一种数据库的建立方法和遗传疾病的风险预测方法与流程
技术特征:
1.一种数据库的建立方法,其特征在于,包括:
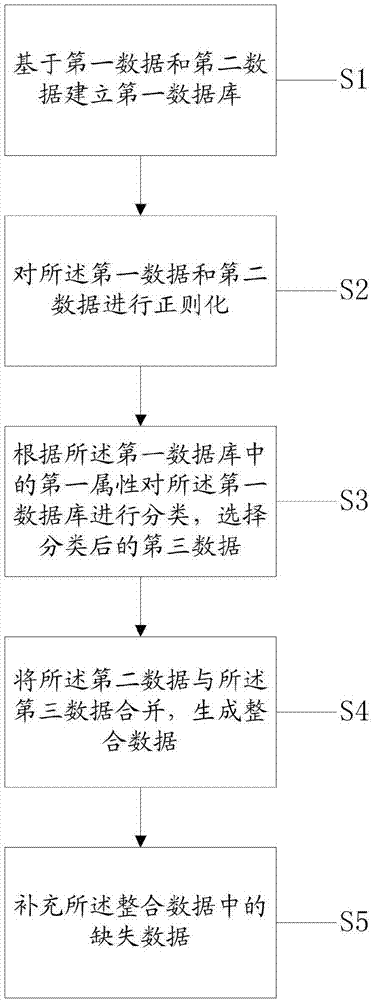
基于第一数据和第二数据建立第一数据库;
根据所述第一数据库中的第一属性对所述第一数据库进行分类,选择分类后的第三数据;
将所述第二数据与所述第三数据合并,生成整合数据;
根据所述整合数据建立第二数据库。
2.如权利要求1所述的数据库的建立方法,其特征在于,将所述第二数据与所述第三数据合并,生成整合数据之后,还包括:补充所述整合数据中的缺失数据。
3.如权利要求1所述的数据库的建立方法,其特征在于,基于第一数据和第二数据建立第一数据库之后,还包括:对所述第一数据和第二数据进行正则化。
4.如权利要求2和3所述的数据库的建立方法,其特征在于,所述正则化具体为,用python的正则表达式和文本处理包对数据进行正则化。
5.如权利要求2和3所述的数据库的建立方法,其特征在于,所述数据库为一种遗传疾病变异数据库,所述第一数据为Clinvar数据,所述第二数据为GWAS数据,所述方法包括:
基于Clinvar数据和GWAS数据建立第一数据库;
对所述Clinvar数据和所述GWAS数据进行正则化;
根据所述Clinvar数据库中的Clinical significance属性对所述第一数据库进行分类,选择分类后的GWAS,risk factor和protective三类数据作为第三数据;
对所述第三数据进行正则化;
将所述GWAS数据与所述第三数据合并,生成整合数据;
补充所述整合数据中的缺失数据;
根据所述整合数据建立所述遗传疾病变异数据库。
6.一种遗传疾病的风险预测方法,其特征在于,所述方法基于遗传疾病变异数据库,所述方法包括:
筛选风险SNP位点,并获取所述遗传疾病变异数据库中SNP位点集合信息;
计算样本的遗传疾病的风险值。
7.如权利要求6所述的遗传疾病的风险预测的方法,其特征在于,所述计算样本的遗传疾病的风险值之后,还包括:用实际数据对计算结果进行评估。
8.如权利要求6所述的遗传疾病的风险预测的方法,其特征在于,所述计算样本的遗传疾病的风险值,具体为:所述a为疾病的发病率;所述s为基因名称;所述OR为每个SNP位点的比值比;所述WORi(s,OR)为每个SNP位点加权后的比值比;所述
为样本的遗传疾病的风险值。
- 还没有人留言评论。精彩留言会获得点赞!