一种基于矩阵分解的食物-疾病关联预测方法与流程
本发明属于食品安全领域,尤其是一种基于矩阵分解的食物-疾病关联预测方法。
背景技术:
随着我国国民经济的迅速发展和人民健康意识的不断提高,人们对生命质量的要求也越来越高,为追求健康,对饮食指南的需求越来越强烈。已有研究表明,膳食与疾病的发生、发展有着密切的关系,典型的如内分泌代谢疾病与高脂食物之间,粗粮饮食与乳腺癌之间;喝咖啡与结肠癌之间的、盐渍萝卜和腌制肉类与胃癌之间存在的相关关系等。
目前,为了研究上述关系,只能通过局部人口学采样、调查问卷、口述内容或者活体实验得到相关数据,并进行统计分析。但这种关联获取方式需要消耗极大的人力物力,尤其置信度高的活体实验,仍旧存在较大的风险,难以满足人民细致的食物-疾病关联的知情需求。典型的风险主要在于调查问卷被调查对象错误信息的填写,调查问卷中指标的有偏统计,被调查者多方面因素综合作用,并非单一食品变量因素。活体实验中实验者的操作也是风险来源之一。此外,随着食品种类的快速增长,实验和调查的成本成指数级增长,而由于人力物力限制,事实研究不能及时更新,只能集中在少数疾病和少数食品范畴。
综上所述,食品与疾病的关联是目前热门的关注领域。对于广泛的食品和疾病的关联尚未出现置信度高、受众广的预测方法。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出一种基于矩阵分解的食物-疾病关联预测方法,解决食物疾病预测任务的准确性低以及采用随机试验带来的大量的人力和资源的消耗。
本发明解决其技术问题是采取以下技术方案实现的:
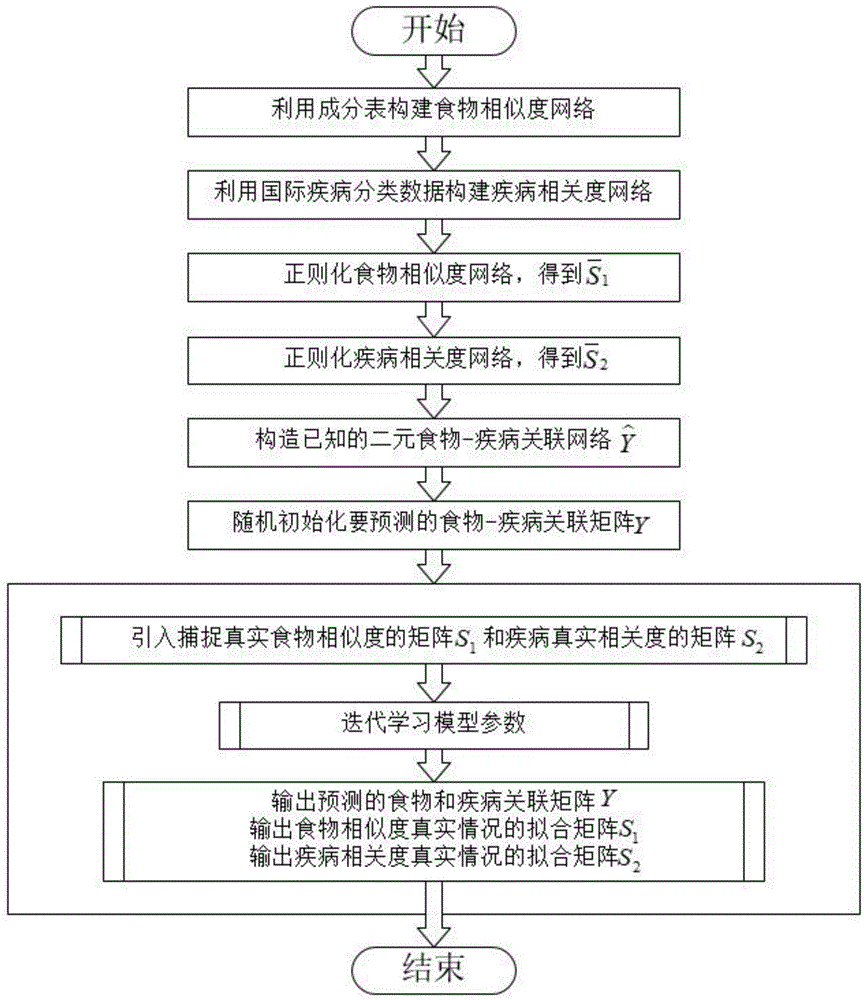
一种基于矩阵分解的食物-疾病关联预测方法,包括以下步骤:
步骤1:利用成分表构建食物相似度网络w1;
步骤2:利用国际疾病分类数据构建疾病相关度网络w2;
步骤3:正则化食物相似度网络,得到正则化的食物相似度网络
步骤4:正则化疾病相关度网络,得到正则化的疾病相关度网络
步骤5:构造已知的二元食物-疾病关联网络
步骤6:随机初始化要预测的食物-疾病关联矩阵y;
步骤7:引入捕捉真实食物相似度的矩阵s1和疾病真实相关度的矩阵s2,迭代学习模型参数,输出预测的食物和疾病关联矩阵y、食物相似度真实情况的拟合矩阵s1和疾病相关度真实情况的拟合矩阵s2。
进一步,所述步骤1的具体实现方法为:将每一个节点设置为“食物-量-食用方法”的组合,在“量-食用方法”不同的情况下,将两两节点关系置为0;在“量-食用方法”相同的情况下,根据食物成分表,利用余弦公式,计算两两食物之间的相似度,作为节点关系值,从而得到食物相似度网络w1。
进一步,所述步骤2的具体实现方法为:根据国际疾病分类数据,如果两种疾病同属同一类目,则相关度设置为k,如果两种疾病同属同一亚目,则相关度设置为2k,如果两种疾病同属同一细目,则相关度设置为3k,其中3k<1,从而得到疾病相关度网络w2。
进一步,所述步骤3的具体实现方法为:设n为“食物名-量-食用方法”的组合数,w1∈rn×n是食物相似度网络,则w1用于构造正则化的食物相似度网络
进一步,所述步骤4的具体实现方法为:设m为疾病数,w2∈rm×m是疾病相关度网络,则w2用于构造正则化的疾病相关度网络
进一步,所述步骤5的具体实现方法为:设已知的食物-疾病关联由二进制矩阵
进一步,所述步骤6的具体实现方法为:通过对食物-疾病关联矩阵y中的每一个值赋予0-1之间的任意数作为初始化。
进一步,所述步骤7的具体实现方法为:对食物-疾病关联进行建模,在建模过程中进行如下设定:相似度高的食物可能会导致同一个疾病、同一种食物可能会导致密切相似的疾病、食物相似度矩阵和疾病相关度矩阵的数值是含噪的;引入捕捉真实食物相似度的矩阵s1和疾病真实相关度的矩阵s2,在拟学习的食物-疾病关联矩阵y上传播食物相似和疾病相似关系,设计如下损失函数:
其中,ψ1(y,s1)、ψ2(y,s2)分别为疾病关联矩阵y与真实食物相似度的矩阵s1的损失函数和疾病关联矩阵y与疾病真实相关度的矩阵s2的损失函数;μ、ζ、ν、η分别为对应项的权重,权重均为人为指定的超参数;i为单位矩阵,该单位矩阵对角线元素全部为1,其他元素全部为0;tr(a)是矩阵a的主对角线上各个元素的总和;
本发明的优点和积极效果是:
1、本发明在不考虑由于致病因子导致的食源性疾病的情况下,结合食物之间相似度和疾病相关度,对已知关联和要预测关联进行矩阵近似建模,在建模过程中,添加约束项同时考虑食物同构网络、疾病同构网络,考虑相似度高的食物可能会导致相同疾病的可能以及相关度高的疾病可能是由同种食物导致的,使用食物与疾病关联研究的机器学习方法,可在人力物力消耗极低的情况下,为进一步的食物疾病关联研究提供指导,可作为营养学家食物优选的参考;改善了以往采用的交替迭代学习方法时食物相似度网络只能用作固定输入,食物相似度网络中偏差的问题,大大有助于减少数据干扰,提高食物疾病预测任务的预测准确性。
2、通过食物相似度网络和疾病相关网络关系在原始的食物-疾病关联网络上传播相似关系,避免了已知疾病食物关联较少时的方法失效。同时,通过将食物相似度网络矩阵和疾病相关度矩阵也作为预测矩阵建模,模拟了食物相似度和疾病相关性描述不准确的潜在偏差,进行异构网络端到端的建模,增强了模型的鲁棒性。
附图说明
图1是本发明的整体处理流程图;
图2是本发明的算法实现流程图。
具体实施方式
以下结合附图对本发明实施例做进一步详述。
本发明的设计思想是:
在营养学和食品安全领域,利用机器学习理论和技术,通过结合食物相似性网络、疾病相关度网络、食物-疾病关联网络,来构建异质网络。受标签传播算法,本发明在构建的异质网络上设计矩阵分解框架。本发明假设相似度高的食物会导致同一种疾病,相关度高的疾病可能由同一种食物导致更新网络,以此交替学习参数。进一步地,本发明受食物相似度网络中假阳性关系启发,假阳性关系启发本发明将食物相似度网络和疾病相关度网络视为需要学习的变量,而不是一个固定输入,以此减少和修正原始网络的噪音,防止模型过拟合。在具体求解过程中,本发明提出了一种有效的闭合解决方案来提高计算效率。
基于上述设计思想,本发明的基于矩阵分解的食物-疾病关联预测方法,如图1所示,包括以下步骤:
步骤1:利用成分表构建食物相似度网络w1。
食物相似度网络中,每一个节点为“食物-量-食用方法”的组合。在“量-食用方法”不同的情况下,两两节点关系置为0;在“量-食用方法”相同的情况下,根据食物成分表,利用余弦公式,计算两两食物表示向量的余弦值作为两两食物相似度,作为节点关系值,得到食物相似度网络w1。
其中,成分表指的是每100克该食物的可食用部分所能提供的热量、食物、膳食纤维、钙、镁、铁、锰、锌等元素的值。此处使用的余弦公式如下:
其中,a,b分别为两个食物成分向量。
步骤2:利用国际疾病分类数据构建疾病相关度网络w2。
利用国际疾病分类数据,如果两种疾病同属同一类目,则相似度设置为k,如果两种疾病同属同一亚目,则相似度设置为2k,如果两种疾病同属同一细目,则相似度设置为3k,其中3k<1。
此处,k设置的小,则认为类目、亚目、细目之间的差异不大;k设置的大,则认为类目、亚目、细目之间的差异大。
步骤3:正则化食物相似度网络,得到正则化食物相似度网络的
设n为“食物名-量-食用方法”的组合数,w1∈rn×n是二进制食物相关度网络,则w1用于构造正则化网络
步骤4:正则化疾病相关度网络,得到正则化的疾病相关度网络
设m为疾病数,w2∈rm×m是二进制疾病相关网络,则w2用于构造正则化网络
步骤5:构造已知的二元食物-疾病关联网络
在本实施例中,已知的食物-疾病关联由二进制矩阵
步骤6:随机初始化要预测的食物-疾病关联矩阵y。
步骤的具体实现方法如下:随机初始化要预测的食物-疾病关联矩阵y,即通过对y矩阵中的每一个值赋予0-1之间的任意数作为初始化。
步骤7:引入捕捉真实食物相似度的矩阵s1和疾病真实相关度的矩阵s2,迭代学习模型参数,输出预测的食物和疾病关联矩阵y,食物相似度真实情况的拟合矩阵s1,疾病相关度真实情况的拟合矩阵s2。
在本步骤中,首先声明下列公式中项的含义。n为“食物名-量-食用方法”的组合数,m为疾病数,xi·为矩阵x的第i行,x·j为矩阵x的第j行,w1∈rn×n是食品相似度网络,w2∈rm×m是二进制疾病相关网络,
i为单位矩阵,即对角线元素全部为1,其他元素全部为0。其中,tr(a)指的是计算a矩阵的迹,即矩阵a的主对角线(从左上方至右下方的对角线)上各个元素的总和。
在本步骤中,对食物-疾病关联进行建模,建模过程中引入三个假设,a)相似度高的食物可能会导致同一个疾病,b)同一种食物可能会导致密切相似的疾病,c)食物相似度矩阵和疾病相关度矩阵的数值是含噪的。针对假设c)引入捕捉真实食物相似度的矩阵s1和疾病真实相关度的矩阵s2,针对假设a)和b)建模过程中在拟学习的食物-疾病关联矩阵上传播食物相似和疾病相似关系,设计损失函数,
参照链式法则,交替优化ψ1(y,s1)和ψ2(y,s2),输出预测的食物和疾病关联矩阵y,食物相似度真实情况的拟合矩阵s1,疾病相关度真实情况的拟合矩阵s2。
根据食物相似度网络中的假阳性食物相似度表明,
接下来扩展预测该食物与所有疾病的关联,具体表示如下,
为了最小化上式中的损失函数,本发明采用交替迭代更新模式,优化一个变量在固定其他变量的时候。
关于y和s1的解析解可以表示为:
疾病相关度矩阵
对于所有的食物来说,上式还可以扩展到预测关联,
关于y和s2的解析解可以表示为:
在参数学习时,设定超参数α,β,γ,α′,β′,γ′;由于约束α+β=1和α′+β′=1的存在,β和β′的值随着α和α′的确定而确定。
对于交叉检验的数据,本发明使用五折交叉检验方式选择参数值:将数据分为五份,选用80%数据作为训练数据,20%的数据进行验证,这个过程重复五次,每次轮流把每一折作为验证集。五折的平均结果用于选择最佳参数。参数值的选择中,本发明考虑以下值的所有组合:α和α′在{0.0001,0.001,0.01,0.1,1}中选择,γ和γ′在{1,10,100,1,000,10,000}中选择。
最后,输出预测的食物和疾病关联矩阵y,食物相似度真实情况的拟合矩阵s1,疾病相关度真实情况的拟合矩阵s2。
本发明的上述方法可以通过图2所示的算法流程在计算机上实现。
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!