高直链淀粉小麦-III的制作方法
本申请要求2016年7月5日提交的澳大利亚临时专利申请号2016902643的优先权,该临时专利申请的整个公开内容通过引用包括在本文中。本说明书描述了获得具有高直链淀粉的六倍体小麦植物的方法和此类植物,并且特别是来自此类植物的籽粒或淀粉在食物和非食物产品范围内的用途。
背景技术:
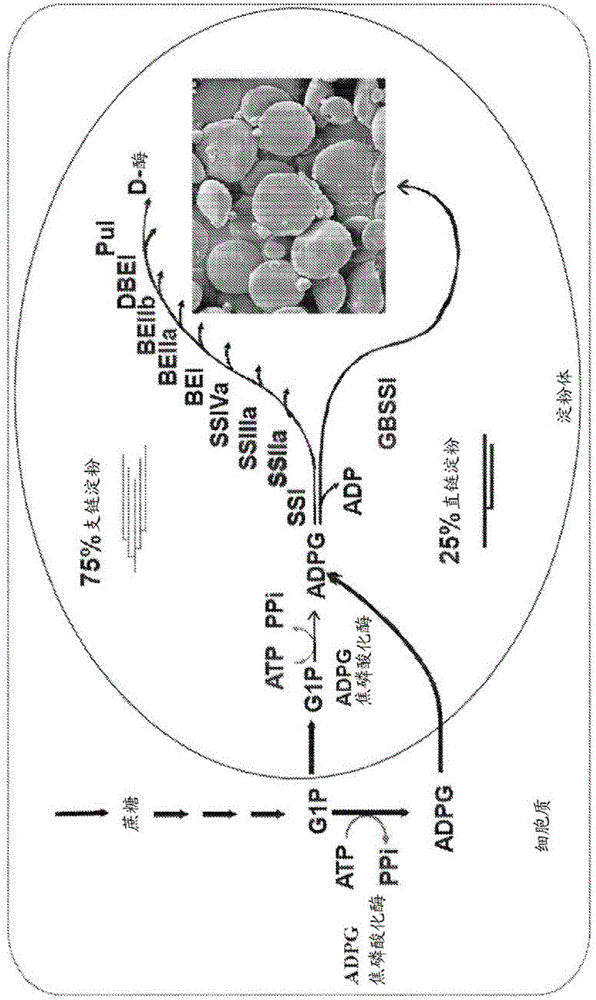
:在本说明书中对任何现有技术的参考不是,并且不应被视为对这种现有技术形成任何国家中公知常识的一部分的承认或任何形式的暗示。在本申请全文中,参考了各种出版物,包括在圆括号内参考的。在说明书的结尾紧接着权利要求之前可以发现以字母顺序列出的对在圆括号中参考的出版物的完整引用。所有参考的出版物的公开内容以引用的方式整体并入本申请以便更全面描述本发明涉及的技术现状。由小麦籽粒生产的食物为世界人口供应至少20%的食物千焦耳,并且提供很大一部分的蛋白质和非淀粉多糖以及人类膳食的能量摄入。淀粉是小麦籽粒的主要组分并且用于广泛食物和非食物产品中。淀粉特征会变化并且它们在确定小麦淀粉对特定最终用途的适用性方面起着关键作用。尽管有这么庞大的全球消耗量,并且尽管已经逐渐意识到淀粉功能对最终产品质量的重要性,但是对小麦中的遗传变异和它对淀粉的特征的确切影响的研究仍滞后于其他在商业上重要的植物作物。碳水化合物占成熟小麦籽粒的约65%-75%(stone和morell,2009)。小麦籽粒中的主要碳水化合物是淀粉,其由葡萄糖的两种聚合物即直链淀粉和支链淀粉组成。直链淀粉是α-1,4连接的葡萄糖单元的基本上线性的聚合物,具有少量分支,而支链淀粉是相对高度支化的,具有连接α-1,4连接的葡萄糖单元的直链的α-1,6糖苷单元键。直链淀粉与支链淀粉的比率在以下方面似乎是主要决定因素:(i)小麦籽粒和小麦淀粉的健康益处和(ii)包含小麦淀粉的产品的最终质量。小麦籽粒中对于健康的第二重要决定因素是籽粒中非淀粉多糖(形成膳食纤维的一部分)的量。野生型小麦籽粒具有按重量计约1%的寡糖诸如棉子糖、约1%的果聚糖和约10%的细胞壁多糖,主要是纤维素、阿拉伯木聚糖和β-葡聚糖(stone和morell,2009)。这些形成膳食纤维的主要组分,它们在小肠中不被消化和吸收,而是进入结肠,在结肠中它经历细菌降解。膳食纤维对于调节血糖和胰岛素水平以及肠健康很重要。具有含有相对量增加的直链淀粉的淀粉的谷物籽粒对其健康益处特别重要。已发现包含增加的直链淀粉的食物的抗性淀粉(rs)(一种膳食纤维形式)水平较高。rs是淀粉或部分消化的淀粉产品,其在小肠中不被消化和吸收。已经逐渐看出抗性淀粉在促进肠道健康和预防疾病诸如结肠直肠癌、ii型糖尿病、肥胖症、心脏病和骨质疏松症中具有重要作用。作为一种促进肠健康的手段,已经在用于食物中的某些谷物诸如玉米和小麦中开发高直链淀粉的淀粉。抗性淀粉的有益作用由于向其中向肠道微生物群给予能源的大肠提供营养素而产生,其经发酵形成短链脂肪酸。这些短链脂肪酸为结肠细胞提供营养素、增强大肠对某些营养素的摄取并促进结肠的生理活动。通常,如果不向结肠提供抗性淀粉或其他膳食纤维,则结肠在代谢上变得相对不活跃。因此,高直链淀粉产品具有提供增加的纤维消耗的潜力。消耗高直链淀粉小麦籽粒或其产品诸如淀粉的进一步潜在健康益处包括增强血液中糖、胰岛素和脂质水平的调节。另外,此类食物可以促进饱腹感、改善轻泻、促进益生菌的生长和增强粪便胆汁酸的排泄。大多数加工的淀粉类食物含有非常少的rs。使用野生型小麦粉和常规配方和烘焙工艺制成的面包含有<1%rs。相比之下,使用相同工艺和储存条件烘焙但由于降低籽粒中淀粉分支酶活性而含有高直链淀粉小麦粉的面包具有高达10倍的rs水平(wo2006/069422)。作为人类膳食中rs的少数丰富来源之一的豆类含有通常<5%的rs水平。因此,以成人通常所消耗的量(例如200g/d)计,消耗高直链淀粉的小麦面包将轻易地供应至少5-12g的rs。因此,将高直链淀粉小麦籽粒掺入到食物产品中具有对人类的膳食rs摄取作出巨大贡献的潜力。淀粉最初在植物中的光合作用组织(诸如叶子)的叶绿体中以过渡淀粉形式合成。这在随后的暗期过程中被调动,从而供应碳以用于输出到库器官和能量代谢或用于储存于诸如种子或块茎的器官中。淀粉的合成和长期储存发生于储存器官(诸如谷物胚乳)的淀粉体中,在所述淀粉体中淀粉是以直径高达100μm的半结晶颗粒形式沉积的。颗粒含有直链淀粉和支链淀粉,前者通常作为天然淀粉颗粒中的非晶态物质,而后者通过线性糖苷链的堆叠而是半结晶的。颗粒还含有一些参与淀粉生物合成的蛋白质。胚乳中淀粉的合成涉及至少四种类型的酶(图1)。首先,adp-葡萄糖焦磷酸化酶(adgp)催化从葡萄糖-1-磷酸和atp合成adp-葡萄糖。其次,各种各样的淀粉合酶(ss;ec2.4.1.21)催化葡萄糖残基通过α-1,4键从adp-葡萄糖转移至非还原端以延长α-葡聚糖链。第三,淀粉分支酶(sbe)在α-聚葡聚糖中形成新的α-1,6键。最后,淀粉脱支酶(dbe)然后通过尚未完全解析的机制去除一些分支键。虽然很明显至少这四种活性是高等植物中正常淀粉颗粒合成所必需的,但是在高等植物的胚乳中发现了每种酶的多种同工型。已经基于突变分析或通过使用转基因方法修饰基因表达水平,提出了一些同工酶的特定作用(abel等人,1996;jobling等人,1999;schwall等人,2000)。然而,每种同工酶的贡献在物种之间显著不同,并且每种同工型对淀粉生物合成的确切贡献仍然是未知的。对于六倍体面包小麦(普通小麦(triticumaestivum))尤其如此,其具有定义基因组a、b和d的三组同源染色体。六倍体被认为是研究和开发可用的小麦变体的重要障碍。事实上,关于小麦的同源基因如何相互作用、它们的表达如何被调节,以及由同源基因产生的不同蛋白质如何单独或协同工作的知识是有限的。在玉米、稻米和小麦中,酶淀粉合酶i(ssi)、淀粉合酶iia(ssiia)和淀粉合酶iiia(ssiiia)可能与其他ss一起参与支链淀粉合成。例如,在稻米中,存在10种不同的淀粉合酶,包括两种颗粒结合形式(gbss)。已经分离出ssiia缺陷的小麦、大麦和稻米突变体,但这三种物种在因ssiia丧失产生的表型上显示出不同影响,特别是在影响程度上。完全缺乏sgp-1(ssiia)蛋白的ssiia突变型小麦植物通过使缺乏a、b和d基因组特异性形式的sgp-1蛋白的株系杂交而产生(yamamori等人,2000)。ssiia三重无效籽粒表现出变形的淀粉颗粒并且淀粉具有改变的支链淀粉结构。淀粉的直链淀粉含量为30%-37%w/w,相比于野生型水平增加约8%,并且淀粉含量实质上降低(yamamori等人,2000)。与来自相应野生型籽粒的淀粉相比,来自ssiia三重无效突变体的淀粉表现出降低的糊化温度。ssiia三重无效籽粒的淀粉含量从野生型籽粒中的至少60%w/w降低至小于50%。在yamamori等人,(2000)中没有提出通过组合ssiia基因突变可以产生其淀粉中直链淀粉含量大于45%的小麦的示意,实际上yamamori等人教导了相反的情况。konik-rose等人(2007)证实了这一点,他们在与小麦品种sunco杂交的三重无效ssiia突变体的淀粉中获得了最大43.98%的直链淀粉。在大麦中,ssiia基因中化学诱导的无效突变大大降低了支链淀粉的合成,从而将籽粒淀粉中直链淀粉的比例提高到65%-70%w/w(wo02/37955-a1;morell等人,2003)。粳稻包含ssiia突变,该ssiia突变相对于籼稻减少了胚乳中的ssiia酶,但与籼稻籽粒淀粉相比,粳稻籽粒淀粉中的直链淀粉水平没有实质性升高。在稻米中,sbeiib和ssiiia基因的突变组合对直链淀粉的相对量具有更实质性的影响(asai等人,2014)。小麦、大麦和稻米中ssiia无效突变的不同影响归因于缺乏ssiia蛋白对淀粉合酶i(ssi)和淀粉分支酶iib(sbeiib)酶在发育这些ssiia突变体的胚乳中的淀粉颗粒内外分配的不同程度的多效性作用(luo等人,2015)。此外,对ssi和sbeiib蛋白的翻译后水平的不同影响可能影响了剩余的支链淀粉结构。这是一个实例,其中一种谷物物种中的观察结果不能简单地外推到淀粉合成领域的另一种谷物物种。在玉米和稻米中,通过编码淀粉分支酶iib的sbeiib基因(也称为直链淀粉扩展子(ae)基因)而不是ssiia基因中的突变产生高直链淀粉表型(boyer和preiss,1981;mizuno等人,1993;nishi等人,2001)。在这些sbeiib突变体中,直链淀粉含量以占淀粉含量的比例计显著升高,残留支链淀粉的分支频率降低并且短链(<dp17,尤其是dp8-12)的比例降低。此外,淀粉的糊化温度增加。为了在玉米中获得直链淀粉水平的进一步增加,产生了具有降低的淀粉分支酶i(sbei)活性以及sbeii活性几乎完全失活的品种(sidebottom等人,1998)。通过单独降低sbeiia活性(regina等人,2006)而不降低sbeiib或ssiia活性,已经产生了具有以占淀粉含量的比例计至少50%的直链淀粉的小麦。与玉米和稻米相比,单独减少sbeiib的小麦不会产生增加的直链淀粉含量。国际公布号wo2005/001098和国际公布号wo2006/069422描述了包含外源性双链体rna的转基因六倍体小麦,所述外源性双链体rna降低了胚乳中sbeiia和sbeiib基因中的一者或两者的表达。来自转基因株系的籽粒表达降低的sbeiia和/或sbeiib蛋白水平。胚乳中sbeiia蛋白的减少与相对直链淀粉水平增加超过50%相关,而sbeiib蛋白单独的缺乏似乎没有实质上改变籽粒淀粉中直链淀粉的比例。国际公布号wo2012/058730和wo2013/063653报道了实质上缺乏sbeiia和sbeiib蛋白表达的非转基因sbeiia和/或sbeiib三重无效突变体的产生,所述突变体表现出增加的直链淀粉水平。sbeiia三重无效基因型的籽粒是有存活力的,条件是至少一个sbeiia基因突变是点突变而不是越过该基因延伸到邻近区域中的缺失。因此,如果需要产生具有至少50%直链淀粉的高直链淀粉小麦,则sbeiia基因是将在面包小麦中被靶向的基因。在具有降低的sbeii活性并且在其淀粉中直链淀粉增加(>50%)的小麦(例如wo2010/006373)中,非淀粉多糖诸如果聚糖的水平没有增加。本领域需要改进的高直链淀粉小麦植物及其生产方法。技术实现要素:本发明人出乎意料地发现,通过组合小麦a、b和d基因组上的三种ssiia基因的突变,通过育种和选择可以产生六倍体小麦籽粒,所述六倍体小麦籽粒具有以占籽粒的总淀粉含量的重量百分比计至少45%的直链淀粉含量。现有技术已经表明45%的直链淀粉是不可实现的,实际上ssiia突变型小麦中的直链淀粉水平通常为30%-38%(yamamori等人,2000)。三个突变中的至少两个是无效突变,优选所有三个是无效突变。因为ssiia中功能突变的丧失是隐性的,所以当突变处于纯合状态时可以看到表型。本发明人还发现突变体ssiia小麦籽粒具有显著增加的非淀粉多糖,特别是β-葡聚糖、果聚糖、阿拉伯木聚糖和纤维素的水平,每种水平以占籽粒重量的百分比计。这导致总纤维含量的实质性增加,以及蛋白质含量和其他有利表型的相关增加。在第一方面,本发明因此提供了普通小麦物种的小麦籽粒,所述籽粒包含i)在其ssiia基因中的每一种中的突变,使得籽粒对于其ssiia-a基因中的突变是纯合的,对于其ssiia-b基因中的突变是纯合的并且对于其ssiia-d基因中的突变是纯合的,其中所述ssiia基因中的突变中的至少两个是无效突变,优选所有三个均是无效突变,ii)总淀粉含量,所述总淀粉含量包含直链淀粉含量和支链淀粉含量,iii)果聚糖含量,所述果聚糖含量基于重量相对于野生型小麦籽粒是增加的,优选在籽粒重量的3%与12%之间,iv)β-葡聚糖含量,v)阿拉伯木聚糖含量,以及vi)纤维素含量,所述籽粒具有在25mg与60mg之间的籽粒重量,其中所述直链淀粉含量如通过碘结合测定所确定基于重量在所述籽粒的所述总淀粉含量的45%与70%之间,其中所述支链淀粉含量基于重量相对于所述野生型小麦籽粒是降低的,其中所述β-葡聚糖含量、阿拉伯木聚糖含量和纤维素含量中的每一种均基于重量相对于所述野生型小麦籽粒是增加的,使得所述果聚糖含量、β-葡聚糖含量、阿拉伯木聚糖含量和纤维素含量的总和在所述籽粒重量的15%与30%之间。本发明进一步提供了能够产生或获自该籽粒的小麦植物,和由该籽粒产生的产品诸如面粉、麸皮、小麦淀粉颗粒和小麦淀粉。本发明还提供了食物成分,所述食物成分包括本发明的籽粒或由该籽粒产生的材料。还提供了包括这些食物成分的食物产品和包含本发明的籽粒或由该籽粒产生的材料的组合物。食物成分可以是粗磨的、破裂的、煮半熟的、轧制的、成珍珠状的、碾磨的或研磨的籽粒或这些的任何组合。优选的成分是面粉,最优选全麦粉或全麦粉和白面粉的混合物。由于掺入了来自本发明的小麦籽粒的材料,这些成分相对于来自野生型小麦的相应成分具有增加的总纤维水平。在另一方面,本发明提供了用于产生能够产生本发明的籽粒的小麦植物的方法,所述方法包括步骤(i)使两株亲本小麦植物杂交,所述亲本小麦植物各自在一种、两种或三种选自ssiia-a、ssiia-b和ssiia-d的ssiia基因中包含无效突变,或对优选包含所述无效突变中的一种或两种的亲本植物进行诱变;和步骤(ii)筛选由所述杂交或诱变获得的植物或籽粒,或由其获得的子代植物或籽粒,通过分析来自所述植物或籽粒的dna、rna、蛋白质、淀粉颗粒或淀粉进行,以及步骤(iii)选择相对于步骤(i)的所述亲本小麦植物中的至少一株具有降低的ssiia活性的能育小麦植物。在另一方面,本发明提供了用于改善有需要的受试者的代谢健康、肠健康或心血管健康的一个或多个参数,或者预防代谢疾病诸如糖尿病、肠疾病或心血管疾病或降低所述代谢疾病、肠疾病或心血管疾病的严重性或发生率的方法,所述方法包括向所述受试者提供本发明的籽粒或食物产品。在仍另一个方面,本发明提供了产生小麦籽粒料斗的方法,所述方法包括:a)收割包括本发明小麦籽粒的小麦秸秆;b)脱粒和/或风选所述秸秆以将所述籽粒与谷壳分离;以及c)筛选和/或分选步骤b)中分离的所述籽粒,并且将所述筛选和/或分选出的籽粒装入到料斗中,从而产生小麦籽粒料斗。在上述每个方面的实施方案中,小麦籽粒的特征进一步在于如下特征中的一个或多个或全部。直链淀粉含量如通过碘结合测定所确定相对于野生型小麦籽粒是增加的,例如在籽粒的总淀粉含量的48%与70%之间,优选50%与65%之间。在实施方案中,直链淀粉含量在50%与70%之间,或为约48%、约50%、约53%、约55%、约60%或约65%。籽粒的淀粉含量相对于野生型小麦籽粒是降低的,例如为至少25%。在实施方案中,本发明籽粒的淀粉含量在籽粒重量的30%与70%之间、25%与65%之间、25%与60%之间、25%与55%之间、25%与50%之间、30%与70%之间、30%与65%之间、30%与60%之间、30%与55%之间或30%与50%之间。在另外的实施方案中,淀粉含量以占籽粒重量的百分比(w/w)计为约35%、约40%、约45%、约50%、约55%、约60%或约65%。在一个实施方案中,从本发明的籽粒获得的淀粉颗粒的至少50%,优选至少60%或至少70%、更优选至少80%显示出变形的形状和/或表面形态。籽粒的淀粉包含至少2%的抗性淀粉,优选至少3%的抗性淀粉、更优选在3%与15%之间的rs或在3%与10%之间的rs。淀粉的特征在于降低的糊化温度,所述糊化温度可以通过差示扫描量热法(dsc)容易地测量,例如dsc扫描中的第一峰出现在比野生型淀粉低2℃-8℃的温度下。在实施方案中,籽粒的bg含量是β-葡聚糖含量,其基于绝对量相对于野生型籽粒增加1%或2%并且/或者基于重量相对于野生型小麦籽粒增加2倍至7倍。在实施方案中,bg水平为籽粒重量的至少1%或至少2%,优选在1%与4%之间或1%与5%之间,优选约2%、约3%、约4%,更优选在2%与5%之间。在实施方案中,阿拉伯木聚糖含量基于绝对量增加1%至5%并且/或者纤维素含量基于绝对量增加1%至5%。在优选的实施方案中,籽粒(在防止其发芽的任何处理之前)具有相对于野生型小麦籽粒在约70%与约100%之间的发芽率,并且籽粒在播种时产生小麦植物,所述小麦植物是雄性和雌性能育的。这些表型中的每一种均与ssiia活性的降低相关,而籽粒在小麦植物中发育,这是ssiia基因突变的结果。以上概述不是并且不应以任何方式看作是本发明的所有实施方案的一个详尽叙述。附图说明图1.涉及谷物籽粒中针对直链淀粉和支链淀粉的淀粉合成的酶的示意图。图2.小麦株系c57的a基因组中小麦ssiia-a基因突变的示意性基因图谱。上面的行示出ssiia-a基因的外显子的图谱。下面是来自野生型中国春(chinesespring)和突变型c57的ssiia-a基因的区域的核苷酸序列,所述突变型c57显示出包括atg翻译起始密码子的外显子1中的289个核苷酸的缺失和8个核苷酸的插入,净缺失大小为281个核苷酸。示出了引物jkss2ap1f和jkss2ap2r的位置。图3.小麦株系k79的b基因组中小麦ssiia-b基因突变的示意性基因图谱。上面的行示出ssiia-b基因的外显子的图谱。下面是来自野生型中国春(cs)和突变型k79的ssiia-b基因的区域的核苷酸序列,所述突变型k79显示出179个核苷酸插入到ssiia-b的外显子8中。示出了引物jkss2bp7f和jltss2bpr1的位置。图4.小麦株系turkey116的d基因组中小麦ssiia-d基因突变的示意性基因图谱。上面的行示出ssiia-d基因的外显子的图谱。下面是来自野生型中国春(cs)和突变型t116的ssiia-d基因的区域的核苷酸序列,所述突变型t116显示出跨越ssiia-d的外显子5和内含子5的接点(内含子5剪接位点)的63个核苷酸的缺失。示出了引物jtss2d3f和jtss2d4r的位置。图5.用于产生sunco遗传背景中的三重无效ssiia突变体的杂交和回交程序的示意图。图6.用于产生egahume遗传背景中的三重无效ssiia突变体的杂交和回交程序的示意图。图7.用于产生westonia遗传背景中的三重无效ssiia突变体的杂交和回交程序的示意图。图8.在针对egahume、sunco和westonia遗传背景中的各个小麦株系的三重无效ssiia籽粒(abd)和野生型ssiia籽粒(wt)中,上图示出了平均籽粒重量(mg/籽粒)并且下图示出了总脂质含量(占籽粒的重量%)。图9.针对egahume、sunco和westonia遗传背景中的三重无效突变体(abd)和wt基因型的图8中数据的平均值,示出了标准偏差。用相同字母(a、b、c)指示的竖条在统计上没有显著差异,而具有不同字母的竖条具有显著差异。图10.在针对egahume、sunco和westonia遗传背景中的各个小麦株系的三重无效ssiia籽粒(abd)和野生型ssiia籽粒(wt)中,最上图示出了支链淀粉含量(基于重量占淀粉含量的%),中间图示出了直链淀粉含量(基于重量占淀粉含量的%,通过碘结合方法)并且下图示出了总淀粉含量(占籽粒的重量%)。图11.针对egahume、sunco和westonia遗传背景中的三重无效突变体(abd)和wt基因型的图10中数据的平均值,示出了标准偏差。用相同字母(a、b、c)指示的竖条在统计上没有显著差异,而具有不同字母的竖条具有显著差异。图12.在针对egahume、sunco和westonia遗传背景中的各个小麦株系的三重无效ssiia籽粒(abd)和野生型ssiia籽粒(wt)中,上图示出了总纤维含量(基于重量占籽粒的%)并且下图示出了总bg含量(基于重量占籽粒的%)。图13.针对egahume、sunco和westonia遗传背景中的三重无效突变体(abd)和wt基因型的图12中数据的平均值,示出了标准偏差。用相同字母(a、b、c)指示的竖条在统计上没有显著差异,而具有不同字母的竖条具有显著差异。图14.在针对egahume、sunco和westonia遗传背景中的各个小麦株系的三重无效ssiia籽粒(abd)和野生型ssiia籽粒(wt)中,最上图示出了果聚糖含量(基于重量占籽粒的%),中间图示出了阿拉伯木聚糖含量(基于重量占籽粒的%)并且下图示出了纤维素含量(基于重量占籽粒的%)。图15.在针对egahume、sunco和westonia遗传背景中的各个小麦株系的三重无效ssiia籽粒(abd)和野生型ssiia籽粒(wt)中,上图示出了平均籽粒重量(mg/籽粒)并且下图示出了总脂质含量(mg/籽粒)。图16.针对egahume、sunco和westonia遗传背景中的三重无效突变体(abd)和wt基因型的图15中数据的平均值,示出了标准偏差。用相同字母(a、b、c)指示的竖条在统计上没有显著差异,而具有不同字母的竖条具有显著差异。图17.在针对egahume、sunco和westonia遗传背景中的各个小麦株系的三重无效ssiia籽粒(abd)和野生型ssiia籽粒(wt)中,最上图示出了支链淀粉含量(mg/籽粒),中间图示出了直链淀粉含量(mg/籽粒)并且下图示出了总淀粉含量(mg/籽粒)。图18.针对egahume、sunco和westonia遗传背景中的三重无效突变体(abd)和wt基因型的图17中数据的平均值,示出了标准偏差。用相同字母(a、b、c)指示的竖条在统计上没有显著差异,而具有不同字母的竖条具有显著差异。图19.在针对egahume、sunco和westonia遗传背景中的各个小麦株系的三重无效ssiia籽粒(abd)和野生型ssiia籽粒(wt)中,上图示出了总纤维含量(mg/籽粒)并且下图示出了总bg含量(mg/籽粒)。图20.针对egahume、sunco和westonia遗传背景中的三重无效突变体(abd)和wt基因型的图19中数据的平均值,示出了标准偏差。用相同字母(a、b、c)指示的竖条在统计上没有显著差异,而具有不同字母的竖条具有显著差异。图21.在针对egahume、sunco和westonia遗传背景中的各个小麦株系的三重无效ssiia籽粒(abd)和野生型ssiia籽粒(wt)中,最上图示出了果聚糖含量(mg/籽粒),中间图示出了阿拉伯木聚糖含量(mg/籽粒)并且下图示出了纤维素含量(mg/籽粒)。图22.针对egahume、sunco和westonia遗传背景中的三重无效突变体(abd)和wt基因型的图21中数据的平均值,示出了标准偏差。用相同字母(a、b、c)指示的竖条在统计上没有显著差异,而具有不同字母的竖条具有显著差异。图23.在三种选择的sunco遗传背景中的三重无效突变体(sunco-abd)和野生型(wt)籽粒中以占淀粉的百分比计的抗性淀粉含量。三种突变体彼此没有显著差异,但与wt具有显著差异。图24.来自5个三重ssiia突变型株系的脱支淀粉的链长度分布(cld)曲线与相应野生型淀粉相比的平均mol%差异。对于ssiia突变型淀粉,与相应野生型的短链和中间链相比,短链(dp6-10)的频率增加,而中间链(dp11-24)的频率减小。图25.来自三重无效ssiia突变型籽粒的淀粉和相应野生型小麦淀粉在淀粉的异淀粉酶脱支之后的尺寸排阻色谱(sec)曲线。迹线示出了根据其聚合度(x轴线)的洗脱级分的归一化折光指数(ri)信号的分布。第一洗脱峰(i)是直链淀粉,第二个(ii)是长链支链淀粉并且峰iii是(脱支的)支链淀粉。黑色迹线是针对ssiia突变型淀粉,黑色迹线是针对野生型淀粉。图26.对来自突变型ssiia(b22)和野生型ssiia(b70)小麦的成熟小麦籽粒的淀粉颗粒结合型蛋白的免疫学表征。基于与特异性抗血清的结合,蛋白质印记中的顶部条带被鉴定为ssiia,并且来自顶部的第二条带被鉴定为sbeiia和sbeiib的混合物,并且70和60kda的条带为ssi和gbssi。每个条带的身份是经标记的并且由箭头指示。用于不同印迹的抗体的身份标记在左侧或在每个图的下面。m:蛋白质分子量标志(kda)。序列表seqidno:1由小麦a基因组编码的ssiia-a多肽的氨基酸序列;登录号:aad53263,799个氨基酸。seqidno:2由小麦b基因组编码的小麦ssiia-b多肽的氨基酸序列;登录号:cab96627,798个氨基酸。seqidno:3由小麦d基因组编码的ssiia-d多肽的氨基酸序列;登录号:bae48800,799个氨基酸;shimbata等人,(2005)。seqidno:4小麦ssiia-a基因的全长cdna的核苷酸序列;2821个核苷酸;登录号:af155217;li等人,(1999);翻译起始密码子核苷酸89-91,终止密码子2486-2488。seqidno:5小麦ssiia-b基因的全长cdna的核苷酸序列;2793个核苷酸;登录号:aj269504;gao和chibbar,(2000);翻译起始密码子核苷酸135-137,终止密码子2529-2531。seqidno:6小麦ssiia-d基因的全长cdna的核苷酸序列;2846个核苷酸;登录号:aj269502;gao和chibbar,(2000);翻译起始密码子核苷酸210-212,终止密码子2607-2609。由核苷酸201-384编码的转运肽,成熟肽385-2606。seqidno:7小麦的ssiia-a基因的核苷酸序列;登录号:ab201445;6898个核苷酸(iwgsc:染色体7as,traes_7as_53cafb43a,52346437bp至52346905bp,52351676至52351931bp反向链)。seqidno:8小麦的ssiia-b基因的核苷酸序列(登录号:ab201446)(iwgsc:染色体7ds,traes_7ds_e6c8af743,3877787:1至396bp,5137至5419bp正向链),6811个核苷酸。seqidno:9小麦的ssiia-d基因的核苷酸序列(登录号:ab201447)(iwgsc:染色体7ds,traes_7ds_e6c8af743,3877787:1至396bp,5137至5419bp正向链);6950个核苷酸。seqidno:10编码在a基因组中的小麦ssiib-a的氨基酸序列,676个氨基酸,从登录号ak332724的核苷酸序列推导。seqidno:11编码在d基因组中的小麦ssiib-d的氨基酸序列,674个氨基酸,登录号aby56824(与eu333947具有100%同一性)。seqidno:12a基因组上的小麦ssiib-a基因的全长cdna的核苷酸序列;登录号:ak332724。2727个核苷酸(iwgsc:染色体6al,traes_6al_ae01dc0ea,187,500,495bp至187,505,249bp正向链)。seqidno:13b基因组上的小麦ssiib-b的部分长度cdna的核苷酸序列;1282个核苷酸,iwgsc:染色体6dl,基因:traes_6bl_61d83e262,162,113,784bp至162,116,959bp反向链)。seqidno:14d基因组上的小麦ssiib-d的全长cdna的核苷酸序列,2025个核苷酸(登录号:eu333947)(iwgsc:染色体6dl,基因:traes_6dl_19f1042c7,147,049,693bp至147,051,708bp反向链)。seqidno:15-49寡核苷酸引物。seqidno:50-51肽的氨基酸序列具体实施方式在整个本说明书中,除非上下文另有要求,否则词语“包括(comprise)”,或变化形式诸如“包括(comprises)”或“包括(comprising)”将应理解为意指包括所述要素或整数或者要素或整数的组,但是不排除任何其他的要素或整数或者要素或整数的组。关于“由……组成(consistingof)”意指包括(including),并且限于短语“由……组成”后续的任何东西。因此,短语“由……组成”表明所列的要素是必需的或强制性的,并且可以不存在其他要素。关于“由……基本组成”意指包括所述短语后所列出的任何要素,并且限于对公开内容中针对所列出要素说明的活性或作用不干扰或无贡献的其他成分。因此,短语“由……基本组成”表明所列出要素是必需的或强制性的,但是其他要素是任选的,并且根据它们是否影响所列出元素的活性或作用可以存在或可以不存在。如本文所用,除非上下文另外明确指示,否则单数形式“一种/一个(a/an)”和“所述(the)”包括复数方面。因此,例如,对“一个突变”的提及包括单个突变,以及两个或更多个突变;对“一株植物”的参考包括一株植物,以及两株或更多株植物;诸如此类。如本文所用,关于数值或范围的术语“约”旨在涵盖落入指定数值或范围的±10%内的数。除非另外明确陈述,否则本说明书中的每个实施方案将加以必要的变更以适合每一个其他实施方案。基因和其他遗传物质(例如,mrna、构建体等)以斜体表示并且其蛋白质性表达产物以非斜体形式表示。因此,例如,ssiia是ssiia的表达产物。核苷酸和氨基酸序列通过序列标识号(seqidno:)提及。seqidno:数字上对应于序列标识符<400>1(seqidno:1)、<400>2(seqidno:2)等。在权利要求书之后提供了序列表。在图例之后提供了描述序列表中的seqidno的列表。除非另外定义,否则本文使用的所有技术和科学术语都具有与由本发明所属领域普通技术人员通常理解的含义相同的含义。尽管在实施或测试本发明时可使用与本文所述的那些方法和材料类似或等效的任何方法和材料,但描述优选方法和材料。本发明部分基于在本文所述实验中产生的令人惊讶的观察结果,即可以产生六倍体小麦籽粒,所述六倍体小麦籽粒在其三种ssiia基因中的每一种中包含无效突变,具有至少45%(w/w)的直链淀粉含量。基于由其他人产生的观察结果,即三重无效ssiia六倍体小麦籽粒中的直链淀粉水平低于45%(yamamori等人,2000;konik-rose等人,2007),这是出乎意料的。在该含量中,直链淀粉含量被定义为基于重量/重量占籽粒总淀粉含量的百分比。此外,小麦籽粒具有其他所希望的特性,包括增加的总纤维含量(基于果聚糖、β-葡聚糖、阿拉伯木聚糖和纤维素含量的增加),当将籽粒或由籽粒产生的产品用作食物或饲料时,这提供了健康益处。因此,在第一方面,本发明提供了普通小麦物种的小麦籽粒,所述籽粒包含i)在其ssiia基因中的每一种中的突变,使得籽粒对于其ssiia-a基因中的突变是纯合的,对于其ssiia-b基因中的突变是纯合的并且对于其ssiia-d基因中的突变是纯合的,其中所述ssiia基因中的突变中的至少两个是无效突变,ii)总淀粉含量,所述总淀粉含量包含直链淀粉含量和支链淀粉含量,iii)果聚糖含量,所述果聚糖含量基于重量相对于野生型小麦籽粒是增加的,优选在籽粒重量的3%与12%之间,iv)β-葡聚糖含量,v)阿拉伯木聚糖含量,以及vi)纤维素含量,所述籽粒具有在25mg与60mg之间的籽粒重量,其中所述直链淀粉含量如通过碘结合测定所确定基于重量在所述籽粒的所述总淀粉含量的45%与70%之间,其中所述支链淀粉含量基于重量相对于所述野生型小麦籽粒是降低的,其中所述β-葡聚糖含量、阿拉伯木聚糖含量和纤维素含量中的每一种均基于重量相对于所述野生型小麦籽粒是增加的,使得所述果聚糖含量、β-葡聚糖含量、阿拉伯木聚糖含量和纤维素含量的总和在所述籽粒重量的15%与30%之间。本发明进一步提供了产生或获自该籽粒的小麦植物,和由该籽粒产生的面粉和/或小麦淀粉颗粒。本发明还提供了食物成分,所述食物成分包括本发明的籽粒或由该籽粒产生的材料。还提供了包括这些食物成分的食物产品和包含本发明的籽粒或由该籽粒产生的材料的组合物。食物成分可以是粗磨的、破裂的、煮半熟的、轧制的、成珍珠状的、碾磨的或研磨的籽粒或这些的任何组合。在另一方面,本发明提供了用于获得产生本发明的籽粒的小麦植物的方法,所述方法包括步骤(i)使两株亲本小麦植物杂交,所述亲本小麦植物各自在一种、两种或三种选自ssiia-a、ssiia-b和ssiia-d的ssiia基因中包含无效突变,或对包含所述无效突变的亲本植物进行诱变;和步骤(ii)筛选由所述杂交或诱变获得的植物或籽粒,或由其获得的子代植物或籽粒,通过分析来自所述植物或籽粒的dna、rna、蛋白质、淀粉颗粒或淀粉进行,以及步骤(iii)选择相对于步骤(i)的所述亲本小麦植物中的至少一株具有降低的ssiia活性的能育小麦植物。在另一方面,本发明提供了用于改善有需要的受试者的代谢健康、肠健康或心血管健康的一个或多个参数,或者预防代谢疾病诸如糖尿病、肠疾病或心血管疾病或降低所述代谢疾病、肠疾病或心血管疾病的严重性或发生率的方法,所述方法包括向所述受试者提供本发明的籽粒或食物产品。如本文所用,“改善代谢健康的一个或多个参数”是相对术语,并且意指与消耗等量的用野生型小麦产生的食物或饮料相比的改善。在仍另一个方面,本发明提供了产生小麦籽粒料斗的方法,所述方法包括:a)收割包括本发明小麦籽粒的小麦秸秆;b)脱粒和/或风选所述秸秆以将所述籽粒与谷壳分离;以及c)筛选和/或分选步骤b)中分离的所述籽粒,并且将所述筛选和/或分选出的籽粒装入到料斗中,从而产生小麦籽粒料斗。在某些实施方案中,本发明的小麦籽粒的特征进一步在于以下特征中的一个或多个或全部:i)在所述籽粒重量的30%与70%之间的淀粉含量,ii)所述直链淀粉含量如通过碘结合测定所确定在所述籽粒的所述总淀粉含量的45%与65%之间,iii)所述淀粉含量具有如在对淀粉样品脱支之后通过荧光活化的毛细管电泳(face)所测定的链长分布,所述链长分布相对于野生型小麦淀粉在dp7-10链长的比例上是增加的并且在链长dp11-24的比例上是减少,iv)所述果聚糖含量包含dp3-12的果聚糖,使得所述果聚糖含量的至少50%是dp3-12,v)所述果聚糖含量基于重量相对于所述野生型小麦籽粒增加2倍至10倍,vi)所述β-葡聚糖含量基于绝对量增加1%或2%,并且/或者基于重量相对于所述野生型小麦籽粒增加2倍至7倍,vii)所述β-葡聚糖含量在所述籽粒重量的1%与4%之间,viii)所述阿拉伯木聚糖含量基于绝对量增加1%至5%,ix)所述纤维素含量基于绝对量增加1%至5%,x)所述籽粒具有相对于所述野生型小麦籽粒在约70%与约100%之间的发芽率,并且xi)所述籽粒在播种时产生小麦植物,所述小麦植物是雌性和雄性能育的。所述籽粒还可以包含小于所述野生型小麦籽粒中的ssiia蛋白的水平或活性的5%的ssiia蛋白的水平和/或活性,或者缺乏ssiia-a蛋白、ssiia-b蛋白和ssiia-d蛋白中的一种或多种或全部。所述籽粒也可以对于其ssiia-a基因中的无效突变是纯合的、对于其ssiia-b基因中的无效突变是纯合的并且对于其ssiia-d基因中的无效突变是纯合的。每个无效突变可以独立地选自由以下组成的组:缺失突变、插入突变、翻译提前终止密码子、剪接位点突变和非保守氨基酸取代突变,优选其中所述籽粒包含在两种或三种ssiia基因中的每一种中的缺失突变,或整个基因的缺失。在某些实施方案中,所述籽粒进一步包含在编码淀粉合成多肽的内源性基因中的功能丧失突变,或编码降低编码所述淀粉合成多肽的所述内源性基因表达的rna的嵌合多核苷酸,所述淀粉合成多肽选自由ssi、ssiiia和ssiv组成的组,其中所述突变选自由以下组成的组:缺失突变、插入突变、翻译提前终止密码子、剪接位点突变和非保守氨基酸取代突变。优选的是,所述突变中的至少一个、多于一个或全部是i)引入的突变,ii)通过用诱变剂诸如化学剂、生物剂或辐射诱变而诱导于亲本小麦植物或种子中的,或iii)被引入以便修饰植物基因组。优选的是,所述籽粒具有基于重量为籽粒的总淀粉含量的约60%的直链淀粉含量并且/或者所述籽粒是非转基因的或不含任何编码降低ssiia基因和/或sbeiia基因表达的rna的外源性核酸。所述ssiia水平和/或活性通过测定发育中胚乳中的ssiia水平和/或活性,或通过免疫学或其他手段测定收获的籽粒中ssiia蛋白的量来确定。胚乳可以来自获得籽粒的植物或子代植物。本发明的籽粒的淀粉颗粒和/或籽粒的淀粉还可以特征在于选自由以下组成的组的一种或多种特性:i)包含至少2%的抗性淀粉;ii)所述淀粉的特征在于降低的血糖指数(gi);iii)所述淀粉颗粒的形状变形;iv)所述淀粉颗粒当在偏振光下观察时具有降低的双折射率;v)所述淀粉的特征在于减小的溶胀体积;vi)所述淀粉中长链分布和/或分支频率改变;vii)所述淀粉的特征在于降低的峰值糊化温度;viii)所述淀粉的特征在于降低的峰值粘度;ix)淀粉成糊温度降低;x)如通过尺寸排阻色谱法所确定直链淀粉的峰值分子量降低;xi)淀粉结晶度降低;以及xii)a型和/或b型淀粉的比例降低,并且/或者v型结晶淀粉的比例增加;其中每种性质是相对于野生型小麦淀粉颗粒或野生型小麦淀粉的。在本发明的某些实施方案中,所述籽粒经加工以使所述籽粒不再能够发芽。此类加工的籽粒的实例包括热处理的籽粒,和粗磨的、破裂的、煮半熟的、轧制的、成珍珠状的、碾磨的或研磨的籽粒。另选地,籽粒能够以相对于野生型在70%与100%之间的速率发芽。本发明显然扩展至包括在小麦植物中的如上文所述的籽粒。本发明还扩展至产生,或获自本发明的籽粒的小麦植物。此类小麦植物的特征可以在于其胚乳中的ssiia蛋白的水平和/或活性小于野生型小麦籽粒中的ssiia蛋白的水平或活性的5%,或者缺乏ssiia-a蛋白、ssiia-b蛋白和ssiia-d蛋白中的一种或多种或全部。优选地,小麦植物是雄性和雌性能育的。还涵盖了由本发明的籽粒产生的面粉。在一个实施方案中,面粉是白面粉。面粉优选是全麦粉,或白面粉和全麦粉的共混物,例如以1:2至2:1的比例。本发明还提供了来自本发明的籽粒的小麦麸皮。这些产品中的每一种均包含具有小麦籽粒遗传组成(即小麦籽粒的dna)的小麦细胞。由籽粒产生的小麦淀粉颗粒或小麦淀粉也是本发明的一部分。小麦淀粉颗粒或小麦淀粉通常包含45%,优选约50%、约55%或约60%的直链淀粉,或在45%与70%之间的直链淀粉,每种量均基于重量以占淀粉颗粒或淀粉的总淀粉含量的比例计,淀粉颗粒优选包含小麦gbssi多肽。所述淀粉颗粒和/或淀粉的特征还在于以下中的一个或多个:a)如通过免疫学手段所确定不具有可检测的ssiia多肽;b)基于重量包含至少2%的抗性淀粉;c)所述淀粉的特征在于降低的血糖指数(gi);d)所述淀粉颗粒的形状变形;e)所述淀粉颗粒当在偏振光下观察时具有降低的双折射率;f)所述淀粉的特征在于减小的溶胀体积;g)所述淀粉中长链分布和/或分支频率改变;h)所述淀粉的特征在于降低的峰值糊化温度;i)所述淀粉的特征在于降低的峰值粘度;j)淀粉成糊温度降低;k)如通过尺寸排阻色谱法所确定直链淀粉的峰值分子量降低;l)淀粉结晶度降低;以及m)a型和/或b型淀粉的比例降低,并且/或者v型结晶淀粉的比例增加;其中每种性质是相对于野生型小麦淀粉颗粒或淀粉的。本发明还提供了食物成分,所述食物成分包括本发明的籽粒、面粉,优选全麦粉、或小麦麸皮、或小麦淀粉颗粒或小麦淀粉,优选水平为基于干重至少10%,优选约20%至约80%。食物成分可以是粗磨的、破裂的、煮半熟的、轧制的、成珍珠状的、碾磨的或研磨的籽粒或这些的任何组合。食物成分也可以优选以基于干重至少10%的水平掺入食物产品中。本发明还提供一种组合物,所述组合物包含水平为按重量计至少10%的本发明的小麦籽粒、面粉,优选全麦粉或小麦麸皮,或小麦淀粉颗粒或小麦淀粉,或者具有低于45%(w/w)的直链淀粉水平的小麦籽粒或由其获得的面粉、全麦粉、淀粉颗粒或淀粉。所述组合物可以包含面粉的共混物。本发明还提供了用于生产食物的方法,所述方法包括以下步骤:(i)将本发明的食物成分添加至另一种食物成分,和(ii)将所述食物成分混合,从而产生所述食物。所述方法还可以包括在步骤(i)之前加工籽粒以产生食物成分,或者将来自步骤(ii)的混合食物成分在至少100℃的温度下加热至少10分钟的步骤。如本文所用,术语“按重量计”或“基于重量”是指物质的重量占包含所述物质的材料或物品的重量的百分比。这在本文中缩写为“w/w”。例如,直链淀粉含量被定义为直链淀粉的重量占总淀粉含量的重量的百分比。包括小麦的高等植物的胚乳中的淀粉的合成是通过催化四个关键步骤的一套酶进行的,如图1中示意性示出的。首先,adp-葡萄糖焦磷酸化酶(ec2.7.7.27)通过从g-1-p和atp合成adp-葡萄糖而使淀粉的单体前体活化。其次,通过淀粉合酶(ec2.4.1.24)将活化的葡糖基供体adp-葡萄糖转移至先前存在的α-1,4键的非还原端。第三,淀粉分支酶通过使α-1,4连接的葡聚糖的区域裂解,随后将裂解的链转移至受体链上,形成新的α-1,6键而引入分支点。淀粉分支酶是可以将α-1,6键引入到α-聚葡聚糖中的唯一酶,并且因此在支链淀粉的形成中起到必不可少的作用。第四,淀粉脱支酶(ec2.4.4.18)将一些分支键去除。在谷物胚乳中,存在adp-葡萄糖焦磷酸化酶(adgp)的两种同工型,一种形式在淀粉体内,并且一种形式在细胞质中。每种形式由两种亚基类型组成。玉米中的皱缩(sh2)和脆性(bt2)突变体分别代表了大亚基和小亚基的损伤。如本文所用,术语“淀粉合酶”(ss)是指通过α-1,4键将葡糖基残基从活化的葡糖基供体adp-葡萄糖转移至预先存在的葡聚糖链的非还原端的酶(ec2.4.1.24)。可以如由guan和keeling(1998)所述那样测定ss酶活性。在谷物胚乳中(包括在六倍体小麦普通小麦中)发现了至少五个种类的淀粉合酶(ss),即,只位于淀粉颗粒内或结合淀粉颗粒的同工型(颗粒结合型淀粉合酶(gbss))、分配于颗粒与可溶性级分之间的两种形式(ssi和ssii)、全部位于可溶性级分中的形式(ssiii)以及最近的第五形式ssiv(图1)。这些中的每一种均包括在术语“淀粉合酶”中。它们在小麦植物生长过程中的胚乳发育期间(在合成和沉积储存淀粉时)是活跃的,但是在成熟(休眠)小麦籽粒中可以以非活性状态存在。已示出gbss对于直链淀粉合成是必不可少的。ssi-iv中的每一种主要参与基于生物化学和遗传证据的支链淀粉合成。例如,已显示ssii和ssiii基因中的突变改变支链淀粉结构(schondelmaier等人,1992;yamamori等人,2000)。基于与这些种类的已知成员的同源程度,将淀粉合酶根据它们的氨基酸序列分类为属于这五个组中之一。在谷物内,已经鉴定了ssii的至少两个亚类,即ssiia和ssiib,但已经在稻米中鉴定出了第三亚类ssiic(ohdan等人,2005)并且如实施例2中所述那样鉴定出似乎编码相应ssiic酶的基因。淀粉合酶iia(ssiia)通过将葡糖基部分从adp-葡萄糖转移至预先存在的α-1,4-连接的葡聚糖链的非还原端来主要催化谷物胚乳中支链淀粉的中间长度葡聚糖链(dp12-24)的聚合(fontaine等人,1993)。ssiia从而延长了支链淀粉的短链(dp<10)。在小麦ssiia突变体中,dp6-11的葡聚糖链的频率增加,并且dp11-25的链的频率降低(yamamori等人,2000)。不同种类的ssii的区别在于它们与每个种类的典型成员的氨基酸序列的同源性,即通过系统发育分析。不同的ssii酶和在一些情况下不同的小麦ssiia同工酶可以通过多肽中的氨基酸数区分开,如下所述。编码ssii或特别是ssiia的基因的表达水平可以通过诸如经由rna印记杂交分析或经由rt-pcr分析评估转录物水平来评估。在优选方法中,籽粒或发育中胚乳中的ssiia蛋白的量通过以下方式测量:通过电泳将籽粒/胚乳的提取物中的蛋白质在凝胶上进行分离,然后通过蛋白质印迹将蛋白质转移至膜,随后使用特异性抗体定量检测膜上的蛋白质(“蛋白印迹分析”)。用于凝胶电泳和免疫印迹的示例性方法描述于实施例1中。淀粉合酶i(ssi)似乎作为谷物中的单一同工型存在。在稻米中,ssi占胚乳中总可溶性ss活性的约70%(fujita等人,2006)。ssi优先合成dp6-15的短葡聚糖链,优选最短的支链淀粉链作为底物。尽管其重要作用,但在稻米胚乳中完全不存在ssi酶不会影响种子或淀粉颗粒的大小和形状,这表明其他ss酶能够补偿不存在的ssi功能。相比之下,ssiii产生相对较长的支链淀粉链,特别是dp>30的链,并且延伸中间长度的葡聚糖链。ssiii突变体在支链淀粉中表现出中间长度链的增加。存在两种形式,ssiiia是胚乳中表达的主要形式,并且ssiiib是次要形式。关于ssiv同工型对谷物籽粒中葡聚糖链长度的贡献知之甚少,但它似乎主要在叶子中起作用(leterrier等人,2008)。两个ssiv基因即ssiva和ssivb在稻米中在整个植物中表达,并且在籽粒灌浆期间以相对恒定的水平表达,因此它们似乎在整个植物中具有功能。拟南芥属(arabidopsis)中的ssiv突变体具有降低的叶淀粉水平。每种淀粉合酶表达为具有n末端信号肽的多肽,所述n末端信号肽在易位到淀粉体内期间被裂解掉。如本文所用,“淀粉分支酶(sbe)”意指在葡萄糖残基的链之间引入α-1,6糖苷键,从而在支链淀粉中引入α-1,6分支点的酶(ec2.4.1.18)。在植物中已知两个主要的sbe种类,即sbei和sbeii。sbeii在谷物中可以进一步分为两种类型,sbeiia和sbeiib(hedman和boyer,1982;boyer和preiss,1978;mizuno等人,1992;sun等人,1997)。在一些谷物中也报道了其他形式的sbe,即来自小麦的推定的149kdasbei和来自大麦的50/51kdasbe。序列比对揭示了在核苷酸和氨基酸水平两者上序列的高度相似性,并且允许归类到sbei、sbeiia以及sbeiib种类中。sbeiia和sbeiib的氨基酸序列总体上表现出彼此约80%的同一性,主要集中在多肽的中央区域中。sbei、sbeiia和sbeiib也可以通过它们的表达模式区分开,但这在不同的物种中不同。在小麦胚乳中,sbei(morell等人,1997)仅在可溶性级分中发现,而sbeiia和sbeiib在可溶性和淀粉-颗粒相关级分中发现(rahman等人,1995)。在玉米中,sbeiib是胚乳中的主要形式,而sbeiia相对更强地表达于叶子中并且似乎在整个植物中表达(gao等人,1997)。在稻米中,sbeiia和sbeiib均以大约相等的量存在于胚乳中。然而,基因表达的时间也存在差异。sbeiia是在种子发育的早期表达,在开花后3天检测到,并且表达于叶子中,而sbeiib在开花后3天不可检测到,并且在开花后7-10天在发育中种子中最为丰富,并且不表达于叶子中。在小麦胚乳中,sbeiia比sbeiib高约3-4倍地表达。不同的谷物物种示出了在sbeiia和sbeiib表达方面的显著差异,并且在一个物种中得出的结论不能轻易地应用于另一个物种。还可以使用特异性抗体来区分酶。已表征了对于sbe基因中的每一种的基因组和cdna序列(包括对于小麦)。序列比对揭示了在核苷酸和氨基酸水平两者上序列的高度相似性,但也揭示了序列差异,并且允许归类到sbei、sbeiia以及sbeiib种类中。在小麦中,表观基因重复事件已使每一个基因组中的sbei基因的数目增加(rahman等人,1999)。通过对来自a、b和d基因组的sbei基因的最高表达形式中的突变进行组合来消除小麦胚乳中的大于97%的sbei活性对淀粉结构或功能性不具有可测量的影响(regina等人,2004)。相比之下,通过六倍体小麦中的基因沉默构建体减少sbeiia表达导致高直链淀粉水平(>70%),而降低sbeiib表达而非sbeiia的相应构建体具有极小的作用(regina等人,2006)。在大麦中,将使胚乳中的sbeiia和sbeiib表达两者均降低的基因沉默构建体用于产生高直链淀粉大麦籽粒(regina等人,2010)。在玉米中,已知为直链淀粉扩展子(ae)的sbeiib突变体产生高直链淀粉表型。用于检测所有三种同工型sbei、sbeiia和sbeiib的活性的对分支酶的酶活性测定是基于nishi等人,2001的方法,具有如下的微小修改。在电泳之后,将凝胶在含有10%甘油的50mmhepes,ph7.0中洗涤两次并且在室温下在由以下组成的反应混合物中温育16h:50mmhepes,ph7.4、50mm葡萄糖-1-磷酸、2.5mmamp、10%甘油、50u磷酸化酶a、1mmdtt和0.08%麦芽三糖。将条带用0.2%(w/v)i2和2%ki的溶液可视化。在这些电泳条件下分离sbei、sbeiia和sbeiib同工型特异性活性。这通过使用抗sbei、抗sbeiia和抗sbeiib抗体的免疫印迹来确认。进行测量每个条带强度的免疫印迹的光密度分析以确定每种同工型的酶活性水平。淀粉分支酶(sbe)活性可以通过酶测定法测量,例如通过磷酸化酶刺激测定来测量(boyer和preiss,1978)。该测定测量了sbe对将葡萄糖-1-磷酸通过磷酸化酶a并入到甲醇不溶性聚合物(α-d-葡聚糖)中的刺激。sbe的同工型显示出不同的底物特异性,例如sbei在分支直链淀粉中表现出更高的活性,而sbeiia和sbeiib在支链淀粉底物的情况下显示出更高的分支率。sbei通过支化支链较少的聚葡聚糖优先产生dp>16的较长链,而sbeii同工酶产生dp<12的较短链。同工型还可以基于转移的葡聚糖链的长度而区分开。在谷物中已知两类脱支酶(dbe),即异淀粉酶(isa)和普鲁兰酶(pul)。isa主要脱支植物糖原和支链淀粉,而pul作用于普鲁兰多糖(pullulan)和支链淀粉,但不作用于植物糖原(nakamura等人,1996)。用于isa的突变体被称为含糖的并产生更多短链的支链淀粉,并且因此isa似乎在编辑支链淀粉中支化过度的链或不正确支链中起作用。相比之下,据信pul在发芽谷物中的淀粉降解以及淀粉合成中起作用。发育中的六倍体小麦胚乳从a、b和d基因组中的每一种上的ssiia表达ssiia。如本文所用,“从a基因组表达的ssiia”或“ssiia-a”意指其氨基酸序列列示于seqidno:1中或与seqidno:1中列示的氨基酸序列至少99%相同或包含这种序列的多肽。将提供为seqidno:1的氨基酸序列(li等人,1999;基因登录号aad53263)在本文中用作针对野生型ssiia-a多肽的参考序列。seqidno:1的多肽的长是799个氨基酸残基,seqidno:1的氨基酸取代突变体也是如此。该酶的酶促活性变体存在于小麦中,例如栽培品种fielder中,参见登录号cab96626.1(gao和chibbar,2000),其氨基酸序列与seqidno.199.5%(795/799)相同,并且在普通小麦的二倍体近缘种中(诸如来自乌拉尔图小麦(triticumurartu))提供为登录号cus28065.1和cdi68213.1。此类变体包括在“ssiia-a”中。ssiia-a不包括同源多肽ssiia-b和ssiia-d,因为那些多肽与seqidno:1约96%相同。如本文所用,“从b基因组表达的ssiia”或“ssiia-b”意指其氨基酸序列列示于seqidno:2中或与seqidno:2中列示的氨基酸序列至少99%相同或包含这种序列的多肽。提供为seqidno:2的氨基酸序列(基因库登录号cab99627.1)对应于从小麦品种fielder的b基因组表达的淀粉合酶iia,将所述氨基酸序列在本文中用作针对野生型ssiia-b多肽的参考序列。seqidno:2的多肽的长是798个氨基酸,seqidno:2的氨基酸取代突变体也是如此。该酶的酶促活性变体存在于小麦中,此类变体包括在“ssiia-b”中。ssiia-b不包括同源多肽ssiia-a和ssiia-d,因为那些多肽与seqidno:2约96%相同(li等人,1999)。如本文所用,“从d基因组表达的ssiia”或“ssiia-d”意指其氨基酸序列列示于seqidno:3中或与seqidno:3中列示的氨基酸序列至少99%相同或包含这种序列的多肽。seqidno:3的氨基酸序列(基因库登录号bae48800;shimbata等人,2005)对应于从小麦栽培品种中国春的d基因组表达的ssiia,将所述氨基酸序列在本文中用作针对野生型ssiia-d的参考序列。seqidno:3的蛋白质的长是799个氨基酸。该酶的酶促活性变体存在于小麦中,例如栽培品种fielder中,参见登录号cab86618(gao和chibbar,2000),其氨基酸序列与seqidno.399.9%(798/799)相同,并且在普通小麦的二倍体近缘种诸如粗山羊草(aegilopstauschii)(很可能是六倍体小麦的d基因组祖先种)中提供为登录号cab86618。此类变体包括在“ssiia-d”中。ssiia-d不包括同源多肽ssiia-a和ssiia-b,因为那些多肽与seqidno:3约96%相同。提供为seqidno:3的氨基酸序列与seqidno:1和seqidno:2中的每一者95.9%相同。三种氨基酸序列的比对显示出氨基酸差异,其可以用于区分蛋白质或将变体分类为ssiia-a、ssiia-b或ssiia-d。当在此背景下例如通过blastp比较氨基酸序列以确定同一性百分比时,应对全长序列进行比较,并且将序列中的空位算作是氨基酸差异。如本文所用,“ssiia多肽”意指ssiia-a多肽、ssiia-b多肽或ssiia-d多肽。如本文所用,ssiia-a多肽、ssiia-b多肽和ssiia-d多肽中的每一种包括具有减小的或不具有淀粉合酶酶活性的多肽变体,以及具有野生型或基本上野生型酶活性的多肽。利用ssiia多肽的突变形式的氨基酸序列与seqidno:1、2和3的比较来确定其来源于ssiia-a、-b或-d多肽中的哪一种并且从而对突变形式进行分类。例如,如果突变型ssiia多肽的氨基酸序列与seqidno:1比与seqidno:2和3更紧密相关,即具有更高程度的序列同一性,则认为所述突变型ssiia多肽是突变型ssiia-a多肽。类似地,如果突变型ssiia多肽与seqidno:2比与seqidno:1或3更紧密相关,则所述突变型ssiia多肽是突变型ssiia-b多肽,并且如果突变型ssiia多肽与seqidno:3比与seqidno:1和2更密切相关,则所述突变型ssiia多肽是突变型ssiia-d多肽。本领域技术人员从而能够对突变型ssiia多肽进行分类。突变型ssiia多肽可以具有降低的淀粉合酶酶活性(部分突变)体或缺乏淀粉合酶酶活性(无效突变多肽)。可以表达突变型ssiia基因以在小麦胚乳中产生ssiia多肽,例如截短的多肽,或者它可以不表达,并且根本不产生多肽。它也可以表达以产生转录物但不产生翻译产物。还应理解的是,ssiia蛋白可以存在于籽粒、尤其是如常常在商业上收获的成熟籽粒中,但由于籽粒中的生理条件而呈非活性或休眠状态。此类多肽包括在如本文所用的“ssiia多肽”中。ssiia多肽可以在仅部分的籽粒发育期间、尤其是在通常沉积储存淀粉时的发育中胚乳中可以具有酶促活性,但在其他情况下呈非活性状态。此类ssiia多肽可以使用免疫学方法,诸如蛋白质印迹分析容易地进行检测和定量。因此,如本文所用,“野生型”在提及ssiia-a多肽时意指其氨基酸序列列示于seqidno:1中的多肽或在自然界中发现并且具有与seqidno:1基本上相同的活性的在氨基酸序列上至少99%相同的酶促活性变体;如本文所用,“野生型”在提及ssiia-b时意指其氨基酸序列列示于seqidno:2中的多肽或在自然界中发现并且具有与序列提供为seqidno:2的多肽基本上相同的活性的在氨基酸序列上至少99%相同的酶促活性变体;如本文所用,“野生型”在提及ssiia-d时意指其氨基酸序列列示于seqidno:3中的多肽或在自然界中发现并且具有与序列提供为seqidno:3的多肽基本上相同的活性的在氨基酸序列上至少99%相同的酶促活性变体。在每种情况下,野生型多肽具有淀粉合酶ii活性并且未被本发明修饰。野生型小麦产生两种其他种类的ssii多肽,即ssiib和ssiic多肽。如本文所用,“从a基因组表达的ssiib”或“ssiib-a”意指其氨基酸序列列示于seqidno:10中或与seqidno:10中列示的氨基酸序列至少99%相同或包含这种序列的多肽。将提供为seqidno:10的氨基酸序列(由基因库登录号ak332724的核苷酸序列推导)在本文中用作针对野生型ssiib-a多肽的参考序列。seqidno:10的多肽的长是676个氨基酸残基。该酶的酶促活性变体包括在“ssiib-a”中。ssiib-a不包括与seqidno:8约90%相同的同源多肽ssiib-d。如本文所用,“从d基因组表达的ssiib”或“ssiib-d”意指其氨基酸序列列示于seqidno:11中或与seqidno:11中列示的氨基酸序列至少99%相同或包含这种序列的多肽。提供为seqidno:11的氨基酸序列(基因库登录号aby56824)对应于从面包小麦的d基因组表达的淀粉合酶iib,将所述氨基酸序列在本文中用作针对野生型ssiib-d多肽的参考序列。seqidno:11的多肽的长是674个氨基酸。该酶的酶促活性变体包括在“ssiib-d”中。ssiib-d不包括与seqidno:11约90%相同的同源多肽ssiib-a。ssiia同源物和ssiib同源物的氨基酸序列是71%-79%相同,并且因此可以容易地区分多肽,即使它们具有相似的酶活性。如本文实施例2中所述,还鉴定出了小麦ssiic序列,并且可以容易地将其与ssiia序列区分开。如本文所用,术语“ssiia基因”和“小麦ssiia基因”等是指编码ssiia多肽,包括野生型ssiia多肽,诸如存在于其他小麦品种中的同源多肽的基因,以及编码具有降低的活性或不可检测的活性的ssiia多肽的基因的突变形式,或通过突变来源于所述基因的基因。ssiia基因包括但不限于已克隆的小麦ssiia基因,包括表1中列出的注释为ssiia基因的基因组和cdna序列。术语ssiia基因共同地包括更具体的术语分别编码ssiia-a、ssiia-b和ssiia-d多肽的“ssiia-a基因”、“ssiia-b基因”和“ssiia-d基因”中的每一个,或来源于此类基因的突变形式。如本文所用的ssiia基因涵盖完全不编码任何多肽的突变形式,或不具有淀粉合酶活性的多肽,在这种情况下突变形式代表了基因的无效等位基因。基因的等位基因包括缺失至少部分基因的突变等位基因,包括缺失整个基因的突变等位基因,所述等位基因也代表基因的无效等位基因。“内源性ssiia基因”是指ssiia基因,其位于小麦基因组中的天然位置,包括野生型和突变形式。如本领域中所理解的,六倍体小麦诸如面包小麦包含常常被命名为a、b和d基因组的三个基因组,而四倍体小麦诸如硬粒小麦包含通常被命名为a和b基因组的两个基因组。如本领域中熟知的,每个基因组包含7对染色体,所述染色体可以在减数分裂期间通过细胞学方法观察到并且因此鉴定。内源性ssiia-a基因、ssiia-b基因和ssiia-d基因分别位于六倍体小麦中的染色体7a、7b和7d的短臂上。相比之下,术语“分离的ssiia基因”和“外源性ssiia基因”是指不在其天然位置的ssiia基因,例如所述ssiia基因已被从小麦植物中除去、克隆、合成、包含在载体中或呈细胞中转基因,诸如转基因小麦植物中的转基因的形式。在此情形下ssiia基因可以是如下所述的任何特定形式。表1.从谷物表征的淀粉合酶酶基因如本文所用,“小麦的a基因组上的ssiia基因”或“ssiia-a基因”意指编码如本文所定义的ssiia-a多肽或来源于在小麦植物中编码sbeiia-a的多核苷酸的任何多核苷酸,包括天然存在的多核苷酸、序列变体或合成多核苷酸,包括编码具有基本上野生型ssiia活性的ssiia-a多肽的“一种或多种野生型ssiia-a基因”,和不编码具有基本上野生型活性的ssiia-a多肽但可识别地来源于野生型ssiia-a基因的“一种或多种突变型ssiia-a基因”。利用ssiia基因的突变形式的核苷酸序列与一套野生型ssiia基因的比较来确定其来源于哪一种ssiia基因并且从而对其进行分类。例如,如果突变型ssiia基因的核苷酸序列与野生型ssiia-a比与任何其他ssiia基因更紧密相关,即具有更高程度的序列同一性,则认为所述突变型ssiia基因是突变型ssiia-a基因。突变型ssiia-a基因编码具有降低的淀粉合酶活性的ssiia多肽(部分突变体)、或缺乏sbe活性的多肽或完全不编码蛋白质(无效突变基因)。对应于ssiia-a基因的cdna的示例性核苷酸序列在seqidno:4(基因库登录号af155217;li等人,1999)中给出。其他示例性核苷酸序列提供为登录号ak330838(来自栽培品种中国春的ssiia-a基因的cdna,kawaura等人,2009),和登录号aj269503,其提供了来自栽培品种fielder的ssiia-a基因的cdna(gao和chibbar,2000)。如本文所用,术语“b基因组上的ssiia基因”或“ssiia-b基因”和“d基因组上的ssiia基因”或“ssiia-d基因”具有对应于先前段落中针对ssiia-a的含义的含义。对应于ssiia-b基因的cdna的示例性核苷酸序列在seqidno:5(基因库登录号aj269504;gao和chibbar2000)中给出并且对应于ssiia-d基因的cdna的示例性核苷酸序列在seqidno:6(基因库登录号aj269502;来自栽培品种fielder,gao和chibbar,2000)中给出。ssiia基因的部分的序列也在本文中给出,如在图2-4中所提及的。如本文所用,“小麦的a基因组上的ssiib基因”或“ssiib-a基因”意指编码如本文所定义的ssiib-a或来源于编码小麦植物中的ssiib-a的多核苷酸的任何多核苷酸,包括天然存在的多核苷酸、序列变体或合成多核苷酸,包括编码具有基本上野生型活性的ssiib-a多肽的“一种或多种野生型ssiib-a基因”,和不编码具有基本上野生型活性的ssiib-a多肽但可识别地来源于野生型ssiib-a基因的“一种或多种突变型ssiib-a基因”。利用ssiib基因的突变形式的核苷酸序列与一套野生型ssiib基因的比较来确定其来源于哪一种ssiib基因并且从而对其进行分类。例如,如果突变型ssiib基因的核苷酸序列与野生型ssiib-a比与任何其他ssiib基因更紧密相关,即具有更高程度的序列同一性,则认为所述突变型ssiib基因是突变型ssiib-a基因。突变型ssiib-a基因编码具有降低的淀粉合酶活性的ssiib多肽(部分突变体)、或缺乏sbe活性的多肽或完全不编码蛋白质(无效突变基因)。对应于ssiib-a基因的cdna的示例性核苷酸序列在seqidno:12(基因库登录号ak332724)中给出。如本文所用,术语“b基因组上的ssiia基因”或“ssiia-b基因”和“d基因组上的ssiia基因”或“ssiia-d基因”具有对应于先前段落中针对ssiia-a的含义的含义。对应于ssiia-b基因的cdna的示例性核苷酸序列在seqidno:5(基因库登录号aj269504;gao和chibbar2000)中给出并且对应于ssiia-d基因的cdna的示例性核苷酸序列在seqidno:6(基因库登录号aj269502;来自栽培品种fielder,gao和chibbar,2000)中给出。如以上所定义的ssiia基因包括任何调节序列,所述调节序列是转录区的5'或3’(包括启动子区)、调节相关转录区的表达;和转录区内的内含子。ssiia基因的示例性核苷酸序列提供为seqidno:7,其提供了来自小麦的a基因组的ssiia-a基因的核苷酸序列;登录号ab201445。以类似的方式,小麦的野生型ssiia-b基因的核苷酸序列提供为登录号ab201446(iwgsc:染色体7ds,traes_7ds_e6c8af743,3877787:1至396bp,5137至5419bp正向链)并且小麦的ssiia-d基因的核苷酸序列提供为ab201447(iwgsc:染色体7ds,traes_7ds_e6c8af743,3877787:1至396bp,5137至5419bp正向链)。这些野生型基因中的每一个均来自小麦栽培品种中国春(shimbata等人,2005)。应理解的是,来自不同小麦品种的ssiia基因的序列中存在自然变异。这些同源基因容易由技术人员基于序列同一性识别。同源性野生型ssiia基因的核苷酸序列与野生型多肽的氨基酸序列之间的序列同一性的程度是95%-96%。等位基因是在单一基因座处的基因的变体。二倍体生物体具有两套染色体。六倍体小麦是六套染色体,每套中有7个染色体并且被认为是通过贡献a-、b-和d基因组的三个祖先种二倍体植物的杂交而产生。一对染色体中的每个染色体具有每种基因的一个拷贝(即一个等位基因)。如果基因的两个等位基因是相同的,则生物体对于该等位基因或基因来说是纯合的。如果基因的两个等位基因是不同的,则生物体对于该基因来说是杂合的。在基因座处的等位基因之间的相互作用通常被描述为显性或隐性的。小麦植物或籽粒中基因的两个等位基因可以具有彼此相同的突变,因此据说对于该突变是纯合的,或者两个等位基因可以包含彼此不同的突变,并且据说对于那些突变是杂合的。可以使用本领域中已知的方法组合基因的不同等位基因或多个基因的不同等位基因。例如,可以将两株具有不同基因等位基因的亲本小麦植物杂交以产生含有杂合状态中的两个等位基因的子代(f1),并且然后使子代植物自花受精以产生另一代的植物(f2),根据孟德尔遗传学,其包含纯合状态中的一个或另一个等位基因或杂合状态中的两个等位基因。不编码或不能导致产生任何活性酶的等位基因是无效等位基因。此类无效等位基因可以编码或可以不编码多肽,例如编码截短的多肽或相对于野生型ssiia多肽具有氨基酸序列失活变化的多肽。对一个或多个无效突变的提及包括独立地选自由以下组成的组的无效突变:缺失突变、插入突变、剪接位点突变、翻译提前终止突变和移码突变,或其任何组合。在一个实施方案中,一个或多个无效突变是非保守氨基酸取代突变或者无效突变具有两个或更多个非保守氨基酸取代的组合。在此情形下,非保守氨基酸取代如本文所定义。功能丧失突变(包括基因的等位基因中的部分功能丧失突变以及完全功能丧失突变(无效突变))意指等位基因中的突变导致籽粒中酶(诸如ssiia酶)的水平或活性降低。等位基因中的突变可以意指,例如更少的具有野生型或降低的活性的蛋白质被翻译或者野生型或水平降低的转录之后是酶活性降低的酶的翻译,或者优选突变等位基因以与野生型相比降低的速率转录,并且任何翻译产物均具有小于相应野生型多肽的活性。例如,突变可以导致没有或更少的rna从包含突变的基因转录,或者产生的多肽相对于野生型没有活性或具有降低的活性,优选两者。如果例如通过rt-pcr测定没有从等位基因检测到转录物,则该结果表明等位基因是无效等位基因。“点突变”是指单个核苷酸碱基改变,其包括单个核苷酸的缺失、取代或插入。点突变可以进一步是剪接位点突变、翻译提前终止突变、移码突变或其他功能丧失突变,其中突变导致没有蛋白质产生或蛋白质以较少量产生或产生的蛋白质具有降低的ssii活性。基因的蛋白质编码区中的移码突变被认为是无效突变,这是由于它对编码的多肽的结构有影响。同样地,翻译提前终止突变被认为是无效突变,除非它非常接近基因的蛋白质编码区的c末端发生,在这种情况下,可使用酶测定来确定多肽是否具有酶活性。在一些实施方案中,点突变导致保守氨基酸取代或优选是非保守氨基酸取代。多肽或酶活性的“降低”或“减少”的量或水平意指相对于由相应的野生型等位基因或基因产生的量或水平而降低或减少的量或水平。通常,相对于野生型,降低了至少40%,优选至少50%或至少60%,更优选至少80%或90%。在最优选的实施方案中,诸如例如在如本文所述的蛋白质印迹分析中,优选针对ssiia-a、ssiia-b和ssiia-d中的每一种未检测到蛋白质。“降低的”活性意指相对于相应的野生型酶,诸如ssiia、sssiia或其他酶的降低。蛋白质“活性”是指ss活性,其可以通过本领域中已知的和如本文所述的各种手段直接或间接地测量。在一些实施方案中,即使籽粒中多肽分子的数量与野生型中的相同,但每个分子具有比野生型更低的活性,ssiia或其他多肽的按重量计的量也会降低。例如,产生的多肽比野生型ssiia蛋白或其他蛋白质短,诸如,如果突变体ssiia蛋白或其他蛋白质由于翻译提前终止信号而被截短则发生。如本文所用,“ssiia-a基因的两个相同等位基因”意指ssiia-a基因的两个等位基因彼此相同,即植物或籽粒对于那些等位基因或该基因是纯合的;“ssiia-b基因的两个相同等位基因”意指ssiia-b基因的两个等位基因彼此相同;“ssiia-d基因的两个相同等位基因”意指ssiia-d基因的两个等位基因彼此相同。可以在诱变之后产生并鉴定本发明的小麦植物。在一些实施方案中,小麦植物是非转基因的,这在一些市场中是所希望的,或者不含任何降低ssiia基因表达的外源性核酸分子。在另一个实施方案中,小麦植物是转基因的,例如它包含除了降低ssiia基因和/或sbeiia基因表达的外源性核酸分子之外的外源性核酸分子,诸如例如编码赋予植物除草剂耐受性的多肽的外源性核酸分子。在单个ssiia基因中具有突变的突变型小麦植物可以是合成的,例如通过在核酸上进行定点诱变,或者是通过诱变处理诱导的,或者可以是天然存在的,即从天然来源分离的,所述突变可以通过使植物杂交并选择具有其他ssiia基因突变的子代而组合产生本发明的小麦植物。在一些实施方案中,可以对祖先植物细胞、组织、种子或植物进行诱变以产生单个或多个突变,诸如核苷酸取代、缺失、插入和/或密码子修饰。本发明的优选小麦植物和籽粒包含至少一个引入的ssiia基因突变,更优选两个或更多个引入的ssiia基因突变,并且可以不包含来自天然来源的突变,即植物中的所有突变型ssiia等位基因均是通过合成手段或通过诱变处理获得的。如本文所用,“诱导的突变”或“引入的突变”是人工诱导的遗传变异,其可以是化学品、辐射或基于生物学的诱变的结果,例如转座子或t-dna插入、或内切核酸酶诱导的突变。诱变可以通过本领域中熟知的化学或辐射手段,例如ems或叠氮化钠(zwar和chandler,1995)处理种子,或γ辐射实现。化学诱变往往有利于核苷酸取代而不是缺失。已知重离子束(hib)辐射是用于产生新植物栽培品种的突变育种的有效技术,参见例如hayashi等人,2007和kazama等人,2008。离子束辐射关于决定dna损伤的量和dna缺失的大小的生物效应具有两个物理因子,剂量(gy)和let(线性能量转移,kev/μm),并且这些因子可以根据所希望的诱变的程度加以调整。hib产生一批突变体,它们中的许多均包含可以针对特定ssiia基因中的突变加以筛选的缺失。经鉴别的突变体可以与作为轮回亲本的非突变型小麦植物回交,以便去除并且因此减小经诱变的基因组中的不连锁突变的作用。突变体的分离可以通过对经诱变的植物或种子进行筛选来实现。例如,经诱变的小麦群体可以直接针对ssiia基因型筛选或者通过针对由ssiia基因中的突变产生的表型筛选来间接筛选。直接针对基因型的筛选优选地包括针对ssiia基因中突变的存在进行测定,所述突变可以在pcr测定中通过当一些基因缺失时不存在如所预料的特异性ssiia标志物、或如tilling中基于异源双链的测定观察到。筛选优选基于核苷酸测序,其通常基于候选突变体汇集物。针对表型的筛选可以包括通过elisa或亲和色谱法针对一种或多种ssiia多肽的量的损失或降低、或籽粒淀粉中淀粉表型的改变进行筛选。在六倍体小麦中,筛选优选地在已缺乏ssiia活性中的一种或两种的基因型中,例如在三个基因组中的两个上的ssiia基因中已突变的小麦植物中进行,使得探寻进一步缺乏功能活性的突变体。可以进行亲和色谱法以区分ssiia-a、ssiia-b和ssiia-d多肽。经诱变的种子的大型群体(成千或上万的种子)可以使用近红外光谱法(nir)针对高直链淀粉表型筛选。通过这些手段,容易实现高通量筛选,并且允许以每数百个种子约一个的频率分离突变体。本发明的植物和种子可以使用被称为tilling(定向诱导基因组局部突变(targetinginducedlocallesionsingenomes))的方法产生,因为小麦植物或籽粒中的一个或多个突变可以通过此方法产生。在第一步骤中,通过用化学或辐射诱变剂处理种子或花粉而在植物群体中诱导引入的突变诸如新颖单碱基对改变,并且然后使植物发展到突变将稳定遗传的一代,通常是可以鉴别出纯合突变体的m2代。提取dna,并且储存来自群体的所有成员的种子,从而建立可以随时间推移反复地获取的资源。对于tilling测定,设计多种pcr引物以特异性扩增所关注的单个基因靶。接着,可以将经染料标记的引物用于从多个个体汇集的dna扩增pcr产物。使这些pcr产物变性并且再退火,从而允许形成错配的碱基对。错配或异源双链体代表了天然存在的单核苷酸多态性(snp)(即,来自群体的若干个植物很可能携带相同的多态性)和诱导的snp(即,仅极少的个别植物有可能显示突变)两者。在异源双链形成之后,使用识别并且裂解错配的dna的核酸内切酶(诸如celi)或使用高分辨熔解法来在tilling群体内发现新颖的snp。例如,参见botticella等人,2011。使用此方法,可以筛选成千上万种的植物,以鉴定在基因组的任何基因或特定区中具有单碱基改变以及小型插入或缺失(1-30bp)的任何个体。被测定的基因组片段在大小上可以在从0.3至1.6kb的范围内。在每个测定96个泳道的情况下以8倍汇集并且扩增1.4kb片段,此组合允许每单次测定筛选至多达一百万个基因组dna碱基对,使得tilling成为高通量技术。tilling进一步描述于slade和knauf,2005,和henikoff等人,2004中。除允许突变的有效检测以外,高通量tilling技术对于天然多态性的检测也是理想的。因此,通过对已知的序列异源双链化而询问未知的同源dna揭示了多态性位点的数目和位置。核苷酸改变以及小型插入和缺失均可被鉴定,包括至少一些重复数目的多态性。这已被称为ecotilling(comai等人,2004)。可以对含有排成阵列的生态型dna的板,而非来自经诱变的植物的dna汇集物进行筛选。因为检测是在凝胶上以接近碱基对的分辨率进行的,并且背景模式在整个泳道是均一的,所以可以将大小相同的条带匹配,因此在单个步骤中发现多个突变并且对它们进行基因分型。以此方式,对突变的基因的测序是简单而有效的。如本文所用,术语“生物剂”意指可用于产生位点特异性突变体并且包括诱导刺激内源性修复机制的dna中的双链断裂的剂。这些酶包括核酸内切酶、锌指核酸酶、tal效应蛋白、转座酶、位点特异性重组酶并且优选crispr核酸内切酶。锌指核酸酶(zfn)例如促进基因组内选择基因内的定点裂解,允许内源性或其他末端连接的修复机制引入多个缺失或多个插入来修复空位。锌指核酸酶技术综述于leprovost等人,2009,还参见durai等人,2005和liu等人,2010中。成簇规律间隔的短回文重复序列(crispr)是含有短重复碱基序列的原核dna区段。每次重复之后是来自先前暴露于噬菌体病毒或质粒的“间隔dna”的短区段。crispr/cas系统是原核免疫系统,其赋予对外来遗传元件(诸如质粒和噬菌体内存在的那些)的抗性,并且提供获得性免疫的形式。crispr间隔区以类似于真核生物体中rna干扰的方式识别和切割这些外源性遗传元件。在大约40%的测序细菌基因组和90%的测序古细菌中发现了crispr。通过将cas9核酸酶和适当的指导rna递送至细胞中,可以在希望的位置处切割细胞的基因组,从而允许移除现有基因和/或添加新基因。crispr已经与特定的内切核酸酶一起合作用于在各种物种中的基因组编辑和基因调节。关于crispr的进一步信息可以见于wo2013/188638、wo2014/093622和doudna等人,(2014)中。转录激活因子样效应核酸酶(talen)是可以被工程化以切割特定dna序列的限制性酶。它们是通过将tal效应子dna结合结构域与dna裂解结构域(切割dna链的核酸酶)融合而制成。可以将转录激活因子样效应子(tale)工程化以实际上结合任何所需的dna序列,因此当与核酸酶组合时,可以在特定位置切割dna。可以将限制性酶引入细胞中,以用于基因编辑或原位基因组编辑,这种技术被称为用工程化核酸酶进行的基因组编辑。除了锌指核酸酶和crispr/cas9外,talen还是基因组编辑领域中的一个杰出工具。关于talen的进一步信息可以见于boch(2011);juong等人,(2013)和sune等人,(2013)中。然后通过使突变体与所希望的遗传背景的植物杂交,并且进行适合次数的回交以删去最初所不希望的亲本背景,可以将鉴定的突变引入到所希望的遗传背景中。参见,例如本文的实施例3。在一些实施方案中,突变是使基因完全失活的无效突变,诸如无义突变、移码突变、缺失、插入突变或剪接位点变体。核苷酸插入型衍生物包括5'和3’末端融合以及单个或多个核苷酸的序列内插入。插入型核苷酸序列变体是在利用锌指核酸酶(zfn)、crispr核酸酶或其他同源重组方法是可能的预定位点处、或通过随机插入以及对所得产物的适当筛选而将一个或多个核苷酸引入到核苷酸序列中的位点中的那些变体。缺失型变体的特征在于从序列中去除一个或多个核苷酸。在一个实施方案中,相对于野生型基因,突变基因仅具有核苷酸序列的单一插入或缺失。缺失可以是大范围的,足以包括一个或多个外显子或内含子、外显子和内含子两者、内含子-外显子边界、启动子的一部分、翻译起始位点、或甚至整个基因。缺失可以延伸远到足以包括a、b或d基因组上的ssiia基因和一个或多个邻近基因的至少一部分或全部。基因的蛋白质编码区的外显子内的插入或缺失使一定数目的核苷酸插入或缺失,该数目并非三的整倍数,由此在翻译过程中引起阅读框的改变,这几乎总是使包含此类插入或缺失的突变基因的活性消除;此类突变是无效突变。基因的蛋白质编码区的外显子内的插入或缺失使一定数目的核苷酸插入或缺失,该数目是三的整倍数,这可以使或可以不使包含此类插入或缺失的基因的活性消除。在缺失三个核苷酸的确切倍数的情况下,如果缺失的核苷酸编码高度保守的氨基酸,则预期缺失会使编码的多肽失活。酶测定或表型测定可以用于确定插入或缺失突变是否为无效突变。取代型核苷酸变体是序列中的至少一个核苷酸已被去除并且在其位置中插入了不同的核苷酸的变体。在一些实施方案中,相对于野生型基因,突变基因中受取代影响的核苷酸的数目是最大十个核苷酸,更优选地最大是9、8、7、6、5、4、3、或2个,或最优选地是仅一个核苷酸。取代可以“沉默的”,因为核苷酸取代不改变由密码子定义的氨基酸。核苷酸取代可以例如通过降低mrna稳定性或当接近外显子-内含子剪接边界时改变剪接效率而降低翻译效率并且从而降低受影响的ssiia基因的表达水平。预期未改变ssiia基因的翻译效率的沉默取代不会改变基因的活性,并且因此在本文中被视为非突变型的,即,此类基因是活性变体并且不涵盖于“突变基因”中。另选地,一个或多个核苷酸取代可以改变所编码的氨基酸序列并且从而改变所编码的酶的活性,尤其是当保守氨基酸被另一个截然不同的氨基酸取代(即,非保守取代)时。对于保守取代,参见表3。小麦ssiia多肽中的保守氨基酸可以通过比对来自不同物种的ssiia氨基酸序列来鉴定,例如将seqidno:1与拟南芥(arabidopsisthaliana)ssii比对并确定哪些氨基酸是共同的。如本文所用,术语“突变”不包括不影响基因活性的沉默的核苷酸取代,并且因此仅包括影响基因活性的基因序列中的改变。术语“多态性”是指基因的核苷酸序列中的任何改变,包括此类沉默的核苷酸取代。筛选方法可以首先涉及在多态性变体的群组内针对多态性并且其次针对突变进行筛选。突变包括全部或部分基因的缺失、插入诸如插入到基因的外显子中,和核苷酸取代,以及其任何组合。如本文所用,术语“一种或多种植物”和“一种或多种小麦植物”作为名词通常是指完整植物,但是当“植物”或“小麦”作为形容词使用时,所述术语是指植物或小麦植物中存在、从其获得、来源于其或与其相关的任何物质,诸如例如植物器官(例如叶、茎、根、花)、单个细胞(例如花粉)、种子或籽粒、植物细胞(包括例如组织培养的细胞)、由植物产生的产品(诸如“小麦面粉”、“小麦籽粒”、“小麦淀粉”、“小麦淀粉颗粒”等)。已萌发了根和芽的植株和发芽的籽粒也包括在“植物”的含义内。如本文所用,术语“植物部分”是指从完整植物、优选地小麦植物中获得的一个或多个植物组织或器官。如本文所用的植物部分包括植物细胞。植物部分包括营养结构(例如叶子包括(叶鞘和叶片)、茎(包括节间))、根、蘖、花器官/结构诸如穗状花序(也称为穗或谷穗)、花粉、胚珠、种子(包括胚、胚乳和种皮)、植物组织(例如,维管组织、基本组织等)、细胞以及其子代。如本文所用,术语“植物细胞”是指从植物(优选为小麦植物)获得的或所述植物中的细胞,并且包括来源于植物的原生质体或其他细胞、产生配子的细胞以及再生成完整植物的细胞。植物细胞可以是培养的细胞。关于“植物组织”意指植物中的或从植物获得的分化组织(“外植体”)或来源于不成熟或成熟的胚、种子、根、芽、果实、花粉和培养的植物细胞的聚集体的各种形式(诸如愈伤组织)的未分化组织。种子(诸如小麦籽粒)中的或来自所述种子的植物组织是种皮、胚乳、盾片、糊粉层和胚。小麦植物组织或器官和小麦细胞中的每一种均包含所获自的小麦植物的遗传物质(核酸)。如本文所用,谷物意指单子叶植物禾本科(poaceae)或黍草科(graminae)的植物或籽粒,所述植物或籽粒针对其籽粒的可食用组分进行栽培,并且包括小麦、大麦、玉米、燕麦、黑麦、稻米、高粱、黑小麦、小米、荞麦。优选地,谷物植物或籽粒是小麦植物或籽粒。在另一个优选实施方案中,本发明的小麦细胞、植物或籽粒,或来源于其的产品是普通小麦物种的。如本文所用,术语“小麦”是指小麦属的任何物种,包括其祖先种、以及通过与其他物种的杂交而产生的其子代。小麦包括具有aabbdd的基因组组构、包含42个染色体的“六倍体小麦”、和具有aabb的基因组组构、包含28个染色体的“四倍体小麦”。本发明的植物和籽粒是六倍体物种普通小麦的、并且不包括四倍体物种硬粒小麦(t.durum),也称为硬粒小麦(durumwheat)或四倍体圆锥小麦亚种硬粒小麦。普通小麦的二倍体祖先种被认为是针对a基因组的乌拉尔图小麦(t.uartu)、栽培一粒小麦或野生一粒小麦、针对b基因组的拟斯卑尔脱山羊草(aegilopsspeltoides)、以及针对d基因组的节节麦(t.tauschii)(也称为粗山羊草(aegilopssquarrosa或aegilopstauschii))。优选地,本发明的普通小麦植物适用于籽粒的商业生产,它们具有本领域技术人员已知的适合的农艺特征。更优选地,小麦是普通小麦亚种小麦(triticumaestivumssp.aestivum)在本文中也称为“面包小麦”。本发明的方面提供了种植和收获本发明的小麦籽粒的方法,以及生产本发明的小麦籽粒的料斗的方法。例如,在通过犁耕和/或某些其他方法准备好土地之后,通常通过钻孔犁沟并且将种子种植在行中来播种种植。为了防止植物成熟时产生的籽粒散落,可以在完全成熟之前收获小麦,但是通常是当植物显示完全失去绿色时收获小麦。收获有若干个步骤:切割或收割秸秆;脱粒和风选,以将籽粒与穗状花序、颖片和其他谷壳分离;筛选和分选籽粒;通常由联合收割机进行,然后将籽粒装入到卡车中。在一些实施方案中,可以将收获的小麦籽粒储存在阻止害虫进入的干燥、通风良好的建筑物中。在一些实施方案中,收获的小麦籽粒可以在料斗或粮仓中短时间储存。然后可以将小麦籽粒托运到产地谷仓,即干燥和储存籽粒的高大结构中,直到它被出售或运输到终点谷仓。因此,本发明的实施方案提供了产生小麦籽粒料斗的方法,所述方法包括:a)收割包括如本文所定义的小麦籽粒的小麦秸秆;b)脱粒和/或风选秸秆以将籽粒与谷壳分离;以及c)筛选和/或分选步骤b)中分离的籽粒,并且将筛选和/或分选出的籽粒装入到料斗中,从而产生小麦籽粒料斗。本发明的小麦植物和籽粒可以具有除了用于食物或动物饲料以外的用途,例如用于研究或育种。在种子繁殖型作物(诸如小麦)中,植物可以自交以产生对于所希望的基因是纯合的植物,或者可以对单倍体组织(诸如发育中生殖细胞)进行诱导以使染色体组加倍,从而产生纯合的植物。本发明的近交小麦植物从而产生了含有纯合的突变型ssiia等位基因的组合的籽粒。可以使籽粒生长以产生将具有选择的表型(诸如例如其淀粉中直链淀粉含量高)的植物。本发明的小麦植物可以与含有更希望的遗传背景的植物杂交,并且因此本发明包括将降低的ssiia性状转移至其他遗传背景。如本文所用,“杂交(crossing/cross)”是指将一种植物上的花粉施加(人工地或自然地)到另一种植物的花的柱头的方法。在最初的杂交之后,可以进行适合次数的回交,以去除更不希望的背景。ssiia等位基因特异性的基于pcr的标志物(诸如本文所述的那些)可以用于筛选或鉴定具有所希望的等位基因组合的子代植物或籽粒,从而在育种计划中追踪等位基因的存在。所希望的遗传背景可以包含基因的适合组合,该组合提供商业产率和其他特征(诸如农艺性能或非生物逆境抗性)。遗传背景还可以包含其他改变的淀粉生物合成或修饰基因,例如ssiiia基因的无效等位基因或gbss基因的有利等位基因。遗传背景可以包含一个或多个转基因,诸如例如赋予对除草剂(诸如草甘膦)的耐受性的基因。小麦植物的所希望的遗传背景将包括农艺产量和其他特征的考虑因素。此类特征可以包括是否希望具有冬季或春季类型、农艺性能、疾病抗性和非生物逆境抗性。对于澳大利亚使用,可能会想使本发明的小麦植物的改变的淀粉性状杂交到小麦栽培品种诸如baxter、kennedy、janz、frame、rosella、cadoux、diamondbird或其他常见生长的品种中。其他品种将适于其他生长区。优选的是,本发明的小麦植物提供相对于至少一些生长区中的相应野生型品种的产量至少50%,更优选地相对于具有大致相同的遗传背景、在相同条件下生长的野生型品种至少60%或至少70%,或至少80%或至少90%的籽粒产量(公吨或公顷)。在一个实施方案中,籽粒产量小于具有大致相同的遗传背景、在相同条件下生长的野生型品种的90%。产量可以在经控制的田间试验中、或在温室中模拟的田间试验中、优选地在田间容易地测量。标志物辅助选择是针对在与轮回亲本在经典的育种计划中回交时获得的杂合植物进行选择的一种广获认可的方法。每一回交代中的植物的群体对于在回交群体中通常以1:1比率存在的所关注的一种或多种基因将是杂合的,并且连接至基因的分子标志物可以用于区分基因的两个等位基因。可以测定两种标志物的存在,一种针对突变型等位基因并且另一种针对野生型等位基因。通过从例如幼芽提取dna并且针对基因渗入的所希望的性状用特异性标志物测试,进行用于进一步回交的植物的早期选择,同时将能量和资源集中在更少的植物上。诸如使小麦植物杂交、使小麦植物自体受精或标志物辅助选择的程序是标准程序并且是本领域中熟知的。将等位基因从四倍体小麦(诸如硬粒小麦)转移至六倍体中、或其他形式的杂交是更困难的但也是本领域中已知的。为了鉴定所希望的表型特征,通常将含有突变型ssiia或其他所希望的基因的组合的小麦植物与对照植物比较。当评估与突变型ssiia基因相关的表型特征诸如籽粒淀粉中的直链淀粉含量,或总纤维含量或籽粒重量或产量时,使待测试的植物和对照植物在生长箱、温室或优选田间条件下在相同条件(温度、土壤、水分供应、化肥供应、季节等)下生长。对具体表型性状的鉴定和与对照的比较是基于常规的统计分析和评分。基因表达和酶活性是与生长、发育和产量参数相比的,所述参数包括以下中的一个或多个:发芽率、幼苗活力(包括幼苗出土能力)、植物形态、颜色、数目、大小、尺寸、干重和湿重、成熟、地上与地下的生物质比率、以及生长到衰老的不同阶段的时间安排、速率和持续时间(包括营养生长、结果、开花、籽粒产量和休眠)、收获指数以及可溶性碳水化合物含量(包括蔗糖、葡萄糖、果糖和淀粉水平以及内源性淀粉水平)。在一些实施方案中,当在相同条件下生长时,本发明的小麦植物与野生型植物在这些参数中的一个或多个方面相差小于50%、更优选地小于40%、小于30%、小于20%、小于15%、小于10%、小于5%、小于2%或小于1%。优选地,本发明的植物或籽粒与野生型植物或籽粒对于这些参数中的一个或多个是大致相同的。如本文所用,术语“连锁的”或“基因连锁的”是指标志物基因座与第二基因座在染色体上足够接近,使得它们将例如非随机地在超过50%的减数分裂中共同遗传。该定义包括了标志物基因座与第二基因座形成同一基因的一部分的情形。此外,该定义包括了标志物基因座包含会引起所关注的性状的多态性的情形,在这种情况下,所述多态性与所述表型是100%连锁的。由此,每代在基因座之间观察到的重组百分比(以厘摩(cm)计算)将低于50。在本发明的具体实施例中,遗传连锁的基因座可以在染色体上相隔45、35、25、15、10、5、4、3、2、或1cm或更少的cm。优选地,标志物相隔不到5cm或2cm,并且最优选地基本上相隔0cm。如本文所用,“其他遗传标志物”可以是连锁到本发明的小麦植物中的所希望的性状的任何分子。此类标志物是本领域技术人员熟知的,并且包括了连锁到基因决定性状的分子标志物,所述基因决定性状诸如疾病抗性、产量、植物形态、籽粒质量、其他休眠性状,诸如籽粒颜色、种子中的赤霉酸含量、植物高度、面粉颜色等。此类基因的实例是茎锈病抗性基因sr2或sr38、条锈病抗性基因yr10或yr17、线虫抗性基因(诸如cre1和cre3)、决定生面团强度的麦谷蛋白基因座处的等位基因(诸如ax、bx、dx、ay、by和dy等位基因)、决定半矮生长习性并且因此决定倒伏抗性的rht基因(eagles等人,2001;langridge等人,2001;sharp等人,2001)。本发明的小麦植物、小麦植物部分以及来自其的产品优选地对于抑制ssiia基因和/或sbeiia基因表达的基因是非转基因的,即,它们不包含对降低内源性ssiia基因表达的rna分子进行编码的转基因,但是在该实施方案中,它们可以包含其他转基因,例如除草剂耐受性(诸如草甘膦耐受性)基因。更优选地,小麦植物、籽粒以及来自其的产品是非转基因的,即,它们不包含任何转基因,这在一些市场中是优选的。此类产品在本文中还被描述为“非转化的”产品。此类非转基因植物和籽粒包含如本文所述的多个突变型ssiia等位基因,诸如在诱变之后产生的那些。如本文所用,术语“转基因植物”和“转基因小麦植物”是指含有在相同物种、品种或栽培品种的野生型植物中未发现的遗传构建体(“转基因”)的植物。即,转基因植物(转化的植物)含有在转化之前它们所不包含的遗传物质。如本文所提及的“转基因”或“遗传构建体”具有生物
技术领域:
中的标准含义并且是指通过重组dna或rna技术产生或改变的基因序列。如果存在于植物细胞中,则转基因已通过人类引入到植物细胞或祖细胞中。转基因可以包括从以下获得或来源于以下的基因序列:植物细胞、或另一种植物细胞、或非植物来源、或合成序列。通常,转基因通过人类操作,诸如例如通过转化引入到植物中,而且可以使用本领域技术人员所认可的任何方法。遗传物质通常稳定地整合到植物的基因组中。引入的遗传物质可以包含相同物种中天然存在但呈重排的次序或不同的元件排列的序列,例如反义序列或表达抑制性双链rna的序列。含有此类序列的植物在本文中被包括在“转基因植物”中。如本文所定义的转基因植物包括已使用重组技术进行遗传修饰的最初转化和再生的植物(t0植物)的所有子代,所述子代,其中子代包含该转基因。此类子代可以通过原代转基因植物的自体受精或通过使此类植物与相同物种的另一个植物杂交来获得。在一个实施方案中,转基因植物对于已引入的每个基因(转基因)是纯合的,以使得其子代对于所希望的表型不会分离。转基因植物部分包括包含转基因的所述植物的所有部分和细胞,诸如例如种子、培养的组织、愈伤组织和原生质体。“非转基因植物”、优选地非转基因小麦植物是尚未通过利用重组dna技术引入遗传物质来进行遗传修饰的植物。在植物或籽粒中存在通过位点特异性核酸内切酶诸如zfn、crispr类型核酸酶的tal效应子产生的对基因部分的缺失,随后在植物细胞及其子代中进行非同源末端连接修复作为“非转基因的”包括在本文中。如本文所用,“子代”包括来自小麦植物的所有后代,紧邻世代和后续世代,以及植物和种子(籽粒)。子代包括在自体受精(“自交”)后获得的种子和植物,以及由两个亲本植物杂交产生的籽粒和植物,诸如f1后代(第一代),f2、f3、f4及其他是来自f1植物自交后的第二代及其他世代的后代。如本文所用,术语“相应非转基因植物”是指相对于转基因植物,大多数特征相同或类似、优选地等基因或近等基因的,但不具有所关注的转基因的植物。优选地,相应非转基因植物与所关注的转基因植物的祖先种属于相同的栽培品种或品种,或者是缺乏经常称为“分离子”的构建体的同属植物株系,或者是用“空载体”构建体转化的相同栽培品种或品种的植物,并且可以是非转基因植物。如本文所用,“野生型”是指未根据本发明进行修饰的细胞、组织、植物或植物部分,优选普通小麦植物、植物部分或籽粒。这种野生型植物或籽粒至少对于其ssiia基因是野生型的。如本领域中容易理解的,“相应野生型”是指适合作为本发明的细胞、组织、植物、植物部分或植物产品的比较物的野生型细胞、组织、植物、植物部分或植物产品。一般来讲,相应野生型是来自与本发明的植物或植物部分在遗传上类似,优选是等基因,但不具有ssiia基因突变的小麦植物或植物部分。野生型细胞、组织或植物为本领域中已知的并且可以用作对照,以与如本文所述进行修饰的细胞、组织或植物比较基因或多肽序列,特别是ssiia基因序列、ssiia基因表达水平或性状修饰的程度和性质。如本文所用,“野生型小麦籽粒”意指相应的未进行诱变的非转基因的小麦籽粒。如本文所用,特定野生型小麦籽粒包括但不限于sunstate、chara和cadoux。sunstate小麦栽培品种描述于ellison等人,(1994)中。数种方法中的任一种均可以用于确定转化的植物中的转基因的存在。例如,聚合酶链反应(pcr)可以用于对转化的植物所独有的序列进行扩增,并且通过凝胶电泳或其他方法检测所扩增的产物。可以使用常规方法从植物中提取dna,并且使用将对转化和非转化的植物进行区分的引物进行pcr反应。确认阳性转化体的替代方法是利用本领域中熟知的dna印迹杂交进行。转化的小麦植物还可以通过例如由存在选择性标志物基因所赋予的它们的表型,或者通过检测或定量由转基因编码的酶的表达的免疫测定,或者由转基因所赋予的任何其他表型,从非转化的或野生型小麦植物中鉴定出(即,与非转化的或野生型小麦植物区分开)。本发明的(优选普通小麦物种的)小麦植物对于籽粒可以是生长的或收获的,除其他用途之外,主要用作供人类消耗的食物或用作动物饲料、或用于发酵或工业原料生产,诸如乙醇生产。另选地,小麦植物的地上部分可以直接作为饲料使用,直接通过在田间放牧或在收获之后进行使用。秸秆和谷壳也可以用作饲料或用于非食物用途。本发明的植物优选地适用于食物生产并且特别是适用于供人类消耗的商业食物生产。这种食物生产可以包括从籽粒制造面粉、生面团、粗粒小麦粉或其他产品,诸如可以成为商业食物生产中的成分的淀粉颗粒或分离淀粉。如本文所用,术语“籽粒”通常是指植物的成熟的被收获的种子(也称为谷粒),但根据上下文也可以是指在吸涨或发芽之后的籽粒。籽粒包括通过种植者生产的用于除生长另外的植物之外的用途的成熟谷粒。成熟的谷物籽粒,诸如小麦常常具有低于约18%-20%,通常约8%-10%水分的水分含量。如本文所用,术语“种子”包括收获的种子,但也包括在开花后的植物中发育的种子和在收获之前的植物中所包含的成熟种子。籽粒的部分包括外种皮(种皮)、果被(果皮)、糊粉层、淀粉质胚乳和胚(embryo)(胚芽(germ)),其由盾片、幼芽(根出条)和胚根(初生根)组成。组合的外种皮、果被和糊粉层常常被称为“麸皮”,其可以通过碾磨从籽粒除去,其也可以包含胚芽。盾片是分泌一些参与发芽的酶并且从胚乳中淀粉的分解中吸收可溶性糖以用于发芽后的幼苗的生长的区域。围绕淀粉质胚乳的糊粉也在发芽过程中分泌酶。如本文所用,“发芽”是指在吸涨之后根尖(胚根)从种皮萌出。胚根通常首先萌出,然后是幼芽。“发芽率”是指群体中在吸涨之后的一段时间,(例如7或10天)内已发芽的种子的百分比。发芽率可以使用本领域中已知的技术进行计算。例如,可以在数天内每天对种子的群体,通常是至少100个籽粒进行评估以确定随时间推移发芽的百分比。就本发明的籽粒来说,如本文所用,术语“实质上相同的发芽率”意指籽粒的发芽率是相应野生型籽粒的发芽率的至少90%。在一个实施方案中,本发明的籽粒的发芽率相对于野生型籽粒在约70%与约100%之间,优选相对于野生型籽粒在约90%与约100%之间。当测量发芽时,本发明的小麦籽粒和用作对照的野生型籽粒应该在相同条件下生长并且在相同条件下储存大致相同的时间长度。本发明还提供食物成分,诸如面粉,优选全麦粉、麸皮和由籽粒产生的其他产品。这些可以是未加工的或加工的,例如通过热处理、分级分离或漂白进行加工。本发明的籽粒可以使用本领域中已知的任何技术加工以产生食物成分或食物或非食物产品。在一个实施方案中,食物成分是面粉,诸如例如全麦粉(全麦面粉)或白面粉。如本文所用,“面粉”是来自已碾磨成粉末的籽粒的碾磨产品。粉末常常通过筛分、筛选、离心或本领域中已知的其他方法分级分离,并且可以进一步精制、热处理和/或漂白。本文提及的精制面粉或“白面粉”是指通过除去碾磨粉末的至少一些麸皮和胚芽组分进行的相对于全麦粉富含碾磨粉末的胚乳来源部分的面粉。美国食品药品监督管理局(fda)要求面粉符合某些粒度标准,以便包括在精制面粉类别中。根据fda,精制面粉的粒度被描述为这样的面粉,其中不小于98%通过具有的开口不大于命名为“212微米(美国电线70)”的金属丝编织布的开口的布。如本文所用,术语“全麦粉”(也称为全麦面粉或整籽粒面粉)是一种碾磨的面粉,其基本上由100%的籽粒制成,并且包括精制面粉组分(精制面粉或精制面粉)和粗级分(超细碾磨的粗级分)。粗级分包括麸皮和胚芽中的至少一种,通常包括两者。胚芽是在籽粒内发现的胚胎性植物体,包括胚和盾片。胚芽包括脂质、纤维、维生素、蛋白质、矿物质和植物营养素,诸如类黄酮,它们的水平高于籽粒的成熟胚乳中的。麸皮包括若干个细胞层,包括果被(果皮)和外种皮(种皮),并且还具有显著量的脂质、纤维、维生素、蛋白质、矿物质和植物营养素,诸如类黄酮。糊粉层虽然在技术上被认为是成熟籽粒的胚乳的一部分,但表现出许多与麸皮相同的特征,并且因此通常在研磨和/或筛分过程中与麸皮和胚芽一起除去。糊粉层还包括脂质、纤维、维生素、蛋白质、矿物质和植物营养素,诸如类黄酮和阿魏酸。此外,可以将粗级分与精制面粉组分共混。优选地,将粗级分与精制面粉组分均匀混合。可以将粗级分与精制面粉组分混合以形成全麦粉,从而提供与精制面粉相比营养价值、纤维含量和抗氧化能力增加的全麦粉。例如,可以以各种量使用粗级分或全麦粉来代替烘焙食品、零食产品和食物产品中的精制面粉。本发明的全麦粉(即超细碾磨的整籽粒面粉)也可以直接销售给消费者用于其自制的烘焙产品。在示例性实施方案中,全麦粉的粒化曲线使得按全麦粉的重量计98%的粒子的直径小于212微米。在进一步的实施方案中,将全麦粉和/或粗级分的麸和胚芽中存在的酶灭活以稳定化全麦粉和/或粗级分。本发明设想的是“失活”也可以意指抑制、变性等。稳定化是使用蒸汽、热、辐射或其他处理来灭活麸皮和胚芽层中存在的酶的过程。在没有稳定化的情况下,麸皮和胚芽中天然存在的酶催化面粉中化合物的改变,这可能不利地影响面粉的烹饪特征和保质期。灭活的酶不催化面粉中存在的化合物的改变,因此,已经稳定化的面粉保持其烹饪特征并且具有更长的保质期。例如,本发明可以实施双流碾磨技术来研磨粗级分。一旦粗级分被分离并稳定化,然后将粗级分通过研磨机,优选凹口碾磨机研磨,以形成粒度分布小于或等于约500微米的粗级分。筛选后,可以将任何粒径大于500微米的研磨粗级分返回到所述工艺中进行进一步碾磨。在另外的实施方案中,面粉、全麦粉或粗级分可以是食物产品的组分,例如,可以用作食物产品中的成分。食物产品可以是例如百吉饼、饼干、面包、小圆面包、羊角面包、饺子、松饼(诸如英式松饼)、皮塔饼面包、速发面包、冷藏或冷冻面团产品、生面团、烘豆、玉米煎饼、辣椒、墨西哥卷饼、玉米粉蒸肉、玉米粉圆饼、肉馅饼、即食谷物、即食餐、填馅食物、微波炉餐、核仁巧克力饼、蛋糕、奶酪蛋糕、咖啡蛋糕、小甜饼、甜点心、糕点、小甜面包、糖果棒、大馅饼皮、饼馅、婴儿食物、烘焙混合物、面糊、面包屑、肉汁酱粉、肉增量剂、肉类替代品、调味料、汤粉、肉汁、乳酪面粉糊、沙拉酱、汤、酸奶油、面条、意大利面、拉面、炒面、捞面、冰淇淋包含物、雪糕、冰淇淋蛋筒、冰淇淋三明治、梳打饼、烤面包片、甜甜圈、蛋卷、挤压小吃、水果谷物棒、微波炉小吃产品、营养棒、煎饼、预焙烘焙产品、椒盐卷饼、布丁、基于格兰诺拉燕麦卷的产品、小吃片、休闲食品、零食混合物、华夫饼干、比萨饼皮、动物食物或宠物食物。在其他实施方案中,面粉、全麦粉或粗级分可以是营养补充剂的组分。例如,营养补充剂可以是添加到含有一种或多种成分的膳食中的产品,所述一种或多种成分通常包括:维生素、矿物质、脂质诸如ω-3脂肪酸、氨基酸、酶、抗氧化剂诸如叶黄素、草药、香味料、益生菌、提取物、益生元和纤维。本发明的面粉、全麦粉或粗级分包括维生素、矿物质、氨基酸、酶和纤维。例如,粗级分含有浓缩量的膳食纤维以及对健康膳食必不可少的其他必需营养素,诸如b族维生素、硒、铬、锰、镁和抗氧化剂。例如,15克本发明的粗级分递送33%的个人每日推荐的纤维消耗量。此外,只需9克即可提供20%的个体每日推荐的纤维消耗量。因此,粗级分是个体纤维需求消耗的极好补充来源。在另外的实施方案中,全麦粉或粗级分可以是纤维补充剂或其组分。许多目前的纤维补充剂诸如洋车前子壳、纤维素衍生物和水解瓜尔胶具有除其纤维含量之外的有限营养价值。另外,许多纤维补充剂具有不希望的质地和差的味道。因此,在一个实施方案中,本发明的食物成分缺乏衍生自除小麦籽粒之外的来源的纤维补充剂。由小麦籽粒的全麦粉或粗级分制成的补充剂从而提供纤维以及蛋白质和抗氧化剂。纤维补充剂可以以下列形式递送,但不限于以下形式:速溶饮料混合物、即饮饮料、营养棒、薄饼、饼干、薄脆饼干、凝胶丸、胶囊、咀嚼物、咀嚼片和丸剂。一个实施方案以调味的昔固体或麦芽型饮料的形式递送纤维补充剂,该实施方案作为儿童的纤维补充剂可能特别有吸引力。在另外的实施方案中,碾磨和共混方法可以用于制备多种籽粒面粉或多种籽粒粗级分。例如,可以将来自一种类型的籽粒诸如本发明的籽粒的麸皮和胚芽研磨并与研磨的另一种类型的小麦或其他谷物的胚乳或整籽粒面粉混合。设想本发明涵盖将一种或多种籽粒的麸皮、胚芽、胚乳和整籽粒面粉中的一者或多者的任何组合混合。这种多种籽粒方法可以用于制备定制面粉并且利用多种类型的籽粒(例如小麦)的质量和营养含量来制备一种面粉。可以通过本领域中已知的任何碾磨方法产生本发明的面粉或全麦粉。一个示例性实施方案涉及在单一流中研磨籽粒而不将籽粒的胚乳、麸皮和胚芽分离成单独的流。将清洁且调质的籽粒输送到第一通道研磨机,诸如锤磨机、辊磨机、针磨机、冲击式磨机、盘式磨机、空气碾磨机、凹口碾磨机等。研磨后,将籽粒排放出并且输送到筛粉机中。可以使用本领域中已知的用于筛选研磨粒子的任何筛粉机。通过筛粉机的筛网的物质是本发明的整籽粒面粉,并且不需要进一步加工。保留在筛网上的物质被称为第二级分。第二级分需要另外的粒子减小。因此,可以将该第二级分输送到第二通道研磨机。研磨后,可以将第二部分输送到第二筛粉机。设想本发明的面粉、全麦粉、粗级分和/或籽粒产品可通过诸如以下的许多其他方法改性或增强:发酵、速溶化、挤出、封装、烘、烤等。本发明的面粉和全麦粉包含它们来源于的小麦籽粒的遗传物质,包括dna,由它们产生的食物产品也是如此。参见例如,tilley(2004)和bryan等人,(1998)。本发明提供的麦芽基饮料包括通过使用麦芽作为其原料的一部分或全部而产生的酒精饮料(包括蒸馏饮料)和非酒精饮料。实例包括啤酒、发泡酒(低麦芽啤酒饮料)、威士忌,低醇麦芽基饮料(例如含有少于1%的醇的麦芽基饮料),和非酒精饮料。麦芽制造是一种受控地浸泡和发芽然后干燥籽粒的过程。这一系列事件对于合成导致籽粒改性的许多酶是重要的,所述籽粒改性是主要解聚死胚乳细胞壁并调动籽粒营养素的一种过程。在随后的干燥过程中,由于化学褐变反应产生风味和颜色。虽然麦芽的主要用途是用于饮料生产,但它也可用于其他工业过程,例如作为烘焙工业中的酶源,或作为食品工业中的调味剂和着色剂,例如呈麦芽或呈麦芽粉的形式,或间接地呈麦芽糖浆的形式,等等。在一个实施方案中,本发明涉及产生麦芽组合物的方法。所述方法优选地包括以下步骤:(i)提供本发明的小麦籽粒,(ii)浸泡所述籽粒,(iii)使浸泡的籽粒在预定条件下发芽以及(iv)干燥所述发芽的籽粒。可以仅使用本发明的籽粒或在包含其他籽粒的混合物中制备麦芽。麦芽主要用于酿造啤酒,也用于生产蒸馏酒。酿造包括麦芽汁产生、主要发酵和次要发酵以及后处理。首先将麦芽碾磨、搅拌到水中并加热。在这种“糖化”过程中,在麦芽制造中活化的酶将谷粒的淀粉降解成可发酵的糖。将产生的麦芽汁澄清,添加酵母,使混合物发酵并进行后处理。一般来讲,麦芽汁产生过程中的第一步是碾磨麦芽,以便水可以在糖化阶段中能够进入籽粒粒子,这从根本上是酶促解聚底物的麦芽制造过程的扩展。在糖化过程中,将碾磨的麦芽与液体级分诸如水一起温育。将温度保持恒定(等温糖化)或逐渐增加。在任何一种情况下,在通过过滤分离成麦芽汁和残留的固体粒子(称为废麦糟)之前,将麦芽制造和糖化中产生的可溶性物质提取到所述液体级分中。麦芽汁组合物还可以通过将本发明的小麦籽粒或其部分与一种或多种合适的酶(例如酶组合物或酶混合物组合物,例如ultraflo或cereflo(novozymes)一起温育来制备。麦芽汁组合物还可以使用麦芽和未麦芽处理的植物或其部分的混合物制备,任选在所述制备过程中添加一种或多种合适的酶。当掺入食物产品中时,面粉或全麦粉的淀粉提供改变的消化特性,例如食物成分包含相对于由野生型小麦籽粒产生的相应食物成分增加的抗性淀粉,诸如包含1%至20%、2%至18%、3%至18%或5%至15%之间的抗性淀粉,和降低的血糖指数(gi),诸如减少至少5个单位,优选5与25之间个单位。这可以与食物成分中按重量计15%至30%的增加的总纤维含量组合。碳水化合物,即包含一个或多个由碳、氢和氧组成的糖单元的化合物可以根据构成碳水化合物的单糖单元的数量和组成进行分类。这些碳水化合物包括多糖(>10个单糖单元)、寡糖(3-10个单糖单元)、二糖和单糖,包括葡萄糖、果糖、木酮糖和阿拉伯糖。碳水化合物按成熟野生型小麦籽粒的重量计占超过65%,包括65%-75%的淀粉和约10%的细胞壁多糖诸如纤维素、阿拉伯木聚糖和bg。淀粉是大多数植物中的主要储存碳水化合物,包括谷物诸如小麦。“淀粉”在本文中被定义为由通过α-1,4键和没有或一些的α-1,6键聚合的吡喃葡萄糖单元组成的多糖。淀粉是在淀粉体中合成并以颗粒形式形成和储存在发育中的储存器官,诸如籽粒中;它在本文中被称为“储存淀粉”或“籽粒淀粉”。在包括普通小麦的谷物籽粒中,绝大多数的储存淀粉作为淀粉颗粒沉积在胚乳中。淀粉在籽粒发育,特别是植物生长的籽粒灌浆期的期间合成并沉积在淀粉体内,并且形成称为淀粉颗粒的离散结晶结构。在野生型普通小麦中,淀粉颗粒有两种大小等级,即直径在从10-40μm范围内的较大的椭圆形颗粒(a型颗粒)和直径在从1-10μm范围内的较小的球形颗粒(b型颗粒)。淀粉的分子被分类为属于称为直链淀粉和支链淀粉的两个组分级分,所述组分级分是基于它们的聚合度(dp)和聚合物中α-1,6与α-1,4键的比率进行区分的。直链淀粉包含几乎完全线性的α-1,4连接的葡糖基链,可以没有或具有几个通过α-1,6键连接至其他α-1,4连接链的葡聚糖链,并且具有104至105的道尔顿的分子量。术语“直链淀粉”在本文中被定义为包括α-1,4连接的糖苷(吡喃葡萄糖)单元的基本上线性分子,有时被称为“真正的直链淀粉”;和直链淀粉样长链淀粉,它有时也被称为“中间物质”或“直链淀粉样支链淀粉”,它与真正的直链淀粉一起在碘量测定中表现为碘结合物质(takeda等人,1993;fergason,1994)。真正的直链淀粉中的线性分子通常具有在500与5000之间的dp并且含有低于1%的α-1,6键。近期的研究已显示约0.1%的α-1,6-糖苷分支位点可以存在于直链淀粉中,因此它被描述为“基本上线性的”。在此情形下,百分比(%)是指α-1,6-糖苷键相对于糖苷键总数即α-1,4-糖苷键和α-1,6-糖苷键的总和的数量。颗粒结合型淀粉合酶(gbss)是参与直链淀粉合成的主要酶。支链淀粉是相对高度分支的葡聚糖聚合物,其中具有3至60个葡糖基单元的α-1,4连接的葡糖基链通过α-1,6键连接,因此葡糖基键总数的大约4%-6%是α-1,6键。因此,支链淀粉是具有在从5000至500,000范围内的dp的大得多的分子,并且比直链淀粉更加高度地分支。直链淀粉具有螺旋构象,具有约104至约106道尔顿的分子量,而支链淀粉具有约107至约108道尔顿的分子量。这两个类型的淀粉可以通过本领域中熟知的方法容易地区分或分离,例如通过尺寸排阻色谱法或通过其对碘的不同结合亲和力。直链淀粉在小肠中比支链淀粉更慢地被α-淀粉酶消化,所述支链淀粉由于其高度分支的结构而具有多个酶水解位点。来自野生型普通小麦籽粒的淀粉通常包含如通过碘量法测量的20%-30%的直链淀粉和约70%-80%的支链淀粉,而本发明的籽粒的淀粉具有基于重量约45%至约70%的直链淀粉含量。直链淀粉含量可以在45%与70%之间,在一些实施方案中在45%与65%之间,或约50%、约55%、约60%或约65%。水平越高,籽粒越优选。如本文所定义的淀粉中的直链淀粉的比例是基于重量/重量(w/w)的,即,就在进行任何分级分离形成直链淀粉和支链淀粉级分之前的淀粉来说,直链淀粉的重量占从籽粒中可提取的总淀粉的重量的百分比。术语“淀粉中的直链淀粉的比例”和“直链淀粉含量”当在本文中在本发明的籽粒、面粉或其他产品的情形下使用时是基本上可互换的术语。直链淀粉含量可以通过本领域中已知的任何方法确定,所述方法包括尺寸排阻高效液相色谱法(hplc),例如在90%(w/v)dmso中;伴刀豆球蛋白a法(megazymeint,ireland);或优选地通过碘量法,例如如实施例1中所述的。hplc法可能涉及淀粉的脱支(batey和curtin,1996)或不涉及脱支。应了解,诸如仅测定“真正的直链淀粉”的batey和curtin,1996的hplc法的方法可能会低估如本文所定义的直链淀粉含量。诸如hplc或凝胶渗透色谱法的方法取决于淀粉分成直链淀粉和支链淀粉部分的分级分离,而碘量法取决于差异碘结合并且因此不需要分级分离。根据籽粒重量和直链淀粉含量,可以针对测试和对照株系计算出每颗籽粒沉积的直链淀粉的量并且将其进行比较。使用标准方法,例如schulman和kammiovirta,1991的方法,容易从小麦籽粒中分离淀粉。在工业规模上,可以使用湿磨或干磨。淀粉颗粒大小在可能存在将较大的a颗粒与较小的b颗粒的分离的淀粉加工工业中是重要的。商业上生长的野生型小麦在籽粒中具有通常在55%-75%的范围内的淀粉含量,这在某种程度上取决于生长的栽培品种。相比之下,本发明的籽粒具有约25%至约70%的淀粉含量,因此在大多数实施方案中,其淀粉含量相对于相应野生型籽粒降低。在实施方案中,本发明籽粒的淀粉含量在25%与65%之间、25%与60%之间、25%与55%之间、25%与50%之间、30%与70%之间、30%与65%之间、30%与60%之间、30%与55%之间或30%与50%之间。在另外的实施方案中,淀粉含量以占籽粒重量的百分比(w/w)计为约35%、约40%、约45%、约50%、约55%、约60%或约65%。本发明的籽粒的淀粉含量还可以基于相对量,即相当于相应野生型籽粒的淀粉含量进行定义。在实施方案中,淀粉含量在约50%与约90%之间、或在50%与80%之间、在50%与75%之间、在50%与70%之间、在60%与90%之间或在60%与80%之间,每种量均是相对于野生型籽粒的量。淀粉含量还可以相对于野生型籽粒的淀粉含量在90%与100%之间。在每种情况下,应通过在相同条件下,例如在田间试验中生长植物来进行比较。可以通过碾磨方法,任选地随后进行筛选或筛分过程而从籽粒获得本发明的面粉、淀粉颗粒和麸皮。还可以通过碾磨工艺,例如湿磨工艺,随后进一步将淀粉与籽粒的蛋白质、油和纤维分离而从籽粒获得纯化的淀粉。如本文所用,术语“碾磨产品”是指由研磨籽粒,优选本发明的小麦籽粒产生的产品,并且包括面粉(例如,全麦粉)、粗粉(也称为小麦粗粉)、麸皮(包括胚芽)和淀粉颗粒。粗粉通常呈颗粒状粒子的形式并且包括来自籽粒的麸皮和胚芽,并且通常包含约18%蛋白质、20%-30%淀粉和约5%-6%脂质。与白面粉相比,来自碾磨工艺的该级分是相对营养丰富的。籽粒形状是可以影响植物的商业实用性的特征,因为籽粒形状可以影响籽粒可以容易地碾磨的容易性或其他方面。碾磨产率是籽粒商业实用性的重要参数。相对于野生型籽粒,本发明的籽粒的碾磨产率可以降低至少10%,但另选地也可与野生型籽粒大致相同。在另一方面,本发明提供了从本发明的植物的籽粒获得的淀粉颗粒或淀粉。相对于野生型小麦淀粉颗粒,颗粒的淀粉具有增加的直链淀粉比例和降低的支链淀粉比例。碾磨工艺的初始产物是包含淀粉颗粒的混合物或组合物,诸如例如白面粉或全麦粉,并且因此本发明涵盖此类颗粒。来自野生型小麦的淀粉颗粒包含淀粉颗粒结合型蛋白,包括gbss、ssi、sbeiia和sbeiib以及其他蛋白质,并且因此这些蛋白质的存在将小麦淀粉颗粒与其他谷物的淀粉颗粒区分开。相比之下,来自本发明的小麦籽粒的淀粉颗粒包含小麦gbss,包括由六倍体小麦的a、b和d基因组中的每一种编码的gbss多肽,但是对于ssiia多肽是减少的,实际上一些实施方案缺乏ssiia多肽。这些淀粉颗粒还可以包含降低水平的小麦ssi、sbeiia和sbeiib多肽中的一种或多种或全部,即使小麦籽粒对于编码这些酶的基因是野生型。当在光学显微镜下观察时,来自本发明的小麦籽粒的淀粉颗粒通常在形状和表面形态上变形,参见实施例7,特别是对于直链淀粉含量以占籽粒的总淀粉的百分比计至少45%或至少50%的小麦籽粒。在一个实施方案中,从本发明的籽粒获得的淀粉颗粒的至少50%,优选至少60%或至少70%、更优选至少80%显示出变形的形状和/或表面形态。当在偏振光下观察时,淀粉颗粒还显示出双折射率的损失。例如,对于确定双折射的发生率参见本文的实施例7。例如,小于50%或小于25%的淀粉颗粒显示出在偏振光下观察野生型淀粉颗粒时观察到的“马耳他十字”。来自淀粉颗粒的淀粉可以通过在利用热和/或化学处理使淀粉颗粒破坏和分散之后去除蛋白质来纯化。本发明的籽粒的淀粉、淀粉颗粒的淀粉和纯化的淀粉的特征进一步在于以下特性中的一种或多种或全部:i)其淀粉含量以占总淀粉的比例计基于重量为至少45%(w/w),优选在45%与70%之间,或至少50%(w/w)或约60%(w/w)的直链淀粉;ii)包含至少2%的抗性淀粉,优选至少3%的抗性淀粉;iii)所述淀粉的特征在于降低的血糖指数(gi);iv)所述淀粉颗粒的形状变形;v)所述淀粉颗粒当在偏振光下观察时具有降低的双折射率;vi)所述淀粉的特征在于减小的溶胀体积;vii)所述淀粉中长链分布和/或分支频率改变;viii)所述淀粉的特征在于降低的峰值糊化温度;ix)所述淀粉的特征在于降低的峰值粘度;x)淀粉成糊温度降低;xi)如通过尺寸排阻色谱法所确定直链淀粉的峰值分子量降低;xii)淀粉结晶度降低;以及xiii)a型和/或b型淀粉的比例降低,并且/或者v型结晶淀粉的比例增加;每种性质是相对于野生型小麦淀粉颗粒或淀粉的。本发明的面粉或淀粉的特征还可以在于它与野生型面粉或淀粉相比在加热的过量水中的溶胀体积。溶胀体积通常通过将淀粉或面粉与过量水混合并且加热到升高的温度(通常大于90℃)来测量。然后,通过离心来收集样品,并且将溶胀体积表示为沉降的物质的质量除以样品的干重。当所希望的是增加食物制品、特别是水化的食物制品的淀粉含量时,低溶胀特征是有用的。本发明的面粉和淀粉优选具有减少的溶胀体积,诸如例如相对于野生型小麦面粉或淀粉减少30%-70%。改变的支链淀粉结构的一种量度是淀粉的链长度或聚合度的分布。链长分布可以通过在异淀粉酶脱支之后使用荧光团辅助的碳水化合物电泳(face)来确定。本发明的淀粉的支链淀粉可以具有在从5至60范围内的链长分布,或在诸如dp7-11的子范围内的分布,这大于来自野生型植物的淀粉的相应链长分布,和/或在其他子范围例如dp12-24内的频率方面是降低的。参见,例如本文的实施例7。具有较长链长的淀粉也将在分支频率方面具有相称的减少。本发明的籽粒的淀粉与具有降低的sbeiia活性的小麦籽粒的淀粉明显不同(regina等人,2006),其中籽粒的支链淀粉包含如在支链淀粉的异淀粉酶脱支后所测量相对于野生型籽粒的支链淀粉比例增加的dp4-12链长级分。face可以很容易地确定差异。在本发明的另一个方面中,小麦淀粉可以具有改变的糊化温度,优选降低的糊化温度,所述糊化温度可以通过差示扫描量热法(dsc)容易地测量。糊化是在过量水中淀粉颗粒内的分子序态被热驱动瓦解(破坏),并且伴随着且不可逆地发生特性改变,诸如颗粒溶胀、微晶熔融、双折射率损失、粘度发展以及淀粉增溶。与来自野生型植物的淀粉相比,糊化温度可能升高或降低,这取决于剩余支链淀粉的链长。来自玉米的直链淀粉扩展子(ae)突变体的高直链淀粉显示出比普通玉米更高的糊化温度(fuwa等人,1999;krueger等人,1987)。如通过dsc所测量,与从相似的但未改变的籽粒中提取的淀粉相比,糊化温度、特别是第一峰的起始温度或针对第一峰的顶点的温度可以降低至少3℃、优选至少5℃或更优选至少7℃。淀粉可以包含升高的水平的抗性淀粉,具有由特定物理特征指示的改变的结构,所述物理特征包括由以下组成的组中的一种或多种:消化酶的物理难接近性(这可能是由于具有改变的淀粉颗粒形态)、可测量的淀粉相关脂质的存在、改变的结晶度、以及改变的支链淀粉链长分布。直链淀粉的高比例也有助于淀粉被加热且然后冷却时的抗性淀粉的水平。与从野生型小麦籽粒分离的淀粉相比,本发明的小麦的淀粉结构的不同之处还可以在于结晶度降低和/或结晶度类型改变。结晶度通常通过x射线晶体学研究。也认为淀粉的降低的结晶度与增强的感官特性有关并且有助于更平滑的口感。本发明还提供了小麦籽粒、来自所述籽粒的面粉、全麦粉、淀粉颗粒和淀粉,它们至少通过升高rs水平的方式,但也通过增加其他膳食纤维组分诸如阿拉伯木聚糖、β-葡聚糖和果聚糖的方式包含增加量的膳食纤维。如本文所用,“膳食纤维”(df)或“总膳食纤维”(tdf)意指食物中的在健康人类受试者的小肠中未被消化并且在大肠中具有生理益处的碳水化合物聚合物的总和。如本文所用,df与“总纤维含量”(下文)不同。df在小肠中不被消化和吸收,而是传递到结肠,在那里它可能被细菌降解。df包括rs、非α-葡聚糖寡糖和非淀粉多糖(nsp),诸如阿拉伯木聚糖、β-葡聚糖和果聚糖。df通常分为可溶于水(可溶性纤维)或不溶于水(不溶性纤维)的形式,和rs。野生型小麦籽粒中膳食纤维的最促进健康的级分是可溶性纤维,其主要包含ax组分,因为野生型淀粉的rs非常低。相比之下,在燕麦和大麦中,可溶性纤维主要是bg。澳大利亚国家心脏基金会(nationalheartfoundation)对于心血管和结肠健康推荐30-35gdf的每日摄入量。已经在小麦中鉴定了影响膳食纤维含量的多种候选基因(quraishi等人,2011),但没有达到本发明的籽粒所提供的水平。df可以通过方法aoac991.43(megazyme)测量。如本文所用,“益生元”是不可消化的(通过人消化酶)食物成分,其通过在穿过小肠后选择性地刺激通过结肠中的一种或有限数量的细菌的生长和/或活性而有益地影响受试者。例如,果聚糖和bg除了通过细菌活性之外不能被消化,但可以通过特定发酵,产生短链羧酸(包括乙酸盐、丙酸盐和丁酸盐)来改变人肠道微生物的组成。在实施方案中,本发明的小麦籽粒、面粉、淀粉颗粒和淀粉提供改变的消化特性,诸如增加的抗性淀粉。如本文所用,“抗性淀粉”(rs)是指在健康个体的小肠中未被吸收但进入大肠的淀粉和淀粉消化产物。根据上下文,所述抗性淀粉是根据占籽粒的总淀粉的百分比、或占食物中的总淀粉含量的百分比定义的。因此,抗性淀粉不包括在小肠中消化和吸收的产物。因此,rs是食物成分(面粉等)或本发明食物产品的膳食纤维含量的一部分。rs分为五个类别:物理上难以接近的淀粉(rsi),诸如例如在不完全碾磨的籽粒中;抗性淀粉颗粒(rsii),诸如例如在马铃薯和生香蕉中小程度存在的;回生淀粉(rsiii),其在长时间冷却糊化淀粉时形成;化学改性淀粉(rsiv),诸如通过醚化或酯化糖基残基上的游离羟基形成的;以及能够在直链淀粉或支链淀粉长支链与脂质之间形成络合物的淀粉(rsv)(birt等人,2013)。rsiii尤其是由较长的直链淀粉链形成,所述直链淀粉链在糊化后往往重结晶并形成回生淀粉。基于具有升高的直链淀粉含量的淀粉的产物中的rs主要是回生的直链淀粉(hung等人,2006)。本发明的籽粒的淀粉、淀粉颗粒、淀粉和来自其的产品的rs增加被认为是由于rsii和rsv含量的增加以及由于在淀粉已被加热且然后冷却时相对于相应的野生型产品回生后的rsiii。如通过v-复合物结晶度所测量淀粉-脂质缔合也可能有助于抗性淀粉的水平,从而由于本发明的籽粒中脂质含量增加而增加rsv组分。一些淀粉也可以是呈rsi形式,有点难以消化。有若干种方法可用于测量食物成分或食物中的rs水平,所有方法均依赖于使用淀粉水解酶对可消化淀粉的最初去除(dupuis等人,2014)。通过prosky方法(aoac985.29)进行的rs估算利用在α-淀粉酶、葡糖淀粉酶和蛋白酶消化后对膳食纤维的重量测定(prosky等人,1985)。mccleary方法(aoac2009.01)是aoac的官方方法,并且可商购获得(megazymeinternational,ireland)。它是测量rs的优选方法,参见本文的实施例1。在该测定中,通过用胰腺α-淀粉酶处理来增溶非抗性淀粉,将rs回收并溶解在2mkoh中,并且然后用淀粉葡糖苷酶水解成葡萄糖并进行测量。在实施方案中,以占总淀粉含量的百分比计,淀粉具有基于重量在2%与20%之间、2%与18%之间、3%与18%之间、在3%与15%之间或在5%与15%之间的抗性淀粉。在实施方案中,相对于用等量的野生型小麦淀粉制备的相应食物成分或食物产品,rs含量增加2至10倍。在实施方案中,相对于野生型,rs含量增加约3倍、约4倍、约5倍、约6倍、约7倍、约8倍或约9倍。rs增加的程度可以通过将本发明的产物与相应的野生型产物混合来调整。本发明淀粉的改变的淀粉结构且特别是高直链淀粉水平引起在食物中消耗时的rs的增加。rs具有与其在肠中发酵过程中释放的代谢产物(特别是scfa丁酸盐、丙酸盐和乙酸盐)相关的有益生理效应(topping和clifton,2001),并且有效降低餐后血糖水平。本发明的籽粒、食物成分和由其产生的食物产品可以有利地用于提供富含β-葡聚糖、纤维素、果聚糖或阿拉伯木聚糖的组合物的膳食,或用于生产所述组合物,所述提供或生产均基于这些组分在本发明的籽粒中的增加的水平。谷物籽粒的细胞壁是复杂且动态的结构,其由多种多糖组成,所述多糖诸如纤维素、木葡聚糖、果胶(富含半乳糖醛酸残基)、胼胝质(1,3-β-d-葡聚糖)、阿拉伯木聚糖(阿拉伯糖-1,4-β-d-木聚糖,在下文为ax)和bg,以及多酚诸如木质素。在禾本科植物和一些其他单子叶植物的细胞壁中,葡糖醛酸阿拉伯木聚糖和bg占优势,并且果胶多糖、葡甘露聚糖和木葡聚糖的水平相对较低(carpita等人,1993)。这些多糖由大量各种不同的多糖合酶和糖基转移酶合成,其中植物中存在至少70种基因家族,并且在许多情况下,存在基因家族的多个成员。如本文所用,术语“(1,3;1,4)-β-d-葡聚糖”(也称为“β-葡聚糖”并在本文中缩写为“bg”)是指未取代的和基本上无支链的β-吡喃葡糖基单体主要通过1,4-键和一些1,3-键共价连接的基本上线性的聚合物。通过1,4-键和1,3-键连接的吡喃葡糖基残基以非重复但非随机的方式排列,即1,4-键和1,3-键不是随机排列的,但同样地它们不是以规则的重复序列排列(fincher,2009a,2009b)。如燕麦和大麦bg中一样,在小麦bg中,大多数(约90%)的1,3-连接的残基跟随2或3个1,4-连接的残基。因此,bg可以被认为是主要的通过单个β-1,3键连接在一起的β-1,4连接的纤维三糖基(每个具有3个吡喃葡糖基残基)和纤维四糖基(每个具有4个吡喃葡糖基残基)单元以及大约10%的较长β-1,4连接的纤维糊精单元的链,所述纤维糊精单元具有4至约10个1,4-连接的吡喃葡糖基残基,至多达约28个吡喃葡糖基残基(fincher和stone,2004)。通常,bg聚合物具有至少1000个糖基残基并在水性介质中采用延长的构象。三糖单元与四糖单元之比(dp3/dp4比)在不同物种之间变化,并且因此是来自物种的bg的特征。来自不同谷物的bg在其溶解度方面不同,来自燕麦的bg比来自小麦的bg更可溶。认为这与bg聚合物的dp3与dp4之比有关。在野生型小麦籽粒中,整籽粒中的bg水平高于胚乳中的bg水平(henry,1985)。野生型整小麦籽粒的bg含量基于重量为约0.6%,与大麦的约4.2%、燕麦的3.9%和黑麦的2.5%相比较(henry1987)。在野生型小麦籽粒中,所述范围按重量计为0.4%-1.4%(lazaridou等人,2007)。小麦籽粒bg通常具有3-4.5的dp3/dp4比(lazaridou等人,2007)。虽然大麦bg与减少血浆胆固醇、降低血糖指数和降低结肠癌风险相关,但小麦bg与这些影响无关,因为小麦籽粒具有的bg水平远低于大麦。籽粒中bg的水平通常通过将籽粒碾磨成全麦粉并且通过例如实施例1中所述的方法测定bg来测量。在野生型小麦籽粒中,按籽粒的重量计,果聚糖的水平仅为0.6%-2.6%。如本文所用,术语“果聚糖”意指果糖的聚合物,其包含聚合成单末端葡萄糖单元的果糖基残基。果聚糖由蔗糖合成,这解释了末端葡萄糖。果糖部分通过β-1,2和/或β-2,6键彼此连接,并且葡萄糖可以通过在蔗糖中出现的α-1,2键连接至链的末端,所述α-1,2键是通过从蔗糖的重复果糖基转移形成的。涉及果聚糖合成的酶包括形成酮糖的蔗糖-蔗糖果糖基转移酶(ec2.4.1.99),以及1-或6-果聚糖-果聚糖果糖基转移酶(ec2.4.1.100)。聚合度(dp)从3至数百变化,但通常为3-60,并且在本发明的籽粒中主要是dp3-10。鉴于该组合物,果聚糖在水中高度可溶,并且不会在78%乙醇中沉淀。果糖基残基之间的连接仅仅是形成线性分子的β-1,2类型(菊粉),其中果糖基残基与蔗糖起子的果糖基残基连接,或是β-2,6类型(levan),或者两种连接类型均出现在支链果聚糖(革兰明糖)中。包含具有β-1,2分支点的β-2,6-连接的果糖单元并且因此是更复杂的结构的革兰明糖也可以存在于谷物中,并且可以与levan混合。本发明的籽粒中果聚糖的水平通常通过将籽粒碾磨成全麦粉并且通过例如实施例1中所述的方法测定果聚糖来测量,所述方法是基于prosky和hoebregs(1999)的方法。所述方法依赖于果聚糖的水解,随后是对释放糖的测定。果聚糖是非淀粉碳水化合物,作为食物成分对人类健康具有潜在的有益作用(tungland和meyer,2002;ritsema和smeekens,2003)。由于果聚糖键的β-构型,人消化酶α-葡糖苷酶、麦芽糖酶、异麦芽糖酶和蔗糖酶不能水解果聚糖。此外,人类和其他哺乳动物在其小肠中缺乏分解果聚糖的果聚糖外切水解酶,并且因此膳食果聚糖避免在小肠中消化并完整地到达大肠。然而,那里的细菌能够发酵果聚糖,并且从而将它们用作例如用于生长和产生短链脂肪酸(scfa)的能量或碳源。因此,膳食果聚糖能够刺激结肠中的有益细菌诸如双歧杆菌的生长,这有助于预防肠病,诸如便秘和致病性肠道细菌的感染。膳食果聚糖还可以增强膳食中的营养素吸收,特别是钙和铁,这可能是通过产生scfa,进而降低管腔ph值并改变钙种形成且因此改善溶解度,或对粘膜转运途径施加直接影响,从而改善骨骼的矿化并降低缺铁性贫血的风险。此外,高果聚糖膳食可以改善糖尿病患者的健康并且通过抑制作为结肠癌前体的异常隐窝灶来降低结肠癌的风险(kaur和gupta,2002)。此外,果聚糖具有甜味,并且越来越多地用作低卡里里甜味剂和功能性食物成分。相对于现有的果聚糖生产方法(例如涉及从菊苣中提取菊粉),从本发明的籽粒生产分离的果聚糖是成本有效的。通过将籽粒碾磨成全麦面粉,并且然后将包括果聚糖的总糖从面粉提取到水中,可以实现果聚糖的大规模提取。这可以在环境温度下进行,然后将混合物离心或过滤。然后将上清液加热至约80℃并离心以除去蛋白质,然后干燥。另选地,可以使用80%乙醇进行面粉的提取,随后使用水/氯仿混合物进行相分离,并且将含有糖和果聚糖的水相干燥并重新溶解在水中。以任一方式制备的提取物中的蔗糖可以通过添加α-葡糖苷酶以酶促方式除去,并且然后通过凝胶过滤除去己糖(单糖)以产生各种大小的果聚糖级分。这将产生富含果聚糖的级分,所述级分含有至少50%,优选至少60%或至少70%,更优选至少80%的果聚糖。小规模果聚糖测定的开发。谷物籽粒及其衍生食物产品中的果聚糖含量常常使用高效液相色谱法(hplc)(huynh等人,2008)或分光光度法(mccleary等人,2000;mccleary等人,2013;steegmans等人,2004)测量。基于分光光度法的官方aoac方法999.03(aoac,2000b)已被megazymeinternationallimited(bray,ireland)商业化为k-fruchk和k-fruc试剂盒。这些商业试剂盒方便并且易于测量谷物籽粒中的果聚糖水平(karppinen等人,2003;whelan等人,2011)。在k-fruchk测定中,将蔗糖和低聚合度(dp)麦芽糖水解成果糖和葡萄糖。使用分光光度计,用己糖激酶/磷酸葡萄糖异构酶/葡萄糖-6-磷酸脱氢酶(hk/pgi/g6pgh)系统测量它们的浓度。在果聚糖水解后,重新测量果糖和葡萄糖的总浓度,并且然后通过两次测量值之间的差异确定果聚糖含量。在k-fruc测定中,将蔗糖、麦芽糖、麦芽糖糊精和淀粉水解成果糖和葡萄糖,将所述果糖和葡萄糖通过硼氢化钠进一步还原成相应的糖醇(山梨糖醇和甘露糖醇)。将来源于果聚糖水解的果糖和葡萄糖与4-羟基苯甲酸酰肼(pahbah)偶联以在沸水浴中显色,并且使用分光光度计读取它们的吸光度以计算果聚糖含量。最近开发了简化的酶水解随后是hplc分析,用于筛选双单倍体(dh)小麦群体中的果聚糖含量(huynh等人,2008b)。需要准确且快速地测量具有数百至数千个株系的大型繁殖群体中的果聚糖含量。然而,谷物籽粒中使用的所有当前果聚糖测定的效率相对较低,每个工作者每天允许约10个样品,并且需要数克的每种面粉样品。为了开发高通量果聚糖测定,本发明人以允许此测定的板格式按比例缩小k-fruchk和k-fruc测定,如实施例1中所述。阿拉伯木聚糖是在植物细胞壁中(包括在小麦籽粒的细胞壁中)发现的另一种多糖。本发明的籽粒和面粉中阿拉伯木聚糖的水平相对于相应的野生型籽粒和面粉是增加的,例如基于重量增加至少1.5倍或至少2倍。所述水平可以增加1.5倍至3倍。如本文所用,“阿拉伯木聚糖”(ax)是指通过1,4糖苷键连接的β-d-吡喃木糖基残基的直链骨架,其中α-l-阿拉伯呋喃糖基残基在o-2、o-3和/或在o-2,3两个位置处与一些吡喃木糖基残基连接。吡喃木糖基残基是以下中的任何一种:在o-2或o-3处的单取代、在o-2,3处的二取代,和未取代的。除阿拉伯糖残基外,侧支可含有少量的吡喃木糖、吡喃半乳糖、α-d-葡糖醛酸或4-o-甲基-α-d-葡糖醛酸残基。在谷物中,ara/xyl比率可以从0.3至1.1变化。来自外果皮、盾片和胚轴的ax被阿拉伯糖相对高度地取代,而糊粉层和透明层的ax取代较少。ax可以进一步包含氢化肉桂酸、阿魏酸和对香豆酸,所述酸被酯化到与木糖残基的o-3连接的阿拉伯糖残基的o-5上(smith和hartley,1983)。1,4-β-d-木聚糖骨架的生物合成由1,4-β-木糖基转移酶催化,所述酶使用udp-d-木糖作为底物并且将木糖单元转移至木寡糖链的非还原端。谷物中ax的合成涉及使用udp-xyl作为底物的木糖转移酶(xylotransferase),并且可能涉及复杂的四糖作为引物(carpita等人,2011)。阿拉伯木聚糖仅微溶于水,并且需要碱溶剂用于其有效提取。例如,氢氧化钡可以选择性地提取ax(gruppen等人,1992)。相反,氢氧化钠提取bg和ax两者。籽粒中ax的水平通常通过将籽粒碾磨成全麦粉并且通过例如实施例1中所述的方法测定ax来测量。使用玉米、黑麦和小麦ax的研究展示出对盲肠发酵、scfa的产生、血清胆固醇的降低以及钙和镁吸收的改善的积极作用(hopkins等人2003)。如本文所用,纤维素是指形成微纤维的约24-36个(1-4)-β-d-葡聚糖链的结晶阵列,主要存在于植物的细胞壁中。它是自然界中发现的最丰富的聚合物之一。葡聚糖链由质膜上的cesa基因家族的纤维素合酶形成(giddings等人,1980),并且然后将24至36个链组装成功能性微纤维。拟南芥属具有10个cesa基因,其中至少3个在原代细胞壁形成过程中共表达,并且另外3个在次生细胞壁形成过程中共同表达(carpita等人,2011),每个基因均将糖基残基添加至受体葡聚糖链的非还原端以延长聚合物。cesa基因与参与其他多糖合成的单子叶植物和双子叶植物两者的csl基因有关。例如,仅在包括谷物的禾本科植物中发现的cslf和cslh酶参与bg的合成。由籽粒、食物成分、淀粉颗粒和淀粉制成的食物产品的特征在于降低的血糖指数。gi是富含碳水化合物的食物对人类受试者血液中餐后葡萄糖水平的影响的简单标志物。如本文所用,“血糖指数”或“gi”意指在食用含有50g碳水化合物的测试食物的一部分之后的血糖浓度曲线下面积除以用存在于等量的葡萄糖或白面包中的相同量的碳水化合物实现的增量面积的量。因此gi涉及包含淀粉的食物的消化率和对消化产物的摄取率,并且是对血糖浓度的漂移的测试食物的作用与白面包或葡萄糖的作用的比较。gi从而是食物对餐后血清葡萄糖浓度的作用的量度并且与对用于血糖稳态的胰岛素的需求相关。由本发明的食物提供的一个重要特征是相对于用相同量的野生型小麦、面粉、淀粉颗粒或淀粉作为食物成分制成的相应食物降低的gi。此外,与用相同量的野生型小麦作为食物成分制成的相应食物相比,本发明的食物可以具有降低水平的最终消化并且因此是相对低卡路里的。低卡路里产品可以是基于包含由碾磨的小麦籽粒产生的面粉。此类食物可以具有饱腹、增强肠健康、降低餐后血清葡萄糖和脂质浓度以及提供一种低卡路里食物产品的作用。本发明的淀粉,或本发明的食物成分或食物产品的gi使用如本文中实施例9中所述的体外测定法容易地测量。体外测定如在健康人中消耗时发生的那样模拟产品中淀粉的消化,并且预测在消耗产品后在人类受试者中测量的gi。治疗受试者、特别是人类的方法可以包括以下步骤:将如本文所定义的改变的小麦籽粒、面粉、淀粉或食物或饮料产品以一定量在一个或多个剂量中施用至受试者,并持续一段时间,由此改善肠健康或代谢指标中的一个或多个的水平。指标可能相对于相应的未改变小麦淀粉或小麦或其产品的消耗进行变化,如在诸如ph值、scfa水平升高、餐后葡萄糖波动的一些指标的情况下,所述变化在长达24小时的时间段内,或者诸如在粪便体积增加或轻泻改善的情况下,它可能耗费数天,或者诸如在测量丁酸盐增强的正常结肠细胞的增殖的情况下,可能是约为数周或数个月的更长时间。可能所希望的是对改变的淀粉或小麦或小麦产品的施用是终生的。然而,假定改变的淀粉可以相对容易地施用,则可期待所治疗的个体具有良好的顺应性。剂量可以根据所治疗或预防的病状改变,但对于人类预计为每天至少10g本发明的小麦籽粒或淀粉,更优选地每天至少15g,优选地每天至少20或至少30g。每天大于约100克的给予可能需要相当大体积的递送并且降低了顺应性。最优选地,剂量对于人是每天10至100g的本发明的小麦籽粒,或淀粉、全麦粉或改性淀粉,或对于成人是每天20至100g。改善的肠健康的指标可以包括但不必限于:i)肠内含物的ph减小,ii)肠内含物中的总scfa浓度或总scfa量增加,iii)肠内含物中的一种或多种scfa的浓度或量增加,iv)粪便体积增加,v)肠或粪便的总水体积增加,而不腹泻,vi)轻泻改善,vii)一种或多种益生菌物种的数目或活性增加,viii)粪便胆汁酸排泄增加,ix)腐化产物的尿水平降低,x)腐化产物的粪便水平降低,xi)正常结肠细胞的增殖增加,xii)具有肠发炎或肠发炎倾向的个体的肠中炎症减少,xiii)尿毒症患者的尿素、肌酸酐以及磷酸盐中的任一种的粪便或大肠水平降低,以及xiv)以上的任何组合。改善的代谢健康的指标可以包括但不必限于:i)餐后葡萄糖波动的稳定化,ii)血糖应答改善(降低),iii)餐前血浆胰岛素浓度降低,iv)血脂特征曲线改善,v)血浆ldl胆固醇降低,vi)尿毒症患者的尿素、肌酸酐以及磷酸盐中的一种或多种的血浆水平降低,vii)血糖代谢异常应答的改善,或viii)以上的任何组合。肠内含物的ph可以减小至少0.1个单位,优选至少0.15或0.2个单位。肠健康或代谢健康的其他指标中的每一个可以改善至少10%,优选至少20%。应理解的是,本发明的一个益处在于它提供了具有特定营养益处的产品,诸如面包,并且此外它这样做不需要对小麦籽粒的淀粉或其他组分进行收获后改性。然而,可能所希望的是对籽粒的淀粉或其他组分进行改性,并且本发明涵盖此类改性的组分。改性方法是熟知的,并且包括通过常规方法对淀粉或其他组分的提取以及对淀粉的改性以增加抗性形式。淀粉可以通过用热和/或水分处理、以物理方式(例如球磨)、以酶促方式(使用例如α-或β-淀粉酶、普鲁兰酶等)、化学水解(使用液体或气体试剂的湿式或干式)、氧化、用双官能试剂(例如三偏磷酸钠、磷酰氯)交联、或羧甲基化作用来改性。虽然本发明可能特别适用于人类的治疗或预防,但应理解的是,本发明也适用于非人类受试者,包括但不限于农用动物,诸如牛、绵羊、猪等;家养动物,诸如犬或猫;实验动物,诸如兔或啮齿动物,诸如小鼠、大鼠、仓鼠;或可以用于体育的动物,诸如马。所述方法可能特别适用于非反刍类哺乳动物或诸如单胃哺乳动物的动物。本发明还可以适用于其他农用动物,例如家禽,包括例如鸡、鹅、鸭、火鸡、或鹌鹑、或鱼。术语“多肽”和“蛋白质”在本文中总体上可互换使用。如本文所用,术语“蛋白质”和“多肽”还包括如本文所述的本发明的多肽的变体、突变体、修饰体和/或衍生物。如本文所用,“实质上纯化的多肽”是指已从与其在天然状态下相关联的脂质、核酸、其他肽以及其他分子中分离出来的多肽。优选地,实质上纯化的多肽至少60%不含、更优选至少75%不含、并且更优选至少90%不含与其天然相关联的其他组分。关于“重组多肽”意指使用重组技术,即通过重组多核苷酸在细胞、优选地植物细胞并且更优选地小麦细胞中的表达而制得的多肽。在一个实施方案中,多肽具有淀粉合酶活性、特别是ssiia活性,并且与本文所述的ssiia多肽至少98%相同。多肽相对于参考多肽的同一性%可以通过本领域中已知用于比对氨基酸序列的任何程序,诸如程序gap(needleman和wunsch,1970,gcg程序)测定,其中空位产生罚分=5,并且空位延伸罚分=0.3。所述分析将两种序列在参考序列的全长氨基酸序列上进行比对。例如,如果参考序列是列示为seqidno:1的氨基酸序列,则比对是沿着seqidno:1的全长。比对序列中的空位被视为是针对每个缺少的氨基酸的非同一性的位置。关于所定义的多肽,将了解的是,高于以上所提供的那些的%同一性数值将涵盖优选的实施方案。因此,在适用的情况下,根据最小同一性%数值,优选的是多肽包含与相关指定的seqidno至少75%、更优选至少80%、更优选至少85%、更优选至少90%、更优选至少91%、更优选至少92%、更优选至少93%、更优选至少94%、更优选至少95%、更优选至少96%、更优选至少97%、更优选至少98%、更优选地至少99%、更优选至少99.1%、更优选至少99.2%、更优选至少99.3%、更优选至少99.4%、更优选至少99.5%、更优选至少99.6%、更优选至少99.7%、更优选至少99.8%、并且甚至更优选至少99.9%相同的氨基酸序列。氨基酸序列缺失或插入的范围通常为从约1至15个残基,更优选为约1至10个残基并且通常为约1至5个连续残基。然而,它们可以大于15个氨基酸,至多为多肽的全长。多肽序列可以是相对于相应野生型序列或参考序列seqidno的截短序列。例如,如果编码多肽的蛋白质编码区具有翻译提前终止密码子(终止密码子),则所得多肽(如果翻译)将被截短。截短的程度取决于终止密码子的位置,相对于野生型序列,将多肽缩短至少5%,优选至少10%。本发明基因的蛋白质编码区可以通过剪接位点突变的存在而被破坏,所述剪接位点突变引起错误剪接并且可以导致改变的rna转录物,使得开放阅读框被破坏。然后,多肽的氨基酸序列可以是与野生型相同的,直至错误剪接点或该点的下游,并且然后偏离野生型。此类多肽通常以与截短多肽相同的方式影响其活性。ssiia基因中的终止密码子和剪接位点突变的实例描述于本文的实施例11中。取代突变体在多肽中去除至少一个氨基酸残基并且在其位置中插入不同残基。对于用于降低多肽活性的取代诱变最关注的位点包括被鉴别为一个或多个活性位点的位点。所关注的其他位点是从各种品系或物种获得的特定残基是相同的,即是保守氨基酸的那些位点。这些位置对于生物活性可能是重要的。这些氨基酸,尤其是属于至少三个其他相同性保守氨基酸的连续序列内的那些氨基酸优选地以相对保守的方式进行取代以便保留诸如ssiia活性的功能,或以非保守方式进行取代以便降低活性。保守取代示出在表3中的“示例性取代”的标题下。“非保守氨基酸取代”在本文中被定义为除表3中列出的那些(示例性保守取代)以外的取代。预期ssiia多肽中的非保守取代会降低酶的活性,并且许多将对应于由“部分功能丧失突变的ssiia基因”编码的ssiia。表2.氨基酸亚分类表3.示例性且优选的保守氨基酸取代原始残基示例性保守取代优选的保守取代alaval、leu、ilevalarglys、gln、asnlysasngln、his、lys、argglnaspgluglucysserserglnasn、his、lys,asngluasp、lysaspglyproprohisasn、gln、lys、argargileleu、val、met、ala、pheleuleuile、val、met、ala、pheilelysarg、gln、asnargmetleu、ile、pheleupheleu、val、ile、alaleuproglyglyserthrthrthrsersertrptyrtyrtyrtrp、phe、thr、serphevalile、leu、met、phe、alaleu在一些实施方案中,本发明涉及对基因活性、特别是ssiia基因活性的修饰、突变基因的组合、以及嵌合基因的构建和使用。如本文所用,术语“基因”包括包含蛋白质编码区或在细胞中转录但不翻译的任何脱氧核糖核苷酸序列,以及相关的非编码和调节区。术语“基因”还包括野生型基因的突变形式,所述突变基因可以不进行转录和/或翻译,诸如例如在启动子区缺失时。相关的非编码和调节区通常位于5'和3’两个末端上与蛋白质编码区邻近,在任一侧上达约2kb的距离。在这点上,所述基因包括与给定的基因天然相关的控制信号,诸如启动子、增强子、转录终止子和/或聚腺苷酸化信号,或者异源控制信号,在该情况下,基因被称为“嵌合基因”。位于蛋白质编码区的5’端并存在于mrna上的序列被称为5’非翻译序列(5’-utr)。位于蛋白质编码区的3’端或下游并存在于mrna上的序列称为3’非翻译序列(3’-utr)。术语“基因”涵盖基因的cdna和基因组形式。“cdna”是基因的rna转录物的dna拷贝,并且在本文中以“对应于基因”的形式进行描述。例如,列示为seqidno:4的cdna核苷酸序列对应于ssiia-a基因,其野生型序列列示为seqidno:7。术语“基因”包括编码本文所述的本发明的蛋白质的合成或融合分子。基因通常以双链dna形式存在于小麦基因组中。可以将嵌合基因引入到适当载体中以用于细胞中的染色体外维持或用于整合到宿主基因组中。如本文所用,基因或基因型以斜体形式(例如ssiia)提及,而蛋白质、酶或表型以非斜体形式(ssiia)提及。如本文所用,术语“基因型”是指小麦细胞、组织、植物、植物部分或植物产品的遗传组成。所述遗传组成将与获得产品的小麦植物的遗传组成相同。如本文所用,术语“表型”是指细胞、组织、植物、植物部分或植物产品的可观察特征或一组多个特征,所述特征由植物基因型与植物生长环境之间的相互作用造成。含有编码区的基因的基因组形式或克隆可以穿插有称为“内含子”或“间插区”或“间插序列”的非编码序列。如本文所用的“内含子”是基因的区段,所述区段作为初级rna转录物的一部分被转录,但并不存在于成熟mrna分子中。内含子从核或初级转录物中去除或“剪除”;因此,内含子不存在于信使rna(mrna)中。内含子可以含有调节元件诸如增强子。如本文所用,“外显子”是指与存在于成熟mrna或在rna分子未被翻译的情况下的成熟rna分子中的rna序列相对应的dna区。mrna在翻译过程中起作用以指定所编码的多肽中的氨基酸的序列或顺序。本发明涉及各种多核苷酸。如本文所用,“多核苷酸”或“核酸”或“核酸分子”意指核苷酸的聚合物,其可以是dna或rna并且包括例如cdna、mrna、trna、sirna、shrna、hprna以及单链或双链dna。它可以是细胞、基因组或合成来源的dna或rna。优选地,多核苷酸在产生于细胞中时仅仅是dna或仅仅是rna。聚合物可以是单链、基本上双链或部分双链的。部分双链rna分子的实例是发夹rna(hprna)、短发夹rna(shrna)或自身互补rna,其包含通过核苷酸序列与其互补序列之间的碱基配对而形成的双链茎干以及以共价方式连接所述核苷酸序列和其互补序列的环序列。如本文所用,碱基配对是指核苷酸之间的标准碱基配对,包括rna分子中的g:u碱基对。“互补”意指两种多核苷酸能够沿着它们长度的一部分,或者沿着一者或两者的全长(完全互补)形成碱基配对。关于“分离的”意指实质上或基本上不含在其天然状态中通常伴随其的组分的物质。如本文所用,“分离的多核苷酸”或“分离的核酸分子”意指这样的多核苷酸,所述多核苷酸至少部分地从与其在天然状态下相关联或连接的相同类型的多核苷酸序列中分离出来、优选地实质上或基本上不含所述多核苷酸序列。例如,“分离的多核苷酸”包括已从与其在天然存在状态下侧接的多个序列中纯化或分离出来的多核苷酸,例如dna片段,所述dna片段已从通常邻近于所述片段的序列去除。优选地,分离的多核苷酸也至少90%不含诸如蛋白质、碳水化合物、脂质等的其他组分。如本文所用,术语“重组多核苷酸”涉及通过将核酸操纵成在自然界中通常未发现的形式而体外形成的多核苷酸。例如,重组多核苷酸可以呈表达载体的形式。一般来讲,此类表达载体包含可操作地连接至有待在细胞中转录的核苷酸序列的转录和翻译调节核酸。本发明涉及寡核苷酸的使用,所述寡核苷酸可以用作“探针”或“引物”。如本文所用,“寡核苷酸”是至多长为50个核苷酸,优选长为15-50个核苷酸的多核苷酸。它们可以是rna、dna、或任一种的组合或衍生物。寡核苷酸通常是10至30个核苷酸的相对短的单链分子,常常长为15-25个核苷酸,通常包含10-30个或15-25个核苷酸,所述核苷酸与ssiia基因或对应于ssiia基因的cdna的一部分相同或互补。当在扩增反应中用作探针或引物时,这种寡核苷酸的最小大小是用于在寡核苷酸与靶核酸分子上的互补序列之间形成稳定杂交体所需的大小。用作探针的多核苷酸通常与可检测标记(诸如放射性同位素、酶、生物素、荧光分子或化学发光分子)缀合。本发明的寡核苷酸和探针可用于对与所关注的性状(例如改性淀粉)相关的ssiia或其他基因的等位基因进行检测的方法中。此类方法采用了核酸杂交,并且在许多情况下包括通过适合的聚合酶进行的寡核苷酸引物延伸,例如像在pcr中用于对野生型或突变等位基因进行检测或鉴定。优选的寡核苷酸和探针与来自小麦或其他谷物的ssiia基因序列(包括本文所公开的任何序列,例如seqidno:15至49)杂交。优选的寡核苷酸对是跨越一个或多个内含子、或内含子的一部分的那些寡核苷酸对,并且因此可以用于在pcr反应中对内含子序列进行扩增。在本文的实施例中提供了许多实例。术语“多核苷酸变体”和“变体”等是指显示出与参考多核苷酸序列的实质上序列同一性,并且能够以与参考序列类似的方式、或以与参考序列相同的活性起作用的多核苷酸。所述术语还涵盖通过至少一个核苷酸的添加、缺失或取代而与参考多核苷酸不同、或当与天然存在的分子相比时具有一个或多个突变的多核苷酸。因此,术语“多核苷酸变体”和“变体”包括一个或多个核苷酸已添加或缺失、或用不同的核苷酸置换的多核苷酸。在这一点上,本领域中应充分理解的是,可以对参考多核苷酸作出包括突变、添加、缺失以及取代在内的某些改变,由此所改变的多核苷酸保留参考多核苷酸的生物功能或活性。因此,这些术语涵盖编码表现出酶促或其他调节活性的多肽的聚核苷酸、或能够充当选择性探针或其他杂交剂的多核苷酸。术语“多核苷酸变体”和“变体”还包括天然存在的等位基因变体。突变体可以是天然存在的(也就是说,从天然来源中分离)或合成的(例如通过对核酸进行定点诱变)。优选地,编码具有酶活性的多肽的本发明的多核苷酸变体长为相对于野生型的至少90%,至多为基因的全长。本发明的寡核苷酸的变体包括能够在接近本文所定义的特定寡核苷酸分子的位置的一个位置处与例如小麦基因组杂交的大小变化的分子。例如,变体可以包含额外的核苷酸(诸如1、2、3、4、或更多个),或更少的核苷酸,只要它们仍然与靶区杂交即可。此外,可以取代几个核苷酸而不影响寡核苷酸与靶区杂交的能力。此外,可以容易地设计出接近于(例如但不限于在50个核苷酸内)本文所定义的特定寡核苷酸杂交的植物基因组区进行杂交的变体。关于在多核苷酸或多肽的情形下的“对应于(correspondsto/correspondingto)”意指多核苷酸(a)具有与参考多核苷酸序列的至少一部分,优选全部(完全互补)实质上相同或互补的核苷酸序列或(b)编码与多肽中的氨基酸序列相同的氨基酸序列。这一短语在其范围内还包括具有与参考多肽中的氨基酸序列实质上相同的氨基酸序列的多肽。用于描述两种或更多种多核苷酸或多肽之间的序列关系的术语包括“参考序列”、“比较窗口”、“序列同一性”、“序列同一性百分比”、“实质上同一性”以及“相同的”,并且相对于限定的最小数目的核苷酸或氨基酸残基或优选地在全长内定义。术语“序列同一性”和“同一性”在本文中可互换用于指在比较窗口内,在核苷酸对核苷酸的基础上或在氨基酸对氨基酸的基础上序列相同的程度。因此,“序列同一性百分比”是通过以下方式计算的:在比较窗口内比较两个最佳比对的序列,测定在这两个序列中出现相同的核酸碱基(例如a、t、c、g、u)或相同的氨基酸残基的位置数,从而得到匹配位置数,将匹配位置数除以比较窗口中的位置总数(即,窗口大小),并且将结果乘以100,得到序列同一性百分比。多核苷酸对于参考多核苷酸的同一性%可以通过本领域中已知用于该目的任何程序,诸如例如gap(needleman和wunsch,1970,gcg程序)测定,其中空位产生罚分=5,并且空位延伸罚分=0.3。也可以参考blast程序家族,例如像altschul等人,1997所公开的。序列分析的详细的论述可以见于ausubel等人,1994-1998,第15章的第19.3单元中。除非另有说明,否则比对沿着参考序列的全长进行。当核苷酸或氨基酸序列具有至少98%,更特别地至少约98.5%、相当特别地约99%、尤其是约99.5%、更尤其是约99.8%的序列同一性、并且包括所述序列是相同的情况,则所述序列被指示为“基本上相似”。很明显,当rna序列被描述为与dna序列基本上相似、或具有一定程度的序列同一性时,dna序列中的胸腺嘧啶(t)被视为相当于rna序列中的尿嘧啶(u)。关于所定义的多核苷酸,将了解的是,较高的%同一性数值将涵盖优选的实施方案。因此,在适用的情况下,根据最小同一性%数值,优选的是多核苷酸包含与相关指定的seqidno至少75%、更优选至少80%、更优选至少85%、更优选至少90%、更优选至少91%、更优选至少92%、更优选至少93%、更优选至少94%、更优选至少95%、更优选至少96%、更优选至少97%、更优选至少98%、更优选地至少99%、更优选至少99.1%、更优选至少99.2%、更优选至少99.3%、更优选至少99.4%、更优选至少99.5%、更优选至少99.6%、更优选至少99.7%、更优选至少99.8%、并且甚至更优选至少99.9%相同的多核苷酸序列。在一些实施方案中,本发明涉及杂交条件的严格度以限定两个多核苷酸的互补程度。如本文所用,“严格度”是指在杂交过程中的温度和离子强度条件、以及某些有机溶剂的存在或不存在。严格度越高,靶核苷酸序列与标记的多核苷酸序列之间的互补程度将越高。“严格条件”是指使仅具有高频率的互补碱基的核苷酸序列杂交的温度和离子条件。如本文所用,术语“在低严格度、中等严格度、高严格度、或极高严格度条件下杂交”描述了用于杂交和洗涤的条件。对于进行杂交反应的指导可以见于currentprotocolsinmolecularbiology,johnwiley&sons,n.y.(1989),6.3.1-6.3.6中,其以引用的方式并入本文。本文所提及的特定杂交条件如下:1)低严格度杂交条件为在约45℃下,在6x氯化钠/柠檬酸钠(ssc)中,随后在50℃-55℃下,在0.2xssc、0.1%sds中洗涤两次;2)中等严格度杂交条件为在约45℃下,在6xssc中,随后在60℃下,在0.2xssc、0.1%sds中洗涤一次或多次;3)高严格度杂交条件为在约45℃下,在6xssc中,随后在65℃下,在0.2xssc、0.1%sds中洗涤一次或多次;以及4)极高严格度杂交条件为在65℃下,0.5m磷酸钠、7%sds,随在65℃下在0.2xssc、1%sds中洗涤一次或多次。如本文所用,“嵌合基因”或“遗传构建体”是指在其天然位置中并非是天然基因的任何基因,即,它已经人为操纵,包括整合到小麦基因组中的嵌合基因或遗传构建体。通常,嵌合基因或遗传构建体包含在自然界中非共同发现的调节和转录或蛋白质编码序列。因此,嵌合基因或遗传构建体可以包含来源于不同来源的调节序列和编码序列或者来源于相同来源但以不同于自然界中所发现的方式排列的调节序列和编码序列。术语“内源性”在本文中用于指在未被修饰的植物中在与处于研究中的植物(优选地小麦植物)相同的发育阶段通常产生的物质,诸如淀粉或ssiia多肽的ssiia基因。“内源性基因”是指在生物体的基因组中处于其天然位置中的天然基因,优选地是小麦植物中的ssiia基因。术语“外来多核苷酸”或“外源性多核苷酸”或“异源多核苷酸”等是指通过实验操作而引入到细胞的基因组(优选地小麦基因组)中,但并不天然存在于细胞中的任何核酸。这些包括在该细胞中发现的基因序列的修饰形式,只要引入的基因相对于天然存在的基因包含一些修饰,例如引入的突变或存在选择性标志物基因即可。外来或外源性基因可以是插入到非天然生物体中的在自然界中发现的基因、引入到天然宿主内的新位置中的天然基因、或嵌合基因或遗传构建体。术语“遗传修饰”包括将基因引入到细胞中、使细胞中的基因突变,以及人为地改变或调控细胞(通过修饰基因组),或已经进行这些动作的生物体或其子代或部分(诸如籽粒)中的基因调节。本发明涉及可操作地连接(connected/linked)的元件。“可操作地连接(operablyconnected/operablylinked)”等是指处于一种功能关系中的多核苷酸元件的连接。通常,可操作地连接的核酸序列连续地连接,并且在需要时将两个蛋白质编码区连续且符合阅读框地连接。当rna聚合酶将两个编码序列转录成单一rna时,编码序列“可操作地连接至”另编码序列,所述单一rna如果被翻译,那么它接着被翻译成具有来源于这两个编码序列的氨基酸的单一多肽。编码序列不必彼此是连续的,只要所表达的序列最终经加工产生所希望的蛋白质即可。如本文所用,术语“顺式作用序列”、“顺式作用元件”或“顺式调节区”或“调节区”或类似术语应用于意指调节基因序列的表达的任何核苷酸序列。此序列可以是在其天然环境中的天然存在的顺式作用序列,例如调节小麦ssiia基因;或在遗传构建体中的序列,所述序列在相对于可表达的基因序列适当地定位时调节所述基因序列的表达。这种顺式调节区可以能够在转录或转录后水平激活、沉默、增强、抑制或以其他方式改变基因序列的表达水平和/或细胞类型特异性和/或发育特异性。例如,已显示基因的5’-前导子(utr)中内含子的存在使单子叶植物(诸如小麦)中的基因的表达增强(tanaka等人,1990)。顺式作用序列的另一种类型为基质附着区(mar),其可以通过将活性染色质结构域锚定于核基质来影响基因表达。关于“载体”意指核酸分子,优选来源于质粒或植物病毒、其中可以插入核酸序列的dna分子。载体还可以包含选择标志物,诸如可以用于选择适合的细菌或植物转化体的抗生素抗性基因、或增强原核生物或真核生物(尤其是小麦)细胞的转化的序列(诸如t-dna或p-dna序列)。此类抗性基因和序列的实例是本领域技术人员熟知的。关于“标志物基因”意指将不同的表型赋予表达所述标志物基因的细胞并且由此将此类转化的细胞与不具有所述标志物的细胞区分开的基因,并且是本领域中熟知的。“选择性标志物基因”赋予一种性状,基于对选择剂(例如除草剂、抗生素、辐射、热、或对未转化的细胞造成损伤的其他处理)的抗性或基于在可代谢的底物存在下的生长优势,可以针对所述性状进行‘选择’。用于选择植物转化体的示例性选择性标志物包括但不限于:hyg基因,其赋予潮霉素b抗性;新霉素磷酸转移酶(npt)基因,其赋予对卡那霉素等的抗性,如例如由potrykus等人,1985所述的;来自大鼠肝脏的谷胱甘肽-s-转移酶基因,其赋予对谷胱甘肽衍生的除草剂的抗性,如例如ep-a-256223中所述的;谷氨酰胺合成酶基因,其在过表达时赋予对谷氨酰胺合成酶抑制剂(诸草丁膦)的抗性,如例如wo87/05327所述的;来自绿色产色链霉菌(streptomycesviridochromogenes)的乙酰基转移酶基因,其赋予对选择剂草丁膦的抗性,如例如ep-a-275957中所述的;编码5-烯醇莽草酸-3-磷酸合酶(5-enolshikimate-3-phosphatesynthase)(epsps)的基因,其赋予对n-膦酰甲基甘氨酸的耐受性,如例如由hinchee等人,1988所述的;bar基因,其赋予针对双丙氨磷的抗性,如例如wo91/02071中所述的;或腈水解酶基因,诸如来自臭鼻克雷伯氏菌(klebsiellaozaenae)的bxn,其赋予对溴苯腈的抗性(stalker等人,1988)。优选的可筛选的标志物包括但不限于:uida基因,其编码已知各种发色底物的β-葡萄糖醛酸酶(gus)酶;β-半乳糖苷酶基因,其编码已知发色底物的酶;水母发光蛋白基因(prasher等人,1985),其可以用于钙敏感性生物发光检测;绿色荧光蛋白基因(gfp,niedz等人,1995)或其变体之一;荧光素酶(luc)基因(ow等人,1986),其允许生物发光检测;以及本领域中已知的其他标志物。在一些实施方案中,酶活性的水平通过减少编码小麦植物中的酶的基因的表达水平,或增加编码小麦植物中的酶的核苷酸序列的表达水平来调控。增加表达可以在转录水平下通过使用不同强度的启动子或诱导型启动子来实现,所述启动子能够控制从编码序列表达的转录物的水平。可以引入异源序列,所述异源序列编码调控或增强其产物使淀粉合成诸如ssiia下调的基因的表达的转录因子。基因的表达水平可以通过改变构建体的每细胞拷贝数来调控,所述构建体包含编码序列和转录控制元件,所述转录控制元件可操作地连接至所述编码序列并且在细胞中是功能性的。另选地,可以选择多个转化体,并且针对具有由在转基因整合位点附近的内源性序列的影响所引起的有利水平和/或特异性的转基因表达的那些转化体进行筛选。有利水平和模式的转基因表达是引起小麦植物中的直链淀粉含量实质上增加的转基因表达。这可以简单地通过测试转化体来检测。降低基因表达还可以通过引入到小麦植物中的“基因沉默嵌合基因”的引入和转录来实现。基因沉默嵌合基因优选地被稳定地引入到小麦基因组,优选地小麦核基因组中,使得它在子代中稳定地遗传。如本文所用,“基因沉默作用”是指小麦细胞、优选地在植物生长时种子发育期间的胚乳细胞中的靶核酸的表达的降低,这可以通过引入沉默rna来实现。在优选的实施方案中,引入基因沉默嵌合基因,所述基因沉默嵌合基因编码降低一种或多种内源性基因,例如除ssiia基因或优选三种内源性ssiia基因之外的基因的表达的rna分子。这种降低可以是降低转录(包括通过染色质重塑对启动子区的甲基化)、或降低rna分子的转录后修饰(包括通过rna降解)或这两项的结果。基因沉默应不必解释为对靶核酸或基因的表达的消除。靶核酸在沉默rna存在的情况下的表达水平比它不存在的情况下更低就足够了。靶基因的表达水平可以降低至少约40%或至少约45%或至少约50%或至少约55%或至少约60%或至少约65%或至少约70%或至少约75%或至少约80%或至少约85%或至少约90%或至少约95%,或有效地消除到不可检测的水平。反义技术可以用于降低小麦细胞中的基因表达。术语“反义rna”应用于意指rna分子,其与特定mrna分子的至少一部分互补,并且能够降低编码mrna的基因,优选ssiia基因的表达。这种降低通常以序列依赖性方式发生,并且被认为是通过干扰转录后事件(诸如mrna从细胞核转运到细胞质、mrna稳定性或翻译的抑制)发生的。反义方法的使用是本领域中熟知的(参见例如,hartmann和endres,1999)。如本文所用,“人为引入的dsrna分子”是指双链rna(dsrna)分子的引入,所述双链rna分子优选地在小麦细胞中通过从编码这种dsrna分子的嵌合基因转录而合成。rna干扰(rnai)特别可用于特异性地降低基因的表达或抑制特定蛋白质的产生(同样在小麦中)(参见例如,regina等人,2006)。这种技术依赖于dsrna分子的存在,所述dsrna分子包含与所关注的基因的mrna或其一部分基本上相同的序列和其互补序列,从而形成dsrna。方便地,dsrna可以从宿主细胞中的单一启动子产生,其中正义序列和反义序列被转录产生发夹rna,在所述发夹rna中,正义序列和反义序列杂交形成dsrna区,并使(与ssiia基因)相关或无关的序列形成环结构,所以发夹rna包含茎-环结构。适用于本发明的dsrna分子的设计和产生完全在本领域技术人员的能力之内,特别考虑waterhouse等人,1998;smith等人,2000;wo99/32619;wo99/53050;wo99/49029;以及wo01/34815。编码dsrna的dna通常包含以反向重复形式排列的正义序列和反义序列两者。在优选的实施方案中,正义序列和反义序列通过间隔区分开,所述间隔区可以(或可以不)包含内含子,所述内含子在转录成rna时被剪除。已显示出此排列导致基因沉默的效率更高(smith等人,2000)。双链区可以包含从一个或两个dna区转录的一个或两个rna分子。dsrna可以被分类为长hprna,具有可以大部分互补,但不必完全互补(通常大于约200bp,例如在200与1000bp之间)的长的正义区和反义区。hprna也可以相当小,其中双链部分的大小在从约30至约42bp的范围内,但不长于94bp(参见wo04/073390)。认为双链rna区的存在触发了来自内源性植物系统的应答,所述应答破坏来自一个或多个靶植物基因的双链rna以及同源rna转录物,从而有效地降低或消除靶基因的活性。杂交的正义序列和反义序列的长度应各自是至少19个或至少21个连续核苷酸、优选至少30或50个核苷酸,并且更优选至少100、200、500或1000个核苷酸。可以使用对应于整个基因转录物的全长序列。长度最优选地是100-2000个核苷酸。正义序列和反义序列与靶向的转录物的同一性程度应为至少85%,优选地至少90%并且更优选地95%-100%。序列越长,对于总体序列同一性的要求越不严格。rna分子当然可以包含无关序列,所述无关序列可以起到稳定化分子的作用。用于表达dsrna形成构建体的启动子可以是在表达靶基因的细胞中表达的任何类型的启动子,优选地是相对于小麦植物的非籽粒组织优先表达于发育中小麦籽粒的胚乳中的启动子。当靶基因是在胚乳中选择性地表达的ssiia基因时,优选的是不在叶子或茎组织中表达的胚乳启动子,以便不影响其他组织中的一个或多个靶基因的表达。如本文所用,“沉默rna”是具有与从靶基因(优选地ssiia)转录的mrna的区域互补的21至24个连续核苷酸的rna分子。21至24个核苷酸的序列优选地与mrna的21至24个连续核苷酸的序列完全互补,即,与mrna的区域的21至24个核苷酸的互补序列相同。然而,还可以使用在mrna的区域中具有至多五个错配的mirna序列(palatnik等人,2003),并且碱基配对可能涉及一个或两个g-u碱基对。当沉默rna的21至24个核苷酸中不是所有都能够与mrna进行碱基配对时,优选的是在沉默rna的21至24个核苷酸与mrna的区域之间仅存在一个或两个错配。就mirna来说,优选的是向着mirna的3’末端发现任何错配,至多五个的最大值。在优选的实施方案中,在沉默rna与其靶mrna的序列之间不超过一个或两个错配。沉默rna来源于由本发明的嵌合dna编码的多个更长的rna分子。更长的rna分子(在本文中也称为“前体rna”)是通过从小麦细胞中的嵌合dna转录而产生的最初产物,并且具有通过互补区之间的分子内碱基配对而形成的部分双链特征。前体rna由特化类别的rna酶(常常被称为“一种或多种切片机”)加工成通常长为21至24个核苷酸的沉默rna。如本文所用的沉默rna包括短干扰rna(sirna)和微rna(mirna),它们在其生物合成方面不同。sirna来源于完全或部分双链rna,所述完全或部分双链rna具有至少21个连续碱基对,包括可能的g-u碱基对,但没有错配或从双链区凸出的未经碱基配对的核苷酸。这些双链rna是由以下形成的:单一的自身互补转录物,其通过在自身上向后折叠并且形成茎-环结构而形成,在本文中被称为“发夹rna”;或两个分离的rna,所述两个分离的rna至少部分地互补并且杂交形成双链rna区。mirna通过对更长的单链转录物进行加工而产生,所述转录物包含并非完全互补的互补区并且因此形成不完全地碱基配对的结构,因此在部分双链结构内具有错配或未经碱基配对的核苷酸。碱基配对的结构还可以包括g-u碱基对。加工前体rna以形成mirna引起了各自具有特定序列的一种或多种不同的小型rna,即一种或多种mirna的优先累积。它们来源于前体rna的一条链,通常为前体rna的“反义”链,然而加工长的互补前体rna以形成sirna产生了sirna的群体,所述sirna的序列并不均一,但对应于前体的许多部分并且来自所述前体的两条链。本发明的mirna前体rna(在本文中也被称为“人工mirna前体”)通常通过以下方式来源于天然存在的mirna前体:改变天然存在的前体的mirna部分的核苷酸序列使得它与靶mrna的21至24个核苷酸区互补、优选地完全互补,并且改变与mirna序列碱基配对的mirna前体的互补区的核苷酸序列以维持碱基配对。mirna前体rna的剩余部分可以未被改变,并且因此具有与天然存在的mirna前体相同的序列,或者它还可以通过核苷酸取代、核苷酸插入、或优选地核苷酸缺失、或其任何组合而发生序列改变。认为mirna前体rna的剩余部分与被称为切片机样1(dcl1)的切片机酶对结构的识别有关,并且因此优选的是如果对结构的剩余部分作出任何改变则要很少。例如,在不对总体结构产生重大改变下碱基配对的核苷酸可以由其他碱基配对的核苷酸取代。本发明的人工mirna前体所来源于的天然存在的mirna前体可以是来自小麦、另一种植物(诸如另一种谷类植物)、或来自非植物来源。此类前体rna的实例是稻米mi395前体、拟南芥mi159b前体或mi172前体。已在多种植物中展示了人工mirna的用途,例如alvarez等人,2006;parizotto等人,2004;schwab等人,2006。可以用于下调内源性基因表达的另一种分子生物学方法是共抑制。共抑制的机制尚未被完全了解,但认为它涉及转录后基因沉默(ptgs),并且在那一点上,可能与反义抑制的许多实例非常相似。共抑制涉及将基因或其片段的额外拷贝相对于启动子以“正义取向”引入到植物中以用于其表达,如在本文中所用,“正义取向”是指相对于靶基因中的序列与序列的转录和翻译(如果它发生)相同的取向。正义片段的大小、其与靶基因区的对应性以及其与靶基因的同源性程度如同以上针对反义序列所述的。在一些情况下,基因序列的额外拷贝干扰靶植物基因的表达。关于实施共抑制方法的方法,参考专利说明书wo97/20936和欧洲专利说明书0465572。用于降低基因表达的这些技术中的任一种均可以用于以协作的方式降低多个基因的活性。例如,可以针对相关基因的家族,通过靶向基因所共有的区域而靶向一个rna分子。另选地,可以通过在一个rna分子中包含多个区域,每个区域靶向不同的基因,来靶向无关基因。这可以通过在单一启动子的控制下融合多个区域来容易地进行。本领域中工作人员熟知的许多技术可用于将核酸分子引入到小麦细胞中。如本文所用,术语“转化”意指通过引入外来或外源性核酸而使细胞(例如细菌或植物,特别是小麦植物)的基因型改变。关于“转化体”意指进行如此改变的生物体。转化中并不包括通过使亲本植物杂交或通过诱变本身来将dna引入到小麦植物中。核酸分子可以作为染色体外元件被复制,或者优选地稳定地整合到植物的基因组中。关于“基因组”意指细胞、植物或植物部分的全部遗传的遗传互补物,并且包括染色体dna、质体dna、线粒体dna以及染色体外dna分子。在一个实施方案中,将转基因整合在小麦核基因组中,在六倍体小麦中,所述小麦核基因组包含a、b以及d亚基因组(在本文中被称为a、b以及d“基因组”)。用于产生能育的转基因的小麦植物的最常用方法包括两个步骤:将dna递送到可再生的小麦细胞中以及通过体外组织培养的植物再生。两种方法常常用于递送dna:使用根癌土壤杆菌(agrobacteriumtumefaciens)或相关细菌的t-dna转移,以及通过粒子轰击对dna的直接引入,但是其他方法也已用于将dna序列整合到小麦或其他谷物中。技术人员将清楚,将核酸构建体引入到植物细胞中的转化系统的特别选择对于本发明并不是必不可少的或者是本发明的限制,前提条件是它实现可接受水平的核酸转移。用于小麦的此类技术是本领域中熟知的。转化的小麦植物可以通过以下方式产生:将根据本发明的核酸构建体引入到受体细胞中,并且使包含并且表达根据本发明的多核苷酸的新的植物生长。从处于细胞培养中的转化的细胞生长出新的植物的过程在本文中被称为“再生”。可再生的小麦细胞包括成熟胚、分生组织(诸如叶基的叶肉细胞)的、或优选地来自开花后12-20天获得的不成熟胚的盾片、或来源于这些中的任一项的愈伤组织的细胞。回收所再生的小麦植物的最常用的途径是使用培养基诸如补充有生长素(诸如2,4-d)和低水平的细胞分裂素的ms-琼脂的体细胞胚胎发生,参见sparks和jones,2004)。小麦的土壤杆菌属介导的转化可以通过cheng等人.,1997;weir等人,2001;kanna和daggard,2003或wu等人,2003的方法进行。任何具有足够毒性的土壤杆菌属菌株都可以使用,优选地是具有额外毒性基因功能的菌株,诸如lba4404、agl0或agl1(lazo等人,1991)或c58的型式。还可以使用与土壤杆菌属相关的细菌。将从土壤杆菌属转移至受体小麦细胞的dna(t-dna)包含在遗传构建体(嵌合质粒)中,所述遗传构建体含有与有待转移的核酸侧接的野生型ti质粒的t-dna区的一个或两个边界区。遗传构建体可以含有两个或更多个t-dna,例如其中一个t-dna含有所关注的基因并且第二t-dna含有选择性标志物基因,这提供了两个t-dna的独立插入以及选择性标志物基因远离所关注的转基因的可能分离。t-dna载体优选地是如本领域中已知的“超二元”质粒。可以使用任何可再生的小麦类型;已成功地报道了品种bobwhite、fielder、veery-5、cadenza和florida。在这些更容易可再生的品种中的一种中的转化事件可以通过标准回交而转移至任何其他小麦栽培品种(包括优良品种)中。涉及到使用土壤杆菌属的其他方法包括:将土壤杆菌属与培养的分离的原生质体共培养;用土壤杆菌属转化种子、顶端或分生组织;或原位接种,诸如用于拟南芥的浸花法,如由bechtold等人,1993所述的。常常用于将核酸构建体引入到植物细胞中的另一种方法是通过小粒子的高速弹道渗透(也称为粒子轰击或微弹轰击),其中有待引入的核酸包含在多个小珠粒或粒子的基质内、或在它们的表面上,如例如由klein等人,1987所述的。供小麦转化中使用的优选的选择性标志物基因包括吸水链霉菌(streptomyceshygroscopicus)bar基因或pat基因连同使用除草剂草铵膦选择、hpt基因连同抗生素潮霉素、或nptii基因与卡那霉素或g418。另选地,可以使用阳性选择性标志物,诸如编码磷酸甘露糖异构酶(pmi)的mana基因,其中糖甘露糖-6-磷酸作为单一的c来源。由以下非限制性实施例进一步描述本发明。实施例1:材料和方法植物材料。各自在a、b或d基因组上的ssiia基因中包含单无效突变的三个小麦栽培品种由日本筑波国立农业生物资源研究所(nationalinstituteofagrobiologicalresources,tsukuba,japan)的myamamori博士友情提供。它们是chousen57(c57),其在ssiia-a中包含无效突变且因此缺乏ssiia-a多肽(sgp-a1);kanto79(k79),其在ssiia-b中包含无效突变且因此缺乏ssiia-b肽(sgp-b1);以及turkey116(t116),其在ssiia-d中包含无效突变且因此缺乏sgp-d1多肽(yamamori等人,2000)。针对同源组七染色体的中国春(cs)缺体/四体株系,命名为n7at7d、n7bt7d和n7dt7b(sears和miller,1985)由e.lagudah博士(澳大利亚堪培拉(canberra,australia)的csiro农业部)友情提供。将包括c57、k79、t116、三个澳大利亚小麦栽培品种sunco、egahume和westonia的小麦植物在堪培拉的csiro农业部处在具有自然光的温室中并且在18℃(夜晚)和24℃(白天)的温度下生长。收获每个株系的成熟籽粒并且风干至水分含量为大约9%。除非另有指明,否则将5g干燥籽粒/株系使用具有0.5mm目筛网的udy旋风磨机(fortcollins,co,usa)碾磨以生成全麦面粉或使用brabenderquadrumat小型碾磨机(gmbh&co.kg,duisburg,germany)碾磨以获得白面粉。为了如实施例12’中所述那样分析发育中籽粒和成熟籽粒中的蛋白质和淀粉,从由konik-rose等人(2007)报道的双单倍体群体获得突变型和野生型小麦植物(分别为ssiia和ssiia)。在开花后15天(dpa)将二十至四十个发育中胚乳收集在干冰上的管中,并且在-80℃下储存以用于如实施例12中所述分析rna、可溶性蛋白和淀粉颗粒结合型蛋白。为了分析籽粒中的蛋白质和淀粉特性,将籽粒在成熟时从温室或田间生长的植物收获。小麦植物的dna分析。为了通过pcr对基因组dna样品检测突变型ssiia或野生型ssiia等位基因的存在或不存在,从植物收获幼叶,并且使用fastdna试剂盒(bio101系统,q-bio基因)提取基因组dna。对于标志物辅助育种,对于a基因组ssiia基因使用引物对jkss2ap1f(5'-tgcgtttaccccacagagcaca-3'(seqidno:15),位于核苷酸序列登录号ab201445的核苷酸91与113之间)和jkss2ap2r(5'-tgccaaaggtccggaatcatgg-3'(seqidno:16),位于ab201445的核苷酸1225与1246之间)(图2);对于b基因组ssiia基因,使用引物jkss2bp7f(5'-gcggaccaggttgtcgtc-3'(seqidno:17),位于核苷酸序列登录号ab201446的核苷酸5978与5995之间)和jltss2bpr1(5'ctggctcacgatccagggcatc-3'(seqidno:18),位于ab201446的核苷酸6313与6335之间)(图3);并且对于小麦的d基因组ssiia基因,使用引物jtss2d3f(5'-gtaccaaggtatggggactatgaa-3'(seqidno:19),位于核苷酸序列登录号ab201447的核苷酸2369与2392之间)和jtss2d4r(5'-gttggagagatacctcaacagc-3'(seqidno:20),位于ab201447的核苷酸2774与2796之间)(图4)。pcr反应含有50ng基因组dna、1.5mmmgcl2、0.125mm的每种dntp、10pmol引物、0.5m甘氨酸甜菜碱、1μl二甲基亚砜(dmso)和1.5-3.5uhot-startaq聚合酶(qiagen),反应体积为20μl。使用hybaidpcrexpress(integratedsciences)进行扩增反应,其中95℃下5min,1个循环;35个以下循环:94℃下解链45s,退火温度为52℃(a基因组)或60℃(对于b和d基因组),持续30秒,以及在72℃下延伸持续2min30s;然后72℃下10min,1个循环,随后冷却至25℃。将所得的pcr片段在1%或2%琼脂糖凝胶上分离并且在乙啡啶染色之后进行可视化(uvitec)。另外,标准扩增对于退火温度使用59℃,但其他方面使用相同pcr条件,除非另有说明。对来自从冻干的研磨组织较大规模(9ml)提取的dna进行dna印迹杂交分析(stacey和isaac,1994)。将dna样品调整至0.2mg/ml,并且用限制性酶诸如bamhi和ecori消化。如stacey和isaac,(1994)所述进行限制性酶消化、凝胶电泳和真空印迹。从cdna产生32p标记的探针并且将其用于与dna印迹杂交。根据jolly等人(1996)的方法,通过放射自显影法检测杂交序列。rna提取和定量实时pcr(qrt-pcr)。使用rna植物试剂盒(macherey-nagel)从15dpa时的胚乳提取总rna,并且使用nanodrop1000(thermoscientific)定量。使用superscriptiii逆转录酶(invitrogen),在50℃下在50μl反应中使用0.5μg量的rna模板进行cdna合成。使用rt-pcr引物,将cdna模板(100ng)用于10μlqrt-pcr反应中,其中退火温度在58℃下(表4)。作为定量对照,使用一对引物,其扩增位于微管蛋白基因的3'末端处的外显子中的区域。使用greenpcr试剂盒(qiagen)在rotor-gene6000(corbett)中进行扩增反应。使用微管蛋白基因片段的扩增作为参考扩增在实时旋转分析仪软件(corbett)中分析比较定量。对于每个样品,进行一式三份的qrt-pcr反应。表4.用于rna表达测定的qrt-pcr引物从发育中胚乳中分离可溶性蛋白质和淀粉颗粒结合型蛋白。将来自在15dpa时收获的发育中种子的发育中胚乳均质化并且悬浮于1.5μl/mg的预冷冻可溶性蛋白质提取缓冲液中(0.25mk2hpo4,ph7.5,0.05medta,20%甘油,sigma蛋白酶抑制剂混合物和0.5mdtt)。将匀浆在4℃下以16,000g离心15min。使用考马斯加强型(coomassieplus)蛋白质测定试剂(bio-rad)将含有可溶性蛋白质的上清液用于估算蛋白质浓度。如果需要,在分析前将样品储存在-20℃。在用水洗涤后,用蛋白酶k直接处理从可溶性蛋白质制剂中保留的沉淀物,并且然后如下纯化淀粉。根据rahman等人,(1995)并进行微小的改变,用纯化的淀粉制备淀粉颗粒结合型蛋白。将淀粉颗粒在蛋白质变性提取缓冲液(50mmtris缓冲液,ph6.8,10%甘油,5%sds,5%β-巯基乙醇和溴酚蓝)中以15μl/mg淀粉的比率煮沸5-10min。以13,000g离心20min后,将上清液用于sds-page分析。从成熟籽粒中分离淀粉和提取淀粉颗粒结合型蛋白使用wig-l-bug混合器msd(美国),将来自每种植物的整籽粒(100-150mg)在滚珠轴承机中以30rpm的速度研磨30s。首先用12.5mmnaoh处理全麦产物,通过0.5mm尼龙筛过滤,用水洗涤三次,并且然后与0.5mg蛋白酶k一起在1ml50mm磷酸盐缓冲液中在37℃下温育2小时。将通过以5,000g离心获得的淀粉沉淀物悬浮并且用水洗涤3次,随后在每次洗涤后离心。用丙酮洗涤后,将残留的淀粉在37℃下风干过夜。从成熟籽粒淀粉制备淀粉颗粒结合型蛋白与先前针对发育中胚乳淀粉所述的那些相同。sds-page和凝胶染色。为了定量淀粉中的蛋白质含量,使用等量的淀粉(4mg)来提取淀粉颗粒结合型蛋白。对于每个样品将相同体积的含有总蛋白质的上清液上样到nupagenovex4-12%bis-tris凝胶(lifetechnologies)中。这允许检测来自相同量淀粉的蛋白质结合模式的变化。将含有20μg总蛋白质的样品用于可溶性蛋白质。如先前所述(butardo等人2012)那样运行并检测sds-page凝胶。免疫印迹。表5中列出并枚举了来自先前研究的针对gbssi、ssi、ssiia、sbeiia和sbeiib的抗血清,包括它们的抗原来源和特异性。使用与上述相同的蛋白质标准如前所述(butardo等人2012)那样进行蛋白质印迹和检测。表5.用于检测谷物淀粉合酶蛋白的多克隆抗体。在sds-page凝胶和免疫印迹上对蛋白质条带的定量。为了定量和比较不同基因型之间蛋白质的丰度,使用5μlmagicmarktmxp蛋白质梯(invitrogen)中的两个蛋白质条带(80kda和60kda)作为参考。在可视化蛋白质条带后,扫描sds-page凝胶和免疫印迹(epsonperfection2450photo;epsonamericainc.,ca,usa)以成像出用于使用quantityone软件包按照规定的方法(bio-rad)进行条带强度分析的文件。将条带80kda用于定量sbeiia、sbeiib和ssiia,将条带60kda用于定量ssi和gbssi。质谱法。可以在从考马斯蓝染色的sds-page凝胶选择的蛋白质条带上进行凝胶内蛋白水解消化。离子阱串联ms可以如由butardo等人(2012)所述那样进行。通过proteinlynxglobalserver(版本1,micromass),可以通过不间断ms与swissprot/trembl中的条目的相关性来鉴定蛋白质(colgrave等人2013)。籽粒重量。在成熟时从植物收获籽粒,所述成熟被视为植物完全变黄时。收获谷穗并且在37℃下储存至少两周以确保完全干燥,然后如果需要进一步储存则在室温下储存,并且然后脱粒以提供成熟籽粒。对从这种籽粒或从其获得的全麦粉分析取决于籽粒重量的本文所述的参数,以及籽粒重量本身。每个小麦株系的籽粒重量由100个籽粒的总重量确定。用mpaft-nir光谱仪(bruker)测量籽粒的水分含量;对于成熟籽粒,水分含量通常基于重量为约9%。将取决于籽粒重量的参数诸如如本文所述的淀粉含量、bg含量、果聚糖含量等基于干重计算,在未通过nir测量的情况下假设9%水分含量(w/w)。小麦籽粒脂质分析。用氯仿/甲醇/0.1mkcl(比率为2:1:1,v/v/v)的混合物提取来自约300mg全麦粉样品的总脂质。通过将脂质样品在1n甲醇hcl(supelco,bellefonte,pa)中在80℃下温育2h来制备脂肪酸甲酯(fame)。使用己烷:二乙醚:乙酸(70:30:1,v/v/v)的溶剂混合物,通过薄层色谱法(tlc)(硅胶60,merck,germany)从总脂质中分级分离tag和极性膜脂质汇集物,并且使用氯仿/甲醇/乙酸/水(90/15/10/3,v/v/v/v)的溶剂混合物通过tlc分离各个膜脂质种类。将可信的脂质标准品上样并且在相同板上的单独泳道中运行以鉴定脂质种类。使用含有各个种类脂质的二氧化硅条带制备如上文所提到的fame,并且通过气相色谱法gc-fid7890a(agilenttechnologies,paloalto,ca,usa)分析,所述gc-fid7890a配有30mbpx70柱(sge,austin,tx,usa)用于基于已知量的作为内标添加的十七烷酸(heptadecanoin)的峰面积来定量各种脂肪酸。淀粉提取。除非另有说明,否则通过首先使用旋风磨机(cyclote1093,tecator,sweden)将籽粒(10g)研磨成全麦粉来从籽粒样品中提取淀粉。通过蛋白酶提取方法(morrison等人,1984)从全麦粉中分离淀粉,并且在室温下用水洗涤,每克全麦粉使用10ml水,除去了残渣。然后将淀粉冷冻干燥并称重以进行分析。使用regina等人,(2006)的方法,也从发育中小麦籽粒中小规模分离淀粉。淀粉含量。使用由megazyme(bray,cowicklow,republicofireland)供应的总淀粉分析试剂盒(k-tsta),通过aacc方法76.13测定籽粒的总淀粉含量,并且将其基于重量计算为占成熟的未碾磨籽粒重量的百分比。从总籽粒重量中减去淀粉重量得到籽粒的总非淀粉含量确定了总重量的降低是否是由于淀粉含量的降低导致。直链淀粉含量。除非另有说明,否则淀粉样品的直链淀粉含量通过如下稍作修改的morrison和laignelet(1983)的碘量(碘结合)法一式三份地测定。将大约2mg淀粉精确称量(精确至0.1mg)到盖子中配有橡皮垫圈的2ml螺旋盖管中。为了除去脂质,将1ml85%(v/v)甲醇与淀粉混合,并且将管在65℃水浴中加热1小时,伴有偶尔涡旋。以13,000g离心5min后,小心地除去上清液并且重复提取步骤。然后将淀粉在65℃下干燥1小时,并且溶解在尿素-二甲基亚砜溶液(udmso;9体积的二甲基亚砜与1体积的6m尿素)中,每2mg淀粉使用1mludmso。立即将混合物剧烈涡旋并且在95℃水浴中温育1小时,伴有间歇性涡旋以使淀粉完全溶解。将等分试样的淀粉-udmso溶液(50μl)用20μli2-ki试剂处理,所述i2-ki试剂每ml水含有2mg碘和20mg碘化钾。用水将混合物补足至1ml。通过将200μl转移至微孔板并且使用emaxprecision微板读取器(moleculardevices,usa)读取吸光度来测量混合物在620nm处的吸光度。将含有从0至100%直链淀粉和100%至0%支链淀粉的标准样品由马铃薯直链淀粉(sigma目录号a-0512)和马铃薯支链淀粉(sigma,目录号a-8515)制成,并且如对于测试样品的那样进行处理。使用由标准样品的吸光度导出的回归方程,根据吸光度值确定直链淀粉含量(直链淀粉百分比)。淀粉样品的直链淀粉含量还通过脱支淀粉样品来测定(当规定时),并且然后如前所述(butardo等人2012;castro等人2005)使用尺寸排阻色谱法(sec)测量。通过该方法,将由支链淀粉脱支产生的短链与较长的直链淀粉链分离并且测定相对量。将使用mark-houwink-sakaruda方程校准的普鲁兰多糖标准品(shodexp-82)用于从洗脱时间估算分子量。制备样品并且一式三份地进行分析。也可以根据case等人,(1998)或通过如由batey和curtin,(1996)所述那样使用90%dmso用于分离脱支淀粉的hplc方法进行对非脱支淀粉的直链淀粉/支链淀粉比率的分析。抗性淀粉(rs)含量。使用由megazyme(bray,cowicklow,republicofireland)供应的rs分析试剂盒(k-rstarch)一式三份地测定籽粒的rs含量,并且将其基于重量计算为占淀粉的百分比。代替在rs分析试剂盒中提出的100mg样品,对于该工作中的每个测定,在15ml锥形底盖管(目录号:188271,greinerbio-one)中使用减少量的全麦粉(40mg),按比例使用来自试剂盒的溶液和缓冲液。含有从0至20mg/ml的葡萄糖的标准样品由葡萄糖(k-rstarch试剂盒)制成,并且如对于测试样品的那样进行处理。使用从标准样品的吸光度导出的回归方程,根据吸光度值确定测试样品的基于重量的rs含量和非抗性淀粉含量。然后将rs含量计算为rs的重量占总淀粉含量的重量的百分比。如wo2012/058730中所述,还可以在体外测量食物样品诸如面包中rs的水平。该方法描述了通常食用的食物中淀粉的样品制备和体外消化。所述方法具有两部分:首先,将食物中的淀粉在模拟生理条件下水解;其次,通过洗涤除去副产物,并且在均化和干燥样品后测定rs。在消化处理结束时定量的淀粉代表食物的rs含量。β-葡聚糖(bg)。使用由megazyme(bray,co,wicklow,republicofireland)供应的试剂盒(k-bglu)一式三份地测定bg水平。果聚糖含量。使用如下修改的美格兹密果聚糖试剂盒(k-fruc)测定程序在2ml管或96孔板(2ml孔)中进行果聚糖提取和测定。将小麦全麦粉(40mg)与1ml水(80℃)混合,并且在80℃下在振荡(1200rpm)下温育30min。冷却至室温后,将管离心5min,并且移取出20μl的含有果聚糖和其他糖的上清液用于果聚糖测定。通过添加来自k-fruc试剂盒的20μl含有蔗糖酶、淀粉酶和麦芽糖酶的酶溶液将上清液中的蔗糖、麦芽糖、麦芽糖糊精和淀粉水解成葡萄糖和果糖,并且将混合物在40℃下在振荡(1000rpm)下温育30min。然后通过添加20μl10mg/ml碱性硼氢化物溶液并且在40℃下在振荡(1000rpm)下温育30min来还原样品中的葡萄糖和果糖。将该溶液中的果聚糖用果聚糖酶(40℃,持续30min,以1000rpm振荡)水解成葡萄糖和果糖。添加对羟基苯甲酸酰肼(pahbah)以在98℃下将颜色复合物显色6min。冷却样品后,使用分光光度计在410nm处测量颜色复合物,并且使用含有从0至0.27mg/ml果糖(美格兹密,k-fruc试剂盒)并且用果聚糖酶水解后如对于测试样品的那样进行处理的标准曲线将吸光度值转换为果聚糖含量。使用由标准样品的吸光度导出的回归方程,根据吸光度值确定测试样品的果聚糖含量(果聚糖百分比)。以板格式进行按比例缩小的果聚糖测定。对于按比例缩小的果聚糖测定,将美格兹密试剂盒中的酶溶液、缓冲液和试剂的所有量按比例缩小10倍,并且将反应在96孔板中进行。使用对于具有高果聚糖含量的样品的20mg全麦样品,或具有约0.5%-2%的较低果聚糖水平的40mg样品。果糖提取不需要用乙醇预润湿面粉-在提取果聚糖之前将全麦粉通过涡旋充分分散在热水中。对于果聚糖提取,20min提取时间是足够的。将水解反应在1.1ml96孔板(用盖子密封)中在40℃下进行30min,使用bioshakeiq和96孔适配器(德国耶拿(jena)的qinstruments)以1,000rpm振荡。在修改的k-fruc测定中,在果聚糖水解和添加对羟基苯甲酸酰肼(pahbah)后将板用盖子密封并且紧紧夹在定制的板保持器中,以用于使用水浴在100℃下显色6min(wisebath,thermolinescientific,wetherillpark,nsw,australia)。将水解的样品(250μl)转移至96孔平底微量滴定板(微孔板或ps-微孔板,greinerbio-one,germany)中以使用multiskanspectrum读板仪(thermoscientific,finland)读取340nm(对于k-fruchk)或410nm(对于k-fruc)处的吸光度。总的阿拉伯木聚糖(ax)。使用20mg全麦粉样品在2ml螺旋盖管中测量ax。将每个样品与1ml0.5m硫酸混合,涡旋,并且将混合物在99℃下在振荡(1000rpm)下温育30min。然后将管在冰水中冷却5min。将管以10,000g离心5min,并且将来自每个管的上清液(800μl)转移至96孔板。如果需要,在进一步处理之前将这些板储存在-20℃下。对于稀释,将100μl等份的上清液转移至另一个96孔板(greinerbio-onemasterblock)中,并且向每个孔中添加900μlmilliq水。将稀释的上清液(100μl)转移至测定板(bioradtitre管波纹状微型管,目录号223-9390)。为了制备木糖标准品,使用2mg/ml储备溶液(sigma,目录号x-3877)制备浓度为30、50、75、100、150和200μg/ml的100μl标准溶液。向每个孔添加0.5ml新鲜制备的间苯三酚试剂(pgr,见下文)。将板用microcap条(nationalscientific,tn3346-08c)密封,夹紧,并且在通风橱中在100℃下温育25min。然后通过倒置板将样品充分混合。之后,将200μl样品转移至通风橱中的uvstar板。使用板式分光光度计例如thermomultiscan在510和552nm处测量每个样品的吸光度。对于通风橱中的每个测定,新鲜制备间苯三酚试剂(pgr)。为此,分别制备两种溶液,并且然后混合。通过在50ml管将0.6g间苯三酚(sigma,目录号7933)在2.4ml无水乙醇中溶解几分钟来制备溶液1。溶液2包含55ml冰乙酸,将1.1ml浓盐酸(hcl)缓慢添加至乙酸中。将溶液1转移至250ml瓶中。然后用溶液2冲洗含有溶液1残余物的50ml管以定量转移所有溶液1,并且然后将所有溶液2与瓶中的溶液1混合。最后,将0.6ml葡萄糖溶液(70mg/ml,在milliq水中)添加至溶液1和2的混合物中。纤维素含量。使用50mg全麦粉样品在2ml管或96孔板(2ml孔)中进行纤维素测定。通过添加600μl乙酸硝酸试剂(80%乙酸:70%硝酸的10:1(v/v)混合物)并且将混合物在99℃下在振荡(1000rpm)下温育1小时来除去全麦粉中的木质素、半纤维素和溶解淀粉。冷却后,将样品以最大速度离心5min,并且弃去上清液。用1ml水洗涤每种沉淀物,以最大速度离心5min,并且弃去每种上清液。为了增溶每种沉淀物中的结晶纤维素,向每个样品管中添加1ml72%h2so4。基于估算的纤维素含量和纤维素标准品稀释样品。对于显色,将100μl蒽酮试剂(在72%h2so4中的0.2%蒽酮)添加至每个样品管,并且将混合物在98℃下温育10min。使用分光光度计在620nm处读取处理的样品的吸光度,并且通过参考使用0至0.75mg/ml纤维素(sigma:目录号g-6413)的标准曲线计算纤维素含量。链长分布分析。通过在使淀粉样品脱支之后根据morell等人,(1998)使用毛细管电泳单元进行荧光活化毛细管电泳(face)来测定对支链淀粉链长分布。如先前所述(o’shea和morell,1996)那样制备样品。淀粉糊化。在pyris1差示扫描量热计(perkinelmer,norwalkct,usa)中测量淀粉样品的糊化温度曲线。将淀粉溶液的粘度在快速粘度分析仪(rva,newportscientificptyltd,warriewood,sydney)上测量,例如使用如由batey等人,(1997)报道的条件。测量的参数包括峰值粘度(最大热糊粘度)、保持强度、最终粘度和成糊温度。根据konik-rose等人,(2001)的方法测定面粉或淀粉的溶胀体积。通过在将面粉或淀粉样品在限定温度下的水中混合之前和之后以及在糊化物质的收集之后对样品进行称量来测量水的吸收。淀粉颗粒形态。通过显微术检查淀粉颗粒形态。使用leica-dmr复合显微镜在普通光和偏振光两者下检查水中的纯化的淀粉颗粒悬浮液,以测定淀粉颗粒形态。使用joeljsm35c仪器进行扫描电子显微术。将纯化的淀粉用金溅涂并且在室温下以15kv扫描。对胚乳中的蛋白质表达的分析。通过蛋白质印迹程序分析胚乳中的sbei、sbeiia和sbeiib蛋白的特异性表达,特别是这些蛋白质的表达或累积的水平。从所有母体组织中切下胚乳,并且将大约0.2mg的样品在600μl50mmph7.5的磷酸钾缓冲液(42mmk2hpo4和8mmkh2po4)中均化,所述磷酸钾缓冲液含有5mmedta、20%甘油、5mmdtt和1mmpefabloc。将研磨的样品以13,000g离心10min,并且将上清液等分并且冷冻在-80℃下直到使用。对于总蛋白质估算,使用0.25mg/mlbsa标准品的0、20、40、60、80以及100μl等分试样建立bsa标准曲线。用蒸馏水将样品(3μl)补足到100μl,并且向每一份中添加1ml考马斯加强型蛋白质试剂。5min后,使用来自标准曲线的零bsa样品作为空白,在595nm下读取吸光度,并且测定样品中的蛋白质水平。使每个胚乳的包含20μg总蛋白质的样品在含有0.34mtris-hcl(ph8.8)、丙烯酰胺(8.0%)、过硫酸铵(0.06%)和temed(0.1%)的8%非变性聚丙烯酰胺凝胶上运行。在电泳之后,根据morell等人,1997将蛋白质转移至硝化纤维素膜,并且与sbeiia、sbeiib或sbei特异性抗体发生免疫反应(表5)。使用具有成熟小麦sbeiia的n端序列的氨基酸序列aaspgkvlvpdgesddl(seqidno:49)的合成肽生成针对小麦sbeiia蛋白的抗血清(抗wbeiia)(rahman等人,2001)。使用n末端合成肽aggpsgevmi(seqidno:50)以类似方式生成针对小麦sbeiib的抗血清(抗wbeiib)(regina等人,(2005)。该肽被认为代表成熟sbeiib肽的n末端序列,并且还与大麦sbeiib蛋白的n末端相同(sun等人,1998)。使用n末端合成肽vsaprdytmataedgv(seqidno:51)以类似方式合成针对小麦sbei的多克隆抗体(morell等人,1997)。根据标准方法从用合成肽免疫的兔获得这种抗血清。统计分析。使用第16版用于windows的genstat(vsninternationalltd,herts,uk)进行对直链淀粉数据的统计分析。使用graphpadprism5.01版对其他数据进行统计学分析(t检验和单因素anova,以及tukey后检验)。误差棒表示平均值的标准误差(sem)。统计学显著性定义为p<0.05和p<0.01。实施例2.对小麦ssiib和ssiic基因的cdna序列和基因组dna序列和所编码的多肽的鉴定以及与ssiia的比较为了鉴定小麦中对应于稻米中的ssiib和ssiic(ohdan等人,2005)的编码淀粉合酶ii同工酶(ssiib和ssiic)的基因并将它们与ssiia进行比较,使用来自稻米的cdna序列,即ssiia的登录号af419099、ssiib的af395537和ssiic的af383878搜索ncbi数据库。小麦同系物鉴定如下。对于小麦ssiia基因,鉴定了对应于小麦中ssiia基因的三种同源cdna序列。这些同源cdna序列是针对a基因组上的ssiia-a的登录号af155217(seqidno:4)、针对b基因组上的ssiia-b的登录号aj269504(seqidno:5)和针对d基因组上的ssiia-d的登录号aj269502(seqidno:6)。鉴定了对应于这三种同源cdna序列的基因组dna核苷酸序列:针对ssiia-a基因(seqidno:7)的登录号ab201445、针对ssiia-b基因(seqidno:8)的登录号ab201446和针对ssiia-d基因(seqidno:9)的登录号ab201447。搜索iwgsc数据库,分别在染色体7as(traes_7as_53cafb43a,7a:52346437-52346905bp,反向链)、7bs(iwgsc:染色体7bs,traes_7bs_7beaf5ec0,7b:31821573-31821749bp正向链)和7ds(iwgsc:染色体7ds,traes_7ds_e6c8af743,iwgsc_css_7ds_scaff_3877787:1至396bp,5137至5419bp正向链)上鉴定三个相应的同源基因的位置。氨基酸序列分别为:针对ssiia-a的登录号aad53263、针对ssiia-b的登录号cab96627和针对ssiia-d多肽的登录号cab86618。当将ssiia氨基酸和相应的核苷酸序列通过blast在全长序列上成对比较时,对于每个比较的同源序列是95%-96%相同的。因此,它们很容易彼此区分开。在编码小麦ssiib基因的ncbi数据库中鉴定了两个cdna序列,其是来自a基因组的登录号ak332724和来自d基因组的eu333947。在ncbi数据库中没有鉴定出相应的基因组dna序列,然而,在iwgsc数据库中发现了基因组dna序列。鉴定了编码ssiib的三种同源基因组dna序列,即染色体6al上的ssiib-a基因(与iwgsc:染色体6al同源,traes_6al_ae01dc0ea,6a:187503905bp至187505233bp,在ensemblplants网站通过blast搜索的正向链)(cdna序列seqidno:12)、染色体6bl上的ssiib-b基因(染色体6bl,基因:traes_6bl_61d83e262,6b:162116364-162116691bp,在ensemblplants网站通过blast搜索的反向链)(cdna序列seqidno:13)以及染色体6dl上的ssiib-d基因(与iwgsc:染色体6dl同源,基因:traes_6dl_19f1042c7,6d:147050072-147051031bp,在ensemblplants网站通过blast搜索的反向链)(cdna序列seqidno:14)。在ncbi数据库中鉴定出一种氨基酸序列(登录号:aby56824,seqidno:11),其与从eu333947推导的氨基酸序列100%相同;因此,它是ssiib-d多肽序列。对于ssiib-a多肽,从ak332724的核苷酸序列推导出全长氨基酸序列(seqidno:10),其与来自d基因组ssiib的aby56824具有90%的同源性。从来自iwgsc的dna片段(traes_6bl_61d83e262,6b:162116364-162116691bp,反向链)推导出ssiib-b多肽的氨基酸序列。全长ssiib-a和ssiib-d氨基酸序列大约90%相同。当成对比较时,三个相应的cdna核苷酸序列是91%-95%相同的。当与ssiia氨基酸或核苷酸序列比较时,ssiib序列与相应的ssiia旁系同源物71%-79%相同。因此,任何ssii序列都可以容易地从氨基酸或核苷酸序列鉴定为ssiia或ssiib。对于小麦ssiic基因,在ncbi数据库中鉴定了一种cdna序列(登录号:eu307274),其对应于位于小麦染色体1dl上的基因(与iwgsc:染色体1dl同源,基因:traes_1dl_f667ed844,iwgsc_css_1dl_scaff_2205619:1950-3041bp,在ensemblplants网站通过blast搜索的正向链),因此该cdna序列对应于ssiic-d。通过搜索iwgsc数据库鉴定了针对另一种ssiic基因的cdna序列,该基因位于染色体1al上(iwgsc:染色体1al,基因:traes_1al_729bf3204,1a:68687585-68688377,在ensemblplants网站通过blast搜索的正向链)。cdna序列与登录号:eu307274的从核苷酸1679至2469的序列具有98%同一性。还鉴定了来自染色体1bl的序列,其是ssiic-b的部分长度cdna序列(iwgsc:染色体1bl,基因:traes_1bl_447468bde,1b:31475067-314776087bp,在ensemblplants网站通过blast搜索的正向链)。在ncbi数据库中鉴定了一种氨基酸序列(登录号:aby639),其与从登录号eu307274的cdna序列推导的氨基酸序列具有100%同一性。还从a和b基因组的ssiic的基因组dna片段的核苷酸序列推导出两个部分长度的氨基酸序列。当成对比较时,ssiic序列彼此接近于98%相同。它们与ssiia序列非常不同。结论是可以很容易地将ssiia基因和ssiia多肽序列与相应的ssiib和ssiic序列区分开。实施例3.用于标志物辅助育种的基因组特异性dna标志物为了产生与若干种不同遗传背景中的野生型植物同基因的三重无效ssiia突变植物,将三种小麦株系c57(ssiia-a无效)、k79(ssiia-b无效)和t116(ssiia-d无效)植物(yamamori等人,2000)用于一系列杂交、回交和互交中。为了检测和跟踪突变(每个突变均是隐性的),在具有分子标志物的育种程序中,设计并使用基于ssiia基因序列的基因组特异性dna标志物。由shimbata等人,(2005)报道了分别在a、b和d基因组上的c57、k79和t116ssiia基因中的特异性突变。每个突变是相应ssiia基因内的dna缺失或插入(图2至4),并且因此这些突变对于设计分子标志物是理想的。通过使正向寡核苷酸引物位于每个突变位点的上游并且使反向引物位于每个突变位点之后来设计针对每个基因的dna标志物,序列描述于实施例1“小麦植物的dna分析”中。将这些引物用于扩增对来自野生型和ssiia无效突变植物的每种基因组具有特异性的dna片段。对于a基因组ssiia基因,从野生型扩增1072bp片段并且从ssiia-a无效突变基因扩增778bp片段。对于b基因组ssiia基因,从野生型扩增374bp片段并且从ssiia-b无效突变基因扩增522bp片段。对于d基因组ssiia基因,从野生型扩增427bp片段并且从ssiia-d无效突变基因扩增364bp片段。这些基因组特异性片段通过凝胶电泳容易地区分它们的大小,并且因此可以用作共显性dna标志物来检测突变型和野生型等位基因。可以容易地设计基于ssiia基因序列的其他特异性引物对以提供替代性分子标志物。实施例4.产生在不同遗传背景中的三重ssiia无效突变体为了产生在若干种不同遗传背景中同基因的三重无效ssiia突变植物,将三种小麦株系c57(ssiia-a无效)、k79(ssiia-b无效)和t116(ssiia-d无效)植物(yamamori等人,2000)用于一系列杂交、回交、互交和子代选择中,如图5-7中示意性示出的。将实施例1中所述的dna标志物用于筛选每代中的子代植物,从而允许将ssiia无效突变等位基因和用作轮回亲本的小麦品种sunco、egahume或westonia中的相应野生型等位基因区分开。首先将c57、k79和t116的植物与小麦栽培品种sunco的植物杂交,使用sunco植物作为雌性植物,以产生c57-suncof1、k79-suncof1和t116-suncof1。然后通过杂交sunco背景中的单无效突变体,随后使子代自交以从杂交种产生f2植物来产生c57-k79-suncof1和k79-t116-suncof1的双无效ssiia突变体。将dna标志物用于选择对于两个无效ssiia突变是杂合的子代。然后将这些突变体用于与作为轮回亲本的sunco进行三轮连续回交以产生具有两个无效突变的bc3杂合子。然后将bc3植物杂交并且使子代自交,并选择sunco遗传背景中的三重无效ssiia突变体(c57-k79-t116-suncobc3f2)(图5)。产生在栽培品种egahume、sunco和westonia背景中的ssiia无效突变体和野生型小麦株系的bc3f8种子。为了产生除sunco以外的两种不同遗传背景中的植物和籽粒,将sunco中的双突变体(c57-k79-suncof1或f2、k79-t116-suncof1或f2)用作与栽培品种egahume和westonia的植物杂交的花粉供体(图6和7),其中使用每代中的dna标志物来检测和选择子代中的突变等位基因。将选择的双突变ssiia子代用于与作为轮回亲本的egahume或westonia进行三轮连续回交,产生bc3植物。使双突变体杂交并自交,产生466个f2子代,从中选择总共21个三重无效ssiia植物(命名为“abd”基因型)(图6和7)。466个子代包括野生型、单无效ssiia和双无效ssiia基因型以及三种ssiia基因的杂合子的所有组合。在产生和选择覆盖三种遗传背景的21个三重无效突变体之后,进行三代单种子传代(ssd)以在三种遗传背景中的每一种中产生增加的纯合性,从而提供籽粒的bc3f3、bc3f4和bc3f5代。bc3f5籽粒在三代生长中进一步增大,以产生每个株系的bc3f8代的10至20g籽粒。还从杂交种产生三重野生型ssiia分离子(abd基因型)并且将其选择作为对照株系。在每一代中,将所有三个基因组的dna标志物用于选择针对每一代的每种基因组的ssiia突变体或野生型ssiia等位基因。最终,分别针对egahume、sunco和westonia遗传背景产生bc3f8代的4、6和11个三重无效突变ssiia株系,并且针对egahume、sunco和westonia遗传背景中的每一种产生5个野生型ssiiabc3f8株系。将这些株系在相同的生长条件下同时生长,在植物成熟时收获籽粒,并且将籽粒干燥至约9%水分含量(基于重量)。分析这些籽粒批次的各种参数,包括种子重量、淀粉含量、直链淀粉含量、总膳食纤维、脂质含量等,如下文所述。实施例5.对籽粒和淀粉参数的分析籽粒重量。通过测量来自每个株系的100个籽粒的重量来计算三个遗传背景中的三重无效ssiia突变体和野生型籽粒的平均籽粒重量(mg/籽粒)。对于ssiia无效突变体,平均每籽粒重量范围为从25mg至36mg,并且对于野生型株系,平均每籽粒重范围为29mg至48mg(表6,图8)。植物在远非理想的生长条件下生长,这解释了低重量,甚至对于野生型对照也是如此。平均数据如图9所示。与野生型株系相比,三重无效突变ssiia籽粒具有较低的籽粒重量,对于包括sunco的每种遗传背景,差异是显著的(p<0.05)(表7,图9)。sunco、egahume和westonia的突变体分别具有25%、15%和30%的籽粒重量。考虑到ssiia编码参与淀粉产生的淀粉合酶并且已知ssiia的突变体产生较少的淀粉(yamamoto等人,2000;konik-rose等人,2007),该结果并不令人惊讶。sunco与westonia突变体的籽粒重量之间没有统计学上显著的差异。egahume突变籽粒具有比其他两个遗传背景中的三无效ssiia突变体显著更重的籽粒重量。脂质含量。如实施例1中所述测量总脂肪酸含量(脂质含量)。针对各个株系的数据示出在表5和图8中。注意到与野生型相比,三重无效ssiia株系中的tfa含量显著增加。特别地,来自三个sunco突变型株系(jtsbc3f7_190、jtsbc3f7_287和jtsbc3f7_294)的籽粒具有以占籽粒重量的百分比计实质性增加的脂质含量。当基于每个籽粒计算脂质含量时,观察到突变体株系表现出增加的脂质水平(以mg/籽粒计)(图15和16)。直链淀粉含量。如实施例1中所述,通过碘结合测定测量三种遗传背景中的三重无效ssiia突变体和野生型籽粒中以占淀粉的比例计的直链淀粉含量。数据提供在表6和图10中并且平均值示出在表7和图11中(sunco)。直链淀粉含量范围对于三重无效突变体为从36.6%至64%,并且对于野生型籽粒为从22.6%至31.0%。与野生型籽粒相比,无效ssiia突变体具有更大的以占总淀粉的比例计的直链淀粉含量,并且差异在统计学上具有显著性。与相应的野生型相比,sunco、egahume和westonia突变型籽粒分别具有187%、135%和165%的直链淀粉水平。比较三种遗传背景中的三重无效突变型籽粒,sunco籽粒含有显著高于其他两种无效突变型籽粒样品的直链淀粉比例。egahume与westonia突变体之间在统计学上没有显著性差异。同样,三种野生型籽粒样品之间在统计学上没有显著性差异。来自6个sunco三重无效突变型株系中的3个的籽粒含有以占籽粒中淀粉的比例计61.6%、64%和55.1%的直链淀粉。这些值远高于先前对六倍体小麦中ssiia突变型籽粒观察的(yamamoto等人,2000;konik-rose等人,2007),并且因此对于本发明人来说是出乎意料和令人惊讶的。当基于每籽粒计算直链淀粉含量(每籽粒的直链淀粉mg)时,观察到突变型株系通常不表现出增加的直链淀粉水平(以mg/籽粒计)(图17和18),而是表现出降低的支链淀粉水平,并且因此降低总淀粉含量。本发明人得出结论,这是由于三种ssiia基因中的突变,并且因此由于随着植物生长的胚乳发育期间ssiia酶活性的丧失。淀粉含量。如实施例1中所述测量针对三种三重无效ssiia突变体和三个野生型株系的籽粒中的淀粉含量。数据呈现在表6和图10中并且平均值示出在表7(sunco)和图11中。淀粉含量范围对于三重无效ssiia突变体为从30.4%至70.0%并且对于野生型籽粒为从58.1%至74.3%。与野生型株系的淀粉含量相比,egahume、sunco和westonia突变型籽粒分别具有平均比其相应的野生型株系少15%、28%和18%的淀粉。这些差异在统计学上具有显著性(p<0.05)。sunco突变型籽粒比其他两个遗传背景中的ssiia突变型籽粒含有显著更少的淀粉。egahume突变型籽粒的淀粉含量与westonia籽粒没有显著性差异。来自三个sunco突变型株系(jtsbc3f7_190、jtsbc3f7_287和jtsbc3f7_294)的籽粒分别具有42.5%、34.8%和30.4%下的低淀粉含量。这些相同的株系也具有以占其淀粉的比例计最高的直链淀粉含量,这表明在这些株系中支链淀粉合成降低最多。当基于mg淀粉/籽粒计算时,ssiia突变型籽粒中淀粉含量的降低是明显的(图17和18),同样是由ssiia活性的丧失引起。β-葡聚糖含量。如实施例1中所述测量三重无效ssiia突变型籽粒和野生型籽粒的β-葡聚糖(bg)含量。数据示出在表6和图12中(以占整籽粒的重量/重量百分比计)并且平均值示出在表7(sunco)和图13中。bg含量范围对于三重无效ssiia突变体为从1.3%至3.3%并且对于野生型籽粒为从0.3%至0.8%。与野生型籽粒相比,突变型egahume、sunco和westonia分别具有多144%、245%和177%的bg。这种约1.5至2.5倍的增加对于发明人来说是令人惊讶的,因为先前没有对六倍体小麦中这种特征的报道。sunco突变型籽粒比egahume和westonia突变型籽粒具有显著更多的bg(p<0.05)。具有最高水平的直链淀粉的三种sunco突变型株系(jtsbc3f7_190、jtsbc3f7_287和jtsbc3f7_294)的籽粒也含有分别为2.5%、3.3%和3.2%的最高bg含量。这证明了ssiia突变体中直链淀粉含量增加与bg含量增加之间的相关性,每种含量均基于重量。当基于每籽粒计算时,观察到突变型籽粒具有显著增加的bg水平(图19和20)。本发明人认为这是由于作为二糖或单糖进入籽粒中的碳相对于野生型从支链淀粉转移到bg中。果聚糖含量。如实施例1中所述测量三重无效ssiia突变型籽粒和野生型籽粒的葡聚糖含量。数据示出在表6和图14中(以占整籽粒的重量/重量百分比计)并且针对sunco的平均值示出在表7中。果聚糖含量范围对于三重无效ssiia突变体为从3.1%至10.8%并且对于野生型籽粒为从0.7%至1.5%。与野生型籽粒相比,egahume、sunco和westonia突变型籽粒分别具有多242%、521%和376%的果聚糖。sunco突变型籽粒比egahume和westonia突变型籽粒具有显著更多的果聚糖(p<0.05)。三种高直链淀粉sunco突变型株系(jtsbc3f7_190、jtsbc3f7_287和jtsbc3f7_294)也含有分别为7.7%、10.8%和10.5%的最高葡聚糖含量。基于重量的这种果聚糖水平先前从未在六倍体小麦籽粒中报道过。这证明了ssiia突变体中不仅直链淀粉增加与bg增加,还与果聚糖增加之间的相关性。当基于每籽粒计算时,观察到突变型籽粒具有显著增加的果聚糖水平(图21和22)。本发明人认为这是由于作为二糖或单糖进入籽粒中的碳在胚乳发育期间相对于野生型从支链淀粉转移到果聚糖中。阿拉伯木聚糖含量。如实施例1中所述测量三重无效ssiia突变型籽粒和野生型籽粒的阿拉伯木聚糖(ax)含量。数据示出在表6和图14中(以占整籽粒的重量/重量百分比计)并且针对sunco的平均值示出在表7中。ax含量范围对于三重无效ssiia突变体为从6.7%至8.8%并且对于野生型籽粒为从4.3%至5.7%。与野生型籽粒相比,egahume、sunco和westonia突变型籽粒分别具有多35%、65%和43%的ax。sunco突变型籽粒比egahume和westonia突变型籽粒具有显著更多的ax(p<0.05)。三种高直链淀粉sunco突变型株系(jtsbc3f7_190、jtsbc3f7_287和jtsbc3f7_294)含有分别为8.7%、8.5%和8.4%的最高ax含量。这证明了ssiia突变体中四个参数,即直链淀粉增加、bg增加、果聚糖增加和ax增加之间的相关性。基于每籽粒的阿拉伯木聚糖含量也显著增加(图21和22)。纤维素含量。如实施例1中所述测量三重无效ssiia突变型籽粒和野生型籽粒的纤维素含量。数据示出在表6和图14中(以占整籽粒的重量/重量百分比计)并且针对sunco的平均值示出在表7中。纤维素含量范围对于三重无效ssiia突变体为从2.6%至4.6%并且对于野生型籽粒为从2.0%至3.4%。与野生型株系相比,突变型egahume、sunco和westonia分别具有多19%、43%和29%的纤维素。三种无效突变体之间的纤维素含量没有显著性差异。三种高直链淀粉sunco株系(jtsbc3f7_190、jtsbc3f7_287和jtsbc3f7_294)也含有分别为4.3%、3.9%和4.6%的高纤维素含量。基于每籽粒纤维素含量没有显著性增加(图21和22)。总纤维含量。将三重无效ssiia突变型籽粒和野生型籽粒的总纤维含量计算为β-葡聚糖(bg)、果聚糖、阿拉伯木聚糖(ax)和纤维素含量(各自均以占籽粒重量的百分比计)的总和。数据提供在表6和图12中(以占整籽粒的重量/重量百分比计)并且平均值提供在表7和图13中。籽粒中的总纤维含量范围对于ssiia无效突变体为从15.9%至27.5%,并且对于野生型籽粒为从8.5%至10.4%。与野生型籽粒相比,egahume、sunco和westonia中的突变体分别具有大68%、125%和88%的总纤维含量。sunco突变型籽粒比egahume和westonia突变型籽粒具有显著更多的总纤维(p<0.05)。egahume与westonia突变型籽粒之间的总纤维含量没有显著性差异。三种高直链淀粉sunco突变型株系(jtsbc3f7_190、jtsbc3f7_287和jtsbc3f7_294)含有分别为23.2%、26.5%和27.5%的最高总纤维含量。基于每籽粒总纤维含量也显著增加(图19和20)。抗性淀粉(rs)含量。如实施例1中所述,使用商业抗性淀粉分析试剂盒测量sunco遗传背景中的三重无效ssiia突变体和野生型籽粒中以占淀粉的百分比计的rs含量。数据提供在表8中并且平均值示出在图23中。rs含量范围对于三重无效突变体为从1.0%至3.8%,并且对于野生型籽粒为从0.4%至0.8%。与野生型籽粒相比,ssiia突变体具有大约5倍的rs含量,并且差异在统计学上具有显著性。来自sunco遗传背景中的6个三重无效ssiia突变型株系中的3个的籽粒含有以占籽粒中淀粉的百分比计3.8%、2.8%和3.1%rs(图23,上图)。以mg/籽粒计算的rs水平也实质性增加(图23,下图)。讨论。先前已报道在三重无效ssiia六倍体小麦中改变了多种淀粉特性,包括淀粉颗粒形态、直链淀粉含量、支链淀粉链长度分布、结晶度和淀粉糊化温度、rva和溶胀能力(yamamori等人2000;yamamori等人2006;konik-rose等人2007)。本研究发现ssiia无效突变的遗传背景对籽粒组成参数(包括淀粉中的直链淀粉含量)具有影响,对于本发明人惊讶的是,淀粉中的直链淀粉含量在一些株系中增加45%以上。使用商业培育的小麦栽培品种在不同的遗传背景中产生三个回交群体,并且使用dna标志物针对ssiia无效突变进行基因分型。对每种遗传背景中的三重无效ssiia突变体的4至11个株系和来自三个育种群体中的每一个的5个野生型株系进行了选择和分析。通过分析每个遗传背景中的种子重量和籽粒组成,鉴定了三种高直链淀粉、高纤维、高ax和bg以及高果聚糖株系。这三个株系来自具有相同遗传背景即sunco的杂交种。对含有约60%直链淀粉、超过23%的总纤维和超过7%的果聚糖的小麦株系进行鉴定和选择。此类水平之前从未针对六倍体小麦报道过,并且对本发明人来说完全出乎意料。还基于每籽粒观察了增加。这些高直链淀粉ssiia无效突变体还含有增加的bg、ax和纤维素,证明了这些参数的相关性。然而,由于支链淀粉合成实质性地减少,这三种突变型株系显示出降低的淀粉含量和种子重量。表6.三种遗传背景中ssiia三重突变体(abd)和ssiia野生型(abd)的籽粒参数实施例6.ssiia突变和其他淀粉合成基因突变或抑制性构建体的组合。将作为如实施例1中所述的针对三种ssiia基因的三重无效突变体的小麦植物与包含命名为hp-sbeiia的发夹rna构建体并且在胚乳中具有降低的淀粉分支酶ii(sbeii)活性的植物(regina等人,2006)杂交。hp-sbeiia亲本植物在籽粒淀粉中显示出高直链淀粉表型(regina等人,2006)。获得f1植物并且使其自交以产生f2子代籽粒。使用由konik-rose等人(2007)描述的三种不同引物对通过pcr进行对288个f2籽粒的筛选,每个引物对对于来自特定基因组的ssiia突变基因具有特异性。这导致鉴定出一个纯合的三重无效ssiia籽粒(命名为ydh7),其缺乏针对三种ssiia基因中每一种的野生型等位基因。对ydh7dna的进一步测试确认,除了三种突变的ssiia基因外,该籽粒中还存在hp-sbeiia遗传构建体。使籽粒发芽以产生子代植物和籽粒,在本文中命名为ydh7株系。以类似的方式,将包含ssiia中的三重无效突变的植物与regina等人,2004中描述的sbei三重无效小麦株系的植物杂交。使用从小麦sbei基因的内含子2区域设计的基于pcr的裂解扩增产物(cap)标志物,针对每种sbei基因中的无效突变筛选从f2半种子提取的dna。标志物从来自d基因组的sbei-d基因产生460bpdna片段,从来自b基因组的sbei-b基因产生390bpdna片段并且从来自a基因组的sbei-a基因产生200bpdna片段。除了这些sbei基因组特异性片段外,该caps标志物还产生对于sbei基因非特异性并且可用作pcr反应中的内部对照的250bpdna片段。鉴定出缺乏从野生型基因扩增的sbei特异性dna片段的籽粒,这表明它们是针对sbei的三重无效突变体。然后通过pcr测试这些三重无效籽粒是否存在ssiia无效突变。将这些籽粒播种以产生含有ssiia和sbei突变的组合的植物和籽粒,其对于每个突变等位基因是纯合的。实施例7:对淀粉颗粒和淀粉特性的分析检查了由三重突变型ssiia籽粒产生的全麦粉中的淀粉颗粒。还分析了从全麦粉中提取的淀粉的特性,如下所述。对于这些分析,从konik-rose等人(2007)的双单倍体群体中选择五个ssiia突变型小麦株系(命名为a24、b22、b29、b63和e24)并且对其分析淀粉和颗粒特性。将来自每个株系和相应野生型株系的籽粒样品(20g)在将籽粒调理至水分含量为14%之后在quadramat小型碾磨机(brabender,cyrulla’sinstruments,sydney,australia)中碾磨成全麦粉。将淀粉通过蛋白酶提取方法(morrison等人,1984)从全麦粉样品中分离,随后水洗并除去残渣。淀粉颗粒形态和双折射率的变化。对于全麦粉样品中的颗粒检查淀粉颗粒形态及其在偏振光下的双折射率。使用扫描电子显微术来鉴定淀粉颗粒大小和结构的总体变化。与野生型颗粒相比,来自缺乏ssiia的胚乳的淀粉颗粒显示出显著的形态改变。它们在形状上高度不规则,并且a颗粒(直径>10μm)中的许多似乎为镰刀形状的。相比之下,野生型全麦粉中的a和b(直径<10μm)淀粉颗粒均为表面平滑的并且形状为球形或椭圆形。当在偏振光下显微观察时,野生型淀粉颗粒通常显示出强的双折射图案。然而,对于来自三重无效ssiia籽粒的颗粒,双折射的发生率大大降低。当在偏振光下观察时,来自突变型ssiia颗粒的淀粉颗粒的小于10%是双折射的。相比之下,约94%的野生型淀粉颗粒表现出完全双折射。因此双折射率的损失与ssiia的缺乏和直链淀粉含量的增加相关。根据face的淀粉的链长分布。如实施例1中所述,通过荧光团辅助的碳水化合物电泳(face)测定异淀粉酶脱支的淀粉的链长分布。该技术提供了对在从dp1至50范围内的链长分布以及与野生型淀粉相比改性淀粉中不同长度的链的相对频率的高分辨率分析。从将野生型淀粉的归一化链长分布从三重突变型ssiia淀粉的归一化分布中减去的摩尔差异图(图24)中,观察到在来自三重无效ssiia籽粒的淀粉中,dp7-10链长的比例显著增加并且dp11-24的链长实质性减少。dp26-36的链长也略有增加。支链淀粉和直链淀粉的分子量。在异淀粉酶脱支后,通过尺寸排阻色谱法(sec)测定来自突变型籽粒的淀粉的分子量分布。异淀粉酶脱支处理裂解了支链淀粉中的每个α-1,6-键以释放单独的链但使得直链淀粉大部分未被触及,从而允许基于大小将直链淀粉(首先洗脱)和葡聚糖链与支链淀粉分离。图25示出了脱支淀粉根据其聚合度的所得sec迹线。三重无效ssiia突变型籽粒的淀粉中直链淀粉(第一峰)的相对量相对于野生型淀粉实质上增加,并且与野生型相比,支链淀粉(峰iii)的量大大降低。三重无效ssiia突变型籽粒的淀粉中直链淀粉的平均分子量似乎与野生型淀粉中的直链淀粉的平均分子量相比降低,其中直链淀粉峰位置在274kda处,而野生型的在330kda处(图25)。淀粉溶胀能力(ssp)。根据konik-rose(2001)的小规模测试来测定糊化淀粉的淀粉溶胀能力,该测试测量了在淀粉糊化过程中水的吸收。与来自野生型的淀粉(11.79)相比,对于来自三重无效ssiia籽粒的淀粉,ssp的估算值显著更低,具有6.85的数值。淀粉成糊特性。基本上如regina等人,(2004)中所述使用快速粘度分析仪(rva)测定淀粉糊粘度参数。rva的温度曲线包括以下阶段:在60℃保持2min,在6min内加热至95℃,在95℃保持4min,在4min内冷却至50℃,并且在50℃保持4min。结果显示,与野生型小麦淀粉(分别为232.3和350.6)相比,来自三重无效ssiia籽粒的淀粉中的峰值和最终粘度显著降低(分别为105.5和208.6)。淀粉糊化特性。如regina等人,(2004)所述,使用差示扫描量热法(dsc)研究淀粉的糊化特性。在perkinelmerpyris1差示扫描量热计上进行dsc。将淀粉和水以1:2的比率预混合,并且将大约50mg称重到dsc盘中,将所述dsc盘密封并使其平衡过夜。使用10℃/分钟的加热速率将测试样品和参考样品从30加热至130℃。使用与仪器一起可用的软件来分析数据。结果清楚地显示,与对照(67.1℃)相比,对于来自三重无效ssiia籽粒的淀粉的终点糊化温度(61.5℃)降低。与对照淀粉(61.3℃)相比,三重无效ssiia淀粉中的峰值糊化温度(55.4℃)也更低。因此,来自三重无效ssiia籽粒的淀粉具有显著更低的糊化温度和降低的糊化焓。籽粒组成变化。分析三重无效ssiia小麦籽粒的近似组成以确定由于ssii活性丧失而在籽粒组分中诱导的变化。ssiia全麦面粉中的蔗糖水平相对于来自野生型小麦nb1的蔗糖水平增加。与野生型淀粉相比,ssiia突变型淀粉中的总糖含量也更高。来自ssiia籽粒和包含hp-sbeiia遗传构建体的第二籽粒(regina等人,2006)的全麦粉均在籽粒中具有>19%的蛋白质水平增加,而野生型全麦粉具有在11%-13%范围内的水平。与野生型值11.0%相比,ssiia淀粉中的总膳食纤维(tdf)更高,具有19.2%的水平。ssiia面粉中的其他籽粒组分诸如中性非淀粉多糖(nnsp)、总抗氧化剂和总脂质的水平与野生型小麦相比相对较高。对于nnsp,对于ssiia突变体记录的最高值为13.8%,而野生型nb1中的最高值为8.3%。ssiia突变型籽粒中的总淀粉含量为约为53%,而nb1和ydh7中的总淀粉含量>60%。实施例8:面包和其他食物产品的生产食物产品诸如面包和早餐谷物是将改性小麦淀粉递送到膳食中的有效方式。为了显示高直链淀粉的小麦可以容易地掺入到面包和早餐谷物中并且检查允许食物质量保持的因素,生产了面粉的样品,对其分析并且将其用于烘焙或挤出实验中。使用ydh7面粉进行小规模面包烘焙,与来自包含hp-sbeiia遗传构建体和野生型nb1的籽粒的面粉的烘焙相比,所述ydh7面粉具有三种添加水平,即30%、60%和100%。增加ydh7或hp-sbeiia面粉的添加水平导致rs的显著增加和gi的降低。由来自ssiia突变型小麦的全麦粉制备挤出的早餐谷物,并且将其与来自野生型小麦的相应早餐谷物进行比较。与野生型小麦(1.3%)相比,当使用三重无效ssiia小麦时,早餐谷物含有增加水平的rs(4.3%)。当使用三重无效ssiia小麦时,在挤出过程中熔融温度从110℃增加至140℃使得rs含量略微降低。结果还显示,来自三重无效ssiia小麦的全麦早餐谷物具有较低的hi(用于估算gi值的水解指数)值,为72,相较之下来自野生型小麦的hi为82。采用以下方法以较大规模从ssiia小麦生产面包。将小麦籽粒的量调理至16.5%水分含量过夜,之后进行碾磨和筛选以实现约150μm的最终平均粒子大小。碾磨样品的蛋白质和水分含量根据aacc方法39-11(1999)通过红外反射(nir)来测定,或根据aacc方法44-15a(aacc51999)通过dumas法使用空气烘箱来测定。微型z形臂混合。使用具有恒定角速度的z形臂混合器测定小麦面粉的最佳吸水率值,例如,每次混合使用4g测试面粉(gras等人,(2001);bekes等人,(2002),其中快速和慢速刀片的轴速度分别为96和64rpm。将混合进行约20分钟。在将水添加至面粉之前,通过仅将固体组分混合来自动地记录基线30秒。使用自动水泵在一个步骤中进行水添加。通过采用平均值从各个混合实验中测定以下参数:wa%-吸水率是在500brabender单位(bu)生面团稠度下测定的;生面团形成时间(ddt):达到峰值阻力的时间(秒)。揉混曲线图谱(mixogram)。为了测定在改性小麦面粉的情况下的最佳生面团混合参数,将具有与通过z形臂混合器测定的吸水率对应的可变吸水率的样品在揉混仪中混合,保持总生面团质量恒定。对于每个面粉样品,记录以下参数:mt-混合时间(秒);pr-揉混仪峰值阻力(任意单位,au);bwpr-在峰值阻力下的带宽(任意单位,au);rbd-阻力丧失(%);bwbd-带宽丧失(%);tmbw-达到最大带宽的时间(秒);以及mbw-最大带宽(任意单位,a.u.)。如下测量生面团拉伸性参数:在揉混仪中将生面团混合到峰值生面团形成。拉伸测试在ta.xt2i质构分析仪上利用经修改的几何形状kieffer生面团和麸质拉伸装备以1cm/s进行(mann等人,2003)。用于拉伸测试的生面团样品(约1.0g/测试)用kieffer模制机模制并且在30℃和90%rh下静置45分钟,之后进行拉伸测试。在exceedexpert软件(smewing,tx2质构分析仪手册,smsltd:surrey,uk,1995)帮助下由数据确定r_max和ext_rmax。基于14g占100%的面粉的示意性配方如下:面粉100%、盐2%、干酵母1.5%、植物油2%、以及改良剂(抗坏血酸100ppm、真菌直链淀粉15ppm、木聚糖酶40ppm、大豆粉0.3%,从goodmanfielderptyltd,australia获得)1.5%。水添加水平是基于针对该完整配方进行调整的z形臂吸水率值。在揉混仪中将面粉(14g)和其他成分混合至峰值生面团形成时间。利用两个醒发(proofing)步骤在40c下在85%rh下进行模制和淘选。将烘焙在rotel烘箱中在190℃进行15min。在将面包条于支架上冷却2小时之后,进行面包条体积(通过油菜种子置换法测定)和重量的测量。通过随时间推移对面包进行称重来测量净失水量。可以将所述面粉或全麦粉与来自非改性的小麦或其他谷物(诸如大麦)的面粉或全麦粉共混,以提供所希望的生面团和面包制作或营养质量。例如,来自栽培品种chara或glenlea的面粉具有高的生面团强度,而来自栽培品种janz的面粉具有中等的生面团强度。特别地,面粉中的高和低分子量麦谷蛋白亚基的水平与生面团强度呈正相关,并且进一步受存在的等位基因的性质影响。根据上文对于生面团制备和面包制作所述的方法以100%、60%和30%添加水平使用来自株系ydh7的面粉。即,将100%的来自ydh7的面粉或对照面粉,或按重量计60%或30%的ydh7面粉与烘焙对照(b.extra))面粉共混。百分比是在面包配方中的总面粉中所占的百分比。未改性的小麦面粉来自野生型栽培品种nb1。将籽粒样品在brabenderquadramat小型碾磨机中碾磨。如上所述,所有面粉共混物的吸水率均在z形臂混合器上测定,并且最佳混合时间在揉混仪上测定。将这些条件用于制备测试烘焙面包条。混合特性。除了使用完整野生型面粉的对照样品(烘焙对照,nb1)以外,所有其他小麦样品均都给出了升高的吸水率值。来自ydh7株系的面粉的掺入水平的增加也导致最佳揉混仪混合时间的减少。与吸水率数据一致,包含来自ydh7株系的面粉的面包都表现出比面包条体积的降低(面包条体积/面包条重量),所述降低与增加的ydh7面粉添加水平相关。这些研究显示,具有包括可接受的屑粒结构、质构和外观在内的商业潜力的面包可以使用与对照面粉样品共混的改性ssiia小麦面粉来获得。此外,高直链淀粉ssiia小麦可以与以下联合使用:优选的遗传背景特征(例如优选的高和低分子量麦谷蛋白);或食物加工中的改性,诸如例如改良剂诸如麸质、抗坏血酸盐或乳化剂的加入;或不同面包制作方式(例如发面团面包制作(spongeanddoughbread-making)、酸面团、混粒、或全麦粉)的使用,从而提供具有特定效用和营养功效的一系列产品以用于改善肠和代谢健康。其他食物产品:使用标准bri研究面条制造方法(briresearchnoodlemanufacturingmethod)(afl029)在hobart混合器中制备黄色碱性面条(yan)(100%面粉、32%水、1%na2co3)。在otake面条机的不锈钢滚筒中形成面条片。在静置(30min)之后,面条片减小并被切成多股。面条的尺寸为1.5x1.5mm。使用标准bri研究面条制造方法(afl028)在hobart混合器中制备方便面(100%面粉、32%水、1%nacl和0.2%na2co3)。在otake面条机的不锈钢滚筒中形成面条片。在静置(5min)之后,面条片减小并被切成多股。面条的尺寸为1.0x1.5x25mm。将该多股面条汽蒸3.5min,然后在150℃下在油中煎炸45秒。发面团(s&d)面包。bri研究发面团烘焙涉及两步工艺。在第一步骤中,通过将全部面粉的一部分与水、酵母和酵母食料混合来制得发面。使发面发酵4h。在第二步骤中,将发面与余下的面粉、水和其他成分掺在一起以制得生面团。所述工艺的发面阶段是用200g面粉进行并且给出4h的发酵。通过将其余100g面粉和其他成分与发酵的发面混合来制备生面团。意大利面-意大利式细面条(pasta-spaghetti)。用于意大利面生产的方法如sissons等人,(2007)中所述。将来自ssiia改性的小麦和野生型小麦的面粉与manildra粗粒小麦粉以各种百分比(测试样品:0、20%、40%、60%、80%、100%)混合,以获得用于小规模意大利面制备的面粉混合物。将样品校正到30%水分。将所希望的水量添加至样品,并且简单混合,之后转移到50g淀粉测定记录仪碗中再进行2min混合。将所得到的类似于咖啡豆大小的屑粒的生面团转移到不锈钢的腔室中,并且在7000kpa的压力下在50℃下静置9min。然后将意大利面以恒定速率挤出并且切成大约48cm的长度。将意大利面使用温度和湿度箱干燥。干燥循环使用25℃的保持温度,随后增加至65℃,持续45min,然后在50℃下约13h的时间,随后进行冷却。在循环过程中对湿度进行控制。将干燥的意大利面切成7cm的股供后续测试。实施例9:食物样品的血糖指数(gi)的体外测量如下对食物样品的血糖指数(gi)进行体外测量。体外方法模拟在被人类受试者消耗时食物样品所发生的变化并且是对体内gi测量值的预测。将食物样品用家用食物加工器均化。将代表大约50mg碳水化合物的量的样品称重到120ml塑料样品容器中,并且在不存在α-淀粉酶的情况下添加100μl碳酸盐缓冲液。添加碳酸盐缓冲液后大约15-20秒,将5ml胃蛋白酶溶液(65mg胃蛋白酶(sigma)溶解于65ml0.02m,ph2.0hcl中,在使用当天配制)添加,并且在37℃下将混合物在以70rpm往复运动的水浴中温育30分钟。在温育之后,将样品用5mlnaoh(0.02m)中和,并且添加25ml0.2m,ph6乙酸盐缓冲液。然后添加溶解于乙酸钠缓冲液(乙酸钠缓冲液,0.2m,ph6.0,含有0.20m氯化钙和0.49mm氯化镁)中的含有2mg/ml胰酶(α-淀粉酶,sigma)和来自黑曲霉(amg,sigma)的28u/ml淀粉葡糖苷酶的5ml酶混合物,并且将混合物温育2-5分钟。将1ml溶液从每个烧瓶中转移到1.5ml试管中,并且以3000rpm离心10分钟。将上清液转移到新的试管并且储存在冷冻机中。将每个样品的剩余部分用铝箔覆盖,并且将容器在37℃下在水浴中温育5小时。然后,从每个烧瓶中再收集1ml溶液,离心并且如先前那样转移上清液。将上清液储存在冷冻机中,直到可以读取吸光度。将所有上清液解冻并且以3000rpm离心10min。必要时对样品进行稀释(1比10稀释通常足够),按一式两份或一式三份将10μl上清液从每个样品转移到96孔微量滴定板。使用葡萄糖(0mg、0.0625mg、0.125mg、0.25mg、0.5mg和1.0mg)制备针对每个微量滴定板的标准曲线。将20μl葡萄糖trinder试剂(microgeneticsdiagnosticsptyltd,lidcombe,nsw)添加至每个孔,并且将板在室温下温育大约20分钟。使用读板仪在505nm下测量每个样品的吸光度,并且参照标准曲线计算葡萄糖的量。使用以上所述的方法,测试以下物质的gi:使用来自ydh7小麦种系的面粉烘焙的面包条、由非转化的野生型小麦制成的面包,以及使用其中ydh7面粉的掺入水平为60%和30%而剩余的40%或70%面粉来自野生型籽粒的两种面粉的共混物制成的面包。如通过体外测试所测量,ydh7面粉的掺入增加导致gi的显著降低。实施例10:高直链淀粉的小麦的加工和所得rs水平进行小规模研究以测定在已经轧制或成薄片状的来自ydh7小麦的经加工籽粒中的抗性淀粉(rs)含量。所述技术涉及将籽粒调理到25%的水分含量,保持一小时,随后对籽粒进行汽蒸。在汽蒸之后,使用小规模辊使籽粒成薄片状。然后,将薄片在烘箱中在120℃下焙烧35min。在来自具有减少的ssiia的高直链淀粉小麦和野生型对照小麦(栽培品种hartog)的大约200g样品上使用两种辊宽度和三种汽蒸时间安排。所测试的辊宽度为0.05mm和0.15mm。所测试的汽蒸时间安排为60′、45′和35′。本研究显示出,与对照相比经加工的高直链淀粉小麦中的rs的量明显且实质上增加。似乎加工条件对rs水平也存在一定影响。例如,在高直链淀粉籽粒的情况下,增加的汽蒸时间引起rs水平略微降低,这很可能是由于在汽蒸过程中淀粉糊化增加。除了在最长汽蒸时间下之外,更宽的辊间隙产生较高的rs水平。这可能是由于当籽粒在更窄间隙处轧制时淀粉颗粒的剪切破坏增加,从而使rs水平略微降低。更窄的辊间隙也在hartog对照中引起更高的rs水平,但是总体rs水平远为更低。与高直链淀粉结果对比,增加汽蒸时间导致引起更高的rs水平,这可能是由于在更长汽蒸时间下淀粉糊化增加,这有助于在后续加工和冷却过程中更多淀粉回生。实施例11:对另外的ssiia突变的产生和鉴定通过重离子轰击诱变小麦。通过辐射,诸如通过重离子轰击(hib)进行的诱变容易地在小麦基因组中以实用性频率产生缺失突变。通过对小麦种子的hib在小麦品种chara(常常使用的商业品种)中产生诱变的小麦群体。将两种重离子来源(即,碳和氖)用于诱变,所述诱变在wako,saitama,japan的理化研究所仁科中心(rikennishinacentre)进行。将经诱变的种子播种在温室中以获得m1植物。然后使这些植物自交以产生m2代。从大约15,000株m2植物(每株来自不同的m1植物)中的每一株中分离dna样品。针对ssiia基因中的每一种中的突变,使用基因组特异性寡核苷酸引物通过pcr对每个dna样品进行单独地筛选,所述引物产生针对a、b和d基因组上的ssiia基因中的每一种的扩增片段。本领域技术人员可以通过以下方式容易地设计此类诊断性pcr引物:比较三种基因组核苷酸序列(seqidno:7、8和9)并且选择与一种基因组序列特异性退火但不与其他两种基因组序列特异性退火的寡核苷酸序列,或者其中通过限制性酶消化差异地裂解所得的扩增片段,以产生针对三种基因组ssiia基因的不同大小的片段。在野生型(未诱变的)dna样品上的pcr反应中的每一个从而产生了3种不同的扩增产物,所述扩增产物对应于a、b和d基因组上的ssiia基因的扩增区域,而在来自经诱变的m2dna样品的pcr中不存在所述片段中的一种指示了在基因组中的一种中不存在相应的区域,即,存在基因的至少一部分缺失的突变等位基因。此类突变等位基因将一定是无效等位基因。当使用sbeiia和sbeiib基因特异性引物以这种方式筛选时,15,000株m2植物鉴定出作为sbeiia和/或sbeiib基因的缺失突变体的总共34个突变体(wo2012/058730),这表明在该诱变的m2群体中针对所关注基因的缺失突变的频率为每1000个株系约1个。因此,对m2株系的筛选鉴定出约15个突变体,每个突变体具有ssiia基因的或ssiia基因中的缺失突变。因为a、b和d基因组上的ssiia基因通过诊断pcr反应来区分,所以根据不存在何种扩增产物来将突变等位基因指定到基因组中的一种。以这种方式从15,000株m2植物的群体中针对ssiia-a、ssiia-b和ssiia-d基因中的每一种鉴定出约5个突变体。每一个突变体中的染色体缺失的程度通过微卫星作图而测定。在这些突变体上对先前作图到ssiia基因的染色体位置染色体7a、7b和7d的短臂的微卫星标志物进行测试,以确定每个突变体中的每个标志物的存在或不存在。基于反应中适当扩增产物的产生,推断所有或大多数特异性染色体微卫星标志物被保留的突变型植株是相对较小缺失的突变体。考虑到其他重要的基因更不可能受到突变影响,此类突变体是优选的。突变体的杂交。选择如通过微卫星标志物分析所判断对于ssiia基因的或ssiia基因中的较小缺失是纯合的突变型植株用于杂交,以产生在多种基因组上具有突变型ssiia等位基因的子代植物和籽粒。使来自杂交种的f1子代植物自交,并且获得f2种子并且针对其ssiia基因型分析。此类突变体还可以与包含ssiia基因中的点突变的突变体杂交以产生具有缺失和点ssiia突变的组合的三重基因突变体。点突变。包含单核苷酸多态性(snp)的点突变可以在诱变小麦植物的公开可获得的文库中鉴定出。此类文库包括例如可从johninnescentre,uk获得的文库。使用小麦ssiia核苷酸序列(基因库登录号:ab201445)使用blast软件询问johninnescentre小麦数据库,并且鉴定出在三种ssiia基因的每一种中包含snp的株系。snp分为三个种类。第一组包括具有突变的ssiia基因的突变体,所述基因在基因的蛋白质编码区中包含新的终止密码子。预测这些突变会导致该基因编码的ssiia蛋白翻译提前终止。提前终止突变,也称为无义突变或“获得终止密码子的突变”,几乎总是无效突变,前提条件是突变不接近蛋白质编码区的3'末端,尽管即使那些也可能是无效突变。第二组突变体包括在剪接供体位点或剪接受体位点中在ssiia基因的剪接位点具有核苷酸多态性的株系。预计此类突变会引起来自ssiia基因的rna转录物的错误剪接并且严重影响mrna;剪接位点突变最通常地是无效突变。第三组由包含ssiia基因之一中的点突变的突变体组成,所述点突变导致所编码的ssiia多肽中的氨基酸取代;这些被称为“错义突变”。使用blosum62和pam250矩阵预测每个错义突变对所编码的蛋白质结构的影响。在第一组和第二组中鉴定的ssiia基因突变体列于表9中。对于ssiia-a基因,从数据库中鉴定出5个无义突变、2个剪接位点突变和49个错义突变。在不同汇集物中鉴定的两个无义突变是相同的。对于ssiia-b基因,鉴定出了2个无义突变、7个剪接位点变体和22个错义突变。对于ssiia-d基因,鉴定出了2个剪接突变和49个错义突变。若干种突变体在ssiia基因中具有多于一种的多态性,包括在内含子中具有多态性以及在蛋白质编码区中具有多态性的一些突变体。通过tilling对突变的鉴定。使用wo2014/028980中所述的方法,在对小麦栽培品种sunstate的种子进行叠氮化钠诱变后,开发出突变的植物株系。使五千株m1植物生长到成熟,允许它们自花受精。从每株植物中分别收获m2种子,从而产生5000个株系的诱变群体。从来自每个株系的植物的叶子部分(约2cm)中提取dna。使用读板仪(fluostaromega,bmglabtech)定量小麦叶子dna,并且使用机器人机器(corbettlifescience)归一化至10ng/μl。对于tilling,将来自8株植物的组的dna样品在每个96孔板中汇集在一起。进行pcr反应以扩增ssiia基因的区段,例如其中95℃下5min,1个循环;然后35个以下循环:94℃下解链45s,退火温度为60℃至62℃,持续30s,以及在72℃下延伸2min30s;然后72℃下10min,1个循环,随后冷却至25℃。将所得的pcr片段(5μl)在1%或2%琼脂糖凝胶上分离并且在乙啡啶染色之后进行可视化(uvitec)以便检查pcr扩增的质量。使用pcr机进行pcr片段与野生型rna转录物的异源双链化,其中99℃下5min,1个循环;从70℃开始退火并且以0.6℃/循环的速率降低,持续20秒,70个循环,随后冷却至25℃。使用5μl异源双链化的pcr产物以及5μl2x缓冲液混合物和0.5μlceli酶,用celi酶消化异源双链体。缓冲液混合物由20mmhepes,ph7.5,20mmmgso4,20mmkcl,0.004%tritonx-100和0.4μg/mlbsa组成。将组装的反应物混合并且在45℃下温育15-30min。然后将消化的dna样品上样到dna片段分析仪(advancedanalyticaltechnologies),以便根据mutationdiscovery试剂盒(dnf-910-k1000t)分离dna片段。另选地,在将pcr产物归一化后汇集10种扩增产物的组,并且每个流动池用一种dna汇集物测序。分析序列数据以选择具有ssiia基因多态性的株系。基于kaspar技术针对每种多态性设计snp测定,并且在对特定多态性呈阳性的每种汇集物中的m1株系进行基因分型。由此,鉴定出含有每种突变基因的各个突变型株系并且确认了突变型ssiia序列。使在单一ssiia基因中含有点突变的植物与在其他两种ssiia基因中含有突变的植物杂交,以产生三重无效ssiia突变体。实施例12:对ssiia突变型籽粒中蛋白质的分析ssiia突变体中淀粉生物合成基因的表达。从konik-rose等人(2007)的双单倍体群体中选择五个ssiia突变型小麦株系(命名为a24、b22、b29、b63和e24)并且如下分析若干种淀粉生物合成mrna和蛋白质的含量。如实施例1中所述,通过定量逆转录pcr(qrt-pcr)将ssiia突变型小麦植物的15dpa时的发育中籽粒中的mrna表达水平与野生型进行比较。通过参考组成型表达的微管蛋白基因进行对每个样品中rna的定量。qrt-pcr数据揭示,纯合三重突变型ssiia胚乳中ssiiamrna的水平显著低于相应野生型籽粒中的ssiiamrna的水平(p<0.01),仅是相对于相应野生型小麦胚乳的水平的约8%左右。相比之下,突变型籽粒中ssi、sbeiia和sbeiib转录物的水平与相应的野生型发育中籽粒中的水平大致相同。这指示了对突变型胚乳中ssiiamrna的特异性作用。对成熟籽粒淀粉中颗粒结合型蛋白的丰度的分析。为了比较蛋白质凝胶上的蛋白质条带强度和上样在凝胶上的蛋白质样品的量,使用1至4mg呈来自成熟ssiia突变型和ssiia野生型籽粒的淀粉颗粒形式的淀粉来提取淀粉颗粒结合型蛋白。如实施例1中所述,在蛋白质凝胶上分离蛋白质。在野生型成熟籽粒中观察到分子量至少为60kda的四种蛋白质与淀粉颗粒结合。在ssiia突变型籽粒中,在大约60kda处观察到鉴定为gbssi的单一蛋白质。当定量蛋白质条带时,对于来自野生型籽粒的ssiia、sbeii和ssi和对于突变型籽粒中的gbssi,蛋白质条带强度与用于蛋白质提取的淀粉量之间存在正相关性。由于淀粉颗粒内的ssiia、sbeii和ssi蛋白水平低,所以选择4mg淀粉的量用于提取淀粉颗粒结合型蛋白以用于如下所述的进一步分析。当使野生型小麦籽粒的蛋白质提取物经历凝胶电泳并用sypro染色时,观察到分子量为约60kda或更高的四种淀粉颗粒结合型蛋白。通过免疫印迹分析将它们鉴定为ssiia(约88kda)、sbeiia和sbeiib(各自约83kda)、ssi(约75kda)和gbssi(约60kda)多肽。sbeiia和sbeiib在凝胶上在几乎相同的位置迁移,但是如通过sypro染色所判断野生型淀粉颗粒内的sbeiib的丰度远大于sbeiia。当通过凝胶电泳分析来自ssiia突变型小麦淀粉颗粒的蛋白质时,未检测到ssiia和sbeiia蛋白。通过sypro染色未检测到ssi和sbeiib蛋白,但可通过免疫印迹分析检测到,但是它们的丰度非常低,以致无法进行准确的定量(图26)。对可溶性基质中的和发育中胚乳的淀粉颗粒内的淀粉生物合成酶蛋白丰度的分析。为了确定成熟突变型籽粒中淀粉颗粒内的低浓度ssi、sbeiia和sbeiib是否是由于籽粒发育期间的合成速率较低,在ssiia蛋白不存在于突变型籽粒中的时候,在15dpa时对可溶性基质级分和发育中胚乳的淀粉颗粒内的ssi、sbeiia和sbeiib蛋白进行定量。通过免疫检测进行定量。当分析发育中胚乳的可溶性蛋白质时,与在相同阶段(15dpa)的ssiia野生型发育中籽粒相比,ssiia突变型籽粒中存在显著增加量的sbeiib和ssi。相比之下,ssiia突变体和ssiia野生型籽粒中sbeiia的水平是相似的。在淀粉体的可溶性级分中sbeiia比sbeiib更丰富。结论是淀粉颗粒内的ssi、sbeiia和sbeiib蛋白水平的降低不是由于表达水平降低,而是反映了淀粉颗粒中的结合降低,这表明远离淀粉颗粒定位并且进入基质中的可溶性级分中。当分析发育中籽粒中的淀粉颗粒结合型蛋白时,通过免疫印迹分析在突变型小麦ssiia籽粒中未检测到ssiia蛋白。与野生型相比,sbeiib的水平降低至约25%。突变型ssiia的淀粉颗粒内的ssi水平也是野生型水平的大约25%。在成熟胚乳中观察到类似的淀粉颗粒结合型蛋白量的降低模式。然而,基于每种淀粉,由于成熟籽粒胚乳中较高淀粉水平的稀释效应,发育中胚乳的淀粉颗粒结合型蛋白中的淀粉生物合成酶的浓度高于成熟籽粒中的淀粉生物合成酶的浓度。参考文献abeletal.,(1996).plantjournal10:981-991.altschuletal.,(1997).nucl.acidsres.25:3389-3402.alvarezetal.,(2006).plantcell18:1134-1151.asaietal.,(2014).j.exper.biol.65:5497-5507,bateyandcurtin,(1996).starch48:338-344.bateyetal.,(1997).cerealchemistry74:497-501.bechtoldetal.,(1993).c.r.acad.sci.paris,316:1194-1199.bekesetal.,(2002).critcaremed.30:1906-1907.birtetal.,(2013).adv.nutrition4:587-601.boch(2011).naturebiotechnology,29:135-136.botticellaetal.,(2011).bmcplantbiology11:156.boyerandpreiss,(1978).carbohydrateresearch,61:321-334.boyerandpreiss,(1981).plantphys.67:1141-1145.bryanetal.,(1998).j.cerealsci.28:135-145.butardoetal.,(2012).jagrfoodchem60:11576-11585.ausubeletal.,″currentprotocolsinmolecularbiology″,johnwiley&sonsinc,chapter15,1994-1998carpitaetal.,(1993).plantj.3:1-30.carpitaetal..(2011)plantphysiol.155:171-184.caseetal.,(1998).journalofcerealscience27:301-314.castroetal.,(2005).biomacromolecules6:2260-2270.chengetal.,(1997).plantphysiol115:971-980.colgraveetal.,(2013).foodresint54:1001-1012.comaietal.,(2004).plantj.37:778-786.doudnaetal.,(2014)science346(6213).dupuisetal.,(2014).comprehensivereviewsinfoodscienceandfoodsafety13:1219-1234.duraietal.,(2005).nucleicacidsresearch33:5978-5990.eaglesetal.,(2001).aust.j.agric.res.52:1349-1356.ellisonetal.,(1994)aust.j.exp.agric.34:869-869.fergason,(1994).specialitycornseds.crcpressinc.pp55-77.fontaineetal.,(1993).jbiolchem268:16223-16230.fujitaetal.,(2006).plantphysiol140:1070-1084.fuwaetal.,(1999).51:147-151.gaoetal.,(1997).plantphysiol114:69-78.gaoandchibbar(2000).genome43:768-775.giddingsetal.,(1980).jcellbiol.84:327-339.grasetal.,(2001).in:proc.icc11thint.cerealandbreadcongress.raci:melbourne.gruppenetal.,(1992).j.cerealsci.16:41-51.guanandkeeling(1998).trendsglycosci.glycotechnol.10:307-319.harnctal.,(1998).plantmol.biol.37:639-649.hartmannandendres,(1999).manualofantisensemethodology,kluwer.hayashietal.,(2007).cyclotronsandtheirapplications.eighteenthinternationalconference237-239.hedmanandboyer,(1982).biochemicalgenetics20:483-492.henikoffetal.,(2004).plantphysiol.135:630-636.henry(1985).j.sci.foodagric.36:1243-1253.hincheeetal.,(1988).biotech.,6:915-922.hopkinsetal.,(2003).appl.environ.microhiol.69:6354-6360.hungetal.,(2006).trendsfoodsci.technol.17:448-456.huynhetal(2008a).jcerealsci.48:369-378.huynhetal(2008b).theor.appl.genet.117:701-709.joblingetal.,(1999).plantjournal18:163-171.jollyetal.(1996).proc.natl.acad.sci.u.s.a.93:2408-2413.juongetal,(2013).natrevmolcellbiol14:49-55.kannaanddaggard,(2003).plantcellrep21:429-436.karppinenctal.,(2003).cerealchem.80:168-171.kaurandgupta(2002)j.biosci.27:703-714.kawauraetal.,(2009).bmcgenomics10:271.kazamaetal.,(2008).plantbiotechnology25:113-117.kleinetal.,(1987).nature327:70-73.konik-roseetal.,(2001).53:14-20.konik-roseetal.,(2007).theorapplgenet115:1053-1065.kosar-hashemietal.,(2007).functplantbiol.34:431-438.kruegeretal.,(1987).cerealchemistry64:187-190.langridgeetal.,(2001).aust.j.agric.res.52:1043-1077.lazaridouetal.,(2007).in:biliaderisandizydorczyk(eds.)functionalfoodcarbohydrates(pp1-72).crcpress,bocaratonfl.lazoetal.,(1991).biotechnology(ny).9(10):963-967.leprovostetal.,(2009).trendsinbiotechnology28(3):134-141.leterrieretal.,(2008)bmcplantbiol.8:98.lietal.,(1999a).plantphysiol120:1147-1155.lietal.,(1999b).theor.appl.genet.98:1208-1216.lietal.,(2000).plantphysiol123:613-624.lietal.,(2003).funct.integr.genomics3:76-85.liuetal.,(2010).biotechnologyandbioengineering,106:97-105.luoetal..(2015).theor.appl.genet.128:1407-1419.mannetal.,(2003).in′workshoponglutenproteins′eds.lafiandraetal.,theroyalsocietyofchemistry:cambridge,uk,pp.215-218.matsumotoetal.,(2011).plantphysiol.156:20-28.mcclearyetal.,(2000).jaoacint.83:997-1005.mcclearyetal.,(2013).cerealchem.90:396-414.mizunoetal.,(1992).j.biochem112:643-651.mizunoetal.,(1993).j.biol.chem.268:19084-19091.morelletal.,(1998).electrophoresis19:2603-2611.morelletal.,(1997).plantphysiol113:201-208.morelletal.,(2003).plantj34:172-184.morrisonandlaignelet,(1983).jcerealsci,1:9-20.morrisonetal.,(1984).jcerealsci.2:257-271.nakamuraetal.,(1996).planta199:209-218.nakamuraandyamanouchi,(1992).plantphysiol.99:1265-1266.needlemanandwunsch,(1970)..j.mol.biol.48:443-453.niedzetal.,(1995).plantcellreports,14:403-406.nishietal.,(2001).plantphysiol127:459-472.ohdanetal.,(2005).jexpbot56:3229-3244.o’sheaandmorell(1996).electrophoresis17:681-686.owetal.,(1986).science,234:856-859.palatniketal.,(2003).nature425:257-263.parizottoetal.,(2004).genesdev18:2237-2242.potrykusetal.,(1985).mol.gen.genet.,199:183-188.prasheretal.,(1985).biochem.biophys.res.comm.126:1259-1268.proskyetal.,(1985).jassoc.off.anal.chem.int.68:677-679.quraishietal.,(2011).functintegrgenomics11:71-83.rahmanetal.,(1999).theor.appl.genet.98:156-163.rahmanetal.,(1995).aust.j.plantphysiol.22:793-803.rahmanetal.,(2001).plantphysiol125:1314-1324.reginaetal.,(2006).proc.natl.acad.sci.u.s.a.103:3546-3551.reginaetal.,((2005).planta222:899-909.reginaetal.,(2010).jexpbot.61(5):1469-1482.reginaetal.,(2004).functplantbiol,31:591-601.ritsemaandsmeekens(2003)curr.opin.plantbiol.6:223-230.salanoubatetal.,(2000).nature408:820-822.schnableetal.,(2009).science326:1112-1115.schondelmaieretal.,(1992)plantbreeding109:274-280.schulmanandkammiovirta,(1991).starch43:387-389.schwabetal.,(2006).plantcell18:1121-1133.schwalletal.,(2000).naturebiotechnology18:551-554.sestilietal.,(2010).molbreeding25:145-154.sharpetal.,(2001).austjagricres52:1357-1366.shimbataetal.,(2005).theor.appl.genet.111:1072-1079.sidebottometal.,(1998).j.cerealsci27:279-287.sissonsetal.,(2007).j.sci.foodandagric.87:1874-1885.sladeandknauf,(2005).transgenicres.14:109-115.smewing.(1995).tx2textureanalyzerhandbook,smsltd:surrey,uk.smithetal.,(2000).nature,407:319-320.smithandhartley(1983).carbohydrateresearch118:65-80.sparksandjones(2004).intransgeniccropsoftheworld-essentialprotocols,ed.ipcurtis,kluweracademicpublishers,dordrecht,netherlands,pp19-34.stalkeretal.,(1988).science,242:419-423.steegmansetal(2004).j.aoacint.87,1200e1207.stoneandmorell(2009).in:khanandshewry(eds.)wheat:chemistryandtechnology.americanassociationofcerealchemists,stpaul,mn,pp299-362.sunetal.,(1997).newphytol.137:215-222.sunetal.,(1998).plantphysiol118:37-49.suneetal.,(2013).biotechnologyandbioengineering110:1811-1821.takedaetal.,(1993).carbohydrateresearch246:273-281.tanakaetal.,(1990).nucl.acidsres.18:6767-6770.tilley(2004).cerealchem81:44-47.toyotaetal.,(2006).planta223:248-257.tunglandandmeyer(2002)comprehensivereviewsinfoodscienceandfoodsafety2:73-77.waterhouseetal.,(1998).proc.natl.acad.sci.u.s.a.95:13959-13964.weiretal.,(2001).austjplantphysiol28:807-818.whelanetal(2011).intj.foodsci.nutr.62:498-503.wuetal.,(2003).plantcellrep21:659-668.yamamorietal.,(2000).theorapplgenet101:21-29.yamamorietal.,(2006).aust.j.agric.res.57:531-535.yanetal.,(2008).plantsci.176:51-57.zwarandchandler,(1995).planta197:39-48.序列表<110>联邦科学工业研究组织<120>高直链淀粉小麦-iii<130>35269906/wjp<160>51<170>patentin3.5版<210>1<211>799<212>prt<213>普通小麦<400>1metserseralavalalaseralaalaserpheleualaleualaser151015alaserproglyargserargargargalaargvalseralapropro202530prohisalaglyalaglyargleuhistrpproprotrpproprogln354045argthralaargaspglyglyvalalaalaargalaalaglylyslys505560aspalaargvalaspaspaspalaalaseralaargglnproargala65707580argargglyglyalaalathrlysvalalagluargargaspproval859095lysthrleuaspargaspalaalagluglyglyalaproalapropro100105110alaproargglnaspalaalaargproprosermetasnglythrpro115120125valasnglygluasnlysserthrglyglyglyglyalathrlysasp130135140serglyleuproalaproalaargalaprohisproserthrglnasn145150155160argvalprovalasnglygluasnlysalaasnvalalaserpropro165170175thrserilealagluvalvalalaproaspseralaalathrileser180185190ileserasplysalaprogluservalvalproalaglulyspropro195200205proserserglyserasnphevalvalseralaseralaproargleu210215220aspileaspseraspvalgluprogluleulyslysglyalavalile225230235240valgluglualaproasnprolysalaleuserproproalaalapro245250255alavalglngluaspleutrpaspphelyslystyrileglypheglu260265270gluprovalglualalysaspaspglytrpalavalalaaspaspala275280285glyserphegluhishisglnasnhisaspserglyproleualagly290295300gluasnvalmetasnvalvalvalvalalaalaglucysserprotrp305310315320cyslysthrglyglyleuglyaspvalalaglyalaleuprolysala325330335leualalysargglyhisargvalmetvalvalvalproargtyrgly340345350asptyrgluglualatyraspvalglyvalarglystyrtyrlysala355360365alaglyglnaspmetgluvalasntyrphehisalatyrileaspgly370375380valaspphevalpheileaspalaproleuphearghisargglnglu385390395400aspiletyrglyglyserargglngluilemetlysargmetileleu405410415phecyslysalaalavalgluvalprotrphisvalprocysglygly420425430valprotyrglyaspglyasnleuvalpheilealaasnasptrphis435440445thralaleuleuprovaltyrleulysalatyrtyrargasphisgly450455460leumetglntyrthrargserilemetvalilehisasnilealahis465470475480glnglyargglyprovalaspglupheprophethrgluleuproglu485490495histyrleugluhispheargleutyraspprovalglyglygluhis500505510alaasntyrphealaalaglyleulysmetalaaspglnvalvalval515520525valserproglytyrleutrpgluleulysthrvalgluglyglytrp530535540glyleuhisaspileileargglnasnasptrplysthrargglyile545550555560valasnglyileaspasnmetglutrpasnprogluvalaspvalhis565570575leulysseraspglytyrthrasnpheserleuglythrleuaspser580585590glylysargglncyslysglualaleuglnarggluleuglyleugln595600605valargalaaspvalproleuleuglypheileglyargleuaspgly610615620glnlysglyvalgluileilealaaspalametprotrpilevalser625630635640glnaspvalglnleuvalmetleuglythrglyarghisaspleuglu645650655sermetleuarghisphegluarggluhishisasplysvalarggly660665670trpvalglypheservalargleualahisargilethralaglyala675680685aspalaleuleumetproserargphegluprocysglyleuasngln690695700leutyralametalatyrglythrvalprovalvalhisalavalgly705710715720glyvalargaspthrvalpropropheasppropheasnhissergly725730735leuglytrpthrpheaspargalaglualahislysleuilegluala740745750leuglyhiscysleuargthrtyrargasptyrlysglusertrparg755760765glyleuglngluargglymetserglnaspphesertrpgluhisala770775780alalysleutyrgluaspvalleuleulysalalystyrglntrp785790795<210>2<211>798<212>prt<213>普通小麦<400>2metserseralavalalaseralaalaserpheleualaleualaser151015alaserproglyargserargargargthrargvalseralaserpro202530prohisthrglyalaglyargleuhistrpproproserproprogln354045argthralaargaspglyalavalalaalaargalaalaglylyslys505560aspalaglyileaspaspalaalaproalaargglnproargalaleu65707580argglyglyalaalathrlysvalalagluargargaspprovallys859095thrleuaspargaspalaalagluglyglyalaproserproproala100105110proargglngluaspalaargleuprosermetasnglymetproval115120125asnglygluasnlysserthrglyglyglyglyalathrlysaspser130135140glyleuproalaproalaargalaproglnproserserglnasnarg145150155160valprovalasnglygluasnlysalaasnvalalaserproprothr165170175serilealagluvalalaalaproaspproalaalathrileserile180185190serasplysalaprogluservalvalproalaglulysalapropro195200205serserglyserasnphevalproseralaseralaproglyserasp210215220thrvalseraspvalgluleugluleulyslysglyalavalileval225230235240lysglualaproasnprolysalaleuserproproalaalaproala245250255valglnglnaspleutrpaspphelyslystyrileglyphegluglu260265270provalglualalysaspaspglyargalavalalaaspaspalagly275280285serphegluhishisglnasnhisaspserglyproleualaglyglu290295300asnvalmetasnvalvalvalvalalaalaglucysserprotrpcys305310315320lysthrglyglyleuglyaspvalalaglyalaleuprolysalaleu325330335alalysargglyhisargvalmetvalvalvalproargtyrglyasp340345350tyrgluglualatyraspvalglyvalarglystyrtyrlysalaala355360365glyglnaspmetgluvalasntyrphehisalatyrileaspglyval370375380aspphevalpheileaspalaproleuphearghisargglngluasp385390395400iletyrglyglyserargglngluilemetlysargmetileleuphe405410415cyslysalaalavalgluvalprotrphisvalprocysglyglyval420425430protyrglyaspglyasnleuvalpheilealaasnasptrphisthr435440445alaleuleuprovaltyrleulysalatyrtyrargasphisglyleu450455460metglntyrthrargserilemetvalilehisasnilealahisgln465470475480glyargglyprovalaspglupheprophethrgluleuprogluhis485490495tyrleugluhispheargleutyraspprovalglyglygluhisala500505510asntyrphealaalaglyleulysmetalaaspglnvalvalvalval515520525serproglytyrleutrpgluleulysthrvalgluglyglytrpgly530535540leuhisaspileileargglnasnasptrplysthrargglyileval545550555560asnglyileaspasnmetglutrpasnprogluvalaspvalhisleu565570575lysseraspglytyrthrasnpheserleuglythrleuaspsergly580585590lysargglncyslysglualaleuglnarggluleuglyleuglnval595600605argglyaspvalproleuleuglypheileglyargleuaspglygln610615620lysglyvalgluileilealaaspalametprotrpilevalsergln625630635640aspvalglnleuvalmetleuglythrglyarghisaspleuglugly645650655metleuarghisphegluarggluhishisasplysvalargglytrp660665670valglypheservalargleualahisargilethralaglyalaasp675680685alaleuleumetproserargphegluprocysglyleuasnglnleu690695700tyralametalatyrglythrvalprovalvalhisalavalglygly705710715720leuargaspthrvalpropropheasppropheasnhisserglyleu725730735glytrpthrpheaspargalaglualaglnlysleuileglualaleu740745750glyhiscysleuargthrtyrargasptyrlysglusertrparggly755760765leuglngluargglymetserglnaspphesertrpgluhisalaala770775780lysleutyrgluaspvalleuvallysalalystyrglntrp785790795<210>3<211>799<212>prt<213>普通小麦<400>3metserseralavalalaseralaalaserpheleualaleualaser151015alaserproglyargserargargargalaargvalseralaglnpro202530prohisalaglyalaglyargleuhistrpproprotrpproprogln354045argthralaargaspglyalavalalaalaleualaalaglylyslys505560aspalaglyileaspaspalaalaalaservalargglnproargala65707580leuargglyglyalaalathrlysvalalagluargargaspproval859095lysthrleuaspargaspalaalagluglyglyglyproserpropro100105110alaalaargglnaspalaalaargproprosermetasnglymetpro115120125valasnglygluasnlysserthrglyglyglyglyalathrlysasp130135140serglyleuprothrproalaargalaprohisproserthrglnasn145150155160argalaprovalasnglygluasnlysalaasnvalalaserpropro165170175thrserilealaglualaalaalaseraspseralaalathrileser180185190ileserasplysalaprogluservalvalproalaglulysthrpro195200205proserserglyserasnphegluserseralaseralaproglyser210215220aspthrvalseraspvalgluglngluleulyslysglyalavalval225230235240valgluglualaprolysprolysalaleuserproproalaalapro245250255alavalglngluaspleutrpaspphelyslystyrileglypheglu260265270gluprovalglualalysaspaspglyargalavalalaaspaspala275280285glyserphegluhishisglnasnhisaspserglyproleualagly290295300gluasnvalmetasnvalvalvalvalalaalaglucysserprotrp305310315320cyslysthrglyglyleuglyaspvalalaglyalaleuprolysala325330335leualalysargglyhisargvalmetvalvalvalproargtyrgly340345350asptyrgluglualatyraspvalglyvalarglystyrtyrlysala355360365alaglyglnaspmetgluvalasntyrphehisalatyrileaspgly370375380valaspphevalpheileaspalaproleuphearghisargglnglu385390395400aspiletyrglyglyserargglngluilemetlysargmetileleu405410415phecyslysalaalavalgluvalprotrphisvalprocysglygly420425430valprotyrglyaspglyasnleuvalpheilealaasnasptrphis435440445thralaleuleuprovaltyrleulysalatyrtyrargasphisgly450455460leumetglntyrthrargserilemetvalilehisasnilealahis465470475480glnglyargglyprovalaspglupheprophethrgluleuproglu485490495histyrleugluhispheargleutyraspprovalglyglygluhis500505510alaasntyrphealaalaglyleulysmetalaaspglnvalvalval515520525valserproglytyrleutrpgluleulysthrvalgluglyglytrp530535540glyleuhisaspileileargglnasnasptrplysthrargglyile545550555560valasnglyileaspasnmetglutrpasnprogluvalaspalahis565570575leulysseraspglytyrthrasnpheserleuargthrleuaspser580585590glylysargglncyslysglualaleuglnarggluleuglyleugln595600605valargalaaspvalproleuleuglypheileglyargleuaspgly610615620glnlysglyvalgluileilealaaspalametprotrpilevalser625630635640glnaspvalglnleuvalmetleuglythrglyarghisaspleuglu645650655sermetleuglnhisphegluarggluhishisasplysvalarggly660665670trpvalglypheservalargleualahisargilethralaglyala675680685aspalaleuleumetproserargphegluprocysglyleuasngln690695700leutyralametalatyrglythrvalprovalvalhisalavalgly705710715720glyleuargaspthrvalpropropheasppropheasnhissergly725730735leuglytrpthrpheaspargalaglualahislysleuilegluala740745750leuglyhiscysleuargthrtyrargaspphelysglusertrparg755760765alaleuglngluargglymetserglnaspphesertrpgluhisala770775780alalysleutyrgluaspvalleuvallysalalystyrglntrp785790795<210>4<211>2821<212>dna<213>普通小麦<400>4gctgccaccacctccgcctgcgccgcgctctgggcggaggaccaacccgcgcatcgtacc60atcgcccgccccgatcccggccgccgccatgtcgtcggcggtcgcgtccgccgcgtcctt120cctcgcgctcgcctccgcctcccccgggagatcacgcaggcgggcgagggtgagcgcgcc180gccaccccacgccggggccggcaggctgcactggccgccgtggccgccgcagcgcacggc240tcgcgacggaggtgtggccgcgcgcgccgccgggaagaaggacgcgagggtcgacgacga300cgccgcgtccgcgaggcagccccgcgcacgccgcggtggcgccgccaccaaggtcgcgga360gcggagggatcccgtcaagacgctcgatcgcgacgccgcggaaggtggcgcgccggcacc420gccggcaccgaggcaggacgccgcccgtccaccgagtatgaacggcacgccggtgaacgg480tgagaacaaatctaccggcggcggcggcgcgaccaaagacagcgggctgcccgcacccgc540acgcgcgccccatccgtcgacccagaacagagtaccagtgaacggtgaaaacaaagctaa600cgtcgcctcgccgccgacgagcatagccgaggtcgtggctccggattccgcagctaccat660ttccatcagtgacaaggcgccggagtccgttgtcccagccgagaagccgccgccgtcgtc720cggctcaaatttcgtggtctcggcttctgctcccaggctggacattgacagcgatgttga780acctgaactgaagaagggtgcggtcatcgtcgaagaagctccaaacccaaaggctctttc840gccgcctgcagcccccgctgtacaagaagacctttgggacttcaagaaatacattggctt900cgaggagcccgtggaggccaaggatgatggctgggctgttgcagatgatgcgggctcctt960tgaacatcaccagaaccatgattccggacctttggcaggggagaacgtcatgaacgtggt1020cgtcgtggctgctgaatgttctccctggtgcaaaacaggtggtcttggagatgttgccgg1080tgctttgcccaaggctttggcgaagagaggacatcgtgttatggttgtggtaccaaggta1140tggggactatgaggaagcctacgatgtcggagtccgaaaatactacaaggctgctggaca1200ggatatggaagtgaattatttccatgcttatatcgatggagttgattttgtgttcattga1260cgctcctctcttccgacaccgccaggaagacatttatgggggcagcagacaggaaattat1320gaagcgcatgattttgttctgcaaggccgctgtcgaggttccttggcacgttccatgcgg1380cggtgtcccttatggggatggaaatctggtgtttattgcaaatgattggcacacggcact1440cctgcctgtctatctgaaagcatattacagggaccatggtttgatgcagtacactcggtc1500cattatggtgatacataacatcgcgcaccagggccgtggcccagtagatgaattcccgtt1560caccgagttgcctgagcactacctggaacacttcagactgtacgaccccgtgggtggtga1620gcacgccaactacttcgccgccggcctgaagatggcggaccaggttgtcgtggtgagccc1680cgggtacctgtgggagctcaagacggtggagggcggctgggggcttcacgacatcatacg1740gcagaacgactggaagacccgcggcatcgtcaacggcatcgacaacatggagtggaaccc1800cgaggtggacgtccacctcaagtcggacggctacaccaacttctccctggggacgctgga1860ctccggcaagcggcagtgcaaggaggccctgcagcgcgagctgggcctgcaggtccgcgc1920cgacgtgccgctgctcggcttcatcggccgcctggacgggcagaagggcgtggagatcat1980cgcggacgccatgccctggatcgtgagccaggacgtgcagctggtcatgctgggcaccgg2040ccgccacgacctggagagcatgctgcggcacttcgagcgggagcaccacgacaaggtgcg2100cgggtgggtggggttctccgtgcgcctggcgcaccggatcacggcgggcgccgacgcgct2160cctcatgccctcccggttcgagccgtgcgggttgaaccagctttacgccatggcctacgg2220caccgtccccgtcgtgcacgccgtcggcggggtgagggacaccgtgccgccgttcgaccc2280cttcaaccactccggcctcgggtggacgttcgaccgcgccgaggcgcacaagctgatcga2340ggcgctcgggcactgcctccgcacctaccgggactacaaggagagctggaggggcctcca2400ggagcgcggcatgtcgcaggacttcagctgggagcatgccgccaagctctacgaggacgt2460cctcctcaaggccaagtaccagtggtgaacgctagctgctagccgctccagccccgcatg2520cgtgcatgcatgagagggtggaactgcgcattgcgcccgcaggaacgtgccatccttctc2580gatgggagcgccggcatccgcgaggtgcagtgacatgagaggtgtgtgtggttgagacgc2640tgattccgatctcgatctggtccgtagcagagtagagcggacgtagggaagcgctccttg2700ttgcaggtatatgggaatgttgtcaacttggtattgtagtttgctatgttgtatgcgtta2760ttacaatgttgttacttattcttgttaagtcggaggcaaagggcgaaagctagctcacat2820g2821<210>5<211>2793<212>dna<213>普通小麦<400>5gcactccagtccagtccagcccactgccgcgctactccccactcccactgccaccacctc60cgcctgcgccgcgctctgggcggaccaacccgcgcatcgtatcacgatcacccaccccga120tcccggccgccgccatgtcgtcggcggtcgcgtccgccgcgtccttcctcgcgctcgcgt180ccgcctcccccgggagatcacggaggaggacgagggtgagcgcgtcgccaccccacaccg240gggctggcaggttgcactggccgccgtcgccgccgcagcgcacggctcgcgacggagcag300tggccgcgcgcgccgccgggaagaaggacgcggggatcgacgacgccgcgcccgcgaggc360agccccgcgcactccgcggtggcgccgccaccaaggttgcggagcggagggatcccgtca420agacgctcgatcgcgacgccgcggaaggtggcgcgccgtccccgccggcaccgaggcagg480aggacgcccgtctgccgagcatgaacggcatgccggtgaacggtgaaaacaaatctaccg540gcggcggcggcgcgactaaagacagcgggctgcccgcacccgcacgcgcgccccagccgt600cgagccagaacagagtaccggtgaatggtgaaaacaaagctaacgtcgcctcgccgccga660cgagcatagccgaggtcgcggctccggatcccgcagctaccatttccatcagtgacaagg720cgccagagtccgttgtcccagccgagaaggcgccgccgtcgtccggctcaaatttcgtgc780cctcggcttctgctcccgggtctgacactgtcagcgacgtggaacttgaactgaagaagg840gtgcggtcattgtcaaagaagctccaaacccaaaggctctttcgccgcctgcagcacccg900ctgtacaacaagacctttgggacttcaagaaatacattggtttcgaggagcccgtggagg960ccaaggatgatggccgggctgttgcagatgatgcgggctccttcgaacaccaccagaatc1020acgattccgggcctttggcaggggagaacgtcatgaacgtggtcgtcgtggctgctgaat1080gttctccctggtgcaaaacaggtggtcttggagatgttgccggtgctttgcccaaggctt1140tggcgaagagaggacatcgtgttatggttgtggtaccaaggtatggggactatgaggaag1200cctacgatgtcggagtccgaaaatactacaaggctgctggacaggatatggaagtgaatt1260atttccatgcttatatcgatggagttgattttgtgttcattgacgctcctctcttccgac1320accgccaggaagacatttatgggggcagcagacaggaaattatgaagcgcatgattttgt1380tctgcaaggccgctgtcgaggttccatggcacgttccatgcggcggtgtcccttatgggg1440atggaaatctggtgtttattgcaaatgattggcacacggcactcctgcctgtctatctga1500aagcatattacagggaccatggtttgatgcagtacactcggtccattatggtgatacata1560acatcgctcaccagggccgtggcccagtagatgagttcccgttcaccgagttgcctgagc1620actacctggaacacttcagactgtacgaccccgtgggtggtgaacacgccaactacttcg1680ccgccggcctgaagatggcggaccaggttgtcgtcgtgagcccggggtacctgtgggagc1740tgaagacggtggagggcggctgggggcttcacgacatcatacggcagaacgactggaaga1800cccgcggcatcgtgaacggcatcgacaacatggagtggaaccccgaggtggacgtccacc1860tcaagtcggacggctacaccaacttctccctggggacgctggactccggcaagcggcagt1920gcaaggaggccctgcagcgggagctgggcctgcaggtccgcggcgacgtgccgctgctcg1980gcttcatcgggcgcctggacgggcagaagggcgtggagatcatcgcggacgcgatgccct2040ggatcgtgagccaggacgtgcagctggtcatgctgggcaccgggcgccacgacctggagg2100gcatgctgcggcacttcgagcgggagcaccacgacaaggtgcgcgggtgggtggggttct2160ccgtgcggctggcgcaccggatcacggccggcgccgacgcgctcctcatgccctcccggt2220tcgagccgtgcggactgaaccagctctacgccatggcctacggcaccgtccccgtcgtgc2280atgccgtcggcggcctgagggacaccgtgccgccgttcgaccccttcaaccactccgggc2340tcgggtggacgttcgaccgcgcagaggcgcagaagctgatcgaggcgctcgggcactgcc2400tccgcacctaccgggactacaaggagagctggagggggctccaggagcgcggcatgtcgc2460aggacttcagctgggagcatgccgccaagctctacgaggacgtcctcgtcaaggccaagt2520accagtggtgaacgctagctgctagccggtccagccccgcatgcgtgcatgacaggatgg2580aattgcgcattgcgcacgcaggaatgtgccatggagcgccggcatccgcgaagtacagtg2640acatgaggtgtgtgtggttgagacgctgattccgatctggtccgtagcagagtagagcgg2700aggtagggaagcgctccttgttacaggtatatgggaatgttgttaacttggtattgtaat2760ttgttatgttgtgtgcattattacaaagggcaa2793<210>6<211>2846<212>dna<213>普通小麦<400>6ggagaatagccacatccctggtttggagagaccatcgcagcaacaaccattaccaccaca60acaaacattatcgcaccaacaaccacaacaacccatccagtccagcccactgccaccgcg120ctactctccactcccactgccaccacctccgcctgcgccgcgctctgggcggaccaaccc180gcgaaccgtaccatctcccgccccgatccatgtcgtcggcggtcgcgtccgccgcatcct240tcctcgcgctcgcgtcagcctcccccgggagatcacgcaggcgggcgagggtgagcgcgc300agccaccccacgccggggccggcaggttgcactggccgccgtggccgccgcagcgcacgg360ctcgcgacggagctgtggcggcgctcgccgccgggaagaaggacgcggggatcgacgacg420ccgccgcgtccgtgaggcagccccgcgcactccgcggtggcgccgccaccaaggtcgcgg480agcgaagggatcccgtcaagacgctcgaccgcgacgccgcggaaggcggcgggccgtccc540cgccggcagcgaggcaggacgccgcccgtccgccgagtatgaacggcatgccggtgaacg600gcgagaacaaatctaccggcggcggcggcgcgactaaagacagcgggctgcccacgcccg660cacgcgcgccccatccgtcgacccagaacagagcaccggtgaacggtgaaaacaaagcta720acgtcgcctcgccgccgacgagcatagccgaggccgcggcttcggattccgcagctacca780tttccatcagcgacaaggcgccggagtccgttgtcccagctgaggagacgccgccgtcgt840ccggctcaaatttcgagtcctcggcctctgctcccgggtctgacactgtcagcgacgtgg900aacaagaactgaagaagggtgcggtcgttgtcgaagaagctccaaagccaaaggctcttt960cgccgcctgcagcccccgctgtacaagaagacctttgggatttcaagaaatacattggtt1020tcgaggagcccgtggaggccaaggatgatggccgggctgtcgcagatgatgcgggctcct1080ttgaacaccaccagaatcacgactccggacctttggcaggggagaatgtcatgaacgtgg1140tcgtcgtggctgctgagtgttctccctggtgcaaaacaggtggtctgggagatgttgcgg1200gtgctctgcccaaggctttggcaaagagaggacatcgtgttatggttgtggtaccaaggt1260atggggactatgaagaagcctacgatgtcggagtccgaaaatactacaaggctgctggac1320aggatatggaagtgaattatttccatgcttatatcgatggagttgattttgtgttcattg1380acgctcctctcttccgacaccgtcaggaagacatttatgggggcagcagacaggaaatta1440tgaagcgcatgattttgttctgcaaggccgctgttgaggttccatggcacgttccatgcg1500gcggtgtcccttatggggatggaaatctggtgtttattgcaaatgattggcacacggcac1560tcctgcctgtctatctgaaagcatattacagggaccatggtttgatgcagtacactcggt1620ccattatggtgatacataacatcgctcaccagggccgtggccctgtagatgaattcccgt1680tcaccgagttgcctgagcactacctggaacacttcagactgtacgaccccgtgggtggtg1740aacacgccaactacttcgccgccggcctgaagatggcggaccaggttgtcgtggtgagcc1800ccgggtacctgtgggagctgaagacggtggagggcggctgggggcttcacgacatcatac1860ggcagaacgactggaagacccgcggcatcgtcaacggcatcgacaacatggagtggaacc1920ccgaggtggacgcccacctcaagtcggacggctacaccaacttctccctgaggacgctgg1980actccggcaagcggcagtgcaaggaggccctgcagcgcgagctgggcctgcaggtccgcg2040ccgacgtgccgctgctcggcttcatcggccgcctggacgggcagaagggcgtggagatca2100tcgcggacgccatgccctggatcgtgagccaggacgtgcagctggtgatgctgggcaccg2160ggcgccacgacctggagagcatgctgcagcacttcgagcgggagcaccacgacaaggtgc2220gcgggtgggtggggttctccgtgcgcctggcgcaccggatcacggcgggggcggacgcgc2280tcctcatgccctcccggttcgagccgtgcgggctgaaccagctctacgccatggcctacg2340gcaccgtccccgtcgtgcacgccgtcggcggcctcagggacaccgtgccgccgttcgacc2400ccttcaaccactccgggctcgggtggacgttcgaccgcgccgaggcgcacaagctgatcg2460aggcgctcgggcactgcctccgcacctaccgagacttcaaggagagctggagggccctcc2520aggagcgcggcatgtcgcaggacttcagctgggagcacgccgccaagctctacgaggacg2580tcctcgtcaaggccaagtaccagtggtgaacgctagctgctagccgctccagccccgcat2640gcgtgcatgacaggatggaactgcattgcgcacgcaggaaagtgccatggagcgccggca2700tccgcgaagtacagtgacatgaggtgtgtgtggttgagacgctgattccaatccggcccg2760tagcagagtagagcggaggtatatgggaatcttaacttggtattgtaatttgttatgttg2820tgtgcattattacaatgttgttactt2846<210>7<211>6898<212>dna<213>普通小麦<400>7gggggccgttcgtacgtacccgcccctcgtgtaaagccgccgccgtcgtcgccgtccccc60gctcgcggccatttccccggcctgaccccgtgcgtttaccccacagagcacactccagtc120cagtccagcccactgccgccgcgctactccccactcccgctgccaccacctccgcctgcg180ccgcgctctgggcggaggaccaacccgcgcatcgtaccatcgcccgccccgatcccggcc240gccgccatgtcgtcggcggtcgcgtccgccgcgtccttcctcgcgctcgcctccgcctcc300cccgggagatcacgcaggcgggcgagggtgagcgcgccgccaccccacgccggggccggc360aggctgcactggccgccgtggccgccgcagcgcacggctcgcgacggaggtgtggccgcg420cgcgccgccgggaagaaggacgcgagggtcgacgacgacgccgcgtccgcgaggcagccc480cgcgcacgccgcggtggcgccgccaccaaggtagttggttcgttatgacttgctgtatgg540cgcgtgcgcctcgagatcagctcacgaattgtttctacaaaacgcacgcgctcgtgtgca600ggtcgcggagcggagggatcccgtcaagacgctcgatcgcgacgccgcggaaggtggcgc660gccggcaccgccggcaccgaggcaggacgccgcccgtccaccgagtatgaacggcacgcc720ggtgaacggtgagaacaaatctaccggcggcggcggcgcgaccaaagacagcgggctgcc780cgcacccgcacgcgcgccccatccgtcgacccagaacagagtaccagtgaacggtgaaaa840caaagctaacgtcgcctcgccgccgacgagcatagccgaggtcgtggctccggattccgc900agctaccatttccatcagtgacaaggcgccggagtccgttgtcccagccgagaagccgcc960gccgtcgtccggctcaaatttcgtggtctcggcttctgctcccaggctggacattgacag1020cgatgttgaacctgaactgaagaagggtgcggtcatcgtcgaagaagctccaaacccaaa1080ggctctttcgccgcctgcagcccccgctgtacaagaagacctttgggacttcaagaaata1140cattggcttcgaggagcccgtggaggccaaggatgatggctgggctgttgcagatgatgc1200gggctcctttgaacatcaccagaaccatgattccggacctttggcaggggagaacgtcat1260gaacgtggtcgtcgtggctgctgaatgttctccctggtgcaaaacaggcatggacattac1320ctcttcagtctctcttcccgttgttcataaaactttgctcgaatcactcataagaacaaa1380cattgtgttgcataggtggtcttggagatgttgcgggtgctctgcccaaggctttggcaa1440agagaggacatcgtgttatggtactgcaggctttcacttaactctgttgagtccatatgt1500tcgaataatatcagtgattggcataatgttattaagtgcaagacatgaaagtgttcttct1560gttagagtatttcatagccaaccctggaggttaggttgttggggcctactgggtgcggga1620gggggtttgcaaaaagtggtggttagcagtcggatttcacaaataaggaggctgataacc1680acgccatcagtgaagggaatgagtgtcgggtacccgatcgaccgttttgcccgacgtcag1740gtttacctgccctgtagatccgaataagtagttcctatcctcagttaagtaccaaatatc1800gccagcacccgtgtgtgtatttatagtactggatgatcaatttatcaacatttccggtta1860atggttgctatcatattcactgtaattgttagtaaacagtggatgtttgtaatgtagatg1920atggctaaatgtatgttgtcaagctttcattttaaagaaaattttattgggagctagttt1980tcgggtttggttagagccaccaaaaccccagaatttttgggagttggcttgtgacagagg2040gttttggggagttaactttcgggattcagttagagacgctcttactagttccagtaaaga2100gtaaactattttctgcagtcatcccaattgttctgtagaaattaaaagtagaaaatagtt2160gtggtatcatataaaccatatattattcaaaatctagaatcatggacttggctagacttt2220gatgatctgaaattttaaatttgatgataattgagaaatgatcctttctatcttaggttg2280tggtaccaaggtatggggactatgaggaagcctacgatgtcggagtccgaaaatactaca2340aggctgctggacaggtaagcgaaaatgcaatcaaaggggagctgaaatttcaatgcttac2400tatcataataaatcaattttaagtaaaaaaatttgtcctgcaggatatggaagtgaatta2460tttccatgcttatatcgatggagttgattttgtgttcattgacgctcctatcttccgaca2520ccgtcaggaagacatttatgggggcagcagacaggttaattttctatatgttggtgtttg2580attgcactgataaactgagaataagccaaggcctactgactggcatatgattacacattt2640tattttttcaggaaattatgaagcgcatgattttgttctgcaaggccgctgtcgaggtat2700cctctccaactcaattgacaacctattaccactatacaattatgtgtatgcatgtatttc2760aacagatacgtaatctcccttgtgaagtgtatatatactaataacatttcaatacctcac2820atgcacatttggtcaagcgttatgatttaacttctgataatctattgcactgatgaacaa2880taatattgatgatccttgttacttcatcgttatgtttatgttctcttcaccggcgcattg2940attttggaaatagcatttccacctgccacaaacaataatatatactcctactttcatcca3000atgtagatattttcgcacttggcatatcatcccattaaatattattggtccatcattttt3060attcctctataatttgcaggttccttggcacgttccatgcggcggtgtcccttatgggga3120tggaaatctggtgtttattgcaaatgattggcacacggcactcctgcctgtctatctgaa3180agcatattacagggaccatggtttgatgcagtacactcggtccattatggtgatacataa3240catcgcgcaccaggttccttttctcctaatcttgttttttctctagtctctactattcac3300tccacattgtttgaggaaactaaaggggttgcaaaattatgatggcttatgaaagttatg3360gaggtaaatgcatcagtggtgcttgaacttgtcacgcatgttcactttggtgcttacagt3420tgtagactacggaaaactggtgcaaaaacttggctattgtgtgcaatacggtgtattttc3480cgtatgtagggtcaaatgttgcctatgtggcattgtattcccgtctatagatgttagacc3540gtgcctacatcgccattgggcccacacactccctattacatgtgggacccacttgtcagc3600ctatgacataaataaaatggaaatttataataaaaatgatggcctggggtcttgaaaatg3660ggacctcgcaggtatgccgctagccagcacgccctaatcattaatcccctatgcacttca3720gtatgtgtgtgtctgtgtgtggagtcggggggggggggggtatgtattcttatatccttt3780gctctaaggctatcattggcgtgctagcaccgccgggtctccatcaacaccgacatcatc3840cacgaccccatccagctcttcctcaacaagcccacctccagcctcaactcgggcagcacc3900ttcatggtggcctaggtgctctgcaccatcgctcgaagtggcaacgtcgttgtcatgacc3960atccaccaacccaacacgcaaaatcctcaacatcatttgacagtgagcatgcccctcttg4020tcatttccccctcatacccaaacctgtctcgataacccttggagctgcacaagttgtgac4080catcgcctgcgtcgctgcacaacgcctgacctagccggaccattatagaagcctgccttg4140ggagcccatacctccctgcacatcctcctctttccccatagaccgtgccgccatcgcaaa4200tcgacttctcctctcctccttctcctgctctggccgttttccccgccgcgaagctgcaat4260ccatggcgagttggccatggccctattccccaattgctcgcactaggaggtcctccttga4320agcctagcacctttccccctcactaattgcaagttggggagcccctcacgagctccctac4380attggccgtagtcgcctgccgcctcaactctggtccagacctcgttcccgtggcctcgac4440gacatctcctcgacctcccattccacacgcggcctggagaggatcaccgcatgttcatcc4500atccgacccgaatcatcatagaaccaacgccagagaggtcatcccgacgacgtcgcactg4560ttcctctatttcccccaagctgtgtcgcgtcataatataagacgggcttgtttgtatctc4620taggggtcatcgggttcaatggctagctcatgcatggacctgactttaggtcccaggttc4680gaacccccgcgtgcacataatttatttgctatttatttctcctatctactaataagtggg4740acccacacatcatactaagccctttttgtctcttgcctgctgataagtgggacccacacg4800caatacttagccagagagagaacatgagcttgttggtgccgcgttggcaagccacgccag4860cagtcttaacggctacaaacagaggatatggtgtcacatcaacgtgcagagcgtttacga4920atggaaagtgtactatatgcacacaagagccagagccaggtttttgcaccagttttttgt4980attctacaactgcgagcaccaaagtgtacatgccgaaccaaagtgaacacggcgagtcca5040ttcttttctggtacgatgggtggctcaaagacaccccaatagaagctatcacctcggaca5100ttgccaattgggtgccgaactacattaaagtggcaaggtcagttgattgcgctatgtgtt5160ggatcagggacataaacgattccataaatattgcaatgttcattcaaattcttaacattt5220gcgaggcgcttcatgatttccatctccctcatatcagagacatttggtcgtgtacactaa5280atttctcaggtcacttctcgtctaaatccgcatatgtagctcacttcaatgacttgactt5340tggtccagctaacgccatttggcgctcttgggcccctttgcgtagcaattttttcatatg5400gctcgctccgcgcaataggatttggatcacgggcagacgcgctagatgaggtcttccaca5460caatgaacattgcgttctttgctctgctcttccagaagacacttgtgattttattacgag5520ttgtgccatagatgccggtgggtttcagctaggaacagggtgtcaccttcggacaagaag5580aagttgcatagtttggtcgtcttaactgcttggtcgatttggaaggagcacaacaacagt5640ctttgaaggcaaagctaattccctcgatcaagttattagacggatcaaatgtggtacagt5700gccatggctagttgcttggagtcacttttaagctaggtcgcttgccatcacgctttgtgt5760taagcgcttggggtcgcttttgctcaatttgtattttgttgttatgtgtttttagttatg5820tagcctgaactttctggacttagttttttcctctataatgatcacatgctttggtcagtt5880attcctttcttgggtactccgttgggctaattctttctcttgattgatgttgtatatgca5940gggccgtggcccagtagatgaattcccgttcaccgagttgcctgagcactacctggaaca6000cttcagactgtacgaccccgtgggtggtgagcacgccaactacttcgccgccggcctgaa6060gatggcggaccaggttgtcgtggtgagccccgggtacctgtgggagctcaagacggtgga6120gggcggctgggggcttcacgacatcatacggcagaacgactggaagacccgcggcatcgt6180caacggcatcgacaacatggagtggaaccccgaggtggacgtccacctccagtcggacgg6240ctacaccaacttctccctgagcacgctggactccggcaagcggcagtgcaaggaggccct6300gcagcgcgagctgggcctgcaggtccgcgccgacgtgccgctgctcggcttcatcggccg6360cctggacgggcagaagggcgtggagatcatcgcggacgccatgccctggatcgtgagcca6420ggacgtgcagctggtcatgctgggcaccggccgccacgacctggagagcatgctgcggca6480cttcgagcgggagcaccacgacaaggtgcgcgggtgggtggggttctccgtgcgcctggc6540gcaccggatcacggcgggcgccgacgcgctcctcatgccctcccggttcgagccgtgcgg6600gctgaaccagctctacgccatggcctacggcaccgtccccgtcgtgcacgccgtcggcgg6660gctgagggacaccgtgccgccgttcgaccccttcaaccactccggcctcgggtggacgtt6720cgaccgcgccgaggcgcacaagctgatcgaggcgctcgggcactgcctccgcacctaccg6780ggactacaaggagagctggaggggcctccaggagcgcggcatgtcgcaggacttcagctg6840ggagcatgccgccaagctctacgaggacgtcctcctcaaggccaagtaccagtggtga6898<210>8<211>6811<212>dna<213>普通小麦<400>8gggggccgttcgtacgtacccacccctcgtgtaaagccgccgccgtcgtcgccgtccccc60gctcgcggccatttcctcggcctgaccccgtgcgtttaccccacacagagcacactccag120tccagtccagcccactgccgcgctactccccactcccactgccaccacctccgcctgcgc180cgcgctctgggcggaccaacccgcgcatcgtatcacgatcacccaccccgatcccggccg240ccgccatgtcgtcggcggtcgcgtccgccgcgtccttcctcgcgctcgcgtccgcctccc300ccgggagatcacggaggaggacgagggtgagcgcgtcgccaccccacaccggggctggca360ggttgcactggccgccgtcgccgccgcagcgcacggctcgcgacggagcagtggccgcgc420gcgccgccgggaagaaggacgcggggatcgacgacgccgcgcccgcgaggcagccccgcg480cactccgcggtggcgccgccaccaaggtagttagttatgaccaagttatgacgcgtgcgc540gcgccttgagatcatcgtcgtctcgctgacaaattgtttatacaaaacgcacgcgcgcgc600gtgtgtgcaggttgcggagcggagggatcccgtcaagacgctcgatcgcgacgccgcgga660aggtggcgcgccgtccccgccggcaccgaggcaggaggacgcccgtctgccgagcatgaa720cggcatgccggtgaacggtgaaaacaaatctaccggcggcggcggcgcgactaaagacag780cgggctgcccgcacccgcacgcgcgccccagccgtcgagccagaacagagtaccggtgaa840tggtgaaaacaaagctaacgtcgcctcgccgccgacgagcatagccgaggtcgcggctcc900ggatcccgcagctaccatttccatcagtgacaaggcgccagagtccgttgtcccagccga960gaaggcgccgccgtcgtccggctcaaatttcgtgccctcggcttctgctcccgggtctga1020cactgtcagcgacgtggaacttgaactgaagaagggtgcggtcattgtcaaagaagctcc1080aaacccaaaggctctttcgccgcctgcagcacccgctgtacaacaagacctttgggactt1140caagaaatacattggtttcgaggagcccgtggaggccaaggatgatggccgggctgttgc1200agatgatgcgggctccttcgaacaccaccagaatcacgattccgggcctttggcagggga1260gaacgtcatgaacgtggtcgtcgtggctgctgaatgttctccctggtgcaaaacaggcat1320ggacattacctcttcagtgtcttttttctctctgttcataaaacctggcttgaattactc1380ataagaacaaacgttgtgttgcataggtggtcttggagatgttgccggtgctttgcccaa1440ggctttggcgaagagaggacatcgtgttatggtaccacatgctttcatttaactctgttg1500aatccatatgttcgaataatatcagtgagcagtataatgttattaagtgcaagacatgaa1560agtgttcttctgttatagagtatttcatagccaaccctggaggttaggttgttggggcct1620actgggtgtgggagggggtttgaaaaaagtgttggttagcagtcggatttcacaaagaac1680gctgataaccacgccatcagtgaagggaatgaatgtcgggtacccgatcgaccgttttgc1740ccgacgtcaggtttacccgccctgtaggtccgaataagtagttcctatcctcagttaagt1800accaaatatcggcagcgcccgtgtgtgtatttatagtactggatgatcaatttatcaaca1860ttttcagttaatggttgctatcatattcactgtaattgttagtaaacagtggatgtttgt1920aatgtagatgatggctaaatgtatgttgtcaagctttcatttcaatgcaatttttattgg1980gagctagttttggggttcggttagagccaccaaaaccccagaatttctgggagttggctt2040gtgagagagggttttggcgagttgactttcgggattcagttagagacgctcttactagtt2100ccagtaaagaagtaaactattttctgcagacatcccaattattctgtagaaattagaagt2160agaaaatagttatggtatcatataaccatatattattcaaaatctagaatcatggacttg2220gctagactttgatgatctgaaattttaaatttgatgataattgagaaatgatcctttcta2280tcttaggttgtggtaccaaggtatggggactatgaggaagcctacgatgtcggagtccga2340aaatactacaaggctgctggacaggtaagcgaaaatgcaatcaaaggggagctgaaattt2400caatgcttactatcataataaatcaattttaagtgtttttttttgtcctgcaggatatgg2460aagtgaattatttccatgcttatatcgatggagttgattttgtgttcattgacgctcctc2520tcttccgacaccgccaggaagacatttatgggggcagcagacaggttaatcttctatatg2580ttggtgtttgattgcactgataaactgagaacaagccaaggcctactgaccggcatatga2640ttacacattttattttttcaggaaattatgaagcgcatgattttgttctgcaaggccgct2700gtcgaggtatcctctccaactcaattgacaacctattacaactatacaattatgtgtatg2760catgtatttcaacagatacgtaatctcttgtgaagtgcatatatactaacaacatttcaa2820taccttacatgcacatttggtcaagcgttatgatttaacttctaataatctattgcactg2880atgaacaattatcttgatgatccttggtacttcatcgttatgtttccatgttctcttcac2940cgattgatttggaaatagcatttccacctgccacaaacaataatatacactcctactttc3000atccaatgtagatattttcgcacttggcatatcatcccattaaatattattggtccatca3060tttttattcctctataatttgcaggttccatggcacgttccatgcggcggtgtcccttat3120ggggatggaaatctggtgtttattgcaaatgattggcacacggcactcctgcctgtctat3180ctgaaagcatattacagggaccatggtttgatgcagtacactcggtccattatggtgata3240cataacatcgctcaccaggttccttttctccaaatcttgatttttctctagtctctacta3300tttactccacattgtttgaggaaactaaacgggttgcaaaattatgatggcttatgaaag3360ttatagtcttatataggtaaatgcaccagtggtgcttgcacttgtcacgcgtgttcactt3420tggtgcttacagttgtagacaataaaaaactagtgcaaaaacttggctgttgtgtgcaat3480acggtgcattttccgtatgtaggagtcaaatattgcctgtgtggcattgtattcccgtct3540atagctgttagaccatgcctacgtcgccattgggcccacacaccctctattacatgtggg3600ccccacttgtcagcctatgacataaataaatggaaatttataatgaaaatgatggcctgg3660ggtcttgaaaatgggccgtcgcaggtatgctggtagccagcatgccctaatcattaatcc3720ccctatgcacttcatgtcttgtgtatgtgtgtgtgggaaagggggggggtatgtatgctt3780atgcttatatcctttgctccaaggctgccatcctcaacaagcccacctccagcttcaaca3840cggccagcgccttcatgatggcccaggtgctccgcaccatcgatcgaagcggcaacgtcg3900tcgtcacgaccatccaccaacccaacgcacaaaatcctcaggctccgttcggtacggagg3960aagagaaaatgcaggaaaaaacaacttcatgggaacaaggtttggtgaacagtaaaaaca4020tgtggaatctgaaaatgtaggtaccagaaaaaccggcctgttcggtttgcaggaaaaagc4080atacttgcagcagcactgtttggccctttccagtgtaaggctaaccatagtgggagtaac4140ataactaatattatgtacttggaactcacaaacatgcttatgtggcaggcaattaaagaa4200gagagagagagtcatagtaacatagttagataccgtatcataataaatattatgttacta4260tgtgtcatgcatgacaataaatgagaccatctgtgatactacgttatgatattatgcact4320atagatgtagtatcatacactagtatcatatgcatgatactagtgtatgttactccccac4380tatgaccagcctaacgaggggatgggcatcagtagtgattaccagtttttattatttttt4440attcggctggacgccctactcttgtggtgcgtagcggaaaaaggcagtgctagcttcggg4500actccgcgagcacatgaggttctaccggattttagatttcctataaaaagtacaggctca4560cgcaacttttcaatggaacagaccatcaagattcctttgaaccgaacgcactgcatgcaa4620gaattccaatgaaaaacgagccgtcaaatgttcctgcgaatttcctctataccgaacaga4680ccctcaacatcctcaaatagtgagcatgcccctcttgtcctttccccctcgtacccaaac4740gccatttggcgctcttggtgttggatcatttgcctcgggcatttgccaatttggcgccga4800accatattaaagctatgactacttggtgttggatcagggacgcaaagaatcccataaata4860ttgcaacgttcattcaaattcttaacatttgcgaggcgcttcatgatttccatctccgtc4920aggtctgagacatttggtcgtgtacactaaatttctcaggtcacttctcgtctaaatccg4980catatgtagctcacttcaatgacttgcctttggtctagctaacgccatttggcgctcttg5040ggcccccttgcttagcaaatttttcatatggctcgcactgcgcaagaggatttagatcac5100gggcagacgcgctagacgaggtcttccgcacaatgaacattgcgttctttgctctgctct5160tcccggagacacttgtgatcttattacgagttgtgccatttcaaacatctgtctctccat5220ggtcgctccagccatagatgccttgttctctgaatggtgggtttcagctaggaacagggt5280gccaccttcgacaagaagttgcatagtttggtcgtcttgactgcttggtcgatttggaag5340gaacgcaacataagagtctttgaaggcaaagctaatttctttgatcaagttattagccag5400atcaaatgtgatgtattctactggtacaaggccggggctatttgctttgagtcacttttt5460agctaaggccgcttgggctaagcgcttggggtcgtttttgctcaactgtagcctgaactt5520tctggactttgtaattttttttatcctctataatgatcacatacagctctcctgcatggt5580tcgaaaaggaaaaatgtgaacatgtgtggcaagtttaagcacaacccgtgcatttacctc5640aaagttatacaacactgacatgctgaattacattttttttgaggatctgacatgccgaat5700tacatgctttggacagttattcatttcttcggtacaccattggctaattatttctcttga5760cagttgctgaattagtacatgctttggtcgcagttattcctttgttcggtactctgttgg5820gctaattatttctcttgattgatgttgcatgcagggccgtggcccagtagatgagttccc5880gttcaccgagttgcctgagcactacctggaacacttcagactgtacgaccccgtgggtgg5940tgaacacgccaactacttcgccgccggcctgaagatggcggaccaggttgtcgtcgtgag6000cccggggtacctgtgggagctgaagacggtggagggcggctgggggcttcacgacatcat6060acggcagaacgactggaagacccgcggcatcgtgaacggcatcgacaacatggagtggaa6120ccccgaggtggacgtccacctcaagtcggacggctacaccaacttctccctggggacgct6180ggactccggcaagcggcagtgcaaggaggccctgcagcgggagctgggcctgcaggtccg6240cggcgacgtgccgctgctcggcttcatcgggcgcctggacgggcagaagggcgtggagat6300catcgcggacgcgatgccctggatcgtgagccaggacgtgcagctggtcatgctgggcac6360cgggcgccacgacctggagggcatgctgcggcacttcgagcgggagcaccacgacaaggt6420gcgcgggtgggtggggttctccgtgcggctggcgcaccggatcacggccggcgccgacgc6480gctcctcatgccctcccggttcgagccgtgcggactgaaccagctctacgccatggccta6540cggcaccgtccccgtcgtgcatgccgtcggcggcctgagggacaccgtgccgccgttcga6600ccccttcaaccactccgggctcgggtggacgttcgaccgcgcagaggcgcagaagctgat6660cgaggcgctcgggcactgcctccgcacctaccgggactacaaggagagctggagggggct6720ccaggagcgcggcatgtcgcaggacttcagctgggagcatgccgccaagctctacgagga6780cgtcctcgtcaaggccaagtaccagtggtga6811<210>9<211>6950<212>dna<213>普通小麦<400>9gggggccgttcgtacgtacccgcccctcgtgtaaagccgccgccgtcgtcgccgtccccc60gctcgcggccatttcttcggcctgaccccgttcgtttacccccacacagagcacactcca120gtccagtccagcccactgccaccgcgctactctccactcccactgccaccacctccgcct180gcgccgcgctctgggcggaccaacccgcgaaccgtaccatctcccgccccgatccatgtc240gtcggcggtcgcgtccgccgcatccttcctcgcgctcgcgtcagcctcccccgggagatc300acgcaggcgggcgagggtgagcgcgcagccaccccacgccggggccggcaggttgcactg360gccgccgtggccgccgcagcgcacggctcgcgacggagctgtggcggcgctcgccgccgg420gaagaaggacgcggggatcgacgacgccgccgcgtccgtgaggcagccccgcgcactccg480cggtggcgccgccaccaaggtagttagttatgaccaagttatgacgcgtgcgcgcgcctc540gagatcatcgtcgtctcgctcacgaattgtttatttatacaaaacgcacgcccgcgtgtg600caggtcgcggagcgaagggatcccgtcaagacgctcgaccgcgacgccgcggaaggcggc660gggccgtccccgccggcagcgaggcaggacgccgcccgtccgccgagtatgaacggcatg720ccggtgaacggcgagaacaaatctaccggcggcggcggcgcgactaaagacagcgggctg780cccacgcccgcacgcgcgccccatccgtcgacccagaacagagcaccggtgaacggtgaa840aacaaagctaacgtcgcctcgccgccgacgagcatagccgaggccgcggcttcggattcc900gcagctaccatttccatcagcgacaaggcgccggagtccgttgtcccagctgagaagacg960ccgccgtcgtccggctcaaatttcgagtcctcggcctctgctcccgggtctgacactgtc1020agcgacgtggaacaagaactgaagaagggtgcggtcgttgtcgaagaagctccaaagcca1080aaggctctttcgccgcctgcagcccccgctgtacaagaagacctttgggatttcaagaaa1140tacattggtttcgaggagcccgtggaggccaaggatgatggccgggctgtcgcagatgat1200gcgggctcctttgaacaccaccagaatcacgactccggacctttggcaggggagaatgtc1260atgaacgtggtcgtcgtggctgctgagtgttctccctggtgcaaaacaggcatggacatt1320acctcttcagtctctcttcctgttgttcataaaactttgctcgaattactcataagaaca1380aacattgtgttgcataggtggtctgggagatgttgcgggtgctctgcccaaggctttggc1440aaagagaggacatcgtgttatggtactacaagctttcatttaactctgttgggtccatat1500gttcgaataatatcagtgagtagtataatgttattaagtgcaagacatgaaagtgttctt1560ttgtcatactccctccgtaaattaatataagagcgtttagattactactttagtgatcta1620aacgctcttatagtagtttacagacggagtagagtatttcatagccaaccctggaggtta1680ggttgctgaggcctactgggtgggggagggggtttgaaacaagtggtggttagcagccag1740atttcacaaagaaggaggctgataaccacaccatcagtgaaggaatgaatgtcgggtacc1800cgatcgaccgttttgcccaacgtcgggtttacccgccctatagatccgaataagtagttc1860ctatcttcaattaggtaccaaatatcgccagcgcccgtgtgtgtatttatactactggat1920gatcaatttatcaacatttccggttaatggtttctatcatattcactgtaattgttagta1980aacagtagatgtttgtaatgtagatgatggataaatgtatgttgtcgagctttcatttca2040atgcaattttgattgggagctagtttcgcggttcggttagagccatcaaaaccccagaat2100ttttgggagttggcttgtgagagagggttttggggagttaactttcgggattcagttaga2160gacgctcttactagttccagtaaagagtaaactattttctgcaggcatcccaattattct2220gtagaaattagaagtggaaaatagttatggtatcatataaaccatatattattcaaaatc2280tagaatcatggacttggctagactttgataatctgaaattttaaatttgatgataattga2340gaaatgatcctttctatcttaggttgtggtaccaaggtatggggactatgaagaagccta2400cgatgtcggagtccgaaaatactacaaggctgctggacaggtaagcaaaaatgcaatcga2460aggggagctgaaattttattgcttattgtcataataaatcaatttttaagtgtttttttt2520gtcctgcaggatatggaagtgaattatttccatgcttatatcgatggagttgattttgtg2580ttcattgacgctcctctcttccgacaccgtcaggaagacatttatgggggcagcagacag2640gttaatcttctatatgttggtgtttgattgcactgataaactgagaacaagccaaggcct2700actgactggcatatgattacacattttattttttcaggaaattatgaagcgcatgatttt2760gttctgcaaggccgctgttgaggtatctctccaactcaattgacaacctattaccactat2820acaattatgtgtatgcatgtatttcaacagatacataatctcttgtgaagtgcatatata2880ctaataacatttcaataccttacatgcacatttggtcaagcgttatgatttaacttctga2940taatctattgcactgatgaacaattatcttgatgatccttgttacttcatcgttatgttt3000ccatgttctcttcaccgcgaattgatttggaaatagcatttccacctgccacaaacaata3060atatacactcctactttcatccaatttagatattttcgtacttggcatatcatcccatta3120aatattattggtccatcatttttattcctctataatttgcaggttccatggcacgttcca3180tgcggcggtgtcccttatggggatggaaatctggtgtttattgcaaatgattggcacacg3240gcactcctgcctgtctatctgaaagcatattacagggaccatggtttgatgcagtacact3300cggtccattatggtgatacataacatcgctcaccaggttccttttctcctaatcttgatt3360tttctctagtctctactatttactccacattgtttgaggaaactaaacgggttgcaaaat3420tatgatggcttatgaaagttatagtcttatagaggtaaatgcaccagtggtgcttgaact3480tgtcacgcgtgttcactttggtgcttacagttgtagactatgaaaaacgggtgcaaaaac3540ttgctgttgtgtgccatacggtgcattttccgtatgtaggagtcaaacgttgcctatgtg3600ggcattgtattcccgtctatagctgttagaccgtgcctacgtcgccattgggcccacaca3660ctctctatttacatgtgggccccacttgtcaacctatgacataaataaatggaaatttat3720aataaaaatgatggcctggggtcttgaaaatgggacctcgcaggtatgctggtagccagc3780acgccctaaacattaatcccctatgcacttcatgtcttgtgtatgtgtgtgtctgtgtgg3840ggagggggggggtatgtatgcttatatcctttgctccaaggctaccatcctcaacaagcc3900cacctccgcttcaacacggccagcgccttcatgatggcccaggtgctccgcaccatcgct3960caaagcggcaacgtcgttgtcatgaccatccaccaacccaacacacaaaatcctcaacat4020ccgcaaatagtgagcatgcccctcttgtcctttcccctcgtacccaaacatgtcttgata4080acccttggagctgcacaagttgtgaccatcgcctgcgtcgcctcatagagcccgacctag4140ccggaccgttatagaagcctacttgggagcccatacctccctgcacatcctcctctttcc4200ccatagatcgtgccgccatcgcaaaccaacttctcctctccttctcccactctggccgtt4260tcccccgccgcgaagctgcaatacatgccgagttggccatggccctattccccaattgct4320cgcactaggaggtcctcctctaagcctagcaccttttcccctcaccaattgcaagttggg4380gagcccctcgcgagctccctacgtcggctgcagttgcctgccgcctcaactctgatccag4440acctcgttcccgtggcctcggcgacatctcctcgacctcccattccacacgtggcctggc4500gaggatcaccgcatgttcatccatgtgaaccgaatcatcatagaactaacaccggagagg4560tcatcccgacggcgtcgcactgttcctctattccccccaagccgtgtcgcgtcataatat4620aagacggacttatttgtatcccttgggtcatcggttcaatggctatttctttctcctgtc4680tactgataagtgggacccacacgccacactaagccctttctttctcctacccgttgataa4740gtgggacccacacacagtacttagccagagagagaacatgagcttgttggtgccacgtcg4800gcaagccatgtcagcagtcttaacggctacaaacaacggatatggtgtcacgtgagcgtt4860tacgaatggaaagtgcatcatactgcatgcgagagccagagccaggtttttgcaccagtt4920ttctgtattttacaactgcgagcatcaaagtgtacatatgccgaaccaaagtgaacatgg4980tgagtccattcttttctggtgcggtgggtggctcaaagacaccccaatagaagctattgc5040ctccgacattgccaattcggtgccgaaccatattgaagtggtgaggtcagttgcttgtgc5100tatgactactaggtattggatgagggacataaaggatctcataaatattgcaatgttcat5160tcaaattcttaacatttgcgaagcgcttcatgatttccatctcccctagatcagagacac5220ttggtcgtgtacactgaatttctcaggtcgcttctcgtctaaatccgcatatgtagctca5280cttcaatgacttgcctttggtccagctaacgccatttgcgtagcaaatttttcatatggc5340tcgctctgcgcaagaggatttggatcacgggcagacgcgctagacaaggtcttccgcaca5400atgaacattgagttttttgatccgctcttcccgaagacacttgtgatcttattacgagtt5460gtgccatttcaaacatctgtctctccatggtcgccccagccatagatgccttgttctctg5520aatggtgggtttcagctaggaacagggtgccaccttcggacaagaagttgcgtagtttgg5580tcgtcttaactgcttggttgatttggaaggaacacaacaacagtctttgaaggcaaagct5640aattccttcgatcaagttattagacggatcaagtgtgatgaatcctactggtacaatgcc5700gttgctagttgcttggagtcactatttggctaggtcgcttgccatcccgctctgtgctaa5760gcgcttggggtcgcttttgctcaatttgtattttgttgttatgtgtttttagtaatgtaa5820cctgaactttctggactaagtagaaaaaaattctcctccataatgatcacatacagttct5880cctgcatggttcgaaaaaaaaatgagaacatccgtggcaagtttaagcaccaccggtgca5940tttttacctcaaagttatatacaacactgacatgccgaattacatgctttggtcagttat6000tccattcttcggtactccgttgggctaattctttctcttcatgttgcatgcagggccgtg6060gccctgtagatgaattcccgttcaccgagttgcctgagcactacctggaacacttcagac6120tgtacgaccccgtgggtggtgaacacgccaactacttcgccgccggcctgaagatggcgg6180accaggttgtcgtggtgagccccgggtacctgtgggagctgaagacggtggagggcggct6240gggggcttcacgacatcatacggcagaacgactggaagacccgcggcatcgtcaacggca6300tcgacaacatggagtggaaccccgaggtggacgcccacctcaagtcggacggctacacca6360acttctccctgaggacgctggactccggcaagcggcagtgcaaggaggccctgcagcgcg6420agctgggcctgcaggtccgcgccgacgtgccgctgctcggcttcatcggccgcctggacg6480ggcagaagggcgtggagatcatcgcggacgccatgccctggatcgtgagccaggacgtgc6540agctggtgatgctgggcaccgggcgccacgacctggagagcatgctgcagcacttcgagc6600gggagcaccacgacaaggtgcgcgggtgggtggggttctccgtgcgcctggcgcaccgga6660tcacggcgggggcggacgcgctcctcatgccctcccggttcgagccgtgcgggctgaacc6720agctctacgccatggcctacggcaccgtccccgtcgtgcacgccgtcggcggcctcaggg6780acaccgtgccgccgttcgaccccttcaaccactccgggctcgggtggacgttcgaccgcg6840ccgaggcgcacaagctgatcgaggcgctcgggcactgcctccgcacctaccgagacttca6900aggagagctggagggccctccaggagcgcggcatgtcgcaggacttcagc6950<210>10<211>676<212>prt<213>普通小麦<400>10metleuglyhisilealaserserseralaalapheleuleuleuval151015alaserserserserserargargtrpargserserserproargser202530pheglyalaalaglythrargleuhistrpgluargargglypheser354045argaspglyservalprocysargargvalseralaalaalaalaval505560alaglyglyglugluglyalaglylysalailealaglygluglyser65707580argglnalaalaserglyglnargglylysleuglualaalagluasn859095gluaspalavalserglnlysservalalaseralaproargproasp100105110serthrvalalagluglnhistrpalaalaglyserargsergluval115120125aspproseralaprovalseralaalaalaserglytyrtrplysasp130135140valvalvalalagluglnvalglyalalysvalaspalaglyglyasp145150155160alaalalysvaltrpserserprovalaspsergluasnmetglyser165170175alaproleualaglyproasnvalmetasnvalilevalvalalaser180185190glucysalaprophecyslysthrglyglyleuglyaspvalvalgly195200205alaleuprolysalaleualaargargglyhisargvalmetvalval210215220ileprolystyrglyasptyrglyglualaargaspleuglyvalarg225230235240lysargtyrlysvalalaglyglnaspsergluvalsertyrphehis245250255sertyrileaspglyvalaspphevalpheleuglualaproprophe260265270arghisarghisasnaspiletyrglyglygluargproaspvalleu275280285lysargmetileleuphecyslysalaalavalgluvalprotrptyr290295300alaprocysglyglythriletyrglyaspglyasnleuvalpheile305310315320alaasnasptrphisthralaleuleuprovaltyrleulysalatyr325330335tyrargaspasnglyleumetglntyrthrargservalleuvalile340345350hisasnilealahisglnglyargglyprovalaspasppheasnile355360365metaspleuprogluhistyrmetasphisphelysleutyrasppro370375380leuglyglyglnhisasnasnvalphealaalaglyleulysmetala385390395400aspargvalvalthrvalserhisglytyrmettrpgluleulysthr405410415metgluglyglytrpglyleuhisaspileileasnglnasnasptrp420425430lysleuaspglyilevalasnglyileaspthralaglutrpasnpro435440445alavalaspvalhisleuhisseraspasptyrthrasntyrthrarg450455460aspthrleuaspileglylysargglncyslysalaalaleuglnarg465470475480gluleuglyleuglnvalargaspaspvalproleuileglypheile485490495glyargleuasphisglnlysglyvalaspileilealaalaalamet500505510protrpilealaglnglnaspvalglnleuvalmetleuglythrgly515520525argproaspleugluaspmetleuargargphegluglygluhisarg530535540asplysvalargglytrpvalglypheservalargmetalahisarg545550555560ilethralaglyalaaspvalleuleumetproserleupheglupro565570575cysglyleuasnglnleutyralametalatyrglythrvalproval580585590valhisalavalglyglyleuargaspthrvalalapropheasppro595600605pheglyglythrglyleuglytrpthrpheaspargalaaspalagly610615620argmetileaspalaleuglyhiscysleuasnthrtyrtrpasntyr625630635640lysglusertrpargglyleuglnvalargglymetserglnaspleu645650655sertrpaspargalaalagluleutyrgluasnvalleuvallysala660665670lystyrglntrp675<210>11<211>674<212>prt<213>普通小麦<400>11metserglyalailealaserserseralaalapheleuleuleuval151015alasersersercysserserserserproargargtrpargserser202530serproargserphealaalaalaglythrargleuhistrpgluarg354045argglypheserargaspglyprovalprocysargserprocysala505560alaalaglyglygluaspglyalaalaalaglygluserserlysglu65707580glyvalalaglyleuargglylysleulysalaalagluasngluasp859095provalserglnlysservalalaseralaproargleuaspserser100105110valalagluglnasnglyalaalaalathrargserlysalaasppro115120125seralaprovalseralaalaalaserglytyrtrplysaspvalval130135140valalagluglnvalglythrlysvalaspthrglyglyaspalaala145150155160gluvalserargserprovalaspsergluasnlysglyseralapro165170175leualaglyproasnvalmetasnvalilevalvalalaserglucys180185190alaprophecyslysthrglyglyleuglyaspvalvalglyalaleu195200205prolysalaleualaargargglyhisargvalmetvalvalilepro210215220lystyrglyasptyralaglualaargaspleuglyvalarglysarg225230235240tyrlysvalalaglyglnaspsergluvalsertyrphehissertyr245250255ileaspglyvalaspphevalpheleuglualaproprophearghis260265270arghisasnaspiletyrglyglygluargproaspvalleulysarg275280285metileleuphecyslysalaalavalgluvalproargtyralaleu290295300cysglyglythriletyrglyaspglyasnleuvalpheilealaasn305310315320asptrphisthralaleuleuprovaltyrleulysalatyrtyrarg325330335aspasnglyleumetglntyrthrargservalleuvalilehisasn340345350ilealahisglnglyargglyprovalaspasppheasnilemetasp355360365leuproasphistyrmetglyhisphelysleuhisaspproleugly370375380glygluhisasnasnvalphealaalaglyleulysmetalaasparg385390395400valvalthrvalserhisglytyrmettrpgluleulysthrvalglu405410415glyglytrpglyleuhisaspileileasnglnasnasptrplysleu420425430aspglyilevalasnglyileaspthralaglutrpasnproalaval435440445aspvalhisleuhisseraspasptyrthrasntyrthrargaspthr450455460leuaspileglylysargglncyslysalaalaleuglnarggluleu465470475480glyleuglnvalargaspaspvalproleuileglypheileglyarg485490495leuasphisglnlysglyvalaspileilealaalaalametprotrp500505510ilealaglnglnaspvalglnleuvalmetleuglythrglyargpro515520525aspleugluaspmetleuargargphegluglygluhisargasplys530535540valargglytrpvalglypheservalargmetalahisargilethr545550555560alaglyalaaspvalleuleumetproserleuphegluprocysgly565570575leuasnglnleutyralavalalatyrglythrvalprovalvalhis580585590alavalglyglyleuargaspthrvalalapropheaspprophegly595600605glythrglyleuglytrpthrpheaspargalaaspalaglyargmet610615620ileaspalaleuglyhiscysleuasnthrtyrtrpasntyrlysglu625630635640sertrpargglyleuglnvalargglymetserglnaspleusertrp645650655asphisalaalagluleutyrgluasnvalleuvallysalalystyr660665670glntrp<210>12<211>2727<212>dna<213>普通小麦<400>12acccgtcgtcttcctcggcgcgggcgctctagctcttcccagtctcggcctccgagctcc60accacacaagccgctcgcctgtccccggcctccagttcctccgcctcccgcccccccccc120cccccccgctccgtaccgccgcaaaaaacctgcagccacacgtagccagcgcagatcttt180cttccacccgcgcttaatttccctcgtgctcgcgccgctcgccgtcgccctcgtccacta240ctactctgccttgtttgtccggctgtttctgttcatccccgaagacttctggcgcgtcgg300atcccgggatgttggggcacatcgcttcctcgtccgcggcgttcctcttgctcgtggcct360cctcctcgtcgtcgcggcgctggcggagcagctcaccgcgctctttcggtgccgccggta420cgcggctgcattgggaacggcgagggttttctcgggacggatcggtgccgtgccgccgtg480tttcagcagcagcggcagtggctggtggtgaggagggcgcggggaaggcaatagcagggg540agggctcgaggcaggcagcctctgggcagcgcggcaagctcgaggctgctgaaaatgagg600atgctgtttcacaaaaatcagttgcatctgcacccaggccagatagtaccgttgcagagc660aacattgggcagctgggagcagatccgaagtcgatccgtcagctcctgtctcggcggcgg720catcaggttattggaaagacgtcgttgtcgctgaacaggttggggctaaggttgatgccg780gtggagatgcagcaaaagtgtggagttctccggttgacagtgagaacatggggtctgctc840ctttggctggcccgaatgtgatgaatgtcatcgttgtggcttctgaatgtgctcctttct900gtaaaacaggtgggcttggagatgttgtgggtgctttgccgaaggctctggcaagaagag960ggcatcgtgttatggtcgtgataccaaaatatggagattacggagaagctcgtgatctag1020gtgttcgcaaacgttacaaggtagctggccaggattcagaagtgagctactttcattctt1080atatcgatggagttgattttgtgttcttagaggccccgcccttccgccaccggcacaatg1140atatttatggaggagaaagaccggatgtgctgaagcgcatgattttgttctgcaaggctg1200ctgtggaggttccttggtacgctccatgcggtggtactatctacggtgatggcaatttag1260tcttcattgcaaacgattggcatactgcacttctacctgtttatctgaaggcgtattacc1320gagacaatggcctgatgcagtatactcgttctgttctcgtgatccataacattgctcatc1380agggacgtggccctgtagatgacttcaacatcatggacttgcctgagcactacatggatc1440acttcaaactgtatgatccccttggcggccagcacaacaacgtgttcgctgctggcctga1500agatggcagaccgggtggtcaccgtcagccatggctacatgtgggagctgaagacgatgg1560aaggcggctggggcctccacgacataataaaccagaacgactggaagctggacggcatcg1620tgaacggcatcgacacggccgagtggaaccccgcagtcgacgtgcacctgcactccgacg1680actacaccaactacacccgagacacgctggacatcggcaagcggcagtgcaaggcggccc1740tgcagcgcgagctgggcctgcaggtccgcgacgacgtgccgctcatcgggttcatcgggc1800ggctggaccaccagaagggcgtggacatcatcgcggcggcgatgccgtggatcgcgcagc1860aggacgtgcagctggtgatgctgggcacggggcggccggacctggaggacatgctgcggc1920ggttcgagggggagcaccgggacaaggtgcgcgggtgggtggggttctcggtgcggatgg1980cgcaccggatcacggcgggcgcggacgtgctcctcatgccgtcgctgttcgagccgtgcg2040ggctgaaccagctgtacgcgatggcgtacgggaccgtgcccgtggtgcacgccgtcggcg2100ggctccgggacacggtggcgccgttcgacccgttcggcggcaccgggctggggtggacgt2160tcgaccgcgcggacgccggcaggatgatcgacgcgctcgggcactgcctcaacacgtact2220ggaactacaaggagagctggaggggcctgcaggtccgcggcatgtcgcaggacctcagct2280gggaccgcgccgccgagctctacgagaacgtcctcgtcaaggccaagtaccagtggtgat2340gcggctgatgctgacccctctactgcaacgcatgcacgtacttaggggacagccggaagt2400ggtgcccacgatcgcgatcactggcgccccggagtagccaagtgtcacgcgatgccaccg2460gcggcagccggacgacggtggaggtagtgaaccgtgcccgtggcgccgcccaacttttgg2520gttcacgagttgtacacaccagttcagtcaggttcgtggcttctgtgaattaccgagtcg2580taggcgatcaaataggaagttgcagagtttctatactgccaattttctcagctcttggtg2640tggaaaaacacagttctgagaaggttcatcactggacgctgaccacgttcacgttctgtt2700tcatgctcaaaaaaaaaaaaaaaacga2727<210>13<211>1282<212>dna<213>普通小麦<400>13tggtgaggatggcgcggcggcaggggagagctcgaaggagggggtcgctgggctgcgcgg60caagctcaaggttggtaacgctatcattccttcttctgatggattccatttcgtgctcag120gctgctgaaaatgaggatccggtttcacaaaaatcagttgcatctgcacccaggctagac180agtagcgttgcagagcaaaatggggcagctgcgaccagatccaaagccgatccgtcagct240cctgtctcggcggcagcatcaggttattggaaagacgtcgttgtcgctgaacaggttgga300actaaggttgacaccggtggagatgcagcagaagtgtcgagatctcccgttgacagtgag360aacaaggggtctgctcctttggctggcccgaatgtgatgaatgtcatcgttgtggcttct420gagtgtgctcctttctgtaaaacaggtgcgcatacataaactgagcaatttgaccaataa480tgatatcatgcataggcgggcttggagatgtcgtgggtgctttgcccaaggctctggcca540gaagagggcatcgcgttatggtacccactcctttgcttttctcttatacaagtatttctt600tcaattttaggttgtgataccaaagtatggcgattacgcagaagctcgtgatcttggtgt660tcgcaaacgttacaaggtagctggccaggtatgttaaataacgagtctgcagtaattgaa720ttgtgttctggtttgcaggattcagaagtgagttactttcactcttatatcgatggagtt780gattttgtattcttagaggccccgcccttccgccaccggcacaatgatatttatggagga840gaaagaccggtaagcgtctgtttccctagagctttgtacatttccatcatttttggcagg900atgtgctgaagcgcatgattttgttctgcaaggctgctgtcgaggtaccttcacaaattg960tattgctattgttcatctgttcgagcatttgtaggttccttggtacgctccatgtggtgg1020tactatctacggagatggcaatttggtcttcattgcaaacgattggcatactgcacttct1080acctgtttatctaaaggcatattaccgagacaatggcctgatgcagtatactcgttctgt1140tctcgtgatccataacattgctcatcaggttttacacctcaatctttaactgctggacac1200taaaattttgctttgcagggacgtggccctgtagatgacttcaacatcatggacttgcct1260gaccactacatgggtcacttca1282<210>14<211>2025<212>dna<213>普通小麦<400>14atgtcgggggcaatagcttcctcgtccgcggcgttcctcttgctcgtggcctcctcctcc60tgctcctcctcgtcgccgcggcgctggcggagcagctcaccgcgctctttcgctgccgcc120ggtacgcggctgcattgggaacggcgaggattctctcgggacggaccggtgccgtgccgg180agcccctgcgcagcagctggtggtgaggatggcgcggcggcaggggagagctcgaaggag240ggggtcgctgggctgcgcggcaagctcaaggctgctgaaaatgaggatccggtttcacaa300aaatcagttgcatctgcacccaggctagacagtagcgttgcagagcaaaatggggcagct360gcgaccagatccaaagccgatccgtcagctcctgtctcggcggcagcatcaggttattgg420aaagacgtcgttgtcgctgaacaggttggaactaaggttgacaccggtggagatgcagca480gaagtgtcgagatctcccgttgacagtgagaacaaggggtctgctcctttggctggcccg540aatgtgatgaatgtcatcgttgtggcttctgagtgtgctcctttctgtaaaacaggcggg600cttggagatgtcgtgggtgctttgcccaaggctctggccagaagagggcatcgcgttatg660gttgtgataccaaagtatggcgattacgcagaagctcgtgatcttggtgttcgcaaacgt720tacaaggtagctggccaggattcagaagtgagttactttcactcttatatcgatggagtt780gattttgtattcttagaggccccgcccttccgccaccggcacaatgatatttatggagga840gaaagaccggatgtgctgaagcgcatgattttgttctgcaaggctgctgtcgaggttcct900aggtacgctctatgtggtggtactatctacggagatggcaatttggtcttcattgcaaac960gattggcatactgcacttctacctgtttatctaaaggcatattaccgagacaatggcctg1020atgcagtatactcgttctgttctcgtgatccataacattgctcatcagggacgtggccct1080gtagatgacttcaacatcatggacttgcctgaccactacatgggtcacttcaaactgcat1140gacccccttggtggcgagcacaacaacgtgttcgccgctggcctgaagatggcagaccgg1200gtggtcaccgtcagccatggctacatgtgggagctgaagacggtggaaggcggctggggc1260ctccacgacataataaaccagaacgactggaaactggacggcatcgtgaacggcatcgac1320acggccgagtggaaccccgcggtcgacgtgcacctgcactccgacgactacaccaactac1380acccgagacacgctggacatcggcaagcggcagtgcaaggcggccctgcagcgcgagctg1440ggcctgcaggtccgcgacgacgtgccgctcatcgggttcatcgggcggctggaccaccag1500aagggcgtggacatcatcgcggcggcgatgccgtggatcgcgcagcaggacgtgcagctg1560gtgatgctgggcacggggcggccggacctggaggacatgctgcggcggttcgagggggag1620caccgggacaaggtgcgcgggtgggtggggttctcggtgcggatggcgcaccggatcacg1680gcgggcgcggacgtcctgctgatgccgtcgctgttcgagccgtgcgggctgaaccagctg1740tacgcggtggcgtacgggaccgtgcccgtggtgcacgccgtcggcgggctccgggacacg1800gtggcgccgttcgacccgttcggcggcaccgggctggggtggacgttcgaccgcgcggac1860gccggcaggatgatcgacgcgctcgggcactgcctcaacacgtactggaactacaaggag1920agctggaggggcctccaggtccgcggcatgtcgcaggacctcagctgggaccacgccgcc1980gagctctacgagaacgtcctcgtcaaggccaagtaccagtggtga2025<210>15<211>20<212>dna<213>合成的<400>15tgcgtttaccccacagagca20<210>16<211>22<212>dna<213>合成的<400>16tgccaaaggtccggaatcatgg22<210>17<211>18<212>dna<213>合成的<400>17gcggaccaggttgtcgtc18<210>18<211>22<212>dna<213>合成的<400>18ctggctcacgatccagggcatc22<210>19<211>24<212>dna<213>合成的<400>19gtaccaaggtatggggactatgaa24<210>20<211>22<212>dna<213>合成的<400>20gttggagagatacctcaacagc22<210>21<211>23<212>dna<213>合成的<400>21aaggtctccaccgtgtctcgaag23<210>22<211>23<212>dna<213>合成的<400>22gacgtacagtttgtcatgcttgg23<210>23<211>23<212>dna<213>合成的<400>23ctgctggacaggatatggaagtg23<210>24<211>23<212>dna<213>合成的<400>24gtatcaccataacggagcgactg23<210>25<211>25<212>dna<213>合成的<400>25caatcactgatggtgtaaccaaagg25<210>26<211>23<212>dna<213>合成的<400>26ccttcatgttggtcaatagcagc23<210>27<211>25<212>dna<213>合成的<400>27cagaatggacaaagaatcatccacg25<210>28<211>24<212>dna<213>合成的<400>28gaaaatacatccatgcctccatcg24<210>29<211>21<212>dna<213>合成的<400>29agggtacagggtgggcgttct21<210>30<211>20<212>dna<213>合成的<400>30gtagggttggtccacgaagg20<210>31<211>20<212>dna<213>合成的<400>31ttcgaccccttcaaccactc20<210>32<211>20<212>dna<213>合成的<400>32acgtcctcgtagagcttggc20<210>33<211>20<212>dna<213>合成的<400>33tgacgaatcttggaaaatgg20<210>34<211>23<212>dna<213>合成的<400>34ggcggcatttatcataactattg23<210>35<211>22<212>dna<213>合成的<400>35gtagatgcggtcgtttacttga22<210>36<211>20<212>dna<213>合成的<400>36ccagccaccttctgtttgtt20<210>37<211>19<212>dna<213>合成的<400>37gggccttcatggatcaacc19<210>38<211>20<212>dna<213>合成的<400>38ccgcttcaagcatcctcatc20<210>39<211>23<212>dna<213>合成的<400>39ctggacaggatctggaagtgaaa23<210>40<211>22<212>dna<213>合成的<400>40ggaacctcaacagcagccttac22<210>41<211>19<212>dna<213>合成的<400>41gccaatgccaggaagatga19<210>42<211>20<212>dna<213>合成的<400>42gcgcaacataggatgggttt20<210>43<211>30<212>dna<213>合成的<400>43tacgaattctccagcggaatgagaacacca30<210>44<211>30<212>dna<213>合成的<400>44tacggtacccaagatgtacagaagtgcaga30<210>45<211>22<212>dna<213>合成的<400>45ggaaatacatggcttgctgctt22<210>46<211>22<212>dna<213>合成的<400>46tctcttcgtcttgatggttgca22<210>47<211>20<212>dna<213>合成的<400>47caggcttgtatcccaggtca20<210>48<211>20<212>dna<213>合成的<400>48gcgtaggaggaaagcatgaa20<210>49<211>17<212>prt<213>合成的<400>49alaalaserproglylysvalleuvalproaspglygluseraspasp151015leu<210>50<211>10<212>prt<213>合成的<400>50alaglyglyproserglygluvalmetile1510<210>51<211>16<212>prt<213>合成的<400>51valseralaproargasptyrthrmetalathralagluaspglyval151015当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1