l、横向的长度w和高度方向的长度h,以预测车辆内部空间的大小,并且基于车辆内部空间的大小,预测车辆内部空间的声音特性,例如,回声特性、混响特性等。
[0084]
随后,处理单元42将声音内容32的声音特性转换成已经预测的声音特性,并且例如将虚拟扬声器spc设置在车辆前侧的中心位置处,并且将虚拟扬声器spl和spr设置在分别从中心向左和向右偏离30
°
的位置处。
[0085]
然后,处理单元42转换声音内容32的声音特性,使得可以听到声音,就好像它们是从三个虚拟扬声器pcc、spl和spr输出的一样,并且将已经经过转换的声音特性输出到提供单元43。处理单元42使提供单元43向用户终端11发送声音内容32。
[0086]
因此,例如,当用户u用耳机收听声音内容32时,声音处理装置1能够给用户u以逼真的感觉,好像用户u正在用高质量的汽车音频收听声音内容32。
[0087]
此外,如图8所示,在一些情况下,获取单元41获取当用户u呆在家中的客厅中时用户u已经捕捉到停留位置的图像pic2以及对视频内容31和声音内容32的提供请求。
[0088]
此外,在这种情况下,在一些情况下,获取单元41获取指示例如用户u已经从图像pic2中选择了包括用户u的视野中心的预定区域a(在此处,电视tv周围的区域)的信息。
[0089]
在这种情况下,处理单元42将对应于声音内容32的音频输出位置的虚拟扬声器sp1、sp2、sp3、sp4、sp5和sp6设置成围绕预定区域a。然后,处理单元42转换声音内容32的声音特性,并将已经经过转换的声音特性输出到提供单元43,使得可以听到声音,就好像它们是从虚拟扬声器sp1、sp2、sp3、sp4、sp5和sp6输出的一样。
[0090]
提供单元43向用户终端11发送用户u已经对其做出提供请求的视频内容31和其声音特性已经由处理单元42进行转换的声音内容32,并且使得用户终端11显示视频内容31并再生声音内容32的声场。
[0091]
因此,在用户u用耳机收听声音内容32的情况下,声音处理装置1能够在电视tv上显示视频内容31的同时,给予用户u逼真的感觉,就好像用户u正在用高质量的音频装置收听声音内容32一样。
[0092]
另外,在这种情况下,例如,如图9所示,在某些情况下,用户u正在电视tv上观看和收听动画产品vd。在这种情况下,声音处理装置1还能够在头戴式显示器cb上显示出现在用户周围的产品vd中的角色的增强现实(ar:增强现实)图像ca、cc和cd。因此,声音处理装置1能够进一步增强给予用户u的真实感。
[0093]
应注意,在此处,从用户u已经捕捉的图像中预测用户的停留位置。然而,这是一个示例。获取单元41还能够获取例如用户u的位置信息,其位置由包括在用户终端11中的全球定位系统(gps)测量。
[0094]
在这种情况下,处理单元42根据已经由获取单元获取的用户的位置信息来预测用户的停留位置,将声音内容32的声音特性转换成已经预测的停留位置的声音特性,并且再生声场。因此,处理单元42能够将声音内容32的声音特性转换成根据已经由gps测量的精确停留位置的声音特性。
[0095]
此外,获取单元41还能够获取从用户u过去从用户终端11捕捉的图像中选择的图像或者用户u经由通信网络n观看的图像。
[0096]
在这种情况下,处理单元42预测已经由获取单元41获取的图像中出现的位置的声音特性,将声音内容的声音特性转换成已经预测的声音特性,并再生声场。因此,声音处理装置1给用户u一种真实的感觉,例如,好像用户u正在用户u过去访问过的存储器的位置或用户u过去观看过的图像中出现的喜爱的位置收听声音内容32。
[0097]
此外,处理单元42根据从用户u正在停留的图像预测的空间大小,改变要被设置为声音内容32的音频输出位置的虚拟扬声器的数量和虚拟扬声器的音频输出特性。例如,随着要预测的空间的大小变大,处理单元42增加要排列的虚拟扬声器的数量。
[0098]
此外,在要预测的空间的大小变得更大的情况下,处理单元42设置例如具有音频输出特性的虚拟扬声器,使得可以像环绕扬声器一样从360
°
方向听到声音内容32。因此,声音处理装置1能够使用户终端11根据用户u的停留位置的大小来再生最佳声场。
[0099]
此外,在一些情况下,获取单元41从已经创建声音内容32的创建者获取例如对声音内容32的声音信息34和再生声音内容32的声场的位置的vr整体球形视频的提供请求。
[0100]
在这种情况下,如图10所示,声音处理装置1的处理单元42使得提供单元43将已经为创建者终端101做出了提供请求的声音内容32、声音信息34和vr视频信息33发送到由创
建者终端101使用的创建者终端101。
[0101]
因此,创建者cr能够基于创建者自己的创作意图来改变例如声音信息34,同时观看包括在vr视频信息33中的电影院的vr整体球形视频vr。例如,在当前状态下,创建者cr能够将可以听到就好像虚拟扬声器sp设置在电影院的屏幕的两侧的声音信息34改变为可以听到就好像虚拟扬声器sp设置在远离屏幕的两侧的声音信息34。
[0102]
此外,创建者cr能够改变例如可以听到的声音信息34,就好像新的虚拟扬声器spu被设置在屏幕上方并且新的虚拟扬声器spd被设置在屏幕下方。在这种情况下,创建者cr收听已经应用了创建者自己的hrtf的声音内容32,并改变声音信息34。
[0103]
然后,创建者cr将已经改变的声音信息34a、声音内容32a和vr视频信息33从创建者终端101发送到声音处理装置1。声音处理装置1使存储单元3存储已经从创建者终端101接收的声音信息34a、声音内容32a和vr视频信息33。
[0104]
因此,当下次向用户u提供声音内容32a时,声音处理装置1能够利用反映了创建者cr的创作意图的声音特性来再生声音内容32a的声场。在这种情况下,声音处理装置1向用户u提供已经应用了用户u的hrtf的声音内容32a,并且能够再生对用户u具有最佳声音特性的声音内容32a的声场。
[0105]
(4.由声音处理装置执行的过程)
[0106]
接下来,将参照图11至图13描述由声音处理装置1的控制器4执行的处理的示例。图11至图13是示出由根据本公开的声音处理装置1的控制器4执行的处理的示例的流程图。
[0107]
当声音处理装置1的控制器4从用户终端11的用户u获取对包括声音和视频的内容的提供请求时,控制器4执行图11所示的处理。具体地,当控制器4从用户u获取内容的提供请求时,控制器4首先从用户u获取用户u期望的内容和位置信息(步骤s101)。
[0108]
随后,控制器4根据对应于位置信息的声音特性,将对应于用户期望的内容的声音内容的声音特性转换成声音特性(步骤s102)。然后,控制器4向用户u提供视频内容、声音特性已经转换的声音内容、以及当再生声音内容和视频内容时要由用户u视觉识别的vr整体球形视频,以便再生声场(步骤s103),并且结束该过程。
[0109]
此外,当从用户获取对声音内容的提供请求和用户已经捕捉的用户的停留位置的图像时,控制器4执行图12所示的处理。具体地,当控制器4从用户u获取内容和捕捉图像的提供请求时,控制器4首先预测出现在捕捉图像中的空间的声音特性(步骤s201)。
[0110]
随后,控制器4将对应于用户u期望的内容的声音内容的声音特性转换成在步骤s201中预测的空间的声音特性(步骤s202)。然后,控制器4向用户u提供声音特性已经经历转换的声音内容,再生声场(步骤s203),并结束处理。
[0111]
此外,在用户选择在捕捉的图像中的预定区域a的情况下,控制器4执行设置声音内容的音频输出位置,以便包围预定区域a的处理,并且向用户u提供声音内容。
[0112]
在这种情况下,控制器4根据用户选择的预定区域a的大小来改变要排列的声音内容的音频输出位置的数量和音频输出特性,并向用户u提供声音内容。
[0113]
应注意,同样当从用户u获取包括声音和视频的内容的提供请求以及用户的停留位置出现在其中的捕捉图像时,控制器4能够预测出现在捕捉图像中的空间的声音特性,并且向用户u提供声音特性已经转换成预测的声音特性的声音内容。
[0114]
此外,当从声音内容的创建者cr获取例如声音内容的声音信息和位置的提供请求
时,控制器4执行图13所示的处理,在该位置中再生声音内容的声场。
[0115]
具体地,当从创建者cr获取对声音信息和位置的提供请求时,控制器4首先向创建者cr提供声音信息和该位置的vr整体球形视频,其中,再生对应于声音信息的声音内容的声场(步骤s301)。
[0116]
随后,控制器4确定是否已经从创建者cr获取了改变的声音信息(步骤s302)。然后,当控制器4确定尚未从创建者cr获取声音信息时(步骤s302,否),控制器4重复步骤s302的确定过程,直到获取声音信息。
[0117]
然后,当确定已经从创建者cr获取了声音信息时(步骤s302,是),控制器4存储已经与已经为创建者cr提供的vr整体球形视频相关联地获取的声音特性(步骤s303),并且结束处理。
[0118]
应注意,本说明书中描述的效果仅仅是示例而非限制性的,并且可以获得其他效果。
[0119]
应注意,本技术也可以具有以下配置。
[0120]
(1)一种声音处理装置,包括:
[0121]
获取单元,被配置为获取关于收听声音内容的用户观看的位置的位置信息;
[0122]
存储单元,被配置为存储关于该位置处的声音的声音信息;以及
[0123]
处理单元,被配置为基于声音信息将声音内容的声音特性转换成根据位置的声音特性,并且被配置为再生声场。
[0124]
(2)根据上述(1)所述的声音处理装置,
[0125]
其中,存储单元
[0126]
存储该位置的虚拟现实整体球形视频,并且
[0127]
处理单元
[0128]
使得用户在视觉上识别虚拟现实整体球形视频,同时再生声音内容的声场。
[0129]
(3)根据上述(2)所述的声音处理装置,
[0130]
其中,存储单元
[0131]
存储包括屏幕和屏幕的周围环境的图像的虚拟现实整体球形视频,在屏幕上在该位置处显示对应于声音内容的视频内容,并且
[0132]
处理单元
[0133]
在虚拟现实整体球形视频中的屏幕上显示视频内容。
[0134]
(4)根据上述(2)所述的声音处理装置,
[0135]
其中,存储单元
[0136]
存储包括四个屏幕的虚拟现实整体球形视频,在四个屏幕上在该位置处显示对应于所述声音内容的视频内容,并且
[0137]
处理单元
[0138]
在虚拟现实整体球形视频的四个屏幕中的一个屏幕上显示视频内容,并在其他三个屏幕上显示该位置的周围环境的图像。
[0139]
(5)根据上述(1)所述的声音处理装置,
[0140]
其中,获取单元
[0141]
获取用户已经捕捉的停留位置的图像,并且
[0142]
处理单元
[0143]
从停留位置的图像预测停留位置的声音特性,将声音内容的声音特性转换成已经预测的声音特性,并再生声场。
[0144]
(6)根据上述(5)所述的声音处理装置,
[0145]
其中,处理单元
[0146]
基于要从停留位置的图像预测的停留位置的空间的大小,预测停留位置的空间的声音特性。
[0147]
(7)根据上述(6)所述的声音处理装置,
[0148]
其中,处理单元
[0149]
预测空间中的混响特性和回声特性。
[0150]
(8)根据上述(6)所述的声音处理装置,
[0151]
其中,处理单元
[0152]
根据要从停留位置的图像预测的停留位置的空间的大小,改变要排列的声音内容的音频输出位置的数量和音频输出特性。
[0153]
(9)根据上述(5)至(8)中任一项所述的声音处理装置,
[0154]
其中,在用户从停留位置的图像中选择包括用户的视野的中心的预定区域的情况下,处理单元
[0155]
排列声音内容的音频输出位置,以包围预定区域。
[0156]
(10)根据上述(1)所述的声音处理装置,
[0157]
其中,获取单元
[0158]
获取从用户过去捕捉的图像中选择的图像或者用户经由通信网络观看的图像,并且
[0159]
处理单元
[0160]
预测出现在图像中的位置的声音特性,将声音内容的声音特性转换成已经预测的声音特性,并再生声场。
[0161]
(11)根据上述(1)所述的声音处理装置,
[0162]
其中,获取单元
[0163]
获取由全球定位系统(gps)测量的用户的位置信息,并且
[0164]
处理单元
[0165]
从用户的位置信息预测用户的停留位置,将声音内容的声音特性转换成已经预测的停留位置的声音特性,并再生声场。
[0166]
(12)根据上述(2)所述的声音处理装置,还包括:
[0167]
提供单元,被配置为向声音内容的创建者提供声音内容以及再生声音内容的声场的位置的虚拟现实整体球形视频和声音信息,
[0168]
其中,获取单元
[0169]
获取已经由创建者改变的声音信息,并且
[0170]
存储单元
[0171]
将已经被提供给创建者的声音内容和再生声音内容的声场的位置的虚拟现实整体球形视频与已经被所述创建者改变的声音信息相关联地进行存储。
[0172]
(13)根据上述(1)至(12)中任一项所述的声音处理装置,其中,存储单元
[0173]
存储已经基于在该位置处测量的声音生成的声音信息。
[0174]
(14)根据上述(1)至(13)中任一项所述的声音处理装置,其中,存储单元
[0175]
存储用户的头部相关传递函数,并且
[0176]
处理单元
[0177]
为每个用户应用用户的头部相关传递函数,以转换声音内容的声音特性。
[0178]
(15)根据上述(14)所述的声音处理装置,
[0179]
其中,存储单元
[0180]
存储头部相关传递函数,头部相关传递函数是基于已经由用户佩戴的耳用麦克风录制的声音导出的。
[0181]
(16)根据上述(14)所述的声音处理装置,
[0182]
其中,存储单元
[0183]
存储基于由用户佩戴的耳用麦克风录制的、声波特性取决于用户的周期内的声音和由玩偶佩戴的耳用麦克风录制的、声波特性取决于该位置的周期内的声音导出的头部相关传递函数。
[0184]
(17)根据上述(14)所述的声音处理装置,
[0185]
其中,存储单元
[0186]
存储基于用户的耳朵的图像导出的头部相关传递函数。
[0187]
(18)一种由计算机执行的声音处理方法,该声音处理方法包括:
[0188]
获取步骤,用于获取关于收听声音内容的用户观看的位置的位置信息;存储步骤,用于存储关于该位置处的声音的声音信息;以及
[0189]
处理步骤,用于基于声音信息,将声音内容的声音特性转换成根据位置的声音特性,并再生声场。
[0190]
(19)一种声音处理程序,使计算机执行:
[0191]
获取过程,用于获取关于收听声音内容的用户观看的位置的位置信息;存储过程,用于存储关于该位置处的声音的声音信息;以及
[0192]
处理过程,用于基于声音信息,将声音内容的声音特性转换成根据位置的声音特性,并再生声场。
[0193]
附图标记列表
[0194]
1 声音处理装置
[0195]
2 通信单元
[0196]
3 存储单元
[0197]
31 视频内容
[0198]
32 声音内容
[0199]
33 vr视频信息
[0200]
34 声音信息
[0201]
4 控制器
[0202]
41 获取单元
[0203]
42 处理单元
[0204]
43 提供单元。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1