一种基于深度强化学习算法的增强型ALOHA接入方法
一种基于深度强化学习算法的增强型aloha接入方法
技术领域
1.本发明涉及一种基于深度强化学习算法的增强型aloha接入方法,属于无线通信技术领域。
背景技术:
2.随着移动通信网络的快速发展,尤其是面向m2m(machine-to-machine)的应用场景需满足海量设备的接入需求。海量业务终端对基站提出接入请求,并以调度方式完成设备接入时,由于设备数量过大,极容易造成接入过载,以及调度信令拥塞。这将导致业务接入时延过大并造成极高的调度开销,使得资源利用率低,为了降低调度开销,随机接入成为研究的热点。
3.aloha作为一种经典的随机接入方式,用户以在数据到达时即发送的方式完成接入,大大降低信令开销。但是当网络负载较重时,节点极易产生冲突,导致网络吞吐量仅为0.18。与此同时,部分用户可能长时间无法成功发送,产生通信过程的公平性问题。时隙aloha(slotted aloha,sa)是对aloha进行改进,通过划分相等的时间片,每个时间片对应一个时隙,通过该限制减少了时间片内发生冲突的概率。时隙aloha信道利用率最高为0.368。分集时隙aloha(dsa)是在sa的基础上,采用了时间分集的方式,将各用户的数据包分成若干份,不同时间重复发送,以提升吞吐量。但是,上述方案中没有考虑到用户的等待时延这一指标,在发送过程中让用户随机发送,这样会导致部分用户产生过长的等待时间,使aoi过高,同时无法实时优化发送策略,使发送效率一直保持较优,而产生数据冲突导致的通信堵塞问题以及用户通信公平性问题。
技术实现要素:
4.针对现有的随机接入方案,存在接入用户量复杂变化出现的发送策略无法适应,从而产生数据冲突导致的通信堵塞问题以及用户通信公平性问题,本发明的主要目的是提供一种基于深度强化学习算法的增强型aloha接入方法,通过实时智能改变发送策略,提升通信吞吐能力,并为通信公平性提供增益。
5.本发明的目的是通过以下方案实现的:
6.本发明公开的一种基于深度强化学习算法的增强型aloha接入方法,采用强化学习,在探索学习中适应接入情况的复杂变化,实时进行随机接入策略的调制,具有更好的适应能力。采用dpsa接入方法,对于冲突数据进行恢复,基于强化学习算法确定每帧最佳发送概率,在低信令开销的情况下,提升通信吞吐能力。根据等待时间长短对用户进行分类,并对其采取不同的发送策略,缩减用户整体aoi差距,解决通信公平性问题。实现系统面对用户激活状况复杂变化的实时智能适应,选择合适的帧时隙发送概率,实现通信吞吐量与通信公平性的提升。
7.本发明公开的一种基于深度强化学习算法的增强型aloha接入方法,包括以下步骤:
8.步骤1:小区用户以预定激活概率被随机激活,用户根据增强型aloha接入策略在每一帧发送数据。在接收端解码,得到当前帧通信吞吐能力以及等待时间最长用户的aoi,并分别构造解码成功用户集合与解码失败用户集合。具体步骤为:
9.步骤1.1:小区用户以一定概率激活,激活用户构成激活用户集合;
10.步骤1.2:aoi降序排列,标记序列前端部分用户为等待时间过长用户,其余标记为非等待时间过长用户;
11.步骤1.3:非等待时间过长用户,以一定基准帧时隙发送概率,在当前帧的m个时隙中分别随机决定是否发送数据包;等待时间过长用户,在上述基准帧时隙发送概率下,将概率提高,在当前帧的m个时隙中分别随机决定是否发送数据包。若在同一时隙中存在多个用户同时发送数据包而产生冲突,则对各用户数据包进行叠加发送;
12.步骤1.4:接收端根据干扰消除技术对数据进行译码。当前帧数据译码成功用户构成解码成功用户集合,当前帧数据译码失败用户构成解码失败用户集合;
13.步骤1.5:解码成功用户所对应状态中aoi清零,解码失败用户对应状态中aoi增大;
14.步骤1.6:计算得到当前帧通信吞吐能力以及等待时间最长用户的aoi,其中当前帧通信吞吐能力为解码成功用户数除以当前帧激活用户数,等待时间最长用户的aoi为状态中用户aoi的最大值。
15.步骤2:搭建强化学习框架,构建深度q网络,即deep q network,dqn,具体步骤为:
16.步骤2.1:构建状态空间与动作空间,其中状态空间由各用户当前激活状态与各用户aoi组成,动作空间由不同帧时隙基准发送概率组成,确定状态s为状态空间中的元素,动作a为动作空间中的元素;
17.步骤2.2:根据当前帧通信吞吐能力与等待时间最长用户的aoi给定阶梯化奖励;
18.步骤2.3:构建目标q网络与实际q网络,二者结构相同,采用全连接神经网络结构;
19.步骤2.4:使用均方误差损失作为损失函数。
20.步骤3:智能体前x帧在强化学习框架下进行探索,通过引入随机动作扩充经验回放池,为智能体提供学习数据,步骤具体为:
21.步骤3.1:智能体以ε的贪婪率进行贪婪学习,根据贪婪算法选择动作a;
22.步骤3.2:动作a作为帧时隙发送概率,进行dpsa随机接入,得到当前帧通信吞吐能力与等待时间最长用户的aoi以及下一帧的状态s
′
;
23.步骤3.3:根据当前帧通信吞吐能力与等待时间最长用户的aoi确定当前帧的奖励r;
24.步骤3.4:将当前帧状态s、当前帧动作a、当前帧奖励r、下一帧状态s
′
存储到经验回放池中。
25.步骤4:x帧后,随机采样经验回放池中的样本进行学习,训练神经网络拟合接入策略,并继续发送数据,设置批大小为b,学习率为α,衰减因子为γ,具体步骤为:
26.步骤4.1:随机采样b个样本,将其中下一帧状态s
′
输入到目标q网络中,输出qn;
27.步骤4.2:根据样本中奖励r、衰减因子γ以及qn得到q
t
=r+γ(max(qn));
28.步骤4.3:上述样本中当前帧状态s输入到实际q网络中,输出qe;
29.步骤4.4:设置损失函数为qe与q
t
的均方误差;
30.步骤4.5:根据梯度下降方法训练实际q网络,学习率设置为α,批大小设置为b;
31.步骤4.6:每间隔y帧,从实际q网络中复制其权重以更新目标q网络权重;
32.步骤4.7:x帧后,智能体将当前状态s输入到实际q网络中,得到各动作对于q值,选择q值最大的作为当前帧动作a,以动作a作为当前帧发送概率发送数据,并得到此帧发送概率下的用户最大aoi以及通信吞吐性能情况,且在一定帧数后,用户平均最大aoi减小,通信吞吐性能明显提升。
33.有益效果
34.1、本发明公开的一种基于深度强化学习算法的增强型aloha接入方法,采用强化学习,在探索学习中适应接入情况的复杂变化,实时进行随机接入策略的调制,动态选择帧发送概率,有效提升通信平均吞吐量,避免传统方案存在的通信堵塞问题。
35.2、本发明公开的一种基于深度强化学习算法的增强型aloha接入方法,采用dpsa接入方法,对于冲突数据进行恢复,基于强化学习算法确定每帧最佳发送概率,在低信令开销的情况下,提升通信吞吐能力。
36.3、本发明公开的一种基于深度强化学习算法的增强型aloha接入方法,根据等待时间长短对用户进行分类,提高等待时间aoi过大用户的发送概率,缩减用户整体aoi差距,解决通信公平性问题。
附图说明
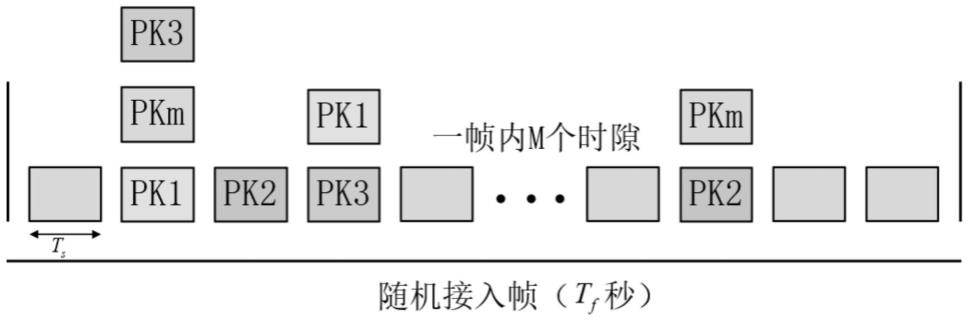
37.图1为本发明公开的一种基于深度强化学习算法的增强型aloha接入方法所述dpsa随机接入帧结构示意图;
38.图2为本发明公开的一种基于深度强化学习算法的增强型aloha接入方法的dqn流程示意图;
39.图3为本发明公开的一种基于深度强化学习算法的增强型aloha接入方法中的通信吞吐能力随帧数变化仿真示意图;
40.图4为本发明公开的一种基于深度强化学习算法的增强型aloha接入方法中的通信公平性性能仿真示意图。
具体实施方式
41.下面将结合附图和实施例对本发明加以详细说明。同时也叙述了本发明技术方案解决的技术问题及有益效果,需要指出的是,所描述的实施例仅旨在便于对本发明的理解,而对其不起任何限定作用。
42.实施例1
43.实施例的场景为一个蜂窝小区的200个用户,用户设备为手机,用户采用随机接入方法,每个用户以一定的概率随机激活,在全小区同步的帧时隙下发送,每一帧由100个均匀时隙组成。
44.小区用户接入方案采用本发明公开的一种基于深度强化学习算法的增强型aloha接入方法,具体操作流程如下:
45.步骤1:小区用户以一定激活概率被随机激活,并根据增强型aloha的接入策略发送,具体步骤为:
46.步骤1.a:小区用户以一定概率激活,激活用户构成激活用户集合;
47.步骤1.b:aoi降序排列,前10%用户标记为等待时间过长用户,其余标记为非等待时间过长用户;
48.步骤1.c:非等待时间过长用户以一定基准帧时隙发送概率在当前帧的100个时隙中分别随机决定是否发送数据包,等待时间过长用户在上述基准帧时隙发送概率下,将概率提高10%,在当前帧的100个时隙中分别随机决定是否发送数据包,若在同一时隙中存在多个用户同时发送数据包而产生冲突,则对各用户数据包进行叠加发送;
49.步骤1.d:接收端根据干扰消除技术对数据进行译码,当前帧数据译码成功用户构成解码成功用户集合,当前帧数据译码失败用户构成解码成功用户集合;
50.步骤1.e:解码成功用户所对应状态中aoi清零,解码失败用户对应状态中aoi加1;
51.步骤1.f:计算得到当前帧通信吞吐能力以及等待时间最长用户的aoi,其中当前帧通信吞吐能力为解码成功用户数除以当前帧激活用户数,等待时间最长用户的aoi为状态中用户aoi的最大值;
52.综上所述,用户根据增强型aloha接入策略在每一帧发送数据,在接收端解码,得到当前帧通信吞吐能力以及等待时间最长用户的aoi,并分别构造解码成功用户集合与解码失败用户集合。
53.步骤2:搭建强化学习框架,设计深度q网络(deep q network,dqn),具体步骤为:
54.步骤2.a:构建状态空间与动作空间,状态空间由各用户当前激活状态与各用户aoi组成,动作空间由不同帧时隙基准发送概率组成,确定状态a为状态空间中的元素,动作a为动作空间中的元素,其中动作空间为{0.03,0.05,0.07,0.09,0.13,0.15,0.17,0.19,0.21,0.23,0.25,0.27,0.29};
55.步骤2.b:根据当前帧通信吞吐能力与等待时间最长用户的aoi给定阶梯化奖励;
56.步骤2.c:构建目标q网络与实际q网络,二者结构相同,采用全连接神经网络结构;
57.步骤2.d:使用均方误差损失作为损失函数。
58.步骤3:系统在强化学习框架下进行探索,步骤具体为:
59.步骤3.a:前2000帧,系统以0.8的贪婪率进行贪婪学习,根据贪婪算法选择动作a;
60.步骤3.b:动作a作为帧时隙发送概率,进行dpsa随机接入,得到当前帧通信吞吐能力与等待时间最长用户的aoi以及下一帧的状态s
′
;
61.步骤3.c:根据当前帧通信吞吐能力与等待时间最长用户的aoi确定当前帧的奖励r;
62.步骤3.d:将当前帧状态s、当前帧动作a、当前帧奖励r、下一帧状态s
′
存储到经验回放池中。
63.步骤4:2000帧后,随机采样经验回放池中样本进行学习并继续发送数据,设置批大小为64,学习率为0.01,衰减因子为0.8,具体步骤为:
64.步骤4.a:随机采样64个样本,将其中下一帧状态s
′
输入到目标q网络中,输出qn;
65.步骤4.b:根据样本中奖励r、衰减因子γ以及qn得到q
t
=r+0.8(max(qn));
66.步骤4.c:上述样本中下一帧状态s
′
输入到实际q网络中,输出qe;
67.步骤4.d:设置损失函数为qe与q
t
的均方误差;
68.步骤4.e:根据梯度下降方法训练实际q网络;
69.步骤4.f:每间隔50帧,从实际q网络中复制其权重以更新目标q网络权重;
70.步骤4.g:2000帧后,系统将当前状态s输入到实际q网络中,得到各动作对于q值,选择q值最大的作为当前帧动作a,以动作a作为当前帧发送概率发送数据。
71.从步骤1到步骤4,完成了本实施例一种基于深度强化学习算法的增强型aloha接入方法。本实施例中,通过2000帧的贪婪学习后,通信吞吐能力逐步提升到0.65附近,如图3所示,稳定优于固定发送概率的其他方案。同时其aoi稳定在3.1左右,如图4所示,稳定低于固定发送概率的其他方案。
72.实验表明,本实施例公开的一种基于深度强化学习算法的增强型aloha接入方法,通过探索学习,对用户实时随机接入策略智能调整,动态选择帧发送概率,有效提升通信平均吞吐量,避免传统方案存在的通信堵塞问题;同时提高等待时间aoi(age of information)过大用户的发送概率,从而有效减少部分用户长时间无法发送的概率,为通信公平性提供了增益。实现用户的等待时间性能以及吞吐量性能之间的权衡优化。
73.以上所述的具体描述,对发明的目的、技术方案和有益效果进行进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1