多重推理方式的专家分诊系统及其方法与流程
本发明涉及医疗
技术领域:
,具体涉及一种多重推理方式的专家分诊系统及其方法。
背景技术:
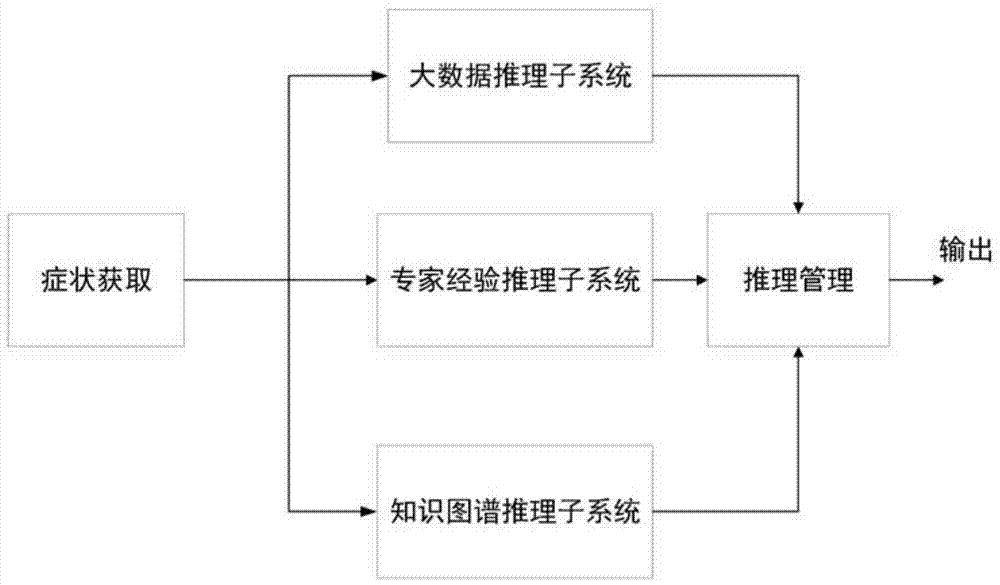
:分诊登记是情况比较严重的节点之一,分诊是指根据病人的主要症状及体征判断病人病情的轻重缓急及其隶属专科,并安排其就诊的过程。但是目前分诊的结果还存在很多不合理的地方。现在大多数医院都只设立就诊指引台,就诊人向护士简要描述症状,由护士的主观经验来初步判断疾病类型;由于工作量大,询问不仔细或医学知识及经验不足,疾病判断准确率低,还是解决不了重复排队、重复诊断的问题。现有技术中,已经出现了基于智能设备的分诊系统,通过与患者交互得到症状信息,从而推理出病患可能患有的疾病,从而提示病患前往正确的科室就诊;然而,此类系统多采用单一的推理模式,而每种推理模式都存在着其自己的不足,当病患给出的症状信息不足支撑该推理模式的推理时,推理结果要么是准确率低,要么是无法得到,造成了分诊效率的下降。技术实现要素:本发明的目的之一是提供一种基于多重推理模式的专家分诊系统,通过各个模式的互补,保证推理结果的输出,提高推理的准确性,从而提高分诊效率。多重推理方式的专家分诊系统,包括症状获取模块,专家经验推理子系统、大数据推理子系统和推理管理模块;所述症状获取模块用于获取症状信息,并同时发送至专家经验推理子系统和大数据推理子系统;所述症状信息包括症状名称和症状的严重程度信息;所述专家经验推理子系统包括,专家经验规则库,用于存储多条规则,所述规则为某一疾病和该疾病的所有症状及症状的严重程度信息;模糊化模块,对所述症状信息以及所述规则中的严重程度信息通过隶属函数进行模糊化;模糊推理模块:用于根据模糊化后的症状信息以及专家经验规则库内的规则,利用模糊推理计算出专家经验规则库内规则所对应的疾病发生的概率,并从中选出概率最高的多个疾病及其概率作为推理结果;大数据推理子系统包括,关键特征值模块,用于获取病例文本数据,并从中获取每一病例的关键特征值,进而形成关键特征值库;所述关键特征值库内的数据包括,疾病名及其对应的关键特征值;推理模块,用于将获取的症状信息以关键特征值的形式表示,并计算症状信息的关键特征值与关键特征值库中各疾病所对应的关键特征值的匹配度,以及每个关键特征值所对应的疾病发生的概率,并从中选出匹配度最高的多个疾病及其概率作为推理结果;所述推理管理模块,用于从所述专家经验推理子系统和大数据推理子系统所反馈的推理结果中选出对应的发生概率最高的指定数量个疾病作为用于分诊参考的输出。本系统利用模糊化的输入和专家经验规则库可以较准确的推断用户所患疾病,结论足以满足分诊的需求,专家经验规则库的使用避免医学知识及经验不足所造成的疾病判断准确率低;然而专家经验会存在主观性,所以同时引入大数据病例规则库,通过真实的病例数据去弥补专家经验的不足之处,使得对用户所患疾病的推断更为准确;模糊推理为数学方法,属于模糊数学范畴,其原理是在已知规则和规则的结论的基础上,获取的条件从而在已知的结论中匹配得到最接近的结论,同时还能得知条件与规则间的差距,从而估计该结论正确的概率,当今常用的模糊推理方法很多,在此不作赘述,这些方法均可利用计算机等智能设备完成,推理过程不依靠人力,大大提高了分诊的效率,通过两个模式的互补,保证推理结果的输出,提高推理的准确性,从而提高分诊效率。进一步,还包括知识图谱推理子系统包括,存储有医学知识图谱的知识数据库和语义网络查询模块;所述语义网络查询模块根据其所获取的症状信息生成查询语句,以从所述知识数据库中查询出相应的疾病名称作为推理结果。知识图谱在两种推理模式得出的结论的概率较低时进行补充,避免无法在两种推理模式得不到结论时,无法给用户提供建议。进一步,所述推理管理模块,用于从所述专家经验推理子系统和大数据推理子系统所反馈的,对应的发生概率高于一阈值的疾病中选出发生概率最高的指定数量个疾病作为输出;如发生概率高于一阈值的疾病的数量不足,则输出知识图谱推理子系统的推理结果以补足。采用本方案可以避免低概率的结论被发送给用户,同时给出多个结论,降低遗漏疾病的可能性,为用户提供更为多样的建议。进一步,所述推理管理模块,还用于将概率差小于5%的推理结果视为概率相同,并在概率相等的情况下优先选择专家推理系统的推理结果。进一步,所述推理模块使用等值维度计算法计算关键特征值间的匹配度。专家推理系统的优先级被设为最高,同时避免偶然出现的过小的概率差让系统作出错误的判断。本发明的目的之二是提供一种基于多重推理模式的专家分诊系统的方法,通过各个模式的互补,保证推理结果的输出,提高推理的准确性,从而提高分诊效率。一种多重推理方式的专家分诊系统的方法包括以下内容;症状获取步骤:获取用户的症状信息,所述症状信息包括症状名称和症状的严重程度信息;同时进行的专家经验推理步骤和大数据推理步骤;所述专家经验推理步骤包括以下内容,规则获取步骤:从存储有多条规则的专家经验规则库中获取规则,所述规则为某一疾病和该疾病的所有症状及症状的严重程度信息;模糊化步骤:对所述症状信息以及所述规则中的严重程度信息通过隶属函数进行模糊化;模糊推理步骤:根据模糊化后的症状信息以及专家经验规则库内的规则,利用模糊推理计算出专家经验规则库内规则所对应的疾病发生的概率,并从中选出概率最高的多个疾病及其概率作为推理结果;所述大数据推理步骤包括以下内容,关键特征值获取步骤:获取病例文本数据,并从中获取每一病例的关键特征值,进而形成关键特征值库,所述关键特征值库内的数据包括,疾病名及其对应的关键特征值;推理步骤,将获取的症状信息以关键特征值的形式表示,并计算症状信息的关键特征值与关键特征值库中各疾病所对应的关键特征值的匹配度,以及每个关键特征值所对应的疾病发生的概率,并从中选出匹配度最高的多个疾病及其概率作为推理结果;推理管理步骤,从所述专家经验推理步骤和大数据推理步骤所得到的推理结果中选出对应的发生概率最高的指定数量个疾病用于分诊。本方法利用模糊化的输入和专家经验规则库可以较准确的推断用户所患疾病,结论足以满足分诊的需求,专家经验规则库的使用避免医学知识及经验不足所造成的疾病判断准确率低;然而专家经验会存在主观性,所以同时引入大数据病例规则库,通过真实的病例数据去弥补专家经验的不足之处,使得对用户所患疾病的推断更为准确;模糊推理为数学方法,属于模糊数学范畴,其原理是在已知规则和规则的结论的基础上,获取的条件从而在已知的结论中匹配得到最接近的结论,同时还能得知条件与规则间的差距,从而估计该结论正确的概率,当今常用的模糊推理方法很多,在此不作赘述,这些方法均可利用计算机等智能设备完成,推理过程不依靠人力,大大提高了分诊的效率,通过两个模式的互补,保证推理结果的输出,提高推理的准确性,从而提高分诊效率。进一步,还包括与所述专家经验推理步骤和大数据推理同时进行的知识图谱推理步骤,包括以下内容:根据所述症状信息生成查询语句,采用该查询语句从知识数据库中查询出相应的疾病名称作为推理结果;所述知识数据库内存储有医学知识图谱。知识图谱在两种推理模式得出的结论的概率较低时进行补充,避免无法在两种推理模式得不到结论时,无法给用户提供建议。进一步,所述推理管理步骤中,还包括从所述专家经验推理步骤和大数据推理步骤所得的,对应的发生概率高于一阈值的推理结果中选出发生概率最高的指定数量个结果,并将这些结果所对应的疾病用作分诊的参考;如发生概率高于一阈值的疾病的数量不足,则输出知识图谱推理子系统的推理结果以补足。采用本方法可以避免低概率的结论被发送给用户,同时给出多个结论,降低遗漏疾病的可能性,为用户提供更为多样的建议。进一步,所述推理管理步骤中,还包括,将概率差小于5%的推理结果视为概率相同,并在概率相等的情况下优先选择专家推理系统的推理结果。专家推理系统的优先级被设为最高,同时避免偶然出现的过小的概率差让系统作出错误的判断。进一步,所述推理模块步骤中,使用等值维度计算法计算关键特征值间的匹配度。对于文本处理来说,维度算法简单易行,且准确度较高。附图说明图1为本发明实施例多重推理方式的专家分诊系统的示意性框图。图2为本发明实施例中专家经验推理子系统的示意性框图。图3为本发明实施例中关键特征值模块所用的基于语法分析的文本预处理模型的示意图。图4为本发明实施例中知识图谱推理子系统的工作流程图。图5为本发明推理管理模块的工作流程示意图。具体实施方式下面通过具体实施方式进一步详细说明:本实施例中的多重推理方式的专家分诊系统的方法包括以下内容:症状获取步骤:获取用户的症状信息,所述症状信息包括症状名称和症状的严重程度信息;同时进行的专家经验推理步骤、大数据推理步骤和知识图谱推理步骤;所述专家经验推理步骤包括以下内容,规则获取步骤:从存储有多条规则的专家经验规则库中获取规则,所述规则为某一疾病和该疾病的所有症状及症状的严重程度信息;模糊化步骤:对所述症状信息以及所述规则中的严重程度信息通过隶属函数进行模糊化;模糊推理步骤:根据模糊化后的症状信息以及专家经验规则库内的规则,利用模糊推理计算出专家经验规则库内规则所对应的疾病发生的概率,并从中选出概率最高的多个疾病及其概率作为推理结果;所述大数据推理步骤包括以下内容,关键特征值获取步骤:获取病例文本数据,并从中获取每一病例的关键特征值,进而形成关键特征值库,所述关键特征值库内的数据包括,疾病名及其对应的关键特征值;推理步骤,将获取的症状信息以关键特征值的形式表示,并使用等值维度计算法计算症状信息的关键特征值与关键特征值库中各疾病所对应的关键特征值的匹配度,以及每个关键特征值所对应的疾病发生的概率,并从中选出匹配度最高的多个疾病及其概率作为推理结果;知识图谱推理步骤,包括以下内容:根据所述症状信息生成查询语句,采用该查询语句从知识数据库中查询出相应的疾病名称作为推理结果;所述知识数据库内存储有医学知识图谱;在上述三个推理步骤得出结果后,进入推理管理步骤,包括,从所述专家经验推理步骤和大数据推理步骤所得的,对应的发生概率高于一阈值的推理结果中选出发生概率最高的指定数量个结果,并将这些结果所对应的疾病用作分诊的参考,其中将概率差小于5%的推理结果视为概率相同,并在概率相等的情况下优先选择专家推理系统的推理结果;如发生概率高于一阈值的疾病的数量不足,则输出知识图谱推理子系统的推理结果以补足。该方法通过基本如附图1所示多重推理方式的专家分诊系统来实现:该系统包括症状获取模块,专家经验推理子系统、大数据推理子系统、只是图谱推理子系统和推理管理模块,下面逐一说明每一部分。如图2所示,专家经验推理子系统,包括:症状获取模块,用于获取用户的症状信息,所述症状信息包括症状的名称及症状的严重程度信息;专家经验规则库,用于存储多条规则,所述规则为某一疾病和该疾病的所有症状及症状的严重程度;模糊化模块,用于对所述症状信息以及所述规则中的严重程度信息通过隶属函数进行模糊化;模糊推理模块:用于根据模糊化后的症状信息以及专家经验规则库内的规则,利用模糊推理计算出专家经验规则库内规则所对应的疾病发生的概率;本模块中通过计算症状信息与专家经验规则库内的各个规则的贴近度作为各规则所对应的疾病发生的概率;修正模块,用于通过修正函数对所得贴近度进行修正,得出最终修正结果表征这些规则所对应的疾病发生的概率。专家经验规则库本实施例中的专家经验规则库通过数据库体现的知识主要包括疾病、症状及疾病每个症状对应的发生概率,数据库分为症状库、疾病库、疾病隶属度库和规则库。其中,每种疾病和它的所有症状及症状的严重程度就构成一条专家系统的规则,本实施例中的规则库事先由医学专业人士填写制定,也可以从医学书籍中得到,或是从实际病例数据中提取,总的来说,是从既往的经验中提取出来的。以下三个表格分别是专家系统中用到的症状库、疾病库、规则库的示例。表1症状库表2疾病库表3规则库(部分)表3中行为症状库中的编号,列为疾病库中的编号;而为了使系统能够更好的进行疾病诊断,我们把每个症状遵循疾病医学诊断的评判标准划分为了由低到高的多个等级,每个等级用一个模糊量词来表示,为了方便,用于表征严重程度的模糊量词用表内的数字记,即“特别严重”=0,“很严重”=1,“严重”=2,“比较严重”=3,“一般”=4,“有点”=5,“轻微”=6,“无”=7记模糊量词“特别严重”=0,“很严重”=1,“严重”=2,“比较严重”=3,“一般”=4,“有点”=5,“轻微”=6,“无”=7,症状及其严重程度组成了规则的条件部分,而疾病则是规则的结论部分。同时,疾病也有严重程度之分,采用同样的等级来区分,而疾病的严重程度信息保存在如表4所示的疾病隶属度库中。所以,在更为完备结论库和规则库中,疾病及其规则均被进一步按照严重程度细分,即多个编号对应同一疾病名称,但他们各自在疾病隶属度库中所对应的严重程度不同,本实施例中,疾病的严重程度和症状的严重程度采用同样的模糊量词;表4疾病隶属度库病症y1y2y3y4y5y6y7y8y9y10y11y12y13隶属度2310331234212y14y15y16y17y18y19y20y21y22y23y24y25y264302344112233如此,诸如“如果有比较严重的咳嗽和一般程度的咳痰,那么该病人有严重的支气管哮喘病。”这样的经验知识,则可被表示为规则库中的规则1(表3中对应编号y1的第一行),其前提为“有比较严重的咳嗽和一般程度情况下的咳痰”,结论为“有严重的支气管哮喘病”。模糊化模糊化过程主要是把分明值转换成模糊集的隶属函数。由于严重程度是一个模糊的概念,采用的是模糊量词,其模糊度需要用隶属函数来表示;为了使系统能够更好的进行疾病诊断,也更为贴近实际情况,本实施例中的各个模糊量词的隶属函数采用了如表5所示的正态分布(0到1之间)。为了便于计算机处理,我们将模糊量词的隶属函数经抽样离散化后得到表6中的长度为6的隶属度向量(下文中简称隶属度)。表5各模糊量词所对应的隶属函数表6各模糊量词值离散化后的隶属度向量模糊推理模糊推理通过各种控制规则的推理,结果被合成在一起,产生一个“模糊推理输出”的集合,本实施例采用贴近度推理算法,具体过程如下:首先,本实施例所使用的隶属度a和隶属度b的贴近度计算公式为:其次,模式匹配,也就是将病人出现的症状与规则库中疾病对应的症状进行贴近度计算。病人提供的是一个症状集合x,先用贴近度公式计算病人症状xi与规则库中规则r1的症状xi的贴近度,得到i个症状的贴近度后,将这i个贴近度求和后除以i,得到的就是病人症状集x与规则r1的贴近度,也就是病人患疾病r1的概率。依次计算病人症状集x与规则库中其它规则(r2,r3,r4……)的贴近度,最终得到病人患有规则库中疾病的全部概率。最后,根据事先确定的贴近度的阈值σ判断是否激发某一规则,即是否将其纳入“模糊推理输出”的集合。例如:假设用户出现了比较严重的腹痛,轻微的腹胀,轻微的恶心和有点呕吐的症状。阈值σ=0.9,根据表6可知:“无”=[1,0,0,0,0,0],“比较严重”=[0,0.03,0.11,0.83,0.83,0.11]。与规则有r1进行比较:设r为规则内的症状严重程度隶属度,t为所得症状集中的症状严重程度隶属度;计算第一个症状:因为症状“热”在规则r1和所得症状中都没有,所以sm1(r1,t1)=1计算第二个症状:同理,得出与规则r1所有症状的贴近度的计算。为了方便把记为s1,为了方便把sm1(r1,t1)记为s1,sm2(r2,t2)记为s2,以此类推,所得结果如表7所示。表7输入症状与规则r1的匹配结果s1s2s3s4s5s6s7s8s9s10s11s1210.380.3811110.3810.7811s13s14s15s16s17s18s19s20s21s22s231110.680.78111111将所得的上表结果求和平均计算后得贴进度为0.88,即,与第一条规则匹配后的值为0.88,同理得出与所有规则比较的结果,如表8。表8输入症状与规则库的匹配结果r1r2r3r4r5r6r7r8r9r10r11r12r130.880.870.870.840.890.870.850.880.940.940.900.940.89r14r15r16r17r18r19r20r21r22r23r24r25r260.900.930.910.950.980.880.860.920.900.900.870.880.91通过与阈值α=0.9比较,当结果大于该阈值时,规则被激发;否则规则不被激发,所得结果如表9。表9匹配结果与阈值比较结果r9r10r11r12r14r15r16r17r18r21r22r23r260.940.940.900.940.900.930.910.950.980.920.900.900.91最后通过比较得出规则r18的值为最大值。修正模块对于基于贴近度计算得到的结果,通常用修正函数加以改进,使系统得出的结果更符合实际情况,本实施例选择衰减型修正函数,遵循zadeh的模糊数乘法运算。使用所选规则所对应的疾病的严重程度的隶属度,与贴进度进行模糊数乘法运算;例如,r18的严重程度为“比较严重”,而根据表6“比较严重”=[0,0.03,0.11,0.83,0.83,0.11],用该向量与贴近度(0.98)做模糊数乘法运算以得到修正后的贴进度如下:b*=(0∧0.98)∨(0.03∧0.98)∨(0.11∧0.98)∨(0.83∧0.98)∨(0.83∧0.98)∨(0.11∧0.98)=0.83所以,患者患有所选规则所对应的疾病的概率为83%。系统及其工作流程本实施例中的系统,连接有输入和输出设备,用户的症状及症状的严重程度作为系统的输入到症状获取模块,例如,用户输入非常头痛,则输入即为症状——头痛和程度——非常。系统根据输入的症状和症状的严重程度进行模糊推理,得出用户可能患有的疾病及患该疾病的概率放入临时数据库,该数据库按疾病概率由大到小排序。当输入的症状数量达到上限(症状数量阈值n,此处暂设为5)时,系统结束推理,根据疾病概率阈值p(即贴近度阈值σ),输出概率最大且大于p的m个疾病(疾病输出数量m此处暂设为3,例如,经模糊推理后,有4种疾病概率均大于p,则输出概率最大的3种疾病)。其中,整个基于贴近度的推理算法的步骤如下:第一步:初始化1)确定阈值σ的大小。2)令i=1,j=1。其中i=1,2,…n,j=1,2,…,m;n为库内规则的个数,m为获取的症状的个数。第二步:模式匹配,将病人出现的症状与规则库中疾病对应的症状进行贴近度计算,将用户数据与某条规则进行贴近度计算;第三步:规则的选取;规则选取的过程为:1)当病人的症状和专家经验规则库中的某一条规则贴近度≥σ时,那么这条规则将被激发,此时若i=n,j=m,则转入3),否则转入第二步;若贴近度<σ时,该规则不被激发,此时若i=n,j=m,则转入3),否则转入第二步。2)当只有一条规则被激发时,系统会输出该规则的结论部分;若没有一条规则被激发,系统输出“没有符合条件的疾病,建议用户去医院就诊”。3)当有来自专家经验规则库的多条规则被激发时,系统会自动对满足结果的值进行比较,因为贴近度值越大说明规则越接近,所以选出贴近度值最大的一条或多条规则,并且输出这些规则的结论部分,结论包括了疾病名称、疾病严重程度;若有多条规则的贴近度值同样大时,系统会同时输出这几条规则的结论部分。第四步:计算推理结果用第三步结论中的疾病严重程度的隶属度对所选规则的贴近度进行相应的修正,得出最终修正结果。系统最终输出的结果包括,是否患有疾病、何种疾病、疾病的严重情况以及患病的概率,如“患有疾病肠梗阻比较严重0.83”。大数据推理子系统包括,关键特征值模块,用于获取病例文本数据,并从中获取每一病例的关键特征值,进而形成关键特征值库;所述关键特征值库内的数据包括,疾病名及其对应的关键特征值;推理模块,用于将获取的症状信息以关键特征值的形式表示,并计算症状信息的关键特征值与关键特征值库中各疾病所对应的关键特征值的匹配度,以及关键特征值所对应的疾病发生的概率,并从中选出匹配度最高的多个疾病及其概率作为推理结果.关键特征值模块采用如图3所示的基于语法分析的文本预处理模型,进行病例文本的预处理和特征选取,其中:文本预处理算法步骤包括,删除否定短语,比如:头颅无畸形,淋巴结不肿大,无意义。语法分析,一共分为三类(使用stanfordcorenlp语法分词工具);①n-a/n-v式,名词+形容词,名词+动词,比如:神情痛苦,面部抽搐;②数量式短语,比如:体温38℃;③其他类型短语;中文分词和噪音消除,根据语法分析的结果分三种情况,①n-a/n-v式,使用键值对分词法。形式如下表10-1键值对分词的形式键值1值2……值n比如:脊柱两侧肌肉紧张有压痛,其分词形式如下表:表10-2脊柱两侧肌肉紧张有压痛的键值对分词的形式键值1值2脊柱两侧肌肉紧张有压痛②数量式短语,从数值判断到键值对。数量短语基本都是测量值,所以依然可以使用键值对来进行表示。同时,根据项目名匹配数据库中标准,将数据替换成偏高,偏低等,比如:“wbc(12.1×109)”,“hgb(118)”;“rbc(5.25×1012)”,“plt(3×109)”;其中wbc表示白细胞,hgb表示血红蛋白,rbc表示红细胞,plt表示血小板,这个数据可以表示如下表:表10-3数量式短语的键值对表示键值键值wbc偏低rbc偏高hgb正常plt偏高③其他句型,本实施例使用mecab软件进行中文分词,得到平行单词。特征选择:①对于键值对:直接提取键值加入到关键特征集。②对于平行单词,使用信息增益算法,选择重要单词加入关键特征集。其中信息增益算法较为现有,在此不做赘述。用向量表示文本首先,将关键特征集里所有内容加上标签;比如:文本1:斑丘疹,四肢,营养(良好),神智(清洗),体温(正常);文本2:腹痛,呕吐,营养(欠佳),神智(模糊),体温(偏高);文本3:斑丘疹,牙龈,营养(良好),体温(偏低),血压(正常);得到的关键特征集为:“斑丘疹,四肢,营养,神智,体温,腹痛,呕吐,牙龈,血压”,依次标记为w1,w2,…,w9,其中的w1,w2,…,w9就是标签。其次,将键值对应的所有属性值从0开始编号:比如:体温有偏低,正常,偏高,分别表示为1,2,3,数字0表示文本不存在该特征。最后,对文本进行赋值:对于前面的示例,赋值如下表所示:表10-4w1w2w3w4w5w6w7w8w9d1111120000d2002231100d3101010011那么文本向量表示为:d1=(1,1,1,1,2,0,0,0,0),d2=(0,0,2,2,3,1,1,0,0),d3(1,0,1,0,1,0,0,1,1)。在操作中,使用每一篇病历的诊断结果即疾病名替换文章名,使用mysql数据库进行疾病名,关键特征集的值,诊断结果的存储,形成特征库。如果多篇病历诊断结果为同一疾病,则进行合并:病历中有相同症状,则症状权重减1,使用负数记录权重(正数用来记录症状情况);有不同症状,则进行症状补充。于是,将d1、d2和d3合并后文本实际表示为:d=((1,-1),(1,-1),(1,-1),(1,-1),(2,-1),0,0,0,0)。推理模块在该模块中,文本向量的等值维度计算法如下,其中,n表示相关特征集纬度,d表示文档,pk表示第1篇文档中特征k对应的属性值。比如:d1=(1,1,1,1,2,0,0,0,0),d2=(0,0,2,2,3,1,1,0,0),d3=(1,0,1,0,1,0,0,1,1),那么s(d1,d2)=0,s(d1,d3)=2。即d1和d3相似,且匹配度为3。在该模块中,概率计算的方法如下统计相同病症对应的不同疾病,比如数据库中发现“腹痛”导致了两例胃病,两例癌症,一例胆结石则认为患有腹痛后,40%的概率诊断为胃病,40%的概率诊断为癌症,20%的概率诊断为胆结石。在本实施例中,具体做法是:统计特征库中每一列里相同的数字,根据出现病历库中出现次数即权重值进行概率计算,如:d1=((1,-1),(1,-1),(1,-1),(1,-1),(2,-1),0,0,0,0),d2=((1,-3),(2,-1),(1,-1),(1,-1),(2,-1),0,0,0,0),则认为症状1导致d1的概率为1/(1+3)=25%,导致d2的概率为3/(1+3)=75%,并添加进特征库中,使用小数保存,即文本实际表示为:d1=((1,-1,0.25),(1,-1,1.00),(1,-1,0.5),(1,-1,0.33),(2,-1,0.1),0,0,0,0)本实施例中整个推理的过程如下:1、对用户的症状信息进行文本向量表示,输入症状信息之后,按照数据预处理方法表示为文本向量,达到和特征库存储的知识相匹配的目的。2、检索:第一步:如果查询输入小于3个症状,则向症状获取模块所用病历中最频繁的三个特征词汇,用于提示,返回第一步;第二步:当输入大于3个时,使用等值维度匹配计算出匹配度最高的三篇文档;第三步:如果用户输入小于5个症状,则返回三篇文档中重复率最高的且用户未包含的病症,继续提问,返回第一步;若输入大于5个病症,则返回三篇文档的诊断信息。在另一些实施例中,可以利用上述对病历文档的处理,提取出疾病、症状和症状的严重程度信息,从而形成形式如同表3的规则库,再利用相同的模糊推理算法得出用户最有可能患有的几种疾病以及每种疾病的患病的概率输出,此处的推理过程与模糊推理模块中无异,只是规则库的数据源从专家变成了病例文档。知识图谱推理子系统知识图谱推理包括,储有医学知识图谱的知识数据库和语义网络查询模块。本实施例中为了综合表达能力和对推理的支持,选用owldl子语言(owl子语言的一种,兼顾表达能力和对推理的支持)来表示医学知识图谱内的知识。同时选用jena作为平台,构建医学知识图。jena是一个免费开源的支持构建语义网络和数据链接应用的java框架,由惠普实验室开发,支持内存和永久存储。本实施例主要针对医学领域的老年病科,采用“兰州大学临床医学知识服务系统”中老年病科的相关数据作为本体构建根据。知识模式的构建大致分为四部分:(1)类别(class)的定义本实施例定义了最基本的两大类分别是:①“疾病”②“症状”(2)类别层次(上下位关系)的定义本实施例中依附subclassof,在获取到了层次信息后进行添加。(3)对象属性的定义本实施例中对象属性的定义域通常为类别或者实例,值域为某种值,例如string,int等,以及“疾病”的“别称”、“英文名称”“并发症”属性;而由于症状类实体较为特殊,不存在属性关系。(4)语义关系的定义定义、值域均为类别或者实例。根据设定的两类实体的实际相关性分析,共创建了两种语义关系,分别为:①hazhengzhuang(有症状):疾病--症状,可以用来连接疾病与症状;②hasbingfazheng(并发症):疾病--疾病,可以用来连接疾病与疾病,表示几种疾病在同一患者身上发生,也就是疾病共同出现关系。综合以上对属性提取、语义关系创建,每个类别的最基本关系如下:(1)class:疾病属性:别称,类别:string;属性:英文名称,类别:string;属性:haszhengzhuang,类别:症状;属性:hasbingfazheng,类别:疾病;(2)class:症状类别:症状。本实施例利用jenaapi创建模型,添加和修改属性和属性值、生成本体。本实施例中,知识图谱数据存储需要完成的基本数据存储,具体为主、谓、宾三元组形式的知识,以rdf文本格式存储在硬盘当中,再利用jena将构建好的知识库固化为tdb的格式进行存储。为了方便管理本体或知识图谱,将rdf固化到一个通用的数据库中是最优做法。基于以上考虑,本实施例选择jena作为平台,jena支持rdb、sdb、tdb三种模式来固化rdf。采用tdb(jena用于rdf存储和查询的模块)来固化rdf。将其他形式的数据转换成rdf(owl)数据,再进一步存为tdb的形式。知识图谱构建完成后,通过语义网络查询模块接收输入的症状和并发症以及其查询需求。查询处理的过程如下:s1、获取病人的症状信息,并生成查询语句,根据查询语句查询出知识图谱db1中所有与该症状信息匹配的疾病数据data1进行“∩”运算到疑似疾病集data;s2、将疑似疾病集data中的疾病数据data1进行“∪”运算,将运算得到的结果输出显示;s21、在s2中,在“∪”运算的结果不为空时,将“∪”运算得到的结果作为查询得到的疾病数据data1输出,在“∪”运算的结果为空时,输出症状询问信息,在有补充的症状信息时,将补充的症状信息与原有的症状信息作为新的症状信息进行查询,得到疾病数据data1,若没有补充的症状信息,则输出空的查询结果。具体的,对知识图谱db1的存储是利用jena平台先将第三方医学知识存储为owl文件,然后利用tdb模块将其存储发布到服务器上,上述的tdb模块是jena平台中用于rdf存储和查询的模块,并且支持所有jenaapi。而知识图谱作为语义网络的发展,其存储的格式之一即为rdf,rdf是一个三元组(triple)模型,即每一份知识可以被分解为如下形式:(subject(主),predicate(谓),object(宾))。而虽然owl比rdf推理能力更强,但本质上还是rdf,完全兼容rdf语法。owl可理解为一组主谓宾的语句,一条owl存储一组主谓宾,所以叫三元组,如(感冒,有症状,咳嗽),如果有多个症状就会有多个语句,即(感冒,有症状,咳嗽)、(感冒,有症状,发烧)、(感冒,有症状,食欲不振)等,系统中的所有的数据都用这种形式存在owl文件中,然后再用jena平台的tdb模块统一固化,也就完成知识图谱在数据库中的存储;在查询的时候,同样的也是利用tdb模块,可以固定主语,谓语,从而查出比如上面的语句集就可以查出所有症状。表11如图4和表11所示,患有疾病a的病人在诊断时,医生根据病人提供的信息向交互子系统输入病症信息,如病人描述了症状a和症状c,医生此时向系统输入这些症状信息,输入的方式可以有多种,如利用键盘,采用打字输入的方式,也可以使用麦克风,采用语音输入的方式,还可以使用手写板,采用手写输入的方式;然后查询语句生成模块根据输入的症状信息生成查询语句,如系统的查询语句格式为(症状a,症状b,疾病,缺省),输入的症状信息为“症状a,症状c,症状d”,生成的查询语句为(症状a,症状c,症状d,疾病,缺省);查询模块在接收到查询语句后,依次查询各症状所属疾病,其中针对症状a的查询结果,也就是症状a的疑似疾病集为是[疾病a、疾病b、疾病d],症状c的疑似疾病集为[疾病a、疾病c、d],症状d的疑似疾病集为[疾病a、疾病c],然后运算模块将上述查询得到的三个疑似疾病集进行∩运算,运算结果为[疾病a],再做∪运算,运算结果还是[疾病a],因此最终的查询结果也就是a,即输出模块输出的结果为(症状a,症状c,疾病,疾病a),从而完成整个系统的查询操作。另外,用户给出的症状信息比较主观,很容易受到情绪的影响,在描述自己的病情时,容易受到悲观情绪影响,进而将症状的严重程度向更严重的方向偏移,如果直接采纳用户的描述进行查询,势必造成查询结果的偏移。因此,这种情况下有必要甄别用户是否是在受到负面情绪的影响下给出了症状描述,若识别出是确实受到负面情绪的影响,则在进行疾病的推理时,就需要适当的减轻症状。出于这一目的,本实施例中的知识图谱推理子系统还包括有情绪识别模块以及症状修正模块,知识图谱数据库还存储有按照严重程度相互关联的症状信息,程度划分可统一采用如表5中所给出的示例。情绪识别模块对病人的声音、脸部图像信息进行采集识别,在识别出采集到的信息中带用情绪信息后,症状修正模块对症状信息进行修正,将输入的症状信息修正为相关联的严重程度低的症状信息;最后采用修正后的症状信息进行查询。具体的,情绪识别模块通过外设的麦克风或摄像头对用户的声音和表情图像进行采集,当情绪识别模块识别到病人的声音或表情中具有情绪信息时,例如用户此时处于恐慌状态,而如用户此时给出的是“严重”,症状修正模块就会对输入的症状信息进行修正,即将症状“严重”修正为症状“比较严重”,以消除用户受情绪影响给出的症状信息对诊断结果的影响。而在上述过程中,考虑到用户有时可能会因为突发原因产生惊恐情绪,如临时受到了惊吓,而惊吓的影响一直延续,此时不光是需要排除情绪的干扰,还需要分析用户的情绪是受病情的影响还是其他因素的影响,若是其他因素的影响,那么在进行推理时的时候,则不需要对症状信息进行修正。为此,本实施例中的知识图谱推理子系统还包括有监控模块和推送模块;监控模块安装在用户终端上,可以为用户的手机,用户采用手机登录本实施例中的知识图谱推理子系统,在手机完成登录后,监控模块就会定期启动外设的麦克风和摄像头对用户的情绪进行监控,若用户使用本实施例的知识图谱推理子系统时,情绪识别模块识别到情绪信息时,如带有恐慌的情绪,同时若监控模块监控到用户长期处于恐慌的状态,此时推送模块还会根据用户联系人中的分组,将这个信息推送给用户的亲朋好友,用户的亲朋好友通过自己用户终端接收到“某某是否长期处于恐慌状态?”的推送信息后,则可以利用自己的用户终端向知识图谱推理子系统进行反馈,若被推送者这确认用户的确是因为自己的病情而处于恐慌状态的话,则向知识图谱推理子系统反馈表示肯定的信息,若是若被推送者不确认则反馈表示否定的信息;而若知识图谱推理子系统接收到的反馈信息为表示肯定的信息时,知识图谱推理子系统则根据情绪识别模块识别到的情绪信息、监控模块监控到用户长期处于恐慌的状态以及被推送者发来的肯定的反馈信息就可以识别用户的恐慌确实是由自己病情而导致的,此时边控制症状修正模块进行症状的修正,输入的症状信息修正为相关联的严重程度低的症状信息;而若知识图谱推理子系统接收到的反馈信息为表示否定的信息时,根据情绪识别模块识别到的情绪信息、监控模块监控到病人长期处于恐慌的状态以及亲朋好友否定的反馈信息就可以识别用户的恐慌并不是由自己病情所致,则不命令症状修正模块进行修正;若情绪识别模块识别到用户处于恐慌状态时,而监控模块监控到用户之前并没有任何恐慌状态,则表明用户只是当前处于恐慌状态,极可能是在上次监控至当前时间内受到了其他事情突发事件的影响而导致了恐慌情趣,此时症状修正模块同样不进行修正。通过外设麦克风和摄像头采集声音及用户面部图像进行情绪识别的技术对于本领域的技术人员来说,属于较为现有的技术,在次不做赘述。推理管理模块推理管理模块的工作流程图如图5所示,由于专家经验推理、大数据推理和知识图谱推理是同时进行的,推理管理模块会同时收到3份推理结果,因此需要对这3份结果进行选择。其中专家经验推理系统的准确性是最高的,大数据推理系统次之,所以优先选择专家推理系统结果,然后选择病大数据推理系统结果,最后选择知识图谱结果。由于本系统给出的诊断结果只是对用户的初步诊断,准确度不能完全保证,所以系统每次输出3个诊断结果及其对应的患病概率。如果专家系统和大数据可以给出3个结果,则直接输出概率最大的3个疾病。若专家系统和大数据无法给出结果或结果少于3个,则从知识图谱的结果中进行选择,如果其中某个疾病是专家系统或大数据中所具有的,说明患该病的概率较低,则舍弃该疾病;若某个疾病在另外两个库中都没有,则输出该疾病。如果专家系统和大数据都没有满足各自输出条件的结果,或者两者满足条件的结果很多(此处设置为大于5个)且概率基本一致(此处设置患病概率差值小于5%则认为它们概率基本一致),无法再根据概率选择疾病,这两种情况下都选择输出知识图谱的结果。图5中使用的参数、符号及其对应的含义如下表所示。表12参数、符号及其含义疾病集a专家经验推理结果疾病集b大数据推理结果疾病集c知识图谱结果疾病集d系统预输出疾病集n0系统输出疾病数量,n1预输出疾病集数量阈值,α患病概率差值阈值,以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属
技术领域:
所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1