一种制丝批加香模式下加香比例预设置方法与流程
本发明涉及一种制丝批加香模式下加香比例预设置方法,属于工业大数据分析应用领域。
背景技术:
1、在烟草制丝工艺中,加香工序作为最后一道工序,用于调节烟丝香气,提升感官质量。加香工序添加香糖料的方式一般有两种:比例加香和批加香。比例加香,即根据入口物料瞬时流量,按照某一固定比例添加香糖料;批加香,即预先将整批需添加的香糖料备好,不论批次间的重量差异,保持整批的加香量恒定。目前行业内普遍采用批加香的方式进行加香。批加香模式下,若对批次累计重量预估不准确,就无法给出合理的加香比例,从而导致生产接近尾声时香糖料已用尽或仍有大量剩余,使得批次加香的稳定性和完整性受到影响,进而影响成品烟丝的质量。
2、目前,批加香模式加香比例的设置有两种方式:一、工艺人员计算历史批次的加香入口累计重量均值,结合工艺标准中需要添加的香糖料重量,计算得到加香比例;二、工艺人员根据历史批次的前工序出口累计重量和加香入口累计重量,计算“折重系数”(折重系数=加香入口累计重量/前工序出口累计重量),结合当前生产批次的前工序出口累计重量、工艺标准中需要添加的香糖料重量,计算得到加香比例。方式一以历史批次的加香入口累计重量均值作为当前生产批次的预估值,忽视了批次间的差异性;方式二考虑了批次间的差异性,但环境温湿度的差异、烟丝水分差异、贮丝时间差异等都会影响“折重系数”,因此使用“折重系数”进行加香入口累计重量的预估也存在明显缺陷。
3、因此,提出了一种制丝批加香模式下加香比例预设置方法,通过构建集成模型预测加香工序入口累计重量,计算加香比例,降低加香入口累计重量预测和加香比例设定的随机性,规避数据质量问题的影响。
技术实现思路
1、为了克服背景技术中存在的问题,本发明提出了一种制丝批加香模式下加香比例预设置方法,使用大量历史数据完成多个基模型的训练,构建集成模型,并分配权重;对在线流数据进行异常检测,并根据异常检测结果选择不同的方式输出加香入口累计重量预测值;同时避免模型失配,对模型进行在线更新和模型权重调整,提升了模型的泛化性。解决了批加香模式下,由于入口累计重量无法准确预估、加香比例设定不合理导致加香的稳定性和完整性较低的问题。
2、为了克服背景技术中存在的问题,为解决上述问题,本发明通过如下技术方案实现:
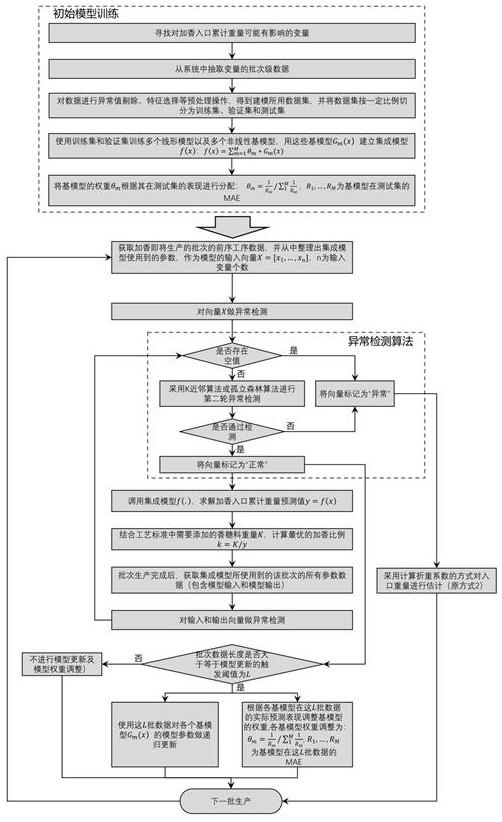
3、一种制丝批加香模式下加香比例预设置方法包括以下步骤:
4、步骤1,业务调研及数据收集,对加香工序及前序工序的生产过程进行研究,寻找对加香入口累计重量有影响的变量,并从已有mes业务系统中导出历史批次数据;
5、步骤2,集成模型(ensemble model)建立,基于历史批次数据,训练不同结构的加香入口累计重量预测基模型,构成集成模型;
6、步骤3,在线数据流处理,随着生产的进行,不断收集生产过程的批次级流数据,从每一条新的数据样本中筛选出集成模型中使用到的参数,进行数据清洗、异常检测;
7、步骤4,加香入口累计重量预测,根据步骤三异常检测的结果,对加香入口累计重量预测值进行求解,同时计算推荐的加香比例;
8、步骤5,模型更新及模型权重调整,批次生产结束后,获取完整批次数据,对集成模型进行更新,同时调整模型权重。
9、优选地,所述步骤2中,集成模型建立前,对步骤一获取的历史批次数据进行异常值剔除、特征选择,得到建模所用数据集,并按照样本的实际生产顺序切分训练集、验证集和测试集。
10、优选地,所述步骤2中集成模型为,使用训练集和验证集训练线形基模型,包括递归最小二乘法、在线中心归一化最小二乘法、自适应递归最小二乘法、岭回归模型,以及非线性基模型包括决策树模型、随机森林模型、在线神经网络模型,以选用的线性基模型和非线性基模型作为基模型线形组合成集成模型,其形式如下所示:
11、
12、式中,f(x)为集成模型,g(x)为基模型,m为基模型的个数,θ为基模型的权重。
13、优选地,所述步骤2中集成模型的权重分配方式为,各基模型的权重根据其在测试集的表现进行分配,模型在测试集的表现由预测值和实际值的平均绝对误差(mae)描述,基模型权重计算的数学表达式为:
14、
15、式中,rm为各基模型在测试集的绝对误差(mae)。
16、优选地,所述步骤3中批次级在线数据流处理方法为,获取即将加香生产批次的前序工序数据,从中整理出集成模型使用到的参数,作为模型的输入向量:
17、
18、式中,n为集成模型的输入变量个数;
19、然后,对输入向量x做异常检测,根据检测结果将输入向量x标记为“正常”或“异常”。
20、优选地,所述向量x异常检测方法为,判断输入向量x中是否存在空值,若存在空值,将输入向量x标记为“异常”;若不存在空值,则继续对x做第二轮异常检测,第二轮异常检测由异常检测模型实现,采用k近邻算法或孤立森林算法构建,若第二轮异常检测未通过,将输入向量x标记为“异常”,反之,将输入向量x标记为“正常”。
21、优选地,所述步骤4中加香入口累计重量预测方法为,若步骤三将输入向量x标记为“正常”,则调用集成模型f(x),得到加香入口累计重量预测值y=f(x),再结合工艺标准中需要添加的香糖料重量,计算得到最优的加香比例:
22、k=k/y (4)
23、式中,k表示加香比例,k表示香糖料重量,y表示加香入口累计重量预测值;
24、若输入向量x标记为“异常”,此时集成模型失效,改为根据历史批次的前工序出口累计重量和加香入口累计重量,计算折重系数,结合当前生产批次的前工序出口累计重量、工艺标准中需要添加的香糖料重量,计算得到加香比例。
25、优选地,所述步骤5中模型更新及模型权重调整方法为,每当新的批次生产完成后,获取集成模型所使用到的该批次的所有参数数据,对其进行异常检测和标记,异常检测和标记方法与步骤三所述方法相同;取模型更新的触发阈值,判断被标记为“正常”的批次数据长度是否大于等于触发阈值,若不满足,则不进行模型更新及模型权重调整,流程结束;若满足,则使用这批数据对各个基模型的模型参数做递归更新,同时,根据各基模型在这批数据的实际预测表现调整基模型的权重。
26、本发明的有益效果为:
27、本发明大幅提升了加料加香的均匀性和精度,对烟丝质量控制起到显著提升性作用,通过集成模型(ensemble model)预测烟丝加香工序入口累计重量,并推荐加香比例,充分考虑了生产过程中各个参数对加香入口累计重量的影响,降低了加香入口累计重量预测和加香比例设定的随机性,在加香入口累计重量预测前对输入数据进行异常检测,并根据异常检测结果选择不同的方式输出加香入口累计重量预测值,有效规避了实际生产过程中出现的数据质量问题对加香入口累计重量预测的影响,提高模型预测准确性,且对生产结束后的模型进行在线自更新和模型权重调整,实现了模型的迭代更新,优化了模型的预测精度,提升了模型的泛化性。
- 还没有人留言评论。精彩留言会获得点赞!