一种视频压缩系统、方法、计算机可读存储介质及服务器与流程
1.本发明涉及视频处理技术领域,尤其涉及一种视频压缩系统、方法、计算机可读存储介质及服务器。
背景技术:
2.传统的基板管理控制芯片中视频压缩系统有以下两种方案:方案1:主机端的视频数据,通过pcie(peripheral component interconnect express,一种高速串行计算机扩展总线标准)传递到基板管理控制芯片后,生成rgb(red green blue,红绿蓝)原始视频信息后,写到片外ddr(double data rate,双倍速率同步动态随机存储器)进行缓存,通过色彩空间转换模块(rgb2yuv),将原始的rgb格式的视频数据转换为yuv(一种颜色编码方法,y表示明亮度(luminance、luma),u和v则是色度、浓度(chrominance、chroma))格式的数据,然后将y、u、v数据,分别存储在片外不同起始地址的ddr空间(y_addr,u_addr,v_addr),同时将y、u、v的起始地址通过cpu配置给视频压缩ip。cmp(视频压缩控制模块)根据视频压缩ip的要求,按照block(块)数据的顺序,产生读片外ddr的地址,然后按照block数据的顺序输入给视频压缩控制模块,完成压缩之后,将数据写入到ddr,emac(网卡)驱动读取完成压缩的数据,通过网络将视频数据传输至远程,进行远程显示。
3.方案2:主机端的视频数据,通过pcie传递到基板管理控制芯片后,生成rgb原始视频信息后,写到片外ddr进行缓存,通过色彩空间转换模块(rgb2yuv),将原始的rgb格式的视频数据转换为yuv格式的数据,然后将y、u、v数据用片内的存储资源(fifo)进行缓存,按照block格式转换的需求(支持yuv444/yuv422/yuv420压缩格式),需要16个y_fifo,16个u_fifo,16个v_fifo,同时根据项目实践经验,针对最大分辨率下的(1920*1200)下,fifo((first in first out,先进先出))的深度为16384,宽度为8bits,需要的fifo的总存储容量为768kb,才能满足fifo不会出现满的情况,不会出现丢数据的情况。
4.传统方案1存在的缺点是,基板管理控制芯片需要非常频繁的访问片外ddr,导致视频功能占用的内存带宽很高,极大影响cpu(central processing unit,中央处理器)上运行的其他软件对内存的访问,影响基板管理控制芯片的整体性能。
5.传统方案2的缺点是,需要极大的占用很大的片内资源,而对于芯片项目而言,片内的存储资源(fifo)是很珍贵的,fifo数量多会增大芯片的面积。同时数量、容量很大的fifo对于芯片的时序约束、后端设计、封装制造等过程造成很大的难题。
技术实现要素:
6.有鉴于此,本发明提出了一种视频压缩系统、方法、计算机可读存储介质及服务器,解决了传统的视频压缩系统,占用较多片内资源以及fifo数量多会引发的增大芯片的制造面积、封装制造困难、引起时序约束、降低视频压缩效率等问题。
7.基于上述目的,本发明实施例的一方面提供了一种用于基板管理控制芯片的视频
压缩系统,视频压缩系统具体包括:色彩空间转换模块、存储器、fifo阵列模块、读写控制模块、视频压缩控制模块,所述存储器包括缓存空间和压缩数据存储空间,所述fifo阵列模块包括多个fifo,所述fifo用于存储y分量或v分量或u分量数据;基板管理控制芯片配置为将接收到的rgb视频数据以行的方式写入所述缓存空间;所述色彩空间转换模块配置为依次从所述缓存空间读取每一行的rgb视频数据,并将所述rgb视频数据转换成y分量、u分量和v分量数据;所述fifo阵列模块配置为基于所述fifo的数量对应设置所述fifo的位宽以使所述fifo同时存储相邻两行的y分量或u分量或v分量数据;所述读写控制模块配置为在每个时钟周期读取对应位置的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存;所述读写控制模块还配置为在接收到视频压缩控制模块发出的读数据请求后,在每个时钟周期按照所述fifo阵列中每个fifo的排列顺序依次从对应的fifo中读取相邻两行对应位置的y分量或u分量或v分量数据组成block数据发送给所述视频压缩控制模块;所述视频压缩控制模块配置为对接收到的block数据进行压缩,并将压缩后的数据写入压缩数据存储空间。
8.在一些实施方式中,所述fifo阵列模块包括24个fifo,所述fifo阵列模块配置为将第1~8个fifo设置为存储y分量数据、第9~16个fifo设置为存储u分量数据、第17~24个fifo设置为存储v分量数据,并将每个fifo的位宽设置为16比特以同时存储相邻两行的y分量或u分量或v分量数据。
9.在一些实施方式中,所述读写控制模块具体配置为根据压缩格式对转换后的y分量、u分量和v分量数据进行丢弃,并在完成数据丢弃后,在每个时钟周期读取保留的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存。
10.在一些实施方式中,所述缓存空间采用乒乓缓存结构,包括第一缓存空间和第二缓存空间;所述基板管理控制芯片还配置为将接收到的rgb视频数据以行的方式依次写入第一缓存空间和第二缓存空间;所述色彩空间转换模块还配置为依次从所述第一缓存空间和第二缓存空间读取相邻两行的rgb视频数据,并将相邻两行的rgb视频数据并行地转换成y分量、u分量和v分量数据;所述读写控制模块还配置为根据压缩格式对转换后的y分量、u分量和v分量数据进行丢弃,并在完成数据丢弃后,在每个时钟周期并行地读取相邻两行相同列号保留的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存。
11.在一些实施方式中,所述读写控制模块还具体配置为在接收到视频压缩控制模块发出的读数据请求后,在每个时钟周期根据压缩格式以及所述fifo阵列中每个fifo的排列顺序依次从对应的fifo中读取相邻两行对应位置的y分量或u分量或v分量数据组成符合所述压缩格式要求的block数据发送给所述视频压缩控制模块。
12.在一些实施方式中,按以下公式将所述rgb视频数据转换成y分量、u分量和v分量
数据:y = 0.257*r + 0.504*g + 0.098*b + 16u =
ꢀ‑
0.148*r
ꢀ‑ꢀ
0.291*g + 0.439*b + 128v = 0.439*r
‑ꢀ
0.368*g
ꢀ‑ꢀ
0.071*b + 128,其中,r表示rgb视频数据中的r分量,g表示rgb视频数据中的g分量,b表示rgb视频数据中的b分量。
13.在一些实施方式中,视频压缩系统还包括网卡,所述网卡配置为从所述压缩数据存储空间读取压缩后的数据发送至远端以进行远端显示。
14.本发明实施例的另一方面,还提供了一种用于基板管理控制芯片的视频压缩方法,基于如上所述视频压缩系统,执行以下步骤:基板管理控制芯片将接收到的rgb视频数据以行的方式写入缓存空间;色彩空间转换模块依次从所述缓存空间读取每一行的rgb视频数据,并将所述rgb视频数据转换成y分量、u分量和v分量数据;fifo阵列模块基于fifo的数量对应设置所述fifo的位宽以使所述fifo同时存储相邻两行的y分量或u分量或v分量数据;读写控制模块在每个时钟周期读取每一行对应位置的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存;所述读写控制模块在接收到视频压缩控制模块发出的读数据请求后,在每个时钟周期按照所述fifo阵列中每个fifo的排列顺序依次从对应的fifo中读取相邻两行对应位置的y分量或u分量或v分量数据组成block数据发送给视频压缩控制模块;所述视频压缩控制模块对接收到的block数据进行压缩,并将压缩后的数据写入压缩数据存储空间。
15.本发明实施例的另一方面,还提供了一种计算机可读存储介质,计算机可读存储介质存储有被处理器执行时实现如上方法步骤的计算机程序。
16.本发明实施例的另一方面,还提供了一种服务器,包括如上所述的视频压缩系统。
17.本发明至少具有以下有益技术效果:通过减少传统视频压缩系统中的fifo数量并增大每个fifo的位宽,以及优化读写控制模块的读控制逻辑的读出过程,降低了fifo所需的存储容量,节省了fifo在芯片上的占用空间,降低了项目成本,降低了传统视频压缩系统中由于fifo数量过多而引起的时序约束、封装制造困难等问题,提高了视频数据的读出速度以及视频压缩速度;在读写控制模块的视频数据读出速度加快的前提下,通过采用乒乓结构的双缓存空间以及优化色彩空间转换模块的转换运算逻辑使读写控制模块通过在一个时钟周期写入更多的yuv视频数据,提高了视频数据的写入速度,以使后级视频压缩模块可以更快的进行数据压缩,提高了视频压缩效率。
附图说明
18.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的实施例。
19.图1为传统视频压缩系统的示意图;图2为不同yuv压缩格式要求的block数据组成示意图;图3为本发明提供的用于基板管理控制芯片的视频压缩系统的一实施例的示意图;图4为本发明提供的视频压缩系统存储y分量数据与传统视频压缩系统存储y分量数据的对比示意图;图5为本发明提供的视频压缩系统存储u分量数据与传统视频压缩系统存储u分量数据的对比示意图;图6为本发明提供的视频压缩系统存储v分量数据与传统视频压缩系统存储v分量数据的对比示意图;图7为本发明提供的用于基板管理控制芯片的视频压缩方法的一实施例的框图;图8为本发明提供的计算机可读存储介质的一实施例的结构示意图;图9为本发明提供的服务器的一实施例的结构示意图。
具体实施方式
20.为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明实施例进一步详细说明。
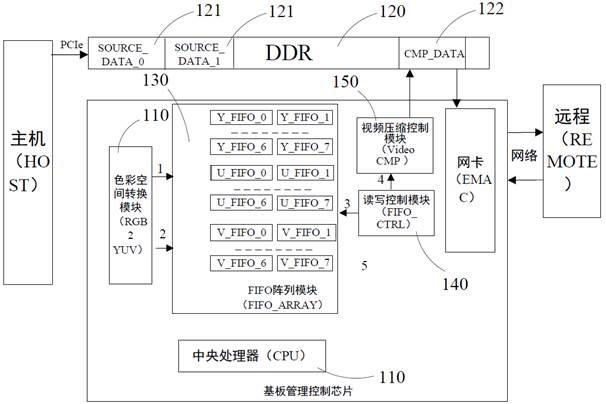
21.需要说明的是,本发明实施例中所有使用“第一”和“第二”的表述均是为了区分两个相同名称非相同的实体或者非相同的参量,可见“第一”“第二”仅为了表述的方便,不应理解为对本发明实施例的限定,后续实施例对此不再一一说明。
22.如图1所示,为传统方案2的视频压缩系统的示意图。
23.如图2所示,其示出了不同yuv压缩格式要求的block数据组成。
24.在图2中,cb代表u分量,cr代表v分量,图2的左侧为yuv格式的视频数据的源图像图片(source image picture),经离散余弦变换(discrete cosine transform,简称dct)后,组成block格式数据进行存储,图2的右侧,height代表方框的高度,width代表方框的宽度,每一个小方框表示图2左侧的8*8像素点,大方框表示16*16像素点,长方框是8*16像素点。以yuv420举例,y块表示4个8*8像素点的y分量,cb块表示1个8*8块的u分量,cr块表示1个8*8块的v分量。
25.也就是说,若当前的压缩格式是yuv420,video cmp(视频压缩控制模块)要产生读16*16的y分量的地址顺序,8*8的u分量的地址顺序,8*8的v分量的地址顺序,然后依次循环;若当前的压缩格式是yuv422,video cmp要产生读16*16的y分量的地址顺序,8*16的u分量的地址顺序,8*16的v分量的地址顺序,然后依次循环;若当前的压缩格式是yuv444,video cmp要产生读8*8的y分量的地址顺序,8*8的u分量的地址顺序,8*8的v分量的地址顺序,然后依次循环。
26.如图1所示的视频压缩系统,主机端(host)的视频数据是rgb格式的,通过pcie传递到基板管理控制芯片后,生成rgb原始视频信息后,写到片外ddr进行缓存,色彩空间转换模块(rgb2yuv)从片外ddr读取rgb格式的视频数据,将原始的rgb格式的视频数据转换为yuv格式的数据,然后读写控制模块(fifo _ctrl)根据压缩格式(支持yuv444/yuv422/yuv420压缩格式)读取转换后的yuv格式的数据,将y、u、v数据用片内的fifo阵列(fifo_
array)进行缓存,并按照block格式的需求从fifo阵列读出后发送给视频压缩控制模块(video cmp),传统方案下,为满足block格式的转换需求,需要16个y_fifo,16个u_fifo,16个v_fifo组成fifo阵列。
27.在视频数据压缩过程中,fifo_ctrl(fifo读写控制模块)不关心video cmp发出的读地址,而由fifo_ctrl本身产生读写控制逻辑,去读取相应的fifo。
28.通过fifo_ ctrl进行yuv数据写控制逻辑如下:在yuv420格式下,保留全部的y数据,保留偶数行偶数列的u/v数据,具体如下:将第0/16/32/48
…
行的y数据写进y_ram_0;将第1/17/33/49
…
行的y数据写进y_ram_1;将第2/18/34/50
…
行的y数据写进y_ram_2;
……
将第15/31/47/63
…
行的y数据写进y_ram_15;将第0/16/32/48
…
行的偶数列u数据写进u_ram_0;将第2/18/34/50
…
行的偶数列u数据写进u_ram_1;
……
将第14/30/46/62
…
行的偶数列u数据写进u_ram_7;将第0/16/32/48
…
行的偶数列u数据写进v_ram_0;将第2/18/34/50
…
行的偶数列u数据写进v_ram_1;
……
将第14/30/46/62
…
行的偶数列u数据写进v_ram_7。
29.在yuv422格式下,保留全部的y数据,保留偶数列的u/v数据,具体如下:将第0/16/32/48
…
行的y数据写进y_ram_0;将第1/17/33/49
…
行的y数据写进y_ram_1;将第2/18/34/50
…
行的y数据写进y_ram_2;
……
将第15/31/47/63
…
行的y数据写进y_ram_15;将第0/16/32/48
…
行的偶数列u数据写进u_ram_0;将第1/17/33/49
…
行的偶数列u数据写进u_ram_1;将第2/18/34/50
…
行的偶数列u数据写进u_ram_2;
……
将第15/31/47/63
…
行偶数列的u数据写进u_ram_15;将第0/16/32/48
…
行的偶数列v数据写进v_ram_0;将第1/17/33/49
…
行的偶数列v数据写进v_ram_1;将第2/18/34/50
…
行的偶数列v数据写进v_ram_2;
……
将第15/31/47/63
…
行偶数列的v数据写进v_ram_15。
30.在yuv444格式下,保留全部行全部列的y/u/v数据,具体如下:将第0/8/16/24
…
行的y数据写进y_ram_0;将第1/9/17/25
…
行的y数据写进y_ram_1;
将第2/10/18/26
…
行的y数据写进y_ram_2;
……
将第7/15/23/31
…
行的y数据写进y_ram_7;将第0/8/16/24
…
行的u数据写进u_ram_0;将第1/9/17/25
…
行的u数据写进u_ram_1;将第2/10/18/26
…
行的u数据写进u_ram_2;
……
将第7/15/23/31
…
行的u数据写进u_ram_7;将第0/8/16/24
…
行的v数据写进v_ram_0;将第1/9/17/25
…
行的v数据写进v_ram_1;将第2/10/18/26
…
行的v数据写进v_ram_2;
……
将第7/15/23/31
…
行的v数据写进v_ram_7。
31.通过fifo_wr_ctrl进行yuv数据读控制逻辑如下:在yuv420格式下,ram_rd_ctrl不关心video cmp ip发出的读地址,而只关心video cmp发出的读使能,依次去读16次y_fifo_0,16次y_fifo_1,
……
,16次y_fifo_15,8次u_fifo_0,8次u_fifo_1,
……
,8次u_fifo_7,8次v_fifo_0,8次v_fifo_1,
……
,8次v_fifo_7,然后依次循环。
32.yuv422格式下,ram_rd_ctrl不关心video cmp发出的读地址,而只关心video cmp ip发出的读使能,依次去读16次y_fifo_0,16次y_fifo_1,
……
,16次y_fifo_15,8次u_fifo_0,8次u_fifo_1,
……
,8次u_fifo_15,8次v_fifo_0,8次v_fifo_1,
……
,8次v_fifo_15,然后依次循环。
33.yuv444格式下,ram_rd_ctrl不关心video cmp ip发出的读地址,而只关心video cmp发出的读使能,依次去读8次y_fifo_0,8次y_fifo_1,
……
,8次y_fifo_7,8次u_fifo_0,8次u_fifo_1,
……
,8次u_fifo_7,8次v_fifo_0,8次v_fifo_1,
……
,8次v_fifo_7,然后依次循环。
34.上述传统的视频压缩系统,存在以下缺点:占用较多片内资源,fifo数量多会引发以下问题:增大芯片的制造面积、封装制造困难、引起时序约束、降低视频压缩效率等问题。例如,video cmp的数据总线接口是32bits或64bits,传统方案的读逻辑是每次读8bits,需要缓存4笔或8笔之后才能传输给video cmp进行压缩,加长了压缩时间,降低了压缩效率。
35.基于上述目的,本发明实施例的第一个方面,提出了一种用于基板管理控制芯片的视频压缩系统,如图3所示,视频压缩系统具体包括:色彩空间转换模块110、存储器120、fifo阵列模块130、读写控制模块140、视频压缩控制模块150,所述存储器120包括缓存空间121和压缩数据存储空间122,fifo阵列模块130包括多个fifo;基板管理控制芯片配置为将接收到的rgb视频数据以行的方式写入所述缓存空间121;所述色彩空间转换模块110配置为依次从所述缓存空间121读取每一行的rgb视频数据,并将所述rgb视频数据转换成y分量、u分量和v分量数据;所述fifo阵列模块130配置为基于所述fifo的数量对应设置所述fifo的位宽以使
所述fifo同时存储相邻两行的y分量或u分量或v分量数据;将第1~8个fifo设置为存储y分量数据、第9~16个fifo设置为存储u分量数据、第17~24个fifo设置为存储v分量数据,并将每个fifo的位宽设置为16比特以同时存储相邻两行的y分量或u分量或v分量数据;所述读写控制模块140配置为在每个时钟周期读取对应位置的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存;所述读写控制模块140还配置为在接收到视频压缩控制模块发出的读数据请求后,在每个时钟周期按照所述fifo阵列中每个fifo的排列顺序依次从对应的fifo中读取相邻两行对应位置的y分量或u分量或v分量数据组成block数据发送给所述视频压缩控制模块150;所述视频压缩控制模块150配置为对接收到的block数据进行压缩,并将压缩后的数据写入压缩数据存储空间。
36.具体的,存储器可以为sram(static random-access memory,静态随机存取存储器)、sdram(synchronous dynamic random-access memory,同步动态随机存取内存)和ddr等存储器中的任意一种,本实施例选用ddr。
37.本实施例中,fifo阵列模块包括24个fifo,并将每个fifo的位宽设置为16比特以同时存储相邻两行的y分量或u分量或v分量数据。需要说明的是,fifo阵列模块还可包括其他数量的fifo,但由于本发明的目的为同时存储相邻两行的y分量或u分量或v分量数据,以提高视频数据(y分量或u分量或v分量数据)的读出速度,因此,优选的,fifo阵列模块包括24个fifo,并将每个fifo的位宽设置为16比特,以在提高视频数据读出速度的前提下,保证视频数据的写入速度不会减慢。
38.基板管理控制芯片配置为执行以下步骤:接收主机发送的原始的rgb视频数据,并将接收到的rgb视频数据以行的方式写入缓存空间(source_data)。例如,原始的rgb视频数据的分辨率为1024*768,则每次写入768行rgb数据,每行写入的rgb数据的数量为1024个。将rgb数据以行方式写入缓存空间,有利于后续进行rgb数据到yuv数据的转换。
39.色彩空间转换模块配置为执行以下步骤:依次从缓存空间读取每一行的rgb视频数据,并将rgb视频数据的r分量、g分量和b分量数据转换成yuv数据,即y分量数据、u分量数据和v分量数据,其中,rgb视频数据为24bit,r分量、g分量和b分量分别占8bit。
40.fifo阵列模块配置为执行以下步骤:将前8个fifo设置为存储y分量数据、中间8个fifo设置为存储u分量数据、后8个fifo设置为存储v分量数据,并将每个fifo的位宽设置为16bit以同时存储相邻两行的y分量或u分量或v分量数据,如图4~图6所示,图4~图6左侧分别为传统的fifo阵列存储y分量数据、u分量数据、v分量数据的示意,右侧为本发明方案的fifo阵列存储y分量数据、u分量数据、v分量数据的示意,由此可以看出将每个fifo的位宽设置为16bit,减少了fifo阵列中fifo的数量,所需的总体缓存占用的面积减少,节约了制造成本。
41.读写控制模块包括写控制逻辑和读控制逻辑,写控制逻辑配置为执行以下步骤:将进行了格式转换后的yuv数据,按照cpu下发的压缩格式(yuv444或yuv422或
yuv420)进行yuv数据丢弃后,例如:yuv422压缩格式,需保留全部的y数据和偶数列的u/v数据;yuv420压缩格式需保留全部的y数据和偶数行偶数列的u/v数据;yuv444压缩格式需保留全部行全部列的y/u/v数据,根据各个压缩格式的要求进行相应的数据丢弃后,将保留的yuv数据写入fifo阵列,具体的写入过程为:在每个时钟周期读取同时对应行对应列的y分量、u分量和v分量数据,将同时读取的y分量、u分量和v分量数据分别同时写入各自对应的fifo进行缓存,例如:在一时钟周期内,同时读取第0行第0列的y分量、u分量和v分量数据,分别对应写入y_fifo_0、u_fifo_0、v_fifo_0。
42.更进一步的,读写控制模块还可以在写入过程中,根据cpu下发的压缩格式读取并写入需要保留的数据后,再对其余的数据进行丢弃。
43.结合图4~图6,对读写控制模块的写控制逻辑的写入过程进行说明,具体写入过程如下:1)yuv420格式a)y分量将第0/16/32/48
……
行的y数据依次写进y_fifo_new_0的前8bits空间,将第1/17/33/49
……
行的y数据依次写进y_fifo_new_0的后8bits空间,将第2/18/34/50
……
行的y数据依次写进y_fifo_new_1的前8bits空间,将第3/19/35/51
……
行的y数据依次写进y_fifo_new_1的后8bits空间,将第4/20/36/52
……
行的y数据依次写进y_fifo_new_2的前8bits空间,将第5/21/37/53
……
行的y数据依次写进y_fifo_new_2的后8bits空间,将第6/22/38/54
……
行的y数据依次写进y_fifo_new_3的前8bits空间,将第7/23/39/55
……
行的y数据依次写进y_fifo_new_3的后8bits空间,
……
,将第14/30/46/62
……
行的y数据依次写进y_fifo_new_7的前8bits空间,将第15/31/47/63
……
行的y数据依次写进y_fifo_new_7的后8bits空间。
44.b)u分量将第0/16/32/48
…
行的偶数列u数据写进u_fifo_new_0的前8bits空间,将第2/18/34/50
…
行的偶数列u数据写进u_fifo_ new_0的后8bits空间,
……
,将第12/28/44/60
…
行的偶数列u数据写进u_fifo_new_3的前8bits空间,将第14/30/46/62
…
行的偶数列u数据写进u_fifo_new_3的后8bits空间。
45.c)v分量将第0/16/32/48
…
行的偶数列v数据写进v_fifo_new_0的前8bits空间,将第2/18/34/50
…
行的偶数列v数据写进v_fifo_ new_0的后8bits空间,
……
,将第12/28/44/60
…
行的偶数列v数据写进v_fifo_new_3的前8bits空间,将第14/30/46/62
…
行的偶数列v数据写进v_fifo_new_3的后8bits空间。
46.2)yuv422压缩格式a)y分量将第0/16/32/48
……
行的y数据依次写进y_fifo_new_0的前8bits空间,将第1/17/33/49
……
行的y数据依次写进y_fifo_new_0的后8bits空间,将第2/18/34/50
……
行的y数据依次写进y_fifo_new_1的前8bits空间,将第3/19/35/51
……
行的y数据依次写进y_fifo_new_1的后8bits空间,将第4/20/36/52
……
行的y数据依次写进y_fifo_new_2的前8bits空间,将第5/21/37/53
……
行的y数据依次写进y_fifo_new_2的后8bits空间,将第6/
22/38/54
……
行的y数据依次写进y_fifo_new_3的前8bits空间,将第7/23/39/55
……
行的y数据依次写进y_fifo_new_3的后8bits空间,
……
,将第14/30/46/62
……
行的y数据依次写进y_fifo_new_7的前8bits空间,将第15/31/47/63
……
行的y数据依次写进y_fifo_new_7的后8bits空间。
47.b)u分量将第0/16/32/48
…
行的偶数列u数据写进u_fifo_new_0的前8bits空间,将第1/17/33/49
…
行的偶数列u数据写进u_fifo_new_0的后8bits空间,将第2/18/34/50
…
行的偶数列u数据写进u_fifo_new_1的前8bits空间,将第3/19/35/51
…
行的偶数列u数据写进u_fifo_new_1的后8bits空间,
……
,将第14/30/46/62
…
行偶数列的u数据写进u_fifo_new_7的前8bits空间,将第15/31/47/63
…
行偶数列的u数据写进u_fifo_new_7的后8bits空间。
48.c)v分量将第0/16/32/48
…
行的偶数列v数据写进v_fifo_new_0的前8bits空间,将第1/17/33/49
…
行的偶数列v数据写进v_fifo_new_0的后8bits空间,将第2/18/34/50
…
行的偶数列v数据写进v_fifo_new_1的前8bits空间,将第3/19/35/51
…
行的偶数列v数据写进v_fifo_new_1的后8bits空间,
……
,将第14/30/46/62
…
行偶数列的v数据写进v_fifo_new_7的前8bits空间,将第15/31/47/63
…
行偶数列的v数据写进v_fifo_new_7的后8bits空间。
49.3)yuv444格式a)y分量将第0/8/16/24
…
行的y数据写进y_fifo_new_0的前8bits存储空间,将第1/9/17/25
…
行的y数据写进y_fifo_new_0的后8bits存储空间,将第2/10/18/26
…
行的y数据写进y_fifo_new_1的前8bits存储空间,将第6/14/22/30
…
行的y数据写进y_fifo_new_3的前8bits存储空间,将第7/15/23/31
…
行的y数据写进y_fifo_new_3的后8bits存储空间。
50.b)u分量将第0/8/16/24
…
行的u数据写进u_fifo_new_0的前8bits存储空间,将第1/9/17/25
…
行的u数据写进u_fifo_new_0的后8bits存储空间,将第2/10/18/26
…
行的u数据写进u_fifo_new_1的前8bits存储空间,
……
,将第6/14/22/30
…
行的u数据写进u_fifo_new_3的前8bits存储空间,将第7/15/23/31
…
行的u数据写进u_fifo_new_3的后8bits存储空间。
51.c)v分量将第0/8/16/24
…
行的v数据写进v_fifo_new_0的前8bits存储空间,将第1/9/17/25
…
行的v数据写进v_fifo_new_0的后8bits存储空间,将第2/10/18/26
…
行的v数据写进v_fifo_new_1的前8bits存储空间,
……
,将第6/14/22/30
…
行的v数据写进v_fifo_new_3的前8bits存储空间,将第7/15/23/31
…
行的v数据写进v_fifo_new_3的后8bits存储空间。
52.上述方案实现了每个fifo的位宽设置为16bit时,yuv数据的写入。
53.读控制逻辑配置为执行以下步骤:在接收到视频压缩控制模块发出的读数据请求后,在每个时钟周期按照所述fifo阵列中每个fifo的排列顺序依次从对应的fifo中读取相邻两行对应位置的y分量或u分量或v分量数据组成block数据发送给视频压缩控制模块。
54.首先以yuv420格式下读取相邻两行对应位置的y分量数据组成第一个block数据为例,对读出的过程进行说明。
55.第一个由y数据组成的block,由第0行,第1行,
……
,第15行的前16个y分量数据组成,读16次y_fifo_new_0,一次读出16bits,共读出16*16=256bits数据,用y_fifo_new_0的前8bits空间的数据(共16*8=128bits)组成block数据的第1行,用y_fifo_new_0的后8bits空间的数据(共16*8=128bits)组成block数据的第2行,读16次y_fifo_new_1,用y_fifo_new_1的前8bits空间的数据(共16*8=64bits)组成block数据的第3行,用y_fifo_new_1的后8bits空间的数据(共16*8=64bits)组成block数据的第4行,
……
,读16次y_fifo_new_7,用y_fifo_new_7的前8bits空间的数据(共16*8=64bits)组成block数据的第14行,用y_fifo_new_7的后8bits空间的数据(共16*8=64bits)组成block数据的第15行。
56.由此可以看出,在传统方案的一个block数据全部读出,需要读16*16=256次fifo,即需要256个时钟才可以读出一个block数据的全部数据,本发明实施例读出组成一个block数据需要16*8=128次fifo,即只需要128个时钟周期就可以读出一个block数据。因此在写入侧的写入速度与传统方案一致的情况下,本发明实施例的读出速度较传统方案提升了1倍,大大的提高了视频压缩效率。
57.继续对yuv420格式下读取其他分量数据、yuv422格式下读出y、u、v分量数据和yuv444格式下读出y、u、v分量数据组成block数据的过程进行说明。
58.yuv420格式下的u分量读取过程为:读8次u_fifo_new_0,组成block的第0、1行,读8次u_fifo_new_1,组成block的第2、3行,读8次u_fifo_new_2,组成block的第4、5行,读8次u_fifo_new_3,组成block的第6、7行。传统方案下,需要读64次u_fifo,本发明实施例只需读32次。
59.yuv420格式下的v分量读取过程为:读8次v_fifo_new_0,组成block的第0、1行,读8次v_fifo_new_1,组成block的第2、3行,读8次v_fifo_new_2,组成block的第4、5行,读8次v_fifo_new_3,组成block的第6、7行,传统方案下,需要读64次v_fifo,本发明实施例只需要读32次。
60.然后依次循环,读阵列中对应的fifo中下一个位置的y、u、v分量数据组成下一个block数据。
61.yuv422格式的y分量读取过程为:读16次y_fifo_new_0,得到y_block数据的第0和1行,读16次y_fifo_new_1,得到y_block数据的第2和3行,
……
,读16次y_fifo_new_7,得到y_block数据的第14和15行,传统方案下,需要读y_fifo,16*16=256次,本发明实施例读16*8=128次。
62.yuv422格式的u分量读取过程为:读8次u_fifo_new_0,得到u_block数据的第0和1行,读8次u_fifo_new_1,得到u_block数据的第2和3行,
……
,读8次u_fifo_new_7,得到u_block数据的第14和15行,传统方案下,需要读u_fifo,16*8=128次,本发明实施例只需要读8*8=64次。
63.yuv422格式的v分量读取过程为:读8次v_fifo_new_0,得到v_block数据的第0和1行,读8次v_fifo_new_1,得到v_block数据的第2和3行,
……
,读8次v_fifo_new_7,得到v_block数据的第14和15行,传统方案下,需要读v_fifo,16*8=128次,本发明实施例只需要读8*8=64次。
64.yuv444格式的y分量读取过程为:读8次y_fifo_new_0,得到y_block数据的第0和1行,读8次y_fifo_new_1,得到y_
block数据的第2和3行,
……
,读8次y_fifo_new_3,得到y_block数据的第6和7行,传统方案下,需要读y_fifo,8*8=64次,本发明实施例只需要读8*4=32次。
65.yuv444格式的u分量读取过程为:读8次u_fifo_new_0,得到u_block数据的第0和1行,读8次u_fifo_new_1,得到u_block数据的第2和3行,
……
,读8次u_fifo_new_3,得到u_block数据的第6和7行,传统方案下,需要读u_fifo,8*8=64次,本设计方案下,只需要读8*4=32次。
66.yuv444格式的v分量读取过程为:读8次v_fifo_new_0,得到v_block数据的第0和1行,读8次v_fifo_new_1,得到v_block数据的第2和3行,
……
,读8次v_fifo_new_3,得到v_block数据的第6和7行,传统方案下,需要读v_fifo,8*8=64次,本发明实施例只需要读8*4=32次。
67.然后依次循环,读阵列中对应的fifo中下一个位置的y、u、v分量数据组成下一个block数据。
68.由此可以看出读写控制模块的视频数据读出速度大大提高,视频压缩效率大大提高。
69.读写控制模块将读出的数据发送到视频压缩控制模块,视频压缩控制模块对接收到的block数据进行压缩,并将压缩后的数据写入压缩数据存储空间(cmp_data)。
70.本实施例中,fifo阵列中yuv数据被读出的速度加快,导致yuv数据在fifo阵列中缓存的时间变短,因此需要的fifo容量将比传统的视频压缩系统小,根据项目经验,最高分辨率1920*1200下,需要的fifo深度是4096,需要的fifo的总的存储容量为192kb,较传统的768kb大大的较少,因此极大节省了项目成本,降低了传统视频压缩系统中由于fifo数量过多而引起的时序约束、封装制造困难等问题。
71.本实施例通过减少传统视频压缩系统中的fifo数量并增大每个fifo的位宽,以及优化读写控制模块的读控制逻辑的读出过程,降低了fifo所需的存储容量,节省了fifo在芯片上的占用空间,降低了项目成本,降低了传统视频压缩系统中由于fifo数量过多而引起的时序约束、封装制造困难等问题,提高了视频数据的读出速度以及视频压缩速度。
72.在一些实施方式中,所述fifo阵列模块包括24个fifo,所述fifo阵列模块配置为将第1~8个fifo设置为存储y分量数据、第9~16个fifo设置为存储u分量数据、第17~24个fifo设置为存储v分量数据,并将每个fifo的位宽设置为16比特以同时存储相邻两行的y分量或u分量或v分量数据。
73.本发明实施例,fifo阵列模块包括24个fifo,并将每个fifo的位宽设置为16比特,以在提高视频数据读出速度的前提下,保证视频数据的写入速度不会减慢。
74.在一些实施方式中,所述读写控制模块具体配置为根据压缩格式对转换后的y分量、u分量和v分量数据进行丢弃,并在完成数据丢弃后,在每个时钟周期读取保留的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存。
75.读写控制模块按照cpu下发的压缩格式(yuv444或yuv422或yuv420),对进行了格式转换后的yuv数据,进行对应的yuv数据丢弃后,将保留的yuv数据写入fifo阵列。例如:yuv422压缩格式,需保留全部的y数据和偶数列的u/v数据;yuv420压缩格式需保留全部的y数据和偶数行偶数列的u/v数据;yuv444压缩格式需保留全部行全部列的y/u/v数据。具体的写入过程为:在每个时钟周期读取同时对应行对应列的y分量、u分量和v分量数据,将同
时读取的y分量、u分量和v分量数据分别同时写入各自对应的fifo进行缓存,例如:在一时钟周期内,同时读取第1行第2列的y分量、u分量和v分量数据,分别对应写入y_fifo_0、u_fifo_0、v_fifo_0。
76.在一些实施方式中,所述缓存空间采用乒乓缓存结构,包括第一缓存空间和第二缓存空间;所述基板管理控制芯片还配置为将接收到的rgb视频数据以行的方式依次写入第一缓存空间和第二缓存空间;所述色彩空间转换模块还配置为依次从所述第一缓存空间和第二缓存空间读取相邻两行的rgb视频数据,并将相邻两行的rgb视频数据并行地转换成y分量、u分量和v分量数据;所述读写控制模块还配置为根据压缩格式对转换后的y分量、u分量和v分量数据进行丢弃,并在完成数据丢弃后,在每个时钟周期并行地读取相邻两行相同列号保留的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存。
77.结合图3,对本实施例进行说明,本实施例的大部分过程已在上一个实施例进行了详细解释说明,在此不再赘述,本实施中仅对区别部分进行解释说明。
78.为了进一步的加快视频数据处理速度,缓存空间采用乒乓缓存结构,包括第一缓存空间(source_data_0)和第二缓存空间(source_data_1)。
79.基板管理控制芯片将接收到的rgb视频数据以行的方式依次写入第一缓存空间和第二缓存空间,例如,将第0/2/4/6
…
行的rgb视频数据写入source_data_0地址空间,将第1/3/5/7
…
行的rgb视频数据写入spurce_data_1地址空间,第一缓存空间和第二缓存空间在存储的rgb视频数据被全部读出之后,对各自的缓存空间进行清除以继续存储下一行的rgb视频数据。
80.色彩空间转换模块依次从第一缓存空间和第二缓存空间读取相邻两行的rgb视频数据,并将相邻两行的rgb视频数据并行地转换成y分量、u分量和v分量数据,例如,色彩空间转换模块依次从source_data_0和source_data_1读取第0和第1行的rgb视频数据,将第0和第1行的rgb视频数据并行地转换为y分量、u分量和v分量数据,此处由于需要转换的rgb视频数据从之前的1行增加为2行,相应的增加色彩空间转换模块中的加法器和乘法器的数量以满足并行转换的需求。
81.读写控制模块根据压缩格式对转换后的y分量、u分量和v分量数据进行丢弃,并在完成数据丢弃后,在每个时钟周期并行地读取相邻两行相同列号保留的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存,即在每个时钟周期同时读取相邻两行相同列号保留的y分量、u分量和v分量数据,同时写入各自对应的fifo进行缓存。例如,在同一个时钟周期,将第0行的第0个y分量和第1行的第0个y分量,一起写入y_fifo_new_0。
82.本实施例在读写控制模块的视频数据读出速度加快的前提下,通过采用乒乓结构的双缓存空间以及优化色彩空间转换模块的转换运算逻辑使读写控制模块通过在一个时钟周期写入更多的yuv视频数据,提高了视频数据的写入速度,以使后级视频压缩模块可以更快的进行数据压缩,提高了视频压缩效率。
83.读写控制模块写入速度的加快,使原始rgb数据在存储器中的缓存时间变短,由此需要的缓存空间减小,soc(system on chip,片上系统)可以将更多的存储器的存储空间分
配给操作系统和/或其他模块,进一步的提升了soc系统的性能。
84.在一些实施方式中,所述读写控制模块还具体配置为在接收到视频压缩控制模块发出的读数据请求后,在每个时钟周期根据压缩格式以及所述fifo阵列中每个fifo的排列顺序依次从对应的fifo中读取相邻两行对应位置的y分量或u分量或v分量数据组成符合所述压缩格式要求的block数据发送给所述视频压缩控制模块。
85.在一些实施方式中,按以下公式将所述rgb视频数据转换成y分量、u分量和v分量数据:y = 0.257*r + 0.504*g + 0.098*b + 16u =
ꢀ‑
0.148*r
ꢀ‑ꢀ
0.291*g + 0.439*b + 128v = 0.439*r
‑ꢀ
0.368*g
ꢀ‑ꢀ
0.071*b + 128,其中,r表示rgb视频数据中的r分量,g表示rgb视频数据中的g分量,b表示rgb视频数据中的b分量。
86.具体的,传统的视频压缩系统需要9个乘法器和9个加法器,在本发明的采用乒乓结构的双缓存空间后,对应的将乘法器和加法器的数量修改为18个。
87.在一些实施方式中,视频压缩系统还包括网卡,所述网卡配置为从所述压缩数据存储空间读取压缩后的数据发送至远端以进行远端显示。
88.基于同一发明构思,根据本发明的另一个方面,如图7所示,本发明的实施例还提供了一种用于基板管理控制芯片的视频压缩方法,基于如上所述视频压缩系统,执行以下步骤:步骤s101、基板管理控制芯片将接收到的rgb视频数据以行的方式写入缓存空间;步骤s103、色彩空间转换模块依次从所述缓存空间读取每一行的rgb视频数据,并将所述rgb视频数据转换成y分量、u分量和v分量数据;步骤s105、fifo阵列模块基于fifo的数量对应设置所述fifo的位宽以使所述fifo同时存储相邻两行的y分量或u分量或v分量数据;步骤s107、读写控制模块在每个时钟周期读取每一行对应位置的y分量、u分量和v分量数据,并行地写入各自对应的fifo进行缓存;步骤s109、所述读写控制模块在接收到视频压缩控制模块发出的读数据请求后,在每个时钟周期按照所述fifo阵列中每个fifo的排列顺序依次从对应的fifo中读取相邻两行对应位置的y分量或u分量或v分量数据组成block数据发送给视频压缩控制模块;步骤s111、所述视频压缩控制模块对接收到的block数据进行压缩,并将压缩后的数据写入压缩数据存储空间。
89.本发明实施例的另一方面,还提供了一种计算机可读存储介质,计算机可读存储介质存储有被处理器执行时实现如上方法步骤的计算机程序。
90.基于同一发明构思,根据本发明的另一个方面,如图8所示,本发明的实施例还提供了一种计算机可读存储介质40,计算机可读存储介质40存储有被处理器执行时执行如上方法的计算机程序410。
91.基于同一发明构思,根据本发明的另一个方面,如图9所示,本发明的实施例还提供了一种服务器90,包括如上所述的视频压缩系统910。
92.本发明实施例还可以包括相应的计算机设备。计算机设备包括存储器、至少一个
处理器以及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时执行上述任意一种方法。
93.其中,存储器作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块,如本技术实施例中的所述视频压缩方法对应的程序指令/模块。处理器通过运行存储在存储器中的非易失性软件程序、指令以及模块,从而执行装置的各种功能应用以及数据处理,即实现上述方法实施例的视频压缩方法。
94.存储器可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据装置的使用所创建的数据等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,存储器可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至本地模块。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
95.本领域技术人员还将明白的是,结合这里的公开所描述的各种示例性逻辑块、模块、电路和算法步骤可以被实现为电子硬件、计算机软件或两者的组合。为了清楚地说明硬件和软件的这种可互换性,已经就各种示意性组件、方块、模块、电路和步骤的功能对其进行了一般性的描述。这种功能是被实现为软件还是被实现为硬件取决于具体应用以及施加给整个系统的设计约束。本领域技术人员可以针对每种具体应用以各种方式来实现的功能,但是这种实现决定不应被解释为导致脱离本发明实施例公开的范围。
96.以上是本发明公开的示例性实施例,但是应当注意,在不背离权利要求限定的本发明实施例公开的范围的前提下,可以进行多种改变和修改。根据这里描述的公开实施例的方法权利要求的功能、步骤和/或动作不需以任何特定顺序执行。上述本发明实施例公开实施例序号仅仅为了描述,不代表实施例的优劣。此外,尽管本发明实施例公开的元素可以以个体形式描述或要求,但除非明确限制为单数,也可以理解为多个。
97.应当理解的是,在本文中使用的,除非上下文清楚地支持例外情况,单数形式“一个”旨在也包括复数形式。还应当理解的是,在本文中使用的“和/或”是指包括一个或者一个以上相关联地列出的项目的任意和所有可能组合。
98.所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本发明实施例公开的范围(包括权利要求)被限于这些例子;在本发明实施例的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,并存在如上的本发明实施例的不同方面的许多其它变化,为了简明它们没有在细节中提供。因此,凡在本发明实施例的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明实施例的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1