用于监视和调节植物生产率的系统和方法与流程
本文中描述的实施方式总体上涉及用于监视植物生产率(productivity)的系统和方法,更具体的,涉及用于促进植物生产率的数据驱动调节的系统和方法。
背景技术:
已经使用了试图提高植物生产率的各种技术。特别地,旨在提高作物产量的系统和方法是已知的。例如,可以控制灌溉系统以调整土壤中的水分的含量。作为另一示例,可以对植物进行遗传改进以增加其对干旱或昆虫的抗性。
技术实现要素:
以下发明内容仅用于说明性目的,并不旨在限制或约束具体实施方式。以下发明内容仅以简化的形式呈现了各种描述的方面,作为下面提供的更详细描述的序言。
根据各个方面,本技术涉及一种用于监视和调节植物生产率的系统。该系统可通信耦接至能够部署在至少一个作物现场中的多个监视传感器。该系统还可通信耦接至至少一个可控装置,该可控装置能够操作以改变至少一个作物现场的至少一个生产环境状况,其中,该系统包括:至少一个存储器,该至少一个存储器用于存储多个指令,以及;至少一个处理器,该至少一个处理器用于执行多个指令,以使监视和调节植物生产率的方法被执行。根据各个方面,该方法包括:从多个监视传感器接收现场数据,该现场数据与在监视阶段内感测到的至少一个作物现场的状况相关联;由执行机器学习算法的至少一个处理器计算与至少一个作物现场的至少一个生产环境状况相关联的至少一个变量的预测值,机器学习算法已经基于训练集被训练过,训练集包括以下中的一个或两个:(a)来自多个监视传感器的现场数据,以及(b)从现场数据中导出的至少一个生成特征;和以及基于与至少一个变量相关联的阈值来确定至少一个变量的预测值指示要启动对至少一个作物现场的干预;以及响应于确定而使至少一个可控装置改变至少一个生产环境状况。
现场数据可以包括与植物生产率有关并且彼此具有多种交互的多个因素。例如,现场数据可以包括与作物现场的土壤(例如土壤含水量、渗透势、土壤硝酸盐水平、土壤温度)、空气(例如空气温度、相对湿度、风速和风向、大气压力、叶片湿度、太阳辐射和降雨)、野生动植物(例如孢子定量、昆虫定量、觅食蜂活动)和灌溉水(例如灌溉水的量、灌溉水温度、ph、盐度、硝酸盐含量、肥料含量)有关的数据。
至少一个变量包括以下中的一个或更多个:土壤张力、土壤含水量、土壤温度、ph、土壤硝酸盐含量、土壤盐度、灌溉水量、灌溉水ph、灌溉水温度等。
在某些实施方式中,机器学习算法同时考虑了现场数据和/或至少一个生成的数据的多个因素之间的交互。
在某些实施方式中,与至少一个变量相关联的阈值被实时动态地调整,以改进、优化或保持植物生产率。
根据其他方面,该系统被布置成从诸如另一处理器的其他源接收现场数据。
根据至少一个实施方式,该方法还包括基于训练集来训练机器学习算法。
根据至少一个实施方式,该方法还包括接收至少一种外部数据类型的数据,并且训练集还至少包括至少一种外部数据类型的数据的子集。
根据至少一个实施方式,训练集还包括从以下组中选择的至少一种外部数据类型的数据:来自除了至少一个作物现场之外的作物现场的数据、卫星数据、无人机数据、环境数据、天气数据、股票价格数据、资源成本数据、资源可用性数据和经济数据。
根据至少一个实施方式,该方法还包括将训练集中的数据存储在至少一个多元矩阵中。
根据至少一个实施方式,该方法还包括:在确定预测值指示要启动对至少一个作物现场的干预之前,由执行机器学习算法的至少一个处理器调整与至少一个变量相关联的阈值。
根据至少一个实施方式,方法的至少一些动作被重复至少一个随后迭代,使得针对每个随后迭代,在接收时,现场数据与在相应的随后监视阶段内的至少一个作物现场的状况相关联。
根据至少一个实施方式,使至少一个可控装置改变至少一个生产环境状况响应于确定自动地执行。
根据至少一个实施方式,该方法还包括:输出期望对至少一个作物现场的干预的警报,以及在使至少一个可控装置改变至少一个生产环境状况之前,响应于警报而接收用户确认。
根据至少一个实施方式,该方法还包括生成干预安排,以允许手动评估是否期望对至少一个作物现场的干预。
根据至少一个实施方式,该方法还包括生成至少一个性能评估报告,以允许在监视阶段内手动评估至少一个作物现场的作物现场性能。
根据至少一个实施方式,确定至少一个变量的预测值指示要启动在至少一个作物现场中的干预包括:基于至少一个输出参数对优化植物生产率的至少一个变量的一个或更多个值进行评估。
根据至少一个实施方式,至少一个输出参数包括从以下组中选择的输出参数中的一个或更多个:作物产量、获利能力、水的使用、能源的使用、肥料的淋滤和温室气体排放。
根据至少一个实施方式,至少一个输出参数包括多个输出参数,其中,该方法还包括对多个输出参数进行优先级排序,并且其中,对优化植物生产率的至少一个变量的一个或更多个值的评估基于已经进行过优先级排序的多个输出参数。
根据至少一个实施方式,该方法还包括:使现场数据标准化,其中,标准化包括:在空间维度和时间维度中的至少一个中对现场数据进行对准,并且其中,至少一个变量的预测值包括空间分量和时间分量中的至少一个。
根据至少一个实施方式,从现场数据中导出的至少一个生成特征包括根据与现场数据相关联的至少一个时间序列的分解计算出的多个元素。
根据至少一个实施方式,使至少一个可控装置改变至少一个生产环境状况包括:在至少一个作物现场中启动在从以下组中选择的以下元素中的至少一个的变化:水、能源、氮、其他元素、化学输入。在某些实施方式中,化学输入包括农药。
从其他方面,提供了一种计算装置,该计算装置包括至少一个装置处理器和至少一个装置存储器,至少一个装置处理器用于由以上系统的至少一个处理器启动监视和调节植物生产率的方法的执行,其中,在经由至少一个网络连接通信耦接至计算装置的一个或更多个联网装置上执行方法的一个或更多个动作。
从又一方面,提供了一种监视和调节植物生产率的方法,该方法包括:从多个监视传感器接收现场数据,现场数据与在监视阶段内感测到的至少一个作物现场的状况相关联;由执行机器学习算法的至少一个处理器计算与至少一个作物现场的至少一个生产环境状况相关联的至少一个变量的预测值,机器学习算法已经基于训练集被训练过,训练集包括以下中的一个或两个:(a)来自多个监视传感器的现场数据,以及(b)从现场数据中导出的至少一个生成特征;以及基于与至少一个变量相关联的阈值来确定至少一个变量的预测值指示要启动对至少一个作物现场的干预;以及响应于确定而使至少一个可控装置改变至少一个生产环境状况。
从其他方面,提供了一种监视和调节植物生产率的方法,该方法包括:由执行机器学习算法的至少一个处理器计算与至少一个作物现场的至少一个生产环境状况相关联的至少一个变量的预测值,机器学习算法已经基于训练集被训练过,训练集包括以下中的一个或两个:(a)来自多个监视传感器的现场数据,现场数据与在监视阶段内感测到的至少一个作物现场的状况相关联,以及(b)从现场数据中导出的至少一个生成特征;以及基于与至少一个变量相关联的阈值来确定至少一个变量的预测值指示要启动对至少一个作物现场的干预;以及响应于确定而使至少一个可控装置改变至少一个生产环境状况。
根据至少一个实施方式,该方法还包括:基于训练集来训练机器学习算法。
根据至少一个实施方式,该方法还包括:接收至少一种外部数据类型的数据,并且其中,训练集还至少包括至少一种外部数据类型的数据的子集。
根据至少一个实施方式,该方法还包括:从多个监视传感器接收现场数据。
根据至少一个实施方式,其中,训练集还包括从以下组中选择的至少一种外部数据类型的数据:来自除了至少一个作物现场之外的作物现场的数据、卫星数据、无人机数据、环境数据、天气数据、股票价格数据、资源成本数据、资源可用性数据和经济数据。
根据至少一个实施方式,该方法还包括:将训练集中的数据存储在至少一个多元矩阵中。
根据至少一个实施方式,该方法还包括:在确定预测值指示要启动对至少一个作物现场的干预之前,由执行机器学习算法的至少一个处理器调整与至少一个变量相关联的阈值。
根据至少一个实施方式,方法的至少一些动作被重复至少一个随后迭代,使得针对每个随后迭代,在接收时,现场数据与在相应的随后监视阶段内的至少一个作物现场的状况相关联。
根据至少一个实施方式,使至少一个可控装置改变至少一个生产环境状况响应于确定而自动地被执行。
根据至少一个实施方式,该方法还包括:进一步包括:输出期望在至少一个作物现场的干预的警报,以及在使至少一个可控装置改变至少一个生产环境状况之前,响应于警报而接收用户确认。
根据至少一个实施方式,该方法还包括:生成干预安排,以允许手动评估是否期望对至少一个作物现场中的干预。
根据至少一个实施方式,该方法还包括:生成至少一个性能评估报告,以允许在监视阶段内手动评估至少一个作物现场的作物现场性能。
根据至少一个实施方式,确定至少一个变量的预测值指示要启动对至少一个作物现场的干预包括:基于至少一个输出参数对优化植物生产率的至少一个变量的一个或更多个值进行评估。
根据至少一个实施方式,至少一个输出参数包括从以下组中选择的输出参数的中一个或更多个:作物产量、获利能力、水的使用、能源的使用、肥料的淋滤和温室气体排放。
根据至少一个实施方式,至少一个输出参数包括多个输出参数,并且其中,该方法还包括:对多个输出参数进行优先级排序,并且其中,对优化植物生产率的至少一个变量的一个或更多个值的评估基于已经进行过优先级排序的多个输出参数。
根据至少一个实施方式,该方法还包括:使现场数据标准化,其中,标准化包括:在空间维度和时间维度中的至少一个中对现场数据进行对准,并且其中,至少一个变量的预测值包括空间分量和时间分量中的至少一个。
根据至少一个实施方式,从现场数据中导出的至少一个生成特征包括根据与现场数据相关联的至少一个时间序列的分解计算出的多个元素。
根据至少一个实施方式,使至少一个可控装置改变至少一个生产环境状况包括:在至少一个作物现场中启动在从以下组中选择的以下元素中的至少一个的变化:水、能源、氮、其他元素、化学输入。
从其他方面,提供了一种存储指令的非暂态计算机可读介质,当指令由包括至少一个处理器和至少一个存储器的计算机执行时,使至少一个处理器执行如以上描述的方法。
从又一方面,提供了一种用于监视和调节植物生产率的系统,其中,该系统可通信耦接至能够部署在至少一个作物现场中的多个监视传感器,其中,系统还可通信耦接至至少一个可控装置,该可控装置能够操作以改变至少一个作物现场的至少一个生产环境状况,该系统被配置成基于将至少一个生产环境状况的至少一个测量与针对至少一个测量的至少一个自动调节的阈值进行比较来使至少一个生产环境状况改变。
根据各个方面,本技术还涉及一种包括至少一个装置处理器和至少一个装置存储器的计算装置。根据本文中描述的至少一个实施方式,该装置处理器由系统的处理器启动监视和调节植物生产率的方法的执行,其中,在经由至少一个网络连接通信耦接至计算装置的一个或更多个联网装置上执行方法的一个或更多个动作。
在以上的某些方面和实施方式中,自动化或半自动化的方法是可能的。该方法可以实时执行。在某些实施方式中,不需要对土壤进行预先的物理表征。有利地,在某些实施方式中,考虑作物现场的许多生产环境状况以确定是否需要干预。考虑生产环境状况之间的相互关系,使得不仅考虑与至少一个变量直接有关的参数,而且也考虑具有间接影响的次级参数。
此处的概述不是本文中描述的新颖特征的详尽列表,并且不限制权利要求。这些和其他特征将在下面更详细地描述。
附图说明
关于以下描述、权利要求和附图,将更好地理解本公开内容的这些和其他特征、方面和优点。本公开内容通过示例的方式示出,并且不受附图的限制,在附图中类似的附图标记指示相似的元件。
图1示出了可以用于实现本文中描述的任何方法的示例计算系统。
图2示出了示例传感器装置。
图3示出了其中从传感器装置收集数据的示例实现方式。
图4是根据本公开内容的一个或更多个说明性方面的用于监视和调节植物生产率的系统的图。
图5a和图5b是示出某些常规监视系统与根据本公开内容的一个或更多个说明性方面的用于监视和调节植物生产率的系统的至少一个实施方式的特征之间的一些差异的图。
图6a至图6c是示出根据本公开内容的一个或更多个说明性方面的用于监视和调节植物生产率的方法的四个示例阶段的框图。
图7是涉及根据本公开内容的一个或更多个说明性方面的监视和调节植物生产率的方法的流程图。
图8是涉及根据本公开内容的一个或更多个说明性方面的处理现场数据和外部数据的方法的流程图。
图9是涉及根据本公开内容的一个或更多个说明性方面的准备训练数据的方法的流程图。
图10是示出根据本发明内容的一个或更多个说明性方面的时间序列的分析的图。
图11是其中相对于时间绘制张力数据的示例图。
图12是涉及根据本公开内容的一个或更多个说明性方面的基于一个或更多个模型来生成动作计划的方法的流程图。
图13是涉及根据本公开内容的一个或更多个说明性方面的控制装置以改变环境状况的方法的流程图。
图14是涉及根据本公开内容的一个或更多个说明性方面的报告的方法的流程图。
图15a至图15c示出了根据本公开内容的一个或更多个说明性方面进行操作的植物生产率控制系统的示例实现方式的细节。
应当明确地理解,描述和附图仅是用于说明本技术的某些实施方式的目的,并且有助于理解。描述和附图不旨成为本技术的限制的定义。
具体实施方式
在以下对各种说明性实施方式的描述中,参照附图,这些附图形成了本说明书的一部分,并且在附图中通过说明的方式示出了其中可以实践本公开内容的方面的各种实施方式。应当理解,在不脱离本公开内容的范围的情况下,可以利用其他实施方式,并且可以进行结构或功能上的修改。
如本文所使用的,单数形式的“一(a)”、“一个(an)”和“该(the)”包括复数引用,除非上下文另外明确指出。
本文所使用的表达“和/或”应当被视为具有或不具有其他特征或部件的两个指定特征或部件中的每一个的具体公开。例如,“a和/或b”应当被视为(i)a、(ii)b和(iii)a和b中的每一个的具体公开,就像每一个在本文中单独列出一样。
用于提高作物产量的至少一些常规方法侧重于仅检测和校正一种或少量压力源。然而,作物产量损失通常是由于作物在其生长期间或者在休眠和收获后时段期间经受的众多压力造成的。例如,主要或仅侧重于灌溉实践的修改可能无法说明土壤水分含量与潜在影响植物生产率的其他因素之间的交互作用。
在广义方面,本文中公开了能够说明可以影响植物生产率的多个因素的系统和方法。关于至少一个示例实施方式,该系统和方法不仅通过从现场传感器获得的数据的收集来促进对现场状况的监视,而且它们还能够通过直接控制可以改变预期影响植物生产率的那些状况装置以自主地方式调节植物生产率。受控装置可以起到例如使水分胁迫、热胁迫、来自霜冻的损害、土壤养分缺乏、由于疾病或害虫引起的损害等最小化的作用。
通过说明的方式,用于监视和调节植物生产率的系统和方法的至少一些实施方式可以评估传感器数据(历史和/或实时)、从传感器数据中导出的数量或特征、来自各种外部源的数据、以及它们的不同的组合之间的交互。在一些实施方式中,还可以评估生产率、效率和/或获利能力因素。
此外,所执行的分析可以包括学习算法的应用,该学习算法包括预测性机器学习算法,该预测性机器学习算法的性能被预期随着时间变化而改进,这是因为与对由系统发起的校正动作的响应相关联的数据被反馈至系统。因此,可以控制装置不仅降低检测到的压力水平,而且还发起预防措施,以解决在不存在干预的情况下被确定为可能的压力的潜在增加,或者以其他方式增强对可能不利地影响生长的预期状况的保护。可以动态调整可以定义何时要采取预防和/或校正动作的阈值。这可能导致由作物所经受的压力水平的总体下降,这进而可以造成作物健康和/或作物产量的显著提高。该系统还可以促进对一个或更多个其他感兴趣参数的优化,所述感兴趣参数包括作物质量、大小(或等级)、根系发育(例如,针对幼树或藤本植物)等。
根据以下的描述,这些以及其他示例方面和实施方式将是明显的。
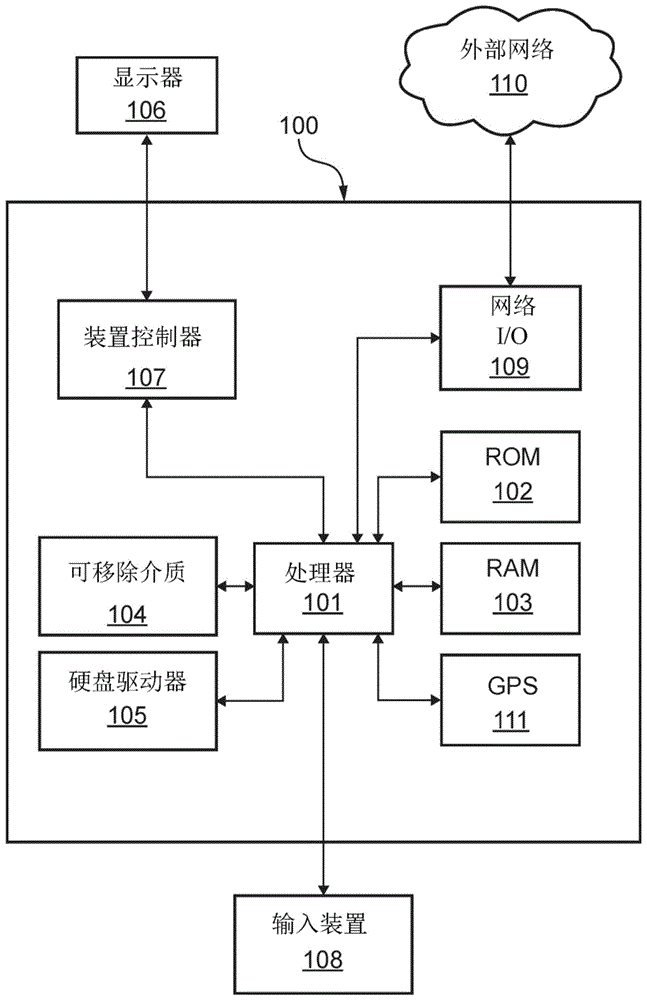
图1示出了可以用于实现本文中讨论的各种计算装置中的任何一个的示例计算系统100。在一个示例实现方式中,如本领域技术人员将理解的,通常采用可以包括系统100的除了其他部件(为简洁起见未示出)之外的一些或全部部件的服务器。作为示例,服务器或其他计算装置的功能可以在各种装置上执行,包括但不限于:个人计算机、笔记本计算机、平板计算机和/或移动通信装置。
计算系统100可以包括一个或更多个处理器——在图1中被统称为处理器101。处理器101可以执行计算机程序的指令以执行本文中描述的特征中的任何一个。处理器101可以包括例如一个或更多个中央处理单元(cpu)、一个或更多个图形处理单元(gpu)、和/或一个或更多个张量处理单元(tpu)。指令可以存储在任何类型的计算机可读介质或存储器中,以配置处理器101的操作。例如,指令可以存储在以下中的一个或更多个中:只读存储器(rom)102、随机存取存储器(ram)、可移除介质104,例如通用串行总线(usb)驱动器、光盘(cd)或数字多功能盘(dvd)、软盘驱动器、闪存或任何其他期望的存储介质。指令还可以存储在附接的或内部的硬盘驱动器105中。计算系统100可以包括一个或更多个输出装置例如一个或更多个显示器——在图1中统称为显示器106,并且可以包括一个或更多个输出装置控制器107,例如视频处理器。还可以存在一个或更多个用户输入装置108,例如键盘、鼠标、触摸屏、麦克风等。输入装置108还可以包括或通信耦接至提供传感器数据的装置,例如加速度计、装置温度传感器等。计算系统100还可以包括一个或更多个网络接口,例如网络输入/输出(i/o)电路109例如网卡,以与外部网络110和/或其他联网装置通信。网络i/o电路109可以是有线接口、无线接口或两者的组合。计算系统100可以包括位置检测装置例如全球定位系统(gps)微处理器111,该全球定位系统(gps)微处理器111可以被配置成接收和处理全球定位信号,并且利用来自外部服务器和天线的可能辅助来确定计算系统100的地理位置。
图1示出了计算系统100的示例实现方式中的计算装置的硬件配置,但是应当理解,所示出的部件中的一些或全部可以被实现为软件。在一些实现方式中,硬件和软件元件可以共存于共用物理平台中。另外地,可以进行修改以添加、移除、组合或分布计算系统100的部件。
本公开内容的一个或更多个方面可以体现在由一个或更多个计算装置和/或其他装置执行的计算机可用数据或计算机可执行指令中,例如在一个或更多个程序模块中。通常,程序模块包括例程、程序、对象、部件、数据结构以及当由计算装置或其他装置中的处理器执行时执行特定任务或实现特定抽象数据类型的其他元件。计算机可执行指令可以存储在一个或更多个计算机可读介质上,包括但不限于:硬盘、光盘、固态存储器、ram、rom、可移除存储介质、闪存等。在各种实施方式中,程序模块的功能可以组合到驻留在一个或更多个装置上的一个或更多个模块中或者分布在驻留在一个或更多个装置上的一个或更多个模块中;该功能还可以全部或部分地体现在固件或硬件等同物中,包括但不限于:集成电路、现场可编程门阵列(fpga)等。
图2示出了可以在本文中描述的一个或更多个实施方式中使用的示例传感器装置200。传感器装置200可以包括中继器206和传感器212。传感器装置200可以与通信网络202通信,该通信网络202可以是网络110(图1)的一部分或者耦接至网络110。通信网络202可以连接至一个或更多个数据处理系统(例如,图1的计算系统100)或者与之通信,并且每个数据处理系统可以管理从传感器装置200接收的一些或全部数据。从传感器装置200接收的数据可以存储在数据库(图2中未明确示出)中。
中继器206(可以称为“网关”)可以在传感器212与中继器206之间建立通信连接208。中继器206可以在中继器206与通信网络202或使用通信网络202所访问的系统例如数据处理系统之间建立通信连接204。在某些操作的实例中,通信连接204和通信连接208两者都可以被初始化和/或激活,而在其他实例中,仅通信连接中的一个可以被激活,或者更多数目的通信连接可以被初始化和/或激活。在一些实现方式中,通信连接204和/或208可以是无线的,其中其上的通信由一个或更多个无线通信协议支配。无线通信协议可以用于在可以安装在地面上方的中继器206与可以在地面上方或埋在地下的传感器212之间交换数据。有线或无线通信可以用于通过地面区域210传输数据。无线通信协议可以使用低功耗。传感器212可以与其他传感器(例如,至少一个其他传感器212)通信。可以对在中继器206、传感器212和/或通信网络202之间通信的数据进行加密。
传感器212(也可以称为“现场传感器”或“探针”)可以是独立的和/或可以包括电源。传感器212可以测量与土壤状况相关联的一个或更多个变量。可以测量的变量的示例包括但不限于:土壤张力、土壤含水量、土壤温度、ph、土壤硝酸盐含量和土壤盐度。在本公开内容中的其他地方可以识别和描述其他示例。
由传感器212测量的数据可以通过中继器206传输至通信网络202。传感器212可以位于地面上方以及/或者可以埋在一定深度处。可以基于要测量的变量的类型来选择传感器212的深度。可以基于传感器212是否要保持与中继器206的通信链路208来选择传感器212的位置和/或深度。可以在不通过中继器206或网关等的情况下发生传感器212与通信网络202之间的通信。
在一些实现方式中,传感器装置200可以连续地和/或实时地测量数据。此外,可以将一个或更多个传感器装置200或传感器装置200的一个或更多个部分组合在一起以形成传感器站。取决于特定的实现方式,传感器站可以包括一个或更多个中继器,并且可以直接或间接地连接至一个或更多个数据处理系统。
图3示出了其中从传感器装置收集数据的示例实现方式。图3示出了通过通信网络202与数据处理系统302通信的多个传感器装置(例如,图2的传感器装置200)。传感器装置位于包括土地的四个地块310、320、330和340的区域中。地块310包括传感器312和中继器314,它们形成一个传感器装置。地块320包括两个传感器322和326以及一个中继器324。地块330包括三个传感器332、337和338以及三个中继器334、336和339。地块340包括一个传感器346和一个中继器342。
传感器312、322、326、332、337、338和346部署在地块310、320、330和340中,并且可以测量变量,例如指示地块310、320、330和340中的土壤状况的变量。传感器312、322、326、332、337、338和346中的每一个可以测量与它们各个区域的土壤状况相关联的一个或更多个变量。中继器314、324、334、336、339和342可以使用通信网络202传输数据。数据处理系统302可以接收由中继器314、324、334、336、339和342传输的数据。数据处理系统302可以传输接收到的数据,分析接收到的数据,将接收到的数据存储在数据库中以及/或者利用接收到的数据的全部或部分执行任何其他功能。
数据处理系统302可以接收和/或存储各种类型的数据,例如地形数据、土壤数据、水文数据、土壤使用数据、野生动植物数据、植物数据、气象数据和/或其他类型的数据。例如,数据处理系统302可以接收和/或存储区域310、320、330和340的可见光波谱数据和/或不可见光波谱数据。该区域的不可见光波谱数据可以包括从紫外线到微波的波长范围的测量值。
由传感器装置测量和/或由数据处理系统302管理的数据可以如下面进一步详细描述的用于管理植物生产率。
图4是示出根据本公开内容的一个或更多个说明性方面的用于监视和调节植物生产率的植物生产率系统400的示例部件的框图。图4所示的系统可以使用传感器,例如实时传感器。另外地,系统400可以采用统计和数值分析和/或机器学习技术来调节影响植物生产率的状况。在至少一个实施方式中,系统400能够操作以推荐对当前或未来的操作的变化,以优化植物生产率,或更广泛地说,以优化期望的输出。
监视传感器420可以收集现场数据430(本文中通常也称为传感器数据),例如指示土壤状况、天气、水质的数据,或者与可能对植物生产率具有影响的因素有关的潜在地实时或近实时的任何其他数据。监视传感器420可以包括以上描述的传感器装置200(图2),或者可以是任何其他类型的传感器。现场数据430可以包括与植物生产率有关的多个因素,多个因素中的至少一些具有彼此交互。在一些实施方式中,多个因素具有多种交互。
监视传感器420可以各自进行测量并且获得与一个或更多个变量有关的传感器数据。例如,监视传感器420可以评估土壤用于向作物提供水和养分的能力,并且更一般地检测有利状况或不期望状况的存在。监视传感器420可以位于地面上方或地面下方、水中、建筑物上或附接至建筑物,或者适于测量变量的任何其他位置。监视传感器420可以被集成在装置或系统中。系统400中可以使用任何数目和类型的监视传感器420。
监视传感器420可以位于生产站点的不同位置处以及/或者在不同设备或机器上或集成在不同设备或机器内。由监视传感器420接收的传感器数据可以反映跨不同位置和/或随时间变化的现场状况的变化。
通过说明的方式,可以收集与一个或更多个土壤状况相关联的传感器数据,土壤状况包括但不限于:水张力、含水量、硝酸盐含量、养分含量、电导率、盐度、渗透势、水位深度、温度、曝气水平或空气含量以及ph水平。可以收集与一个或更多个水状况相关联的传感器数据,水状况包括但不限于:水位、温度、电导率、盐度、硝酸盐含量、养分含量、污染物水平和ph水平。可以收集与一个或更多个植物状况或生理活性相关联的传感器数据,植物状况或生理活性包括但不限于:冠层温度、树木测量数据、叶片湿度、叶片温度、树干液流、茎直径或茎生长以及木质部电位。可以收集与一个或更多个生物活性相关联的传感器数据,生物活性包括但不限于:害虫水平、疾病水平、孢子水平、杂草水平、微生物活性水平和授粉者活性水平。可以收集与一个或更多个天气状况相关联的传感器数据,天气状况包括但不限于:温度、相对湿度、大气压力、太阳辐射、降水水平、风速和风向。可以收集与一个或更多个设备性能测量相关联的传感器数据,设备性能测量包括但不限于:泵压力水平和油压力水平。以上描述的由监视传感器420接收的各种类型的数据不旨是限制性的;特别地,系统400可以适于对其他数据的监视、收集和分析,所述其他数据可以或可能变得已知潜在地影响植物生产率。在一些实例中,从监视传感器420接收的传感器数据可以由源自例如现场中的对给定状况的视觉检查的另外的数据来补充。
在至少一个实施方式中,系统400的核心处理功能可以由计算系统440提供。在一些实现方式中,计算系统440可以包括一个或更多个系统或装置,例如图1中描绘为100的系统或装置。计算系统440可以包括数据接收器442、智能植物生产率调节器444、设备控制器446和/或性能评估器448。
数据接收器442可以从监视传感器420接收数据。例如,数据接收器442可以在测量(例如实时)时和/或以各种间隔从监视传感器420接收现场数据430。例如,一些监视传感器420可以在数据被测量时连续地将现场数据430传输至计算系统440,而其他监视传感器420可以以预设间隔例如每天或每周传输现场数据430。在以某些间隔传送传感器数据的情况下,数据可以反映给定传输时的状况和/或给定传输之前的一段时间内的状况。
在变型实施方式中,在计算系统440的一个或更多个部件确定满足某些状况时,监视系统420可以在与预设间隔不同的时间传输现场数据430。例如,关于空气温度,温度数据可以在默认的情况下以30分钟的预设间隔传输,但是在即将霜冻时更频繁地传输。因此,当满足某些(例如温度)阈值时,可以修改传输频率以及/或者可以在除了由预设间隔限定的那些时刻之外的时刻进行传输。作为另一示例,在灌溉期间,可以比默认间隔更频繁地传输水张力数据。
如图4所描绘的,数据接收器442还可以接收和/或收集外部数据450。外部数据可以包括与植物生产率有关的数据,该数据可以从除了由部署在特定现场或感兴趣站点处的监视传感器420直接测量的来源之外的来源收集。作为示例,外部数据可能不源自现场传感器,或者其可以源自由部署在感兴趣站点外部的一个或更多个站点处的传感器获得的数据(例如实时、历史和/或预测)。因此,外部数据可以属于一个或更多个类别的数据,包括但不限于:外部站点数据、环境数据、卫星数据、资源数据和经济数据。可以经由网站、网络服务、数据库、经由应用编程接口(api)、服务器、计算系统、装置和/或其他数据源来使数据可访问。
例如,外部数据450可以包括天气数据,例如本地的、区域的和/或预测的天气数据。天气数据可以包括风速、空气湿度、温度、降水、云量指数、大气压力、露点、蒸散(et)和/或任何其他测量的或预测的天气数据。外部数据450可以包括通过各种方法例如固定摄像装置、无人机、飞机、卫星等获得的成像数据和摄谱仪数据。外部数据450可以包括土壤剖面数据、土壤质地或类别数据、土壤粒度测量数据、土壤压实数据、以及描述在给定站点处的土壤的某些(例如,先前测量和/或报告的)特性以及土壤的物理化学、水力和/或生物特性的其他数据;针对该站点的水文数据、针对该站点的地形数据、针对该站点的位置数据等。外部数据450可以包括描述在适当位置的作物的数据,例如物种、品种、种植密度、种植日期、生理阶段、收获目标、灌溉系统类型等;还可以提供历史数据,例如历史产量数据。外部数据450可以包括与经济变量例如股票市场价格、输入、能源和劳动力成本等有关的数据。外部数据450可以包括描述法律和法规约束例如对某些资源或输入的使用的限制的数据。外部数据450可以包括与灌溉约束、安排约束、耕作实践等相关联的数据。
再次参照图4,计算系统440包括智能植物生产率调节器444,该智能植物生产率调节器444可以对现场数据430、外部数据450和/或任何其他收集的数据进行分析。设备控制器446与可控装置452通信。可以包括设备和/或机器的可控装置452可以由设备控制器446指示来控制各种子系统的启动、操作和/或关闭例如灌溉、施肥和各种产品的应用,包括它们在罐中的可用性。例如,设备控制器446可以用于自动将水和肥料引入现场中,干预疾病和害虫的预防,以及/或者启动其他干预,例如播种、植物切割、耕作等。可控装置452可以包括控制泵(开/关)的致动器和/或控制(打开/关闭)用于灌溉现场的阀的螺线管。由可控装置452的操作引起的任何变化可以随后由监视传感器420检测,因此完成了反馈回路。至少一些装置(发动机、泵、肥料喷射器、过滤器等)具有提供数据的传感器,所述数据可以被传输回至计算系统440的可以用作反馈的部件。在装置未配备有这种传感器的情况下(或另外的反馈即使在这种装置配备有这种传感器的情况下也有帮助时),可以采用一个或更多个反馈传感器来帮助确定给定装置是否正常操作。该反馈数据可以是可以在机器学习和优化任务中使用的另一数据源,如下面将讨论的。
性能评估器448可以生成一个或更多个状况和/或活性报告454。
数据接收器442、智能植物生产调节器444、设备控制器446和/或性能评估器448的功能的至少一些可以在一个或更多个联网装置460上执行,联网装置460可以包括可以经由因特网(例如,“云”)可访问的装置。类似地,由数据接收器442、智能植物生产调节器444、设备控制器446和/或性能评估器448利用的至少一些数据可以临时和/或永久地存储在一个或更多个联网装置460上,联网装置460可以包括经由因特网(例如“云”)可访问的装置。在本文中将参照以下附图来描述计算系统440的这些和其他部件的进一步细节。
图5a和图5b是示出某些常规监视系统与根据本公开内容的一个或更多个说明性方面的用于监视和调节植物生产率的系统的至少一个实施方式的特征之间的一些差异的图。特别地,从广泛的用户的角度来看,当采用图5a的常规监视系统时,系统用户对于决策制定和干预过程至关重要。用户考虑接收到的测量值,该测量值可以包括传感器数据,但是通常确定要应用的阈值,并且做出关于需要什么变化的决策。用户通常将负责确定适当的安排(例如,针对设备的操作安排)和动作计划,并且随后可以根据那些计划的动作来操作设备。相反,再次从广泛的用户的角度来看,在本文中描述的系统和方法的至少一个实施方式中,在使用户干预最小化的情况下,用户可以扮演更被动的角色。例如,如图5b所示,对于各种支持的变量,系统可以确定并动态地调节阈值以优化性能。取决于实现方式和期望的用户交互的水平,系统可以建立临时日历,执行动作项,向用户提供警报和报告,并且响应于可以影响植物生产率的变化状况来调节动作计划和安排。可以向用户提供变化的信息(例如,包括实时、历史和预测的数据),以帮助确定是否需要根据期望手动干预。
图6a至图6c是通常示出为600的框图,示出了根据本公开内容的一个或更多个说明性方面的用于监视和调节植物生产率的方法的四个示例阶段,以及可以在相应的阶段接收、收集、计算、控制、输出和/或以其他方式处理的数据的类型。应当强调的是,在这些附图中(特别是在图6b和图6c中)识别的项在本文中仅作为示例提供和描述,并且不旨在以任何方式穷举或限制。
第一阶段610(图6a和图6b)可以被称为模型馈送阶段。包括传感器数据(例如,现场监视数据;还参见图4和所附描述)、外部数据(例如,站点描述数据)和/或其他数据项(例如,远程传感器数据)的许多类型的数据可以被测量以或以其他方式获得用于(例如,通过图4的计算系统440)进一步处理。
第二阶段620(图6a和图6b)可以被称为动作计划或安排计算阶段。如将参照随后的附图进一步详细地讨论的,可以基于在第一阶段610处接收到的数据来计算(例如,特征生成)另外的数据。可以采用统计模型和/或机器学习算法来确定用于(例如,经由可控装置)控制感兴趣站点处的环境的优化的动作计划或安排。可以促进系统与用户之间的用户交互,其中在对优化的动作计划或安排的确定时可以考虑用户输入。
第三阶段630(图6a和图6c)可以被称为动作计划或安排执行阶段。如将参照随后的附图进一步详细地讨论的,各种设备、机器和其他装置(例如,图4的可控装置452)可以由系统控制以执行(例如,以自动化方式,或者潜在地以允许某种程度的用户控制的半自动化方式)在第二阶段620处确定的优化的动作计划或安排。这可能需要例如水和肥料的受控注入,以及用于最佳能源消耗的安排任务。在第三阶段630中,自动化的库存管理任务也可以由系统执行。
第四阶段640(图6a和图6c)可以被称为性能分析阶段。如将参照随后的附图进一步详细地讨论的,可以进行各种分析并将其报告给用户。可以提供在该阶段中报告的某些数据,这些数据反映了在感兴趣站点处的植物生产率(例如,作物产量)的当前状况。还可以提供关于历史数据和/或与感兴趣站点处的植物生产率有关的未来推测的数据。通过进一步示例的方式,还可以报告资源(例如水、养分、能源、劳动力等)水平和使用。
在环境和植物生产率的变化可能至少部分地由于在第三阶段630处执行的动作计划或安排而受到影响的情况下,用作输入至系统(例如,如在第二阶段620处所处理的)的至少一些数据(参见第一阶段610)将经历变化,因此提供自然反馈回路(例如,如图6a所示)。例如,还可以直接经由一个或更多个现场传感器来接收反馈。因此,监视和调节植物生产率的方法的至少一些实施方式将涉及通过四个阶段的连续循环。然而,应当注意的是,如可以参照图6a至图6c和其他附图描述的,出于说明的目的提供了阶段的数目、阶段的顺序、所识别的描述性类别、在每个阶段处执行的处理以及在每个阶段处处理的数据;本领域技术人员将理解,在变型实现方式中,可以不同地限定对阶段的数目、阶段的顺序、所识别的类别、在每个阶段处执行的处理和/或在每个阶段处处理的数据的修改。这可以包括例如跨相同或不同数目的阶段的某些处理任务的组合和/或分布;对更少的、另外的和/或不同的数据项的考虑;某些任务或计算的顺序的变型(例如,某些任务可以以不同的顺序执行和/或某些任务可以被被排序以允许并行计算,潜在地在不同的处理单元上等)等。通过进一步示例的方式,在至少一些实施方式中,在针对不同迭代中的不同阶段的任务被启动之前,针对给定的迭代不需要全部地完成如图6a至图6c中的任何一个描绘的给定阶段。在某些实施方式中,如本文中进一步描述的用于监视和调节植物生产率的系统可以适于自动地确定不再需要在特定时间点执行对某些数据的监视,并且因此放弃对此类型的数据的收集和/或记录。类似地,如果某些数据没有或不再被收集和/或记录,则该系统可以适于确定需要从特定时间点开始收集(或需要恢复收集)对数据的监视,并且因此启动(或重新启动)此类型的数据的收集和/或记录。
图7是根据本公开内容的一个或更多个说明性方面的通常示出为700的用于监视和调节植物生产率的方法的流程图。在一个或更多个实施方式中,方法700或其一个或更多个动作可以由一个或更多个计算装置或实体执行。例如,方法700的一个或更多个动作可以由图4的计算系统440或图1的计算装置100的部件执行。方法700或其一个或更多个动作可以体现在存储在诸如非暂态计算机可读介质的计算机可读介质上的计算机可执行指令中。流程图中的一些动作或部分动作可以省略或以不同的顺序执行。
在710处,可以接收现场数据(例如,图4的430)和/或外部数据(例如,图4的450)。现场数据可以通过位于感兴趣站点(“现场”)处的传感器来测量。例如,可以接收指示变送器和传感器的系统性能(例如,如与通信、功率、电子的功能等有关)的多个测量值,并且可以潜在地用于识别和/或预测设备故障的实例和/或原因。接收到的数据可以经历另外的预处理,包括例如标准化和/或数据清理。还可以在710处执行对接收到的数据的验证。该任务可以与图6的第一阶段610对应。下面将参照图8描述关于该任务的进一步细节。
在720处,可以生成包括用于训练(例如,机器学习)模型的数据的训练集。在710处接收到的现场数据和/或外部数据(例如,包括历史数据)可以用于生成训练集。可以从在710处接收到的现场数据和/或外部数据中导出或以其他方式生成另外的数据(例如,特征),以包括在训练集中。相反地,可以从训练集中选择性地排除(例如,通过维度降低)针对某些特征的数据。计算系统440在其操作的过程中可以确定某些特征要被排除。该任务可以与图6的第二阶段620对应。下面将参照图9描述关于该任务的进一步细节。
在730处,可以采用从在720处生成的训练集中的数据来生成动作计划或安排。这可能需要在某些约束下确定针对各种可控装置的最佳值,以及用于优化植物生产率的一组相应的动作。可以考虑与植物生产率相关联的变量之间的交互,并且可以计算针对与植物生产率相关联的一个或更多个变量的预测值。例如,来自训练集的至少一些数据可以用于训练机器学习算法和/或构建统计模型,该统计模型然后可以用于生成针对感兴趣变量的预测。该任务可以与图6的第二阶段620对应。下面将参照图12描述关于该任务的进一步细节。
通过示例的方式,在系统被布置成生成考虑与诸如土壤张力和土壤盐度的参数有关的数据的动作计划的情况下,本技术的方法可以包括分别地评估针对两个参数的不同模型,以及评估针对不同环境的土壤张力与土壤盐度的模型的所有组合之间的交互。环境是作物、地区、发展阶段、环境状况等的组合。分别针对不同环境的土壤张力和土壤盐度以及结合测试的土壤张力和土壤盐度,在多维矩阵中保存评估(“度量”)。所使用的度量可以是平均绝对误差(mae)、均方根误差(rmse)等。该系统计算针对土壤张力和土壤盐度的预测,以提供在具体环境中的动作计划。这是基于根据先前评估的最佳模型的选择生成的。优化器可以用于基于最小的负面影响来生成动作计划。当检测到新的环境或达到预定的阈值时,系统考虑新的环境或更新的阈值来重新计算针对参数的预测。这些操作中的至少一些可以彼此并行地执行。这些操作中的至少一些可以被预先计算,以实时地提高系统的性能。
在740处,执行在730处生成的动作计划或安排。这可能需要使可控装置(例如,图4的452)根据动作计划改变植物生产环境状况。例如,可以指示灌溉系统根据动作计划操作。该任务可以与图6的第三阶段630对应。下面将参照图13描述关于该任务的进一步细节。
在750处,可以对植物生产率系统的性能进行分析,并且可以生成相关联的报告。该任务可以与图6的第四阶段640对应。下面将参照图14描述关于该任务的进一步细节。
图8是用于示出在至少一个示例实施方式中的方法700的710的其他方面的流程图。其一个或更多个动作可以由一个或更多个计算装置或实体执行;其一个或更多个动作可以体现在存储在诸如非暂态计算机可读介质的计算机可读介质上的计算机可执行指令中。一些动作或其部分可以省略或以不同的顺序执行。
在810处,从诸如监视传感器420(图4)的传感器接收现场数据。数据可以经历某些预处理动作(例如,数据清理),如在815处所示。
在820处,可以对数据例如在810处接收到的现场数据执行异常检测。可以采用一个或更多个算法或机器学习技术来执行异常检测。例如,可以执行回归树、聚类分析、各种时间序列分析和/或深度学习方法以识别数据中的异常。
在830处,可以接收外部数据(例如,包括历史数据)。外部数据源可以包括例如卫星图像数据、地形调查数据、土壤地图数据和天气预测数据(还参见图4和图6以及针对其他示例的所附描述)。数据可以经历某些预处理动作(例如,数据清理),如在825处所示。
在840处,可以存储在830处接收到的外部数据(例如,用于备份和/或存档目的)。例如,接收到的外部数据可以存储在数据库中,该数据库可以全部或部分地驻留在远程装置(例如,云存储)上。
在850处,可以使在830处接收到的外部数据标准化。为了使数据标准化,可以例如经由智能内插和/或外推在空间上和时间上对数据进行对准,这可以致使另外的数据的创建。所采用的标准化技术可以特定于正在标准化的数据的类型。可以采用专家系统来帮助确定如何可以执行标准化。
在860处,可以初始化阈值,例如生产率阈值。可以针对考虑给定作物、生长阶段和地理区域、土壤类型等的一组变量中的每一个来初始化阈值。可以从诸如科学文献或其他数据的外部数据中检索已知和/或历史数据,以帮助设置初始阈值。一些阈值也可以是用户供应的。一些阈值还可以由系统推断或学习(例如,作为机器学习算法的先前执行和/或机器学习模块的训练的结果)。一些阈值可以基于在一个或更多个其他站点处的类似情况的分析来确定。
在870处,编译默认生产安排。生产安排可以指示针对当前或即将到来的季节的操作推测。生产安排可以包括有关切割、播种、耕作、基础设施和机器的维护、收获或可能影响植物生产率的其他操作的信息。
图9是用于示出在至少一个示例实施方式中的方法700的720的其他方面的流程图。其一个或更多个动作可以由一个或更多个计算装置或实体执行;其一个或更多个动作可以体现在存储在诸如非暂态计算机可读介质的计算机可读介质上的计算机可执行指令中。一些动作或其部分可以省略或以不同的顺序执行。
在910处,可以接收现场数据和/或外部数据。例如,可以通过执行710(参见图7和图8)的一个或更多个动作来处理接收到的数据。在针对初级变量的数据可以从感兴趣站点直接收集(例如,经由图4的传感器420)或者从外部源获得的情况下,可以执行计算以生成另外的数据,所述另外的数据可以被称为次级变量。该任务也可以称为特征生成。
次级变量可以根据两个或更多个初级或外部变量来计算。此外,次级变量不仅可以通过组合初级变量来生成,而且还可以通过将次级变量和初级变量进一步组合在一起或者将次级变量和三级变量组合在一起等来生成。为了便于说明,直接或间接地从初级变量中导出的数据在本文中被称为次级变量。
每个次级变量可以代表可以与次级变量所基于的变量互补或不同的因子,并且它们的构造可以有助于优化学习算法的性能。例如,次级变量可以包括生长度日、蒸汽压差、蒸散(et)等。
在920处,可以对在910处接收到的一些或全部数据执行空间和/或时间分析。所执行的分析可以包括聚类、分类和/或相似性分析。可以从数据库中选择适当的模型以应用于数据的第一迭代,从而启动学习过程。可以针对每个新植入的站点执行分析。
在930处,可以从在910处接收到的现场数据和/或外部数据中导出生成特征。可以执行对所有变量的时空序列的自动特征识别。可以执行时间和空间分析以合成多个参数形式的信息。这些多个参数可以保存在多维矩阵中。如本文使用的,参数指代生产率系统或其环境的影响植物生产率并且可以由一个或更多个变量来测量或限定的元素、活性或状况。参数的示例包括但不限于作物对水的需求、对养分的需求以及疾病和害虫的发生或存在(“m&r”)。这些参数分别通过若干个测量的或计算的变量来评估。
该系统还可以允许对使变量达到临界限制的情况的识别。可以评估给定时间序列的各种特性以识别这些情况以及它们如何使变量达到它们的临界限制,包括但不限于:局部最小值和最大值、拐点、幅度、方差、均值、第一、第二和更高阶导数、趋势、频率、自相关结构、季节性、平稳性、傅立叶变换、小波分解、分形分析、过去值等(例如,参见图10,其中示出了剖析针对给定变量的时间序列的示例方法)。可以剖析在给定时间序列处的变量,以区分与所识别的情况相关联的不同非线性动态阶段或模式。在一些实例中,由于若干个变量之间的相互作用而产生或阐述了所述情况。例如,图11示出了关于张力的时间序列的分解如何可以有助于识别影响该变量的某些现象的动态。在张力的情况下,土壤排水和湿润循环、天气状况、作物的类型、生理阶段、疾病或昆虫的存在、土壤温度、盐度等的历史可能具有影响。至于任何其他变量,张力受所有其他变量之间的相互作用的影响,无论它们是当前的、过去的还是未来的。
在940处,构造一个或更多个多元矩阵以存储随后将在其上训练学习模型的数据(例如,无论是直接从传感器或从外部源获得,或通过特征生成的过程)。
图12是用于示出在至少一个示例实施方式中的方法700的730的其他方面的流程图。其一个或更多个动作可以由一个或更多个计算装置或实体执行;其一个或更多个动作可以体现在存储在诸如非暂态计算机可读介质的计算机可读介质上的计算机可执行指令中。一些动作或其部分可以省略或以不同的顺序执行。
在1210处,可以接收包括训练数据的训练集。这可以是一个或多个多元矩阵的形式,如在940处(图9)可能生成的。在1220处,可以执行特征重要性分析。可以识别和选择特征或特性。可以限定关系和多模型结构。可以基于对植物生产率的重要性对特征进行排名或分组。可以使用局部和全局灵敏度、回归树、分类、分组、相关矩阵、主分量、多维定位和/或顺序回归以及其他技术来执行特征的排名。特征排名可以有助于模型解释,并且还可以被采用以识别随后用于在模型训练时提高效率的较小的数据子集。不同的结果可以独立地集成以选择特征。这些所选择的特征可以用于限定多元模型的关系结构。在特征重要性分析期间可以识别特征之间的关系。可以确定用于多元模型的限定中的逻辑结构。这些多元模型可以用于预测变量。
在1230处,可以生成一个或更多个多元模型。这可以涉及各种机器学习算法的应用和/或统计模型的构建。可以采用各种统计技术(方差的分析、线性和非线性回归、半变异函数)、成分分析、微分方程和积分方程的解、体积元和有限元、神经网络的使用(例如,深度学习)、支持向量机和/或其他算法。
在1240处,可以预测感兴趣变量的时间和/或空间分量,并且将其与在1250处的相应阈值进行比较。可以根据确定的或预期的可以与特定的动作和/或活动相关的重要性的测量来执行对一个或更多个感兴趣变量的选择。例如,在养分管理中,“硝酸盐”可以被认为为是最重要的变量。可以确定生产率区域的自我调节的阈值并对其进行优先级排序。可以使用基于与灵敏度分析、决策树、风险分析组合的模拟的迭代优化方法以及/或者用于对动作进行优先级排序的其他方法来执行层次化。阈值可以被设计为同时优化对所有变量的正面影响,这可以使对变量的负面影响最小化。
即使一个以上变量将受益于干预的情况下,也可以确定针对动作的优先级排序。可以产生同时满足多个阈值的干预的安排。干预的安排还可以满足其他约束,例如基础设施约束、个人约束或经济约束。这些约束可以是变化的,并且可以是由不支持某些部件的自动化的生产基础设施引起的,例如工作人员安排、对有限输入(例如水、肥料、农药和/或能源)的可访问性、和/或操作成本和对销售价格的推测以及其他约束。
可以生成优先级排序的动作的操作的逻辑顺序。操作的顺序可以以生产安排的形式,或者操作的顺序可以用于生成生产安排。生产安排可以连续更新,或以设置的间隔更新。
通过示例的方式,约束的两个示例可以是:(1)由于不存在可用的灌溉器,因此在周末不能灌溉;(2)泵x当时具有仅灌溉100英亩的能力。在这种环境下,可以给用户选择(与其中考虑将系统被配置成学习如何考虑这些约束的情况相比),以根据每个约束来优化安排。例如,用户可以能够提供反映对提示的响应的输入:“如果灌溉事件被安排在星期天,您想将灌溉事件推迟至星期一或者在星期五的较早时间执行?”
约束的其他两个示例可以是:(1)土壤中硝酸盐的水平超过由法律和/或法规允许的水平,这将防止作为媒介手段的施肥,或者(2)在水分胁迫的情况下,对水的使用的限制将防止执行灌溉。在被馈送有这些约束中的一个之后,系统将考虑并向用户建议可替选的干预,以基于对其他现场数据和/或现场数据和/或生成的数据的多个因素之间的交互的分析来减轻压力的水平并且保持植物生产率。
图13是示出在至少一个示例实施方式中的方法700的740的其他方面的流程图。其一个或更多个动作可以由一个或更多个计算装置或实体执行;其一个或更多个动作可以体现在存储在诸如非暂态计算机可读介质的计算机可读介质上的计算机可执行指令中。一些动作或其部分可以省略或以不同的顺序执行。
在1310处,可以接收安排(或动作计划)。接收到的安排可以是根据730(参见图7和图12)的输出生成的安排。安排可以指示要执行的各种活动。安排可以包括可以自动地执行的活动和/或可以由用户执行的活动。操作安排可以涉及自动化操作、输入订单、农业推荐以及针对未自动支持的活动的指令。
在1320处,可以操作可控装置(例如,图4的452)以自动地改变环境状况。在1310处接收到的安排可以包括用于操作这些受控装置的信息。
在1330处,可以执行其他自动化操作。例如,可以初始化用水、燃料、肥料等填充储水器/罐,以订购肥料和/或保持泵注满以准备在需要时启动的自动化过程。
在1340处,可以针对未自动支持的活动输出用户指令。该指令可以涉及例如生产基础设施的输入管理或维护,例如用于准备订单输入的库存、水罐的填充以及灌溉用水的状况和质量。指令可以包括关于要由用户执行的活动的安排。指令可以包括推荐、干预请求、风险指数、警告或任何其他类型的指令或通知。
可以在1350处对安排进行用户调整。在应用或推荐任何自动化或非自动化动作(例如,参见1320至1340)之前,可以提示和/或允许用户进行操作调整。例如,可以通过用户接口将安排输出至用户,并且可以通过用户接口来接收对安排的调整。
图14是用于示出在至少一个示例实施方式中的方法700的750的其他方面的流程图。其一个或更多个动作可以由一个或更多个计算装置或实体执行;其一个或更多个动作可以体现在存储在诸如非暂态计算机可读介质的计算机可读介质上的计算机可执行指令中。一些动作或其部分可以省略或以不同的顺序执行。
在1410处,可以对植物生产率系统的性能进行分析。可以执行对系统性能和效率的完整评估。性能分析可以包括编译所有可用的变量,例如与所确定的阈值和安排有关的实时测量值、描述性变量、外部数据和次级变量,以在1410处生成性能数据和/或报告并且将性能数据和/或报告输出至系统用户,所述性能数据和/或报告潜在地经由用户接口以打印形式或一些其他输出格式用于显示在仪表板中。例如,该系统可以获知,对泵送能力的限制可能比购买将增加泵送能力的更大泵的成本具有更大的成本影响。
产量或潜在产量的测量或指标可以在生长季节和/或在收获结束期间获得,并且这些测量或指标可以用于改进由系统使用的模型。例如,可以取决于接收到的新数据来调整阈值;还可以基于响应于显示信息的用户输入来修改操作。
评估可以确定另外的数据将改进系统的性能。评估可以包括确定是否应当添加或从系统中移除传感器或其他设备。例如,如果在确定多个变量中的每个变量的重要性的过程中,如果确定由传感器测量的变量以对模型不具有影响或具有可忽略的影响,则系统可以推荐移除该传感器。作为另一示例,可以确定两个装置正在两个并排现场中报告完全相同的数据;系统可以推荐移除两个装置中的一个。
可以针对关于目标和安排的相关参数计算合规水平。可以评估所使用的资源,例如能源和输入的数量。技术和经济性能可以通过效率的统计的提供以及可比较的区域作物的可用指数、过去的性能或任何其他用于参考的可比性的提供来限定。可以实现系统性能的可追溯回路,以基于新获取的数据连续地优化在植物生产率系统中使用的算法。考虑到新的训练数据,可以以预先设置的间隔(例如每天)对模型进行再训练。通过这些评估,可以确定自我调节的精确阈值。
示例
为了更清楚地说明如何使本文中描述的某些实施方式可以生效,现在将参照图15a至图15c描述根据本公开内容的一个或更多个说明性方面的植物生产率控制系统的虚构示例实现方式。提供这些细节仅出于说明性目的,并且不应当以任何方式解释为限制实施方式。特别地,变型实现方式不需要包含在该示例中描述的所有特征或特征的任何特定组合。
本文中提供了基于位于加利福尼亚的中央谷地中的4岁的40英亩块的杏树的情况研究的细节。作物通过传统的作物管理方法进行管理。土壤表面相对平坦,并且土壤包括在前3英尺中的均质壤土砂,这与根部区域的深度对应。
通过将由公共天气提供者在三个灌溉事件中计算出的潜在每周蒸散数据进行划分来灌溉整个现场。水直接从配备有手动启动和停止的电机的井中泵送(成本为$a/英亩/小时)。井深为600英尺,并且水深为300英尺。石膏罐连接至灌溉系统,以便在石膏变得受限制时应用石膏以提高水的渗透率。由于从过去的每月水分析中示出了针对来自井的水太碱性(高ph)的趋势,因此已经安装了酸燃烧器。在每次灌溉事件时,系统地注入石膏(用于提高渗透率;成本为$v/小时/英亩)和酸(用于提高ph和养分可用率;成本为$b/小时/英亩)。
肥料接近泵储备在3米高的10,000升圆柱形罐中,并且除了主灌溉泵之外,还需要打开喷射泵以$z/英亩/小时的成本提供施肥(即,经由灌溉系统输送的液态肥料)。由农艺师($t/英亩/年)根据在季节开始时分析的土壤和叶片样品构建的施肥计划被提供给种植者,并且基本上包括每周一次施肥事件。
在花期阶段期间,沿现场的周边安装了蜂箱,以帮助授粉。当害虫控制顾问(pca)推荐遵循他每周的侦察($u/英亩/年)喷洒农药时,可以用由工人驱动的机动车辆在现场中应用农药($c/英亩)。即使需要3名全职工人来完成上述所有任务,由于该区域中的劳动力稀缺,因此从周一至周五从上午7:00至下午4:00也只有2名工人的工作人员仍可用(成本为$d/小时/工人)。在加班工作的阶段期间,成本增加至1.5*$d/小时/工人。在侦察时,pca还注意到杂草覆盖。在收获时,在季节开始时估计产量的收入为$e/lb。下面表1概述了情况研究的细节:
表1:情况研究的细节
上面提及的信息被提供给植物生产率系统(例如,图4的系统400),用于确定推荐要安装多少个站和传感器。泵站配备有中继器,以在无人干预的情况下激活泵、酸燃烧器和石膏喷射器。井中的水的深度和水的温度、盐度、硝酸盐含量和ph利用适当的传感器来监视。罐中还安装了用于监视肥料水平的传感器。
通过查阅来自外部源的地形图和历史卫星影像(例如,图4的外部数据450),系统推荐在现场的中心安装一个现场站。该站在土壤的12英寸、24英寸和36英寸的深度处配备有张力计、土壤含水量探针、渗透势探针、硝酸盐传感器和土壤温度传感器,以监视整个根区域状况。在该站处,在冠层中测量空气温度和相对湿度。树木之间安装了孢子和昆虫分析仪,以在无任何人干预的情况下检测和定量孢子和昆虫。在蜂箱处安装有觅食蜂活动计数器。最后,在现场的边界安装了气象站,以测量空气温度、相对湿度、风速和风向、大气压力、叶片湿度、太阳辐射和降雨。
系统根据这些变量来计算次级变量。土壤中的水通量根据土壤含水量和张力数据来计算。土壤总势根据张力、渗透和重力势数据的总和来计算。根据冠层中的空气温度和相对湿度来计算蒸汽压差和露点。根据气象站数据来计算蒸散、露点、寒冷时间和部分,并且评估害虫和疾病发展风险(例如,链格孢叶斑病、脐橙螟、疮痂病、穿孔、棒茎枯萎病等)。计算罐中肥料的量。由于所有初级变量实时连续报告,因此补充变量也可以连续计算。
通过预测这些多元动态变量之间的相互作用,该系统动态地自动调整获利能力阈值(状况),考虑相对于不动作的成本的动作的收入,以预测、安排和操作动作(灌溉、淋滤、施肥、肥料供应、水ph调整等),以使作物获利能力最大化。
系统通过使用一些验证变量来连续确认安排(动作计划)的影响。在树木的叶片周围安装干水势,并且安装测树仪以测量树干的生长或收缩。这些传感器可能不用于安排动作,因为它们是反应性的且不是预测性的,但是系统可以依赖于它们以验证结果和策略。来自卫星图像的诸如归一化植被指数(ndvi)值的外部指数也可以用于验证该策略的有效性并用于在空间-时间的基础上外推数据。这些图像还可以用于评估地面上的杂草覆盖,以安排杂草清除操作。
一旦安装了以上描述的设备,系统就开始从现场收集数据。该系统基于学术文献和从其数据库中发现的其他类似站点获得的数据使用预设阈值。一旦系统收集了新的本地数据,就会根据系统对本地状况和数据的学习来调整获利能力阈值。树木仍处于休眠状况,并且系统考虑潜在产量仍为100%,并且因此潜在获利能力更高。
图15a示出了一个月的活动之后的张力水平。在该月期间,已经连续调整获利能力阈值以反映由系统获知的本地状况。在收获时的潜在产量已经下降至97%,这是因为灌溉泵的机械故障在3天期间损害了灌溉,并且在这些天期间呈现水分胁迫状况。该系统通过分析在其他类似站点中的数据获知,当在树木苏醒期间出现水分胁迫时,产量损失每天达到1%。在这三天期间,随着树干收缩,水分胁迫已经通过测树仪测量验证。该系统在它获利时偶尔已经打开酸燃烧器以降低ph,但仍然未注入石膏,这是因为渗透率数据分析未示出任何限制。
图15a中示出的时间段处于花期阶段的中期。在下周内的养殖操作计划如下:在28日之前没有计划。在28日,灌溉将在7:00pm运行直到11:00pm为止。上周历史数据、当前数据和导致该安排的预测数据在图15a中示出。
图15b示出了2月25日在4:00pm的时间段。该系统已经连续地核实和验证安排,并且在图15b中示出的安排已经改变成经由自动化模式运行灌溉,以在25日从6:00pm至10:00pm应用水,经由自动化模式在27日9:30pm运行施肥直到在28日3:00am为止,由工人在28日8:00am用安装在机动车辆上的喷雾器施加杀真菌剂。在接下来的7天内没有安排其他动作。
基于以下分析,系统已经认为图15b所示的安排是最佳的:
i)在花期阶段期间,尚未达到针对启动灌溉的预先确定的状况,并且在28日之前未计划灌溉,但是系统正在检测根部区域中测量的张力和水通量中的突然变化。由于系统之前从未在该站点上面对当前状况,因此无法预料到这种突然变化。然而,系统认识到这种突然变化(例如,参见图15b,在图10和图11中描绘的过程的环境中,)要是含氢状况的下述预兆:限制根系吸收水足以影响在花期期间发生的以每小时0.1%/英亩的水分胁迫状况下在季末的产量。现在该系统立即开始通过动态预测和同时预测所有多元变量之间的交互来评估触发灌溉事件的获利能力。
iii)由于当微型喷头打开超过15分钟时对觅食蜜蜂的影响使得产量以每小时0.15%/英亩下降,因此直到蜜蜂在6:00pm停止它们的活动为止,运行灌溉将是不获利的。在没有用于控制灌溉的自动化系统的情况下,灌溉将在第二天的7:00am开始,这是因为在此之前没有工人可用然后以启动灌溉。在这一天期间的这些灌溉将影响蜜蜂从8:00am到12:00pm的活动,并且导致额外的产量损失。在仅基于土壤张力的单变量作物管理系统中,最佳运行时间将被计算为6小时,以将土壤张力降低至固定阈值,而不考虑对授粉影响。利用传统的作物管理,所有这些将被遗漏。相反,系统400确定最佳运行时间为4小时。在这些特定情况下,灌溉事件将不会对除养分含量之外的其他变量有显著影响。水的ph正处于最佳水平,此处无需调整。通过考虑灌溉水的泵送成本、土壤中的养分含量和肥料注入的成本,系统确定4小时的灌溉是较长的限制,以免将硝酸盐压向下推得太快和太深。该系统已经评估了当灌溉比4小时长时,硝酸盐向下移动的速率加速。由于灌溉之前的硝酸盐含量略低,因此灌溉比4小时多时将导致针对在灌溉系统中注入养分的需要。与在4小时之后停止灌溉相比,在这些状况下添加肥料的成本实际上是不获利的。
iii)在安排过程的运行迭代之后,即使系统预测直到28日的晚上为止也将有足够的养分和水,系统仍在27日9:30pm安排了施肥事件。然而,在28日8:00am安排杀真菌剂应用,并且在杀真菌剂应用之后的接下来的24小时内,叶片将需要保持干燥,这意味着在此间隔期间不允许施肥。然后,由该新任务的系统按其安排通知工人。该系统识别了针对该杀菌剂应用的需要,因为即使在过去8天期间由孢子传感器计数的孢子的数目已经接近于0,该系统也预测其中在3天内达到可获利的喷洒的阈值,这是因为从西部吹来的大风导致的,其中在该区域中的孢子的数目根据其他站点的系统分析实际上非常高。与之前一天相比,将其中喷洒可获利的阈值调整为较低的值,因为外部天气预测已经更新,并且现在3天内的天气状况适于疾病发展。为了得出在3天内可获利的喷洒的结论,系统分析了喷洒事件的成本(劳动力成本+农药成本+附带成本),并且确定该成本比与植物的叶片上疾病的发展相关联的产量损失(10%/英亩)低。在这种情况下,唯一的附带成本是对授粉的影响。该系统自动地通知养蜂人关闭蜂箱的门,以防止蜜蜂在喷洒之后24小时内在处理过的叶片上觅食,这将导致2.5%/英亩的产量损失。喷洒这种农药防止工人进入现场,因为重新进入间隔为24小时,但是这不会影响任何操作,因为那天没有针对工人安排任何事。
iv)在得出施肥事件将安排在27日的晚上的结论之前,系统评估了其他情况,例如将施肥推迟至星期六(1日),但是这比在27日的晚上安排施肥将造成更大的损失(3%/英亩)。然后识别27日的晚上最获利的场景。在安排此动作之前,系统还同时考虑了该施肥事件对所有其他变量的影响。添加养分将增加根部区域的渗透势,但是总势将仍然保持在最佳水平处,因为张力将降低。然而,施肥运行时间已经被优化,以允许充足的空气含量,并且避免缺氧应激和养分的过量应用。为了该优化,该系统分析了在所有历史施肥事件期间和所有历史施肥事件之后的水和硝酸盐移动速率。由于预测的土壤、水和空气温度异常高,因此该系统预料水力传导率比在25日灌溉期间的水力传导率高。这些状况导致计算出的运行时间为5.5小时。如果用仅基于土壤张力的单变量模型计算,则运行时间将仍像在25日的用于灌溉的时间一样为6个小时,因为今天的张力与25日的状况类似。然而,6小时的灌溉事件将导致在0.5小时期间根部区域下面的水和养分的损失,这是因为水和硝酸盐由于高温度状况而渗透更快。系统不能确定对所有其他变量将存在任何显著影响。已经计算出9:30pm的时间是用于启动泵的最佳时间,因为系统根据叶片湿度数据分析,在灌溉事件之后叶片至少需要5个小时才能干燥。由于农药安排在8:00am施加在干燥叶片上,因此灌溉应当在3:00am之前停止并且不晚于9:30pm开始。
v)在25日7:00pm,系统确定灌溉事件的前2个小时内泵送的水具有可接受的ph水平,但是最后的数据点显示ph迅速升高。因此,需要通过酸燃烧器降低ph。如果当ph升高时泵正在浇水,则系统预测土壤ph将达到其中将限制养分物吸收的阈值,这导致0.2%/天的产量损失直到接下来的灌溉事件为止。该系统自动启动酸燃烧器,因为运行其的成本($y/英亩/小时)实际上比与泵送超过ph阈值的水相关的产量损失低。由于系统模拟如不受酸的注入的影响的所有其他参数,因此其余安排将保持相同。
vi)在2月28日5:00pm,系统对与冠层中温度有关的阈值定义应用了修正,以防止热胁迫。文献中不存在关于在花期期间该阈值的可用数据。该系统对来自所有站点的数据进行分析,并且发现杏树在花期期间对热胁迫的响应的较大变型,即使阈值考虑了空气和冠层温度与土壤含氢和养分状况的交互。温度、相对湿度和蒸汽压差(vpd)在下午达到了预测数目,并且根据由系统获得的信息,无需冷却灌溉。然而,该系统刚刚在关于图13的以上描述的验证过程期间已经测量了树干收缩。水和养分通量不限制根系吸收,因此系统然后将树干收缩归因于热胁迫。当一天结束并且温度已经开始下降时,其太晚而不能对这种压力做出反应,但是系统从这种经验中获知,并且将在未来相应地调整其阈值。
图15c示出了在2月29日1:00pm系统的状况。由于外部天气预测源预测温度为30℃,因此无法预料当前的空气温度为32℃。冠层中的空气温度为34℃。该系统根据自花期阶段期间的开始收集的数据已经确定蜂箱外部觅食蜂的数目与冠层中温度之间的显著强关系。当冠层温度在23℃至33℃之间时,蜜蜂活度在其最高点处,在33℃处开始线性下降,并且在37℃之后加速下降。该系统通过评估过去几年中所有其他杏树现场的产量数目来确定由于高温时线性地影响蜜蜂活度的每一天导致收获时的产量损失为3%/英亩以及在曲线下降开始加速之后的每天5%/英亩。在井中的水在6℃且空气温度在33℃的情况下,系统预测在15分钟的灌溉事件之后,水将在19℃离开微型喷头,并且在3小时内将冠层温度降低7℃,并且这防止蜜蜂活度的减少。然后,在已经模拟该灌溉事件将不对系统的任何其他参数或状况产生负面影响并且与该灌溉事件有关的成本比与产量损失相关联的金钱损失小之后,系统通过启动15分钟的灌溉事件对该新状况做出反应。
在作物的前3年中,每年的这个时候需要进行杂草清除操作。然而,今年,随着系统改进水管理,已经实现灌溉中的25%的减少。这导致杂草覆盖仍低于其中杂草清除获利的阈值。在下一月之前,系统不能预料季节的首次杂草清除操作。由于该系统仍未测量任何渗透问题,因此该季节从未开启过石膏注射器。在该系统负责许多操作的情况下,现在2名工人的工作人员足以完成对农场的所有手动操作。在该示例情况研究的一周期间,在收获时针对杏树的预料价格没有变化。
虽然已经结合本技术的具体实施方式描述了本技术,但是应当理解本技术能够进一步修改,并且本申请旨在涵盖通常遵循本技术的原理并且包括与本公开内容的这种偏离的任何变型、用途或改编,只要它们落入在本技术所属领域内的已知或惯用实践中,并且可以应用于上文阐述的基本特征,并且落入在所附权利要求书的范围内即可。
通过引用并入
在本说明书中引用的所有参考文献以及它们的参考文献在适当的情况下通过引用整体并入本文,以用于另外的或可替选的细节、特征和/或技术背景的教导。
等同方案
虽然已经参照特定实施方式特别地示出和描述了本公开内容,但是应当理解,以上公开的变型和其他特征和功能或其替代可以被期望地组合到许多其他不同的系统或应用中。此外,本领域技术人员随后可以在本文进行各种当前未预见的或未预料的替代、修改、变型或改进,这些替代、修改、变型或改进也旨在被所附权利要求书所涵盖。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:乔斯林·布德罗;文森特·佩尔蒂埃;扬·佩里亚尔拉里韦;罗克·沙博
- 技术所有人:霍陶有限公司
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、李老师:1. 木质生物质转化利用 2. 绿色包装材料
- 2、刘老师:1. 木质生物质化学及材料 2. 纸基功能材料
- 3、温老师:1. 纤维素纳米纤维材料的制备、改性及应用 2. 造纸法再造烟叶、新型烟草开发 3.生物质资源基油田助剂(封堵、驱油和钻井) 4. 改性植物纤维开发
- 4、张老师:1.合成生物学 2. 微生物代谢工程
- 5、李老师:1.水平基因转移的分子机制及应用研究 2.植物细胞工厂构建
- 如您是高校老师,可以点此联系我们加入专家库。
- 还没有人留言评论。精彩留言会获得点赞!