一种高效的联邦衍生特征逻辑回归建模方法与流程
1.本发明涉及衍生特征逻辑回归建模技术领域,尤其涉及一种高效的联邦衍生特征逻辑回归建模方法。
背景技术:
2.在实际业务中,很多变量没有实际含义,不适合直接建模,如用户地址(多种属性值的分类变量)、用户日消费金额(弱数值变量),而此类变量在做一定的变换或者组合后,往往具有较强的信息价值,对数据敏感性和机器学习实战经验能起到较大的帮助作用,所以实际场景需要对基础特征做一些衍生类的工作,也就是业内常说的如何生成万维数据。
3.特征衍生常用于金融风控场景。目前,发起方、参与方联合建模时,需要发起方的基础数据与参与方的基础数据采用明文方式进行特征衍生,得到明文的衍生特征后,发起方、参与方利用衍生特征、双方的基础数据进行逻辑回归建模,然而这种建模方法采用明文方式进行,会将自己的数据泄露给对方,无法保护各自的数据隐私。
4.发起方、参与方也可采用《aby
ꢀ–ꢀ
a framework for efficient mixed-protocol secure two-party computation》这篇论文的方法,利用秘密分享算法计算发起方的基础特征和参与方的基础特征的联邦衍生特征,发起方、参与方各自保留对应的密文状态的衍生特征分片,但是,现有的逻辑回归建模方法无法使用密文状态的衍生特征分片。
技术实现要素:
5.本发明为了解决上述技术问题,提供了一种高效的联邦衍生特征逻辑回归建模方法,其可以在发起方、参与方的数据不出库的情况下完成特征衍生及逻辑回归建模,保护了双方的数据隐私,避免数据泄露。
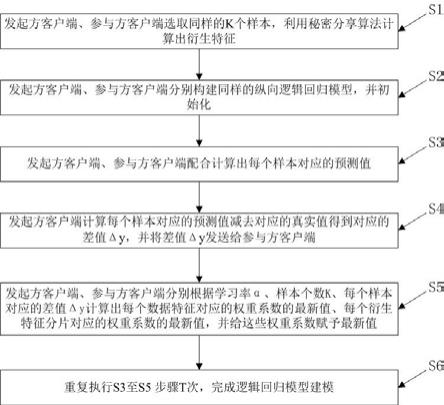
6.为了解决上述问题,本发明采用以下技术方案予以实现:本发明的一种高效的联邦衍生特征逻辑回归建模方法,包括以下步骤:s1:发起方客户端从自身数据库中采集k个样本对应的样本数据集xa,样本数据集xa中包含若干个数据特征,参与方客户端从自身数据库中采集相同的k个样本对应的样本数据集xb,样本数据集xb中包含若干个数据特征,发起方客户端、参与方客户端利用秘密分享算法根据样本数据集xa中的数据特征、样本数据集xb中的数据特征进行特征衍生,得到保存在发起方客户端的与每个样本对应的衍生特征分片<xc>a、保存在参与方客户端的与每个样本对应的衍生特征分片<xc>b;s2:发起方客户端、参与方客户端分别构建同样的纵向逻辑回归模型,初始化样本数据集xa中的每个数据特征对应的权重系数、样本数据集xb中的每个数据特征对应的权重系数、衍生特征分片<xc>a对应的权重系数、衍生特征分片<xc>b对应的权重系数;s3:发起方客户端计算出每个样本的样本数据集xa对应的预测得分ya,参与方客户端计算出每个样本的样本数据集xb对应的预测得分yb,发起方客户端、参与方客户端利用秘密分享乘法联邦计算每个样本的衍生特征对应的预测得分yc,发起方客户端根据预测得分
ya、预测得分yb、预测得分yc计算出每个样本对应的预测值yd;s4:发起方客户端计算每个样本对应的预测值yd减去对应的真实值ye得到对应的差值δy,并将差值δy发送给参与方客户端;s5:发起方客户端根据学习率α、样本个数k、每个样本对应的差值δy计算出样本数据集xa中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>a对应的权重系数的最新值,并给这些权重系数赋予最新值;参与方客户端根据差值δy、学习率α、样本个数k计算出样本数据集xb中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>b对应的权重系数的最新值,并给这些权重系数赋予最新值;s6:重复执行s3至s5步骤t次,发起方客户端得到样本数据集xa中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>a对应的权重系数的最新值,参与方客户端得到样本数据集xb中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>b对应的权重系数的最新值,完成逻辑回归模型建模。
7.在本方案中,发起方、参与方选取同样的k个样本用于逻辑回归建模,利用秘密分享算法计算出衍生特征,得到保存在发起方的与每个样本对应的衍生特征分片<xc>a、保存在参与方的与每个样本对应的衍生特征分片<xc>b。接着,发起方、参与方分别构建同样的纵向逻辑回归模型,并初始化。发起方、参与方配合计算出每个样本对应的预测值yd,从而可以得到每个样本对应的差值δy,发起方、参与方分别根据学习率α、样本个数k、每个样本对应的差值δy计算出每个数据特征对应的权重系数的最新值、每个衍生特征分片对应的权重系数的最新值,并给这些权重系数赋予最新值,重复上述步骤t次后,发起方得到样本数据集xa中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>a对应的权重系数的最新值,参与方得到样本数据集xb中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>b对应的权重系数的最新值,完成逻辑回归模型建模。
8.在整个建模过程中,发起方、参与方的数据都没有明文出库,衍生特征分片<xc>a、衍生特征分片<xc>b都是密文状态,发起方、参与方都无法获取对方的数据,也无法获取衍生特征的明文值,保护了双方的数据隐私,避免了数据泄露。本方案利用秘密分享算法生成衍生特征,并将秘密分享生成的衍生特征用于逻辑回归建模,计算量小,可用于高带宽场景下,无需借助计算加速卡等硬件就能实现海量联邦衍生特征筛选的大规模商业落地。本方案的方法适用于风控场景、营销场景,比如,发起方为金融机构,参与方为运营商,金融机构与运营商之间使用专网通信,采用本方案的方法实现联邦特征衍生、联合建模,用于预测金融机构的金融机构用户等级。
9.作为优选,所述衍生特征分片<xc>a与衍生特征分片<xc>b之和为样本数据集xa中的某个数据特征与样本数据集xb中的某个数据特征做加法运算或减法运算或乘法运算或除法运算的结果。
10.假设发起方客户端、参与方客户端利用秘密分享算法根据样本数据集xa中的数据特征f与样本数据集xb中的数据特征e进行特征衍生,得到保存在发起方客户端的与每个样本对应的衍生特征分片<xc>a、保存在参与方客户端的与每个样本对应的衍生特征分片<xc>b,则满足下述情况种的一种:f+e=<xc>a+<xc>b;
f-e=<xc>a+<xc>b;e-f=<xc>a+<xc>b;f*e=<xc>a+<xc>b;f/e=<xc>a+<xc>b;e/f=<xc>a+<xc>b。
11.作为优选,所述步骤s1包括以下步骤:发起方客户端从自身数据库中采集k个样本对应的样本数据集xa,k个样本依次编号为1,2
……
k,每个样本对应的样本数据集xa的结构相同,样本数据集xa中包含若干个数据特征,将样本数据集xa中的数据特征依次标记为x
a1
、x
a2
……
x
an
,n为样本数据集xa中包含的数据特征的数量,n≥1,则编号为i的样本对应的样本数据集为xa(i),1≤i≤k,样本数据集xa(i)的结构为xa(i)={x
a1
(i)、x
a2
(i)、
……
x
an
(i)},参与方客户端从自身数据库中采集相同的k个样本对应的样本数据集xb,每个样本的编号与发起方相同样本的编号一致,每个样本对应的样本数据集xb的结构相同,样本数据集xb中包含若干个数据特征,将样本数据集xb中的数据特征依次标记为x
b1
、x
b2
……
x
bm
,m为样本数据集xb中包含的数据特征的数量,m≥1,则编号为i的样本对应的样本数据集为xb(i),1≤i≤k,样本数据集xb(i)的结构为xb(i)={x
b1
(i)、x
b2
(i)、
……
x
bm (i)};发起方客户端、参与方客户端利用秘密分享算法根据样本数据集xa中的数据特征、样本数据集xb中的数据特征进行特征衍生,得到保存在发起方客户端的与每个样本对应的衍生特征分片<xc>a、保存在参与方客户端的与每个样本对应的衍生特征分片<xc>b,保存在发起方客户端的编号为i的样本对应的衍生特征分片为<xc>a(i),保存在参与方客户端的编号为i的样本对应的衍生特征分片为<xc>
b (i)。
12.每个样本都有唯一对应的标识,发起方采集的k个样本的标识与参与方采集的k个样本的标识一致。
13.作为优选,所述步骤s2包括以下步骤:发起方客户端、参与方客户端分别构建同样的纵向逻辑回归模型:y=sigmoid(wada+<wc>aea+ wbd
b +<wc>beb),其中,wa=[w
a1 w
a2
…wan
],wa表示数据特征x
a1
、x
a2
……
x
an
对应的权重系数组成的向量,w
ap
为数据特征x
ap
对应的权重系数,1≤p≤n,,e
a =[<xc>a(1) <xc>a(2)
…
<xc>a(k)],wb=[w
b1 w
b2
…wbm
],wb表示数据特征x
b1
、x
b2
……
x
bm
对应的权重系数组成的向量,w
bq
为数据特征x
bq
对应的权重系数,1≤q≤m,,e
b =[<xc>
b (1) <xc>
b (2)
…
<xc>
b (k)],
<wc>a表示衍生特征分片<xc>a对应的权重系数,<wc>b表示衍生特征分片<xc>b对应的权重系数;发起方客户端初始化样本数据集xa中的每个数据特征对应的权重系数、衍生特征分片<xc>a对应的权重系数,参与方客户端初始化样本数据集xb中的每个数据特征对应的权重系数、衍生特征分片<xc>b对应的权重系数。
[0014]
作为优选,所述步骤s3包括以下步骤:发起方客户端计算出每个样本的样本数据集xa对应的预测得分ya,编号为i的样本的样本数据集xa对应的预测得分ya(i)=wa*xa(i),参与方客户端计算出每个样本的样本数据集xb对应的预测得分yb,编号为i的样本的样本数据集xb对应的预测得分yb(i)=wb*xb(i),发起方客户端、参与方客户端利用秘密分享乘法联邦计算每个样本的衍生特征对应的预测得分yc,编号为i的样本的衍生特征对应的预测得分yc(i)=<wc>a<xc>
b (i)+<wc>b<xc>a(i)+<wc>a<xc>a(i)+<wc>b<xc>
b (i),发起方客户端根据预测得分ya、预测得分yb、预测得分yc计算出每个样本对应的预测值yd,编号为i的样本对应的预测值yd(i)= sigmoid(ya(i)+yb(i)+yc(i))。
[0015]
作为优选,所述步骤s5包括以下步骤:发起方客户端根据学习率α、样本个数k、每个样本对应的差值δy计算出样本数据集xa中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>a对应的权重系数的最新值,并给这些权重系数赋予最新值;给数据特征x
ap
对应的权重系数w
ap
重新赋值的公式如下,1≤p≤n:,y=[δy(1) δy(2)
…
δy(k)],x
ap
=[x
ap
(1) x
ap
(2)
ꢀ…
x
ap
(k)],其中,δy(i)表示编号为i的样本对应的差值,1≤i≤k,给衍生特征分片<xc>a对应的权重系数<wc>a重新赋值的公式如下:,e
a =[<xc>a(1) <xc>a(2)
…
<xc>a(k)];参与方客户端根据差值δy、学习率α、样本个数k计算出样本数据集xb中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>b对应的权重系数的最新值,并给这些权重系数赋予最新值;给数据特征x
bq
对应的权重系数w
bq
重新赋值的公式如下,1≤q≤m:,y=[δy(1) δy(2)
…
δy(k)],x
bq
=[x
bq (1) x
bq (2)
ꢀ…
x
bq (k)],
给衍生特征分片<xc>b对应的权重系数<wc>b重新赋值的公式如下:,e
b =[<xc>
b (1) <xc>
b (2)
…
<xc>
b (k)]。
[0016]
作为优选,所述步骤s2还包括以下步骤:发起方和参与方初始化参数t、学习率、乘法三元组。乘法三元组主要用于多方安全计算协议中的乘法计算,它的应用范围为加法和乘法均为线性的秘密分享机制。
[0017]
本发明的有益效果是:(1)可以在发起方、参与方的数据不出库的情况下完成特征衍生及逻辑回归建模,保护了双方的数据隐私,避免数据泄露。(2)计算量小,可用于高带宽场景下,无需借助计算加速卡等硬件就能实现海量联邦衍生特征筛选的大规模商业落地。
附图说明
[0018]
图1是实施例的流程图;图2是实施例中举例的模型参数表。
具体实施方式
[0019]
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
[0020]
实施例:本实施例的一种高效的联邦衍生特征逻辑回归建模方法,用于金融机构和运营商之间联合风控建模,如图1所示,包括以下步骤:s1:发起方客户端从自身数据库中采集k个样本(样本为用户样本)对应的样本数据集xa,每个样本都有唯一对应的标识,k个样本依次编号为1,2
……
k,每个样本对应的样本数据集xa的结构相同,样本数据集xa中包含若干个数据特征,将样本数据集xa中的数据特征依次标记为x
a1
、x
a2
……
x
an
,n为样本数据集xa中包含的数据特征的数量,n≥1,则编号为i的样本对应的样本数据集为xa(i),1≤i≤k,样本数据集xa(i)的结构为xa(i)={x
a1
(i)、x
a2
(i)、
……
x
an
(i)},参与方客户端从自身数据库中采集相同的k个样本对应的样本数据集xb,该k个样本的标识与发起方采集的k个样本的标识一致,每个样本的编号与发起方相同样本的编号一致,每个样本对应的样本数据集xb的结构相同,样本数据集xb中包含若干个数据特征,将样本数据集xb中的数据特征依次标记为x
b1
、x
b2
……
x
bm
,m为样本数据集xb中包含的数据特征的数量,m≥1,则编号为i的样本对应的样本数据集为xb(i),1≤i≤k,样本数据集xb(i)的结构为xb(i)={x
b1
(i)、x
b2
(i)、
……
x
bm (i)};发起方客户端、参与方客户端利用秘密分享算法根据样本数据集xa中的某个数据特征、样本数据集xb中的某个数据特征进行特征衍生,得到保存在发起方客户端的与每个样本对应的衍生特征分片<xc>a、保存在参与方客户端的与每个样本对应的衍生特征分片<xc>b,保存在发起方客户端的编号为i的样本对应的衍生特征分片为<xc>a(i),保存在参与方客户端的编号为i的样本对应的衍生特征分片为<xc>
b (i);s2:发起方客户端、参与方客户端分别构建同样的纵向逻辑回归模型:y=sigmoid(wada+<wc>aea+ wbd
b +<wc>beb),其中,wa=[w
a1 w
a2
…wan
],wa表示数据特征x
a1
、x
a2
……
x
an
对应的权重系数组成的向
量,w
ap
为数据特征x
ap
对应的权重系数,1≤p≤n,,e
a =[<xc>a(1) <xc>a(2)
…
<xc>a(k)],wb=[w
b1 w
b2
…wbm
],wb表示数据特征x
b1
、x
b2
……
x
bm
对应的权重系数组成的向量,w
bq
为数据特征x
bq
对应的权重系数,1≤q≤m,,e
b =[<xc>
b (1) <xc>
b (2)
…
<xc>
b (k)],<wc>a表示衍生特征分片<xc>a对应的权重系数,<wc>b表示衍生特征分片<xc>b对应的权重系数;发起方客户端初始化样本数据集xa中的每个数据特征对应的权重系数、衍生特征分片<xc>a对应的权重系数,参与方客户端初始化样本数据集xb中的每个数据特征对应的权重系数、衍生特征分片<xc>b对应的权重系数;发起方和参与方初始化参数t、学习率α、乘法三元组;s3:发起方客户端计算出每个样本的样本数据集xa对应的预测得分ya,编号为i的样本的样本数据集xa对应的预测得分ya(i)=wa*xa(i),参与方客户端计算出每个样本的样本数据集xb对应的预测得分yb,编号为i的样本的样本数据集xb对应的预测得分yb(i)=wb*xb(i),并发送给发起方客户端;发起方客户端、参与方客户端利用秘密分享乘法联邦计算每个样本的衍生特征对应的预测得分yc,编号为i的样本的衍生特征对应的预测得分yc(i)=<wc>a<xc>
b (i)+<wc>b<xc>a(i)+<wc>a<xc>a(i)+<wc>b<xc>
b (i),发起方客户端根据预测得分ya、预测得分yb、预测得分yc计算出每个样本对应的预测值yd,编号为i的样本对应的预测值yd(i)= sigmoid(ya(i)+yb(i)+yc(i));s4:发起方客户端计算每个样本对应的预测值yd减去对应的真实值ye得到对应的差值δy,并将差值δy发送给参与方客户端;(发起方客户端拥有每个样本对应的真实值ye)编号为i的样本对应的差值δy(i)= yd(i)-ye(i),ye(i)表示编号为i的样本对应的真实值;s5:发起方客户端根据学习率α、样本个数k、每个样本对应的差值δy计算出样本数据集xa中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>a对应的权重系数的最新值,并给这些权重系数赋予最新值;给数据特征x
ap
对应的权重系数w
ap
重新赋值的公式如下,1≤p≤n:,
y=[δy(1) δy(2)
…
δy(k)],x
ap
=[x
ap
(1) x
ap
(2)
ꢀ…
x
ap
(k)],其中,δy(i)表示编号为i的样本对应的差值,1≤i≤k,给衍生特征分片<xc>a对应的权重系数<wc>a重新赋值的公式如下:,e
a =[<xc>a(1) <xc>a(2)
…
<xc>a(k)];参与方客户端根据差值δy、学习率α、样本个数k计算出样本数据集xb中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>b对应的权重系数的最新值,并给这些权重系数赋予最新值;给数据特征x
bq
对应的权重系数w
bq
重新赋值的公式如下,1≤q≤m:,y=[δy(1) δy(2)
…
δy(k)],x
bq
=[x
bq (1) x
bq (2)
ꢀ…
x
bq (k)],给衍生特征分片<xc>b对应的权重系数<wc>b重新赋值的公式如下:,e
b =[<xc>
b (1) <xc>
b (2)
…
<xc>
b (k)];s6:重复执行s3至s5步骤t次,发起方客户端得到样本数据集xa中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>a对应的权重系数的最新值,参与方客户端得到样本数据集xb中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>b对应的权重系数的最新值,完成纵向逻辑回归模型建模。
[0021]
在本方案中,发起方、参与方选取同样的k个样本用于逻辑回归建模,利用秘密分享算法计算出衍生特征,得到保存在发起方的与每个样本对应的衍生特征分片<xc>a、保存在参与方的与每个样本对应的衍生特征分片<xc>b。接着,发起方、参与方分别构建同样的纵向逻辑回归模型,并初始化。发起方、参与方配合计算出每个样本对应的预测值yd,从而可以得到每个样本对应的差值δy,发起方、参与方分别根据学习率α、样本个数k、每个样本对应的差值δy计算出每个数据特征对应的权重系数的最新值、每个衍生特征分片对应的权重系数的最新值,并给这些权重系数赋予最新值,重复上述步骤t次后,发起方得到样本数据集xa中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>a对应的权重系数的最新值,参与方得到样本数据集xb中的每个数据特征对应的权重系数的最新值、衍生特征分片<xc>b对应的权重系数的最新值,完成纵向逻辑回归模型建模。
[0022]
在整个建模过程中,发起方、参与方的数据都没有明文出库,衍生特征分片<xc>a、衍生特征分片<xc>b都是密文状态,发起方、参与方都无法获取对方的数据,也无法获取衍生特征的明文值,保护了双方的数据隐私,避免了数据泄露。本方案利用秘密分享算法生成衍生特征,并将秘密分享生成的衍生特征用于逻辑回归建模,计算量小,可用于高带宽场景下,无需借助计算加速卡等硬件就能实现海量联邦衍生特征筛选的大规模商业落地。本方案的方法适用于风控场景、营销场景,比如,发起方为金融机构,参与方为运营商,金融
机构与运营商之间使用专网通信,采用本方案的方法实现联邦特征衍生、联合建模,用于预测金融机构的金融机构用户等级。
[0023]
衍生特征分片<xc>a与衍生特征分片<xc>b之和为样本数据集xa中的某个数据特征与样本数据集xb中的某个数据特征做加法运算或减法运算或乘法运算或除法运算的结果。
[0024]
假设发起方客户端、参与方客户端利用秘密分享算法根据样本数据集xa中的数据特征f与样本数据集xb中的数据特征e进行特征衍生,得到保存在发起方客户端的与每个样本对应的衍生特征分片<xc>a、保存在参与方客户端的与每个样本对应的衍生特征分片<xc>b,则满足下述情况种的一种:f+e=<xc>a+<xc>b;f-e=<xc>a+<xc>b;e-f=<xc>a+<xc>b;f*e=<xc>a+<xc>b;f/e=<xc>a+<xc>b;e/f=<xc>a+<xc>b。
[0025]
乘法三元组主要用于多方安全计算协议中的乘法计算,它的应用范围为加法和乘法均为线性的秘密分享机制。
[0026]
举例说明:发起方、参与方都采集id为1、2、3的三个样本,依次编号为1、2、3,发起方、参与方的初始参数如图2所示,学习率α为0.1、样本个数k为3,迭代t轮。
[0027]
样本数据集xa中的数据特征依次标记为x
a1
、x
a2
,样本数据集xa(1)的结构为x
a (1)={xa1(1)、xa2(1)}={4、3 };样本数据集x
a (2)的结构为x
a (2)={2、1 };样本数据集x
a (3)的结构为x
a (3)={3、1 };样本数据集xb中的数据特征依次标记为x
b1
、x
b2
,样本数据集x
b (1)的结构为x
b (1)={2、3 };样本数据集x
b (2)的结构为x
b (2)={2、1 };样本数据集x
b (3)的结构为x
b (3)={3、1 };发起方客户端、参与方客户端分别构建同样的纵向逻辑回归模型:y=sigmoid(wada+<wc>aea+ wbd
b +<wc>beb);第一次迭代:发起方客户端计算出编号为1的样本的样本数据集xa对应的预测得分ya(1)=wa*xa(1)= [1 2] *[2 1]=4;参与方客户端计算出编号为1的样本的样本数据集xb对应的预测得分yb(1)= [1 2] *[2 1]=4;发起方客户端、参与方客户端利用秘密分享乘法联邦计算编号为1的样本的衍生特征对应的预测得分yc(1)=1*0.8+2*0.2+1*0.2+2*0.8=3,发起方客户端根据预测得分ya(1)、预测得分yb(1)、预测得分yc(1)计算出编号为2的样本对应的预测值yd(1)= sigmoid(4+4+3)= sigmoid(11)= 0.999999;
发起方客户端计算编号为1的样本对应的差值δy(1)=yd(1)-ye(1)= 0.999999-1=-0.000001;同理,发起方客户端计算出编号为2的样本对应的差值δy(2)=1,编号为3的样本对应的差值δy(3)=1,并将差值δy(1)、δy(2)、δy(3)发送给参与方客户端;发起方客户端给w
a1
、w
a2
、<wc>a重新赋值:w
a1
=1-0.1/3*(-0.000001*2+1*4+1*3)=0.766667;w
a1
=1-0.1/3*(-0.000001*1+1*3+1*1)=0.866667;<wc>a=1-0.1/3*(-0.000001*0.2+1*0.3+1*1.1)=0.953333;参与方客户端给w
b1
、w
b2
、<wc>b重新赋值:w
b1
=1-0.1/3*(-0.000001*2+1*2+1*3)=0.833333;w
b2
=1-0.1/3*(-0.000001*1+1*3+1*1)=0.866667;<wc>
b =1-0.1/3*(-0.000001*0.8+1*0.7+1*0.9)=0.946667;重复上述步骤迭代t轮,发起方客户端获得最终的w
a1
、w
a2
、<wc>a的值,参与方客户端获得最终的w
b1
、w
b2
、<wc>b的值,完成联邦衍生特征逻辑回归模型建模。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1