基于DDPG网络的混合辐射源信号分离方法
基于ddpg网络的混合辐射源信号分离方法
技术领域
1.本发明属于信号分离技术领域,更为具体地讲,涉及一种基于ddpg网络的混合辐射源信号分离方法。
背景技术:
2.准确高效地从混合信号中取得需要的信号是通信领域中一个重要的研究课题,决定着通信系统的接收能力。其中,盲信号分离指在源信号和信道未知或部分已知的情况下将信号分离,是近年来现代信号处理领域的热点,在无线通信、语音识别、生物医学、机械工程等方面都有应用。对无线通信而言,盲信号分离在合作通信和非合作通信领域都有着重要的意义。在合作通信领域,mimo通信系统、卫星通信系统中的信号间干扰都可以通过盲分离进行干扰抑制和信号分离。在非合作通信领域,现代信息战中,需要在己方敌方混合信息中准确地分离出信号,有利于及早地侦察到敌情,并且对敌方设备进行正确判断,采取相应的行动。盲信号分析在通信领域也相应地面对了更大地困难,由于信号的相似性,复杂性,其他领域的分离方法不一定可以很好的适用。
技术实现要素:
3.本发明的目的在于克服现有技术的不足,提供一种基于ddpg网络的混合辐射源信号分离方法,通过引入ddpg网络,有效提高对混合信号分离的准确度。
4.为了实现上述发明目的,本发明基于ddpg网络的混合辐射源信号分离方法包括以下步骤:
5.s1:记实际应用环境中设置有辐射源的位置数量为k,在每个位置配置一个样本辐射源进行长度为l的调制信号发送,记第j个样本辐射源发送的调制信号为源信号f
j
,j=1,2,
…
,k;在应用环境中配置k个信号测试天线,首先令每个样本辐射源单独发送调制信号,每个信号测试天线分别对该样本辐射源所发送的信号进行采集得到一个数据样本,记第i根信号测试天线对第j个样本辐射源所采集得到的数据样本为d
i,j
,i=1,2,
…
,k;然后令k个辐射源同时进行调制信号发送,每个信号测试天线分别对接收到的混合信号进行采集得到一个混合信号样本,记第i根信号测试天线采集得到的混合信号样本为x
i
;
6.s2:对于ddpg网络,ddpg动作空间采用以下方法设计:
7.设置一个k阶的矩阵c,其每个元素均服从标准正态分布,将该k阶矩阵c按照行优先转化为k
×
k维的向量其中c
k
表示向量c
′
中第k个元素,k=1,2,
…
,k2,对应矩阵c中第行第k%k列元素,表示向下取整,%表示求余;然后定义一个边界值bound,将向量c
′
和边界值bound构成ddpg网络的动作空间
8.ddpg状态空间采用以下方法设计:
9.设置一个k阶的分离矩阵w,将该k阶矩阵w按照行优先转化为k
×
k维的分离向量
其中w
k
表示向量w
′
中第k个元素,对应矩阵w中第行第k%k列元素;
10.记第i根信号测试天线接收的长度为l的混合信号为x
i
,按照预设数据位置从混合信号x
i
中取样p个数据点,与源信号f
j
中对应的p个数据点求比值,将p个比值构成比值向量,将对应同一混合信号的k个比值向量拼接得到比值向量h
i,j
,将k个比值向量h
i,j
拼接得到维度为k
×
k
×
p的向量x_state;
11.记当前更新步骤的分离信号矩阵y=wx,x表示由混合信号x
i
作为行向量所构成的k
×
l的混合信号矩阵,将分离信号矩阵y的第j个行向量作为第j个辐射源的源信号分离结果y
j
,按照预设数据位置在每个源信号分离结果y
j
中取样p个数据点,与源信号f
j
中对应的p个数据点求比值,将p个比值构成比值向量g
j
,将k个比值向量g
j
拼接得到维度为k
×
p的向量y_state;
12.定义参数on
‑
goal表示当前步骤是否达到预设目标,如果是,则on
‑
goal=1,否则on
‑
goal=0;
13.将分离向量向量x_state、向量y_state和参数on
‑
goal构成ddpg网络的状态空间
14.ddpg奖励函数采用以下方法设计:
15.对于当前步骤得到的k个分离信号y
j
分别计算信干比sir
j
,计算公式如下:
[0016][0017]
其中,|| ||2表示求取2范数;
[0018]
判断当前步骤是否达到预设目标,即是否每个分离信号y
j
的信干比sir
j
均大于预设阈值,如果是则令奖励函数δ表示预设的常数,否则奖励函数
[0019]
s3:根据步骤s2设计的动作空间和状态空间构建ddpg网络,包括当前策略网络、当前价值网络、目标策略网络和目标价值网络,其中:
[0020]
当前策略网络的输入信息为状态s,输出信息为动作a;
[0021]
当前价值网络的输入信息为状态s和动作a,输出信息为价值q;
[0022]
目标策略网络:输入输出同当前策略网络,定期复制当前策略网络参数;
[0023]
目标价值网络:输入输出同当前价值网络,定期复制当前价值网络参数;
[0024]
s4:将步骤s1中得到的k个混合信号样本x
i
输入ddpg网络,对ddpg网络进行训练,具体包括以下步骤:
[0025]
s4.1:随机初始化ddpg网络中的四个网络的参数;
[0026]
s4.2:令迭代次数e=1;
[0027]
s4.3:随机初始化分离矩阵w,然后计算分离信号矩阵y=wx,将分离信号矩阵y的第j个行向量作为第j个辐射源的源信号分离结果y
j
,根据当前的源信号分离结果y
j
确定当
前状态s;
[0028]
s4.4:初始化本次迭代中步数t=1;
[0029]
s4.5:判断是否本次迭代中步数t<t,t表示预设的每次迭代中的最大步数,如果是,进入步骤s4.6,否则进入步骤s4.11;
[0030]
s4.6:当前策略网络根据当前状态s得到动作a,根据动作a调整分离矩阵w,重新计算各个辐射源的源信号分离结果y
′
j
,生成下一状态s
′
;当前价值网络根据当前状态s和动作a,得到当前的价值q;从当前状态s中提取出各个源信号分离结果y
j
,计算当前状态s对应的奖励值r;然后将当前状态s、动作a、奖励值r和下一状态s
′
作为一组经验放入经验池中;如果经验放入时经验池已满,即按照先入先出原则将最早的经验删除,然后将当前经验放入;
[0031]
s4.7:判断是否经验池已满,如果是,进入步骤s4.8,否则进入步骤s4.10;
[0032]
s4.8:将当前策略网络的参数软拷贝至目标策略网络,将当前价值网络的参数软拷贝至目标价值网络;
[0033]
s4.9:对于当前策略网络,将价值q作为损失函数采用梯度策略对当前策略网络的参数进行更新;
[0034]
对于当前价值网络,计算损失函数并根据该损失函数对当前价值网络的参数进行更新,损失函数的计算方法如下:
[0035]
从经验池中取出m组经验,将每组经验中的下一状态s
′
m
输入目标策略网络得到下一动作a
′
m
,m=1,2,
…
,m,然后将状态s
′
m
和动作a
′
m
输入目标价值网络得到价值q
m
,采用如下公式计算目标回报值z
m
:
[0036]
z
m
=γq
m
+r
m
[0037]
其中,γ表示折扣因子,r
m
表示第m组经验中的奖励值;
[0038]
采用如下公式计算当前价值网络的损失函数loss:
[0039][0040]
s4.10:令当前状态s=s
′
,t=t+1,返回步骤s4.5;
[0041]
s4.11:判断是否达到迭代结束条件,如果是,则训练完毕,如果不是,进入步骤s4.12;
[0042]
s4.12:令e=e+1,返回步骤s4.3;
[0043]
s5:在实际应用时,由每个信号测试天线得到k个辐射源的长度为l的混合信号将k个混合信号输入步骤s4训练好的ddpg网络进行再次训练;此时的ddpg动作空间采用以下方法设计:
[0044]
将k阶矩阵c按照行优先转化为k
×
k维的向量将向量c
′
和边界值bound构成ddpg网络的动作空间
[0045]
ddpg状态空间采用以下方法设计:
[0046]
将k阶分离矩阵w按照行优先转化为k
×
k维的分离向量
[0047]
对于第i根信号测试天线的混合信号按照预设数据位置从混合信号中取样p个数据点,将p个数据构成数据向量h
′
i,j
,将数据向量h
′
i,j
复制k次并拼接得到长度为k
×
p的数据向量将k个数据向量拼接得到维度为k
×
k
×
p的向量
[0048]
记当前更新步骤的分离信号矩阵记当前更新步骤的分离信号矩阵表示由混合信号作为行向量所构成的k
×
l的混合信号矩阵,将分离信号矩阵的第j个行向量作为第j个辐射源的源信号分离结果按照预设数据位置在每个源信号分离结果中取样p个数据点构成数据向量g
′
j
,将k个数据向量g
′
j
拼接得到维度为k
×
p的向量
[0049]
定义参数表示当前迭代次数是否小于预设阈值e,如果是,则否则
[0050]
将分离向量向量x_state、向量y_state和参数on
‑
goal构成ddpg网络的状态空间
[0051]
ddpg网络再次训练的具体步骤包括:
[0052]
s5.1:令迭代次数e=1;
[0053]
s5.2:随机初始化分离矩阵w,然后计算分离信号矩阵s5.2:随机初始化分离矩阵w,然后计算分离信号矩阵表示由混合信号作为行向量所构成的k
×
l的混合信号矩阵,将分离信号矩阵的第j个行向量作为第j个辐射源的源信号分离结果根据当前的源信号分离结果确定当前状态s;
[0054]
s5.3:初始化本次迭代中步数t=1;
[0055]
s5.4:判断是否本次迭代中步数t<t,t表示预设的每次迭代中的最大步数,如果是,进入步骤s5.5,否则进入步骤s5.7;
[0056]
s5.5:当前策略网络根据当前状态s得到动作a,根据动作a调整分离矩阵w,重新计算各个辐射源的源信号分离结果y
′
j
,生成下一状态s
′
;
[0057]
s5.6:令当前状态s=s
′
,t=t+1,返回步骤s5.4;
[0058]
s5.7:判断是否迭代次数e<e
′
,e
′
表示预设的再次训练的迭代次数,e
′
>e,如果是,则进入步骤s5.8,否则再次训练完毕,进入步骤s5.9;
[0059]
s5.8:令e=e+1,返回步骤s5.2;
[0060]
s5.9:根据最后一个状态确定分离矩阵然后计算分离信号矩阵将分离信号矩阵的第j个行向量作为第j个辐射源最终的源信号分离结果
[0061]
本发明基于ddpg网络的混合辐射源信号分离方法,首先采用k个信号测试天线对k个样本辐射源的辐射源信号样本进行采集,处理得到混合信号样本,将分离矩阵看作一个智能体,矩阵元素的加减看作动作,将信号的分离程度看作环境,对ddpg网络进行设计,然后采用混合信号样本对ddpg网络进行训练,在实际应用时,由每个信号测试天线得到k个辐射源的混合信号,将混合信号输入训练好的ddpg网络进行再次训练,得到信号分离结果。
[0062]
本发明具有以下有益效果:
[0063]
1)本发明可以未知混合信道的情况下,通过样本辐射源的先验知识实现信号分离;
[0064]
2)本发明采用ddpg网络,将分离的动作和信号环境进行交互,更符合实际中的分离场景,提高信号分离效果。
附图说明
[0065]
图1是本发明基于ddpg网络的混合辐射源信号分离方法的具体实施方式结构图;
[0066]
图2是本发明中ddpg网络训练的流程图;
[0067]
图3是本实施例中更新网络参数的示意图;
[0068]
图4是本发明中ddpg网络再次训练的流程图;
[0069]
图5是本实施例中分离得到的手机信号与源信号的波形对比图;
[0070]
图6是本实施例中分离得到的usrp设备信号与源信号的波形对比图。
具体实施方式
[0071]
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
[0072]
实施例
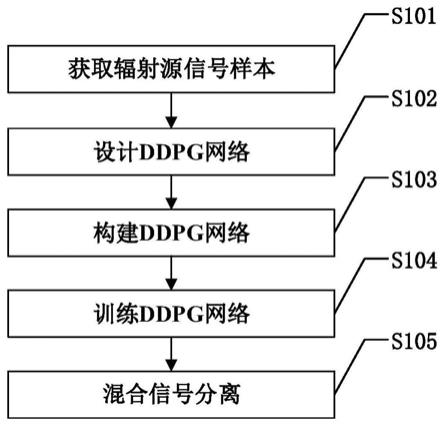
[0073]
图1是本发明基于ddpg网络的混合辐射源信号分离方法的具体实施方式结构图。如图1所示,本发明基于ddpg网络的混合辐射源信号分离方法的具体步骤包括:
[0074]
s101:获取辐射源信号样本:
[0075]
记实际应用环境中设置有辐射源的位置数量为k,在每个位置配置一个样本辐射源进行长度为l的调制信号发送,记第j个样本辐射源发送的调制信号为源信号f
j
,j=1,2,
…
,k。在应用环境中配置k个信号测试天线,首先令每个样本辐射源单独发送调制信号,每个信号测试天线分别对该样本辐射源所发送的信号进行采集得到一个数据样本,记第i根信号测试天线对第j个样本辐射源所采集得到的数据样本为d
i,j
,i=1,2,
…
,k。然后令k个辐射源同时进行调制信号发送,每个信号测试天线分别对接收到的混合信号进行采集得到一个混合信号样本,记第i根信号测试天线采集得到的混合信号样本为x
i
。
[0076]
本实施例中,为了使采集得到的信号样本更能准确地表征信道特征,使后续得到的分离矩阵更为准确,每个样本辐射源所发送的调制信号需要满足以下条件:该调制信号由各个信号测试天线所采集得到的信号样本,在转化为iq两路数据后,iq两路数据中每个数据点的模值均大于预设阈值。
[0077]
此外,为了使训练得到的ddpg网络能够适应辐射源的小幅度位置变动,可以在步骤s101获取辐射源信号样本时,若干次小幅度移动辐射源,得到不同的发送场景,对于每个发送场景,获取第i根信号测试天线对第j个样本辐射源的若干数据样本,以及该发送场景下的混合信号样本,每个发送场景下的k
×
k个数据样本d
i,j
和k个混合信号样本x
i
即构成一组辐射源信号样本,将所有发送场景的辐射源信号样本构成辐射源信号样本集。
[0078]
s102:设计ddpg网络:
[0079]
在本发明中,将分离矩阵看作一个智能体,矩阵元素的加减看作动作,将信号的分
离程度看作环境,通过智能体与环境的交互,环境对智能体的反馈,实现理想的信号分离。基于该思想,对ddpg网络进行设计,具体方法为:
[0080]
1)设计ddpg动作空间
[0081]
设置一个k阶的矩阵c,其每个元素均服从标准正态分布,将该k阶矩阵c按照行优先转化为k
×
k维的向量其中c
k
表示向量c
′
中第k个元素,k=1,2,
…
,k2,对应矩阵c中第行第k%k列元素,表示向下取整,%表示求余。然后定义一个边界值bound,将向量c
′
和边界值bound构成ddpg网络的动作空间
[0082]
2)设计ddpg状态空间
[0083]
设置一个k阶的分离矩阵w,将该k阶矩阵w按照行优先转化为k
×
k维的分离向量其中w
k
表示向量w
′
中第k个元素,对应矩阵w中第行第k%k列元素。
[0084]
记第i根信号测试天线接收的长度为l的混合信号为x
i
,按照预设数据位置从混合信号x
i
中取样p个数据点,与源信号f
j
中对应的p个数据点求比值,将p个比值构成比值向量,将对应同一混合信号的k个比值向量拼接得到比值向量h
i,j
,将k个比值向量h
i,j
拼接得到维度为k
×
k
×
p的向量x_state。
[0085]
记当前更新步骤的分离信号矩阵y=wx,x表示由混合信号x
i
作为行向量所构成的k
×
l的混合信号矩阵,将分离信号矩阵y的第j个行向量作为第j个辐射源的源信号分离结果y
j
,按照预设数据位置在每个源信号分离结果y
j
中取样p个数据点,与源信号f
j
中对应的p个数据点求比值,将p个比值构成比值向量g
j
,将k个比值向量g
j
拼接得到维度为k
×
p的向量y_state。
[0086]
定义参数on
‑
goal表示当前步骤是否达到预设目标,如果是,则on
‑
goal=1,否则on
‑
goal=0。
[0087]
将分离向量向量x_state、向量y_state和参数on
‑
goal构成ddpg网络的状态空间
[0088]
3)设计ddpg奖励函数
[0089]
对于当前步骤得到的k个分离信号y
j
分别计算信干比sir
j
,计算公式如下:
[0090][0091]
其中,|| ||2表示求取2范数。
[0092]
判断当前步骤是否达到预设目标,即是否每个分离信号y
j
的信干比sir
j
均大于预设阈值,如果是则令奖励函数δ表示预设的常数,否则奖励函数
[0093]
本实施例中令信干比的阈值为30,δ的值为100。采用以上方式,可以令奖励函数既能表征当前步骤是否达到预设目标,又能衡量信号的分离程度。
[0094]
s103:构建ddpg网络:
[0095]
根据步骤s102设计的动作空间和状态空间构建ddpg网络,包括当前策略网络、当前价值网络、目标策略网络和目标价值网络,其中:
[0096]
当前策略网络的输入信息为状态s,输出信息为动作a;
[0097]
当前价值网络的输入信息为状态s和动作a,输出信息为价值q;
[0098]
目标策略网络:输入输出同当前策略网络,定期复制当前策略网络参数;
[0099]
目标价值网络:输入输出同当前价值网络,定期复制当前价值网络参数。
[0100]
s104:训练ddpg网络:
[0101]
将步骤s101中得到的k个混合信号样本x
i
输入ddpg网络,对ddpg网络进行训练。
[0102]
图2是本发明中ddpg网络训练的流程图。如图2所示,本发明中ddpg网络训练的具体步骤包括:
[0103]
s201:初始化网络:
[0104]
随机初始化ddpg网络中的四个网络的参数。
[0105]
s202:初始化迭代参数:
[0106]
令迭代次数e=1。
[0107]
s203:初始化分离矩阵:
[0108]
随机初始化分离矩阵w,然后计算分离信号矩阵y=wx,x表示由混合信号x
i
作为行向量所构成的k
×
l的混合信号矩阵,将分离信号矩阵y的第j个行向量作为第j个辐射源的源信号分离结果y
j
,根据当前的源信号分离结果y
j
确定当前状态s。
[0109]
当步骤s101中获取的是数据样本集时,在步骤s203中从辐射源信号样本集中任意选择一组辐射源信号样本计算分离信号矩阵以及进行后续操作。
[0110]
s204:初始化本次迭代中步数t=1。
[0111]
s205:判断是否本次迭代中步数t<t,t表示预设的每次迭代中的最大步数,本实施例中t=500,如果是,进入步骤s206,否则进入步骤s211。
[0112]
s206:生成新经验:
[0113]
当前策略网络根据当前状态s得到动作a,根据动作a调整分离矩阵w,重新计算各个辐射源的源信号分离结果y
′
j
,生成下一状态s
′
。当前价值网络根据当前状态s和动作a,得到当前的价值q。从当前状态s中提取出各个源信号分离结果y
j
,计算当前状态s对应的奖励值r。然后将当前状态s、动作a、奖励值r和下一状态s
′
作为一组经验放入经验池中。如果经验放入时经验池已满,即按照先入先出原则将最早的经验删除,然后将当前经验放入。
[0114]
s207:判断是否经验池已满,如果是,进入步骤s208,否则进入步骤s210。
[0115]
s208:复制网络参数:
[0116]
将当前策略网络的参数软拷贝至目标策略网络,将当前价值网络的参数软拷贝至目标价值网络。
[0117]
s209:更新网络参数:
[0118]
图3是本实施例中更新网络参数的示意图。如图3所示,对于当前策略网络,将价值q作为损失函数采用梯度策略对当前策略网络的参数进行更新。
[0119]
对于当前价值网络,计算损失函数并根据该损失函数对当前价值网络的参数进行更新,损失函数的计算方法如下:
[0120]
从经验池中取出m组经验,将每组经验中的下一状态s
′
m
输入目标策略网络得到下一动作a
′
m
,m=1,2,
…
,m,然后将状态s
′
m
和动作a
′
m
输入目标价值网络得到价值q
m
,采用如下公式计算目标回报值z
m
:
[0121]
z
m
=γq
m
+r
m
[0122]
其中,γ表示折扣因子,r
m
表示第m组经验中的奖励值。
[0123]
采用如下公式计算当前价值网络的损失函数loss:
[0124][0125]
s210:令当前状态s=s
′
,t=t+1,返回步骤s205。
[0126]
s211:判断是否达到迭代结束条件,如果是,则训练完毕,如果不是,进入步骤s212。ddpg网络训练的迭代结束条件一般有两种,一种是迭代次数达到预设的阈值,本实施例中设计为10000,一种是奖励值达到预设阈值,根据需要设置即可。
[0127]
s212:令e=e+1,返回步骤s203。
[0128]
s105:混合信号分离:
[0129]
在实际应用时,由每个信号测试天线得到k个辐射源的长度为l的混合信号将k个混合信号输入步骤s104训练好的ddpg网络进行再次训练。此时的ddpg动作空间采用以下方法设计:
[0130]
将k阶矩阵c按照行优先转化为k
×
k维的向量将向量c
′
和边界值bound构成ddpg网络的动作空间
[0131]
ddpg状态空间采用以下方法设计:
[0132]
将k阶分离矩阵w按照行优先转化为k
×
k维的分离向量
[0133]
对于第i根信号测试天线的混合信号为按照预设数据位置从混合信号中取样p个数据点,将p个数据构成数据向量h
′
i,j
,将数据向量h
′
i,j
复制k次并拼接得到长度为k
×
p的数据向量将k个数据向量拼接得到维度为k
×
k
×
p的向量
[0134]
记当前更新步骤的分离信号矩阵记当前更新步骤的分离信号矩阵表示由混合信号作为行向量所构成的k
×
l的混合信号矩阵,将分离信号矩阵的第j个行向量作为第j个辐射源的源信号分离结果按照预设数据位置在每个源信号分离结果中取样p个数据点构成数据向量g
′
j
,将k个数据向量g
′
j
拼接得到维度为k
×
p的向量
[0135]
定义参数表示当前迭代次数是否小于预设阈值e,如果是,则否则
[0136]
将分离向量向量x_state、向量y_state和参数on
‑
goal构成ddpg网络的状态空间
[0137]
再次训练时,无需对ddpg网络的参数进行更新。图4是本发明中ddpg网络再次训练的流程图。如图4所示,本发明中ddpg网络再次训练的具体步骤包括:
[0138]
s401:令迭代次数e=1。
[0139]
s402:初始化分离矩阵:
[0140]
随机初始化分离矩阵w,然后计算分离信号矩阵随机初始化分离矩阵w,然后计算分离信号矩阵表示由混合信号作为行向量所构成的k
×
l的混合信号矩阵,将分离信号矩阵的第j个行向量作为第j个辐射源的源信号分离结果根据当前的源信号分离结果确定当前状态s。
[0141]
s403:初始化本次迭代中步数t=1。
[0142]
s404:判断是否本次迭代中步数t<t,t表示预设的每次迭代中的最大步数,如果是,进入步骤s405,否则进入步骤s407;
[0143]
s405:生成下一状态:
[0144]
当前策略网络根据当前状态s得到动作a,根据动作a调整分离矩阵w,重新计算各个辐射源的源信号分离结果y
′
j
,生成下一状态s
′
。
[0145]
s406:令当前状态s=s
′
,t=t+1,返回步骤s404;
[0146]
s407:判断是否迭代次数e<e
′
,e
′
表示预设的再次训练的迭代次数,e
′
>e,如果是,则进入步骤s408,否则再次训练完毕,进入步骤s409;
[0147]
s408:令e=e+1,返回步骤s402。
[0148]
s409:得到信号分离结果:
[0149]
根据最后一个状态确定分离矩阵然后计算分离信号矩阵将分离信号矩阵的第j个行向量作为第j个辐射源最终的源信号分离结果
[0150]
为了更好地说明本发明的技术效果,采用一个具体实施例对本发明进行仿真验证。
[0151]
本实施例中设置3个辐射源,分别为1部手机和2台usrp(universal software radio peripheral,通用软件无线电外设)设备。利用ad9361软件无线电平台中的天线作为信号测试天线,对辐射源发送的调制信号进行采集,采样频段为430
‑
440mhz,采样频率为20mhz。采集数据样本对ddpg网络进行训练,然后离线分离实际的混合信号。
[0152]
图5是本实施例中分离得到的手机信号与源信号的波形对比图。图6是本实施例中分离得到的usrp设备信号与源信号的波形对比图。如图5和图6所示,本发明分离得到的信号与源信号相比非常接近,经统计分离信号信干比达到30以上,相关系数0.99以上,完全可以适应工程应用的需求。
[0153]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1