乳腺癌和卵巢癌疫苗的制作方法
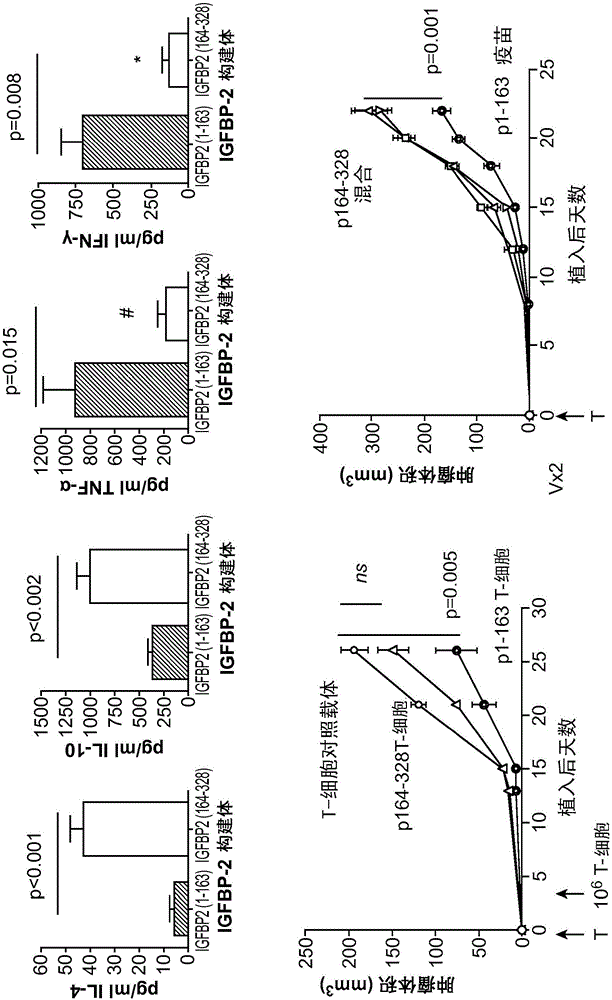
本申请要求2014年3月28日提交的美国临时专利申请第61/972,176号的权益,其全文通过引用纳入本文。有关联邦资助的研究的声明本发明在国防部的资助号W81XWH-11-1-0760,国立癌症研究院的资助号P50CA083636和国立癌症研究院的资助号R01CA098761下在美国政府的支持下完整。背景传统上通过手术减少肿瘤重量和随后的化疗和/或放疗来完成癌症治疗。该策略可减少肿瘤,并且在较早阶段,通常导致完全缓解。不幸的是,对更晚期肿瘤的预后在过去的50年间几乎没有变化,并且由于后续转移导致大量癌症相关死亡。需要新的预防性和治疗性处理来对抗日益增加的癌症。每年全世界有超过一百万人诊断出乳腺癌并且每年有超过400000人死于乳腺癌。估计每8个妇女中就有1个将在其寿命中的一些时间点诊断出乳腺癌。防止乳腺癌发展会对所有个体有显著的健康和经济益处。如果人们不再需要接收昂贵的癌症相关监控和治疗性介入,则将节约数十亿美元。需要预防和治疗乳腺癌的新方法。发明概述在一些方面中,本文所述的组合物包括,包含以下的组合物:第一质粒,其包含第一核苷酸序列,所述第一核苷酸序列编码由与乳腺癌相关的细胞表达的第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码由与乳腺癌相关的细胞表达的第二抗原的第二表位,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在另一方面中,本发明提供一种组合物,其包含:包含第一核苷酸序列的第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是HIF-1α肽的部分,其中所述第一核苷酸序列位于质粒中。在另一方面中,本发明包括一种组合物,其包含:包含第一核苷酸序列的第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位是HIF-1α肽的部分,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些方面中,本文所述的组合物包含,包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是选自CD105、Yb-1、SOX-2、CDH3或MDM2的肽的部分,其中所述第一核苷酸序列位于质粒中。在其他方面中,本发明包括一种组合物,其包含:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位独立地选自CD105、Yb-1、SOX-2、CDH3或MDM2,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些方面中,本文所述的组合物包含,包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是选自IGFBP-2、HER-2、IGF-1R的肽的部分,其中所述第一核苷酸序列位于质粒中。在其他一些方面中,本发明包括一种组合物,其包含:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位独立地选自IGFBP-2、HER-2或IGF-1R,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些方面中,本文所述的组合物包含,包含以下的组合物:由与乳腺癌相关的细胞表达的第一抗原的第一表位;和由与乳腺癌相关的细胞表达的第二抗原的第二表位。在另一方面中,本发明包括一种组合物,其包含:至少第一抗原的第一表位,所述第一表位是来自HIF-1α的肽的部分。在其他方面中,本发明包括一种组合物,其包含:至少第一抗原的第一表位,至少第二抗原的第二表位,所述第一和第二表位来自HIF-1α。在其他方面中,本发明包括一种组合物,其包含:至少第一抗原的第一表位,所述第一表位是选自CD105、Yb-1、SOX-2、CDH3或MDM2的肽的部分。在其他方面中,本发明包括一种组合物,其包含:至少第一抗原的第一表位,至少第二抗原的第二表位,所述第一和第二表位独立地选自CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,本发明包括包含分离并纯化的质粒和赋形剂的组合物,该质粒包含编码多肽的核苷酸序列,其中所述多肽包含多种(个)表位。有时,多种(个)表位包括与选自SEQIDNO:1、6、8-10、14-16、20、25-28、32-34、46-56、60-62、66-75、82-85、和87的氨基酸序列含有至少90%序列相同性的一种或多种表位。有时,分离并纯化的质粒还可包含编码由与乳腺癌相关的细胞表达的第一抗原的第一表位的第一核苷酸序列。在一些情况中,组合物还包含编码由与乳腺癌相关的细胞表达的第二抗原的第二表位的第二核苷酸序列。第一核苷酸序列和第二核苷酸序列可位于一个或多个分离并纯化的质粒中。第一表位和第二表位可独立地选自与选自SEQIDNO:82-84的氨基酸序列有至少90%序列相同性的HIF-1α肽的部分。第一和第二表位可独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2,其中第一核苷酸序列和第二核苷酸序列位于一个或多个分离并纯化的质粒中。第一和第二表位可独立地选自:IGFBP-2、HER-2或IGF-1R,其中第一核苷酸序列和第二核苷酸序列位于一个或多个分离并纯化的质粒中。第一和第二核酸序列可位于第一分离并纯化的质粒上。第二核酸序列可位于第二分离并纯化的质粒上。在一些情况中,本发明包括组合物,其包含由与乳腺癌或卵巢癌相关的细胞表达的第一抗原的第一表位;和由与乳腺癌或卵巢癌相关的细胞表达的第二抗原的第二表位;其中第一和第二表位独立地与选自SEQIDNO:1、6、8-10、14-16、20、25-28、32-34、46-56、60-62、66-75、82-85、和87的氨基酸序列有至少90%序列相同性。在一些情况中,本发明包括包含质粒和赋形剂的组合物,该质粒包含至少一个编码与选自SEQIDNO:54、73、85、和87的表位序列有至少70%序列相同性的多肽的核苷酸序列。在一些情况中,本发明包括包含质粒和赋形剂的组合物,该质粒包含4个核苷酸序列,其中4个核苷酸序列各自独立地编码与选自SEQIDNO:54、73、85、和87的表位序列有至少70%序列相同性的多肽。有时,本发明包括包含质粒和赋形剂的组合物,该质粒包含编码与SEQIDNO:89有至少80%序列相同性的多肽的核苷酸序列。有时,本发明包括包含多肽的组合物,该多肽与SEQIDNO:89有至少80%序列相同性。在一些情况中,本文公开了向对象给予一种或多种本文所述的组合物的方法。有时,对象可能需要一种或多种组合物。有时,本文描述了预防对象中乳腺癌或卵巢癌的方法,其中该方法包括向该对象给予本文所述的组合物。有时,癌症可以是卵巢癌。癌症可以是乳腺癌。本文描述了预防对象中乳腺癌的方法,其中该方法包括向该对象给予本文所述的组合物。有时,本文描述了治疗对象中乳腺癌或卵巢癌的方法,其中该方法包括向该对象给予本文所述的组合物。有时,癌症可以是卵巢癌。癌症可以是乳腺癌。本文描述了治疗对象中乳腺癌的方法,其中该方法包括向该对象给予本文所述的组合物。有时,给药还包括向对象递送至少一剂的本文所述的组合物。有时,给药还包括通过皮下注射、皮内注射、肌内注射、血管内注射、局部施涂或吸入向对象递送本文所述的组合物。在一些情况中,本文描述了在患有乳腺癌或卵巢癌的对象中产生免疫响应的方法,其包括向对象给予本文所述的组合物。本发明还包括分离并纯化的质粒,其包含至少一个编码与选自SEQIDNO:82-84的表位序列有至少90%序列相同性的多肽的核苷酸序列。分离并纯化的质粒可包含2种或更多种核苷酸序列的组,其中2种或更多种核苷酸序列各自独立地编码与选自SEQIDNO:82-84的序列有至少90%序列相同性的多肽。分离并纯化的质粒可包含2种或更多种核苷酸序列,其中2种或更多种核苷酸序列各自编码与选自SEQIDNO:82-84的序列有至少90%序列相同性的多肽;并且在2种或更多种核苷酸序列的组内的各核苷酸不相同。本发明还可包括分离并纯化的质粒,其包含至少一个编码与选自SEQIDNO:1、6、8-10、14-16、20、25-28、和32-34的表位序列有至少90%序列相同性的多肽的核苷酸序列。分离并纯化的质粒可包含2种或更多种核苷酸序列的组,其中2种或更多种核苷酸序列各自独立地编码与选自SEQIDNO:1、6、8-10、14-16、20、25-28、和32-34的序列有至少90%序列相同性的多肽。分离并纯化的质粒可包含2种或更多种核苷酸序列的组,其中2种或更多种核苷酸序列各自编码与选自SEQIDNO:1、6、8-10、14-16、20、25-28、和32-34的序列有至少90%序列相同性的多肽;并且在2种或更多种核苷酸序列的组内的各核苷酸不相同。本发明可包括分离并纯化的质粒,其包含至少一个编码与选自SEQIDNO:46-56、60-62、或66-75的表位序列有至少90%序列相同性的多肽的核苷酸序列。分离并纯化的质粒可包含2种或更多种核苷酸序列的组,其中2种或更多种核苷酸序列各自独立地编码与选自SEQIDNO:46-56、60-62、或66-75的序列有至少90%序列相同性的多肽。分离并纯化的质粒可包含2种或更多种核苷酸序列的组,其中2种或更多种核苷酸序列各自编码与选自SEQIDNO:46-56、60-62、或66-75的序列有至少90%序列相同性的多肽;并且在2种或更多种核苷酸序列的组内的各核苷酸不相同。有时,本发明还可包括分离并纯化的质粒,其包含至少一个编码与选自SEQIDNO:54、73、85、和87的表位序列有至少70%序列相同性的多肽的核苷酸序列。通过引用纳入本说明书中提到的所有发表物和专利申请通过引用纳入本文,就好像将各篇单独的发表物和专利申请特别和单独地通过引用纳入本文那样。附图的简要说明所附权利要求书中具体说明了本发明的新特征。可参考以下说明和附图更好地理解本发明的特征和优点,这些详述列出利用本发明原理的说明性实施方式:图1证明Th1和Th2表位在功能性亲合力上不同。图2显示了Th2消除Th1的抗肿瘤功效。图3显示了抗原特异性IgG免疫。图4显示了基于群的表位筛选。图5证明了乳腺癌对象的特性。图6显示了针对干细胞/EMT蛋白质的抗原特异性IFNγ应答。图7显示了针对干细胞/EMT蛋白质的抗原特异性IL-10应答。图8显示了延伸序列的表位验证为具有CD105延伸表位(52aa)QNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTEL(SEQIDNO:1)的天然表位。图9显示了基于IFNγ/IL-10活性比率的Yb-1的延伸表位。图10显示了IFNγ主导的量级和发生率。CDH3抗原的IFNγ/IL-10活性比率。图11显示了IFNγ主导的量级和发生率。HIF1α抗原的IFNγ/IL-10活性比率。图12显示了小鼠中同时体内评价的图表。图13显示了示例性Yb-1质粒基疫苗在小鼠中的免疫原性和功效。图14显示了本文所述的组合物的图、免疫原性和示例性序列。SEQIDNO:39如图14所示。图15A显示了肽特异性T-细胞示例性验证为天然表位。图15B显示了使用本文所述的组合物的临床试验的时间线。图15C显示了使用本文所述的组合物的I期临床试验的研究方案。图16显示了对在单质粒、pHIF1α和编码5种抗原的质粒BCMA5中HIF1α表达的Western印迹分析。图17显示了IFNγ主导的量级和发生率。CD105抗原的IFNγ/IL-10活性比率。图18显示了IFNγ主导的量级和发生率。MDM-2抗原的IFNγ/IL-10活性比率。图19显示了IFNγ主导的量级和发生率。SOX-2抗原的IFNγ/IL-10活性比率。图20显示了IFNγ主导的量级和发生率。Yb-1抗原的IFNγ/IL-10活性比率。图21显示了HIF1α肽和质粒疫苗在小鼠中的免疫原性和功效。图22显示了CD105肽和质粒疫苗在小鼠中的免疫原性和功效。图23显示了CDH3肽和质粒疫苗在小鼠中的免疫原性和功效。图24显示了SOX2肽和质粒疫苗在小鼠中的免疫原性和功效。图25显示了MDM2肽和质粒疫苗在小鼠中的免疫原性和功效。图26显示了最后疫苗后3个月的小鼠质量。图27显示了最后疫苗后10天的小鼠质量。图28证明IGFBP-2C-端与N-端相比对诱导IL-10-分泌T-细胞的表位富集。图29显示了N-端,但不是C-端的IGFBP-2疫苗同时刺激I型免疫并抑制肿瘤生长。图30显示了IGFBP-2疫苗-诱导的Th2消除IGFBP-2-特异性Th1的抗肿瘤效果。图31证明基于HER2Th1表位的疫苗可增加存活率,其与在晚期HER2+乳腺癌患者中扩散的表位相关。图32证明基于延伸的Th质粒的疫苗比基于肽的疫苗在生成肿瘤抗原特异性Th1免疫力上更有效。图33显示了在基于质粒DNA的免疫结束后超过一年的持续性HER2ICD特异性免疫力。图34显示了通过ELISPOT就IFNγ和IL-10T-细胞分泌筛选的IGF-1R表位。图35证明多表位IGF-1R疫苗抑制植入的乳腺癌生长。图36显示了多抗原多表位疫苗预防小鼠中乳腺癌发展。图37显示了由HER2免疫诱导的示例性细胞因子分泌模式。图38显示了对干细胞/EMT抗原的ROC分析。图39显示了在干细胞和/或EMT中过表达的候选蛋白质。图40显示了本文所述的构建体的动画图。图41显示了IGFBP-2、生存素、HIF-1A、和IGF-IR表达的Western印迹图像。图42A-图42D显示了在ID8卵巢癌移植模型中多抗原疫苗的抗肿瘤效果。在植入ID8-Luc后三周时,小鼠在IVIS生物发光成像仪上成像。在原发植入(图42A)和转移位点(图42B)中测量总流量(光子/秒)。相应的动物显示为仅佐剂(图42C),和三抗原免疫(图42D)。图43A和图43B显示了随着蛋白质序列变化的TH1响应。在生存素的C-端和HIF1a的N-端中鉴定选择性TH1诱导序列。由供体类型显示每种肽的平均cSPWx发生率。正y-轴上显示了志愿供体(n=20)(白色)和癌症供体(n=20)(灰色)的IFN-gcSPWx发生率。负y-轴上显示了志愿供体(实心黑)和癌症供体(虚黑)的IL-10cSPWx发生率。图43A显示了关于HIF-1A肽的TH1响应。图43B显示了关于生存素肽的TH1响应。垂直线显示选择的序列。图44A-图44D显示了在卵巢癌患者和志愿者中的IgG抗体表达水平的比较。与支援者对照相比,对候选抗原有特异性的IgG抗体在卵巢癌患者中明显升高。显示了IGF-IR(图44A)、IGFBP-2(图44B)、HIF-1A(图44C)、和生存素(图44D)的IgG(以ug/ml计)(y-轴)和实验群(X-轴)。志愿者对照(虚线)的平均和2标准偏差,*p<0.05;**p<0.01;***p<0.001。发明详述本发明提供了乳腺癌疫苗和卵巢癌疫苗的组合物,通常用于预防或治疗乳腺癌或卵巢癌。本发明还提供了向对象给予乳腺癌疫苗或卵巢癌疫苗的方法。本文所示的组合物可与本文所示的方法联用来预防或治疗乳腺癌或卵巢癌。在一些情况中,组合物可包括:编码乳腺癌或卵巢癌抗原的表位的核酸序列,该表位可在对象中引发免疫应答,含有本文所述的序列的质粒,佐剂,药物运载体,和适用于药物组合物的惰性化学物。乳腺癌或卵巢癌抗原可以是在对象中表达的任意抗原中的至少一个,该对象可患有或可发展乳腺癌或卵巢癌。通常,由乳腺癌细胞,卵巢癌细胞,和/或组织如乳腺癌或卵巢癌干细胞(CSC)来表达乳腺癌或卵巢癌抗原。CSC可显示能够自我更新,不受调控的生长,和药物抗性。在一些情况中,CSC可表达蛋白质(例如,抗原),并且例如,由CSC表达的蛋白质(例如,抗原)的水平可上调(例如,相对于给定量增加表达)或下调(例如,相对于给定量降低表达)。在一些情况中,与正常组织或细胞相比由CSC上调的蛋白质可参与乳腺癌或卵巢癌的发展和/或进展。例如,可使用本文所述的组合物和方法来鉴定蛋白质并且靶向抗原表位。在一些情况中,可在组合物中使用一种乳腺癌或卵巢癌抗原表位。在其他情况中,可在组合物中使用超过一种乳腺癌或卵巢癌抗原表位。在其他情况中,可在组合物中使用超过2种抗原,超过3种,超过4种,超过5种,超过6种,超过7种,超过8种,超过9种,超过10种,超过15种,超过20种,超过25种或超过30种乳腺癌或卵巢癌抗原。在一些情况中,抗原可以相同。在其他情况中,抗原可以不同。可配制本文所述的乳腺癌或卵巢癌疫苗的组合物用于预防乳腺癌或卵巢癌。例如,预防组合物可消除具有异常(例如,上调)表达的蛋白质的细胞(例如,CSC,如乳腺CSC或卵巢CSC)以预防乳腺癌或卵巢癌。在一些情况中,一种和/或多种表位可在相同的乳腺癌或卵巢癌抗原上,或者一种和/或多种表位可在不同的乳腺癌或卵巢癌抗原上。在一些情况中,可在组合物中使用一种乳腺癌或卵巢癌抗原上的表位。在其他情况中,可在组合物中使用超过一种乳腺癌或卵巢癌抗原上的表位,超过2种抗原,超过3种,超过4种,超过5种,超过6种,超过7种,超过8种,超过9种,超过10种,超过15种,超过20种,超过25种或超过30种乳腺癌或卵巢癌抗原上的表位。本文所述的组合物和方法可引发对象中的免疫应答。免疫应答可以是针对组合物(例如,疫苗)中抗原的表位的免疫应答。疫苗装备对象的免疫系统,使得该免疫系统可检测并破坏对象中含有疫苗的抗原的那些物质。本文所述的组合物和方法可引发对象中的1型(Th1)免疫应答。Th1免疫应答可包括由免疫细胞(例如,抗原特异性T细胞)亚组分泌炎性细胞因子(例如,IFNγ,TNFα)。在一些情况中,炎性细胞因子使另一亚型的免疫细胞(例如,细胞毒性T细胞)活化,其可破坏对象中含有抗原的那些物质。使用本文所述的筛选方法来鉴定表位并结合来自肿瘤抗原的肽,可针对诱导Th1免疫应答筛选多种抗原的表位。例如,筛选方法可鉴定来自至少一种引发针对乳腺癌或卵巢癌抗原,包括CSC抗原(例如,乳腺CSC或卵巢CSC)的Th1应答的肿瘤抗原的表位(例如,优选导致Th1细胞因子分泌),如本文所述。在一些情况中,用于本文所述的组合物和方法的表位和/或抗原可被对象的免疫系统识别以引发Th1免疫应答并释放I型细胞因子。可通过表位和T细胞(更具体地,由T细胞表达的主要组织相容性复合物(MHC))之间的相互作用来引发Th1应答,。例如,表位与MHC受体的高亲和性结合可刺激Th1应答。MHC受体可以是多种类型的MHC受体中的至少一种。T细胞上的MHC受体可在群中的个体之间变化。除了编码抗原表位的核酸以外,本文所述的组合物可包括其他组分。在一些情况中,组合物可包括至少一种佐剂。在一些情况中,组合物可包括至少一种药物运载体。在一些情况中,组合物可包括至少一种适用于药物组合物的惰性化学物。在一些情况中,组合物可包括至少一种佐剂和至少一种药物运载体。在一些情况中,组合物可包括至少一种佐剂和至少一种适用于药物组合物的惰性化学物。在一些情况中,组合物可包括至少一种适用于药物组合物的惰性化学物和药物运载体。在一些情况中,组合物可含有多种佐剂、多种药物运载体和多种适用于药物组合物的惰性化学物。在一些情况中,可在组合物中使用一种佐剂。在其他情况中,可在组合物中使用超过1种佐剂、超过2种佐剂、超过3种佐剂、超过4种佐剂、超过5种佐剂、超过6种佐剂、超过7种佐剂、超过8种佐剂、超过9种佐剂或超过10种佐剂。在一些情况中,可在组合物中使用一种药物运载体。在其他情况中,可在组合物中使用超过1种药物运载体、超过2种药物运载体、超过3种药物运载体、超过4种药物运载体、超过5种药物运载体、超过6种药物运载体、超过7种药物运载体、超过8种药物运载体、超过9种药物运载体或超过10种药物运载体。在一些情况中,可在组合物中使用一种化学物。在其他情况中,可在组合物中使用超过1种化学物、超过2种化学物、超过3种化学物、超过4种化学物、超过5种化学物、超过6种化学物、超过7种化学物、超过8种化学物、超过9种化学物或超过10种化学物。本发明还描述了向对象给予乳腺癌疫苗或卵巢癌疫苗的方法。在一些情况中,该方法可包括构建靶向这些抗原的基于质粒的疫苗并且确定给予疫苗是否是安全的、免疫原性的、并且有效预防乳腺癌发展。例如,组合物可以是基于多抗原Th1多表位质粒的疫苗。在一些情况中,该方法可包括进行至少一次临床试验以确定患有乳腺癌或卵巢癌的对象中基于质粒的疫苗的安全性和免疫原性。例如,抗原可由CSC(例如,乳腺CSC或卵巢CSC)表达或与其相关,和/或将细胞从上皮细胞转化成间充质细胞(EMT)。在一些情况中,组合物的表位可衍生自抗原,其中表位可引发对象中的Th1免疫应答。例如,Th1免疫应答可包括免疫细胞,通常是CD4+T细胞。在一些情况中,组合物可以是核酸(例如,基于质粒的疫苗),其可包括编码超过一种抗原或抗原的超过一种(个)表位的核酸。在一些情况中,可使用该方法来确定本文所述的组合物是否在多种生物体中预防乳腺癌或卵巢癌发展,例如,在使用遗传上相似的啮齿类(例如,小鼠),使用遗传上多样化的啮齿类(例如,小鼠)的癌症(例如,乳腺癌或卵巢癌)模型中,和在可能患有或未患有乳腺癌或卵巢癌的对象中。在一些情况中,癌症可以是乳腺癌。在一些情况中,乳腺癌可以是三阴性乳腺癌(TNBC)。抗原鉴定本文所述的组合物和方法包括鉴定和工程改造药物组合物(例如,疫苗)中的乳腺癌或卵巢癌抗原。虽然本领域普通技术人员已知的任何技术都可用于鉴定由患有乳腺癌或卵巢癌的对象表达的抗原,在示例性情况中,可使用本文所述的方法来鉴定合适抗原。在一些情况中,该方法可包括筛选来自对象的血清。在一些情况中,筛选可以是抗体筛选。例如,筛选的抗体可以是IgG抗体。在一些情况中,血清可来自患有乳腺癌或卵巢癌的对象。在其他情况中,血清可来自未患有乳腺癌或卵巢癌的对象。癌症抗原,例如,乳腺癌抗原或卵巢癌抗原可以是蛋白质的部分、肽的部分或多氨基酸的部分。在一些情况中,该部分可以是蛋白质的百分比、肽的百分比或多氨基酸的百分比。在一些情况中,百分比可小于蛋白质、肽或多氨基酸的1%、5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%或100%。在一些情况中,该部分可位于蛋白质、肽或多氨基酸的C端处。在其他情况中,该部分可位于蛋白质、肽或多氨基酸的C端附近。例如,C端附近可以在总蛋白质、肽或多氨基酸长度上距离中点1%、5%、10%、15%、20%、25%、30%、35%、40%、45%、50%内。在一些情况中,该部分可位于蛋白质、肽或多氨基酸的N端处。在其他情况中,该部分可位于蛋白质、肽或多氨基酸的N端附近。例如,N端附近可以在总蛋白质、肽或多氨基酸长度上距离中点1%、5%、10%、15%、20%、25%、30%、35%、40%、45%、50%内。在一些情况中,该部分可位于蛋白质、肽或多氨基酸的中间附近。在其他情况中,该部分可位于蛋白质、肽或多氨基酸的中间附近。例如,中间附近可以在总蛋白质、肽或多氨基酸长度上距离末端1%、5%、10%、15%、20%、25%、30%、35%、40%、45%、50%内。可鉴定并筛选至少一种抗原作为本文所述的组合物(例如,疫苗)中的抗原的适用性。在一些情况中,可鉴定并筛选一种抗原。在其他情况中,可鉴定并筛选超过1种抗原、可鉴定并筛选超过2种抗原、可鉴定并筛选超过3种抗原、可鉴定并筛选超过4种抗原、可鉴定并筛选超过5种抗原、可鉴定并筛选超过6种抗原、可鉴定并筛选超过7种抗原、可鉴定并筛选超过8种抗原、可鉴定并筛选超过9种抗原、可鉴定并筛选超过10种抗原、可鉴定并筛选超过11种抗原、可鉴定并筛选超过12种抗原、可鉴定并筛选超过13种抗原、可鉴定并筛选超过14种抗原、可鉴定并筛选超过15种抗原、可鉴定并筛选超过20种抗原、可鉴定并筛选超过25种抗原、可鉴定并筛选超过30种抗原、可鉴定并筛选超过35种抗原、可鉴定并筛选超过40种抗原、可鉴定并筛选超过45种抗原、并且可鉴定并筛选超过50种抗原的疫苗适用性。在示例性情况中,鉴定并筛选5种抗原的疫苗适用性。使用本领域普通技术人员已知的筛选技术,筛选疫苗适用性的抗原可衍生自在来自患有乳腺癌或卵巢癌的对象的血清中检测到的任意蛋白质。在一些情况中,筛选通常可以是抗体筛选。虽然蛋白质可以是来自患有乳腺癌或卵巢癌的对象的血清中检测到的任意蛋白质,在示例性情况中,抗原所衍生的蛋白质可被分类为干细胞蛋白质和/或EMT蛋白质。例如,在乳腺癌中,干细胞/EMT蛋白质可包括SOX2、YB1、CD105、MDM2、CDH3+/-和HIF1α。通常,抗原在乳腺癌对象中和没有乳腺癌的对象中可都有免疫原性。抗原表位作图本文提供的组合物和方法包括对抗原内至少一种(个)表位进行作图,使得表位在给予对象时产生Th1免疫应答。在一些情况中,可作为乳腺癌疫苗或卵巢癌疫苗给予表位。虽然本领域普通技术人员已知的任意技术可用于鉴定可引发由对象产生的Th1免疫应答的表位,仍然优选使用本文所述的方法。在一些情况中,表位可以是抗原的部分(例如,上述鉴定的)。例如,表位可以是抗原性蛋白质的肽和/或抗原性蛋白质的部分。在一些情况中,表位可以是衍生自乳腺癌或卵巢癌抗原的人白细胞抗原(HLA)I类表位。例如,HLAI类表位可包括结合至HLA-A、-B、和-C分子的表位。在一些情况中,表位可以是衍生自用于癌症疫苗(例如,乳腺癌或卵巢癌)开发的乳腺癌或卵巢癌抗原的II类表位。例如,HLAII类表位可包括结合至HLA-DP、-DM、-DOA、-DOB、-DQ和-DR分子的表位。在一些情况中,除了本文所述的方法以外,可使用以下步骤来对表位作图,(1)通过至少一种HLA等位基因(例如,HLA-DR,即通用表位)确定表位是否结合MHC(例如,以高亲和性),(2)确定表位是否刺激IFNγ而非IL-10分泌(例如,来自抗原特异性T-细胞),和(3)确定T-细胞是否可识别经抗原呈递细胞(APC)处理的肽(例如,表位),即是天然表位。在一些情况中,可以使用T-细胞系。例如,T-细胞系可以是表位衍生的T-细胞系。在一些情况中,T-细胞可以是经工程改造以表达嵌合抗原受体构建体的外源性T-细胞,该构建体以高度选择性和亲合力结合表位。在一些情况中,表位可衍生自蛋白质(例如,重组蛋白质)。在其他情况中,蛋白质可以是天然蛋白质。在一些情况中,蛋白质可经内源性加工。在其他情况中,蛋白质可经外源性加工。在一些情况中,蛋白质可经自体APC的内源性加工。在其他情况中,蛋白质可经自体APC的外源性加工。在所有情况中,肽是从抗原作图的表位,并且可使用本文所述的方法鉴定用于选择肽表位。在一些情况中,表位可衍生自可直接在基于肽的疫苗中使用的人蛋白质。在其他情况中,表位可衍生自人蛋白质并且编码核酸序列可整合到设计成在给药后诱导对象中表位表达的核酸构建体中。例如,核酸构建体可允许针对自蛋白质的特定组的待产生、扩增、减弱、抑制或消除的至少一种(个)表位的免疫应答。在一些情况中,肽或核酸构建体可优化成基于蛋白质或质粒的免疫来诱导、扩增或产生Th1免疫应答。在一些情况中,表位可以是延伸的Th1表位。在其他情况中,肽或核酸构建体可优化成基于蛋白质或质粒的免疫以在有此需要的对象(例如,人或动物)中抑制、减弱或消除致病性应答。在一些情况中,肽位于蛋白质、肽或多氨基酸的部分内,使得蛋白质、肽或多氨基酸刺激IFNγ分泌。在一些情况中,肽位于蛋白质、肽或多氨基酸的部分内,使得蛋白质、肽或多氨基酸抑制IFNγ分泌。在一些情况中,肽位于蛋白质、肽或多氨基酸的部分内,使得蛋白质、肽或多氨基酸刺激IL-10分泌。在一些情况中,肽位于蛋白质、肽或多氨基酸的部分内,使得蛋白质、肽或多氨基酸抑制IL-10分泌。在一些情况中,肽可刺激IFNγ分泌并抑制IL-10分泌。在其他情况中,肽可刺激IL-10分泌并抑制IFNγ分泌。在一些情况中,肽可刺激IFNγ分泌并刺激IL-10分泌。在其他情况中,肽可抑制IL-10分泌并抑制IFNγ分泌。在一些情况中,可调节包含肽的氨基酸,使得可实现肽对IFNγ分泌的所需效果和/或肽对IL-10分泌的所需效果。例如,可调节同时刺激IFNγ和IL-10分泌的肽,使得肽的长度被缩短以消除刺激IL-10分泌的氨基酸,使得肽仅刺激IFNγ分泌。在一些情况中,可在延伸的肽疫苗的疫苗组合物中包括鉴定的表位。在一些情况中,延伸的表位可以是40-80聚体肽。在一个示例性情况中,核酸序列或肽序列并列用于构建延伸的肽序列。在母蛋白质内选择的肽的并置(例如,互相10个氨基酸内)允许构建串联延伸的表位,其可含有耐受性和/或抑制性表位。例如,串联延伸的表位可含有短的间插的<10个氨基酸的序列。单独的这些肽和/或延伸的表位中的任意(体现为肽本身,或相应核酸构建体)或任意组合可优化到基于蛋白质或质粒的免疫中,其将在有此需要的对象(动物或人)中特异性诱导、放大或产生保护性免疫应答,或者,将抑制、减弱或消除致病性应答。在一些情况中,表位可以是一定长度的氨基酸。在一些情况中,表位可以少于5个氨基酸、少于10个氨基酸、少于15个氨基酸、少于20个氨基酸、少于25个氨基酸、少于30个氨基酸、少于35个氨基酸、少于40个氨基酸、少于45个氨基酸、少于50个氨基酸、少于55个氨基酸、少于60个氨基酸、少于70个氨基酸、少于75个氨基酸、少于80个氨基酸、少于85个氨基酸、少于90个氨基酸、少于95个氨基酸、少于100个氨基酸、少于110个氨基酸、少于120个氨基酸、少于130个氨基酸、少于140个氨基酸、少于150个氨基酸、少于160个氨基酸、少于170个氨基酸、少于180个氨基酸、少于190个氨基酸、少于200个氨基酸、少于210个氨基酸、少于220个氨基酸、少于230个氨基酸、少于240个氨基酸、少于250个氨基酸、少于260个氨基酸、少于270个氨基酸、少于280个氨基酸、少于290个氨基酸、少于300个氨基酸、少于350个氨基酸、少于400个氨基酸、少于450个氨基酸或少于500个氨基酸。在一些情况中,本发明提供包含分离并纯化的质粒和赋形剂的组合物,该质粒包含编码多肽的核苷酸序列,其中所述多肽包含多种(个)表位。在一些情况中,多种(个)表位包括与选自SEQIDNO:1、6、8-10、14-16、20、25-28、32-34、46-56、60-62、66-75、82-85、和87的氨基酸序列含有至少90%序列相同性的一种或多种表位。在一些情况中,多种(个)表位包括与选自SEQIDNO:82-84的氨基酸序列含有至少90%序列相同性的一种或多种表位。在一些情况中,多种(个)表位包括与选自SEQIDNO:1、6、8-10、14-16、20、25-28、或32-34的氨基酸序列含有至少90%序列相同性的一种或多种表位。在一些情况中,多种(个)表位包括与选自SEQIDNO:46-56、60-62、或66-75的氨基酸序列含有至少90%序列相同性的一种或多种表位。在一些情况中,多种(个)表位包括与选自SEQIDNO:54、73、85、和87的氨基酸序列含有至少90%序列相同性的一种或多种表位。在一些情况中,多种(个)表位包括选自SEQIDNO:1、6、8-10、14-16、20、25-28、32-34、46-56、60-62、66-75、82-85、和87的一种或多种表位。在一些情况中,多种(个)表位是多种邻近的表位。在一些情况中,邻近的表位还包括位于一个或多个表位序列之间的接头。在一些情况中,第一和第二表位的氨基酸序列被接头氨基酸序列分开。在一些情况中,第一表位的氨基酸序列与第二表位的氨基酸序列毗邻。在一些情况中,组合物还包括其他分离并纯化的质粒,该质粒包含编码附加多肽的其他核苷酸序列,其中其他多肽包含多种(个)表位,包括与选自SEQIDNO:1、6、8-10、14-16、20、25-28、32-34、46-56、60-62、66-75、82-85、和87的氨基酸序列含有至少90%序列相同性的一种(个)或多种(个)表位。有时,组合物还包括附加的分离并纯化的质粒,该质粒包含编码其他多肽的其他核苷酸序列,其中其他多肽包含选自SEQIDNO:1、6、8-10、14-16、20、25-28、32-34、46-56、60-62、66-75、82-85、和87的多种(个)表位。在一些情况中,多肽和附加多肽的序列是不同的。在一些情况中,免疫应答是1型免疫应答。在一些情况中,免疫应答表征为大于1的I型细胞因子产生与II型细胞因子产生之比。在一些情况中,免疫应答表征为小于1的I型细胞因子产生与II型细胞因子产生之比。在一些情况中,免疫应答表征为大于1的IFNγ产生与IL-10产生之比。在一些情况中,免疫应答表征为小于1的IFNγ产生与IL-10产生之比。在一些情况中,向对象给予组合物。在一些情况中,对象需要给予组合物。在一些情况中,组合物在对象中有效引发免疫应答。在一些情况中,组合物在对象中有效消除与乳腺癌或卵巢癌相关的多种细胞。在一些情况中,组合物可用于在对象中防止与乳腺癌或卵巢癌相关的细胞的生长。在一些情况中,癌症是乳腺癌。在一些情况中,乳腺癌是复发性或难治性或转移的乳腺癌。在一些情况中,所述癌症是卵巢癌。在一些情况中,卵巢癌是复发性或难治性或转移的卵巢癌。在一些情况中,在药物组合物中含有至少第一表位。在一些情况中,在另外包含药物运载体的药物组合物中含有至少第一表位。在一些情况中,在另外包含药物运载体和佐剂的药物组合物中含有至少第一表位。在一些情况中,在另外包含佐剂的药物组合物中含有至少第一表位。在一些情况中,组合物还包含佐剂和药物运载体。在一些情况中,佐剂是GM-CSF。本发明还提供了用于制备本文所述的组合物的试剂盒,该试剂盒包含用于制备组合物的说明书。本发明还提供了用于给予本文所述的组合物的试剂盒,该试剂盒包含用于给予组合物的说明书。包含乳腺癌疫苗的表位的组合物本文所述的组合物包括,包含以下的组合物:包含第一核苷酸序列的第一质粒,所述第一核苷酸序列编码由与乳腺癌相关的细胞表达的第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码由与乳腺癌相关的细胞表达的第二抗原的第二表位,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些情况中,组合物可包括编码来自以下蛋白质的表位的核酸:CD105、HIF1α、MDM2、Yb1、SOX-2、HER-2、IGFBP2、IGF-1R、CDH3和生存素在一些情况中,组合物可包括,包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是选自CD105、Yb-1、SOX-2、CDH3或MDM2的肽的部分,其中所述第一核苷酸序列位于质粒中。在其他情况中,组合物可包括,包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位独立地选自CD105、Yb-1、SOX-2、CDH3或MDM2,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些情况中,组合物可包括编码来自以下蛋白质的表位和核酸:CD105、MDM2、Yb-1、SOX-2、和CDH3。在一些情况中,组合物可包括编码肽CD105的表位的核酸序列,其选自下组:与核苷酸序列CAGAACGGCACCTGGCCCCGCGAGGTGCTGCTGGTGCTGTCCGTGAACTCCTCCGTGTTCCTGCACCTACAGGCCCTGGGCATCCCCCTGCACCTGGCCTACAACTCCTCCCTGGTGACCTTCCAGGAGCCCCCCGGCGTGAACACCACCGAGCTG(SEQIDNO:2)有至少90%序列相同性的核苷酸序列;与核苷酸序列ACCGTGTTCATGCGCCTGAACATCATCTCCCCCGACCTGTCCGGCTGCACCTCCAAGGGCCTGGTGCTGCCCGCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCTCCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCC(SEQIDNO:3)有至少90%序列相同性的核苷酸序列;与核苷酸序列ACCGTGTCCATGCGCCTGAACATCGTGTCCCCCGACCTGTCCGGCAAGGGCCTGGTGCTGCCCTCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCGGCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCC(SEQIDNO:4)有至少90%序列相同性的核苷酸序列;与核苷酸序列ACCGTGTCCATGCGCCTGAACATCGTGTCCCCCGACCTGTCCGGCAAGGGCCTGGTGCTGCCCTCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCGCCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCC(SEQIDNO:5)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列EARMLNASIVASFVELPL(SEQIDNO:6)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列QNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTEL(SEQIDNO:7)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:8)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRGPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:9)有至少90%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRAPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:10)有至少90%序列相同性。在一些情况中,组合物可包括编码肽Yb-1的表位的核酸序列,其选自下组:与核苷酸序列GGAGTGCCAGTGCAGGGCTCCAAGTACGCTGCCGACCGCAACCACTACCGCCGCTACCCACGCCGTCGCGGCCCACCCCGCAACTACCAGCAGAAC(SEQIDNO:11)有至少90%序列相同性的核苷酸序列;与核苷酸序列GGCGTGCCCGTGCAGGGCTCCAAGTACGCCGCCGACCGCAACCACTACCGCCGCTACCCCCGCCGCCGCGGCCCCCCCCGCAACTACCAGCAGAAC(SEQIDNO:12)有至少90%序列相同性的核苷酸序列;与核苷酸序列GGCGTGCCCGTGCAGGGCTCCAAGTACGCCGCCGACCGCAACCACTACCGCCGCTACCCCCGCCGCCGCGGCCCCCCCCGCAACTACCAGCAGAAC(SEQIDNO:13)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列EDVFVHQTAIKKNNPRK(SEQIDNO:14)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列YRRNFNYRRRRPEN(SEQIDNO:15)有至少90%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列GVPVQGSKYAADRNHYRRYPRRRGPPRNYQQN(SEQIDNO:16)有至少90%序列相同性。在一些情况中,组合物可包括编码肽SOX-2的表位的核酸序列,其选自下组:与核苷酸序列GGCCTCAATGCGCACGGCGCAGCGCAGATGCAGCCCATGCACCGCTACGACGTGAGCGCCCTGCAGTACAACTCCATGACCAGCTCGCAGACCTACATGAACGGCTCGCCCACCTACAGCATGTCCTACTCGCAGCAGGGCACCCCTGGCATGGCTCTTGGCTCCATGGGTTCGGTG(SEQIDNO:17)有至少90%序列相同性的核苷酸序列;与核苷酸序列GGCCTGAACGCCCACGGCGCCGCCCAGATGCAGCCCATGCACCGCTACGACGTGTCCGCCCTGCAGTACAACTCCATGACCTCCTCCCAGACCTACATGAACGGCTCCCCCACCTACTCCATGTCCTACTCCCAGCAGGGCACCCCCGGCATGGCCCTGGGCTCCATGGGCTCCGTG(SEQIDNO:18)有至少90%序列相同性的核苷酸序列;与核苷酸序列GGCCTGAACGCCCACGGCGCCGCCCAGATGCAGCCCATGCACCGCTACGACGTGTCCGCCCTGCAGTACAACTCCATGACCTCCTCCCAGACCTACATGAACGGCTCCCCCACCTACTCCATGTCCTACTCCCAGCAGGGCACCCCCGGCATGGCCCTGGGCTCCATGGGCTCCGTG(SEQIDNO:19)有至少90%序列相同性的核苷酸序列;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列GLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSV(SEQIDNO:20)有至少90%序列相同性。在一些情况中,组合物可包括编码肽CDH3的表位的核酸序列,其选自下组:与核苷酸序列AGGTCACTGAAGGAAAGGAATCCATTGAAAATCTTCCCATCCAAACGTATCTTACGAAGACACAAGAGAGATTGGGTGGTTGCTCCAATATCTGTCCCTGAAAATGGCAAGGGTCCCTTCCCACAGAGACTGAATCAGCTCAAGTCTAATAAAGATAGAGACACCAAGATTTTCTACAGCATCACGGGGCCGGGTGCAGACAGCCCACCTGAGGGTGTCTTCGCTGTAGAGAAGGAGACA(SEQIDNO:21)有至少90%序列相同性的核苷酸序列;与核苷酸序列TTGAAAATCTTCCCATCCAAACGTATCTTACGAAGACACAAGAGAGATTGGGTGGTTGCTCCAATATCTGTCCCTGAAAATGGCAAGGGTCCCTTCCCACAGAGACTGAATCAGCTCAAGTCTAATAAAGATAGAGACACCAAGATTTTCTACAGCATCACGGGGCCGGGTGCAGACAGCCCACCTGAGGGTGTCTTCGCTGTAGAGAAGGAGACA(SEQIDNO:22)有至少90%序列相同性的核苷酸序列;与核苷酸序列GCCATGCACTCCCCCCCCACCCGCATCCTGCGCCGCCGCAAGCGCGAGTGGGTGATGCCCCCCATCTTCGTGCCCGAGAACGGCAAGGGCCCCTTCCCCCAGCGCCTGAACCAGCTGAAGTCCAACAAGGACCGCGGCACCAAGATCTTCTACTCCATCACCGGCCCCGGCGCCGACTCCCCCCCCGAGGGCGTGTTCACCATCGAGAAGGAGTCC(SEQIDNO:23)有至少90%序列相同性的核苷酸序列;与核苷酸序列GTGATGAACTCCCCCCCCTCCCGCATCCTGCGCCGCCGCAAGCGCGAGTGGGTGATGCCCCCCATCTCCGTGCCCGAGAACGGCAAGGGCCCCTTCCCCCAGCGCCTGAACCAGCTGAAGTCCAACAAGGACCGCGGCACCAAGCTGTTCTACTCCATCACCGGCCCCGGCGCCGACTCCCCCCCCGAGGGCGTGTTCACCATCGAGAAGGAGACC(SEQIDNO:24)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列RSLKERNPLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKET(SEQIDNO:25)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列LKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKET(SEQIDNO:26)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列AMHSPPTRILRRRKREWVMPPIFVPENGKGPFPQRLNQLKSNKDRGTKIFYSITGPGADSPPEGVFTIEKES(SEQIDNO:27)有至少90%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列VMNSPPSRILRRRKREWVMPPISVPENGKGPFPQRLNQLKSNKDRGTKLFYSITGPGADSPPEGVFTIEKET(SEQIDNO:28)有至少90%序列相同性。在一些情况中,组合物可包括编码肽MDM2的表位的核酸序列,其选自下组:与核苷酸序列ACCTACACCATGAAGGAGGTGCTGTTCTACCTGGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACCTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAaATCTACACCATGATCTACCGCAACCTGGTGGTGGTGAACCAGCAGGAGTCCTCCGACTCCGGCACCTCCGTGTCC(SEQIDNO:29)有至少90%序列相同性的核苷酸序列;与核苷酸序列ACCTACACCATGAAGGAGATCATCTTCTACATCGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACGTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAGATCTACGCCATGATCTACCGCAACCTGGTGGCCGTGTCCCAGCAGGACTCCGGCACCTCCCTGTCC(SEQIDNO:30)有至少90%序列相同性的核苷酸序列;与核苷酸序列ATCTACACCATGAAGGAGATCATCTTCTACATCGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACGTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAGATCTACGCCATGATCTACCGCAACCTGGTGGTGGTGTCCCAGCAGGACTCCGGCACCTCCCCCTCC(SEQIDNO:31)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSV(SEQIDNO:32)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVAVSQQDSGTSLS(SEQIDNO:33)有至少90%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列IYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVVVSQQDSGTSPS(SEQIDNO:34)有至少90%序列相同性。在示例性情况中,组合物可包括编码5种(个)表位的融合肽的核酸序列,其选自下组:与核苷酸序列ATGGCGGTACCCATGCAACTGTCCTGCTCTAGACAGAACGGCACCTGGCCCCGCGAGGTGCTGCTGGTGCTGTCCGTGAACTCCTCCGTGTTCCTGCACCTACAGGCCCTGGGCATCCCCCTGCACCTGGCCTACAACTCCTCCCTGGTGACCTTCCAGGAGCCCCCCGGCGTGAACACCACCGAGCTGAGATCCACCGGTGGAGTGCCAGTGCAGGGCTCCAAGTACGCTGCCGACCGCAACCACTACCGCCGCTACCCACGCCGTCGCGGCCCACCCCGCAACTACCAGCAGAACACGCGTGGCCTCAATGCGCACGGCGCAGCGCAGATGCAGCCCATGCACCGCTACGACGTGAGCGCCCTGCAGTACAACTCCATGACCAGCTCGCAGACCTACATGAACGGCTCGCCCACCTACAGCATGTCCTACTCGCAGCAGGGCACCCCTGGCATGGCTCTTGGCTCCATGGGTTCGGTGAGATCCCAATTGAGGTCACTGAAGGAAAGGAATCCATTGAAAATCTTCCCATCCAAACGTATCTTACGAAGACACAAGAGAGATTGGGTGGTTGCTCCAATATCTGTCCCTGAAAATGGCAAGGGTCCCTTCCCACAGAGACTGAATCAGCTCAAGTCTAATAAAGATAGAGACACCAAGATTTTCTACAGCATCACGGGGCCGGGTGCAGACAGCCCACCTGAGGGTGTCTTCGCTGTAGAGAAGGAGACAAGATCCGCCGGCGAAACCTACACCATGAAGGAGGTGCTGTTCTACCTGGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACCTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAAATCTACACCATGATCTACCGCAACCTGGTGGTGGTGAACCAGCAGGAGTCCTCCGACTCCGGCACCTCCGTGTCCAGATCTTAG(SEQIDNO:35)有至少90%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCCATGACCGTGTTCATGCGCCTGAACATCATCTCCCCCGACCTGTCCGGCTGCACCTCCAAGGGCCTGGTGCTGCCCGCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCTCCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCCACCGGTGGAGTGCCAGTGCAGGGCTCCAAGTACGCTGCCGACCGCAACCACTACCGCCGCTACCCACGCCGTCGCGGCCCACCCCGCAACTACCAGCAGAACACGCGTGGCCTCAATGCGCACGGCGCAGCGCAGATGCAGCCCATGCACCGCTACGACGTGAGCGCCCTGCAGTACAACTCCATGACCAGCTCGCAGACCTACATGAACGGCTCGCCCACCTACAGCATGTCCTACTCGCAGCAGGGCACCCCTGGCATGGCTCTTGGCTCCATGGGTTCGGTGAGATCCCAATTGTTGAAAATCTTCCCATCCAAACGTATCTTACGAAGACACAAGAGAGATTGGGTGGTTGCTCCAATATCTGTCCCTGAAAATGGCAAGGGTCCCTTCCCACAGAGACTGAATCAGCTCAAGTCTAATAAAGATAGAGACACCAAGATTTTCTACAGCATCACGGGGCCGGGTGCAGACAGCCCACCTGAGGGTGTCTTCGCTGTAGAGAAGGAGACAAGATCCGCCGGCGAAACCTACACCATGAAGGAGGTGCTGTTCTACCTGGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACCTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAAATCTACACCATGATCTACCGCAACCTGGTGGTGGTGAACCAGCAGGAGTCCTCCGACTCCGGCACCTCCGTGTCCAGATCTTAG(SEQIDNO:36)有至少90%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCCATGACCGTGTCCATGCGCCTGAACATCGTGTCCCCCGACCTGTCCGGCAAGGGCCTGGTGCTGCCCTCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCGGCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCCACCGGTGGCGTGCCCGTGCAGGGCTCCAAGTACGCCGCCGACCGCAACCACTACCGCCGCTACCCCCGCCGCCGCGGCCCCCCCCGCAACTACCAGCAGAACACGCGTGGCCTGAACGCCCACGGCGCCGCCCAGATGCAGCCCATGCACCGCTACGACGTGTCCGCCCTGCAGTACAACTCCATGACCTCCTCCCAGACCTACATGAACGGCTCCCCCACCTACTCCATGTCCTACTCCCAGCAGGGCACCCCCGGCATGGCCCTGGGCTCCATGGGCTCCGTGAGATCCCAATTGGCCATGCACTCCCCCCCCACCCGCATCCTGCGCCGCCGCAAGCGCGAGTGGGTGATGCCCCCCATCTTCGTGCCCGAGAACGGCAAGGGCCCCTTCCCCCAGCGCCTGAACCAGCTGAAGTCCAACAAGGACCGCGGCACCAAGATCTTCTACTCCATCACCGGCCCCGGCGCCGACTCCCCCCCCGAGGGCGTGTTCACCATCGAGAAGGAGTCCAGATCCGCCGGCGAAACCTACACCATGAAGGAGATCATCTTCTACATCGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACGTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAGATCTACGCCATGATCTACCGCAACCTGGTGGCCGTGTCCCAGCAGGACTCCGGCACCTCCCTGTCCAGATCTTAG(SEQIDNO:37)有至少90%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCCATGACCGTGTCCATGCGCCTGAACATCGTGTCCCCCGACCTGTCCGGCAAGGGCCTGGTGCTGCCCTCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCGCCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCCACCGGTGGCGTGCCCGTGCAGGGCTCCAAGTACGCCGCCGACCGCAACCACTACCGCCGCTACCCCCGCCGCCGCGGCCCCCCCCGCAACTACCAGCAGAACACGCGTGGCCTGAACGCCCACGGCGCCGCCCAGATGCAGCCCATGCACCGCTACGACGTGTCCGCCCTGCAGTACAACTCCATGACCTCCTCCCAGACCTACATGAACGGCTCCCCCACCTACTCCATGTCCTACTCCCAGCAGGGCACCCCCGGCATGGCCCTGGGCTCCATGGGCTCCGTGAGATCCCAATTGGTGATGAACTCCCCCCCCTCCCGCATCCTGCGCCGCCGCAAGCGCGAGTGGGTGATGCCCCCCATCTCCGTGCCCGAGAACGGCAAGGGCCCCTTCCCCCAGCGCCTGAACCAGCTGAAGTCCAACAAGGACCGCGGCACCAAGCTGTTCTACTCCATCACCGGCCCCGGCGCCGACTCCCCCCCCGAGGGCGTGTTCACCATCGAGAAGGAGACCAGATCCGCCGGCGAAATCTACACCATGAAGGAGATCATCTTCTACATCGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACGTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAGATCTACGCCATGATCTACCGCAACCTGGTGGTGGTGTCCCAGCAGGACTCCGGCACCTCCCCCTCCAGATCTTAG(SEQIDNO:38)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMQLSCSRQNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTELRSTGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLRSLKERNPLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKETRSAGETYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSVSRS(SEQIDNO:39)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKETRSAGETYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSVSRS(SEQIDNO:40)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMTVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRGPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLAMHSPPTRILRRRKREWVMPPIFVPENGKGPFPQRLNQLKSNKDRGTKIFYSITGPGADSPPEGVFTIEKESRSAGETYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVAVSQQDSGTSLSRS(SEQIDNO:41)有至少90%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMTVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRAPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLVMNSPPSRILRRRKREWVMPPISVPENGKGPFPQRLNQLKSNKDRGTKLFYSITGPGADSPPEGVFTIEKETRSAGEIYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVVVSQQDSGTSPSRS(SEQIDNO:42)有至少90%序列相同性。在一些情况中,组合物可包括编码来自以下蛋白质的表位和核酸:HER-2、IGFBP2和IGF-1R。在一些情况中,组合物可包含包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是选自IGFBP-2、HER-2、IGF-1R的肽的部分,其中所述第一核苷酸序列位于质粒中。在一些情况中,组合物可包含:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位独立地选自IGFBP-2、HER-2或IGF-1R,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些情况中,组合物可包括编码肽IGFBP-2的表位的核酸序列,其选自下组:与核苷酸序列ATGCTGCCGAGAGTGGGCTGCCCCGCGCTGCCGCTGCCGCCGCCGCCGCTGCTGCCGCTGCTGCCGCTGCTGCTGCTGCTACTGGGCGCGAGTGGCGGCGGCGGCGGGGCGCGCGCGGAGGTGCTGTTCCGCTGCCCGCCCTGCACACCCGAGCGCCTGGCCGCCTGCGGGCCCCCGCCGGTTGCGCCGCCCGCCGCGGTGGCCGCAGTGGCCGGAGGCGCCCGCATGCCATGCGCGGAGCTCGTCCGGGAGCCGGGCTGCGGCTGCTGCTCGGTGTGCGCCCGGCTGGAGGGCGAGGCGTGCGGCGTCTACACCCCGCGCTGCGGCCAGGGGCTGCGCTGCTATCCCCACCCGGGCTCCGAGCTGCCCCTGCAGGCGCTGGTCATGGGCGAGGGCACTTGTGAGAAGCGCCGGGACGCCGAGTATGGCGCCAGCCCGGAGCAGGTTGCAGACAATGGCGATGACCACTCAGAAGGAGGCCTGGTGGAG(SEQIDNO:43)有至少90%序列相同性的核苷酸序列;与核苷酸序列ATGCTGCCCCGCCTGGGCGGCCCCGCCCTGCCCCTGCTGCTGCCCTCCCTGCTGCTGCTGCTGCTGCTGGGCGCCGGCGGCTGCGGCCCCGGCGTGCGCGCCGAGGTGCTGTTCCGCTGCCCCCCCTGCACCCCCGAGCGCCTGGCCGCCTGCGGCCCCCCCCCCGACGCCCCCTGCGCCGAGCTGGTGCGCGAGCCCGGCTGCGGCTGCTGCTCCGTGTGCGCCCGCCAGGAGGGCGAGGCCTGCGGCGTGTACATCCCCCGCTGCGCCCAGACCCTGCGCTGCTACCCCAACCCCGGCTCCGAGCTGCCCCTGAAGGCCCTGGTGACCGGCGCCGGCACCTGCGAGAAGCGCCGCGTGGGCACCACCCCCCAGCAGGTGGCCGACTCCGACGACGACCACTCCGAGGGCGGCCTGGTGGAG(SEQIDNO:44)有至少90%序列相同性的核苷酸序列;与核苷酸序列ATGCTGCCCCGCCTGGGCGGCCCCGCCCTGCCCCTGCTGCTGCCCTCCCTGCTGCTGCTGCTGCTGCTGGGCGCCGGCGGCTGCGGCCCCGGCGTGCGCGCCGAGGTGCTGTTCCGCTGCCCCCCCTGCACCCCCGAGCGCCTGGCCGCCTGCGGCCCCCCCCCCGACGCCCCCTGCGCCGAGCTGGTGCGCGAGCCCGGCTGCGGCTGCTGCTCCGTGTGCGCCCGCCAGGAGGGCGAGGCCTGCGGCGTGTACATCCCCCGCTGCGCCCAGACCCTGCGCTGCTACCCCAACCCCGGCTCCGAGCTGCCCCTGAAGGCCCTGGTGACCGGCGCCGGCACCTGCGAGAAGCGCCGCGTGGGCACCACCCCCCAGCAGGTGGCCGACTCCGAGGACGACCACTCCGAGGGCGGCCTGGTGGAG(SEQIDNO:45)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列NHVDSTMNMLGGGGS(SEQIDNO:46)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列ELAVFREKVTEQHRQ(SEQIDNO:47)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列LGLEEPKKLRPPPAR(SEQIDNO:48)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列DQVLERISTMRLPDE(SEQIDNO:49)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列GPLEHLYSLHIPNCD(SEQIDNO:50)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列KHGLYNLKQCKMSLN(SEQIDNO:51)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列PNTGKLIQGAPTIRG(SEQIDNO:52)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列PECHLFYNEQQEARG(SEQIDNO:53)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MLPRVGCPALPLPPPPLLPLLPLLLLLLGASGGGGGARAEVLFRCPPCTPERLAACGPPPVAPPAAVAAVAGGARMPCAELVREPGCGCCSVCARLEGEACGVYTPRCGQGLRCYPHPGSELPLQALVMGEGTCEKRRDAEYGASPEQVADNGDDHSEGGLVE(SEQIDNO:54)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGTTPQQVADSDDDHSEGGLVE(SEQIDNO:55)有至少90%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGATPQQVADSEDDHSEGGLVE(SEQIDNO:56)有至少90%序列相同性。在一些情况中,组合物可包括编码肽HER-2的表位的核酸序列,其选自下组:与核苷酸序列ACGATGCGGAGACTGCTGCAGGAAACGGAGCTGGTGGAGCCGCTGACACCTAGCGGAGCGATGCCCAACCAGGCGCAGATGCGGATCCTGAAAGAGACGGAGCTGAGGAAGGTGAAGGTGCTTGGATCTGGCGCTTTTGGCACAGTCTACAAGGGCATCTGGATCCCTGATGGGGAGAATGTGAAAATTCCAGTGGCCATCAAAGTGTTGAGGGAAAACACATCCCCCAAAGCCAACAAAGAAATCTTAGACGAAGCATACGTGATGGCTGGTGTGGGCTCCCCATATGTCTCCCGCCTTCTGGGCATCTGCCTGACATCCACGGTGCAGCTGGTGACACAGCTTATGCCCTATGGCTGCCTCTTAGACCATGTCCGGGAAAACCGCGGACGCCTGGGCTCCCAGGACCTGCTGAACTGGTGTATGCAGATTGCCAAGGGGATGAGCTACCTGGAGGATGTGCGGCTCGTACACAGGGACTTGGCCGCTCGGAACGTGCTGGTCAAGAGTCCCAACCATGTCAAAATTACAGACTTCGGGCTGGCTCGGCTGCTGGACATTGACGAGACAGAGTACCATGCAGATGGGGGCAAGGTGCCCATCAAGTGGATGGCGCTGGAGTCCATTCTCCGCCGGCGGTTCACCCACCAGAGTGATGTGTGGAGTTATGGTGTGACTGTGTGGGAGCTGATGACTTTTGGGGCCAAACCTTACGATGGGATCCCAGCCCGGGAGATCCCTGACCTGCTGGAAAAGGGGGAGCGGCTGCCCCAGCCCCCCATCTGCACCATTGATGTCTACATGATCATGGTCAAATGTTGGATGATTGACTCTGAATGTCGGCCAAGATTCCGGGAGTTGGTGTCTGAATTCTCCCGCATGGCCAGGGACCCCCAGCGCTTTGTGGTCATCCAGAATGAGGACTTGGCTCCCGGAGCTGGCGGCATGGTGCACCACAGGCACCGCAGCTCATCTCCTCTGCCTGCTGCCCGACCTGCTGGTGCCACTCTGGAAAGGCCCAAGACTCTCTCCCCAGGGAAGAATGGGGTCGTCAAAGACGTTTTTGCCTTTGGGGGTGCCGTGGAGAACCCCGAGTACTTG(SEQIDNO:57)有至少90%序列相同性的核苷酸序列;与核苷酸序列ACCATGCGCCGCCTGCTGCAGGAGACCGAGCTGGTGGAGCCCCTGACCCCCTCCGGCGCCGTGCCCAACCAGGCCCAGATGCGCATCCTGAAGGAGACCGAGCTGCGCAAGCTGAAGGTGCTGGGCTCCGGCGCCTTCGGCACCGTGTACAAGGGCATCTGGATCCCCGACGGCGAGAACGTGAAGATCCCCGTGGCCATCAAGGTGCTGCGCGAGAACACCTCCCCCAAGGCCAACAAGGAGATCCTGGACGAGGCCTACGTGATGGCCGGCGTGGGCTCCCCCTACGTGTCCCGCCTGCTGGGCATCTGCCTGACCTCCACCGTGCAGCTGGTGACCCAGCTGATGCCCTACGGCTGCCTGCTGGACCACGTGCGCGAGCACCGCGGCCGCCTGGGCTCCCAGGACCTGCTGAACTGGTGCGTGCAGATCGCCAAGGGCATGTCCTACCTGGAGGAGGTGCGCCTGGTGCACCGCGACCTGGCCGCCCGCAACGTGCTGGTGAAGTCCCCCAACCACGTGAAGATCACCGACTTCGGCCTGGCCCGCCTGCTGGACATCGACGAGACCGAGTACCACGCCGACGGCGGCAAGGTGCCCATCAAGTGGATGGCCCTGGAGTCCATCCTGCGCCGCCGCTTCACCCACCAGTCCGACGTGTGGTCCTACGGCGTGACCGTGTGGGAGCTGATGACCTTCGGCGCCAAGCCCTACGACGGCATCCCCGCCCGCGAGATCCCCGACCTGCTGGAGAAGGGCGAGCGCCTGCCCCAGCCCCCCATCTGCACCATCGACGTGTACATGATCATGGTGAAGTGCTGGATGATCGACTCCGAGTGCCGCCCCCGCTTCCGCGAGCTGGTGTCCGAGTTCTCCCGCATGGCCCGCGACCCCCAGCGCTTCGTGGTGATCCAGAACGAGGACCTGGCCCTGGGCACCGGCTCCACCGCCCACCGCCGCCACCGCTCCTCCTCCCCCCCCCCCCCCATCCGCCCCGCCGGCGCCACCCTGGAGCGCCCCAAGACCCTGTCCCCCGGCAAGAACGGCGTGGTGAAGGACGTGTTCGCCTTCGGCGGCGCCGTGGAGAACCCCGAGTACCTG(SEQIDNO:58)有至少90%序列相同性的核苷酸序列;与核苷酸序列ACCATGCGCCGCCTGCTGCAGGAGACCGAGCTGGTGGAGCCCCTGACCCCCTCCGGCGCCATGCCCAACCAGGCCCAGATGCGCATCCTGAAGGAGACCGAGCTGCGCAAGGTGAAGGTGCTGGGCTCCGGCGCCTTCGGCACCGTGTACAAGGGCATCTGGATCCCCGACGGCGAGAACGTGAAGATCCCCGTGGCCATCAAGGTGCTGCGCGAGAACACCTCCCCCAAGGCCAACAAGGAGATCCTGGACGAGGCCTACGTGATGGCCGGCGTGGGCTCCCCCTACGTGTCCCGCCTGCTGGGCATCTGCCTGACCTCCACCGTGCAGCTGGTGACCCAGCTGATGCCCTACGGCTGCCTGCTGGACCACGTGCGCGAGCACCGCGGCCGCCTGGGCTCCCAGGACCTGCTGAACTGGTGCGTGCAGATCGCCAAGGGCATGTCCTACCTGGAGGACGTGCGCCTGGTGCACCGCGACCTGGCCGCCCGCAACGTGCTGGTGAAGTCCCCCAACCACGTGAAGATCACCGACTTCGGCCTGGCCCGCCTGCTGGACATCGACGAGACCGAGTACCACGCCGACGGCGGCAAGGTGCCCATCAAGTGGATGGCCCTGGAGTCCATCCTGCGCCGCCGCTTCACCCACCAGTCCGACGTGTGGTCCTACGGCGTGACCGTGTGGGAGCTGATGACCTTCGGCGCCAAGCCCTACGACGGCATCCCCGCCCGCGAGATCCCCGACCTGCTGGAGAAGGGCGAGCGCCTGCCCCAGCCCCCCATCTGCACCATCGACGTGTACATGATCATGGTGAAGTGCTGGATGATCGACTCCGAGTGCCGCCCCCGCTTCCGCGAGCTGGTGTCCGAGTTCTCCCGCATGGCCCGCGACCCCCAGCGCTTCGTGGTGATCCAGAACGAGGACCTGACCCCCGGCACCGGCTCCACCGCCCACCGCCGCCACCGCTCCTCCTCCCCCCTGCCCCCCGTGCGCCCCGCCGGCGCCACCCTGGAGCGCCCCAAGACCCTGTCCCCCGGCAAGAACGGCGTGGTGAAGGACGTGTTCGCCTTCGGCGGCGCCGTGGAGAACCCCGAGTACCTG(SEQIDNO:59)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVRENRGRLGSQDLLNWCMQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLAPGAGGMVHHRHRSSSPLPAARPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:60)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAVPNQAQMRILKETELRKLKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEEVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLALGTGSTAHRRHRSSSPPPPIRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:61)有至少90%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLTPGTGSTAHRRHRSSSPLPPVRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:62)有至少90%序列相同性。在一些情况中,组合物可包括编码肽IGF-1R的表位的核酸序列,其选自下组:与核苷酸序列TGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGAGGCCGCAAGAACGAGCGCGCCCTGCCC(SEQIDNO:63)有至少90%序列相同性的核苷酸序列;与核苷酸序列TGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGCGGCCGCGCCAACGAGCGCGCCCTGCCC(SEQIDNO:64)有至少90%序列相同性的核苷酸序列;与核苷酸序列TGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGCGGCCGCGCCAACGAGCGCGCCCTGCCC(SEQIDNO:65)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列DYRSYRFPKLTVITE(SEQIDNO:66)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列IRGWKLFYNYALVlF(SEQIDNO:67)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列VVTGYVKIRHSHALV(SEQIDNO:68)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列FFYVQAKTGYENFIH(SEQIDNO:69)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列LIIALPVAVLLIVGG(SEQIDNO:70)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列LVIMLYVFHRKRNNS(SEQIDNO:71)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列NCHHVVRLLGVVSQG(SEQIDNO:72)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALP(SEQIDNO:73)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRANERALP(SEQIDNO:74)有至少90%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGVLVLRASFDERQPYAHMNGGRANERALP(SEQIDNO:75)有至少90%序列相同性。在一些情况中,组合物可包括编码三种肽的融合蛋白的核酸序列,其选自下组:与核苷酸序列ATGGCGGTACCAATGCTGCCGAGAGTGGGCTGCCCCGCGCTGCCGCTGCCGCCGCCGCCGCTGCTGCCGCTGCTGCCGCTGCTGCTGCTGCTACTGGGCGCGAGTGGCGGCGGCGGCGGGGCGCGCGCGGAGGTGCTGTTCCGCTGCCCGCCCTGCACACCCGAGCGCCTGGCCGCCTGCGGGCCCCCGCCGGTTGCGCCGCCCGCCGCGGTGGCCGCAGTGGCCGGAGGCGCCCGCATGCCATGCGCGGAGCTCGTCCGGGAGCCGGGCTGCGGCTGCTGCTCGGTGTGCGCCCGGCTGGAGGGCGAGGCGTGCGGCGTCTACACCCCGCGCTGCGGCCAGGGGCTGCGCTGCTATCCCCACCCGGGCTCCGAGCTGCCCCTGCAGGCGCTGGTCATGGGCGAGGGCACTTGTGAGAAGCGCCGGGACGCCGAGTATGGCGCCAGCCCGGAGCAGGTTGCAGACAATGGCGATGACCACTCAGAAGGAGGCCTGGTGGAGCAATTGACGATGCGGAGACTGCTGCAGGAAACGGAGCTGGTGGAGCCGCTGACACCTAGCGGAGCGATGCCCAACCAGGCGCAGATGCGGATCCTGAAAGAGACGGAGCTGAGGAAGGTGAAGGTGCTTGGATCTGGCGCTTTTGGCACAGTCTACAAGGGCATCTGGATCCCTGATGGGGAGAATGTGAAAATTCCAGTGGCCATCAAAGTGTTGAGGGAAAACACATCCCCCAAAGCCAACAAAGAAATCTTAGACGAAGCATACGTGATGGCTGGTGTGGGCTCCCCATATGTCTCCCGCCTTCTGGGCATCTGCCTGACATCCACGGTGCAGCTGGTGACACAGCTTATGCCCTATGGCTGCCTCTTAGACCATGTCCGGGAAAACCGCGGACGCCTGGGCTCCCAGGACCTGCTGAACTGGTGTATGCAGATTGCCAAGGGGATGAGCTACCTGGAGGATGTGCGGCTCGTACACAGGGACTTGGCCGCTCGGAACGTGCTGGTCAAGAGTCCCAACCATGTCAAAATTACAGACTTCGGGCTGGCTCGGCTGCTGGACATTGACGAGACAGAGTACCATGCAGATGGGGGCAAGGTGCCCATCAAGTGGATGGCGCTGGAGTCCATTCTCCGCCGGCGGTTCACCCACCAGAGTGATGTGTGGAGTTATGGTGTGACTGTGTGGGAGCTGATGACTTTTGGGGCCAAACCTTACGATGGGATCCCAGCCCGGGAGATCCCTGACCTGCTGGAAAAGGGGGAGCGGCTGCCCCAGCCCCCCATCTGCACCATTGATGTCTACATGATCATGGTCAAATGTTGGATGATTGACTCTGAATGTCGGCCAAGATTCCGGGAGTTGGTGTCTGAATTCTCCCGCATGGCCAGGGACCCCCAGCGCTTTGTGGTCATCCAGAATGAGGACTTGGCTCCCGGAGCTGGCGGCATGGTGCACCACAGGCACCGCAGCTCATCTCCTCTGCCTGCTGCCCGACCTGCTGGTGCCACTCTGGAAAGGCCCAAGACTCTCTCCCCAGGGAAGAATGGGGTCGTCAAAGACGTTTTTGCCTTTGGGGGTGCCGTGGAGAACCCCGAGTACTTGGGCCGGCCGGTACCTTGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGAGGCCGCAAGAACGAGCGCGCCCTGCCCGCGGCCGCATAG(SEQIDNO:76)有至少90%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCAATGCTGCCCCGCCTGGGCGGCCCCGCCCTGCCCCTGCTGCTGCCCTCCCTGCTGCTGCTGCTGCTGCTGGGCGCCGGCGGCTGCGGCCCCGGCGTGCGCGCCGAGGTGCTGTTCCGCTGCCCCCCCTGCACCCCCGAGCGCCTGGCCGCCTGCGGCCCCCCCCCCGACGCCCCCTGCGCCGAGCTGGTGCGCGAGCCCGGCTGCGGCTGCTGCTCCGTGTGCGCCCGCCAGGAGGGCGAGGCCTGCGGCGTGTACATCCCCCGCTGCGCCCAGACCCTGCGCTGCTACCCCAACCCCGGCTCCGAGCTGCCCCTGAAGGCCCTGGTGACCGGCGCCGGCACCTGCGAGAAGCGCCGCGTGGGCACCACCCCCCAGCAGGTGGCCGACTCCGACGACGACCACTCCGAGGGCGGCCTGGTGGAGCAATTGACCATGCGCCGCCTGCTGCAGGAGACCGAGCTGGTGGAGCCCCTGACCCCCTCCGGCGCCGTGCCCAACCAGGCCCAGATGCGCATCCTGAAGGAGACCGAGCTGCGCAAGCTGAAGGTGCTGGGCTCCGGCGCCTTCGGCACCGTGTACAAGGGCATCTGGATCCCCGACGGCGAGAACGTGAAGATCCCCGTGGCCATCAAGGTGCTGCGCGAGAACACCTCCCCCAAGGCCAACAAGGAGATCCTGGACGAGGCCTACGTGATGGCCGGCGTGGGCTCCCCCTACGTGTCCCGCCTGCTGGGCATCTGCCTGACCTCCACCGTGCAGCTGGTGACCCAGCTGATGCCCTACGGCTGCCTGCTGGACCACGTGCGCGAGCACCGCGGCCGCCTGGGCTCCCAGGACCTGCTGAACTGGTGCGTGCAGATCGCCAAGGGCATGTCCTACCTGGAGGAGGTGCGCCTGGTGCACCGCGACCTGGCCGCCCGCAACGTGCTGGTGAAGTCCCCCAACCACGTGAAGATCACCGACTTCGGCCTGGCCCGCCTGCTGGACATCGACGAGACCGAGTACCACGCCGACGGCGGCAAGGTGCCCATCAAGTGGATGGCCCTGGAGTCCATCCTGCGCCGCCGCTTCACCCACCAGTCCGACGTGTGGTCCTACGGCGTGACCGTGTGGGAGCTGATGACCTTCGGCGCCAAGCCCTACGACGGCATCCCCGCCCGCGAGATCCCCGACCTGCTGGAGAAGGGCGAGCGCCTGCCCCAGCCCCCCATCTGCACCATCGACGTGTACATGATCATGGTGAAGTGCTGGATGATCGACTCCGAGTGCCGCCCCCGCTTCCGCGAGCTGGTGTCCGAGTTCTCCCGCATGGCCCGCGACCCCCAGCGCTTCGTGGTGATCCAGAACGAGGACCTGGCCCTGGGCACCGGCTCCACCGCCCACCGCCGCCACCGCTCCTCCTCCCCCCCCCCCCCCATCCGCCCCGCCGGCGCCACCCTGGAGCGCCCCAAGACCCTGTCCCCCGGCAAGAACGGCGTGGTGAAGGACGTGTTCGCCTTCGGCGGCGCCGTGGAGAACCCCGAGTACCTGGGCCGGCCGGTACCTTGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGCGGCCGCGCCAACGAGCGCGCCCTGCCCGCGGCCGCATAG(SEQIDNO:77)有至少90%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCAATGCTGCCCCGCCTGGGCGGCCCCGCCCTGCCCCTGCTGCTGCCCTCCCTGCTGCTGCTGCTGCTGCTGGGCGCCGGCGGCTGCGGCCCCGGCGTGCGCGCCGAGGTGCTGTTCCGCTGCCCCCCCTGCACCCCCGAGCGCCTGGCCGCCTGCGGCCCCCCCCCCGACGCCCCCTGCGCCGAGCTGGTGCGCGAGCCCGGCTGCGGCTGCTGCTCCGTGTGCGCCCGCCAGGAGGGCGAGGCCTGCGGCGTGTACATCCCCCGCTGCGCCCAGACCCTGCGCTGCTACCCCAACCCCGGCTCCGAGCTGCCCCTGAAGGCCCTGGTGACCGGCGCCGGCACCTGCGAGAAGCGCCGCGTGGGCGCCACCCCCCAGCAGGTGGCCGACTCCGAGGACGACCACTCCGAGGGCGGCCTGGTGGAGCAATTGACCATGCGCCGCCTGCTGCAGGAGACCGAGCTGGTGGAGCCCCTGACCCCCTCCGGCGCCATGCCCAACCAGGCCCAGATGCGCATCCTGAAGGAGACCGAGCTGCGCAAGGTGAAGGTGCTGGGCTCCGGCGCCTTCGGCACCGTGTACAAGGGCATCTGGATCCCCGACGGCGAGAACGTGAAGATCCCCGTGGCCATCAAGGTGCTGCGCGAGAACACCTCCCCCAAGGCCAACAAGGAGATCCTGGACGAGGCCTACGTGATGGCCGGCGTGGGCTCCCCCTACGTGTCCCGCCTGCTGGGCATCTGCCTGACCTCCACCGTGCAGCTGGTGACCCAGCTGATGCCCTACGGCTGCCTGCTGGACCACGTGCGCGAGCACCGCGGCCGCCTGGGCTCCCAGGACCTGCTGAACTGGTGCGTGCAGATCGCCAAGGGCATGTCCTACCTGGAGGACGTGCGCCTGGTGCACCGCGACCTGGCCGCCCGCAACGTGCTGGTGAAGTCCCCCAACCACGTGAAGATCACCGACTTCGGCCTGGCCCGCCTGCTGGACATCGACGAGACCGAGTACCACGCCGACGGCGGCAAGGTGCCCATCAAGTGGATGGCCCTGGAGTCCATCCTGCGCCGCCGCTTCACCCACCAGTCCGACGTGTGGTCCTACGGCGTGACCGTGTGGGAGCTGATGACCTTCGGCGCCAAGCCCTACGACGGCATCCCCGCCCGCGAGATCCCCGACCTGCTGGAGAAGGGCGAGCGCCTGCCCCAGCCCCCCATCTGCACCATCGACGTGTACATGATCATGGTGAAGTGCTGGATGATCGACTCCGAGTGCCGCCCCCGCTTCCGCGAGCTGGTGTCCGAGTTCTCCCGCATGGCCCGCGACCCCCAGCGCTTCGTGGTGATCCAGAACGAGGACCTGACCCCCGGCACCGGCTCCACCGCCCACCGCCGCCACCGCTCCTCCTCCCCCCTGCCCCCCGTGCGCCCCGCCGGCGCCACCCTGGAGCGCCCCAAGACCCTGTCCCCCGGCAAGAACGGCGTGGTGAAGGACGTGTTCGCCTTCGGCGGCGCCGTGGAGAACCCCGAGTACCTGGGCCGGCCGGTACCTTGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGCGGCCGCGCCAACGAGCGCGCCCTGCCCGCGGCCGCATAG(SEQIDNO:78)有至少90%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMLPRVGCPALPLPPPPLLPLLPLLLLLLGASGGGGGARAEVLFRCPPCTPERLAACGPPPVAPPAAVAAVAGGARMPCAELVREPGCGCCSVCARLEGEACGVYTPRCGQGLRCYPHPGSELPLQALVMGEGTCEKRRDAEYGASPEQVADNGDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVRENRGRLGSQDLLNWCMQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLAPGAGGMVHHRHRSSSPLPAARPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALPAAA(SEQIDNO:79)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGTTPQQVADSDDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAVPNQAQMRILKETELRKLKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEEVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLALGTGSTAHRRHRSSSPPPPIRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRANERALPAAA(SEQIDNO:80)有至少90%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGATPQQVADSEDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLTPGTGSTAHRRHRSSSPLPPVRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGVLVLRASFDERQPYAHMNGGRANERALPAAA(SEQIDNO:81)有至少90%序列相同性。在一些情况中,组合物可包括独立地选自以下的第一和第二表位:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物可包括第三表位,第一、第二和第三表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物可包括第三和第四表位,第一、第二、第三和第四表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物可包括第三、第四和第五表位,第一、第二、第三、第四和第五表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物可包括独立地选自以下的第一和第二表位:IGFBP2、HER-2或IGF-1R。在一些情况中,组合物可包括第三表位,第一、第二和第三表位独立地选自:IGFBP2、HER-2或IGF-1R。在一些情况中,组合物能够给予对象。在一些情况中,对象需要给予组合物。在一些情况中,组合物在对象中有效引发免疫应答。在一些情况中,组合物在对象中有效消除与乳腺癌相关的多种细胞。在一些情况中,组合物可用于在对象中防止与乳腺癌相关的细胞的生长。在一些情况中,第一和第二核酸序列位于第一质粒上。在一些情况中,第二核酸序列位于第二质粒上。在一些情况中,与乳腺癌相关的细胞选自:表达异常特征的乳腺细胞、肿瘤前乳腺细胞、乳腺癌细胞、侵入前乳腺癌细胞、乳腺癌干细胞、上皮细胞、间充质细胞、体细胞、或其组合。在一些情况中,第一和第二核酸序列纯化至至少70%纯。在一些情况中,第一和第二核酸序列位于第一质粒上并且被接头核酸序列分开。在一些情况中,第一核酸序列与在第一质粒上的第二核酸序列毗邻。在一些情况中,在药物组合物中含有至少第一质粒。在一些情况中,在另外包含药物运载体的药物组合物中含有至少第一质粒。在一些情况中,在另外包含药物运载体和佐剂的药物组合物中含有至少第一质粒。在一些情况中,在另外包含佐剂的药物组合物中含有至少第一质粒。在一些情况中,组合物还包含佐剂和药学上可接受的运载体。在一些情况中,佐剂是GM-CSF。在一些情况中,对象选自:患有乳腺癌的人、患有乳腺癌的小鼠或患有乳腺癌的大鼠。在一些情况中,对象选自:未患有乳腺癌的人、未患有乳腺癌的小鼠或未患有乳腺癌的大鼠。在一些情况中,免疫应答是1型免疫应答。在一些情况中,第一核酸序列是选自人、小鼠或大鼠的物种。在一些情况中,第二核酸序列是选自人、小鼠或大鼠的物种。在一些情况中,免疫应答表征为大于1的I型细胞因子产生与II型细胞因子产生之比。在一些情况中,免疫应答表征为小于1的I型细胞因子产生与II型细胞因子产生之比。在一些情况中,免疫应答表征为大于1的IFNγ产生与IL-10产生之比。在一些情况中,免疫应答表征为小于1的IFNγ产生与IL-10产生之比。在一些情况中,组合物包括包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是HIF-1α肽的部分,其中所述第一核苷酸序列位于质粒中。在其他情况中,组合物包括包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位是HIF-1α肽的部分,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。编码选自以下蛋白质的表位的核酸序列与本文所列的那些不同:CD105、HIF1α、MDM2、Yb1、SOX-2、HER-2、IGFBP2、IGF-1R和CDH3。在一些情况中,与本文所述的那些有超过95%、90%、85%、80%、75%、70%、65%、60%、55%或超过50%同源的核酸序列可用于本文所述的组合物中。在一些情况中,本文所述的组合物可包括,包含以下的组合物:由与乳腺癌相关的细胞表达的第一抗原的第一表位;和由与乳腺癌相关的细胞表达的第二抗原的第二表位。在一些情况中,组合物可包含:至少第一抗原的第一表位,所述第一表位是选自CD105、Yb-1、SOX-2、CDH3或MDM2的肽的部分。在一些情况中,组合物可包含:至少第一抗原的第一表位,至少第二抗原的第二表位,所述第一和第二表位独立地选自CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,肽CD105的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列EARMLNASIVASFVELPL(SEQIDNO:6)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列QNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTEL(SEQIDNO:1)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列TVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:8)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列TVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRGPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:9)有至少90%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列TVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRAPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:10)有至少90%序列相同性。在一些情况中,肽Yb-1的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列EDVFVHQTAIKKNNPRK(SEQIDNO:14)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列YRRNFNYRRRRPEN(SEQIDNO:15)有至少90%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列GVPVQGSKYAADRNHYRRYPRRRGPPRNYQQN(SEQIDNO:16)有至少90%序列相同性。在一些情况中,肽SOX-2的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列GLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSV(SEQIDNO:20)有至少90%序列相同性。在一些情况中,肽CDH3的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列RSLKERNPLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKET(SEQIDNO:25)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列LKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKET(SEQIDNO:26)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列AMHSPPTRILRRRKREWVMPPIFVPENGKGPFPQRLNQLKSNKDRGTKIFYSITGPGADSPPEGVFTIEKES(SEQIDNO:27)有至少90%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列VMNSPPSRILRRRKREWVMPPISVPENGKGPFPQRLNQLKSNKDRGTKLFYSITGPGADSPPEGVFTIEKET(SEQIDNO:28)有至少90%序列相同性。在一些情况中,肽MDM-2的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列TYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSV(SEQIDNO:32)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列TYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVAVSQQDSGTSLS(SEQIDNO:33)有至少90%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列IYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVVVSQQDSGTSPS(SEQIDNO:34)有至少90%序列相同性。在一些情况中,本文所述的组合物包括5种(个)表位的融合肽的氨基酸序列,其选自下组:氨基酸序列,该氨基酸序列与氨基酸序列MAVPMQLSCSRQNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTELRSTGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLRSLKERNPLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKETRSAGETYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSVSRS(SEQIDNO:39)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MAVPMTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKETRSAGETYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSVSRS(SEQIDNO:40)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MAVPMTVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRGPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLAMHSPPTRILRRRKREWVMPPIFVPENGKGPFPQRLNQLKSNKDRGTKIFYSITGPGADSPPEGVFTIEKESRSAGETYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVAVSQQDSGTSLSRS(SEQIDNO:41)有至少90%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列MAVPMTVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRAPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLVMNSPPSRILRRRKREWVMPPISVPENGKGPFPQRLNQLKSNKDRGTKLFYSITGPGADSPPEGVFTIEKETRSAGEIYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVVVSQQDSGTSPSRS(SEQIDNO:42)有至少90%序列相同性。本文所述的组合物还包括,包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是选自IGFBP-2、HER-2或IGF-1R的肽的部分,其中所述第一核苷酸序列位于质粒中。在一些情况中,组合物可包含:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位独立地选自IGFBP-2、HER-2或IGF-1R,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些情况中,肽IGFBP-2的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列NHVDSTMNMLGGGGS(SEQIDNO:46)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列ELAVFREKVTEQHRQ(SEQIDNO:47)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列LGLEEPKKLRPPPAR(SEQIDNO:48)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列DQVLERISTMRLPDE(SEQIDNO:49)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列GPLEHLYSLHIPNCD(SEQIDNO:50)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列KHGLYNLKQCKMSLN(SEQIDNO:51)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列PECHLFYNEQQEARG(SEQIDNO:53)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MLPRVGCPALPLPPPPLLPLLPLLLLLLGASGGGGGARAEVLFRCPPCTPERLAACGPPPVAPPAAVAAVAGGARMPCAELVREPGCGCCSVCARLEGEACGVYTPRCGQGLRCYPHPGSELPLQALVMGEGTCEKRRDAEYGASPEQVADNGDDHSEGGLVE(SEQIDNO:54)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGTTPQQVADSDDDHSEGGLVE(SEQIDNO:55)有至少90%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列MLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGATPQQVADSEDDHSEGGLVE(SEQIDNO:56)有至少90%序列相同性。在一些情况中,肽HER-2的至少第一表位选自下组:编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVRENRGRLGSQDLLNWCMQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLAPGAGGMVHHRHRSSSPLPAARPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:60)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAVPNQAQMRILKETELRKLKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEEVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLALGTGSTAHRRHRSSSPPPPIRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:61)有至少90%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLTPGTGSTAHRRHRSSSPLPPVRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:62)有至少90%序列相同性。在一些情况中,编码肽IGF-1R的表位的核酸序列选自下组:氨基酸序列,该氨基酸序列与氨基酸序列DYRSYRFPKLTVITE(SEQIDNO:66)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列IRGWKLFYNYALVIF(SEQIDNO:67)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列VVTGYVKIRHSHALV(SEQIDNO:68)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列FFYVQAKTGYENFIH(SEQIDNO:69)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列LIIALPVAVLLIVGG(SEQIDNO:70)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列LVIMLYVFHRKRNNS(SEQIDNO:71)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列NCHHVVRLLGVVSQG(SEQIDNO:72)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALP(SEQIDNO:73)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRANERALP(SEQIDNO:74)有至少90%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGVLVLRASFDERQPYAHMNGGRANERALP(SEQIDNO:75)有至少90%序列相同性。本文所述的组合物还可包括编码三种(个)表位的融合蛋白的核酸序列,其选自下组:氨基酸序列,该氨基酸序列与氨基酸序列MAVPMLPRVGCPALPLPPPPLLPLLPLLLLLLGASGGGGGARAEVLFRCPPCTPERLAACGPPPVAPPAAVAAVAGGARMPCAELVREPGCGCCSVCARLEGEACGVYTPRCGQGLRCYPHPGSELPLQALVMGEGTCEKRRDAEYGASPEQVADNGDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVRENRGRLGSQDLLNWCMQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLAPGAGGMVHHRHRSSSPLPAARPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALPAAA(SEQIDNO:79)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MAVPMLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGTTPQQVADSDDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAVPNQAQMRILKETELRKLKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEEVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLALGTGSTAHRRHRSSSPPPPIRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRANERALPAAA(SEQIDNO:80)有至少90%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列MAVPMLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGATPQQVADSEDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLTPGTGSTAHRRHRSSSPLPPVRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGVLVLRASFDERQPYAHMNGGRANERALPAAA(SEQIDNO:81)有至少90%序列相同性。在一些情况中,组合物包括独立地选自以下的第一和第二表位:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物还包括第三表位,第一、第二和第三表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物还包括第三和第四表位,第一、第二、第三和第四表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物还包括第三、第四和第五表位,第一、第二、第三、第四和第五表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物包括独立地选自以下的第一和第二表位:IGFBP2、HER-2或IGF-1R。在一些情况中,组合物还包括第三表位,第一、第二和第三表位独立地选自:IGFBP2、HER-2或IGF-1R。在一些情况中,组合物可包含:至少第一抗原的第一表位,所述第一表位是来自HIF-1α的肽的部分。在一些情况中,组合物可包含:至少第一抗原的第一表位,至少第二抗原的第二表位,所述第一和第二表位来自HIF-1α。在一些情况中,组合物可包括编码肽HIF-1α的表位的核苷酸序列,其选自下组:编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列DSKTFLSRHSLDMKFSYCDERITELMGYEPEELLGRSIYEYYHALDSDHLTKTHHDMFTKGQVTTGQYRMLAKRGGYVWVETQATVIYN(SEQIDNO:82)有至少90%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列SDNVNKYMGLTQFELTGHSVFDFTHP(SEQIDNO:83)有至少90%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列GGYVWVETQATVIYNTKNSQ(SEQIDNO:84)有至少90%序列相同性。在一些情况中,组合物可包括肽HIF-1α的至少第一表位,其选自下组:氨基酸序列,该氨基酸序列与氨基酸序列DSKTFLSRHSLDMKFSYCDERITELMGYEPEELLGRSIYEYYHALDSDHLTKTHHDMFTKGQVTTGQYRMLAKRGGYVWVETQATVIYN(SEQIDNO:82)有至少90%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列SDNVNKYMGLTQFELTGHSVFDFTHP(SEQIDNO:83)有至少90%序列相同性;和氨基酸序列,该氨基酸序列与氨基酸序列GGYVWVETQATVIYNTKNSQ(SEQIDNO:84)有至少90%序列相同性。编码选自以下蛋白质的表位的氨基酸序列与本文所列的那些不同:CD105、HIF1α、MDM2、Yb1、SOX-2、HER-2、IGFBP2、IGF-1R和CDH3。在一些情况中,与本文所述的那些超过95%、90%、85%、80%、75%、70%、65%、60%、55%或超过50%同源的氨基酸序列可用于本文所述的组合物中。在一些情况中,第一氨基酸序列选自下组物种:人、小鼠和大鼠。在一些情况中,第二氨基酸序列选自下组物种:人、小鼠和大鼠。在一些情况中,第一和第二核酸序列位于第一质粒上。在一些情况中,第二核酸序列位于第二质粒上。在一些情况中,第一和第二表位的氨基酸序列被接头氨基酸序列分开。在一些情况中,第一表位的氨基酸序列与第二表位的氨基酸序列毗邻。在一些情况中,免疫应答是1型免疫应答。在一些情况中,免疫应答表征为大于1的I型细胞因子产生与II型细胞因子产生之比。在一些情况中,免疫应答表征为小于1的I型细胞因子产生与II型细胞因子产生之比。在一些情况中,免疫应答表征为大于1的IFNγ产生与IL-10产生之比。在一些情况中,免疫应答表征为小于1的IFNγ产生与IL-10产生之比。在一些情况中,向对象给予组合物。在一些情况中,对象需要给予组合物。在一些情况中,组合物在对象中有效引发免疫应答。在一些情况中,组合物在对象中有效消除与乳腺癌相关的多种细胞。在一些情况中,组合物可用于在对象中防止与乳腺癌相关的细胞的生长。在一些情况中,对象选自下组:患有乳腺癌的人、患有乳腺癌的小鼠和患有乳腺癌的大鼠。在一些情况中,对象选自下组:未患有乳腺癌的人、未患有乳腺癌的小鼠和未患有乳腺癌的大鼠。在一些情况中,与乳腺癌相关的细胞选自:表达异常特征的乳腺细胞、肿瘤前乳腺细胞、乳腺癌细胞、侵入前乳腺癌细胞、乳腺癌干细胞、上皮细胞、间充质细胞、体细胞、或其组合。在一些情况中,在药物组合物中含有至少第一表位。在一些情况中,在另外包含药物运载体的药物组合物中含有至少第一表位。在一些情况中,在另外包含药物运载体和佐剂的药物组合物中含有至少第一表位。在一些情况中,在另外包含佐剂的药物组合物中含有至少第一表位。在一些情况中,组合物还包含佐剂和药物运载体。在一些情况中,佐剂是GM-CSF。在一些情况中,可向对象给予组合物。在一些情况中,对象有此需要。在一些情况中,本文提供了用于在对象中防止乳腺癌的方法,使得该方法包括向对象给予本文所述的组合物。在一些情况中,本文提供了用于在对象中治疗乳腺癌的方法,使得该方法包括向对象给予本文所述的组合物。在一些情况中,给药还包括向对象递送至少一剂的本文所述的组合物。在一些情况中,给药还包括通过皮下注射、皮内注射、肌内注射、血管内注射、局部施涂或吸入向对象递送本文所述的组合物。在一些情况中,对象选自下组:患有乳腺癌的人、患有乳腺癌的小鼠和患有乳腺癌的大鼠。在一些情况中,对象选自下组:未患有乳腺癌的人、未患有乳腺癌的小鼠和未患有乳腺癌的大鼠。本发明还提供了用于制备本文所述的组合物的试剂盒,该试剂盒包含用于制备组合物的说明书。本发明还提供了用于给予本文所述的组合物的试剂盒,该试剂盒包含用于给予组合物的说明书。包含选自生存素、HIF-1α、IGFBP-2、和IGF-1R的表位的组合物本文所述的组合物包含质粒和赋形剂,该质粒包含编码与选自SEQIDNO:54、73、85、和87的表位有至少70%序列相同性的多肽的至少一个核苷酸序列。该组合物可包含质粒,该质粒包含编码与选自SEQIDNO:54、73、85、和87的表位有至少80%序列相同性的多肽的至少一个核苷酸序列。该组合物可包含质粒,该质粒包含编码与选自SEQIDNO:54、73、85、和87的表位有至少90%序列相同性的多肽的至少一个核苷酸序列。该组合物可包含质粒,该质粒包含编码与选自SEQIDNO:54、73、85、和87的表位有至少95%序列相同性的多肽的至少一个核苷酸序列。该组合物可包含质粒,该质粒包含编码与选自SEQIDNO:54、73、85、和87的表位有至少99%序列相同性的多肽的至少一个核苷酸序列。该组合物可包含质粒,该质粒包含编码与选自SEQIDNO:54、73、85、和87的表位有100%序列相同性的多肽的至少一个核苷酸序列。该组合物可包含质粒,该质粒包含编码由选自SEQIDNO:54、73、85、和87的表位的全长有100%序列相同性的多肽的至少一个核苷酸序列。有时,至少一种核苷酸序列可编码与SEQIDNO:85的至少20个连续氨基酸有至少70%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:85的至少20个连续氨基酸有至少80%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:85的至少20个连续氨基酸有至少90%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:85的至少20个连续氨基酸有至少95%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:85的至少20个连续氨基酸有至少99%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:85的至少20个连续氨基酸有至少100%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:87的至少60个连续氨基酸有至少70%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:87的至少60个连续氨基酸有至少80%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:87的至少60个连续氨基酸有至少90%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:87的至少60个连续氨基酸有至少95%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:87的至少60个连续氨基酸有至少99%序列相同性的多肽。有时,至少一种核苷酸序列可编码与SEQIDNO:87的至少60个连续氨基酸有至少100%序列相同性的多肽。在一些情况中,组合物包含分离的质粒,其包含至少4个核苷酸序列。有时,至少4个核苷酸序列各自独立编码与选自SEQIDNO:54、73、85、和87的表位序列有至少60%、70%、80%、90%、95%、99%、或100%序列相同性的多肽。有时,分离的质粒可包含4个核苷酸序列。有时,4个核苷酸序列各自可独立编码与选自SEQIDNO:54、73、85、和87的表位序列有至少60%、70%、80%、90%、95%、99%、或100%序列相同性的多肽。另外,4个核苷酸序列各自可编码不同的多肽。有时,不同多肽各自可与选自SEQIDNO:54、73、85、和87的表位序列有至少60%、70%、80%、90%、95%、99%、或100%序列相同性。有时,4个核苷酸序列之一可编码与SEQIDNO:85的至少20个连续氨基酸有至少70%序列相同性的多肽。4个核苷酸序列之一可编码与SEQIDNO:85的至少20个连续氨基酸有至少80%序列相同性的多肽。4个核苷酸序列之一可编码与SEQIDNO:85的至少20个连续氨基酸有至少90%序列相同性的多肽。4个核苷酸序列之一可编码与SEQIDNO:85的至少20个连续氨基酸有至少95%序列相同性的多肽。4个核苷酸序列之一可编码与SEQIDNO:85的至少20个连续氨基酸有至少100%序列相同性的多肽。有时,4个核苷酸序列之一可编码与SEQIDNO:87的至少60个连续氨基酸有至少70%序列相同性的多肽。4个核苷酸序列之一可编码与SEQIDNO:87的至少60个连续氨基酸有至少80%序列相同性的多肽。4个核苷酸序列之一可编码与SEQIDNO:87的至少60个连续氨基酸有至少90%序列相同性的多肽。4个核苷酸序列之一可编码与SEQIDNO:87的至少60个连续氨基酸有至少95%序列相同性的多肽。4个核苷酸序列之一可编码与SEQIDNO:87的至少60个连续氨基酸有至少100%序列相同性的多肽。在一些情况中,4个核苷酸序列在质粒内串联排列。可由接头核酸序列分隔4个核苷酸序列。接头核酸序列的长度可以是约1至约150、约5至约100、或约10至约50个核酸。在一些情况中,核酸可编码一个或多个氨基酸残基。有时,接头的氨基酸序列长度可以是约1至约50、或约5至约25个氨基酸残基。有时,接头可包括如图14中下划线所示的接头(SEQIDNO:14)。有时,组合物还可包含至少一种其他的分离质粒。有时,组合物还可包含至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45、50或更多种其他的分离质粒。在一些情况中,至少一种其他的分离质粒包含编码与选自SEQIDNO:54、73、85、和87的表位有至少70%序列相同性的多肽的核苷酸序列。至少一种其他的分离质粒可包含编码与选自SEQIDNO:54、73、85、和87的表位有至少80%序列相同性的多肽的核苷酸序列。至少一种其他的分离质粒可包含编码与选自SEQIDNO:54、73、85、和87的表位有至少90%序列相同性的多肽的核苷酸序列。至少一种其他的分离质粒可包含编码与选自SEQIDNO:54、73、85、和87的表位有至少95%序列相同性的多肽的核苷酸序列。至少一种其他的分离质粒可包含编码与选自SEQIDNO:54、73、85、和87的表位有至少99%序列相同性的多肽的核苷酸序列。至少一种其他的分离质粒可包含编码与选自SEQIDNO:54、73、85、和87的表位有100%序列相同性的多肽的核苷酸序列。有时,本文所述的组合物可包括包含质粒和赋形剂的组合物,该质粒包含编码与SEQIDNO:89有至少80%序列相同性的多肽的核苷酸序列。该组合物可包含质粒,该质粒包含编码与SEQIDNO:89有至少90%序列相同性的多肽的核苷酸序列。该组合物可包含质粒,该质粒包含编码与SEQIDNO:89有至少95%序列相同性的多肽的核苷酸序列。该组合物可包含质粒,该质粒包含编码与SEQIDNO:89有100%序列相同性的多肽的核苷酸序列。该组合物可包含质粒,该质粒包含编码与SEQIDNO:89的序列相同性为100%的多肽的核苷酸序列。本文所述的组合物可包括包含多肽的组合物,该多肽与SEQIDNO:89有至少80%序列相同性。该组合物可包括多肽,其与SEQIDNO:89有至少90%序列相同性。该组合物可包括多肽,其与SEQIDNO:89有至少95%序列相同性。该组合物可包括多肽,其与SEQIDNO:89有100%序列相同性。该组合物可包括多肽,其与SEQIDNO:89的序列相同性为100%。可配制该组合物用于治疗对象中的乳腺癌或卵巢癌。乳腺癌可以是复发或难治性乳腺癌。卵巢癌可以是复发或难治性卵巢癌。乳腺癌可以是转移的乳腺癌。卵巢癌可以是转移的卵巢癌。组合物可引发免疫应答。免疫应答可表征为大于1的I型细胞因子产生与II型细胞因子产生之比。免疫应答可表征为小于1的I型细胞因子产生与II型细胞因子产生之比。免疫应答可表征为大于1的IFN-γ产生与IL-10产生之比。免疫应答可表征为小于1的IFN-γ产生与IL-10产生之比。有时,组合物还可包含佐剂。有时,佐剂是GM-CSF。组合物还可包含赋形剂。赋形剂可以是药学上可接受的运载体。通常,可配制组合物用于皮下、肌内或皮内给药。本发明还提供了用于制备本文所述的组合物的试剂盒,该试剂盒包含用于制备组合物的说明书。本发明还提供了用于给予本文所述的组合物的试剂盒,该试剂盒包含用于给予组合物的说明书。用于药物组合物的质粒在一些情况中,表位可衍生自可直接在基于肽的疫苗中使用的人蛋白质。在其他情况中,表位可衍生自人蛋白质并且编码表位的编码核酸序列可整合到设计成在给药后诱导对象中表位表达的核酸构建体中。例如,从核酸构建体编码的表位可允许针对蛋白质(例如,自蛋白质)的特定组的待产生、扩增、减弱、抑制或消除的至少一种(个)表位的免疫应答。在一些情况中,肽或核酸构建体可优化成基于蛋白质或质粒的免疫来诱导、扩增或产生Th1免疫应答。在一些情况中,表位可以是延伸的Th1表位。在其他情况中,肽或核酸构建体可优化成基于蛋白质或质粒的免疫以在有此需要的对象(例如,人或动物)中抑制、减弱或消除致病性应答。本文所述的组合物可包括含有核酸序列的质粒以在给予组合物(例如,疫苗)之后在对象中表达至少一种(个)表位。可在本文所述的组合物中使用本领域普通技术人员已知的适用于表达核酸的药物应用的任意质粒主链(例如,载体)。在一些情况中,可使用市售质粒主链。例如,可使用质粒pUMVC3。在一些情况中,在使用前,可修饰、突变、工程改造或克隆市售质粒主链。在其他情况中,可使用非市售质粒主链。在插入至少一种(个)表位的核酸序列之前,质粒主链的长度可小于约500bp、约1.0kB、约1.2kB、约1.4kB、约1.6kB、约1.8kB、约2.0kB、约2.2kB、约2.4kB、约2.6kB、约2.8kB、约3.0kB、约3.2kB、约3.4kB、约3.6kB、约3.8kB、约4.0kB、约4.2kB、约4.4kB、约4.6kB、约4.8kB、约5.0kB、约5.2kB、约5.4kB、约5.6kB、约5.8kB、约6.0kB、约6.2kB、约6.4kB、约6.6kB、约6.8kB、约7.0kB、约7.2kB、约7.4kB、约7.6kB、约7.8kB、约8.0kB、约8.2kB、约8.4kB、约8.6kB、约8.8kB、约9.0kB、约9.2kB、约9.4kB、约9.6kB、约9.8kB、约10.0kB、约10.2kB、约10.4kB、约10.6kB、约10.8kB、约11.0kB、约11.2kB、约11.4kB、约11.6kB、约11.8kB、约12.0kB、约12.2kB、约12.4kB、约12.6kB、约12.8kB、约13.0kB、约13.2kB、约13.4kB、约13.6kB、约13.8kB、约14kB、约14.5kB、约15kB、约15.5kB、约16kB、约16.5kB、约17kB、约17.5kB、约18kB、约18.5kB、约19kB、约19.5kB、约20kB、约30kB、约40kB、约50kB、约60kB、约70kB、约80kB、约90kB、约100kB、约110kB、约120kB、约130kB、约140kB、约150kB、约160kB、约170kB、约180kB、约190kB或约200kB。在示例性情况中,在加入编码至少一种(个)表位的核酸序列之前,质粒长度为约4kB。在一些情况中,本文所述的组合物可包括一种质粒。在其他情况中,本文所述的组合物可包括超过一种质粒。例如,本文所述的组合物可包括2种质粒、3种质粒、4种质粒、5种质粒、6种质粒、7种质粒、8种质粒、9种质粒、10种质粒、11种质粒、12种质粒、13种质粒、14种质粒、15种质粒、16种质粒、17种质粒、18种质粒、19种质粒、20种质粒或超过20种质粒。在一些情况中,编码质粒的至少一种(个)表位的核酸可以是脱氧核糖核酸。例如,脱氧核糖核酸可以是单链、双链或互补的。脱氧核糖核酸可来自基因组、线粒体或质粒脱氧核糖核酸。在其他情况中,质粒的核酸可以是核糖核酸。例如,核糖核酸可以是单链或双链。在一些情况中,核糖核酸可以是微、反义、短发夹、小干扰、信使、转移、核糖体核糖核酸等。在一些情况中,质粒的核酸可以是脱氧核糖核酸的部分或核糖核酸的部分。编码质粒的至少一种(个)表位的核酸可衍生自任意物种,使得从核酸表达的表位在对象中产生免疫应答。在一些情况中,对象可以是啮齿类、非人灵长类或人。编码质粒的表位的核酸可使用本领域技术人员已知的方法和技术分离自任意核酸来源。编码质粒的表位的核酸可使用本领域技术人员已知的方法和技术克隆到质粒主链中。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的CD105的核酸序列来在人中表达CD105。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的CD105的核酸序列来在人中表达CD105。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中CD105的天然核酸序列在对象中表达CD105。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中CD105的天然核酸序列并且可用于在对象中表达CD105。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的CD105的核酸序列来在人中表达CD105。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的CD105的核酸序列在人中表达CD105。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中CD105的天然核酸序列在对象中表达CD105。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中CD105的天然核酸序列并且可用于在对象中表达CD105。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的HIF-1A的核酸序列来在人中表达HIF-1A。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的HIF-1A的核酸序列在人中表达HIF-1A。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中HIF-1A的天然核酸序列在对象中表达HIF-1A。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中HIF-1A的天然核酸序列并且可用于在对象中表达HIF-1A。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的HIF-1A的核酸序列在人中表达HIF-1A。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的HIF-1A的核酸序列在人中表达HIF-1A。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中HIF-1A的天然核酸序列在对象中表达HIF-1A。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中HIF-1A的天然核酸序列并且可用于在对象中表达HIF-1A。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的MDM2的核酸序列在人中表达MDM2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的MDM2的核酸序列在人中表达MDM2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中MDM2的天然核酸序列在对象中表达MDM2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中MDM2的天然核酸序列并且可用于在对象中表达MDM2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的MDM2的核酸序列来在人中表达MDM2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的MDM2的核酸序列在人中表达MDM2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中MDM2的天然核酸序列在对象中表达MDM2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中MDM2的天然核酸序列并且可用于在对象中表达MDM2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的Yb-1的核酸序列在人中表达Yb-1。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的Yb-1的核酸序列在人中表达Yb-1。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中Yb-1的天然核酸序列在对象中表达Yb-1。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中Yb-1的天然核酸序列并且可用于在对象中表达Yb-1。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的Yb-1的核酸序列在人中表达Yb-1。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的Yb-1的核酸序列在人中表达Yb-1。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中Yb-1的天然核酸序列在对象中表达Yb-1。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中Yb-1的天然核酸序列并且可用于在对象中表达Yb-1。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的SOX-2的核酸序列在人中表达SOX-2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的SOX-2的核酸序列在人中表达SOX-2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中SOX-2的天然核酸序列在对象中表达SOX-2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中SOX-2的天然核酸序列并且可用于在对象中表达SOX-2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的SOX-2的核酸序列在人中表达SOX-2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的SOX-2的核酸序列在人中表达SOX-2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中SOX-2的天然核酸序列在对象中表达SOX-2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中SOX-2的天然核酸序列并且可用于在对象中表达SOX-2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的HER-2的核酸序列在人中表达HER-2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的HER-2的核酸序列在人中表达HER-2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中HER-2的天然核酸序列在对象中表达HER-2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中HER-2的天然核酸序列并且可用于在对象中表达HER-2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的HER-2的核酸序列在人中表达HER-2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的HER-2的核酸序列在人中表达HER-2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中HER-2的天然核酸序列在对象中表达HER-2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中HER-2的天然核酸序列并且可用于在对象中表达HER-2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的IGFBP2的核酸序列在人中表达IGFBP2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的IGFBP2的核酸序列在人中表达IGFBP2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中IGFBP2的天然核酸序列在对象中表达IGFBP2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中IGFBP2的天然核酸序列并且可用于在对象中表达IGFBP2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的IGFBP2的核酸序列在人中表达IGFBP2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的IGFBP2的核酸序列在人中表达IGFBP2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中IGFBP2的天然核酸序列在对象中表达IGFBP2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中IGFBP2的天然核酸序列并且可用于在对象中表达IGFBP2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的IGF-1R的核酸序列在人中表达IGF-1R。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的IGF-1R的核酸序列在人中表达IGF-1R。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中IGF-1R的天然核酸序列在对象中表达IGF-1R。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中IGF-1R的天然核酸序列并且可用于在对象中表达IGF-1R。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的IGF-1R的核酸序列在人中表达IGF-1R。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的IGF-1R的核酸序列在人中表达IGF-1R。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中IGF-1R的天然核酸序列在对象中表达IGF-1R。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中IGF-1R的天然核酸序列并且可用于在对象中表达IGF-1R。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的CDH3的核酸序列在人中表达CDH3。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的CDH3的核酸序列在人中表达CDH3。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中CDH3的天然核酸序列在对象中表达CDH3。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中CDH3的天然核酸序列并且可用于在对象中表达CDH3。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的CDH3的核酸序列在人中表达CDH3。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的CDH3的核酸序列在人中表达CDH3。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中CDH3的天然核酸序列在对象中表达CDH3。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中CDH3的天然核酸序列并且可用于在对象中表达CDH3。本文所述的组合物包括,包含以下的组合物:包含第一核苷酸序列的第一质粒,所述第一核苷酸序列编码由与乳腺癌相关的细胞表达的第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码由与乳腺癌相关的细胞表达的第二抗原的第二表位,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些情况中,组合物可包括编码来自以下蛋白质,CD105、HIF1α、MDM2、Yb-1、SOX-2、HER-2、IGFBP2、IGF-1R和CDH3的表位的核酸。在一些情况中,组合物可包括,包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是选自CD105、Yb-1、SOX-2、CDH3或MDM2的肽的部分,其中所述第一核苷酸序列位于质粒中。在其他情况中,组合物可包括,包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位独立地选自CD105、Yb-1、SOX-2、CDH3或MDM2,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些情况中,组合物可包括编码来自以下蛋白质的表位和核酸:CD105、MDM2、Yb-1、SOX-2、和CDH3。在一些情况中,该组合物可包括编码肽CD105的表位的核酸序列,其选自下组:与核苷酸序列CAGAACGGCACCTGGCCCCGCGAGGTGCTGCTGGTGCTGTCCGTGAACTCCTCCGTGTTCCTGCACCTACAGGCCCTGGGCATCCCCCTGCACCTGGCCTACAACTCCTCCCTGGTGACCTTCCAGGAGCCCCCCGGCGTGAACACCACCGAGCTG(SEQIDNO:2)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ACCGTGTTCATGCGCCTGAACATCATCTCCCCCGACCTGTCCGGCTGCACCTCCAAGGGCCTGGTGCTGCCCGCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCTCCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCC(SEQIDNO:3)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ACCGTGTCCATGCGCCTGAACATCGTGTCCCCCGACCTGTCCGGCAAGGGCCTGGTGCTGCCCTCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCGGCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCC(SEQIDNO:4)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ACCGTGTCCATGCGCCTGAACATCGTGTCCCCCGACCTGTCCGGCAAGGGCCTGGTGCTGCCCTCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCGCCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCC(SEQIDNO:5)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列EARMLNASIVASFVELPL(SEQIDNO:6)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列QNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTEL(SEQIDNO:1)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:8)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRGPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:9)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRAPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:10)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,该组合物可包括编码肽Yb-1的表位的核酸序列,其选自下组:与核苷酸序列GGAGTGCCAGTGCAGGGCTCCAAGTACGCTGCCGACCGCAACCACTACCGCCGCTACCCACGCCGTCGCGGCCCACCCCGCAACTACCAGCAGAAC(SEQIDNO:11)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列GGCGTGCCCGTGCAGGGCTCCAAGTACGCCGCCGACCGCAACCACTACCGCCGCTACCCCCGCCGCCGCGGCCCCCCCCGCAACTACCAGCAGAAC(SEQIDNO:12)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列GGCGTGCCCGTGCAGGGCTCCAAGTACGCCGCCGACCGCAACCACTACCGCCGCTACCCCCGCCGCCGCGGCCCCCCCCGCAACTACCAGCAGAAC(SEQIDNO:12)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列EDVFVHQTAIKKNNPRK(SEQIDNO:14)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列YRRNFNYRRRRPEN(SEQIDNO:15)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列GVPVQGSKYAADRNHYRRYPRRRGPPRNYQQN(SEQIDNO:16)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,该组合物可包括编码肽SOX-2的表位的核酸序列,其选自下组:与核苷酸序列GGCCTCAATGCGCACGGCGCAGCGCAGATGCAGCCCATGCACCGCTACGACGTGAGCGCCCTGCAGTACAACTCCATGACCAGCTCGCAGACCTACATGAACGGCTCGCCCACCTACAGCATGTCCTACTCGCAGCAGGGCACCCCTGGCATGGCTCTTGGCTCCATGGGTTCGGTG(SEQIDNO:17)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列GGCCTGAACGCCCACGGCGCCGCCCAGATGCAGCCCATGCACCGCTACGACGTGTCCGCCCTGCAGTACAACTCCATGACCTCCTCCCAGACCTACATGAACGGCTCCCCCACCTACTCCATGTCCTACTCCCAGCAGGGCACCCCCGGCATGGCCCTGGGCTCCATGGGCTCCGTG(SEQIDNO:18)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列GGCCTGAACGCCCACGGCGCCGCCCAGATGCAGCCCATGCACCGCTACGACGTGTCCGCCCTGCAGTACAACTCCATGACCTCCTCCCAGACCTACATGAACGGCTCCCCCACCTACTCCATGTCCTACTCCCAGCAGGGCACCCCCGGCATGGCCCTGGGCTCCATGGGCTCCGTG(SEQIDNO:18)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列GLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSV(SEQIDNO:20)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。。在一些情况中,该组合物可包括编码肽CDH3的核酸序列,其选自下组:与核苷酸序列AGGTCACTGAAGGAAAGGAATCCATTGAAAATCTTCCCATCCAAACGTATCTTACGAAGACACAAGAGAGATTGGGTGGTTGCTCCAATATCTGTCCCTGAAAATGGCAAGGGTCCCTTCCCACAGAGACTGAATCAGCTCAAGTCTAATAAAGATAGAGACACCAAGATTTTCTACAGCATCACGGGGCCGGGTGCAGACAGCCCACCTGAGGGTGTCTTCGCTGTAGAGAAGGAGACA(SEQIDNO:21)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列TTGAAAATCTTCCCATCCAAACGTATCTTACGAAGACACAAGAGAGATTGGGTGGTTGCTCCAATATCTGTCCCTGAAAATGGCAAGGGTCCCTTCCCACAGAGACTGAATCAGCTCAAGTCTAATAAAGATAGAGACACCAAGATTTTCTACAGCATCACGGGGCCGGGTGCAGACAGCCCACCTGAGGGTGTCTTCGCTGTAGAGAAGGAGACA(SEQIDNO:22)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列GCCATGCACTCCCCCCCCACCCGCATCCTGCGCCGCCGCAAGCGCGAGTGGGTGATGCCCCCCATCTTCGTGCCCGAGAACGGCAAGGGCCCCTTCCCCCAGCGCCTGAACCAGCTGAAGTCCAACAAGGACCGCGGCACCAAGATCTTCTACTCCATCACCGGCCCCGGCGCCGACTCCCCCCCCGAGGGCGTGTTCACCATCGAGAAGGAGTCC(SEQIDNO:23)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列GTGATGAACTCCCCCCCCTCCCGCATCCTGCGCCGCCGCAAGCGCGAGTGGGTGATGCCCCCCATCTCCGTGCCCGAGAACGGCAAGGGCCCCTTCCCCCAGCGCCTGAACCAGCTGAAGTCCAACAAGGACCGCGGCACCAAGCTGTTCTACTCCATCACCGGCCCCGGCGCCGACTCCCCCCCCGAGGGCGTGTTCACCATCGAGAAGGAGACC(SEQIDNO:24)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列RSLKERNPLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKET(SEQIDNO:25)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列LKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKET(SEQIDNO:26)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列AMHSPPTRILRRRKREWVMPPIFVPENGKGPFPQRLNQLKSNKDRGTKIFYSITGPGADSPPEGVFTIEKES(SEQIDNO:27)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列VMNSPPSRILRRRKREWVMPPISVPENGKGPFPQRLNQLKSNKDRGTKLFYSITGPGADSPPEGVFTIEKET(SEQIDNO:28)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,该组合物可包括编码肽MDM2的表位的核酸序列,其选自下组:与核苷酸序列ACCTACACCATGAAGGAGGTGCTGTTCTACCTGGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACCTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAaATCTACACCATGATCTACCGCAACCTGGTGGTGGTGAACCAGCAGGAGTCCTCCGACTCCGGCACCTCCGTGTCC(SEQIDNO:29)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ACCTACACCATGAAGGAGATCATCTTCTACATCGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACGTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAGATCTACGCCATGATCTACCGCAACCTGGTGGCCGTGTCCCAGCAGGACTCCGGCACCTCCCTGTCC(SEQIDNO:30)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、9/%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ATCTACACCATGAAGGAGATCATCTTCTACATCGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACGTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAGATCTACGCCATGATCTACCGCAACCTGGTGGTGGTGTCCCAGCAGGACTCCGGCACCTCCCCCTCC(SEQIDNO:31)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSV(SEQIDNO:32)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVAVSQQDSGTSLS(SEQIDNO:33)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列IYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVVVSQQDSGTSPS(SEQIDNO:34)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一个示例性情况中,该组合物可包括编码5种(个)表位的融合肽的核酸序列,其选自下组:与核苷酸序列ATGGCGGTACCCATGCAACTGTCCTGCTCTAGACAGAACGGCACCTGGCCCCGCGAGGTGCTGCTGGTGCTGTCCGTGAACTCCTCCGTGTTCCTGCACCTACAGGCCCTGGGCATCCCCCTGCACCTGGCCTACAACTCCTCCCTGGTGACCTTCCAGGAGCCCCCCGGCGTGAACACCACCGAGCTGAGATCCACCGGTGGAGTGCCAGTGCAGGGCTCCAAGTACGCTGCCGACCGCAACCACTACCGCCGCTACCCACGCCGTCGCGGCCCACCCCGCAACTACCAGCAGAACACGCGTGGCCTCAATGCGCACGGCGCAGCGCAGATGCAGCCCATGCACCGCTACGACGTGAGCGCCCTGCAGTACAACTCCATGACCAGCTCGCAGACCTACATGAACGGCTCGCCCACCTACAGCATGTCCTACTCGCAGCAGGGCACCCCTGGCATGGCTCTTGGCTCCATGGGTTCGGTGAGATCCCAATTGAGGTCACTGAAGGAAAGGAATCCATTGAAAATCTTCCCATCCAAACGTATCTTACGAAGACACAAGAGAGATTGGGTGGTTGCTCCAATATCTGTCCCTGAAAATGGCAAGGGTCCCTTCCCACAGAGACTGAATCAGCTCAAGTCTAATAAAGATAGAGACACCAAGATTTTCTACAGCATCACGGGGCCGGGTGCAGACAGCCCACCTGAGGGTGTCTTCGCTGTAGAGAAGGAGACAAGATCCGCCGGCGAAACCTACACCATGAAGGAGGTGCTGTTCTACCTGGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACCTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAAATCTACACCATGATCTACCGCAACCTGGTGGTGGTGAACCAGCAGGAGTCCTCCGACTCCGGCACCTCCGTGTCCAGATCTTAG(SEQIDNO:35)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCCATGACCGTGTTCATGCGCCTGAACATCATCTCCCCCGACCTGTCCGGCTGCACCTCCAAGGGCCTGGTGCTGCCCGCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCTCCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCCACCGGTGGAGTGCCAGTGCAGGGCTCCAAGTACGCTGCCGACCGCAACCACTACCGCCGCTACCCACGCCGTCGCGGCCCACCCCGCAACTACCAGCAGAACACGCGTGGCCTCAATGCGCACGGCGCAGCGCAGATGCAGCCCATGCACCGCTACGACGTGAGCGCCCTGCAGTACAACTCCATGACCAGCTCGCAGACCTACATGAACGGCTCGCCCACCTACAGCATGTCCTACTCGCAGCAGGGCACCCCTGGCATGGCTCTTGGCTCCATGGGTTCGGTGAGATCCCAATTGTTGAAAATCTTCCCATCCAAACGTATCTTACGAAGACACAAGAGAGATTGGGTGGTTGCTCCAATATCTGTCCCTGAAAATGGCAAGGGTCCCTTCCCACAGAGACTGAATCAGCTCAAGTCTAATAAAGATAGAGACACCAAGATTTTCTACAGCATCACGGGGCCGGGTGCAGACAGCCCACCTGAGGGTGTCTTCGCTGTAGAGAAGGAGACAAGATCCGCCGGCGAAACCTACACCATGAAGGAGGTGCTGTTCTACCTGGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACCTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAAATCTACACCATGATCTACCGCAACCTGGTGGTGGTGAACCAGCAGGAGTCCTCCGACTCCGGCACCTCCGTGTCCAGATCTTAG(SEQIDNO:36)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCCATGACCGTGTCCATGCGCCTGAACATCGTGTCCCCCGACCTGTCCGGCAAGGGCCTGGTGCTGCCCTCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCGGCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCCACCGGTGGCGTGCCCGTGCAGGGCTCCAAGTACGCCGCCGACCGCAACCACTACCGCCGCTACCCCCGCCGCCGCGGCCCCCCCCGCAACTACCAGCAGAACACGCGTGGCCTGAACGCCCACGGCGCCGCCCAGATGCAGCCCATGCACCGCTACGACGTGTCCGCCCTGCAGTACAACTCCATGACCTCCTCCCAGACCTACATGAACGGCTCCCCCACCTACTCCATGTCCTACTCCCAGCAGGGCACCCCCGGCATGGCCCTGGGCTCCATGGGCTCCGTGAGATCCCAATTGGCCATGCACTCCCCCCCCACCCGCATCCTGCGCCGCCGCAAGCGCGAGTGGGTGATGCCCCCCATCTTCGTGCCCGAGAACGGCAAGGGCCCCTTCCCCCAGCGCCTGAACCAGCTGAAGTCCAACAAGGACCGCGGCACCAAGATCTTCTACTCCATCACCGGCCCCGGCGCCGACTCCCCCCCCGAGGGCGTGTTCACCATCGAGAAGGAGTCCAGATCCGCCGGCGAAACCTACACCATGAAGGAGATCATCTTCTACATCGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACGTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAGATCTACGCCATGATCTACCGCAACCTGGTGGCCGTGTCCCAGCAGGACTCCGGCACCTCCCTGTCCAGATCTTAG(SEQIDNO:37)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCCATGACCGTGTCCATGCGCCTGAACATCGTGTCCCCCGACCTGTCCGGCAAGGGCCTGGTGCTGCCCTCCGTGCTGGGCATCACCTTCGGCGCCTTCCTGATCGGCGCCCTGCTGACCGCCGCCCTGTGGTACATCTACTCCCACACCCGCGCCCCCTCCAAGCGCGAGCCCGTGGTGGCCGTGGCCGCCCCCGCCTCCTCCGAGTCCTCCTCCACCAACCACTCCATCGGCTCCACCCAGTCCACCCCCTGCTCCACCTCCTCCATGGCCACCGGTGGCGTGCCCGTGCAGGGCTCCAAGTACGCCGCCGACCGCAACCACTACCGCCGCTACCCCCGCCGCCGCGGCCCCCCCCGCAACTACCAGCAGAACACGCGTGGCCTGAACGCCCACGGCGCCGCCCAGATGCAGCCCATGCACCGCTACGACGTGTCCGCCCTGCAGTACAACTCCATGACCTCCTCCCAGACCTACATGAACGGCTCCCCCACCTACTCCATGTCCTACTCCCAGCAGGGCACCCCCGGCATGGCCCTGGGCTCCATGGGCTCCGTGAGATCCCAATTGGTGATGAACTCCCCCCCCTCCCGCATCCTGCGCCGCCGCAAGCGCGAGTGGGTGATGCCCCCCATCTCCGTGCCCGAGAACGGCAAGGGCCCCTTCCCCCAGCGCCTGAACCAGCTGAAGTCCAACAAGGACCGCGGCACCAAGCTGTTCTACTCCATCACCGGCCCCGGCGCCGACTCCCCCCCCGAGGGCGTGTTCACCATCGAGAAGGAGACCAGATCCGCCGGCGAAATCTACACCATGAAGGAGATCATCTTCTACATCGGCCAGTACATCATGACCAAGCGCCTGTACGACGAGAAGCAGCAGCACATCGTGTACTGCTCCAACGACCTGCTGGGCGACGTGTTCGGCGTGCCCTCCTTCTCCGTGAAGGAGCACCGCAAGATCTACGCCATGATCTACCGCAACCTGGTGGTGGTGTCCCAGCAGGACTCCGGCACCTCCCCCTCCAGATCTTAG(SEQIDNO:38)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMQLSCSRQNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTELRSTGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLRSLKERNPLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKETRSAGETYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSVSRS(SEQIDNO:39)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKETRSAGETYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSVSRS(SEQIDNO:40)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMTVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRGPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLAMHSPPTRILRRRKREWVMPPIFVPENGKGPFPQRLNQLKSNKDRGTKIFYSITGPGADSPPEGVFTIEKESRSAGETYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVAVSQQDSGTSLSRS(SEQIDNO:41)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMTVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRAPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLVMNSPPSRILRRRKREWVMPPISVPENGKGPFPQRLNQLKSNKDRGTKLFYSITGPGADSPPEGVFTIEKETRSAGEIYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVVVSQQDSGTSPSRS(SEQIDNO:42)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,组合物可包括编码来自以下蛋白质的表位和核酸:HER-2、IGFBP2和IGF-1R。在一些情况中,组合物可包含包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是选自IGFBP-2、HER-2、IGF-1R的肽的部分,其中所述第一核苷酸序列位于质粒中。在一些情况中,组合物可包含:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位独立地选自IGFBP-2、HER-2或IGF-1R,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一个示例性情况中,该组合物可包括编码肽IGFBP-2的表位的核酸序列,其选自下组:与核苷酸序列ATGCTGCCGAGAGTGGGCTGCCCCGCGCTGCCGCTGCCGCCGCCGCCGCTGCTGCCGCTGCTGCCGCTGCTGCTGCTGCTACTGGGCGCGAGTGGCGGCGGCGGCGGGGCGCGCGCGGAGGTGCTGTTCCGCTGCCCGCCCTGCACACCCGAGCGCCTGGCCGCCTGCGGGCCCCCGCCGGTTGCGCCGCCCGCCGCGGTGGCCGCAGTGGCCGGAGGCGCCCGCATGCCATGCGCGGAGCTCGTCCGGGAGCCGGGCTGCGGCTGCTGCTCGGTGTGCGCCCGGCTGGAGGGCGAGGCGTGCGGCGTCTACACCCCGCGCTGCGGCCAGGGGCTGCGCTGCTATCCCCACCCGGGCTCCGAGCTGCCCCTGCAGGCGCTGGTCATGGGCGAGGGCACTTGTGAGAAGCGCCGGGACGCCGAGTATGGCGCCAGCCCGGAGCAGGTTGCAGACAATGGCGATGACCACTCAGAAGGAGGCCTGGTGGAG(SEQIDNO:43)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ATGCTGCCCCGCCTGGGCGGCCCCGCCCTGCCCCTGCTGCTGCCCTCCCTGCTGCTGCTGCTGCTGCTGGGCGCCGGCGGCTGCGGCCCCGGCGTGCGCGCCGAGGTGCTGTTCCGCTGCCCCCCCTGCACCCCCGAGCGCCTGGCCGCCTGCGGCCCCCCCCCCGACGCCCCCTGCGCCGAGCTGGTGCGCGAGCCCGGCTGCGGCTGCTGCTCCGTGTGCGCCCGCCAGGAGGGCGAGGCCTGCGGCGTGTACATCCCCCGCTGCGCCCAGACCCTGCGCTGCTACCCCAACCCCGGCTCCGAGCTGCCCCTGAAGGCCCTGGTGACCGGCGCCGGCACCTGCGAGAAGCGCCGCGTGGGCACCACCCCCCAGCAGGTGGCCGACTCCGACGACGACCACTCCGAGGGCGGCCTGGTGGAG(SEQIDNO:44)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ATGCTGCCCCGCCTGGGCGGCCCCGCCCTGCCCCTGCTGCTGCCCTCCCTGCTGCTGCTGCTGCTGCTGGGCGCCGGCGGCTGCGGCCCCGGCGTGCGCGCCGAGGTGCTGTTCCGCTGCCCCCCCTGCACCCCCGAGCGCCTGGCCGCCTGCGGCCCCCCCCCCGACGCCCCCTGCGCCGAGCTGGTGCGCGAGCCCGGCTGCGGCTGCTGCTCCGTGTGCGCCCGCCAGGAGGGCGAGGCCTGCGGCGTGTACATCCCCCGCTGCGCCCAGACCCTGCGCTGCTACCCCAACCCCGGCTCCGAGCTGCCCCTGAAGGCCCTGGTGACCGGCGCCGGCACCTGCGAGAAGCGCCGCGTGGGCACCACCCCCCAGCAGGTGGCCGACTCCGAGGACGACCACTCCGAGGGCGGCCTGGTGGAG(SEQIDNO:45)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列NHVDSTMNMLGGGGS(SEQIDNO:46)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列ELAVFREKVTEQHRQ(SEQIDNO:47)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列LGLEEPKKLRPPPAR(SEQIDNO:48)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列DQVLERISTMRLPDE(SEQIDNO:49)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列GPLEHLYSLHIPNCD(SEOIDNO:50)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列KHGLYNLKQCKMSLN(SEQIDNO:51)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列PNTGKLIQGAPTIRG(SEQIDNO:52)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列PECHLFYNEQQEARG(SEQIDNO:53)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MLPRVGCPALPLPPPPLLPLLPLLLLLLGASGGGGGARAEVLFRCPPCTPERLAACGPPPVAPPAAVAAVAGGARMPCAELVREPGCGCCSVCARLEGEACGVYTPRCGQGLRCYPHPGSELPLQALVMGEGTCEKRRDAEYGASPEQVADNGDDHSEGGLVE(SEQIDNO:54)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGTTPQQVADSDDDHSEGGLVE(SEQIDNO:55)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGATPQQVADSEDDHSEGGLVE(SEQIDNO:56)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,该组合物可包括编码肽HER-2的表位的核酸序列,其选自下组:与核苷酸序列ACGATGCGGAGACTGCTGCAGGAAACGGAGCTGGTGGAGCCGCTGACACCTAGCGGAGCGATGCCCAACCAGGCGCAGATGCGGATCCTGAAAGAGACGGAGCTGAGGAAGGTGAAGGTGCTTGGATCTGGCGCTTTTGGCACAGTCTACAAGGGCATCTGGATCCCTGATGGGGAGAATGTGAAAATTCCAGTGGCCATCAAAGTGTTGAGGGAAAACACATCCCCCAAAGCCAACAAAGAAATCTTAGACGAAGCATACGTGATGGCTGGTGTGGGCTCCCCATATGTCTCCCGCCTTCTGGGCATCTGCCTGACATCCACGGTGCAGCTGGTGACACAGCTTATGCCCTATGGCTGCCTCTTAGACCATGTCCGGGAAAACCGCGGACGCCTGGGCTCCCAGGACCTGCTGAACTGGTGTATGCAGATTGCCAAGGGGATGAGCTACCTGGAGGATGTGCGGCTCGTACACAGGGACTTGGCCGCTCGGAACGTGCTGGTCAAGAGTCCCAACCATGTCAAAATTACAGACTTCGGGCTGGCTCGGCTGCTGGACATTGACGAGACAGAGTACCATGCAGATGGGGGCAAGGTGCCCATCAAGTGGATGGCGCTGGAGTCCATTCTCCGCCGGCGGTTCACCCACCAGAGTGATGTGTGGAGTTATGGTGTGACTGTGTGGGAGCTGATGACTTTTGGGGCCAAACCTTACGATGGGATCCCAGCCCGGGAGATCCCTGACCTGCTGGAAAAGGGGGAGCGGCTGCCCCAGCCCCCCATCTGCACCATTGATGTCTACATGATCATGGTCAAATGTTGGATGATTGACTCTGAATGTCGGCCAAGATTCCGGGAGTTGGTGTCTGAATTCTCCCGCATGGCCAGGGACCCCCAGCGCTTTGTGGTCATCCAGAATGAGGACTTGGCTCCCGGAGCTGGCGGCATGGTGCACCACAGGCACCGCAGCTCATCTCCTCTGCCTGCTGCCCGACCTGCTGGTGCCACTCTGGAAAGGCCCAAGACTCTCTCCCCAGGGAAGAATGGGGTCGTCAAAGACGTTTTTGCCTTTGGGGGTGCCGTGGAGAACCCCGAGTACTTG(SEQIDNO:57)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ACCATGCGCCGCCTGCTGCAGGAGACCGAGCTGGTGGAGCCCCTGACCCCCTCCGGCGCCGTGCCCAACCAGGCCCAGATGCGCATCCTGAAGGAGACCGAGCTGCGCAAGCTGAAGGTGCTGGGCTCCGGCGCCTTCGGCACCGTGTACAAGGGCATCTGGATCCCCGACGGCGAGAACGTGAAGATCCCCGTGGCCATCAAGGTGCTGCGCGAGAACACCTCCCCCAAGGCCAACAAGGAGATCCTGGACGAGGCCTACGTGATGGCCGGCGTGGGCTCCCCCTACGTGTCCCGCCTGCTGGGCATCTGCCTGACCTCCACCGTGCAGCTGGTGACCCAGCTGATGCCCTACGGCTGCCTGCTGGACCACGTGCGCGAGCACCGCGGCCGCCTGGGCTCCCAGGACCTGCTGAACTGGTGCGTGCAGATCGCCAAGGGCATGTCCTACCTGGAGGAGGTGCGCCTGGTGCACCGCGACCTGGCCGCCCGCAACGTGCTGGTGAAGTCCCCCAACCACGTGAAGATCACCGACTTCGGCCTGGCCCGCCTGCTGGACATCGACGAGACCGAGTACCACGCCGACGGCGGCAAGGTGCCCATCAAGTGGATGGCCCTGGAGTCCATCCTGCGCCGCCGCTTCACCCACCAGTCCGACGTGTGGTCCTACGGCGTGACCGTGTGGGAGCTGATGACCTTCGGCGCCAAGCCCTACGACGGCATCCCCGCCCGCGAGATCCCCGACCTGCTGGAGAAGGGCGAGCGCCTGCCCCAGCCCCCCATCTGCACCATCGACGTGTACATGATCATGGTGAAGTGCTGGATGATCGACTCCGAGTGCCGCCCCCGCTTCCGCGAGCTGGTGTCCGAGTTCTCCCGCATGGCCCGCGACCCCCAGCGCTTCGTGGTGATCCAGAACGAGGACCTGGCCCTGGGCACCGGCTCCACCGCCCACCGCCGCCACCGCTCCTCCTCCCCCCCCCCCCCCATCCGCCCCGCCGGCGCCACCCTGGAGCGCCCCAAGACCCTGTCCCCCGGCAAGAACGGCGTGGTGAAGGACGTGTTCGCCTTCGGCGGCGCCGTGGAGAACCCCGAGTACCTG(SEQIDNO:58)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ACCATGCGCCGCCTGCTGCAGGAGACCGAGCTGGTGGAGCCCCTGACCCCCTCCGGCGCCATGCCCAACCAGGCCCAGATGCGCATCCTGAAGGAGACCGAGCTGCGCAAGGTGAAGGTGCTGGGCTCCGGCGCCTTCGGCACCGTGTACAAGGGCATCTGGATCCCCGACGGCGAGAACGTGAAGATCCCCGTGGCCATCAAGGTGCTGCGCGAGAACACCTCCCCCAAGGCCAACAAGGAGATCCTGGACGAGGCCTACGTGATGGCCGGCGTGGGCTCCCCCTACGTGTCCCGCCTGCTGGGCATCTGCCTGACCTCCACCGTGCAGCTGGTGACCCAGCTGATGCCCTACGGCTGCCTGCTGGACCACGTGCGCGAGCACCGCGGCCGCCTGGGCTCCCAGGACCTGCTGAACTGGTGCGTGCAGATCGCCAAGGGCATGTCCTACCTGGAGGACGTGCGCCTGGTGCACCGCGACCTGGCCGCCCGCAACGTGCTGGTGAAGTCCCCCAACCACGTGAAGATCACCGACTTCGGCCTGGCCCGCCTGCTGGACATCGACGAGACCGAGTACCACGCCGACGGCGGCAAGGTGCCCATCAAGTGGATGGCCCTGGAGTCCATCCTGCGCCGCCGCTTCACCCACCAGTCCGACGTGTGGTCCTACGGCGTGACCGTGTGGGAGCTGATGACCTTCGGCGCCAAGCCCTACGACGGCATCCCCGCCCGCGAGATCCCCGACCTGCTGGAGAAGGGCGAGCGCCTGCCCCAGCCCCCCATCTGCACCATCGACGTGTACATGATCATGGTGAAGTGCTGGATGATCGACTCCGAGTGCCGCCCCCGCTTCCGCGAGCTGGTGTCCGAGTTCTCCCGCATGGCCCGCGACCCCCAGCGCTTCGTGGTGATCCAGAACGAGGACCTGACCCCCGGCACCGGCTCCACCGCCCACCGCCGCCACCGCTCCTCCTCCCCCCTGCCCCCCGTGCGCCCCGCCGGCGCCACCCTGGAGCGCCCCAAGACCCTGTCCCCCGGCAAGAACGGCGTGGTGAAGGACGTGTTCGCCTTCGGCGGCGCCGTGGAGAACCCCGAGTACCTG(SEQIDNO:59)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVRENRGRLGSQDLLNWCMQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLAPGAGGMVHHRHRSSSPLPAARPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:60)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAVPNQAQMRILKETELRKLKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEEVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLALGTGSTAHRRHRSSSPPPPIRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:61)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLTPGTGSTAHRRHRSSSPLPPVRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:62)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一个示例性情况中,该组合物可包括编码肽IGF-1R的表位的核酸序列,其选自下组:与核苷酸序列TGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGAGGCCGCAAGAACGAGCGCGCCCTGCCC(SEQIDNO:63)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列TGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGCGGCCGCGCCAACGAGCGCGCCCTGCCC(SEQIDNO:64)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列TGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGCGGCCGCGCCAACGAGCGCGCCCTGCCC(SEQIDNO:65)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列DYRSYRFPKLTVITE(SEQIDNO:66)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列IRGWKLFYNYALVIF(SEQIDNO:67)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列VVTGYVKIRHSHALV(SEQIDNO:68)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列FFYVQAKTGYENFIH(SEQIDNO:69)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列LIIALPVAVLLIVGG(SEQIDNO:70)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列LVIMLYVFHRKRNNS(SEQIDNO:71)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列NCHHVVRLLGVVSQG(SEQIDNO:72)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALP(SEQIDNO:73)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRANERALP(SEQIDNO:74)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGVLVLRASFDERQPYAHMNGGRANERALP(SEQIDNO:75)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,该组合物可包括编码3种(个)表位的融合肽的核酸序列,其选自下组:与核苷酸序列ATGGCGGTACCAATGCTGCCGAGAGTGGGCTGCCCCGCGCTGCCGCTGCCGCCGCCGCCGCTGCTGCCGCTGCTGCCGCTGCTGCTGCTGCTACTGGGCGCGAGTGGCGGCGGCGGCGGGGCGCGCGCGGAGGTGCTGTTCCGCTGCCCGCCCTGCACACCCGAGCGCCTGGCCGCCTGCGGGCCCCCGCCGGTTGCGCCGCCCGCCGCGGTGGCCGCAGTGGCCGGAGGCGCCCGCATGCCATGCGCGGAGCTCGTCCGGGAGCCGGGCTGCGGCTGCTGCTCGGTGTGCGCCCGGCTGGAGGGCGAGGCGTGCGGCGTCTACACCCCGCGCTGCGGCCAGGGGCTGCGCTGCTATCCCCACCCGGGCTCCGAGCTGCCCCTGCAGGCGCTGGTCATGGGCGAGGGCACTTGTGAGAAGCGCCGGGACGCCGAGTATGGCGCCAGCCCGGAGCAGGTTGCAGACAATGGCGATGACCACTCAGAAGGAGGCCTGGTGGAGCAATTGACGATGCGGAGACTGCTGCAGGAAACGGAGCTGGTGGAGCCGCTGACACCTAGCGGAGCGATGCCCAACCAGGCGCAGATGCGGATCCTGAAAGAGACGGAGCTGAGGAAGGTGAAGGTGCTTGGATCTGGCGCTTTTGGCACAGTCTACAAGGGCATCTGGATCCCTGATGGGGAGAATGTGAAAATTCCAGTGGCCATCAAAGTGTTGAGGGAAAACACATCCCCCAAAGCCAACAAAGAAATCTTAGACGAAGCATACGTGATGGCTGGTGTGGGCTCCCCATATGTCTCCCGCCTTCTGGGCATCTGCCTGACATCCACGGTGCAGCTGGTGACACAGCTTATGCCCTATGGCTGCCTCTTAGACCATGTCCGGGAAAACCGCGGACGCCTGGGCTCCCAGGACCTGCTGAACTGGTGTATGCAGATTGCCAAGGGGATGAGCTACCTGGAGGATGTGCGGCTCGTACACAGGGACTTGGCCGCTCGGAACGTGCTGGTCAAGAGTCCCAACCATGTCAAAATTACAGACTTCGGGCTGGCTCGGCTGCTGGACATTGACGAGACAGAGTACCATGCAGATGGGGGCAAGGTGCCCATCAAGTGGATGGCGCTGGAGTCCATTCTCCGCCGGCGGTTCACCCACCAGAGTGATGTGTGGAGTTATGGTGTGACTGTGTGGGAGCTGATGACTTTTGGGGCCAAACCTTACGATGGGATCCCAGCCCGGGAGATCCCTGACCTGCTGGAAAAGGGGGAGCGGCTGCCCCAGCCCCCCATCTGCACCATTGATGTCTACATGATCATGGTCAAATGTTGGATGATTGACTCTGAATGTCGGCCAAGATTCCGGGAGTTGGTGTCTGAATTCTCCCGCATGGCCAGGGACCCCCAGCGCTTTGTGGTCATCCAGAATGAGGACTTGGCTCCCGGAGCTGGCGGCATGGTGCACCACAGGCACCGCAGCTCATCTCCTCTGCCTGCTGCCCGACCTGCTGGTGCCACTCTGGAAAGGCCCAAGACTCTCTCCCCAGGGAAGAATGGGGTCGTCAAAGACGTTTTTGCCTTTGGGGGTGCCGTGGAGAACCCCGAGTACTTGGGCCGGCCGGTACCTTGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGAGGCCGCAAGAACGAGCGCGCCCTGCCCGCGGCCGCATAG(SEQIDNO:76)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCAATGCTGCCCCGCCTGGGCGGCCCCGCCCTGCCCCTGCTGCTGCCCTCCCTGCTGCTGCTGCTGCTGCTGGGCGCCGGCGGCTGCGGCCCCGGCGTGCGCGCCGAGGTGCTGTTCCGCTGCCCCCCCTGCACCCCCGAGCGCCTGGCCGCCTGCGGCCCCCCCCCCGACGCCCCCTGCGCCGAGCTGGTGCGCGAGCCCGGCTGCGGCTGCTGCTCCGTGTGCGCCCGCCAGGAGGGCGAGGCCTGCGGCGTGTACATCCCCCGCTGCGCCCAGACCCTGCGCTGCTACCCCAACCCCGGCTCCGAGCTGCCCCTGAAGGCCCTGGTGACCGGCGCCGGCACCTGCGAGAAGCGCCGCGTGGGCACCACCCCCCAGCAGGTGGCCGACTCCGACGACGACCACTCCGAGGGCGGCCTGGTGGAGCAATTGACCATGCGCCGCCTGCTGCAGGAGACCGAGCTGGTGGAGCCCCTGACCCCCTCCGGCGCCGTGCCCAACCAGGCCCAGATGCGCATCCTGAAGGAGACCGAGCTGCGCAAGCTGAAGGTGCTGGGCTCCGGCGCCTTCGGCACCGTGTACAAGGGCATCTGGATCCCCGACGGCGAGAACGTGAAGATCCCCGTGGCCATCAAGGTGCTGCGCGAGAACACCTCCCCCAAGGCCAACAAGGAGATCCTGGACGAGGCCTACGTGATGGCCGGCGTGGGCTCCCCCTACGTGTCCCGCCTGCTGGGCATCTGCCTGACCTCCACCGTGCAGCTGGTGACCCAGCTGATGCCCTACGGCTGCCTGCTGGACCACGTGCGCGAGCACCGCGGCCGCCTGGGCTCCCAGGACCTGCTGAACTGGTGCGTGCAGATCGCCAAGGGCATGTCCTACCTGGAGGAGGTGCGCCTGGTGCACCGCGACCTGGCCGCCCGCAACGTGCTGGTGAAGTCCCCCAACCACGTGAAGATCACCGACTTCGGCCTGGCCCGCCTGCTGGACATCGACGAGACCGAGTACCACGCCGACGGCGGCAAGGTGCCCATCAAGTGGATGGCCCTGGAGTCCATCCTGCGCCGCCGCTTCACCCACCAGTCCGACGTGTGGTCCTACGGCGTGACCGTGTGGGAGCTGATGACCTTCGGCGCCAAGCCCTACGACGGCATCCCCGCCCGCGAGATCCCCGACCTGCTGGAGAAGGGCGAGCGCCTGCCCCAGCCCCCCATCTGCACCATCGACGTGTACATGATCATGGTGAAGTGCTGGATGATCGACTCCGAGTGCCGCCCCCGCTTCCGCGAGCTGGTGTCCGAGTTCTCCCGCATGGCCCGCGACCCCCAGCGCTTCGTGGTGATCCAGAACGAGGACCTGGCCCTGGGCACCGGCTCCACCGCCCACCGCCGCCACCGCTCCTCCTCCCCCCCCCCCCCCATCCGCCCCGCCGGCGCCACCCTGGAGCGCCCCAAGACCCTGTCCCCCGGCAAGAACGGCGTGGTGAAGGACGTGTTCGCCTTCGGCGGCGCCGTGGAGAACCCCGAGTACCTGGGCCGGCCGGTACCTTGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGCGGCCGCGCCAACGAGCGCGCCCTGCCCGCGGCCGCATAG(SEQIDNO:77)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;与核苷酸序列ATGGCGGTACCAATGCTGCCCCGCCTGGGCGGCCCCGCCCTGCCCCTGCTGCTGCCCTCCCTGCTGCTGCTGCTGCTGCTGGGCGCCGGCGGCTGCGGCCCCGGCGTGCGCGCCGAGGTGCTGTTCCGCTGCCCCCCCTGCACCCCCGAGCGCCTGGCCGCCTGCGGCCCCCCCCCCGACGCCCCCTGCGCCGAGCTGGTGCGCGAGCCCGGCTGCGGCTGCTGCTCCGTGTGCGCCCGCCAGGAGGGCGAGGCCTGCGGCGTGTACATCCCCCGCTGCGCCCAGACCCTGCGCTGCTACCCCAACCCCGGCTCCGAGCTGCCCCTGAAGGCCCTGGTGACCGGCGCCGGCACCTGCGAGAAGCGCCGCGTGGGCGCCACCCCCCAGCAGGTGGCCGACTCCGAGGACGACCACTCCGAGGGCGGCCTGGTGGAGCAATTGACCATGCGCCGCCTGCTGCAGGAGACCGAGCTGGTGGAGCCCCTGACCCCCTCCGGCGCCATGCCCAACCAGGCCCAGATGCGCATCCTGAAGGAGACCGAGCTGCGCAAGGTGAAGGTGCTGGGCTCCGGCGCCTTCGGCACCGTGTACAAGGGCATCTGGATCCCCGACGGCGAGAACGTGAAGATCCCCGTGGCCATCAAGGTGCTGCGCGAGAACACCTCCCCCAAGGCCAACAAGGAGATCCTGGACGAGGCCTACGTGATGGCCGGCGTGGGCTCCCCCTACGTGTCCCGCCTGCTGGGCATCTGCCTGACCTCCACCGTGCAGCTGGTGACCCAGCTGATGCCCTACGGCTGCCTGCTGGACCACGTGCGCGAGCACCGCGGCCGCCTGGGCTCCCAGGACCTGCTGAACTGGTGCGTGCAGATCGCCAAGGGCATGTCCTACCTGGAGGACGTGCGCCTGGTGCACCGCGACCTGGCCGCCCGCAACGTGCTGGTGAAGTCCCCCAACCACGTGAAGATCACCGACTTCGGCCTGGCCCGCCTGCTGGACATCGACGAGACCGAGTACCACGCCGACGGCGGCAAGGTGCCCATCAAGTGGATGGCCCTGGAGTCCATCCTGCGCCGCCGCTTCACCCACCAGTCCGACGTGTGGTCCTACGGCGTGACCGTGTGGGAGCTGATGACCTTCGGCGCCAAGCCCTACGACGGCATCCCCGCCCGCGAGATCCCCGACCTGCTGGAGAAGGGCGAGCGCCTGCCCCAGCCCCCCATCTGCACCATCGACGTGTACATGATCATGGTGAAGTGCTGGATGATCGACTCCGAGTGCCGCCCCCGCTTCCGCGAGCTGGTGTCCGAGTTCTCCCGCATGGCCCGCGACCCCCAGCGCTTCGTGGTGATCCAGAACGAGGACCTGACCCCCGGCACCGGCTCCACCGCCCACCGCCGCCACCGCTCCTCCTCCCCCCTGCCCCCCGTGCGCCCCGCCGGCGCCACCCTGGAGCGCCCCAAGACCCTGTCCCCCGGCAAGAACGGCGTGGTGAAGGACGTGTTCGCCTTCGGCGGCGCCGTGGAGAACCCCGAGTACCTGGGCCGGCCGGTACCTTGGTCCTTCGGCGTGGTGCTGTGGGAGATCGCCACCCTGGCCGAGCAGCCCTACCAGGGCCTGTCCAACGAGCAGGTGCTGCGCTTCGTGATGGAGGGCGGCCTGCTGGACAAGCCCGACAACTGCCCCGACATGCTGTTCGAGCTGATGCGCATGTGCTGGCAGTACAACCCCAAGATGCGCCCCTCCTTCCTGGAGCACAAGGCCGAGAACGGCCCCGGCGTGCTGGTGCTGCGCGCCTCCTTCGACGAGCGCCAGCCCTACGCCCACATGAACGGCGGCCGCGCCAACGAGCGCGCCCTGCCCGCGGCCGCATAG(SEQIDNO:78)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核苷酸序列;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMLPRVGCPALPLPPPPLLPLLPLLLLLLGASGGGGGARAEVLFRCPPCTPERLAACGPPPVAPPAAVAAVAGGARMPCAELVREPGCGCCSVCARLEGEACGVYTPRCGQGLRCYPHPGSELPLQALVMGEGTCEKRRDAEYGASPEQVADNGDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVRENRGRLGSQDLLNWCMQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLAPGAGGMVHHRHRSSSPLPAARPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALPAAA(SEQIDNO:79)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGTTPQQVADSDDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAVPNQAQMRILKETELRKLKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEEVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLALGTGSTAHRRHRSSSPPPPIRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRANERALPAAA(SEQIDNO:80)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列MAVPMLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGATPQQVADSEDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLTPGTGSTAHRRHRSSSPLPPVRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGVLVLRASFDERQPYAHMNGGRANERALPAAA(SEQIDNO:81)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,组合物可包括独立地选自以下的第一和第二表位:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物可包括第三表位,第一、第二和第三表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物可包括第三和第四表位,第一、第二、第三和第四表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物可包括第三、第四和第五表位,第一、第二、第三、第四和第五表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物可包括独立地选自以下的第一和第二表位:IGFBP2、HER-2或IGF-1R。在一些情况中,组合物可包括第三表位,第一、第二和第三表位独立地选自:IGFBP2、HER-2或IGF-1R。在一些情况中,组合物能够给予对象。在一些情况中,对象需要给予组合物。在一些情况中,组合物在对象中有效引发免疫应答。在一些情况中,组合物在对象中有效消除与乳腺癌相关的多种细胞。在一些情况中,组合物可用于在对象中防止与乳腺癌相关的细胞的生长。在一些情况中,第一和第二核酸序列位于第一质粒上。在一些情况中,第二核酸序列位于第二质粒上。在一些情况中,与乳腺癌相关的细胞选自:表达异常特征的乳腺细胞、肿瘤前乳腺细胞、乳腺癌细胞、侵入前乳腺癌细胞、乳腺癌干细胞、上皮细胞、间充质细胞、体细胞、或其组合。在一些情况中,第一和第二核酸序列纯化至至少70%纯。在一些情况中,第一和第二核酸序列位于第一质粒上并且被接头核酸序列分开。在一些情况中,在第一质粒上,第一核酸序列与第二核酸序列毗邻。在一些情况中,在药物组合物中含有至少第一质粒。在一些情况中,在另外包含药物运载体的药物组合物中含有至少第一质粒。在一些情况中,在另外包含药物运载体和佐剂的药物组合物中含有至少第一质粒。在一些情况中,在另外包含佐剂的药物组合物中含有至少第一质粒。在一些情况中,组合物还包含佐剂和药学上可接受的运载体。在一些情况中,佐剂是GM-CSF。在一些情况中,对象选自:患有乳腺癌的人、患有乳腺癌的小鼠或患有乳腺癌的大鼠。在一些情况中,对象选自:未患有乳腺癌的人、未患有乳腺癌的小鼠或未患有乳腺癌的大鼠。在一些情况中,免疫应答是1型免疫应答。在一些情况中,第一核酸序列是选自人、小鼠或大鼠的物种。在一些情况中,第二核酸序列是选自人、小鼠或大鼠的物种。在一些情况中,免疫应答表征为大于1的I型细胞因子产生与II型细胞因子产生之比。在一些情况中,免疫应答表征为小于1的I型细胞因子产生与II型细胞因子产生之比。在一些情况中,免疫应答表征为大于1的IFNγ产生与IL-10产生之比。在一些情况中,免疫应答表征为小于1的IFNγ产生与IL-10产生之比。在一些情况中,组合物包括包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是HIF-1α肽的部分,其中所述第一核苷酸序列位于质粒中。在其他情况中,组合物包括包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位是HIF-1α肽的部分,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。编码选自以下蛋白质的表位的核酸序列与本文所列的那些不同:CD105、HIF1α、MDM2、Yb-1、SOX-2、HER-2、IGFBP2、IGF-1R和CDH3。在一些情况中,与本文所述的那些超过50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%或超过50%同源的核酸序列可用于本文所述的组合物中。在一些情况中,本文所述的组合物可包括,包含以下的组合物:由与乳腺癌相关的细胞表达的第一抗原的第一表位;和由与乳腺癌相关的细胞表达的第二抗原的第二表位。在一些情况中,组合物可包含:至少第一抗原的第一表位,所述第一表位是选自CD105、Yb-1、SOX-2、CDH3或MDM2的肽的部分。在一些情况中,组合物可包含:至少第一抗原的第一表位,至少第二抗原的第二表位,所述第一和第二表位独立地选自CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,肽CD105的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列EARMLNASIVASFVELPL(SEQIDNO:6)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列QNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTEL(SEQIDNO:1)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列TVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:8)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列TVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRGPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:9)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列TVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRAPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMA(SEQIDNO:10)有至少50%、60%、70%、R0%、90%、91%、92%、93%、94%、9气%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,肽Yb-1的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列EDVFVHQTAIKKNNPRK(SEQIDNO:14)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列YRRNFNYRRRRPEN(SEQIDNO:15)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列GVPVQGSKYAADRNHYRRYPRRRGPPRNYQQN(SEQIDNO:16)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,肽SOX-2的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列GLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSV(SEQIDNO:20)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,肽CDH3的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列RSLKERNPLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKET(SEQIDNO:25)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列LKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKET(SEQIDNO:26)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列AMHSPPTRILRRRKREWVMPPIFVPENGKGPFPQRLNQLKSNKDRGTKIFYSITGPGADSPPEGVFTIEKES(SEQIDNO:27)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列VMNSPPSRILRRRKREWVMPPISVPENGKGPFPQRLNQLKSNKDRGTKLFYSITGPGADSPPEGVFTIEKET(SEQIDNO:28)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,肽MDM-2的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列TYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSV(SEQIDNO:32)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列TYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVAVSQQDSGTSLS(SEQIDNO:33)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列IYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVVVSQQDSGTSPS(SEQIDNO:34)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,本文所述的组合物包括5种(个)表位的融合肽的氨基酸序列,其选自下组:氨基酸序列,该氨基酸序列与氨基酸序列MAVPMQLSCSRQNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTELRSTGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLRSLKERNPLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKETRSAGETYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSVSRS(SEQIDNO:39)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MAVPMTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLLKIFPSKRILRRHKRDWVVAPISVPENGKGPFPQRLNQLKSNKDRDTKIFYSITGPGADSPPEGVFAVEKETRSAGETYTMKEVLFYLGQYIMTKRLYDEKQQHIVYCSNDLLGDLFGVPSFSVKEHRKIYTMIYRNLVVVNQQESSDSGTSVSRS(SEQIDNO:40)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MAVPMTVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRGPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLAMHSPPTRILRRRKREWVMPPIFVPENGKGPFPQRLNQLKSNKDRGTKIFYSITGPGADSPPEGVFTIEKESRSAGETYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVAVSQQDSGTSLSRS(SEQIDNO:41)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列MAVPMTVSMRLNIVSPDLSGKGLVLPSVLGITFGAFLIGALLTAALWYIYSHTRAPSKREPVVAVAAPASSESSSTNHSIGSTQSTPCSTSSMATGGVPVQGSKYAADRNHYRRYPRRRGPPRNYQQNTRGLNAHGAAQMQPMHRYDVSALQYNSMTSSQTYMNGSPTYSMSYSQQGTPGMALGSMGSVRSQLVMNSPPSRILRRRKREWVMPPISVPENGKGPFPQRLNQLKSNKDRGTKLFYSITGPGADSPPEGVFTIEKETRSAGEIYTMKEIIFYIGQYIMTKRLYDEKQQHIVYCSNDLLGDVFGVPSFSVKEHRKIYAMIYRNLVVVSQQDSGTSPSRS(SEQIDNO:42)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。本文所述的组合物还包括,包含以下的组合物:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位,所述第一表位是选自IGFBP-2、HER-2或IGF-1R的肽的部分,其中所述第一核苷酸序列位于质粒中。在一些情况中,组合物可包含:包含第一核苷酸序列第一质粒,所述第一核苷酸序列编码第一抗原的第一表位;和第二核苷酸序列,所述第二核苷酸序列编码第二抗原的第二表位,其中所述第一和第二表位独立地选自IGFBP-2、HER-2或IGF-1R,其中所述第一核苷酸序列和所述第二核苷酸序列位于一个或多个质粒中。在一些情况中,肽IGFBP-2的至少第一表位选自下组:氨基酸序列,该氨基酸序列与氨基酸序列NHVDSTMNMLGGGGS(SEQIDNO:46)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列ELAVFREKVTEQHRQ(SEQIDNO:47)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列LGLEEPKKLRPPPAR(SEQIDNO:48)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列DQVLERISTMRLPDE(SEQIDNO:49)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列GPLEHLYSLHIPNCD(SEQIDNO:50)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列KHGLYNLKQCKMSLN(SEQIDNO:51)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列PECHLFYNEQQEARG(SEQIDNO:53)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MLPRVGCPALPLPPPPLLPLLPLLLLLLGASGGGGGARAEVLFRCPPCTPERLAACGPPPVAPPAAVAAVAGGARMPCAELVREPGCGCCSVCARLEGEACGVYTPRCGQGLRCYPHPGSELPLQALVMGEGTCEKRRDAEYGASPEQVADNGDDHSEGGLVE(SEQIDNO:54)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGTTPQQVADSDDDHSEGGLVE(SEQIDNO:55)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列MLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGATPQQVADSEDDHSEGGLVE(SEQIDNO:56)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,肽HER-2的至少第一表位选自下组:编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVRENRGRLGSQDLLNWCMQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLAPGAGGMVHHRHRSSSPLPAARPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:60)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAVPNQAQMRILKETELRKLKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEEVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLALGTGSTAHRRHRSSSPPPPIRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:61)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列TMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLTPGTGSTAHRRHRSSSPLPPVRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYL(SEQIDNO:62)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,该组合物可包括编码肽IGF-1R的表位的核酸序列,其选自下组:氨基酸序列,该氨基酸序列与氨基酸序列DYRSYRFPKLTVITE(SEQIDNO:66)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列IRGWKLFYNYALVIF(SEQIDNO:67)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列VVTGYVKIRHSHALV(SEQIDNO:68)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列FFYVQAKTGYENFIH(SEQIDNO:69)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列LIIALPVAVLLIVGG(SEQIDNO:70)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列LVIMLYVFHRKRNNS(SEQIDNO:71)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列NCHHVVRLLGVVSQG(SEQIDNO:72)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALP(SEQIDNO:73)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRANERALP(SEQIDNO:74)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列WSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGVLVLRASFDERQPYAHMNGGRANERALP(SEQIDNO:75)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。。本文所述的组合物还可包括编码三种(个)表位的融合蛋白的核酸序列,其选自下组:氨基酸序列,该氨基酸序列与氨基酸序列MAVPMLPRVGCPALPLPPPPLLPLLPLLLLLLGASGGGGGARAEVLFRCPPCTPERLAACGPPPVAPPAAVAAVAGGARMPCAELVREPGCGCCSVCARLEGEACGVYTPRCGQGLRCYPHPGSELPLQALVMGEGTCEKRRDAEYGASPEQVADNGDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVRENRGRLGSQDLLNWCMQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLAPGAGGMVHHRHRSSSPLPAARPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRKNERALPAAA(SEQIDNO:79)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列MAVPMLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGTTPQQVADSDDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAVPNQAQMRILKETELRKLKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEEVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLALGTGSTAHRRHRSSSPPPPIRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGPGVLVLRASFDERQPYAHMNGGRANERALPAAA(SEQIDNO:80)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;或氨基酸序列,该氨基酸序列与氨基酸序列MAVPMLPRLGGPALPLLLPSLLLLLLLGAGGCGPGVRAEVLFRCPPCTPERLAACGPPPDAPCAELVREPGCGCCSVCARQEGEACGVYIPRCAQTLRCYPNPGSELPLKALVTGAGTCEKRRVGATPQQVADSEDDHSEGGLVEQLTMRRLLQETELVEPLTPSGAMPNQAQMRILKETELRKVKVLGSGAFGTVYKGIWIPDGENVKIPVAIKVLRENTSPKANKEILDEAYVMAGVGSPYVSRLLGICLTSTVQLVTQLMPYGCLLDHVREHRGRLGSQDLLNWCVQIAKGMSYLEDVRLVHRDLAARNVLVKSPNHVKITDFGLARLLDIDETEYHADGGKVPIKWMALESILRRRFTHQSDVWSYGVTVWELMTFGAKPYDGIPAREIPDLLEKGERLPQPPICTIDVYMIMVKCWMIDSECRPRFRELVSEFSRMARDPQRFVVIQNEDLTPGTGSTAHRRHRSSSPLPPVRPAGATLERPKTLSPGKNGVVKDVFAFGGAVENPEYLGRPVPWSFGVVLWEIATLAEQPYQGLSNEQVLRFVMEGGLLDKPDNCPDMLFELMRMCWQYNPKMRPSFLEHKAENGPGVLVLRASFDERQPYAHMNGGRANERALPAAA(SEQIDNO:81)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,组合物包括独立地选自以下的第一和第二表位:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物还包括第三表位,第一、第二和第三表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物还包括第三和第四表位,第一、第二、第三和第四表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物还包括第三、第四和第五表位,第一、第二、第三、第四和第五表位独立地选自:CD105、Yb-1、SOX-2、CDH3或MDM2。在一些情况中,组合物包括独立地选自以下的第一和第二表位:IGFBP2、HER-2或IGF-1R。在一些情况中,组合物还包括第三表位,第一、第二和第三表位独立地选自:IGFBP2、HER-2或IGF-1R。在一些情况中,组合物可包含:至少第一抗原的第一表位,所述第一表位来自HIF-1α的肽的部分。在一些情况中,组合物可包含:至少第一抗原的第一表位,至少第二抗原的第二表位,所述第一和第二表位来自HIF-1α。在一些情况中,组合物可包括编码肽HIF-1α的表位的核苷酸序列,其选自下组:编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列DSKTFLSRHSLDMKFSYCDERITELMGYEPEELLGRSIYEYYHALDSDHLTKTHHDMFTKGQVTTGQYRMLAKRGGYVWVETQATVIYN(SEQIDNO:82)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列SDNVNKYMGLTQFELTGHSVFDFTHP(SEQIDNO:83)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;和编码氨基酸序列的核苷酸序列,该氨基酸序列与氨基酸序列GGYVWVETQATVIYNTKNSQ(SEQIDNO:84)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。在一些情况中,组合物可包括肽HIF-1α的至少第一表位,其选自下组:氨基酸序列,该氨基酸序列与氨基酸序列DSKTFLSRHSLDMKFSYCDERITELMGYEPEELLGRSIYEYYHALDSDHLTKTHHDMFTKGQVTTGQYRMLAKRGGYVWVETQATVIYN(SEQIDNO:82)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;氨基酸序列,该氨基酸序列与氨基酸序列SDNVNKYMGLTQFELTGHSVFDFTHP(SEQIDNO:83)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性;和氨基酸序列,该氨基酸序列与氨基酸序列GGYVWVETQATVIYNTKNSQ(SEQIDNO:84)有至少50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性。本文所述的组合物可含有在单质粒主链上编码的短表位。在一些情况中,质粒主链可编码一个短表位。在其他情况中,本文所述的质粒可编码超过一个短表位。例如,本文所述的组合物可编码2个短表位、3个短表位、4个短表位、5个短表位、6个短表位、7个短表位、8个短表位、9个短表位、10个短表位、11个短表位、12个短表位、13个短表位、14个短表位、15个短表位、16个短表位、17个短表位、18个短表位、19个短表位、20个短表位、或超过20个短表位。在示例性情况中,质粒编码不超过6个短表位。本文所述的组合物可含有在单质粒主链上编码的延伸表位。在一些情况中,质粒可编码一个延伸表位。在其他情况中,组合物可编码超过一个延伸表位。例如,质粒可编码2个延伸表位、3个延伸表位、4个延伸表位、5个延伸表位、6个延伸表位、7个延伸表位、8个延伸表位、9个延伸表位、10个延伸表位、11个延伸表位、12个延伸表位、13个延伸表位、14个延伸表位、15个延伸表位、16个延伸表位、17个延伸表位、18个延伸表位、19个延伸表位、20个延伸表位、或超过20个延伸表位。在示例性情况中,质粒编码不超过4个延伸表位。本文所述的乳腺癌疫苗的组合物可含有单质粒主链上的短表位和延伸表位。在一些情况中,质粒可包含一个短表位。在其他情况中,本文所述的质粒的组合物可包含超过一个短表位。例如,本文所述的质粒的组合物可包含2个短表位、3个短表位、4个短表位、5个短表位、6个短表位、7个短表位、8个短表位、9个短表位、10个短表位、11个短表位、12个短表位、13个短表位、14个短表位、15个短表位、16个短表位、17个短表位、18个短表位、19个短表位、20个短表位、或超过20个短表位。在一些情况中,质粒可编码一个延伸表位。在其他情况中,本文所述的组合物可编码超过一个延伸表位。例如,本文所述的组合物可编码2个延伸表位、3个延伸表位、4个延伸表位、5个延伸表位、6个延伸表位、7个延伸表位、8个延伸表位、9个延伸表位、10个延伸表位、11个延伸表位、12个延伸表位、13个延伸表位、14个延伸表位、15个延伸表位、16个延伸表位、17个延伸表位、18个延伸表位、19个延伸表位、20个延伸表位、或超过20个延伸表位。用于含有超过一种编码表位的序列的组合物的质粒可在各表位序列之间含有间隔子。在一些情况中,可串联编码短表位的序列而不使用间隔子。在一些情况中,可串联编码延伸表位的序列而不使用间隔子。在一些情况中,可使用间隔子串联编码短表位的序列。在一些情况中,可使用间隔子串联编码延伸表位的序列。在一个示例性情况中,组合物可以是基于质粒的疫苗,其含有短和延伸抗原性表位。可使用4kB质粒主链(例如,pUMVC3或pNGVL3)来构建疫苗的一种(个)或多种(个)质粒。通常,质粒可含有抗生素抗性基因。例如,除了用于在细菌中选择和增殖的复制起点以外,pUMVC3含有卡那霉素抗性基因。在一些情况中,pUMVC3中的多克隆位点可侧接真核转录控制元件以促进插入的序列(例如,基因盒)在真核细胞中的表达。例如,插入的序列可以是表位。在示例性情况中,可用质粒主链中Kozak共有翻译起始序列、终止密码子、和克隆位点来组装抗原性表位肽的核酸编码序列。可使用本领域普通技术人员已知的标准分子技术包括合成寡核苷酸、聚合酶链反应扩增、限制性内切核酸酶、和核酸连接酶(例如,DNA连接酶)来生成核酸(例如,DNA片段)并将核酸片段插入质粒载体主链中。在一些情况中,质粒可含有编码至少一个标签的核酸序列。在一些情况中,标签可被翻译成肽。本领域技术人员已知的标签的任意核酸序列可与本文所述的质粒联用。例如,标签可以是具有3个组氨酸残基的组氨酸标签、具有4个组氨酸残基的组氨酸标签、具有5个组氨酸残基的组氨酸标签、或具有6个组氨酸残基的组氨酸标签等。可使用本领域技术人员已知的任意合适技术来确定标签在对象中的表达。在一些情况中,可使用本领域普通技术人员已知的任意测序技术来对质粒进行测序,使得测序的结果提供对整个质粒的核苷酸水平解析。在一些方面中,组合物可以是多抗原乳腺癌疫苗。例如,多抗原乳腺癌疫苗可含有多种抗原。在一些情况中,一种抗原的表达可影响不同抗原的表达。在一些情况中,超过一种抗原的表达可影响不同抗原的表达。在一些情况中,一种抗原的表达可影响超过一种不同抗原的表达。在一些情况中,一种抗原的表达可能不影响不同抗原的表达。在一些情况中,超过一种抗原的表达可能不影响不同抗原的表达。在一些情况中,一种抗原的表达可能不影响超过一种不同抗原的表达。例如,抗原性组合物可限制多抗原疫苗的免疫原性。可使用本领域普通技术人员已知的任意技术来确定在给予多抗原疫苗后引发的免疫应答是否是与单一抗原疫苗的各抗原相当的量级。例如,ELISPOT(例如,用于分泌IFNγ)可确定免疫应答的量级。在一些情况中,ELISPOT可检测啮齿类、非人灵长类或人肽。质粒-生存素、HIF-1A、IGF-1R、和/或IGFBP2本文所述的组合物可包括基于核酸的疫苗,其包含编码选自生存素、HIF-1A、IGF-1R、或IGFBP2的一种(个)或多种(个)表位的质粒。有时,表位可衍生自人蛋白质并且编码表位的编码核酸序列可整合到设计成在给药后诱导对象中表位表达的核酸构建体中。例如,从核酸构建体编码的表位可允许针对蛋白质(例如,自蛋白质)的特定组的待产生、扩增、减弱、抑制或消除的至少一种(个)表位的免疫应答。在一些情况中,本文所述的疫苗是基于肽的疫苗。基于肽的疫苗可包含质粒,其编码选自生存素、HIF-1A、IGF-1R、或IGFBP2的一种(个)或多种(个)表位。表位可衍生自可直接在基于肽的疫苗中使用的人蛋白质。在一些情况中,肽或核酸构建体可优化成基于蛋白质或质粒的免疫来诱导、扩增或产生TH1免疫应答。在一些情况中,表位可以是延伸的TH1表位。在其他情况中,肽或核酸构建体可优化成基于蛋白质或质粒的免疫以在有此需要的对象(例如,人或动物)中抑制、减弱或消除致病性应答。本文所述的组合物可包括含有核酸序列的质粒以在给予组合物(例如,疫苗)之后在对象中表达至少一种(个)表位。可在本文所述的组合物中使用本领域普通技术人员已知的适用于表达核酸的药物应用的任意质粒主链(例如,载体)。载体可以是环状质粒或线性核酸。环状质粒或线性核酸能够引导特定核苷酸序列在合适对象细胞中表达。载体可具有与编码多肽的核苷酸序列可操作连接的启动子,其可操作地连接至终止信号。载体也可含有核苷酸序列的适当翻译所需的序列。包含感兴趣的核苷酸序列的载体可以是嵌合的,意味着其组分中的至少一种相对于其他组分中的至少一种是异源的。表达盒中的核苷酸序列的表达可处于组成型启动子或诱导性启动子的控制下,其可仅在宿主细胞接触一些特定外部刺激时引发转录。所述载体可为质粒。质粒可用于用编码多肽的核酸来转染细胞,其中转染的宿主细胞可在发生多肽表达的条件下培养并维持。质粒可包含核酸序列,其编码本文所述的多种多肽中的一种(个)或多种(个)。单一质粒可含有单一多肽的编码序列,或者超过一种多肽的编码序列。有时,质粒还可包含编码佐剂,如免疫刺激分子,如细胞因子的编码序列。质粒还可包含起始密码子,其可在编码序列的上游,和终止密码子,其可在编码序列的下游。起始密码子和终止密码子可在编码序列的框架中。质粒也可包含可操作连接至编码序列的启动子,和编码序列上游的增强子。增强子可以是人肌动蛋白、人肌球蛋白、人血红蛋白、人肌肉肌氨酸或病毒增强子如来自CMV、FMDV、RSV或EBV的增强子。美国专利号5,593,972、5,962,428和W094/016737中描述了多核苷酸功能增强子。质粒也可包含哺乳动物复制起点以使质粒保持在染色体外并且在细胞中产生质粒的多拷贝。示例可以是来自英杰公司(加利福尼亚州圣迭戈)的pVAXI、pCEP4或pREP4。质粒也可包含调节序列,其也适于给予质粒的细胞中的基因表达。编码序列可包含密码子,其可允许在宿主细胞中更高效地转录编码序列。在一些情况中,可使用市售质粒主链。例如,可使用质粒pUMVC3。在一些情况中,在使用前,可修饰、突变、工程改造或克隆市售质粒主链。在其他情况中,可使用非市售质粒主链。其他质粒可包括pSE420(加利福尼亚州圣迭戈的英杰公司),其可用于在大肠杆菌(E.coli)中产生蛋白质。质粒也可以是pYES2(加利福尼亚州圣迭戈的英杰公司),其可用于在酵母的酿酒酵母菌株中产生蛋白质。质粒也可以是MAXBACTM完全杆状病毒表达系统(加利福尼亚州圣迭戈的英杰公司),其可用于在昆虫细胞中产生蛋白质。质粒也可以是pcDNAI或pcDNA3(加利福尼亚州圣迭戈的英杰公司),其可用于在哺乳动物细胞如中华仓鼠卵巢(CHO)细胞中产生蛋白质。载体可以是环状质粒,其可通过整合到细胞基因组中或存在于染色体外(例如,具有复制起点的自复制质粒)来转化靶细胞。示例性的载体包括pVAX、pcDNA3.0、或provax或任何其他能够表达编码抗原的DNA并且使细胞能够将序列翻译成被免疫系统识别的抗原的表达载体。基于核酸的疫苗可以是线性核酸疫苗,或线性表达盒(“LEC”),其能够通过电转被高效递送到对象中并且表达一种或多种本文所述的多肽。LEC可以是去除了磷酸主链的任意线性DNA。DNA可编码一种或多种本文所述的多肽。LEC可含有启动子、内含子、终止密码子和/或聚腺苷酸化信号。多肽的表达可受到启动子的控制。LEC可能不含有任何抗生素抗性基因和/或磷酸主链。LEC可能不含有与多肽表达不相关的其他核酸序列。LEC可衍生自能够被线性化的任何质粒。质粒可表达多肽。示例性的质粒包括pNP(PuertoRico/34)、pM2(NewCaledonia/99)、WLV009、pVAX、pcDNA3.0、或provax或任何其他能够表达编码抗原的DNA并且使细胞能够将序列翻译成被免疫系统识别的抗原的表达载体。在插入至少一种(个)表位的核酸序列之前,质粒主链的长度可小于约500bp、约1.0kB、约1.2kB、约1.4kB、约1.6kB、约1.8kB、约2.0kB、约2.2kB、约2.4kB、约2.6kB、约2.8kB、约3.0kB、约3.2kB、约3.4kB、约3.6kB、约3.8kB、约4.0kB、约4.2kB、约4.4kB、约4.6kB、约4.8kB、约5.0kB、约5.2kB、约5.4kB、约5.6kB、约5.8kB、约6.0kB、约6.2kB、约6.4kB、约6.6kB、约6.8kB、约7.0kB、约7.2kB、约7.4kB、约7.6kB、约7.8kB、约8.0kB、约8.2kB、约8.4kB、约8.6kB、约8.8kB、约9.0kB、约9.2kB、约9.4kB、约9.6kB、约9.8kB、约10.0kB、约10.2kB、约10.4kB、约10.6kB、约10.8kB、约11.0kB、约11.2kB、约11.4kB、约11.6kB、约11.8kB、约12.0kB、约12.2kB、约12.4kB、约12.6kB、约12.8kB、约13.0kB、约13.2kB、约13.4kB、约13.6kB、约13.8kB、约14kB、约14.5kB、约15kB、约15.5kB、约16kB、约16.5kB、约17kB、约17.5kB、约18kB、约18.5kB、约19kB、约19.5kB、约20kB、约30kB、约40kB、约50kB、约60kB、约70kB、约80kB、约90kB、约100kB、约110kB、约120kB、约130kB、约140kB、约150kB、约160kB、约170kB、约180kB、约190kB或约200kB。在示例性情况中,在加入编码至少一种(个)表位的核酸序列之前,质粒长度为约4kB。在一些情况中,本文所述的组合物可包括一种质粒。在其他情况中,本文所述的组合物可包括超过一种质粒。例如,本文所述的组合物可包括2种质粒、3种质粒、4种质粒、5种质粒、6种质粒、7种质粒、8种质粒、9种质粒、10种质粒、11种质粒、12种质粒、13种质粒、14种质粒、15种质粒、16种质粒、17种质粒、18种质粒、19种质粒、20种质粒或超过20种质粒。编码质粒的至少一种(个)表位的核酸可衍生自任意物种,使得从核酸表达的表位在对象中产生免疫应答。在一些情况中,对象可以是啮齿类、非人灵长类或人。编码质粒的表位的核酸可使用本领域技术人员已知的方法和技术分离自任意核酸来源。编码质粒的表位的核酸可使用本领域技术人员已知的方法和技术克隆到质粒主链中。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的生存素的核酸序列在人中表达生存素。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的生存素的核酸序列在人中表达生存素。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中生存素的天然核酸序列在对象中表达生存素。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中生存素的天然核酸序列并且可用于在对象中表达生存素。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的HIF-1A的核酸序列在人中表达HIF-1A。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的HIF-1A的核酸序列在人中表达HIF-1A。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中HIF-1A的天然核酸序列在对象中表达HIF-1A。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中HIF-1A的天然核酸序列并且可用于在对象中表达HIF-1A。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的IGFBP2的核酸序列在人中表达IGFBP2。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的IGFBP2的核酸序列在人中表达IGFBP2。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中IGFBP2的天然核酸序列在对象中表达IGFBP2。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中IGFBP2的天然核酸序列并且可用于在对象中表达IGFBP2。在一些情况中,编码表位的核酸序列可以是对于对象而言的内源性核酸序列。例如,可使用来自人的IGF-1R的核酸序列在人中表达IGF-1R。在其他情况中,编码抗原性表位的核酸序列可以是对于对象而言的外源性核酸序列。例如,可使用来自非人的IGF-1R的核酸序列在人中表达IGF-1R。在一些情况中,用于表达抗原性表位的核酸序列可以是野生型核酸序列。例如,可使用在物种基因组中IGF-1R的天然核酸序列在对象中表达IGF-1R。在其他情况中,表达表位的核酸序列可以是合成核酸序列。例如,可使用本领域普通技术人员已知的分子技术来修饰对象基因组中IGF-1R的天然核酸序列并且可用于在对象中表达IGF-1R。在一些情况中,组合物可包括编码一种或多种来自以下蛋白质的表位的核酸:生存素、HIF-1A、IGFBP2和IGF-1R。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)有至少90%序列相同性的多肽的核酸序列。有时,质粒可包含编码与IGFBP-2(SEQIDNO:54)有至少95%序列相同性的多肽的核酸序列。有时,质粒可包含编码与IGFBP-2(SEQIDNO:54)有至少99%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少100至至少163个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少105至至少160、至少110至至少155、或至少120至至少145个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少100至至少163个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少105至至少160、至少110至至少155、或至少120至至少145个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少100至至少163个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少105至至少160、至少110至至少155、或至少120至至少145个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少100至至少163个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少105至至少160、至少110至至少155、或至少120至至少145个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少100至至少163个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少105至至少160、至少110至至少155、或至少120至至少145个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少100至至少163个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与IGFBP-2(SEQIDNO:54)的至少105至至少160、至少110至至少155、或至少120至至少145个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含与IGFBP-2(SEQIDNO:43)有至少50%序列相同性的核酸序列。在一些情况中,质粒可包含与IGFBP-2(SEQIDNO:43)有至少55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%、或100%序列相同性的核酸序列。在一些情况中,质粒可包含与IGFBP-2(SEQIDNO:43)有至少70%序列相同性的核酸序列。在一些情况中,质粒可包含与IGFBP-2(SEQIDNO:43)有至少80%序列相同性的核酸序列。在一些情况中,质粒可包含与IGFBP-2(SEQIDNO:43)有至少90%序列相同性的核酸序列。有时,质粒可包含与IGFBP-2(SEQIDNO:43)有至少95%序列相同性的核酸序列。有时,质粒可包含与IGFBP-2(SEQIDNO:43)有至少99%序列相同性的核酸序列。在一些情况中,质粒可包含与IGFBP-2(SEQIDNO:43)有100%序列相同性的核酸序列。在一些情况中,质粒可包含与IGFBP-2(SEQIDNO:43)的序列相同性为100%的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)有至少90%序列相同性的多肽的核酸序列。有时,质粒可包含编码与生存素(SEQIDNO:85)有至少95%序列相同性的多肽的核酸序列。有时,质粒可包含编码与生存素(SEQIDNO:85)有至少99%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少10至至少38个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少12至至少35、至少15至至少30、或至少20至至少25个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、32、34、或36个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少10至至少38个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少12至至少35、至少15至至少30、或至少20至至少25个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、32、34、或36个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少10至至少38个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少12至至少35、至少15至至少30、或至少20至至少25个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、32、34、或36个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少10至至少38个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少12至至少35、至少15至至少30、或至少20至至少25个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、32、34、或36个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少10至至少38个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少12至至少35、至少15至至少30、或至少20至至少25个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、32、34、或36个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少10至至少38个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少12至至少35、至少15至至少30、或至少20至至少25个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与生存素(SEQIDNO:85)的至少13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、32、34、或36个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含与生存素(SEQIDNO:86)有至少50%序列相同性的核酸序列。在一些情况中,质粒可包含与生存素(SEQIDNO:86)有至少55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%、或100%序列相同性的核酸序列。在一些情况中,质粒可包含与生存素(SEQIDNO:86)有至少70%序列相同性的核酸序列。在一些情况中,质粒可包含与生存素(SEQIDNO:86)有至少80%序列相同性的核酸序列。在一些情况中,质粒可包含与生存素(SEQIDNO:86)有至少90%序列相同性的核酸序列。有时,质粒可包含与生存素(SEQIDNO:86)有至少95%序列相同性的核酸序列。有时,质粒可包含与生存素(SEQIDNO:86)有至少99%序列相同性的核酸序列。在一些情况中,质粒可包含与生存素(SEQIDNO:86)有100%序列相同性的核酸序列。在一些情况中,质粒可包含与生存素(SEQIDNO:86)的序列相同性为100%的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)有至少90%序列相同性的多肽的核酸序列。有时,质粒可包含编码与HIF-1A(SEQIDNO:87)有至少95%序列相同性的多肽的核酸序列。有时,质粒可包含编码与HIF-1A(SEQIDNO:87)有至少99%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少89个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少85、至少50至至少80、或至少55至至少75、或至少60至至少70个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、或88个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少89个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少85、至少50至至少80、或至少55至至少75、或至少60至至少70个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、或88个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少89个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少85、至少50至至少80、或至少55至至少75、或至少60至至少70个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、或88个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少89个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少85、至少50至至少80、或至少55至至少75、或至少60至至少70个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、或88个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少89个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少85、至少50至至少80、或至少55至至少75、或至少60至至少70个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、或88个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少89个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少40至至少85、至少50至至少80、或至少55至至少75、或至少60至至少70个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与HIF-1A(SEQIDNO:87)的至少61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、或88个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含与HIF-1A(SEQIDNO:88)有至少50%序列相同性的核酸序列。在一些情况中,质粒可包含与HIF-1A(SEQIDNO:88)有至少55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%、或100%序列相同性的核酸序列。在一些情况中,质粒可包含与HIF-1A(SEQIDNO:88)有至少70%序列相同性的核酸序列。在一些情况中,质粒可包含与HIF-1A(SEQIDNO:88)有至少80%序列相同性的核酸序列。在一些情况中,质粒可包含与HIF-1A(SEQIDNO:88)有至少90%序列相同性的核酸序列。有时,质粒可包含与HIF-1A(SEQIDNO:88)有至少95%序列相同性的核酸序列。有时,质粒可包含与HIF-1A(SEQIDNO:88)有至少99%序列相同性的核酸序列。在一些情况中,质粒可包含与HIF-1A(SEQIDNO:88)有100%序列相同性的核酸序列。在一些情况中,质粒可包含与HIF-1A(SEQIDNO:88)的序列相同性为100%的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)有至少90%序列相同性的多肽的核酸序列。有时,质粒可包含编码与IGF-IR(SEQIDNO:73)有至少95%序列相同性的多肽的核酸序列。有时,质粒可包含编码与IGF-IR(SEQIDNO:73)有至少99%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的至少50至至少104个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的至少55至至少100、至少60至至少90、或至少70至至少80个连续氨基酸有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的至少50至至少104个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的至少55至至少100、至少60至至少90、或至少70至至少80个连续氨基酸有至少80%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的至少50至至少104个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的至少55至至少100、至少60至至少90、或至少70至至少80个连续氨基酸有至少90%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的至少50至至少104个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-IR(SEQIDNO:73)的至少55至至少100、至少60至至少90、或至少70至至少80个连续氨基酸有至少95%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-1R(SEQIDNO:73)的至少50至至少104个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-1R(SEQIDNO:73)的至少55至至少100、至少60至至少90、或至少70至至少80个连续氨基酸有100%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-1R(SEQIDNO:73)的至少50至至少104个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含编码与IGF-1R(SEQIDNO:73)的至少55至至少100、至少60至至少90、或至少70至至少80个连续氨基酸的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含与IGF-IR(SEQIDNO:63)有至少50%序列相同性的核酸序列。在一些情况中,质粒可包含与IGF-IR(SEQIDNO:63)有至少55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%、或100%序列相同性的核酸序列。在一些情况中,质粒可包含与IGF-IR(SEQIDNO:63)有至少70%序列相同性的核酸序列。在一些情况中,质粒可包含与IGF-IR(SEQIDNO:63)有至少80%序列相同性的核酸序列。在一些情况中,质粒可包含与IGF-IR(SEQIDNO:63)有至少90%序列相同性的核酸序列。有时,质粒可包含与IGF-IR(SEQIDNO:63)有至少95%序列相同性的核酸序列。有时,质粒可包含与IGF-IR(SEQIDNO:63)有至少99%序列相同性的核酸序列。在一些情况中,质粒可包含与IGF-IR(SEQIDNO:63)有100%序列相同性的核酸序列。在一些情况中,质粒可包含与IGF-IR(SEQIDNO:63)的序列相同性为100%的核酸序列。有时,分离并纯化的质粒可包含至少一种编码与选自SEQIDNO:54、73、85、和87的表位序列有至少70%序列相同性的多肽的核苷酸序列。质粒可包含至少一种编码与选自SEQIDNO:54、73、85、和87的表位序列有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的多肽的核苷酸序列。质粒可包含至少一种编码与选自SEQIDNO:54、73、85、和87的表位有至少80%序列相同性的多肽的核酸序列。质粒可包含至少一种编码与选自SEQIDNO:54、73、85、和87的表位序列有至少90%序列相同性的多肽的核酸序列。质粒可包含至少一种编码与选自SEQIDNO:54、73、85、和87的表位序列有至少95%序列相同性的多肽的核酸序列。质粒可包含至少一种编码与选自SEQIDNO:54、73、85、和87的表位序列有至少99%序列相同性的多肽的核酸序列。质粒可包含至少一种编码与选自SEQIDNO:54、73、85、和87的表位序列有100%序列相同性的多肽的核酸序列。质粒可包含至少一种编码与选自SEQIDNO:54、73、85、和87的表位序列的序列相同性为100%的多肽的核酸序列。有时,分离并纯化的质粒可包含至少4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少70%序列相同性的多肽。质粒可包含至少4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的多肽。质粒可包含至少4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少80%序列相同性的多肽。质粒可包含至少4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少90%序列相同性的多肽。质粒可包含至少4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少95%序列相同性的多肽。质粒可包含至少4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少99%序列相同性的多肽。质粒可包含至少4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有100%序列相同性的多肽。质粒可包含至少4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列的序列相同性为100%的多肽。在一些情况中,至少4种核酸序列独立地编码针对选自SEQIDNO:54、73、85、和87的表位序列的多肽。在其他情况中,至少4种核酸序列编码针对选自SEQIDNO:54、73、85、和87的表位序列的不同多肽。有时,质粒可包含4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少70%序列相同性的多肽。质粒可包含4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的多肽。质粒可包含4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少80%序列相同性的多肽。质粒可包含4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少90%序列相同性的多肽。质粒可包含4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少95%序列相同性的多肽。质粒可包含4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有至少99%序列相同性的多肽。质粒可包含4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列有100%序列相同性的多肽。质粒可包含4种核酸序列,其中4种核酸序列各自编码与选自SEQIDNO:54、73、85、和87的表位序列的序列相同性为100%的多肽。在一些情况中,4种核酸序列独立地编码针对选自SEQIDNO:54、73、85、和87的表位序列的多肽。在其他情况中,4种核酸序列编码针对选自SEQIDNO:54、73、85、和87的表位序列的不同多肽。在一些情况中,质粒可包含编码与SEQIDNO:89有至少70%序列相同性的多肽的核酸序列。在一些情况中,质粒可包含编码与SEQIDNO:89有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的多肽的核酸序列。质粒可包含编码与SEQIDNO:89有至少80%序列相同性的多肽的核酸序列。质粒可包含编码与SEQIDNO:89有至少90%序列相同性的多肽的核酸序列。质粒可包含编码与SEQIDNO:89有至少95%序列相同性的多肽的核酸序列。质粒可包含编码与SEQIDNO:89有至少99%序列相同性的多肽的核酸序列。质粒可包含编码与SEQIDNO:89有100%序列相同性的多肽的核酸序列。质粒可包含编码与SEQIDNO:89的序列相同性为100%的多肽的核酸序列。在一些情况中,质粒可包含与SEQIDNO:90有至少70%序列相同性的核酸序列。在一些情况中,质粒可包含与SEQIDNO:90有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核酸序列。质粒可包含与SEQIDNO:90有至少80%序列相同性的核酸序列。质粒可包含与SEQIDNO:90有至少90%序列相同性的核酸序列。质粒可包含与SEQIDNO:90有至少95%序列相同性的核酸序列。质粒可包含与SEQIDNO:90有至少99%序列相同性的核酸序列。质粒可包含与SEQIDNO:90有100%序列相同性的核酸序列。质粒可包含与SEQIDNO:90的序列相同性为100%的核酸序列。在一些情况中,质粒可包含与SEQIDNO:91有至少70%序列相同性的核酸序列。在一些情况中,质粒可包含与SEQIDNO:91有至少75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%序列相同性的核酸序列。质粒可包含与SEQIDNO:91有至少80%序列相同性的核酸序列。质粒可包含与SEQIDNO:91有至少90%序列相同性的核酸序列。质粒可包含与SEQIDNO:91有至少95%序列相同性的核酸序列。质粒可包含与SEQIDNO:91有至少99%序列相同性的核酸序列。质粒可包含与SEQIDNO:91有100%序列相同性的核酸序列。质粒可包含与SEQIDNO:91的序列相同性为100%的核酸序列。有时,包含超过一种(个)表位序列的质粒可在各表位序列之间包含间隔子。在一些情况中,可串联编码表位序列而不使用间隔子。在一些情况中,可使用间隔子串联编码表位序列。在一些情况中,间隔子可包含编码约1至约50、约3至约40、约5至约35、或约10至约30个氨基酸残基的序列。在一些情况中,间隔子可包含编码约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、25、或30个氨基酸残基的序列。在一些情况中,质粒可含有编码至少一个标签的核酸序列。在一些情况中,标签可被翻译成肽。本领域技术人员已知的标签的任意核酸序列可与本文所述的质粒联用。例如,标签可以是具有3个组氨酸残基的组氨酸标签、具有4个组氨酸残基的组氨酸标签、具有5个组氨酸残基的组氨酸标签、或具有6个组氨酸残基的组氨酸标签等。可使用本领域技术人员已知的任意合适技术来确定标签在对象中的表达。在一些情况中,可使用本领域普通技术人员已知的任意测序技术来对质粒进行测序,使得测序的结果提供对整个质粒的核苷酸水平解析。在一些方面中,组合物可以是多抗原乳腺癌疫苗或多抗原卵巢癌疫苗。例如,多抗原乳腺癌疫苗或多抗原卵巢癌疫苗可含有多种抗原。在一些情况中,一种抗原的表达可影响不同抗原的表达。在一些情况中,超过一种抗原的表达可影响不同抗原的表达。在一些情况中,一种抗原的表达可影响超过一种不同抗原的表达。在一些情况中,一种抗原的表达可能不影响不同抗原的表达。在一些情况中,超过一种抗原的表达可能不影响不同抗原的表达。在一些情况中,一种抗原的表达可能不影响超过一种不同抗原的表达。例如,抗原性组合物可限制多抗原疫苗的免疫原性。可使用本领域普通技术人员已知的任意技术来确定在给予多抗原疫苗后引发的免疫应答是否是与单一抗原疫苗的各抗原相当的量级。例如,ELISPOT(例如,用于分泌IFNγ)可确定免疫应答的量级。在一些情况中,ELISPOT可检测啮齿类、非人灵长类或人肽。在一些情况中,多抗原乳腺癌或卵巢癌疫苗可包含多种(个)表位,这些表位衍生自选自生存素、HIF-1α、IGF-1R、和/或IGFBP-2的多种抗原。核酸分离的核酸分子是从其天然环境取出(即经人工操作)的核酸分子,其天然环境是天然发现该核酸分子的基因组或染色体。因此,“分离”不一定反映核酸分子的纯化程度,但表明该分子不包含天然发现该核酸分子的完整基因组或完整染色体。分离的核酸分子可包含基因。包含基因的分离核酸分子不是包含这个基因的染色体片段,而包含与该基因有关的编码区和调控区,但不含同一染色体上天然发现的其它基因。分离核酸分子也可包含侧接(即在该序列的5′和/或3′末端侧接)其它核酸的特定核酸序列,所述其它核酸在天然情况下通常不侧接所述的特定核酸序列(即,异源序列)。分离的核酸分子可以是DNA,包括基因组和cDNA,RNA或杂交体,其中所述核酸可以含有脱氧核糖核苷酸和核糖核苷酸的组合,以及碱基的组合,包括尿嘧啶、腺嘌呤、胸腺嘧啶、胞嘧啶、鸟嘌呤、肌苷、黄嘌呤、次黄嘌呤、异胞嘧啶、和异鸟嘌呤。可通过化学合成方法或通过重组方法来获得核酸。虽然术语“核酸分子”主要指代物理核酸分子并且术语“核酸序列”主要指代核酸分子上的核苷酸序列,但两个术语可互换使用,尤其是相对于能够编码蛋白质或蛋白质结构域的核酸分子,或核酸序列而言。核酸分子可指代共价连接在一起的至少2个核苷酸。虽然在如下所述(例如,在引物和探针如标记探针的构建中)许多情况中,本文所述的核酸可含有磷酸二酯键,但可包括可具有交替主链的核酸类似物,包括,例如,磷酰胺(Beaucage等,Tetrahedron49(10):1925(1993)及其参考文献;Letsinger,J.Org.Chem.35:3800(1970);Sprinzl等,Eur.J.Biochem.81:579(1977);Letsinger等,Nucl.AcidsRes.14:3487(1986);Sawai等,Chem.Lett.805(1984),Letsinger等,J.Am.Chem.Soc.110:4470(1988);和Pauwels等,ChemicaScripta26:141(1986)),硫代磷酸酯(Mag等,NucleicAcidsRes.19:1437(1991);和美国专利号5,644,048),二硫代磷酸酯(Briu等,J.Am.Chem.Soc.111:2321(1989)),O-甲基亚磷酰胺连接(参见Eckstein,《寡核苷酸和类似物:实践方法》(OligonucleotidesandAnalogues:APracticalApproach),牛津大学出版社),和肽核酸(在本文中也称为“PNA”)主链和连接(参见Egholm,J.Am.Chem.Soc.114:1895(1992);Meier等,Chem.Int.Ed.Engl.31:1008(1992);Nielsen,Nature,365:566(1993);Carlsson等,Nature380:207(1996),其全部通过引用纳入本文)。其他类似核酸包括具有双环结构的那些,包括锁核酸(在本文中也称为“LNA”),Koshkin等,J.Am.Chem.Soc.120.132523(1998);正电主链(Denpcy等,Proc.Natl.Acad.Sci.USA92:6097(1995));非离子型主链(美国专利号5,386,023,5,637,684,5,602,240,5,216,141和4,469,863;Kiedrowshi等,Angew.Chem.Intl.Ed.English30:423(1991);Letsinger等,J.Am.Chem.Soc.110:4470(1988);Letsinger等,Nucleoside&;Nucleotide13:1597(1994);第2章和第3章,ASCSymposiumSeries580,“《反义研究中的糖修饰》(CarbohydrateModificationsinAntisenseResearch)”,Y.S.Sanghui和P.DanCook编;Mesmaeker等,Bioorganic&MedicinalChem.Lett.4:395(1994);Jeffs等,J.BiomolecularNMR34:17(1994);TetrahedronLett.37:743(1996))和非核糖主链,包括美国专利号5,235,033和5,034,506中所述的那些,和第6章和第7章,ASCSymposiumSeries580,“《反义研究中的糖修饰》(CarbohydrateModificationsinAntisenseResearch)”,Y.S.Sanghui和P.DanCook编。含有一个或多个碳环糖的核酸也包括在核酸的定义中(参见Jenkins等,Chem.Soc.Rev.(1995),第169-176页)。几种核酸类似物描述于Rawls,C&ENews,1997年6月2日,第35页。“锁核酸”也包括在核酸类似物的定义中。LNA是一类核酸类似物,其中核糖环被连接2′-O原子与4′-C原子的亚甲基桥“锁定”。所有这些参考文献以参考的方式并入本文中。可进行核糖-磷酸酯主链的这些修饰以增加这类分子在生理环境中的稳定性和半衰期。例如,PNA:DNA和LNA-DNA杂交体可显示出更高的稳定性并因此可用于一些实施方式中。靶核酸可以是单链或双链的,如本文具体所示,或同时含有双链或单链序列的部分。根据应用,核酸可以是DNA(包括,例如,基因组DNA、线粒体DNA、和cDNA)、RNA(包括,例如,mRNA和rRNA)或杂交体,其中核酸含有脱氧核糖-核苷酸和核糖-核苷酸的任意组合,碱基的任意组合,包括尿嘧啶、腺嘌呤、胸腺嘧啶、胞嘧啶、鸟嘌呤、肌苷、次黄嘌呤、异胞嘧啶、和异鸟嘌呤等。重组核酸分子是包括编码本文所述的任意一种或多种蛋白质的任意核酸序列中的至少一种的分子,这些蛋白质可操作地连接到能够有效调节核酸分子在待转染的细胞中的表达的任何转录控制序列中的至少一种。虽然术语“核酸分子”主要指代物理核酸分子并且术语“核酸序列”主要指代核酸分子上的核苷酸序列,但两个术语可互换使用,尤其是相对于能够编码蛋白质的核酸分子,或核酸序列而言。另外,术语“重组分子”主要指可操作连接至转录控制序列的核酸分子,但可与给予动物的术语“核酸分子”互换使用。重组核酸分子包括重组载体,其是任意核酸序列,一般是异源序列,其可操作地连接至编码本发明的融合蛋白的分离的核酸分子,其能够使融合蛋白重组产生,并且其能够根据本发明将核酸分子递送到宿主细胞中。这种载体可含有未在自然发现与待插入载体的分离的核酸分子毗邻的核酸序列。该载体可以是真核或原核的RNA或DNA,并且优选在本发明中是病毒或质粒。重组载体可用于核酸分子的克隆、测序和/或操作,并且可用于递送这类分子(例如,在DNA组合物中或基于病毒载体的组合物中)。重组载体优选用于核酸分子的表达,并且也可称为表达载体。优选的重组载体能够在转染的宿主细胞中表达。在本发明的重组分子中,核酸分子可操作地连接至含有调节序列如转录控制序列、翻译控制序列、复制起点、和其他调节序列的表达载体,这些调节序列与宿主细胞相容并且控制本发明的核酸分子的表达。具体地,本发明的重组分子包括可操作连接至一种或多种表达控制序列的核酸分子。术语“可操作连接”是指将核酸分子以使该分子在转染(即,转化、转导或转染)到宿主细胞中时表达的方式连接到表达控制序列。药物组合物本发明的免疫原性组合物优选配制成疫苗用于对象的体内给药,使得它们赋予用于可接受的对象百分比的各抗原性组分优于血清保护标准的抗体效价。众所周知抗原的关联抗体效价,高于该效价就认为对象针对所述抗原发生血清转化,该类效价由诸如WHO的组织公布。优选多于80%的具有统计学显著性的对象样品发生血清转化,更优选多于90%,更优选多于93%,最优选96-100%。佐剂本发明的免疫原性组合物优选佐剂化。佐剂可用于提高接受疫苗的患者中引发的免疫应答(体液和/或细胞)。有时,佐剂可引发TH1-型应答。有时,佐剂可引发TH2-型应答。TH1-型应答可表征为产生细胞因子如IFN-γ,这与TH-2型应答相反,其可表征为产生细胞因子如IL-4、IL-5和IL-10。佐剂可包括刺激分子,如细胞因子。细胞因子的非限制性示例包括:CCL20、α-干扰素(IFN-α)、β-干扰素(IFN-β)、γ-干扰素、血小板衍生生长因子(PDGF)、TNFa、TNFp、粒细胞-巨噬细胞集落刺激因子(GM-CSF)、表皮生长因子(EGF)、皮肤T细胞虏获趋化因子(CTACK)、表皮胸腺-表达趋化因子(TECK)、粘膜-相关表皮趋化因子(MEC)、IL-12、IL-15、IL-28、MHC、CD80、CD86、IL-1、IL-2、IL-4、IL-5、IL-6、IL-10、IL-18、MCP-1、MIP-1a、MIP-1-、IL-8、L-选择素、P-选择素、E-选择素、CD34、GlyCAM-1、MadCAM-1、LFA-1、VLA-1、Mac-1、p150.95、PECAM、ICAM-1、ICAM-2、ICAM-3、CD2、LFA-3、M-CSF、G-CSF、IL-18的突变形式、CD40、CD40L、血管生长因子、成纤维细胞生长因子、IL-7、神经生长因子、血管表皮生长因子、Fas、TNF受体、Fit、Apo-1、p55、WSL-1、DR3、TRAMP、Apo-3、AIR、LARD、NGRF、DR4、DRS、KILLER、TRAIL-R2、TRICK2、DR6、胱冬酶ICE、Fos、c-jun、Sp-1、Ap-1、Ap-2、p38、p65Rel、MyD88、IRAK、TRAF6、IkB、失活NIK、SAPK、SAP-I、JNK、干扰素响应基因、NFkB、Bax、TRAIL、TRAILrec、TRAILrecDRC5、TRAIL-R3、TRAIL-R4、RANK、RANKLIGAND、Ox40、Ox40LIGAND、NKG2D、MICA、MICB、NKG2A、NKG2B、NKG2C、NKG2E、NKG2F、TAPI、和TAP2。在一些情况中,佐剂是GM-CSF。其他佐剂包括:MCP-1、MIP-1a、MIP-1p、IL-8、RANTES、L-选择素、P-选择素、E-选择素、CD34、GlyCAM-1、MadCAM-1、LFA-1、VLA-1、Mac-1、p150.95、PECAM、ICAM-1、ICAM-2、ICAM-3、CD2、LFA-3、M-CSF、G-CSF、IL-4、IL-18的突变形式、CD40、CD40L、血管生长因子、成纤维细胞生长因子、IL-7、IL-22、神经生长因子、血管表皮生长因子、Fas、TNF受体、Fit、Apo-1、p55、WSL-1、DR3、TRAMP、Apo-3、AIR、LARD、NGRF、DR4、DR5、KILLER、TRAIL-R2、TRICK2、DR6、胱冬酶ICE、Fos、c-jun、Sp-1、Ap-1、Ap-2、p38、p65Rel、MyD88、IRAK、TRAF6、IkB、失活NIK、SAPK、SAP-1、JNK、干扰素响应基因、NFkB、Bax、TRAIL、TRAILrec、TRAILrecDRC5、TRAIL-R3、TRAIL-R4、RANK、RANKLIGAND、Ox40、Ox40LIGAND、NKG2D、MICA、MICB、NKG2A、NKG2B、NKG2C、NKG2E、NKG2F、TAP1、TAP2及其功能性片段。在一些方面中,佐剂可以是toll样受体的调节剂。toll样受体的调节剂的示例包括TLR-9拮抗剂并且不限于小分子调节剂,如toll-样受体如咪喹莫特。可与本文所述的疫苗联用的佐剂的其他示例可包括并且不限于皂苷、CpGODN等。有时,佐剂可包括铝盐,如氢氧化铝凝胶(alum)、磷酸铝,钙、铁或锌盐,或可以是酰化酪氨酸的不溶性悬浮液,或酰化糖,阳离子或阴离子衍生多糖,或聚磷腈。有时,促进主要Th1应答的合适佐剂系统包括单磷酰脂质A或其衍生物,尤其是3-脱-O-酰化单磷酰脂质A,以及单磷酰脂质A,优选3-脱-O-酰化单磷酰脂质A(3D-MPL)与铝盐的组合。强化系统包括单磷酰脂质A和皂苷衍生物的组合,尤其是QS21和3D-MPL的组合,如WO94/00153中所述,或反应原性较低的组合物,其中用胆固醇猝灭QS21,如WO96/33739中所述。在水包油乳液中包括QS21、3D-MPL和生育酚的特别强效的佐剂制剂描述于WO95/17210。疫苗还可包含皂苷,更优选QS21。制剂还可包含水包油乳液和生育酚(WO95/17210)。含有未甲基化的CpG的寡核苷酸(WO96/02555)也是潜在的Th1应答诱导剂并且适用于本发明。在一些情况中,使用铝盐。有时,为了最小化本发明组合物中的佐剂水平,多糖偶联物可未佐剂化。有时,合适的佐剂系统可包括佐剂或免疫刺激剂,诸如但不限于来自任意来源的脱毒脂质A和脂质A的无毒衍生物、皂苷和其他能够刺激TH1型应答的试剂。已知肠细菌脂多糖(LPS)是免疫系统的强效刺激剂,虽然其在佐剂中的用途已经受到其毒性作用的限制。Ribi等(1986,细菌内毒素免疫学和体液药学(Immunologyandhnmunopharmacologyofbacterialendotoxins),PlenumPubl.Corp.,NY,第407-419页)已经描述了LPS的无毒性衍生物,单磷酰脂质A(MPL),其通过从末端缩短的葡糖胺中去除核心糖基团和磷酸而产生。通过从二糖主链的3-位去除酰基链产生进一步脱毒形式的MPL,并且称为3-O-脱酰化单磷酰脂质A(3D-MPL)。已经通过GB2122204B所述的方法纯化并制备,其参考文献也公开了二磷酰脂质A及其3-O-脱酰化变体的制备。在一些情况中,3D-MPL处于具有直径小于0.2μm的小粒度的乳液形式,并且其制备方法描述于WO94/21292。包含单磷酰脂质A和表面活性剂的水性制剂已经描述于WO9843670A2。可从细菌来源纯化并加工待在本发明的组合物中配制的细菌脂多糖衍生的佐剂,或者它们可以是合成的。例如,纯化的单磷酰脂质A描述于Ribi等,1986(同上),并且衍生自沙门氏菌的二磷酰脂质A或3-O-脱酰化单磷酰脂质A描述于GB2220211和US4912094。已经描述了其他纯化和合成的脂多糖(Hilgers等,1986,Int.ArchAllergy.Immunol,79(4):392-6;Hilgers等,1987,Immunology,60(1):141-6;和EP0549074B1)。特别优选的细菌脂多糖佐剂是3D-MPL。因此,可用于本发明的LPS衍生物是在结构上与LPS或MPL或3D-MPL相似的那些免疫刺激剂。在本发明的另一个方面中,LPS衍生物可以是酰化单糖,其是MPL的上述结构的子区域。皂苷描述于Lacaille-Dubois,M和WagnerH.(1996.皂苷生物和药学活性综述(Areviewofthebiologicalandpharmacologicalactivitiesofsaponins).Phytomedicine,第2卷,第363-386页)。皂苷是广泛分布在植物和海洋动物界的类固醇或三萜皂苷。皂苷用于在水中形成胶体溶液,其在摇晃中形成泡沫,并用于使胆固醇沉淀。当皂苷接近细胞膜时,它们在膜中产生孔状结构,其导致膜破裂。红细胞的溶血是这种现象的示例,其是某些而非全部皂苷的性质。皂苷已知作为全身给药疫苗中的佐剂。在本领域中已经深入研究了单个皂苷的佐剂和溶血活性(Lacaille-Dubois和Wagner,同上)。例如,QuilA(衍生自南美洲皂皮树的树皮)及其部分描述于US5,057,540和“用作疫苗佐剂的皂苷(Saponinsasvaccineadiuvants)”,Kensil,C.R.,CritRevTherDrugCarrierSyst,1996,12(1-2):1-55;以及EP0362279B1。称为免疫刺激复合物(ISCOMS)的包含QuilA部分的颗粒结构是溶血性的并且已经用于制备疫苗(Morein,B.,EP0109942B1;WO96/11711;WO96/33739)。溶血性皂苷QS21和QS17(QuilA的HPLC纯化部分)已经描述为强效全身佐剂,并且其生产方法描述于美国专利号5,057,540和EP0362279B1。已经用于全身免疫研究的其他皂苷包括衍生自其他植物物种如石竹和肥皂草的那些(Bomford等,Vaccine,10(9):572-577,1992)。强化系统包括无毒脂质A衍生物和皂苷衍生物的组合,尤其是QS21和3D-MPL的组合,如WO94/00153中所述,或反应原性较低的组合物,其中用胆固醇猝灭QS21,如WO96/33739中所述。有时,佐剂选自细菌类毒素、聚氧丙烯-聚氧乙烯嵌段聚合物、铝盐、脂质体、CpG聚合物、水包油乳液、或其组合。有时,佐剂是水包油乳液。水包油乳液可包含至少一种油和至少一种表面活性剂,其中所述油和表面活性剂是生物可降解的(可代谢)且生物相容的。乳液中的油滴直径通常小于5μm,甚至可具有亚微米直径,通过微流化床实现这种小尺寸以提供稳定乳剂。优选尺寸小于220nm的液滴,因为其可进行过滤灭菌。使用的油可包括如动物(如鱼)或植物来源的油。植物油的来源可包括坚果、种籽和谷物。最常见的坚果油的示例有花生油、大豆油、椰子油和橄榄油。可以采用例如获自霍霍巴豆的霍霍巴油。种籽油包括红花油、棉花籽油、葵花籽油、芝麻籽油等。谷物组可包括:玉米油和其它谷类如小麦、燕麦、裸麦、稻、画眉草、黑小麦等的油。甘油和1,2-丙二醇的6-10碳脂肪酸酯虽然不天然存在于种籽油中,但可从坚果和种籽油开始,通过水解、分离和酯化合适物质来制备。来自哺乳动物乳液的脂肪和油可以是可代谢的并且因此可用于本文所述的疫苗中。获得动物来源的纯油所必需的分离、纯化、皂化和其它方法的过程是本领域中熟知的。鱼类可含有容易回收的可代谢油。例如,可用于本文的鱼油的几种示例有鳕鱼肝油、鲨鱼肝油和鲸油(诸如鲸蜡)。可通过生化途径以5-碳异戊二烯单位合成许多支链油,其总称为萜类。鲨鱼肝油含有称为角鲨烯的支链不饱和萜类化合物,2,6,10,15,19,23-六甲基-2,6,10,14,18,22-二十四碳六烯。也可采用角鲨烯的饱和类似物角鲨烷。包括角鲨烯和角鲨烷在内的鱼油易于从市售来源获得,或可以通过本领域已知的方法获得。其他可用的油包括生育酚,其可包括在用于老年患者(如年龄在60岁以上的患者)的疫苗中,因为据报道维生素E在此患者群体中对免疫应答有正面作用。另外,生育酚具有抗氧化特性,这种特性有助于稳定该乳液。存在各种生育酚(α、β、γ、δ、ε或ξ),但通常使用α-生育酚。α-生育酚的示例是DL-α-生育酚。琥珀酸α-生育酚与癌症疫苗相容,并且是有用的替代含汞化合物的防腐剂。可使用油混合物,例如,角鲨烯和和α-生育酚。可使用的油含量为2-20%(体积)。表面活性剂可以按其“HLB”(亲水/亲脂平衡)分类。在一些情况中,表面活性剂的HLB为至少10、至少15、和/或至少16。表面活性剂可包括,但不限于:聚氧乙烯脱水山梨糖醇酯表面活性剂(通常称为吐温),特别是聚山梨酯20和聚山梨酯80;以商品名DOWFAXTM出售的环氧乙烷(EO)、环氧丙烷(PO)和/或环氧丁烷(BO)的共聚物,如直链EO/PO嵌段共聚物;重复乙氧基(氧-1,2-乙二基)数量不同的辛苯聚醇,特别感兴趣的是辛苯聚醇9(曲通(Triton)X-100或叔辛基苯氧基聚乙氧基乙醇);(辛基苯氧基)聚乙氧基乙醇(IGEPALCA-630/NP-40);磷脂,如磷脂酰胆碱(卵磷脂);壬酚乙醇酯,如特吉托(Tergitol)TMNP系列;衍生自月桂醇、鲸蜡醇、硬脂醇和油醇的聚氧乙烯脂肪醚(称为苄泽(Brij)表面活性剂),如三乙二醇单月桂基醚(苄泽30);以及脱水山梨糖醇酯(通常称为司盘(SPAN)),如脱水山梨糖醇三油酸酯(司盘85)和脱水山梨糖醇单月桂酸酯。本文中可使用非离子型表面活性剂。可使用表面活性剂的混合物,如吐温80/司盘85混合物。聚氧乙烯失水山梨糖醇酯和辛苯聚醇的组合也是合适的。另一种组合包括月桂醇聚醚-9加聚氧乙烯山梨糖醇酯和/或辛苯聚醇。表面活性剂的量(重量%)可以是:聚氧乙烯去水山梨糖醇酯(如吐温80)0.01-1%,特别是约0.1%;辛基-或壬基-苯氧基聚氧乙醇(如曲通X100或曲通系列的其它去污剂)0.001-0.1%,特别是0.005-0.02%;聚氧乙烯醚(如月桂醇聚醚9)0.1-20%,优选0.1-10%,特别是0.1-1%或约0.5%。具体水包油乳液佐剂包括但不限于:角鲨烯、聚山梨酯80和山梨糖醇三油酸酯的亚微米乳剂。所述乳液的体积组成可以是约5%角鲨烯、约0.5%聚山梨酯80和约0.5%司盘85。以重量计,这些比例为4.3%角鲨烯、0.5%聚山梨酯80和0.48%司盘85。这种佐剂称为“MF59”。MF59乳液宜包含柠檬酸根离子,如10mM柠檬酸钠缓冲液。角鲨烯、生育酚和聚山梨酯80的亚微米乳液。这些乳剂可含有2-10%角鲨烯、2-10%生育酚和0.3-3%聚山梨酯80,且角鲨烯:生育酚的重量比优选≤1(例如0.90),因为这能提供更稳定的乳剂。角鲨烯和聚山梨酯80的体积比可以约为5∶2,或者重量比约为11∶5。可通过下述方法制备一种这样的乳液:将吐温80溶解于PBS得到2%溶液,然后将90ml该溶液与5gDL-α-生育酚和5ml角鲨烯的混合物混合,然后使该混合物微流体化。所得乳液含有如平均直径为100-250nm,优选约180nm的亚微米油滴。该乳液也可含有3-脱-O-酰化单磷酰脂质A(3d-MPL)。此种类型的另一有用乳液可包含(每人剂量)0.5-10mg角鲨烯、0.5-11mg生育酚和0.1-4mg聚山梨酯80。角鲨烯、生育酚和曲通去污剂(如曲通X-100)的乳液。该乳液还可包含3d-MPL(见下文)。该乳液可包含磷酸盐缓冲液。含有聚山梨酯(如聚山梨酯80)、曲通去污剂(如曲通X-100)和生育酚(如α-生育酚琥珀酸盐)的乳液。该乳液可包含这三种组分,其质量比约为75∶11∶10(如750μg/ml聚山梨酯80、110μg/ml曲通X-100和100μg/ml琥珀酸α-生育酚),这些浓度应包括抗原中这些组分的贡献。该乳液还可包含角鲨烯。该乳液也可包含3d-MPL。水相可包含磷酸盐缓冲液。角鲨烷、聚山梨酯80和泊洛沙姆401(“PluronicTML121”)的乳液。该乳液可用pH7.4的磷酸盐缓冲盐水配制。该乳液是一种有用的胞壁酰二肽递送载体,且可与含苏氨酰基-MDP的“SAF-1”佐剂(0.05-1%Thr-MDP、5%角鲨烯、2.5%普流罗尼克L121和0.2%聚山梨酸酯80)一起使用。也可不与Thr-MDP一起使用,例如用“AF”佐剂(5%角鲨烯、1.25%普流罗尼克L121和0.2%聚山梨酸酯80)。含有角鲨烯、水溶剂、聚氧乙烯烷基醚亲水性非离子型表面活性剂(如聚氧乙烯(12)十六十八醚)和疏水性非离子型表面活性剂(如去水山梨糖醇酯或二缩甘露醇酯,如去水山梨糖醇单油酸酯或“司盘80”)的乳液。该乳液可为热可逆的和/或其中至少90%油滴(以体积计)的尺寸小于200nm。乳液也可包含以下的一种或多种:糖醇;低温保护剂(例如糖,如十二烷基麦芽苷和/或蔗糖);和/或烷基聚糖苷。该乳液可包含TLR4激动剂。可将这类乳液冻干。角鲨烯、泊洛沙姆-105和Abil-Care的乳液。含佐剂化疫苗中这些组分的终浓度(重量)可以是5%角鲨烯、4%泊洛沙姆-105(普流罗尼克多元醇)和2%Abil-Care85(双-PEG/PPG-16/16PEG/PPG-16/16二甲硅油;辛酸/癸酸甘油三酯)。含有0.5-50%油、0.1-10%磷脂和0.05-5%非离子型表面活性剂的乳液。磷脂组分可包括磷脂酰胆碱、磷脂酰乙醇胺、磷脂酰丝氨酸、磷脂酰肌醇、磷脂酰甘油、磷脂酸、鞘磷脂和心磷脂。优选亚微米液滴尺寸。不可代谢油(如轻质矿物油)和至少一种表面活性剂(如卵磷脂、吐温80或司盘80)的亚微米水包油乳液。添加剂可包括,例如QuilA皂苷、胆固醇、皂苷-亲脂偶联物(如通过葡糖醛酸的羧基将脂族胺加到脱酰基皂苷上而产生的GPI-0100)、二甲基双十八烷基溴化铵和/或N,N-双十八烷基-N,N-双(2-羟乙基)丙二胺。运载体和赋形剂在一些情况中,本文所述的组合物还可包含运载体和赋形剂(包括但不限于缓冲剂、碳水化合物、甘露醇、蛋白质、多肽或氨基酸如甘氨酸、抗氧化剂、抑菌剂、螯合剂、悬浮剂、增稠剂和/或防腐剂),水,油,包括来自石油、动物、植物或合成来源的油,如花生油、大豆油、矿物油、芝麻油等,盐水溶液,水性右旋糖和甘油溶液,风味剂,着色剂,防粘剂和其他可接受的添加剂,佐剂,或粘合剂,模拟生理条件所需的其他药学上可接受的辅助性物质,如pH缓冲剂,张力调节剂、乳化剂、润湿剂等。赋形剂的示例包括淀粉、葡萄糖、乳糖、蔗糖、明胶、麦芽、大米、面粉、白垩(chalk)、硅胶、硬脂酸钠、单硬脂酸甘油酯、滑石粉、氯化钠、脱脂奶粉、甘油、丙烯、二醇、水、乙醇等。在其他情况中,药物制备优选不含防腐剂。在其他情况中,药物制备可含有至少一种防腐剂。药物剂型的一般方法发现于Ansel等,《药物剂型和药物递送系统》(PharmaceuticalDosageFormsandDrugDeliverySystems)(LippencottWilliams&Wilkins,BaltimoreMd.(1999))。将认识到,虽然本领域普通技术人员已知的任意合适运载体可用于给予本文所述的药物组合物,运载体的类型将根据给药方式变化。在一些情况中,组合物可包含表面活性剂。示例性的表面活性剂可包括辛基苯氧基聚氧基乙醇和聚氧乙烯失水山梨糖醇酯,如Attwood和Florence编的《表面活性剂体系》(SurfactantSystems)(1983,ChapmanandHall)中所述。辛基苯氧基聚氧基乙醇(辛苯聚醇)包括叔辛基苯氧基聚乙氧基乙醇(曲通X-100TM),也描述于《默克索引条目》(MerckIndexEntry)6858(第1162页,第12版,Merck&Co.Inc.,WhitehouseStation,N.J.,USA;ISBN0911910-12-3)。聚氧乙烯失水山梨糖醇酯包括聚氧乙烯失水山梨糖醇单酯(吐温80TM),也描述于《默克索引条目》(MerckIndexEntry)7742(第1308页,第12版,Merck&Co.Inc.,WhitehouseStation,N.J.,USA;ISBN0911910-12-3)。两者都可使用本文所述的方法制备,或购自市售来源如西格玛公司(SigmaInc)。示例性的非离子型表面活性剂可包括曲通X-45、叔辛基苯氧基一聚乙氧基乙醇(曲通X-100)、曲通X-102、曲通X-114、曲通X-165、曲通X-205、曲通X-305、曲通-57、曲通-101、曲通-128、Breij35、聚氧乙烯-9-月桂基醚(laureth9)和聚氧乙烯-9-硬脂醇醚(steareth9)。聚氧乙烯醚可包括聚氧乙烯-8-硬脂醇醚、聚氧乙烯-4-月桂基醚、聚氧乙烯-35-月桂基醚、和聚氧乙烯-23-月桂基醚。聚氧乙烯月桂基醚的其他术语或名称描述于CAS登记中。聚氧乙烯-9-月桂基醚的CAS登记号是9002-92-0。聚氧乙烯醚如聚氧乙烯月桂基醚描述于默克索引中(第12版:条目7717,Merck&Co.Inc.,WhitehouseStation,N.J.,USA;ISBN0911910-12-3)。通过将环氧乙烷与十二烷醇反应来形成Laureth9,并且其具有平均9个环氧乙烷单元。表面活性剂中聚氧乙烯部分的长度与烷基链的长度之比(即,n:烷基链长度之比)影响了这类表面活性剂在水性介质中的溶解性。因此,本发明的表面活性剂可以在溶液中,或者可形成颗粒结构,如胶束或囊泡。作为溶液,本发明的表面活性剂是安全的,易于灭菌,并且给药简便,并且可以简单方式制备,而不没有与均匀颗粒结构形成相关的GMP和QC问题。一些聚氧乙烯醚,如laureth9能够形成非囊泡溶液。然而,聚氧乙烯-8棕榈酰醚(C18E8)能够形成囊泡。因此,聚氧乙烯-8棕榈酰醚与至少一种其他非离子型表面活性剂组合的囊泡可用于本发明的制剂中。在这种生物试验的固有实验误差内,约0.5-0.0001%,更优选0.05-0.0001%,更优选0.005-0.0001%,并且最优选0.003-0.0004%的本发明的通式(I)的聚氧乙烯醚或表面活性剂优选具有溶血活性。理想地,所述聚氧乙烯醚或酯应该具有与聚氧乙烯-9月桂基醚或聚氧乙烯-8硬脂醇醚相似的溶血活性(即,在10倍差异内)。来自不同组所述表面活性剂的2种或更多种非离子型表面活性剂可存在于本文所述的疫苗制剂中。具体地,优选聚氧乙烯去水山梨糖醇酯如聚氧乙烯去水山梨糖醇单油酸酯(吐温80TM)和辛苯聚糖如叔辛基苯氧基聚乙氧基乙醇(曲通)X-100TM的混合物。另一个特别优选的非离子型表面活性剂的组合包含laureth9加上聚氧乙烯失水山梨糖醇酯或辛苯聚醇或两者。优选地,各非离子型表面活性剂以0.001至20%,更优选0.01至10%,并且最优选高至2%(w/v)的浓度存在于最终疫苗制剂中。在存在一种或两种表面活性剂的情况中,通常以各高至约2%,一般以各高至约0.6%的浓度存在于最终制剂中。可存在一种或多种其他表面活性剂,通常各高至约1%的浓度,并且一般各高至约0.2%或0.1%的痕量。表面活性剂的任意混合物可存在于本发明的疫苗制剂中。如上所述那些的非离子型表面活性剂在最终疫苗组合物中具有以下的优选浓度:聚氧乙烯失水山梨糖醇酯如吐温80TM:0.01至1%,最优选约0.1%(w/v);辛基-或壬基苯氧基聚氧乙醇如曲通X-100TM或曲通系列的其它去污剂:0.001至0.1%,最优选0.005至0.02%(w/v);通式(I)的聚氧乙烯醚如laureth9:0.1至20%,优选0.1至10%并且最优选0.1至1%或约0.5%(w/v)。也可采用熟知技术将组合物包封在脂质体中。生物可降解微球也可用作本发明的药物组合物的运载体。合适的生物可降解微球公开于例如美国专利号4,897,268、5,075,109、5,928,647、5,811,128、5,820,883、5,853,763、5,814,344和5,942,252。可将组合物给予至脂质体或微球(或微颗粒)中。制备用于给予患者的脂质体和微球的方法是本领域技术人员所熟知的。美国专利号4,789,734描述了将生物材料包封到脂质体中的方法,其内容通过引用纳入本文。具体地,材料溶于水性溶液中,加入合适的磷脂和脂质以及需要的表面活性剂,并且在需要时透析或超声处理材料。G.Gregoriadis,第14章,“脂质体”,《生物学和医学中的药物运载体》(DrugCarriersinBiologyandMedicine),第2页.sup.87-341(学术出版社,1979)提供了已知方法的综述。由聚合物或蛋白质形成的微球是本领域技术人员所熟知的,并且可经调整用于通过胃肠道直接进入血流。或者,可纳入化合物并且可植入微球或微球复合物来在从数天到数月的时间段内缓释。例如,参加美国专利4,906,474、4,925,673和3,625,214,和Jein,TIPS19:155-157(1998),其内容被纳入本文作为参考。组合物可含有防腐剂,如硫柳汞或2-苯氧乙醇。在一些情况中,疫苗基本不含(例如,<10μg/ml)含汞物质,例如不含硫柳汞。琥珀酸α-生育酚可用作含汞化合物的替代物。为了控制张力,疫苗中可包括生理盐如钠盐。其他盐可包括氯化钾、磷酸二氢钾、磷酸氢二钠、和/或氯化镁等。组合物可具有200mOsm/kg至400mOsm/kg,240至360mOsm/kg或290至310mOsm/kg范围内的渗透压。组合物可包含一种或多种缓冲剂,如Tris缓冲剂;硼酸盐缓冲剂;琥珀酸盐缓冲剂;组氨酸缓冲剂(具体是有氢氧化铝佐剂时);或柠檬酸盐缓冲剂。在一些情况中,包含的缓冲剂的浓度一般为5-20mM的范围。组合物的pH可以是约5.0至约8.5、约6.0至约8.0、约6.5至约7.5、或约7.0至约7.8。组合物可以无菌。该疫苗可无热原,如小于1EU/剂量(内毒素单位,标准量度),并且可小于0.1EU/剂量。该组合物可不含谷蛋白。组合物可包含去污剂,如聚氧乙烯去水山梨糖醇酯表面活性剂(称为“吐温”)、辛苯聚醇(如辛苯聚醇-9(曲通X-100)或叔辛基苯氧基聚乙氧基乙醇)、溴化十六烷基三甲铵(“CTAB”)或脱氧胆酸钠,特别适用于裂解疫苗或表面抗原疫苗。去污剂可仅以痕量存在。因此,疫苗中可包含各自的含量小于1mg/ml的辛苯聚醇-10和聚山梨醇酯80。其它痕量残留组分可以是抗生素(如新霉素、卡那霉素、多粘菌素B)。组合物可配制成无菌溶液或悬液,合适载剂,如本领域所熟知。药物组合物可通过熟知的常规灭菌技术灭菌,或可经无菌过滤。所得水性溶液可经包装用于原样(as-is)使用,或经冻干,冻干的制剂在给予之前与无菌溶液合并。合适的制剂和其他运载体描述于《雷明顿:药物科学和实践》(Remington:TheScienceandPracticeofPharmacy)(第20版,LippincottWilliams&Wilkins,BaltimoreMd.),其通过引用全文纳入本文。可用一种或多种药学上可接受的盐来配制组合物。药学上可视的盐可包括无机离子的那些,例如,钠、钾、钙、镁离子等。这类盐可包括无机或有机酸,如盐酸、氢溴酸、磷酸、硝酸、硫酸、甲磺酸、对甲苯磺酸、乙酸、富马酸、琥珀酸、乳酸、扁桃酸、苹果酸、柠檬酸、酒石酸或马来酸的盐。另外,如果试剂含有羧基或其他酸性基团,其可被转化成与无机或有机碱的药学上可接受的加成盐。合适的碱的示例包括氢氧化钠、氢氧化钾、氨、环己胺、二环己基、乙醇胺、二乙醇胺、三乙醇胺等。加成盐可包含胆汁酸或其衍生物。这些包括胆酸衍生物及其盐,尤其是胆酸或胆酸衍生物的钠盐。胆汁酸及其衍生物的示例包括胆酸、脱氧胆酸、鹅脱氧胆酸、石胆酸、乌索脱氧胆酸、猪脱氧胆酸和衍生物如前述胆汁酸的糖-、牛磺-、氨基丙基-1-丙磺酸-、氨基丙基-2-羟基-1-丙磺酸衍生物,或N,N-双(3D葡糖氨基丙基)脱氧胆胺。特别优选的示例是脱氧胆酸钠(NaDOC),其可存在于最终疫苗制剂中。本文所述包含活性佐剂如肽或核酸与一种或多种佐剂的组合物可使用一种或多种生理上可接受的运载体,包括赋形剂、稀释剂和/或助剂以常规方式配制,例如,其促进将活性剂加工成可给予的制剂。合适的试剂可至少部分取决于所选的给药途径。可使用多种给药途径或模式来递送本文所述的试剂,包括,口服、口颊、局部、直肠、透皮、粘膜、皮下、静脉内、和肌内应用,以及通过吸入。活性剂也可配制用于胃肠外给药(例如注射,如推注或连续输注),并可制成单位剂型装在安瓿、预填充注射器、小体积输液瓶或加入防腐剂的多剂量容器中。组合物可采取这类形式,如油性或水性载剂中的悬液、溶液或乳液,例如,水性聚乙二醇中的溶液。对于注射制剂,载剂可选自本领域已知的合适的那些,包括水性溶液或油悬液,或乳液,以及芝麻油、玉米油、棉籽油或花生油,以及酏剂、甘露醇、右旋糖或无菌水溶液,和类似的药物载剂。制剂还可包含聚合物组合物,其是生物相容的或可生物降解的,如聚(乳酸-共-乙醇酸)。这些材料可制成微球或纳米球,加载药物并且进一步涂覆或衍生化以产生优异的持续释放性质。适用于眼周或眼内注射的载剂包括,例如,在注射级水、脂质体和适于亲脂性物质的载剂中的治疗剂悬液。用于眼周或眼内注射的其他载剂为本领域所熟知。在一些情况中,按照常规方法将组合物配制成适合静脉内给予人类的药物组合物。静脉内给予的组合物通常是溶于无菌等渗水性缓冲液的溶液。如果需要,组合物也可含有增溶剂和局部麻醉剂(如利多卡因)来减轻注射部位的疼痛。通常,各成分单独提供或混合在一起以单位剂型的形式提供,例如作为标明活性物质含量的密封容器(如安瓿或药囊)中的冻干粉末或无水浓缩物。通过输液给予该组合物时,可用含有无菌药物级水或盐水的输液瓶分配该组合物。通过注射给予该组合物时,可提供一安瓿的无菌注射用水或盐水,以便在给药前与药物成分混合。当通过注射给药时,活性试剂可配制在水溶液中,具体在生理相容性缓冲液中,如汉克斯溶液、林格溶液或生理盐水缓冲液。该溶液可包含配制剂,如助悬剂、稳定剂和/或分散剂。或者,活性化合物可以是使用前用合适的运载体如无菌无热原的水进行重建的粉末形式。在另一个实施方式中,药物组合物不包含用于添加以强化由肽刺激的免疫应答的佐剂或任何其他物质。在另一个实施方式中,药物组合物包含抑制对肽的免疫应答的物质。配制的方法为本领域所知,例如,如最新版的《雷明顿药物科学》,马克出版公司(MackPublishingCo.),EastonP中所述。除上述制剂外,活性试剂也可配制成长效制剂。这种长效制剂可通过植入或经皮递送(例如,皮下或肌内),肌内注射或使用透皮贴片来给予。因此,例如,试剂也可与合适的聚合物材料或疏水材料(例如,用可接受的油配制成乳剂)或离子交换树脂配制在一起,或者配制成微溶性衍生物,例如,微溶性盐。在一些情况中,包含一种或多种试剂的组合物在局部给予或者在特定注射位点处或附近注射时显示出局部和区域性效果。粘稠液体、溶液、悬液、二甲亚砜(DMSO)-基溶液、脂质体制剂、凝胶、胶状物、霜、乳液、油膏、栓剂、泡沫、或气溶胶喷雾的直接局部施用可用于局部给药,以产生例如局部和/或区域性效果。用于这种配制的药学上的合适载剂包括,例如,低级脂肪醇、多元醇(例如,甘油,或聚乙二醇)、脂肪酸的酯、油、脂肪、硅酮等。这类制备物也可包括防腐剂(例如,对羟基苯甲酸酯)和/或抗氧化剂(例如,抗坏血酸和生育酚)。也参见《皮肤病制剂:经皮吸收》(DermatologicalFormulations:Percutaneousabsorption),Barry(编),MarcelDekkerIncl,1983。在另一个实施方式中,包含转运剂、运载体、或离子通道抑制剂的局部制剂可用于治疗表皮或粘膜病毒感染。组合物可含有美容或皮肤可接收的运载体。这类运载体与皮肤、指甲、粘膜、组织和/或头发相容,并且可包括满足这些要求的任何常用美容或皮肤运载体。本领域普通技术人员可易于选择这类运载体。在配制皮肤油膏中,可在油性烃类基、水性吸收基、油包水吸收基、水包油水可去除基和/或水溶基中配制试剂或试剂组合。这类运载体和赋形剂的示例包括但不限于致湿剂(例如,尿素)、二醇(例如,聚乙二醇)、醇(例如,乙醇)、脂肪酸(例如,油酸)、表面活性剂(例如,肉豆蔻酸异丙酯和月桂基硫酸钠)、吡咯烷酮、单月桂酸甘油酯、亚砜、萜烯(例如,薄荷醇)、胺、酰胺、烷烃、烷醇、水、碳酸钙、磷酸钙、各种糖、淀粉、纤维素衍生物、明胶、和聚合物如聚乙二醇。可用水性或油性基料,加入合适的增稠剂和/或凝胶剂来配制软膏剂和乳膏剂。洗剂可用水性或油性基料配制,且通常还含有一种或多种乳化剂、稳定剂、分散剂、悬浮剂、增稠剂或着色剂。用于递送药物试剂的透皮贴片的构建和使用是本领域所熟知的。参见美国专利5,023,252、4,992,445和5,001,139。可构建这类贴片用于连续、脉冲或根据需要递送药物试剂。可用于形成药物组合物和剂型的润滑剂包括但不限于,硬脂酸钙、硬脂酸镁、矿物油、轻矿物油、甘油、山梨醇、甘露醇、聚乙二醇、其它二醇、硬脂酸、十二烷基硫酸钠、滑石、氢化植物油(例如,花生油、棉籽油、葵花油、芝麻油、橄榄油、玉米油和大豆油)、硬脂酸锌、油酸乙酯、月桂酸乙酯、琼脂或其混合物。其他润滑剂包括,例如,塞罗得(syloid)硅胶、合成氧化硅的凝结气溶胶、或其混合物。润滑剂可任选地以小于药物组合物的约1重量%的量添加。组合物可以是适于局部施用的任意形式,包括水性、水性-醇或油性溶液、乳液或血清分散体、水性、无水或油性凝胶、通过将脂肪相分散到水相中获得的乳液(O/W或水包油),或者相反(W/O或油包水)、微乳液或者微囊、微粒或者离子型和/或非离子型的脂质载剂分散体。可按照常规方法来制备这些组合物。除了本发明的试剂以外,本发明的组合物的各种组分的量按照本领域常规选择。这些组合物具体构成用于面部、手、身体和/或粘膜,或用于清洁皮肤的保护、治疗或护理油膏、乳、乳液或泡沫。组合物也可由构成肥皂或清洁皂的固体制备物组成。组合物可含有佐剂,如亲水性或亲脂性胶凝剂、亲水性或亲脂性活性剂、防腐剂、抗氧化剂、溶剂、芳香剂、填充剂、防晒剂、除臭剂和染料。这些佐剂的量是用于所考虑领域中的常规的量,例如,组合物总重量的约0.01%至约20%。根据其性质,这些佐剂可导入脂肪相,导入水性和/或导入脂质囊泡中。就口服给药而言,通过组合所述活性试剂和本领域熟知的药学上可接受载体能容易地配制所述活性试剂。能使本发明试剂配制为例如片剂(包括咀嚼片)、丸剂、糖衣剂、胶囊、锭剂、硬糖、液体、凝胶、糖浆、浆液、粉末、混悬液、酏剂、薄片等,所述制剂由待治疗的患者口服咽下。这类制剂可包含药学上可接受的运载体,包括固体稀释剂或填充剂、无菌水性介质和各种无毒性有机溶剂。固体运载体可为一种或多种还能用作稀释剂、调味剂、稳定剂、润滑剂、助悬剂、粘合剂、防腐剂、片剂崩解剂、或包封材料的物质。在粉末剂中,运载体一般是细碎的固体,其与细碎的活性组分混合。在片剂中,所述活性组分一般与具有所需结合能力的运载体以合适比例混合并压缩为所需的形状和大小。含有占活性化合物的约1%至约70%的粉末和片剂。合适的运载体包括但不限于碳酸镁、硬脂酸镁、滑石、糖、乳糖、果胶、糊精、淀粉、明胶、黄蓍胶、甲基纤维素、羧甲基纤维素钠、低熔点蜡、可可油等。一般而言,包括占口服剂型的总组合物重量的约0.5%、约5%、约10%、约20%、或约30%至约50%、约60%、约70%、约80%或约90%的活性试剂,其量足以提供所需的单位剂量。口服使用的水性悬液可含有活性试剂和药学上可接受的赋形剂,如悬浮剂(例如,甲基纤维素)、润湿剂(例如,卵磷脂、溶血卵磷脂和/或长链脂肪醇)、以及着色剂、防腐剂、风味剂等。可能需要油或非水性溶剂来将活性试剂带入溶液中,由于,例如,存在大亲脂性部分。或者,可使用乳液、悬液或其他制备物,例如,脂质体制备物。对于脂质体制备物,可使用制备用于治疗病症的脂质体的任何已知方法。参见,例如,Bangham等,J.Mol.Biol.23:238-252(1965)和Szoka等,Proc.Natl.Acad.Sci.USA75:4194-4198(1978),通过引用纳入本文。配体也可连接至脂质体以引导这些组合物至特定作用位点。可通过以下方法获得口服用途的药物制剂:以固体赋形剂,任选地研磨所得混合物,并在加入合适的辅助剂(如果需要)后加工该颗粒混合物,以获得片剂或糖衣丸芯体。合适的赋形剂是,具体地,填充剂如糖,包括乳糖、蔗糖、甘露醇或山梨醇;风味元素,纤维素制品例如玉米淀粉、小麦淀粉、水稻淀粉、马铃薯淀粉、明胶、黄蓍胶、甲基纤维素、羟丙基甲基纤维素、羧甲基纤维素钠和/或聚乙烯吡咯烷酮(PVP)。如果需要,可加入崩解剂,例如交联聚乙烯吡咯烷酮、琼脂、或藻酸或其盐如藻酸钠。试剂也可配制成缓释制剂。糖衣剂芯体能具有合适包衣。出于这种目的,可使用浓缩糖溶液,其可任选地含有阿拉伯胶、滑石、聚乙烯吡咯烷酮、卡波姆凝胶、聚乙二醇和/或二氧化钛、漆溶液和合适的有机溶剂或溶剂混合物。可将染料或颜料加入片剂或糖衣剂包衣中,用于标识或表征活性试剂的不同组合。可口服使用的药物制剂包括明胶制成的推入式(push-fit)胶囊,以及明胶和增塑剂(如甘油或山梨糖醇)制成的密封软胶囊。推入式胶囊可含有活性成分,该活性成分可混合填充剂如乳糖、粘合剂如淀粉和/或润滑剂如滑石粉或硬脂酸镁以及任选的稳定剂。在软胶囊中,活性试剂可溶解或悬浮于合适液体如脂肪油、液体石蜡或液体聚乙二醇中。此外可加入稳定剂。所有的口服给予制剂的剂量应该适于给药方式。适于口服给药的其他形式包括液体形式制备物,包括乳液、糖浆、酏剂、水溶液、水性悬液、或固体形式制备物,其可在使用前短期内转换成液体形式制备物。乳液可制备成溶液,例如,水性聚乙二醇溶液或者可含有乳化剂,例如,卵磷脂、失水山梨糖醇单油酸酯或阿拉伯胶。可通过将活性组分溶解于水中并添加合适的着色剂、调味剂、稳定剂和增稠剂来制备水溶液。水性悬液可通过用粘性材料将细碎活性组分分散于水中制备,所述粘性材料如天然或合成树胶、树脂、甲基纤维素、羧甲基纤维素钠的和其他熟知的悬浮剂。可与组合物一起给予的合适填充剂或运载体包括以合适量使用的糖、醇、脂肪、乳糖、淀粉、纤维素衍生物、多糖、聚乙烯吡咯烷酮、氧化硅、无菌盐水等,或其混合物。除活性组分外,固体形式制备物包括溶液、悬液和乳液并且可含有着色剂、调味剂、稳定剂、缓冲剂、人工和天然甜味剂、分散剂、增稠剂、增溶剂等。可通过向糖,例如蔗糖的浓缩水性溶液(其中可添加任何助剂)中添加活性化合物来制备糖浆或悬液。这类助剂可包括风味剂,阻止糖或试剂结晶以增加任意其他成分溶解性的试剂,例如,多元醇,例如,甘油或山梨糖醇。当配制用于口服给药的化合物时,需要采用胃滞留制剂来增强胃肠(GI)道吸收。在胃中滞留几个小时的制剂可缓慢释放本发明的化合物并提供可在本文中使用的缓释。这类胃滞留制剂的内容发现于Klausner,E.A.;Lavy,E.;Barta,M.;Cserepes,E.;Friedman,M.;Hoffman,A.2003“新胃滞留剂型:人中胃滞留性及其对左旋多巴影响的评估(Novelgastroretentivedosageforms:evaluationofgastroretentivityanditseffectonlevodopainhumans).”Pharm.Res.20,1466-73,Hoffman,A.;Stepensky,D.;Lavy,E.;Eyal,S.Klausner,E.;Friedman,M.2004“胃滞留剂型的药代动力学和药效方面(Pharmacokineticandpharmacodynamicaspectsofgastroretentivedosageforms)”Int.J.Pharm.11,141-53,Streubel,A.;Siepmann,J;Bodmeier,R.;2006“胃滞留药物递送系统(Gastroretentivedrugdeliverysystems)”ExpertOpin.DrugDeliver.3,217-3,和Chavanpatil,M.D.;Jain,P.;Chaudhari,S.;Shear,R.;Vavia,P.R.“用于氟嗪酸的新缓释可吞咽且生物粘附胃滞留药物递送系统(Novelsustainedrelease,swellableandbioadhesivegastroretentivedrugdeliverysystemforolfoxacin)”Int.J.Pharm.2006epub3月24日。可采用可膨胀浮动生物粘附技术来最大化本发明化合物的吸收。可通过组合物中的表面活性剂或其他合适的助溶剂来增强组合物组分的溶解性。这类助溶剂包括聚山梨酯20、60和80,普流罗尼克F68、F-84和P-103,环糊精,或本领域技术人员已知的其他试剂。通常约在0.01-2重量%的水平上使用这些助溶剂。可以多剂形式包装组合物。防腐剂可优选用于防止使用期间的微生物污染。合适的药剂包括:苯扎氯铵、硫柳汞、氯代丁醇、对羟基苯甲酸甲酯、对羟基苯甲酸丙酯、苯乙醇、乙二胺四乙酸二钠、山梨酸、OnamerM、或其他本领域技术人员已知的试剂。在现有技术的眼科产品中,这类防腐剂可以0.004%至0.02%的水平采用。在本发明的组合物中,防腐剂,优选苯扎氯铵可以0.001重量%至小于0.01重量%,例如0.001重量%至0.008重量%,优选约0.005重量%的水平使用。已经发现0.005%的苯扎氯铵浓度足够保护本发明的组合物免受微生物攻击。在与局部施用相关的情况中,组合物可包括一种或多种渗透增强剂。例如,制剂可包含合适的固相或凝胶相运载体或赋形剂,其增加了渗透并有助于本发明的试剂或试剂组合递送通过渗透屏障,例如,皮肤。许多这类渗透增强化合物是局部制剂领域技术人员已知的,并且包括,例如,水、醇(例如,萜烯如甲醇、乙醇、2-丙醇),亚砜(例如,二甲亚砜、癸基甲基亚砜、四癸基甲基亚砜),吡咯烷酮(例如,2-吡咯烷酮、N-甲基-2-吡咯烷酮、N-(2-羟乙基)吡咯烷酮),月桂氮卓酮,丙酮,二甲基乙酰胺,二甲基甲酰胺,四氢糠醇,L-α-氨基酸,阴离子、阳离子、两性或非离子型表面活性剂(例如,肉豆蔻酸异丙酯和月桂基硫酸钠),脂肪酸,脂肪醇(例如,油酸),胺,酰胺,氯贝酸酰胺,六亚甲基月桂酰胺,蛋白水解酶,α-没药醇,d-柠檬烯,尿素和N,N-二乙基-间-甲苯酰胺等。其他示例包括致湿剂(例如,尿素)、二醇(例如,丙二醇和聚乙二醇)、单月桂酸甘油酯、烷烃、烷醇、水、ORGELASE、碳酸钙、磷酸钙、各种糖、淀粉、纤维素衍生物、明胶和/或其他聚合物。在另一个实施方式中,组合物可包含一种或多种这类渗透增强剂。局部施用的组合物可包含一种或多种抗微生物防腐剂,如季铵化合物、有机汞、对羟基苯甲酸、芳族醇、氯丁醇等。组合物可配制成气溶胶溶液、悬液或干粉。可通过呼吸系统或鼻通道来给予气溶胶。例如,本领域技术人员将认识到本发明的组合物可在合适运载体中悬浮或溶液,例如,药学上可接受的推进剂,并且使用鼻喷雾或吸入剂直接给予肺中。例如,包含转运剂、运载体、或离子通道抑制剂的气溶胶制剂可在推进剂或溶剂与推进剂的混合物中溶解、悬浮或乳化,例如,用于以鼻喷雾或吸入剂给予。气溶胶制剂可含有任何在压力下可接受的推进剂,如化妆或皮肤或药学上可接受的推进剂,如本领域常规使用的那样。用于鼻给药的气溶胶制剂一般是设计成以液滴或喷雾给予鼻通道的水溶液。鼻溶液可与鼻分泌物相似,即它们一般是等渗的并且稍加缓冲以维持约5.5至约6.5的pH,虽然可额外使用在该范围以外的pH值。制剂中也可包含抗微生物剂或防腐剂。可设计用于吸入的气溶胶制剂或吸入剂,使得试剂或试剂组合在通过鼻或口腔呼吸途径给予时被运载到对象的呼吸道中。可例如通过喷雾器来给予吸入溶液。包含细粉末或液体药物的吸入或吹入可以推进剂中的试剂或试剂组合的溶液或悬液的药物气溶胶递送到呼吸系统中,例如,辅助补偿。推进剂可以是液化的气体,包括卤代烃,例如,碳氟化合物如氟化氯化烃、氢氯氟烃、和氢氯烃、以及烃类和烃醚。卤代烃推进剂可包括碳氟化合物推进剂(其中所有氢都被氟取代)、氯氟烃推进剂(其中所有氢都被氯和至少一个氟取代)、含氢氟碳化合物推进剂、和含氢氯氟烃推进剂。卤代烃推进剂描述于Johnson的1994年12月27日授权的美国专利号5,376,359;Byron等的1993年3月2日授权的美国专利号5,190,029;和Purewal等的1998年7月7日授权的美国专利号5,776,434。可用于本发明的烃推进剂包括,例如,丙烷、异丁烷、正丁烷、戊烷、异戊烷和新戊烷。烃类的掺混物也可用作推进剂。醚推进剂包括,例如,二甲醚以及醚。本发明的气溶胶制剂也可包含超过一种推进剂。例如,气溶胶制剂可包含超过一种相同类别的推进剂,如2种或更多种含氟烃;或超过一种、超过2种、超过3种来自不同类别的推进剂,如含氟烃和烃。本发明的药物组合物也可用压缩气体分散,例如,惰性气体如二氧化碳、一氧化氮或氮气。气溶胶制剂也可包括其他组分,例如,乙醇、异丙醇、丙二醇、以及表面活性剂或其他组分如油和去污剂。这些组分可用于使制剂和/或润滑价值组分稳定化。气溶胶制剂可在压力下包装并且可配制为使用溶液、悬液、乳液、粉末和半固体制备物的气溶胶。例如,溶液气溶胶制剂可包含在(基本)纯的推进剂中本发明的试剂,如转运剂、运载体或离子通道抑制剂的溶液,或推进剂与溶剂的混合物。溶剂可用于溶解试剂和/或阻滞推进剂蒸发。溶剂可包括例如,水、乙醇和二醇。合适溶剂的任意组合可任选地以防腐剂、抗氧化剂、和/或其他气溶胶组分联用。气溶胶制剂可以是分散体或悬液。悬浮气溶胶制剂可包含本发明的试剂或试剂组合的悬液,例如,转运剂、运载体或离子通道抑制剂,和分散剂。分散剂可包括,例如,失水山梨糖醇三油酸酯、油酰基醇、油酸、卵磷脂和玉米油。悬浮气溶胶制剂也可包括润滑剂、防腐剂、抗氧化剂和/或其他气溶胶组分。气溶胶制剂可与乳液类似配制。乳液气溶胶制剂可包括,例如,醇如乙醇、表面活性剂、水和推进剂,以及本发明的试剂或试剂组合,例如,转运剂、运载体或离子通道。使用的表面活性剂可以是非离子、阴离子或阳离子的。乳液气溶胶制剂的一个示例包含,例如,乙醇、表面活性剂、水和推进剂。乳液气溶胶制剂的另一个示例包括,例如,植物油、单硬脂酸甘油酯和丙烷。化合物也可以配制用于作为栓剂给予。低熔蜡,如甘油三酯、脂肪酸甘油酯、WitepsolS55(德国诺贝尔化学(DynamiteNobelChemical,Germany)的商标)或可可油的混合物首先熔化并且通过例如搅拌使活性组分均匀分散。然后将熔化均匀的混合物倒入常规尺寸的模具中,使其冷却,从而固化。可配制化合物用于阴道给予。本领域已知阴道栓剂、棉塞剂,乳膏剂、凝胶剂、贴剂、泡沫剂或喷雾剂也是适合的。化合物可以可释放地附连至生物相容聚合物用于缓释制剂,或附连至惰性物体用于局部、眼内、眼周或全身给予。从生物相容聚合物受控释放也可用于水溶性聚合物以形成可灌注制剂。从生物相容聚合物例如PLGA微球或纳米球受控释放可用于使用眼内植入或用于持续释放给药注射的制剂。可使用任意合适的生物可降解且生物相容的聚合物。剂量、给药途径和治疗方案本文所述的组合物和方法可在对象中引发针对抗原性肽的表位的免疫应答。在一些情况中,组合物可以是乳腺癌疫苗或卵巢癌疫苗。在一些情况中,乳腺癌疫苗可以是多抗原乳腺癌疫苗。在一些情况中,卵巢癌疫苗可以是多抗原卵巢癌疫苗。在一些情况中,对象可在给予疫苗之前携带肿瘤。在其他情况中,对象可在给予疫苗之前不携带肿瘤。在其他情况中,对象在给予疫苗之前不携带肿瘤,但是在给予疫苗之后携带肿瘤。在其他情况中,对象在给予疫苗之前不携带肿瘤并且可能不在给予疫苗之后携带肿瘤。在一些情况中,肿瘤可以是乳腺癌肿瘤。在一些情况中,啮齿动物中的乳腺癌肿瘤是DMBA-诱导的肿瘤。例如,啮齿动物中的乳腺癌肿瘤可衍生自M6或MMC细胞。通常,人中的乳腺癌肿瘤是人中的三阴性肿瘤。本文所述的组合物可作为疫苗给予有此需要的对象。在一些情况中,可用多抗原乳腺癌疫苗或多抗原卵巢癌疫苗来免疫对象。例如,疫苗可以是乳腺癌疫苗(例如,多抗原疫苗)或卵巢癌疫苗(例如,多抗原疫苗)。本文所述的疫苗可通过多种途径递送。递送途径可包括口服(包括口颊和舌下)、直肠、经鼻、局部、透皮贴片、经肺、阴道、栓剂或胃肠外(包括肌内、动脉内、鞘内、皮内、腹膜内、皮下和静脉内)给药或适于通过气溶胶化、吸入或吹入给药的形式。药物递送系统的一般内容发现于Ansel等,《药物剂型和药物递送系统》(PharmaceuticalDosageFormsandDrugDeliverySystems)(LippencottWilliams&Wilkins,BaltimoreMd.(1999))。本文所述的疫苗可给予肌肉,或可通过皮内或皮下注射给予,或透皮,如通过离子透入。可采用疫苗的表皮给予。在一些情况中,也可配制疫苗用于通过鼻通道给予。适用于经鼻给药的制剂(其中运载体是固体)包括粒度范围为约10至约500微米的粗粉末,其以摄取鼻烟的方式给予,即从保持在靠近鼻部的处的粉末容器中通过鼻部通道迅速吸入。该制剂可以是鼻喷雾剂,鼻滴剂,或通过喷雾器的气溶胶给予。该制剂可包含疫苗的水溶液或油性溶液。疫苗可以是液体制备物如悬液、糖浆或酏剂。疫苗也可以是用于胃肠外、皮下、皮内、肌内或静脉内给予(例如,注射给予)的制备物,如无菌悬液或乳液。疫苗可含有单次免疫的物质,或者可含有多次免疫的物质(即“多剂”药盒)。多剂量配置优选含有防腐剂。作为多剂量组合物中包含防腐剂的替代方案(或补充方案),该组合物可包含在装有无菌接头以取出物质的容器中。疫苗可以约0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、或1.0mL的剂体积给予。有时,疫苗可以例如超过1ml的较高剂量给予。在一些情况中,可用一剂疫苗来免疫对象。在其他情况中,可用超过一剂疫苗来免疫对象。例如,可用超过1剂、超过2剂、超过3剂、超过4剂、超过5剂、超过6剂、超过7剂、超过8剂、超过9剂、超过10剂、超过11剂、超过12剂、超过13剂、超过14剂、超过15剂、超过16剂、超过17剂、超过18剂、超过19剂、或超过20剂疫苗来免疫对象。在示例性情况中,用3剂疫苗来免疫对象。在对象接受超过1剂疫苗的情况中,时间可在疫苗的第一剂和各后续剂之间流逝。在一些情况中,在疫苗的第一剂和各后续剂之间流逝的时间可以是数秒、数分钟、数小时、数天、数周、数月或数年。例如,可间隔给予对象超过1剂。在一些情况中,间隔可以是数秒、数分钟、数小时、数天、数周、数月或数年。在一些情况中,对象可接受加强剂。例如,可用超过1剂、超过2剂、超过3剂、超过4剂、超过5剂、超过6剂、超过7剂、超过8剂、超过9剂、超过10剂、超过11剂、超过12剂、超过13剂、超过14剂、超过15剂、超过16剂、超过17剂、超过18剂、超过19剂、或超过20剂加强剂的疫苗来向对象给予加强剂。在示例性情况中,对象可接受高至3剂加强剂疫苗。在一些情况中,间隔可在疫苗各剂之间相同。在一些情况中,间隔可在疫苗各加强剂之间相同。在一些情况中,间隔可在疫苗各剂之间不同。在一些情况中,间隔可在疫苗各加强剂之间不同。在示例性情况中,在至少1天的间隔下给予对象超过1剂。在一些情况中,间隔可以是1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天或30天间隔。在其他情况中,间隔可以是天的范围,例如,天的范围可以是1-5天、1-7天、1-10天、3-15天、5-10天、5-15天、5-20天、7-10天、7-15天、7-20天、7-25天、10-15天、10-20天、10-25天、15-20天、15-25天、15-30天、20-30天、20-35天、20-40天、20-50天、25-50天、30-50天、35-50天、或40-50天。可在给予疫苗之后评价对象。在一些情况中,可在最后给予疫苗的1个月内(例如,短期)评价对象。例如,短期可以是最后给予疫苗后的1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天、30天或31天。在一些情况中,可在最后给予疫苗的4个月内(例如,常期)评价对象。例如,短期可以是最后给予疫苗后的1周、2周、3周、4周、5周、6周、7周、8周、9周、10周、11周、12周、13周、14周、15周、16周、17周、18周、19周、20周、21周、22周、23周、24周、25周、26周、27周、28周、29周、30周或31周。在一些情况中,对象可在最后给予疫苗剂量后接受至少1剂疫苗加强剂。例如,至少1剂加强剂可在最后给予疫苗后的1周、2周、3周、4周、5周、6周、7周、8周、9周、10周、11周、12周、13周、14周、15周、16周、17周、18周、19周、20周、21周、22周、23周、24周、25周、26周、27周、28周、29周、30周或31周后给予对象。在一些情况中,对象可接受1剂加强、2剂加强、3剂加强、4剂加强、5剂加强、6剂加强、7剂加强、8剂加强、9剂加强、10剂加强、11剂加强、12剂加强、13剂加强、14剂加强、15剂加强、16剂加强、17剂加强、18剂加强、19剂加强、20剂加强、21剂加强、22剂加强、23剂加强、24剂加强、25剂加强、26剂加强、27剂加强、28剂加强、29剂加强、或30剂加强剂。本发明在另一个方面提供了一种包含皮内给药装置和本文所述的疫苗制剂的药盒。该装置优选已填充疫苗。优选地,疫苗处于小于常规肌内疫苗的液体体积,如本文所述,具体是约0.05ml至0.2ml的体积。优选地,装置是用于向真皮给予疫苗的短针递送装置。用于本文所述的皮内疫苗的合适装置包括短针装置,如US4,886,499、US5,190,521、US5,328,483、US5,527,288、US4,270,537、US5,015,235、US5,141,496、US5,417,662中所述的那些。也可通过限制针在皮肤内的有效渗透长度的装置及其功能等价物来给予皮内疫苗,如WO99/34850中所述的那些,其通过引用纳入本文。喷射注射装置也是合适的,其通过液体喷射注射器或通过针向真皮递送液体疫苗,该针穿透角质层并且产生到达真皮的喷射。喷射注射装置描述于,例如,US5,480,381、US5,599,302、US5,334,144、US5,993,412、US5,649,912、US5,569,189、US5,704,911、US5,383,851、US5,893,397、US5,466,220、US5,339,163、US5,312,335、US5,503,627、US5,064,413、US5,520,639、US4,596,556、US4,790,824、US4,941,880、US4,940,460、WO97/37705和WO97/13537。弹道粉末/颗粒递送系统也是合适的,其使用压缩气体来加速粉末形式的疫苗通过皮肤的外层到达真皮。另外,常规注射器可用于皮内给予的经典曼托测试法(mantoux)中。然而,常规注射器的使用要求有高度技能的操作者,并且优选能够准确递送而不需要高度技能使用者的装置。本发明的另一种情况涉及针对疾病免疫对象或对象群以在该对象或对象群中预防疾病、和/或降低疾病严重性的方法。该方法包括向未感染疾病(或被认为未感染疾病)的对象或对象群给予本发明的组合物的步骤。可使用本领域技术人员熟知的技术来给予本发明的一种情况的组合物。优选地,可通过遗传免疫来配制并给予化合物。配制和给药的技术可发现于《雷明顿药物科学》,第18版,1990,宾西马尼亚州伊斯顿的马克出版公司。合适的途径可包括胃肠外递送,如肌内、皮内、皮下、髓内、以及鞘内、直接心室内、静脉内、腹膜内、或眼内注射等。其他途径包括口服或透皮递送。就注射而言,本发明的一种情况的组合物可配制在水溶液中,所述水溶液优选生理相容性缓冲液,如汉克斯溶液、林格溶液或生理盐水缓冲液。就胃肠外施用而言,包括肌内、皮内、皮下、鼻内、囊内、脊柱内、胸骨内、和静脉内注射,特别合适的是可注射无菌溶液,优选油性或水性溶液,以及悬液,或植入物,包括栓剂。用于注射的制剂可以单位剂型存在,例如装在安瓿或多剂量容器中,其添加有防腐剂。这些组合物可采取的形式诸如含悬浮剂、溶液剂或油性或水性载剂中的乳液,并且可含有配制剂,例如助悬剂、稳定剂和/或分散剂。或者,活性成分可以是使用前用合适的运载体如无菌无热原的水进行重建的粉末形式。就肠道施用而言,特别合适的是片剂、糖衣丸、液体、滴剂、栓剂或胶囊。药物组合物可通过常规方式与药学上可接受的赋形剂如粘合剂(如预胶化玉米淀粉、聚乙烯吡咯烷酮或羟丙基甲基纤维素);填充剂(如乳糖、微晶纤维素或磷酸氢钙);润滑剂(如硬脂酸镁、滑石粉或二氧化硅);崩解剂(如马铃薯淀粉或淀粉乙醇酸钠);或湿润剂(如月桂基硫酸钠)一起制备。可按照本领域熟知方法对片剂进行包衣。口服液体制剂可以是(例如)溶液剂、糖浆剂或混悬剂的形式,或者可制成临用前用水或其它合适的载体进行重建的干燥产品。可通过常规方式用药学上可接受的添加剂如助悬剂(如,山梨糖醇糖浆、纤维素衍生物或氢化食用脂肪);乳化剂(如,卵磷脂或阿拉伯胶);非水性载体(如,杏仁油、油性酯、乙醇或分馏植物油);和防腐剂(如,对羟基苯甲酸甲酯或丙酯,或山梨酸)配制这类液体制剂。该制剂还可适当地含有缓冲盐、调味剂、着色剂和甜味剂。可使用糖浆、酏剂等,其中采用甜味载剂。可配制持续或引导释放组合物,例如,脂质体或其中活性化合物受到可差异降解的涂层的保护,例如,微囊化、多涂层等。也可能冻干新化合物并且使用获得的冻干物,例如,用于制备用于注射的产物。就吸入给药而言,使用合适推进剂(如二氯二氟甲烷、三氯氟甲烷、二氯四氟乙烷、二氧化碳或其它合适的气体)从加压包装或喷雾器中以气溶胶喷雾形式方便地递送按本发明的一种情况使用的化合物。在加压气溶胶的情况下,可通过阀门递送计量用量,以确定剂量单位。可将用于吸入器或吹入器内的胶囊和药筒(例如,由明胶制成)配制成含有化合物和合适粉末基料(如乳糖或淀粉)的粉末混合物。对于局部或透皮施用,可采用非可喷雾形式,粘性至半固体或固体形式,其包含与局部施用相容的运载体并具有优选比水大的动态粘度。合适的制剂包括但不限于溶液剂、混悬剂、乳剂、乳膏剂、油膏剂、粉末剂、搽剂、软膏剂、气溶胶等,需要的话它们可以是无菌的并与辅料(如防腐剂、稳定剂、湿润剂、缓冲剂或盐)混合以影响渗透压等。对于局部施用,可喷雾的气溶胶制备物也是合适的,其中优选与固体或液体惰性运载体材料组合的活性成分包装到挤压瓶中或与压缩的挥发物混合,通常是气体推进剂,例如,氟利昂。如果需要,可将该组合物装入包装或分配装置中,所述包装或分配装置可包含一个或多个含有活性成分的单位剂型。例如,该包装可包括金属或塑料薄片,如泡罩包装。所述包装或分配装置可附有给药说明书。根据本发明的一种情况,组合物可以包含药学上可接受的赋形剂、运载体、缓冲液、稳定剂或本领域技术人员熟知的其他材料。这些材料应无毒,不应干扰活性成分的效力。运载体或其他材料的精确性质可取决于给药途径,例如,静脉内、皮肤或皮下、粘膜内(例如,肠)、鼻内、肌内、或腹膜内途径。一般而言,术语“生物活性”表示化合物(包括蛋白质或肽)有至少一种可检测的活性,其对细胞或生物体的代谢或其他过程有影响,如体内(即,在中性生理环境中)或体外(即,在实验室条件下)测量或观察的那样。组合物的免疫原性可在对象中评价本文所述的组合物的免疫原性。在一些情况中,可在接受对象中评价由组合物(例如,基于质粒的疫苗)编码的表位。例如,接受对象可以是啮齿类、非人灵长类或人。一些情况中,啮齿类是小鼠。例如,小鼠可以是neu-TG小鼠、C3小鼠或FVB小鼠。本文所述的组合物和方法可在对象中引发针对抗原性肽的表位的免疫应答。在一些情况中,组合物可以是乳腺癌疫苗或卵巢癌疫苗。在一些情况中,乳腺癌疫苗可以是多抗原乳腺癌疫苗。在一些情况中,卵巢癌疫苗可以是多抗原卵巢癌疫苗。免疫应答可以是I型免疫应答、II型免疫应答或同时I型和II型免疫应答。在一些情况中,I型免疫应答可导致抗原特异性T-细胞分泌炎性细胞因子(例如,IFNγ,TNFα)。炎性细胞因子(例如,I型细胞因子)可激活细胞毒性T-细胞,其例如可杀死表达至少一种由疫苗编码(例如,核酸,质粒)或递送(例如,肽,蛋白质)的表位的细胞。在一些情况中,Th1细胞因子可激活其他免疫细胞。在一些情况中,II型免疫应答可导致调节T-细胞分泌免疫抑制细胞因子(例如,IL-10,IL-4和IL-5)。免疫抑制细胞因子(例如,II型细胞因子)可激活细胞毒性T-细胞,其例如可不杀死表达至少一种由疫苗编码(例如,核酸,质粒)或递送(例如,肽,蛋白质)的表位而只是抑制Th1免疫应答的细胞。可发生在对象中的Th1或Th2免疫应答,或两者同时可能是表位与MHC-T细胞受体相互作用之间的亲和性的结果。在一些情况中,对MHC分子的结合肽的亲和性可能是高的。在其他情况中,对MHC分子的结合肽的亲和性可能是低的。在一些情况中,低亲和性结合肽可诱导Th2应答。在其他情况中,高亲和性结合肽可诱导Th1应答。可筛选针对MHC分子的候选结合肽的亲和性。例如,可入本文所述或使用本领域普通技术人员已知的技术确定由候选结合肽诱导的IFNγ和IL-10分泌。可使用本领域普通技术人员已知的多种方法中的任一种来分析疫苗在对象中的免疫原性。在一些情况中,可通过检测对象中由给予对象的疫苗编码的肽的表达来分析免疫原性。例如,检测方法可包括ELISPOT、ELISA、Western印迹、流式细胞术、组织学、色谱、质谱等。通常,可分析对象中响应疫苗产生的针对分离的肽的免疫原性。在一些情况中,可分析取自对象的肿瘤细胞、癌细胞、脾细胞或正常细胞的样品。在一些情况中,可从对象分离淋巴细胞用于分析免疫原性。例如,淋巴细胞可分离自脾、分离自淋巴结和/或分离自引流淋巴结。在一些情况中,可在给予单剂疫苗之后分离淋巴细胞。在其他情况中,可在给予多剂疫苗的最后一剂之后分离淋巴细胞。例如,可在最后给予单剂疫苗后的1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天或30天分离淋巴细胞。在一些情况中,可在给予多剂疫苗的最后一剂之后分离淋巴细胞。在其他情况中,可在给予多剂疫苗的最后一剂之后分离淋巴细胞。例如,可在最后给予多剂疫苗的最后一剂后的1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天或30天分离淋巴细胞。在一些情况中,可使用蛋白质检测方法来确定由对象产生的由组合物(例如,基于质粒的疫苗)的核酸编码的各肽的量。例如,可进行ELISPOT并且ELISPOT可检测IFNγ。又例如,可进行差异ELISPOT并且ELISPOT可检测粒酶B。在一些情况中,可使用蛋白质检测方法来确定由对象产生的响应组合物(例如,基于质粒的疫苗)的蛋白质特异性T-细胞的存在。例如,可进行ELISPOT并且ELISPOT可检测IFNγ。又例如,可进行差异ELISPOT并且ELISPOT可检测粒酶B。可通过比较给予组合物(例如,疫苗)后的对象的结果与给予对照组合物(例如,质粒不编码任何物质或无肽)的对象的本文所述方法的结果来确定疫苗编码的肽的免疫原性。在一些情况中,对照可以是仅佐剂。在其他情况中,对照可以是阴性对照(例如,缺少抗原性肽表位的空白质粒)。可通过产生的IFNγ的量的增加(ELISPOT上的IFNγ阳性点)或产生的肿瘤特异性粒酶B的量的增加(ELISPOT上的粒酶B阳性点)来确定免疫原性。与给予对照组合物的对象相比,可在给予组合物(例如,疫苗)之后在对象中观察到增加。在一些情况中,增加可在统计学上与对照不同,如P值所示(例如,p<0.05)。通常,在p<0.05的统计学差异是统计学显著的。例如,可通过以98%效力比较2组(n=10个对象/组)来确定免疫原性的统计学显著性,其中至少双侧水平可以是0.05并且真效应量可以是2.0。在一些情况中,效应量可定义为平均特异性T-细胞应答水平之差除以共同标准差。约1.5或更小的真效应量将是不显著的。可在给予至少一剂疫苗之后分析其他参数。在一些情况中,可从对象中分离血液并且对血液进行本领域普通技术人员已知的多种测试。例如,进行基础代谢组和/或完全血计数。在一些情况中,可检查其他组织。例如,可在给予至少一剂疫苗后检查脾、皮肤、骨骼肌、淋巴结、骨、骨髓、卵巢、输卵管、子宫、外周神经、脑、心、胸腺、肺、肾、肝和/或胰腺。使用模型系统的组合物功效本文所述的组合物可用于多种小鼠模型系统。在一些情况中,小鼠模型可包括遗传多样性小鼠模型。在一些情况中,小鼠模型可以是肿瘤移植模型。例如,小鼠可包括TgMMTV-neu(neu-TG)和TgC3(I)-Tag(C3)。在一些情况中,可使用遗传相似的小鼠模型。例如,neu-TG小鼠模型系统可具有与以下2种不同类型的人癌症相似的基因型:(1)人腺癌并且是雌激素受体阴性(ER-)和(2)HER2+人乳腺癌并且过表达neu癌基因。在其他情况中,C3小鼠具有可与基础乳腺癌和/或三阴性乳腺癌相似的基因型。在FVB小鼠中DMBA诱导的乳腺癌的小鼠模型可以是异种的并且可具有与多种亚型的人乳腺癌相当的肿瘤。例如,遗传上相似的小鼠模型可以是在FVB小鼠中的甲羟孕酮-DMBA-诱导的肿瘤(DMBA)。在一些情况中,小鼠模型可以是肿瘤移植模型。例如,如图35所示的肿瘤移植模型可用于分析本文所述的组合物的治疗功效。例如,组合可以是乳腺癌疫苗。在一些情况中,可将肿瘤细胞皮下植入小鼠中。例如,可将至少1,000、2,500、5,000、7,500、10,000、12,500、15,000、17,500、20,000、22,500、25,000、27,500、30,000、35,000、40,000、45,000、50,000、75,000、100,000、125,000、150,000、175,000、200,000、225,000、250,000、275,000、300,000、350,000、400,000、450,000、500,000、750,000、1,000,000、1,250,000、1,500,000、1,750,000、2,000,000、2,500,000、3,000,000、3,500,000、4,000,000、4,500,000、5,000,000、5,500,000、6,000,000、6,500,000、7,000,000、7,500,000、8,000,000、8,500,000、9,000,000、9,500,000或至少1,000,000,000个肿瘤细胞皮下植入小鼠中。在一些情况中,肿瘤细胞可以是MMA细胞。可使用本领域普通技术人员已知的方法来测量肿瘤生长。例如,测量方法可包括肿瘤直径、肿瘤体积、肿瘤质量等。在一些情况中,可使用成像、提取或组织学技术。例如,任意技术可包括使用造影剂。在一些情况中,可通过相对于对照(例如,未免疫的小鼠或用对照疫苗处理的小鼠)的肿瘤生长的尺寸来确定疫苗功效。例如,在没有免疫的情况下,超过90%的小鼠可发展肿瘤,并且在有免疫的情况下,可观察到60%的肿瘤生长抑制。在一些情况中,免疫可抑制至少2%、5%、7%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%或至少99%的肿瘤生长。在给予疫苗之后,对象可以是100%无肿瘤。在其他情况中,对象可在给予疫苗之后低于100%无肿瘤。例如,对象可在给予疫苗之后低于99%、95%、90%、85%、80%、75%、70%、65%、60%、55%、50%、45%、40%、35%、30%、25%、20%、15%或低于10%无肿瘤。在一些情况中,对象可在给予疫苗后数小时变得无肿瘤。例如,对象可在给予疫苗后1小时、2小时、3小时、4小时、5小时、6小时、7小时、8小时、9小时、10小时、11小时、12小时、13小时、14小时、15小时、16小时、17小时、18小时、19小时、20小时、21小时、22小时、23小时、24小时、25小时、26小时、27小时、28小时、29小时、30小时、31小时、32小时、33小时、34小时、35小时、36小时、37小时、38小时、39小时、40小时、41小时、42小时、43小时、44小时、45小时、46小时、47小时、48小时、49小时、50小时或更久变得无肿瘤。在其他情况中,对象可在给予疫苗后数天变得无肿瘤。例如,对象可在给予疫苗后1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天、30天、31天、32天、33天、34天、35天、36天、37天、38天、39天、40天、41天、42天、43天、44天、45天、46天、47天、48天、49天、50天或更久变得无肿瘤。在其他情况中,对象可在给予疫苗后数周变得无肿瘤。例如,对象可在给予疫苗后1周、2周、3周、4周、5周、6周、7周、8周、9周、10周、11周、12周、13周、14周、15周、16周、17周、18周、19周、20周、21周、22周、23周、24周、25周、26周、27周、28周、29周、30周、31周、32周、33周、34周、35周、36周、37周、38周、39周、40周、41周、42周、43周、44周、45周、46周、47周、48周、49周、50周或更久变得无肿瘤。在其他情况中,对象可在给予疫苗后数月变得无肿瘤。例如,对象可在给予疫苗后1个月、2个月、3个月、4个月、5个月、6个月、7个月、8个月、9个月、10个月、11个月、12个月、13个月、14个月、15个月、16个月、17个月、18个月、19个月、20个月、21个月、22个月、23个月、24个月、25个月、26个月、27个月、28个月、29个月、30个月、31个月、32个月、33个月、34个月、35个月、36个月、37个月、38个月、39个月、40个月、41个月、42个月、43个月、44个月、45个月、46个月、47个月、48个月、49个月、50个月或更久变得无肿瘤。在其他情况中,对象可在给予疫苗后数年变得无肿瘤。例如,对象可在给予疫苗后1年、2年、3年、4年、5年、6年、7年、8年、9年、10年、11年、12年、13年、14年、15年、16年、17年、18年、19年、20年、21年、22年、23年、24年、25年、26年、27年、28年、29年、30年、31年、32年、33年、34年、35年、36年、37年、38年、39年、40年、41年、42年、43年、44年、45年、46年、47年、48年、49年、50年或更久变得无肿瘤。在一些情况中,可通过相对于对照(例如,未免疫的小鼠)的免疫对象(例如,小鼠)中产生的IFNγ的量来确定疫苗的功效。在一些情况中,可通过相对于对照(例如,未免疫的小鼠)的免疫对象(例如,小鼠)中产生的IL-10的量来确定疫苗的功效。在一些方面中,可评价表位特异性免疫应答的多克隆性。在一些方面中,可通过估计响应给予的疫苗的表位产生的IgG抗体来评价多克隆性。在一些情况中,可针对异种抗原引发IgG。在其他情况中,可针对多种抗原引发IgG。在一些情况中,可从取自对象的样品中制备裂解物并且从对象的免疫前和免疫后血清评价。例如,对象可以是neu-TG小鼠模型的小鼠,并且使用肽检测方法如ELISA或ELISPOT检测IgG。在一些情况中,可使用统计学方法来分析免疫前对象(例如,小鼠)和免疫后对象(例如,小鼠)之间针对各抗原的应答。例如,统计学方法可包括使用单因素ANOVA的分析。在一些情况中,可进行在免疫过程期间针对对象(例如,小鼠)发展免疫的抗原数量的分析。组合物的毒性和安全性概况可评价本文所述的组合物的毒性和安全性。本领域普通技术人员已知的评价毒性和安全性的方法可用于本文所述的组合物。在一些情况中,可进行剂量递增研究。在一些情况中,可针对对象中疾病发展、对象中器官破坏、对象中组织破坏、对象中细胞破坏、血液病症等来筛选毒性和安全性研究。例如,疾病可包括自身免疫疾病。组合物的制备和质量控制可按照cGMP生物学生产设施(BPF)的现有标准来进行本文所述组合物(例如,基于质粒的疫苗)的制备的测试。过程开发可包括用对cGMPBPF的卡那霉素选择标记物对含有合适质粒构建体的各候选细胞(例如,细胞系)转化。在一些情况中,可从细菌储库中生成研究库。例如,可采用匹配更新cGMP生产的中试生产来评价质粒产率和纯度。在一些情况中,可建立最初生产批次记录和质量控制测试方案。例如,可从各细菌储库中生成主细胞库。在一些情况中,可进行质量控制测试,包括:质粒和宿主细胞身份、质粒拷贝数、纯度、活力、和抗生物抗性保留(质粒保留)。在一些情况中,最终并批准的生产批次记录和标准操作过程可按照疫苗质粒的cGMP生产和纯化,并且可开发大量投放标准。在一些情况中,最终总/汇集的纯化产物可按照现有的规章指南进行质量控制测试,并且然后可按照验证的填充和精制标准操作流程瓶装为单一单位剂型。按照cGMP规定,瓶装的产物在最终投放之前可经过质量控制测试。卵巢癌的临床试验本文所述的组合物和方法可给予有此需要的人对象。虽然按照联邦农业部(FDA)和任何其他相关政府部门的规定和规则进行标准时间,但可按照已建立的指南向人对象给予本文所述的组合物和方法。在一些情况中,制备了研究前新药(IND)包。在一些情况中,用于生产本文所述的质粒的标准操作流程(SOP)可用于生产目的。例如,生产可发生在良好的生产实施(GMP)设施中。在一些情况中GMP设施可包括主细胞库。可进行临床试验来评价安全性并且确定基于多抗原DNA质粒的疫苗的最优免疫原性的剂量。在一些情况中,可进行临床试验来确定在可能患有卵巢癌的对象(例如,患者)中多抗原疫苗(例如,三剂量)给药(例如,皮内)的安全性并确定对象中组合物(例如,多抗原疫苗)的免疫原性剂量。在一些情况中,可进行临床试验来确定在可能患有卵巢癌的对象(例如,患者)中多抗原疫苗(例如,三剂量)给药(例如,皮内)的安全性并确定对象中组合物(例如,多抗原疫苗)的免疫原性剂量。临床试验可以是针对本文所述的组合物(例如,疫苗)的安全性和免疫原性的I期试验。在一些情况中,可招募患有非转移性卵巢癌的对象。在一些情况中,患者可已治疗到完全缓解。在一些情况中,患者可已用初步或康复疗法治疗。在一些情况中,在招募到临床试验中之前,患者可已经完全化疗、放疗和/或使用全身类固醇。例如,患者可处在最后的细胞毒性化疗和/或放疗和全身类固醇的任意使用后1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天、30天、31天、32天、33天、34天、35天、36天、37天、38天、39天、40天、41天、42天、43天、44天、45天、46天、47天、48天、49天、50天或更久。在示例性情况中,患者可处在最后细胞毒性化疗和/或放疗和全身类固醇的任意使用后28天。在一些情况中,I期可评价3个剂量水平的组合物(例如,疫苗)。例如,对象可分配到以下三种剂量之一:组1(150mcg)、组2(300mcg)、和组3(600mcg)。在一些情况中,在各组中可招募不超过10个对象。例如,可向各对象给予三剂疫苗,使得各剂之间有一个月流逝。在一些情况中,可在第三剂疫苗之后向对象给予加强剂。例如,可给予加强剂,使得在第三剂疫苗后2个月给予1个加强剂并且在加强剂后4个月给予1个加强剂。在一些情况中,如果剂量在组1中是安全的,则可在I期试验中招募组2的10个对象。在一些情况中,如果组2是安全的,则可检验组1和组2的免疫原性功效。例如,如果组1剂量更有效,则试验可结束。在一些情况中,如果与组1剂量相比,组2剂量的功效更大,则可将对象招募到组3剂量方案中。在一些情况中,如果组3剂量似乎是安全的,则将检验组2和3之间的免疫功效。例如,可按照CTEPCTCAEv.4.0评价安全性。在一些情况中,移向下一组的安全性基准可以是≤15%的3级毒性率和≤15%的4级毒性率。可通过评价T细胞生成来评价3剂量的免疫功效。在一些情况中,免疫功效可定义为在疫苗中实现针对抗原的加强的IFN-gT-细胞免疫。设计和招募计划I期临床试验的2个终点可以是(1)确定GM-CSF和佐剂的疫苗的皮内给药的安全性和(2)确定疫苗的免疫原性。在一些情况中,可用基于质粒的疫苗来免疫对象(例如,100μg总质粒/对象)。在一些情况中,对象可在间隔(30天)之间接受3次疫苗。例如,可在引流淋巴结的三角肌区域处向对象给予疫苗(图5)。可在试验中招募已经治疗到完全缓解的患有IIb、III、和IV期卵巢癌的对象。在一些情况中,试验可累积目标数量的对象(例如,22个对象)。对象可在研究开始时经过白血球单采术(例如,用于基线免疫评价)和抽血(例如,用于基线毒性评价)并且在最后免疫之后1、6和12个月时抽取180cc血液。在一些情况中,可分析血液的血清化学变化作为对潜在毒性的评价。可评价在这些时间点上收集的外周血单核细胞和血清的肿瘤特异性免疫的发展,如本文所述。可在最后免疫之后(例如,3个月)获得白血球单采术产物用于其他研究。安全性。在一些情况中,疫苗可引发立即过敏反应。在一些情况中,由于免疫靶向其他不相关组织的免疫结果,疫苗可导致副作用。在一些情况中,在评价这些毒性之后,可建立停止治疗和从研究中移出对象的标准。在I期期间,超过200个对象可接受卵巢癌疫苗。在一些情况中,组合物可包含与卵巢癌疫苗混合的GM-CSF(100-150μg)。在一些情况中,可使用每月皮内注射的方法持续3-6个月来给予组合物。例如,皮内给药可导致皮肤的过敏反应。在一些情况中,可在免疫之后监测对象(例如,持续1小时)。可在给予疫苗之后定期回访时检查对象。在一些情况中,可基于改良国立癌症研究院毒性标准在每次回访时评价对象。在一些情况中,对象可经过完全身体检查。另外,可评价各对象的血清化学,包括肾功能测试、尿酸、血液计数、血清葡萄糖和肝功能测试。在一些情况中,可评价结缔组织病症和实验室自抗体应答的发展作为与使用DNA免疫相关的潜在免疫毒性。在一些情况中,可评价抗-DNA抗体的发展,例如,抗-ANA、抗-C3、抗-甲状腺和ds-DNA抗体。在一些情况中,可在免疫方案结束时,并且在之后的12个月时进行评价。可在试验各组中招募22个对象的样品量。在一些情况中,如果没有产生毒性,产生毒性的概率可以是至少90%,如果任意3级或4级毒性为10%或更低。例如,产生毒性可表示低于10%的毒性率。在一些情况中,试验将继续并且可被认为足够安全,只要观察到的毒性率与15%或更低的真3级率和5%或更低的真4级率一致。在一些情况中,将采用停止规则,使得如果有足够的证据表明真毒性率超过了这些阈值,则停止研究。例如,足够的证据可以是超过合适阈值的较低单侧置信限。对于3级,可在如下情况下达到这种限,如果前3个中的2个或更少,前7个中的3个或更少,前12个中的4个或更少,前17个中的5个或更少,或前22个中的6个或更少的招募对象中出现这种毒性水平。对于4级,以下之一可导致试验停止:前10个中的2个或更少,前22个中的3个或更少的招募对象经历4级毒性。例如,如果3级毒性的真概率为10%或30%,则研究停止的概率可分别为约.06和.76。如果4级毒性的真概率为3%或23%,则停止的概率大概分别为.05和.93(从5000次模拟估计的概率)。免疫原性。疫苗可在对象中引发免疫应答。在一些情况中,可确定在免疫之后引发的免疫应答类型。例如,本文所述的组合物可在给予对象时引发Th1免疫应答。在一些情况中,Th1免疫应答可包括形成和维持识别疫苗的至少一种肽的抗原特异性T细胞。例如,肽可以是干细胞和/或EMT抗原。可通过评价由抗原特异性T细胞分泌的细胞因子的类型来确定免疫应答的类型。在一些情况中,可使用ELISPOT试验来鉴定细胞因子的类型。例如,ELISPOT方法可包括对抗原刺激后(例如,72小时)的样品上清的分析。在一些情况中,可评价样品上清的一组细胞因子。在一些情况中,评价可以是多重分析。例如,对细胞因子的多重分析可包括Th1(例如,IFN-g、IL-2、TNF-a、IL-1b、GM-CSF)、Th17(IL-17)、和Th2(例如,IL-6、IL-4、IL-10、IL-13)的细胞因子。示例性数据组示于图37。在一些情况中,也可分析样品上清中是否存在TGF-β。例如,可使用ELISA方法来分析TGF-β。在一些情况中,分泌的模式或量级可用作免疫后临床结果的生物标记物。可从多重细胞因子数据中生成热图。在一些情况中,根据接种的抗原特异性细胞因子增加或减少的量级对热图进行颜色编码。在一些情况中,热图可显示针对至少一种免疫抗原的免疫应答的量级和类型的特异性图案。在一些情况中,对象可分类为通过针对大多数免疫抗原有强于1∶20,000PBMC的蛋白质特异性前体频率的发展而免疫。在一些情况中,如果对象预先存在针对任意抗原的免疫,则应答可增强超过2倍的基线应答。在一些情况中,对免疫原性的分析可确定Th1抗原特异性免疫应答的量级。例如,可通过进行IFN-gELISPOT来确定Th1应答,其在2.0和3.5x105PBMC/孔之间是线性且精确的,具有1∶60,000的监测限,并且具有93%的检测效率。在一些情况中,可同时分析疫苗前和疫苗后样品以校正差异。例如,可使用与新鲜分离的PBMC相比在冷冻细胞中保存抗原特异性T细胞应答的冻存方法。在一些情况中,样品可包括1μg/ml蛋白质抗原(例如,在所有提出的候选抗原上可及的重组蛋白质,人肌红蛋白(阴性对照))或1μg/ml的CMV裂解物和0.5U/mltt(阳性对照)和以10μg/ml包括在疫苗内的肽抗原)。卵巢癌疫苗可显示免疫成功,其可使用统计学方法分析。通常,疫苗的免疫成功可以是针对超过50%的由疫苗内的质粒表达的抗原出现免疫应答(例如,Th1)。在一些情况中,可向一组对象(例如,22个对象)给予疫苗,使得在真成功率为40%时观察的超过50%成功率的概率低于0.1。例如,观察的成功率可以是.06。在一些情况中,可向一组对象(例如,22个对象)给予疫苗,使得在真成功率为70%时观察到超过50%成功率的概率大于0.7。例如,使用一组22名患者可以80%的置信度证明估计的免疫应答可在至少.14的真响应率内。在一些情况中,如果一半对象引发免疫应答,则对于统计学显著(在.05的两侧水平上)和连续测量中的差异(如果真效应量是1.5)来说,功效可以是至少91%。例如,可使用斯皮尔曼相关系数来估计2次连续测量之间的相关性。在一些情况中,数据可估计较大群中的预期响应率。又例如,25%的对象可引发针对疫苗的良好应答。在一些情况中,25%的具有良好响应的对象可以是基线以评价疫苗功效。在一些情况中,真响应率可以是60%,其中与25%的固定率相比(单侧显著水平.05),使用一组22个对象可针对统计学显著的响应率提供97%的功效。乳腺癌的临床试验在一些情况中,临床试验可以是患有非转移性乳腺癌的对象针对本文所述的组合物(例如,疫苗)的安全性和免疫原性的I期试验。在一些情况中,乳腺癌可以是结阳性三阴性(ER(-)PR(-)HER2/neu(-))乳腺癌(TNBC)。在一些情况中,患者已经治疗到完全缓解。在一些情况中,患者已经用初步或康复疗法治疗。在一些情况中,在招募到临床试验中之前,患者可已经完全化疗、放疗和/或使用全身类固醇。例如,患者可处在最后的细胞毒性化疗和/或放疗和全身类固醇的任意使用后1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天、28天、29天、30天、31天、32天、33天、34天、35天、36天、37天、38天、39天、40天、41天、42天、43天、44天、45天、46天、47天、48天、49天、50天或更久。在示例性情况中,患者可处在最后细胞毒性化疗和/或放疗和全身类固醇的任意使用后28天。在一些情况中,如上所述,I期可评价组合物(例如,疫苗)的3种剂量水平,例如,组1(150mcg)、组2(300mcg)、和组3(600mcg)。在一些情况中,在各组中可招募不超过10个对象。例如,可向各对象给予三剂疫苗,使得各剂之间有一个月流逝。在一些情况中,可在第三剂疫苗之后向对象给予加强剂。例如,可给予加强剂,使得在第三剂疫苗后2个月给予1个加强剂并且在加强剂后4个月给予1个加强剂。在一些情况中,如果剂量在组1中是安全的,则可在I期试验中招募组2的10个对象。在一些情况中,如果组2是安全的,则可检验组1和组2的免疫原性功效。例如,如果组1剂量更有效,则试验可结束。在一些情况中,如果与组1剂量相比,组2剂量的功效更大,则可将对象招募到组3剂量方案中。在一些情况中,如果组3剂量看起来是安全的,则将检验组2和3之间的免疫功效。例如,可按照CTEPCTCAEv.4.0评价安全性。在一些情况中,移向下一组的安全性基准可以是≤15%的3级毒性率和≤15%的4级毒性率。可通过评价T细胞生成来评价3剂量的免疫功效。在一些情况中,免疫功效可定义为在疫苗中实现针对抗原的加强的IFNγT-细胞免疫。设计和招募计划。I期临床试验的2个终点可以是(1)确定GM-CSF和佐剂的疫苗的皮内给药的安全性和(2)确定疫苗的免疫原性。在一些情况中,可用基于质粒的疫苗来免疫对象(例如,100μg总质粒/对象)。在一些情况中,对象可在间隔(30天)之间接受3次疫苗。例如,可在引流淋巴结的三角肌区域处向对象给予疫苗(图5)。可在试验中招募已经治疗到完全缓解的患有IIb、III、和IV期乳腺癌(例如,三阴性)的对象。在一些情况中,试验可累积目标数量的对象(例如,22个对象)。对象可在研究开始时经过白血球单采术(例如,用于基线免疫评价)和抽血(例如,用于基线毒性评价)并且在最后免疫之后1、6和12个月时抽取180cc血液。在一些情况中,可分析血液的血清化学变化作为对潜在毒性的评价。可评价在这些时间点上收集的外周血单核细胞和血清的肿瘤特异性免疫的发展,如本文所述。可在最后免疫之后(例如,3个月)获得白血球单采术产物用于其他研究。安全性。在一些情况中,疫苗可引发立即过敏反应。在一些情况中,由于免疫靶向其他不相关组织的免疫结果,疫苗可导致副作用。在一些情况中,在评价这些毒性之后,可建立停止治疗和从研究中移出对象的标准。在I期期间,超过200个对象可接受乳腺癌疫苗。在一些情况中,组合物可包含与HER2肽/蛋白质/或DNA-基疫苗混合的GM-CSF(100-150μg)。在一些情况中,可使用每月皮内注射的方法持续3-6个月来给予组合物。例如,皮内给药可导致皮肤的过敏反应。在一些情况中,可在免疫之后监测对象(例如,持续1小时)。可在给予疫苗之后定期回访时检查对象。在一些情况中,可基于改良国立癌症研究院毒性标准在每次回访时评价对象。在一些情况中,对象可经过完全身体检查。另外,可评价各对象的血清化学,包括肾功能测试、尿酸、血液计数、血清葡萄糖和肝功能测试。在一些情况中,可评价结缔组织病症和实验室自抗体应答的发展作为与使用DNA免疫相关的潜在免疫毒性。在一些情况中,可评价抗-DNA抗体的发展,例如,抗-ANA、抗-C3、抗-甲状腺和ds-DNA抗体。在一些情况中,可在免疫方案结束时,并且在之后的12个月时进行评价。可在试验各组中招募22个对象的样品量。在一些情况中,如果没有产生毒性,产生毒性的概率可以是至少90%,如果任意3级或4级毒性为10%或更低。例如,产生毒性可表示低于10%的毒性率。在一些情况中,试验将继续并且可被认为足够安全,只要观察到的毒性率与15%或更低的真3级率和5%或更低的真4级率一致。在一些情况中,将采用停止规则,使得如果有足够的证据表明真毒性率超过了这些阈值,则停止研究。例如,足够的证据可以是超过合适阈值的较低单侧置信限。对于3级,可在如下情况下达到这种限:如果前3个中的2个或更少,前7个中的3个或更少,前12个中的4个或更少,前17个中的5个或更少,或前22个中的6个或更少的招募对象中出现这种毒性水平。对于4级,以下之一可导致试验停止:前10个中的2个或更少,前22个中的3个或更少的招募对象经历4级毒性。例如,如果3级毒性的真概率为10%或30%,则研究停止的概率可分别为约.06和.76。如果4级毒性的真概率为3%或23%,则停止的概率大概分别为.05和.93(从5000次模拟估计的概率)。免疫原性。疫苗可在对象中引发免疫应答。在一些情况中,可确定在免疫之后引发的免疫应答类型。例如,本文所述的组合物可在给予对象时引发Th1免疫应答。在一些情况中,Th1免疫应答可包括形成和维持识别疫苗的至少一种肽的抗原特异性T细胞。例如,肽可以是干细胞和/或EMT抗原。可通过评价由抗原特异性T细胞分泌的细胞因子的类型来确定免疫应答的类型。在一些情况中,可使用ELISPOT试验来鉴定细胞因子的类型。例如,ELISPOT方法可包括对抗原刺激后(例如,72小时)的样品上清的分析。在一些情况中,可评价样品上清的一组细胞因子。在一些情况中,评价可以是多重分析。例如,对细胞因子的多重分析可包括Th1(例如,IFNγ、IL-2、TNFα、IL-1b、GM-CSF)、Th17(IL-17)、和Th2(例如,IL-6、IL-4、IL-10、IL-13)的细胞因子。示例性数据组示于图37。在一些情况中,也可分析样品上清中是否存在TGF-β。例如,可使用ELISA方法来分析TGF-β。在一些情况中,分泌的模式或量级可用作免疫后临床结果的生物标记物。可从多重细胞因子数据中生成热图。在一些情况中,根据接种的抗原特异性细胞因子增加(例如,红色,参见图37)或减少(例如,蓝色,参见图37)的数量级对热图进行颜色编码。例如,颜色强度可表示响应的最低(例如,浅,参见图37)到最高(例如,深,参见图37)四分位。在一些情况中,热图可显示针对至少一种免疫抗原的免疫应答的量级和类型的特异性图案。例如,细胞因子分泌的量级。在一些情况中,对象可分类为通过针对大多数免疫抗原有强于1∶20,000PBMC的蛋白质特异性前体频率的发展而免疫。在一些情况中,如果对象预先存在针对任意抗原的免疫,则应答可增强超过2倍的基线应答。在一些情况中,对免疫原性的分析可确定Th1抗原特异性免疫应答的量级。例如,可通过进行IFNγELISPOT来确定Th1应答,其在2.0和3.5x105PBMC/孔之间是线性且精确的,具有1∶60,000的监测限,并且具有93%的检测效率。在一些情况中,可同时分析疫苗前和疫苗后样品以校正差异。例如,可使用与新鲜分离的PBMC相比在冷冻细胞中保存抗原特异性T细胞应答的冻存方法。在一些情况中,样品可包括1μg/ml蛋白质抗原(例如,在提出的候选抗原的全部上可及的重组蛋白质,人肌红蛋白(阴性对照))或1μg/ml的CMV裂解物和0.5U/mltt(阳性对照)和以10μg/ml包括在疫苗内的肽抗原)。乳腺癌疫苗可显示免疫成功,其可使用统计学方法分析。通常,疫苗的免疫成功可以是针对超过50%的由疫苗内的质粒表达的抗原出现免疫应答(例如,Th1)在一些情况中,可向一组22个对象给予疫苗,使得真成功率为40%时观察到超过50%成功率的概率低于0.1,。例如,观察的成功率可以是.06。在一些情况中,可向一组22个对象给予疫苗,使得真成功率为70%时观察到超过50%成功率的概率大于0.7。例如,使用一组22名患者可以80%的置信度证明估计的免疫应答可在至少.14的真响应率内。在一些情况中,如果一半对象引发免疫应答,则对于统计学显著(在0.05的两侧水平上)和连续测量中的差异(如果真效应量是1.5)来说,则功效可以是至少91%。例如,可使用斯皮尔曼相关系数来估计2次连续测量之间的相关性。在一些情况中,数据可估计较大群中的预期响应率。又例如,25%的对象可引发针对疫苗的良好应答。在一些情况中,25%的具有良好响应的对象可以是基线以评价疫苗功效。在一些情况中,真响应率可以是60%,其中与25%的固定率相比(单侧显著水平0.05),使用一组22个对象可针对统计学显著的响应率提供97%的功效。应用本文所述的组合物可给予需要疫苗来预防乳腺癌或卵巢癌的对象。在一些情况中,所述癌症是乳腺癌。在一些情况中,所述癌症是卵巢癌。本文所述的方法可与本文所述的组合物结合来给予需要疫苗来预防乳腺癌或卵巢癌的对象。在一些情况中,给予疫苗可引发细胞消除以及细胞开始表达增加水平的作为疫苗组分的蛋白质。在一些情况中,蛋白质可以是干细胞/EMT相关的。例如,可在将正常细胞恶性转化成癌细胞,例如乳腺癌细胞或卵巢癌细胞,期间表达增加水平的蛋白质。在一些情况中,在疾病临床明显之前消除乳腺癌或卵巢癌细胞可防止对象发生癌症。在一些情况中,在疾病临床明显之前消除乳腺癌或卵巢癌细胞可防止对象发生乳腺癌或卵巢癌。用于预防乳腺癌或卵巢癌的疫苗可以单剂给予对象,剂量为至少10μg、15μg、20μg、25μg、30μg、35μg、40μg、45μg、50μg、55μg、60μg、65μg、70μg、75μg、80μg、85μg、86μg、87μg、88μg、89μg、90μg、91μg、92μg、93μg、4μg、95μg、96μg、97μg、98μg、99μg、100μg、101μg、102μg、103μg、104μg、105μg、106μg、107μg、108μg、109μg、110μg、111μg、112μg、113μg、114μg、115μg、116μg、117μg、118μg、119μg、120μg、125μg、130μg、135μg、140μg、145μg、150μg、155μg、160μg、165μg、170μg、175μg、180μg、185μg、190μg、195μg、或至少200μg/质粒。在示例性情况中,给予对象的单剂量是100μg/质粒。用于预防乳腺癌或卵巢癌的疫苗可以超过一剂给予对象,各剂为至少10μg、15μg、20μg、25μg、30μg、35μg、40μg、45μg、50μg、55μg、60μg、65μg、70μg、75μg、80μg、85μg、86μg、87μg、88μg、89μg、90μg、91μg、92μg、93μg、4μg、95μg、96μg、97μg、98μg、99μg、100μg、101μg、102μg、103μg、104μg、105μg、106μg、107μg、108μg、109μg、110μg、111μg、112μg、113μg、114μg、115μg、116μg、117μg、118μg、119μg、120μg、125μg、130μg、135μg、140μg、145μg、150μg、155μg、160μg、165μg、170μg、175μg、180μg、185μg、190μg、195μg、或至少200μg/质粒。在一些情况中,给予对象的各剂可大于或小于之前给予对象的剂。本文所述的组合物可给予需要疫苗来治疗乳腺癌或卵巢癌的对象。本文所述的方法可与本文所述的组合物结合来给予需要疫苗来治疗乳腺癌或卵巢癌的对象。在一些情况中,给予疫苗可引发细胞消除,所述细胞表达增加水平的作为疫苗组分的蛋白质消除。在一些情况中,蛋白质可以是干细胞/EMT相关的。例如,癌细胞,例如乳腺癌细胞或卵巢癌细胞可表达增加水平的蛋白质。在一些情况中,在疾病临床明显之后消除癌细胞可防止对象中乳腺癌或卵巢癌的持续和进展。在一些情况中,在疾病临床明显之后消除乳腺癌或卵巢癌细胞可防止对象中乳腺癌或卵巢癌的持续和进展。对象本文所述的组合物可给予需要针对乳腺癌或卵巢癌的疫苗的对象。本文所述的方法可与本文所述的组合物结合来给予需要针对乳腺癌或卵巢癌的疫苗的对象。在一些情况中,疫苗可给予未患有乳腺癌或卵巢癌的对象。在其他情况中,疫苗可给予曾患有乳腺癌或卵巢癌的对象。在其他情况中,疫苗可给予患有乳腺癌或卵巢癌的对象。在一些情况中,对象可以是健康个体。在一些情况中,对象可以是患有乳腺癌或卵巢癌的个体。例如,个体可以是患者。在一些情况中,该对象是人个体。在其他情况中,该对象是非人个体。例如,非人个体可以是非人灵长类,包括例如大猩猩和其他猿类和猴;农场动物如牛、绵羊、猪、山羊和马;家养哺乳动物如狗和猫;实验室动物包括啮齿类如小鼠、大鼠和豚鼠;包括家养、野生和狩猎鸟类在内的禽类如鸡、火鸡和其他鹑鸡类禽、鸭、鹅等。术语“对象”不表示特定年龄。因此,旨在覆盖成年和新生个体。乳腺癌和卵巢癌在某些实施方式中,本文所述的是用于治疗乳腺癌或卵巢癌的疫苗。在一些情况中,乳腺癌是复发性或难治性乳腺癌。在一些情况中,卵巢癌是复发性或难治性卵巢癌。在一些情况中,乳腺癌是转移的乳腺癌。在一些情况中,卵巢癌是转移的卵巢癌。乳腺癌类型本文所述的组合物可给予需要针对癌症的疫苗的对象,通常该癌症是乳腺癌。本文所述的方法可与本文所述的组合物结合来给予需要针对癌症的疫苗的对象。通常,乳腺癌可以是任意类型的乳腺癌,例如,乳腺癌可以是原位导管肿瘤、叶状原位癌、侵入性导管癌、浸润性导管癌、炎性乳腺癌、三阴性乳腺癌、乳头佩吉特病、叶状肿瘤、血管肉瘤、舌腺样囊性癌、腺样囊性癌、低级腺癌、髓样癌、黏液癌、胶质癌、乳头状癌、管状癌、化生性癌、纺锤细胞癌、鳞状细胞癌、微乳头状癌和混合癌。在一些情况中,可用具体级的乳腺癌对对象进行分类。例如,乳腺癌的级别可以是X级、1级、2级、3级或4级。又例如,乳腺癌可表示为小管形成,核级和/或有丝分裂率的类别。各类别也可在1和3之间分配具体分数。在一些情况中,对象可患有具体阶段的乳腺癌。在一些情况中,可基于肿瘤、区域性淋巴结和/或末梢代谢来分配阶段。例如,分配给肿瘤的阶段可以是TX、T0、Tis、T1、T2、T3或T4。例如,分配给区域淋巴结的阶段可以是NX、N0、N1、N2或N3。例如,分配给末梢代谢的阶段可以是MX、M0或M1。在一些情况中,阶段可以是0期、I期、II期、III期或IV期。通常,乳腺癌分类为超过1个级或癌症阶段。其他治疗剂在一些情况中,本文所述的乳腺或卵巢癌疫苗可与其他治疗剂一起给予患者。在一些情况中,其他治疗剂是化疗剂、类固醇、免疫治疗剂、靶向疗法或其组合。在一些实施方式中,其他治疗剂选自:阿霉素、放线菌素D、博来霉素、长春花碱、顺铂、阿西维辛、阿柔比星、盐酸阿考达唑、阿克罗宁、阿多来新、阿地白介素、六甲蜜胺、安波霉素、乙酸阿美蒽醌、氨鲁米特、安吖啶、阿那曲唑、安曲霉素、门冬酰胺酶、曲林菌素、阿扎胞苷、阿扎替派、阿佐霉素、巴马司他、苯佐替派、比卡鲁胺、盐酸比生群、二甲磺酸双奈法德、比折来新、硫酸博来霉素、布喹那钠、溴匹立明、白消安、放线菌素C、卡普睾酮、卡醋胺、卡贝替姆、卡铂、卡莫司汀、盐酸卡柔比星、卡折来新、西地芬戈、苯丁酸氮芥、西罗霉素、克拉屈滨、甲磺酸克立那托、环磷酰胺、阿糖胞苷、达卡巴嗪、盐酸柔红霉素、地西他滨、右奥马铂、地扎胍宁、甲磺酸地扎胍宁、地吖醌、多柔比星、盐酸多柔比星、屈洛昔芬、柠檬酸屈洛昔芬、丙酸屈他雄酮、达佐霉素、依达曲沙、盐酸依氟鸟氨酸、依沙芦星、恩洛铂、恩普氨酯、依匹哌啶、盐酸表柔比星、厄布洛唑、盐酸依索比星、雌莫司汀、雌莫司汀磷酸钠、依他硝唑、依托泊苷、磷酸依托泊苷、氯苯乙嘧胺、盐酸法倔唑、法扎拉滨、芬维A胺、氮尿苷、磷酸氟达拉滨、氟尿嘧啶、氟西他滨、磷喹酮、福司曲星钠、吉西他滨、盐酸吉西他滨、羟基脲、盐酸伊达比星、异环磷酰胺、伊莫福新、白介素2(包括重组白介素2或rIL2),干扰素α-2a、干扰素α-2b、干扰素α-n1、干扰素α-n3、干扰素β-Ia、干扰素γ-Ib、异丙铂、盐酸伊立替康、乙酸兰瑞肽、来曲唑、乙酸亮丙瑞林、盐酸利阿唑、洛美曲索钠、洛莫司汀、盐酸洛索蒽醌、马索罗酚、美登素、盐酸氮芥、乙酸基孕甾酮、乙酸美仑孕酮、苯丙氨酸氮芥、美诺立尔、巯嘌呤、氨甲喋呤、氨甲喋呤钠、氯苯氨啶、美妥替哌、米丁度胺、米托卡星、丝裂红素、米托洁林、丝裂马菌素、丝裂霉素、米托司培、米托坦、盐酸米托蒽醌、霉酚酸、诺考达唑、诺拉霉素、奥马铂、奥昔舒仑、培门冬酶、培利霉素、奈莫司汀、硫酸培洛霉素、培磷酰胺、哌泊溴烷、哌泊舒凡、盐酸吡罗蒽醌、普卡霉素、普洛美坦、卟菲尔钠、泊非霉素、泼尼莫司汀、盐酸丙卡巴肼、嘌罗霉素、盐酸嘌罗霉素、吡唑呋喃菌素、利波腺苷、罗谷亚胺、沙芬戈、盐酸沙芬戈、司莫司汀、辛曲秦、磷乙酰天冬氨酸钠、司帕霉素、盐酸锗螺胺、螺莫司汀、螺铂、链黑霉素、链佐星、磺氯苯脲、他利霉素、替可加兰钠、替加氟、盐酸替洛蒽醌、替莫泊芬、替尼泊苷、替罗昔隆、睾内酪、硫咪嘌呤、硫鸟嘌呤、塞替派、噻唑呋林、替拉扎明、柠檬酸托瑞米芬、乙酸曲托龙、磷酸曲西立滨、三甲曲沙、葡糖醛酸三甲曲沙、曲普瑞林、盐酸妥布氯唑、乌拉莫司汀、乌瑞替派、伐普肽、维替泊芬、硫酸长春碱、硫酸长春新碱、长春地辛、硫酸长春地辛、硫酸长春匹定、硫酸长春甘酯、硫酸长春罗新、酒石酸长春瑞滨、硫酸长春罗定、硫酸长春利定、伏氯唑、折尼铂、净司他丁、盐酸佐柔比星。在一些实施方式中,其他治疗剂选自:20-表-1,25二羟基维生素D3、5-乙炔基尿嘧啶、阿比特龙、阿柔比星、酰基富烯、腺环戊醇(adecypenol)、阿多来新、阿地白介素、ALL-TK拮抗剂、六甲蜜胺、氨莫司汀、阿米多克斯(amidox)、氨磷汀、氨基乙酰丙酸、氨柔比星、安吖啶、阿那格雷、阿那曲唑、穿心莲内酯、血管新生抑制剂、拮抗剂D、拮抗剂G、安雷利克斯、抗-背侧化形成蛋白-1、抗雄激素前列腺癌、抗雌激素、抗瘤酮(antineoplaston)、甘氨酸阿非迪霉素、凋亡基因调节剂、凋亡调节剂、脱嘌呤核酸、ara-CDP-DL-PTBA、精氨酸脱氨酶、阿苏拉科林(asulacrine)、阿他美坦、阿莫司汀、阿西他汀(axinastatin)1、阿西他汀2、阿西他汀3、阿扎司琼、阿扎毒素、重氮酪氨酸、浆果赤霉素III衍生物、巴拉醇(balanol)、巴马司他、BCR/ABL拮抗剂、苯并二氢卟酚(benzochlorin)、苯甲酰星孢素、β内酰胺衍生物、β-阿里辛(beta-alethine)、贝塔克拉霉素(betaclamycin)B、桦木酸、bFGF抑制剂、比卡鲁胺、比生群、双氮丙啶精胺、双奈法德、比特迪尼(bistratene)A、比折来新、贝伏特(breflate)、溴匹立明、布度钛、丁基硫堇亚胺、卡泊三醇、卡弗他丁(calphostin)C、喜树碱衍生物、金丝雀痘IL-2、卡培他滨、羧酰胺-氨基-三唑、羧基酰胺三唑、CaRestM3、CARN700、软骨衍生的抑制剂、卡折来新、酪蛋白激酶抑制剂(ICOS)、澳粟精胺、杀菌肽B、西曲瑞克、氯代喹喔啉磺酰胺、西卡前列素、顺-卟啉、克拉屈滨、恩氯米芬类似物、克霉唑、克利霉素(collismycin)A、克利霉素B、考布他汀A4、考布他汀类似物、克纳宁(conagenin)、科莱贝司丁(crambescidin)816、克立那托、自念珠藻环肽(cryptophycin)8、自念珠藻环肽A衍生物、麻疯树毒蛋白(curacin)A、环戊蒽醌(cyclopentanthraquinone)、环普拉坦(cycloplatam)、塞培霉素(cypemycin)、阿糖胞苷十八烷基磷酸钠、细胞裂解因子、磷酸己烷雌酚(cytostatin)、达昔单抗、地西他滨、脱氢代代宁B、地洛瑞林、地塞米松、右异环磷酰胺、右雷佐生、右维拉帕米、地吖醌、代代宁B、二羟基苯并氧肟酸(didox)、二乙基正精胺、二氢-5-氮杂胞苷、二氧霉素(dioxamycin)、二苯基螺莫斯汀、多西他赛、多拉司琼、去氧氟尿苷、屈洛昔芬、屈大麻酚、多卡霉素SA、依布硒、依考莫司汀、依地福新、依决洛单抗、依氟鸟氨酸、榄香烯、乙嘧替氟、表柔比星、依立雄胺、雌莫司汀类似物、雌激素激动剂、雌激素拮抗剂、依他硝唑、磷酸依托泊甙、依西美坦、法倔唑、法扎拉滨、芬维A胺、非格司亭、非那雄胺、黄皮酮(flavopiridol)、氟卓斯汀、夫卢丝龙(fluasterone)、氟达拉滨、盐酸氟代柔红霉素(fluorodaunorunicin)、福酚美克、福美坦、福司曲星、福莫司汀、德卟啉钆(gadoliniumtexaphyrin)、硝酸镓、加洛他滨、加尼瑞克、明胶酶抑制剂、吉西他滨、谷胱甘肽抑制剂、赫舒反(hepsulfam)、调蛋白、环己基双乙酰胺、金丝桃蒽酮、伊班膦酸、黄胆素、艾多昔芬、伊决孟酮、伊莫福新、伊洛马司他、咪唑并吖啶酮、咪喹莫特、免疫刺激肽、胰岛素样生长因子-1受体抑制剂、干扰素激动剂、干扰素、白介素、碘苄胍、碘阿霉素、甘薯苦醇,4-、伊罗普拉、伊索拉定、异本格唑(isobengazole)、异高软海绵素(isohomohalicondrin)B、伊他司琼、结丝立得(jasplakinolide)、卡哈拉得(kahalalide)F、片螺素(lamellarin)-N三乙酸、兰瑞肽、雷纳霉素(leinamycin)、来格司亭、硫酸蘑菇多糖、莱托斯汀(leptolstatin)、来曲唑、白血病抑制因子、白细胞_干扰素、亮丙瑞林+雌激素+孕酮、亮丙瑞林、左旋咪唑、利阿唑、直链多胺类似物、亲脂性二糖肽、亲脂性铂化合物、利索纳得(lissoclinamide)7、洛铂、胍乙基磷酸丝氨酸、洛美曲索、氯尼达明、洛索蒽醌、洛伐他汀、洛索立宾、勒托替康、德卟啉镥(lutetiumtexaphyrin)、莱索菲林(lysofylline)、细胞裂解肽、美坦新、慢诺他汀(mannostatin)A、马立马司他、马索罗酚、马斯平(maspin)、基质溶解因子抑制剂、基质金属蛋白酶抑制剂、美诺立尔、硫巴妥苯胺、美替瑞林、甲硫氨酸酶、甲氧氯普胺、MIF抑制剂、米非司酮、米替福新、米立司亭、错配的双链RNA、米托胍腙、二溴卫矛醇、丝裂霉素类似物、米托萘胺、米托毒素(mitotoxin)成纤维细胞生长因子-皂草毒蛋白、米托蒽醌、莫法罗汀、莫拉司亭、单克隆抗体,人绒毛膜促性腺激素、单磷酰基脂质A+分支杆菌细胞壁骨架、莫哌达醇、多药耐药基因抑制剂、基于多肿瘤抑制物1的治疗、芥类抗癌剂、印度洋海绵(mycaperoxide)B、分枝杆菌细胞壁提取物、米亚普龙(myriaporone)、N-乙酰基地那林、N-取代的苯甲酰胺、那法瑞林、那瑞替喷(nagrestip)、纳洛酮+镇痛新、纳帕英(napavin)、萘萜二醇(naphterpin)、那托司亭、奈达铂、奈莫柔比星、奈立膦酸、中性内肽酶、尼鲁米特、尼萨霉素(nisamycin)、氮氧化物调节剂、硝基氧抗氧化剂、尼多林(nitrullyn)、O6-苄基鸟嘌呤、奥曲肽、奥可斯酮(okicenone)、寡核苷酸、奥那司酮、昂丹司琼、昂丹司琼、奥莱辛(oracin)、口服细胞因子诱导物、奥马铂、奥沙特隆、奥沙利铂、氧杂奥诺霉素(oxaunomycin)、帕劳胺(palauamine)、棕榈酰根霉素、帕米磷酸、人参炔三醇、帕诺米芬、副菌铁素(parabactin)、帕折普汀、培门冬酶、培得星、戊聚硫钠、喷司他丁、喷托唑(pentrozole)、全氟溴烷、培磷酰胺、紫苏子醇、苯那霉素(phenazinomycin)、乙酸苯酯(phenylacetate)、磷酸酶抑制剂、皮西巴尼(picibanil)、盐酸匹鲁卡品、吡柔比星、吡曲克辛、胎盘素(placetin)A、胎盘素B、纤溶酶原激活物抑制剂、铂络合物、铂化合物、铂-三胺络合物、卟菲尔钠、泊非霉素、氯泼尼松、丙基双吖啶酮、前列腺素J2、蛋白酶体抑制剂、基于蛋白A的免疫调节剂、蛋白激酶C抑制剂、蛋白激酶C抑制剂,微藻(microalgal)、蛋白质酪氨酸磷酸酶抑制剂、嘌呤核苷磷酸化酶抑制剂、红紫素、吡唑啉吖啶、吡哆醛化的血红蛋白聚氧乙烯偶联物、raf拮抗剂、雷替曲塞、雷莫司琼、ras法尼基蛋白转移酶抑制剂、ras抑制剂、ras-GAP抑制剂、去甲基化的瑞替普汀、依替膦酸铼Re186、根霉素、核酶、RII维甲酰胺(retinamide)、罗谷亚胺、罗希吐碱(rohitukine)、罗莫肽、罗喹美克、卢比格酮(rubiginone)B1、卢伯西(ruboxyl)、沙芬戈、伞托平(saintopin)、SarCNU、萨可菲醇(sarcophytol)A、沙格司亭、Sdi1模拟物、司莫司汀、衰老衍生的抑制剂1、有义寡核苷酸、信号转导抑制剂、信号转导调节剂、单链抗原结合蛋白、西佐喃、索布佐生、硼卡钠、苯基乙酸钠、索尔醇(solverol)、生长调节素结合蛋白、索纳明、膦门冬酸、斯卡霉素(spicamycin)D、螺莫司汀、脾脏五肽(splenopentin)、海绵他汀(spongistatin)1、角鲨胺、干细胞抑制剂、干细胞分裂抑制剂、斯提酰胺(stipiamide)、基质分解素抑制剂、斯菲诺辛(sulfinosine)、强效血管活性肠肽拮抗剂、素拉迪塔(suradista)、苏拉明、苦马豆碱、合成粘多糖、他莫司汀、他莫昔芬甲碘化物、牛磺莫司汀、他扎罗汀、替可加兰钠、替加氟、碲吡喃洋(tellurapyrylium)、端粒酶抑制剂、替莫泊芬、替莫唑胺、替尼泊苷、十氧化四氯(tetrachlorodecaoxide)、四佐胺(tetrazomine)、泰立拉汀(thaliblastine)、噻可拉林、血小板生成素、血小板生成素模拟物、胸腺法新、胸腺生成素受体激动剂、胸腺曲南、促甲状腺激素、本紫红素乙酯锡、替拉扎明、二氯环戊二烯钛、拓扑森汀(topsentin)、托瑞米芬、全能干细胞因子、翻译抑制剂、维甲酸、三乙酰基尿苷、曲西立滨、三甲曲沙、曲普瑞林、托烷司琼、妥罗雄脲、酪氨酸激酶抑制剂、酪氨酸磷酸化抑制剂(tyrphostin)、UBC抑制剂、乌苯美司、泌尿生殖窦衍生的生长抑制因子、脲激酶受体拮抗剂、伐普肽、瓦立奥林(variolin)B、载体系统,红细胞基因治疗、维拉雷琐、藜芦明、瓦尔丁(verdins)、维替泊芬、长春瑞滨、威科萨汀(vinxaltine)、维他辛(Vitaxin)、伏氯唑、扎诺特隆、折尼铂、亚苄维C、和净司他丁斯酯。在一些实施方式中,其他治疗剂选自:通过由于稳定化的微管将细胞阻滞在G2-M期而发挥作用的试剂,例如,厄布洛唑(也称为R-55104)、多拉司他汀10(也称为DLS-10和NSC-376128)、羟乙基磺酸米伏布林(也称为CI-980)、长春新碱、NSC-639829、淅皮海绵内酯(也称为NVP-XX-A-296)、ABT-751(雅培公司(Abbott),也称为E-7010)、奥图来尔亭(如奥图来尔亭A和奥图来尔亭C)、海绵司达汀(如海绵司达汀1、海绵司达汀2、海绵司达汀3、海绵司达汀4、海绵司达汀5、海绵司达汀6、海绵司达汀7、海绵司达汀8和海绵司达汀9)、盐酸西马多亭(也称为LU-103793和NSC-D-669356)、埃坡霉素类(如埃坡霉素A、埃坡霉素B、埃坡霉素C(也称为去氧埃坡霉素A或dEpoA)、埃坡霉素D(也称为KOS-862、dEpoB和去氧埃坡霉素B)、埃坡霉素E、埃坡霉素F、埃坡霉素BN-氧化物、埃坡霉素AN-氧化物、16-氮杂-埃坡霉素B、21-氨基埃坡霉素B(也称为BMS-310705见知)、21-羟基埃坡霉素D(也称为去氧埃坡霉素F和dEpoF)、26-氟埃坡霉素)、奥立司达汀PE(也称为NSC-654663)、索卜利多亭(也称为TZT-1027)、LS-4559-P(Pharmacia公司,也称为LS-4557)、LS-4578(Pharmacia公司,也称为LS-477-P)、LS-4477(Pharmacia公司)、LS-4559(Pharmacia公司)、RPR-112378(Aventis公司)、硫酸长春新碱、DZ-3358(Daiichi公司)、FR-182877(Fujisawa公司,也称为WS-9885B)、GS-164(Takeda公司)、GS-198(Takeda公司)、KAR-2(匈牙利科学院)、BSF-223651(BASF,也称为ILX-651和LU-223651)、SAH-49960(礼来/诺华公司)、SDZ-268970(礼来/诺华公司)、AM-97(Armad/KyowaHakko公司)、AM-132(Armad公司)、AM-138(Armad/KyowaHakko公司)、IDN-5005(Indena公司)、克来普妥素52(也称为LY-355703)、AC-7739(Ajinomoto公司,也称为AVE-8063A和CS-39.HCl)、AC-7700(Ajinomoto公司,也称为AVE-8062、AVE-8062A和CS-39-L-Ser.HCl和RPR-258062A)、维替乐福酰胺、吐卜溶素A、加纳单索、矢车菊黄素(也称为NSC-106969)、T-138067(Tularik公司,也称为T-67、TL-138067、TI-138067)、COBRA-1(帕克-休斯研究中心,也称为DDE-261和WHI-261)、H10(堪萨斯州立大学)、H16(堪萨斯州立大学)、杀肿瘤素A1(也称为BTO-956和DIME)、DDE-313(帕克-休斯研究中心)、非将诺来B、劳力马来、SPA-2(帕克-休斯研究中心)、SPA-1(帕克-休斯研究中心,也称为SPIKET-P)、3-IAABU(细胞骨架公司/西奈山医学院,也称为MF-569)、纳可辛(也称为NSC-5366)、纳司卡滨、D-24851(Asta医学公司)、A-105972(雅培公司)、丰星素、3-BAABU(细胞骨架公司/西奈山医学院,也称为MF-191)、TMPN(亚利桑那大学)、乙酰基丙酮酸凡纳多新、T-138026(Tularik公司)、孟沙醇、引纳诺新(也称为NSC-698666)、3-IAABE(细胞骨架公司/西奈山医学院)、A-204197(雅培公司)、T-607(Tularik公司,也称为T-900607)、RPR-115781(Aventis公司)、艾榴素类(如去甲基艾榴素、去乙酰基艾榴素、异艾榴素-A和Z-艾榴素)、卡利贝苷、卡利贝林、海利软骨胶B、D-64131(Asta医学公司)、D-68144(Asta医学公司)、重氮酰胺A、A-293620(雅培公司)、NPI-2350(Nereus公司)、他卡诺洛来A、TUB-245(Aventis公司)、A-259754(雅培公司)、二奥唑司达汀、(-)-苯基阿西司汀(也称为NSCL-96F037)、D-68838(Asta医学公司)、D-68836(Asta医学公司)、肌割蛋白B、D-43411(Zentaris公司,也称为D-81862)、A-289099(雅培公司)、A-318315(雅培公司)、HTI-286(也称为SPA-110,三氟乙酸盐)(惠氏药厂)、D-82317(Zentaris公司)、D-82318(Zentaris公司)、SC-12983(NCI)、力司弗拉司达汀磷酸钠、BPR-OY-007(国立卫生研究院),和SSR-250411(Sanofi公司)。在一些实施方式中,其他治疗剂选自:影响肿瘤微环境(如细胞信号转导网络,例如,磷脂酰肌醇3-激酶(PI3K)信号转导通路,来自B-细胞受体和IgE受体的信号转导)的试剂。影响肿瘤微环境的试剂的示例包括PI3K信号转导抑制剂、syc激酶抑制剂、蛋白激酶抑制剂例如达沙替尼、埃罗替尼、依维莫司、吉非替尼、伊马替尼、拉帕替尼、尼罗替尼、帕宗纳尼、索拉非尼、舒尼替尼、坦西莫司;其他血管生成抑制剂例如GT-111、JI-101、R1530;其他激酶抑制剂例如AC220、AC480、ACE-041、AMG900、AP24534、Arry-614、AT7519、AT9283、AV-951、阿西替尼、AZD1152、AZD7762、AZD8055、AZD8931、巴非替尼、BAY73-4506、BGJ398、BGT226、BI811283、BI6727、BIBF1120、BIBW2992、BMS-690154、BMS-777607、BMS-863233、BSK-461364、CAL-101、CEP-11981、CYC116、DCC-2036、迪那希(dinaciclib)、乳酸多韦替尼、E7050、EMD1214063、ENMD-2076、福斯塔玛替尼二钠、GSK2256098、GSK690693、INCB18424、INNO-406、JNJ-26483327、JX-594、KX2-391、里尼非尼(linifanib)、LY2603618、MGCD265、MK-0457、MK1496、MLN8054、MLN8237、MP470、NMS-1116354、NMS-1286937、ON01919.Na、OSI-027、OSI-930、Btk抑制剂、PF-00562271、PF-02341066、PF-03814735、PF-04217903、PF-04554878、PF-04691502、PF-3758309、PHA-739358、PLC3397、造血生长因子、R547、R763、雷莫芦单抗、瑞格拉芬尼、RO5185426、SAR103168、SCH727965、SGI-1176、SGX523、SNS-314、TAK-593、TAK-901、TKI258、TLN-232、TTP607、XL147、XL228、XL281RO5126766、XL418、XL765。在一些实施方式中,其他治疗剂选自:丝裂原活化蛋白激酶信号转导抑制剂,例如U0126、PD98059、PD184352、PD0325901、ARRY-142886、SB239063、SP600125、BAY43-9006、渥曼青霉素或LY294002;Syk抑制剂;mTOR抑制剂;和抗体(例如,利妥昔)。在一些实施方式中,其他治疗剂选自:干扰素、白介素、肿瘤坏死因子、生长因子等。在一些实施方式中,其他治疗剂选自:安西司亭、非格司亭、来格司亭、莫拉司亭、聚乙二醇非格司亭、沙格司亭;干扰素例如天然干扰素α、干扰素α-2a、干扰素α-2b、干扰素alfacon-1、干扰素α-n1、天然干扰素β、干扰素β-1a、干扰素β-1b、干扰素γ、聚乙二醇干扰素α-2a、聚乙二醇干扰素α-2b;白介素例如阿地白介素、奥普瑞白介素;其他免疫刺激剂例如卡介苗、醋酸格拉替雷、二盐酸组胺、免疫花青、蘑菇多糖、黑色素瘤疫苗、米伐木肽、培加酶、匹多莫德、普乐沙福、聚I:C、聚ICLC、罗喹美克、他索纳明、胸腺五肽;免疫抑制剂例如阿巴西普、阿贝莫司、依坦西普、抗淋巴细胞免疫球蛋白(马)、抗胸腺细胞免疫球蛋白(兔)、依库丽单抗、依法利珠单抗、依维莫司、胍立莫司、来氟米特、莫罗单抗-CD3、霉酚酸、那他珠单抗、西罗莫司;TNF-α抑制剂例如阿达木单抗、阿非莫单抗、赛妥珠单抗、依坦西普、戈利木单抗、英夫利昔单抗;白介素抑制剂例如阿那白滞素、巴利昔单抗、卡纳努单抗、达珠单抗、美泊利单抗、利纳西普、托珠单抗、乌斯克努单抗;神经钙蛋白抑制剂例如环孢素、他克莫司;其他免疫抑制剂例如硫唑嘌呤、甲氨蝶呤、来那度胺、沙利度。在一些实施方式中,其他治疗剂选自:阿达木单抗、阿来组单抗、巴利昔单抗、贝伐单抗、西妥昔单抗、赛妥珠单抗、达利珠单抗、依库丽单抗、依法利珠单抗、吉姆单抗、替伊莫单抗、英夫利昔单抗、莫罗单抗-CD3、那他珠单抗、帕尼单抗、利妥昔单抗、托西莫单抗、曲妥珠单抗、兰尼单抗等或其组合。在一些实施方式中,其他治疗剂选自:单克隆抗体例如阿仑单抗、贝伐单抗、西妥昔单抗、卡妥索单抗、依决洛单抗、吉姆单抗、帕尼单抗、利妥昔单抗、曲妥珠单抗;免疫抑制剂,依库丽单抗、依法利珠单抗、莫罗单抗-CD3、那他珠单抗;TNF-α抑制剂例如阿达木单抗、阿达木单抗、阿非莫单抗、戈利木单抗、英夫利昔单抗;白介素抑制剂,巴利昔单抗、卡纳努单抗、达珠单抗、美泊利单抗、托珠单抗、乌斯克努单抗;放射性药物,替伊莫单抗、单克隆抗体托西莫单抗;其他单克隆抗体例如阿巴伏单抗、阿德木单抗、阿仑单抗、抗CD30单克隆抗体Xmab2513、抗Met单克隆抗体MetMAb、阿泊珠单抗、阿伯单抗、阿西莫单抗、巴利昔单抗、双特异性抗体2B1、博纳吐单抗、布妥昔单抗、卡罗单抗喷地肽、西妥木单抗、克劳昔单抗、可那木单抗、达西珠单抗、地诺单抗、依库丽单抗、依帕珠单抗、依帕珠单抗、厄马索单抗、伊塔木单抗、芬妥木单抗、弗瑞索单抗、加利昔单抗、加尼单抗、吉妥单抗、格来莫单抗、替伊莫单抗、奥英妥珠单抗、伊匹单抗、来沙木单抗、林妥珠单抗、林妥珠单抗、鲁卡木单抗、马帕木单抗、马妥珠单抗、米拉妥珠单抗、单克隆抗体CC49、耐昔木单抗、尼妥珠单抗、奥戈伏单抗、帕妥珠单抗、拉马单抗、兰尼单抗、西利珠单抗、松匹珠单抗、他尼珠单抗、托西莫单抗、曲妥珠单抗、曲美木单抗、西莫白介素单抗、维妥珠单抗、维西珠单抗、弗洛昔单抗、扎鲁木单抗。在一些实施方式中,其他治疗剂选自:氮芥类如苯达莫司汀、苯丁酸氮芥、氮芥、环磷酰胺、异环磷酰胺、美法仑、泼尼氮芥、氯乙环磷酰胺;烷基磺酸盐如白消安、甘露舒凡、曲奥舒凡;乙烯亚胺如卡波醌、噻替哌、三亚胺醌;亚硝基脲类像卡莫司汀、福莫司汀、洛莫司汀、尼莫司汀、雷莫司汀、司莫司汀、链脲菌素;环氧化合物,例如乙环氧啶;其它烷化剂,例如达卡巴嗪、二溴甘露醇、哌血生、替莫唑胺;叶酸类似物如氨甲喋呤、培美曲塞、普拉曲沙、雷替曲塞;嘌呤类似物例如克拉屈滨、氯法拉滨、氟达拉滨、巯嘌呤、奈拉滨、硫鸟嘌呤;嘧啶类似物例乐阿扎胞苷、卡培他滨、卡莫氟、阿糖胞苷、地西他滨、氟尿嘧啶、吉西他滨、替加氟;长春花生物碱例如长春碱、长春新碱、长春碱、长春氟宁、盖诺;鬼臼毒素衍生物例如依托泊苷、替尼泊甙;秋水仙碱衍生物例如秋水仙碱;紫杉类药物如多西紫杉醇、紫杉醇、聚谷氨酸紫杉醇;其他植物生物碱和天然产物例如曲贝替定;放线菌素类化合物例如更生霉素;蒽环类例如柔红霉素、阿霉素、阿柔比星、表柔比星、伊达比星、米托蒽醌、吡柔比星、戊柔比星、祖鲁比星;其他细胞毒性抗生素例如博莱霉素、伊沙匹隆、丝裂霉素、普卡霉素;铂化合物例如卡铂、顺铂、奥沙利铂、赛特铂;甲基肼例如甲基苄肼;增敏剂如氨基酮戊酸、增敏剂、甲基氨基酮戊酸,卟吩姆钠、替莫泊芬;蛋白激酶抑制剂例如厄洛替尼、吉非替尼、达沙替尼、依维莫司、伊马替尼、拉帕替尼、尼洛替尼、帕宗纳尼、索拉非尼、舒尼替尼、替西罗莫司;其他抗肿瘤药物例如阿利维A酸、六甲蜜胺、安吖啶、阿那格雷、三氧化二砷、门冬酰胺酶、贝沙罗汀、硼替佐米、塞来昔布、地尼白介素、雌莫司汀、羟基脲、伊立替康、氯尼达明,马索丙考、米替福新、丙脒腙、米托坦、奥利默森、培门冬酶、喷司他丁、罗米地辛、塞西马集、噻唑呋林、拓扑替康、维甲酸、伏立诺他;雌激素例如二乙基茋、炔雌醇、磷雌酚、聚磷酸雌二醇;孕激素例如诺孕酮、甲孕酮、甲地孕酮;促性腺激素释放激素类似物例如布舍瑞林、戈舍瑞林、亮丙瑞林、曲普瑞林;抗雌激素例如氟维司群、他莫昔芬、托瑞米芬;抗雄激素例如比卡鲁胺、氟他胺、尼鲁米特、酶抑制剂、氨鲁米特、阿那曲唑、来曲唑、依西美坦、福美坦、伏氯唑;其他激素拮抗剂例如阿巴瑞克、地加瑞克;免疫刺激剂例如二盐酸组胺、米伐木肽、匹多莫德、普乐沙福、罗喹美克、胸腺五肽;免疫抑制剂例如依维莫司、胍立莫司、来氟米特、霉酚酸、西罗莫司;钙调神经磷酸酶抑制剂例如环孢素、他克莫司;其他免疫抑制剂例如硫唑嘌呤、甲氨蝶呤、沙利度胺、来那度胺;和放射性药物例如碘苄胍。在一些实施方式中,其他治疗剂选自检验点抑制剂。示例性的检验点抑制剂包括:PD-L1抑制剂如Genentech的MPDL3280A(RG7446)、来自BioXcell的抗-小鼠PD-L1抗体克隆10F.9G2(目录号BE0101)、来自Bristol-Meyer’sSquibb的抗-PD-L1单克隆抗体MDX-1105(BMS-936559)和BMS-935559,MSB0010718C,小鼠抗-PD-L1克隆29E.2A3,和AstraZeneca的MEDI4736;PD-L2抑制剂如葛兰素史克的AMP-224(Amplimmune),和rHIgM12B7;来自BioXcell的PD-1抑制剂如抗-小鼠PD-1抗体克隆J43(目录号BE0033-2),来自BioXcell的抗-小鼠PD-1抗体克隆RMP1-14(目录号BE0146),小鼠抗-PD-1抗体克隆EH12,默克的MK-3475抗-小鼠PD-1抗体(Keytruda,帕姆单抗,兰波单抗),称为ANB011的AnaptysBio的抗-PD-1抗体,抗体MDX-1106(ONO-4538),Bristol-MyersSquibb的人IgG4单克隆抗体纳武单抗(BMS-936558,MDX1106),AstraZeneca的AMP-514和AMP-224,来自治愈技术公司(CureTechLtd)的匹迪单抗(Pidilizumab)(CT-011);CTLA-4抑制剂如BristolMeyersSquibb的抗-CTLA-4抗体伊匹单抗(也称为MDX-010,BMS-734016和MDX-101),来自密理博的抗-CTLA4抗体克隆9H10,辉瑞的特姆单抗(CP-675,206,替西木单抗),和来自Abcam的抗-CTLA4抗体克隆BNI3;LAG3抑制剂如来自eBioscience的抗-Lag-3抗体克隆eBioC9B7W(C9B7W),来自LifeSpanBiosciences的抗-Lag3抗体LS-B2237,来自Immutep的IMP321(ImmuFact),抗-Lag3抗体BMS-986016,和LAG-3嵌合抗体A9H12;B7-H3抑制剂如MGA271;KIR抑制剂如利瑞单抗(Lirilumab)(IPH2101);CD137抑制剂如乌鲁单抗(urelumab)(BMS-663513,Bristol-MyersSquibb),PF-05082566(抗-4-1BB,PF-2566,辉瑞),或XmAb-5592(Xencor);PS抑制剂如巴维昔单抗;和抑制剂,如针对TIM3、CD52、CD30、CD20、CD33、CD27、OX40、GITR、ICOS、BTLA(CD272)、CD160、2B4、LAIR1、TIGHT、LIGHT、DR3、CD226、CD2、或SLAM的抗体或其片段(例如,单克隆抗体、人、人源化、或嵌合抗体)、RNAi分子、或小分子。样品用于分析免疫原性、安全性和/或毒性的样品可分离自个体。在一些情况中,样品可选自下组:全血,分离的血,血清,血浆,汗水,泪水,耳流体,痰,淋巴,骨髓悬液,淋巴,尿液,唾液,精液,阴道流体,粪便,经子宫颈的灌洗,脑脊液,脑液,腹水,母乳,玻璃体液,房水,皮脂,内淋巴(endolympth),腹膜液,胸膜液,耵聍,心外膜流体,以及呼吸道、肠道和泌尿生殖道的分泌物。在一些情况中,样品可以是组织,通常是活检样品。例如,活检可含有皮肤组织、心脏组织、腺组织、骨骼肌组织和/或脂肪组织。试剂盒本文也提供试剂盒和制品用于本文所述的一种或多种方法。试剂盒可含有本文所述的核酸分子中的一种或多种和/或多肽中的一种或多种,如SEQIDNO:1-91所示的多肽和核酸,或具有与选自SEQIDNO:1-91的多肽或核酸有至少40%、50%、60%、70%、80%、90%、95%或更高序列同源性的序列的多肽和/或核酸分子。该试剂盒也可含有编码一种或多种本文所述多肽的核酸。该试剂盒还可含有制备和递送疫苗所需的佐剂、试剂、和缓冲剂。该试剂盒可包含运载体、包装或容器,其经分隔可容纳一个或多个容器例如小瓶、管等,每个容器包含一种用于本文所述方法的单独元素,如多肽和佐剂。合适的容器包括例如瓶、小瓶、注射器和试管。该容器可由各种材料如玻璃或塑料制成。本发明提供的制品含有包装材料。药用包装材料的示例包括但不限于泡罩包装、瓶、管、包、容器、瓶和任何适用于所需制剂和期望的给药和治疗方式的包装材料。试剂盒一半包含列出组分和/或使用说明的标签,以及带有使用说明的包装插页。一般装有一套说明书。实施例虽然本文显示和描述了本发明的优选实施方式,但本领域技术人员显然了解这些实施方式仅以举例方式提供。本领域技术人员在不背离本发明的情况下可以作出多种改变、变化和取代。应理解,本文所述的本发明实施方式的各种替代形式可用于实施本发明。下列权利要求书确定了本发明范围,这些权利要求范围内的方法和结构以及其等同物均为本发明所涵盖。实施例1鉴定乳腺癌抗原并确定引发Th1CD4+T-细胞应答的表位使用224个个体的血清来进行抗体分析。评价了124名I/II期乳腺癌(BrCA)患者针对各候选蛋白质的抗体应答:78ER+(63%),31HER2+(25%),和15TNBC(12%)。对照组由100名年龄匹配的妇女组成。使用小鼠模型在下述附图中显示了分析免疫原性的候选蛋白质。另外,分析免疫原性的候选蛋白质列于图19和23。使用重组蛋白质的间接ELISA。重组蛋白质可用于所有提出的候选抗原。一式两份或一式三份在1∶100和1∶200的效价下分析对象血清。Western印迹分析证明,除了不可通过Western印迹验证的CD105以外,ELISA试验的灵敏性和特异性为70%或更高。筛选乳腺癌病理和对照。所有测试的蛋白质都是免疫原性的,即,至少有1个分析个体证明针对特定抗原的可检测IgG抗体免疫,其可通过用合适的特异性对照(例如,图3中的CDH3)的Western印迹来显示。可在志愿者对照和癌症患者中鉴定到抗体应答。为了说明针对特定抗原的免疫率,使用平均ug/ml和2个标准差的对照群来确定95%置信度下认为响应为阳性的截止值。测试的抗原的抗体免疫率的范围为2%(针对Yb-1的BrCA患者)至13%(针对CDC25b的BrCA患者)阳性。证明在6种抗原上针对BrCA患者和供体之间的响应率有超过2倍的差异:CDC25b、CDH3、生存素、MDM2、SATB1、和ID1。应注意,与癌症患者相比,在更大数量的志愿者供体中发现SATB1和ID1应答。图4组图B显示了9种抗原的结果,其中在BrCA患者和供体之间发生率上有2倍或更少的差异。针对免疫应答的癌症特异性的统计学分析。抗原中的四种使用韦尔氏校正的未配对T检验证明在癌症患者和对照之间在免疫性上有统计学显著差异。BrCA患者有比志愿者对照更高水平的针对CDC25B(p=0.02)、CDH3(p=0.0002)、生存素(p=0.09)的抗体免疫水平。鉴定候选抗原用于表位作图。鉴定15种与干细胞/EMT相关的免疫原性蛋白质移向表位作图。例如,参见图28,其显示了响应来自IGFBP-2的C末端的表位的T-细胞分泌IFNγ和IL-10。具体地,图28在(A)部分中显示了针对IGFBP-2肽的乳腺癌患者PBMC中IFNγ(白色)和IL-10(黑色)的ELISPOT,显示为带杜克晶须(Tukeywhisker)的四分位盒图。由水平线表示每孔中值校正点(CSPW)。在(B)部分中,在ELISPOT中用IGFBP-2肽刺激的PBMC诱导IFNγ(白色柱)应答、IL-10(黑色柱)应答、或两者(灰色柱)的百分比。在另一个示例中,参见图29,其显示针对IGFBP-2的N-端而非C-端的肿瘤生长抑制和Th1免疫应答。(A)来自用所示疫苗免疫的小鼠的脾细胞的IFNγELISPOT。数据表示为每孔校正点(CSPW)。水平线表示平均CSPW±SEM。n=10只小鼠/组;*p<0.01。(B)用仅pUMVC3(●)、pUMVC3-hIGFBP2(1-328)(■)、pUMVC3-hIGFBP2(164-328)(▲)或pUMVC3-hIGFBP2(1-163)(o)注射的小鼠的平均肿瘤体积(mm3±SEM)。n=5只小鼠/组;**p<0.001。在另一个示例中,参见图30,其显示了IGFBP-2疫苗-诱导的Th2消除IGFBP-2-特异性Th1的抗肿瘤效果。用IGFBP2(1-163)或IGFBP2(164-328)中的肽扩大来自T-细胞系的II型细胞因子IL-4和IL-10(A)以及I型细胞因子TNFα和IFNγ(B)的分泌(平均ng/mI±SD);**p<0.001,*p<0.01和#p<0.05。(C)输注CD3+T-细胞的小鼠的平均肿瘤体积(mm3±SEM),所述CD3+T-细胞用pUMVC3-hIGFBP2(1-163)(o),pUMVC3-hIGFBP2(164-328)(▲)或天然T-细胞(●)免疫的小鼠放大。n=4只小鼠/组;*p<0.01。(D)来自用仅pUMVC3(●)、pUMVC3-hIGFBP2(164-328)(▲)、pUMVC3-hIGFBP2(1-163)(o)或pUMVC3-hIGFBP2(1-163)+pUMVC3-hIGFBP2(164-328)注射的小鼠的平均肿瘤体积(mm3±SEM)。n=5只小鼠/组;*p<0.01。图1证明Th1和Th2表位在功能性亲合力上不同。又例如,参见图16,其显示了对在单质粒、pHIF1α和编码5种抗原的质粒、BCMA5中HIF1α表达的Western印迹分析。在沿着所示虚线进行切割后,使用抗-HIFα(0.1-10μg/μL)的10倍稀释来探测印迹。每个抗体效价仅使用一个加载裂解物的泳道。实施例2鉴定衍生自干细胞/EMT抗原的混杂高亲和性结合II类表位使用来自20个BrCA患者和20个对照供体的存档白血球单采术。BRCA患者的平均年龄为63(范围49-87)并且对照的平均年龄为38(范围29-65)。在BrCA患者中,81%在诊断时为I期或II期,10%是未知阶段并且其余为III期。按照计算机作图来构建肽。使用算法方法来预测前6种免疫原性BCS/EMT蛋白质的II类表位。简言之,使用3种公开的基于网页的算法筛选候选抗原的蛋白质序列的潜在MHCII表位。在最常见的14HLA-DR等位基因之间筛选各蛋白质。基于估计的结合亲和性选择/等位(allele)最大20个表位。各预测表位中的各氨基酸(aa)根据aa在预测高结合表位中出现的次数给出评分(总分)。总分乘以包含该特定氨基酸的表位的等位基因的数量,因此,各氨基酸分配多个评分,其是在广泛群范围上增加结合亲和性的频率与预测响应的混杂性的结果。构建衍生自基于各肽的多评分选择的全部6种候选蛋白质的49种肽用于筛选。选择允许覆盖至少25%的全长蛋白质的肽。候选蛋白质的中值肽覆盖为总序列的28%(范围26-45%)。由IFNγELISPOT筛选样品。图6显示了所有供体对响应抗原的所有肽/抗原的IFNγ应答的累积数据。通常,与BrCA患者相比,IFNγ应答在志愿者供体中更高,并且对于以下统计学上更高:生存素(BIRC5);p<0.001,MDM2;p<0.001,SOX-2;p=0.01,和Yb-1;p<0.001。阳性应答定义为实验重复的平均值统计学上大于(p<0.05)无抗原孔的平均重复。发生率百分比在供体类型之间相似,24-38%的对象对应于响应中值以上的特定抗原。针对IFNγ应答,检测实验组或肽之间差异的双向ANOVA产生响应供体类型的2.82%差异(p=0.0265)和响应测试的特定肽的71.33%差异(p=0.003)。虽然供体类型的显著性弱,但产生的差异小。对来自各候选抗原的肽的鉴定和筛选。针对IFNγ应答,鉴定来自各候选抗原的4种(个)表位。实施例3评价干细胞/EMT抗原衍生的表位优选引发分泌IFNγ或IL-10的T-细胞,并且选择肽作为低免疫抑制潜力的候选疫苗表位,由IL-10ELISPOT筛选样品。图7显示了所有供体对响应抗原的所有肽/抗原的IL-10应答的累积数据。一般而言,IL-10应答处于比IFNγ应答更低的量级,并且志愿者供体显示针对大多数抗原统计学显著的更高的中值应答:生存素(birc5);p<0.0001,CDC25b;p=0.044,CDH3;p=0.037,FOXQ1;p=0.0014,HIF1α;p=0.017,MDM2;p=0.0039,SOX-2;p=0.044,和Yb-1;p=0.0007。与IFNγ数据相似,供体类型占抗原间差异的不到0.01%(p=0.911)而单个肽占90.51%(p<0.0001)。鉴定与IL-10分泌T-细胞相比诱导抗原特异性IFNγ分泌T-细胞的肽。使用优选用于延伸表位的体内评价的抗原的基质评分系统,其证明在群间没有IL-10活性的情况下的IFNγ特异性活性。延伸表位优于较短的II类表位,因为较长的表位引发由T细胞和B细胞组成的多样性免疫应答并且抗肿瘤应答同时依赖CD4和CD8T-细胞。含有多个表位的候选抗原中的区域优选诱导更大的量级和频率的IFNγ并且鉴定到很少或没有IL-10诱导活性。评价了抗原特异性IL-10诱导的发生率X量级/抗原特异性IFNγ诱导的发生率X量级的比率(IFNγ/IL-10活性比率)(参见图10和11)。例如,图10显示了IFNγ主导的较高量级和发生率。选择抗原的IFNγ/IL-10活性比率。由供体类型显示定义为每种肽的平均cSPWx的IFNγ/IL-10比率。正y轴上显示IFNγcSPWx发生率,白色柱为志愿者供体,黑底白色柱显示癌症供体。负y轴上显示IL-10cSPWx发生率,黑色柱为志愿者供体,白底黑色柱显示癌症供体。(A)CDH3,(B)HIF1α,(C)生存素,和(D)FOXQ1。例如,图11显示了较低量级和发生率IFNγ优势。选择抗原的IFNγ/IL-10活性比率。由供体类型显示定义为每种肽的平均cSPWx的IFNγ/IL-10比率。正y轴上显示了IFNγcSPWx发生率,白色柱为志愿者供体,黑底白色柱显示癌症供体。负y轴上显示IL-10cSPWx发生率,黑色柱为志愿者供体,白底黑色柱显示癌症供体。(A)CDH3,(B)HIF1α,(C)生存素,和(D)FOXQ1。评价的抗原基于IFNγ/IL-10活性比率分成4个主要组。CDH3的第一组(图10)显示高发生率/量级IFNγ应答和非常少的IL-10活性。这种模式表明顶级(toptier)抗原,包括CDH3、SOX2、MDM2、和Yb-1。第二级抗原在选择的延伸表位区域中证明类似的优势IFNγ应答和很小至没有IL-10诱导,然而免疫应答的量级比顶级候选物低超过一个对数。图11,HIF1α显示这种分离,其也包括CD105、CDC25B和SATB1。疫苗候选物衍生自这些类别(参见图10和11)。其他2组有对疫苗免疫原而言不太希望的特性。虽然有刺激高量级和发生率IFNγ的表位,这些序列在测试的个体中以相等的发生率等价地诱导高量级IL-10免疫。抗原如c-met、IGF-1R、PRL3、和SIX1被分入这一类别。最后,一些候选抗原没有免疫原性,如任何免疫应答的低发生率和低量级所示,如图19中FOXQ1所示。ID1和SNAIL也与免疫应答的非常低发生率和量级相关。有免疫原性并且诱导高量级和发生率的IL-10应答,或弱免疫原性,后两个类别的抗原将从用于最终疫苗制剂的进一步考虑中排除。在图9中,显示了基于IFNγ/IL-10活性比率的延伸表位列表。也参见图17-20。实施例4鉴定表位特异性Th1细胞对内源性APC上呈递的蛋白质的应答针对候选表位生成T细胞系。用10ug/ml的抗原性肽来刺激衍生自3个已经在ELISPOT试验中证明阳性应答的供体的PBMC。在第5天向培养物中加入IL-12(10ng/ml)和IL-2(10u/ml)。以7-10天的间隔重复肽刺激和细胞因子添加。随后用CD3/CD28珠来扩大培养物。每2-3天向培养物中加入IL-2(30u/ml)持续10-11天。然后用3天IFNγELISPOT试验来评价建立的肽特异性T-细胞系。用不同浓度的加载到自体APC上的肽和市售重组蛋白质来刺激培养的T-细胞。不相关肽和蛋白质用作阴性对照。与无抗原对照相比,在至少一个供体中,针对肽和蛋白质抗原的应答显著增加(p<0.05),如阳性应答所示。向一些抗原刺激的孔中加入MHCII和MHCI封闭抗体(10μg/ml)来验证表位是否是MHC限制性的。另外,一部分的T-细胞用CD3FITC、CD4PE-Cy7、CD45ROAPC、和CD62LPE或CCR7PE染色以与抗原刺激前的细胞(PBMC)相比评价T-细胞系中的中心记忆细胞群。针对阳性和阴性对照筛选T-细胞系的对肽和重组蛋白质的特异性。图29显示了作为代表性示例的HIF1α肽p60-82的验证数据。HIF1αp60-82特异性T-细胞系响应在内源性APC上呈递的肽和重组HIF1α蛋白质。肽(10ug/ml和50ug/ml)和蛋白质(1ug/ml)都显著刺激来自肽特异性T-细胞系的IFNγ应答。不相关肽(HIVp52-68)和蛋白质(CD105)并不这样(图15A)。MHCII显著抑制肽和蛋白质诱导的IFNγ应答,但MHCI抗体并不这样(图15A)。与培养前的PBMC中的基线水平(9%)相比在培养的T-细胞系中增殖CD45RO+CD62L+CD4+中心记忆细胞(73%)。例如,参见图8,其显示了延伸序列中的肽验证为天然表位。CD105延伸表位(52aa)QNGTWPREVLLVLSVNSSVFLHLQALGIPLHLAYNSSLVTFQEPPGVNTTEL(SEQIDNO:1)(序列中的2个表位之一)。类似地,验证的肽经鉴定并衍射自CD105、SATB1、CDH3、SOX2、YB1、和MDM2。在验证的肽中,所有肽特异性T-细胞系证明统计学阳性肽应答。在75%的评价的肽特异性系中,MHCII抗体抑制超过70%的肽特异性应答,并且在20%的系中,MHCI抗体抑制超过70%的肽应答。在所有阳性蛋白质应答物中(90%),MHCII抗体抑制>70%的蛋白质特异性应答。中心记忆T-细胞群在培养后显著增加。对于顶级和第二级组的6种抗原,CDH3、SOX2、MDM2、YB1、HIF1α、和CD105,鉴定了适于以高到中等高IFNγ比率和低至很低IL-10比率免疫的延伸表位的区域。各序列包括2个或更多个较短(15-22aa)验证的II类表位。延伸序列的长度范围是32-aa至90-aa(参见表6)。将衍生自CDH3、Yb-1、MDM2、SOX2和CD105的序列连接在一起,编码称为“STEMVAC”的独特融合肽(参见补充表5)。鉴定来自各候选抗原的用于包含在多抗原疫苗中的候选表位。5个延伸表位衍生自15个适于疫苗的候选抗原中的5个,其优选诱导IFNγ分泌而很少鉴定到Th2(IL-10)。这些序列合并成独特融合蛋白STEMVAC,其为乳腺癌疫苗的基础。实施例5构建基于多抗原Th1多表位质粒的疫苗靶向干细胞/EMT抗原以及确定安全性和免疫原性使用TgMMTVneu小鼠模型和IGF-1R抗原来确定含有短Th表位或延伸Th表位中的任意或两者的基于质粒的疫苗构建体的免疫原性和效果。为了直接比较短和延伸表位质粒疫苗控制肿瘤生长的能力,采用同系肿瘤抑制模型。将小鼠(TgMMTVneu)分成4个免疫组(pIGF-IRexep、pIGF-IRshep、载体和IGF-IR肽)并且在第三次免疫后7天植入同系乳腺癌细胞(MMC)。剂量如上所述。测量了MMC细胞形成肿瘤的能力,和肿瘤生长速率。与仅用载体免疫的组相比,IGF-IR肽疫苗,短表位质粒疫苗,和延伸表位质粒疫苗全部显著控制肿瘤生长(p<0.0001,从14-31天)。用pIGF-IRexep免疫的小鼠有最慢生长的肿瘤,但是它们在用pIGF-IRshep免疫的动物中的肿瘤生长上没有显著差异。例如,图2,Th2免疫应答消除了Th1免疫应答的抗肿瘤功效。例如,图21,确定了HIF1α肽和质粒在小鼠中的免疫原性和功效。(A)通过在施加50%DMSO中的HIF1α肽混合物后24小时的耳厚度(mm)变化测量DTH应答。所绘是来自不同免疫组的单个FVB/NJ小鼠的应答:对照(仅佐剂和载体组,参见方法)、HIF1αPeps(肽疫苗)和pHif1a(质粒疫苗)。虚线表示耳厚度与基线有0.0mm变化。***p<0.001对比对照。(B)在施加在50%DMSO中的HIF1α肽混合物后24小时测量的DTH应答。所绘是来自上述不同免疫组的单个MMTV-C3(1)-标签转基因小鼠的应答。***p<0.001对比对照。(C)通过测量MMTV-C3(1)-标签转基因小鼠中植入后随时间(天)的肿瘤体积(mm3)来评价疫苗控制M6肿瘤生长的功效。免疫组为仅佐剂(○)、载体(□)、HIF1α肽(▲)、或pHIF1α(■)误差线显示各组的SEM。对比早至植入后24天,HIF1α肽免疫的小鼠和HIF1αDNA免疫的小鼠有明显较小的肿瘤负荷。****p<0.0001对比仅佐剂组。(D)IFNγELISPOT评价针对肽或对照刺激的T-细胞应答。各所绘点表示在用仅佐剂(○),载体(□),HIF1α肽(▲),或pHif1a(■)处理的免疫组中单个FVB/NJ小鼠的每孔点。线显示了应答的平均和SEM。***p<0.001HIF1α肽对比无抗原应答。虽然HIF1α质粒生成DTH应答,IFNγELISPOT是低水平的。又例如,图22,确定了CD105肽和质粒在小鼠中的免疫原性和功效。(A)通过在施加50%DMSO中的CD105肽混合物后24小时的耳厚度(mm)变化测量DTH应答。所绘是来自不同免疫组的单个FVB/NJ小鼠的应答:对照(仅佐剂和载体组,参见方法)、CD105Peps(肽疫苗)和pCD105(质粒疫苗)。虚线表示耳厚度与基线有0.0mm变化。*p<0.05,***p<0.001对比对照。(B)在施加在50%DMSO中的CD105肽混合物后24小时测量的DTH应答。所绘是来自上述不同免疫组的单个MMTV-C3(1)-标签转基因小鼠的应答。***p<0.001对比对照。(C)通过测量MMTV-C3(1)-标签转基因小鼠中植入后随时间(天)的肿瘤体积(mm3)来评价疫苗控制M6肿瘤生长的功效。免疫组为仅佐剂(○)、载体(□)、CD105肽(▲)、或pCD105(■)。误差线显示各组的SEM。对比植入后24天,CD105肽免疫的小鼠和CD105DNA免疫的小鼠有明显较小的肿瘤负荷。****p<0.0001对比仅佐剂组。(D)IFNγELISPOT评价针对肽或对照刺激的T-细胞应答。各所绘点表示在用仅佐剂(○),载体(□),CD105肽(▲),或pCD105(■)处理的免疫组中单个FVB/NJ小鼠的每孔点。线显示了应答的平均和SEM。在任意组中都没有CD105肽应答的显著发现。又例如,图23,确定了CDH3肽和质粒在小鼠中的免疫原性和功效。(A)通过在施加50%DMSO中的CDH3肽混合物后24小时的耳厚度(mm)变化测量DTH应答。所绘是来自不同免疫组的单个FVB/NJ小鼠的应答:对照(参见方法)、CDH3Peps(肽疫苗)、pCDH3(质粒疫苗)和pUbVV-CDH3。虚线表示耳厚度与基线有0.0mm变化。*p<0.05,**p<0.01对比对照。(B)在施加在50%DMSO中的CDH3肽混合物后24小时测量的DTH应答。所绘是来自上述不同免疫组的单个FVB/N/Tg-neu转基因小鼠的应答。*p<0.05,**p<0.01对比对照。(C)通过测量FVB/N/Tg-neu转基因小鼠中植入后随时间(天)的肿瘤体积(mm3)来评价疫苗控制MMC肿瘤生长的功效。免疫组为仅佐剂(○)、载体(□)、CDH3肽(▲)、pCDH3(■)、或pUBVV-CDH3(◆)。误差线显示各组的SEM。与对照小鼠相比,CDH3肽或DNA免疫的小鼠都没有明显较小的肿瘤负荷。(D)IFNγELISPOT评价针对肽或对照刺激的T-细胞应答。各所绘点表示在用仅佐剂(○),CDH3肽(▲),pCDH3(■),或pUBVV-CDH3(◆)处理的免疫组中单个FVB/NJ小鼠的每孔点。线显示了应答的平均和SEM。****p<0.0001CDH3肽对比无抗原应答。又例如,图24,确定了SOX2肽和质粒在小鼠中的免疫原性和功效。(A)通过在施加50%DMSO中的SOX2肽混合物后24小时的耳厚度(mm)变化测量DTH应答。所绘是来自不同免疫组的单个FVB/NJ小鼠的应答:对照(参见方法)、SOX2Peps(肽疫苗)、pSOX2(质粒疫苗)和pUbVV-SOX2。虚线表示耳厚度与基线有0.0mm变化。相比对照没有发现显著。(B)在施加在50%DMSO中的SOX2肽混合物后24小时测量的DTH应答。所绘是来自上述不同免疫组的单个FVB/N/Tg-neu转基因小鼠的应答。*p<0.05对比对照。(C)通过测量FVB/N/Tg-neu转基因小鼠中植入后随时间(天)的肿瘤体积(mm3)来评价疫苗控制MMC肿瘤生长的功效。免疫组为仅佐剂(○)、载体(□)、SOX2肽(▲)、pSOX2(■)、或pUBVV-SOX2(◆)。误差线显示各组的SEM。***p<0.001,****p<0.0001对比仅佐剂组。(D)IFNγELISPOT评价针对肽或对照刺激的T-细胞应答。各所绘点表示在用仅佐剂(○),SOX2肽(▲),pSOX2(■),或pUBVV-SOX2(◆)处理的免疫组中单个FVB/NJ小鼠的每孔点。线显示了应答的平均和SEM。***p<0.001SOX2肽,****p<0.0001pSOX2,****p<0.0001pUbVV-SOX2对比无抗原应答。虽然SOX2肽和质粒生成IFNγELISPOT应答,但是DTH应答为低水平或者在质粒和肽中不显著。又例如,图25,确定了MDM2肽和质粒在小鼠中的免疫原性和功效。(A)通过在施加50%DMSO中的MDM2肽混合物后24小时的耳厚度(mm)变化测量DTH应答。所绘是来自不同免疫组的单个FVB/NJ小鼠的应答:对照(参见方法)、MDM2Peps(肽疫苗)、pMDM2(质粒疫苗)和pUbVV-MDM2。虚线表示耳厚度与基线有0.0mm变化。***p<0.001对比对照。(B)在施加在50%DMSO中的MDM2肽混合物后24小时测量的DTH应答。所绘是来自上述不同免疫组的单个FVB/N/Tg-neu转基因小鼠的应答。***p<0.001对比对照。(C)IFNγELISPOT评价针对肽或对照刺激的T-细胞应答。各所绘点表示在用仅佐剂(○),载体(□),MDM2肽(▲),pMDM2(■),或pUBVV-MDM2(◆)处理的免疫组中单个FVB/NJ小鼠的每孔点。线显示了应答的平均和SEM。***p<0.001pMDM2对比无抗原应答。免疫后,测定小鼠重量。例如,图26显示了最后疫苗后3个月的小鼠质量。小鼠(n=5)放置未处理、用仅pUMVC3、pUMVC3-hHif1a(30-119)、或pUMVC3-hCD105(87-138),x轴,CFA/IFA作为佐剂。在最后疫苗后3个月记录各小鼠的重量,y轴,(平均±SEM)。也在最后疫苗后10天测定小鼠重量。参见图27,小鼠(n=5)放置未处理、用仅pUMVC3、pUMVC3-hHif1a(30-119)、或pUMVC3-hCD105(87-138),x轴,CFA/IFA作为佐剂。在最后疫苗后10天记录各小鼠的重量,y轴,(平均±SEM)。从IGF-1R确定并构建短和延伸表位的序列。构建2个质粒,验证DNA序列,并且用于免疫实验。短表位质粒,pIGF-IRshep,表达具有对应于人IGF-IR的串联MHCII表位的蛋白质。另外,在N-端有4个氨基酸(MAVP)且在C-端有3个氨基酸(AAA)与IGF-IR序列无关。延伸表位质粒,pIGF-IRexep,表达具有2个1360的蛋白质。另外,在N-端有4个氨基酸(MAVP)且在C-端有3个氨基酸(AAA)与IGF-IR序列无关。各质粒的载体主链是pUMVC3,其含有CMV启动子,引导哺乳动物细胞中基因的组成型表达。该载体适用于临床应用。用合成肽测试IGF-IR的C-端区中的选择表位并且在人PBMC样品的ELISPOT试验中证明了与Th2(IL-10)细胞相比诱导Th1(IFNγ)的更大刺激的倾向(原始提议中所述)。通过TgMMTVneu小鼠中的IFNγELISPOT来评价短且延伸的IGF-1R表位的免疫原性。设计免疫实验来测试TgMMTVneu小鼠中短且延伸的IGF-IR表位质粒在过继细胞转化试验中的免疫原性。每组8只小鼠以2周间隔用pIGF-IRexep、pIGF-IRshep、IGF-IR肽(p1196-1210、p1242-1256、p1332-1351、和p1341-1355)或pUMVC3(仅载体)免疫5次。用CFA-IFA佐剂以50ug/注射配制质粒和肽。在最后免疫后2周,分离各免疫组的脾细胞并使用负选择小鼠T-细胞的磁珠(MACS)来分成CD3+T-细胞和CD3-阴性部分。通过流式细胞术监测各细胞部分以确定各部分中T和B细胞的百分比。对于所有组,CD3+部分含有>96%T-细胞和<3.3%B细胞。对于所有组,CD3-阴性部分含有71-75%B细胞和2.4-6%T-细胞。然后将脾细胞部分注射到5天前已植入MMC肿瘤细胞(2x105MMC/小鼠)的未免疫TgMMTVneu小鼠的尾静脉中(106个细胞/小鼠)。测量肿瘤体积。与载体对照相比,来自肽免疫的小鼠的CD3+T-细胞显著抑制肿瘤生长(p<0.001),但是来自任一IGF-IR质粒疫苗组的CD3+T-细胞并不促进明显肿瘤保护。与载体对照相比,来自pIGF-IRexep免疫的动物的CD3-阴性脾细胞(大部分B细胞)并不显著抑制肿瘤生长(p<0.001)。来自pIFG-IRshep的CD3-阴性细胞或肽免疫的小鼠都没有控制肿瘤生长。由于T-细胞免疫是生成抗肿瘤抗体所必需的,进行了延迟型过敏(DTH)试验以显示由pIGF-IRexep免疫生成抗原特异性反应性T-细胞。FVB小鼠以2周间隔接受3次注射:pIGF-IRexep、pUMVC3载体、IGF-IR肽,或仅佐剂(质粒和肽以50ug/注射用CFA/IFA佐剂配制)。在第三次免疫后2周,通过在小鼠耳上剧烈摩擦PBS或IGF-IR肽混合物来进行DTH试验,并且监测耳肿胀3天。结果证明与用PBS处理耳相比,与载体和佐剂对照相比,在肽免疫和pIGF-IRexep-免疫的小鼠中发生针对IGF-IR肽的显著DTH应答(p<0.05,4-48小时,单向ANOVA)。与PBS处理相比,载体或佐剂对照都没有明显的DTH反应。在TgMMTVneu小鼠中短对比延伸IGF-IR表位的临床功效评价。为了直接比较短和延伸表位质粒疫苗控制肿瘤生长的能力,采用同系肿瘤抑制模型。将小鼠(TgMMTVneu)分成4个免疫组(pIGF-IRexep、pIGF-IRshep、载体和IGF-IR肽)并且在第三次免疫后7天植入同系乳腺癌细胞(MMC)。剂量如上所述。测量了MMC细胞形成肿瘤的能力,和肿瘤生长速率。与仅用载体免疫的组相比,IGF-IR肽疫苗,短表位质粒疫苗,和延伸表位质粒疫苗全部显著控制肿瘤生长(p<0.0001,从14-31天)。用pIGF-IRexep免疫的小鼠有最慢生长的肿瘤,但是它们在用pIGF-IRshep免疫的动物中的肿瘤生长上没有显著差异。通过封闭研究来确定治疗功效的作用机制。为了进一步描述B细胞和T-细胞在pIGF-IRexep和IGF-IR肽疫苗介导的肿瘤保护中的作用,使用针对T和B细胞特异性的消耗抗体来封闭重要效应物。小鼠在免疫后用特异性抗体消耗淋巴细胞类。在消耗T细胞或B细胞的动物中测量免疫后的MMC肿瘤生长。除了在其中已经消耗了B细胞或T细胞的组,与载体免疫的动物相比,pIGF-IRexep疫苗是肿瘤保护性的(p<0.01)。这一结果表明两种淋巴细胞类在保护性免疫应答中的作用。除了在其中已经消耗了T细胞的组,与载体免疫的动物相比,pIGF-IR肽疫苗是肿瘤保护性的(p<0.01)。B细胞消耗对于肽疫苗的肿瘤保护没有显著影响。延伸表位质粒疫苗可通过B细胞和T-细胞诱导肿瘤保护性免疫,但是短表位肽仅诱导肿瘤保护性T-细胞免疫。实施例6确定单个抗原疫苗的安全性和免疫原性干细胞/EMT相关蛋白质引发IgG抗体免疫。图4显示了BrCA患者和志愿者供体中抗体免疫干细胞/EMT抗原的发生率。阳性志愿者供体%显示为白色柱,而阳性BrCA患者显示为黑色柱。(A)2群之间发生率超过2倍差异的抗原,(B)2群之间阳性发生率2倍或更低。Y-轴,阳性%,X-轴,抗原。图5显示了基于群的表位筛选实验的结果。图6更详细地显示了针对干细胞/EMT蛋白质的抗原特异性IFNγ应答。针对干细胞/EMT抗原的IFNγELISPOT应答。Y-轴显示了校正的点/孔(针对背景校正)并且X-轴显示针对两个志愿者供体(白色柱)和BrCA患者(灰色柱)测试的抗原。数据表示为带杜克晶须的四分位盒图。由水平线表示中值CSPW。图7还显示了针对干细胞/EMT蛋白质的抗原特异性IL-10应答。针对干细胞/EMT抗原的IL-10ELISPOT应答。Y-轴显示了校正的点/孔(针对背景校正)并且X-轴显示针对两个志愿者供体(白色柱)和BrCA患者(灰色柱)测试的抗原。数据表示为带杜克晶须的四分位盒图。由水平线表示中值CSPW。从相同的标准操作流程(SOP)进行所有啮齿类实验,其与FDS的研究新药(IND)应用提交的要求一致。对于免疫研究,FVB/NJ小鼠(n=7/组)每7-10天用以下在耳中皮内免疫4次:CFA/IFA+PBS(对照),CFA/IFA+50μgpUMVC3(载体对照),CFA/IFA+50μg混合的各验证的从单个抗原衍生的肽,或CFA/IFA+50μg编码来自单个抗原的延伸表位的pUMVC3。在第四次免疫后3天,进行延迟型过敏测试(DTH)。肽和DNA免疫的小鼠给予50μg的等体积DMSO中的各抗原性肽,其在其未免疫的耳上摩擦。用以下处理CFA/IFA和CFA/IFA+50μgpUMVC3对照小鼠:免疫肽(n=4)、对照肽(n=4)、或DMSO+PBS(n=6),在未免疫的耳上摩擦。用DMSO中的抗原特异性肽的混合物来测试实验组。在处理前(0小时)和24小时测量耳,并且比较了2个时间点之间耳厚度的总体变化。通过杜凯氏事后检验的单向ANOVA在p=0.05水平上测量显著性以确定各对处理组之间的差异。DTH后10天,处死小鼠并处理脾用于IFNγELISPOT试验,在用抗原性刺激物或对照的2天培养中300,000个细胞/孔。通过邦弗朗尼事后检验的双向ANOVA在p=0.05水平上测量IFNγ应答的显著差异以确定比较无抗原刺激(NoAg)与各其他刺激的各处理组内的差异。对于临床功效研究,MMTV-neuTG(neuTG)或MMTV-C3(1)Tg(C3T)转基因小鼠(n=6/group)每7-10天在耳中皮内用以下免疫四次:CFA/IFA+PBS,CFA/IFA+50μgpUMVC3,CFA/IFA+50μg混合的各鉴定的短肽表位,或CFA/IFA+50μg编码所选延伸表位序列的PUMVC3。第四次免疫后的7-10天,皮下植入5x105个针对特定模型的同系肿瘤细胞。在肿瘤发展之后,每周测量2-3次。在邦弗朗尼事后检验的双向ANOVA在p=0.05水平上认为肿瘤体积有显著差异以确定在测量时间点上的各处理组对之间的差异。肿瘤植入后28天进行DTH。肽和DNA免疫的小鼠给予50μg各免疫肽+等体积DMSO,其在其未免疫的耳上摩擦。用以下处理CFA/IFA和CFA/IFA+50μgpUMVC3对照小鼠:免疫肽(n=3),对照肽(n=3),或DMSO+PBS(n=5),在未免疫的耳上摩擦。在处理前(0小时)和24小时测量耳,并且比较了2个时间点之间耳厚度的总体变化。通过杜凯氏事后检验的单向ANOVA在p=0.05水平上测量显著性以确定各对处理组之间的差异。在鼠冻存细胞上进行IFNγELISPOT,并且验证的DTH应答与IFNγELISPOT相关。在DTH与IFNγELISPOT的匹配分析,97个匹配试验和对7种不同抗原的分析中,2个测试之间有统计学显著的相关性,p<0.0001。在小鼠中进行安全性研究。图35显示多表位IGF-1R疫苗抑制植入的乳腺癌生长。小鼠每隔一周用IGF-1R肽免疫,然后皮下注射1x106MMC个细胞。数据显示8只小鼠的平均植入肿瘤测量±SEM(仅PBS(●);IGF-1R疫苗(○))。另外,图13显示了基于Yb-1质粒的疫苗的免疫原性和功效。Yb-1肽和质粒在小鼠中的免疫原性和功效。(A)通过在施加50%DMSO中的Yb-1肽混合物后24小时的耳厚度(mm)变化测量DTH应答。所绘是来自不同免疫组的单个FVB/NJ小鼠的应答:对照(参见方法)、YB1Peps(肽疫苗)、pYB1(质粒疫苗)和pUbVV-YB1。虚线表示耳厚度与基线有0.0mm变化。*p<0.05,**p<0.01,***p<0.001对比对照。(B)在施加在50%DMSO中的YB1肽混合物后24小时测量的DTH应答。所绘是来自上述不同免疫组的单个FVB/N/Tg-neu转基因小鼠的应答。*p<0.05,**p<0.01对比对照。(C)IFNγELISPOT评价针对肽或对照刺激的T-细胞应答。各所绘点表示在用仅佐剂(○),载体(□),YB1肽(▲),pYB1(■),或pUBVV-YB1(◆)处理的免疫组中单个FVB/NJ小鼠的每孔点。线显示了应答的平均和SEM。在任意组中都没有YB1肽应答的显著发现。也在TgMMTNneu小鼠中同时进行体内评价(参见图12)。构建疫苗。迄今产生的质粒构建体显示于补充表25。在pUMVC3中编码各延伸表位。一旦完成单抗原毒性研究,在用于测试的制备物中生成含多种抗原的多个构建体。通过转染到HEK293细胞中测试所有构建体的表达并且评价在存在或不存在蛋白酶体抑制剂MG132的情况下所得细胞裂解物的抗原表达。已经检测了在所有生成的构建体中转染的延伸表位的表达蛋白质。针对延伸表位的一抗是从兔抗血清亲和纯化的,该血清获自用长肽或市售抗体的延伸表位接种的兔。当在单质粒中编码多表位时,与单抗原构建体相比,HEK293细胞中单个抗原的表达的蛋白质显著增加(参见图16)。在质粒转染的HEK293细胞裂解物中的Western印迹分析证明HIF1α延伸表位表达。各质粒针对预期尺寸蛋白质表达,其在载体转染对照中不存在。分别在pHIF1α(单抗原疫苗)和pBCMA5(5抗原疫苗)-转染的HEK293裂解物中验证了HIF1α肽(10.4kDa)和BCMA5融合蛋白(43.2kDa)的HIF1α片段的表达。为了解决在一个载体中编码的多个抗原或3个单个抗原编码质粒的治疗功效,在18周用针对neu、IGF-IR和IGFBP-2的疫苗来免疫neuTG小鼠。处理仅佐剂对照组,衍生自抗原的肽的组,编码来自各单抗原的表位的3个质粒的组(50ug/各),和编码连接在一起的来自3种抗原的表位的单质粒的组。与对照相比,所有疫苗在转基因动物中显著延迟乳腺肿瘤发展,肽;p=0.0004,3质粒;p,0.0001和带3种抗原的单质粒;p=0.0003。3种疫苗方法各自之间在功效上没有统计学差异。除CDH3以外,通过DTH和ELIPOST中的任一,迄今为止测试的所有抗原在啮齿类模型中显示出免疫原性和抗肿瘤效果。例如,图3证明了抗原特异性IgG免疫。响应CDH3的IgG抗体的Western印迹验证。使用(I)多克隆抗CDH3Ab,代表性的ELISA阳性BrCA患者样品(II)和ELISA阴性对象样品(III)的探测重组人CDH3的Western印迹。分子量标(最左)。CDH3的大小标记为175kDa。通过血液化学和组织学研究来确定免疫的毒性。在用任意抗原免疫的任意小鼠中没有观察到免疫的不希望效果。小鼠在最终分析之前没有经历体重减轻或理毛减少。对单个抗原疫苗的急性和慢性毒性研究没有看到毒性;血液,化学或组织学。急性和慢性毒性报告(针对SATB1和CDC25B)。在第四次免疫后1周进行急性毒性研究并且在第四次免疫后3个月进行慢性毒性研究。如图36所示,多抗原多表位疫苗在neu-TG小鼠中防止乳腺癌发展。(A)无疾病存活(B)总存活(n=15/组)。SATB1和CDC25B毒性结果慢性毒性研究。使用CFA/IFA,每隔7-10天用100mcg仅pUMVC3、pUMVC3-hSATB1(387-450)或pUMVC3-hCDC25B(124-164)注射小鼠4次。对照小鼠未处理(参见表1和3)。表1:免疫和组织/血液收集时间血清化学和CBC。所有组的所有血清化学和完全血液计数值与对照(未处理)小鼠没有显著差异,除了CDC25B组中的HCT、SATB1组中的MCH、以及pUMVC3和SATB1组中的Polys(参见表5和6)。应注意,所有组的HCT值在所建立的范围限内。另外,虽然SATB1组的MCH值明显不同,其比对照组更接近获自杰克逊实验室的建立的值范围(15.2-15.6pg)。pUMVC3载剂也实现了Polys%的显著性,其表示差异可能是载剂作用而不是SATB1插入的直接结果(参见表5-16)。病理学。没有与治疗相关的病灶,其可被认为与区分组之间的毒性响应相一致(参见表13-16)。重量。免疫后3个月,接受pUMVC3-hSATB1(387-450)的动物重量为23.4±2.3克(g),接受pUMVC3-hCDC25B(124-164)的为23.4±1.3g,接受pUMVC3的为23.6±1.4g并且健康未处理对照为21.5±1.1。在任意组之间没有统计学显著差异(参见表17-24)。急性毒性研究。使用CFA/IFA,每隔7-10天用100mcg仅pUMVC3、pUMVC3-hSATB1(387-450)或pUMVC3-hCDC25B(124-164)注射小鼠4次。对照小鼠未处理(参见表2)。表2:免疫和组织/血液收集时间血清化学和CBC。所有组的所有血清化学和完全血液计数值与对照(未处理)小鼠没有显著差异,除了SATB1和CDC25B组中的氯,CDC25B组中的钙、Osm、ALT、Polys,和pUMVC3组中的淋巴(参见表7和8)。应注意,SATB1和CDC25B组中的氯比对照组更接近建立的范围(110-204meq/l)。类似地,CDC25B组中的Osm比对照组更接近建立的范围(321-330任意单位)。所有组的ALT在建立的范围限内(参见表5-16)。病理学。没有与治疗相关的病灶,其可被认为与区分组之间的毒性响应相一致(表17-24)。重量。免疫后10天,接受pUMVC3-hSATB1(387-450)的动物重量为20.9±0.7克(g),接受pUMVC3-hCDC25B(124-164)的为21±1.2g,接受pUMVC3的为21.3±1.0g并且健康未处理对照为21.4±1.5g。任意组间没有统计学显著差异。Hif1a和CD105毒性结果慢性毒性研究。使用CFA/IFA,每隔7-10天用100mcg仅pUMVC3、pUMVC3-hHif1a(30-119)或pUMVC3-hCD105(87-138)注射小鼠4次。对照小鼠未处理(参见表3)。表3:免疫和组织/血液收集时间血清化学和CBC。所有组的所有血清化学和完全血液计数值与对照(未处理)小鼠没有显著差异,除了pUMVC3和Hif1a组中的BUN、所有组中的阴离子间隙、pUMVC3组中的渗透压、以及Hif1a和CD105组中的胆固醇(参见表9和10)。应注意,明显不同组中的BUN和阴离子间隙比对照组更接近建立的范围(分别是18-28mg/dl和23.3-27任意单位)。渗透压的建立的范围是321-330,但没有组在该范围内,并且处理组与未处理小鼠没有显著差异。虽然与对照组相比,处理组中胆固醇明显不同,但所有组的值在50-138的建立的范围限内(参见表5-16)。病理学。收集器官用于该研究,但还未由病理学家分析(参见表17-24)。重量。免疫后3个月,接受pUMVC3-hHif1a(30-119)的动物重量为23.4±2.4克(g),接受pUMVC3-hCD105(87-138)的为22.3±1.6g,接受pUMVC3的为21.5±1.4g并且健康未处理对照为23.1±1.7g。任意组间没有统计学显著差异。急性毒性研究。使用CFA/IFA,每隔7-10天用100mcg仅pUMVC3、pUMVC3-hHif1a(30-119)或pUMVC3-hCD105(87-138)注射小鼠4次。对照小鼠未处理(参见表4)。表4:免疫和组织/血液收集时间血清化学和CBC。所有组的所有血清化学和完全血液计数值与对照(未处理)小鼠没有显著差异,除了Hif1a组中的胆固醇和球蛋白,所有组的磷,pUMVC3组中的钙,CD105组中的氯,以及pUMVC3和Hif1a组中的淋巴和白细胞(参见表5-16)。虽然与对照组相比胆固醇、白细胞和钙在Hif1a组中明显不同,但所有组的值分别在50-138mg/dl、2-15K/μL和8-14meq/l的建立的范围限内。应注意,治疗组中的球蛋白、氯和磷比对照组更接近建立的范围(分别为1.9-2.4g/dL,110-204meq/l和4.6-10.8mg/dl)(参见表5-16)。病理学。没有与治疗相关的病灶,其可被认为与区分组之间的毒性响应相一致(表17-24)。重量。免疫后10天,接受pUMVC3-hHif1a(30-119)的动物重量为20.8±1.6克(g),接受pUMVC3-hCD105(87-138)的为20.5±1.4g,接受pUMVC3的为21.5±2.2g并且健康未处理对照为21.1±1.1g。在任意组之间没有统计学显著差异(参见表5-16)。表5:所有组的(慢性)血清化学汇总(中值和范围)*p<0.05与对照(未处理)相比表6:所有组的(慢性)CBC汇总(中值和范围)*p<0.05与对照(未处理)相比表7:所有组的(急性)血清化学汇总(中值和范围)*p<0.05与对照(未处理)相比表8:所有组的(急性)CBC汇总(中值和范围)*p<0.05与对照(未处理)相比表9:所有组的(慢性)血清化学汇总(中值和范围)**p<0.01与对照(未处理)相比*p<0.05与对照(未处理)相比表10:所有组的(慢性)血清化学汇总(中值和范围)表11:所有组的(急性)血清化学汇总(中值和范围)*p<0.05与对照(未处理)相比表12:所有组的(急性)血清化学汇总(中值和范围)*p<0.05与对照(未处理)相比表13:对照(未处理)小鼠(慢性)组织学NSL:无明显病灶MF:多病灶MG:微肉芽肿NA:组织不可得表14:pUMVC3免疫小鼠(慢性)组织学FE:病灶扩大LH:淋巴增生MZ:边缘区EMH:髓外造血PV:副血管PB:副支气管LA:淋巴聚集表15:pUMVC3-hSATB1(387-450)免疫小鼠(慢性)组织学表16:pUMVC3-hCDC25B(124-164)免疫小鼠(慢性)组织学表17:对照(未处理)小鼠组织学表18:pUMVC3免疫小鼠组织学表19:pUMVC3-hSATB1(387-450)免疫小鼠组织学表20:pUMVC3-hCDC25B(124-164)免疫小鼠组织学ISCH:窦内细胞过多表21:未处理(对照)小鼠组织学表22:pUMVC3免疫小鼠组织学表23:pUMVC3-hHif1a(30-119)免疫小鼠组织学表24:pUMVC3-hHif1a(87-138)免疫小鼠组织学DLN:引流淋巴结表25中提供了基于质粒的疫苗的示例性列表,其中的一些如本文所述向对象给予。表25:现已构建的基于质粒的疫苗实施例7确定多表位抗原疫苗在人中的安全性和免疫原性示例性组合物示于图14,组合物是疫苗并称为STEMVAC。图15A显示了肽特异性T-细胞验证为天然表位。肽(A)和HIF1α蛋白质(B)诱导IFNγ应答。*表示p<0.05对比无抗原(白色柱)。C-D,肽(10ug/ml;C)和蛋白质(1ug/ml;D)(黑色柱)诱导被MHCIIAb而非MHC1Ab(深灰色)抑制的应答。**表示p<0.05对比肽或蛋白质。浅灰色,仅MHCII和MHCIAb。另一种示例性的组合物是包含HER2表位的疫苗。图31显示基于HER2Th1表位的疫苗可增加存活率,其与在晚期HER2+乳腺癌患者中扩散的表位相关。(A)在中值跟踪8.5年时,HER2Th1免疫后的IV期乳腺癌患者的总存活率为38%。时间0表示免疫起点。(B)免疫患者的卡普兰-迈耶曲线;表位扩散阳性(ES+,实线)(中值84个月)和阴性(ES-,虚线)患者(中值24个月)之间的总存活率。图32显示了比较基于质粒和肽的疫苗的结果。基于延伸的Th质粒的疫苗比基于肽的疫苗在生成肿瘤抗原特异性Th1免疫上更有效。显示了组1(○)和组2(●)的免疫后ELISPOT应答。针对HER2ICDTh肽776和HER2ICD或ECD蛋白质结构域的ELISPOT应答报告为抗原特异性T-细胞/106PBMC,各圆圈表示单个患者应答;并且粗线表示所有组的中值。在基于质粒DNA的免疫结束后超过一年的持续性HER2ICD特异性免疫力。10名患者显示了针对HER2ICD的HER2ICD特异性IFNγELISPOT应答。参见图33。针对各对象绘制的值是免疫前(pre)、免疫期间的最大应答(max)和1年后应答(LTFU)。在对来自接受免疫的8名晚期HER2+乳腺癌患者的HER2肽疫苗的II期研究进行期间使用来自ELISPOT试验的上清。图37中,通过细胞因子多重化收集的值经颜色编码为接种的抗原特异性细胞因子增加(红色)或减少(蓝色)的量级(显示为细胞因子“热图”)。颜色的强度象征应答的最低(浅)到最高(深)四分位。数据显示了针对HER2ICD蛋白质(免疫抗原)的Th应答的具体图案;Th1/17,Th2,和“混合”。患者12和17通过免疫增加HER2特异性I型细胞因子和IL-17分泌。Th1型应答与在用设计为引发Th1免疫的疫苗免疫后所预期的相似。患者16同时减少HER2特异性Th1和Th17细胞因子产生。该现象可能限制了肿瘤抗原特异性免疫的发展或停留。数据表示为疫苗后减去疫苗前细胞因子水平(最后疫苗后1个月)。深红:第四(最高)四分位显示细胞因子水平增加,分别反映第三、第二和第一四分位增加的递减红色。深蓝:第四(最高)四分位显示细胞因子水平减少,分别反映第三、第二和第一四分位减少的递减蓝色。实施例8表26.表位和构建体序列实施例9多抗原构建体设计和表达pUMVC3-IGFBP2-生存素-HIF1a-IGF1R融合构建体按照图40和表27。融合蛋白在HEK-293细胞中表达,并且通过Western印迹分析来检验蛋白质表达。进一步使用NIHImageJ软件来对蛋白质表达条带进行定量。图41显示了IGFBP-2、生存素、HIF-1A、和IGF-1R的蛋白质表达。表27.肿瘤抗原RefSeq编号氨基酸小鼠同源性IGFBP-2NP_0005881-16372%生存素NP_00115983-12087%HIF1aNP_00152130-11994%IGF-IRNP_0008661196-1261100%1323-136097%实施例10用荧光素酶载体通过慢病毒感染ID8和细胞系选择在8μg/ml聚凝胺(EMD密理博公司)存在下,用2mL/孔的pLentiIII-Luc2病毒载体上清(应用生物材料公司)来感染衍生自C57B6小鼠的卵巢表皮细胞,ID8细胞。在37℃/5%CO2下过夜孵育之后,去除病毒上清和含聚凝胺的培养基,并且在加入预热的培养基之前用PBS洗涤。细胞在生长培养基中培养72小时,然后置于每天添加的1μg/mL嘌呤霉素(英杰公司)的药物选择下。在白色96孔板(EMD密理博公司)中每孔加入100μl的细胞,并且刚好在读取之前加入等体积的3000μg/mld-荧光素。基于在加入底物后的作为功能性荧光素酶表达测量的最大相对光单位来选择细胞系。ID8-luc2肿瘤的体内增殖。AlbinoC57/BL/6/BrdCsHsd-Tyrc(哈伦实验室(HarlanLaboratories))给予200μL的5X106个ID8细胞的腹膜内注射。对于仰卧位的小鼠,使用左下象限的25号针来注射一半剂量,并且在右下象限注射另一半。在肿瘤植入后的预定间隔时,小鼠经称重、采血和成像以监测肿瘤增殖。生物发光/成像。用使用D-荧光素的XenogenIVIS(体内成像方案)来拍摄生物发光图像(图42A-42B)。用LivingImage软件(帕金埃尔默公司)来对图像进行标准化。计算并且报告各小鼠的上腹部(转移)或下腹部(原发)区域的每秒总光子流和最大发光强度。图42A显示了原发植入物的总流(光子/秒)并且图3B显示了转移部位处的总流。另外,相应的动物显示为仅佐剂(图42C),和三抗原免疫(图42D)。实施例11鉴定用于开发人疫苗的混杂MHCII类表位的方法。使用从3个不同公开算法的汇编结果鉴定常见的HLA-DR蛋白质中14种的预测MHCII表位。使用算法生成表位结合评分来对预测含有与多种HLA-DR蛋白质相互作用的表位的蛋白质序列内的表位进行作图,这些表位称为“混杂表位”。算法筛选的14种HLA-DR蛋白质为:HLA-DRB1*0101、HLA-DRB1*0301、HLA-DRB1*0401、HLA-DRB1*0404、HLA-DRB1*0405、HLA-DRB1*0701、HLA-DRB1*0802、HLA-DRB1*0901、HLA-DRB1*1101、HLA-DRB1*1201、HLA-DRB1*1302、HLA-DRB1*1501、HLA-DRB4*0101、和HLA-DRB5*0101。采用的基于网页的算法是SYFPEITHI(http://www.syfpeithi.de/Scripts/MHCServer.dll/EpitopePrediction.htm)、PROPRED(http://www.imtech.res.in/raghava/propred/)、和RANKPEP(http://imed.med.ucm.es/Tools/rankpep.html)。可用于筛选的HLA-DR蛋白质的数量在各网站之间变化(上述14种中的6、11或13种)。从NCBI数据库中获得参考蛋白质序列并且复制到FASRA格式中用于进入算法搜索引擎并且使用各HLA-DR蛋白质的前20种评分表位来产生参考蛋白质的“MHCII热图”。为了汇编和分析表位预测数据,开发基于MSExcel的工作簿,称为“MHCII热图模板”。由于三种算法各自有鉴定表位的不同评分系统,在汇编来自不同检索方法的结果之前首先标准化表位评分。为了标准化表位评分,所有评分除以通过各算法获得的顶部分数,使得具有最高预测亲和性的表位应具有1.0的标准化评分。然后将标准化的评分粘贴到MHCII热图模板中,其用多个包埋的等式和功能来进行以下任务:(i)特定表位的各氨基酸分配表位的标准化评分,(ii)计算并绘制在各氨基酸位置处有表位的不同HLA-DR蛋白质/等位基因的数量,(iii)在各氨基酸位置处计算并绘制各表位的标准化评分的总和,和(iv)计算并绘制“多评分”,其为标准化的评分总和与HLA-DR等位基因的积。多评分表示表位结合强度和表位混杂性,并且可使用该值来产生参考蛋白质的MHCII热图。氨基酸位置(x轴)对比多评分(y轴)的图能够易于观察预测含有混杂表位的蛋白质区。另外,产生MSAccess应用以简化FASTA蛋白质序列输入到MHCII热图模板的纵列。一旦蛋白质序列已经进入,可通过基于多评分值的氨基酸颜色编码产生MHCII热图来辅助用于免疫试验的肽选择。一般而言,颜色编码表示75-100%、50-75%、25-50%、和10-25%的多评分。基于复合评分来构建肽。通过针对由覆盖最少25%蛋白质的预测表位诱导的抗原特异性IFN-γ(g)和IL-10产生的ELISPOT来评价来自40个人供体的外周血单核细胞(PBMC)。对于IFN-gELISPOT,细胞以2x105/孔(96孔板)接种到含10μg/mL各种肽或HIVp17,PHA(1μg/ml),CEF(2.5μg/mL)的培养基中或仅培养基中在37℃下5%CO2中持续7天。在第5天,加入重组人IL-2(10U/ml)。通过在第8天向原始培养物加入2x105肽-加载的(与上述相同浓度)自体辐射(3000rads)人PBMC进行第二体外刺激(IVS),并孵育24小时。用10ug/ml抗-人IFN-g包被96孔硝酸纤维素板。用DPBS中2%牛血清白蛋白之后用PBMC培养复孵育24小时来封闭洗涤的硝酸纤维素板。在充分洗涤后,加入生物素化的抗-人IFN-g持续2小时。对于IL-10ELISPOT,如上所述封闭抗-人IL-10包被(2μg/ml)硝酸纤维素96孔板。PBMC浓度和肽刺激如上所述,除了以20μg/ml使用PHA。在充分洗涤后,加入生物素化的抗-人IL-10持续2小时。在充分洗涤之后,加入1μg/mL链霉亲和素-AP持续45分钟。通过用BCIP孵育平板使点可视化并且在C.T.L.ELISPOT酶标仪上对NBT溶液点进行计数。原始数据输入TVG数据库ELISPOT工具并且通过实验孔中5个重复点的平均数与无抗原对照孔的平均数之间的统计学显著差异(p<0.05)来定义阳性应答。产生TH1/TH2比率,其使用以下算法分析各预测的II类特异性肽的ELISPOT应答的量级和频率:(每孔校正平均点)x(响应供体百分比)。使用抗原特异性T-细胞刺激介质以及通过针对复合TH1/TH2表型的多重试验,TH1/TH2活性比率也衍生自针对I型和II型细胞因子的ELISA试验。以相似方式将发生率和量级纳入这些分析中。图43A和图43B显示了随着蛋白质序列变化的TH1响应。在生存素的C-端和HIF1a的N-端中鉴定选择性TH1诱导序列。由供体类型显示每种肽的平均cSPWx发生率。正y-轴上显示了志愿供体(n=20)(白色)和癌症供体(n=20)(灰色)的IFN-gcSPWx发生率。负y-轴上显示了志愿供体(实心黑)和癌症供体(虚点黑)的IL-10cSPWx发生率。图43A显示了相应于HIF-1A肽的TH1响应。图43B显示了相应于生存素肽的TH1响应。垂直线显示选择的序列。实施例12抗体免疫的研究显示IGF-IR、HIF1a和生存素也是卵巢癌抗原(图44)。之前证明IGFBP-2在卵巢癌患者中有免疫原性。在120名卵巢癌患者的初次手术时获取血清样品,并通过使用市售重组蛋白质的间接ELISA分析。以相似的方式分析100名年龄匹配的志愿者对照血清。IgG抗体评价为细胞免疫的指示物,因为需要同系CD4+T-细胞来将免疫球蛋白类型从IgM转化成IgG。通过Western印迹确认结果。卵巢癌患者有比对照明显更高水平的针对抗原性蛋白质的抗体(图44)。患者也证明比对照明显(范围1-6%)更高的抗体发生率,其范围8-25%阳性(中值15%)。序列表<110>M·L·迪西斯(Disis,MaryL.)D·塞西尔(Cecil,Denise)M·斯洛塔(Slota,Meredith)<120>乳腺癌和卵巢癌疫苗<130>41299-768.602<150>US61/972,176<151>2014-03-28<160>91<170>PatentInversion3.5<210>1<211>52<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>1GlnAsnGlyThrTrpProArgGluValLeuLeuValLeuSerValAsn151015SerSerValPheLeuHisLeuGlnAlaLeuGlyIleProLeuHisLeu202530AlaTyrAsnSerSerLeuValThrPheGlnGluProProGlyValAsn354045ThrThrGluLeu50<210>2<211>156<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>2cagaacggcacctggccccgcgaggtgctgctggtgctgtccgtgaactcctccgtgttc60ctgcacctacaggccctgggcatccccctgcacctggcctacaactcctccctggtgacc120ttccaggagccccccggcgtgaacaccaccgagctg156<210>3<211>276<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>3accgtgttcatgcgcctgaacatcatctcccccgacctgtccggctgcacctccaagggc60ctggtgctgcccgccgtgctgggcatcaccttcggcgccttcctgatcggcgccctgctg120accgccgccctgtggtacatctactcccacacccgctccccctccaagcgcgagcccgtg180gtggccgtggccgcccccgcctcctccgagtcctcctccaccaaccactccatcggctcc240acccagtccaccccctgctccacctcctccatggcc276<210>4<211>267<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>4accgtgtccatgcgcctgaacatcgtgtcccccgacctgtccggcaagggcctggtgctg60ccctccgtgctgggcatcaccttcggcgccttcctgatcggcgccctgctgaccgccgcc120ctgtggtacatctactcccacacccgcggcccctccaagcgcgagcccgtggtggccgtg180gccgcccccgcctcctccgagtcctcctccaccaaccactccatcggctccacccagtcc240accccctgctccacctcctccatggcc267<210>5<211>267<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>5accgtgtccatgcgcctgaacatcgtgtcccccgacctgtccggcaagggcctggtgctg60ccctccgtgctgggcatcaccttcggcgccttcctgatcggcgccctgctgaccgccgcc120ctgtggtacatctactcccacacccgcgccccctccaagcgcgagcccgtggtggccgtg180gccgcccccgcctcctccgagtcctcctccaccaaccactccatcggctccacccagtcc240accccctgctccacctcctccatggcc267<210>6<211>18<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>6GluAlaArgMetLeuAsnAlaSerIleValAlaSerPheValGluLeu151015ProLeu<210>7<211>52<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>7GlnAsnGlyThrTrpProArgGluValLeuLeuValLeuSerValAsn151015SerSerValPheLeuHisLeuGlnAlaLeuGlyIleProLeuHisLeu202530AlaTyrAsnSerSerLeuValThrPheGlnGluProProGlyValAsn354045ThrThrGluLeu50<210>8<211>92<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>8ThrValPheMetArgLeuAsnIleIleSerProAspLeuSerGlyCys151015ThrSerLysGlyLeuValLeuProAlaValLeuGlyIleThrPheGly202530AlaPheLeuIleGlyAlaLeuLeuThrAlaAlaLeuTrpTyrIleTyr354045SerHisThrArgSerProSerLysArgGluProValValAlaValAla505560AlaProAlaSerSerGluSerSerSerThrAsnHisSerIleGlySer65707580ThrGlnSerThrProCysSerThrSerSerMetAla8590<210>9<211>89<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>9ThrValSerMetArgLeuAsnIleValSerProAspLeuSerGlyLys151015GlyLeuValLeuProSerValLeuGlyIleThrPheGlyAlaPheLeu202530IleGlyAlaLeuLeuThrAlaAlaLeuTrpTyrIleTyrSerHisThr354045ArgGlyProSerLysArgGluProValValAlaValAlaAlaProAla505560SerSerGluSerSerSerThrAsnHisSerIleGlySerThrGlnSer65707580ThrProCysSerThrSerSerMetAla85<210>10<211>89<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>10ThrValSerMetArgLeuAsnIleValSerProAspLeuSerGlyLys151015GlyLeuValLeuProSerValLeuGlyIleThrPheGlyAlaPheLeu202530IleGlyAlaLeuLeuThrAlaAlaLeuTrpTyrIleTyrSerHisThr354045ArgAlaProSerLysArgGluProValValAlaValAlaAlaProAla505560SerSerGluSerSerSerThrAsnHisSerIleGlySerThrGlnSer65707580ThrProCysSerThrSerSerMetAla85<210>11<211>96<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>11ggagtgccagtgcagggctccaagtacgctgccgaccgcaaccactaccgccgctaccca60cgccgtcgcggcccaccccgcaactaccagcagaac96<210>12<211>96<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>12ggcgtgcccgtgcagggctccaagtacgccgccgaccgcaaccactaccgccgctacccc60cgccgccgcggccccccccgcaactaccagcagaac96<210>13<211>96<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>13ggcgtgcccgtgcagggctccaagtacgccgccgaccgcaaccactaccgccgctacccc60cgccgccgcggccccccccgcaactaccagcagaac96<210>14<211>17<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>14GluAspValPheValHisGlnThrAlaIleLysLysAsnAsnProArg151015Lys<210>15<211>14<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>15TyrArgArgAsnPheAsnTyrArgArgArgArgProGluAsn1510<210>16<211>32<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>16GlyValProValGlnGlySerLysTyrAlaAlaAspArgAsnHisTyr151015ArgArgTyrProArgArgArgGlyProProArgAsnTyrGlnGlnAsn202530<210>17<211>177<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>17ggcctcaatgcgcacggcgcagcgcagatgcagcccatgcaccgctacgacgtgagcgcc60ctgcagtacaactccatgaccagctcgcagacctacatgaacggctcgcccacctacagc120atgtcctactcgcagcagggcacccctggcatggctcttggctccatgggttcggtg177<210>18<211>177<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>18ggcctgaacgcccacggcgccgcccagatgcagcccatgcaccgctacgacgtgtccgcc60ctgcagtacaactccatgacctcctcccagacctacatgaacggctcccccacctactcc120atgtcctactcccagcagggcacccccggcatggccctgggctccatgggctccgtg177<210>19<211>177<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>19ggcctgaacgcccacggcgccgcccagatgcagcccatgcaccgctacgacgtgtccgcc60ctgcagtacaactccatgacctcctcccagacctacatgaacggctcccccacctactcc120atgtcctactcccagcagggcacccccggcatggccctgggctccatgggctccgtg177<210>20<211>59<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>20GlyLeuAsnAlaHisGlyAlaAlaGlnMetGlnProMetHisArgTyr151015AspValSerAlaLeuGlnTyrAsnSerMetThrSerSerGlnThrTyr202530MetAsnGlySerProThrTyrSerMetSerTyrSerGlnGlnGlyThr354045ProGlyMetAlaLeuGlySerMetGlySerVal5055<210>21<211>240<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>21aggtcactgaaggaaaggaatccattgaaaatcttcccatccaaacgtatcttacgaaga60cacaagagagattgggtggttgctccaatatctgtccctgaaaatggcaagggtcccttc120ccacagagactgaatcagctcaagtctaataaagatagagacaccaagattttctacagc180atcacggggccgggtgcagacagcccacctgagggtgtcttcgctgtagagaaggagaca240<210>22<211>216<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>22ttgaaaatcttcccatccaaacgtatcttacgaagacacaagagagattgggtggttgct60ccaatatctgtccctgaaaatggcaagggtcccttcccacagagactgaatcagctcaag120tctaataaagatagagacaccaagattttctacagcatcacggggccgggtgcagacagc180ccacctgagggtgtcttcgctgtagagaaggagaca216<210>23<211>216<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>23ttgaaaatcttcccatccaaacgtatcttacgaagacacaagagagattgggtggttgct60ccaatatctgtccctgaaaatggcaagggtcccttcccacagagactgaatcagctcaag120tctaataaagatagagacaccaagattttctacagcatcacggggccgggtgcagacagc180ccacctgagggtgtcttcgctgtagagaaggagaca216<210>24<211>216<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>24gtgatgaactcccccccctcccgcatcctgcgccgccgcaagcgcgagtgggtgatgccc60cccatctccgtgcccgagaacggcaagggccccttcccccagcgcctgaaccagctgaag120tccaacaaggaccgcggcaccaagctgttctactccatcaccggccccggcgccgactcc180ccccccgagggcgtgttcaccatcgagaaggagacc216<210>25<211>80<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>25ArgSerLeuLysGluArgAsnProLeuLysIlePheProSerLysArg151015IleLeuArgArgHisLysArgAspTrpValValAlaProIleSerVal202530ProGluAsnGlyLysGlyProPheProGlnArgLeuAsnGlnLeuLys354045SerAsnLysAspArgAspThrLysIlePheTyrSerIleThrGlyPro505560GlyAlaAspSerProProGluGlyValPheAlaValGluLysGluThr65707580<210>26<211>72<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>26LeuLysIlePheProSerLysArgIleLeuArgArgHisLysArgAsp151015TrpValValAlaProIleSerValProGluAsnGlyLysGlyProPhe202530ProGlnArgLeuAsnGlnLeuLysSerAsnLysAspArgAspThrLys354045IlePheTyrSerIleThrGlyProGlyAlaAspSerProProGluGly505560ValPheAlaValGluLysGluThr6570<210>27<211>72<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>27AlaMetHisSerProProThrArgIleLeuArgArgArgLysArgGlu151015TrpValMetProProIlePheValProGluAsnGlyLysGlyProPhe202530ProGlnArgLeuAsnGlnLeuLysSerAsnLysAspArgGlyThrLys354045IlePheTyrSerIleThrGlyProGlyAlaAspSerProProGluGly505560ValPheThrIleGluLysGluSer6570<210>28<211>72<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>28ValMetAsnSerProProSerArgIleLeuArgArgArgLysArgGlu151015TrpValMetProProIleSerValProGluAsnGlyLysGlyProPhe202530ProGlnArgLeuAsnGlnLeuLysSerAsnLysAspArgGlyThrLys354045LeuPheTyrSerIleThrGlyProGlyAlaAspSerProProGluGly505560ValPheThrIleGluLysGluThr6570<210>29<211>231<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>29acctacaccatgaaggaggtgctgttctacctgggccagtacatcatgaccaagcgcctg60tacgacgagaagcagcagcacatcgtgtactgctccaacgacctgctgggcgacctgttc120ggcgtgccctccttctccgtgaaggagcaccgcaaaatctacaccatgatctaccgcaac180ctggtggtggtgaaccagcaggagtcctccgactccggcacctccgtgtcc231<210>30<211>222<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>30acctacaccatgaaggagatcatcttctacatcggccagtacatcatgaccaagcgcctg60tacgacgagaagcagcagcacatcgtgtactgctccaacgacctgctgggcgacgtgttc120ggcgtgccctccttctccgtgaaggagcaccgcaagatctacgccatgatctaccgcaac180ctggtggccgtgtcccagcaggactccggcacctccctgtcc222<210>31<211>222<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>31atctacaccatgaaggagatcatcttctacatcggccagtacatcatgaccaagcgcctg60tacgacgagaagcagcagcacatcgtgtactgctccaacgacctgctgggcgacgtgttc120ggcgtgccctccttctccgtgaaggagcaccgcaagatctacgccatgatctaccgcaac180ctggtggtggtgtcccagcaggactccggcacctccccctcc222<210>32<211>76<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>32ThrTyrThrMetLysGluValLeuPheTyrLeuGlyGlnTyrIleMet151015ThrLysArgLeuTyrAspGluLysGlnGlnHisIleValTyrCysSer202530AsnAspLeuLeuGlyAspLeuPheGlyValProSerPheSerValLys354045GluHisArgLysIleTyrThrMetIleTyrArgAsnLeuValValVal505560AsnGlnGlnGluSerSerAspSerGlyThrSerVal657075<210>33<211>74<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>33ThrTyrThrMetLysGluIleIlePheTyrIleGlyGlnTyrIleMet151015ThrLysArgLeuTyrAspGluLysGlnGlnHisIleValTyrCysSer202530AsnAspLeuLeuGlyAspValPheGlyValProSerPheSerValLys354045GluHisArgLysIleTyrAlaMetIleTyrArgAsnLeuValAlaVal505560SerGlnGlnAspSerGlyThrSerLeuSer6570<210>34<211>74<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>34IleTyrThrMetLysGluIleIlePheTyrIleGlyGlnTyrIleMet151015ThrLysArgLeuTyrAspGluLysGlnGlnHisIleValTyrCysSer202530AsnAspLeuLeuGlyAspValPheGlyValProSerPheSerValLys354045GluHisArgLysIleTyrAlaMetIleTyrArgAsnLeuValValVal505560SerGlnGlnAspSerGlyThrSerProSer6570<210>35<211>987<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>35atggcggtacccatgcaactgtcctgctctagacagaacggcacctggccccgcgaggtg60ctgctggtgctgtccgtgaactcctccgtgttcctgcacctacaggccctgggcatcccc120ctgcacctggcctacaactcctccctggtgaccttccaggagccccccggcgtgaacacc180accgagctgagatccaccggtggagtgccagtgcagggctccaagtacgctgccgaccgc240aaccactaccgccgctacccacgccgtcgcggcccaccccgcaactaccagcagaacacg300cgtggcctcaatgcgcacggcgcagcgcagatgcagcccatgcaccgctacgacgtgagc360gccctgcagtacaactccatgaccagctcgcagacctacatgaacggctcgcccacctac420agcatgtcctactcgcagcagggcacccctggcatggctcttggctccatgggttcggtg480agatcccaattgaggtcactgaaggaaaggaatccattgaaaatcttcccatccaaacgt540atcttacgaagacacaagagagattgggtggttgctccaatatctgtccctgaaaatggc600aagggtcccttcccacagagactgaatcagctcaagtctaataaagatagagacaccaag660attttctacagcatcacggggccgggtgcagacagcccacctgagggtgtcttcgctgta720gagaaggagacaagatccgccggcgaaacctacaccatgaaggaggtgctgttctacctg780ggccagtacatcatgaccaagcgcctgtacgacgagaagcagcagcacatcgtgtactgc840tccaacgacctgctgggcgacctgttcggcgtgccctccttctccgtgaaggagcaccgc900aaaatctacaccatgatctaccgcaacctggtggtggtgaaccagcaggagtcctccgac960tccggcacctccgtgtccagatcttag987<210>36<211>1059<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>36atggcggtacccatgaccgtgttcatgcgcctgaacatcatctcccccgacctgtccggc60tgcacctccaagggcctggtgctgcccgccgtgctgggcatcaccttcggcgccttcctg120atcggcgccctgctgaccgccgccctgtggtacatctactcccacacccgctccccctcc180aagcgcgagcccgtggtggccgtggccgcccccgcctcctccgagtcctcctccaccaac240cactccatcggctccacccagtccaccccctgctccacctcctccatggccaccggtgga300gtgccagtgcagggctccaagtacgctgccgaccgcaaccactaccgccgctacccacgc360cgtcgcggcccaccccgcaactaccagcagaacacgcgtggcctcaatgcgcacggcgca420gcgcagatgcagcccatgcaccgctacgacgtgagcgccctgcagtacaactccatgacc480agctcgcagacctacatgaacggctcgcccacctacagcatgtcctactcgcagcagggc540acccctggcatggctcttggctccatgggttcggtgagatcccaattgttgaaaatcttc600ccatccaaacgtatcttacgaagacacaagagagattgggtggttgctccaatatctgtc660cctgaaaatggcaagggtcccttcccacagagactgaatcagctcaagtctaataaagat720agagacaccaagattttctacagcatcacggggccgggtgcagacagcccacctgagggt780gtcttcgctgtagagaaggagacaagatccgccggcgaaacctacaccatgaaggaggtg840ctgttctacctgggccagtacatcatgaccaagcgcctgtacgacgagaagcagcagcac900atcgtgtactgctccaacgacctgctgggcgacctgttcggcgtgccctccttctccgtg960aaggagcaccgcaaaatctacaccatgatctaccgcaacctggtggtggtgaaccagcag1020gagtcctccgactccggcacctccgtgtccagatcttag1059<210>37<211>1041<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>37atggcggtacccatgaccgtgtccatgcgcctgaacatcgtgtcccccgacctgtccggc60aagggcctggtgctgccctccgtgctgggcatcaccttcggcgccttcctgatcggcgcc120ctgctgaccgccgccctgtggtacatctactcccacacccgcggcccctccaagcgcgag180cccgtggtggccgtggccgcccccgcctcctccgagtcctcctccaccaaccactccatc240ggctccacccagtccaccccctgctccacctcctccatggccaccggtggcgtgcccgtg300cagggctccaagtacgccgccgaccgcaaccactaccgccgctacccccgccgccgcggc360cccccccgcaactaccagcagaacacgcgtggcctgaacgcccacggcgccgcccagatg420cagcccatgcaccgctacgacgtgtccgccctgcagtacaactccatgacctcctcccag480acctacatgaacggctcccccacctactccatgtcctactcccagcagggcacccccggc540atggccctgggctccatgggctccgtgagatcccaattggccatgcactccccccccacc600cgcatcctgcgccgccgcaagcgcgagtgggtgatgccccccatcttcgtgcccgagaac660ggcaagggccccttcccccagcgcctgaaccagctgaagtccaacaaggaccgcggcacc720aagatcttctactccatcaccggccccggcgccgactccccccccgagggcgtgttcacc780atcgagaaggagtccagatccgccggcgaaacctacaccatgaaggagatcatcttctac840atcggccagtacatcatgaccaagcgcctgtacgacgagaagcagcagcacatcgtgtac900tgctccaacgacctgctgggcgacgtgttcggcgtgccctccttctccgtgaaggagcac960cgcaagatctacgccatgatctaccgcaacctggtggccgtgtcccagcaggactccggc1020acctccctgtccagatcttag1041<210>38<211>1041<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>38atggcggtacccatgaccgtgtccatgcgcctgaacatcgtgtcccccgacctgtccggc60aagggcctggtgctgccctccgtgctgggcatcaccttcggcgccttcctgatcggcgcc120ctgctgaccgccgccctgtggtacatctactcccacacccgcgccccctccaagcgcgag180cccgtggtggccgtggccgcccccgcctcctccgagtcctcctccaccaaccactccatc240ggctccacccagtccaccccctgctccacctcctccatggccaccggtggcgtgcccgtg300cagggctccaagtacgccgccgaccgcaaccactaccgccgctacccccgccgccgcggc360cccccccgcaactaccagcagaacacgcgtggcctgaacgcccacggcgccgcccagatg420cagcccatgcaccgctacgacgtgtccgccctgcagtacaactccatgacctcctcccag480acctacatgaacggctcccccacctactccatgtcctactcccagcagggcacccccggc540atggccctgggctccatgggctccgtgagatcccaattggtgatgaactcccccccctcc600cgcatcctgcgccgccgcaagcgcgagtgggtgatgccccccatctccgtgcccgagaac660ggcaagggccccttcccccagcgcctgaaccagctgaagtccaacaaggaccgcggcacc720aagctgttctactccatcaccggccccggcgccgactccccccccgagggcgtgttcacc780atcgagaaggagaccagatccgccggcgaaatctacaccatgaaggagatcatcttctac840atcggccagtacatcatgaccaagcgcctgtacgacgagaagcagcagcacatcgtgtac900tgctccaacgacctgctgggcgacgtgttcggcgtgccctccttctccgtgaaggagcac960cgcaagatctacgccatgatctaccgcaacctggtggtggtgtcccagcaggactccggc1020acctccccctccagatcttag1041<210>39<211>328<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>39MetAlaValProMetGlnLeuSerCysSerArgGlnAsnGlyThrTrp151015ProArgGluValLeuLeuValLeuSerValAsnSerSerValPheLeu202530HisLeuGlnAlaLeuGlyIleProLeuHisLeuAlaTyrAsnSerSer354045LeuValThrPheGlnGluProProGlyValAsnThrThrGluLeuArg505560SerThrGlyGlyValProValGlnGlySerLysTyrAlaAlaAspArg65707580AsnHisTyrArgArgTyrProArgArgArgGlyProProArgAsnTyr859095GlnGlnAsnThrArgGlyLeuAsnAlaHisGlyAlaAlaGlnMetGln100105110ProMetHisArgTyrAspValSerAlaLeuGlnTyrAsnSerMetThr115120125SerSerGlnThrTyrMetAsnGlySerProThrTyrSerMetSerTyr130135140SerGlnGlnGlyThrProGlyMetAlaLeuGlySerMetGlySerVal145150155160ArgSerGlnLeuArgSerLeuLysGluArgAsnProLeuLysIlePhe165170175ProSerLysArgIleLeuArgArgHisLysArgAspTrpValValAla180185190ProIleSerValProGluAsnGlyLysGlyProPheProGlnArgLeu195200205AsnGlnLeuLysSerAsnLysAspArgAspThrLysIlePheTyrSer210215220IleThrGlyProGlyAlaAspSerProProGluGlyValPheAlaVal225230235240GluLysGluThrArgSerAlaGlyGluThrTyrThrMetLysGluVal245250255LeuPheTyrLeuGlyGlnTyrIleMetThrLysArgLeuTyrAspGlu260265270LysGlnGlnHisIleValTyrCysSerAsnAspLeuLeuGlyAspLeu275280285PheGlyValProSerPheSerValLysGluHisArgLysIleTyrThr290295300MetIleTyrArgAsnLeuValValValAsnGlnGlnGluSerSerAsp305310315320SerGlyThrSerValSerArgSer325<210>40<211>352<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>40MetAlaValProMetThrValPheMetArgLeuAsnIleIleSerPro151015AspLeuSerGlyCysThrSerLysGlyLeuValLeuProAlaValLeu202530GlyIleThrPheGlyAlaPheLeuIleGlyAlaLeuLeuThrAlaAla354045LeuTrpTyrIleTyrSerHisThrArgSerProSerLysArgGluPro505560ValValAlaValAlaAlaProAlaSerSerGluSerSerSerThrAsn65707580HisSerIleGlySerThrGlnSerThrProCysSerThrSerSerMet859095AlaThrGlyGlyValProValGlnGlySerLysTyrAlaAlaAspArg100105110AsnHisTyrArgArgTyrProArgArgArgGlyProProArgAsnTyr115120125GlnGlnAsnThrArgGlyLeuAsnAlaHisGlyAlaAlaGlnMetGln130135140ProMetHisArgTyrAspValSerAlaLeuGlnTyrAsnSerMetThr145150155160SerSerGlnThrTyrMetAsnGlySerProThrTyrSerMetSerTyr165170175SerGlnGlnGlyThrProGlyMetAlaLeuGlySerMetGlySerVal180185190ArgSerGlnLeuLeuLysIlePheProSerLysArgIleLeuArgArg195200205HisLysArgAspTrpValValAlaProIleSerValProGluAsnGly210215220LysGlyProPheProGlnArgLeuAsnGlnLeuLysSerAsnLysAsp225230235240ArgAspThrLysIlePheTyrSerIleThrGlyProGlyAlaAspSer245250255ProProGluGlyValPheAlaValGluLysGluThrArgSerAlaGly260265270GluThrTyrThrMetLysGluValLeuPheTyrLeuGlyGlnTyrIle275280285MetThrLysArgLeuTyrAspGluLysGlnGlnHisIleValTyrCys290295300SerAsnAspLeuLeuGlyAspLeuPheGlyValProSerPheSerVal305310315320LysGluHisArgLysIleTyrThrMetIleTyrArgAsnLeuValVal325330335ValAsnGlnGlnGluSerSerAspSerGlyThrSerValSerArgSer340345350<210>41<211>346<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>41MetAlaValProMetThrValSerMetArgLeuAsnIleValSerPro151015AspLeuSerGlyLysGlyLeuValLeuProSerValLeuGlyIleThr202530PheGlyAlaPheLeuIleGlyAlaLeuLeuThrAlaAlaLeuTrpTyr354045IleTyrSerHisThrArgGlyProSerLysArgGluProValValAla505560ValAlaAlaProAlaSerSerGluSerSerSerThrAsnHisSerIle65707580GlySerThrGlnSerThrProCysSerThrSerSerMetAlaThrGly859095GlyValProValGlnGlySerLysTyrAlaAlaAspArgAsnHisTyr100105110ArgArgTyrProArgArgArgGlyProProArgAsnTyrGlnGlnAsn115120125ThrArgGlyLeuAsnAlaHisGlyAlaAlaGlnMetGlnProMetHis130135140ArgTyrAspValSerAlaLeuGlnTyrAsnSerMetThrSerSerGln145150155160ThrTyrMetAsnGlySerProThrTyrSerMetSerTyrSerGlnGln165170175GlyThrProGlyMetAlaLeuGlySerMetGlySerValArgSerGln180185190LeuAlaMetHisSerProProThrArgIleLeuArgArgArgLysArg195200205GluTrpValMetProProIlePheValProGluAsnGlyLysGlyPro210215220PheProGlnArgLeuAsnGlnLeuLysSerAsnLysAspArgGlyThr225230235240LysIlePheTyrSerIleThrGlyProGlyAlaAspSerProProGlu245250255GlyValPheThrIleGluLysGluSerArgSerAlaGlyGluThrTyr260265270ThrMetLysGluIleIlePheTyrIleGlyGlnTyrIleMetThrLys275280285ArgLeuTyrAspGluLysGlnGlnHisIleValTyrCysSerAsnAsp290295300LeuLeuGlyAspValPheGlyValProSerPheSerValLysGluHis305310315320ArgLysIleTyrAlaMetIleTyrArgAsnLeuValAlaValSerGln325330335GlnAspSerGlyThrSerLeuSerArgSer340345<210>42<211>346<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>42MetAlaValProMetThrValSerMetArgLeuAsnIleValSerPro151015AspLeuSerGlyLysGlyLeuValLeuProSerValLeuGlyIleThr202530PheGlyAlaPheLeuIleGlyAlaLeuLeuThrAlaAlaLeuTrpTyr354045IleTyrSerHisThrArgAlaProSerLysArgGluProValValAla505560ValAlaAlaProAlaSerSerGluSerSerSerThrAsnHisSerIle65707580GlySerThrGlnSerThrProCysSerThrSerSerMetAlaThrGly859095GlyValProValGlnGlySerLysTyrAlaAlaAspArgAsnHisTyr100105110ArgArgTyrProArgArgArgGlyProProArgAsnTyrGlnGlnAsn115120125ThrArgGlyLeuAsnAlaHisGlyAlaAlaGlnMetGlnProMetHis130135140ArgTyrAspValSerAlaLeuGlnTyrAsnSerMetThrSerSerGln145150155160ThrTyrMetAsnGlySerProThrTyrSerMetSerTyrSerGlnGln165170175GlyThrProGlyMetAlaLeuGlySerMetGlySerValArgSerGln180185190LeuValMetAsnSerProProSerArgIleLeuArgArgArgLysArg195200205GluTrpValMetProProIleSerValProGluAsnGlyLysGlyPro210215220PheProGlnArgLeuAsnGlnLeuLysSerAsnLysAspArgGlyThr225230235240LysLeuPheTyrSerIleThrGlyProGlyAlaAspSerProProGlu245250255GlyValPheThrIleGluLysGluThrArgSerAlaGlyGluIleTyr260265270ThrMetLysGluIleIlePheTyrIleGlyGlnTyrIleMetThrLys275280285ArgLeuTyrAspGluLysGlnGlnHisIleValTyrCysSerAsnAsp290295300LeuLeuGlyAspValPheGlyValProSerPheSerValLysGluHis305310315320ArgLysIleTyrAlaMetIleTyrArgAsnLeuValValValSerGln325330335GlnAspSerGlyThrSerProSerArgSer340345<210>43<211>489<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>43atgctgccgagagtgggctgccccgcgctgccgctgccgccgccgccgctgctgccgctg60ctgccgctgctgctgctgctactgggcgcgagtggcggcggcggcggggcgcgcgcggag120gtgctgttccgctgcccgccctgcacacccgagcgcctggccgcctgcgggcccccgccg180gttgcgccgcccgccgcggtggccgcagtggccggaggcgcccgcatgccatgcgcggag240ctcgtccgggagccgggctgcggctgctgctcggtgtgcgcccggctggagggcgaggcg300tgcggcgtctacaccccgcgctgcggccaggggctgcgctgctatccccacccgggctcc360gagctgcccctgcaggcgctggtcatgggcgagggcacttgtgagaagcgccgggacgcc420gagtatggcgccagcccggagcaggttgcagacaatggcgatgaccactcagaaggaggc480ctggtggag489<210>44<211>423<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>44atgctgccccgcctgggcggccccgccctgcccctgctgctgccctccctgctgctgctg60ctgctgctgggcgccggcggctgcggccccggcgtgcgcgccgaggtgctgttccgctgc120cccccctgcacccccgagcgcctggccgcctgcggccccccccccgacgccccctgcgcc180gagctggtgcgcgagcccggctgcggctgctgctccgtgtgcgcccgccaggagggcgag240gcctgcggcgtgtacatcccccgctgcgcccagaccctgcgctgctaccccaaccccggc300tccgagctgcccctgaaggccctggtgaccggcgccggcacctgcgagaagcgccgcgtg360ggcaccaccccccagcaggtggccgactccgacgacgaccactccgagggcggcctggtg420gag423<210>45<211>423<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>45atgctgccccgcctgggcggccccgccctgcccctgctgctgccctccctgctgctgctg60ctgctgctgggcgccggcggctgcggccccggcgtgcgcgccgaggtgctgttccgctgc120cccccctgcacccccgagcgcctggccgcctgcggccccccccccgacgccccctgcgcc180gagctggtgcgcgagcccggctgcggctgctgctccgtgtgcgcccgccaggagggcgag240gcctgcggcgtgtacatcccccgctgcgcccagaccctgcgctgctaccccaaccccggc300tccgagctgcccctgaaggccctggtgaccggcgccggcacctgcgagaagcgccgcgtg360ggcaccaccccccagcaggtggccgactccgaggacgaccactccgagggcggcctggtg420gag423<210>46<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>46AsnHisValAspSerThrMetAsnMetLeuGlyGlyGlyGlySer151015<210>47<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>47GluLeuAlaValPheArgGluLysValThrGluGlnHisArgGln151015<210>48<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>48LeuGlyLeuGluGluProLysLysLeuArgProProProAlaArg151015<210>49<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>49AspGlnValLeuGluArgIleSerThrMetArgLeuProAspGlu151015<210>50<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>50GlyProLeuGluHisLeuTyrSerLeuHisIleProAsnCysAsp151015<210>51<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>51LysHisGlyLeuTyrAsnLeuLysGlnCysLysMetSerLeuAsn151015<210>52<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>52ProAsnThrGlyLysLeuIleGlnGlyAlaProThrIleArgGly151015<210>53<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>53ProGluCysHisLeuPheTyrAsnGluGlnGlnGluAlaArgGly151015<210>54<211>163<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>54MetLeuProArgValGlyCysProAlaLeuProLeuProProProPro151015LeuLeuProLeuLeuProLeuLeuLeuLeuLeuLeuGlyAlaSerGly202530GlyGlyGlyGlyAlaArgAlaGluValLeuPheArgCysProProCys354045ThrProGluArgLeuAlaAlaCysGlyProProProValAlaProPro505560AlaAlaValAlaAlaValAlaGlyGlyAlaArgMetProCysAlaGlu65707580LeuValArgGluProGlyCysGlyCysCysSerValCysAlaArgLeu859095GluGlyGluAlaCysGlyValTyrThrProArgCysGlyGlnGlyLeu100105110ArgCysTyrProHisProGlySerGluLeuProLeuGlnAlaLeuVal115120125MetGlyGluGlyThrCysGluLysArgArgAspAlaGluTyrGlyAla130135140SerProGluGlnValAlaAspAsnGlyAspAspHisSerGluGlyGly145150155160LeuValGlu<210>55<211>141<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>55MetLeuProArgLeuGlyGlyProAlaLeuProLeuLeuLeuProSer151015LeuLeuLeuLeuLeuLeuLeuGlyAlaGlyGlyCysGlyProGlyVal202530ArgAlaGluValLeuPheArgCysProProCysThrProGluArgLeu354045AlaAlaCysGlyProProProAspAlaProCysAlaGluLeuValArg505560GluProGlyCysGlyCysCysSerValCysAlaArgGlnGluGlyGlu65707580AlaCysGlyValTyrIleProArgCysAlaGlnThrLeuArgCysTyr859095ProAsnProGlySerGluLeuProLeuLysAlaLeuValThrGlyAla100105110GlyThrCysGluLysArgArgValGlyThrThrProGlnGlnValAla115120125AspSerAspAspAspHisSerGluGlyGlyLeuValGlu130135140<210>56<211>141<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>56MetLeuProArgLeuGlyGlyProAlaLeuProLeuLeuLeuProSer151015LeuLeuLeuLeuLeuLeuLeuGlyAlaGlyGlyCysGlyProGlyVal202530ArgAlaGluValLeuPheArgCysProProCysThrProGluArgLeu354045AlaAlaCysGlyProProProAspAlaProCysAlaGluLeuValArg505560GluProGlyCysGlyCysCysSerValCysAlaArgGlnGluGlyGlu65707580AlaCysGlyValTyrIleProArgCysAlaGlnThrLeuArgCysTyr859095ProAsnProGlySerGluLeuProLeuLysAlaLeuValThrGlyAla100105110GlyThrCysGluLysArgArgValGlyAlaThrProGlnGlnValAla115120125AspSerGluAspAspHisSerGluGlyGlyLeuValGlu130135140<210>57<211>1101<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>57acgatgcggagactgctgcaggaaacggagctggtggagccgctgacacctagcggagcg60atgcccaaccaggcgcagatgcggatcctgaaagagacggagctgaggaaggtgaaggtg120cttggatctggcgcttttggcacagtctacaagggcatctggatccctgatggggagaat180gtgaaaattccagtggccatcaaagtgttgagggaaaacacatcccccaaagccaacaaa240gaaatcttagacgaagcatacgtgatggctggtgtgggctccccatatgtctcccgcctt300ctgggcatctgcctgacatccacggtgcagctggtgacacagcttatgccctatggctgc360ctcttagaccatgtccgggaaaaccgcggacgcctgggctcccaggacctgctgaactgg420tgtatgcagattgccaaggggatgagctacctggaggatgtgcggctcgtacacagggac480ttggccgctcggaacgtgctggtcaagagtcccaaccatgtcaaaattacagacttcggg540ctggctcggctgctggacattgacgagacagagtaccatgcagatgggggcaaggtgccc600atcaagtggatggcgctggagtccattctccgccggcggttcacccaccagagtgatgtg660tggagttatggtgtgactgtgtgggagctgatgacttttggggccaaaccttacgatggg720atcccagcccgggagatccctgacctgctggaaaagggggagcggctgccccagcccccc780atctgcaccattgatgtctacatgatcatggtcaaatgttggatgattgactctgaatgt840cggccaagattccgggagttggtgtctgaattctcccgcatggccagggacccccagcgc900tttgtggtcatccagaatgaggacttggctcccggagctggcggcatggtgcaccacagg960caccgcagctcatctcctctgcctgctgcccgacctgctggtgccactctggaaaggccc1020aagactctctccccagggaagaatggggtcgtcaaagacgtttttgcctttgggggtgcc1080gtggagaaccccgagtacttg1101<210>58<211>1101<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>58accatgcgccgcctgctgcaggagaccgagctggtggagcccctgaccccctccggcgcc60gtgcccaaccaggcccagatgcgcatcctgaaggagaccgagctgcgcaagctgaaggtg120ctgggctccggcgccttcggcaccgtgtacaagggcatctggatccccgacggcgagaac180gtgaagatccccgtggccatcaaggtgctgcgcgagaacacctcccccaaggccaacaag240gagatcctggacgaggcctacgtgatggccggcgtgggctccccctacgtgtcccgcctg300ctgggcatctgcctgacctccaccgtgcagctggtgacccagctgatgccctacggctgc360ctgctggaccacgtgcgcgagcaccgcggccgcctgggctcccaggacctgctgaactgg420tgcgtgcagatcgccaagggcatgtcctacctggaggaggtgcgcctggtgcaccgcgac480ctggccgcccgcaacgtgctggtgaagtcccccaaccacgtgaagatcaccgacttcggc540ctggcccgcctgctggacatcgacgagaccgagtaccacgccgacggcggcaaggtgccc600atcaagtggatggccctggagtccatcctgcgccgccgcttcacccaccagtccgacgtg660tggtcctacggcgtgaccgtgtgggagctgatgaccttcggcgccaagccctacgacggc720atccccgcccgcgagatccccgacctgctggagaagggcgagcgcctgccccagcccccc780atctgcaccatcgacgtgtacatgatcatggtgaagtgctggatgatcgactccgagtgc840cgcccccgcttccgcgagctggtgtccgagttctcccgcatggcccgcgacccccagcgc900ttcgtggtgatccagaacgaggacctggccctgggcaccggctccaccgcccaccgccgc960caccgctcctcctccccccccccccccatccgccccgccggcgccaccctggagcgcccc1020aagaccctgtcccccggcaagaacggcgtggtgaaggacgtgttcgccttcggcggcgcc1080gtggagaaccccgagtacctg1101<210>59<211>1101<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>59accatgcgccgcctgctgcaggagaccgagctggtggagcccctgaccccctccggcgcc60atgcccaaccaggcccagatgcgcatcctgaaggagaccgagctgcgcaaggtgaaggtg120ctgggctccggcgccttcggcaccgtgtacaagggcatctggatccccgacggcgagaac180gtgaagatccccgtggccatcaaggtgctgcgcgagaacacctcccccaaggccaacaag240gagatcctggacgaggcctacgtgatggccggcgtgggctccccctacgtgtcccgcctg300ctgggcatctgcctgacctccaccgtgcagctggtgacccagctgatgccctacggctgc360ctgctggaccacgtgcgcgagcaccgcggccgcctgggctcccaggacctgctgaactgg420tgcgtgcagatcgccaagggcatgtcctacctggaggacgtgcgcctggtgcaccgcgac480ctggccgcccgcaacgtgctggtgaagtcccccaaccacgtgaagatcaccgacttcggc540ctggcccgcctgctggacatcgacgagaccgagtaccacgccgacggcggcaaggtgccc600atcaagtggatggccctggagtccatcctgcgccgccgcttcacccaccagtccgacgtg660tggtcctacggcgtgaccgtgtgggagctgatgaccttcggcgccaagccctacgacggc720atccccgcccgcgagatccccgacctgctggagaagggcgagcgcctgccccagcccccc780atctgcaccatcgacgtgtacatgatcatggtgaagtgctggatgatcgactccgagtgc840cgcccccgcttccgcgagctggtgtccgagttctcccgcatggcccgcgacccccagcgc900ttcgtggtgatccagaacgaggacctgacccccggcaccggctccaccgcccaccgccgc960caccgctcctcctcccccctgccccccgtgcgccccgccggcgccaccctggagcgcccc1020aagaccctgtcccccggcaagaacggcgtggtgaaggacgtgttcgccttcggcggcgcc1080gtggagaaccccgagtacctg1101<210>60<211>367<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>60ThrMetArgArgLeuLeuGlnGluThrGluLeuValGluProLeuThr151015ProSerGlyAlaMetProAsnGlnAlaGlnMetArgIleLeuLysGlu202530ThrGluLeuArgLysValLysValLeuGlySerGlyAlaPheGlyThr354045ValTyrLysGlyIleTrpIleProAspGlyGluAsnValLysIlePro505560ValAlaIleLysValLeuArgGluAsnThrSerProLysAlaAsnLys65707580GluIleLeuAspGluAlaTyrValMetAlaGlyValGlySerProTyr859095ValSerArgLeuLeuGlyIleCysLeuThrSerThrValGlnLeuVal100105110ThrGlnLeuMetProTyrGlyCysLeuLeuAspHisValArgGluAsn115120125ArgGlyArgLeuGlySerGlnAspLeuLeuAsnTrpCysMetGlnIle130135140AlaLysGlyMetSerTyrLeuGluAspValArgLeuValHisArgAsp145150155160LeuAlaAlaArgAsnValLeuValLysSerProAsnHisValLysIle165170175ThrAspPheGlyLeuAlaArgLeuLeuAspIleAspGluThrGluTyr180185190HisAlaAspGlyGlyLysValProIleLysTrpMetAlaLeuGluSer195200205IleLeuArgArgArgPheThrHisGlnSerAspValTrpSerTyrGly210215220ValThrValTrpGluLeuMetThrPheGlyAlaLysProTyrAspGly225230235240IleProAlaArgGluIleProAspLeuLeuGluLysGlyGluArgLeu245250255ProGlnProProIleCysThrIleAspValTyrMetIleMetValLys260265270CysTrpMetIleAspSerGluCysArgProArgPheArgGluLeuVal275280285SerGluPheSerArgMetAlaArgAspProGlnArgPheValValIle290295300GlnAsnGluAspLeuAlaProGlyAlaGlyGlyMetValHisHisArg305310315320HisArgSerSerSerProLeuProAlaAlaArgProAlaGlyAlaThr325330335LeuGluArgProLysThrLeuSerProGlyLysAsnGlyValValLys340345350AspValPheAlaPheGlyGlyAlaValGluAsnProGluTyrLeu355360365<210>61<211>367<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>61ThrMetArgArgLeuLeuGlnGluThrGluLeuValGluProLeuThr151015ProSerGlyAlaValProAsnGlnAlaGlnMetArgIleLeuLysGlu202530ThrGluLeuArgLysLeuLysValLeuGlySerGlyAlaPheGlyThr354045ValTyrLysGlyIleTrpIleProAspGlyGluAsnValLysIlePro505560ValAlaIleLysValLeuArgGluAsnThrSerProLysAlaAsnLys65707580GluIleLeuAspGluAlaTyrValMetAlaGlyValGlySerProTyr859095ValSerArgLeuLeuGlyIleCysLeuThrSerThrValGlnLeuVal100105110ThrGlnLeuMetProTyrGlyCysLeuLeuAspHisValArgGluHis115120125ArgGlyArgLeuGlySerGlnAspLeuLeuAsnTrpCysValGlnIle130135140AlaLysGlyMetSerTyrLeuGluGluValArgLeuValHisArgAsp145150155160LeuAlaAlaArgAsnValLeuValLysSerProAsnHisValLysIle165170175ThrAspPheGlyLeuAlaArgLeuLeuAspIleAspGluThrGluTyr180185190HisAlaAspGlyGlyLysValProIleLysTrpMetAlaLeuGluSer195200205IleLeuArgArgArgPheThrHisGlnSerAspValTrpSerTyrGly210215220ValThrValTrpGluLeuMetThrPheGlyAlaLysProTyrAspGly225230235240IleProAlaArgGluIleProAspLeuLeuGluLysGlyGluArgLeu245250255ProGlnProProIleCysThrIleAspValTyrMetIleMetValLys260265270CysTrpMetIleAspSerGluCysArgProArgPheArgGluLeuVal275280285SerGluPheSerArgMetAlaArgAspProGlnArgPheValValIle290295300GlnAsnGluAspLeuAlaLeuGlyThrGlySerThrAlaHisArgArg305310315320HisArgSerSerSerProProProProIleArgProAlaGlyAlaThr325330335LeuGluArgProLysThrLeuSerProGlyLysAsnGlyValValLys340345350AspValPheAlaPheGlyGlyAlaValGluAsnProGluTyrLeu355360365<210>62<211>367<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>62ThrMetArgArgLeuLeuGlnGluThrGluLeuValGluProLeuThr151015ProSerGlyAlaMetProAsnGlnAlaGlnMetArgIleLeuLysGlu202530ThrGluLeuArgLysValLysValLeuGlySerGlyAlaPheGlyThr354045ValTyrLysGlyIleTrpIleProAspGlyGluAsnValLysIlePro505560ValAlaIleLysValLeuArgGluAsnThrSerProLysAlaAsnLys65707580GluIleLeuAspGluAlaTyrValMetAlaGlyValGlySerProTyr859095ValSerArgLeuLeuGlyIleCysLeuThrSerThrValGlnLeuVal100105110ThrGlnLeuMetProTyrGlyCysLeuLeuAspHisValArgGluHis115120125ArgGlyArgLeuGlySerGlnAspLeuLeuAsnTrpCysValGlnIle130135140AlaLysGlyMetSerTyrLeuGluAspValArgLeuValHisArgAsp145150155160LeuAlaAlaArgAsnValLeuValLysSerProAsnHisValLysIle165170175ThrAspPheGlyLeuAlaArgLeuLeuAspIleAspGluThrGluTyr180185190HisAlaAspGlyGlyLysValProIleLysTrpMetAlaLeuGluSer195200205IleLeuArgArgArgPheThrHisGlnSerAspValTrpSerTyrGly210215220ValThrValTrpGluLeuMetThrPheGlyAlaLysProTyrAspGly225230235240IleProAlaArgGluIleProAspLeuLeuGluLysGlyGluArgLeu245250255ProGlnProProIleCysThrIleAspValTyrMetIleMetValLys260265270CysTrpMetIleAspSerGluCysArgProArgPheArgGluLeuVal275280285SerGluPheSerArgMetAlaArgAspProGlnArgPheValValIle290295300GlnAsnGluAspLeuThrProGlyThrGlySerThrAlaHisArgArg305310315320HisArgSerSerSerProLeuProProValArgProAlaGlyAlaThr325330335LeuGluArgProLysThrLeuSerProGlyLysAsnGlyValValLys340345350AspValPheAlaPheGlyGlyAlaValGluAsnProGluTyrLeu355360365<210>63<211>312<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>63tggtccttcggcgtggtgctgtgggagatcgccaccctggccgagcagccctaccagggc60ctgtccaacgagcaggtgctgcgcttcgtgatggagggcggcctgctggacaagcccgac120aactgccccgacatgctgttcgagctgatgcgcatgtgctggcagtacaaccccaagatg180cgcccctccttcctggagcacaaggccgagaacggccccggccccggcgtgctggtgctg240cgcgcctccttcgacgagcgccagccctacgcccacatgaacggaggccgcaagaacgag300cgcgccctgccc312<210>64<211>312<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>64tggtccttcggcgtggtgctgtgggagatcgccaccctggccgagcagccctaccagggc60ctgtccaacgagcaggtgctgcgcttcgtgatggagggcggcctgctggacaagcccgac120aactgccccgacatgctgttcgagctgatgcgcatgtgctggcagtacaaccccaagatg180cgcccctccttcctggagcacaaggccgagaacggccccggccccggcgtgctggtgctg240cgcgcctccttcgacgagcgccagccctacgcccacatgaacggcggccgcgccaacgag300cgcgccctgccc312<210>65<211>306<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>65tggtccttcggcgtggtgctgtgggagatcgccaccctggccgagcagccctaccagggc60ctgtccaacgagcaggtgctgcgcttcgtgatggagggcggcctgctggacaagcccgac120aactgccccgacatgctgttcgagctgatgcgcatgtgctggcagtacaaccccaagatg180cgcccctccttcctggagcacaaggccgagaacggccccggcgtgctggtgctgcgcgcc240tccttcgacgagcgccagccctacgcccacatgaacggcggccgcgccaacgagcgcgcc300ctgccc306<210>66<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>66AspTyrArgSerTyrArgPheProLysLeuThrValIleThrGlu151015<210>67<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>67IleArgGlyTrpLysLeuPheTyrAsnTyrAlaLeuValIlePhe151015<210>68<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>68ValValThrGlyTyrValLysIleArgHisSerHisAlaLeuVal151015<210>69<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>69PhePheTyrValGlnAlaLysThrGlyTyrGluAsnPheIleHis151015<210>70<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>70LeuIleIleAlaLeuProValAlaValLeuLeuIleValGlyGly151015<210>71<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>71LeuValIleMetLeuTyrValPheHisArgLysArgAsnAsnSer151015<210>72<211>15<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>72AsnCysHisHisValValArgLeuLeuGlyValValSerGlnGly151015<210>73<211>104<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>73TrpSerPheGlyValValLeuTrpGluIleAlaThrLeuAlaGluGln151015ProTyrGlnGlyLeuSerAsnGluGlnValLeuArgPheValMetGlu202530GlyGlyLeuLeuAspLysProAspAsnCysProAspMetLeuPheGlu354045LeuMetArgMetCysTrpGlnTyrAsnProLysMetArgProSerPhe505560LeuGluHisLysAlaGluAsnGlyProGlyProGlyValLeuValLeu65707580ArgAlaSerPheAspGluArgGlnProTyrAlaHisMetAsnGlyGly859095ArgLysAsnGluArgAlaLeuPro100<210>74<211>104<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>74TrpSerPheGlyValValLeuTrpGluIleAlaThrLeuAlaGluGln151015ProTyrGlnGlyLeuSerAsnGluGlnValLeuArgPheValMetGlu202530GlyGlyLeuLeuAspLysProAspAsnCysProAspMetLeuPheGlu354045LeuMetArgMetCysTrpGlnTyrAsnProLysMetArgProSerPhe505560LeuGluHisLysAlaGluAsnGlyProGlyProGlyValLeuValLeu65707580ArgAlaSerPheAspGluArgGlnProTyrAlaHisMetAsnGlyGly859095ArgAlaAsnGluArgAlaLeuPro100<210>75<211>102<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>75TrpSerPheGlyValValLeuTrpGluIleAlaThrLeuAlaGluGln151015ProTyrGlnGlyLeuSerAsnGluGlnValLeuArgPheValMetGlu202530GlyGlyLeuLeuAspLysProAspAsnCysProAspMetLeuPheGlu354045LeuMetArgMetCysTrpGlnTyrAsnProLysMetArgProSerPhe505560LeuGluHisLysAlaGluAsnGlyProGlyValLeuValLeuArgAla65707580SerPheAspGluArgGlnProTyrAlaHisMetAsnGlyGlyArgAla859095AsnGluArgAlaLeuPro100<210>76<211>1947<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>76atggcggtaccaatgctgccgagagtgggctgccccgcgctgccgctgccgccgccgccg60ctgctgccgctgctgccgctgctgctgctgctactgggcgcgagtggcggcggcggcggg120gcgcgcgcggaggtgctgttccgctgcccgccctgcacacccgagcgcctggccgcctgc180gggcccccgccggttgcgccgcccgccgcggtggccgcagtggccggaggcgcccgcatg240ccatgcgcggagctcgtccgggagccgggctgcggctgctgctcggtgtgcgcccggctg300gagggcgaggcgtgcggcgtctacaccccgcgctgcggccaggggctgcgctgctatccc360cacccgggctccgagctgcccctgcaggcgctggtcatgggcgagggcacttgtgagaag420cgccgggacgccgagtatggcgccagcccggagcaggttgcagacaatggcgatgaccac480tcagaaggaggcctggtggagcaattgacgatgcggagactgctgcaggaaacggagctg540gtggagccgctgacacctagcggagcgatgcccaaccaggcgcagatgcggatcctgaaa600gagacggagctgaggaaggtgaaggtgcttggatctggcgcttttggcacagtctacaag660ggcatctggatccctgatggggagaatgtgaaaattccagtggccatcaaagtgttgagg720gaaaacacatcccccaaagccaacaaagaaatcttagacgaagcatacgtgatggctggt780gtgggctccccatatgtctcccgccttctgggcatctgcctgacatccacggtgcagctg840gtgacacagcttatgccctatggctgcctcttagaccatgtccgggaaaaccgcggacgc900ctgggctcccaggacctgctgaactggtgtatgcagattgccaaggggatgagctacctg960gaggatgtgcggctcgtacacagggacttggccgctcggaacgtgctggtcaagagtccc1020aaccatgtcaaaattacagacttcgggctggctcggctgctggacattgacgagacagag1080taccatgcagatgggggcaaggtgcccatcaagtggatggcgctggagtccattctccgc1140cggcggttcacccaccagagtgatgtgtggagttatggtgtgactgtgtgggagctgatg1200acttttggggccaaaccttacgatgggatcccagcccgggagatccctgacctgctggaa1260aagggggagcggctgccccagccccccatctgcaccattgatgtctacatgatcatggtc1320aaatgttggatgattgactctgaatgtcggccaagattccgggagttggtgtctgaattc1380tcccgcatggccagggacccccagcgctttgtggtcatccagaatgaggacttggctccc1440ggagctggcggcatggtgcaccacaggcaccgcagctcatctcctctgcctgctgcccga1500cctgctggtgccactctggaaaggcccaagactctctccccagggaagaatggggtcgtc1560aaagacgtttttgcctttgggggtgccgtggagaaccccgagtacttgggccggccggta1620ccttggtccttcggcgtggtgctgtgggagatcgccaccctggccgagcagccctaccag1680ggcctgtccaacgagcaggtgctgcgcttcgtgatggagggcggcctgctggacaagccc1740gacaactgccccgacatgctgttcgagctgatgcgcatgtgctggcagtacaaccccaag1800atgcgcccctccttcctggagcacaaggccgagaacggccccggccccggcgtgctggtg1860ctgcgcgcctccttcgacgagcgccagccctacgcccacatgaacggaggccgcaagaac1920gagcgcgccctgcccgcggccgcatag1947<210>77<211>1881<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>77atggcggtaccaatgctgccccgcctgggcggccccgccctgcccctgctgctgccctcc60ctgctgctgctgctgctgctgggcgccggcggctgcggccccggcgtgcgcgccgaggtg120ctgttccgctgccccccctgcacccccgagcgcctggccgcctgcggccccccccccgac180gccccctgcgccgagctggtgcgcgagcccggctgcggctgctgctccgtgtgcgcccgc240caggagggcgaggcctgcggcgtgtacatcccccgctgcgcccagaccctgcgctgctac300cccaaccccggctccgagctgcccctgaaggccctggtgaccggcgccggcacctgcgag360aagcgccgcgtgggcaccaccccccagcaggtggccgactccgacgacgaccactccgag420ggcggcctggtggagcaattgaccatgcgccgcctgctgcaggagaccgagctggtggag480cccctgaccccctccggcgccgtgcccaaccaggcccagatgcgcatcctgaaggagacc540gagctgcgcaagctgaaggtgctgggctccggcgccttcggcaccgtgtacaagggcatc600tggatccccgacggcgagaacgtgaagatccccgtggccatcaaggtgctgcgcgagaac660acctcccccaaggccaacaaggagatcctggacgaggcctacgtgatggccggcgtgggc720tccccctacgtgtcccgcctgctgggcatctgcctgacctccaccgtgcagctggtgacc780cagctgatgccctacggctgcctgctggaccacgtgcgcgagcaccgcggccgcctgggc840tcccaggacctgctgaactggtgcgtgcagatcgccaagggcatgtcctacctggaggag900gtgcgcctggtgcaccgcgacctggccgcccgcaacgtgctggtgaagtcccccaaccac960gtgaagatcaccgacttcggcctggcccgcctgctggacatcgacgagaccgagtaccac1020gccgacggcggcaaggtgcccatcaagtggatggccctggagtccatcctgcgccgccgc1080ttcacccaccagtccgacgtgtggtcctacggcgtgaccgtgtgggagctgatgaccttc1140ggcgccaagccctacgacggcatccccgcccgcgagatccccgacctgctggagaagggc1200gagcgcctgccccagccccccatctgcaccatcgacgtgtacatgatcatggtgaagtgc1260tggatgatcgactccgagtgccgcccccgcttccgcgagctggtgtccgagttctcccgc1320atggcccgcgacccccagcgcttcgtggtgatccagaacgaggacctggccctgggcacc1380ggctccaccgcccaccgccgccaccgctcctcctccccccccccccccatccgccccgcc1440ggcgccaccctggagcgccccaagaccctgtcccccggcaagaacggcgtggtgaaggac1500gtgttcgccttcggcggcgccgtggagaaccccgagtacctgggccggccggtaccttgg1560tccttcggcgtggtgctgtgggagatcgccaccctggccgagcagccctaccagggcctg1620tccaacgagcaggtgctgcgcttcgtgatggagggcggcctgctggacaagcccgacaac1680tgccccgacatgctgttcgagctgatgcgcatgtgctggcagtacaaccccaagatgcgc1740ccctccttcctggagcacaaggccgagaacggccccggccccggcgtgctggtgctgcgc1800gcctccttcgacgagcgccagccctacgcccacatgaacggcggccgcgccaacgagcgc1860gccctgcccgcggccgcatag1881<210>78<211>1875<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>78atggcggtaccaatgctgccccgcctgggcggccccgccctgcccctgctgctgccctcc60ctgctgctgctgctgctgctgggcgccggcggctgcggccccggcgtgcgcgccgaggtg120ctgttccgctgccccccctgcacccccgagcgcctggccgcctgcggccccccccccgac180gccccctgcgccgagctggtgcgcgagcccggctgcggctgctgctccgtgtgcgcccgc240caggagggcgaggcctgcggcgtgtacatcccccgctgcgcccagaccctgcgctgctac300cccaaccccggctccgagctgcccctgaaggccctggtgaccggcgccggcacctgcgag360aagcgccgcgtgggcgccaccccccagcaggtggccgactccgaggacgaccactccgag420ggcggcctggtggagcaattgaccatgcgccgcctgctgcaggagaccgagctggtggag480cccctgaccccctccggcgccatgcccaaccaggcccagatgcgcatcctgaaggagacc540gagctgcgcaaggtgaaggtgctgggctccggcgccttcggcaccgtgtacaagggcatc600tggatccccgacggcgagaacgtgaagatccccgtggccatcaaggtgctgcgcgagaac660acctcccccaaggccaacaaggagatcctggacgaggcctacgtgatggccggcgtgggc720tccccctacgtgtcccgcctgctgggcatctgcctgacctccaccgtgcagctggtgacc780cagctgatgccctacggctgcctgctggaccacgtgcgcgagcaccgcggccgcctgggc840tcccaggacctgctgaactggtgcgtgcagatcgccaagggcatgtcctacctggaggac900gtgcgcctggtgcaccgcgacctggccgcccgcaacgtgctggtgaagtcccccaaccac960gtgaagatcaccgacttcggcctggcccgcctgctggacatcgacgagaccgagtaccac1020gccgacggcggcaaggtgcccatcaagtggatggccctggagtccatcctgcgccgccgc1080ttcacccaccagtccgacgtgtggtcctacggcgtgaccgtgtgggagctgatgaccttc1140ggcgccaagccctacgacggcatccccgcccgcgagatccccgacctgctggagaagggc1200gagcgcctgccccagccccccatctgcaccatcgacgtgtacatgatcatggtgaagtgc1260tggatgatcgactccgagtgccgcccccgcttccgcgagctggtgtccgagttctcccgc1320atggcccgcgacccccagcgcttcgtggtgatccagaacgaggacctgacccccggcacc1380ggctccaccgcccaccgccgccaccgctcctcctcccccctgccccccgtgcgccccgcc1440ggcgccaccctggagcgccccaagaccctgtcccccggcaagaacggcgtggtgaaggac1500gtgttcgccttcggcggcgccgtggagaaccccgagtacctgggccggccggtaccttgg1560tccttcggcgtggtgctgtgggagatcgccaccctggccgagcagccctaccagggcctg1620tccaacgagcaggtgctgcgcttcgtgatggagggcggcctgctggacaagcccgacaac1680tgccccgacatgctgttcgagctgatgcgcatgtgctggcagtacaaccccaagatgcgc1740ccctccttcctggagcacaaggccgagaacggccccggcgtgctggtgctgcgcgcctcc1800ttcgacgagcgccagccctacgcccacatgaacggcggccgcgccaacgagcgcgccctg1860cccgcggccgcatag1875<210>79<211>648<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>79MetAlaValProMetLeuProArgValGlyCysProAlaLeuProLeu151015ProProProProLeuLeuProLeuLeuProLeuLeuLeuLeuLeuLeu202530GlyAlaSerGlyGlyGlyGlyGlyAlaArgAlaGluValLeuPheArg354045CysProProCysThrProGluArgLeuAlaAlaCysGlyProProPro505560ValAlaProProAlaAlaValAlaAlaValAlaGlyGlyAlaArgMet65707580ProCysAlaGluLeuValArgGluProGlyCysGlyCysCysSerVal859095CysAlaArgLeuGluGlyGluAlaCysGlyValTyrThrProArgCys100105110GlyGlnGlyLeuArgCysTyrProHisProGlySerGluLeuProLeu115120125GlnAlaLeuValMetGlyGluGlyThrCysGluLysArgArgAspAla130135140GluTyrGlyAlaSerProGluGlnValAlaAspAsnGlyAspAspHis145150155160SerGluGlyGlyLeuValGluGlnLeuThrMetArgArgLeuLeuGln165170175GluThrGluLeuValGluProLeuThrProSerGlyAlaMetProAsn180185190GlnAlaGlnMetArgIleLeuLysGluThrGluLeuArgLysValLys195200205ValLeuGlySerGlyAlaPheGlyThrValTyrLysGlyIleTrpIle210215220ProAspGlyGluAsnValLysIleProValAlaIleLysValLeuArg225230235240GluAsnThrSerProLysAlaAsnLysGluIleLeuAspGluAlaTyr245250255ValMetAlaGlyValGlySerProTyrValSerArgLeuLeuGlyIle260265270CysLeuThrSerThrValGlnLeuValThrGlnLeuMetProTyrGly275280285CysLeuLeuAspHisValArgGluAsnArgGlyArgLeuGlySerGln290295300AspLeuLeuAsnTrpCysMetGlnIleAlaLysGlyMetSerTyrLeu305310315320GluAspValArgLeuValHisArgAspLeuAlaAlaArgAsnValLeu325330335ValLysSerProAsnHisValLysIleThrAspPheGlyLeuAlaArg340345350LeuLeuAspIleAspGluThrGluTyrHisAlaAspGlyGlyLysVal355360365ProIleLysTrpMetAlaLeuGluSerIleLeuArgArgArgPheThr370375380HisGlnSerAspValTrpSerTyrGlyValThrValTrpGluLeuMet385390395400ThrPheGlyAlaLysProTyrAspGlyIleProAlaArgGluIlePro405410415AspLeuLeuGluLysGlyGluArgLeuProGlnProProIleCysThr420425430IleAspValTyrMetIleMetValLysCysTrpMetIleAspSerGlu435440445CysArgProArgPheArgGluLeuValSerGluPheSerArgMetAla450455460ArgAspProGlnArgPheValValIleGlnAsnGluAspLeuAlaPro465470475480GlyAlaGlyGlyMetValHisHisArgHisArgSerSerSerProLeu485490495ProAlaAlaArgProAlaGlyAlaThrLeuGluArgProLysThrLeu500505510SerProGlyLysAsnGlyValValLysAspValPheAlaPheGlyGly515520525AlaValGluAsnProGluTyrLeuGlyArgProValProTrpSerPhe530535540GlyValValLeuTrpGluIleAlaThrLeuAlaGluGlnProTyrGln545550555560GlyLeuSerAsnGluGlnValLeuArgPheValMetGluGlyGlyLeu565570575LeuAspLysProAspAsnCysProAspMetLeuPheGluLeuMetArg580585590MetCysTrpGlnTyrAsnProLysMetArgProSerPheLeuGluHis595600605LysAlaGluAsnGlyProGlyProGlyValLeuValLeuArgAlaSer610615620PheAspGluArgGlnProTyrAlaHisMetAsnGlyGlyArgLysAsn625630635640GluArgAlaLeuProAlaAlaAla645<210>80<211>626<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>80MetAlaValProMetLeuProArgLeuGlyGlyProAlaLeuProLeu151015LeuLeuProSerLeuLeuLeuLeuLeuLeuLeuGlyAlaGlyGlyCys202530GlyProGlyValArgAlaGluValLeuPheArgCysProProCysThr354045ProGluArgLeuAlaAlaCysGlyProProProAspAlaProCysAla505560GluLeuValArgGluProGlyCysGlyCysCysSerValCysAlaArg65707580GlnGluGlyGluAlaCysGlyValTyrIleProArgCysAlaGlnThr859095LeuArgCysTyrProAsnProGlySerGluLeuProLeuLysAlaLeu100105110ValThrGlyAlaGlyThrCysGluLysArgArgValGlyThrThrPro115120125GlnGlnValAlaAspSerAspAspAspHisSerGluGlyGlyLeuVal130135140GluGlnLeuThrMetArgArgLeuLeuGlnGluThrGluLeuValGlu145150155160ProLeuThrProSerGlyAlaValProAsnGlnAlaGlnMetArgIle165170175LeuLysGluThrGluLeuArgLysLeuLysValLeuGlySerGlyAla180185190PheGlyThrValTyrLysGlyIleTrpIleProAspGlyGluAsnVal195200205LysIleProValAlaIleLysValLeuArgGluAsnThrSerProLys210215220AlaAsnLysGluIleLeuAspGluAlaTyrValMetAlaGlyValGly225230235240SerProTyrValSerArgLeuLeuGlyIleCysLeuThrSerThrVal245250255GlnLeuValThrGlnLeuMetProTyrGlyCysLeuLeuAspHisVal260265270ArgGluHisArgGlyArgLeuGlySerGlnAspLeuLeuAsnTrpCys275280285ValGlnIleAlaLysGlyMetSerTyrLeuGluGluValArgLeuVal290295300HisArgAspLeuAlaAlaArgAsnValLeuValLysSerProAsnHis305310315320ValLysIleThrAspPheGlyLeuAlaArgLeuLeuAspIleAspGlu325330335ThrGluTyrHisAlaAspGlyGlyLysValProIleLysTrpMetAla340345350LeuGluSerIleLeuArgArgArgPheThrHisGlnSerAspValTrp355360365SerTyrGlyValThrValTrpGluLeuMetThrPheGlyAlaLysPro370375380TyrAspGlyIleProAlaArgGluIleProAspLeuLeuGluLysGly385390395400GluArgLeuProGlnProProIleCysThrIleAspValTyrMetIle405410415MetValLysCysTrpMetIleAspSerGluCysArgProArgPheArg420425430GluLeuValSerGluPheSerArgMetAlaArgAspProGlnArgPhe435440445ValValIleGlnAsnGluAspLeuAlaLeuGlyThrGlySerThrAla450455460HisArgArgHisArgSerSerSerProProProProIleArgProAla465470475480GlyAlaThrLeuGluArgProLysThrLeuSerProGlyLysAsnGly485490495ValValLysAspValPheAlaPheGlyGlyAlaValGluAsnProGlu500505510TyrLeuGlyArgProValProTrpSerPheGlyValValLeuTrpGlu515520525IleAlaThrLeuAlaGluGlnProTyrGlnGlyLeuSerAsnGluGln530535540ValLeuArgPheValMetGluGlyGlyLeuLeuAspLysProAspAsn545550555560CysProAspMetLeuPheGluLeuMetArgMetCysTrpGlnTyrAsn565570575ProLysMetArgProSerPheLeuGluHisLysAlaGluAsnGlyPro580585590GlyProGlyValLeuValLeuArgAlaSerPheAspGluArgGlnPro595600605TyrAlaHisMetAsnGlyGlyArgAlaAsnGluArgAlaLeuProAla610615620AlaAla625<210>81<211>624<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>81MetAlaValProMetLeuProArgLeuGlyGlyProAlaLeuProLeu151015LeuLeuProSerLeuLeuLeuLeuLeuLeuLeuGlyAlaGlyGlyCys202530GlyProGlyValArgAlaGluValLeuPheArgCysProProCysThr354045ProGluArgLeuAlaAlaCysGlyProProProAspAlaProCysAla505560GluLeuValArgGluProGlyCysGlyCysCysSerValCysAlaArg65707580GlnGluGlyGluAlaCysGlyValTyrIleProArgCysAlaGlnThr859095LeuArgCysTyrProAsnProGlySerGluLeuProLeuLysAlaLeu100105110ValThrGlyAlaGlyThrCysGluLysArgArgValGlyAlaThrPro115120125GlnGlnValAlaAspSerGluAspAspHisSerGluGlyGlyLeuVal130135140GluGlnLeuThrMetArgArgLeuLeuGlnGluThrGluLeuValGlu145150155160ProLeuThrProSerGlyAlaMetProAsnGlnAlaGlnMetArgIle165170175LeuLysGluThrGluLeuArgLysValLysValLeuGlySerGlyAla180185190PheGlyThrValTyrLysGlyIleTrpIleProAspGlyGluAsnVal195200205LysIleProValAlaIleLysValLeuArgGluAsnThrSerProLys210215220AlaAsnLysGluIleLeuAspGluAlaTyrValMetAlaGlyValGly225230235240SerProTyrValSerArgLeuLeuGlyIleCysLeuThrSerThrVal245250255GlnLeuValThrGlnLeuMetProTyrGlyCysLeuLeuAspHisVal260265270ArgGluHisArgGlyArgLeuGlySerGlnAspLeuLeuAsnTrpCys275280285ValGlnIleAlaLysGlyMetSerTyrLeuGluAspValArgLeuVal290295300HisArgAspLeuAlaAlaArgAsnValLeuValLysSerProAsnHis305310315320ValLysIleThrAspPheGlyLeuAlaArgLeuLeuAspIleAspGlu325330335ThrGluTyrHisAlaAspGlyGlyLysValProIleLysTrpMetAla340345350LeuGluSerIleLeuArgArgArgPheThrHisGlnSerAspValTrp355360365SerTyrGlyValThrValTrpGluLeuMetThrPheGlyAlaLysPro370375380TyrAspGlyIleProAlaArgGluIleProAspLeuLeuGluLysGly385390395400GluArgLeuProGlnProProIleCysThrIleAspValTyrMetIle405410415MetValLysCysTrpMetIleAspSerGluCysArgProArgPheArg420425430GluLeuValSerGluPheSerArgMetAlaArgAspProGlnArgPhe435440445ValValIleGlnAsnGluAspLeuThrProGlyThrGlySerThrAla450455460HisArgArgHisArgSerSerSerProLeuProProValArgProAla465470475480GlyAlaThrLeuGluArgProLysThrLeuSerProGlyLysAsnGly485490495ValValLysAspValPheAlaPheGlyGlyAlaValGluAsnProGlu500505510TyrLeuGlyArgProValProTrpSerPheGlyValValLeuTrpGlu515520525IleAlaThrLeuAlaGluGlnProTyrGlnGlyLeuSerAsnGluGln530535540ValLeuArgPheValMetGluGlyGlyLeuLeuAspLysProAspAsn545550555560CysProAspMetLeuPheGluLeuMetArgMetCysTrpGlnTyrAsn565570575ProLysMetArgProSerPheLeuGluHisLysAlaGluAsnGlyPro580585590GlyValLeuValLeuArgAlaSerPheAspGluArgGlnProTyrAla595600605HisMetAsnGlyGlyArgAlaAsnGluArgAlaLeuProAlaAlaAla610615620<210>82<211>89<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>82AspSerLysThrPheLeuSerArgHisSerLeuAspMetLysPheSer151015TyrCysAspGluArgIleThrGluLeuMetGlyTyrGluProGluGlu202530LeuLeuGlyArgSerIleTyrGluTyrTyrHisAlaLeuAspSerAsp354045HisLeuThrLysThrHisHisAspMetPheThrLysGlyGlnValThr505560ThrGlyGlnTyrArgMetLeuAlaLysArgGlyGlyTyrValTrpVal65707580GluThrGlnAlaThrValIleTyrAsn85<210>83<211>26<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>83SerAspAsnValAsnLysTyrMetGlyLeuThrGlnPheGluLeuThr151015GlyHisSerValPheAspPheThrHisPro2025<210>84<211>20<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>84GlyGlyTyrValTrpValGluThrGlnAlaThrValIleTyrAsnThr151015LysAsnSerGln20<210>85<211>38<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>85GlyCysAlaPheLeuSerValLysLysGlnPheGluGluLeuThrLeu151015GlyGluPheLeuLysLeuAspArgGluArgAlaLysAsnLysIleAla202530LysGluThrAsnAsnLys35<210>86<211>114<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>86ggctgcgccttcctgtccgtgaagaagcagttcgaggagctgaccctgggcgagttcctg60aagctggaccgcgagcgcgccaagaacaagatcgccaaggagaccaacaacaag114<210>87<211>88<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>87ArgSerLysGluSerGluValPheTyrGluLeuAlaHisGlnLeuPro151015LeuProHisAsnValSerSerHisLeuAspLysAlaSerValMetArg202530LeuThrIleSerTyrLeuArgValArgLysLeuLeuAspAlaGlyAsp354045LeuAspIleGluAspMetLysAlaGlnMetAsnCysPheTyrLeuLys505560AlaLeuAspGlyPheValMetValLeuThrAspAspGlyAspMetIle65707580TyrIleSerAspAsnValAsnLys85<210>88<211>267<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>88cgctccaaggagtccgaggtgttctacgagctggcccaccagctgcccctgccccacaac60gtgtcctcccacctggacaaggcctccgtgatgcgcctgaccatctcctacctgcgcgtg120cgcaagctgctggacgctggcgacctggacatcgaggacgacatgaaggcccagatgaac180tgcttctacctgaaggccctggacggcttcgtgatggtgctgaccgacgacggcgacatg240atctacatctccgacaacgtgaacaag267<210>89<211>415<212>PRT<213>人工序列<220><223>合成多核苷酸或多肽<400>89MetAlaValProMetLeuProArgValGlyCysProAlaLeuProLeu151015ProProProProLeuLeuProLeuLeuProLeuLeuLeuLeuLeuLeu202530GlyAlaSerGlyGlyGlyGlyGlyAlaArgAlaGluValLeuPheArg354045CysProProCysThrProGluArgLeuAlaAlaCysGlyProProPro505560ValAlaProProAlaAlaValAlaAlaValAlaGlyGlyAlaArgMet65707580ProCysAlaGluLeuValArgGluProGlyCysGlyCysCysSerVal859095CysAlaArgLeuGluGlyGluAlaCysGlyValTyrThrProArgCys100105110GlyGlnGlyLeuArgCysTyrProHisProGlySerGluLeuProLeu115120125GlnAlaLeuValMetGlyGluGlyThrCysGluLysArgArgAspAla130135140GluTyrGlyAlaSerProGluGlnValAlaAspAsnGlyAspAspHis145150155160SerGluGlyGlyLeuValGluGlnLeuGlyCysAlaPheLeuSerVal165170175LysLysGlnPheGluGluLeuThrLeuGlyGluPheLeuLysLeuAsp180185190ArgGluArgAlaLysAsnLysIleAlaLysGluThrAsnAsnLysGly195200205SerGluPheArgSerLysGluSerGluValPheTyrGluLeuAlaHis210215220GlnLeuProLeuProHisAsnValSerSerHisLeuAspLysAlaSer225230235240ValMetArgLeuThrIleSerTyrLeuArgValArgLysLeuLeuAsp245250255AlaGlyAspLeuAspIleGluAspAspMetLysAlaGlnMetAsnCys260265270PheTyrLeuLysAlaLeuAspGlyPheValMetValLeuThrAspAsp275280285GlyAspMetIleTyrIleSerAspAsnValAsnLysTyrArgSerGly290295300ArgProValProTrpSerPheGlyValValLeuTrpGluIleAlaThr305310315320LeuAlaGluGlnProTyrGlnGlyLeuSerAsnGluGlnValLeuArg325330335PheValMetGluGlyGlyLeuLeuAspLysProAspAsnCysProAsp340345350MetLeuPheGluLeuMetArgMetCysTrpGlnTyrAsnProLysMet355360365ArgProSerPheLeuGluHisLysAlaGluAsnGlyProGlyProGly370375380ValLeuValLeuArgAlaSerPheAspGluArgGlnProTyrAlaHis385390395400MetAsnGlyGlyArgLysAsnGluArgAlaLeuProAlaAlaAla405410415<210>90<211>1248<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>90atggcggtaccaatgctgccgagagtgggctgccccgcgctgccgctgccgccgccgccg60ctgctgccgctgctgccgctgctgctgctgctactgggcgcgagtggcggcggcggcggg120gcgcgcgcggaggtgctgttccgctgcccgccctgcacacccgagcgcctggccgcctgc180gggcccccgccggttgcgccgcccgccgcggtggccgcagtggccggaggcgcccgcatg240ccatgcgcggagctcgtccgggagccgggctgcggctgctgctcggtgtgcgcccggctg300gagggcgaggcgtgcggcgtctacaccccgcgctgcggccaggggctgcgctgctatccc360cacccgggctccgagctgcccctgcaggcgctggtcatgggcgagggcacttgtgagaag420cgccgggacgccgagtatggcgccagcccggagcaggttgcagacaatggcgatgaccac480tcagaaggaggcctggtggagcaattgggctgcgccttcctgtccgtgaagaagcagttc540gaggagctgaccctgggcgagttcctgaagctggaccgcgagcgcgccaagaacaagatc600gccaaggagaccaacaacaagggatccgaattccgctccaaggagtccgaggtgttctac660gagctggcccaccagctgcccctgccccacaacgtgtcctcccacctggacaaggcctcc720gtgatgcgcctgaccatctcctacctgcgcgtgcgcaagctgctggacgctggcgacctg780gacatcgaggacgacatgaaggcccagatgaactgcttctacctgaaggccctggacggc840ttcgtgatggtgctgaccgacgacggcgacatgatctacatctccgacaacgtgaacaag900tacagatccggccggccggtaccttggtccttcggcgtggtgctgtgggagatcgccacc960ctggccgagcagccctaccagggcctgtccaacgagcaggtgctgcgcttcgtgatggag1020ggcggcctgctggacaagcccgacaactgccccgacatgctgttcgagctgatgcgcatg1080tgctggcagtacaaccccaagatgcgcccctccttcctggagcacaaggccgagaacggc1140cccggccccggcgtgctggtgctgcgcgcctccttcgacgagcgccagccctacgcccac1200atgaacggaggccgcaagaacgagcgcgccctgcccgcggccgcatag1248<210>91<211>5248<212>DNA<213>人工序列<220><223>合成多核苷酸或多肽<400>91tggccattgcatacgttgtatccatatcataatatgtacatttatattggctcatgtcca60acattaccgccatgttgacattgattattgactagttattaatagtaatcaattacgggg120tcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccg180cctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccata240gtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcc300cacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgac360ggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttgg420cagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatc480aatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtc540aatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactcc600gccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagct660cgtttagtgaaccgtcagatcgcctggagacgccatccacgctgttttgacctccataga720agacaccgggaccgatccagcctccgcggccgggaacggtgcattggaacgcggattccc780cgtgccaagagtgacgtaagtaccgcctatagactctataggcacacccctttggctctt840atgcatgctatactgtttttggcttggggcctatacacccccgcttccttatgctatagg900tgatggtatagcttagcctataggtgtgggttattgaccattattgaccactccaacggt960ggagggcagtgtagtctgagcagtactcgttgctgccgcgcgcgccaccagacataatag1020ctgacagactaacagactgttcctttccatgggtcttttctgcagtcaccgtcgtcgacg1080gtatcgataagcttgatatcgaattgccgccaccatggcggtaccaatgctgccgagagt1140gggctgccccgcgctgccgctgccgccgccgccgctgctgccgctgctgccgctgctgct1200gctgctactgggcgcgagtggcggcggcggcggggcgcgcgcggaggtgctgttccgctg1260cccgccctgcacacccgagcgcctggccgcctgcgggcccccgccggttgcgccgcccgc1320cgcggtggccgcagtggccggaggcgcccgcatgccatgcgcggagctcgtccgggagcc1380gggctgcggctgctgctcggtgtgcgcccggctggagggcgaggcgtgcggcgtctacac1440cccgcgctgcggccaggggctgcgctgctatccccacccgggctccgagctgcccctgca1500ggcgctggtcatgggcgagggcacttgtgagaagcgccgggacgccgagtatggcgccag1560cccggagcaggttgcagacaatggcgatgaccactcagaaggaggcctggtggagcaatt1620gggctgcgccttcctgtccgtgaagaagcagttcgaggagctgaccctgggcgagttcct1680gaagctggaccgcgagcgcgccaagaacaagatcgccaaggagaccaacaacaagggatc1740cgaattccgctccaaggagtccgaggtgttctacgagctggcccaccagctgcccctgcc1800ccacaacgtgtcctcccacctggacaaggcctccgtgatgcgcctgaccatctcctacct1860gcgcgtgcgcaagctgctggacgctggcgacctggacatcgaggacgacatgaaggccca1920gatgaactgcttctacctgaaggccctggacggcttcgtgatggtgctgaccgacgacgg1980cgacatgatctacatctccgacaacgtgaacaagtacagatccggccggccggtaccttg2040gtccttcggcgtggtgctgtgggagatcgccaccctggccgagcagccctaccagggcct2100gtccaacgagcaggtgctgcgcttcgtgatggagggcggcctgctggacaagcccgacaa2160ctgccccgacatgctgttcgagctgatgcgcatgtgctggcagtacaaccccaagatgcg2220cccctccttcctggagcacaaggccgagaacggccccggccccggcgtgctggtgctgcg2280cgcctccttcgacgagcgccagccctacgcccacatgaacggaggccgcaagaacgagcg2340cgccctgcccgcggccgcatagtgatagatctttttccctctgccaaaaattatggggac2400atcatgaagccccttgagcatctgacttctggctaataaaggaaatttattttcattgca2460atagtgtgttggaattttttgtgtctctcactcggaaggacatatgggagggcaaatcat2520ttaaaacatcagaatgagtatttggtttagagtttggcaacatatgcccattcttccgct2580tcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcac2640tcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtga2700gcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccat2760aggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaac2820ccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcct2880gttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcg2940ctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctg3000ggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgt3060cttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacagg3120attagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactac3180ggctacactagaagaacagtatttggtatctgcgctctgctgaagccagttaccttcgga3240aaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtggttttttt3300gtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttt3360tctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgaga3420ttatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatc3480taaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacct3540atctcagcgatctgtctatttcgttcatccatagttgcctgactcggggggggggggcgc3600tgaggtctgcctcgtgaagaaggtgttgctgactcataccaggcctgaatcgccccatca3660tccagccagaaagtgagggagccacggttgatgagagctttgttgtaggtggaccagttg3720gtgattttgaacttttgctttgccacggaacggtctgcgttgtcgggaagatgcgtgatc3780tgatccttcaactcagcaaaagttcgatttattcaacaaagccgccgtcccgtcaagtca3840gcgtaatgctctgccagtgttacaaccaattaaccaattctgattagaaaaactcatcga3900gcatcaaatgaaactgcaatttattcatatcaggattatcaataccatatttttgaaaaa3960gccgtttctgtaatgaaggagaaaactcaccgaggcagttccataggatggcaagatcct4020ggtatcggtctgcgattccgactcgtccaacatcaatacaacctattaatttcccctcgt4080caaaaataaggttatcaagtgagaaatcaccatgagtgacgactgaatccggtgagaatg4140gcaaaagcttatgcatttctttccagacttgttcaacaggccagccattacgctcgtcat4200caaaatcactcgcatcaaccaaaccgttattcattcgtgattgcgcctgagcgagacgaa4260atacgcgatcgctgttaaaaggacaattacaaacaggaatcgaatgcaaccggcgcagga4320acactgccagcgcatcaacaatattttcacctgaatcaggatattcttctaatacctgga4380atgctgttttcccggggatcgcagtggtgagtaaccatgcatcatcaggagtacggataa4440aatgcttgatggtcggaagaggcataaattccgtcagccagtttagtctgaccatctcat4500ctgtaacatcattggcaacgctacctttgccatgtttcagaaacaactctggcgcatcgg4560gcttcccatacaatcgatagattgtcgcacctgattgcccgacattatcgcgagcccatt4620tatacccatataaatcagcatccatgttggaatttaatcgcggcctcgagcaagacgttt4680cccgttgaatatggctcataacaccccttgtattactgtttatgtaagcagacagtttta4740ttgttcatgatgatatatttttatcttgtgcaatgtaacatcagagattttgagacacaa4800cgtggctttccccccccccccattattgaagcatttatcagggttattgtctcatgagcg4860gatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttcccc4920gaaaagtgccacctgacgtctaagaaaccattattatcatgacattaacctataaaaata4980ggcgtatcacgaggccctttcgtctcgcgcgtttcggtgatgacggtgaaaacctctgac5040acatgcagctcccggagacggtcacagcttgtctgtaagcggatgccgggagcagacaag5100cccgtcagggcgcgtcagcgggtgttggcgggtgtcggggctggcttaactatgcggcat5160cagagcagattgtactgagagtgcaccatatgcggtgtgaaataccgcacagatgcgtaa5220ggagaaaataccgcatcagattggctat5248当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1