一种决策结果确定方法、装置、设备及可读存储介质与流程
本申请涉及自然语言处理技术领域,更具体地说,涉及一种决策结果确定方法、装置、设备及可读存储介质。
背景技术
虽然近些年来我国医疗行业快速发展,但仍然不能完全满足人民群众医疗方面的巨大需求,因此目前国家政策大力支持基层医疗的发展。而对于发展基层医疗,其核心在于提升基层医生的诊疗水平。
临床决策支持系统(clinicaldecisionsupportsystem,cdss)是一种针对医生诊疗的计算机辅助应用系统,它存储和运用大量医学知识,根据患者的基本信息、病情信息等在医生的诊疗过程中给出多方面的辅助和提示,用以帮助医生更加合理高效地完成诊疗工作、提升整体医疗服务水平。现有的临床决策支持系统一般包括:知识库模块和推理模块。
1、知识库模块,主要负责知识的存储和调用,知识库存储的知识可以是结构化知识,如疾病库、检查库、药品库及其之间的关系等。知识库的构建需要人工参与,并且需要不断的知识更新。
2、推理模块,包含了一系列由医学专家总结的基于知识库的推理规则,这些规则是专家经验和知识的直接反映。推理模块根据用户数据,利用推理规则进行逻辑判断,得出诊断结论供医护人员参考。
本案发明人研究发现,现有的临床决策支持系统存在一定缺点,如知识库的构建及更新需要大量医学专家的人工投入,成本较高。且由于医学知识纷繁复杂,将这些知识总结出来,表示为可以用于逻辑推理的推理规则并不容易,需要大量的专家投入。且由于很多医学知识和经验是模糊的,不容易表示为规则。并且,当规则达到一定数量时,可能会存在逻辑上的冲突。
因此,现有技术亟需一种新的决策结果确定方案,以避免现有技术的缺陷。
技术实现要素:
有鉴于此,本申请提供了一种决策结果确定方法、装置、设备及可读存储介质,用于减少对知识库的依赖,且在不需要总结推理规则的情况下,实现决策结果的确定。
为了实现上述目的,现提出的方案如下:
一种决策结果确定方法,包括:
获取目标场景下与目标问题对应的至少两个候选答案;
针对每一候选答案,在目标场景对应的语料库中,检索与所述候选答案及所述目标问题的组合相关的证据语料;
根据所述证据语料对所述候选答案及所述目标问题中词的包含情况,获取所述候选答案与所述目标问题的匹配特征;
根据每一所述候选答案与所述目标问题的匹配特征,在各所述候选答案中确定所述目标问题的匹配答案。
优选地,所述针对每一候选答案,在目标场景对应的语料库中,检索与所述候选答案及所述目标问题的组合相关的证据语料,包括:
针对每一候选答案,利用所述候选答案及所述目标问题各自包含的词生成检索式;
依据所述检索式,在目标场景对应的语料库中检索,检索得到证据语料。
优选地,所述根据所述证据语料对所述候选答案及所述目标问题中词的包含情况,确定所述候选答案与所述目标问题的匹配特征,包括:
参考所述证据语料构建证据链图,所述证据链图中的节点由既出现在所述证据语料中,又出现在所述候选答案或所述目标问题中的词组成;
根据所述证据链图,获取所述候选答案与所述目标问题的匹配特征。
优选地,所述参考所述证据语料构建证据链图,包括:
针对每一条所述证据语料,构建对应的单证据图,所述单证据图中的节点由所述证据语料包含的所述候选答案及所述目标问题中的词组成;
将各条所述证据语料各自对应的单证据图,以包含的相同边为基准进行融合,得到融合后的证据链图。
优选地,所述针对每一条所述证据语料,构建对应的单证据图,包括:
按照设定的n(8)种构建方式,针对每一条所述证据语料,构建对应的n种单证据图;
所述将各条所述证据语料各自对应的单证据图,以包含的相同边为基准进行融合,得到融合后的证据链图,包括:
将各条所述证据语料按照同一种构建方式所构建的单证据图,以包含的相同边为基准,按照设定的m(2)种融合方式进行融合,得到n*m种融合后的证据链图。
优选地,所述根据所述证据链图,获取所述候选答案与所述目标问题的匹配特征,包括:
按照设定的匹配特征模板,在所述证据链图中,获取所述候选答案与所述目标问题的匹配特征。
优选地,在所述检索与所述候选答案及所述目标问题的组合相关的证据语料之前,该方法还包括:
对所述候选答案及所述目标问题进行预处理,该预处理过程包括:进行分词、去除特殊字符及标点、去除停用词、确定词权重。
优选地,所述根据每一所述候选答案与所述目标问题的匹配特征,在各所述候选答案中确定所述目标问题的匹配答案,包括:
将每一所述候选答案与所述目标问题的匹配特征输入预置的答案评估模型,得到答案评估模型输出的所述候选答案的匹配状态;
所述答案评估模型为,预先以问题训练数据与候选答案训练数据的匹配特征为样本,以各所述候选答案训练数据是否为匹配答案的标注结果为样本标签进行训练得到;
根据各所述候选答案的匹配状态,从中确定所述目标问题的匹配答案。
一种决策结果确定装置,包括:
数据获取单元,用于获取目标场景下与目标问题对应的至少两个候选答案;
检索单元,用于针对每一候选答案,在目标场景对应的语料库中,检索与所述候选答案及所述目标问题的组合相关的证据语料;
匹配特征获取单元,用于根据所述证据语料对所述候选答案及所述目标问题中词的包含情况,获取所述候选答案与所述目标问题的匹配特征;
匹配答案确定单元,用于根据每一所述候选答案与所述目标问题的匹配特征,在各所述候选答案中确定所述目标问题的匹配答案。
优选地,所述检索单元包括:
检索式生成单元,用于针对每一候选答案,利用所述候选答案及所述目标问题各自包含的词生成检索式;
检索式检索单元,用于依据所述检索式,在目标场景对应的语料库中检索,检索得到证据语料。
优选地,所述匹配特征获取单元包括:
证据链图构建单元,用于参考所述证据语料构建证据链图,所述证据链图中的节点由既出现在所述证据语料中,又出现在所述候选答案或所述目标问题中的词组成;
证据链图使用单元,用于根据所述证据链图,获取所述候选答案与所述目标问题的匹配特征。
优选地,所述证据链图构建单元包括:
单证据图构建单元,用于针对每一条所述证据语料,构建对应的单证据图,所述单证据图中的节点由所述证据语料包含的所述候选答案及所述目标问题中的词组成;
单证据图融合单元,用于将各条所述证据语料各自对应的单证据图,以包含的相同边为基准进行融合,得到融合后的证据链图。
优选地,所述匹配答案确定单元包括:
模型使用单元,用于将每一所述候选答案与所述目标问题的匹配特征输入预置的答案评估模型,得到答案评估模型输出的所述候选答案的匹配状态;
所述答案评估模型为,预先以问题训练数据与候选答案训练数据的匹配特征为样本,以各所述候选答案训练数据是否为匹配答案的标注结果为样本标签进行训练得到;
结果确定单元,用于根据各所述候选答案的匹配状态,从中确定所述目标问题的匹配答案。
一种决策结果确定设备,包括存储器和处理器;
所述存储器,用于存储程序;
所述处理器,用于执行所述程序,实现如上公开的决策结果确定方法的各个步骤。
一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上公开的决策结果确定方法的各个步骤。
从上述的技术方案可以看出,本申请实施例提供的决策结果确定方法,获取到目标场景下与目标问题对应的至少两个候选答案,该目标场景可以是医疗诊断场景或其他场景,对应的目标问题及候选答案可以是患者信息及疾病诊断方案,本申请针对每一候选答案,在目标场景对应的语料库中检索与候选答案和目标问题的组合相关的证据语料,并根据证据语料对候选答案与目标问题中词的包含情况,获取候选答案与目标问题的匹配特征,该匹配特征反映了候选答案作为目标问题的匹配答案的支持度,因此可以根据每一候选答案与目标问题的匹配特征,在各候选答案中确定目标问题的匹配答案。本申请方案从自然语言理解及推理的角度,直接基于目标场景对应的语料库进行决策,不需要专家构建及更新知识库中问题及答案间的关系,也不需要总结推理规则,节省了成本且保证决策过程不存在规则冲突,使得确定的决策结果更加可靠。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
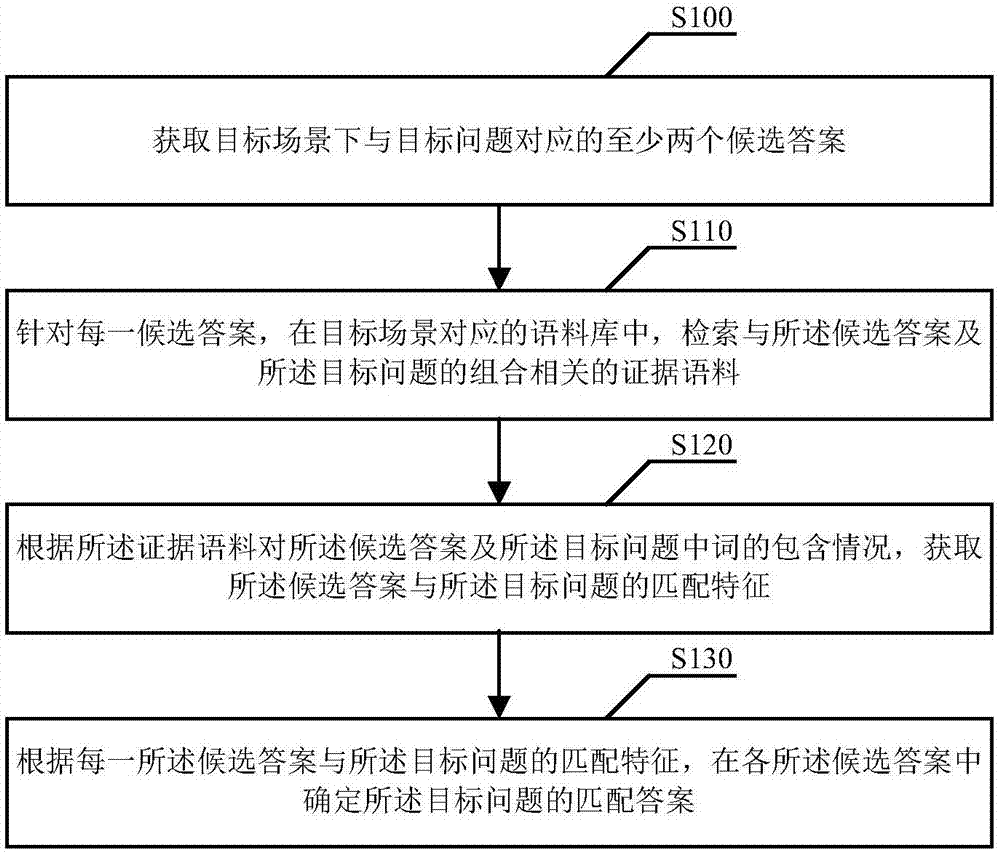
图1为本申请实施例公开的一种决策结果确定方法流程图;
图2a-图2b分别示例了两条证据语料构建的单证据图;
图3示例了两个单证据图融合得到证据链图;
图4示例了证据链图对应的最大生成树示意图;
图5示例了证据链图对应的二部图;
图6为本申请实施例公开的一种决策结果确定装置结构示意图;
图7为本申请实施例公开的一种决策结果确定设备的硬件结构框图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
在很多场景下均存在问-答需求,即给出一个问题后,需要给出问题对应的匹配答案。以医疗诊断场景为例,临床决策支持系统即是解决问-答需求的。输入的患者信息即为问题,需要给出对应的诊断方案,该诊断方案即为答案。诊断方案可以是疾病诊断、治疗、手术、用药等。
仍以医疗诊断场景的临床决策支持系统为例,其存在众多的缺陷:
知识库的构建及更新需要大量医学专家的人工投入,成本较高。且由于医学知识纷繁复杂,将这些知识总结出来,表示为可以用于逻辑推理的推理规则并不容易,需要大量的专家投入。且由于很多医学知识和经验是模糊的,不容易表示为规则。并且,当规则达到一定数量时,可能会存在逻辑上的冲突。
本案发明人为了解决现有技术的缺陷,创造性的提出了一种解决方案,在避开知识库及推理模块的情况下,直接从自然语言理解与推理的角度,基于目标场景对应的语料库进行决策支持。接下来,详细介绍本申请方案,如图1所示,方法包括:
步骤s100、获取目标场景下与目标问题对应的至少两个候选答案。
具体地,本申请方案可以适用于多种场景,只要存在问-答需求即可。目标场景可以是医疗诊断场景或其他场景。
本步骤中,获取目标场景下与目标问题对应的至少两个候选答案。其中,目标问题即给出的需要解决的问题,用户可以给出目标问题对应的多个候选答案。当然,若用户未给出候选答案,则可以将目标问题所有可能的答案均作为候选答案。
以医疗诊断为例,目标问题是:用户感冒流鼻涕,吃什么药?可以由用户提供若干个候选答案,也可以将所有药品均作为候选答案。
步骤s110、针对每一候选答案,在目标场景对应的语料库中,检索与所述候选答案及所述目标问题的组合相关的证据语料。
具体地,目标场景对应的语料库存储的均是与目标场景相关的语料。以目标场景为医疗诊断场景为例,对应的语料库中可以存储医学书籍、文献、诊断报告、病例等。可以理解的是,目标场景对应的语料库包含了目标场景下所有问题及对应的答案。
基于此,本步骤中针对每一个候选答案,将其与目标问题作为组合,在目标场景对应的语料库中检索组合相关的证据语料。检索到的证据语料作为支持组合中候选答案成为目标问题的匹配答案的证据。
根据语料的组织形式不同,检索到的证据语料可以是句子、段落或完整的篇章等。
步骤s120、根据所述证据语料对所述候选答案及所述目标问题中词的包含情况,获取所述候选答案与所述目标问题的匹配特征。
具体地,由于前述检索的是与候选答案与目标问题的组合相关的证据语料,因此证据语料会同时包含候选答案和目标问题中的词,但是包含的数量、词间的距离等信息根据不同的证据语料会存在变化。本步骤中,根据证据语料对候选答案及目标问题中词的包含情况,获取候选答案与目标问题的匹配特征。该匹配特征反映了候选答案与目标问题的匹配度,即候选答案成为目标问题的匹配答案的可能性。
步骤s130、根据每一所述候选答案与所述目标问题的匹配特征,在各所述候选答案中确定所述目标问题的匹配答案。
具体地,前述已经针对每一候选答案,均确定了其与目标问题的匹配特征。匹配特征反映了候选答案与目标问题的匹配度,因此本步骤中根据匹配特征,在各候选答案中确定出目标问题的匹配答案。
可以理解的是,作为目标问题的匹配答案的候选答案,其与目标问题的匹配特征所反映的匹配度应该是较高的,如选取匹配度最高的一个或topn个候选答案,作为目标问题的匹配答案。
本申请实施例提供的决策结果确定方法,从自然语言理解及推理的角度,直接基于目标场景对应的语料库进行决策,不需要专家构建及更新知识库中问题及答案间的关系,也不需要总结推理规则,节省了成本且保证决策过程不存在规则冲突,使得确定的决策结果更加可靠。
可选的,在上述步骤s100与步骤s110之间,本申请实施例还可以进一步增加对候选答案及目标问题进行预处理的过程。
预处理的过程可以包括:
1、对候选答案、目标问题均进行分词处理。
2、去除候选答案、目标问题中的特殊符号及标点。
3、去除候选答案、目标问题中的停用词。停用词可以是idf(inversedocumentfrequency,逆文本频率指数)较低的词,如“的”、“了”等。
4、对分词处理得到的词确定其词权重。具体可以采用标准的idf作为词权重。
在本申请的另一个实施例中,对上述步骤s110,针对每一候选答案,在目标场景对应的语料库中,检索与所述候选答案及所述目标问题的组合相关的证据语料的过程进行介绍。
为了实现对候选答案与目标问题的组合的相关语料的检索,本实施例中可以针对每一候选答案,利用该候选答案及目标问题各自包含的词生成检索式。进一步,依据生成的检索式,在目标场景对应的语料库中检索,检索得到证据语料。
其中,所述检索式中候选答案包含的词之间以“或”连接,目标问题包含的词之间以“或”连接,从而提高召回率。
进一步,候选答案与目标问题之间以“和”连接,从而保证检索得到的证据语料与候选答案及目标问题的组合相关,即保证检索结果的精确率。
本实施例中依据检索式在语料库中检索的过程,可以采用lucene搜索引擎进行检索。当然,还可以采用其它搜索引擎进行检索。
可选的,前述介绍了对候选答案与目标问题进行预处理的过程。预处理过程进行了分词、特殊符号及标点去除、停用词去除及词权重确定。因此,在生成检索式时,检索式中可以不包含特殊符号、标点及停用词。进一步,检索式中词还可以标记有词权重。
接下来通过医疗诊断场景下的一个具体实例说明检索式生成过程。
目标问题是根据患者信息确定首选的避孕药品是什么。患者信息包括:女,宫颈呈糜烂状态,宫颈口松,子宫前位。
候选答案包括a-e,分别如下:
a、托吡酯b、卡马西平c、乙琥胺d、左乙拉西坦e、氯硝西泮
针对候选答案a,确定其与目标问题的组合对应的检索式为:
(宫颈^6.34||糜烂^8.86||状态^4.50||口松^5.82||子宫^4.77||前位^3.54)&&(托吡酯^11.23)
其中,“^”之后的数值为词权重,如“宫颈^6.34”表示“宫颈”的词权重为6.34。“||”表示“或”的连接关系。“&&”表示“和”的连接关系。
上述词权重是根据词的idf确定的。
在生成检索式之后,可以利用lucene搜索引擎在目标场景对应的语料库中进行检索,如在医疗诊断对应的语料库中检索,可以保留检索得到的全部结果作为证据语料,也可以取前n个结果作为证据语料。
在本申请的又一个实施例中,对上述步骤s120,根据所述证据语料对所述候选答案及所述目标问题中词的包含情况,获取所述候选答案与所述目标问题的匹配特征的过程进行介绍。
本实施例中可以参考证据语料来构建证据链图。证据链图可以是无向图形式。证据链图中的节点由既出现在证据语料中,又出现在候选答案或目标问题中的词组成。节点间连线代表两个节点对应的词在证据语料中共现,且节点间连线的权重由两个节点对应词在共现证据语料中的出现情况决定。该出现情况可以包括出现次数、两个节点对应词在共现证据语料中的距离等。
在构建了证据链图之后,可以根据该证据链图,获取候选答案与目标问题的匹配特征。
可以理解的是,针对每一个候选答案,均可以利用候选答案对应的证据语料构建对应的证据链图,进而根据证据链图获取候选答案与目标问题的匹配特征。
该匹配特征反映了候选答案与目标问题的匹配度,即候选答案成为目标问题的匹配答案的可能性。
需要说明的是,针对每一候选答案与目标问题的组合所检索得到的证据语料,其证据语料的条数可以是多条。基于此,每一候选答案对应多条证据语料。本申请实施例详细介绍上述参考证据语料构建证据链图的过程:
1)针对候选答案的每一条证据语料,构建对应的单证据图。
其中,单证据图中的节点由该条证据语料包含的候选答案及目标问题中的词组成。节点间连线的权重由两个节点对应词在该条证据语料中的出现情况决定。
假设候选答案a对应有x条证据语料,则针对每一条证据语料均可以构建对应的单证据图。因此,共计可以为候选答案a构建x个单证据图。由于候选答案a对应的x条证据语料对候选答案与目标问题中分词的包含情况不同,因此x个单证据图中节点对应的分词可能不太,且节点间连线的权重也可能不同。
参照图2a和图2b,其分别示例了针对两条证据语料构建的单证据图。
具体地,目标问题是根据患者信息确定首选的治疗方法是什么。患者信息包括:女,摔倒后左肩部着地受伤,肩部肿胀,疼痛,肩关节活动障碍。x线片显示左侧肱骨外壳胫骨皮质连续性中断,无明显移位。
候选答案包括a-e,分别如下:
a、三角巾悬吊贴胸部固定b、石膏外固定c、切开复位内固定d、小夹板外固定e、尺骨鹰嘴骨牵引+夹板固定
以候选答案a为例,检索与候选答案a及目标问题的组合相关的证据语料。以检索得到的两条证据语料1、2为例,其中:
证据语料1:……有上肢外展外旋或后伸着地受伤史,肩部疼痛、肿胀……即应考虑有肩关节脱位可能……肩胛盂处有空虚感,上肢有弹性固定
证据语料2:单纯性肩关节脱位复位后可用三角巾悬吊上肢,肘关节屈曲90度,腋窝处垫棉垫固定3周
上述证据语料中共现的候选答案a及目标问题中的词用下划线做了标记。
其中,证据语料1对应构建的单证据图如图2a所示,证据语料2对应构建的单证据图如图2b所示。
图2a和图2b示例的单证据图仅仅示例了节点及节点间连接关系,对于节点权重、边权重等参数图中并未标记。
通过图2a和图2b可以看出,对于证据语料中共现的词,在对应的单证据图中均以节点形式出现,且图中任意两个节点之间均存在连线,表示节点对应的词在同一证据语料中共现。
图2a和图2b中,节点“固定”、“悬吊”、“三角巾”为候选答案a中出现的词,其它节点为目标问题中出现的词。
可选的,在针对每一条证据语料,构建对应的单证据图时,可以按照预先设定的多种构建方式进行构建。假定预先设定了n种构建方式,则针对每一条证据语料,构建对应的n种单证据图。
不同构建方式下,所构建的单证据图的节点权重、边权重、证据权重的计算方式。参照下表1,其示例了节点权重、边权重、证据权重的若干种计算方式:
表1
显然,上述表1中示例了1种节点权重计算方式,2种边权重计算方式,4种证据权重计算方式,节点权重、边权重、证据权重计算方式可以任意组合,因此共存在1*2*4=8种构建方式。
当然,表1仅仅示例了若干种权重计算方式,除此之外还可以设置其他权重计算方式。
2)将各条所述证据语料各自对应的单证据图,以包含的相同边为基准进行融合,得到融合后的证据链图。
具体地,上述1)针对候选答案的每一条证据语料构建了对应的单证据图,本步骤中将各个单证据图进行融合,得到融合后的证据链图。
具体地,在进行单证据图融合时,以包含的相同边为基准进行融合。其中,相同的边即为相同的两个节点间的连线。
仍以图2a和图2b对应的两个单证据图为例,介绍二者的融合过程,参见图3所示,图3示例了图2a和图2b对应的两个单证据图融合过程示意图。
图2a和图2b对应的两个单证据图在融合时,以“肩”、“关节”、“固定”三个节点之间的边为基准进行融合。作为基准的边在融合后的证据链图中的边权重按照设定融合方式重新计算,其余边权重保持不变。
本实施例中融合方式可以存在m种,而前述实施例说明了可以存在n种单证据图构建方式,因此每条证据语料对应有n种单证据图。基于此,可以将各条所述证据语料按照同一种构建方式所构建的单证据图,以包含的相同边为基准,按照设定的m种融合方式进行融合,得到n*m种融合后的证据链图。
接下来介绍两种可选的融合方式:
第一种:相同边权重叠加
wedge_merge=(wnode1+wnode2)(wedge1wevd1+wedge2wevd2)
其中,wnode1和wnode2为单证据图1和2中相同边两侧节点权重,wedge1和wedge2为单证据图1和2中相同边的边权重,wevd1和wevd2为单证据图1和2的证据权重,wedge_merge为单证据图1和2中相同边在融合后证据链图中边的边权重。
第二种:最大边权重
wedge_merge=(wnode1+wnode2)max(wedge1wevd1,wedge2wevd2)
其中公式中各个参数的定义与第一种方式相同。
以上述实施例示例的n=8,m=2为例,则共计可以得到8*2=16种融合后证据链图。
进一步地,在构建了证据链图之后,可以根据证据链图获取候选答案与目标问题的匹配特征。
具体地,本实施例中可以设定若干种匹配特征模板,如设定β种匹配特征模板,进而在证据链图中,按照设定的匹配特征模板获取匹配特征。
可以理解的是,上述已经说明可以生成n*m种证据链图,本步骤中可以按照β种匹配特征模板获取匹配特征,进而能够获取到n*m*β种匹配特征,也即获取到n*m*β维匹配特征。
接下来,介绍几种匹配特征模板。
1、将证据链图的最大生成树的边权重之和作为匹配特征。
具体地,首先生成证据链图的最大生成树,进而将最大生成树的边权重之和作为匹配特征。
生成树是一种连通图的处理方式,目标是去除原图中的环切仍然保持连通。而最大生成树便是所有可能的生成树中边权重之和最大的一种。生成树能够体现图的连通性,也就是证据链的连通性。
以图3示例的融合后的证据链图为例,生成该证据链图的最大生成树,效果如图4所示。
2、将证据链图的最小生成树的边权重之和作为匹配特征。
具体地,首先生成证据链图的最小生成树,进而将最小生成树的边权重之和作为匹配特征。最小生成树是证据链图对应的所有可能的生成树中边权重之和最小的一种。
3、将证据链图的二部图的最大生成树的边权重之和作为匹配特征。
具体地,首先生成证据链图的二部图,进一步生成二部图的最大生成树,将最大生成树的边权重之和作为匹配特征。
可以理解的是,证据链图包含的节点可以分为两部分,一部分是属于目标问题包含的词,另一部分是属于候选答案包含的词。按照这两部分,生成证据链图的二部图。在生成二部图时,将证据链图中每一部分内的词间的边去掉,仅保留两部分之间的边。以图3示例的融合后的证据链图为例,生成该证据链图的二部图,效果如图5所示。
图5中,右侧的“固定”、“悬吊”、“三角巾”属于候选答案包含的词,作为二部图的一部分,剩余分词属于目标问题包含的词,作为二部图的另一部分。
4、将证据链图的二部图的最小生成树的边权重之和作为匹配特征。
具体地,首先生成证据链图的二部图,进一步生成二部图的最小生成树,将最小生成树的边权重之和作为匹配特征。
5、将证据链图中的节点个数作为匹配特征。
6、将证据链图中节点个数占目标问题所有词数的比例作为匹配特征。
本实施例中示例了6种匹配特征模板,可以理解的是,除此之外还可以设置其它类型的匹配特征模板。
以上述实施例示例的n=8,m=2,β=6为例,则共计可以得到8*2*6=96维匹配特征。
在上述实施例介绍的获取到每一候选答案与目标问题的n*m*β维匹配特征之后,进一步介绍步骤s130,根据每一所述候选答案与所述目标问题的匹配特征,在各所述候选答案中确定所述目标问题的匹配答案的过程。
本实施例中可以通过神经网络模型来实现匹配答案的预测。具体地,可以预先训练答案评估模型,该答案评估模型为神经网络模型,如mlp(multi-layerperceptron,多层感知器)类型的神经网络模型,或其它形式的神经网络模型。
本申请可以预先获取问题训练数据和候选答案训练数据,针对同一问题训练数据,对应有多个候选答案训练数据,且预先为每个候选答案训练数据标注了样本标签,即通过样本标签标记其是否为匹配答案。进一步,获取问题训练数据与候选答案训练数据的匹配特征,将获取的匹配特征作为样本,将各候选答案训练数据是否为匹配答案的标注结果为样本标签,训练答案评估模型。
本实施例中可以将每一所述候选答案与所述目标问题的匹配特征输入训练好的答案评估模型中,并得到答案评估模型输出的所述候选答案的匹配状态。其中,候选答案的匹配状态可以是定性结果或定量结果,如候选答案的匹配状态为:候选答案与目标问题匹配、候选答案与目标问题不匹配;或者,候选答案的匹配状态为:候选答案的匹配率数值。
根据各所述候选答案的匹配状态,从中确定所述目标问题的匹配答案。如当匹配状态为定性结果时,可以选取匹配的候选答案,作为目标问题的匹配答案。当匹配状态为定量结果时,可以选取匹配率最高的候选答案,作为目标问题的匹配答案。
下面对本申请实施例提供的决策结果确定装置进行描述,下文描述的决策结果确定装置与上文描述的决策结果确定方法可相互对应参照。
参见图6,图6为本申请实施例公开的一种决策结果确定装置结构示意图。如图6所示,该装置可以包括:
数据获取单元11,用于获取目标场景下与目标问题对应的至少两个候选答案;
检索单元12,用于针对每一候选答案,在目标场景对应的语料库中,检索与所述候选答案及所述目标问题的组合相关的证据语料;
匹配特征获取单元13,用于根据所述证据语料对所述候选答案及所述目标问题中词的包含情况,获取所述候选答案与所述目标问题的匹配特征;
匹配答案确定单元14,用于根据每一所述候选答案与所述目标问题的匹配特征,在各所述候选答案中确定所述目标问题的匹配答案。
可选的,所述检索单元可以包括:
检索式生成单元,用于针对每一候选答案,利用所述候选答案及所述目标问题各自包含的词生成检索式;
检索式检索单元,用于依据所述检索式,在目标场景对应的语料库中检索,检索得到证据语料。
可选的,所述匹配特征获取单元可以包括:
证据链图构建单元,用于参考所述证据语料构建证据链图,所述证据链图中的节点由既出现在证据语料中,又出现在所述候选答案或所述目标问题中的词组成;
证据链图使用单元,用于根据所述证据链图,获取所述候选答案与所述目标问题的匹配特征。
可选的,所述证据链图构建单元可以包括:
单证据图构建单元,用于针对每一条所述证据语料,构建对应的单证据图,所述单证据图中的节点由所述证据语料包含的所述候选答案及所述目标问题中的词组成;
单证据图融合单元,用于将各条所述证据语料各自对应的单证据图,以包含的相同边为基准进行融合,得到融合后的证据链图。
可选的,所述单证据图构建单元可以包括:
第一单证据图构建子单元,用于按照设定的n种构建方式,针对每一条所述证据语料,构建对应的n种单证据图。基于此,
所述单证据图融合单元可以包括:
第一单证据图融合子单元,用于将各条所述证据语料按照同一种构建方式所构建的单证据图,以包含的相同边为基准,按照设定的m种融合方式进行融合,得到n*m种融合后的证据链图。
可选的,所述证据链图使用单元可以包括:
第一证据链图使用子单元,用于按照设定的匹配特征模板,在所述证据链图中,获取所述候选答案与所述目标问题的匹配特征。
可选的,本申请实施例公开的决策结果确定装置还可以包括:
预处理单元,用于在检索与所述候选答案及所述目标问题的组合相关的证据语料之前,对所述候选答案及所述目标问题进行预处理,该预处理过程包括:进行分词、去除特殊字符及标点、去除停用词、确定词权重。
可选的,所述匹配答案确定单元可以包括:
模型使用单元,用于将每一所述候选答案与所述目标问题的匹配特征输入预置的答案评估模型,得到答案评估模型输出的所述候选答案的匹配状态;
所述答案评估模型为,预先以问题训练数据与候选答案训练数据的匹配特征为样本,以各所述候选答案训练数据是否为匹配答案的标注结果为样本标签进行训练得到;
结果确定单元,用于根据各所述候选答案的匹配状态,从中确定所述目标问题的匹配答案。
本申请实施例提供的决策结果确定装置可应用于决策结果确定设备,如pc终端、云平台、服务器及服务器集群等。可选的,图7示出了决策结果确定设备的硬件结构框图,参照图7,决策结果确定设备的硬件结构可以包括:至少一个处理器1,至少一个通信接口2,至少一个存储器3和至少一个通信总线4;
在本申请实施例中,处理器1、通信接口2、存储器3、通信总线4的数量为至少一个,且处理器1、通信接口2、存储器3通过通信总线4完成相互间的通信;
处理器1可能是一个中央处理器cpu,或者是特定集成电路asic(applicationspecificintegratedcircuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;
存储器3可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatilememory)等,例如至少一个磁盘存储器;
其中,存储器存储有程序,处理器可调用存储器存储的程序,所述程序用于:
获取目标场景下与目标问题对应的至少两个候选答案;
针对每一候选答案,在目标场景对应的语料库中,检索与所述候选答案及所述目标问题的组合相关的证据语料;
根据所述证据语料对所述候选答案及所述目标问题中词的包含情况,获取所述候选答案与所述目标问题的匹配特征;
根据每一所述候选答案与所述目标问题的匹配特征,在各所述候选答案中确定所述目标问题的匹配答案。
可选的,所述程序的细化功能和扩展功能可参照上文描述。
本申请实施例还提供一种存储介质,该存储介质可存储有适于处理器执行的程序,所述程序用于:
获取目标场景下与目标问题对应的至少两个候选答案;
针对每一候选答案,在目标场景对应的语料库中,检索与所述候选答案及所述目标问题的组合相关的证据语料;
根据所述证据语料对所述候选答案及所述目标问题中词的包含情况,获取所述候选答案与所述目标问题的匹配特征;
根据每一所述候选答案与所述目标问题的匹配特征,在各所述候选答案中确定所述目标问题的匹配答案。
可选的,所述程序的细化功能和扩展功能可参照上文描述。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!