一种基于种群熵的阶段性蛋白质结构预测方法与流程
本发明涉及生物信息学、计算机应用领域,尤其涉及的是一种基于种群熵的阶段性蛋白质结构预测方法。
背景技术:
蛋白质是生命活动的主要承担者,人体内蛋白质的种类很多,每种蛋白质都有着特定的功能。蛋白质是由氨基酸以“脱水缩合”的方式组合成的多肽经过折叠形成的具有一定空间结构的物质。蛋白质特定的空间结构决定了其特定的功能,家族性高胆固醇症、白内障等疾病就是因为蛋白质的空间结构发生变化导致其功能缺失而引起的。如果能确定蛋白质的空间结构,将有助于人们更全面的了解其特定的功能,设计出新型药物对抗疾病。
根据实验测定蛋白质三维结构的方法主要包括x射线晶体衍射、核磁共振和冷冻电镜技术,这些实验方法测定的蛋白质三维结构精度很高,但是这些方法对实验条件要求苛刻,并且测定周期长、费用昂贵。相比如三维结构蛋白质的氨基酸序列是很容易获取的,而anfinsen等人的实验表明蛋白质的结构信息蕴含于其氨基酸序列之中。因此,根据蛋白质的氨基酸序列结合计算机技术预测蛋白质的三维结构成为测定蛋白质三维结构的另一种选择。
根据氨基酸序列预测蛋白质三维结构的方法主要分为同源建模法和从头预测法。其中从头预测法不依赖目标蛋白的同源信息,能够发现新的蛋白质结构类型。目前比较成功的从头蛋白质结构预测方法有baker团队开发的davidrosetta和张阳团队开发的quark等。
根据氨基酸序列预测蛋白质三维结构实质上是在能量模型引导下的构象空间优化问题。由于蛋白质构象空间十分庞大,因此,一个高效的构象空间搜索方法尤为重要。但是,现有的构象空间优化方法存在搜索效率低、收敛速度慢等问题,并且容易陷入局部最优,影响预测精度。
因此,目前的构象空间优化方法在搜索效率和预测精度上存在不足,需要改进。
技术实现要素:
为了克服现有的构象空间优化方法存在搜索效率和预测精度较低的不足,本发明提供一种搜索效率和预测精度较高的基于种群熵的阶段性蛋白质结构预测方法。本方法分成探索阶段和增强阶段,在探索阶段,利用排挤策略使种群进化的同时保留多样性;在增强阶段,根据每一代个体状态间的转换构建马尔科夫模型计算种群的熵值,再根据熵值信息指导下一代种群中变异策略的选择,从而在全局探测和局部增强间达到平衡,更高效的搜索构象空间。
本发明解决其技术问题所采用的技术方案是:
一种基于种群熵的阶段性蛋白质结构预测方法,所述方法包括以下步骤:
1)输入预测蛋白质的序列信息;
2)设置参数:种群规模np,最大迭代次数g1、g2,交叉概率cr,聚类数k;
3)种群初始化:迭代rosetta协议第一、二阶段,产生具有np个个体的种群p={p1,p2,...,pnp};
4)探索阶段,过程如下:
4.1)设g1=1,其中g1∈{1,2,...,g1};
4.2)设n1=1,其中n1∈{1,2,...,np};
4.3)令
4.4)变异操作,过程如下:
4.4.1)从种群p中随机选择两个互异且不同于
4.4.2)在[0,l-9]内生成均匀随机整数rand1和rand2,其中l表示氨基酸序列长度;
4.4.3)将ptarget的第rand1至rand1+8号残基的二面角值替换成pselect1对应残基号的二面角值,将ptarget的第rand2至rand2+8号残基的二面角值替换成pselect2对应残基号的二面角值;
4.5)生成均匀随机小数rand3,rand3∈[0,1];若cr<rand3,转至步骤4.6);否则,执行交叉操作,过程如下:
4.5.1)在[0,l-9]内生成均匀随机整数rand4;
4.5.2)将ptarget的第rand4至rand4+8号残基的二面角值替换成
4.6)利用rosetta协议第三阶段对ptarget执行局部搜索操作,生成构象ptrial;
4.7)选择操作,过程如下:
4.7.1)计算ptrial与种群p中除
4.7.2)用rosettascore5能量函数计算ptrial和pselect的能量,并根据metropolis准则决定是否用ptrial替换种群p中的个体pselect;
4.8)n1=n1+1;若n1≤np,转至步骤4.3);
4.9)g1=g1+1;若g1≤g1,转至步骤4.2);否则结束探索阶段;
5)利用pam聚类方法对种群p进行聚类,过程如下:
5.1)计算种群p中任意两个个体的rmsd,得到相异度矩阵d(np×np),dmn表示种群中第m个个体与第n个个体的rmsd,其中m和n均∈{1,2,...,np};
5.2)根据相异度矩阵d(np×np),利用pam聚类方法对种群进行聚类,得到k个聚类中心以及每个类所包含的个体;
6)增强阶段,过程如下:
6.1)令
6.2)设g2=1,其中g2∈{1,2,...,g2};
6.3)设n2=1,其中n2∈{1,2,...,np};
6.4)令
6.5)变异操作,过程如下:
6.5.1)若g2=1,执行步骤6.5.2);否则,转至步骤6.5.3);
6.5.2)第一代变异操作,过程如下:
6.5.2.1)从种群pnew中随机选择两个互异且不同于
6.5.2.2)在[0,l-3]内生成均匀随机整数rand5和rand6,其中l表示氨基酸序列长度;
6.5.2.3)将ptarget的第rand5至rand5+2号残基的二面角值替换成
6.5.2.4)转至步骤6.6);
6.5.3)生成均匀随机小数rand7,rand7∈[0,1];若在步骤6.11)中计算的相邻两代种群间的熵值e≥rand7,执行步骤6.5.4);否则,执行步骤6.5.5);
6.5.4)利用熵值e指导变异操作,过程如下:
6.5.4.1)从种群pnew中选出能量最低的两个个体
6.5.4.2)在[0,l-3]内生成均匀随机整数rand8和rand9,其中l表示构象ptarget的残基数;
6.5.4.3)将ptarget的第rand8至rand8+2号残基的二面角值替换成
6.5.4.4)转至步骤6.6);
6.5.5)无熵值e指导的变异操作,过程与步骤6.5.2)相同;
6.6)生成均匀随机小数rand10,rand10∈[0,1];若cr<rand10,转至步骤
6.7);否则,执行交叉操作,过程如下:
6.6.1)在[0,l-3]内生成均匀随机整数rand11;
6.6.2)将ptarget的第rand11至rand11+2号残基的二面角值替换成
6.7)利用rosetta协议第四阶段对ptarget执行局部搜索操作,生成构象ptrial;
6.8)用rosettascore3能量函数计算ptrial和
6.9)n2=n2+1;若n2≤np,转至步骤6.4);
6.10)保持k个聚类中心不变,重新划分聚类,过程如下:
6.10.1)设n=1,其中n∈{1,2,...,np};
6.10.2)计算种群pnew中第n个个体
6.10.3)n=n+1;若n≤np,转至步骤6.10.2);
6.11)计算相邻两代种群间的熵值,过程如下:
6.11.1)根据相邻两代种群p和pnew的k个类中个体的相互转移确定转移矩阵t(k×k),tij表示上一代种群p的第i个类中的个体在新一代种群pnew转移到第j个类的概率,其中i和j均∈{1,2,...,k};
6.11.2)根据公式
6.12)p=pnew;
6.13)g2=g2+1;若g2≤g2,转至步骤6.3);否则结束增强阶段;
7)根据rosetta聚类算法对种群p中的个体聚类,选出最大类的类心构象作为最终预测结果。
本发明的有益效果为:在差分进化算法的框架下,利用种群中个体状态间的转变选择不同的变异策略,在全局探测和局部增强间达到平衡。在探索阶段,利用排挤策略,使种群在进化的保证种群的多样性;在增强阶段,根据种群中个体状态间的转变构建马尔科夫模型,根据构建马尔科夫型计算种群熵值,再根据计算的熵值信息指导下一代种群中变异策略的选择,从而在全局探测和局部增强间达到平衡,在不断搜索更好的构象的同时避免陷入局部最优,提高构象空间的探索性能。
附图说明
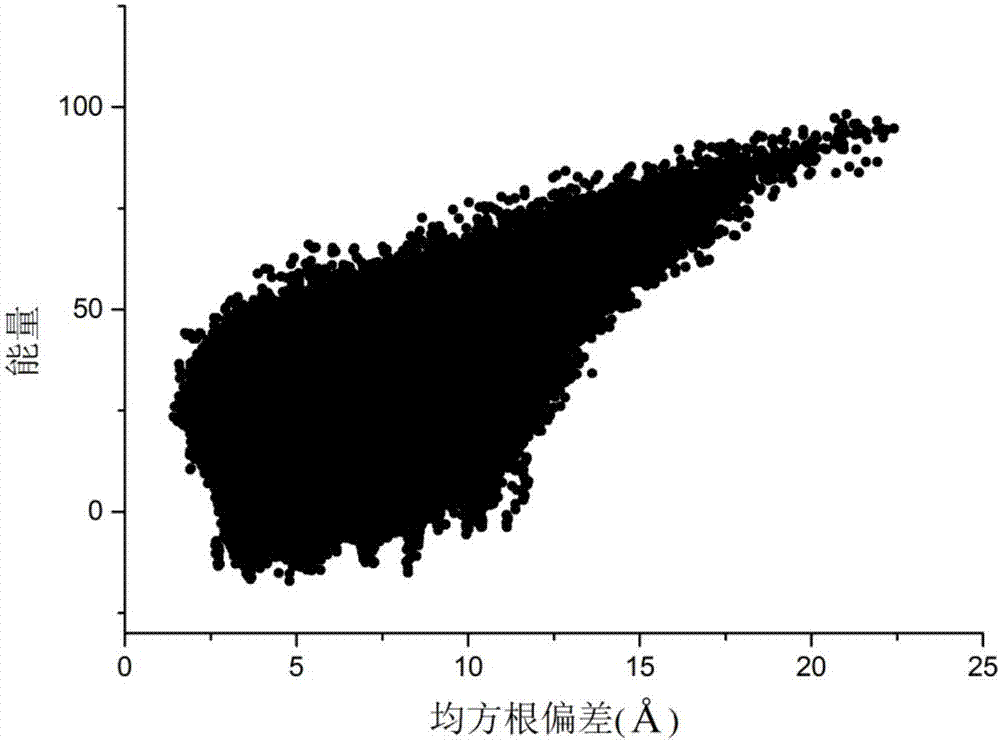
图1是一种基于种群熵的阶段性蛋白质结构预测方法对蛋白质1enh进行结构预测时的构象更新示意图。
图2是一种基于种群熵的阶段性蛋白质结构预测方法对蛋白质1enh进行结构预测得到的三维结构图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1和图2,一种基于种群熵的阶段性蛋白质结构预测方法,包括以下步骤:
1)输入预测蛋白质的序列信息;
2)设置参数:种群规模np,最大迭代次数g1、g2,交叉概率cr,聚类数k;
3)种群初始化:迭代rosetta协议第一、二阶段,产生具有np个个体的种群p={p1,p2,...,pnp};
4)探索阶段,过程如下:
4.1)设g1=1,其中g1∈{1,2,...,g1};
4.2)设n1=1,其中n1∈{1,2,...,np};
4.3)令
4.4)变异操作,过程如下:
4.4.1)从种群p中随机选择两个互异且不同于
4.4.2)在[0,l-9]内生成均匀随机整数rand1和rand2,其中l表示氨基酸序列长度;
4.4.3)将ptarget的第rand1至rand1+8号残基的二面角值替换成pselect1对应残基号的二面角值,将ptarget的第rand2至rand2+8号残基的二面角值替换成pselect2对应残基号的二面角值;
4.5)生成均匀随机小数rand3,rand3∈[0,1];若cr<rand3,转至步骤4.6);否则,执行交叉操作,过程如下:
4.5.1)在[0,l-9]内生成均匀随机整数rand4;
4.5.2)将ptarget的第rand4至rand4+8号残基的二面角值替换成
4.6)利用rosetta协议第三阶段对ptarget执行局部搜索操作,生成构象ptrial;
4.7)选择操作,过程如下:
4.7.1)计算ptrial与种群p中除
4.7.2)用rosettascore5能量函数计算ptrial和pselect的能量,并根据metropolis准则决定是否用ptrial替换种群p中的个体pselect;
4.8)n1=n1+1;若n1≤np,转至步骤4.3);
4.9)g1=g1+1;若g1≤g1,转至步骤4.2);否则结束探索阶段;
5)利用pam聚类方法对种群p进行聚类,过程如下:
5.1)计算种群p中任意两个个体的rmsd,得到相异度矩阵d(np×np),dmn表示种群中第m个个体与第n个个体的rmsd,其中m和n均∈{1,2,...,np};
5.2)根据相异度矩阵d(np×np),利用pam聚类方法对种群进行聚类,得到k个聚类中心以及每个类所包含的个体;
6)增强阶段,过程如下:
6.1)令
6.2)设g2=1,其中g2∈{1,2,...,g2};
6.3)设n2=1,其中n2∈{1,2,...,np};
6.4)令
6.5)变异操作,过程如下:
6.5.1)若g2=1,执行步骤6.5.2);否则,转至步骤6.5.3);
6.5.2)第一代变异操作,过程如下:
6.5.2.1)从种群pnew中随机选择两个互异且不同于
6.5.2.2)在[0,l-3]内生成均匀随机整数rand5和rand6,其中l表示氨基酸序列长度;
6.5.2.3)将ptarget的第rand5至rand5+2号残基的二面角值替换成
6.5.2.4)转至步骤6.6);
6.5.3)生成均匀随机小数rand7,rand7∈[0,1];若在步骤6.11)中计算的相邻两代种群间的熵值e≥rand7,执行步骤6.5.4);否则,执行步骤6.5.5);
6.5.4)利用熵值e指导变异操作,过程如下:
6.5.4.1)从种群pnew中选出能量最低的两个个体
6.5.4.2)在[0,l-3]内生成均匀随机整数rand8和rand9,其中l表示构象ptarget的残基数;
6.5.4.3)将ptarget的第rand8至rand8+2号残基的二面角值替换成
6.5.4.4)转至步骤6.6);
6.5.5)无熵值e指导的变异操作,过程与步骤6.5.2)相同;
6.6)生成均匀随机小数rand10,rand10∈[0,1];若cr<rand10,转至步骤
6.7);否则,执行交叉操作,过程如下:
6.6.1)在[0,l-3]内生成均匀随机整数rand11;
6.6.2)将ptarget的第rand11至rand11+2号残基的二面角值替换成
6.7)利用rosetta协议第四阶段对ptarget执行局部搜索操作,生成构象ptrial;
6.8)用rosettascore3能量函数计算ptrial和
6.9)n2=n2+1;若n2≤np,转至步骤6.4);
6.10)保持k个聚类中心不变,重新划分聚类,过程如下:
6.10.1)设n=1,其中n∈{1,2,...,np};
6.10.2)计算种群pnew中第n个个体
6.10.3)n=n+1;若n≤np,转至步骤6.10.2);
6.11)计算相邻两代种群间的熵值,过程如下:
6.11.1)根据相邻两代种群p和pnew的k个类中个体的相互转移确定转移矩阵t(k×k),tij表示上一代种群p的第i个类中的个体在新一代种群pnew转移到第j个类的概率,其中i和j均∈{1,2,...,k};
6.11.2)根据公式
6.12)p=pnew;
6.13)g2=g2+1;若g2≤g2,转至步骤6.3);否则结束增强阶段;
7)根据rosetta聚类算法对种群p中的个体聚类,选出最大类的类心构象作为最终预测结果。
本实施例以序列长度为54的蛋白质1enh为实施例,一种基于种群熵的阶段性蛋白质结构预测方法,其中包含以下步骤:
1)输入预测蛋白质的序列信息;
2)设置参数:种群规模np=50,探索阶段的最大迭代次数g1=100,增强阶段的最大迭代次数g2=100,交叉概率cr=0.1,聚类数k=5;
3)种群初始化:迭代rosetta协议第一、二阶段,产生具有np个个体的种群p={p1,p2,...,pnp};
4)探索阶段,过程如下:
4.1)设g1=1,其中g1∈{1,2,...,g1};
4.2)设n1=1,其中n1∈{1,2,...,np};
4.3)令
4.4)变异操作,过程如下:
4.4.1)从种群p中随机选择两个互异且不同于
4.4.2)在[0,l-9]内生成均匀随机整数rand1和rand2,其中l表示氨基酸序列长度;
4.4.3)将ptarget的第rand1至rand1+8号残基的二面角值替换成pselect1对应残基号的二面角值,将ptarget的第rand2至rand2+8号残基的二面角值替换成pselect2对应残基号的二面角值;
4.5)生成均匀随机小数rand3,rand3∈[0,1];若cr<rand3,转至步骤4.6);否则,执行交叉操作,过程如下:
4.5.1)在[0,l-9]内生成均匀随机整数rand4;
4.5.2)将ptarget的第rand4至rand4+8号残基的二面角值替换成
4.6)利用rosetta协议第三阶段对ptarget执行局部搜索操作,生成构象ptrial;
4.7)选择操作,过程如下:
4.7.1)计算ptrial与种群p中除
4.7.2)用rosettascore5能量函数计算ptrial和pselect的能量,并根据metropolis准则决定是否用ptrial替换种群p中的个体pselect;
4.8)n1=n1+1;若n1≤np,转至步骤4.3);
4.9)g1=g1+1;若g1≤g1,转至步骤4.2);否则结束探索阶段;
5)利用pam聚类方法对种群p进行聚类,过程如下:
5.1)计算种群p中任意两个个体的rmsd,得到相异度矩阵d(np×np),dmn表示种群中第m个个体与第n个个体的rmsd,其中m和n均∈{1,2,...,np};
5.2)根据相异度矩阵d(np×np),利用pam聚类方法对种群进行聚类,得到k个聚类中心以及每个类所包含的个体;
6)增强阶段,过程如下:
6.1)令
6.2)设g2=1,其中g2∈{1,2,...,g2};
6.3)设n2=1,其中n2∈{1,2,...,np};
6.4)令
6.5)变异操作,过程如下:
6.5.1)若g2=1,执行步骤6.5.2);否则,转至步骤6.5.3);
6.5.2)第一代变异操作,过程如下:
6.5.2.1)从种群pnew中随机选择两个互异且不同于
6.5.2.2)在[0,l-3]内生成均匀随机整数rand5和rand6,其中l表示氨基酸序列长度;
6.5.2.3)将ptarget的第rand5至rand5+2号残基的二面角值替换成
6.5.2.4)转至步骤6.6);
6.5.3)生成均匀随机小数rand7,rand7∈[0,1];若在步骤6.11)中计算的相邻两代种群间的熵值e≥rand7,执行步骤6.5.4);否则,执行步骤6.5.5);
6.5.4)利用熵值e指导变异操作,过程如下:
6.5.4.1)从种群pnew中选出能量最低的两个个体
6.5.4.2)在[0,l-3]内生成均匀随机整数rand8和rand9,其中l表示构象ptarget的残基数;
6.5.4.3)将ptarget的第rand8至rand8+2号残基的二面角值替换成
6.5.4.4)转至步骤6.6);
6.5.5)无熵值e指导的变异操作,过程与步骤6.5.2)相同;
6.6)生成均匀随机小数rand10,rand10∈[0,1];若cr<rand10,转至步骤
6.7);否则,执行交叉操作,过程如下:
6.6.1)在[0,l-3]内生成均匀随机整数rand11;
6.6.2)将ptarget的第rand11至rand11+2号残基的二面角值替换成
6.7)利用rosetta协议第四阶段对ptarget执行局部搜索操作,生成构象ptrial;
6.8)用rosettascore3能量函数计算ptrial和
6.9)n2=n2+1;若n2≤np,转至步骤6.4);
6.10)保持k个聚类中心不变,重新划分聚类,过程如下:
6.10.1)设n=1,其中n∈{1,2,...,np};
6.10.2)计算种群pnew中第n个个体
6.10.3)n=n+1;若n≤np,转至步骤6.10.2);
6.11)计算相邻两代种群间的熵值,过程如下:
6.11.1)根据相邻两代种群p和pnew的k个类中个体的相互转移确定转移矩阵t(k×k),tij表示上一代种群p的第i个类中的个体在新一代种群pnew转移到第j个类的概率,其中i和j均∈{1,2,...,k};
6.11.2)根据公式
6.12)p=pnew;
6.13)g2=g2+1;若g2≤g2,转至步骤6.3);否则结束增强阶段;
7)根据rosetta聚类算法对种群p中的个体聚类,选出最大类的类心构象作为最终预测结果。
以氨基酸序列长度为54的蛋白质1enh为实施例,运用以上方法得到了该蛋白质的近天然态构象,其构象更新示意图如图1所示,预测的蛋白质的均方根偏差为
以上阐述是本发明给出的一个实施的预测效果,本发明不仅适合上述实施例,在不偏离本发明基本思想及不超出本发明实质内容的前提下可对其做种种改进加以实施。
- 还没有人留言评论。精彩留言会获得点赞!