一种基于梯度掩膜的智能波束选择性能提升方法
1.本发明涉及无线通信技术领域,尤其涉及基于深度学习的波束选择方法。
背景技术:
2.近年来,智能波束选择方法受到越来越多的关注,因其能够直接预测最优波束,节省信道估计或波束搜索开销而被广泛研究。一般而言,智能波束选择方法的基本范式是利用无线通信系统中的数据资源,训练一个神经网络学习输入数据与最优波束之间的映射关系,然后通过训练好的神经网络预测新数据对应的最优波束。因此,神经网络在新数据上的泛化性能对智能波束选择方法至关重要。过拟合是一个常见的损害神经网络泛化性能的原因,即仅在训练数据上获得很好的拟合,而在测试数据上不能准确的预测。特别的,过拟合问题在训练数据较少的情况下尤其严重,会大大降低基于深度学习的波束选择算法在实际使用时的准确率。
技术实现要素:
3.本发明的目的在于提供一种基于梯度掩膜的智能波束选择性能提升方法,通过一个基于梯度掩膜的正则化步骤,解决现有方法由于严重的过拟合现象带来的性能损失问题。
4.本发明的技术方案如下:一种基于梯度掩膜的智能波束选择性能提升方法,包括以下步骤:
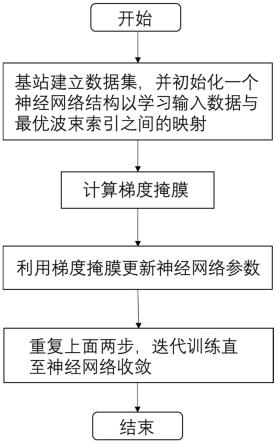
5.步骤1,基站收集数据,包括用户位置、光探测和测距数据、基站位置(作为神经网络的输入)和最优波束索引(作为神经网络的标签),建立数据集d。
6.进一步地,将同一时刻收集到的用户位置、光探测和测距数据、基站位置整合成为神经网络的输入x,并将该时刻的最优波束索引作为与之对应的标签y。一对输入和标签构成数据集中的一个样本(x,y)。
7.步骤2,基站建立并初始化一个以w为参数的深度神经网络结构,以学习输入数据与最优波束索引之间的映射。
8.进一步地,将所述的波束选择问题建模为在固定码本约束下接收信号功率最大化问题,具体如下:
[0009][0010]
其中,表示最优波束索引,m表示子载波数量,h表示信道,wq和f
p
表示用户端固定码本中的第q个码字和基站端固定码本中的第p个码字,(
·
)h表示转置。
[0011]
进一步地,所建立的神经网络结构具体如下:
[0012]
神经网络由3层卷积层和1层全连接层连接而成,卷积层提取输入的隐式特征,全
连接层将特征映射为预测的波束索引;
[0013]
神经网络使用激活函数引入非线性成分,增加模型的表达力。
[0014]
优选地,所述激活函数采用relu函数。
[0015]
步骤3,每一个训练回合开始之前,利用数据集d计算一个梯度掩膜。
[0016]
进一步地,具体计算方法如下:
[0017]
(1)用数据集d中的数据在当前神经网络上进行前向传播,根据选定的损失函数计算当前网络参数的梯度具体如下:
[0018][0019]
其中,l代表损失函数,w
t
代表当前训练回合的神经网络参数。
[0020]
(2)建立一个与梯度形状相同的张量,即梯度掩膜m
t
。
[0021]
(3)对张量中的梯度值求绝对值,将其按从大到小的顺序排序。对于前α的绝对值,梯度掩膜m
t
中的相应位置设为1;对于其余绝对值,梯度掩膜m
t
中的相应位置设为0。α是所述方法的超参数,0《α≤1,α越接近0,正则化程度越强。特别的,当α=1,所述方法将与一般的训练过程相同。
[0022]
优选地,所述损失函数采用交叉熵损失函数。
[0023]
步骤4,训练过程中,使用随机梯度下降算法更新神经网络的参数。每次执行更新之前,将梯度乘以事先计算的梯度掩膜,得到被遮挡的梯度,使用被遮挡的梯度代替原始梯度执行更新。
[0024]
进一步地,所述更新规则具体如下:
[0025]
(1)用数据集d中的数据在当前神经网络上进行前向传播,根据选定的损失函数计算当前网络参数的梯度g
t
,具体如下:
[0026][0027]
(2)梯度g
t
乘以梯度掩膜m
t
,得到被遮挡的梯度,使用被遮挡的梯度代替原始梯度更新神经网络的参数,具体如下:
[0028]wt+1
=w
t
+ηg
tmt
[0029]
其中,w
t+1
为更新的网络参数,η为学习率。
[0030]
进一步地,训练目标为数据在神经网络上的期望损失最小,具体如下:
[0031][0032]
其中,函数f表示优化目标,w表示神经网络的参数,函数l代表损失函数。
[0033]
步骤5,重复步骤3和步骤4,迭代训练直至模型收敛。
[0034]
本发明的有益效果:
[0035]
本发明提供一种基于梯度掩膜的智能波束选择性能提升方法,通过一个基于梯度掩膜的正则化步骤,减轻现有的基于深度学习的波束选择方法中常见的过拟合现象,从而提高波束选择的性能。
附图说明
[0036]
图1为本发明一种基于梯度掩膜的智能波束选择性能提升方法的流程图。
[0037]
图2为智能波束选择方法在测试数据集上的准确率曲线。
[0038]
图3为智能波束选择方法在测试数据集上的损失曲线。
具体实施方式
[0039]
下面结合附图和实施例对本发明的技术方案作进一步的说明。
[0040]
本实施例考虑一个下行的多输入多输出毫米波系统中的波束选择问题。系统中的基站配有32根天线,基站端码本中包含32个码字,用户配有8根天线,用户端码本中包含8个码字。
[0041]
如图1所示,本发明提出的基于梯度掩膜的智能波束选择性能提升方法的具体实施步骤包括:
[0042]
步骤1,基站收集数据,包括用户位置、光探测和测距数据、基站位置(作为神经网络的输入)和最优波束索引(作为神经网络的标签),建立数据集d。
[0043]
具体地,步骤1包括:
[0044]
步骤1.1,将同一时刻收集到的用户位置、光探测和测距数据、基站位置整合成为神经网络的输入x,并将该时刻的最优波束索引作为与之对应的标签y。一对输入和标签构成数据集中的一个样本(x,y)。
[0045]
步骤2,基站建立并初始化一个以w为参数的深度神经网络结构,以学习输入数据与最优波束索引之间的映射。
[0046]
具体地,步骤2包括:
[0047]
步骤2.1,将所述的波束选择问题建模为在固定码本约束下接收信号功率最大化问题,具体如下:
[0048][0049]
其中,表示最优波束索引,m表示子载波数量,h表示信道,wq和f
p
表示用户端固定码本中的第q个码字和基站端固定码本中的第p个码字,(
·
)h表示转置。
[0050]
步骤2.2,基站建立并初始化一个神经网络。具体的,神经网络结构如下:
[0051]
神经网络由3层卷积层和1层全连接层连接而成,卷积层提取输入的隐式特征,全连接层将特征映射为预测的波束索引;
[0052]
神经网络使用激活函数引入非线性成分,增加模型的表达力。具体的,本实施例采用relu函数作为激活函数。
[0053]
步骤3,每一个训练回合开始之前,利用数据集d计算一个梯度掩膜。
[0054]
具体地,步骤3包括:
[0055]
步骤3.1,用数据集d中的数据在当前神经网络上进行前向传播,根据选定的损失函数计算当前网络参数的梯度具体如下:
[0056][0057]
其中,l代表损失函数,w
t
代表当前训练回合的神经网络参数。具体的,本实施例使用交叉熵损失函数。
[0058]
步骤3.2,建立一个与梯度形状相同的张量,即梯度掩膜m
t
。
[0059]
步骤3.3,对张量中的梯度值求绝对值,将其按从大到小的顺序排序。对于前α的绝对值,梯度掩膜m
t
中的相应位置设为1;对于其余绝对值,梯度掩膜m
t
中的相应位置设为0。α是所述方法的超参数,0《α≤1,α越接近0,正则化程度越强。特别的,当α=1,所述方法将与一般的训练过程相同。具体的,本实施例中α=0.05。
[0060]
步骤4,训练过程中,使用随机梯度下降算法更新神经网络的参数。每次执行更新之前,将梯度乘以事先计算的梯度掩膜,得到被遮挡的梯度,使用被遮挡的梯度代替原始梯度执行更新。
[0061]
具体地,步骤4包括:
[0062]
步骤4.1,用数据集d中的数据在当前神经网络上进行前向传播,根据选定的损失函数计算当前网络参数的梯度g
t
,具体如下:
[0063][0064]
步骤4.2,用梯度g
t
乘以梯度掩膜m
t
,得到被遮挡的梯度,使用被遮挡的梯度代替原始梯度更新神经网络的参数,具体如下:
[0065]wt+1
=w
t
+ηg
tmt
[0066]
其中,w
t+1
为更新的网络参数,η为学习率。
[0067]
步骤4.3,按照上述加入梯度掩码的训练过程训练神经网络,训练目标为数据在神经网络上的期望损失最小,具体如下:
[0068][0069]
其中,函数f表示优化目标,w表示神经网络的参数,函数l代表损失函数。
[0070]
步骤5,重复步骤3和步骤4,迭代训练直至模型收敛。
[0071]
如图2所示,无梯度掩膜的传统深度学习方法出现了过拟合现象,测试数据准确率在达到最高值后,随训练回合数增加明显呈下降趋势。本发明提出的基于梯度掩膜的方法缓解了这种现象,在更长的训练回合中保持准确率上升趋势,并因此达到了更高的测试数据准确率,提升了波束选择性能。
[0072]
如图3所示,无梯度掩膜的传统深度学习方法在测试数据上的损失在降低到最低值后显著上升,本发明提出的基于梯度掩膜的方法减轻了这种上升趋势和程度,缓解了过拟合现象,使得智能波束算法拥有更好的泛化性能。
[0073]
以上所述,仅为本发明的具体实施方式,并不用于限定本发明的保护范围。对本发明技术方案的任何修改或等效替换,凡不脱离本发明技术方案的精神和范围,均涵盖在本发明的权力要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1